Not All Correct Answers Are Equal: Why Your Distillation Source Matters
并非所有正确答案都同等重要:为何你的蒸馏来源至关重要
Abstract
摘要
Distillation has emerged as a practical and effective approach to enhance the reasoning capabilities of open-source language models. In this work, we conduct a largescale empirical study on reasoning data distillation by collecting verified outputs from three state-of-the-art teacher models—AM-Thinking-v1, Qwen3-235B-A22B, and DeepSeek-R1—on a shared corpus of 1.89 million queries. We construct three parallel datasets and analyze their distributions, revealing that AM-Thinking-v1- distilled data exhibits greater token length diversity and lower perplexity. Student models trained on each dataset are evaluated on reasoning benchmarks including AIME2024, AIME2025, MATH500, and Live Code Bench. The AM-based model consistently achieves the best performance (e.g., 84.3 on AIME2024, 72.2 on AIME2025, 98.4 on MATH500, and 65.9 on Live Code Bench) and demonstrates adaptive output behavior—producing longer responses for harder tasks and shorter ones for simpler tasks. These findings highlight the value of high-quality, verified reasoning traces. We release the AM-Thinking-v1 and Qwen3-235B-A22B distilled datasets to support future research on open and high-performing reasoning-oriented language models. The datasets are publicly available on Hugging Face2.
蒸馏已成为增强开源语言模型推理能力的实用且有效方法。本研究通过从三个前沿教师模型(AM-Thinking-v1、Qwen3-235B-A22B和DeepSeek-R1)在189万条共享查询语料上收集已验证输出,开展了大规模推理数据蒸馏实证研究。我们构建了三个平行数据集并分析其分布特征,发现AM-Thinking-v1蒸馏数据具有更显著的token长度多样性和更低困惑度。在各数据集上训练的学生模型在AIME2024、AIME2025、MATH500和Live Code Bench等推理基准测试中接受评估。基于AM的模型始终表现最佳(如AIME2024达84.3分、AIME2025达72.2分、MATH500达98.4分、Live Code Bench达65.9分),并展现出适应性输出行为——对困难任务生成更长响应,对简单任务生成更短响应。这些发现凸显了高质量已验证推理轨迹的价值。我们开源AM-Thinking-v1和Qwen3-235B-A22B蒸馏数据集以支持未来开放高性能推理导向语言模型研究,数据集已在Hugging Face平台公开。
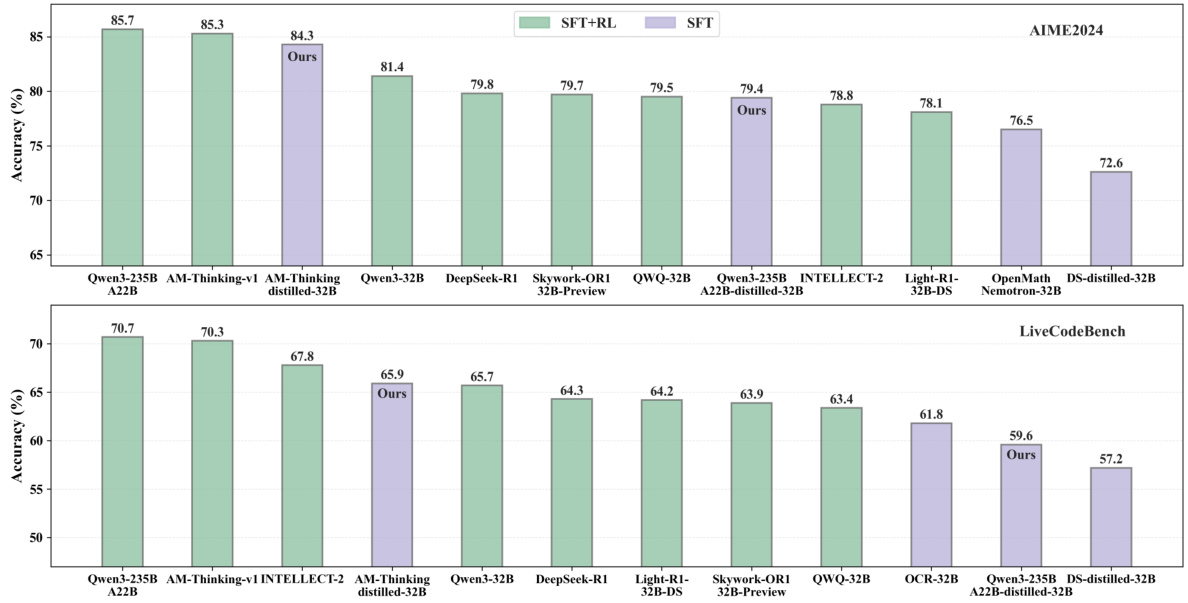
Figure 1: Open-source model benchmarks on AIME2024/Live Code Bench.
图 1: AIME2024/Live Code Bench 上的开源模型基准测试。
1 Introduction
1 引言
Recent work has demonstrated the effectiveness and efficiency of distillation-based training for enhancing the reasoning ability of Large Language Models (LLMs) [1, 2, 3]. By transferring reasoning traces from stronger teacher models, distilled data enables smaller or open-source models to achieve significant improvements on challenging tasks such as mathematics, coding, and scientific reasoning.
