VideoMAE V2: Scaling Video Masked Auto encoders with Dual Masking
VideoMAE V2: 采用双重掩码策略扩展视频掩码自编码器
Abstract
摘要
Scale is the primary factor for building a powerful foundation model that could well generalize to a variety of downstream tasks. However, it is still challenging to train video foundation models with billions of parameters. This paper shows that video masked auto encoder (VideoMAE) is a scalable and general self-supervised pre-trainer for building video foundation models. We scale the VideoMAE in both model and data with a core design. Specifically, we present a dual masking strategy for efficient pre-training, with an encoder operating on a subset of video tokens and a decoder processing another subset of video tokens. Although VideoMAE is very efficient due to high masking ratio in encoder, masking decoder can still further reduce the overall computational cost. This enables the efficient pre-training of billion-level models in video. We also use a progressive training paradigm that involves an initial pre-training on a diverse multi-sourced unlabeled dataset, followed by a post-pre-training on a mixed labeled dataset. Finally, we successfully train a video ViT model with a billion parameters, which achieves a new state-of-the-art performance on the datasets of Kinetics $90.0%$ on K400 and $89.9%$ on K600) and Something-Something $(68.7%$ on V1 and $77.0%$ on V2). In addition, we extensively verify the pre-trained video ViT models on a variety of downstream tasks, demonstrating its effectiveness as a general video representation learner.
规模是构建能够良好泛化到各种下游任务的强大基础模型 (foundation model) 的主要因素。然而,训练具有数十亿参数的视频基础模型仍然具有挑战性。本文表明,视频掩码自编码器 (VideoMAE) 是一种可扩展且通用的自监督预训练方法,可用于构建视频基础模型。我们通过核心设计在模型和数据两方面对 VideoMAE 进行了扩展。具体而言,我们提出了一种双掩码策略以实现高效预训练:编码器处理视频 token 的一个子集,解码器处理另一个子集。尽管 VideoMAE 由于编码器的高掩码率已经非常高效,但对解码器进行掩码仍能进一步降低整体计算成本。这使得在视频领域高效预训练十亿级模型成为可能。我们还采用了一种渐进式训练范式:首先在多样化的多源无标注数据集上进行初始预训练,然后在混合标注数据集上进行后预训练。最终,我们成功训练了一个具有十亿参数的视频 ViT 模型,在 Kinetics (K400 上 90.0%,K600 上 89.9%) 和 Something-Something (V1 上 68.7%,V2 上 77.0%) 数据集上取得了新的最先进性能。此外,我们在多种下游任务上广泛验证了预训练视频 ViT 模型的效果,证明了其作为通用视频表示学习器的有效性。
1. Introduction
1. 引言
Effectively pre-training large foundation models [11] on huge amounts of data is becoming a successful paradigm in learning generic representations for multiple data modalities (e.g., language [12, 24], audio [20, 71], image [6, 35, 107], video [28, 90, 104], vision-language [42, 80]). These foundation models could be easily adapted to a wide range of downstream tasks through zero-shot recognition, linear probe, prompt tuning, or fine tuning. Compared with the specialized model to a single task, they exhibit excellent generalization capabilities and have become the main driving force for advancing many areas in AI.
在大量数据上有效预训练大规模基础模型 [11] 正成为学习多模态数据 (如语言 [12, 24]、音频 [20, 71]、图像 [6, 35, 107]、视频 [28, 90, 104]、视觉-语言 [42, 80]) 通用表征的成功范式。这些基础模型可通过零样本识别、线性探测、提示调优或微调轻松适配多种下游任务。与针对单一任务的专用模型相比,它们展现出卓越的泛化能力,并成为推动人工智能多领域发展的主要驱动力。
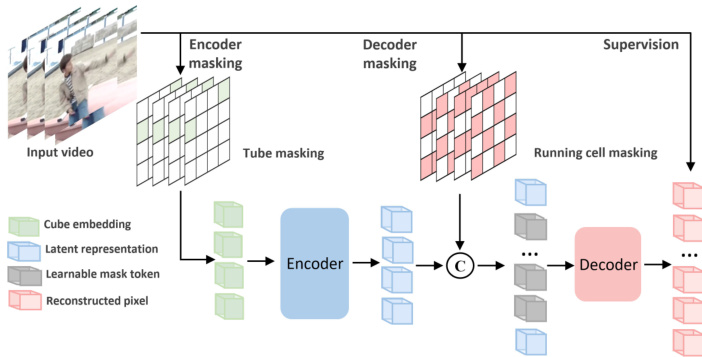
Figure 1. VideoMAE with dual masking. To improve the overall efficiency of computation and memory in video masked autoencoding, we propose to mask the decoder as well and devise the dual masking strategy. Like encoder, we also apply a masking map to the deocoder and simply reconstruct a subset of pixel cubes selected by the running cell masking. The final reconstruction loss only applies for the invisible tokens dropped by the encoder.
图 1: 采用双重掩码的VideoMAE。为提升视频掩码自编码在计算和内存方面的整体效率,我们提出对解码器也进行掩码处理,并设计了双重掩码策略。与编码器类似,我们同样对解码器施加掩码图,仅通过动态单元掩码选择部分像素块进行重建。最终的重建损失仅针对编码器丢弃的不可见Token计算。
For vision research, many efforts have been devoted to developing effective pre-trained models. Among them, Transformer [92] with masked auto encoding [24] is becoming a conceptually simple yet effective self-supervised visual learner (e.g., BEiT [6], SimMIM [107], MAE [35] for images, and MaskFeat [104], VideoMAE [90], MAEST [28] for videos). Meanwhile, based on the results in language models [12], scaling model capacity and data size is an important ingredients for its remarkable performance improvement. However, for pre-trained vision models, very few work [62] has tried to scale up this masked auto encoder pre-training to the billion-level models in image domain, partially due to the high data dimension and the high computational overhead. This issue is even more serious for scaling up video masked auto encoder pre-training owning to its extra time dimension and strong temporal variations.
在视觉研究领域,众多工作致力于开发高效的预训练模型。其中,结合掩码自动编码 (masked auto encoding) [24] 的Transformer [92] 逐渐成为一种概念简洁却高效的自监督视觉学习器(例如图像领域的BEiT [6]、SimMIM [107]、MAE [35],以及视频领域的MaskFeat [104]、VideoMAE [90]、MAEST [28])。同时,基于大语言模型的研究成果 [12],扩大模型容量与数据规模是实现显著性能提升的关键要素。然而,在视觉预训练模型中,仅有极少数工作 [62] 尝试将掩码自动编码预训练扩展到图像领域的十亿级规模,部分归因于高数据维度与高昂计算开销。这一问题在视频掩码自动编码预训练的扩展中更为严峻,因其额外的时间维度和强烈的时序变化特性。
Following the promising findings in languages and images, we aim to study the scaling property of video masked auto encoder (VideoMAE), and push its performance limit on a variety of video downstream tasks. We scale VideoMAE in both model and data. For model scaling, we try to instantiate the VideoMAE with vision transformer (ViT) [26] having billion-level parameters (e.g., ViTg [115]), and for data scaling, we hope to increase the pretraining dataset size to million-level to fully unleash the power of billion-level ViT model. However, to successfully train giant VideoMAE on such huge amounts of data and achieve impressive improvements on all considered downstream tasks, we still need to carefully address a few issues.
继语言和图像领域取得突破性进展后,我们致力于研究视频掩码自编码器(VideoMAE)的扩展特性,并探索其在各类视频下游任务中的性能极限。我们从模型和数据两个维度进行扩展:模型层面尝试采用参数规模达十亿级的视觉Transformer(ViT) [26] (如ViTg [115]) 实现VideoMAE;数据层面则将预训练数据集规模提升至百万级,以充分释放十亿级ViT模型的潜力。但要在海量数据上成功训练巨型VideoMAE,并在所有目标下游任务中取得显著提升,仍需审慎解决若干关键问题。
First, we find computational cost and memory consumption is the bottleneck of scaling VideoMAE on the current GPUs with limited memory. Although VideoMAE [90] has improved its pre-training efficiency and reduced its memory consumption by employing the efficient asymmetric encoder-decoder architecture [35] (i.e., dropping large numbers of tokens in encoder), it still fails to well support the billion-level video transformer pre-training. It takes more than two weeks to pre-train a ViT $\mathbf{g}$ model with VideoMAE on 64 A100 GPUs. To further improve its pre-training efficiency, we find video data redundancy can be used to not only mask a high portion of cubes in the encoder, but also drop some cubes in the decoder. This solution yields higher pre-training efficiency and creates a similarly challenging and meaningful self-supervised task. In practice, it will increase the pre-training batchsize and reduce the pre-training time by a third with almost no performance drop.
首先,我们发现计算成本和内存消耗是当前内存有限的GPU上扩展VideoMAE的瓶颈。尽管VideoMAE [90]通过采用高效的非对称编码器-解码器架构 [35](即在编码器中丢弃大量token)提升了预训练效率并降低了内存占用,但仍无法很好地支持十亿级视频Transformer的预训练。在64块A100 GPU上使用VideoMAE预训练一个ViT $\mathbf{g}$ 模型需要超过两周时间。为了进一步提升预训练效率,我们发现视频数据冗余不仅可以用于在编码器中掩码高比例的立方块,还能在解码器中丢弃部分立方块。该方案能实现更高的预训练效率,同时创建出具有类似挑战性和意义的自监督任务。实际应用中,这种方法可将预训练批次大小提升三分之一,且几乎不会造成性能下降。
Second, MAE is still demanding for large data [108] and billion-level video transformer tends to overfit on relatively small data. Unlike images, the existing public video dataset is much smaller. For example, there are only 0.24M videos in the Kinetics 400 dataset [43], while the ImageNet $22\mathrm{k}$ dataset [23] has $14.2\mathbf{M}$ images, let alone those publicly inaccessible image datasets such as JFT-3B [115]. Therefore, we need to come up with new ways to build a larger video pre-training dataset to well support the billion-level video transformer pre-training. We show that simply mixing the video datasets from multiple resources could produce an effective and diverse pre-training dataset for VideoMAE and improve its downstream performance of pre-trained models.
其次,MAE (Masked Autoencoder) 对数据量的要求仍然较高 [108],而十亿级参数的视频 Transformer 在相对较小的数据集上容易过拟合。与图像不同,现有的公开视频数据集规模要小得多。例如,Kinetics 400 数据集 [43] 仅包含 0.24M 视频,而 ImageNet $22\mathrm{k}$ 数据集 [23] 拥有 $14.2\mathbf{M}$ 图像,更不用说那些无法公开获取的图像数据集(如 JFT-3B [115])。因此,我们需要探索新方法来构建更大的视频预训练数据集,以更好地支持十亿级视频 Transformer 的预训练。实验表明,简单地混合来自多个来源的视频数据集可以为 VideoMAE 构建一个有效且多样化的预训练数据集,并提升预训练模型的下游性能。
Finally, it is still unknown how to adapt the billionlevel pre-trained model by VideoMAE. Masked autoencoding is expected to learn invariant features that provide a favored initialization for vision transformer fine-tuning [46]. However, directly fine-tuning billion-level pre-trained models on a relatively small video dataset (e.g., 0.24M videos) might be suboptimal, as the limited labeled samples might lead to over fitting issue in fine-tuning. In fact, in image domain, the intermediate fine-tuning technique [6, 62] has been employed to boost the performance of masked pretrained models. We show that collecting multiple labeled video datasets and building a supervised hybrid dataset can act as a bridge between the large-scale unsupervised dataset and the small-scale downstream target dataset. Progressive fine-tuning of the pre-trained models through this labeled hybrid dataset could contribute to higher performance in the downstream tasks.
最后,如何通过VideoMAE适应十亿级预训练模型仍属未知。掩码自编码方法有望学习到不变特征,为视觉Transformer (Vision Transformer) 微调提供有利的初始化条件 [46]。然而,直接在较小规模视频数据集(例如24万条视频)上微调十亿级预训练模型可能并非最优选择,因为有限的标注样本可能导致微调过程中的过拟合问题。事实上,在图像领域,已有研究采用中间微调技术 [6,62] 来提升掩码预训练模型的性能。我们证明:收集多个标注视频数据集并构建有监督混合数据集,能够作为大规模无监督数据集与小规模下游目标数据集之间的桥梁。通过该标注混合数据集对预训练模型进行渐进式微调,可提升下游任务性能。
Based on the above analysis, we present a simple and efficient way to scale VideoMAE to billion-level ViT models on a dataset containing million-level pre-training videos. Our technical improvement is to introduce the dual masking strategy for masked auto encoder pipeline as shown in Figure 1. In addition to the masking operation in encoder, we propose to mask decoder as well based on the data redundancy prior in video. With this dual-masked VideoMAE, we follow the intermediate fine-tuning in images [6, 62], and use a progressive training pipeline to perform the video masked pre-training on the million-level unlabeled video dataset and then post-pre-training on the labeled hybrid dataset. These core designs contribute to an efficient billion-level video auto encoding framework, termed as VideoMAE V2. Within this framework, we successfully train the first video transformer model with one billion parameters, which attains a new state-of-the-art performance on a variety of downstream tasks, including action recognition [31, 43, 48, 82], spatial action detection [32, 51], and temporal action detection [41, 61].
