Atlas: Few-shot Learning with Retrieval Augmented Language Models
Atlas: 基于检索增强的大语言模型的少样本学习
Abstract
摘要
Large language models have shown impressive few-shot results on a wide range of tasks. However, when knowledge is key for such results, as is the case for tasks such as question answering and fact checking, massive parameter counts to store knowledge seem to be needed. Retrieval augmented models are known to excel at knowledge intensive tasks without the need for as many parameters, but it is unclear whether they work in few-shot settings. In this work we present Atlas, a carefully designed and pre-trained retrieval augmented language model able to learn knowledge intensive tasks with very few training examples. We perform evaluations on a wide range of tasks, including MMLU, KILT and Natural Questions, and study the impact of the content of the document index, showing that it can easily be updated. Notably, Atlas reaches over 42% accuracy on Natural Questions using only 64 examples, outperforming a 540B parameters model by 3% despite having 50x fewer parameters.
大语言模型在广泛任务上展现了令人印象深刻的少样本学习能力。然而,当任务结果高度依赖知识时(如问答和事实核查),似乎需要海量参数来存储知识。检索增强模型虽以较少参数就能在知识密集型任务中表现优异,但其在少样本环境下的有效性尚不明确。本研究提出的Atlas是一个经过精心设计和预训练的检索增强语言模型,能够通过极少量训练样本掌握知识密集型任务。我们在MMLU、KILT和Natural Questions等多样化任务上展开评估,并分析文档索引内容的影响,证明其可轻松更新。值得注意的是,Atlas仅用64个样本就在Natural Questions任务中达到42%以上的准确率,以50倍的参数劣势超越5400亿参数模型3个百分点。
1 Introduction
1 引言
Large language models (LLMs) are impressive few-shot learners (Brown et al., 2020; Rae et al., 2021; Hoffmann et al., 2022; Chowdhery et al., 2022). They are able to learn new tasks with very few examples or even from instructions alone. For this generalisation ability to emerge, the key ingredients are scaling both the parameter count of the model, and the size of the training data. Large language models owe this improvement to both a larger computational budget, enabling more complex reasoning, and the ability to memorize more information related to downstream tasks from the larger training data. While it is intuitive to assume that increased reasoning abilities lead to better generalisation, and hence few-shot learning, the same is not true for in-parameter mem or is ation. Specifically, it is unclear to what extent effective few-shot learning requires vast knowledge in the parameters of the model.
大语言模型 (LLMs) 是出色的少样本学习者 (Brown et al., 2020; Rae et al., 2021; Hoffmann et al., 2022; Chowdhery et al., 2022)。它们能够通过极少量示例甚至仅凭指令学习新任务。这种泛化能力的关键在于同步扩展模型参数量与训练数据规模。大语言模型的提升既得益于更大的计算资源预算(支持更复杂的推理能力),也得益于从海量训练数据中记忆更多下游任务相关信息。虽然增强推理能力会带来更好的泛化表现(即少样本学习)这一假设符合直觉,但模型参数内的记忆机制却并非如此。具体而言,目前尚不清楚有效的少样本学习究竟需要模型参数中存储多大体量的知识。
In this paper, we investigate whether few-shot learning requires models to store a large amount of information in their parameters, and if mem or is ation can be decoupled from generalisation. To do so, we leverage the fact that memory can be outsourced and replaced by an external non-parametric knowledge source by employing a retrieval-augmented architecture. These models employ a non-parametric memory, e.g. a neural retriever over a large, external, potentially non-static knowledge source to enhance a parametric language model. In addition to their mem or is ation abilities, such architectures are attractive due to a number of other established advantages in terms of adaptability, interpret ability and efficiency (Guu et al., 2020; Lewis et al., 2020; Yogatama et al., 2021; Borgeaud et al., 2021, inter alia). However, retrieval-augmented models have yet to demonstrate compelling few-shot learning capabilities. In this work we address this gap, and present Atlas, a retrieval-augmented language model capable of strong few-shot learning, despite having lower parameter counts than other powerful recent few-shot learners.
本文研究了少样本学习是否需要模型在参数中存储大量信息,以及记忆能力是否可与泛化能力解耦。为此,我们利用记忆可被外包至外部非参数化知识源的特性,采用检索增强架构。这类模型通过神经检索器等非参数化记忆组件,从大规模外部(可能动态更新的)知识源中获取信息,从而增强参数化语言模型的性能。除记忆能力外,此类架构还具备适应性、可解释性和效率等多重优势 (Guu et al., 2020; Lewis et al., 2020; Yogatama et al., 2021; Borgeaud et al., 2021等) 。然而,检索增强模型尚未展现出显著的少样本学习能力。本研究填补了这一空白,提出Atlas——一个参数量少于当前先进少样本学习模型,却具备强大少样本学习能力的检索增强语言模型。
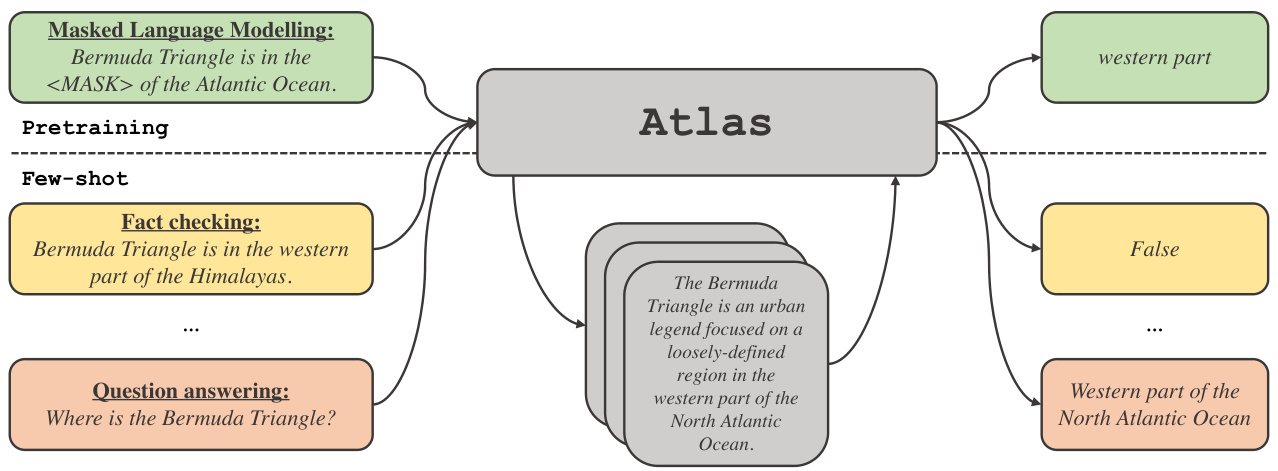
Figure 1: We introduce Atlas, a retrieval-augmented language model that exhibits strong few-shot perfor mance on knowledge tasks, and uses retrieval during both pre-training and fine-tuning.
图 1: 我们介绍了Atlas,这是一个检索增强的大语言模型,在知识任务上表现出强大的少样本性能,并在预训练和微调期间都使用了检索。
Atlas retrieves relevant documents based on the current context by using a general-purpose dense retriever using a dual-encoder architecture, based on the Contriever (Izacard et al., 2022). The retrieved documents are processed, along with the current context, by a sequence-to-sequence model using the Fusion-in-Decoder architecture (Izacard $\text{&}$ Grave, 2020) that generates the corresponding output. We study the impact of different techniques to train Atlas on its few-shot performance on a range of downstream tasks, including question answering and fact checking. We find that jointly pre-training the components is crucial for few-shot performance, and we carefully evaluate a number of existing and novel pre-training tasks and schemes for this purpose. Atlas achieves strong downstream performance in both few-shot and resource-rich settings. For example, with only 11B parameters, Atlas achieves an accuracy of $42.4%$ on Natural Questions using 64 training examples (45.1% with a Wikipedia-only index), outperforming PaLM (Chowdhery et al., 2022), a 540B parameter model by almost 3 points, and $64.0%$ in a full-dataset setting with a Wikipedia index, establishing a new state of the art by 8 points.
Atlas 通过基于 Contriever (Izacard et al., 2022) 的双编码器架构通用密集检索器,根据当前上下文检索相关文档。检索到的文档与当前上下文一起,由采用 Fusion-in-Decoder 架构 (Izacard & Grave, 2020) 的序列到序列模型处理并生成相应输出。我们研究了不同训练技术对 Atlas 在问答和事实核查等一系列下游任务中少样本性能的影响,发现联合预训练各组件对少样本性能至关重要,为此我们系统评估了多种现有及新颖的预训练任务与方案。Atlas 在少样本和资源充足场景下均展现出强劲的下游任务性能。例如,仅用 110 亿参数的 Atlas 在使用 64 个训练样本时,在 Natural Questions 上达到 42.4% 准确率(仅使用维基百科索引时为 45.1%),以近 3 个百分点的优势超越 5400 亿参数的 PaLM (Chowdhery et al., 2022);在维基百科索引的全数据集设置中达到 64.0% 准确率,以 8 个百分点的优势创下新纪录。
In summary we make the following contributions:
我们主要贡献如下:
Our code, pretrained Atlas checkpoints, and various supporting data are available at https://github.com/ facebook research/atlas
我们的代码、预训练的Atlas检查点以及各种支持数据可在 https://github.com/facebookresearch/atlas 获取
Figure 2: Examples of query and output pairs for different tasks from KILT.
| Task | Query | Output |
| Fact Checking | Bermuda Triangle is in the western part of the HiP malayas. | False |
| QuestionAnswering | who is playing the halftime show at super bowl 2016 | Coldplay |
| Entity Linking | NTFS-3G is an open source | Cross-platformsoftware |
图 2: KILT中不同任务的查询与输出示例。
| 任务 | 查询 | 输出 |
|---|---|---|
| 事实核查 | 百慕大三角位于喜马拉雅山脉西部。 | 错误 |
| 问答 | 谁在2016年超级碗中场秀表演 | Coldplay |
| 实体链接 | NTFS-3G是一个开源的跨平台实现,支持读写Microsoft Windows NTFS文件系统。 | 跨平台软件 |
2 Method
2 方法
Our approach follows the text-to-text framework (Raffel et al., 2019). This means that all the tasks are framed as follows: the system gets a text query as input, and generates a text output. For example, in the case of question answering, the query corresponds to the question and the model needs to generate the answer. In the case of classification tasks, the query corresponds to the textual input, and the model generates the lexical i zed class label, i.e. the word corresponding to the label. We give more examples of downstream tasks, from the KILT benchmark in Figure 2. As many natural language processing tasks require knowledge, our goal is to enhance standard text-to-text models with retrieval, which, as we hypothesis e in the introduction, may be crucial to endow models with few-shot capabilities.
我们的方法遵循文本到文本(text-to-text)框架(Raffel et al., 2019)。这意味着所有任务都被构造成如下形式:系统接收文本查询作为输入,并生成文本输出。例如在问答任务中,查询对应问题而模型需要生成答案;在分类任务中,查询对应文本输入,模型则生成词汇化的类别标签(即与标签对应的单词)。我们在图2中展示了来自KILT基准测试的更多下游任务示例。由于许多自然语言处理任务需要知识,我们的目标是通过检索机制增强标准文本到文本模型——正如引言中假设的,这对于赋予模型少样本能力可能至关重要。
2.1 Architecture
2.1 架构
Our model is based on two sub-models: the retriever and the language model. When performing a task, from question answering to generating Wikipedia articles, our model starts by retrieving the top-k relevant documents from a large corpus of text with the retriever. Then, these documents are fed to the language model, along with the query, which in turns generates the output. Both the retriever and the language model are based on pre-trained transformer networks, which we describe in more detail below.
我们的模型基于两个子模型:检索器(Retriever)和大语言模型(Language Model)。在执行任务时,无论是问答还是生成维基百科文章,模型首先通过检索器从大型文本语料库中检索出前k个相关文档。随后,这些文档与查询语句一起输入大语言模型,由后者生成最终输出。检索器和大语言模型均基于预训练的Transformer网络架构,下文将对此进行更详细的说明。
Retriever. Our retriever module is based on the Contriever (Izacard et al., 2022), an information retrieval technique based on continuous dense embeddings. The Contriever uses a dual-encoder architecture, where the query and documents are embedded independently by a transformer encoder (Huang et al., 2013; Karpukhin et al., 2020). Average pooling is applied over the outputs of the last layer to obtain one vector representation per query or document. A similarity score between the query and each document is then obtained by computing the dot product between their corresponding embeddings. The Contriever model is pre-trained using the MoCo contrastive loss (He et al., 2020), and uses unsupervised data only. As shown in the following section, an advantage of dense retrievers is that both query and document encoders can be trained without document annotation, using standard techniques such as gradient descent and distillation.
检索器。我们的检索器模块基于Contriever (Izacard等人,2022),这是一种基于连续密集嵌入的信息检索技术。Contriever采用双编码器架构,其中查询和文档通过Transformer编码器 (Huang等人,2013;Karpukhin等人,2020) 独立嵌入。通过对最后一层输出应用平均池化,获得每个查询或文档的向量表示。然后通过计算相应嵌入之间的点积,获得查询与每个文档之间的相似度分数。Contriever模型使用MoCo对比损失 (He等人,2020) 进行预训练,并且仅使用无监督数据。如下一节所示,密集检索器的一个优势是,无需文档标注,即可使用梯度下降和蒸馏等标准技术训练查询和文档编码器。
Language model. For the language model, we rely on the T5 sequence-to-sequence architecture (Raffel et al., 2019). We rely on the Fusion-in-Decoder modification of sequence-to-sequence models, and process each document independently in the encoder (Izacard $\text{&}$ Grave, 2020). We then concatenate the outputs of the encoder corresponding to the different documents, and perform cross-attention over this single sequence in the decoder. Following Izacard & Grave (2020), we concatenate the query to each document in the encoder. Another way to process the retrieved documents in the language model would be to concatenate the query and all the documents, and to use this long sequence as input of the model. Unfortunately, this approach does not scale with the number of documents, since the self-attention in the encoder results in a quadratic complexity with respect to the number of documents.
语言模型。对于语言模型,我们采用T5序列到序列架构(Raffel et al., 2019)。我们基于序列到序列模型的Fusion-in-Decoder改进方案,在编码器中独立处理每个文档(Izacard $\text{&}$ Grave, 2020)。然后将不同文档对应的编码器输出进行拼接,在解码器中对这个单一序列执行交叉注意力机制。遵循Izacard & Grave(2020)的方法,我们在编码器中将查询语句与每个文档拼接。另一种处理检索文档的方式是将查询语句与所有文档拼接,并将这个长序列作为模型输入。但这种方法会随着文档数量增加而面临可扩展性问题,因为编码器中的自注意力机制会导致计算复杂度随文档数量呈平方级增长。
2.2 Training objectives for the retriever
2.2 检索器的训练目标
In this section, we discuss four different loss functions to train the retriever jointly with the language model. We consider loss functions that leverage the language model to provide supervisory signal to train the retriever. In other words, if the language model finds a document useful when generating the output, the retriever objective should encourage the retriever to rank said document higher. This allows us to train models using only query and output pairs from the task of interest, without relying on document annotations. For example, in the case of fact checking, a model only requires pairs of claims and corresponding verdicts but no documents containing the evidence to back up the verdict. In practice, we can apply this approach on any task, including self-supervised pre-training. As shown in the experimental section, pre-training is critical for obtaining models that exhibit few-shot learning abilities.
在本节中,我们讨论四种不同的损失函数,用于联合训练检索器与大语言模型。我们考虑的损失函数利用大语言模型提供监督信号来训练检索器。换句话说,如果大语言模型在生成输出时发现某个文档有用,检索器的目标函数应鼓励检索器将该文档排名更高。这使得我们仅使用目标任务中的查询和输出对即可训练模型,而无需依赖文档标注。例如,在事实核查任务中,模型仅需要声明和相应判定组成的配对,而不需要包含支撑判定的证据文档。实践中,该方法可应用于包括自监督预训练在内的任何任务。如实验部分所示,预训练对于获得具备少样本学习能力的模型至关重要。
Attention Distillation (ADist). The first loss that we consider is based on the attention scores of the language model, and is heavily inspired by Izacard $\text{&}$ Grave (2021). The main idea is that the cross-attention scores between the input documents and the output, can be used as a proxy of the importance of each input document when generating the output. In particular, Izacard $\text{&}$ Grave (2021) showed that these scores can be aggregated across attention heads, layers and tokens for a given document to obtain a single score for each document. Then, these scores can be distilled into the retriever by minimizing the KL-divergence with the probability distribution $p_{\mathrm{RETR}}$ over the top-K documents ${\mathbf{d}_ {k}}_{1,\ldots,K}$ obtained from the retriever:
注意力蒸馏 (ADist)。我们考虑的第一个损失函数基于语言模型的注意力分数,其灵感主要来自 Izacard $\text{&}$ Grave (2021)。核心思想是:输入文档与输出之间的交叉注意力分数,可以作为生成输出时各输入文档重要性的代理指标。具体而言,Izacard $\text{&}$ Grave (2021) 证明这些分数可以跨注意力头、网络层和 token 进行聚合,从而为每个文档计算单一分数。随后,通过最小化这些分数与检索器返回的 top-K 文档 ${\mathbf{d}_ {k}}_ {1,\ldots,K}$ 概率分布 $p_{\mathrm{RETR}}$ 之间的 KL 散度,即可将注意力分数蒸馏到检索器中:
$$
p_{\mathrm{RETR}}\left(\mathbf{d}\mid\mathbf{q}\right)=\frac{\exp(s(\mathbf{d},\mathbf{q})/\theta)}{\sum_{k=1}^{K}\exp(s(\mathbf{d}_{k},\mathbf{q})/\theta)},
$$
$$
p_{\mathrm{RETR}}\left(\mathbf{d}\mid\mathbf{q}\right)=\frac{\exp(s(\mathbf{d},\mathbf{q})/\theta)}{\sum_{k=1}^{K}\exp(s(\mathbf{d}_{k},\mathbf{q})/\theta)},
$$
where $s$ is the dot-product between the query and documents vectors and $\theta$ is a temperature hyper-parameter.
其中 $s$ 是查询向量与文档向量的点积,$\theta$ 是温度超参数。
In the original paper, it was proposed to use the pre-softmax scores from the decoder cross-attentions, and average across heads, layers and tokens. Here, we propose an alternative which gives slightly stronger results, which relies on the following observation. In the attention mechanism, as defined by
在原论文中,提出使用解码器交叉注意力层的预softmax分数,并在注意力头、层和token之间取平均。我们在此提出一个能获得略好结果的替代方案,该方案基于以下观察:在注意力机制中,如定义所述
$$
\mathbf{y}=\sum_{n=1}^{N}\alpha_{n}\mathbf{v}_{n},
$$
$$
\mathbf{y}=\sum_{n=1}^{N}\alpha_{n}\mathbf{v}_{n},
$$
the contribution to the output $\mathbf{y}$ of a particular token $n$ cannot be evaluated from the attention score $\alpha_{n}$ alone, but should also take the norm of the value ${\bf v}_ {n}$ into account. Hence, we use the quantity $\alpha_{n}|\mathbf{v}_ {n}|_ {2}$ as the measure of relevance for token $n$ . Following Izacard $\text{&}$ Grave (2021), we average these scores over all attention heads, layers, and tokens to obtain a score for each document. We apply the Softmax operator over the resulting scores, to obtain a distribution $p_{\mathrm{ATTN}}(\mathbf{d}_ {k})$ over the top-K retrieved documents. We then minimize the KL-divergence between $p_{\mathrm{ATTN}}(\mathbf{d}_ {k})$ , and the distribution $p_{\mathrm{RETR}}$ from the retriever defined in Equation 1:
特定token $n$ 对输出 $\mathbf{y}$ 的贡献不能仅通过注意力分数 $\alpha_{n}$ 来评估,还应考虑值向量 ${\bf v}_ {n}$ 的范数。因此,我们使用 $\alpha_{n}|\mathbf{v}_ {n}|_ {2}$ 作为token $n$ 的相关性度量。遵循Izacard $\text{&}$ Grave (2021) 的方法,我们对所有注意力头、层和token的分数进行平均,从而为每个文档获得一个分数。我们对结果分数应用Softmax算子,得到前K个检索文档上的分布 $p_{\mathrm{ATTN}}(\mathbf{d}_ {k})$。然后,我们最小化 $p_{\mathrm{ATTN}}(\mathbf{d}_ {k})$ 与检索器在公式1中定义的分布 $p_{\mathrm{RETR}}$ 之间的KL散度:
$$
\mathrm{KL}(p_{\mathrm{ATTN}}\parallel p_{\mathrm{RETR}})=\sum_{k=1}^{K}p_{\mathrm{ATTN}}(\mathbf{d}_ {k})\log\left(\frac{p_{\mathrm{ATTN}}(\mathbf{d}_ {k})}{p_{\mathrm{RETR}}(\mathbf{d}_{k})}\right).
$$
$$
\mathrm{KL}(p_{\mathrm{ATTN}}\parallel p_{\mathrm{RETR}})=\sum_{k=1}^{K}p_{\mathrm{ATTN}}(\mathbf{d}_ {k})\log\left(\frac{p_{\mathrm{ATTN}}(\mathbf{d}_ {k})}{p_{\mathrm{RETR}}(\mathbf{d}_{k})}\right).
$$
Here, this loss is only used to optimize the parameters of the retriever, and not the language model. When using recent deep learning frameworks, this is achieved by applying a Stop Gradient operator on $p_{\mathrm{ATTN}}$ .
在这里,该损失仅用于优化检索器的参数,而不用于优化语言模型。在使用现代深度学习框架时,这是通过在 $p_{\mathrm{ATTN}}$ 上应用 Stop Gradient 算子来实现的。
End-to-end training of Multi-Document Reader and Retriever (EMDR2). Next, we consider the method introduced by Sachan et al. (2021), which is inspired by the expectation-maximization algorithm, treating retrieved documents as latent variables. Given a query $\mathbf{q}$ , the corresponding output $\mathbf{a}$ and the set $\mathcal{D}_{K}$ of top-K retrieved documents with the current retriever, the EMDR $^2$ loss to train the retriever is
端到端多文档阅读器与检索器联合训练 (EMDR2)。接下来我们分析 Sachan 等人 (2021) 提出的方法,该方法受期望最大化算法启发,将检索文档视为隐变量。给定查询 $\mathbf{q}$、对应输出 $\mathbf{a}$ 以及当前检索器返回的 top-K 文档集合 $\mathcal{D}_{K}$,训练检索器的 EMDR$^2$ 损失函数为
$$
\log\left[\sum_{k=1}^{K}p_{\mathrm{LM}}({\bf a}\mid{\bf q},{\bf d}_ {k})p_{\mathrm{RETR}}({\bf d}_{k}\mid{\bf q})\right],
$$
$$
\log\left[\sum_{k=1}^{K}p_{\mathrm{LM}}({\bf a}\mid{\bf q},{\bf d}_ {k})p_{\mathrm{RETR}}({\bf d}_{k}\mid{\bf q})\right],
$$
where $p_{\mathrm{RETR}}$ is again the probability over the top-K documents obtained with the retriever, as defined by Equation 1. Again, only the parameters of the retriever are updated by applying a Stop Gradient operator around $p_{\mathrm{LM}}$ . One should note that the probability distribution over documents that maximizes this loss function is an indicator of the document corresponding to the highest probability of the output according to the language model. Finally, in practice, the EMDR $_{,^{-}}^{2}$ loss function is applied at the token level, and not at the sequence level.