近期研究表明,基于蒸馏的训练方法能有效提升大语言模型(LLMs)的推理能力[1,2,3]。通过从更强的教师模型中迁移推理轨迹,经蒸馏处理的数据可使较小规模或开源模型在数学、编程和科学推理等复杂任务上取得显著进步。
Building on this line of research, we systematically distilled reasoning data from three state-ofthe-art models: DeepSeek-R1 [1], Qwen3-235B-A22B [3], and AM-Thinking-v1 [4]. For each of approximately 1.89 million identical queries, we collected full chain-of-thought responses from all three models, resulting in three parallel large-scale datasets. This unique setup allows for a direct comparison of reasoning styles and data distributions across leading models.
基于这一研究方向,我们系统性地从三个前沿模型中提取了推理数据:DeepSeek-R1 [1]、Qwen3-235B-A22B [3] 和 AM-Thinking-v1 [4]。针对约189万条相同查询,我们收集了这三个模型的完整思维链响应,最终形成三个并行的大规模数据集。这一独特设置实现了对领先模型间推理风格与数据分布的直接对比。
We carefully processed and cleaned all three datasets, including thorough de duplication, strict filtering, and contamination removal. We further analyzed the data distributions and content diversity to provide a comprehensive understanding of the strengths and characteristics of each distillation source.
我们仔细处理和清理了所有三个数据集,包括彻底的去重、严格过滤和污染去除。进一步分析了数据分布和内容多样性,以全面了解每个蒸馏来源的优势和特点。
Our experiments show that models trained with data distilled from AM-Thinking-v1 achieve particularly strong performance. On challenging reasoning benchmarks, such as AIME2024 [5] (84.3), AIME2025 [6] (72.2), MATH500 [7] (98.4), and LiveCodeBench [8] (65.9), the AM-Thinking-v1 distilled model consistently outperforms those trained on Qwen3-235B-A22B or DeepSeek-R1 data. Moreover, our analysis reveals that the AM-Thinking-v1 distilled model exhibits an adaptive generation length: producing longer responses on harder tasks (e.g., AIME, Live Code Bench), and shorter ones on simpler datasets (e.g., MATH500). This behavior aligns with the token-level distribution of the AM-distilled dataset, which contains both short and long responses more frequently than the other two sources.
我们的实验表明,使用AM-Thinking-v1蒸馏数据训练的模型展现出特别强劲的性能。在AIME2024 [5] (84.3)、AIME2025 [6] (72.2)、MATH500 [7] (98.4) 和 LiveCodeBench [8] (65.9) 等具有挑战性的推理基准测试中,AM-Thinking-v1蒸馏模型的表现始终优于基于Qwen3-235B-A22B或DeepSeek-R1数据训练的模型。此外,分析显示该模型具有自适应生成长度的特性:在较难任务(如AIME、Live Code Bench)上生成更长响应,在较简单数据集(如MATH500)上生成更短响应。这一特性与AM蒸馏数据集的token级分布相吻合——相比其他两种数据源,该数据集同时包含更多高频出现的短响应和长响应。
These results highlight the practical value of large-scale, high-quality reasoning data distillation, for improving open-source LLMs. To promote further progress in the field, we release both the AM-Thinking-v1 and Qwen3-235B-A22B distilled datasets3. We hope our work provides valuable resources and insights for the open-source community, enabling more effective reasoning-focused model development and contributing to the broader progress of reasoning research.
这些结果突显了大规模高质量推理数据蒸馏对于提升开源大语言模型的实用价值。为推动该领域进一步发展,我们同时发布了AM-Thinking-v1和Qwen3-235B-A22B蒸馏数据集[3]。希望我们的工作能为开源社区提供宝贵资源与洞见,助力开发更高效的推理导向模型,并推动推理研究领域的整体进步。
2 Data
2 数据
This section first introduces the data preprocessing and distillation pipeline used to construct our training corpus, and then presents a detailed analysis of the resulting datasets in terms of distribution, length, and quality.
本节首先介绍用于构建训练语料库的数据预处理和蒸馏流程,随后从分布、长度和质量三个维度对最终数据集进行详细分析。
2.1 Data Collection and Query Processing
2.1 数据收集与查询处理
To support robust and comprehensive model training, we constructed a large-scale training corpus by aggregating data from a diverse set of publicly available open-source corpora. These corpora span a broad range of NLP tasks, including mathematical reasoning, code generation, scientific reasoning, instruction following, multi-turn dialogue, and general reasoning. For downstream analysis and targeted data processing, each data source was systematically assigned to a specific task category.
为支持稳健且全面的模型训练,我们通过整合多种公开开源语料库构建了大规模训练数据集。这些语料涵盖数学推理、代码生成、科学推理、指令跟随、多轮对话和通用推理等广泛NLP任务。为便于下游分析和定向数据处理,每个数据源均被系统归类至特定任务范畴。
Training Data Categories The aggregated training data were classified as follows:
训练数据类别
汇总后的训练数据分类如下:
Query Preprocessing To guarantee the reliability of subsequent model training, we applied rigorous multi-stage preprocessing to the raw queries:
查询预处理
为确保后续模型训练的可靠性,我们对原始查询进行了严格的多阶段预处理:
- De duplication: Exact duplicate queries (identical text) were removed.
- 去重:完全重复的查询(文本相同)被移除。
2. Filtering:
- 过滤:
- Decontamination: To mitigate data contamination, especially regarding the core evaluation set (e.g., AIME2024 [5]), we conducted both exact match filtering and semantic deduplication. The latter leveraged the bge-m3 embedding model [26] to compute semantic similarity, removing queries exceeding a threshold of 0.9 with respect to the evaluation set.
