When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories
何时不应信任语言模型:探究参数化与非参数化记忆的有效性
Alex Mallen∗♢ Akari Asai∗♢ Victor Zhong♢ Rajarshi Das♢ Daniel Khashabi♠ Hannaneh Hajishirzi♢♡ ♢University of Washington ♠Johns Hopkins University ♡Allen Institute for AI {atmallen,akari,vzhong,rajarshi,hannaneh}@cs.washington.edu danielk@jhu.edu
Alex Mallen∗♢ Akari Asai∗♢ Victor Zhong♢ Rajarshi Das♢ Daniel Khashabi♠ Hannaneh Hajishirzi♢♡
♢华盛顿大学 ♠约翰霍普金斯大学 ♡艾伦人工智能研究所
{atmallen,akari,vzhong,rajarshi,hannaneh}@cs.washington.edu danielk@jhu.edu
Abstract
摘要
Despite their impressive performance on diverse tasks, large language models (LMs) still struggle with tasks requiring rich world knowledge, implying the difficulty of encoding a wealth of world knowledge in their parameters. This paper aims to understand LMs’ strengths and limitations in memorizing factual knowledge, by conducting large-scale knowledge probing experiments on two open-domain entity-centric QA datasets: POPQA, our new dataset with 14k questions about long-tail entities, and Entity Questions, a widely used opendomain QA dataset. We find that LMs struggle with less popular factual knowledge, and that retrieval augmentation helps significantly in these cases. Scaling, on the other hand, mainly improves memorization of popular knowledge, and fails to appreciably improve memorization of factual knowledge in the long tail. Based on those findings, we devise a new method for retrieval augmentation that improves performance and reduces inference costs by only retrieving non-parametric memories when necessary.1
尽管大语言模型(LM)在各种任务上表现优异,但在需要丰富世界知识的任务上仍存在困难,这表明在其参数中编码大量世界知识具有挑战性。本文旨在通过在两个开放域实体中心问答数据集上进行大规模知识探测实验,来理解大语言模型在记忆事实知识方面的优势与局限:我们新构建的POPQA数据集(包含1.4万个关于长尾实体的问题)以及广泛使用的开放域问答数据集Entity Questions。研究发现,大语言模型对冷门事实知识的记忆能力较弱,而检索增强技术在这些情况下能显著提升性能。另一方面,模型缩放主要提升了对热门知识的记忆能力,却无法明显改善对长尾事实知识的记忆。基于这些发现,我们设计了一种新的检索增强方法,通过仅在必要时检索非参数化记忆,既提升了性能又降低了推理成本[20]。
1 Introduction
1 引言
Large language models (LMs; Brown et al. 2020; Raffel et al. 2020) have been shown to be competitive on diverse NLP tasks, including knowledgeintensive tasks that require fine-grained memorization of factual knowledge (Chowdhery et al., 2022; Yu et al., 2022). Meanwhile, LMs have also been shown to have limited memorization for less frequent entities (Kandpal et al., 2022), are prone to hallucinations (Shuster et al., 2021), and suffer from temporal degradation (Kasai et al., 2022; Jang et al., 2022). Incorporating non-parametric knowledge (i.e., retrieved text chunks) largely helps address those issues stemming from reliance on LMs’ parametric knowledge—knowledge stored in their parameters (Izacard et al., 2022b)—but it is unclear whether it is strictly superior or complementary to parametric knowledge. Understanding when we should not trust LMs’ outputs is also crucial to safely deploying them in real-world applications (Kadavath et al., 2022).
大语言模型(LMs;Brown等人2020;Raffel等人2020)已被证明在多样化自然语言处理任务中具有竞争力,包括需要精细记忆事实性知识的知识密集型任务(Chowdhery等人,2022;Yu等人,2022)。然而,研究也表明大语言模型对低频实体的记忆能力有限(Kandpal等人,2022),容易产生幻觉输出(Shuster等人,2021),并存在时效性退化问题(Kasai等人,2022;Jang等人,2022)。引入非参数化知识(即检索到的文本块)能显著缓解因依赖模型参数化知识(存储于参数中的知识,Izacard等人2022b)所引发的问题,但目前尚不清楚这种方案是严格优于参数化知识,还是与之形成互补关系。理解何时不应信任大语言模型的输出,对于其在实际应用中的安全部署同样至关重要(Kadavath等人,2022)。
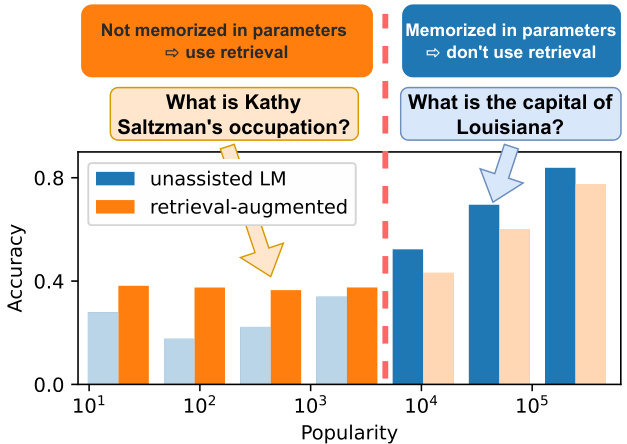
Figure 1: Relationship between subject entity popularity in a question and GPT-3 performance in open-domain QA, with and without retrieved passages. Adaptive Retrieval only retrieves when necessary (orange bars) based on the heuristic ally-decided threshold (red line).
图 1: 问题中主语实体流行度与GPT-3在开放域问答中性能的关系(含/不含检索段落)。自适应检索(Adaptive Retrieval)仅根据启发式设定的阈值(红线)在必要时进行检索(橙色柱状图)。
This work conducts a large-scale knowledge probing of LMs on factual knowledge memorization, to understand when we should and should not rely on LMs’ parametric knowledge, and how scaling and non-parametric memories (e.g., retrieval- augmented LMs) can help. In particular, we aim to address the following research questions:
本研究对大语言模型(LM)的事实知识记忆能力进行了大规模探测,旨在明确何时应依赖或不应依赖其参数化知识,以及模型规模扩展和非参数化记忆(如检索增强型LM)如何发挥作用。具体而言,我们致力于解决以下研究问题:
We hypothesize that factual knowledge frequently discussed on the web is easily memorized by LMs, while the knowledge that is less discussed may not be well captured and thus they require retrieving external non-parametric memories. We evaluate ten large LMs of three families (i.e., GPTNeo, OPT, and GPT-3) with varying scales on the open-domain question answering (QA) task in a zero- or few-shot prompting manner. We construct a new dataset, POPQA, consisting of 14k questions to cover factual information in the long tail that might have been missed in popular QA datasets (Kwiatkowski et al., 2019). We use Wikipedia page views as a measure of popularity and convert knowledge triples from Wikidata, with diverse levels of popularity, into natural language questions, anchored to the original entities and relationship types. We also use Entity Questions (Sciavolino et al., 2021), an open-domain QA dataset with a long-tail distribution.
我们假设,网络上频繁讨论的事实性知识容易被大语言模型(LM)记住,而那些较少讨论的知识可能无法被充分掌握,因此需要检索外部非参数化记忆。我们在开放域问答(QA)任务中,以零样本或少样本提示的方式评估了三个系列(即GPTNeo、OPT和GPT-3)的十种不同规模的大语言模型。我们构建了一个新数据集POPQA,包含14k个问题,覆盖了长尾中的事实性信息,这些信息可能在流行的QA数据集中被遗漏(Kwiatkowski等人,2019)。我们使用维基百科页面浏览量作为流行度的衡量标准,并将来自Wikidata的、具有不同流行度水平的知识三元组转换为自然语言问题,锚定到原始实体和关系类型。我们还使用了Entity Questions(Sciavolino等人,2021),这是一个具有长尾分布的开放域QA数据集。
On both datasets, LMs’ memorization $(R Q_{1})$ is often limited to the popular factual knowledge and even GPT-3 davinci-003 fails to answer the majority of the long-tail questions. Moreover, on such questions, scaling up models does not significantly improve the performance (e.g., for the 4,000 least popular questions in POPQA, GPT-j 6B has $16%$ accuracy and GPT-3 davinci-003 has $19%$ accuracy). This also suggests that we can predict if LMs memorize certain knowledge based on the information presented in the input question only.
在两个数据集上,大语言模型的记忆能力$(R Q_{1})$通常仅限于流行事实知识,甚至GPT-3 davinci-003也无法回答大多数长尾问题。此外,对于这类问题,扩大模型规模并未显著提升性能(例如,在POPQA数据集中最冷门的4,000个问题上,GPT-j 6B准确率为$16%$,GPT-3 davinci-003准确率为$19%$)。这也表明,我们可以仅根据输入问题中的信息来预测大语言模型是否记忆了特定知识。
We next investigate whether a semi-parametric approach that augments LMs with retrieved evidence can mitigate the low performance on questions about less popular entities $(R Q_{2})$ . Nonparametric memories largely improve performance on long-tail distributions across models. Specifically, we found that retrieval-augmented LMs are particularly competitive when subject entities are not popular: a neural dense retriever (Izacard et al., 2022a)-augmented GPT-neo 2.7B outperforms GPT-3 davinci-003 on the 4,000 least popular questions. Surprisingly, we also find that retrieval augmentation can hurt the performance of large LMs on questions about popular entities as the retrieved context can be misleading.
我们接下来研究一种半参数化方法——通过检索证据增强大语言模型 (LM) 能否缓解冷门实体相关问题的低性能表现 $(R Q_{2})$ 。非参数化记忆显著提升了各类模型在长尾分布上的表现。具体而言,当主体实体不热门时,检索增强的大语言模型表现尤为突出:基于神经密集检索器 (Izacard et al., 2022a) 增强的 GPT-neo 2.7B 在最冷门的 4,000 个问题上优于 GPT-3 davinci-003。值得注意的是,检索增强反而会损害大语言模型在热门实体问题上的表现,因为检索到的上下文可能产生误导。
As a result, we devise a simple-yet-effective retrieval-augmented LM method, Adaptive Retrieval, which adaptively combines parametric and non-parametric memories based on popularity $(R Q_{3})$ . This method further improves performance on POPQA by up to $10%$ , while significantly reducing the inference costs, especially with larger
因此,我们设计了一种简单而有效的检索增强语言模型方法——自适应检索 (Adaptive Retrieval) ,该方法基于流行度 $(R Q_{3})$ 自适应地结合参数化与非参数化记忆。该方法在POPQA上的性能最高可提升 $10%$ ,同时显著降低推理成本(尤其在处理更大规模数据时)。
LMs (e.g., reducing GPT-3 API costs by half), indicating the potential for future research in more efficient and powerful retrieval-augmented LMs.
大语言模型 (例如将GPT-3 API成本降低一半) ,这表明未来在更高效、更强大的检索增强大语言模型方面具有研究潜力。
2 Related Work
2 相关工作
Parametric and non-parametric knowledge. Petroni et al. (2019) demonstrate that large pretrained LMs such as BERT (Devlin et al., 2019) memorize the significant amount of world knowledge in their parameters (parametric knowledge), and Roberts et al. (2020) show that fine-tuned T5 without any reference documents (closedbook QA) can achieve competitive performance on open-domain QA. More recent and powerful LMs (Brown et al., 2020; Chowdhery et al., 2022) further improve performance on diverse knowledge-intensive tasks, leveraging their strong parametric memories (Kandpal et al., 2022; Yu et al., 2022). However, relying solely on their parameters to encode a wealth of world knowl- edge requires a prohibitively large number of parameters and the knowledge can become obsolete quickly (Kasai et al., 2022; Jang et al., 2022). Re- cent work shows that augmenting LMs with nonparametric memories (i.e., retrieved text chunks) enables much smaller models to match the performance of larger models (Izacard et al., 2022b; Khandelwal et al., 2020; Min et al., 2022), although Chen et al. (2022) and Longpre et al. (2021) show that even those models can ignore non-parametric knowledge and rely on parametric knowledge.
参数化与非参数化知识。Petroni等人(2019)研究表明,像BERT(Devlin等人,2019)这样的大型预训练大语言模型会在参数中记忆大量世界知识(参数化知识);Roberts等人(2020)则证明,经过微调的T5模型无需任何参考文档(闭卷问答)就能在开放域问答中取得有竞争力的表现。更先进的大语言模型(Brown等人,2020;Chowdhery等人,2022)通过强大的参数化记忆能力(Kandpal等人,2022;Yu等人,2022),在各种知识密集型任务中实现了更优性能。然而,仅靠模型参数来编码海量世界知识需要极其庞大的参数量,且这些知识会快速过时(Kasai等人,2022;Jang等人,2022)。最新研究表明,通过引入非参数化记忆(即检索文本片段)增强大语言模型,可使较小模型达到与大型模型相当的性能(Izacard等人,2022b;Khandelwal等人,2020;Min等人,2022),不过Chen等人(2022)和Longpre等人(2021)指出,这类模型仍可能忽视非参数化知识而依赖参数化知识。
Understanding memorization. Several prior work establishes a positive relationship between string frequency in pre-training corpora and memorization (Carlini et al., 2022; Razeghi et al., 2022). Concurrent to our work, Kandpal et al. (2022) show that the co-occurrence of the question and answer entities in pre training corpora has a positive correlation with models’ QA accuracy on popular open-domain QA benchmarks such as Natural Questions (Kwiatkowski et al., 2019). This work, instead, attempts to predict memorization using the variables available in the input question only and uses popularity to obtain a proxy for how frequently an entity is likely to be discussed on the web. Importantly, by constructing a new dataset, we can conduct fine-grained controlled experiments across a wide range of popular i ties, allowing the investigation of hypotheses that might have been missed in prior analysis using existing open QA datasets. We further analyze the effectiveness and limitations of retrieval-augmented LMs and introduce Adaptive Retrieval. Prior work investigates the effectiveness of deciding when to use non-parametric memories at the token level in $k$ -nn LM (He et al., 2021). This work is the first work to study the effectiveness of deciding whether to retrieve for each query and show their effectiveness in retrieval-augmented LM prompting.