其中 $p_{\mathrm{RETR}}$ 仍为检索器获取的Top-K文档概率(由公式1定义)。同样地,仅通过应用 $p_{\mathrm{LM}}$ 周围的Stop Gradient算子来更新检索器参数。需注意,使该损失函数最大化的文档概率分布,即为语言模型输出最高概率对应文档的指示器。实际应用中,EMDR$_{,^{-}}^{2}$ 损失函数是在token级别而非序列级别进行计算的。
Perplexity Distillation (PDist). Third, we discuss a simpler loss function which is loosely inspired by the objectives from the attention distillation and EMDR $^2$ methods (Izacard & Grave, 2021; Sachan et al., 2021). More precisely, we want to train the retriever to predict how much each document would improve the language model perplexity of the output, given the query. To this end, we minimize the KL-divergence between the documents distribution of the retriever (Eqn. 1), and the documents posterior distribution according to the language model, using a uniform prior:
困惑度蒸馏 (PDist) 。第三,我们讨论了一种更简单的损失函数,其灵感大致来自注意力蒸馏和EMDR$^2$方法 (Izacard & Grave, 2021; Sachan et al., 2021) 的目标。具体而言,我们希望训练检索器在给定查询时预测每篇文档能多大程度改善输出的大语言模型困惑度。为此,我们最小化检索器文档分布 (公式1) 与大语言模型文档后验分布之间的KL散度,其中先验分布采用均匀分布:
$$
p_{k}\propto p_{L M}(\mathbf{a}\mid\mathbf{d}_{k},\mathbf{q}).
$$
$$
p_{k}\propto p_{L M}(\mathbf{a}\mid\mathbf{d}_{k},\mathbf{q}).
$$
Using the Softmax operator, we have that
使用 Softmax 算子时,我们有
$$
p_{k}=\frac{\exp(\log p_{L M}(\mathbf{a}\mid\mathbf{d}_ {k},\mathbf{q}))}{\sum_{i=1}^{K}\exp(\log p_{L M}(\mathbf{a}\mid\mathbf{d}_{i},\mathbf{q}))}.
$$
$$
p_{k}=\frac{\exp(\log p_{L M}(\mathbf{a}\mid\mathbf{d}_ {k},\mathbf{q}))}{\sum_{i=1}^{K}\exp(\log p_{L M}(\mathbf{a}\mid\mathbf{d}_{i},\mathbf{q}))}.
$$
Leave-one-out Perplexity Distillation (LOOP). Finally, we propose an objective based on how much worse the prediction of the language model gets, when removing one of the top $\mathrm{k\Omega}$ retrieved documents. To do so, we compute the log probability of the output for each subset of k-1 documents, and use the negative value as relevance score for each document. Following the previous loss function, we use the softmax operator to obtain a probability distribution over documents:
留一困惑度蒸馏 (LOOP)。最后,我们提出一种基于当移除前 $\mathrm{k\Omega}$ 篇检索文档中的一篇时,语言模型预测结果变差程度的评估目标。具体实现时,我们计算每组 k-1 篇文档子集对应输出的对数概率,并将该负值作为每篇文档的相关性分数。沿用先前损失函数的思路,我们使用 softmax 算子得到文档的概率分布:
$$
p_{\mathrm{LOOP}}(\mathbf{d}_ {k})=\frac{\exp(-\log p_{L M}(\mathbf{a}\mid\mathcal{D}_ {K}\setminus{\mathbf{d}_ {k}},\mathbf{q}))}{\sum_{i=1}^{K}\exp(-\log p_{L M}(\mathbf{a}\mid\mathcal{D}_ {K}\setminus{\mathbf{d}_{i}},\mathbf{q}))}.
$$
$$
p_{\mathrm{LOOP}}(\mathbf{d}_ {k})=\frac{\exp(-\log p_{L M}(\mathbf{a}\mid\mathcal{D}_ {K}\setminus{\mathbf{d}_ {k}},\mathbf{q}))}{\sum_{i=1}^{K}\exp(-\log p_{L M}(\mathbf{a}\mid\mathcal{D}_ {K}\setminus{\mathbf{d}_{i}},\mathbf{q}))}.
$$
As before, we then minimize the KL-divergence between this distribution, and the one obtained with retriever. This loss is more expensive to compute than PDist and EMDR, but, like ADist, employs the language model more closely to the way it is trained i.e. the LM is trained to be conditioned on a set of $K$ documents. For LOOP, the language model is conditioned on $(K-1)$ documents, rather than a single document as in EMDR $^2$ and PDist.
与之前一样,我们随后最小化该分布与通过检索器获得分布之间的KL散度。该损失的计算成本高于PDist和EMDR,但与ADist类似,它更贴近语言模型的训练方式,即语言模型被训练为以一组$K$篇文档为条件。对于LOOP,语言模型以$(K-1)$篇文档为条件,而非像EMDR$^2$和PDist那样仅以单篇文档为条件。
For all losses, we can also use a temperature hyper-parameter when computing the target or retriever distributions to control the distribution’s peakiness of, which might be important for some tasks or losses. Indeed, for PDist and LOOP, the perplexity of the output may not vary much when conditioning on different documents, especially in the case of long outputs.
对于所有损失函数,在计算目标分布或检索器分布时,我们也可以使用温度超参数来控制分布的峰值程度,这对某些任务或损失函数可能很重要。实际上,对于PDist和LOOP而言,当基于不同文档进行条件生成时,输出的困惑度可能变化不大,尤其是在生成长文本的情况下。
2.3 Pretext tasks
2.3 前置任务
In this section, we describe pretext tasks that can be used to jointly pre-train the retriever and the language model using only unsupervised data.
在本节中,我们将介绍仅使用无监督数据即可联合预训练检索器与大语言模型的代理任务 (pretext tasks)。
Prefix language modeling. First, we consider a standard language modeling task as potential pre-training objective. To cast language modeling in the text-to-text framework, we consider a chunk of $N$ words, and split this chunk in two sub-sequences of equal length $N/2$ . Then, the first sub-sequence is used as the query, and the second corresponds to the output. We thus retrieve relevant documents by using the first sub-sequence of $N/2$ tokens, to generate the output.
前缀语言建模。首先,我们将标准语言建模任务视为潜在的预训练目标。为了在文本到文本框架中实现语言建模,我们考虑一个包含 $N$ 个单词的块,并将其拆分为两个长度均为 $N/2$ 的子序列。然后,第一个子序列用作查询,第二个子序列对应输出。因此,我们通过使用前 $N/2$ 个 token 的子序列来检索相关文档以生成输出。
Masked language modeling. Second, we consider masked language modeling, as formulated by Raffel et al. (2019). Again, starting from a chunk of $N$ words, we sample $k$ spans of average length 3 tokens, leading to a masking ratio of $15%$ . We then replace each span by a different special token. The model is then trained to generate the masked spans, each span beginning with the special sentinel mask token that was inserted in the input sequence. We retrieve documents using the masked query, but replace the special mask tokens with a mask token supported by the retriever vocabulary.
掩码语言建模。其次,我们考虑由Raffel等人 (2019) 提出的掩码语言建模方法。同样,从包含$N$个单词的文本块出发,我们采样$k$个平均长度为3个token的文本片段,掩码比例达到$15%$。随后,每个片段被替换为不同的特殊token。模型被训练用于生成被掩码的片段,每个片段以输入序列中插入的特殊哨兵掩码token开头。我们使用掩码查询检索文档,但需将特殊掩码token替换为检索器词表支持的掩码token。
Title to section generation. Finally, we consider a more abstract ive generation task, generating sections from Wikipedia articles, given the article and section title. Here, the query corresponds to the title of the article, together with the title of the section, and the output corresponds to the text of the section. We exclude sections “See also”, “References”, “Further reading” and “External links”.
标题生成章节。最后,我们考虑一个更抽象的生成任务:在给定文章和章节标题的情况下,从维基百科文章中生成章节内容。此处的查询对应文章标题与章节标题的组合,输出则对应章节正文。我们排除了"参见"、"参考文献"、"延伸阅读"和"外部链接"等章节。
2.4 Efficient retriever fine-tuning
2.4 高效检索器微调
Retrieval is facilitated by using a document index, which is a pre-computed collection of the document embeddings for all the documents in the retrieval corpus. When jointly training the retriever and language model, the index needs to be updated regularly, otherwise, the embeddings of the documents stored in the index become stale relative to the updated retriever. This means that we need to recompute the embeddings for the full collection of documents regularly during training to keep the index fresh, which can be computationally expensive for large indices. This is particularly true at fine-tuning time, where the number of training examples could be small relative to the number of documents in the index. Training the retriever could thus add an important computational overhead compared to standard language model finetuning. In this section, we analyse strategies that might make this process more efficient, alleviating the need to re-compute the embeddings of all the documents too often.
通过使用文档索引可以方便检索,该索引是检索语料库中所有文档的预计算文档嵌入集合。在联合训练检索器和语言模型时,需要定期更新索引,否则索引中存储的文档嵌入会相对于更新后的检索器变得过时。这意味着我们需要在训练期间定期为整个文档集合重新计算嵌入以保持索引新鲜,对于大型索引来说这可能带来高昂的计算成本。在微调阶段尤其如此,此时训练样本数量可能远少于索引中的文档数量。因此与传统语言模型微调相比,训练检索器可能带来显著的计算开销。本节我们将分析可能提升该过程效率的策略,从而减少频繁重新计算所有文档嵌入的需求。
Full index update. Let us start by analysing the overhead due to updating the index, compared to using a fixed retriever. To compare the computation time of different models, we will make the following assumption: the time required to perform a forward pass on a document with a model of $P$ parameters is $O(P)$ . While this computation model may seem naive, the main assumption is that document sizes are constant.1 Since we split long documents into passages with similar number of words, and use padding when processing documents of different sizes, this assumption is reasonable in practice. Let $K$ be the number of documents that are retrieved and processed by the language model, $P_{\mathrm{LM}}$ be the number of parameters of the language model and $B$ the batch size. Each training step has a complexity of $4\times B\times K\times P_{\mathrm{LM}}$ .2
完整索引更新。我们首先分析相比使用固定检索器,更新索引带来的开销。为了比较不同模型的计算时间,我们做出以下假设:在参数量为 $P$ 的模型上对文档执行前向传播所需时间为 $O(P)$。虽然这个计算模型看似简单,但核心假设是文档大小恒定。由于我们将长文档分割为词数相近的段落,并在处理不同大小文档时使用填充(padding),该假设在实践中是合理的。设 $K$ 为语言模型检索处理的文档数量,$P_{\mathrm{LM}}$ 为语言模型的参数量,$B$ 为批量大小。每个训练步骤的计算复杂度为 $4\times B\times K\times P_{\mathrm{LM}}$。
Next, let $N$ be the number of documents in the index, and $P_{\mathrm{RETR}}$ be the number of parameters of the retriever. Then, re-computing the full index has a complexity of $N\times P_{\mathrm{RETR}}$ . If we refresh the index every $R$ training steps, we obtain the following overhead:
接下来,设 $N$ 为索引中的文档数量,$P_{\mathrm{RETR}}$ 为检索器的参数量。那么,重新计算完整索引的复杂度为 $N\times P_{\mathrm{RETR}}$。若每 $R$ 个训练步骤刷新一次索引,则得到以下开销:
$$
\frac{N\times P_{\mathrm{RETR}}}{4\times B\times K\times P_{\mathrm{LM}}\times R}.
$$
$$
\frac{N\times P_{\mathrm{RETR}}}{4\times B\times K\times P_{\mathrm{LM}}\times R}.
$$
If we use the BERT-base architecture for our retriever and T5-XL for our language model, we get $\begin{array}{r}{\frac{P_{\mathrm{RETR}}}{P_{\mathrm{LM}}}\approx\frac{1}{25}}\end{array}$ lading to the overhead:
如果我们使用BERT-base架构作为检索器,T5-XL作为大语言模型,就会得到 $\begin{array}{r}{\frac{P_{\mathrm{RETR}}}{P_{\mathrm{LM}}}\approx\frac{1}{25}}\end{array}$ 从而导致开销:
$$
\frac{N}{100\times B\times K\times R}.
$$
$$
\frac{N}{100\times B\times K\times R}.
$$
If we use an index containing $37M$ documents (the size of our Wikipedia index), train with a batch size of 64 with 20 retrieved documents and refresh the index every 1000 steps, this results in an overhead of $\sim30%$ .
如果我们使用包含 $37M$ 个文档的索引(维基百科索引的大小),以 64 的批量大小训练并检索 20 个文档,每 1000 步刷新一次索引,这将导致约 $\sim30%$ 的开销。
Re-ranking. A second strategy is to retrieve a larger number of documents $L$ with the retriever, and to re-embed and rerank these documents with the up-to-date retriever, and pass the resulting top $K$ to the language model. In that case, the overhead of reranking the top $L$ documents is equal to $B\times L\times P_{\mathrm{RETR}}$ Since we perform this operation at every time step, the overhead is equal to
重排序。第二种策略是使用检索器检索更多文档$L$,并用最新的检索器对这些文档重新嵌入和排序,然后将排名前$K$的文档传递给大语言模型。在这种情况下,对前$L$个文档进行重排序的开销等于$B\times L\times P_{\mathrm{RETR}}$。由于我们在每个时间步都执行此操作,因此总开销为
$$
\frac{L\times P_{\mathrm{RETR}}}{4\times K\times P_{\mathrm{LM}}}.
$$
$$
\frac{L\times P_{\mathrm{RETR}}}{4\times K\times P_{\mathrm{LM}}}.
$$
Using the same assumption as before, we finally get that the overhead is of the order of 100L×K . If we re-rank 10x more documents than what the language model processes (i.e., $L=10\times K$ ), we get an overhead of $10%$ . However, note that if many updates are performed on the retriever, the index might still need to be fully updated, as the true top $\mathrm{k\Omega}$ documents may not be retrieved in the top-L results from the stale index. In practice, it is possible to track the positions of the top-K re-ranked documents in the top-L, and estimate when the index needs to be updated.
采用与之前相同的假设,我们最终得出开销约为100L×K量级。若对大语言模型处理文档量的10倍进行重排序(即$L=10\times K$),则会产生$10%$的开销。但需注意,若对检索器进行多次更新,索引可能仍需完整更新,因为在过期索引的top-L结果中可能无法检索到真实的top-$\mathrm{k\Omega}$文档。实际应用中,可通过追踪top-K重排文档在top-L中的位置来预估索引更新时间。
Query-side fine-tuning. Finally, the last strategy is to decouple the encoding of the queries and documents. In this case, we fix the parameters corresponding to the document encoder, and only train the parameters corresponding to the query encoder. Thus, the embeddings of documents are fixed, and we do not need to refresh the index, and thus there is no computational overhead. As we will see in practice, the impact of fixing the documents encoder varies greatly for different tasks when a large training dataset is available. For most of the few-shot settings that we consider, query-side finetuning does not have large performance impact, and sometimes even slightly improves performance.
查询端微调。最后一种策略是将查询和文档的编码解耦。在这种情况下,我们固定文档编码器对应的参数,仅训练查询编码器对应的参数。因此,文档的嵌入向量保持不变,无需刷新索引,也就没有计算开销。实际应用中我们会发现,当拥有大规模训练数据集时,固定文档编码器对不同任务的影响差异很大。在我们考察的大多数少样本场景中,查询端微调对性能影响不大,有时甚至能略微提升性能。
3 Related work
3 相关工作
3.1 Retrieval in natural language processing
3.1 自然语言处理中的检索
Retrieval for knowledge intensive tasks. Previous work has shown that retrieval improves performance across a variety of tasks such as question answering (Voorhees et al., 1999; Chen et al., 2017; Kwiatkowski et al., 2019), fact checking (Thorne et al., 2018), dialogue (Dinan et al., 2019) or citation recommendation (Petroni et al., 2022). Historically, this information retrieval step was implemented using term-matching methods, such as TF-IDF or BM25 (Jones, 1972; Robertson et al., 1995). For open-domain question answering (Voorhees et al., 1999), documents are often retrieved from Wikipedia (Chen et al., 2017). Recently, dense retrievers based on neural networks have become popular. These usually follow a dual-encoder architecture (Yih et al., 2011; Huang et al., 2013; Shen et al., 2014), where queries and passages are encoded independently as vectors, and relevance is computed using the inner product or Euclidean distance. Popular supervised retrievers include DPR (Karpukhin et al., 2020), which is trained to discriminate the relevant passage among negative passages, and extensions such as ANCE (Xiong et al., 2020) which improved the hard negatives mining process. We refer the reader to Yates et al. (2021) for a survey of dense retrieval techniques.
知识密集型任务中的检索。先前的研究表明,检索能提升多种任务的性能,例如问答 (Voorhees et al., 1999; Chen et al., 2017; Kwiatkowski et al., 2019)、事实核查 (Thorne et al., 2018)、对话 (Dinan et al., 2019) 或引文推荐 (Petroni et al., 2022)。传统上,这一信息检索步骤通过词项匹配方法实现,例如 TF-IDF 或 BM25 (Jones, 1972; Robertson et al., 1995)。在开放域问答任务中 (Voorhees et al., 1999),文档通常从维基百科中检索 (Chen et al., 2017)。近年来,基于神经网络的密集检索器逐渐流行,这类方法通常采用双编码器架构 (Yih et al., 2011; Huang et al., 2013; Shen et al., 2014),将查询和段落独立编码为向量,并通过内积或欧氏距离计算相关性。常见的监督式检索器包括 DPR (Karpukhin et al., 2020)——其训练目标是区分相关段落与负样本段落,以及改进硬负样本挖掘过程的扩展方法如 ANCE (Xiong et al., 2020)。关于密集检索技术的综述可参阅 Yates et al. (2021)。
After retrieval, the relevant documents are processed to produce the final output. In open-domain QA, models can extract a span of text from retrieved documents as the answer (Chen et al., 2017; Clark & Gardner, 2018; Wang et al., 2019; Karpukhin et al., 2020), a method inspired by reading comprehension (Richardson, 2013; Rajpurkar et al., 2016). Recently, generating the answer as free-form text, using a seq2seq model conditioned on retrieved documents have become prevalent (Lewis et al., 2020; Izacard & Grave, 2020; Min et al., 2020). These architectures have also been shown to reduce hallucination in dialogue agents (Shuster et al., 2021).
检索后,相关文档经过处理生成最终输出。在开放域问答中,模型可以从检索到的文档中提取一段文本作为答案 (Chen et al., 2017; Clark & Gardner, 2018; Wang et al., 2019; Karpukhin et al., 2020),这种方法受到阅读理解任务的启发 (Richardson, 2013; Rajpurkar et al., 2016)。近年来,基于检索文档的序列到序列 (seq2seq) 模型生成自由形式答案的方法逐渐流行 (Lewis et al., 2020; Izacard & Grave, 2020; Min et al., 2020)。这些架构也被证明可以减少对话智能体中的幻觉现象 (Shuster et al., 2021)。
Retriever training. The need for expensive query-document annotations for training the retriever can be bypassed, by leveraging signals from the language model, or using unsupervised learning. REALM (Guu et al., 2020) and RAG (Lewis et al., 2020) jointly train the retriever and language model by modelling documents as latent variable, and minimizing the objective with gradient descent. REALM pre-trains end-to-end with an MLM approach but uses an extractive BERT-style model (Devlin et al., 2019). Guu et al. (2020) also explore a query-side finetuning at finetuning time to avoid index refreshes, which is also explored in the context of phrase-based retrieval by Lee et al. (2021b). Izacard & Grave (2020) proposed to use cross-attention scores as supervision with knowledge distillation. Sachan et al. (2021) perform joint training of the reader and the retriever by leveraging the perplexity of the output generated by the reader. Sachan et al. (2021) and Lee et al. (2021a) both employ salient span masking to pre-train retrievers, leveraging the perplexity and attention scores from the language model. The inverse cloze task was proposed by Lee et al. (2019) to pre-train dense retrievers in an unsupervised way. Paranjape et al. (2021) propose a method to train retrieval-augmented generators using a second “informed” retriever with access to the output, which the test-time retriever can be distilled from, and Hofstätter et al. (2022) recently proposed a training set filtering/weighting approach to train stronger retrieval-augmented generators. Izacard et al. (2022) explored different contrastive learning methods to train retrievers, while Ram et al. (2022) used recurring spans within a document to create pseudo-positive query-document pairs.
检索器训练。通过利用语言模型的信号或采用无监督学习,可以绕过训练检索器时对昂贵查询-文档标注的需求。REALM (Guu等,2020) 和 RAG (Lewis等,2020) 通过将文档建模为隐变量,并用梯度下降最小化目标函数,联合训练检索器和语言模型。REALM采用MLM方法进行端到端预训练,但使用的是抽取式BERT风格模型 (Devlin等,2019)。Guu等 (2020) 还在微调阶段探索了查询侧微调以避免索引更新,Lee等 (2021b) 在基于短语的检索场景中也研究了该方法。Izacard & Grave (2020) 提出使用交叉注意力分数作为知识蒸馏的监督信号。Sachan等 (2021) 通过利用阅读器生成输出的困惑度,实现了阅读器与检索器的联合训练。Sachan等 (2021) 和 Lee等 (2021a) 都采用显著片段掩码来预训练检索器,利用了语言模型的困惑度和注意力分数。Lee等 (2019) 提出逆完形填空任务,以无监督方式预训练稠密检索器。Paranjape等 (2021) 提出使用能访问输出结果的第二"知情"检索器来训练检索增强生成器的方法,测试时检索器可从中蒸馏知识,Hofstätter等 (2022) 最近提出通过训练集过滤/加权方法来训练更强的检索增强生成器。Izacard等 (2022) 探索了不同对比学习方法来训练检索器,而Ram等 (2022) 则利用文档内重复出现的片段创建伪正例查询-文档对。
Retrieval-augmented language models. Continuous cache models (Grave et al., 2017b) defines a probability distribution over recent tokens, by computing the similarity between previous and current representations of tokens. This distribution is then interpolated with the distribution of the language model, to improve predictions. Later, the amount of tokens used to compute this distribution was extended to a much larger memory by leveraging approximate nearest neighbors search (Grave et al., 2017a). The related kNN-LM model (Khandelwal et al., 2020) replaced LSTMs by transformer networks, and scaled the memory to billions of tokens, leading to strong performance improvements. More recently, RETRO (Borgeaud et al., 2021) extended these by scaling the retrieval memory to trillions of tokens, and changing the model architecture to take retrieved documents as input.
检索增强的语言模型。连续缓存模型 (Grave et al., 2017b) 通过计算token历史表示与当前表示的相似度,定义了一个针对近期token的概率分布。该分布随后与大语言模型的分布进行插值,以提升预测效果。后续研究 (Grave et al., 2017a) 通过近似最近邻搜索算法,将用于计算该分布的token数量扩展至更大的存储规模。相关研究kNN-LM模型 (Khandelwal et al., 2020) 用Transformer网络替代了LSTM,并将记忆规模扩展至数十亿token,实现了显著的性能提升。最新进展RETRO模型 (Borgeaud et al., 2021) 进一步将检索记忆规模扩展至万亿级token,并通过修改模型架构将检索文档作为输入。
Retrieval-Augmentation with Search Engines. Recently, different works have proposed to train large language models to interact with a search engine, by generating text queries, and using the retrieved documents as additional context (Nakano et al., 2021; Thoppilan et al., 2022; Shuster et al., 2022). In the context of few-shot question answering, Lazaridou et al. (2022) used the question to perform a search query, and retrieved documents are added to the prompt of a large language model performing in-context learning.
搜索引擎增强检索。近期多项研究提出训练大语言模型与搜索引擎交互,通过生成文本查询并将检索到的文档作为附加上下文 (Nakano et al., 2021; Thoppilan et al., 2022; Shuster et al., 2022)。在少样本问答场景中,Lazaridou et al. (2022) 将问题作为搜索查询,并将检索到的文档添加至执行上下文学习的大语言模型提示中。
3.2 Few-shot learning
3.2 少样本学习
Few-shot learning, the task of learning from very few examples, has been studied for decades (Thrun & Pratt, 1998; Fink, 2005; Vinyals et al., 2016), but has recently seen an explosion of interest in NLP with the arrival of large pre-trained models, which exhibit emergent few-shot learning abilities (Wei et al., 2022).