- 去污染处理:为减轻数据污染问题,特别是针对核心评估集(如 AIME2024 [5]),我们同时进行了精确匹配过滤和语义去重。后者采用 bge-m3 嵌入模型[26]计算语义相似度,移除与评估集相似度超过0.9阈值的查询项。
2.2 Data Distilling
2.2 数据蒸馏
After preprocessing, we performed large-scale data distillation to further enhance the quality of our training corpus.
预处理后,我们进行了大规模数据蒸馏以进一步提升训练语料的质量。
Distillation Framework For each pre processed query, we adopted an incremental distillation strategy using three state-of-the-art models: AM-Thinking-v1 [4], Qwen3-235B-A22B [3], and DeepSeek-R1 [1]. Each query was independently distilled by these three models. For every model, the distillation process was repeated on the same query until the generated response satisfied the verification criterion (i.e., the verification score $\geq0.9$ ). Consequently, each query yielded up to three high-quality distilled outputs, corresponding to the three models, with each output refined iterative ly until it passed the automatic verification.
蒸馏框架
针对每个预处理后的查询,我们采用了一种增量式蒸馏策略,利用三个前沿模型:AM-Thinking-v1 [4]、Qwen3-235B-A22B [3] 和 DeepSeek-R1 [1]。每个查询均由这三个模型独立进行蒸馏处理。对于每个模型,同一查询的蒸馏过程会重复进行,直到生成的响应满足验证标准(即验证分数 $\geq0.9$)。因此,每个查询最多可产生三个高质量的蒸馏输出,分别对应三个模型,且每个输出均经过迭代优化直至通过自动验证。
Automatic Verification and Scoring To ensure the reliability and correctness of the distilled data, we employed automatic verification procedures tailored for each data category, assigning a verification score (verify score) to every model-generated response:
自动验证与评分
为确保蒸馏数据的可靠性和正确性,我们针对每类数据定制了自动验证流程,为每个模型生成的回答分配验证分数 (verify score):
• Multi-turn Conversations and General Reasoning: Decision-Tree-Reward-Llama-3.1- 8B [29] was used to evaluate coherence, correctness, and helpfulness, which were aggregated into a normalized composite score.
- 多轮对话与通用推理:使用 Decision-Tree-Reward-Llama-3.1-8B [29] 评估连贯性、正确性和实用性,并汇总为标准化综合得分。
A unified verification score threshold of 0.9 was used across all data categories.
所有数据类别均采用统一的验证分数阈值0.9。
Quality Assurance Measures To further enhance data quality, we introduced several additional validation and filtering strategies:
质量保障措施
为进一步提升数据质量,我们引入了多项额外的验证与过滤策略:
Ultimately, this process yielded a comprehensive dataset of 1.89 million queries, each paired with high-quality, verified responses distilled from all three models.
最终,这一过程生成了一个包含189万条查询的全面数据集,每条查询都与从三个模型中提炼出的高质量、已验证回答配对。
2.3 Data Analysis
2.3 数据分析
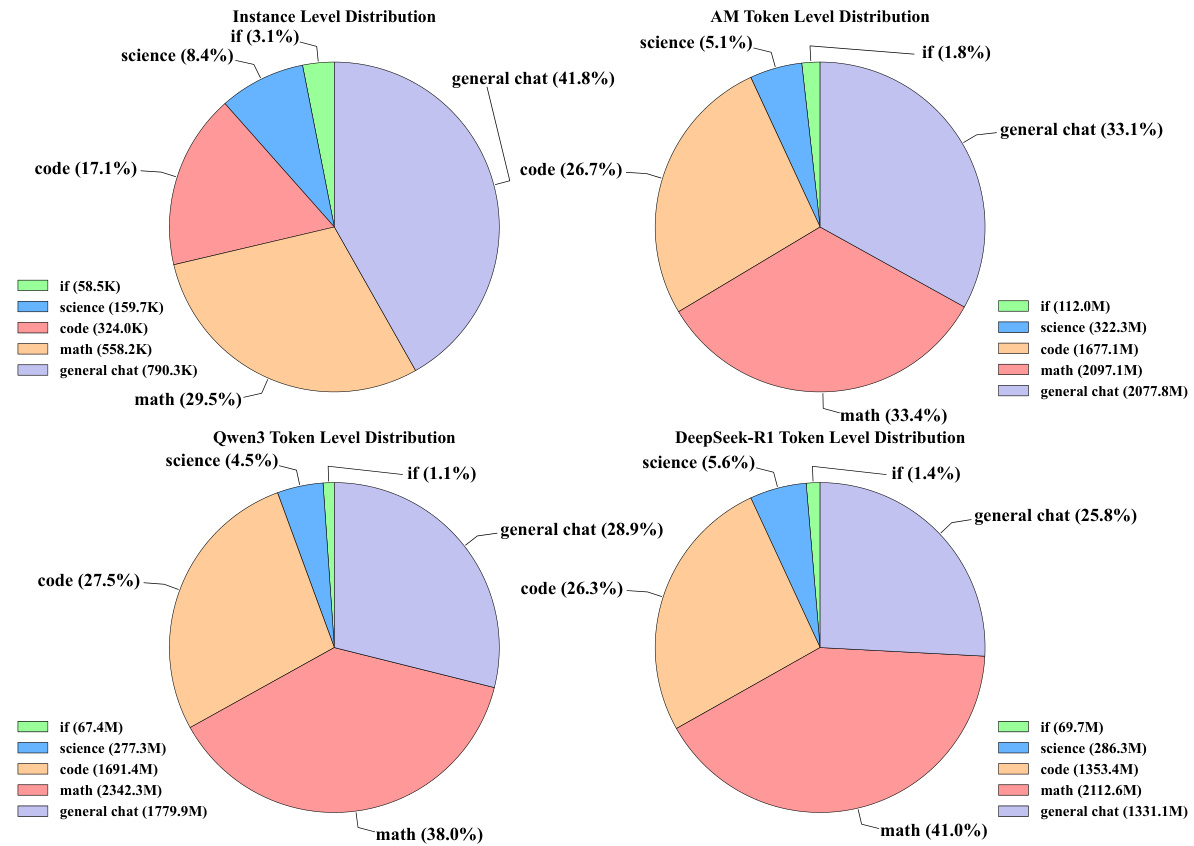
Figure 2: Instance-level and token-level output distributions are analyzed for AM-Thinkin-v1, Qwen3- 235B-A22B, and DeepSeek-R1. The general chat includes both multi-turn conversations and other types of data.