基于上述分析,我们提出了一种简单高效的方法,将VideoMAE扩展到包含百万级预训练视频数据集上的十亿级ViT模型。我们的技术改进是在掩码自编码器流程中引入双重掩码策略,如图1所示。除了编码器中的掩码操作外,我们还基于视频数据冗余先验,提出对解码器也进行掩码处理。通过这种双重掩码的VideoMAE,我们遵循图像领域的中间微调方法[6, 62],采用渐进式训练流程:先在百万级无标注视频数据集上进行视频掩码预训练,随后在标注混合数据集上进行后预训练。这些核心设计构成了高效的十亿级视频自编码框架VideoMAE V2。在该框架下,我们成功训练出首个具有十亿参数的视频Transformer模型,在动作识别[31, 43, 48, 82]、空间动作检测[32, 51]和时间动作检测[41, 61]等多种下游任务中取得了新的最优性能。
2. Related Work
2. 相关工作
Vision foundation models. The term of foundation model was invented in [11]. It refers to those powerful models that are pre-trained on broad data and can be adapted to a wide range of downstream tasks. Early research works in vision focused on pre-training CNNs [49] or Transformers [92] on large-scale labeled datasets such as ImageNet-1k [37, 47], ImageNet-22k [63,101], and JFT [115]. Some recent works tried to perform unsupervised pre-training using contrastive learning [17, 36, 105] or siamese learning [18]. Meanwhile, following the success in NLP [12, 24], masked autoencoding was also introduced to pre-train image foundation models in a self-supervised manner, such as BEiT [6], SimMIM [107], and MAE [35]. Some vision-language pretrained models, such as CLIP [80] and ALIGN [42], were proposed by learning from the alignment between images and text on noisy web-scale samples. They have shown excellent performance on zero-shot transfer.
视觉基础模型 (Vision foundation models)。基础模型这一术语源于[11],指的是那些经过广泛数据预训练、能够适应多种下游任务的强大模型。早期视觉领域的研究主要集中于在ImageNet-1k[37,47]、ImageNet-22k[63,101]和JFT[115]等大规模标注数据集上预训练CNN[49]或Transformer[92]。近期一些研究尝试通过对比学习[17,36,105]或孪生学习[18]进行无监督预训练。与此同时,受自然语言处理领域成功案例[12,24]的启发,掩码自编码技术也被引入到图像基础模型的自我监督预训练中,例如BEiT[6]、SimMIM[107]和MAE[35]。一些视觉语言预训练模型如CLIP[80]和ALIGN[42]通过从网络规模噪声数据中学习图像与文本的对齐关系,在零样本迁移任务中展现出卓越性能。
Concerning video foundation models, their progress lags behind images, partially due to the relatively smaller video datasets and higher complexity of video modeling. Since the introduction of Kinetics benchmarks [43], some supervised pre-trained models on it have been transferred to small-scale datasets for action recognition, such as 2D CNNs (TSN [99], TSM [58], TANet [66], TDN [98]), 3D CNNs (I3D [13], $\mathrm{R}(2+1)\mathrm{D}$ [91], ARTNet [97], SlowFast [29]), Transformer (TimeS former [8], Video Swin [65],
关于视频基础模型,其进展落后于图像,部分原因是视频数据集相对较小且视频建模复杂度更高。自Kinetics基准[43]推出以来,一些在其上监督预训练的模型已被迁移至小规模动作识别数据集,例如2D CNN(TSN[99]、TSM[58]、TANet[66]、TDN[98])、3D CNN(I3D[13]、$\mathrm{R}(2+1)\mathrm{D}$[91]、ARTNet[97]、SlowFast[29])、Transformer(TimeSformer[8]、Video Swin[65])。
UniFormer [52]). Recently, some self-supervised video models are developed based on masked auto encoding such as BEVT [100], MaskedFeat [104], VideoMAE [90], and MAE-ST [28] by directly extending these image masked modeling frameworks. However, these video foundation models often limit in their pre-training data size and model scale. More importantly, their downstream tasks have a narrow focus on action recognition, without consideration of other video tasks such as temporal action localization.
UniFormer [52])。最近,一些自监督视频模型基于掩码自动编码技术被开发出来,例如BEVT [100]、MaskedFeat [104]、VideoMAE [90]和MAE-ST [28],这些模型直接扩展了图像掩码建模框架。然而,这些视频基础模型通常受限于预训练数据规模和模型体量。更重要的是,它们的下游任务仅聚焦于动作识别,未考虑其他视频任务(如时序动作定位)。
Masked visual modeling. Early works treated masking in denoised auto encoders [93] or context inpainting [74]. Inspired by the great success in NLP [12, 24], iGPT [15] operated pixel sequences for prediction and ViT [26] investigated the masked token prediction for self-supervised pretraining. Recently, there has been a surge of research into Transformer-based architectures for masked visual modeling [6, 28, 35, 90, 100, 104, 107]. BEiT [6], BEVT [100], and VIMPAC [86] learned visual representations by predicting discrete tokens. MAE [35] and SimMIM [107] directly performed pixel masking and reconstruction for pre-training without discrete token representation. MaskFeat [104] reconstructed the HOG [22] features of masked tokens to perform self-supervised pre-training in videos. VideoMAE [90] and MAE-ST [28] extended MAE [35] to video domain for self-supervised video pre-training and achieved impressive performance on action recognition.
掩码视觉建模。早期研究将掩码处理应用于去噪自编码器 [93] 或上下文修复 [74]。受 NLP [12, 24] 领域重大成功的启发,iGPT [15] 对像素序列进行预测操作,ViT [26] 则探索了掩码 token 预测用于自监督预训练。近期,基于 Transformer 的掩码视觉建模架构研究激增 [6, 28, 35, 90, 100, 104, 107]。BEiT [6]、BEVT [100] 和 VIMPAC [86] 通过预测离散 token 来学习视觉表征。MAE [35] 和 SimMIM [107] 直接进行像素掩码与重建的预训练,无需离散 token 表征。MaskFeat [104] 通过重建掩码 token 的 HOG [22] 特征实现视频自监督预训练。VideoMAE [90] 和 MAE-ST [28] 将 MAE [35] 扩展至视频领域进行自监督视频预训练,在动作识别任务中取得显著性能。
Vision model scaling. Many works tried to scale up CNNs to improve recognition performance [37, 81, 84]. EfficientNet [88] presented a scaling strategy to balance depth, width, and resolution for CNN design. Several works [40, 45, 69] tried to train much larger CNNs to obtain excellent performance by enlarging model capacities and training data size. Recently, a few works [62, 115] tried to scale up the vision transformer to the billion-level models with large-scale supervised pre-training on JFT-3B [115] or selfsupervised pre-training on IN-22K-ext-70M [62]. VideoMAE [90] and MAE-ST [28] have trained the huge video transformer with millions of parameters. MAE-ST [28] also tried the MAE pre-training on 1M IG-uncurated clips but failed to obtain better performance on Kinetics than smallscale pre-training. We are the first work to train video transformer with billion-level parameters.
视觉模型扩展。许多研究尝试通过扩大卷积神经网络(CNN)的规模来提升识别性能[37,81,84]。EfficientNet[88]提出了一种平衡CNN深度、宽度和分辨率的扩展策略。部分工作[40,45,69]尝试通过增加模型容量和训练数据规模来训练更大的CNN以获得优异性能。近期,若干研究[62,115]尝试将视觉Transformer扩展到十亿参数级别,分别在JFT-3B[115]上进行大规模监督预训练或在IN-22K-ext-70M[62]上进行自监督预训练。VideoMAE[90]和MAE-ST[28]训练了具有数百万参数的巨型视频Transformer。MAE-ST[28]还尝试在100万条IG未剪辑视频片段上进行MAE预训练,但在Kinetics数据集上的表现未能超越小规模预训练。我们是首个成功训练十亿级参数视频Transformer的研究团队。
3. VideoMAE V2
3. VideoMAE V2
In this section, we first revisit VideoMAE and analyze its property. Then we present the dual masking strategy for the efficient training of VideoMAE. Finally, we present the scaling details of VideoMAE for large-scale pre-training.
在本节中,我们首先回顾VideoMAE并分析其特性,随后提出用于高效训练VideoMAE的双重掩码策略,最后阐述VideoMAE在大规模预训练中的扩展细节。
3.1. VideoMAE Revisited
3.1. VideoMAE 再探
We scale the video masked auto encoder (VideoMAE) due to its simplicity and high performance. VideoMAE processes the down sampled frames $\mathbf{I}\in\mathbb{R}^{C\times T\times H\times W}$ from a clip with stride $\tau$ , and uses the cube embedding $\Phi_{e m b}$ to transform the frames into a sequence of tokens. Then, it designs a customized tube masking strategy to drop tokens with an extremely high ratio $\rho$ (e.g., $90%$ ). Finally, the unmasked tokens are fed into a video auto encoder $\left(\Phi_{e n c},\Phi_{d e c}\right)$ for reconstructing the masked pixels. Specifically, VideoMAE is composed of three core components: cube embedding, encoder, and decoder. First, cube embedding encodes the local s patio temporal features and builds the token list: $\mathbf{T}=\Phi_{e m b}(\mathbf{I})$ , where $\mathbf{T}={T_{i}}_{i=1}^{N}$ is the token sequence, $T_{i}$ is the token produced by the embedding layer and then added with positional embedding, and $N$ is the total token number. Then the encoder simply operates on the unmasked tokens $\mathbf{T}^{u}$ with a vanilla ViT of joint space-time attention: ${\bf Z}=\Phi_{e n c}({\bf T}^{u})$ , where $\mathbf{T}^{u}$ represents the unmasked visible tokens Tu = {Ti}i (1 M(ρ)), $\mathbb{M}(\rho)$ is the masking map, and its token length $N^{e}$ is equal to $0.1N$ . Finally, the decoder takes the combined tokens $\mathbf{Z}^{c}$ as inputs and performs reconstruction with another ViT: $\hat{\mathbf{I}}=\Phi_{d e c}(\mathbf{Z}^{c})$ , where the combined tokens $\mathbf{Z}^{c}$ is the concatenated sequence of encoded token features $\mathbf{Z}$ and the learnable masked tokens [MASK] (with position embeddings), and its token length $N^{d}$ is equal to the original token number $N$ . The loss function is the mean squared error (MSE) loss between the normalized masked pixels and the reconstructed pixels: $\begin{array}{r}{\ell=\frac{1}{\rho N}\sum_{i\in\mathbb{M}(\rho)}|{\bf I}_{i}-\hat{\hat{\bf I}}_{i}|^{2}}\end{array}$ .
我们选择扩展视频掩码自编码器 (VideoMAE) 因其简洁高效。VideoMAE 以步长 $\tau$ 处理视频片段降采样后的帧 $\mathbf{I}\in\mathbb{R}^{C\times T\times H\times W}$,并通过立方体嵌入 $\Phi_{e m b}$ 将帧转换为token序列。随后采用定制化的管状掩码策略,以极高比例 $\rho$ (例如 $90%$) 丢弃token。最终,未掩码的token被输入视频自编码器 $\left(\Phi_{e n c},\Phi_{d e c}\right)$ 以重建掩码像素。具体而言,VideoMAE 包含三个核心组件:立方体嵌入、编码器和解码器。
首先,立方体嵌入编码局部时空特征并构建token列表:$\mathbf{T}=\Phi_{e m b}(\mathbf{I})$,其中 $\mathbf{T}={T_{i}}_{i=1}^{N}$ 是token序列,$T_{i}$ 由嵌入层生成后加入位置嵌入,$N$ 为总token数。编码器仅对未掩码token $\mathbf{T}^{u}$ 执行联合时空注意力的标准 ViT 操作:${\bf Z}=\Phi_{e n c}({\bf T}^{u})$,其中 $\mathbf{T}^{u}$ 表示未掩码可见token Tu = {Ti}i (1 M(ρ)),$\mathbb{M}(\rho)$ 为掩码映射图,其token长度 $N^{e}$ 等于 $0.1N$。
解码器以拼接token $\mathbf{Z}^{c}$ 为输入,通过另一 ViT 进行重建:$\hat{\mathbf{I}}=\Phi_{d e c}(\mathbf{Z}^{c})$。拼接token $\mathbf{Z}^{c}$ 由编码token特征 $\mathbf{Z}$ 与可学习的掩码token [MASK] (含位置嵌入) 连接而成,其token长度 $N^{d}$ 等于原始token数 $N$。损失函数为归一化掩码像素与重建像素间的均方误差 (MSE):$\begin{array}{r}{\ell=\frac{1}{\rho N}\sum_{i\in\mathbb{M}(\rho)}|{\bf I}_{i}-\hat{\hat{\bf I}}_{i}|^{2}}\end{array}$。
Computational cost analysis. High efficiency is an important characteristic of masked auto encoder. VideoMAE employs an asymmetric encoder-decoder architecture [35], where token sequence length of encoder is only one-tenth of decoder (i.e. $N^{e}=0.1N^{d} $ ). This smaller encoder input contributes to more efficient pre-training pipeline compared with other masked auto encoding frameworks [6,107]. However, when scaling VideoMAE in both depth and width (channels) to a billion-level model, the overall computation and memory consumption is still the bottleneck for the current available GPUs with limited memory. Therefore, the current asymmetric encoder-decoder architecture needs to be further improved for scaling VideoMAE.