理解记忆机制。多项先前研究证实了预训练语料中字符串频率与记忆效果之间的正相关关系 (Carlini et al., 2022; Razeghi et al., 2022)。与本研究同期,Kandpal等人 (2022) 发现预训练语料中问题与答案实体的共现频率,与模型在Natural Questions (Kwiatkowski et al., 2019) 等主流开放领域问答基准上的准确率呈正相关。本研究则尝试仅通过输入问题中的变量来预测记忆行为,并利用网络流行度作为实体在网络讨论中出现频率的代理指标。通过构建新数据集,我们能够对各类流行实体进行细粒度控制实验,从而验证那些在使用现有开放问答数据集的分析中可能被忽略的假设。我们进一步分析了检索增强型大语言模型 (retrieval-augmented LMs) 的效能与局限,并提出自适应检索 (Adaptive Retrieval) 方法。前人研究探讨了在 $k$ -nn LM (He et al., 2021) 中基于token级别决定是否使用非参数化记忆的有效性。本研究首次系统分析了针对每个查询决策检索时机的有效性,并验证了其在检索增强型大语言模型提示中的实践价值。
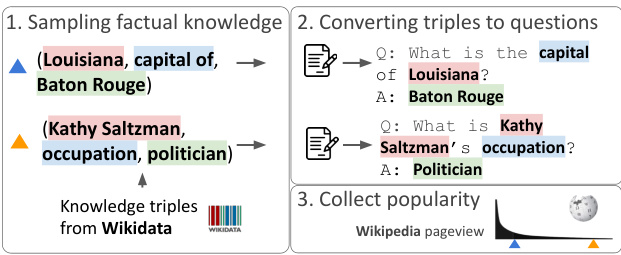
Figure 2: POPQA is created by sampling knowledge triples from Wikidata and converting them to natural language questions, followed by popularity calculation.
图 2: POPQA通过从Wikidata采样知识三元组并将其转换为自然语言问题后,经过流行度计算而创建。
3 Evaluation Setup
3 评估设置
We evaluate LMs’ ability to memorize factual knowledge through closed-book QA tasks with fewshot samples. We evaluate LMs on our new dataset, POPQA (Figure 2), and Entity Questions, both of which have long-tail distributions (Figure 3).
我们通过带有少样本示例的闭卷问答任务来评估大语言模型记忆事实知识的能力。我们在新数据集POPQA (图 2) 和Entity Questions上评估模型性能,这两个数据集均呈现长尾分布 (图 3)。
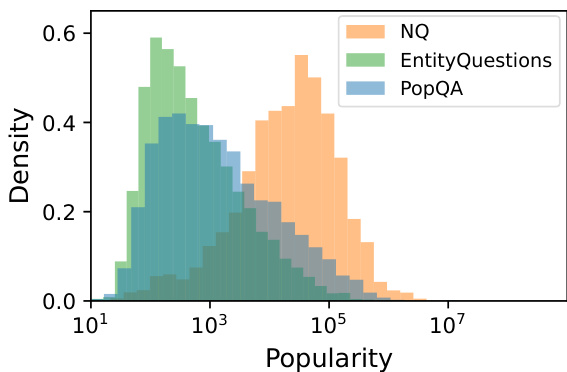
Figure 3: Distribution of subject entity popularity for Ent it y Questions, POPQA, and for NQ-open for reference. Details on NQ entities can be found in Appendix A.
图 3: 实体问题 (Entity Questions)、POPQA 以及作为参考的 NQ-open 中主体实体流行度分布。关于 NQ 实体的详细信息可参阅附录 A。
3.1 Focus and Task
3.1 聚焦与任务
Focus: factual knowledge. Among diverse types of world knowledge, this work focuses on factual knowledge (Adams, 2015) of entities—knowledge about specific details of the target entities. We define factual knowledge as a triplet of (subject, relationship, object) as in Figure 2 left.
重点:事实性知识。在多种类型的世界知识中,本研究聚焦于实体的事实性知识 (Adams, 2015) ——关于目标实体具体细节的知识。我们将事实性知识定义为如图2左侧所示的(主体, 关系, 客体)三元组。
Task format: open-domain QA. We formulate the task as open-domain QA (Roberts et al., 2020):
任务格式:开放域问答。我们将任务设定为开放域问答 (Roberts et al., 2020):
given a question, a model predicts an answer without any pre-given ground-truth paragraph. As in Kandpal et al. (2022), we study few-shot settings and prompt LMs without any parameter updates, instead of fine-tuning them on QA datasets such as in Roberts et al. (2020).
给定一个问题时,模型无需任何预先提供的真实段落即可预测答案。如Kandpal等人 (2022) 的研究所示,我们探索少样本设置,并在不更新参数的情况下提示大语言模型,而非像Roberts等人 (2020) 那样在问答数据集上进行微调。
Metrics: accuracy. We mark a prediction as correct if any substring of the prediction is an exact match of any of the gold answers.
指标:准确率。若预测结果的任何子字符串与任一标准答案完全匹配,则判定该预测为正确。
3.2 Dimensions of Analysis
3.2 分析维度
We hypothesize that factual knowledge that is less frequently discussed on the web may not be wellmemorized by LMs. Previous research often uses the term frequency of object entities in pre training corpora to understand memorization (Févry et al., 2020; Kandpal et al., 2022; Razeghi et al., 2022). Instead, we investigate whether it’s possible to pre- dict memorization based on the input information only, and then apply the findings for modeling improvements, unlike prior analyses. Therefore, our work focuses on the other two variables in a factual knowledge triple: the subject entity and the relationship type.
我们假设,网络上较少讨论的事实知识可能未被语言模型充分记忆。先前研究常使用预训练语料中对象实体的词频来理解记忆机制 [20][21][22]。与之不同,我们探索仅基于输入信息预测记忆效果的可能性,并将发现应用于模型改进。因此,本研究聚焦于事实知识三元组中的另外两个变量:主体实体和关系类型。
Subject entity popularity. We use the popularity of the entities measured by Wikipedia monthly page views as a proxy for how frequently the entities are likely to be discussed on the web, instead of using the occurrence of entities or strings in the pre training corpus (Carlini et al., 2022; Kandpal et al., 2022; Razeghi et al., 2022). Calculating fre- quencies over large pre training corpora requires massive computations to link entities over billions of tokens, or can result in noisy estimations.3 Our initial studies show that this is much cheaper4 and aligns well with our intuition.
主题实体流行度。我们采用维基百科月度页面浏览量作为衡量实体流行度的指标,以此反映这些实体在网络上的讨论频率,而非使用预训练语料库中实体或字符串的出现频次 (Carlini et al., 2022; Kandpal et al., 2022; Razeghi et al., 2022)。在大规模预训练语料库上计算频率需要耗费巨大算力来链接数十亿token中的实体,或可能导致噪声估计。3我们的初步研究表明,该方法成本更低4且更符合直觉。
Relationship type. We also consider the relationship types as key factors for factual knowledge memorization. For example, even given the same combinations of the subject and object entities, model performance can depend on the relationship types; relationship types widely discussed can be easier to be memorized, while types that are less discussed may not be memorized much.
关系类型。我们还将关系类型视为事实知识记忆的关键因素。例如,即使给定相同的主客体实体组合,模型性能也可能取决于关系类型;被广泛讨论的关系类型可能更容易被记忆,而较少讨论的类型可能记忆效果不佳。
3.3 Benchmarks
3.3 基准测试
POPQA. In our preliminary studies, we found that existing common open-domain QA datasets such as Natural Questions (NQ; Kwiatkowski et al. 2019) are often dominated by subject entities with high popularity, and it is often hard to identify relationship types due to diverse question surface forms. To enable a fine-grained analysis of memorization based on the aforementioned analysis dimensions, we construct POPQA, a new large-scale entitycentric open-domain QA dataset about entities with a wide variety of popularity, as shown in Figure 3.
POPQA。在初步研究中,我们发现现有常见的开放域问答数据集(如Natural Questions (NQ; Kwiatkowski等人2019))通常由高热度主题实体主导,且由于问题表面形式多样,往往难以识别关系类型。为了基于前述分析维度对记忆行为进行细粒度分析,我们构建了POPQA——一个关于不同热度实体的大规模以实体为中心的开放域问答数据集,如图3所示。
To construct POPQA, we randomly sample knowledge triples of 16 diverse relationship types from Wikidata and convert them into natural language questions, using a natural language template (depicted in Figure 2). We verbalize a knowledge triple $(S,R,O)$ into a question that involves substituting the subject $S$ into a template manually written for the relationship type $R$ . The full list of templates is found in Table 2 of the Appendix. The set of acceptable answers to the question is the set of entities $E$ such that $(S,R,E)$ exists in the knowledge graph. We tried various templates and found that the results were fairly robust to the templates. Since POPQA is grounded to a knowledge base, links to Wikidata entities allow for reliable analysis of popularity and relationship types.
为构建POPQA,我们从Wikidata中随机抽取16种不同关系类型的知识三元组,并使用自然语言模板(如图2所示)将其转化为自然语言问题。我们将知识三元组$(S,R,O)$表述为问题,具体方法是将主语$S$代入为关系类型$R$手动编写的模板。完整模板列表见附录表2。问题的可接受答案集是知识图谱中存在$(S,R,E)$关系的实体集合$E$。我们尝试了多种模板,发现结果对模板选择具有较强鲁棒性。由于POPQA基于知识库构建,通过Wikidata实体链接可实现对流行度和关系类型的可靠分析。
Entity Questions. We test on another popular opendomain QA dataset, Entity Questions (Sciavolino et al., 2021), which also covers a long-tail entity distribution. They use Wikipedia hyperlink counts as a proxy of the frequency of entities and sample knowledge triples from WikiData, from the frequency distributions. Unlike POPQA, EntityQuestions doesn’t provide entity annotations, so we only use $82%$ of the questions, where the mention of the subject entity has a unique match with a Wikidata entity.
实体问题(Entity Questions)。我们在另一个流行的开放域问答数据集Entity Questions (Sciavolino等人,2021)上进行测试,该数据集同样覆盖长尾实体分布。研究者使用维基百科超链接计数作为实体频率的代理指标,并根据频率分布从WikiData中采样知识三元组。与POPQA不同,EntityQuestions未提供实体标注,因此我们仅使用其中82%的问题——这些问题的主题实体提及能与Wikidata实体唯一匹配。
4 Memorization Depends on Popularity and Relationship Type
4 记忆能力取决于流行度与关系类型
We evaluate a range of LMs with varying numbers of parameters, to quantify how much factual knowledge they memorize and how different factors affect those memorization behaviors $(R Q_{1})$ .
我们评估了不同参数规模的大语言模型,以量化它们记忆的事实知识量以及不同因素如何影响这些记忆行为 $(R Q_{1})$。
4.1 Experimental Setup
4.1 实验设置
Models. We evaluate ten models with a varying scale of model size: OPT (Zhang et al. 2022; 1.3, 2.7, 6.7, and 13 billion), GPT-Neo (Black et al.
模型。我们评估了十种不同规模的模型:OPT (Zhang et al. 2022; 13亿、27亿、67亿和130亿参数)、GPT-Neo (Black et al.
2022; 1.3, 2.7, 6, and 20 billion), and GPT-3 (Brown et al. 2020; davinci-002, davinci-003) on our benchmark without any fine-tuning.
2022年;1.3、2.7、6和200亿参数规模),以及GPT-3 (Brown等人 2020;davinci-002、davinci-003) 在我们的基准测试上未进行任何微调。
Instructions and demonstrations. We use a simple template $\mathbf{\tilde{\gamma}}_{\bigcirc}$ :
指令与演示。我们使用简单模板 $\mathbf{\tilde{\gamma}}_{\bigcirc}$ :
4.2 Results
4.2 结果
Overall model performance. The top left column of Figure 4 illustrates the overall performance on POPQA. As shown, even without using incontext examples, larger LMs exhibit reasonable performance: GPT-3 achieves $35%$ accuracy, and GPT-Neo 20B achieves $25%$ accuracy. This indicates that large LMs memorize factual knowledge in their parameters to some extent. This section examines which types of knowledge are better memorized and what factors influence memorization.
整体模型性能。图4左上栏展示了在POPQA上的总体表现。如图所示,即使不使用上下文示例,更大的大语言模型也展现出合理性能:GPT-3达到35%准确率,GPT-Neo 20B达到25%准确率。这表明大型模型参数中在一定程度上记忆了事实性知识。本节将探讨哪些类型的知识更容易被记忆,以及影响记忆的因素。
Subject entity popularity predicts memorization. Figure 4 (bottom) shows that there is a positive correlation between subject entity popularity and models’ accuracy for almost all relationship types. This supports our hypothesis that subject entity popularity can be a reliable indicator of LMs’ factual knowledge memorization. In general, the correlations between subject entity popularity and accuracy are stronger for larger LMs; GPT-3 003 shows the highest positive correlation (roughly 0.4) while GPT-Neo-1.3B shows relatively weak positive correlations (approximately 0.1).
主题实体流行度可预测记忆效果。图4 (底部) 显示,几乎所有关系类型中,主题实体流行度与模型准确率均呈正相关。这支持了我们的假设:主题实体流行度可作为大语言模型事实知识记忆的可靠指标。总体而言,更大规模的模型展现出更强的主题实体流行度与准确率相关性;GPT-3 003呈现最高的正相关性(约0.4),而GPT-Neo-1.3B的正相关性相对较弱(约0.1)。
Relationship types affects memorization. We find that models have a higher average performance for some relationship types than for others. While this is evidence that factual knowledge of some relationship types are more easily memorized than others, we also observe that questions of certain relationship types can be easily guessed without memorizing the knowledge triple. Specifically, certain relationship types (e.g., nationalities) allow models to exploit surface-level artifacts in subject entity names (Poerner et al., 2020; Cao et al., 2021). Addi- tionally, models often output the most dominant answer entities for questions about relationship types with fewer answer entities (e.g., red for the color relationship type). In Figure 4, relationships with lower correlation (e.g., country, sport) often shows higher accuracy, indicating that on those relationship types, models may exploit surface-level clues. On the other hand, for relationship types with relatively low accuracy (e.g., occupation, author, director), larger LMs often show a high correlation. Further details are in Appendix C.1.