图 2: 针对 AM-Thinkin-v1、Qwen3-235B-A22B 和 DeepSeek-R1 的实例级和 token 级输出分布进行分析。通用聊天数据包含多轮对话及其他类型数据。
We conduct a detailed analysis of the training data distilled from three different large-scale models: AM-Thinking-v1 [4], Qwen3-235B-A22B [3], and DeepSeek-R1 [1]. This comparative analysis covers the instance-level and token-level output distributions, token length characteristics, and perplexity (PPL) distributions, providing insight into the data quality and structural tendencies of each dataset.
我们对三种不同大规模模型的训练数据进行了详细分析:AM-Thinking-v1 [4]、Qwen3-235B-A22B [3] 和 DeepSeek-R1 [1]。这项对比分析涵盖了实例级和 Token 级的输出分布、Token 长度特征以及困惑度 (PPL) 分布,揭示了各数据集的数据质量与结构倾向性。
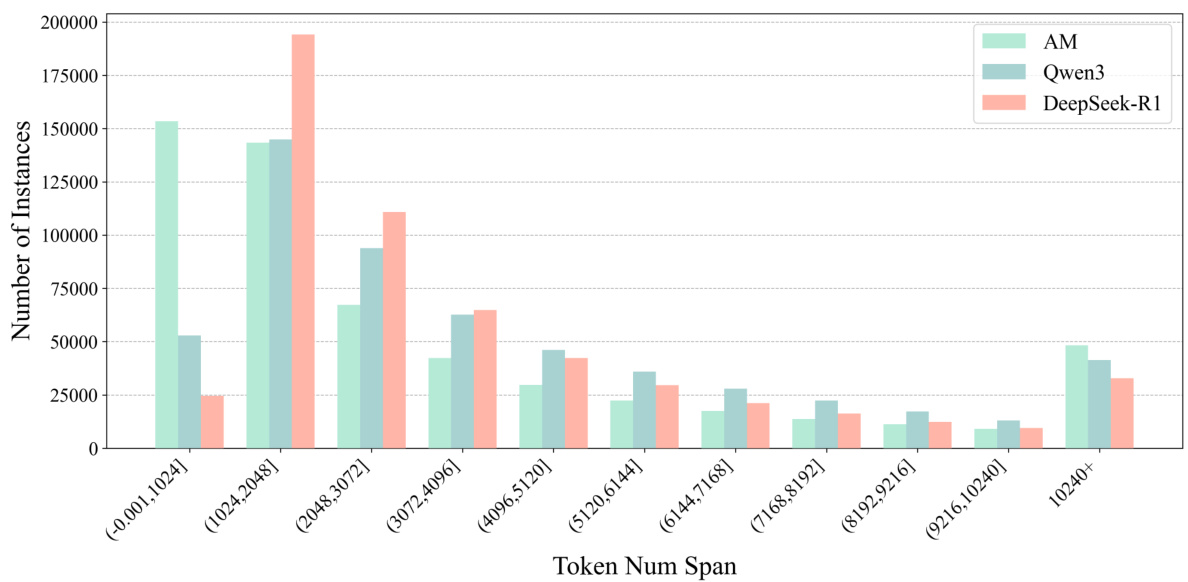
Figure 3: Token span distribution of instances for AM-Thinking-v1, Qwen3-235B-A22B, and DeepSeek-R1 on math.