少样本学习 (Few-shot learning) 是指从极少量样本中学习的任务,已研究数十年 (Thrun & Pratt, 1998; Fink, 2005; Vinyals et al., 2016),但随着具备涌现少样本学习能力的大规模预训练模型的出现 (Wei et al., 2022),该领域近期在自然语言处理领域引发了研究热潮。
In-context Learning with large Language models. Providing language models with natural language descriptions of tasks, as proposed by Radford et al. (2019) has led to significant developments in few-shot learning. GPT-3 (Brown et al., 2020) demonstrated the ability of large language models to perform few-shot predictions, where the model is given a description of the task in natural language with few examples. Scaling model size, data and compute is crucial to enable this learning ability, leading to the further development of large models (Lieber et al., 2021; Rae et al., 2021; Smith et al., 2022; Chowdhery et al., 2022; Smith et al., 2022). Hoffmann et al. (2022) revisited the scaling law from Kaplan et al. (2020), suggesting that training on more data with a smaller model may be more effective, resulting in Chinchilla, a 70B parameter model with improved parameter efficiency.
大语言模型的上下文学习。Radford等人(2019)提出的通过自然语言任务描述来增强语言模型的方法,推动了少样本学习的重大发展。GPT-3(Brown等人,2020)展示了大语言模型进行少样本预测的能力,即模型仅需少量自然语言示例即可理解任务。扩大模型规模、数据量和计算资源对这种学习能力至关重要,这促进了大模型的进一步发展(Lieber等人,2021; Rae等人,2021; Smith等人,2022; Chowdhery等人,2022; Smith等人,2022)。Hoffmann等人(2022)重新审视了Kaplan等人(2020)提出的扩展定律,指出使用较小模型在更多数据上训练可能更有效,由此诞生了参数效率更高的700亿参数模型Chinchilla。
Few-shot finetuning and prompt-based learning. The above models perform few-shot learning with in-context instructions without training the parameters of the language model. Few-shot learning can also be accomplished by combining textual templates (“prompts”) and various forms of model finetuning, either fully updating a model’s parameters, e.g. for classification (Schick & Schütze, 2021a; Schick & Schutze, 2021; Gao et al., 2021; Tam et al., 2021) or generation (Schick & Schütze, 2021b). Prompts themselves can be optimized, for example by search (Jiang et al., 2020; Shin et al., 2020) or by only updating parts of the model (Logan et al., 2021), or learning “soft-prompts” (Lester et al., 2021; Li & Liang, 2021). Due to its simplicity, in this work we either employ simple prompts or simply feed in inputs without preprocessing, and perform full-model finetuning, a method similar to Le Scao & Rush (2021).
少样本微调 (few-shot finetuning) 和基于提示的学习。上述模型通过上下文指令进行少样本学习,无需训练语言模型的参数。少样本学习也可以通过结合文本模板("提示")和多种形式的模型微调来实现,既可以完全更新模型参数(例如用于分类 [Schick & Schütze, 2021a; Schick & Schutze, 2021; Gao et al., 2021; Tam et al., 2021] 或生成任务 [Schick & Schütze, 2021b]),也可以仅优化提示本身——例如通过搜索 [Jiang et al., 2020; Shin et al., 2020]、仅更新模型部分参数 [Logan et al., 2021] 或学习"软提示" [Lester et al., 2021; Li & Liang, 2021]。出于简便性考虑,本研究采用简单提示或直接输入未预处理数据,并执行全模型微调,该方法与 Le Scao & Rush (2021) 类似。
4 Experiments
4 实验
In this section, we report empirical evaluations of our language models on few-shot learning. We start by introducing our experimental setup, describing our evaluation benchmarks in section 4.1, and giving the training details of our models in section 4.2. Then, we perform an ablation study to compare the different technical choices leading to our main model. We finally evaluate this model, called Atlas, on different natural language understanding tasks in few-shot and full dataset settings.
在本节中,我们报告了大语言模型在少样本学习上的实证评估。首先介绍实验设置,在第4.1节描述评估基准,并在第4.2节给出模型训练细节。随后通过消融实验比较了影响主模型性能的不同技术选择。最终,我们在少样本和全数据集两种设定下,评估了名为Atlas的模型在多种自然语言理解任务上的表现。
4.1 Benchmarks
4.1 基准测试
To evaluate our retrieval-augmented language models we consider the following benchmarks, which include different tasks.
为了评估我们的检索增强语言模型,我们考虑了以下包含不同任务的基准测试。
Knowledge-Intensive Language Tasks (KILT). First, we use the KILT evaluation suite (Petroni et al., 2020), containing 11 datasets corresponding to 5 tasks: fact checking, question answering, dialog generation, entity linking and slot-filling. These different tasks require knowledge about the world to be solved, which can be found in Wikipedia. We evaluate our model on the following tasks and datasets included in KILT: question answering: Natural Questions (Kwiatkowski et al., 2019), TriviaQA (Joshi et al., 2017) and HotpotQA (Yang et al., 2018); slot filling: Zero Shot RE (Levy et al., 2017) and T-REx (Elsahar et al., 2018); entity linking: AIDA CoNLL-YAGO (Hoffart et al., 2011); dialogue: Wizard of Wikipedia (Dinan et al., 2019); and fact checking: FEVER (Thorne et al., 2018). The KILT versions of these datasets differ from their original versions, as instances requiring knowledge not present in the August 2019 Wikipedia dump have been removed.
知识密集型语言任务 (KILT) 。首先,我们使用 KILT 评估套件 (Petroni et al., 2020) ,其中包含对应 5 类任务的 11 个数据集:事实核查、问答、对话生成、实体链接和槽填充。这些不同任务需要利用关于世界的知识来解决,而这些知识可以在维基百科中找到。我们在 KILT 包含的以下任务和数据集上评估模型:问答任务:Natural Questions (Kwiatkowski et al., 2019) 、TriviaQA (Joshi et al., 2017) 和 HotpotQA (Yang et al., 2018) ;槽填充任务:Zero Shot RE (Levy et al., 2017) 和 T-REx (Elsahar et al., 2018) ;实体链接任务:AIDA CoNLL-YAGO (Hoffart et al., 2011) ;对话任务:Wizard of Wikipedia (Dinan et al., 2019) ;事实核查任务:FEVER (Thorne et al., 2018) 。这些数据集的 KILT 版本与其原始版本不同,因为需要 2019 年 8 月维基百科转储中不存在知识的实例已被移除。
Massively-Multitask Language Understanding (MMLU). Our second main evaluation benchmark is MMLU (Hendrycks et al., 2021), which contains 57 multi-choice question answering datasets (referred to as domains), sourced from real examinations designed for humans. These cover a very broad range of topics, e.g. high school mathematics, professional law, logical fallacies and clinical knowledge and can be broadly categorized in four subsets: humanities, social sciences, STEM and “other”. We focus on few-shot learning, and the authors of the benchmarks suggest to use 5 training examples per domain. Beyond the 5-shot setting, We also consider three additional settings. The first is a zero-shot setting, with no training data at all. The second, which we call multi-task few-shot, is where we train a single model on the 6-shot data from all tasks, hence leading to a training set of 285 examples. The last, which we call transfer learning, leverages additional training examples from other multiple-choice QA tasks provided by the MMLU authors, namely MCTest (Richardson, 2013), RACE (Lai et al., 2017), ARC (Clark et al., 2018) and OBQA (Mihaylov et al., 2018) leading to a training set of 95k examples.
大规模多任务语言理解 (MMLU)。我们的第二个主要评估基准是 MMLU (Hendrycks et al., 2021),它包含57个多选问答数据集(称为领域),这些数据源自为人类设计的真实考试。这些数据集涵盖非常广泛的主题,例如高中数学、专业法律、逻辑谬误和临床知识,并大致分为四个子集:人文、社会科学、STEM和“其他”。我们专注于少样本学习,基准作者建议每个领域使用5个训练示例。除了5样本设置外,我们还考虑了另外三种设置。第一种是零样本设置,完全没有训练数据。第二种称为多任务少样本,我们在所有任务的6样本数据上训练单一模型,从而形成包含285个示例的训练集。最后一种称为迁移学习,利用MMLU作者提供的其他多选问答任务(即 MCTest (Richardson, 2013)、RACE (Lai et al., 2017)、ARC (Clark et al., 2018) 和 OBQA (Mihaylov et al., 2018))的额外训练示例,最终形成包含95k示例的训练集。
Additional benchmarks. Additionally, we report results on the original open-domain versions of the popular Natural Questions (Kwiatkowski et al., 2019), and TriviaQA (Joshi et al., 2017) datasets. We also evaluate our model on the original version of FEVER (Thorne et al., 2018), which presents fact checking as a three-way classification problem for textual claims (either “Supported”: the text is supported by evidence in Wikipedia, “refuted”: the claim is not consistent with evidence in Wikipedia, or “not enough info”, where there is insufficient evidence to make a judgement). We also perform experiments to assess temporal sensitivity of our models. Here, we construct a dataset from TempLAMA (Dhingra et al., 2022), consisting of a set of time-sensitive cloze questions on a range of topics, where the answer changes from 2017 to 2020. We assess the accuracy of our models when supplied with a index from 2017 vs 2020 to assess to what degree models faithfully reflect the content of the index supplied to them at test time, and how effective updating the index is as a continual learning or model update ability method.
其他基准测试。此外,我们还在流行的Natural Questions (Kwiatkowski等人,2019) 和TriviaQA (Joshi等人,2017) 数据集的原始开放域版本上报告了结果。我们还评估了模型在FEVER (Thorne等人,2018) 原始版本上的表现,该任务将事实核查作为文本声明的三分类问题("支持":文本有维基百科证据支撑,"反驳":声明与维基百科证据不一致,或"信息不足":证据不足以做出判断)。我们还进行了实验来评估模型的时间敏感性。为此,我们从TempLAMA (Dhingra等人,2022) 构建了一个数据集,包含一系列主题的时间敏感性完形填空问题,其答案在2017至2020年间会发生变化。我们通过对比模型在2017年和2020年索引下的准确率,评估模型在测试时对给定索引内容的忠实反映程度,以及更新索引作为持续学习或模型更新方法的有效性。
4.2 Technical details
4.2 技术细节
We now describe the procedure for pre-training and fine-tuning our models. We focus on the setting used for the ablation studies performed in Section 4.3 and Section 4.4. We give more details about the hyper parameters used for our final model later.
我们现在描述模型的预训练和微调流程。重点介绍第4.3节和第4.4节消融实验所使用的配置方案。关于最终模型采用的超参数细节将在后文详述。
Pre-training. For the pre-training, we initialize the retriever module using the unsupervised Contriever model, which uses the BERT-base architecture. We initialize the language model with the T5 pre-trained weight. As the original T5 pre-trained model included supervised data in the training set, we use the version 1.1 models which were trained on unlabeled text only. Specifically, we initialize from the T5-lm-adapt variants due to their improved stability.
预训练。在预训练阶段,我们使用基于BERT-base架构的无监督Contriever模型初始化检索模块,并采用T5预训练权重初始化语言模型。由于原始T5预训练模型包含监督数据,我们选用仅基于无标注文本训练的1.1版本模型。具体而言,我们选用T5-lm-adapt变体进行初始化,因其具有更好的稳定性。
For the ablation studies performed in Section 4.3 and Section 4.4, we use T5-XL which contains 3B weights. We pre-train all our models for 10,000 iterations, using AdamW with a batch size of 64 and a learning rate of $10^{-4}$ for the reader and $10^{-5}$ for the retriever with linear decay and 1,000 warmup steps. We refresh the index every 1,000 steps. This means that the index is recomputed 10 times during the pre-training, leading to an overhead of around $30%$ , compared to training with a fixed retriever. We set the number of retrieved documents to 20. We detail the hyper parameters used for the training of our final model at the beginning of Section 4.5.
在第4.3节和第4.4节进行的消融研究中,我们使用包含30亿参数的T5-XL模型。所有模型均预训练10,000次迭代,采用AdamW优化器:阅读器(reader)的批量大小为64、学习率为$10^{-4}$,检索器(retriever)学习率为$10^{-5}$,并应用线性衰减和1,000步预热。每1,000步更新一次索引,这意味着预训练期间会重新计算10次索引,相比固定检索器训练会产生约$30%$的额外开销。设置检索文档数量为20篇。第4.5节开头详细列出了最终模型的训练超参数。
Table 1: Retriever loss ablation. We compare different loss functions to pre-train the retriever jointly with the language model. We use the prefix MLM task, and the December 2021 Wikipedia dump for both the index and pre-training data. Fine-tuning is performed with query-side fine-tuning and the loss used for pre-training. Best result is bold, second highest underlined.
| 64-shot | 1024-shot | ||||||||
| MLM | NQ | WoW | FEVER | Avg. | NQ | WoW | FEVER | Avg. | |
| Closed-book | 1.083 | 6.5 | 14.1 | 59.0 | 26.5 | 10.7 | 16.5 | 75.3 | 34.2 |
| No Joint pre-training | 9.0 | 14.1 | 67.0 | 30.0 | 9.9 | 16.6 | 78.3 | 34.9 | |
| Fixed retriever | 0.823 | 39.9 | 14.3 | 72.4 | 42.2 | 45.3 | 17.9 | 90.0 | 51.1 |
| ADist | 0.780 | 40.9 | 14.4 | 73.8 | 43.0 | 46.2 | 17.2 | 90.9 | 51.4 |
| EMDR2 | 0.783 | 43.3 | 14.6 | 72.1 | 43.3 | 44.9 | 18.3 | 85.7 | 49.6 |
| PDist | 0.783 | 45.0 | 15.0 | 77.0 | 45.7 | 44.9 | 17.9 | 90.2 | 51.0 |
| LOOP | 0.766 | 41.8 | 15.0 | 74.4 | 43.7 | 47.1 | 17.9 | 87.5 | 50.8 |
表 1: 检索器损失消融实验。我们比较了不同损失函数在预训练检索器与语言模型联合训练时的效果。实验使用前缀 MLM 任务,索引和预训练数据均采用 2021 年 12 月的维基百科数据快照。微调采用查询端微调策略,并沿用预训练阶段的损失函数。最优结果加粗显示,次优结果添加下划线。
| MLM | NQ | WoW | FEVER | Avg. | NQ | WoW | FEVER | Avg. | |
|---|---|---|---|---|---|---|---|---|---|
| Closed-book | 1.083 | 6.5 | 14.1 | 59.0 | 26.5 | 10.7 | 16.5 | 75.3 | 34.2 |
| No Joint pre-training | 9.0 | 14.1 | 67.0 | 30.0 | 9.9 | 16.6 | 78.3 | 34.9 | |
| Fixed retriever | 0.823 | 39.9 | 14.3 | 72.4 | 42.2 | 45.3 | 17.9 | 90.0 | 51.1 |
| ADist | 0.780 | 40.9 | 14.4 | 73.8 | 43.0 | 46.2 | 17.2 | 90.9 | 51.4 |
| EMDR2 | 0.783 | 43.3 | 14.6 | 72.1 | 43.3 | 44.9 | 18.3 | 85.7 | 49.6 |
| PDist | 0.783 | 45.0 | 15.0 | 77.0 | 45.7 | 44.9 | 17.9 | 90.2 | 51.0 |
| LOOP | 0.766 | 41.8 | 15.0 | 74.4 | 43.7 | 47.1 | 17.9 | 87.5 | 50.8 |
Fine-tuning. When performing a downstream task, either in a few-shot setting or with a large training set, we employ fine-tuning to adapt our models to these tasks. For the few-shot KILT ablation experiments, we perform a fixed number of fine-tuning iterations, instead of using early-stopping. More precisely, we decided to use 50 iterations for the 64-shot setting and 200 iterations in the 1024-shot setting. In both cases, we use a batch size of 32 examples, a learning rate of $4\times10^{-5}$ with linear decay and 5 warmup steps for both the reader and the retriever.
微调 (Fine-tuning)。在执行下游任务时,无论是少样本场景还是大规模训练集场景,我们都采用微调技术使模型适配具体任务。在少样本KILT消融实验中,我们采用固定次数的微调迭代,而非早停机制。具体而言,64样本场景设置50次迭代,1024样本场景设置200次迭代。两种情况下均使用32样本的批量大小,学习率设为$4\times10^{-5}$并采用线性衰减策略,同时为阅读器(retriever)和检索器(reader)设置5次预热步数。
Unlabeled datasets. Finally, we discuss the unlabeled text datasets that we use to train our models, which form the retrieval index. First, we consider the Dec. 20, 2021 Wikipedia dump, for which we keep the lists and infoboxes, which are linearized by adding a semi-colon separator between the entries. We split articles by section, and split long sections into passages of equal sizes and containing less than 200 words. This leads to a total of 37M passages, containing 78 words in average. We also use documents from the 2020-10 common crawl dump, pre processed with the CCNet pipeline (Wenzek et al., 2020). We perform additional document filtering, in a similar fashion to Gopher (Rae et al., 2021). More precisely, we filter documents based on document length, average word length, ratio of alphanumeric characters and number of repeated tokens. This leads to a total of 350M passages. The same passages are used for the index and model pre-training. During pre-training, we ensure the passage we are training on is filtered out from the retrieved documents, to prevent the model from simply retrieving the passage it is de-nosing/generating, and trivially using it to solve the pre-training task.
无标注数据集。最后,我们讨论用于训练模型并构成检索索引的无标注文本数据集。首先,我们采用2021年12月20日的维基百科数据转储,保留列表和信息框,并通过在条目间添加分号分隔符进行线性化处理。文章按章节分割,过长的章节被切分为长度相等且不超过200词的段落,最终得到总计3700万段落,平均每段含78词。此外,我们还使用2020年10月Common Crawl转储的文档,这些数据经过CCNet流程预处理(Wenzek et al., 2020)。我们参照Gopher(Rae et al., 2021)的方法进行额外文档过滤,具体包括基于文档长度、平均词长、字母数字字符比例及重复token数量的筛选,最终获得3.5亿段落。这些段落同时用于索引构建和模型预训练。在预训练阶段,我们会确保当前训练段落已从检索文档中排除,以防止模型直接检索到正在去噪/生成的段落并借此简单完成预训练任务。
4.3 Pre-training loss and tasks
4.3 预训练损失与任务
We start our ablation study by comparing different pre-training tasks, and objective functions to jointly train the retriever and the language model. Our goal here is to answer the following research questions:
我们通过比较不同的预训练任务和目标函数来联合训练检索器和大语言模型,从而开始消融研究。我们的目标是回答以下研究问题:
(RQ 1) Does jointly pre-training the whole model lead to better few-shot performance? (RQ 2) What is the best objective function for the retriever, and the best pretext task?
(RQ 1) 联合预训练整个模型是否能带来更好的少样本性能?
(RQ 2) 检索器的最佳目标函数和最佳前置任务是什么?
We start by comparing the training objectives of the retriever, introduced in Section 2.2, by pre-training models using the masked language modelling task. We evaluate these models on a subset of the 64-shot and 1024-shot KILT benchmark: Natural Questions, FEVER and Wizard of Wikipedia, along with two baselines: a ‘closed-book” (i.e. non-augmented T5) baseline, pre-trained on the same data, and initialized from Contriever and T5-lm-adapt. We report results in Table 1. First, we note the poor performance of the closed-book baseline, indicating the importance of augmentation. Next, we observe that pre-training our model with retrieval is important to obtain good performance on few-shot tasks. Indeed, all models that include retrieval during pre-training strongly outperform the baseline without joint pre-training. Next, we compare a model that was pre-trained with a fixed retriever, and models using the various retriever training objectives. On the MLM validation metric corresponding to the pre-training objective, we observe that jointly training the retriever leads to strong improvements. This effect tends to be less marked on 64-shot downstream tasks, and almost non-existent for 1024-shot. We believe that this is evidence that the biggest impact of pre-training is on the language model, which learns to use and aggregate information from the retrieved documents. Lastly, we do not observe significant systematic differences between the different retriever training objectives. We thus decide adopt use Perplexity Distillation for subsequent experiments, as it tends to be more stable than EMDR $_{,^{-}}^{2}$ or ADist, and more computationally efficient than LOOP.
我们首先通过使用掩码语言建模任务预训练模型,比较第2.2节介绍的检索器训练目标。在64样本和1024样本的KILT基准测试子集(Natural Questions、FEVER和Wizard of Wikipedia)上评估这些模型,同时设置两个基线:基于相同数据预训练的"闭卷"(即未增强的T5)基线,以及从Contriever和T5-lm-adapt初始化的模型。结果如表1所示。首先,闭卷基线的较差表现印证了增强的重要性。其次,我们发现通过检索进行模型预训练对少样本任务的良好表现至关重要——所有在预训练阶段包含检索的模型都显著优于未联合预训练的基线。接着比较了使用固定检索器预训练的模型与采用不同检索器训练目标的模型。在与预训练目标对应的MLM验证指标上,联合训练检索器带来了显著提升,但这种效果在64样本下游任务中较弱,在1024样本任务中几乎消失。我们认为这表明预训练最主要的影响是让语言模型学会利用和整合检索文档的信息。最后,不同检索器训练目标之间未呈现显著系统性差异,因此后续实验采用Perplexity Distillation方法,因其比EMDR$_{,^{-}}^{2}$或ADist更稳定,且计算效率高于LOOP。
Table 2: Pretext task ablation. We compare different pretext tasks, used to jointly pre-train our models. Examples are randomly sampled from the training set of the KILT version of the dataset. We report the exact match on Natural Questions, the F1 score on Wizard of Wikipedia and the accuracy on FEVER.
| 64-shot | 1024-shot | |||||||
| NQ | Wow | FEVER | Avg. | NQ | WoW | FEVER | Avg. | |
| Prefix Language Modelling | 41.0 | 14.5 | 64.9 | 40.1 | 44.7 | 17.9 | 86.0 | 49.5 |
| Masked Language Modelling | 42.7 | 14.9 | 69.7 | 42.4 | 44.7 | 18.3 | 88.8 | 50.6 |
| Title-to-section generation | 41.1 | 15.2 | 66.1 | 40.8 | 45.4 | 17.9 | 84.6 | 49.3 |
表 2: 预训练任务消融实验。我们比较了用于联合预训练模型的不同预训练任务。示例随机采样自数据集KILT版本的训练集。我们报告了Natural Questions的精确匹配率、Wizard of Wikipedia的F1分数以及FEVER的准确率。
| 64-shot | 1024-shot | |||||||
|---|---|---|---|---|---|---|---|---|
| NQ | WoW | FEVER | Avg. | NQ | WoW | FEVER | Avg. | |
| Prefix Language Modelling | 41.0 | 14.5 | 64.9 | 40.1 | 44.7 | 17.9 | 86.0 | 49.5 |
| Masked Language Modelling | 42.7 | 14.9 | 69.7 | 42.4 | 44.7 | 18.3 | 88.8 | 50.6 |
| Title-to-section generation | 41.1 | 15.2 | 66.1 | 40.8 | 45.4 | 17.9 | 84.6 | 49.3 |
Table 3: Index content ablation. In this table, we report results for models where the content of the index was changed between the pre-training and the fine-tuning.
| 64-shot | 1024-shot | ||||||||
| Index | Training data | NQ | WoW | FEVER | Avg. | NQ | WoW | FEVER | Avg. |
| Wiki | Wiki | 42.7 | 14.9 | 69.7 | 42.4 | 44.7 | 18.3 | 88.8 | 50.6 |
| Wiki | CC | 40.9 | 15.3 | 67.3 | 41.2 | 44.8 | 18.4 | 88.1 | 50.4 |
| CC | Wiki | 32.9 | 14.5 | 72.1 | 39.8 | 37.8 | 17.1 | 85.8 | 46.9 |
| CC | CC | 38.4 | 14.9 | 70.1 | 41.1 | 42.0 | 17.3 | 88.9 | 49.4 |
表 3: 索引内容消融实验。本表展示了在预训练和微调阶段改变索引内容后的模型结果。
| Index | Training data | NQ | WoW | FEVER | Avg. | NQ | WoW | FEVER | Avg. |
|---|---|---|---|---|---|---|---|---|---|
| Wiki | Wiki | 42.7 | 14.9 | 69.7 | 42.4 | 44.7 | 18.3 | 88.8 | 50.6 |
| Wiki | CC | 40.9 | 15.3 | 67.3 | 41.2 | 44.8 | 18.4 | 88.1 | 50.4 |
| CC | Wiki | 32.9 | 14.5 | 72.1 | 39.8 | 37.8 | 17.1 | 85.8 | 46.9 |
| CC | CC | 38.4 | 14.9 | 70.1 | 41.1 | 42.0 | 17.3 | 88.9 | 49.4 |
Next, we compare the different self-supervised pretext tasks introduced in Section 2.3 in Table 2. Here we observe similar results for all three tasks, with a small advantage for masked language modelling. Thus, in what follows, we adopt masked language modelling for pre-training.