计算成本分析。高效是掩码自编码器 (masked auto encoder) 的重要特性。VideoMAE 采用非对称编码器-解码器架构 [35],其编码器的 token 序列长度仅为解码器的十分之一 (即 $N^{e}=0.1N^{d}$)。与其他掩码自编码框架 [6,107] 相比,这种更小的编码器输入有助于实现更高效的预训练流程。然而,当将 VideoMAE 的深度和宽度 (通道数) 扩展到十亿级模型时,整体计算量和内存消耗仍是当前内存有限的 GPU 的瓶颈。因此,当前的非对称编码器-解码器架构需要进一步改进以实现 VideoMAE 的规模化。
3.2. Dual Masking for VideoMAE
3.2. 视频MAE的双重掩码机制
To better enable large-scale VideoMAE pre-training under a limited computational budget, we present a dual masking scheme to further improve its pre-training efficiency. As shown in Figure 1, our dual masking scheme generates two masking maps ${\mathbb M}{e}={\mathcal M}{e}(\rho^{e})$ and $\mathbb{M}{d}=\mathcal{M}{d}(\rho^{d})$ with two different masking generation strategies and masking ratios. These two masking maps $\mathbb{M}{e}$ and $\mathbb{M}{d}$ are for encoder and decoder, respectively. Like VideoMAE, our encoder operates on the partial and visible tokens under the encoder mask ${\mathbb M}{e}$ , and maps the observed tokens into latent feature representations. But unlike VideoMAE, our decoder takes inputs from the encoder visible tokens and part of the remaining tokens visible under the decoder mask $\mathbb{M}_{d}$ . In this sense, we use the decoder mask to reduce the decoder input length for high efficiency yet attain similar information to the full reconstruction. Our decoder maps the latent features and the remaining incomplete tokens into the pixel values at the corresponding locations. The supervision only applies to the decoder output tokens invisible to the encoder. We will detail the design next.
为了在有限计算预算下更好地实现大规模VideoMAE预训练,我们提出了一种双重掩码方案以进一步提升其预训练效率。如图1所示,我们的双重掩码方案通过两种不同的掩码生成策略和掩码比例,生成两个掩码图${\mathbb M}{e}={\mathcal M}{e}(\rho^{e})$和$\mathbb{M}{d}=\mathcal{M}{d}(\rho^{d})$。这两个掩码图$\mathbb{M}{e}$和$\mathbb{M}{d}$分别用于编码器和解码器。与VideoMAE类似,我们的编码器在编码器掩码${\mathbb M}{e}$下对部分可见的Token进行操作,并将观察到的Token映射为潜在特征表示。但与VideoMAE不同,我们的解码器输入来自编码器可见Token和解码器掩码$\mathbb{M}_{d}$下可见的部分剩余Token。通过这种方式,我们利用解码器掩码缩短解码器输入长度以提高效率,同时获得与完整重建相似的信息。解码器将潜在特征与剩余不完整Token映射至对应位置的像素值,监督信号仅作用于编码器不可见的解码器输出Token。具体设计将在下文详述。
Masking decoder. As analyzed in Section 3.1, the decoder of VideoMAE is still inefficient as it needs to process all the cubes in videos. Thus, we further explore the prior of data redundancy in the decoder and propose the strategy of masking decoder. Our idea is mainly inspired by the recent efficient action recognition transformer [79], which only uses a small portion of tokens to achieve similar performance. It implies data redundancy exists in inference, which applies for our reconstruction target as well.
掩码解码器 (Masking decoder)。如第3.1节所述,VideoMAE的解码器仍需处理视频中所有立方体,效率较低。因此我们进一步探索解码器的数据冗余先验,提出掩码解码器策略。该思路主要受近期高效动作识别Transformer [79] 的启发,该研究仅使用少量token即可达到相近性能。这表明推理过程中存在数据冗余,这一现象同样适用于我们的重建任务。
Our dual masking strategy is composed of encoder masking $\mathcal{M}{e}$ and decoder masking $\mathcal{M}{d}$ . The encoder masking is the random tube masking with an extremely high ratio, which is the same as the original VideoMAE. For decoder masking, our objective is opposite to encoder masking. The tube masking in encoder tries to relieve the issue of “information leakage” caused by temporal correlation. In contrast, in decoder masking, we need to encourage “information complement” to ensure minimal information loss in this partial reconstruction. In this sense, we need to select as diverse cubes as possible to cover the whole video information. In the implementation, we compare different mask- ing strategies and eventually choose the running cell masking [79]. With this decoder masking map $\mathbb{M}_{d}$ 1, we reduce the decoder input length to improve efficiency.
我们的双重掩码策略由编码器掩码 $\mathcal{M}{e}$ 和解码器掩码 $\mathcal{M}{d}$ 组成。编码器掩码采用与原始VideoMAE相同的极高比例随机管状掩码。对于解码器掩码,我们的目标与编码器掩码相反:编码器中的管状掩码旨在缓解时间相关性导致的"信息泄漏"问题,而解码器掩码则需要促进"信息互补"以确保部分重建时的信息损失最小化。为此,我们需要选择尽可能多样化的立方体来覆盖整个视频信息。在实现中,我们比较了不同掩码策略,最终选择了运行单元掩码[79]。通过这种解码器掩码映射 $\mathbb{M}_{d}$ 1,我们缩短了解码器输入长度以提高效率。
VideoMAE with dual masking. Our improved VideoMAE shares the same cube embedding and encoder with the original VideoMAE as described in Section 3.1. For decoder, it processes the combined tokens of encoder output and part the remaining visible tokens under the decoder mask $\mathbb{M}_{d}$ . Specifically, the combined sequence is defined as:
采用双重掩码的VideoMAE。我们改进的VideoMAE与原始VideoMAE共享相同的立方体嵌入和编码器结构(如第3.1节所述)。其解码器会处理编码器输出token与解码器掩码$\mathbb{M}_{d}$下部分剩余可见token的拼接序列,具体定义为:
$$
\mathbf{Z}^{c}=\mathbf{Z}\cup{\mathbf{M}{i}}{i\in\mathbb{M}_{d}},
$$
$$
\mathbf{Z}^{c}=\mathbf{Z}\cup{\mathbf{M}{i}}{i\in\mathbb{M}_{d}},
$$
where $\mathbf{Z}$ is the latent representation from encoder, $\mathbf{M}_{i}$ is the learnable masking token with corresponding positional embedding. With this combined token sequence $\mathbf{Z}^{c}$ , our decoder only reconstructs the visible tokens under the decoder mask. The final MSE loss is computed between the normalized masked pixels I and the reconstructed ones I over the decoder visible cubes:
其中 $\mathbf{Z}$ 是编码器的潜在表示,$\mathbf{M}_{i}$ 是可学习的掩码 token 及其对应的位置嵌入。通过这个组合 token 序列 $\mathbf{Z}^{c}$,我们的解码器仅重建解码器掩码下的可见 token。最终的均方误差 (MSE) 损失是在归一化掩码像素 I 和解码器可见立方体上的重建像素 I 之间计算的:
$$
\ell=\frac{1}{(1-\rho^{d})N}\sum_{i\in\mathbb{M}{d}\cap\mathbb{M}{e}}|{\bf I}{i}-\hat{{\bf I}}_{i}|^{2}.
$$
$$
\ell=\frac{1}{(1-\rho^{d})N}\sum_{i\in\mathbb{M}{d}\cap\mathbb{M}{e}}|{\bf I}{i}-\hat{{\bf I}}_{i}|^{2}.
$$
3.3. Scaling VideoMAE
3.3. 扩展 VideoMAE
Model scaling. Model scale is the primary force in obtaining excellent performance. Following the original VideoMAE, we use the vanilla ViT [26] as the backbone due to its simplicity. According to the scaling law of ViT [115], we build VideoMAE encoder with backbones of different capacities ranging from ViT-B, ViT-L, ViT-H, to ViT-g. Note that $W i T{-}g$ is a large model with billion-level parameters and has never been explored in video domain. Its performance with masked auto encoding for video representation learning is still unknown to the community. More details on these backbone designs could be referred to [115]. For decoder design, we use relatively shallow and lightweight backbones [35, 90] with fewer layers and channels. In addition, we apply our dual masking strategy to further reduce computational cost and memory consumption. More details on the decoder design could be found in the appendix.
模型缩放。模型规模是获得卓越性能的主要驱动力。遵循原始VideoMAE的设计,我们采用简洁的ViT [26]作为主干网络。根据ViT的缩放定律 [115],我们构建了具有不同容量主干的VideoMAE编码器,包括ViT-B、ViT-L、ViT-H和ViT-g。值得注意的是,$W i T{-}g$是一个拥有十亿级参数的大型模型,此前从未在视频领域进行过探索。其基于掩码自编码的视频表征学习性能对学术界仍是未知数。更多关于这些主干设计的细节可参考 [115]。在解码器设计方面,我们采用层数和通道数较少的轻量级浅层主干 [35, 90]。此外,我们应用双重掩码策略进一步降低计算成本和内存消耗。解码器设计的更多细节可在附录中找到。
Data scaling. Data scale is another important factor that influences the performance of VideoMAE pre-training. The original VideoMAE simply pre-train the ViT models on relatively small-scale datasets by emphasizing its data efficiency. In addition, they require to pre-train the individual models specific to each dataset (i.e., Something-Something and Kinetics datasets have different pre-trained models). In contrast, we aim to learn a universal pre-trained model that could be transferred to different downstream tasks. To this end, we try to increase the pre-training video samples to a million-level size and aim to understand the data scaling property for VideoMAE pre-training. Data diversity is important for learning general video representations. Therefore, we build an unlabeled hybrid video dataset covering videos from General Webs, Youtube, Instagram, Movies, and Manual Recordings. We collect videos from the public datasets of Kinetics, Something-Something, AVA, WebVid, and uncurated videos crawled from Instagram. In total, there are 1.35M clips in our unlabeled mixed dataset. Note that pre-training video transformer on a such large-scale and diverse dataset is rare in previous works and it still remains unknown the influence of data scale and diversity on VideoMAE pre-training. More details on our dataset could be found in the appendix.
数据规模。数据规模是影响VideoMAE预训练性能的另一关键因素。原始VideoMAE通过在相对小规模数据集上预训练ViT模型来强调其数据效率,且需为每个特定数据集(如Something-Something与Kinetics数据集)单独预训练不同模型。与之相反,我们的目标是学习一个可迁移至不同下游任务的通用预训练模型。为此,我们将预训练视频样本量提升至百万级别,旨在探究VideoMAE预训练中的数据规模特性。数据多样性对学习通用视频表征至关重要,因此我们构建了一个包含通用网页视频、YouTube、Instagram、电影及人工录制视频的无标注混合数据集,收集了来自Kinetics、Something-Something、AVA、WebVid等公开数据集及Instagram爬取的非精选视频,最终形成包含135万段视频的无标注混合数据集。需注意的是,此前工作中鲜有在此类大规模多样化数据集上预训练视频Transformer的研究,数据规模与多样性对VideoMAE预训练的影响仍属未知领域。更多数据集细节见附录。
Progressive training. Transferring scheme is an important step to adapt the pre-trained large video transformers to the downstream tasks. The masked auto encoder pretraining is expected to learn some invariant features and can provide a favored initialization for vision transformer finetuning [46]. The original VideoMAE directly fine-tunes the pre-trained models on the target dataset only with its corresponding supervision. This direct adapting strategy might fail to fully unleash the power of large pre-trained video transformer due to limited supervision. Instead, in order to relieve the over fitting risk, we argue that we should leverage the semantic supervision signals from multiple sources in multiple stages to gradually adapt the pre-trained video transformers to downstream tasks. Accordingly, following the intermediate fine-tuning in images [6, 62], we devise a progressive training pipeline for the whole training process of billion-level video transformers. First, we conduct unsupervised pre-training with masked auto encoding on the unlabeled hybrid video dataset. Then, we build a labeled hybrid dataset by collecting and aligning multiple existing supervised datasets with labels. We perform the supervised post-pre-training stage on this labeled hybrid dataset to incorporate the semantics from multiple sources into the previous pre-trained video transformers. Finally, we perform the specific fine-tuning stage on the target dataset to transfer the general semantics to the task-centric knowledge.
渐进式训练。迁移方案是将预训练的大型视频Transformer适配到下游任务的重要步骤。掩码自编码器预训练旨在学习某些不变特征,可为视觉Transformer微调提供有利的初始化条件 [46]。原始VideoMAE仅使用目标数据集对应的监督信号直接微调预训练模型。由于监督信号有限,这种直接适配策略可能无法充分释放大型预训练视频Transformer的潜力。相反,为降低过拟合风险,我们认为应分阶段利用多来源的语义监督信号,逐步将预训练视频Transformer适配到下游任务。据此,遵循图像领域的中间微调方法 [6, 62],我们为十亿级视频Transformer的完整训练流程设计了渐进式训练管线:首先在未标注的混合视频数据集上进行掩码自编码的无监督预训练;然后通过收集和对齐多个现有标注数据集构建带标注的混合数据集,在此数据集上进行监督式后预训练阶段,将多来源语义融入预训练视频Transformer;最后在目标数据集上进行特定微调阶段,将通用语义转化为任务核心知识。
Based on the above designs of dual masking, data scaling, and progressive training, we implement a simple and efficient masked auto encoding framework with a billionlevel ViT backbone, termed as VideoMAE V2. With this new framework, we successfully train the first billion-level video transformer and push the vanilla ViT performance limit on a variety of video downstream tasks, including video action recognition, action detection, and temporal action detection.
基于上述双重掩码、数据缩放和渐进式训练的设计,我们实现了一个简单高效的掩码自编码框架,采用十亿级ViT主干网络,称为VideoMAE V2。通过这一新框架,我们成功训练出首个十亿级视频Transformer,并在多种视频下游任务(包括视频动作识别、动作检测和时间动作检测)上突破了原始ViT的性能极限。
4. Experiments
4. 实验
4.1. Implementation and Downstream Tasks
4.1. 实现与下游任务
Model. We conduct investigations on the VideoMAE V2 by scaling its model capacity and pre-training data size. We scale the backbone network from the existing huge ViT model (ViT-H) to the giant ViT model (ViT-g) [115]. The ViT $\mathbf{g}$ has a smaller patch size (14), more encoder blocks (40), a higher dimension of cube embedding and self-attention (1408), and more attention heads (16). It has 1,011M parameters. More details could be referred to [115].