图 3: AM-Thinking-v1、Qwen3-235B-A22B 和 DeepSeek-R1 在数学题上的 Token 跨度分布实例。
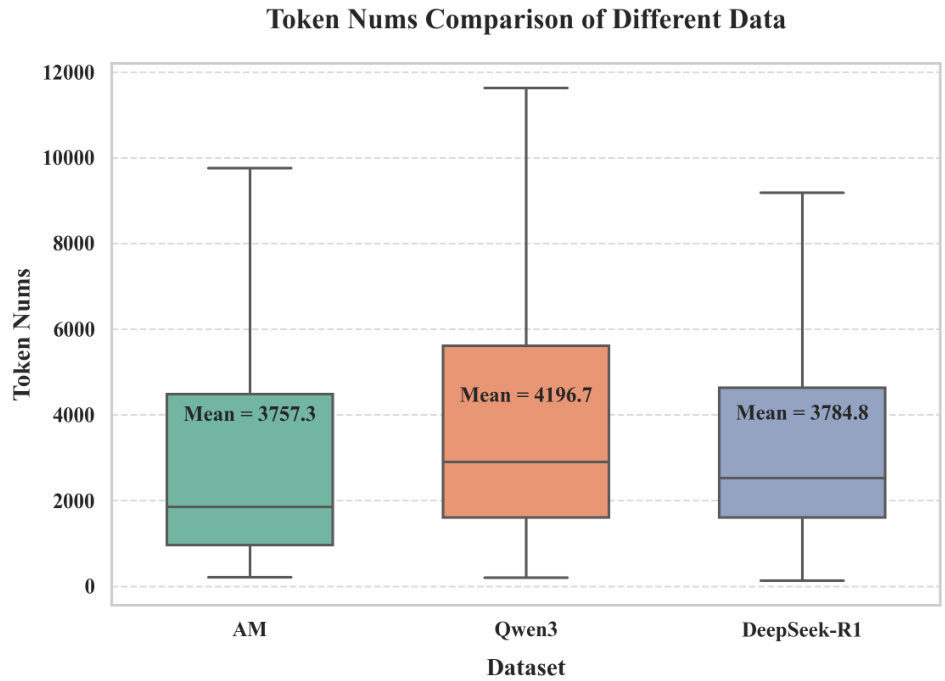
Figure 4: Token count distributions for AM-Thinking-v1, Qwen3-235B-A22B, and DeepSeek-R1 datasets. Box plots show the distribution of token numbers, with means labeled. Qwen3-235B-A22B has the highest average token count, followed by DeepSeek-R1 and AM-Thinking-v1.
图 4: AM-Thinking-v1、Qwen3-235B-A22B 和 DeepSeek-R1 数据集的 Token 数量分布。箱线图展示了 Token 数量的分布情况,并标注了平均值。Qwen3-235B-A22B 的平均 Token 数量最高,其次是 DeepSeek-R1 和 AM-Thinking-v1。
Figure 2 shows the output distribution of these datasets at both the instance and token levels. The instance-level distribution (top-left) reveals that this dataset includes a high proportion of general chat $(41.8%)$ , followed by math $(29.5%)$ and code $(17.1%)$ . In contrast, Qwen3-235B-A22B and DeepSeek-R1 token-level distributions (bottom charts) show a more pronounced focus on math $38.0%$ and $41.0%$ respectively), with general chat and code sharing similar proportions. Notably, AM-Thinking-v1’s token-level distribution (top-right) also emphasizes math $(33.4%)$ , albeit to a lesser extent than DeepSeek-R1. Science and instruction-following (IF) data make up a minor share across all datasets.
图 2 展示了这些数据集在实例级别和token级别的输出分布。实例级分布(左上)显示该数据集包含较高比例的通用聊天$(41.8%)$,其次是数学$(29.5%)$和代码$(17.1%)$。相比之下,Qwen3-235B-A22B和DeepSeek-R1的token级分布(底部图表)显示出更明显的数学侧重($38.0%$和$41.0%$),通用聊天和代码占比相近。值得注意的是,AM-Thinking-v1的token级分布(右上)也强调数学$(33.4%)$,尽管程度低于DeepSeek-R1。科学和指令遵循(IF)数据在所有数据集中占比较小。
Further, Figure 3 presents the token span distribution specifically for math instances. It demonstrates that AM-Thinking-v1’s math data exhibits a highly dispersed distribution—many short sequences (under 1024 tokens) and a substantial portion of very long sequences ( $10240+$ tokens). This reflects the token distribution characteristics under a fixed query set, where AM-Thinking-v1 tends to produce both short and very long responses more frequently. In contrast, Qwen3-235B-A22B’s data generally exhibits longer token spans, indicating a tendency toward producing longer responses. DeepSeekR1’s token spans are mostly concentrated between 1k and $8\mathrm{k\Omega}$ tokens, showing a moderate range of response lengths.