接下来,我们在表2中对比第2.3节介绍的三种自监督预训练任务。结果显示所有任务表现相近,其中掩码语言建模 (masked language modelling) 略占优势。因此后续实验均采用掩码语言建模进行预训练。
Finally, we consider different combinations of data sources—Wikipedia and common crawl—for the index and training data during pre-training. In all cases, we use the Wikipedia 2021 dump as the index when performing few-shot fine-tuning. We report results in Table 3. First, we observe that using a Wikipedia-based index leads to better downstream performance. There could be two explanations for this: first, as we use Wikipedia for the few-shot tasks, the model might be better adapted when trained using the same data. Another explanation might be that Wikipedia is a higher-quality and denser source of knowledge than common crawl. Second, when using a common crawl index, we observe that pre-training on Wikipedia data leads to lower performance than using common crawl data. We believe that the primary reason is that the distribution mismatch between the two domains leads to generally-less relevant retrieved documents. In turn, this probably means that the pre-training is less efficient, because the language model does not leverage as much information from the documents. In the following, we thus decide to combine the data from both domains for both the index and the pre-training data.
最后,我们考虑了预训练阶段索引数据和训练数据的不同组合——维基百科和Common Crawl。在所有情况下,执行少样本微调时均使用2021年版维基百科转储文件作为索引。结果如表3所示:首先发现基于维基百科的索引能带来更好的下游性能,可能有两个原因:(1) 由于少样本任务采用维基百科数据,模型在相同数据训练时适应度更高;(2) 维基百科相比Common Crawl具有更高质量和更密集的知识密度。其次,当使用Common Crawl索引时,预训练采用维基百科数据的效果反而低于Common Crawl数据。我们认为主要原因是两个领域的分布差异导致检索文档的相关性普遍降低,进而使得预训练效率下降——因为语言模型无法从文档中充分提取有效信息。基于此,我们最终决定在索引和预训练数据中同时采用两个领域的数据组合。
表3:
4.4 Fine-tuning
4.4 微调
In this section, we perform an ablation study on how to apply our models on downstream tasks, which relies on fine-tuning. In particular, we want to investigate the following research question:
在本节中,我们对如何将模型应用于依赖微调的下游任务进行了消融研究。具体而言,我们重点探究以下研究问题:
(RQ 3) How to efficiently fine-tune Atlas on tasks with limited training data?
(RQ 3) 如何在训练数据有限的任务上高效微调Atlas?
Table 4: Retriever fine-tuning ablation. Here, we compare different strategies to fine-tune the retriever in a few-shot setting.
| 64-shot | 1024-shot | |||||||
| NQ | Wow | FEVER | Avg. | NQ | Wow | FEVER | Avg. | |
| Standard fine-tuning | 44.3 | 14.9 | 73.2 | 44.1 | 47.0 | 18.4 | 89.7 | 51.7 |
| Top-100 re-ranking | 44.2 | 14.6 | 75.4 | 44.7 | 47.1 | 18.7 | 88.9 | 51.6 |
| Query-side fine-tuning | 45.0 | 15.0 | 77.0 | 45.7 | 44.9 | 17.9 | 90.2 | 51.0 |
| Fixed retriever | 36.8 | 14.5 | 72.0 | 41.1 | 38.0 | 17.7 | 89.3 | 48.3 |
表 4: 检索器微调消融实验。这里我们比较了在少样本设置下微调检索器的不同策略。
| 64-shot | 1024-shot | |||||||
|---|---|---|---|---|---|---|---|---|
| NQ | Wow | FEVER | Avg. | NQ | Wow | FEVER | Avg. | |
| 标准微调 | 44.3 | 14.9 | 73.2 | 44.1 | 47.0 | 18.4 | 89.7 | 51.7 |
| Top-100重排序 | 44.2 | 14.6 | 75.4 | 44.7 | 47.1 | 18.7 | 88.9 | 51.6 |
| 查询端微调 | 45.0 | 15.0 | 77.0 | 45.7 | 44.9 | 17.9 | 90.2 | 51.0 |
| 固定检索器 | 36.8 | 14.5 | 72.0 | 41.1 | 38.0 | 17.7 | 89.3 | 48.3 |
Table 5: Performance on MMLU as a function of model size.
| 5-shot | 5-shot t (multi-task) | Full / Transfer | |||||||
| 770M | 3B | 11B | 770M | 3B | 11B | 770M | 3B | 11B | |
| Closed-book T5 | 29.2 | 35.7 | 36.1 | 26.5 | 40.0 | 43.5 | 42.4 | 50.4 | 54.0 |
| ATLAS | 38.9 | 42.3 | 43.4 | 42.1 | 48.7 | 56.4 | 56.3 | 59.9 | 65.8 |
| △ | +9.8 | +6.6 | +7.3 | +15.6 | +8.7 | +12.9 | +13.9 | +9.5 | +11.8 |
表 5: MMLU性能随模型规模的变化
| 5-shot | 5-shot t (multi-task) | Full / Transfer | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 770M | 3B | 11B | 770M | 3B | 11B | 770M | 3B | 11B | |
| Closed-book T5 | 29.2 | 35.7 | 36.1 | 26.5 | 40.0 | 43.5 | 42.4 | 50.4 | 54.0 |
| ATLAS | 38.9 | 42.3 | 43.4 | 42.1 | 48.7 | 56.4 | 56.3 | 59.9 | 65.8 |
| △ | +9.8 | +6.6 | +7.3 | +15.6 | +8.7 | +12.9 | +13.9 | +9.5 | +11.8 |
To answer this question, we compare the different strategies to fine-tune the retriever module, described in Section 2.4. We report results in Table 4. First, as for pre-training, we observe that keeping the retriever fixed during fine-tuning leads to a significant performance drops, for both 64- and 1024-shot settings. Second, the re-ranking strategy (row 2) leads to very similar results to fully updating the index (row 1), while being significantly more efficient. Lastly, fine-tuning only the query encoder also leads to strong results: in particular, in the 64-shot setup, this is slightly stronger than performing full fine-tuning, which we attribute to there being less opportunity for over-fitting. On the other hand, on the 1024-shot setting, performing a full fine-tuning leads to stronger results, especially on Natural Questions. In the following, we thus use query-side fine-tuning for experiments with small numbers of examples, and standard fine-tuning for larger datasets.
为回答这个问题,我们比较了第2.4节中描述的微调检索器模块的不同策略。结果如表4所示。首先,与预训练类似,我们观察到在微调期间固定检索器会导致性能显著下降,无论是64样本还是1024样本设置。其次,重排序策略(第2行)与完全更新索引(第1行)的结果非常接近,但效率显著更高。最后,仅微调查询编码器也能取得强劲效果:特别是在64样本设置中,其表现略优于完全微调,我们认为这是因为过拟合的机会更少。另一方面,在1024样本设置中,完全微调能带来更好的结果,尤其在Natural Questions数据集上。因此,后续实验中我们对少量样本采用查询端微调,对较大数据集采用标准微调。
4.5 Training and evaluating Atlas
4.5 Atlas的训练与评估
In this section, we apply the findings from the ablations of the previous sections to train a family of Atlas models, ranging from 770M to 11B parameters. More specifically, we use the Perplexity Distillation objective function, along with the masked language modelling pretext task. We pre-train these models using a mix of Wikipedia and Common Crawl data, for both the training data and content of the index. We retrieve 20 documents, and update the index every 2,500 steps and perform re-ranking of the top-100 documents. We pre-train models for 10,000 iterations using AdamW with a batch size of 128.
在本节中,我们应用前几章节的消融实验结果,训练了参数量从7.7亿到110亿不等的Atlas模型系列。具体而言,我们采用困惑度蒸馏(Perplexity Distillation)目标函数,并结合掩码语言建模(masked language modelling)前置任务。预训练数据同时使用Wikipedia和Common Crawl的混合数据集作为训练数据与索引内容,每次检索20篇文档,每2,500步更新一次索引并对Top-100文档进行重排序。所有模型均采用AdamW优化器,以128的批量大小进行了10,000次迭代预训练。
4.5.1 MMLU Results
4.5.1 MMLU 结果
As mentioned in section 4.1, we consider four setting for MMLU: 1) a zero-shot setting where we directly apply the pretrained model with no few-shot finetuning 2) a 5-shot setting, where we finetune a model using 5 training examples for each of the 57 domains 3) a 5-shot multitask setting, where, rather than finetuning a model independently for each domain, we train a single model to perform all tasks and 4) a setting with access to a number of auxiliary datasets, with 95K total training examples. We train the models to generate the letter corresponding to the correct answer option (‘A’, ‘B’, ‘C’ or ‘D’), and pick the answer with the most likely of the 4 letters at test time. Full technical details can be found in appendix A.1.
如第4.1节所述,我们为MMLU考虑了四种设置:1) 零样本设置,直接应用未经少样本微调的预训练模型;2) 5样本设置,针对57个领域中的每个领域使用5个训练样本进行模型微调;3) 5样本多任务设置,不独立微调每个领域的模型,而是训练单一模型处理所有任务;4) 使用包含9.5万训练样本的辅助数据集。我们将模型训练为生成对应正确答案选项的字母('A'、'B'、'C'或'D'),并在测试时选择4个字母中概率最高的答案。完整技术细节见附录A.1。
Performance vs Parameters. We start by comparing Atlas to closed-book models of different sizes for 5-shot, 5-shot multitask and the full setting, and report results in Table 5. Across these settings, Atlas outperforms the closed-book baselines by between 6.6 and 15.6 points, demonstrating consistent utility of retrieval for few-shot language understanding across 57 domains. The closed-book T5 struggles to perform significantly better than random $(25%)$ in few-shot settings with 770M parameters, whereas the equivalent Atlas achieves around $40%$ , significantly better than random, despite its small size. All models improve with more data, but interestingly, the 770M models do not benefit as much from few-shot multitask learning compared to larger models (for closed-book, it actually loses 3 points) suggesting smaller models struggle to grasp the synergies between the tasks in the few-shot setting. Larger models exploit the multi-task setting well, with Atlas improving more than closed-book. For example, Atlas-11B improves by 13 points ( $43.4\rightarrow$ 56.4), but equivalent closed-book only improves by 7 $36.1\rightarrow43.5$ ). Finally, on the transfer learning setting, all models improve, but the relative gaps between closed-book at Atlas models remain similar.
性能与参数对比。我们首先将Atlas与不同规模的闭卷模型在5样本、5样本多任务及完整设置下进行对比,结果如表5所示。在这些设置中,Atlas以6.6至15.6分的优势超越闭卷基线模型,证明了检索机制在57个领域的少样本语言理解任务中具有持续效用。拥有7.7亿参数的闭卷T5模型在少样本设置中表现仅略高于随机水平$(25%)$,而同等规模的Atlas模型能达到约$40%$的准确率,显著优于随机水平。所有模型都随数据量增加而提升,但有趣的是,与更大规模模型相比,7.7亿参数模型从少样本多任务学习中获益较少(闭卷版本反而下降3分),这表明小模型难以在少样本设置中把握任务间的协同效应。大规模模型能更好地利用多任务设置,其中Atlas的改进幅度大于闭卷模型。例如Atlas-110亿参数版本提升13分($43.4\rightarrow$56.4),而同规模闭卷模型仅提升7分($36.1\rightarrow43.5$)。在迁移学习设置中,所有模型均有提升,但闭卷模型与Atlas模型之间的相对差距保持稳定。
Table 6: Standard vs de-biased inference for MMLU These results are reported for Atlas-11B, using cyclic permutations for de-biasing, which increases inference costs by a factor of $4\times$ .
| Zero-shot | 5-shot | 5-shot (multi-task) | Full 1/T Transfer | |
| Standard Inference | 36.8 | 43.4 | 56.4 | 65.8 |
| De-biased Inference | 47.1 | 47.9 | 56.6 | 66.0 |
表 6: MMLU标准推理与去偏推理对比 这些结果是针对Atlas-11B模型报告的,使用循环排列进行去偏处理,这会使推理成本增加 $4\times$ 。
| 零样本 | 少样本(5次) | 少样本(5次,多任务) | 完整1/T迁移 | |
|---|---|---|---|---|
| 标准推理 | 36.8 | 43.4 | 56.4 | 65.8 |
| 去偏推理 | 47.1 | 47.9 | 56.6 | 66.0 |
De-biasing. When finetuning, we permute which answer option appears with which answer letter to reduce over-fitting and encourage a uniform prior over answer letters. However, the model may still exhibit a bias towards some letters, especially in few-shot settings, so we also include a second ‘de-biased’ inference mode in addition the standard inference used above. Here, we run 4 forward passes, one for each cyclic permutation of the answer letter-answer option assignment in the question, e.g. the answer option assigned to letter ‘A’ becomes ‘B’, what was ‘B’ becomes ‘C’ etc.3 We then sum the 4 probabilities to obtain the final prediction, which reduces spurious bias towards one of the answer letters (further details in appendix A.1). The results are shown in Table 6. We find that in zero-shot and 5-shot settings, de-biasing is very effective, improving results by 10.3 and 4.5 points respectively. When more training data is available, the need for de-biasing decreases, leading to only 0.2 point improvement in the multi-task and full data settings.
去偏。在微调时,我们会随机排列答案选项与字母的对应关系,以减少过拟合并促使模型对答案字母保持均匀先验。然而,模型仍可能对某些字母表现出偏好(尤其在少样本场景下),因此除上述标准推理模式外,我们还引入了第二种"去偏"推理模式。该模式下,我们会执行4次前向计算,每次对应问题中答案字母-选项分配的循环置换(例如原分配给字母'A'的选项改为'B','B'改为'C'等)[3]。最终将4次概率求和得到预测结果,以此降低对特定字母的虚假偏好(详见附录A.1)。结果如表6所示:零样本和5样本场景下去偏效果显著,分别提升10.3和4.5个百分点;当训练数据量增加时(多任务和全数据场景),去偏收益降至仅0.2个百分点。
Comparison to published works Next, we compare our Atlas-11B results with de-biasing to recently reported results with state-of-the-art large language models such as GPT-3 or Chinchilla, which required significantly more amount of computation to train. We report results in Table 7. We find that Atlas is able to perform significantly better than random in zero-shot, and in conjunction with de-biased inference, achieves zero-shot scores that exceed 5-shot results reported with GPT3 in the literature (47.1% vs $43.9%$ ) (Hendrycks et al., 2021). For the 5-shot setting, Atlas outperforms GPT-3 by 4%, while using $15\times$ less parameters, and $10\times$ less pre-training compute.4 When multitask-training on the combined 5-shot data, Atlas improves to $56.6%$ close to the 5-shot performance of Gopher $(60.0%)$ ). Finally, on the full data setting, where we train on auxiliary data recommended by the MMLU authors, Atlas reaches an overall accuracy of $65.6%$ , close to the state-of-the-art. Interestingly, in this setup, Atlas significantly outperforms GPT-3, while on the 5-shot setting, their performance is similar.
与已发表工作的对比
接下来,我们将经过去偏处理的Atlas-11B模型结果与最新报道的先进大语言模型(如GPT-3或Chinchilla)进行对比,后者的训练计算量显著更大。结果如表7所示。我们发现Atlas在零样本场景下的表现显著优于随机基线,结合去偏推理后,其零样本得分(47.1%)超越了文献中GPT-3的5样本结果(43.9%)(Hendrycks et al., 2021)。在5样本设定下,Atlas以少15倍的参数量和10倍的预训练计算量,性能仍高出GPT-3达4%。当在组合5样本数据上进行多任务训练时,Atlas提升至56.6%,接近Gopher的5样本表现(60.0%)。最后,在MMLU作者推荐的辅助数据上进行全数据训练时,Atlas达到65.6%的整体准确率,接近当前最优水平。值得注意的是,在此设定下Atlas显著优于GPT-3,而在5样本设定中两者性能相近。
(注:根据规则要求,已对特殊符号/公式保持原样,表格引用格式转换为"表7",引用文献保留原始标注[Hendrycks et al., 2021],技术术语如"zero-shot"译为"零样本"并在首次出现时标注英文)
4.5.2 Open-domain Question Answering Results
4.5.2 开放域问答结果
Next we evaluate Atlas on two open-domain question answering benchmarks: Natural Questions and TriviaQA. We compare to prior work, both in a few-shot setting using 64 examples, and using the full training set, and report results in Table 8. On these benchmarks, which require high-degree of mem or is ation, we clearly see the benefits of retrieval-augmentation. Atlas-11B obtains state-of-the-art results on 64-shot question answering, for both Natural Questions and TriviaQA. In particular, it outperforms significantly larger models, such as PaLM, or models that required significantly more training compute such as Chinchilla. When using the full training set, Atlas also obtains state-of-the-art results, for example improving the accuracy on Natural Questions from $55.9%$ to $60.4%$ . This result is obtained using an index comprised of CCNet and the December 2021 Wikipedia corpora, our default setting for the index. In section 5.2 we consider using indexes composed of Wikipedia corpus archived at different dates, and demonstrate an additional $+3.6%$ on Natural Questions when using an index which is temporally matched to Natural Questions. We report performance as a function of model size as well as detailed hyper parameters in Appendix A.2.
接下来我们在两个开放域问答基准测试上评估Atlas:Natural Questions和TriviaQA。我们将与先前的工作进行比较,包括使用64个示例的少样本设置和使用完整训练集的情况,并在表8中报告结果。在这些需要高度记忆化的基准测试上,我们清楚地看到了检索增强的优势。Atlas-11B在64样本问答任务上取得了最先进的结果,无论是在Natural Questions还是TriviaQA上。特别是,它的表现显著优于规模更大的模型,如PaLM,或需要更多训练计算的模型,如Chinchilla。当使用完整训练集时,Atlas同样取得了最先进的结果,例如将Natural Questions的准确率从$55.9%$提升至$60.4%$。这一结果是使用由CCNet和2021年12月维基百科语料库组成的索引(我们的默认索引设置)获得的。在第5.2节中,我们考虑了使用不同日期存档的维基百科语料库构建索引,并展示了当使用与Natural Questions时间匹配的索引时,准确率可进一步提高$+3.6%$。我们在附录A.2中报告了性能随模型规模变化的函数以及详细的超参数。
Table 7: Comparison to state-of-the-art on MMLU. ∗For the 5-shot setting, Atlas uses fine-tuning, while previous works use in-context learning. The Atlas model uses de-biased inference. Train FLOPS refers to total the amount of computation necessary to train the model, including pre-training and/or fine-tuning.
| Setting | Model | Params | Train FLOPS | All | Hum. | Soc. Sci. | STEM | Other |
| zero-shot | ATLAS | 11B | 3.5e22 | 47.1 | 43.6 | 54.1 | 38.0 | 54.4 |
| 5-shot | GPT-3 | 175B | 3.1e23 | 43.9 | 40.8 | 50.4 | 36.7 | 48.8 |
| Gopher | 280B | 5.0e23 | 60.0 | 56.2 | 71.9 | 47.4 | 66.1 | |
| Chinchilla | 70B | 5.0e23 | 67.5 | 63.6 | 79.3 | 55.0 | 73.9 | |
| ATLAS | 11B | 3.5e22 | 47.9 | 46.1 | 54.6 | 38.8 | 52.8 | |
| 5-shot (multi-task) | ATLAS | 11B | 3.5e22 | 56.6 | 50.1 | 66.4 | 46.4 | 66.2 |
| Full / Transfer | UnifiedQA | 11B | 3.3e22 | 48.9 | 45.6 | 56.6 | 40.2 | 54.6 |
| GPT-3 | 175B | 3.1e23 | 53.9 | 52.5 | 63.9 | 41.4 | 57.9 | |
| ATLAS | 11B | 3.5e22 | 66.0 | 61.1 | 77.2 | 53.2 | 74.4 |
表 7: MMLU 最新技术对比。*在 5-shot 设置中,Atlas 使用微调方法,而先前工作采用上下文学习。Atlas 模型使用去偏推理。训练 FLOPS 指训练模型所需的总计算量,包括预训练和/或微调。
| 设置 | 模型 | 参数量 | 训练 FLOPS | 综合 | 人文 | 社科 | STEM | 其他 |
|---|---|---|---|---|---|---|---|---|
| 零样本 | ATLAS | 11B | 3.5e22 | 47.1 | 43.6 | 54.1 | 38.0 | 54.4 |
| 5-shot | GPT-3 | 175B | 3.1e23 | 43.9 | 40.8 | 50.4 | 36.7 | 48.8 |
| 5-shot | Gopher | 280B | 5.0e23 | 60.0 | 56.2 | 71.9 | 47.4 | 66.1 |
| 5-shot | Chinchilla | 70B | 5.0e23 | 67.5 | 63.6 | 79.3 | 55.0 | 73.9 |
| 5-shot | ATLAS | 11B | 3.5e22 | 47.9 | 46.1 | 54.6 | 38.8 | 52.8 |
| 5-shot (多任务) | ATLAS | 11B | 3.5e22 | 56.6 | 50.1 | 66.4 | 46.4 | 66.2 |
| 全量/迁移 | UnifiedQA | 11B | 3.3e22 | 48.9 | 45.6 | 56.6 | 40.2 | 54.6 |
| 全量/迁移 | GPT-3 | 175B | 3.1e23 | 53.9 | 52.5 | 63.9 | 41.4 | 57.9 |
| 全量/迁移 | ATLAS | 11B | 3.5e22 | 66.0 | 61.1 | 77.2 | 53.2 | 74.4 |
Table 8: Comparison to state-of-the-art on question answering. We report results on Natural Questions, and on TriviaQA for both the filtered set, commonly used for open-domain question answering and the unfiltered hidden set for which evaluation is accessible online: https://competitions.codalab.org/ competitions/17208. For the 64-shot setting, our model uses fine-tuning, while the other models use prompting.
| Model | NQ | TriviaQA filtered | TriviaQA unfiltered | |||
| 64-shot | Full | 64-shot | Full | 64-shot | Full | |
| GPT-3 Brown et al.,2020 | 29.9 | 71.2 | ||||
| Gopher (Rae et al.,2021) | 28.2 | 57.2 | 61.3 | |||
| Chinchilla (Hoffmann et al., 2022 | 35.5 | 64.6 | 72.3 | |||
| PaLM (Chowdhery et al., 2022) | 39.6 | 81.4 | ||||
| RETRO (Borgeaud et al., 2021) | 45.5 | |||||
| FiD (Izacard & Grave, 2020) | 51.4 | 67.6 | 80.1 | |||
| FiD-KD Izacard & Grave, 2021 | 54.7 | 73.3 | ||||
| R2-D2 (] (Fajcik et al., 2021) | 55.9 | 69.9 | ||||
| ATLAS | 42.4 | 60.4 | 74.5 | 79.8 | 84.7 | 89.4 |
表 8: 问答任务与当前最优模型的对比。我们在Natural Questions和TriviaQA数据集上报告结果,其中TriviaQA包含常用于开放域问答的过滤集和可在线上评估的非过滤隐藏集:https://competitions.codalab.org/competitions/17208。在64样本设置中,我们的模型使用微调方法,其他模型则使用提示方法。
| 模型 | NQ 64-shot | NQ Full | TriviaQA filtered 64-shot | TriviaQA filtered Full | TriviaQA unfiltered 64-shot | TriviaQA unfiltered Full |
|---|---|---|---|---|---|---|
| GPT-3 (Brown et al., 2020) | 29.9 | 71.2 | ||||
| Gopher (Rae et al., 2021) | 28.2 | 57.2 | 61.3 | |||
| Chinchilla (Hoffmann et al., 2022) | 35.5 | 64.6 | 72.3 | |||
| PaLM (Chowdhery et al., 2022) | 39.6 | 81.4 | ||||
| RETRO (Borgeaud et al., 2021) | 45.5 | |||||
| FiD (Izacard & Grave, 2020) | 51.4 | 67.6 | 80.1 | |||
| FiD-KD (Izacard & Grave, 2021) | 54.7 | 73.3 | ||||
| R2-D2 (Fajcik et al., 2021) | 55.9 | 69.9 | ||||
| ATLAS | 42.4 | 60.4 | 74.5 | 79.8 | 84.7 | 89.4 |
Atlas also compares favorably to recent work exploring retrieval-augmented few-shot question answering with very large models. Lazaridou et al. (2022) explore Natural Questions in a 15-shot setup using Gopher, augmenting questions with 50 passages retrieved using Google Search. This method consists of generating 4 candidate answers from each retrieved passages, and then re-ranking using either a score inspired by RAG (Lewis et al., 2020) or a more expensive approach. This method (not shown in our tables) achieves exact match scores of 32.7% (RAG) and $38.4%$ (Ensemble), requiring 50 (RAG) or 450 (Ensemble) forward passes of Gopher-280B per test-time question. Atlas, using the same 15 training examples and 50 passages achieves 38.7 EM, despite having 25 $\times$ fewer parameters, and requiring comparatively negligible compute.