关系类型影响记忆效果。我们发现模型在某些关系类型上的平均表现优于其他类型。虽然这表明某些关系类型的事实知识更容易被记忆,但我们也观察到某些关系类型的问题无需记忆知识三元组即可轻易猜测。具体而言,某些关系类型(如国籍)允许模型利用主体实体名称中的表层特征(Poerner等人,2020;Cao等人,2021)。此外,对于答案实体较少的关系类型(如颜色关系类型中的"红色"),模型常输出最占优势的答案实体。在图4中,相关性较低的关系(如国家、运动)往往显示更高准确率,表明模型可能利用表层线索处理这些关系类型。另一方面,对于准确率相对较低的关系类型(如职业、作者、导演),较大的大语言模型通常表现出较高相关性。更多细节见附录C.1。
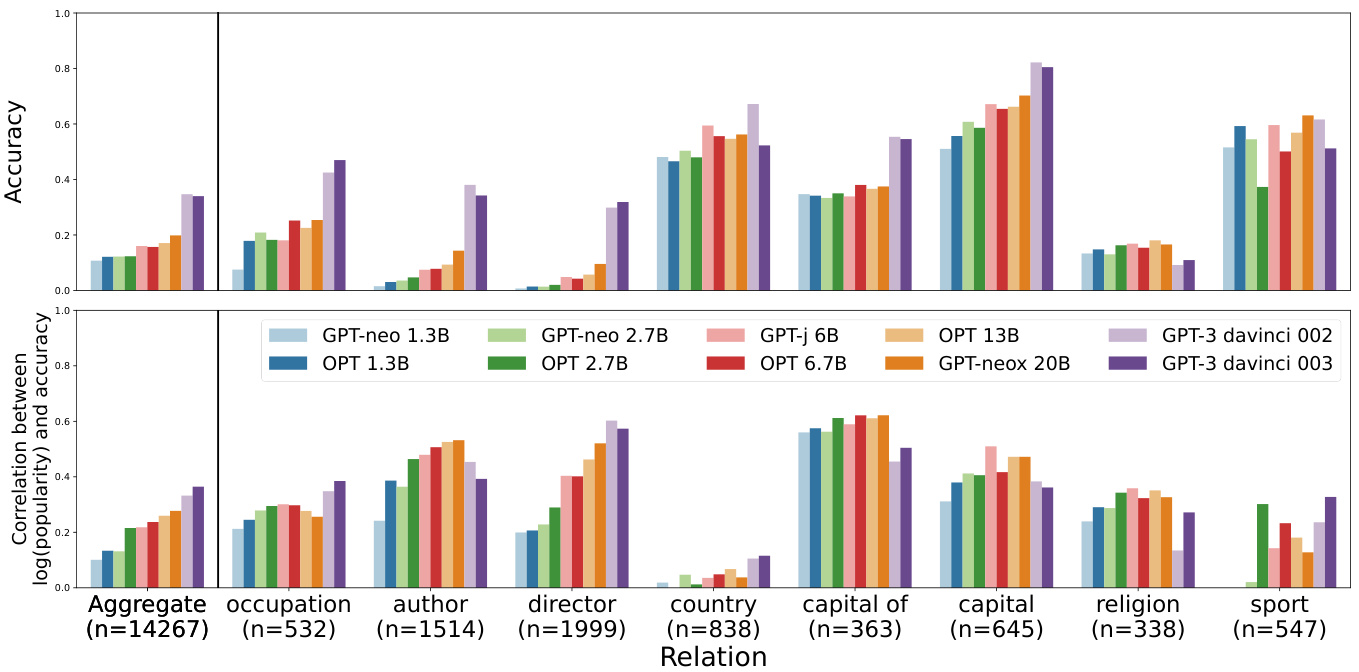
Figure 4: Per relationship type ( $n=$ the number of questions) results on POPQA by model, showing overall accuracy and the correlation between accuracy and log popularity. We uniformly bin the questions by log (popularity), then report the correlation between the bin center and the bin’s accuracy. We see that both subject entity popularity and relationship type are strong predictors of memorization across models. The correlation with popularity exists across relationship types and is stronger for larger LMs. We show a representative subset of relationship types and the complete results are in Figures 16 and 17 in Appendix C.1, including results on Entity Questions.
图 4: 按关系类型划分的POPQA结果( $n=$ 问题数量),展示各模型的总体准确率及准确率与对数流行度的相关性。我们将问题按对数(流行度)均匀分箱,计算箱中心与箱内准确率的相关系数。结果表明,主体实体流行度和关系类型均是预测模型记忆能力的强指标。这种与流行度的相关性普遍存在于各类关系类型中,且模型规模越大相关性越强。图中展示了具有代表性的关系类型子集,完整结果(含实体问题部分)详见附录C.1中的图16和图17。
Scaling may not help with tail knowledge. As seen in the left column of Figure 4, there are clear overall performance improvements with scale on the POPQA dataset. However, Figure 5 shows that on both POPQA and Entity Questions, most of scaling’s positive effect on parametric knowledge comes from questions with high popularity. Specifically, for the questions about the entities whose $\mathrm{log}_{10}$ (popularity) is larger than 4, there is an improvement in accuracy as model size increases (red and yellow lines), while performance on questions with lower popularity remains relatively constant (blue and green lines). For the 4,000 least popular questions, GPT-Neo 6B, 20B, and
扩展规模可能无助于提升长尾知识。如图4左栏所示,在POPQA数据集上,模型规模的扩大带来了明显的整体性能提升。但图5显示,在POPQA和实体问答数据集上,规模扩张对参数化知识的积极影响主要来自高热度问题。具体而言,对于实体热度$\mathrm{log}_{10}$值大于4的问题(红黄曲线),准确率随模型规模增加而提升;而低热度问题的性能(蓝绿曲线)则保持相对稳定。在最冷门的4,000个问题上,GPT-Neo 6B、20B与...
GPT-3 davinci-003 have $15%$ , $16%$ , and $19%$ accuracy, respectively.
GPT-3 davinci-003的准确率分别为$15%$、$16%$和$19%$。
This somewhat dampens prior works’ findings that scaling up models significantly improves their factual knowledge memorization (Roberts et al., 2020; Kandpal et al., 2022). We hypothesize that this is because their evaluations are often conducted on QA datasets with popular entities. In sum, scaling lowers the threshold of popularity for knowledge to be reliably memorized, but is not projected to move the threshold far into the long tail for practical model scales.
这在一定程度上削弱了先前研究的结论,即扩大模型规模能显著提升其事实知识记忆能力 (Roberts et al., 2020; Kandpal et al., 2022) 。我们推测这是因为他们的评估通常基于包含热门实体的问答数据集。总体而言,规模扩大降低了知识被可靠记忆的流行度阈值,但在实际模型规模下,该阈值预计不会深入长尾区域。
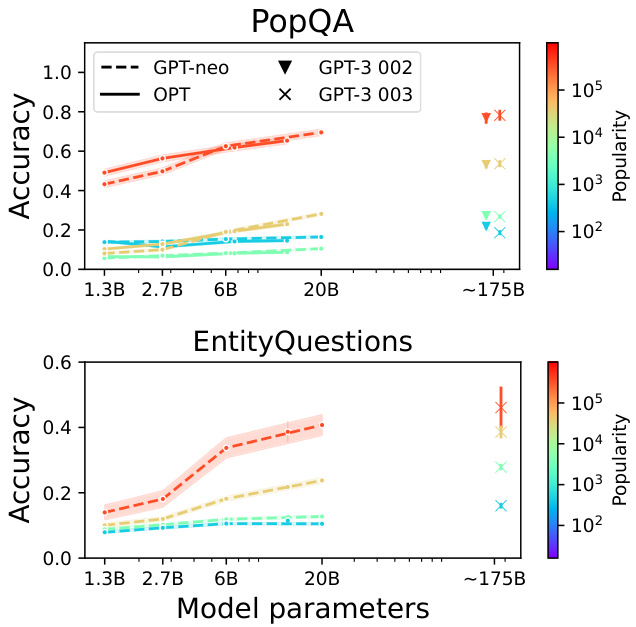
Figure 5: POPQA scaling results, broken down by question popularity level. Scaling mostly improves memorization of more popular factual knowledge. Error bars are $95%$ confidence intervals.
图 5: POPQA扩展实验结果,按问题流行度分层展示。扩展主要提升对流行事实知识的记忆能力。误差线表示95%置信区间。
Relationship type results breakdown. Figure 6 provides a closer look at the relationship between popularity, accuracy, and relationship type; it shows model accuracy over the popularity distributions for director and country. For the first two types, we can see a clear positive trend between popularity and accuracy across models, and as the model size gets larger, the LMs memorize more. On the other hand, in the “country” relationship type, no models show trends, while overall the accuracy is high, indicating the LMs often exploit artifacts to answer less popular questions. We show example models’ predictions in Appendix Section C.3.
关系类型结果细分。图 6 详细展示了流行度、准确性与关系类型之间的关联:它呈现了导演和国家两类关系的模型准确率随流行度分布的变化情况。在前两种类型中,我们可以观察到模型准确率与流行度之间存在明显的正相关趋势,且随着模型规模增大,大语言模型的记忆能力也随之增强。相比之下,在"国家"关系类型中,所有模型均未表现出趋势性变化,但整体准确率较高,这表明大语言模型常利用数据伪影来回答冷门问题。我们在附录C.3节展示了示例模型的预测结果。
5 Non-parametric Memory Complements Parametric Memory
5 非参数记忆对参数记忆的补充
Our analysis indicates that even the current stateof-the-art LMs struggle with less popular subjects or certain relationship types, and increasing the model size does not lead to further performance improvements. In light of this, we extend our analysis to non-parametric sources of knowledge, as outlined in Section $(R Q_{2})$ . Specifically, we investigate the effectiveness of retrieval-augmented LMs (Borgeaud et al., 2022; Lewis et al., 2020), which leverage non-parametric memories (i.e., retrieved text) to improve performance.
我们的分析表明,即使是当前最先进的大语言模型在处理冷门主题或某些关系类型时仍存在困难,且增大模型规模不会带来进一步的性能提升。鉴于此,我们将分析扩展到非参数化知识源,如章节$(R Q_{2})$所述。具体而言,我们研究了检索增强型大语言模型(Borgeaud等人,2022;Lewis等人,2020)的有效性,该模型利用非参数化记忆(即检索文本)来提升性能。
5.1 Experimental Setup
5.1 实验设置
Augmenting input. In this work, we try a simple retrieval-augmented LM approach, where we run an off-the-shelf retrieval system off-line to retrieve context from Wikipedia relevant to a question,7 and then we concatenate the retrieved context with the original question. Although increasing the context size often leads to performance gains (Izacard and Grave, 2021; Asai et al., 2022), we only use the top one retrieved paragraph for simplicity.
增强输入。在本研究中,我们尝试了一种简单的检索增强型大语言模型方法:通过离线运行现成的检索系统,从维基百科中获取与问题相关的上下文7,然后将检索到的上下文与原问题拼接。虽然增加上下文长度通常能提升性能 (Izacard and Grave, 2021; Asai et al., 2022),但为简化流程,我们仅使用检索得分最高的单个段落。
Retrieval models. We use two widely-used retrieval systems: BM25 (Robertson et al., 2009)
检索模型。我们使用两种广泛应用的检索系统:BM25 (Robertson et al., 2009)
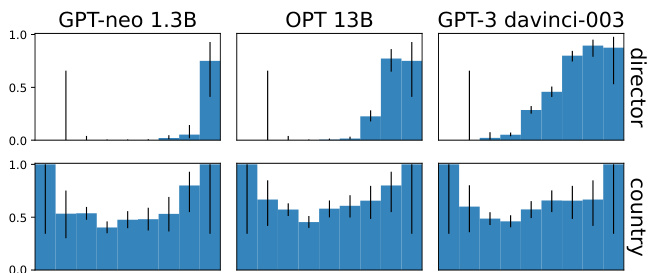
Figure 6: Memorization versus popularity for three models and the relationship types with the largest and small- est correlations. Within a relationship type, generally, there is a monotonically increasing link between popularity and performance, except for “country”. Error bars show Wilson $95%$ confidence intervals.
图 6: 三种模型的记忆效应与流行度对比,以及相关性最大和最小的关系类型。在特定关系类型中,除"country"外,流行度与性能普遍呈现单调递增关系。误差线显示威尔逊95%置信区间。
and Contriever (Izacard et al., 2022a). BM25 is a static term-based retriever without training, while Contriever is pretrained on large unlabeled corpora, followed by fine-tuning on MS MARCO (Bajaj et al., 2016). We also experiment with a parametric augmentation method, GenRead (Yu et al., 2022), which prompts LMs to generate rather than retrieve a contextual document to answer a question. We use the ten LMs in Section 4, resulting in $40\mathrm{LMs}$ and retrieval-augmented LMs.
以及Contriever (Izacard等人,2022a)。BM25是一种无需训练的静态基于术语的检索器,而Contriever则是在大规模无标注语料库上预训练后,再在MS MARCO (Bajaj等人,2016) 上进行微调。我们还尝试了一种参数化增强方法GenRead (Yu等人,2022),该方法通过提示大语言模型生成而非检索上下文文档来回答问题。我们使用了第4节中的十种大语言模型,最终得到40种大语言模型及其检索增强版本。
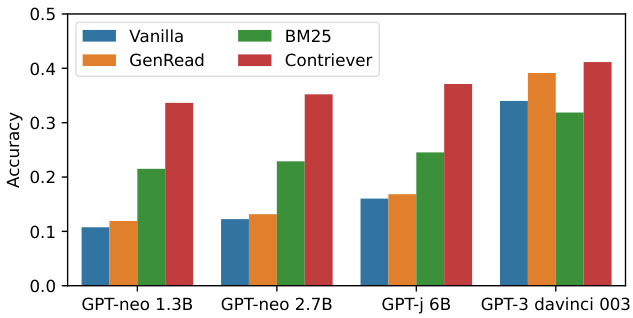
Figure 7: POPQA accuracy of LMs augmented with BM25, Contriever, GenRead, and unassisted (vanilla). Retrieving non-parametric memories significantly improves the performance of smaller models. Complete results on POPQA are found in Figure 13. Entity Questions results are in Figure 14 of the Appendix.