此外,图 3 展示了专门针对数学实例的 token 跨度分布。结果表明,AM-Thinking-v1 的数学数据呈现出高度分散的分布特征——存在大量短序列(低于 1024 token)和相当比例的超长序列(超过 $10240+$ token)。这反映了固定查询集下的 token 分布特性,即 AM-Thinking-v1 更频繁地生成较短或极长的响应。相比之下,Qwen3-235B-A22B 的数据通常表现出更长的 token 跨度,表明其倾向于生成更长的响应。DeepSeekR1 的 token 跨度主要集中在 1k 至 $8\mathrm{k\Omega}$ token 之间,显示出中等范围的响应长度。
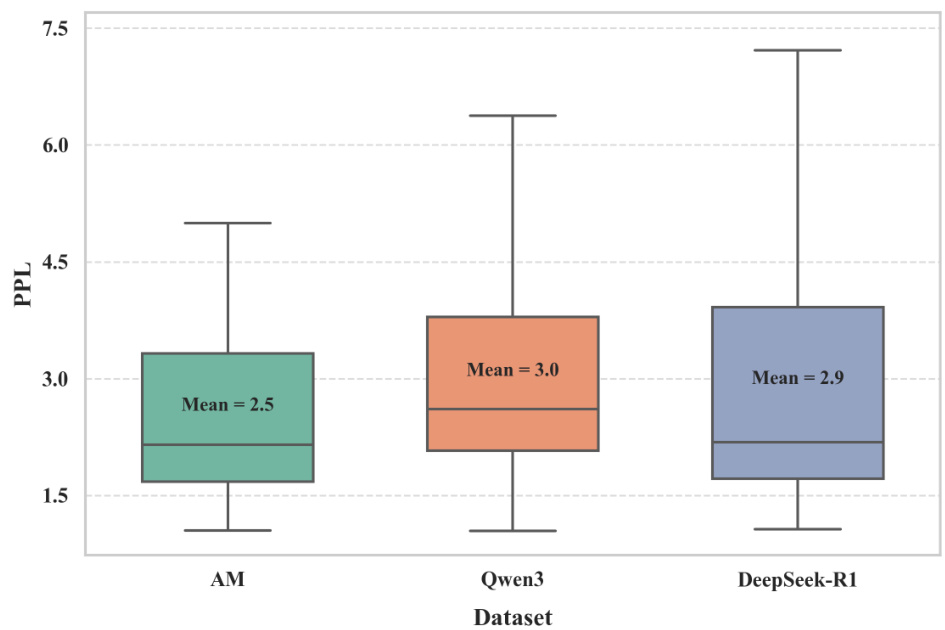
Figure 5: Perplexity (PPL) distributions for AM-Thinking-v1, Qwen3-235B-A22B, and DeepSeek-R1 datasets. Box plots show PPL distributions, with means labeled. AM-Thinking-v1 achieves the lowest mean PPL, indicating better overall quality.
图 5: AM-Thinking-v1、Qwen3-235B-A22B 和 DeepSeek-R1 数据集的困惑度 (PPL) 分布。箱线图展示了 PPL 分布情况,并标注了平均值。AM-Thinking-v1 实现了最低的平均 PPL,表明其整体质量更优。
Box plots in Figure 4 provide further insight into the average token length per instance. The Qwen3- 235B-A22B dataset has the highest mean token count (4196.7), followed by DeepSeek-R1 (3784.8) and AM-Thinking-v1 (3757.3). This aligns with the histogram observation that Qwen3-235B-A22B emphasizes longer instances, whereas AM-Thinking-v1 covers a broader range of lengths, including extremely short and long sequences.
图4中的箱线图进一步展示了每个实例的平均token长度。Qwen3-235B-A22B数据集的平均token数最高(4196.7),其次是DeepSeek-R1(3784.8)和AM-Thinking-v1(3757.3)。这与直方图观察结果一致:Qwen3-235B-A22B侧重较长实例,而AM-Thinking-v1覆盖的范围更广,包含极短和极长序列。
Finally, Figure 5 compares the perplexity (PPL) across the datasets. Perplexity is a key measure of language model performance, with lower values indicating better quality. Among the three datasets, AM-Thinking-v1 achieves the lowest mean PPL (2.5), suggesting that its distilled outputs are generally of higher quality. DeepSeek-R1 (mean $\mathrm{PPL}=2.9\$ ) performs slightly better than Qwen3 (mean $\mathrm{PPL}=3.0\AA$ ), highlighting the relatively strong performance of AM-distilled data in terms of perplexity.
最后,图 5 比较了各数据集的困惑度 (PPL)。困惑度是衡量语言模型性能的关键指标,数值越低表示质量越好。在三个数据集中,AM-Thinking-v1 的平均困惑度最低 (2.5),表明其蒸馏输出通常质量更高。DeepSeek-R1 (平均 $\mathrm{PPL}=2.9\$ ) 略优于 Qwen3 (平均 $\mathrm{PPL}=3.0\AA$ ),凸显了 AM 蒸馏数据在困惑度指标上的相对优势。
3 Experiments
3 实验
3.1 Training Configuration
3.1 训练配置
Training is conducted based on the Qwen2.5-32B [27, 28] base model. As suggested by [2, 4], all three models are trained with a learning rate of 8e-5, a maximum sequence length of $32\mathrm{k\Omega}$ (using sequence packing), and a global batch size of 64 for 2 epochs. Samples longer than $32\mathrm{k\Omega}$ tokens are excluded. We apply cosine warmup with $5%$ of total steps, and the learning rate decays to zero thereafter. For multi-turn dialogues, only the final response containing the reasoning process is used as the training target to focus learning on reasoning.
训练基于Qwen2.5-32B [27, 28]基础模型进行。如[2, 4]所述,所有三个模型均采用8e-5的学习率、$32\mathrm{k\Omega}$的最大序列长度(使用序列打包技术)和全局批次大小64训练2个周期。超过$32\mathrm{k\Omega}$ token的样本会被排除。我们采用余弦预热策略(预热步数占总步数的$5%$),之后学习率衰减至零。对于多轮对话,仅将包含推理过程的最终响应作为训练目标,以聚焦于推理能力的学习。
3.2 Benchmarks and Evaluation Setup
3.2 基准测试与评估设置
To rigorously assess our models’ capabilities, we select a diverse suite of challenging benchmarks across mathematical reasoning, programming, and general chatbot performance:
为了严格评估我们模型的能力,我们选取了一系列涵盖数学推理、编程和通用聊天机器人性能的多样化挑战性基准测试:
All benchmarks were evaluated under uniform conditions. The generation length was capped at 49,152 tokens. For stochastic decoding, we consistently adopted a temperature of 0.6 and top $\mathrm{\nabla\cdotp}$ of 0.95 across applicable tasks.