Atlas在与近期探索检索增强少样本问答的超大模型研究对比中表现优异。Lazaridou等(2022) 使用Gopher模型在15样本设置下研究Natural Questions数据集,通过Google Search检索50个段落增强问题。该方法对每个检索段落生成4个候选答案,再使用RAG (Lewis等, 2020) 启发的评分或更高成本方法进行重排序。该方案 (未在表格中显示) 取得32.7% (RAG) 和$38.4%$ (集成) 的精确匹配分数,每个测试问题需调用Gopher-280B模型50次 (RAG) 或450次 (集成) 前向计算。而Atlas在相同15个训练样本和50个段落条件下,以25$\times$更少的参数量实现38.7 EM分数,且所需计算量相对可忽略。
4.5.3 FEVER Results
4.5.3 FEVER 结果
We report results on the original 3-class FEVER fact checking test set in Table 9. We consider a 64-shot setting, with training examples uniformly sampled from the full training set. Unlike the development and test sets, the train set is imbalanced, with more positive labels than negative, posing a challenge for few-shot learning. In this setting, we achieve an accuracy of $64.3%$ . We also report a 15-shot setting, with 5 examples uniformly sampled from each class to compare with published results from Gopher (Rae et al., 2021), where Atlas scores $56.2%$ , outperforming Gopher by 5.1 points. Lastly we fine-tune our model on the full training set, and achieve a score of 78%, within $1.5%$ of the ProoFVer, which uses a specialized architecture, a retriever trained with sentence-level annotations, and is supplied with the Wikipedia corpus released with FEVER, whereas Atlas retrieves from CCNet and the December 2021 Wikipedia dump. If we give Atlas an index comprised of the FEVER Wikipedia corpus, we set a new state-of-the-art of $80.1%$
我们在表9中报告了原始3类FEVER事实核查测试集的结果。我们采用64样本设置,从完整训练集中均匀采样训练样本。与开发和测试集不同,训练集存在类别不平衡问题,正例标签多于负例,这对少样本学习提出了挑战。在此设置下,我们取得了64.3%的准确率。我们还报告了15样本设置(每类均匀采样5个样本)的结果,Atlas达到56.2%的准确率,比Gopher (Rae et al., 2021)发表的成果高出5.1个百分点。最后,我们在完整训练集上微调模型,获得78%的分数,与采用专用架构、基于句子级标注训练的检索器、并使用FEVER配套维基百科语料的ProoFVer相比,差距仅1.5%。值得注意的是,Atlas的检索源是CCNet和2021年12月维基百科快照。当为Atlas提供FEVER维基百科语料构建的索引时,我们以80.1%的准确率创造了新纪录。
Table 9: Comparison to state-of-the-art on FEVER. We report accuracy on FEVER test set, for which evaluation is available here: https://competitions.codalab.org/competitions/18814. For the few-shot settings, our model uses fine-tuning while other models use prompting. †uses an index composed of the FEVER Wikipedia corpus.
| 15-shot | 65-shot | Full dataset | |
| Gopher Rae et al., 2021 | 51.1 | ||
| ProoFVer Krishna et al., 2021 | 79.5 | ||
| ATLAS | 56.2 | 64.3 | 78.0 / 8 80.1t |
表 9: FEVER任务上与其他先进方法的对比。我们报告了FEVER测试集上的准确率,评估可在此处获取:https://competitions.codalab.org/competitions/18814。在少样本设置中,我们的模型使用微调方法,而其他模型使用提示方法。†表示使用了由FEVER维基百科语料库构建的索引。
| 15-shot | 65-shot | Full dataset | |
|---|---|---|---|
| Gopher Rae et al., 2021 | 51.1 | ||
| ProoFVer Krishna et al., 2021 | 79.5 | ||
| ATLAS | 56.2 | 64.3 | 78.0 / 80.1† |
Table 10: Downstream results on the KILT hidden test sets Downstream metrics are accuracy (AIDA CoNLL-YAGO, FEVER, T-REx, zero-shot RE), exact match (Natural Questions, HotpotQA, TriviaQA), or F1 (Wizard of Wikipedia).
| Model | AIDA ACC | FEV ACC | T-REx ACC | zsRE ACC | NQ EM | HoPo EM | TQA EM | WoW F1 |
| GENRE Cao et al.,2021 | 89.9 | 一 | 一 | 一 | 一 | |||
| Sphere Piktus et al., 2021 | 89.0 | 81.7 | 74.2 | 51.6 | 38.3 | 72.7 | 15.5 | |
| SEAL Bevilacqua et al., 2022 | 89.5 | 83.6 | 74.6 | 53.7 | 40.5 | 70.9 | 18.3 | |
| Re2G Glass et al.,2022 | 89.6 | 87.7 | 51.7 | 76.3 | 18.9 | |||
| FID with RS Hofstätter et al.,2022 | 92.2 | 85.2 | 83.7 | 61.2 | 39.1 | 84.6 | 20.6 | |
| ATLAS,64-shot | 66.5 | 87.1 | 58.9 | 74.9 | 43.6 | 34.7 | 76.4 | 15.5 |
| ATLAs, full train set | 90.6 | 93.5 | 85.1 | 80.8 | 61.3 | 50.6 | 84.0 | 21.6 |
表 10: KILT隐藏测试集的下游任务结果
下游指标分别为准确率 (AIDA CoNLL-YAGO、FEVER、T-REx、零样本RE)、精确匹配 (Natural Questions、HotpotQA、TriviaQA) 或 F1值 (Wizard of Wikipedia)。
| Model | AIDA ACC | FEV ACC | T-REx ACC | zsRE ACC | NQ EM | HoPo EM | TQA EM | WoW F1 |
|---|---|---|---|---|---|---|---|---|
| GENRE Cao et al.,2021 | 89.9 | - | - | - | - | - | - | - |
| Sphere Piktus et al., 2021 | - | 89.0 | 81.7 | 74.2 | 51.6 | 38.3 | 72.7 | 15.5 |
| SEAL Bevilacqua et al., 2022 | - | 89.5 | 83.6 | 74.6 | 53.7 | 40.5 | 70.9 | 18.3 |
| Re2G Glass et al.,2022 | - | 89.6 | 87.7 | - | 51.7 | - | 76.3 | 18.9 |
| FID with RS Hofstätter et al.,2022 | - | 92.2 | 85.2 | 83.7 | 61.2 | 39.1 | 84.6 | 20.6 |
| ATLAS,64-shot | 66.5 | 87.1 | 58.9 | 74.9 | 43.6 | 34.7 | 76.4 | 15.5 |
| ATLAs, full train set | 90.6 | 93.5 | 85.1 | 80.8 | 61.3 | 50.6 | 84.0 | 21.6 |
4.5.4 KILT Results
4.5.4 KILT 结果
Finally we evaluate Atlas on KILT, a benchmark composed of several different knowledge intensive tasks, which was described in section 4.1. We report results on test sets in Table 10 for which evaluation is available online5. The KILT versions of datasets are filtered, and thus results for datasets we have evaluated elsewhere are not directly comparable on KILT (i.e. FEVER, NQ and TQA). We consider both a 64-shot setting and a full fine-tuning setting, in both cases we train Atlas individually on each dataset. More details on the hyper parameters and development set results are reported in Appendix A.3. For 64-shot, we greatly exceed random performance, and are even competitive with some fully-finetuned models on the leader board, such as for FEVER, where our 64-shot Atlas is only 2-2.5 points behind Sphere, SEAL and Re2G, and outperforms Sphere and SEAL on zero-shot RE. In the full dataset setting, Atlas is within 3% to the state-of-the-art for 3 datasets, and sets the state-of-the-art in the remaining five datasets.
最后我们在KILT基准上评估Atlas,该基准由4.1节描述的多个知识密集型任务组成。表10展示了在线可评估的测试集结果。KILT版本的数据集经过过滤,因此我们其他评估过的数据集结果(如FEVER、NQ和TQA)与KILT数据不可直接比较。我们评估了64样本和全量微调两种设置,均采用单数据集独立训练模式。超参数细节和开发集结果详见附录A.3。在64样本设置中,我们显著超越随机基准表现,甚至与排行榜某些全量微调模型相当——例如在FEVER任务中,我们的64样本Atlas仅落后Sphere、SEAL和Re2G 2-2.5分,并在零样本关系抽取(RE)任务上优于Sphere和SEAL。全量数据设置下,Atlas在3个数据集上达到与最优方法3%以内的差距,并在其余5个数据集中创下最新最优记录。
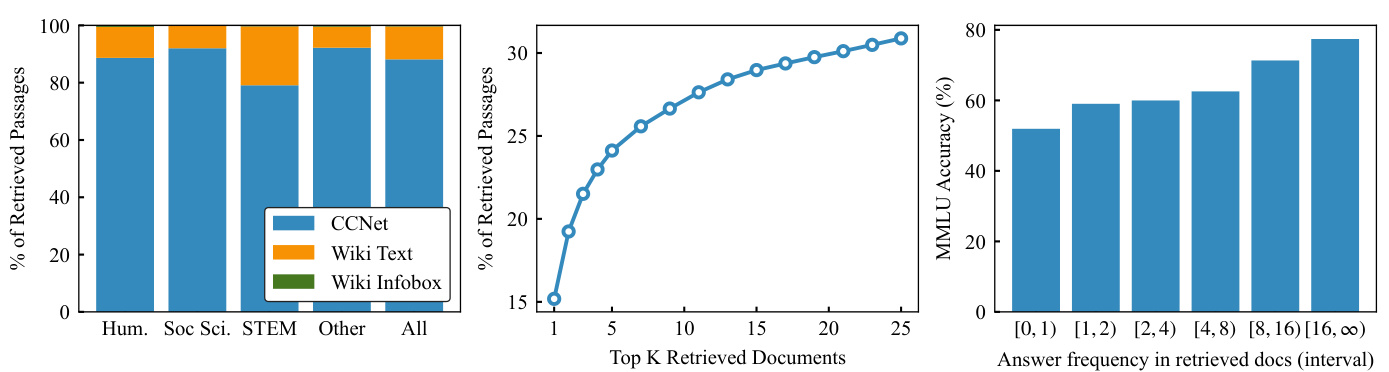
Figure 3: MMLU Retrieval Analysis. Left: Fraction of sources of top 30 retrieved passages for MMLU from CCNet, Wikipedia passages and info boxes for the 5-shot multitask Atlas. Center: How often the text of the correct MMLU answer option appears in retrieved passages, as a function of the number of retrieved passages. Right: MMLU accuracy as a function of answer occurrence frequency in retrieved passages set
图 3: MMLU检索分析。左图: 5样本多任务Atlas从CCNet、维基百科段落和信息框中检索到的MMLU前30段落的来源比例。中图: 正确MMLU答案选项文本出现在检索段落中的频率,作为检索段落数量的函数。右图: MMLU准确率作为答案在检索段落集中出现频率的函数
5 Analysis
5 分析
5.1 Interpret ability and Leakage
5.1 可解释性与泄露风险
An advantage of semi-parametric models like Atlas is the ability to inspect retrieved items to aid interpre t ability. To better understand how well Atlas retrieves, and how it uses retrieved passages, we examine the retrieved passages for multi-task few-shot MMLU. As shown in the left panel of Figure 3, the model retrieves the majority of its passages from CCNet ( $85%$ on average). Wikipedia makes up about $15%$ of retrieved passages, which is higher than we would expect under a uniform prior, given Wikipedia only makes up about $10%$ of the index. The fraction of Wikipedia retrieval varies between MMLU domains, with the model using Wikipedia to a greater extent for STEM domains, and least for social sciences. The domain making the greatest use of Wikipedia is “abstract algebra” (73%), and the least is “moral scenarios” (3 $%$ ). We also note that the MMLU-finetuned Atlas does not make significant use of Wikipedia infobox passages.
Atlas等半参数化模型的优势在于能够检查检索到的条目以提升可解释性。为深入理解Atlas的检索效果及其对检索段落的使用方式,我们分析了多任务少样本MMLU的检索结果。如图3左图所示,该模型主要从CCNet检索段落(平均占比85%)。维基百科约占检索段落的15%,这一比例高于均匀先验下的预期值(因维基百科仅占索引总量的10%)。维基百科检索比例在不同MMLU领域存在差异:模型在STEM领域对维基百科的使用率最高,社会科学领域最低。使用维基百科最多的领域是"抽象代数"(73%),最低的是"道德场景"(3%)。我们还发现,经过MMLU微调的Atlas并未显著利用维基百科信息框段落。
We can also analyse the content of passages to assess how they may useful for accomplishing the downstream task. The middle panel of Figure 3 shows how often retrieved documents contain the text of the correct answer option. There being at least one mention of the correct answer choice in $30%$ of test questions in the top 25 passages.6 The right panel shows that the accuracy on MMLU increases when the correct answer option text occurs more frequently in retrieved passages, rising from $55%$ for questions when the answer option does not appear, to 77% for questions mentioned more than 15 times.
我们还可以分析段落内容,评估它们对完成下游任务的实用性。图3的中部面板展示了检索到的文档包含正确答案选项文本的频率:在前25个段落中,约有30%的测试问题至少出现一次正确答案选项。右侧面板显示,当正确答案选项文本在检索段落中出现频率越高时,MMLU准确率也随之提升——从答案选项未出现时的55%,上升到提及超过15次时的77%。
A human analysis of retrieved documents revealed that documents are helpful for answering questions in a number of different ways. Manual inspection of a sample of 50 correctly-answered questions revealed that $44%$ contained at least partially useful background information. These are documents that would improve the likelihood of a non-expert human answering correctly, such as contextual clues surrounding a quotation from a question, or helpful numerical figures for quantity-based questions, which help to narrow down the answer options to a smaller range. In a further $26%$ of cases, a passage contained all the necessary information to answer the question, stated in a straightforward way. If read competently, such passages make the question simple to answer, and often include information such as canonical definitions, or the exact numerical answer requested in the question. 28% of retrieval sets did not contain obvious information which would make the question easier. Finally, $2%$ contained the verbatim question in a passage, together with its answer.
对检索文档的人工分析显示,这些文档通过多种不同方式为回答问题提供了帮助。通过对50个正确回答问题的样本进行人工检查发现,其中44%的文档至少包含部分有用的背景信息。这类文档能提高非专业人士正确回答问题的概率,例如问题引文周围的上下文线索,或针对数量型问题提供的有用数值,这些信息有助于将答案选项缩小至更小范围。另有26%的案例中,文档段落以直接明了的方式包含了回答问题所需的全部信息。若能准确理解这类段落,问题就会变得简单易答,其中通常包含标准定义或问题所要求的精确数值答案等信息。28%的检索集合未包含能明显降低问题难度的信息。最后,2%的文档段落中直接出现了与问题完全相同的表述及其答案。
Given that MMLU has been created from pre-existing exams, it is possible that these questions appear on the open web. Models trained on web data (or, in our case, retrieving from it) run the risk of answering correctly not through generalisation, but by verbatim mem or is ation, which could lead to misleadingly high scores. In some very large language models, which can verbatim memorize and recall large parts of their pre-training data (Carlini et al., 2021), efforts have sometimes been made to filter occurrences of downstream instances from pre-training data, but this has not been performed for MMLU in the literature. In order to assess the prevalence of MMLU leakage in our index, we manually checked retrieval results for questions where the longest n-gram overlap between the question (without answer options) and a passage was at least $75%$ the length of the question. This resulted in an estimate of leakage of $2.8%$ of questions from our CC-Net corpus.
由于MMLU是基于现有考试创建的,这些题目有可能出现在公开网络上。基于网络数据训练的模型(或在我们的案例中从中检索的模型)存在一种风险:它们可能不是通过泛化能力,而是通过逐字记忆来正确作答,这会导致分数虚高。在某些能够逐字记忆并回忆大部分预训练数据的大型语言模型中(Carlini等人,2021),研究者有时会尝试从预训练数据中过滤下游实例,但文献中尚未对MMLU进行此类处理。为了评估我们索引中MMLU题目泄露的普遍程度,我们手动检查了检索结果——当题目(不含选项)与文本段落的最长n-gram重叠度达到题目长度75%时,估计我们CC-Net语料库中约有2.8%的题目存在泄露情况。
A benefit of retrieval-augmented models such as Atlas is the edit ability of its knowledge (see section 5.2 for additional analysis). To estimate pure, non-leaked performance, we can filter out any potentially-leaked passages from retrieved results and rerun the language model. The MMLU score drops slightly when controlling for this leakage from 56.4 to 55.8% (-.5%).We note that our CC-net corpus is relatively small compared to the pre-trained corpora of recent very large models, which are trained on up to 1.4 trillion tokens (Hoffmann et al., 2022), 35x the size of our index, making it likely that models trained on corpora of that size would observe more MMLU leaked examples, but detecting such leakage is challenging in non-retrieval augmented models.
Atlas等检索增强模型的一个优势在于其知识的可编辑性(更多分析见5.2节)。为评估纯粹的、无泄露的性能表现,我们可以从检索结果中过滤掉所有可能泄露的段落并重新运行语言模型。控制此类泄露后,MMLU分数从56.4%微降至55.8%(降幅0.5%)。值得注意的是,与近期超大规模模型的预训练语料库(如Hoffmann等人[20]使用的1.4万亿token)相比,我们的CC-net语料库规模较小——仅相当于其索引量的1/35。这意味着基于该量级语料库训练的模型可能会接触到更多MMLU泄露样本,但在非检索增强模型中检测此类泄露具有挑战性。
5.2 Temporal Sensitivity and Update ability
5.2 时间敏感性与更新能力
A benefit of retrieval-augmented models is that they can be kept up-to-date without retraining, by updating or swapping their index at test time. To assess the effectiveness of this mechanism in Atlas, we first construct a dataset of time-sensitive questions derived from TempLAMA (Dhingra et al., 2022). TempLAMA is a collection of templated cloze questions derived from Wikidata and Wikidata where the correct answer changes over time. We select a subset of questions from this dataset which have a different answer in 2017 and 2020, for example, Question: Theo Walcott plays for Answer: Arsenal F.C. (2017), Everton F.C. (2020), and form a small training set of 248 training, 112 development and 806 test questions.
检索增强模型的一个优势在于,它们无需重新训练即可通过更新或替换测试时的索引来保持时效性。为评估Atlas中该机制的有效性,我们首先基于TempLAMA (Dhingra et al., 2022) 构建了时效敏感问题数据集。TempLAMA是从Wikidata提取的模板填空题集合,其正确答案会随时间变化。我们从中筛选出2017年与2020年答案不同的问题子集(例如问题:Theo Walcott效力于 答案:阿森纳足球俱乐部 (2017)、埃弗顿足球俱乐部 (2020)),最终形成包含248个训练样本、112个开发样本和806个测试样本的小型数据集。
Using this dataset, we finetune closed-book T5-XXL and Atlas using the questions and the 2017 answers, supplying Atlas with a 2017 Wikipedia index, and then measure exact match accuracy on the 2017 test set. The results can be found in the first row and first two columns of Table 11. We first observe that, as expected, Atlas greatly outperforms T5 $57.7%$ c.f. $12.1%$ ). We also note that, as desired, both T5 and Atlas almost never generate an answer from 2020 when trained with the 2017 answers, scoring $2.8%$ and $1.5%$ respectively (first row, second two columns of Table 11). However, as shown in row 2, we can swap the Atlas index to a 2020 Wikipedia index, without retraining, and find that Atlas updates its predictions accordingly, with 2020 accuracy rising to a similar level to its 2017 performance $(53.1%)$ ), whereas the purely parametric T5 has no such update ability mechanism.
利用该数据集,我们对闭卷式T5-XXL和Atlas进行了微调:使用2017年的问答数据训练模型,并为Atlas提供2017版维基百科索引,随后在2017年测试集上测量精确匹配准确率。结果见表11首行前两列。首先观察到,正如预期那样,Atlas显著优于T5(57.7% vs 12.1%)。同时值得注意的是,T5和Atlas在基于2017年答案训练后,几乎不会生成2020年的答案(分别仅2.8%和1.5%,见表11首行后两列)。但如第二行所示,我们无需重新训练即可将Atlas索引切换至2020版维基百科,此时Atlas的预测会相应更新——其2020年准确率提升至与2017年表现相当的水平(53.1%),而纯参数化的T5则不具备这种更新能力机制。
This demonstrates that Atlas can be faithful and condition strongly on its supplied index. Furthermore, this zero-shot update ability mechanism has the useful property of staying up-to-date without requiring up-to-date annotated data, or continuous, lifelong pre-training, as would be may required for a large parametric-only model. Rows 3 and 4 of Table 11 complete the picture, where this time we train with 2020 answers, and demonstrate Atlas can zero-shot transfer backwards in time to 2017 effectively too (50.1%). Interestingly, T5 is unable answer questions from 2020 well, even when trained with 2020 answers (3.6%), likely because it was pre-trained on data pre-dating 2020 (Dodge et al., 2021).
这表明Atlas能够忠实且强条件地依赖于其提供的索引。此外,这种零样本更新机制具有无需最新标注数据或持续终身预训练即可保持更新的实用特性,而这可能是纯参数化大模型所必需的。表11的第3和第4行完善了这一情况,这次我们使用2020年的答案进行训练,并证明Atlas也能有效地零样本逆向迁移至2017年(50.1%)。有趣的是,T5即使使用2020年的答案训练(3.6%),也无法很好地回答2020年的问题,这可能是因为其预训练数据早于2020年(Dodge et al., 2021)。
We also examine temporal effects for Natural Questions. Natural Questions is a dataset composed of search queries collected via the Google search engine in a short period of time. Thus data have a strong temporal bias, with a lot of questions about the 2018 World Cup for example. Moreover some questions are ambiguous without specification of the temporal context. For instance, for the question “when did ireland last beat england at twickenham”, the expected answer is 2018 in Natural Questions, while Ireland also beat England at Twickenham in 2022 as well as many other times before. In Table 12, we report results obtained by finetuning Atlas using different Wikipedia dumps for the index. We observe that the 2018 December Wikipedia dump, which is close to the date of data collection, leads to the best results for both few-shot and full fine-tuning. In particular, it leads to a new state-of-the-art of 64 EM on Natural Questions.