模型。我们对VideoMAE V2进行了模型容量和预训练数据规模的扩展研究。将主干网络从现有的巨型ViT模型(ViT-H)扩展到超巨型ViT模型(ViT-g) [115]。ViT $\mathbf{g}$采用更小的图像块尺寸(14)、更多的编码器块(40)、更高的立方体嵌入维度与自注意力维度(1408),以及更多的注意力头(16)。该模型参数量达到10.11亿。更多细节可参考[115]。
Data. To well support the billion-level ViT model pretraining, we build two large-scale video datasets for our proposed progressive training. For self-supervised pre-training of VideoMAE V2, we build a million-level unlabeled video dataset by collecting clips from multiple resources such as Movie, Youtube, Instagram, General Webs, and manual recordings from scripts, and the dataset is termed as Unlabeled Hybrid. Specifically, our dataset is built by simply selecting videos from the public available datasets of Kinetics [43], Something-Something [31], AVA [32], WebVid2M [5], and our own crawled Instagram dataset. In total, there are around 1.35M clips in our mixed dataset and this is the largest dataset ever used for video masked autoencoding. For supervised post-pre-training, we collect the larger video dataset with human annotations, termed as Labe led Hybrid. Following [53], we take the union of different versions of Kinetics datasets (K400, K600, K700) by aligning their label semantics and removing the duplicate videos with the validation sets. This labeled hybrid dataset has 710 categories and 0.66M clips. We pre-train our video transformer model on these two datasets and then transfer them to the downstream tasks as detailed next. More details on these pre-training datasets could be found in the appendix.
数据。为了充分支持十亿级ViT模型的预训练,我们为提出的渐进式训练构建了两个大规模视频数据集。针对VideoMAE V2的自监督预训练,我们通过从电影、YouTube、Instagram、通用网站及剧本手动录制等多渠道收集片段,构建了百万级无标注视频数据集Unlabeled Hybrid。具体而言,该数据集通过简单筛选公开可用的Kinetics [43]、Something-Something [31]、AVA [32]、WebVid2M [5]数据集及我们自行爬取的Instagram数据构建而成。混合数据集共包含约135万条视频片段,是当前视频掩码自编码领域使用的最大规模数据集。
对于监督式后预训练,我们收集了带人工标注的更大规模视频数据集Labe led Hybrid。参照[53]的方法,我们通过对齐标签语义并剔除验证集中的重复视频,整合了不同版本的Kinetics数据集(K400/K600/K700)。该标注混合数据集涵盖710个类别和66万条视频片段。我们在这两个数据集上预训练视频Transformer模型,随后迁移至下游任务(详见后续说明)。更多预训练数据集细节可参阅附录。
Tasks. To verify the generalization ability of VideoMAE V2 pre-trained ViTs as video foundation models, we transfer their representations to a variety of downstream tasks.
任务。为了验证VideoMAE V2预训练ViT作为视频基础模型的泛化能力,我们将其表征迁移至多种下游任务。
Video Action Classification. Action classification is the most common task in video understanding. Its objective is to classify each trimmed clip into a predefined action class and evaluated the average accuracy over action classes. According to the original VideoMAE [90], we perform detailed analysis on this task to investigate the property of scaling video masked auto encoding. In experiments, we choose four datasets to report its performance: Kinetics [43], Something-Something [31], UCF101 [82], and HMDB51 [48]. Kinetics and Something-Something are two large-scale action recognition datasets and have their own unique property for action recognition, where Kinetics contains appearance-centric action classes while SomethingSomething focuses on motion-centric action understanding. UCF101 and HMDB51 are two relatively small datasets and suitable to verify the transfer performance of large pretrained models as shown in the appendix.
视频动作分类。动作分类是视频理解中最常见的任务,其目标是将每个剪辑片段归类到预定义的动作类别中,并评估各类别的平均准确率。根据VideoMAE [90] 的原始设定,我们对该任务进行了详细分析,以探究视频掩码自编码 (video masked auto encoding) 的扩展特性。实验中选取了四个数据集进行性能评估:Kinetics [43]、Something-Something [31]、UCF101 [82] 和 HMDB51 [48]。Kinetics 与 Something-Something 是两个大规模动作识别数据集,各自具有独特的动作识别特性——Kinetics 包含以外观为核心的动作类别,而 Something-Something 侧重于以运动为核心的动作理解。UCF101 和 HMDB51 作为两个较小规模的数据集(如附录所示),适合验证大型预训练模型的迁移性能。
Spatial Action Detection. Action detection is an important task in video understanding, and it aims to recognize all action instances and localize them in space. This task is more challenging than action classification as it deals with more fine-grained action classes and needs to capture detailed structure information to discriminate co-occurring action classes. In experiments, we choose two action detec- tion benchmarks to illustrate the effectiveness of our pre- trained models by VideoMAE V2, namely AVA [32] and AVA-Kinetics [51]. AVA contains the box annotations and their corresponding action labels on keyframes (could be more than one label for each human box). The annotations are done at 1FPS over 80 atomic classes. AVA-Kinetics introduces the AVA style annotations to the Kinetics dataset and a single frame of selected video from Kinetics is annotated with AVA labels. The evaluation metric is frame-level Average Precision (mAP) under the IoU threshold of 0.5.
空间动作检测。动作检测是视频理解中的重要任务,旨在识别所有动作实例并在空间中进行定位。该任务比动作分类更具挑战性,因为它处理更细粒度的动作类别,并需要捕捉详细的结构信息以区分共现的动作类别。实验中,我们选择两个动作检测基准(AVA [32] 和 AVA-Kinetics [51])来展示 VideoMAE V2 预训练模型的有效性。AVA 包含关键帧上的边界框标注及其对应的动作标签(每个人体框可能有多个标签),标注以每秒1帧的频率覆盖80个原子类别。AVA-Kinetics 将 AVA 风格的标注引入 Kinetics 数据集,对 Kinetics 选定视频的单个帧进行 AVA 标签标注。评估指标为 IoU 阈值为0.5时的帧级平均精度 (mAP)。
Temporal Action Detection. Temporal action detection is an important task in long-form video understanding. Its goal is to recognize all action instances in an untrimmed video and localize their temporal extent (starting and ending timestamps). Unlike spatial action detection, temporal action localization aims to focus on precise temporal boundary localization. Intuitively, in addition to capturing semantic information for recognition, the pre-trained models should be able to effectively model the temporal evolu- tion of features to detect action boundaries. In experiments, we choose two temporal action detection benchmarks to evaluate the performance of our pre-trained video models: THUMOS14 [61] and FineAction [61]. THUMOS14 is a relatively small and well labeled temporal action detection dataset, that has been widely used by the previous methods. It only includes sports action classes on this dataset. FineAction is a new large-scale temporal action dataset with fine-grained action class definitions. The evaluation metric is the average mAP under different tIoU thresholds.
时序动作检测。时序动作检测是长视频理解中的重要任务,其目标是在未剪辑视频中识别所有动作实例并定位其时间范围(起始与结束时间戳)。与空间动作检测不同,时序动作定位侧重于精确的时间边界定位。直观而言,预训练模型除了需要捕捉语义信息进行识别外,还应能有效建模特征的时间演化以检测动作边界。实验中我们选择两个时序动作检测基准来评估视频预训练模型的性能:THUMOS14 [61] 和 FineAction [61]。THUMOS14 是一个规模较小但标注完善的时序动作检测数据集,已被先前方法广泛采用,该数据集仅包含体育动作类别。FineAction 是具备细粒度动作类别定义的新兴大规模时序动作数据集,评估指标为不同 tIoU 阈值下的平均 mAP。
Table 1. Ablation study on the decoder masking strategies. Experiments are conducted with ViT-B by pre-training on SSv2 with 800 epochs. “None” refers to the original VideoMAE without decoder masking. We use a better fine-tuning setting than the original VideoMAE. 1 Loss computed over all decoder output tokens. 2 Loss computed over only decoder output tokens invisible to encoder. The default setting for VideoMAE v2 is colored in gray .
表 1: 解码器掩码策略的消融研究。实验采用ViT-B架构,在SSv2数据集上进行800轮预训练。"None"表示原始VideoMAE未使用解码器掩码。我们采用了比原始VideoMAE更优的微调设置。1 损失计算基于所有解码器输出token。2 损失仅计算编码器不可见的解码器输出token。VideoMAE v2的默认设置以灰色标注。
| 解码器掩码方式 | pd | Top-1 | FLOPs |
|---|---|---|---|
| None | 0% | 70.28 | 35.48G |
| Frame | 50% | 69.76 | 25.87G |
| Random | 50% | 64.87 | 25.87G |
| Running cell | 50% | 66.74 | 25.87G |
| Running cell 2 | 25% | 70.22 | 31.63G |
| Running cell 2 | 50% | 70.15 | 25.87G |
| Running cell 12 | 75% | 70.01 | 21.06G |
4.2. Main Results
4.2. 主要结果
We first conduct the experimental study on the core designs of our VideoMAE V2 pre-training framework. We report the fine-tuning action recognition accuracy on the datasets of Kinetics-400 and Something-Something (SthSth) V2. Implementation details about the pre-training and fine-tuning could be found in the appendix.
我们首先对VideoMAE V2预训练框架的核心设计进行了实验研究。报告了在Kinetics-400和Something-Something (SthSth) V2数据集上的微调动作识别准确率。预训练和微调的具体实现细节可参阅附录。
Results on dual masking. We first perform an ablation study on the decoder masking strategy. In this study, we use the ViT-B as the backbone and the pre-training is performed on the Sth-Sth V2 dataset with 800 epochs. The results are evaluated with the fine-tuning accuracy on the SthSth V2 and reported in Table 1. We first re-implement the original VideoMAE without decoder masking and achieve slightly better performance $70.28%$ vs. $69.6%$ Top-1 acc.). Then, we try two masking alternatives in decoder: frame masking and random masking. For frame masking, we only reconstruct half of the frames in the decoder, and for random masking, we stochastic ally drop half of the cubes in the decoder for reconstruction. These two alternatives perform worse than the original VideoMAE. Finally, we apply the running cell masking to select a subset of representative cubes for reconstruction. In this setting, we apply loss functions computed over all decoder output tokens or only encoder-invisible tokens. Agreed with the results in MAE and VideoMAE, the loss on all tokens performs worse partially due to information leakage of these visible tokens from encoder. The running cell masking scheme performs on par with the original result $70.28%$ vs. $70.15%$ top-1 acc.). We also ablates the decoder masking ratio and $50%$ keeps a good trade-off between accuracy and efficiency.
双掩码策略实验结果。我们首先对解码器掩码策略进行消融研究。该研究采用ViT-B作为主干网络,在Sth-Sth V2数据集上进行800轮预训练,结果通过SthSth V2微调准确率评估(如表1所示)。我们首先复现了未使用解码器掩码的原始VideoMAE模型,获得了略优于原论文的性能(70.28% vs. 69.6% Top-1准确率)。随后在解码器中尝试两种掩码替代方案:帧掩码(仅重构半数帧)和随机掩码(随机丢弃半数立方体进行重构),这两种方案表现均逊于原始VideoMAE。最终我们采用动态单元掩码选择代表性立方体子集进行重构,此时对比了在所有解码器输出token上计算损失与仅在编码器不可见token上计算损失的方案。与MAE和VideoMAE的研究结论一致,全token损失函数会因编码器可见token的信息泄露而导致性能下降。动态单元掩码方案与原始结果表现相当(70.28% vs. 70.15% Top-1准确率)。我们还测试了不同解码器掩码比例,发现50%能在准确率与效率间取得最佳平衡。
In Table 2, we report the computational cost (FLOPs), memory consumption (Mems), and per-epoch running time (Time) of dual masking, and compare with the original encoder-only masking in VideoMAE. In this comparison, we use a lightweight decoder only with 4 transformer blocks (channel 384 for ViT-B and 512 for ViT-g). Our dual masking can further improve the computational efficiency of the original asymmetric encoder-decoder architecture in MAE [35]. For memory consumption, we can reduce almost half of the overall memory of feature maps, and this is particularly important for pre-training billion-level video transformer under the available GPUs of limited memory.
在表2中,我们报告了双重掩码的计算成本(FLOPs)、内存消耗(Mems)和每轮运行时间(Time),并与VideoMAE中原始的仅编码器掩码进行了对比。本次对比中,我们仅使用含4个Transformer块( ViT-B通道384/ViT-g通道512 )的轻量级解码器。我们的双重掩码能进一步提升MAE[35]原始非对称编码器-解码器架构的计算效率。在内存消耗方面,我们几乎能将特征图的总内存减少一半,这对于在显存有限的GPU上预训练十亿级视频Transformer尤为重要。
Results on data scaling. We study the influence of pretraining data size on the VideoMAE V2 pre-training. In this experiment, we pre-train the video models with backbones from ViT-B, ViT-L, ViT-H, to ViT $\mathbf{\nabla}^{\cdot}\mathbf{g}$ on our built UnlabeledHybrid dataset with around $1.35\mathbf{M}$ videos. The fine-tuning accuracy is shown in Table 3 on the Kinetics-400 and Table 4 on the Sth-Sth V2. We first compare our performance with the original VideoMAE pre-training. We find that for all backbones, our large-scale pre-training obtains better performance than the original VideoMAE pre-trained on the small-scale datasets of Kinetics-400 or Sth-Sth V2. Meanwhile, we see that the performance gap between two pretraining data datasets becomes more evident as the modal capacity scales up. In particular, on the Sth-Sth V2 dataset, our pre-trained ViT-H outperforms the original VideoMAE by $2.0%$ . It implies that data scale is also important for video masked auto encoding. Meanwhile, we compare with MAE-ST of IG-uncurated pre-training (1M clips). With the same ViT-L backbone, our pre-trained model outperforms it by $1%$ on the Kinetics-400 dataset. This result shows that data quality and diversity might be another important factor.