所有基准测试均在统一条件下进行评估。生成长度上限为49,152个token。对于随机解码任务,我们统一采用0.6的温度参数和0.95的top $\mathrm{\nabla\cdotp}$值。
Response sampling was tailored to the nature of each benchmark:
响应采样根据每个基准测试的特性进行了定制:
• AIME2024 and AIME2025: For each question, we generated 64 outputs to estimate pass $@1$ accuracy. • Live Code Bench: We sampled 16 completions per prompt to compute pass $@1$ . • MATH500: Each prompt was answered once, and we sampled 4 times to compute pass $@1$ .
• AIME2024 和 AIME2025: 每个问题生成 64 个输出来估算 pass $@1$ 准确率。
• Live Code Bench: 每个提示采样 16 个补全结果以计算 pass $@1$。
• MATH500: 每个提示回答一次,并采样 4 次以计算 pass $@1$。
Followed by AM-Thinking-v1[4], a unified system prompt was employed across all tasks to standardize output format and encourage reasoning:
继 AM-Thinking-v1[4] 之后,所有任务均采用统一的系统提示 (system prompt) 以标准化输出格式并促进推理:
You are a helpful assistant. To answer the user’s question, you first think about the reasoning process and then provide the user with the answer. The reasoning process and answer are enclosed within
你是一个乐于助人的助手。为了回答用户的问题,你会先思考推理过程,然后向用户提供答案。推理过程和答案分别包含在
User prompts were benchmark-specific:
用户提示词均基于基准测试设定:
• AIME tasks and MATH500: A supplementary instruction was added: Let’s think step by step and output the final answer within \box. • Live Code Bench: Original task prompts were used without any alterations.
• AIME 任务和 MATH500: 补充了一条说明:让我们逐步思考并在 \box 内输出最终答案。
• Live Code Bench: 直接使用原始任务提示,未作任何修改。
4 Results and Analysis
4 结果与分析
We evaluate the models on the reasoning benchmarks described in Section 3.2, using models trained with data distilled from AM-Thinking-v1, Qwen3-235B-A22B, and DeepSeek-R1. The evaluation results are presented in Table 1.
我们在第3.2节描述的推理基准上评估了模型,使用的训练数据来自AM-Thinking-v1、Qwen3-235B-A22B和DeepSeek-R1的蒸馏数据。评估结果如表1所示。
As shown in Table 1, the model distilled from AM-Thinking-v1 consistently achieves the highest accuracy across all benchmarks. On the more challenging math tasks, AIME2024 and AIME2025, it attains scores of 84.3 and 72.2, respectively, outperforming the Qwen3- and DeepSeek-distilled models by a considerable margin. It also leads on MATH500 (98.4) and Live Code Bench (65.9), indicating broad generalization across both mathematical and code-based reasoning tasks.
如表 1 所示,从 AM-Thinking-v1 蒸馏出的模型在所有基准测试中始终保持着最高准确率。在更具挑战性的数学任务 AIME2024 和 AIME2025 上,其得分分别为 84.3 和 72.2,显著优于 Qwen3 和 DeepSeek 的蒸馏模型。该模型在 MATH500 (98.4) 和 Live Code Bench (65.9) 上也保持领先,表明其在数学和代码推理任务中均具备广泛的泛化能力。
To better understand model behavior, we analyze the average generation length per sample across benchmarks (Table 2). Interestingly, the AM-Thinking-v 1 Distilled model produces notably longer outputs on more complex tasks: 15273.8 and 18199.2 tokens for AIME2024 and AIME2025, respectively, and 23426.9 for Live Code Bench. In contrast, on the simpler MATH500 benchmark, its average generation length (3495.7) is shorter than that of the Qwen3-235B-A 22 B Distilled model. This adaptive generation pattern suggests that the AM-distilled model can better modulate its output length based on task complexity—generating more detailed solutions when needed while remaining concise on simpler problems. This aligns with our earlier analysis in Section 2.3, where the AM-Thinking-v1 distilled dataset exhibited a higher proportion of both short and long token sequences. The broader distribution of token lengths in the training data likely contributes to the model’s improved ability to adjust its response length dynamically. Such length modulation is a desirable property in reasoning tasks, where over generation or under generation can negatively impact performance.
为了更好地理解模型行为,我们分析了各基准测试中每个样本的平均生成长度(表2)。有趣的是,AM-Thinking-v1 Distilled模型在更复杂的任务上会产生明显更长的输出:AIME2024和AIME2025分别达到15273.8和18199.2个token,Live Code Bench则达到23426.9个token。相比之下,在较简单的MATH500基准测试中,其平均生成长度(3495.7)比Qwen3-235B-A22B Distilled模型更短。这种自适应生成模式表明,AM-distilled模型能够根据任务复杂度更好地调节输出长度——在需要时生成更详细的解决方案,同时在简单问题上保持简洁。这与我们在2.3节中的早期分析一致,AM-Thinking-v1蒸馏数据集表现出更高比例的短token序列和长token序列。训练数据中更广泛的token长度分布可能有助于模型动态调整响应长度的能力提升。这种长度调节在推理任务中是一个理想特性,因为过度生成或生成不足都会对性能产生负面影响。
Table 1: Comparison across reasoning benchmarks using distilled data from different teacher models.