我们还研究了自然问题 (Natural Questions) 数据集的时间效应。该数据集由短期内通过谷歌搜索引擎收集的搜索查询构成,因此存在显著的时间偏差(例如大量与2018年世界杯相关的问题)。部分问题若缺乏时间上下文会存在歧义,比如问题"when did ireland last beat england at twickenham"在自然问题中的预期答案是2018年,但爱尔兰实际上在2022年以及更早时期也曾多次在特威克纳姆球场战胜英格兰。表12展示了使用不同版本维基百科索引微调Atlas的结果:最接近数据采集时间的2018年12月维基百科版本在少样本和全量微调中都取得了最佳效果,尤其在自然问题上创造了64 EM的最新最高水平。
Table 11: Results on our TempLAMA-derived dataset. We report performance for a static, closed-book T5-11B, as well as Atlas-11B supplied with a test-time Wikipedia index from 2017 or 2020. We evaluate models finetuned on a small training set of 248 time-sensitive cloze-question-answer pairs, using answers either from 2017 or 2020. Good models should score highly when the test set year matches the year of the test-time index, and score low otherwise.
| 2017 Test Set Acc. | 2020 Test Set Acc. | ||||
| Train Set | Test-time Index | Closed-book | ATLAS | Closed-book | ATLAS |
| 2017 answers | 2017 | 12.1 | 57.7 | 2.9 | 1.5 |
| 2020 | 12.1 | 10.2 | 2.9 | 53.1 | |
| 2020 answers | 2017 | 4.8 | 50.1 | 3.6 | 4.2 |
| 2020 | 4.8 | 3.5 | 3.6 | 60.5 | |
表 11: 基于TempLAMA派生数据集的实验结果。我们报告了静态闭卷T5-11B的性能,以及配备2017年或2020年测试时Wikipedia索引的Atlas-11B表现。模型在248个时间敏感性完形填空问答对的微调训练集上进行评估,答案分别来自2017年或2020年。优秀模型应在测试集年份与测试时索引年份匹配时获得高分,反之则应得分较低。
| 训练集 | 测试时索引 | 闭卷准确率 | ATLAS准确率 | 闭卷准确率 | ATLAS准确率 |
|---|---|---|---|---|---|
| 2017年答案 | 2017 | 12.1 | 57.7 | 2.9 | 1.5 |
| 2020 | 12.1 | 10.2 | 2.9 | 53.1 | |
| 2020年答案 | 2017 | 4.8 | 50.1 | 3.6 | 4.2 |
| 2020 | 4.8 | 3.5 | 3.6 | 60.5 |
Table 12: Impact of index data temporal it y on Natural Questions. We report exact match performance on Natural Questions using different Wikipedia dumps in the index. We observe that the dump from December 2018, commonly used for Natural Questions, leads to the best result.
| Dec. 2017 | Dec. 2018 | Aug. 2019 | Dec. 2020 | Dec. 2021 | |
| 64-shot | 44.7 | 45.1 | 44.1 | 44.0 | 41.3 |
| Full | 63.2 | 64.0 | 62.4 | 61.1 | 59.6 |
表 12: 索引数据时效性对Natural Questions的影响。我们使用不同版本的维基百科转储文件作为索引,报告了Natural Questions的精确匹配性能。观察到2018年12月的转储文件(常用于Natural Questions)能获得最佳结果。
| Dec. 2017 | Dec. 2018 | Aug. 2019 | Dec. 2020 | Dec. 2021 | |
|---|---|---|---|---|---|
| 64-shot | 44.7 | 45.1 | 44.1 | 44.0 | 41.3 |
| Full | 63.2 | 64.0 | 62.4 | 61.1 | 59.6 |
5.2.1 Index Compression
5.2.1 索引压缩
Maintaining dense retrieval indices can be memory-intensive, especially as the number of indexed items is scaled. In this section, we briefly analyse the memory requirements of Atlas’s index in the case of a) a Wikipedia index and b) the combined CC and Wikipedia index used in most of the experiments above.
维护密集检索索引可能消耗大量内存,尤其在索引项数量扩展时。本节简要分析Atlas索引在两种场景下的内存需求:(a) 维基百科索引;(b) 前文多数实验中使用的CC与维基百科联合索引。
There are two sources of memory pressure for Atlas’s retrieval component – the passages themselves, and the document embedding index. The tokenized passages, once binarized, require 11GB and 130GB of storage for the Wikipedia and combined indices respectively. These passages do not need to be stored in expensive GPU RAM, and could even be memory-mapped to disk, sharded across nodes or compressed if required, and thus do not represent a limiting hardware challenge in this context. The embedding index itself, however, must be stored in GPU RAM for fast search, and thus its size is more sensitive. In the above experiments, we perform exact search over our index, which is achieved by sharding the index over all the the available GPUs, and computing the search in parallel. The index is stored at fp16 precision, resulting in a total GPU memory requirement of 49 GB and 587 GB for the Wikipedia and combined indices, respectively.
Atlas检索组件的内存压力来自两个方面:文本段落本身和文档嵌入索引。经过分词和二值化处理的文本段落,在Wikipedia索引和混合索引中分别占用11GB和130GB存储空间。这些段落无需存储在昂贵的GPU内存中,甚至可以通过内存映射到磁盘、跨节点分片或按需压缩,因此在此场景下不构成硬件限制。然而,嵌入索引必须存储在GPU内存中以实现快速检索,因此其规模更为敏感。在上述实验中,我们通过在所有可用GPU上分片索引并并行计算,实现了精确搜索。索引以fp16精度存储,Wikipedia索引和混合索引分别需要占用49GB和587GB的GPU显存。
This large GPU memory requirement for the index limits accessibility and ease of deployment. However, many index compression techniques are available for nearest neighbour search, which can often dramatically reduce memory requirements at the cost of some retrieval accuracy. Following Izacard et al. (2020), we explore the effect of Product Quantization (PQ, Jégou et al., 2011), a popular lossy compression technique on Atlas-3B’s accuracy for the 64-shot NQ task at different compression levels.
索引对GPU内存的大容量需求限制了其可访问性和部署便捷性。不过,现有多种近邻搜索索引压缩技术能显著降低内存需求(通常以牺牲部分检索精度为代价)。参照Izacard等人(2020)的研究,我们采用产品量化(PQ, Jégou等人, 2011)这一常用有损压缩技术,测试了不同压缩级别下Atlas-3B在64样本NQ任务中的精度影响。
The results are shown in Figure 4. We find that substantial compression is possible before the onset of significant performance degradation. Namely, the Wikipedia index can be compressed from 49GB to 4GB with negligible drop in retrieval precision and exact match. Likewise, the combined index can be compressed from 587GB to 50GB without serious degradation, indicating that the combined index could be loaded onto a single 80GB GPU.
结果如图4所示。我们发现,在性能显著下降之前可以实现大幅压缩。具体而言,维基百科索引可从49GB压缩至4GB,且检索精度和精确匹配率下降可忽略不计。同样,合并索引可从587GB压缩至50GB而不会出现严重性能衰减,这表明合并索引可加载到单个80GB GPU上。

Figure 4: Index Compression: Atlas-3B 64-shot NQ performance (left column: Retrieval Recall@50, right column: QA Exact Match score), as a function of index size, for different levels of quant is ation. The right-most point in each plot represents the uncompressed index. Top Row: Wikipedia $^+$ CC Index. Bottom Row: Wikipedia Index.
图 4: 索引压缩: Atlas-3B 64样本NQ性能 (左列: 检索召回率@50, 右列: QA精确匹配分数), 作为索引大小的函数, 展示不同量化级别效果。每张图最右侧点代表未压缩索引。上排: Wikipedia $^+$ CC索引。下排: Wikipedia索引。
6 Discussion
6 讨论
In this paper, we introduce Atlas, a large retrieval-augmented language model. By jointly pre-training the retriever module and the language model, we show that Atlas has strong few-shot learning capabilities on a wide range of knowledge intensive tasks, including Natural Questions, TriviaQA, FEVER, 8 KILT tasks and 57 MMLU tasks. For example, Atlas-11B reaches more than 42% accuracy on Natural Questions and 84.7% on TriviaQA when training on 64 examples, which is an improvement of almost 3 points compared to PaLM, a 540B parameters model, which required 50x more pre-training compute. We also provided detailed ablations and analyses for what factors are important when training such retrieval-augmented models, and demonstrated Atlas’s update ability, interpret ability and control ability capabilities. Lastly, we demonstrated that Atlas is also powerful in full-dataset settings obtaining a new state-of-the-art results on Natural Questions, TriviaQA, FEVER, and 5 KILT tasks.
本文介绍了Atlas,一个大型检索增强语言模型。通过联合预训练检索模块和大语言模型,我们证明Atlas在自然问答(Natural Questions)、TriviaQA、FEVER、8项KILT任务和57项MMLU任务等知识密集型任务上具备强大的少样本学习能力。例如,Atlas-11B模型仅用64个训练样本就在Natural Questions上达到42%准确率,在TriviaQA上达到84.7%准确率,相比需要50倍预训练计算量的540B参数模型PaLM提升了近3个百分点。我们还详细分析了训练此类检索增强模型的关键因素,并展示了Atlas的更新能力、可解释性和可控性。最后,我们证明Atlas在全数据集设置下同样表现优异,在Natural Questions、TriviaQA、FEVER和5项KILT任务上创造了新的最先进结果。
References
参考文献
Hady Elsahar, Pavlos Vo ug i ou klis, Arslen Remaci, Christophe Gravier, Jonathon Hare, Frederique Laforest, and Elena Simperl. T-REx: A large scale alignment of natural language with knowledge base triples. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), 2018. URL https://a cl anthology.org/L18-1544. 9
Hady Elsahar、Pavlos Vougiouklis、Arslen Remaci、Christophe Gravier、Jonathon Hare、Frederique Laforest和Elena Simperl。T-REx:大规模自然语言与知识库三元组对齐。载于《第十一届国际语言资源与评估会议论文集》(LREC 2018),2018年。URL https://aclanthology.org/L18-1544。9
Angeliki Lazaridou, Elena Gri bo vs kaya, Wojciech Stokowiec, and Nikolai Grigorev. Internet-augmented language models through few-shot prompting for open-domain question answering. ArXiv, abs/2203.05115, 2022. 8, 14
Angeliki Lazaridou、Elena Gribovskaya、Wojciech Stokowiec 和 Nikolai Grigorev。通过少样本提示实现开放域问答的互联网增强语言模型。ArXiv,abs/2203.05115,2022。8, 14
Ashwin Paranjape, Omar Khattab, Christopher Potts, Matei Zaharia, and Christopher D. Manning. Hindsight: Posterior-guided training of retrievers for improved open-ended generation, 2021. URL https://arxiv. org/abs/2110.07752. 7
Ashwin Paranjape、Omar Khattab、Christopher Potts、Matei Zaharia 和 Christopher D. Manning。Hindsight: 基于后验指导的检索器训练以改进开放式生成,2021。URL https://arxiv.org/abs/2110.07752。7
Fabio Petroni, Patrick Lewis, Aleksandra Piktus, Tim Rock t s chel, Yuxiang Wu, Alexander H Miller, and Sebastian Riedel. How context affects language models’ factual predictions. arXiv preprint arXiv:2005.04611, 2020. 9
Fabio Petroni、Patrick Lewis、Aleksandra Piktus、Tim Rocktäschel、Yuxiang Wu、Alexander H Miller 和 Sebastian Riedel。上下文如何影响语言模型的事实预测。arXiv预印本 arXiv:2005.04611,2020。9
Fabio Petroni, Samuel Broscheit, Aleksandra Piktus, Patrick Lewis, Gautier Izacard, Lucas Hosseini, Jane Dwivedi-Yu, Maria Lomeli, Timo Schick, Pierre-Emmanuel Mazaré, Armand Joulin, Edouard Grave, and Sebastian Riedel. Improving wikipedia verifiability with ai, 2022. URL https://arxiv.org/abs/2207. 06220. 7
Fabio Petroni、Samuel Broscheit、Aleksandra Piktus、Patrick Lewis、Gautier Izacard、Lucas Hosseini、Jane Dwivedi-Yu、Maria Lomeli、Timo Schick、Pierre-Emmanuel Mazaré、Armand Joulin、Edouard Grave 和 Sebastian Riedel。利用AI提升维基百科可验证性,2022。URL https://arxiv.org/abs/2207.06220。7
Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Dmytro Okhonko, Samuel Broscheit, Gautier Izacard, Patrick Lewis, Barlas Oğuz, Edouard Grave, Wen-tau Yih, and Sebastian Riedel. The web is your oyster - knowledge-intensive nlp against a very large web corpus, 2021. URL https://arxiv.org/abs/2112.09924. 15
Aleksandra Piktus、Fabio Petroni、Vladimir Karpukhin、Dmytro Okhonko、Samuel Broscheit、Gautier Izacard、Patrick Lewis、Barlas Oğuz、Edouard Grave、Wen-tau Yih 和 Sebastian Riedel。网络是你的宝库——基于超大规模网络语料库的知识密集型自然语言处理,2021。URL https://arxiv.org/abs/2112.09924。15
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI Technical Report, 2019. 8
Alec Radford、Jeffrey Wu、Rewon Child、David Luan、Dario Amodei 和 Ilya Sutskever。语言模型是无监督多任务学习器。OpenAI 技术报告,2019。8
Jack W. Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, Eliza Rutherford, Tom Hennigan, Jacob Menick, Albin Cassirer, Richard Powell, George van den Driessche, Lisa Anne Hendricks, Maribeth Rauh, Po-Sen Huang, Amelia Glaese, Johannes Welbl, Sumanth Dathathri, Saffron Huang, Jonathan Uesato, John Mellor, Irina Higgins, Antonia Creswell, Nat McAleese, Amy Wu, Erich Elsen, Siddhant Jayakumar, Elena Buch at s kaya, David Budden, Esme Sutherland, Karen Simonyan, Michela Paganini, Laurent Sifre, Lena Martens, Xiang Lorraine Li, Adhiguna Kuncoro, Aida Nematzadeh, Elena Gri bo vs kaya, Domenic Donato, Angeliki Lazaridou, Arthur Mensch, Jean-Baptiste Lespiau, Maria Tsim po uk ell i, Nikolai Grigorev, Doug Fritz, Thibault Sottiaux, Mantas Pajarskas, Toby Pohlen, Zhitao Gong, Daniel Toyama, Cyprien de Masson d’Autume, Yujia Li, Tayfun Terzi, Vladimir Mikulik, Igor Babuschkin, Aidan Clark, Diego de Las Casas, Aurelia Guy, Chris Jones, James Bradbury, Matthew Johnson, Blake Hechtman, Laura Weidinger, Iason Gabriel, William Isaac, Ed Lockhart, Simon Osindero, Laura Rimell, Chris Dyer, Oriol Vinyals, Kareem Ayoub, Jeff Stanway, Lorrayne Bennett, Demis Hassabis, Koray Ka vuk cuo g lu, and Geoffrey Irving. Scaling language models: Methods, analysis & insights from training gopher, 2021. URL https://arxiv.org/abs/2112.11446. 1, 8, 10, 14, 15
Jack W. Rae、Sebastian Borgeaud、Trevor Cai、Katie Millican、Jordan Hoffmann、Francis Song、John Aslanides、Sarah Henderson、Roman Ring、Susannah Young、Eliza Rutherford、Tom Hennigan、Jacob Menick、Albin Cassirer、Richard Powell、George van den Driessche、Lisa Anne Hendricks、Maribeth Rauh、Po-Sen Huang、Amelia Glaese、Johannes Welbl、Sumanth Dathathri、Saffron Huang、Jonathan Uesato、John Mellor、Irina Higgins、Antonia Creswell、Nat McAleese、Amy Wu、Erich Elsen、Siddhant Jayakumar、Elena Buchatskaya、David Budden、Esme Sutherland、Karen Simonyan、Michela Paganini、Laurent Sifre、Lena Martens、Xiang Lorraine Li、Adhiguna Kuncoro、Aida Nematzadeh、Elena Gribovskaya、Domenic Donato、Angeliki Lazaridou、Arthur Mensch、Jean-Baptiste Lespiau、Maria Tsimpoukelli、Nikolai Grigorev、Doug Fritz、Thibault Sottiaux、Mantas Pajarskas、Toby Pohlen、Zhitao Gong、Daniel Toyama、Cyprien de Masson d’Autume、Yujia Li、Tayfun Terzi、Vladimir Mikulik、Igor Babuschkin、Aidan Clark、Diego de Las Casas、Aurelia Guy、Chris Jones、James Bradbury、Matthew Johnson、Blake Hechtman、Laura Weidinger、Iason Gabriel、William Isaac、Ed Lockhart、Simon Osindero、Laura Rimell、Chris Dyer、Oriol Vinyals、Kareem Ayoub、Jeff Stanway、Lorrayne Bennett、Demis Hassabis、Koray Kavukcuoglu 和 Geoffrey Irving。《扩展语言模型:训练Gopher的方法、分析与洞见》,2021年。URL https://arxiv.org/abs/2112.11446。1, 8, 10, 14, 15
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683, 2019. 3, 5
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J Liu。《探索迁移学习的极限:基于统一文本到文本的Transformer》。arXiv预印本 arXiv:1910.10683,2019年。3, 5
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. In Proc. EMNLP, 2016. 7
Pranav Rajpurkar、Jian Zhang、Konstantin Lopyrev和Percy Liang。SQuAD:面向机器理解文本的10万+问题集。见Proc. EMNLP,2016年。7
Ori Ram, Gal Shachaf, Omer Levy, Jonathan Berant, and Amir Globerson. Learning to retrieve passages without supervision. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2687–2700, Seattle, United States, July 2022. Association for Computational Linguistics. URL https://a cl anthology.org/2022.naacl-main. 193. 7
Ori Ram、Gal Shachaf、Omer Levy、Jonathan Berant 和 Amir Globerson。《无监督学习段落检索》。载于《2022年北美计算语言学协会人类语言技术会议论文集》第2687-2700页,美国西雅图,2022年7月。计算语言学协会。URL https://aclanthology.org/2022.naacl-main.193.7
Matthew Richardson. MCTest: A Challenge Dataset for the Open-Domain Machine Comprehension of Text. In Proceedings of the 2013 Conference on Emprical Methods in Natural Language Processing (EMNLP 2013), October 2013. URL https://www.microsoft.com/en-us/research/publication/ mctest-challenge-dataset-open-domain-machine-comprehension-text/. 7, 9
Matthew Richardson. MCTest: 开放领域文本机器理解挑战数据集。2013年10月发表于《自然语言处理实证方法会议论文集》(EMNLP 2013)。URL https://www.microsoft.com/en-us/research/publication/mctest-challenge-dataset-open-domain-machine-comprehension-text/。7, 9
Stephen E Robertson, Steve Walker, Susan Jones, Micheline M Hancock-Beaulieu, Mike Gatford, et al. Okapi at TREC-3. NIST Special Publication Sp, 1995. 7
Stephen E Robertson、Steve Walker、Susan Jones、Micheline M Hancock-Beaulieu、Mike Gatford 等. Okapi 在 TREC-3 中的表现. NIST 特别出版物 Sp, 1995. 7
Devendra Singh Sachan, Siva Reddy, William Hamilton, Chris Dyer, and Dani Yogatama. End-to-end training of multi-document reader and retriever for open-domain question answering, 2021. URL https: //arxiv.org/abs/2106.05346. 4, 5, 7
Devendra Singh Sachan、Siva Reddy、William Hamilton、Chris Dyer 和 Dani Yogatama。面向开放域问答的多文档阅读器与检索器端到端训练,2021年。URL https://arxiv.org/abs/2106.05346。4, 5, 7
for fact extraction and verification. arXiv preprint arXiv:1803.05355, 2018. 7, 9
用于事实提取与验证。arXiv预印本arXiv:1803.05355,2018年。7, 9
Table 13: MMLU scores with de-biasing:
| Setting | Model | All | Hum. | Soc. Sci. | STEM | Other |
| zero-shot | Standard | 36.8 | 37.5 | 39.0 | 30.2 | 39.7 |
| All permutations | 48.5 | 45.7 | 55.2 | 39.4 | 54.4 | |
| Cyclic Permutations | 47.1 | 43.6 | 54.1 | 38.0 | 54.9 | |
| 5-shot | Standard | 43.4 | 41.8 | 49.3 | 33.9 | 48.8 |
| All permutations | 49.0 | 46.0 | 56.1 | 40.5 | 54.6 | |
| Cyclic Permutations | 47.9 | 46.1 | 54.6 | 38.8 | 52.8 |
表 13: 去偏后的 MMLU 分数:
| Setting | Model | All | Hum. | Soc. Sci. | STEM | Other |
|---|---|---|---|---|---|---|
| 零样本 | Standard | 36.8 | 37.5 | 39.0 | 30.2 | 39.7 |
| All permutations | 48.5 | 45.7 | 55.2 | 39.4 | 54.4 | |
| Cyclic Permutations | 47.1 | 43.6 | 54.1 | 38.0 | 54.9 | |
| 少样本(5) | Standard | 43.4 | 41.8 | 49.3 | 33.9 | 48.8 |
| All permutations | 49.0 | 46.0 | 56.1 | 40.5 | 54.6 | |
| Cyclic Permutations | 47.9 | 46.1 | 54.6 | 38.8 | 52.8 |
A Training details and additional results
训练细节与补充结果
A.1 MMLU
A.1 MMLU
A.1.1 Training Details
A.1.1 训练细节
Feat uri z ation MMLU consists of multiple choice questions with four possible lexical i zed answer options. We represent the input using the following template:
特征化
MMLU由四选一的选择题组成,答案选项均为词汇化形式。我们使用以下模板表示输入:
and train the model to generate the mask token followed by the letter of the correct answer:
训练模型生成掩码token (mask token) 后接正确答案字母:
[MASK_0] {correct answer option letter}
[MASK_0] {正确答案选项字母}
This format closely matches the format of MLM pre-training objective, aiding few-shot learning. When training, we permute the order of the answer options, i.e. shuffling which answer option appears as letter A etc. This helps reduce over fitting, and encourages a uniform prior on the letters.
这种格式与MLM预训练目标的形式高度匹配,有助于少样本学习。训练时我们会打乱答案选项的顺序(即随机调整哪个选项对应字母A等),这有助于降低过拟合风险,并促使模型对字母形成均匀的先验分布。
Standard inference Once trained we obtain predictions from the model by selecting the pre-softmax logits for the tokens A, B, C and D, and performing a softmax over them to obtain a distribution over the 4 answer options. For standard inference, we then simply return the answer corresponding to the argmax of this distribution.
标准推理
训练完成后,我们通过选取对应选项A、B、C和D的token的softmax前logits,并对其执行softmax运算,得到四个答案选项的概率分布。在标准推理中,我们直接返回该分布中argmax对应的答案。
De-biased Inference As mentioned in the main text, even though our model is finetuned with data that encourages a uniform prior over answer letters (by permuting which answer option letter is used with which lexical answer option text in training data), this may not be enough to ensure the model has no residual bias towards specific letters. Consider answers $a$ , questions $q$ and a nuisance variable $z\in{\mathcal{Z}}$ , which represents the ordering of the answer options or, equivalently, which answer letter gets assigned to which answer option text. There are 4 answer options in MMLU, and thus $|\mathcal{Z}|=24$ unique ways they can be ordered, or assigned to given letters. Running our model with our standard inference for a question q, corresponds to calculating $p(a|q={\mathfrak{q}},z=z)$ for the answer ordering $\mathbf{Z}$ that happens to appear in the dataset. We can control for $z$ by running the model with all possible answer orderings in the input, and marginal i zing: $\begin{array}{r}{p(a|q=\mathfrak{q})=\sum_{z^{\prime}\in\mathcal{Z}}p(a|q=\mathfrak{q},z=z^{\prime})p(z=z^{\prime}|q=\mathfrak{q})}\end{array}$ , and assuming $p(z=z^{\prime}|q=\mathfrak{q}$ ) is uniform (no answer ordering is m ore likely than another), this reduces to simply $\begin{array}{r}{p(a|q=\mathfrak{q})\propto\sum_{z^{\prime}\in\mathcal{Z}}p(a|q=\mathfrak{q},z=z^{\prime})}\end{array}$ . This procedure requires 24 forward passes, one for each answer ordering, so is $24\times$ slower than standard inference. Table 13 shows the result of applying the full permutation de-biasing, which leads to an $12%$ improvement zero-shot and 6% in 5-shot performance overall. Empirically, using only the cyclic permutations of the answer order provided in the original dataset (of which there are 4) works nearly as well, which is what we report in the main paper, and only increases inference compute by a factor of 4, rather than 24. Cyclic permutation de-biasing improves over standard inference by $10%$ in zero-shot and 5% in 5-shot. Empirically, de-biased inference is largely unnecessary when training in the 5-shot multitask or full dataset setting, as there is enough data for the model to learn a more uniform prior over the letters.