数据规模扩展的结果。我们研究了预训练数据规模对VideoMAE V2预训练的影响。本实验中,我们在自建的UnlabeledHybrid数据集(约135万视频)上,使用ViT-B、ViT-L、ViT-H至ViT $\mathbf{\nabla}^{\cdot}\mathbf{g}$ 骨干网络进行视频模型预训练。表3和表4分别展示了Kinetics-400和Sth-Sth V2的微调准确率。首先与原始VideoMAE小规模预训练(基于Kinetics-400或Sth-Sth V2数据集)对比发现:所有骨干网络在大规模预训练下均表现更优,且模型容量越大时两种预训练数据的性能差距越显著。特别在Sth-Sth V2数据集上,我们的ViT-H预训练模型比原始VideoMAE高出2.0%,表明数据规模对视频掩码自编码同样关键。此外,与基于IG-uncurated预训练的MAE-ST(100万片段)对比发现:相同ViT-L骨干网络下,我们的模型在Kinetics-400数据集上准确率高1%,说明数据质量与多样性可能是另一重要因素。
Results on model scaling. We study the performance trend with different model capacities. We compare the fine-tuning performance of pre-trained models with ViT-B, ViT-L, ViTH, and ViT $\mathrm{g}$ as shown in Table 3 and Table 4. Vit-g is the first billion-level model pre-trained in video domain. We obtain consistent performance improvement with increasing model capacity. For all compared pre-training methods, the performance improvement from ViT-B to ViT-L is more obvious, while the improvement from ViT-L to ViT-H is much smaller. We further scale up the model capacity to ViT $\mathbf{g}$ architecture. We can still boost the fine-tuning performance further on these two benchmarks with a smaller improvement. We also notice that the performance gap between huge and giant model is very small $(0.1%-0.2%)$ in images [108]. We analyze the performance seems to saturate around 87.0 on the Kinetics-400 and 77.0 on the SthSth V2 for methods without using any extra labeled data.
模型缩放结果。我们研究了不同模型容量下的性能趋势,比较了ViT-B、ViT-L、ViT-H和ViT $\mathrm{g}$预训练模型的微调性能,如表3和表4所示。ViT-g是视频领域首个十亿级预训练模型。随着模型容量增加,我们观察到性能持续提升:所有预训练方法从ViT-B扩展到ViT-L时改进更显著,而ViT-L到ViT-H的提升幅度较小。当继续扩展至ViT $\mathbf{g}$架构时,这两个基准上的微调性能仍能获得较小幅度提升。我们注意到图像领域[108]中巨型与超大型模型的性能差距极小$(0.1%-0.2%)$。分析表明,在不使用额外标注数据的方法中,Kinetics-400的性能饱和点约为87.0,SthSth V2约为77.0。
Table 2. Comparison between dual masking and encoder-only masking. We report the computational cost, memory consumption, and running time for comparison. We perform experiments with backbones (ViT-B and ViT-g) and pre-training on two scales of datasets (Sth-Sth V2 and Unlabeled Hybrid). Time is for 1200 epochs on 64 GPUs. 1 is estimated by training 5 epochs.
表 2: 双重掩码与仅编码器掩码的对比。我们报告了计算成本、内存消耗和运行时间以进行比较。实验采用不同骨干网络 (ViT-B 和 ViT-g) 并在两种规模数据集 (Sth-Sth V2 和 Unlabeled Hybrid) 上进行预训练。时间为 64 块 GPU 上训练 1200 个周期的结果。1 表示通过训练 5 个周期估算得出。
| 掩码方式 | 骨干网络 | 预训练数据集 | FLOPs | 内存占用 | 时间 | 加速比 | Top-1 准确率 |
|---|---|---|---|---|---|---|---|
| 编码器掩码 | ViT-B | Something-SomethingV2 | 35.48G | 631M | 28.4h | 70.28 | |
| 双重掩码 | ViT-B | Something-SomethingV2 | 25.87G | 328M | 15.9h | 1.79x | 70.15 |
| 编码器掩码 | ViT-g | UnlabeledHybrid | 263.93G | 1753M | 356h1 | ||
| 双重掩码 | ViT-g | UnlabeledHybrid | 241.61G | 1050M | 241h | 1.48x | 77.00 |
Table 3. Results on the Kinetics-400 dataset. We scale the pre-training of VideoMAE V2 to billion-level $\mathrm{ViT-g}$ model with millionlevel data size. We report the fine-tuning accuracy of multiple view fusion $(5\times3)$ and single view results in the bracket. All models are pre-trained and fine-tuned at the input of $16\times224\times224$ and sampling stride $\tau=4$ .
表 3: Kinetics-400 数据集上的结果。我们将 VideoMAE V2 的预训练扩展到十亿级 $\mathrm{ViT-g}$ 模型和百万级数据规模。我们报告了多视角融合 $(5\times3)$ 的微调准确率,括号内为单视角结果。所有模型均在 $16\times224\times224$ 输入和采样步长 $\tau=4$ 下进行预训练和微调。
| 方法 | 预训练数据 | 数据规模 | 训练周期 | ViT-B | ViT-L | ViT-H | ViT-g |
|---|---|---|---|---|---|---|---|
| MAE-ST[28] | Kinetics400 | 0.24M | 1600 | 81.3 | 84.8 | 85.1 | |
| MAE-ST[28] | IG-uncurated | 1M | 1600 | 84.4 | |||
| VideoMAE V1[90] | Kinetics400 | 0.24M | 1600 | 81.5 | 85.2 | 86.6 | |
| VideoMAE V2 | UnlabeledHybrid | 1.35M | 1200 | 81.5 (77.0) | 85.4 (81.3) | 86.9 (83.2) | 87.2 (83.9) |
| △Acc. with V1 | %0+ | +0.2% | +0.3% |
Table 4. Results on the Something-Something V2 dataset. We scale the pre-training of VideoMAE V2 to billion-level $\mathrm{ViT{-g}}$ model with million-level data size. We report the fine-tuning accuracy of multiple view fusion $(2\times3)$ and single view results in the brackets. All models are pre-trained at input of $16\times224\times224$ and sampling stride $\tau=2$ . Fine-tuning is on the same size as TSN [99] sampling.
表 4. Something-Something V2 数据集上的结果。我们将 VideoMAE V2 的预训练扩展到十亿级 $\mathrm{ViT{-g}}$ 模型,数据规模达百万级。我们报告了多视角融合 $(2\times3)$ 的微调准确率,括号内为单视角结果。所有模型均在 $16\times224\times224$ 输入和采样步长 $\tau=2$ 下进行预训练。微调采样方式与 TSN [99] 相同。
| method | pre-traindata | datasize | epoch | ViT-B | ViT-L | ViT-H | ViT-g |
|---|---|---|---|---|---|---|---|
| MAE-ST[28] | Kinetics400 | 0.24M | 1600 | 72.1 | 74.1 | ||
| MAE-ST[28] | Kinetics700 | 0.55M | 1600 | 73.6 | 75.5 | ||
| VideoMAEV1[90] | Something-SomethingV2 | 0.17M | 2400 | 70.8 | 74.3 | 74.8 | |
| VideoMAEV2 | UnlabeledHybrid | 1.35M | 1200 | 71.2 (69.5) | 75.7 (74.0) | 76.8 (75.5) | 77.0 (75.7) |
| △Acc.withV1 | — | +0.4% | +1.4% | +2.0% |
Table 5. Study on progressive pre-training. We report the finetuning accuracy of multiple view fusion $(5\times3)$ and single view results in the bracket on the Kinetics-400 dataset. The implementation detail is the same with Table 3.
表 5: 渐进式预训练研究。我们在 Kinetics-400 数据集上报告了多视角融合 $(5\times3)$ 的微调准确率,括号内为单视角结果。实现细节与表 3 相同。
| 方法 | 额外监督 | ViT-H | ViT-g |
|---|---|---|---|
| MAE-ST[28] | K600 | 86.8 | |
| VideoMAEV1[90] | K710 | 88.1 (84.6) | |
| VideoMAEV2 | 86.9 (83.2) | 87.2 (83.9) | |
| VideoMAEV2 | K710 | 88.6 (85.0) | 88.5 (85.6) |
| △Acc.withV1 | K710 | +0.5% |
Results on progressive training. We study the influence of the post-pre-training step in our progressive training scheme. To mitigate over-fitting risk and integrate more human supervision into our pre-trained video models, we merge different versions of Kinetics for post-pre-training (intermediate fine-tuning) and evaluate on the Kinetics-400 dataset. The results are reported in Table 5. We observe that the post-pre-training boosts the performance of largescale pre-trained models for both ViT-H and ViT $\mathrm{^{2}}$ . This result agrees with the findings in image domain [6, 62]. We also apply this technique to VideoMAE V1 pre-trained model and it (ViT-H) achieves worse performance $(88.1%$ vs. $88.6%,$ ), demonstrating the effectiveness of large-scale unsupervised pre-training. We also compare with the intermediate fine-tuning of MAE-ST and our performance is better by $1.8%$ with the same ViT-H backbone. This superior performance might be ascribed to the larger unsupervised pre-training dataset and larger intermediate finetuning dataset. We also try this post-pre-training on Sth-Sth V2 dataset but obtain worse performance.
渐进式训练的结果。我们研究了渐进式训练方案中后预训练步骤的影响。为降低过拟合风险并在预训练视频模型中融入更多人工监督,我们合并了不同版本的Kinetics数据集进行后预训练(中间微调),并在Kinetics-400数据集上评估。结果如 表 5 所示。我们观察到后预训练显著提升了ViT-H和ViT $\mathrm{^{2}}$ 大规模预训练模型的性能,该结论与图像领域的研究发现一致[6, 62]。将此技术应用于VideoMAE V1预训练模型时(ViT-H架构),其性能反而下降 $(88.1%$ vs. $88.6%,$ ),这印证了大规模无监督预训练的有效性。与MAE-ST的中间微调相比,在相同ViT-H主干网络下,我们的方法性能提升 $1.8%$ ,优势可能源于更大的无监督预训练数据集和中间微调数据集。在Sth-Sth V2数据集上尝试后预训练时,性能出现下降。
4.3. Performance on Downstream Tasks
4.3. 下游任务性能
To demonstrate the generalization ability of our pretrained models, we transfer their representations to a variety of downstream tasks. In total, we study three kinds of tasks and report performance on ten mainstream benchmarks.
为了展示预训练模型的泛化能力,我们将模型表征迁移到多种下游任务中。总计研究了三类任务,并在十个主流基准测试上汇报了性能表现。
Action classification. We compare with previous stateof-the-art methods on four action recognition benchmarks Kinetics-400/600 and Something-Something V1/V2. On the Kinetics datasets, our VideoMAE V2 achieves the best performance among these methods without using extra inhouse labeled data, and quite competitive performance to the leading performance MTV [111] trained with extra 60M labeled videos. On the Something-Something datasets, our models significantly outperform the previous best performance, and in particular on Something-Something V1, the performance improvement is above $7%$ . The fine-tuning results on UCF101 and HMDB51 are shown in the appendix.
动作分类。我们在四个动作识别基准数据集Kinetics-400/600和Something-Something V1/V2上与之前的最先进方法进行了比较。在Kinetics数据集上,我们的VideoMAE V2在不使用额外内部标注数据的情况下取得了这些方法中的最佳性能,并且与使用额外6000万标注视频训练的领先方法MTV [111] 性能相当。在Something-Something数据集上,我们的模型显著超越了之前的最佳性能,特别是在Something-Something V1上,性能提升超过 $7%$ 。UCF101和HMDB51上的微调结果见附录。
Spatial action detection. We perform a comparison with the previous action detection methods on two datasets: AVA and AVA Kinetics. We follow the same detection pipeline with the original VideoMAE [90]. On the AVA dataset, our pre-trained model is significantly better than the previous state-of-the-art action detector of TubeR [120] and outperforms the previous masked modeling methods by $3.1%$ . On the AVA-Kinetics, we compare the previous challenge winner methods with the model ensemble, and our single model is better than the best performance by $3.4%$ .
空间动作检测。我们在AVA和AVA Kinetics两个数据集上与之前的动作检测方法进行对比,沿用原始VideoMAE [90]的检测流程。在AVA数据集上,我们的预训练模型显著优于TubeR [120]的最先进动作检测器,并以$3.1%$的优势超越此前掩码建模方法。在AVA-Kinetics数据集上,我们对比了往届挑战赛优胜者的模型集成方案,我们的单一模型以$3.4%$的优势超越历史最佳表现。
Temporal action detection. We investigate the transfer performance of our model to the task of temporal action detection. This is an important task yet not to be tested by previous masked pre-training methods. We report performance on two benchmarks: THUMOS14 and FineAction. We use the Action Former [117] detection pipeline as our baseline method and replace its I3D feature with our pre-trained represent ation. On the THUMOS14 dataset, our model outperforms all previous results even with optical flow as input. On the large-scale FineAction dataset, our model is significantly better than a previous best performance by $5%$ .