图 7: 采用BM25、Contriever、GenRead及无辅助(vanilla)检索增强的大语言模型在POPQA上的准确率。检索非参数化记忆显著提升了小模型的性能。POPQA完整结果见图13。实体类问题结果见附录图14。
5.2 Results
5.2 结果
Retrieval largely improves performance. Figure 7 shows that augmenting LMs with nonparametric memories significantly outperforms unassisted vanilla LMs. A much smaller LM (e.g., GPT-Neo 2.7B) augmented by the Contriever retrieval results outperforms vanilla GPT-3. Large LMs such as GPT-3 also enjoy the benefits of nonparametric memories. Contriever gives $7%$ accuracy gains on top of GPT-3 davinci-003. Gen
检索大幅提升性能。图7显示,用非参数记忆增强大语言模型显著优于未经辅助的基础模型。一个更小的大语言模型(如GPT-Neo 2.7B)通过Contriever检索增强后,表现优于基础版GPT-3。像GPT-3这样的大型模型也能从非参数记忆中获益。Contriever在GPT-3 davinci-003基础上带来了7%的准确率提升。
Read shows little-to-no performance improvement over vanilla parametric knowledge for smaller models, while the technique shows sizeable gains for GPT-3, especially davinci-003. In addition to its limited effectiveness with smaller LMs, GenRead has potentially prohibitive inference time costs, with GPT-NeoX 20B taking 70 seconds per query.
Read 方法在较小模型上相比普通参数化知识几乎没有性能提升,而在 GPT-3 (尤其是 davinci-003) 上则表现出显著增益。除了对小规模大语言模型效果有限外,GenRead 还存在较高的推理时间成本,例如 GPT-NeoX 20B 处理每个查询需要 70 秒。
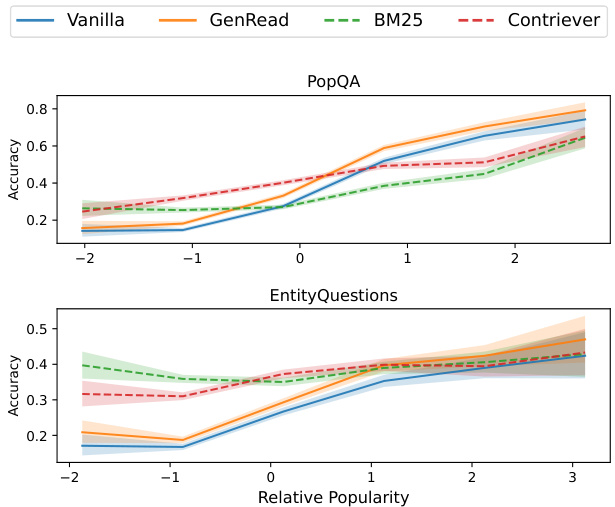
Figure 8: GPT-3 davinci-003 accuracy versus relative popularity (how popular a question is relative to other questions of its relationship type). Retrievalaugmented LMs (dashed) outperform LMs’ parametric memory (solid) for less popular entities, while parametric memory is competitive for more popular entities. Relative popularity is defined as the logpopularity of a question, normalized by the mean and standard deviation of log-popularity for the question’s relationship type (smaller for less popular entities).8 Figure 17 shows per-relationship results.
图 8: GPT-3 davinci-003准确率与相对流行度(某问题在其关系类型中的相对热门程度)对比。检索增强的大语言模型(虚线)在冷门实体上优于参数记忆模型(实线),而参数记忆模型在热门实体上表现相当。相对流行度定义为问题对数流行度经该关系类型对数流行度均值与标准差归一化后的值(数值越小表示实体越冷门)。完整分关系类型结果见图17。
Non-parametric memories are effective for less popular facts. How does retrieval augmentation lead to such significant improvements? Figure 8 shows the relationship between the entity popularity and models’ QA performance. It can be seen that retrieval-augmented LMs guided by Contriever or BM25 have a clear advantage over unassisted vanilla LMs, especially on less popular entities, resulting in a significant performance gain. Overall, Contriever-guided LMs outperform BM25-based ones on POPQA, while the BM25-based models perform better on the least popular entities, consistent with the findings from Sciavolino et al. (2021). On the other hand, for more popular entities, parametric knowledge shows equal or higher accuracy, indicating that the state-of-the-art LMs have already memorized the answers, and augmenting input with retrieved-context doesn’t help much or even hurts the performance. Interestingly, GenRead generally outperforms vanilla LMs despite relying on LMs’ parametric memory. This demonstrates the effectiveness of elicitive prompting (Wei et al., 2022; Sun et al., 2022) as observed in prior work. However, like vanilla LMs, GenRead shows low performance on less popular entities.
非参数化记忆对冷门事实更有效。检索增强为何能带来如此显著的性能提升?图8展示了实体流行度与模型问答性能的关系。可以看出,由Contriever或BM25引导的检索增强语言模型明显优于无辅助的基础语言模型,尤其在冷门实体上表现突出,实现了显著的性能增益。总体而言,在POPQA数据集上Contriever引导的模型优于基于BM25的模型,而BM25模型在最冷门实体上表现更佳,这与Sciavolino等人(2021)的研究结论一致。另一方面,对于热门实体,参数化知识展现出相当或更高的准确率,表明前沿语言模型已记忆了这些答案,检索增强的上下文输入帮助有限甚至会产生负面影响。值得注意的是,尽管依赖语言模型的参数化记忆,GenRead仍普遍优于基础语言模型,这印证了Wei等人(2022)和Sun等人(2022)提出的引导式提示的有效性。不过与基础语言模型类似,GenRead在冷门实体上表现欠佳。
Table 1: The recall $@1$ of Contriever for questions that GPT-3 davinci-003 answered correctly and incorrectly with and without retrieval on POPQA. The percent of questions falling in each category is shown in parentheses. For $10%$ of questions, retrieval is harmful due to low-quality retrieved text (0.14 recall $\ @{\mathbf{1}}$ ).
| Contriever-augmented LM succeeded failed | |
| LM succeeded | |
| 0.83 (24%) | 0.14 (10%) 0.88 (17%) 0.11 (49%) |
表 1: Contriever在POPQA上对GPT-3 davinci-003回答正确和错误问题的召回率$@1$,包括使用检索和不使用检索的情况。括号内显示了每类问题的占比。对于$10%$的问题,由于检索到的文本质量较低(召回率0.14 $\ @{\mathbf{1}}$),检索反而有害。
| Contriever增强的LM成功 失败 | |
|---|---|
| LM成功 | |
| 0.83 (24%) | 0.14 (10%) 0.88 (17%) 0.11 (49%) |
Non-parametric memories can mislead LMs. We conduct an in-depth analysis of why retrievalaugmented models suffer in more popular entities. We hypothesize that retrieval results may not always be correct or helpful, and can mislead LMs. To test this hypothesis, we group the questions based on two axes: whether unassisted GPT-3 davinci-003 predict correctly or not, and whether retrieval-augmented predictions are correct or not. For each of the four categories, we calculate recall $@1$ (whether a gold answer is included in the top 1 document; Karpukhin et al. 2020).
非参数化记忆可能误导大语言模型。我们深入分析了检索增强模型在更流行实体上表现不佳的原因,并提出假设:检索结果可能并不总是正确或有用,反而会误导模型。为验证该假设,我们根据两个维度对问题分组:(1) 无辅助的GPT-3 davinci-003能否正确预测;(2) 检索增强预测是否正确。针对四类情况分别计算召回率$@1$(黄金答案是否出现在top1文档中;Karpukhin等人[20])。
Table 1 shows recall $@1$ for each group with percentages of the questions falling into each of the categories. For $10%$ of questions, retrievalaugmentation causes the LM to incorrectly answer a question it could otherwise answer correctly. We found that on those questions, recall $@1$ is significantly lower than the overall recall $@1$ (0.14 vs 0.42 overall), indicating that failed retrieval can result in performance drops. Conversely, for the $17%$ of questions for which retrieval causes the LM to correctly answer a question it would otherwise have failed to answer, the recall $@1$ is 0.88. We include examples of both cases in Appendix Section C.3.
表 1: 展示了每组在 $@1$ 召回率下的表现,以及问题落入各类别的百分比。对于 $10%$ 的问题,检索增强会导致语言模型错误回答原本能正确回答的问题。我们发现这些问题上的 $@1$ 召回率显著低于整体水平 (0.14 vs 整体 0.42),表明检索失败可能导致性能下降。相反,对于 $17%$ 的检索帮助语言模型正确回答原本会答错的问题,其 $@1$ 召回率达到 0.88。附录 C.3 节包含了这两种情况的示例。
6 Adaptive Retrieval: Using Retrieval Only Where It Helps
6 自适应检索:仅在有益处时使用检索
While incorporating non-parametric memories helps in long-tail distributions, powerful LMs have already memorized factual knowledge for popular entities, and retrieval augmentation can be harmful. As outlined in $(R Q_{3})$ , can we achieve the best of both worlds? We propose a simple-yeteffective method, Adaptive Retrieval, which decides when to retrieve passages only based on input query information and augments the input with retrieved non-parametric memories only when necessary. We show that this is not only more powerful than LMs or retrieval-augmented LMs always retrieving context, but also more efficient than the standard retrieval-augmented setup.
虽然引入非参数化记忆(non-parametric memories)有助于处理长尾分布,但强大语言模型已记忆了热门实体的事实知识,此时检索增强反而可能产生负面影响。如$(R Q_{3})$所述,能否实现两全其美?我们提出一种简单有效的方法——自适应检索(Adaptive Retrieval),该方法仅根据输入查询信息决定何时检索文本段落,仅在必要时用检索到的非参数化记忆增强输入。实验表明,该方法不仅比始终检索上下文的大语言模型或检索增强语言模型更强大,而且比标准检索增强方案更高效。
6.1 Method
6.1 方法
Adaptive Retrieval is based on our findings: as the current best LMs have already memorized more popular knowledge, we can use retrieval only when they do not memorize the factual knowledge and thus need to find external non-parametric knowledge. In particular, we use retrieval for questions whose popularity is lower than a threshold (popularity threshold), and for more popular entities, do not use retrieval at all.
自适应检索基于我们的发现:当前最佳的大语言模型已经记住了更流行的知识,因此我们仅在它们未记住事实知识且需要查找外部非参数化知识时使用检索。具体而言,我们对流行度低于阈值(popularity threshold)的问题使用检索,而对于更流行的实体则完全不使用检索。
Using a development set, the threshold is chosen to maximize the adaptive accuracy, which we define as the accuracy attained by taking the predictions of the retrieval-augmented system for questions below the popularity threshold and the predictions based on parametric knowledge for the rest. We determine the popularity threshold independently for each relationship type.
使用开发集时,选择阈值以最大化自适应准确率。我们将自适应准确率定义为:对于低于流行度阈值的问题,采用检索增强系统的预测结果;其余问题则基于参数化知识进行预测,由此获得的准确率。针对每种关系类型,我们独立确定其流行度阈值。
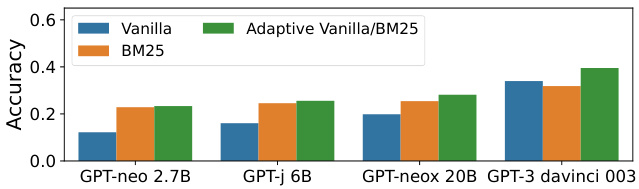
Figure 9: POPQA performance of GPT-neo models and GPT3 davinci-003, with different retrieval methods. Adaptive Retrieval robustly outperforms approaches that always retrieve, especially for larger LMs.
图 9: GPT-neo系列模型与GPT3 davinci-003在POPQA任务中的表现对比(采用不同检索方法)。自适应检索(Adaptive Retrieval)始终优于固定检索策略,该优势在更大规模的大语言模型中尤为显著。
6.2 Results
6.2 结果
Adaptive Retrieval improves performance. Figure 9 shows the results when we adaptively retrieve non-parametric memories based on the perrelationship type thresholds. We can see that adaptively retrieving non-parametric memories is effective for larger models. The best performance on POPQA is using GPT-3 davinci-003 adaptively with GenRead and Contriever, yielding $46.5%$ accuracy, $5.3%$ higher than any non-adaptive method.
自适应检索提升性能表现。图9展示了我们根据每种关系类型的阈值自适应检索非参数记忆时的结果。可以看出,自适应检索非参数记忆对较大模型更有效。POPQA上的最佳表现来自GPT-3 davinci-003结合GenRead和Contriever的自适应方案,准确率达到$46.5%$,比任何非自适应方法高出$5.3%$。
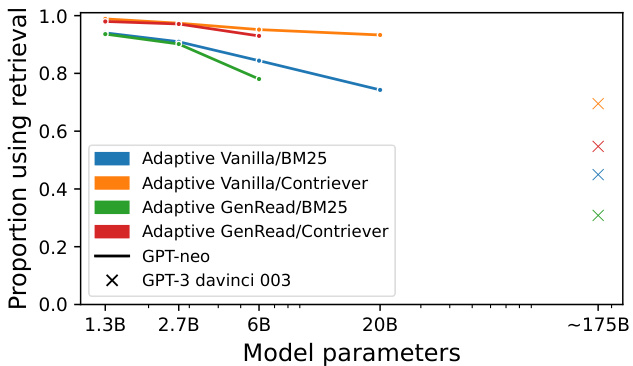
Figure 10: The proportion of questions for which various models use retrieval in the Adaptive Retrieval setup on POPQA. When using Adaptive Retrieval, small models must still rely on non-parametric memory for most questions, while larger models have more reliable parametric memories enabling them to use retrieval less often.