表 1: 使用不同教师模型蒸馏数据的推理基准对比
| AM-Thinking-VlDistilled | Qwen3-235B-A22BDistilled | DeepSeek-R1Distilled | |
|---|---|---|---|
| AIME2024 | 84.3 | 79.4 | 70.9 |
| AIME2025 | 72.2 | 62.2 | 52.8 |
| MATH500 | 98.4 | 93.9 | 95.8 |
| LiveCodeBench (v5, 2024.10-2025.02) | 65.9 | 59.6 | 57.0 |
Table 2: Average generation length (tokens per sample) across reasoning benchmarks.
表 2: 各推理基准的平均生成长度(每样本token数)
| AM-Thinking-VlDistilled | Qwen3-235B-A22BDistiled | DeepSeek-R1 Distilled | |
|---|---|---|---|
| AIME2024 | 15273.8 | 13516.4 | 11853.5 |
| AIME2025 | 18199.2 | 16975.7 | 13495.9 |
| MATH500 | 3495.7 | 6429.4 | 3613.0 |
| LiveCodeBench (v5,2024.10-2025.02) | 23426.9 | 13576.7 | 30731 |

Figure 6: Loss curves of AM-Thinking-v1-Distilled, DeepSeek-R1-Distilled and Qwen3-235B-A22BDistilled.
图 6: AM-Thinking-v1-Distilled、DeepSeek-R1-Distilled 和 Qwen3-235B-A22BDistilled 的损失曲线。
We further compare training dynamics by examining the loss curves shown in Figure 6. The AM-Thinking $\mathrm{\cdotv}1_{\mathrm{Distilled}}$ maintains a consistently lower training loss than its $\mathrm{Qwen}3{-}235\mathrm{B}{\cdot}\mathrm{A}22\mathrm{B}_{\mathrm{Distilled}}$ and DeepSeek-R 1 Distilled counterparts throughout the optimization process. This observation supports the notion that the AM-Thinking-v1 dataset provides more learnable, coherent, and high-quality supervision signals for the base model.
我们进一步通过观察图 6 所示的损失曲线来比较训练动态。AM-Thinking $\mathrm{\cdotv}1_{\mathrm{Distilled}}$ 在整个优化过程中始终保持比 $\mathrm{Qwen}3{-}235\mathrm{B}{\cdot}\mathrm{A}22\mathrm{B}_{\mathrm{Distilled}}$ 和 DeepSeek-R 1 Distilled 更低的训练损失。这一观察结果支持了 AM-Thinking-v1 数据集为基座模型提供了更具可学习性、连贯性和高质量监督信号的观点。
5 Conclusion and Future Work
5 结论与未来工作
In this work, we present a comprehensive empirical study on reasoning data distillation for opensource language models. Using three state-of-the-art teacher models—AM-Thinking-v1, Qwen3- 235B-A22B, and DeepSeek-R1—we constructed a large-scale parallel corpus comprising 1.89 million verified reasoning samples. Through rigorous data preprocessing, verification scoring, and quality assurance, we ensured the construction of high-quality training data suitable for robust student model learning.
在本工作中,我们针对开源语言模型的推理数据蒸馏进行了全面的实证研究。通过使用三个前沿的教师模型——AM-Thinking-v1、Qwen3-235B-A22B和DeepSeek-R1,我们构建了一个包含189万条已验证推理样本的大规模平行语料库。经过严格的数据预处理、验证评分和质量保证流程,我们确保了所构建的训练数据具备高质量特性,适用于学生模型的稳健学习。
Empirical results across a diverse set of benchmarks, including AIME2024 (84.3), AIME2025 (72.2), MATH500 (98.4), and Live Code Bench (65.9), demonstrate that models trained on AM-Thinking-v1- distilled data consistently achieve strong performance.
在包括AIME2024 (84.3)、AIME2025 (72.2)、MATH500 (98.4)和Live Code Bench (65.9)在内的多样化基准测试中,实证结果表明,基于AM-Thinking-v1蒸馏数据训练的模型始终表现出强劲性能。
To gain deeper insights into model behavior, we conducted detailed analysis of generation behavior and training dynamics. We observed that the AM-distilled model exhibits adaptive generation length—producing longer responses on harder tasks and shorter ones on easier benchmarks—indicating its capacity to adjust to task difficulty. This aligns with our earlier data analysis showing that AM-Thinking-v1-distilled data features a wide range of token lengths, providing stronger support for adaptive reasoning.
为深入理解模型行为,我们对生成行为和训练动态进行了详细分析。观察到AM蒸馏模型展现出适应性生成长度特性——在困难任务上生成更长响应,在简单基准测试中生成较短回答——表明其具备根据任务难度自我调节的能力。这一发现与我们早先的数据分析结果一致:AM-Thinking-v1蒸馏数据具有广泛的token长度分布,为适应性推理提供了更强支撑。
Looking ahead, a promising direction for future work is to further enhance these models using reinforcement learning techniques, such as Proximal Policy Optimization (PPO) or Generalized Group Relative Policy Optimization (GRPO), to enhance reasoning ability and alignment. We release the distilled datasets based on AM-Thinking-v1 and Qwen3-235B-A22B to support ongoing research in open and high-performing reasoning-oriented language models.
展望未来,未来工作的一个前景广阔的方向是利用强化学习技术(如近端策略优化(PPO)或广义群组相对策略优化(GRPO))进一步增强这些模型,以提升推理能力和对齐性。我们发布了基于AM-Thinking-v1和Qwen3-235B-A22B的精简数据集,以支持开放且高性能的推理导向大语言模型的持续研究。