时序动作检测。我们研究了模型在时序动作检测任务上的迁移性能。这是一个重要但此前基于掩码预训练方法尚未验证过的任务。我们在THUMOS14和FineAction两个基准上报告性能:以Action Former[117]检测框架为基线方法,将其I3D特征替换为我们的预训练表征。在THUMOS14数据集上,即使以光流作为输入,我们的模型仍超越所有先前结果。在大规模FineAction数据集上,我们的模型以5%的显著优势超越此前最佳性能。
(c) Something-Something V2 (e) AVA
| 方法 | Top 1 | Top 5 | 方法 | Long Feature | mAP |
|---|---|---|---|---|---|
| SlowFast [29] | 63.1 | 87.6 | SlowFast [29] | 29.0 | |
| TEINet [64] | 66.5 | TubeR [120] | 33.4 | ||
| TEA [55] | 65.1 | 89.9 | MaskFeat [104] | 38.8 | |
| TDN [98] | 69.6 | 92.2 | MAE-ST [28] | 39.0 | |
| TimeSformer-L [8] | 62.4 | VideoMAE [90] | 39.5 | ||
| MFormer-HR [76] | 68.1 | 91.2 | VideoMAEV2 | 42.6 | |
| ViViT-L FE [4] | 65.9 | 89.9 | |||
| Video Swin-B [65] | 69.6 | 92.7 | (f) AVA Kinetics | ||
| MViTv2-B [56] | 72.1 | 93.4 90.1 | 方法 | Ensembled | mAP |
| MTV-B [111] BEVT [100] | 67.6 70.6 | ||||
| VIMPAC [86] | 68.1 | AIA++ [106] | 29.0 | ||
| UniFormer [52] | 71.2 | 92.8 | MSF [121] | 33.4 | |
| MaskFeat [104] | 75.0 | 95.0 | ACAR [72] | 40.5 | |
| MAE-ST [28] | 75.5 | 95.0 | VideoMAE V2 | 43.9 | |
| VideoMAE [90] | 75.4 | 95.2 | (g) THUMOS14 | ||
| VideoMAE V2-H | 76.8 | 95.8 | 方法 | Optical Flow | mAF |
| VideoMAEV2-g | 77.0 | 95.9 | RTD-Net [87] | 43.6 | |
| (d) Something-Something V1 | DaoTAD [94] | 50.0 | |||
| 方法 Top 1 | AFSD [57] | 52.0 | |||
| I3D [13] | Top 5 | DCAN [14] TadTR [60] | 52.3 | ||
| 41.6 | 72.2 | TALLFormer [19] | 54.2 | ||
| NL I3D+GCN [103] | 46.1 | 76.8 | BasicTAD [113] | 59.2 | |
| TSM [58] | 49.7 | 78.5 | 59.6 | ||
| V4D [119] | 50.4 | ActionFormer [117] VideoMAE V2 | 66.8 | ||
| TANet [66] | 50.6 | 79.3 | 69.6 | ||
| TEINet [64] | 52.5 51.9 | 80.3 | (h) FineAction | ||
| TEA [55] CorrNet [95] | 53.3 | ||||
| GSM [83] | 55.2 | = | 方法 | Optical Flow | mAE |
| TDN [98] | 56.8 | 84.1 | BMN [59] | 9.25 | |
| UniFormer [52] | 61.0 | 87.6 | G-TAD [110] | 9.06 | |
| BasicTAD [113] | 12.2 | ||||
| VideoMAEV2-H | 66.6 | 90.8 | ActionFormer [117] | 13.2 | |
| VideoMAE V2-g | 68.7 | 91.9 | VideoMAEV2 | 18.2 |
(a) Kinetics 400
| 方法 | Top 1 | Top 5 | Views | TFLOPs | 方法 | Top 1 | Top 5 |
|---|---|---|---|---|---|---|---|
| I3D NL [102] | 77.7 | 93.3 | 10×3 | 10.77 | SlowFast [29] | 63.1 | 87.6 |
| TDN [98] | 79.4 | 94.4 | 10×3 | 5.94 | TEINet [64] | 66.5 | |
| SlowFast R101-NL [29] | 79.8 | 93.9 | 10×3 | 7.02 | TEA [55] | 65.1 | 89.9 |
| TimeSformer-L [8] | 80.7 | 94.7 | 1×3 | 7.14 | TDN [98] | 69.6 | 92.2 |
| MTV-B (320²) [111] | 82.4 | 95.2 | 4×3 | 11.16 | TimeSformer-L [8] | 62.4 | - |
| Video Swin-L (384²) [65] | 84.9 | 96.7 | 10×5 | 105.35 | MFormer-HR [76] | 68.1 | 91.2 |
| ViViT-L FE [4] | 81.7 | 93.8 | 1×3 | 11.94 | ViViT-L FE [4] | 65.9 | 89.9 |
| Video Swin-B [65] | 69.6 | 92.7 | |||||
| MViTv2-L (312²) [56] | 86.1 | 97.0 | 40×3 | 42.42 | MViTv2-B [56] | 72.1 | 93.4 |
| MaskFeat [104] | 87.0 | 97.4 | 4×3 | 45.48 | MTV-B [111] | 67.6 | 90.1 |
| MAE-ST [28] | 86.8 | 97.2 | 4×3 | 25.05 | BEVT [100] | 70.6 | |
| VideoMAE [90] | 86.6 | 97.1 | 5×3 | 17.88 | VIMPAC [86] | 68.1 | |
| VideoMAEV2-H | 88.6 | 97.9 | 5×3 | 17.88 | UniFormer [52] | 71.2 | 92.8 |
| VideoMAEV2-g | 88.5 | 98.1 | 5×3 | 38.16 | 75.0 | 95.0 | |
| VideoMAE V2-g (64×266²) | 90.0 | 98.4 | 2×3 | 160.30 | MaskFeat [104] | 75.5 | 95.0 |
| MAE-ST [28] | |||||||
| 使用内部标注数据的方法 | VideoMAE [90] | 75.4 | 95.2 | ||||
| CoVeR (JFT-3B) [116] | 87.2 | 1×3 | VideoMAE V2-H | ||||
| MTV-H (WTS 280²) [111] | 89.9 | 98.3 | 4×3 | 73.57 | VideoMAE V2-g | 76.8 | 95.8 |
| 77.0 | 95.9 | ||||||
| (b) Kinetics 600 | (d) Something-Something V1 | ||||||
| 方法 | Top 1 | Top 5 | Views | TFLOPs | 方法 | Top 1 | Top 5 |
| SlowFast R101-NL [29] | 81.8 | 95.1 | 10×3 | 7.02 | I3D [13] | 41.6 | 72. |
| TimeSformer-L [8] | 82.2 | 95.6 | 1×3 | 7.14 | NL I3D+GCN [103] | 46.1 | 76.8 |
| MTV-B (320²) [111] | 84.0 | 96.2 | 4×3 | 11.16 | TSM [58] | 49.7 | 78. |
| V4D [119] | |||||||
| ViViT-L FE [4] | 82.9 | 94.6 | 1×3 | 11.94 | TANet [66] | 50.4 | |
| 50.6 | |||||||
| MViTv2-L (352²) [56] | 87.9 | 97.9 | 40×3 | 45.48 | TEINet [64] | 52.5 | 79. |
| MaskFeat [104] | 86.4 | 97.4 | 1×10 | 3.77 | TEA [55] | 51.9 | 80. |
| VideoMAE V2-H | 88.3 | 98.1 | 5×3 | 17.88 | CorrNet [95] | 53.3 | |
| VideoMAE V2-g | 88.8 | 98.2 | 5×3 | 38.16 | GSM [83] | 55.2 | |
| VideoMAE V2-g (64×266²) | 89.9 | 98.5 | 2×3 | 160.30 | TDN [98] | 56.8 | 84. |
| UniFormer [52] | 61.0 | 87. | |||||
| 使用内部标注数据的方法 | |||||||
| CoVeR (JFT-3B) [116] | 87.9 | 97.8 | 1×3 | VideoMAE V2-H | 66.6 | 90.8 | |
| MTV-H (WTS 280²) [111] | 90.3 | 98.5 | 4×3 | 73.57 | VideoMAE V2-g | 68.7 | 91. |
Table 6. Systematic study on the transfer performance of VideoMAE V2 pre-trained models. We use them as the video foundation models and transfer them to three kinds of downstream tasks: action classification, action detection, and temporal action detection, covering eight mainstream video action benchmarks. Entries using extra in-house labeled data for training are in gray. “-”: numbers not available.
表 6: VideoMAE V2预训练模型迁移性能的系统性研究。我们将其作为视频基础模型迁移至三类下游任务:动作分类、动作检测和时间动作检测,涵盖八个主流视频动作基准测试。使用额外内部标注数据训练的条目以灰色标注。"-"表示数据不可用。
5. Conclusion and Discussion
5. 结论与讨论
Building foundation model has turned out to be an effective paradigm to improve the performance of tasks in AI. Simple and scalable algorithms are the core of building powerful foundation models. In this paper, we have presented a simple and efficient way to scale VideoMAE to billion-level model on the million-level pre-training set. Thanks to our core design of dual masking, we are able to successfully the first billion-level video transformer, and demonstrate its effectiveness on a variety of video downstream tasks. Our work shows that video masked autoencoders are general and scalable representation learners for video action understanding. We hope our pre-trained models could provide effective representations for more video understanding tasks in the future.
构建基础模型 (foundation model) 已成为提升AI任务性能的有效范式。简单且可扩展的算法是构建强大基础模型的核心。本文提出了一种在百万级预训练集上将VideoMAE扩展至十亿级模型的简单高效方法。得益于双掩码 (dual masking) 的核心设计,我们成功训练出首个十亿级视频Transformer,并在多种视频下游任务中验证了其有效性。研究表明,视频掩码自编码器是通用且可扩展的视频动作理解表征学习器。我们希望预训练模型能为未来更多视频理解任务提供有效表征。
In spite of these excellent results, challenge still remains. We observe that the performance improvement is smaller when we scale VideoMAE from ViT-H to ViT $\mathbf{g}$ , partially because of performance saturation on these video benchmarks. However, the data scale we have explored for VideoMAE is still several orders of magnitudes smaller than the Image [62,115] and NLP [12,24]. How to train VideoMAE on billions of videos is still extremely challenging for the current software and hardware. We need to come up with more efficient video pre-training framework and hope our work can inspire future work on scaling video pre-training.
尽管取得了这些优异成果,挑战依然存在。我们观察到,当将VideoMAE从ViT-H扩展到ViT $\mathbf{g}$ 时,性能提升较小,部分原因是这些视频基准测试已接近性能饱和。然而,当前VideoMAE探索的数据规模仍比图像领域[62,115]和自然语言处理领域[12,24]小几个数量级。如何在数十亿视频上训练VideoMAE,对现有软硬件而言仍是极大挑战。我们需要提出更高效的视频预训练框架,并希望本研究能启发未来视频预训练的扩展工作。
Acknowledgements. This work is supported by the National Key R&D Program of China (No. 2022 ZD 0160900, No.2022 ZD 0160100), the National Natural Science Foundation of China (No. 62076119, No. 61921006), Shanghai Committee of Science and Technology (Grant No. 21 DZ 1100100), the Youth Innovation Promotion Association of Chinese Academy of Sciences (No. 2020355).
致谢。本研究由国家重点研发计划项目(No. 2022ZD0160900、No. 2022ZD0160100)、国家自然科学基金(No. 62076119、No. 61921006)、上海市科学技术委员会项目(Grant No. 21DZ1100100)以及中国科学院青年创新促进会(No. 2020355)资助。
A. Appendix
A. 附录
In this supplementary material, we provide more details of our VideoMAE V2 and present more experiment results. Specifically, we give a detailed description of the architectures of our VideoMAE V2 in Section B. Then, we present the details on building our pre-training datasets in Section C. After this, we provide more implementation details in our experiments in Section D. Finally, we give more results and analysis on our VideoMAE V2 in Section E.
在本补充材料中,我们将提供VideoMAE V2的更多细节并展示更多实验结果。具体而言,我们将在B节详细描述VideoMAE V2的架构,随后在C节介绍预训练数据集的构建细节,接着在D节提供实验的更多实现细节,最后在E节给出VideoMAE V2的更多结果与分析。
B. Model Architecture
B. 模型架构
We build the encoder and decoder in our VideoMAE V2 by using the vanilla ViT backbone with joint space-time attention. To ensure efficient computation, our decoder does not get larger as the encoder scales up, but always stays at the size of 4 layers and 512 channels. We show the architectures of VideoMAE V2 in Table 7, taking ViT-giant as an example.
我们采用具有联合时空注意力机制的普通ViT主干网络构建VideoMAE V2的编码器和解码器。为确保计算效率,解码器不会随编码器规模扩大而增大,始终保持4层512通道的结构。以ViT-giant为例,VideoMAE V2的架构如 表7 所示。
C. Datasets
C. 数据集
C.1. Unlabeled Hybrid
C.1. 无标签混合
Our Unlabeled Hybrid dataset is a hybrid dataset consisting of Kinetics [43], Something-Something [31], AVA [32], WebVid2M [5], and our self-collected Instagram dataset. When training VideoMAE V2, the sampling stride $\tau$ is 2 on Something-Something, and 4 on the other datasets. The detailed components of Unlabeled Hybrid are shown in Table 8. We now specify the handling of each dataset.