图 10: POPQA数据集上自适应检索(Adaptive Retrieval)设置中各模型使用检索机制的问题比例。采用自适应检索时,小模型仍需对多数问题依赖非参数化记忆,而大模型凭借更可靠的参数化记忆能够减少检索频率。
The threshold shifts with LM scale. While Adaptive Retrieval shows performance gains for larger models, smaller models do not realize the same benefits; as shown in Figure 9, the performance gain from Adaptive Retrieval is much smaller when we use models smaller than 10 billion. Why does this happen? Figure 10 shows that smaller LMs almost always retrieve, indicating that there are not many questions for which small LMs’ parametric knowledge is more reliable than non-parametric memory. In contrast, large models typically retrieve much less. For example, GPT3 davinci-003 only retrieves for $40%$ of questions when paired with BM25, and even the much smaller GPT-neox 20B does not retrieve documents on more than $20%$ of the questions. On EntityQuestions (Appendix Figure 15) all of the LMs retrieve much more, as the questions are mostly about less popular entities.
阈值随大语言模型规模变化而偏移。虽然自适应检索(Adaptive Retrieval)在较大模型上表现出性能提升,但较小模型并未获得同等收益;如图9所示,当使用小于100亿参数的模型时,自适应检索带来的性能增益明显减弱。这种现象的成因是什么?图10显示较小的大语言模型几乎总是触发检索,这表明对于大多数问题而言,小模型的参数化知识可靠性不及非参数化记忆。相比之下,大模型检索频率显著降低——例如GPT3 davinci-003配合BM25时仅对40%的问题触发检索,即便规模小得多的GPT-neox 20B也有超过80%的问题无需检索文档。在EntityQuestions数据集(附录图15)上,所有大语言模型的检索频率都更高,因为该数据集问题主要涉及冷门实体。
Adaptive Retrieval reduces inference-time costs.
自适应检索降低推理成本。
We also found that Adaptive Retrieval improves efficiency; if we know we do not need to retrieve documents, we can skip retrieval components and the input length becomes shorter, which improves latency in both retrieval and language model components. Figure 11 shows the inference latency of GPT-J 6B and GPT-neox 20B, and API costs of GPT-3. Especially for larger LMs, concatenating retrieved context results in significantly increased latency (e.g., for GPT-J 6B, the inference time latency almost doubles). Adaptive retrieval enables reducing inference time up to $9%$ from standard retrieval. We also observe cost reduction on Entity Questions, as shown in Figure 12.
我们还发现,自适应检索 (Adaptive Retrieval) 能提升效率;若确定无需检索文档,则可跳过检索组件并缩短输入长度,从而降低检索和大语言模型组件的延迟。图 11 展示了 GPT-J 6B 和 GPT-neox 20B 的推理延迟,以及 GPT-3 的 API 成本。尤其是对于较大规模的模型,拼接检索到的上下文会显著增加延迟 (例如 GPT-J 6B 的推理延迟几乎翻倍)。自适应检索可使推理时间较标准检索减少最高达 $9%$。如图 12 所示,在实体类问题上我们也观察到了成本降低。
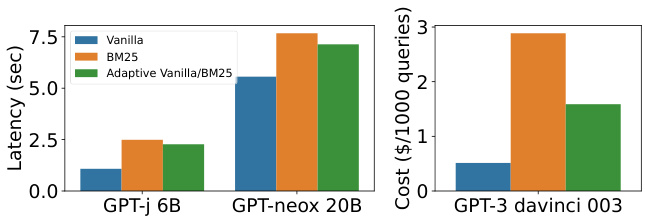
Figure 11: POPQA latency for large GPT-neo models that were run on our machines, and API costs for GPT3. Adaptive retrieval reduces latency and API costs.
图 11: 在我们机器上运行的大型 GPT-neo 模型的 POPQA 延迟,以及 GPT3 的 API 成本。自适应检索降低了延迟和 API 成本。
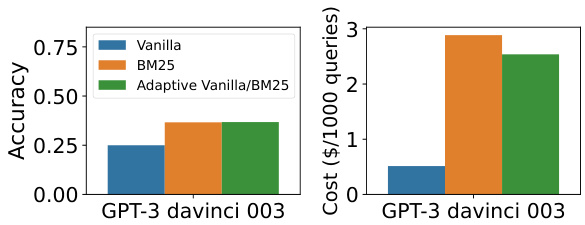
Figure 12: Accuracy and cost savings of Adaptive Retrieval for Entity Questions. Despite Entity Questions’s lack of popular entities (see Figure 3), Adaptive Retrieval is able to reduce API costs by $15%$ while maintaining equivalent performance to retrieval only.
图 12: 实体问题自适应检索(Adaptive Retrieval)的准确性与成本节约。尽管实体问题缺乏热门实体(见图 3),自适应检索仍能在保持与纯检索相当性能的同时,将API成本降低15%。
7 Discussion and Conclusions
7 讨论与结论
This work conducts large-scale knowledge probing to examine the effectiveness and limitations of relying on LMs’ parameters to memorize factual knowledge and to understand what factors affect factual knowledge memorization. Our results show that memorization has a strong correlation with entity popularity and that scaling up models on long-tail distributions may only provide marginal improvements. We also demonstrate that non-parametric memories can greatly aid LMs on these long-tail distributions, but can also mislead LMs on questions about well-known entities, as powerful LMs have already memorized them in their parameters. Based on those findings, we devise simple-yet-effective Adaptive Retrieval, which only retrieves when necessary, using a heuristic based on entity popularity and relationship types. Our experimental results show that this method is not only more powerful than LMs or previous retrieval-augmented LMs but also more efficient.
本研究通过大规模知识探测实验,检验了大语言模型(LM)依赖参数记忆事实知识的有效性及局限,并探究影响事实知识记忆的关键因素。实验结果表明:记忆强度与实体流行度显著相关,在长尾分布上扩大模型规模仅能带来边际收益;非参数化记忆虽能有效提升模型对长尾知识的处理能力,但会干扰模型对知名实体的判断(因为强大LM已将其编码至参数中)。基于这些发现,我们设计了高效的自适应检索(Adaptive Retrieval)机制,通过实体流行度和关系类型的启发式规则实现按需检索。实验证明该方法不仅性能优于纯LM或传统检索增强型LM,还具有更高计算效率。
Limitations
局限性
This work focuses on entity-centric factual knowledge and demonstrates that LMs’ memorization is heavily affected by the popularity of the entities and the aspect of the entities being asked in the questions. It is important to emphasize that for running controlled experiments, we have relied on two synthetic datasets, and the extent to which our results apply to naturally occurring factual knowledge has not been firmly established. While we can be fairly confident about the relationship between scaling, retrieval, popularity, relationship type, and performance for the kinds of knowledge studied here, the effectiveness of Adaptive Retrieval will depend on many details of the question answering pipeline. Moreover, our work depends on a definition of popularity that is time-dependent and may not perfectly reflect how frequently entities are discussed on the web. Wikipedia page views are one possible definition of popularity for which we observe our results, and we invite others to improve upon it in future work. Further research can expand upon this simple approach, perhaps drawing on insights from Kadavath et al. (2022) to improve the effectiveness of Adaptive Retrieval.
本研究聚焦于以实体为中心的事实性知识,并证明大语言模型的记忆能力深受实体流行度及问题所涉实体方面的影响。需要强调的是,为进行受控实验,我们依赖了两个合成数据集,因此研究结果在多大程度上适用于自然发生的事实性知识尚未得到确证。尽管我们对于本文研究的知识类型中规模扩展、检索、流行度、关系类型与性能之间的关系有较高信心,但自适应检索(Adaptive Retrieval)的实际效果将取决于问答管线的诸多细节。此外,我们的研究基于一个具有时间依赖性的流行度定义,该定义可能无法完全反映实体在网络上的讨论频率。维基百科页面浏览量是我们观察结果所采用的流行度定义之一,我们期待后续研究能对此进行改进。未来工作可以拓展这一简单方法,或可借鉴Kadavath等人(2022)的研究见解来提升自适应检索的效能。
It is an open question if the same findings are applicable to other types of world knowledge such as commonsense. We conjecture that the concept of the subject topic (entity), as well as the aspect (relationship type), can be applied with some minor modifications, which future work can quantify memorization following our scheme.
同样的发现是否适用于其他类型的世界知识(如常识)仍是一个开放性问题。我们推测,主题(实体)概念及方面(关系类型)只需稍作修改即可适用,未来工作可按照我们的方案量化记忆程度。
Ethical Considerations
伦理考量
Recent work (Huang et al., 2022) shows that LMs memorize personal information available on the web, which has significant security issues. Our evaluation focuses on the memorization of general entity-centric knowledge, but our findings can be applicable to those areas. Our findings suggest that LMs are likely to have less reliable knowledge of minority groups. Parrish et al. (2022) established that models often rely on stereotypes to answer in uncertain cases, so our results indicate that LMs are likely to rely on stereotypes disproportionately for minority groups. Future work could investigate whether retrieval augmentation reduces bias in these cases.
近期研究 (Huang et al., 2022) 表明,大语言模型会记忆网络上可用的个人信息,这存在重大安全隐患。我们的评估主要关注以通用实体为中心的知识记忆,但研究结果同样适用于这些领域。研究发现,大语言模型对少数群体的知识可信度可能较低。Parrish et al. (2022) 证实模型在不确定情况下常依赖刻板印象作答,因此我们的结果表明大语言模型可能对少数群体过度依赖刻板印象。未来研究可探讨检索增强技术是否能降低此类场景中的偏见。
Acknowledgements
致谢
We thank the UW NLP group members for their helpful discussions, and Joongwon Kim, Wenya Wang, and Sean Welleck for their insightful feedback on this paper. This research was supported by NSF IIS-2044660, ONR N00014-18-1-2826,
我们感谢UW NLP小组成员的宝贵讨论,以及Joongwon Kim、Wenya Wang和Sean Welleck对本论文提出的深刻反馈。本研究得到了NSF IIS-2044660、ONR N00014-18-1-2826的支持。
ONR MURI N00014- 18-1-2670, and Allen Distinguished Award. AM is funded by a Goldwater Scholarship and AA is funded by the IBM PhD Fellowship.
ONR MURI N00014-18-1-2670 和 Allen Distinguished Award。AM 获得 Goldwater Scholarship 资助,AA 获得 IBM PhD Fellowship 资助。
References
参考文献
Nancy E Adams. 2015. Bloom’s taxonomy of cognitive learning objectives. Journal of the Medical Library Association.
Nancy E Adams. 2015. 布鲁姆认知学习目标分类法。 Journal of the Medical Library Association。
Akari Asai, Matt Gardner, and Hannaneh Hajishirzi. 2022. Evident i ali ty-guided generation for knowledge-intensive NLP tasks. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
Akari Asai、Matt Gardner和Hannaneh Hajishirzi。2022。面向知识密集型NLP任务的证据引导生成。载于《2022年北美计算语言学协会人类语言技术会议论文集》。
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, et al. 2016. MS MARCO: A human generated machine reading comprehension dataset.
Payal Bajaj、Daniel Campos、Nick Craswell、Li Deng、Jianfeng Gao、Xiaodong Liu、Rangan Majumder、Andrew McNamara、Bhaskar Mitra、Tri Nguyen等。2016。MS MARCO:一个人工生成的机器阅读理解数据集。
Sidney Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, Usvsn Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, and Samuel Weinbach. 2022. GPT-NeoX-20B: An opensource auto regressive language model. In Proceedings of BigScience Episode #5 – Workshop on Challenges & Perspectives in Creating Large Language Models.
Sidney Black、Stella Biderman、Eric Hallahan、Quentin Anthony、Leo Gao、Laurence Golding、Horace He、Connor Leahy、Kyle McDonell、Jason Phang、Michael Pieler、Usvsn Sai Prashanth、Shivanshu Purohit、Laria Reynolds、Jonathan Tow、Ben Wang 和 Samuel Weinbach。2022。GPT-NeoX-20B:开源自回归大语言模型。收录于《BigScience Episode #5 – 大语言模型创建挑战与前景研讨会论文集》。
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego De Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack Rae, Erich Elsen, and Laurent Sifre. 2022. Improving language models by retrieving from trillions of tokens. In Proceedings of the 39th International Conference on Machine Learning.
Sebastian Borgeaud、Arthur Mensch、Jordan Hoffmann、Trevor Cai、Eliza Rutherford、Katie Millican、George Bm Van Den Driessche、Jean-Baptiste Lespiau、Bogdan Damoc、Aidan Clark、Diego De Las Casas、Aurelia Guy、Jacob Menick、Roman Ring、Tom Hennigan、Saffron Huang、Loren Maggiore、Chris Jones、Albin Cassirer、Andy Brock、Michela Paganini、Geoffrey Irving、Oriol Vinyals、Simon Osindero、Karen Simonyan、Jack Rae、Erich Elsen 和 Laurent Sifre。2022。通过从数万亿token中检索改进语言模型。载于《第39届国际机器学习会议论文集》。
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. In Advances in Neural Information Processing systems.
Tom Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared D Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell 等. 2020. 语言模型是少样本学习者. 发表于《神经信息处理系统进展》.
Boxi Cao, Hongyu Lin, Xianpei Han, Le Sun, Lingyong Yan, Meng Liao, Tong Xue, and Jin Xu. 2021. Knowledgeable or educated guess? revisiting language models as knowledge bases. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing.
Boxi Cao、Hongyu Lin、Xianpei Han、Le Sun、Lingyong Yan、Meng Liao、Tong Xue 和 Jin Xu。2021。知识渊博还是教育猜测?重新审视作为知识库的语言模型。载于《第59届计算语言学协会年会暨第11届自然语言处理国际联合会议论文集》。
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramèr, and Chiyuan Zhang. 2022. Quantifying memorization across neural language models.