去偏推断
如正文所述,尽管我们的模型通过鼓励答案字母均匀先验的数据进行微调(在训练数据中置换答案选项字母与词汇答案文本的对应关系),但这可能不足以确保模型对特定字母没有残留偏差。考虑答案$a$、问题$q$和干扰变量$z\in{\mathcal{Z}}$(代表答案选项的排序,或等效于哪个答案字母被分配给哪个答案选项文本)。MMLU中有4个答案选项,因此$|\mathcal{Z}|=24$种唯一的排序方式。使用标准推断运行模型时,对应于计算数据集中出现的答案排序$\mathbf{Z}$下的$p(a|q={\mathfrak{q}},z=z)$。我们可以通过在输入中使用所有可能的答案排序运行模型并边缘化来控制$z$:$\begin{array}{r}{p(a|q=\mathfrak{q})=\sum_{z^{\prime}\in\mathcal{Z}}p(a|q=\mathfrak{q},z=z^{\prime})p(z=z^{\prime}|q=\mathfrak{q})}\end{array}$。假设$p(z=z^{\prime}|q=\mathfrak{q}$)是均匀的(没有答案排序比其他更可能),则简化为$\begin{array}{r}{p(a|q=\mathfrak{q})\propto\sum_{z^{\prime}\in\mathcal{Z}}p(a|q=\mathfrak{q},z=z^{\prime})}\end{array}$。此过程需要24次前向传递(每次对应一种答案排序),因此比标准推断慢24倍。
表13展示了应用全排列去偏的结果,零样本性能提升12%,5样本整体性能提升6%。实验表明,仅使用原始数据集中提供的循环排列(共4种)效果几乎相同(如主论文所述),且仅将推断计算量增加4倍而非24倍。循环排列去偏在零样本中比标准推断提升10%,在5样本中提升5%。实验发现,在5样本多任务或全数据集设置下训练时,去偏推断大多不必要,因为有足够数据让模型学习更均匀的字母先验。
Table 14: Hyper parameters for MMLU
| 770M | 3B | 11B | |
| Batchsize | 64 | 64 | 64 |
| Learning rate | (5e-5,1e-5) | (5e-5,1e-5) | (5e-5,1e-5) |
| Retriever Temperature | 0.1 | 0.1 | 0.1 |
| 5-shot train steps | 64 | 32 | 16 |
| 5-shot (multitask) max train steps | 2000 | 500 | 250 |
| Full transfer max train steps | 5000 | 2000 | 2000 |
表 14: MMLU超参数
| 770M | 3B | 11B | |
|---|---|---|---|
| Batchsize | 64 | 64 | 64 |
| Learning rate | (5e-5,1e-5) | (5e-5,1e-5) | (5e-5,1e-5) |
| Retriever Temperature | 0.1 | 0.1 | 0.1 |
| 5-shot train steps | 64 | 32 | 16 |
| 5-shot (multitask) max train steps | 2000 | 500 | 250 |
| Full transfer max train steps | 5000 | 2000 | 2000 |
Evaluation We evaluate by following the method of Hendrycks et al. (2021), namely, micro-averaging across all 57 domains to obtain overall accuracy. We quote the results of GPT3 (Brown et al., 2020) and UnifiedQA (Khashabi et al., 2020) from the MMLU leader board at https://github.com/hendrycks/test. For Chinchilla and Gopher, we calculate the scores on the categories using the full MMLU results from Hoffmann et al. (2022).
评估
我们按照 Hendrycks 等人 (2021) 的方法进行评估,即对所有 57 个领域进行微观平均以获取总体准确率。我们从 https://github.com/hendrycks/test 的 MMLU 排行榜中引用了 GPT3 (Brown 等人, 2020) 和 UnifiedQA (Khashabi 等人, 2020) 的结果。对于 Chinchilla 和 Gopher,我们使用 Hoffmann 等人 (2022) 的完整 MMLU 结果计算了各分类的得分。
Index The index used for MMLU for all MMLU experiments in the main paper comprised of concatenation of the Wikipedia passages, Wikipedia info boxes and Common Crawl indices, for a total of 387M passages. We can assess the importance of the index by running a model without the common crawl data, leading to a 5-shot multitask result of $52.8%$ , compared to $56.4%$ for the full model, a drop of $3.6%$ . This indicates that whilst the Wikipedia data is sufficient do well on the task, the addition of the CC data improves results further.
索引
主论文中所有MMLU实验使用的索引由维基百科文章、维基百科信息框和Common Crawl索引拼接而成,总计3.87亿个段落。通过移除Common Crawl数据运行模型,可以评估索引的重要性:零样本多任务结果为$52.8%$,而完整模型为$56.4%$,下降$3.6%$。这表明虽然维基百科数据足以完成任务,但加入CC数据能进一步提升效果。
Hyper parameters and development data Selecting hyper parameters is challenging in few-shot settings. We do not assume access to an in-domain development set for the 5-shot task. Instead, we determine a set of hyper parameters for the 5-shot task using data from RACE, one of the auxiliary datasets provided by MMLU. Here, we sample 5 sets of 5-shot training data, and for each model size, we explore batch size ${32,64}$ , learning rates for the language model and retriever {(5e-5, 1e-5), (4e-5, 4e-5)}, retriever temperature ${0.1,0.01}$ and a fixed number of training steps ${16,32,64,128}$ , picking the setting that achieves strongest RACE validation scores. Having determined these hyper parameters, we apply them directly to the 5-shot MMLU task. For the 5-shot multi-task and full/transfer settings, we use the same batch size, temperatures and learning rates as the 5-shot task, but use a set of 285 MMLU validation examples (5 per domain) in order to determine the total number of training steps and for early stopping. The hyper parameters selected in the MMLU experiments can be found in table 14. We use query-side finetuning for the 5-shot and 5-shot multitask settings, and top-128 reranking for the full setting. For all MMLU runs we retrieve 30 documents
超参数与开发数据
在少样本场景中选择超参数具有挑战性。我们未假设5样本任务存在领域内开发集,而是通过MMLU提供的辅助数据集RACE来确定5样本任务的超参数组合。具体流程为:采样5组5样本训练数据,针对每个模型规模探索批量大小${32,64}$、语言模型与检索器的学习率组合{(5e-5, 1e-5), (4e-5, 4e-5)}、检索器温度${0.1,0.01}$以及固定训练步数${16,32,64,128}$,最终选择RACE验证集得分最优的配置。确定这些超参数后,我们将其直接应用于5样本MMLU任务。
对于5样本多任务和全量/迁移场景,我们沿用5样本任务的批量大小、温度及学习率,但使用285个MMLU验证样本(每个领域5个)来确定总训练步数并实施早停机制。MMLU实验所选超参数详见表14。我们在5样本和5样本多任务场景采用查询侧微调,全量场景采用top-128重排序。所有MMLU实验均检索30份文档。
Inter-run Variance few-shot learning is well-known to suffer from high variance. In the main paper, we quote the result obtained with our first run. In order to assess the effect of noise and variance, we ran the 5-shot experiment with Atlas 5 times.7 We observe high variance for individual domains, sometimes as high as 20%, however, once aggregated across all 57 domains, the inter-run variance is low. The overall scores for these different runs, when using the same hyper parameters are shown in table 15. Due the effects of averaging over the many domains that comprise MMLU, the inter-run variance is quite modest on the aggregated metrics, with a std deviation of 0.5 in this experiment.
跨轮次方差
少样本学习存在高方差问题众所周知。在正文中,我们引用了首次实验获得的结果。为评估噪声和方差的影响,我们对Atlas进行了5次5样本实验。观察到单个领域的方差较高,有时高达20%,但一旦汇总所有57个领域后,跨轮次方差显著降低。表15展示了使用相同超参数时,不同实验轮次的总体得分。由于MMLU包含众多领域,求平均效应使得跨轮次方差在汇总指标上较为稳定,本实验标准差为0.5。
表15:
Closed-Book Baselines The closed book baselines we compare Atlas to in table 5 are initialized from the same T5 model as their respective Atlas, and then pre-trained with MLM for the same number of steps (10K) using the same pre-training data as Atlas, for fairer comparison. The same procedure as for Atlas was used to determine hyper parameters for MMLU for the closed-book model.s
闭卷基线
表5中与Atlas对比的闭卷基线均采用相同T5模型初始化(与其对应Atlas版本一致),并使用与Atlas相同的预训练数据通过MLM(掩码语言建模)进行等量步数(10K步)预训练以确保公平比较。闭卷模型的MMLU超参数调优流程与Atlas完全一致。
Table 15: Interrun Variance for 5-shot MMLU using Atlas-11B
| Run # | All | Hum. | Soc. Sci. | STEM | Other |
| 1 | 45.2 | 40.6 | 54.1 | 37.1 | 51.1 |
| 2 | 45.1 | 39.8 | 54.4 | 37.1 | 52.0 |
| 3 | 45.0 | 40.0 | 54.1 | 37.7 | 51.1 |
| 4 | 45.6 | 41.3 | 54.7 | 37.0 | 51.6 |
| 5 | 44.3 | 40.6 | 50.7 | 38.1 | 49.8 |
| Ave: | 45.0 ± 0.5 | 40.5 ±0.6 | 53.6 ± 1.6 | 37.4 ± 0.5 | 51.1 ± 0.8 |
表 15: 使用Atlas-11B进行5样本MMLU测试的组间方差
| Run # | All | Hum. | Soc. Sci. | STEM | Other |
|---|---|---|---|---|---|
| 1 | 45.2 | 40.6 | 54.1 | 37.1 | 51.1 |
| 2 | 45.1 | 39.8 | 54.4 | 37.1 | 52.0 |
| 3 | 45.0 | 40.0 | 54.1 | 37.7 | 51.1 |
| 4 | 45.6 | 41.3 | 54.7 | 37.0 | 51.6 |
| 5 | 44.3 | 40.6 | 50.7 | 38.1 | 49.8 |
| Ave: | 45.0 ± 0.5 | 40.5 ±0.6 | 53.6 ± 1.6 | 37.4 ± 0.5 | 51.1 ± 0.8 |
A.1.2 Full results
A.1.2 完整结果
A.2 Question answering
A.2 问答
A.2.1 Training Details
A.2.1 训练细节
For question answering, similarly to the MMLU experiments, we format the input using the following template:
对于问答任务,类似于MMLU实验,我们使用以下模板格式化输入:
question: {question text} answer: [MASK_0] and train the model to generate the mask token followed by the answer:
问题:{问题文本} 答案:[MASK_0] 并训练模型生成掩码标记 (mask token) 后接答案:
[MASK_0] {answer}.
[MASK_0] {答案}.
We generate answers using greedy decoding. For both training and testing, we retrieve 40 passages, and truncate the result of the concatenation between the query and the passages to 384 tokens.
我们使用贪心解码(greedy decoding)生成答案。在训练和测试阶段,均检索40个段落,并将查询与段落拼接后的结果截断至384个token。
For few-shot fine-tuning we train Atlas for 30 steps using 64 random samples from the train sets. The retriever is trained using query-side fine-tuning. We select the model after 30 training steps. We use AdamW with a batch size of 32 and a learning rate of $4\times10^{-5}$ with linear decay and 5 iterations of warmup for both the language model and the retriever.
对于少样本微调,我们使用训练集中的64个随机样本对Atlas进行30步训练。检索器采用查询端微调方式进行训练。在完成30个训练步骤后选择最终模型。语言模型和检索器均使用AdamW优化器,批次大小为32,学习率为$4\times10^{-5}$,采用线性衰减策略并包含5次预热迭代。
For the fine-tuning on the full datasets, we train the model for 5k gradient steps and refresh the index every 500 steps for the first 1,000 training steps and every 2k training steps afterwards. We use AdamW with a batch size of 64 and a learning rate of $4\times10^{-5}$ with linear decay and 5 iterations of warmup for both the language model and the retriever. We evaluate models every 500 steps and select the best one on the validation set based on the exact match score.
在对完整数据集进行微调时,我们训练模型执行5,000次梯度更新,并在前1,000次训练步骤中每500步刷新索引,之后每2,000次训练步骤刷新一次。我们使用AdamW优化器,批处理大小为64,学习率为$4\times10^{-5}$,并采用线性衰减策略,语言模型和检索器均进行5轮预热。每500步评估一次模型,根据验证集上的精确匹配分数选择最佳模型。
A.2.2 Impact of scaling
A.2.2 规模扩展的影响
In Table 19, we report performance on Natural Questions and TriviaQA as a function of the number of parameters in the reader module. Both for few-shot learning and full fine-tuning we observe strong improvements by scaling the size of the reader module. However we can notice sign of saturation when finetuning on full datasets, with limited gains when scaling from 3B to 11B parameters (+0.6% on Natural Questions, $+0.5%$ on TriviaQA). While performance improves substantially when scaling from 3B to 11B parameters with 64 training samples, with $+3.7%$ and $+1.2%$ improvement on Natural Questions and TriviaQA respectively. For these experiments we use a setup similar to the one use in Table 8, except that we use an index composed of the December 2018 Wikipedia dump processed as described in section 4.2.
在表19中,我们报告了Natural Questions和TriviaQA任务上阅读器模块参数量对性能的影响。无论是少样本学习还是全量微调,扩大阅读器模块规模都能带来显著提升。但在全数据集微调时观察到饱和迹象:参数量从30亿增至110亿时,Natural Questions仅提升0.6%,TriviaQA提升$+0.5%$。相比之下,使用64个训练样本时,参数量从30亿扩展到110亿使Natural Questions提升$+3.7%$,TriviaQA提升$+1.2%$。本实验采用与表8相似的配置,区别在于使用了2018年12月维基百科快照构建的索引(处理方法见第4.2节)。
A.3 KILT
A.3 KILT
For the results on KILT reported in Table 10 we fine-tune Atlas individually on each dataset. We format the input using a template similar to the one used for question answering:
表 10 中报告的 KILT 结果是在每个数据集上单独微调 Atlas 得到的。我们使用类似于问答任务的模板格式化输入:
| 5-shot | 5-shot (multi-task) | Full Transfer 11B | ||||||
| 770M 3B | 11B | 770M | 3B | 11B 770M | 3B | |||
| All | 38.9 | 42.3 | 43.4 | 42.1 | 48.7 56.4 | 56.3 | 59.9 | 65.8 |
| Humanities | 37.3 | 40.0 | 41.9 | 37.7 46.4 | 50.0 | 50.9 | 53.0 | 60.3 |
| Social Sciences | 41.7 | 46.8 | 49.3 | 47.5 53.7 | 65.6 | 66.0 | 70.8 | 77.2 |
| STEM | 32.3 | 35.0 | 33.9 | 34.4 | 39.4 46.2 | 44.8 | 50.7 | 53.4 |
| Other | 44.9 | 48.1 | 48.8 | 50.4 55.9 | 66.6 | 65.5 | 68.1 | 74.4 |
| abstract algebra | 30.0 | 27.0 | 28.0 | 27.0 31.0 | 30.0 | 22.0 | 27.0 | 33.0 |
| anatomy | 28.9 | 50.4 | 45.2 | 44.4 57.8 | 64.4 | 57.8 | 68.9 | 69.6 |
| astronomy | 55.3 | 59.9 | 59.2 | 52.6 66.4 | 67.8 | 69.1 | 78.3 | 79.6 |
| business ethics | 49.0 | 51.0 | 48.0 | 50.0 62.0 | 60.0 | 51.0 | 70.0 | 68.0 |
| clinical knowledge | 41.9 | 44.9 | 40.0 | 46.8 54.3 | 64.9 | 64.2 | 72.5 | 74.0 |
| college biology | 38.2 | 45.8 | 50.0 | 36.8 52.1 | 63.2 | 63.2 | 72.2 | 78.5 |
| college chemistry | 32.0 | 29.0 | 29.0 | 31.0 33.0 | 38.0 | 45.0 | 39.0 | 45.0 |
| college computer science | 33.0 | 35.0 | 30.0 | 23.0 29.0 | 30.0 | 43.0 | 48.0 | 47.0 |
| college mathematics | 31.0 | 31.0 | 28.0 | 29.0 27.0 | 34.0 | 32.0 | 29.0 | 36.0 |
| college medicine | 31.2 | 35.8 | 38.2 | 50.3 40.5 | 52.0 | 60.1 | 59.5 | 63.6 |
| college physics | 20.6 | 26.5 | 31.4 | 21.6 28.4 | 39.2 | 27.5 | 44.1 | 42.2 |
| computer security | 53.0 | 50.0 | 55.0 | 49.0 61.0 | 64.0 | 69.0 | 71.0 | 76.0 |
| conceptual physics | 34.9 | 41.7 | 37.4 | 40.9 43.4 | 57.0 | 53.2 | 58.3 | 59.6 |
| econometrics | 28.9 | 21.1 | 27.2 | 26.3 25.4 | 34.2 | 28.9 | 37.7 | 36.8 |
| electrical engineering | 26.9 | 31.7 | 31.7 | 38.6 44.1 | 51.7 | 61.4 | 60.7 | 67.6 |
| elementary mathematics | 25.9 | 28.8 | 29.4 | 29.6 30.2 | 32.8 | 29.6 | 35.5 | 33.9 |
| formal logic | 34.9 | 33.3 | 33.3 | 23.0 30.2 | 29.4 | 34.1 | 38.9 | 34.1 |
| global facts | 28.0 | 34.0 | 34.0 | 36.0 40.0 | 49.0 | 50.0 | 49.0 | 52.0 |
| 24.8 | 37.7 | 27.7 | 48.7 57.1 | 66.5 | 66.5 | 76.8 | 81.9 | |
| high school biology | 34.5 | 31.0 | 31.0 | 31.5 36.5 | 48.3 | 44.8 | 52.2 | 52.2 |
| high school chemistry | 31.0 | 39.0 | 28.0 | 37.0 42.0 | 42.0 | 50.0 | 59.0 | 57.0 |
| high school computer science | 42.4 | 49.7 | 53.3 | 50.9 58.2 | 69.7 | 70.9 | 73.9 | 80.0 |
| high school european history | 38.9 | 42.4 | 50.0 | 46.5 56.6 | 69.2 | 74.2 | 80.8 | 82.8 |
| high school geography high school gov. and pol. | 57.5 | 60.6 | 60.1 | 52.9 64.8 | 76.7 | 80.8 | 85.5 | 91.7 |
| high school macroeconomics | 32.8 | 39.7 | 44.9 | 39.0 45.6 | 57.2 | 55.1 | 63.1 | 66.7 |
| high school mathematics | 30.7 | 33.0 | 35.6 | 28.1 27.8 | 37.0 | 30.7 | 34.8 | 37.0 |
| high school microeconomics | 34.5 | 42.9 | 45.4 | 44.1 51.7 | 68.9 | 63.4 | 70.2 | 81.1 |
| high school physics | 18.5 | 24.5 | 22.5 | 25.8 25.8 | 33.1 | 27.2 | 30.5 | 39.7 |
| high school psychology | 52.8 | 61.1 | 59.8 | 56.7 67.2 | 79.4 | 76.3 | 84.0 | 87.0 |
| high school statistics | 39.8 | 29.6 | 34.7 | 27.3 34.7 | 38.0 | 37.0 | 43.1 | 45.8 |
| high school us history | 43.6 | 49.0 | 55.9 | 46.1 57.8 | 59.8 | 62.7 | 72.5 | 76.5 |
| high school world history | 48.1 | 52.7 | 59.9 | 48.1 66.2 | 65.4 | 70.0 | 78.5 | 79.7 |
| human aging | 46.2 | 44.8 | 39.5 | 48.0 55.2 | 60.1 | 56.1 | 68.2 | 73.1 |
| human sexuality | 41.2 | 43.5 | 27.5 | 46.6 51.1 | 59.5 | 77.1 | 72.5 | 81.7 |
| international law | 54.5 | 57.9 | 60.3 | 55.4 72.7 | 73.6 | 81.8 | 82.6 | 85.1 |
| jurisprudence | 38.9 | 55.6 | 32.4 | 53.7 60.2 | 73.1 | 76.9 | 73.1 | 81.5 |
| logical fallacies | 43.6 | 54.0 | 57.1 | 44.2 58.3 31.3 37.5 | 70.6 46.4 | 64.4 36.6 | 73.0 47.3 | 76.7 50.9 |
| machine learning management | 36.6 45.6 | 34.8 51.5 | 28.6 52.4 48.5 | |||||
| 5-shot | 5-shot (multi-task) | Full Transfer 11B | ||||||
|---|---|---|---|---|---|---|---|---|
| 770M 3B | 11B | 770M | 3B | 11B 770M | 3B | |||
| All | 38.9 | 42.3 | 43.4 | 42.1 | 48.7 56.4 | 56.3 | 59.9 | 65.8 |
| Humanities | 37.3 | 40.0 | 41.9 | 37.7 46.4 | 50.0 | 50.9 | 53.0 | 60.3 |
| Social Sciences | 41.7 | 46.8 | 49.3 | 47.5 53.7 | 65.6 | 66.0 | 70.8 | 77.2 |
| STEM | 32.3 | 35.0 | 33.9 | 34.4 | 39.4 46.2 | 44.8 | 50.7 | 53.4 |
| Other | 44.9 | 48.1 | 48.8 | 50.4 55.9 | 66.6 | 65.5 | 68.1 | 74.4 |
| abstract algebra | 30.0 | 27.0 | 28.0 | 27.0 31.0 | 30.0 | 22.0 | 27.0 | 33.0 |
| anatomy | 28.9 | 50.4 | 45.2 | 44.4 57.8 | 64.4 | 57.8 | 68.9 | 69.6 |
| astronomy | 55.3 | 59.9 | 59.2 | 52.6 66.4 | 67.8 | 69.1 | 78.3 | 79.6 |
| business ethics | 49.0 | 51.0 | 48.0 | 50.0 62.0 | 60.0 | 51.0 | 70.0 | 68.0 |
| clinical knowledge | 41.9 | 44.9 | 40.0 | 46.8 54.3 | 64.9 | 64.2 | 72.5 | 74.0 |
| college biology | 38.2 | 45.8 | 50.0 | 36.8 52.1 | 63.2 | 63.2 | 72.2 | 78.5 |
| college chemistry | 32.0 | 29.0 | 29.0 | 31.0 33.0 | 38.0 | 45.0 | 39.0 | 45.0 |
| college computer science | 33.0 | 35.0 | 30.0 | 23.0 29.0 | 30.0 | 43.0 | 48.0 | 47.0 |
| college mathematics | 31.0 | 31.0 | 28.0 | 29.0 27.0 | 34.0 | 32.0 | 29.0 | 36.0 |
| college medicine | 31.2 | 35.8 | 38.2 | 50.3 40.5 | 52.0 | 60.1 | 59.5 | 63.6 |
| college physics | 20.6 | 26.5 | 31.4 | 21.6 28.4 | 39.2 | 27.5 | 44.1 | 42.2 |
| computer security | 53.0 | 50.0 | 55.0 | 49.0 61.0 | 64.0 | 69.0 | 71.0 | 76.0 |
| conceptual physics | 34.9 | 41.7 | 37.4 | 40.9 43.4 | 57.0 | 53.2 | 58.3 | 59.6 |
| econometrics | 28.9 | 21.1 | 27.2 | 26.3 25.4 | 34.2 | 28.9 | 37.7 | 36.8 |
| electrical engineering | 26.9 | 31.7 | 31.7 | 38.6 44.1 | 51.7 | 61.4 | 60.7 | 67.6 |
| elementary mathematics | 25.9 | 28.8 | 29.4 | 29.6 30.2 | 32.8 | 29.6 | 35.5 | 33.9 |
| formal logic | 34.9 | 33.3 | 33.3 | 23.0 30.2 | 29.4 | 34.1 | 38.9 | 34.1 |
| global facts | 28.0 | 34.0 | 34.0 | 36.0 40.0 | 49.0 | 50.0 | 49.0 | 52.0 |
| 24.8 | 37.7 | 27.7 | 48.7 57.1 | 66.5 | 66.5 | 76.8 | 81.9 | |
| high school biology | 34.5 | 31.0 | 31.0 | 31.5 36.5 | 48.3 | 44.8 | 52.2 | 52.2 |
| high school chemistry | 31.0 | 39.0 | 28.0 | 37.0 42.0 | 42.0 | 50.0 | 59.0 | 57.0 |
| high school computer science | 42.4 | 49.7 | 53.3 | 50.9 58.2 | 69.7 | 70.9 | 73.9 | 80.0 |
| high school european history | 38.9 | 42.4 | 50.0 | 46.5 56.6 | 69.2 | 74.2 | 80.8 | 82.8 |
| high school geography high school gov. and pol. | 57.5 | 60.6 | 60.1 | 52.9 64.8 | 76.7 | 80.8 | 85.5 | 91.7 |
| high school macroeconomics | 32.8 | 39.7 | 44.9 | 39.0 45.6 | 57.2 | 55.1 | 63.1 | 66.7 |
| high school mathematics | 30.7 | 33.0 | 35.6 | 28.1 27.8 | 37.0 | 30.7 | 34.8 | 37.0 |
| high school microeconomics | 34.5 | 42.9 | 45.4 | 44.1 51.7 | 68.9 | 63.4 | 70.2 | 81.1 |
| high school physics | 18.5 | 24.5 | 22.5 | 25.8 25.8 | 33.1 | 27.2 | 30.5 | 39.7 |
| high school psychology | 52.8 | 61.1 | 59.8 | 56.7 67.2 | 79.4 | 76.3 | 84.0 | 87.0 |
| high school statistics | 39.8 | 29.6 | 34.7 | 27.3 34.7 | 38.0 | 37.0 | 43.1 | 45.8 |
| high school us history | 43.6 | 49.0 | 55.9 | 46.1 57.8 | 59.8 | 62.7 | 72.5 | 76.5 |
| high school world history | 48.1 | 52.7 | 59.9 | 48.1 66.2 | 65.4 | 70.0 | 78.5 | 79.7 |
| human aging | 46.2 | 44.8 | 39.5 | 48.0 55.2 | 60.1 | 56.1 | 68.2 | 73.1 |
| human sexuality | 41.2 | 43.5 | 27.5 | 46.6 51.1 | 59.5 | 77.1 | 72.5 | 81.7 |
| international law | 54.5 | 57.9 | 60.3 | 55.4 72.7 | 73.6 | 81.8 | 82.6 | 85.1 |
| jurisprudence | 38.9 | 55.6 | 32.4 | 53.7 60.2 | 73.1 | 76.9 | 73.1 | 81.5 |
| logical fallacies | 43.6 | 54.0 | 57.1 | 44.2 58.3 31.3 37.5 | 70.6 46.4 | 64.4 36.6 | 73.0 47.3 | 76.7 50.9 |
| machine learning management | 36.6 45.6 | 34.8 51.5 | 28.6 52.4 48.5 |
Table 16: MMLU Test set scores for Atlas for each model size and each of the 57 domains.