我们的未标注混合数据集 (Unlabeled Hybrid) 由 Kinetics [43]、Something-Something [31]、AVA [32]、WebVid2M [5] 以及我们自行收集的 Instagram 数据集组成。在训练 VideoMAE V2 时,Something-Something 的采样步长 $\tau$ 设为 2,其他数据集设为 4。未标注混合数据集的详细组成如 表 8 所示。下面我们具体说明每个数据集的处理方式。
Kinetics. Videos in Kinetics are from YouTube. We adapt the same method with [3] to make a mixed kinetics dataset. Kinetics has three versions, Kinetics-400/600/700, based on the number of human action categories. We merge the training set and validation set of the three versions, then remove the duplicated videos according to YouTube IDs, and finally delete the validation videos that existed in the training set. As some videos have different category names in different versions of Kinetics, we also group them together, resulting in a Kinetics dataset with 710 categories, termed Kinetics710 (K710) or Labeled Hybrid. K710 contains $658\mathrm{k}$ training videos and 67k validation videos.
Kinetics。Kinetics中的视频来自YouTube。我们采用与[3]相同的方法构建混合版Kinetics数据集。该数据集根据人类动作类别数量分为Kinetics-400/600/700三个版本。我们将三个版本的训练集与验证集合并后,按YouTube ID去重,并剔除验证集中与训练集重复的视频。由于部分视频在不同版本Kinetics中存在类别名称差异,我们对其进行了归类整合,最终形成包含710个类别的Kinetics数据集,称为Kinetics710(K710)或Labeled Hybrid。K710包含$658\mathrm{k}$条训练视频和67k条验证视频。
Something-Something. Videos in Something-Something are shot from video scripts, usually from a first-person perspective. We choose Something-Something V2 (SSV2) as the part of Unlabeled H by rid dataset. SSV2 is a motioncentric dataset containing $169\mathrm{k}$ training videos and $25\mathrm{k\Omega}$ validation videos.
Something-Something。Something-Something中的视频根据脚本拍摄,通常采用第一人称视角。我们选择Something-Something V2 (SSV2)作为未标注H by rid数据集的一部分。SSV2是一个以动作为核心的数据集,包含$169\mathrm{k}$个训练视频和$25\mathrm{k\Omega}$个验证视频。
AVA. Videos in AVA are movie clips, ranging from the 15th to the 30th minute of each movie. We always cut the 15-minute movie clips from the AVA training set by 300 frames, resulting in 21k video clips.
AVA。AVA中的视频是电影片段,每部电影从第15分钟到第30分钟不等。我们总是将AVA训练集中的15分钟电影片段剪切成300帧,最终得到21k个视频片段。
WebVid2M. Videos in WebVid2M are scraped from the internet. We randomly pick $250\mathrm{k}$ training videos from the original datasets.
WebVid2M。WebVid2M中的视频是从互联网上抓取的。我们从原始数据集中随机选取了$250\mathrm{k}$个训练视频。
Self-collected Instagram dataset. We used thousands of category tags from the already publicly available dataset as query phrases to scrape million of videos from Instagram. The average duration of the videos is 34 seconds. We also randomly pick 250k videos from the dataset.
自采集Instagram数据集。我们使用已有公开数据集中的数千个类别标签作为查询短语,从Instagram抓取了数百万个视频。这些视频的平均时长为34秒。我们还从数据集中随机选取了25万个视频。
C.2. Lab led Hybrid
C.2. 实验室主导的混合模式
We build the labeled datasets for our VideoMAE postpre-training by taking the union of different versions of Kinetics dataset. The construction details is following the Uni former V 2 [53] and more details could be referred to the original paper.
我们通过整合不同版本的Kinetics数据集构建了VideoMAE后预训练的标注数据集。具体构建方法遵循UniFormerV2 [53],更多细节可参考原论文。
D. Implementation Details
D. 实现细节
In this section, we will describe the implementation details in the three stages of progressive training: pre-training, post-pre-training, and specific fine-tuning.
在本节中,我们将描述渐进式训练三个阶段(预训练、后预训练和特定微调)的实现细节。
D.1. Pre-training
D.1. 预训练
We pre-train VideoMAE V2, both ViT-huge and ViTgiant, 1200 epochs on the Unlabeled Hybrid dataset with 64 80G-A100 GPUs. Besides the dual masking core design of VideoMAE V2, we also adapt mix-precision training and check pointing at the engineering level to speed up pre-training. To avoid the potential precision overflow risk during model pre-training, we train the encoder with FP16 mixed precision and the decoder with FP32 precision. We adapt repeated augmentation to reduce the video loading overhead. The learning rate is scaled linearly according to the total batch size, i.e. lr = base lr $\times$ batch size / 256. The detailed pre-training setting is shown in Table 10.
我们在Unlabeled Hybrid数据集上使用64块80G-A100 GPU对VideoMAE V2(包括ViT-huge和ViT-giant版本)进行了1200轮预训练。除VideoMAE V2的双重掩码核心设计外,我们还在工程层面采用了混合精度训练和检查点技术以加速预训练过程。为避免模型预训练期间潜在的精度溢出风险,编码器采用FP16混合精度训练,解码器则使用FP32精度。我们采用重复增强技术来降低视频加载开销。学习率根据总批次大小线性缩放,即lr = 基础学习率 $\times$ 批次大小 / 256。具体预训练设置如 表10 所示。
D.2. Post-pre-training
D.2. 后预训练
In the supervised post-pre-training stage, we fine-tune the pre-trained encoder on Labeled Hybrid (K710). When training ViT-giant, we found that the dropout layer before the classification head has little positive effect on preventing over fitting, so the dropout layer was removed and the drop path rate was increased slightly. The clip grading stabilizes the optimization of large models in the early stages of fine-tuning to some extent, and it is advisable to adjust the value of the clip grading with the batch size changing. The choice of layer decay matters. A smaller layer decay better maintains the pre-training effect, but may not provide enough space for improvement in the later stages of fine-tuning. A relatively large layer decay is recommended when the model is well pre-trained, i.e. when it exhibits smaller gradients in the shallow layers and bigger gradients in the deep layers at the early stages of fine-tuning. The detailed settings are shown in Table 11. Notably, this setting also works for fine-tuning directly on the kinetics dataset.
在有监督的后预训练阶段,我们在Labeled Hybrid (K710)数据集上对预训练编码器进行微调。训练ViT-giant时发现,分类头前的dropout层对防止过拟合几乎没有正向作用,因此移除了该dropout层并略微提高了drop path率。梯度裁剪(clip grading)能在微调初期一定程度上稳定大模型的优化过程,建议根据批量大小变化调整梯度裁剪值。层衰减(layer decay)的选择至关重要:较小的层衰减能更好保持预训练效果,但可能无法为微调后期提供足够的改进空间;当模型预训练充分时(表现为微调初期浅层梯度较小而深层梯度较大),建议采用相对较大的层衰减。具体设置如表11所示。值得注意的是,该设置同样适用于直接在kinetics数据集上进行微调的情况。
Table 7. Architectures details of VideoMAE $\mathbf{V}\mathbf{2}\mathbf{-g}$ . The main difference between VideoMAE $\mathbf{v}2$ and VideoMAE v1 is the dual masking design. VideoMAE v2 does not reconstruct the full video clip, while only calculates MSE loss on tokens that are invisible to the encoder.
表 7: VideoMAE $\mathbf{V}\mathbf{2}\mathbf{-g}$ 的架构细节。VideoMAE $\mathbf{v}2$ 与 VideoMAE v1 的主要区别在于双掩码设计。VideoMAE v2 不重建完整视频片段,而仅计算编码器不可见 Token 的 MSE 损失。
| 阶段 | VideoMAE V2-giant | 输出尺寸 |
|---|---|---|
| 数据 | UnlabeldHybrid | 3 × 16 × 224 × 224 |
| 立方体 | 2 × 14 × 14,1408 stride 2 × 14 × 14 | 1408 × 8 × 256 |
| 掩码 | tube masking mask ratio = p | 1408 × 8 × [256 × (1 - p)] |
| 编码器 | MHA(1408) MLP(6144) × 40 | 1408 × 8 × [256 × (1 - p)] |
| 投影器 | MLP(512) | 512 × 8 × [256 × (1 - p)] |
| 解码器掩码 | running cell masking decoder mask ratio = pd concat unmasked learnable tokens | 512 × 8× ([256 ×(1 -p)] + [256 × (1 -pd)]) |
| 解码器 | MHA(512) MLP(2048) ×4 | 512 × 8× ([256 ×(1 -p)] + [256 × (1 -pd)]) |
| 投影器 | discard visible tokens MLP(1176) | 1176 × 8 × [256 × (1 -p%)] |
| 重塑 | from 1176 to 3 × 2 × 14 × 14 | 3 × 16 × [224(1 -pd)]× [224(1 -pd)] |
Table 8. Components of Unlabeled Hybrid. We build our unlabeled pre-train dataset by collecting clips from multiple resources to ensure the generalization ability of learned models by our VideoMAE V2.
表 8: 无标注混合数据集的构成。我们通过从多个来源收集视频片段构建无标注预训练数据集,以确保VideoMAE V2学习到的模型具有泛化能力。
| 数据集 | 数量 | 来源 |
|---|---|---|
| K710 | 658k | YouTube |
| SSV2 | 169k | 剧本拍摄 |
| AVA | 21k | 电影 |
| WebVid2M | 250k | 互联网 |
| 自采集数据 | 250k | |
| UnlabeledHybrid | 1.348M | 多源 |
D.3. Specific fine-tuning
D.3. 特定微调
After the post-pre-training stage, we perform the specific fine-tuning stage to get the specific models on action classification, action detection, and temporal action detection.
在预训练后阶段,我们执行特定的微调阶段,以获得动作分类、动作检测和时间动作检测的专用模型。
D.3.1 Action classification
D.3.1 动作分类
We test the performance of the specific models for action classification on Kinetics [43], Something-Something [31], UCF101 [82] and HMDB51 [48] with regular $16\times224^{2}$ inputs. Further, we also test the performance of the model on Kinetics [43] with larger input shapes $64\times266^{2}$ . The detailed fine-tuning setting of VideoMAE V2- $\mathrm{^{2}}$ can be seen in Table 9. At the specific fine-tuning stage, increasing the dropout and drop path can reduce the risk of over fitting to a certain extent, and the optimization of the model is more stable after the supervised post-pre-training, so clip grading is not necessary.
我们在Kinetics [43]、Something-Something [31]、UCF101 [82]和HMDB51 [48]数据集上测试了特定模型在常规$16\times224^{2}$输入下的动作分类性能。此外,我们还测试了模型在Kinetics [43]上使用更大输入尺寸$64\times266^{2}$的性能。VideoMAE V2-$\mathrm{^{2}}$的详细微调设置见表9。在特定微调阶段,增加dropout和drop path可以在一定程度上降低过拟合风险,且经过监督式后预训练后模型优化更稳定,因此无需进行clip grading。
D.3.2 Action detection
D.3.2 动作检测
We follow the training pipeline of the original VideoMAE i.e. person detection $^+$ action classification. We adapt only two data augmentations, random scale cropping, and random horizontal flipping. When training, we use the groundtruth person boxes, while in testing, we use the person boxes detected by AIA [89]. More settings see in Table 12.
我们遵循原始VideoMAE的训练流程,即人物检测$^+$动作分类。仅采用两种数据增强方式:随机尺度裁剪和随机水平翻转。训练时使用真实人物边界框,测试时则采用AIA [89]检测的人物边界框。更多设置参见表12。
D.3.3 Temporal action detection
D.3.3 时序动作检测
We take the model trained on the Labeled Hybrid dataset as the backbone network and test its generalization performance on the temporal action detection task following the architecture of Action Former [117] on THUMOS14 [41] and FineAction [61]. When training, we use Adam [44] with warm-up and fix the maximum input sequence length. As for inference, we use Soft-NMS [10] on the result action candidates to remove the highly overlap proposals and obtain the final result.
我们以在Labeled Hybrid数据集上训练的模型作为骨干网络,按照Action Former [117]的架构在THUMOS14 [41]和FineAction [61]上测试其在时序动作检测任务中的泛化性能。训练时,我们使用带热启动的Adam [44]优化器,并固定最大输入序列长度。推理阶段则对候选动作结果采用Soft-NMS [10]算法去除高度重叠的提案,最终获得检测结果。
E. More Results
E. 更多结果
More results and analysis. We report more result comparisons on Kinetics with the larger input size in Table 14 and Table 15. We also add the results on UCF101 [82] and HMDB51 [48] in Table 13. From these results, we see that our model can further improve the recognition results by using larger input. Meanwhile, on the smaller benchmarks of UCF101 and HMDB51, our model obtains state-of-the-art performance, which is much better than the VideoMAE V1.
更多结果与分析。我们在表14和表15中报告了Kinetics数据集上采用更大输入尺寸的更多结果对比。同时,我们在表13中补充了UCF101 [82]和HMDB51 [48]数据集的结果。从这些结果可以看出,我们的模型通过使用更大输入尺寸能进一步提升识别效果。此外,在UCF101和HMDB51这类较小规模基准测试中,我们的模型取得了最先进的性能表现,显著优于VideoMAE V1。
Table 9. Action classification setting in specific fine-tuning stage.