Nicholas Carlini、Daphne Ippolito、Matthew Jagielski、Katherine Lee、Florian Tramèr 和 Chiyuan Zhang。2022。量化神经语言模型的记忆效应。
Hung-Ting Chen, Michael JQ Zhang, and Eunsol Choi. 2022. Rich knowledge sources bring complex knowledge conflicts: Re calibrating models to reflect conflicting evidence. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing.
Hung-Ting Chen、Michael JQ Zhang 和 Eunsol Choi。2022。丰富知识源带来复杂知识冲突:重新校准模型以反映矛盾证据。载于《2022年自然语言处理实证方法会议论文集》。
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2022. PaLM: Scaling language modeling with pathways.
Aakanksha Chowdhery、Sharan Narang、Jacob Devlin、Maarten Bosma、Gaurav Mishra、Adam Roberts、Paul Barham、Hyung Won Chung、Charles Sutton、Sebastian Gehrmann 等. 2022. PaLM: 基于Pathways扩展的语言建模.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019. BERT: 面向语言理解的深度双向Transformer预训练。载于《2019年北美计算语言学协会人类语言技术会议论文集》。
Paolo Ferragina and Ugo Scaiella. 2010. TAGME: on-the-fly annotation of short text fragments (by wikipedia entities). In Proceedings of the 19th ACM international conference on Information and knowledge management.
Paolo Ferragina和Ugo Scaiella。2010。TAGME:短文本片段即时标注(基于维基百科实体)。见第19届ACM国际信息与知识管理会议论文集。
Thibault Févry, Livio Baldini Soares, Nicholas FitzGerald, Eunsol Choi, and Tom Kwiatkowski. 2020. En- tities as experts: Sparse memory access with entity supervision. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.
Thibault Févry、Livio Baldini Soares、Nicholas FitzGerald、Eunsol Choi 和 Tom Kwiatkowski。2020。实体即专家:基于实体监督的稀疏记忆访问。载于《2020年自然语言处理实证方法会议论文集》。
Junxian He, Graham Neubig, and Taylor BergKirkpatrick. 2021. Efficient nearest neighbor language models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing.
何俊贤、Graham Neubig 和 Taylor BergKirkpatrick。2021。高效最近邻语言模型。载于《2021年自然语言处理实证方法会议论文集》。
Jie Huang, Hanyin Shao, and Kevin Chen-Chuan Chang. 2022. Are large pre-trained language models leaking your personal information? In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.
Jie Huang、Hanyin Shao 和 Kevin Chen-Chuan Chang。2022。大型预训练语言模型会泄露你的个人信息吗? 载于《2020年自然语言处理实证方法会议论文集》。
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2022a. Unsupervised dense information retrieval with contrastive learning. Transactions on Machine Learning Research.
Gautier Izacard、Mathilde Caron、Lucas Hosseini、Sebastian Riedel、Piotr Bojanowski、Armand Joulin 和 Edouard Grave。2022a。基于对比学习的无监督密集信息检索。机器学习研究汇刊。
Gautier Izacard and Edouard Grave. 2021. Leveraging passage retrieval with generative models for open domain question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics.
Gautier Izacard 和 Edouard Grave. 2021. 利用生成模型与段落检索实现开放域问答. 载于《第16届欧洲计算语言学协会会议论文集》.
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane DwivediYu, Armand Joulin, Sebastian Riedel, and Edouard
Gautier Izacard、Patrick Lewis、Maria Lomeli、Lucas Hosseini、Fabio Petroni、Timo Schick、Jane DwivediYu、Armand Joulin、Sebastian Riedel 和 Edouard
Grave. 2022b. Few-shot learning with retrieval augmented language models.
Grave. 2022b. 基于检索增强语言模型的少样本学习。
Joel Jang, Seonghyeon Ye, Changho Lee, Sohee Yang, Joongbo Shin, Janghoon Han, Gyeonghun Kim, and Minjoon Seo. 2022. Temporal wiki: A lifelong benchmark for training and evaluating ever-evolving language models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.
Joel Jang、Seonghyeon Ye、Changho Lee、Sohee Yang、Joongbo Shin、Janghoon Han、Gyeonghun Kim 和 Minjoon Seo。2022. Temporal Wiki: 面向持续演进语言模型的终身训练与评估基准。载于《2020年自然语言处理实证方法会议论文集》。
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield Dodds, Nova DasSarma, Eli Tran-Johnson, et al. 2022. Language models (mostly) know what they know.
Saurav Kadavath、Tom Conerly、Amanda Askell、Tom Henighan、Dawn Drain、Ethan Perez、Nicholas Schiefer、Zac Hatfield Dodds、Nova DasSarma、Eli Tran-Johnson 等。2022。语言模型 (大多) 知道自己知道什么。
Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. 2022. Large language models struggle to learn long-tail knowledge.
Nikhil Kandpal、Haikang Deng、Adam Roberts、Eric Wallace 和 Colin Raffel。2022. 大语言模型 (Large Language Model) 难以学习长尾知识。
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for opendomain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.
Vladimir Karpukhin、Barlas Oguz、Sewon Min、Patrick Lewis、Ledell Wu、Sergey Edunov、Danqi Chen 和 Wen-tau Yih。2020. 开放域问答的密集段落检索。载于《2020年自然语言处理实证方法会议论文集》。
Jungo Kasai, Keisuke Sakaguchi, Yoichi Takahashi, Ronan Le Bras, Akari Asai, Xinyan Yu, Dragomir Radev, Noah A Smith, Yejin Choi, and Kentaro Inui. 2022. Realtime QA: What’s the answer right now?
Jungo Kasai、Keisuke Sakaguchi、Yoichi Takahashi、Ronan Le Bras、Akari Asai、Xinyan Yu、Dragomir Radev、Noah A Smith、Yejin Choi 和 Kentaro Inui。2022. Realtime QA: 当前答案是什么?
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Z ett le moyer, and Mike Lewis. 2020. Generalization through memorization: Nearest neighbor language models. In International Conference on Learning Representations.
Urvashi Khandelwal、Omer Levy、Dan Jurafsky、Luke Zettlemoyer 和 Mike Lewis。2020。通过记忆实现泛化:最近邻语言模型。发表于 International Conference on Learning Representations。
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Red- field, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics.
Tom Kwiatkowski、Jennimaria Palomaki、Olivia Redfield、Michael Collins、Ankur Parikh、Chris Alberti、Danielle Epstein、Illia Polosukhin、Jacob Devlin、Kenton Lee、Kristina Toutanova、Llion Jones、Matthew Kelcey、Ming-Wei Chang、Andrew M. Dai、Jakob Uszkoreit、Quoc Le 和 Slav Petrov。2019。Natural Questions:问答研究基准。《计算语言学协会汇刊》。
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledgeintensive nlp tasks. In Advances in Neural Information Processing Systems.
Patrick Lewis、Ethan Perez、Aleksandra Piktus、Fabio Petroni、Vladimir Karpukhin、Naman Goyal、Heinrich Küttler、Mike Lewis、Wen-tau Yih、Tim Rocktäschel、Sebastian Riedel 和 Douwe Kiela。2020。面向知识密集型 NLP 任务的检索增强生成。载于《神经信息处理系统进展》。
Shayne Longpre, Kartik Perisetla, Anthony Chen, Nikhil Ramesh, Chris DuBois, and Sameer Singh. 2021. Entity-based knowledge conflicts in question answering. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7052–7063, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.
Shayne Longpre、Kartik Perisetla、Anthony Chen、Nikhil Ramesh、Chris DuBois和Sameer Singh。2021。基于实体的问答知识冲突。载于《2021年自然语言处理实证方法会议论文集》,第7052–7063页,线上及多米尼加共和国蓬塔卡纳。计算语言学协会。
Sewon Min, Weijia Shi, Mike Lewis, Xilun Chen, Wentau Yih, Hannaneh Hajishirzi, and Luke Z ett le moyer. 2022. Non parametric masked language model.
Sewon Min、Weijia Shi、Mike Lewis、Xilun Chen、Wentau Yih、Hannaneh Hajishirzi 和 Luke Zettlemoyer。2022。非参数掩码语言模型。
Alicia Parrish, Angelica Chen, Nikita Nangia, Vishakh Padmakumar, Jason Phang, Jana Thompson, Phu Mon Htut, and Samuel Bowman. 2022. BBQ: A hand-built bias benchmark for question answering. In Findings of the Association for Computational Linguistics: ACL 2022.
Alicia Parrish、Angelica Chen、Nikita Nangia、Vishakh Padmakumar、Jason Phang、Jana Thompson、Phu Mon Htut 和 Samuel Bowman。2022. BBQ: 一个手工构建的问答偏见基准。载于《计算语言学协会发现集: ACL 2022》。
Fabio Petroni, Tim Rock t s chel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. Language models as knowledge bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing.
Fabio Petroni、Tim Rocktäschel、Sebastian Riedel、Patrick Lewis、Anton Bakhtin、Yuxiang Wu和Alexander Miller。2019. 语言模型作为知识库?见《2019年自然语言处理实证方法会议暨第九届自然语言处理国际联合会议论文集》。
Nina Poerner, Ulli Waltinger, and Hinrich Schütze. 2020. E-BERT: Efficient-yet-effective entity embeddings for BERT. In Findings of the Association for Computational Linguistics: EMNLP 2020.
Nina Poerner、Ulli Waltinger 和 Hinrich Schütze。2020。E-BERT:高效而有效的 BERT 实体嵌入。载于《计算语言学协会发现:EMNLP 2020》。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J. Liu。2020。探索基于统一文本到文本Transformer的迁移学习极限。《机器学习研究期刊》。
Yasaman Razeghi, Robert L Logan IV, Matt Gardner, and Sameer Singh. 2022. Impact of pre training term frequencies on few-shot reasoning.
Yasaman Razeghi、Robert L Logan IV、Matt Gardner 和 Sameer Singh。2022. 预训练词频对少样本推理的影响。
Adam Roberts, Colin Raffel, and Noam Shazeer. 2020. How much knowledge can you pack into the parameters of a language model? In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing.
Adam Roberts、Colin Raffel 和 Noam Shazeer。2020. 语言模型的参数能承载多少知识?载于《2020年自然语言处理实证方法会议论文集》。
Stephen Robertson, Hugo Zaragoza, et al. 2009. The probabilistic relevance framework: Bm25 and beyond. Foundations and Trends in Information Retrieval.
Stephen Robertson、Hugo Zaragoza 等. 2009. 概率相关性框架: BM25 及后续模型. 信息检索的基础与趋势.
Christopher Sciavolino, Zexuan Zhong, Jinhyuk Lee, and Danqi Chen. 2021. Simple entity-centric questions challenge dense retrievers. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing.
Christopher Sciavolino, Zexuan Zhong, Jinhyuk Lee, Danqi Chen. 2021. 基于简单实体中心问题的稠密检索器挑战. 载于《2021年自然语言处理实证方法会议论文集》.
Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. 2021. Retrieval augmentation reduces hallucination in conversation. In Findings of the Association for Computational Linguistics: EMNLP 2021.
Kurt Shuster、Spencer Poff、Moya Chen、Douwe Kiela 和 Jason Weston。2021. 检索增强减少对话中的幻觉。载于《计算语言学协会发现:EMNLP 2021》。
Zhiqing Sun, Xuezhi Wang, Yi Tay, Yiming Yang, and Denny Zhou. 2022. Recitation-augmented language models.
Zhiqing Sun、Xuezhi Wang、Yi Tay、Yiming Yang 和 Denny Zhou。2022. 背诵增强的语言模型。
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. 2022. Chain of thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems.
Jason Wei、Xuezhi Wang、Dale Schuurmans、Maarten Bosma、Brian Ichter、Fei Xia、Ed H. Chi、Quoc V Le 和 Denny Zhou。2022。思维链提示激发大语言模型中的推理能力。载于《神经信息处理系统进展》。
Wenhao Yu, Dan Iter, Shuohang Wang, Yichong Xu, Mingxuan Ju, Soumya Sanyal, Chenguang Zhu, Michael Zeng, and Meng Jiang. 2022. Generate rather than retrieve: Large language models are strong context generators. Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, et al. 2022. Glm-130b: An open bilingual pre-trained model. Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher De- wan, Mona Diab, Xian Li, Xi Victoria Lin, et al. 2022. Opt: Open pre-trained transformer language models.
Wenhao Yu、Dan Iter、Shuohang Wang、Yichong Xu、Mingxuan Ju、Soumya Sanyal、Chenguang Zhu、Michael Zeng 和 Meng Jiang。2022。生成而非检索:大语言模型是强大的上下文生成器。Aohan Zeng、Xiao Liu、Zhengxiao Du、Zihan Wang、Hanyu Lai、Ming Ding、Zhuoyi Yang、Yifan Xu、Wendi Zheng、Xiao Xia 等。2022。GLM-130B:一个开放的双语预训练模型。Susan Zhang、Stephen Roller、Naman Goyal、Mikel Artetxe、Moya Chen、Shuohui Chen、Christopher Dewan、Mona Diab、Xian Li、Xi Victoria Lin 等。2022。OPT:开放预训练的Transformer语言模型。
Appendix
附录
A Details of POPQA Constructions
POPQA构建细节
List of the relationship types and templates. In this work, we use the following 16 relationship types, and the authors of this paper manually annotated templates to verbalize knowledge triple to natural language questions. We show the final list of the templates used to create POPQA in Table 2.
关系和模板列表。在本研究中,我们使用了以下16种关系类型,并由本文作者手动标注了将知识三元组转化为自然语言问题的模板。用于构建POPQA的最终模板列表如表2所示。
Figure 3 shows the distribution of subject popularity of POPQAand Entity Questions versus the popular NQ benchmark. NQ may have multiple entities so the distribution of the least popular entity per question is shown. Subject entities from NQ were extracted using TagMe (Ferragina and Scaiella, 2010) on the NQ-open development set with a score threshold of 0.22. TagMe returns the title of a Wikidata entity which can be directly used to find popularity.