表 16: Atlas 各模型尺寸在 57 个领域的 MMLU 测试集分数。
| 5-shot | 5-shot (multi-task) | Full Transfer | |||||||
| 770M | 3B 35.7 | 11B 36.1 | 770M 26.5 | 3B 40.0 | 11B 43.5 | 770M | 3B | 11B | |
| All | 29.2 | 42.4 | 50.4 | 54.0 | |||||
| Humanities | 30.5 | 35.4 | 35.5 | 27.3 | 38.5 | 41.6 | 41.0 | 48.6 | 51.3 |
| Social Sciences | 29.7 | 38.0 | 39.4 | 24.8 | 43.8 | 48.9 | 48.6 | 57.8 | 64.7 |
| STEM | 29.0 | 31.4 | 30.8 38.6 | 26.5 | 32.8 | 35.8 | 33.4 | 40.6 | 41.7 |
| Other | 26.7 | 37.7 | 27.0 | 45.0 | 48.5 | 46.8 | 55.2 | 59.1 | |
| abstract algebra | 26.0 | 23.0 | 21.0 | 29.0 | 30.0 | 26.0 | 23.0 | 29.0 | 26.0 |
| anatomy astronomy | 21.5 | 40.0 | 40.7 | 27.4 | 39.3 | 45.9 | 35.6 | 43.7 | 42.2 |
| 37.5 | 38.8 | 37.5 | 27.6 | 39.5 | 41.4 | 36.2 | 50.7 | 55.3 | |
| business ethics | 29.0 | 54.0 | 42.0 | 26.0 | 47.0 | 55.0 | 53.0 | 64.0 | 60.0 |
| clinical knowledge | 32.5 | 33.6 | 40.0 | 28.7 | 44.2 | 47.9 | 45.3 | 52.8 | 57.7 |
| college biology | 29.9 | 34.7 | 34.0 | 29.9 | 34.7 | 40.3 | 38.2 | 46.5 | 52.1 |
| college chemistry | 37.0 | 22.0 | 32.0 | 20.0 | 35.0 | 33.0 | 36.0 | 34.0 | 36.0 |
| college computer science | 28.0 | 35.0 | 34.0 | 28.0 | 27.0 | 36.0 | 31.0 | 44.0 | 35.0 |
| college mathematics | 31.0 | 29.0 | 27.0 | 22.0 | 34.0 | 27.0 | 30.0 | 33.0 | 32.0 |
| college medicine | 24.3 | 34.7 | 34.1 | 27.2 | 40.5 | 40.5 | 35.8 | 41.6 | 48.6 |
| college physics | 33.3 | 23.5 | 23.5 | 22.5 | 19.6 | 26.5 | 22.5 | 32.4 | 24.5 |
| computer security | 36.0 | 42.0 | 46.0 | 31.0 | 49.0 | 52.0 | 50.0 | 65.0 | 61.0 |
| conceptual physics | 26.4 | 35.7 | 30.2 | 23.4 | 30.6 | 32.8 | 34.5 | 37.4 | 43.8 |
| econometrics | 26.3 | 21.9 | 28.9 | 17.5 | 19.3 | 24.6 | 29.8 | 25.4 | 29.8 |
| electrical engineering | 31.0 | 33.1 | 31.7 | 31.0 | 31.0 | 36.6 | 41.4 | 47.6 | 51.7 |
| elementary mathematics | 26.2 | 27.5 | 28.0 | 27.0 | 31.2 | 33.3 | 25.9 | 31.2 | 35.5 |
| formal logic | 34.1 | 34.1 | 31.7 | 15.1 | 34.9 | 31.0 | 31.7 | 38.1 | 42.1 |
| global facts | 32.0 | 30.0 | 25.0 | 34.0 | 34.0 | 27.0 | 28.0 | 34.0 | 30.0 |
| high school biology | 22.6 | 31.9 | 29.7 | 27.1 | 41.6 | 50.0 | 43.5 | 57.7 | 60.6 |
| high school chemistry | 27.1 | 26.6 | 27.6 | 28.6 | 31.5 | 29.1 | 30.5 | 36.5 | 38.9 |
| high school computer science | 26.0 | 32.0 | 25.0 | 33.0 | 37.0 | 45.0 45.0 | 55.0 | 48.0 | |
| high school european history | 34.5 | 43.0 | 42.4 | 24.2 | 60.0 | 59.4 58.2 | 69.1 | 76.4 | |
| high school geography | 31.3 | 40.4 | 36.9 | 24.7 | 45.5 | 50.5 | 56.1 | 66.7 | 74.2 |
| high school gov. and pol. | 28.0 | 49.2 | 51.3 | 19.2 | 56.0 | 59.6 | 55.4 | 70.5 | 75.6 |
| high school macroeconomics | 25.6 | 37.7 | 32.1 | 26.7 | 42.3 | 43.6 | 41.0 | 51.5 | 56.4 |
| high school mathematics | 35.9 | 35.2 | 35.9 | 28.1 | 26.7 | 31.1 | 27.8 | 36.7 | 31.9 |
| high school microeconomics | 27.3 | 29.8 | 36.1 | 20.6 | 35.7 | 42.9 | 42.9 | 50.8 | 60.5 |
| high school physics | 21.9 | 25.2 | 22.5 | 24.5 | 28.5 | 29.1 | 27.8 | 31.1 | 27.8 |
| high school psychology | 26.1 | 46.4 | 51.0 | 24.8 | 54.3 | 60.2 | 56.3 | 67.3 | 76.1 |
| high school statistics | 27.8 | 33.3 | 33.3 | 17.6 | 30.6 | 33.8 | 32.9 | 33.3 | 37.0 |
| high school us history | 30.4 | 39.7 | 45.6 | 27.5 | 46.1 | 58.3 | 51.0 | 63.2 | 72.5 |
| high school world history | 42.6 | 50.6 | 41.8 | 29.1 | 54.0 | 64.6 | 66.7 | 72.2 | 73.8 |
| human aging | 28.3 | 37.2 | 29.6 41.2 | 26.0 25.2 | 45.3 42.0 | 46.2 44.3 51.1 | 46.6 | 57.0 | 62.8 |
| human sexuality | 29.8 | 34.4 | 41.3 | 57.9 | 58.7 62.8 | 58.0 71.9 71.1 | 59.5 | ||
| international law jurisprudence | 57.9 30.6 | 57.9 33.3 | 34.3 | 44.6 32.4 | 49.1 | ||||
Table 17: MMLU Test scores for the T5 closed book baseline for each model size and each of the 57 domains.
表 17: 各模型尺寸在57个领域的T5闭卷基线MMLU测试分数
| Domain | zero-shot | 5-shot | 5-shot (multi-task) | Full / Transfer |
| All | 47.1 | 47.9 | 56.6 | 66.0 |
| Humanities | 43.6 | 46.1 | 50.1 | 61.1 |
| Social Sciences | 54.1 | 54.6 | 66.4 | 77.2 |
| STEM | 38.0 | 38.8 | 46.4 | 53.2 |
| Other | 53.9 | 52.8 | 66.2 | 74.4 |
| abstract algebra | 22.0 | 26.0 | 31.0 | 31.0 |
| anatomy | 48.9 | 47.4 | 62.2 | 70.4 |
| astronomy | 61.8 | 62.5 | 68.4 | 81.6 |
| business ethics | 60.0 | 57.0 | 62.0 | 70.0 |
| clinical knowledge | 50.6 | 49.4 | 66.4 | 72.8 |
| college biology | 51.4 | 53.5 | 61.1 | 77.8 |
| college chemistry | 36.0 | 39.0 | 39.0 | 45.0 |
| college computer science | 32.0 | 32.0 | 33.0 | 49.0 |
| college mathematics | 30.0 | 35.0 | 35.0 | 34.0 |
| college medicine | 44.5 | 41.0 | 52.6 | 67.6 |
| college physics | 24.5 | 26.5 | 37.3 | 42.2 |
| computer security | 59.0 | 59.0 | 68.0 | 76.0 |
| conceptual physics | 37.0 | 41.3 | 57.0 | 60.0 |
| econometrics | 20.2 | 20.2 | 36.8 | 37.7 |
| electrical engineering | 37.9 | 40.0 | 50.3 | 65.5 |
| elementary mathematics | 31.2 | 28.0 | 30.7 | 36.5 |
| formal logic | 27.8 | 27.0 | 32.5 | 35.7 |
| global facts | 41.0 | 43.0 | 51.0 | 53.0 |
| high school biology | 53.2 | 56.5 | 68.7 | 83.2 |
| high school chemistry | 41.9 | 41.4 | 49.3 | 51.2 |
| high school computer science | 40.0 | 36.0 | 46.0 | 60.0 |
| high school european history | 56.4 | 58.8 | 68.5 | 80.6 |
| high school geography | 57.1 | 59.6 | 71.2 | 81.3 |
| high school gov. and pol. | 67.9 | 67.9 | 77.2 | 90.2 |
| high school macroeconomics | 46.9 | 48.5 | 57.9 | 65.9 |
| high school mathematics | 28.1 | 28.9 | 34.1 | 31.5 |
| high school microeconomics | 51.7 | 51.7 | 68.9 | 82.4 |
| high school physics | 26.5 | 25.8 | 32.5 | 41.1 |
| high school psychology | 66.2 | 65.5 | 78.9 | 86.8 |
| high school statistics | 31.5 | 30.1 | 43.1 | 45.8 |
| high school us history | 57.8 | 54.9 | 64.7 | 77.5 |
| high school world history | 59.1 | 62.9 | 65.4 | 79.3 |
| human aging | 48.4 | 50.7 | 60.5 | 70.4 |
| human sexuality | 55.7 | 54.2 | 61.8 | 84.0 |
| international law | 66.1 | 72.7 | 71.9 | 84.3 |
| jurisprudence | 61.1 | 64.8 | 72.2 | 81.5 |
| logical fallacies | 54.6 | 57.7 | 71.2 | 77.9 |
| machine learning | 37.5 | 39.3 | 43.8 | 44.6 |
| management | 56.3 | 56.3 | 79.6 | 89.3 |
| marketing | 72.2 | 73.1 | 84.6 | 91.9 |
| medical genetics | 55.0 | 58.0 | 71.0 | 81.0 |
| miscellaneous | 69.7 | 67.8 | 83.8 | 90.4 |
| moral disputes | 45.1 | 46.8 | 60.1 | 72.3 |
| moral scenarios | 24.5 | 30.3 | 25.8 | 38.5 |
| nutrition | 56.5 | 53.9 | 67.0 | 77.1 |
| philosophy | 56.3 | 57.6 | 70.7 | 77.2 |
| prehistory | 59.3 | 60.5 | 71.6 | 78.7 |
| professional accounting | 35.1 | 33.0 | 42.2 | 50.7 |
| professional law | 36.3 | 38.4 | 39.4 | 51.7 |
| professional medicine | 35.7 | 33.1 | 52.2 | 60.7 |
| professional psychology | 47.7 | 49.3 | 60.9 | 74.0 |
| public relations | 54.5 | 53.6 | 68.2 | 68.2 |
| security studies | 47.3 | 45.7 | 59.2 | 73.9 |
| sociology | 62.2 | 62.7 | 71.6 | 84.6 |
| us foreign policy | 64.0 | 68.0 | 73.0 | 83.0 |
| virology world religions | 39.8 77.2 | 40.4 74.9 | 44.6 80.7 | 51.8 87.1 |
Table 18: MMLU Test set scores for the de-biased Atlas-XXL using cyclic permutations for each of the 57 domains for zero-shot, 5 shot, 5-shot-multitask and the transfer setting.
| 领域 | 零样本 | 5样本 | 5样本(多任务) | 完整/迁移 |
|---|---|---|---|---|
| 全部 | 47.1 | 47.9 | 56.6 | 66.0 |
| 人文 | 43.6 | 46.1 | 50.1 | 61.1 |
| 社会科学 | 54.1 | 54.6 | 66.4 | 77.2 |
| STEM | 38.0 | 38.8 | 46.4 | 53.2 |
| 其他 | 53.9 | 52.8 | 66.2 | 74.4 |
| 抽象代数 | 22.0 | 26.0 | 31.0 | 31.0 |
| 解剖学 | 48.9 | 47.4 | 62.2 | 70.4 |
| 天文学 | 61.8 | 62.5 | 68.4 | 81.6 |
| 商业伦理 | 60.0 | 57.0 | 62.0 | 70.0 |
| 临床知识 | 50.6 | 49.4 | 66.4 | 72.8 |
| 大学生物学 | 51.4 | 53.5 | 61.1 | 77.8 |
| 大学化学 | 36.0 | 39.0 | 39.0 | 45.0 |
| 大学计算机科学 | 32.0 | 32.0 | 33.0 | 49.0 |
| 大学数学 | 30.0 | 35.0 | 35.0 | 34.0 |
| 大学医学 | 44.5 | 41.0 | 52.6 | 67.6 |
| 大学物理 | 24.5 | 26.5 | 37.3 | 42.2 |
| 计算机安全 | 59.0 | 59.0 | 68.0 | 76.0 |
| 概念物理 | 37.0 | 41.3 | 57.0 | 60.0 |
| 计量经济学 | 20.2 | 20.2 | 36.8 | 37.7 |
| 电气工程 | 37.9 | 40.0 | 50.3 | 65.5 |
| 初等数学 | 31.2 | 28.0 | 30.7 | 36.5 |
| 形式逻辑 | 27.8 | 27.0 | 32.5 | 35.7 |
| 全球常识 | 41.0 | 43.0 | 51.0 | 53.0 |
| 高中生物学 | 53.2 | 56.5 | 68.7 | 83.2 |
| 高中化学 | 41.9 | 41.4 | 49.3 | 51.2 |
| 高中计算机科学 | 40.0 | 36.0 | 46.0 | 60.0 |
| 高中欧洲历史 | 56.4 | 58.8 | 68.5 | 80.6 |
| 高中地理 | 57.1 | 59.6 | 71.2 | 81.3 |
| 高中政府与政治 | 67.9 | 67.9 | 77.2 | 90.2 |
| 高中宏观经济学 | 46.9 | 48.5 | 57.9 | 65.9 |
| 高中数学 | 28.1 | 28.9 | 34.1 | 31.5 |
| 高中微观经济学 | 51.7 | 51.7 | 68.9 | 82.4 |
| 高中物理 | 26.5 | 25.8 | 32.5 | 41.1 |
| 高中心理学 | 66.2 | 65.5 | 78.9 | 86.8 |
| 高中统计学 | 31.5 | 30.1 | 43.1 | 45.8 |
| 高中美国历史 | 57.8 | 54.9 | 64.7 | 77.5 |
| 高中世界历史 | 59.1 | 62.9 | 65.4 | 79.3 |
| 人类衰老 | 48.4 | 50.7 | 60.5 | 70.4 |
| 人类性行为 | 55.7 | 54.2 | 61.8 | 84.0 |
| 国际法 | 66.1 | 72.7 | 71.9 | 84.3 |
| 法理学 | 61.1 | 64.8 | 72.2 | 81.5 |
| 逻辑谬误 | 54.6 | 57.7 | 71.2 | 77.9 |
| 机器学习 | 37.5 | 39.3 | 43.8 | 44.6 |
| 管理学 | 56.3 | 56.3 | 79.6 | 89.3 |
| 市场营销 | 72.2 | 73.1 | 84.6 | 91.9 |
| 医学遗传学 | 55.0 | 58.0 | 71.0 | 81.0 |
| 杂项 | 69.7 | 67.8 | 83.8 | 90.4 |
| 道德争议 | 45.1 | 46.8 | 60.1 | 72.3 |
| 道德情景 | 24.5 | 30.3 | 25.8 | 38.5 |
| 营养学 | 56.5 | 53.9 | 67.0 | 77.1 |
| 哲学 | 56.3 | 57.6 | 70.7 | 77.2 |
| 史前史 | 59.3 | 60.5 | 71.6 | 78.7 |
| 专业会计 | 35.1 | 33.0 | 42.2 | 50.7 |
| 专业法律 | 36.3 | 38.4 | 39.4 | 51.7 |
| 专业医学 | 35.7 | 33.1 | 52.2 | 60.7 |
| 专业心理学 | 47.7 | 49.3 | 60.9 | 74.0 |
| 公共关系 | 54.5 | 53.6 | 68.2 | 68.2 |
| 安全研究 | 47.3 | 45.7 | 59.2 | 73.9 |
| 社会学 | 62.2 | 62.7 | 71.6 | 84.6 |
| 美国外交政策 | 64.0 | 68.0 | 73.0 | 83.0 |
| 病毒学 世界宗教 | 39.8 77.2 | 40.4 74.9 | 44.6 80.7 | 51.8 87.1 |
表 18: 采用循环排列的去偏 Atlas-XXL 在 MMLU 测试集上 57 个领域的零样本、5样本、5样本多任务及迁移设定下的得分。
Table 20: Downstream results on KILT dev sets.
| Number of parameters | 220M | 770M | 3B | 11B |
| NaturalQuestions 64-shot | 27.0 | 35.4 | 41.3 | 45.1 |
| NaturalQuestions full | 54.1 | 60.8 | 63.4 | 64.0 |
| TriviaQA 64-shot | 55.3 | 65.0 | 70.2 | 71.4 |
| TriviaQA full | 71.8 | 74.9 | 77.5 | 78.0 |
表 20: KILT开发集下游任务结果
| 参数量 | 220M | 770M | 3B | 11B |
|---|---|---|---|---|
| NaturalQuestions 64样本 | 27.0 | 35.4 | 41.3 | 45.1 |
| NaturalQuestions 全量 | 54.1 | 60.8 | 63.4 | 64.0 |
| TriviaQA 64样本 | 55.3 | 65.0 | 70.2 | 71.4 |
| TriviaQA 全量 | 71.8 | 74.9 | 77.5 | 78.0 |
Table 19: Impact of model size on question answering datasets. We report exact match performance on the test sets of Natural Questions and TriviaQA filtered depending on the number of parameters in the reader module. For these experiments the index contains the December 2018 Wikipedia dump.
| Model | AIDA ACC | FEV ACC | T-REx ACC | zsRE ACC | NQ EM | HoPo EM | TQA EM | WoW F1 |
| ATLAS 64-shot | 69.0 | 88.1 | 58.5 | 60.2 | 44.2 | 34.1 | 77.1 | 15.4 |
| ATLAs full dataset | 92.7 | 94.4 | 84.8 | 80.9 | 63.4 | 51.4 | 84.4 | 21.0 |
表 19: 模型规模对问答数据集的影响。我们根据阅读器模块参数数量,报告了Natural Questions和TriviaQA测试集上的精确匹配性能。这些实验使用的索引包含2018年12月的Wikipedia数据快照。
| 模型 | AIDA ACC | FEV ACC | T-REx ACC | zsRE ACC | NQ EM | HoPo EM | TQA EM | WoW F1 |
|---|---|---|---|---|---|---|---|---|
| ATLAS 64-shot | 69.0 | 88.1 | 58.5 | 60.2 | 44.2 | 34.1 | 77.1 | 15.4 |
| ATLAS 全数据集 | 92.7 | 94.4 | 84.8 | 80.9 | 63.4 | 51.4 | 84.4 | 21.0 |
question: {query text} answer: [MASK_0] and train the model to generate the mask token followed by the expected output:
问题:{查询文本} 答案:[MASK_0] 并训练模型生成掩码token (mask token) 及预期输出:
[MASK_0] {output}.
[MASK_0] {output}
We retrieve 20 passages and generate answer using greedy decoding. In KILT, FEVER is a two-way classification task of claims. We lexicalize the “SUPPORTS” (resp. ‘REFUTES”) label into “true” (respectively “false”).
我们检索20个段落并使用贪心解码生成答案。在KILT中,FEVER是一个双向分类任务。我们将"SUPPORTS"(对应"REFUTES")标签词汇化为"true"(对应"false")。
For few-shot fine-tuning we train Atlas for 30 steps using 64 random samples from the train sets. The retriever is trained using query-side fine-tuning. We evaluate models every 5 steps and select the best one on the development set based on the reported metric. We use AdamW with a batch size of 32 and a learning rate of $4\times10^{-5}$ with linear decay and 5 iterations of warmup for both the language model and the retriever.
对于少样本微调,我们使用训练集中的64个随机样本对Atlas进行30步训练。检索器采用查询端微调方式进行训练。每5步评估一次模型性能,并根据开发集上的指标得分选择最佳模型。语言模型和检索器均采用AdamW优化器,批处理量为32,学习率为$4\times10^{-5}$,配合线性衰减学习率和5轮预热迭代。
For the fine-tuning on the full datasets, the model is trained for 5k gradient steps. We evaluate models every 500 steps and select the best one on the development set based on the reported metric. The index is refreshed every 500 step for the first 1000 iterations, and every 2k steps afterwards. We use AdamW with a batch size of 64 and a learning rate of $4\times10^{-5}$ with linear decay and 500 iterations of warmup for both the language model and the retriever.
在对完整数据集进行微调时,模型训练了5,000次梯度更新。我们每500步评估一次模型,并根据报告指标在开发集上选择最佳模型。前1,000次迭代每500步更新一次索引,之后每2,000步更新一次。我们使用AdamW优化器,批处理大小为64,学习率为$4\times10^{-5}$,采用线性衰减策略,语言模型和检索器均进行500次预热迭代。
We report results on the development sets in Table 20.
我们在表20中报告了开发集上的结果。