表 9. 特定微调阶段中的动作分类设置。
| 配置 | Kinetics 16 × 2242 | Kinetics 64 × 2662 | Sth-Sth 16 × 2242 | UCF101 16 × 2242 | HMDB51 16 × 2242 |
|---|---|---|---|---|---|
| 优化器 | AdamW | ||||
| 基础学习率 权重衰减 | 1e-5 | 1e-4 | 3e-4 0.05 | 1e-3 | 5e-4 |
| 优化器动量 | |||||
| 批量大小 | 32 | 32 | β1, β2 = 0.9, 0.999 96 | 24 | 24 |
| 学习率调度 | cosine decay | ||||
| 预热周期 | 0 | 0 | 5 | 5 | 5 |
| 周期数 | 3 | 5 | 10 | 50 | 15 |
| 重复增强 | 2 | ||||
| RandAug | (0, 0.5) | ||||
| 标签平滑 | 0.1 | ||||
| mixup | 0.8 | ||||
| cutmix | |||||
| 1.0 | |||||
| drop path | 0.3 | 0.35 | 0.35 | 0.35 | 0.35 |
| 翻转增强 | 是 | 是 | 否 | 是 | 是 |
| 增强 | MultiScaleCrop | ||||
| dropout | 0.5 | ||||
| 分层学习率衰减 | |||||
| 0.9 | |||||
| 梯度裁剪 | None |
Table 10. Pre-training setting, where batch size includes the additional views produced by repeated augmentation and epochs refers to the total number of times the data is sampled.
表 10: 预训练设置,其中批量大小包括通过重复增强产生的额外视图,epoch指数据被采样的总次数。
| 配置 | 值 |
|---|---|
| 掩码比例 | 0.9 |
| 解码器掩码比例 | 0.5 |
| 优化器 | AdamW [68] |
| 基础学习率 权重衰减 | 1.5e-4 0.05 |
| 优化器动量 批量大小 | β1, β2 = 0.9,0.95 |
| 学习率调度 | 8192 余弦衰减 |
| 预热epoch epoch | 120 1200 |
| 重复增强 | 4 |
| 翻转增强 | 否 |
| 增强 | MultiScaleCrop |
| 梯度裁剪 | 0.02 |
Table 11. Post-pre-training setting.
表 11. 后预训练设置。
| Config | Value |
|---|---|
| optimizer baselearningrate | AdamW [68] 1e-3 |
| weight decay optimizermomentum batch size | 0.05 (H), 0.1 (g) β1, β2 = 0.9, 0.999 [15] 128 |
| learning rate schedule warmup epoch | cosine decay [67] 5 |
| epoch | 40 (H), 35 (g) |
| repeated augmentation [38] | 2 |
| RandAug [21] | (0, 0.5) |
| label smoothing [85] | 0.1 |
| mixup [118] | 0.8 |
| cutmix [114] | 1.0 |
| drop path | 0.2 (H), 0.3 (g) |
| flip augmentation | yes |
| augmentation | MultiScaleCrop |
| dropout | 0.5 (H), None (g) |
| layer-wise lr decay [6] | 0.8 (H), 0.9 (g) |
| clip grading | None (H), 5.0 (g) |
Distillation results. Using the procedure of [9], we are able to compress VideoMAE V2-g into a mush smaller ViT-B. Specifically, we initialize the student model with the Video
蒸馏结果。采用[9]的方法流程,我们将VideoMAE V2-g压缩为更小的ViT-B模型。具体而言,我们使用Video初始化学生模型
Table 12. Hyper-parameter settings of action detection.
表 12: 动作检测的超参数设置
| 配置项 | AVA 2.2 | AVA-Kinetics |
|---|---|---|
| optimizer | AdamW 3e-4 | AdamW 3e-4 |
| base learning rate | AdamW 3e-4 | AdamW 3e-4 |
| weight decay | AdamW 3e-4 | AdamW 3e-4 |
| optimizer momentum | 0.05 β1, β2 = 0.9,0.999 | 0.05 β1, β2 = 0.9,0.999 |
| batch size | 128 | 128 |
| learning rate schedule | cosine decay | cosine decay |
| warmup epoch | 2 | 2 |
| epoch | 10 | 10 |
| repeated augmentation | no | no |
| drop path | 0.3 | 0.3 |
| flip augmentation | yes | yes |
| layer-wise lr decay | 0.9 | 0.9 |
| clip grading | None | None |
MAE V2-B weights after the post-pre-training. Then, we conduct the distillation on K710 (or SSv2) dataset for 100 epochs, with the goal of minimizing the KL divergence between the student model’s logits and those of the teacher model. Detailed settings see in Table 16. Our evaluation of the distilled ViT-B model is based on its performance on the K400, K600, and SSv2, as shown in Table 17. From these results, we see that our distilled ViT-B model achieves much better performance than the original VideoMAE ViTB models. We hope our distilled ViT-B model can serve as an efficient foundation model for downstream tasks.
在完成预训练后获得MAE V2-B权重。随后,我们在K710(或SSv2)数据集上进行100个epoch的知识蒸馏,目标是最小化学生模型logits与教师模型logits之间的KL散度。具体设置见表16。我们对蒸馏后ViT-B模型的评估基于其在K400、K600和SSv2上的性能表现(如表17所示)。结果表明,蒸馏后的ViT-B模型性能显著优于原始VideoMAE ViTB模型。我们希望该蒸馏模型能成为下游任务的高效基础模型。
Table 14. Results on the Kinetics-400 dataset. We report the performance of our pre-trained model with larger input resolution and more frames.
表 14: Kinetics-400数据集上的结果。我们报告了预训练模型在更大输入分辨率和更多帧数下的性能。
| 方法 | 模态 | UCF101 | HMDB51 |
|---|---|---|---|
| OPN [50] | V | 59.6 | 23.8 |
| VCOP [109] | V | 72.4 | 30.9 |
| SpeedNet [7] | V | 81.1 | 48.8 |
| VTHCL [112] | V | 82.1 | 49.2 |
| Pace [96] | V | 77.1 | 36.6 |
| MemDPC [33] | V | 86.1 | 54.5 |
| CoCLR [34] | V | 87.9 | 54.6 |
| RSPNet [16] | V | 93.7 | 64.7 |
| VideoMoCo [73] | V | 78.7 | 49.2 |
| Vi2CLR [25] | V | 89.1 | 55.7 |
| CVRL [78] | V | 94.4 | 70.6 |
| CORPf [39] | V | 93.5 | - |
| pSimCLRp=2 [30] | V | 88.9 | 68.0 |
| pSwAV p=2 [30] | V | 87.3 | N/A |
| pMoC0p=2 [30] | V | 91.0 | N/A |
| pBYOLp=4 [30] | V | 94.2 | N/A |
| MIL-NCE [70] | V+T | 91.3 | 72.1 |
| MMV [1] | V+A+T | 92.5 | 61.0 |
| CPD [54] | V+T | 92.8 | 63.8 |
| ELO [77] | V+A | 93.8 | 67.4 |
| XDC [2] | V+A | 94.2 | 67.1 |
| GDT [75] | V+A | 95.2 | 72.8 |
| VideoMAEV1 | V | 96.1 | 73.3 |
| VideoMAEV2 | V | 99.6 | 88.1 |
| 方法 | Top 1 | Top 5 | 视图 | TFLOPs |
|---|---|---|---|---|
| I3D NL [102] | 77.7 | 93.3 | 10×3 | 10.77 |
| TDN [98] | 79.4 | 94.4 | 10×3 | 5.94 |
| SlowFast R101-NL [29] | 79.8 | 93.9 | 10×3 | 7.02 |
| TimeSformer-L [8] | 80.7 | 94.7 | 1×3 | 7.14 |
| MTV-B [111] | 81.8 | 95.0 | 4×3 | 4.79 |
| Video Swin [65] | 83.1 | 95.9 | 4×3 | 7.25 |
| MViT-B [27] | 81.2 | 95.1 | 3×3 | 4.10 |
| ViViT-L FE [4] | 81.7 | 93.8 | 1×3 | 11.94 |
| MViTv2-B [56] | 82.9 | 95.7 | 1×5 | 1.13 |
| MViTv2-L (312p) [56] | 86.1 | 97.0 | 3×5 | 42.42 |
| MaskFeat [104] | 85.1 | 96.6 | 1×10 | 3.78 |
| MaskFeat (352p) [104] | 87.0 | 97.4 | 4×3 | 45.48 |
| MAE-ST [28] | 86.8 | 97.2 | 7×3 | 25.05 |
| VideoMAE [90] | 86.6 | 97.1 | 5×3 | 17.88 |
| VideoMAE (320p) [90] | 87.4 | 97.6 | 4×3 | 88.76 |
| VideoMAEV2-H | 88.6 | 97.9 | 5×3 | 17.88 |
| VideoMAE V2-g | 88.5 | 98.1 | 5×3 | 38.16 |
| VideoMAEV2-H (64×2882) | 89.8 | 98.3 | 4×3 | 153.34 |
| VideoMAEV2-g (64×2662) | 90.0 | 98.4 | 2×3 | 160.30 |
| 使用内部标注数据的方法 | ||||
| CoVeR (JFT-3B) [116] | 87.2 | - | 1×3 | - |
| MTV-H (WTS) [111] | 89.1 | 98.2 | 4×3 | 44.47 |
| MTV-H (WTS 2802) [111] | 89.9 | 98.3 | 4×3 | 73.57 |
Table 13. Comparison with the state-of-the-art methods on UCF101 and HMDB51. ‘V’ refers to visual, ‘A’ is audio, ‘T is text narration. “N/A” indicates the numbers are not available. Table 15. Results on the Kinetics-600 dataset. We report the performance of our pre-trained model with larger input resolution and more frames.
表 13. UCF101和HMDB51数据集上与前沿方法的对比。"V"表示视觉,"A"表示音频,"T"表示文本叙述。"N/A"表示数据不可用。
表 15. Kinetics-600数据集上的结果。我们报告了使用更大输入分辨率和更多帧数的预训练模型的性能。
| 方法 | Top 1 | Top 5 | Views | TFLOPs |
|---|---|---|---|---|
| SlowFastR101-NL[29] | 81.8 | 95.1 | 10×3 | 7.02 |
| TimeSformer-L[8] | 82.2 | 95.6 | 1×3 | 7.14 |
| MTV-B [111] | 83.6 | 96.1 | 4×3 | 4.79 |
| MViT-B [27] | 83.8 | 96.3 | 3×3 | 4.10 |
| ViViT-L FE [4] | 82.9 | 94.6 | 1×3 | 11.94 |
| MViTv2-B[56] | 85.5 | 97.2 | 1×5 | 1.03 |
| MViTv2-L(352p)[56] | 87.9 | 97.9 | 3×4 | 45.48 |
| MaskFeat [104] | 86.4 | 97.4 | 1×10 | 3.77 |
| MaskFeat (312p)[104] | 88.3 | 98.0 | 3×4 | 33.94 |
| VideoMAEV2-H | 88.3 | 98.1 | 5×3 | 17.88 |
| VideoMAEV2-g | 88.8 | 98.2 | 5×3 | 38.16 |
| VideoMAEV2-H (32×3842) | 89.6 | 98.4 | 4×3 | 184.24 |
| VideoMAEV2-g (64×2662) | 89.9 | 98.5 | 2×3 | 160.30 |
| Methods using in-house labeled data | ||||
| CoVeR (JFT-3B)[116] | 87.9 | 97.8 | 1×3 | |
| MTV-H (WTS) [111] | 89.6 | 98.3 | 4×3 | 44.47 |
| MTV-H(WTS 280?)[111] | 90.3 | 98.5 | 4×3 | 73.57 |
Table 16. Knowledge distilling setting.
表 16: 知识蒸馏设置
| Config | Value |
|---|---|
| optimizer | AdamW [68] |
| base learning rate weight decay | 1e-3 (K710), 5e-4 (SSv2) 0.05 |
| optimizer momentum batch size learning rate schedule warmup epoch | β1, β2 = 0.9, 0.999 [15] 1024 (K710), 512 (SSv2) cosine decay [67] 5 100 |
| epoch RandAug [21] mixup [118] | (0, 0.5) 0.8 |
| cutmix [114] drop path flip augmentation | 1.0 0.1 yes |
| augmentation dropout layer-wise lr decay [6] | MultiScaleCrop None 0.75 |
Table 17. The performance of distilled ViT-B models on the datasets of Kinetics 400, Kinetics 600, and Something-Something V2.
| 模型 | K400 | K600 | SSv2 |
|---|---|---|---|
| VideoMAE-B | 81.5 | N/A | 70.8 |
| VideoMAEV2-g | 88.5 | 88.8 | 77.0 |
| Distilled ViT-B | 87.1 | 87.4 | 75.0 |
表 17: 蒸馏版 ViT-B 模型在 Kinetics 400、Kinetics 600 和 Something-Something V2 数据集上的性能表现。
References
参考文献
Xiong, Davide Modolo, Ivan Marsic, Cees G. M. Snoek, and Joseph Tighe. Tuber: Tubelet transformer for video action detection. In CVPR, pages 13588–13597, 2022. 7, 8 [121] Xiantan Zhu, Xuan Tao, Lu Shi, Shaoqi Chen, Rui Yin, Lan Ding, Yuya Obinata, Takuma Yamamoto, and Zhiming Tan. Multi-scale s patio temporal features for action localization. https://static.google user content.com/m edia/research.google.com/es//ava/2020/ Multi-scale S patio temporal Features fo r Action Localization.pdf, 2020. 8
Xiong, Davide Modolo, Ivan Marsic, Cees G. M. Snoek, 和 Joseph Tighe。Tuber: 视频动作检测的 Tubelet transformer。收录于 CVPR,页码 13588–13597,2022 年。7, 8
[121] Xiantan Zhu, Xuan Tao, Lu Shi, Shaoqi Chen, Rui Yin, Lan Ding, Yuya Obinata, Takuma Yamamoto, 和 Zhiming Tan。用于动作定位的多尺度时空特征。https://static.googleusercontent.com/media/research.google.com/es//ava/2020/Multi-scale_Spatio_temporal_Features_for_Action_Localization.pdf,2020 年。8