图 3: 展示了POPQA和实体问题(Entity Questions)与热门基准NQ的主题流行度分布。由于NQ可能包含多个实体,因此展示了每个问题中最不受欢迎实体的分布情况。NQ的主题实体是通过在NQ-open开发集上使用TagMe (Ferragina and Scaiella, 2010)提取的,分数阈值为0.22。TagMe返回的Wikidata实体标题可直接用于查询流行度。
Table 2: Full list of the manually annotated templated used for POP QA creations. [subj] denotes a placeholder for subject entities.
| Relationship | Template |
| occupation | What is [subj] 's occupation? |
| place of birth | In what city was [subj] born? |
| genre | What genre is [subj]? |
| father | Who is the father of [subj] ? |
| country | In what country is [subj] ? |
| producer | Who was the producer of[subj]? |
| director | Who was the director of[subj]? |
| capital of | What is [subj] the capital of? |
| screenwriter | Who was the screenwriter for [subj] ? |
| composer | Who was the composer of [subj] ? |
| color | What color is [subj] ? |
| religion | What is the religion of [subj] ? |
| sport | What sport does [subj] play? |
| author | Who is the author of [subj] ? |
| mother | Who is the mother of [subj] ? |
| capital | What is the capital of [subj] ? |
表 2: 用于构建POP QA的人工标注模板完整列表。[subj]表示主体实体的占位符。
| 关系 | 模板 |
|---|---|
| occupation | [subj]的职业是什么? |
| place of birth | [subj]出生在哪个城市? |
| genre | [subj]属于什么流派? |
| father | [subj]的父亲是谁? |
| country | [subj]位于哪个国家? |
| producer | [subj]的制作人是谁? |
| director | [subj]的导演是谁? |
| capital of | [subj]是哪个地方的首都? |
| screenwriter | [subj]的编剧是谁? |
| composer | [subj]的作曲者是谁? |
| color | [subj]是什么颜色? |
| religion | [subj]的宗教信仰是什么? |
| sport | [subj]从事什么运动? |
| author | [subj]的作者是谁? |
| mother | [subj]的母亲是谁? |
| capital | [subj]的首都是哪里? |
Knowledge triples sampling. In the construction of the POP QA data set, knowledge triples are sampled with higher weight given to more popular entities, otherwise, the distribution would be dominated by the tail and we would not have enough high-popularity entities to complete our analysis. Specifically, when considering whether to sample a particular knowledge triple, we include the knowledge triple if and only if $f>\exp(8R-6)$ , where $R\sim U(0,1)$ is a unit uniform pseudo-random number and $f$ is the exact match term frequency of the subject entity’s aliases in an ${800}\mathbf{MB}$ random sample of C4. To increase diversity, once 2000 knowledge triples of a particular relation type have been sampled, they are no longer sampled.
知识三元组采样。在构建POP QA数据集时,知识三元组的采样会给予更高权重的热门实体,否则数据分布将被长尾实体主导,导致缺乏足够的高热度实体来完成分析。具体而言,在决定是否采样某个特定知识三元组时,当且仅当满足 $f>\exp(8R-6)$ 条件时才会纳入该三元组,其中 $R\sim U(0,1)$ 是单位均匀伪随机数,$f$ 表示主体实体别名在C4数据集 ${800}\mathbf{MB}$ 随机样本中的精确匹配词频。为提升多样性,当特定关系类型的知识三元组采样达到2000条后,将停止该类型的继续采样。
B Experimental Details
B 实验细节
Computational resources and API costs. GPT3 API usage totaled to $\$275$ . We ran 14,282 questions through two GPT-3 davinci models using four different methods: vanilla experiments cost $\$13$ ( $\$0.46$ per 1000 questions), Contrieveraugmented experiments cost $\$88$ ( $\mathbb{S}3.08$ per 1000 questions), BM25-augmented experiments cost $\$81$ $(\$2.80$ per 1000 questions), and GenRead experiments cost $\$93$ $\$3.25$ per 1000 questions).
计算资源和API成本。GPT3 API使用总成本为275美元。我们通过四种不同方法在两个GPT-3 davinci模型上运行了14,282个问题:基础实验花费13美元(每1000个问题0.46美元),Contriever增强实验花费88美元(每1000个问题3.08美元),BM25增强实验花费81美元(每1000个问题2.80美元),GenRead实验花费93美元(每1000个问题3.25美元)。
To run experiments using LMs larger than two billion parameters, we use a single V100 Volta GPU with 32GB GPU memories. We use int8bit (Zeng et al., 2022) quantization with OPT 13 billion and GPT-Neo 20 billion models to make them fit our GPUs. In our preliminary experiments using GPT-Neo 6 billion, we did not observe a notable performance drop by using the quantization.
为了运行参数超过20亿的大语言模型实验,我们使用了一块配备32GB显存的V100 Volta GPU。针对130亿参数的OPT模型和200亿参数的GPT-Neo模型,我们采用了int8bit (Zeng等, 2022) 量化技术使其适配我们的显卡。在前期使用60亿参数GPT-Neo的实验中,量化操作未导致显著性能下降。
Constructing few-shot contexts. For POPQA, we sample few-shot examples stratified by relationship type to diversify the samples: for each of the 15 relationship types other than the one in the test question, we sample one random question-answer pair to include in the context. For Entity Questions, we take a simple random sample of 15 questionanswer pairs because there are more than 16 relationship types.
构建少样本上下文。对于POPQA,我们按关系类型分层抽样少样本示例以多样化样本:对于测试问题之外的15种关系类型,每种随机抽取一个问答对加入上下文。对于实体问题(Entity Questions),我们简单随机抽取15个问答对,因为其关系类型超过16种。
Details of deciding thresholds. We $75%$ of POPQAto determine a popularity threshold for each relation type. Using brute force search, we select the threshold to maximize the adaptive accuracy, which we define as the accuracy attained by taking the predictions of the retrieval-augmented system for questions below the popularity threshold and the predictions based on parametric knowledge for the rest.
确定阈值的细节。我们使用POPQA数据集的75%来确定每种关系类型的流行度阈值。通过暴力搜索,我们选择能够最大化自适应准确率的阈值。自适应准确率定义为:对于低于流行度阈值的问题,采用检索增强系统的预测结果;对于其他问题,则基于参数化知识进行预测,由此获得的准确率即为自适应准确率。
We then evaluate adaptive accuracy using the learned thresholds on the remaining $25%$ of POPQA, and repeat with 100 different random splits and take the mean to obtain the reported adaptive accuracy measurement.
然后,我们在剩余的25% POPQA数据上使用学习到的阈值评估自适应准确率,并重复100次不同的随机分割,取平均值作为报告的自适应准确率测量结果。

Figure 13: Accuracy by LMs and retrieval-augmented LMs on POPQA. This is an extension of Figure 7
图 13: 大语言模型和检索增强大语言模型在POPQA上的准确率。这是图7的扩展

Figure 14: Accuracy by LMs and retrieval-augmented LMs on Entity Questions.
图 14: 大语言模型和检索增强型大语言模型在实体问题上的准确率。

Figure 15: The proportion of questions for which Adaptive Retrieval uses retrieval versus model size for Entity Questions.
图 15: 自适应检索(Adaptive Retrieval)在实体问题中使用检索的比例与模型规模的关系。
C Detailed Results
C 详细结果
C.1 LM results
C.1 大语言模型 (Large Language Model) 结果
Full results of per-relationship type accuracy and correlation. Figure 16 shows the full result of per-relationship type accuracy for all relationship types in POPQA. Figure 17 shows the correlations for all relation types. Figures 19 and 18 show the same results for the Entity Questions dataset.
各关系类型准确率和相关性的完整结果。图16展示了POPQA中所有关系类型的完整准确率结果。图17展示了所有关系类型的相关性。图19和图18展示了实体问答数据集的相同结果。
Negative correlations of capital on EntityQuestions. As shown in Figure 19, the capital relationship types on in Entity Questions, while on POPQA, this relationship shows relatively high correlations. We found that in Entity Questions, this capital relationship type has many low-popularity questions whose answers are included in subject entity names (e.g., subject $\asymp^{\prime}$ "canton of Marseille-Belsunce", object="Marseille"). This causes performance to have a U-shaped relationship with popularity for the capital relationship type, so if most of the questions sampled come from the top half of popularity, the linear correlation will be positive, and vice versa.
实体问题中首都关系的负相关性。如图19所示,实体问题中的首都关系类型表现出负相关性,而在POPQA中,这种关系显示出较高的相关性。我们发现,在实体问题中,这种首都关系类型包含许多低热度问题,其答案直接存在于主语实体名称中(例如主语$\asymp^{\prime}$"马赛-贝尔桑斯区",宾语="马赛")。这导致首都关系类型的性能与热度呈U型关系——若多数采样问题来自热度较高的上半区,线性相关性为正;反之则为负。
C.2 Retrieval-augmented LM results
C.2 检索增强的大语言模型 (Retrieval-augmented LM) 结果
Overall performance of retrieval-augmented LMs. Figure 13 shows the overall performance of 40 LMs and retrieval-augmented LMs on POPQA. Retrieval-augmentation largely improves performance across different LMs, and much smaller models (GPT-Neo 1.3B) can perform on per with GPT-3. Figure 14 shows the results on EntityQuestions. Due to computational and time constraints, we were only able to run vanilla and Contriever results for most models.
检索增强大语言模型的整体性能。图13展示了40个大语言模型和检索增强大语言模型在POPQA上的整体表现。检索增强技术显著提升了各类模型的性能表现,使得更小规模的模型(GPT-Neo 1.3B)能达到与GPT-3相当的水平。图14展示了EntityQuestions数据集上的测试结果。由于算力和时间限制,我们仅对多数模型进行了基础版本和Contriever版本的测试。
Adaptive Retrieval for Entity Questions. Figure 15 shows the proportion of questions above the retrieval threshold for various models using Adaptive Retrieval on Entity Questions. Because Entity Questions has a large quantity of low-popularity questions, models (especially smaller ones) must rely heavily on retrieval.
自适应检索在实体问题中的应用。图 15 展示了不同模型在实体问题上使用自适应检索时,超过检索阈值的问题比例。由于实体问题包含大量低热度问题,模型(尤其是较小规模的模型)必须高度依赖检索。
Full results on all relationship types. Figure 20 shows the full results on POPQA of the retrievalaugmented LMs and unassisted LMs on 16 relationship types using three different LMs as backbones. Figure 21 shows these results for GPT-3 davinci-003 on Entity Questions.
所有关系类型的完整结果。图20展示了基于三种不同大语言模型作为骨干的检索增强型大语言模型和无辅助大语言模型在16种关系类型上对POPQA的完整结果。图21展示了GPT-3 davinci-003在实体问题(Entity Questions)上的这些结果。
C.3 Qualitative Results
C.3 定性结果
Table 3 shows several examples on POPQA, where GPT-3 davinci-003 answers correctly while the Contriever-augmented version fails to answer. Along with the low recall $@1$ of 0.14 for this group, Table 3 suggests that the most common reason retrieval can be harmful is that it retrieves a document about a mistaken entity, such as a person with the same name as the subject, or an entity that simply is not relevant to the question (as in the case of “Noel Black”).
表 3 展示了 POPQA 上的几个示例,其中 GPT-3 davinci-003 回答正确,而 Contriever 增强版本却未能正确回答。结合该组别 0.14 的低召回率 $@1$ ,表 3 表明检索可能有害的最常见原因是它检索到了关于错误实体的文档,例如与主题同名的人物,或与问题完全不相关的实体 (如 "Noel Black" 案例) 。

Figure 16: Accuracy on PopQA for all relationship types and models. This is an extension of Figure 4.
图 16: 各关系类型和模型在PopQA上的准确率。这是图4的扩展。

Figure 17: Correlations on PopQA for all relationship types and models. This is an extension of Figure 4.
图 17: PopQA上所有关系类型和模型的相关性分析。该图是图4的扩展。

Figure 18: Accuracy on Entity Questions for all relationship types and models.
图 18: 所有关系类型和模型在实体问题上的准确率。

Figure 19: Correlations on Entity Questions for all relationship types and models.
图 19: 所有关系类型和模型在实体问题上的相关性。

Figure 20: Accuracy for 3 models on POPQA versus popularity as shown in Figure 8 broken down by relationship type. Popularity bins with less than 5 samples are excluded to avoid cluttering the figures with noisy results that have wide error bars.
图 20: 3种模型在POPQA上的准确率与流行度关系(按关系类型划分),如图8所示。为避免误差条过宽导致的图表杂乱,样本数少于5的流行度区间已被排除。

Figure 21: Accuracy versus popularity for GPT-3 davinci-003 on Entity Questions broken down by relationship type. Popularity bins with less than 5 samples are excluded.
图 21: GPT-3 davinci-003 在 Entity Questions 数据集上按关系类型划分的准确率与流行度对比。样本数少于 5 的流行度区间已被排除。
Table 4 shows several examples on POPQA, where GPT-3 davinci-003 answers correctly only when augmented with Contriever. The recall $@1$ for this case is 0.88, which is significantly higher than the overall recall. Note that in the second example, the retrieval caused the LM to answer correctly, but only by coincidence: the subject entity “Pierre” actually refers to the city in South Dakota, not the Basketball player. Otherwise, retrieval appears to be helpful because it provides the relevant information directly.
表 4: 展示了POPQA上的几个示例,其中GPT-3 davinci-003仅在增强Contriever时才能正确回答。此情况的召回率 $@1$ 为0.88,显著高于整体召回率。值得注意的是,在第二个示例中,检索使大语言模型正确回答了问题,但这只是巧合:主题实体"Pierre"实际指南达科他州的城市,而非篮球运动员。除此之外,检索似乎很有帮助,因为它直接提供了相关信息。
Table 3: Qualitative examples of the questions where only retrieval-augmented LMs fail to answer correctly. The blue underlined text indicates the sub-strings matching the gold answers in the retrieved context.
| Question (answer) | LM | Retrieval-LM | Retrieval |
| Who was the director of Black? (Sanjay Leela Bhansali) | The director of Black is Sanjay Leela Bhansali. | Noel Black x | Noel Black (June 30,1937 -July 5,2014) was an Amer- ican film and television director, screenwriter, and pro- ducer. Black was born in Chicago, Illinois. He won awards at the 1966 ... and subsequently concentrated on directing for television, occasionally directing films such as "Private School". |
| Whowas theproducer of The Faculty?(Robert Rodriguez) | The Faculty was produced by Elizabeth Avellan and Robert Ro- driguez.V | The producer of The Faculty was ElizabethAvel- lan.x | The Faculty is a 1998 American science fiction teen horror film written by Kevin Williamson, directed by Robert Rodriguez, and starring Elijah Wood,.. The film was released on Christmas Day, 1998, by Miramax Films through Dimension Films. ... The film has devel- oped a cult following in the years since its release. |
| What isMichael Shelley's occupation? (singer-songwriter) | Michael Shelley isasinger- songwriter and musician.v | Michael Shelley is an American applied mathe- matician. x | Michael Shelley (mathematician) Michael J. Shelley (born August 17, 1959) is an American applied mathe- matician who works on the modeling and simulation of complex systems arising in physics and biology. This has included free-boundary problems in fuids and mate- rials science... He is also the co-founder and co-director |
| In what city was Zijah Sokolovic born? (Sara- jevo) | Zijah Sokolovic was born 1in Sarajevo√ | Zijah Sokolovic wasborn in Orahovac, Kingdom x | of the Courant Institute's Applied Mathematics Lab. Ali Sokol... (born 8 May 1921 in Orahovac,Kingdom of Serbs,Croats and Slovenes,died 23September 1974) was a Yugoslav pulmonologist . Ali Sokol was born into an agricultural family. He was the third of four children of father and mother Hatixhes Solomon. It is unknown the exact date of birth but the most reliable date is May 8 year in 1921. |
表 3: 仅检索增强的大语言模型回答错误问题的定性示例。蓝色下划线文本表示检索上下文中与标准答案匹配的子字符串。
| 问题 (答案) | 大语言模型 | 检索增强模型 | 检索内容 |
|---|---|---|---|
| Who was the director of Black? (Sanjay Leela Bhansali) | 《Black》的导演是Sanjay Leela Bhansali。 | Noel Black × | Noel Black (1937年6月30日-2014年7月5日) 是美国影视导演、编剧和制片人。他出生于伊利诺伊州芝加哥,曾获1966年...后专注于电视剧导演工作,偶尔执导《Private School》等电影。 |
| Who was the producer of The Faculty? (Robert Rodriguez) | 《The Faculty》由Elizabeth Avellan和Robert Rodriguez联合制片。√ | 该片制片人是Elizabeth Avellan × | 《The Faculty》是1998年由Robert Rodriguez执导,Kevin Williamson编剧的科幻青春恐怖片...影片于1998年圣诞节通过米拉麦克斯旗下Dimension影业发行...该片后来逐渐成为邪典经典。 |
| What is Michael Shelley's occupation? (singer-songwriter) | Michael Shelley是创作型歌手兼音乐人。√ | Michael Shelley是美国应用数学家 × | Michael Shelley (数学家) Michael J. Shelley (1959年8月17日出生) 是美国应用数学家,研究物理和生物学领域的复杂系统建模与仿真...他还是库朗研究所应用数学实验室的联合创始人兼联席主任。 |
| In what city was Zijah Sokolovic born? (Sarajevo) | Zijah Sokolovic出生于萨拉热窝 √ | Zijah Sokolovic出生于Orahovac王国 × | Ali Sokol... (1921年5月8日生于塞尔维亚-克罗地亚-斯洛文尼亚王国的Orahovac) 是南斯拉夫肺科专家。他出身农民家庭,是父母Solomon Hatixhes的第三个孩子,确切出生日期不详但最可靠记录为1921年5月8日。 |
Table 4: Qualitative examples of the questions where only retrieval-augmented LMs successfully answer correctly. The blue underlined text indicates the sub-strings matching the gold answers in the retrieved context.
| Question (answer) | LM | Retrieval-LM | Retrieval |
| What genre is Un- Unknown is not known? (fantasy) | a specific genre of music.It could refer to x | Unknown is a pulp fantasy fic- tion magazine. | Unknown (magazine) Unknown (also known as Un- known Worlds) was an American pulp fantasy fiction magazine, published from 1939 to 1943 by Street & Smith, and edited by John W. Campbell. .. The leading fantasy magazine in the 1930s was "Weird Tales", which focused on shock and horror. |
| Inwhat country isPierre is in Pierre is from Pierre? (United States)France.x | States.V | Jonas Farley Pierre (born May 30, 1980) is an American the United professional basketball player. A center, he has played with three teams in the National Basketball League of Canada (NBL). Pierre last played with the Saint John Mill Rats in Canada. ... He then joined Lincoln Uni- versity in Missouri for his third year.In the summer of 2003, he signed a letter of intent to play with Nicholls State in the NCAA Division I. | |
| Whowas theproducerT ofThe Cocoanuts? (Walter Wanger) | The Cocoanuts was produced by Florenz Ziegfeld. x | The Cocoanuts was produced for Paramount Pictures Walter Wanger, who√ | The Cocoanuts is a 1929 musical comedy film starring the Marx Brothers.Produced for Paramount Pictures by Walter Wanger, who is not credited, the film stars the by four Marx Brothers, Oscar Shaw, Mary Eaton, and Mar- garet Dumont. It was the first sound film to credit more than one director (Robert Florey and Joseph Santley), and was adapted to the screen by Morrie Ryskind from |
| Who was the director of The White SuitLazar Ristovski The White Suit?(Lazarwas Ristovski) | directed by Sachin Kundalkar. x | the George S. Kaufman Broadway musical play. .. In 1999 "The White Suit" an auteur film by Ristovski (director, writer, lead actor, and producer) was at the Cannes Film Festival in the Critics Week program. "The White Suit" was the Serbian entry for the 1999 Academy Awards. Lazar Ristovski is the sole owner of Zillion Film Company In 2006, he made a small appearance in the James Bond film "Casino Royale". He played Caruso in the 2004 movie "King of Thieves". He starred as Dorde in the award-winning 2009 film "St. George |
表 4: 仅检索增强大语言模型能正确回答问题的定性示例。蓝色下划线文本表示检索上下文中与标准答案匹配的子字符串。
| 问题 (答案) | 大语言模型 | 检索增强大语言模型 | 检索内容 |
|---|---|---|---|
| 《Unknown》属于什么类型?(奇幻) | 某种特定的音乐类型,可能指x | 《Unknown》是一本低俗奇幻小说杂志。 | 《Unknown》(杂志) 《Unknown》(又名《Unknown Worlds》)是美国低俗奇幻小说杂志,1939至1943年由Street & Smith出版,John W. Campbell编辑...20世纪30年代主流奇幻杂志是侧重惊悚恐怖题材的《Weird Tales》。 |
| Pierre来自哪个国家?(美国) | 法国。x | 美国。√ | Jonas Farley Pierre(1980年5月30日出生)是美国职业篮球运动员,司职中锋,曾在加拿大国家篮球联盟(NBL)效力于三支球队...2003年夏季他与NCAA一级联盟的Nicholls State签订了意向书。 |
| 《The Cocoanuts》的制片人是谁?(Walter Wanger) | 由Florenz Ziegfeld制作。x | 由派拉蒙影业的Walter Wanger制作√ | 《The Cocoanuts》是1929年由马克思兄弟主演的音乐喜剧电影,由未署名的Walter Wanger为派拉蒙影业制作...改编自George S. Kaufman的百老汇音乐剧。 |
| 《The White Suit》的导演是谁?(Lazar Ristovski) | 由Sachin Kundalkar执导。x | 1999年Ristovski(导演/编剧/主演/制片)的作者电影《The White Suit》入选戛纳电影节影评人周单元...Lazar Ristovski是Zillion电影公司的唯一所有者,2006年曾在007电影《皇家赌场》中客串出演。 |
A For every submission:
对于每份提交:
A1. Did you describe the limitations of your work? Section 7: Limitations
A1. 是否描述了工作的局限性?第7节:局限性
A2. Did you discuss any potential risks of your work? Section 7: Ethical Considerations
A2. 是否讨论了工作的潜在风险?第7节:伦理考量
A3. Do the abstract and introduction summarize the paper’s main claims? Section 1
A3. 摘要和引言是否总结了论文的主要主张? 第1节
A4. Have you used AI writing assistants when working on this paper? Left blank.
A4. 您在撰写本文时是否使用了AI写作助手?留空。
B Did you use or create scientific artifacts?
B 你是否使用或创建了科学制品?
Section 3.3
第3.3节
B1. Did you cite the creators of artifacts you used? Section 3.3
B1. 你是否引用了所使用制品的创作者?第3.3节
B2. Did you discuss the license or terms for use and / or distribution of any artifacts? The license is in our GitHub repository, which will be linked to from the abstract in the non-anonymous version.
B2. 是否讨论了任何产物的使用和/或分发许可或条款?许可证在我们的GitHub仓库中,将在非匿名版本的摘要中提供链接。
α B3. Did you discuss if your use of existing artifact(s) was consistent with their intended use, provided that it was specified? For the artifacts you create, do you specify intended use and whether that is compatible with the original access conditions (in particular, derivatives of data accessed for research purposes should not be used outside of research contexts)? Our dataset only contains data from Wikidata, which is widely used for NLP experiments and is already publicly available.
α B3. 您是否讨论过对现有成果的使用是否符合其指定用途(若已明确说明)?对于您创建的成果,是否明确了预期用途及其是否与原始访问条件兼容(特别是基于研究目的获取的数据衍生品不应在研究场景之外使用)?我们的数据集仅包含来自Wikidata的数据,该数据广泛用于自然语言处理实验且已公开可用。
B4. Did you discuss the steps taken to check whether the data that was collected / used contains any information that names or uniquely identifies individual people or offensive content, and the steps taken to protect / anonymize it? Our dataset only contains data from Wikidata, which is widely used for NLP experiments and is already publicly available.
B4. 是否讨论了检查所收集/使用数据是否包含指名或唯一识别个人身份的信息或冒犯性内容的步骤,以及保护/匿名化数据的措施?我们的数据集仅包含来自Wikidata的数据,该数据广泛用于NLP实验且已公开可用。
B6. Did you report relevant statistics like the number of examples, details of train / test / dev splits, etc. for the data that you used / created? Even for commonly-used benchmark datasets, include the number of examples in train / validation / test splits, as these provide necessary context for a reader to understand experimental results. For example, small differences in accuracy on large test sets may be significant, while on small test sets they may not be.
B6. 你是否报告了所使用/创建数据的相关统计信息(如样本数量、训练/测试/开发集划分细节等)?即使是常用基准数据集,也需包含训练/验证/测试集的样本数量,这些信息能为读者理解实验结果提供必要背景。例如,大测试集上准确率的微小差异可能具有显著性,而小测试集上的差异则未必。
Appendix B
附录 B
C Did you run computational experiments?
C 是否进行了计算实验?
Sections 4, 5, and 6
第4、5、6节
C1. Did you report the number of parameters in the models used, the total computational budget (e.g., GPU hours), and computing infrastructure used? Sections 4.1 and 5.1, Appendix B
C1. 是否报告了所用模型的参数量、总计算预算(如 GPU 小时数)以及使用的计算基础设施?章节 4.1 和 5.1,附录 B
C2. Did you discuss the experimental setup, including hyper parameter search and best-found hyper parameter values? Sections 4, 5, and 6
C2. 是否讨论了实验设置(包括超参数搜索和最优超参数值)? 第4、5、6节
C3. Did you report descriptive statistics about your results .g., errorbars around reults, smmary statistics from sets of experiments), and is it transparent whether you are reporting the max, mean, etc. or just a single run? Sections 4, 5, and 6, Appendix C
C3. 是否报告了结果的描述性统计信息(例如结果周围的误差条、实验集的汇总统计量),并且明确说明报告的是最大值、均值等指标还是仅单次运行结果?第4、5、6节,附录C
C4. If youused existing packages (eg, for preprocessing,for rm aliz ation, or for eva lu at in, dd you report the implementation, model, and parameter settings used (e.g., NLTK, Spacy, ROUGE, etc.)? Appendix A
C4. 如果使用了现有软件包(例如用于预处理、规范化或评估的软件包),是否报告了所使用的实现、模型和参数设置(如 NLTK、Spacy、ROUGE 等)?附录 A
D α Did you use human annotators (e.g., crowd workers) or research with human participants? Left blank.
D α 你是否使用了人工标注者(如众包工作者)或进行了涉及人类受试者的研究? 留空。
□ D1. Did you report the full text of instructions given to participants, including e.g., screenshots, disclaimers of any risks to participants or annotators, etc.? No response.
□ D1. 是否报告了提供给参与者的完整指令文本,包括例如截图、对参与者或标注者的任何风险免责声明等?无回应。
□ D2. Did you report information about how you recruited (e.g., crowd sourcing platform, students) and paid participants, and discuss if such payment is adequate given the participants’ demographic (e.g., country of residence)? No response.
□ D2. 你是否报告了招募参与者(如通过众包平台、学生)和支付报酬的方式,并讨论了根据参与者人口统计特征(如居住国)该报酬是否合理?无回应。
□ D3. Did you discuss whether and how consent was obtained from people whose data you’re using/curating? For example, if you collected data via crowd sourcing, did your instructions to crowd workers explain how the data would be used? No response.
□ D3. 你是否讨论过是否以及如何从数据提供者处获得同意?例如,若通过众包收集数据,是否向众包工作者说明数据用途?无回应。
□ D4. Was the data collection protocol approved (or determined exempt) by an ethics review board? No response.
□ D4. 数据收集方案是否经过伦理审查委员会批准(或判定为豁免)? 无回应。
□ D5. Did you report the basic demographic and geographic characteristics of the annotator population that is the source of the data? No response.
□ D5. 你是否报告了作为数据来源的标注人群的基本人口统计学和地理特征?未回应。