模型地址:https://modelscope.cn/models/Qwen/Qwen3-32B-AWQ
vLLM 版本:v0.8.5
启动命令:
vllm serve /models/qwen/Qwen3-32B-AWQ --port 7869
--served-model-name qwen3
--tensor-parallel-size 2
--gpu-memory-utilization 0.7
--max-model-len 16584
--max-num-batched-tokens 16584
--dtype auto
--enable-chunked-prefill
--trust-remote-code
--enable-auto-tool-choice
--tool-call-parser hermes
--enable-reasoning
--reasoning-parser deepseek_r1
--api-key sk-xxx
压测命令:
nohup python3 -u simple-bench-to-api.py
--url http://10.96.0.180:7869/v1
--model qwen3
--tokenizer_path /data/ai/models/qwen/Qwen3-32B-AWQ
--concurrencys 1,10,30,60,100
--prompt "Introduce the history of China"
--max_tokens 1024,8192,16384
--api_key sk-xxx
--duration_seconds 30 > result-qwen3-32b-awq.log 2>&1 &
压测结果
----- max_tokens=1024 压测结果汇总 -----

----- max_tokens=8192 压测结果汇总 -----
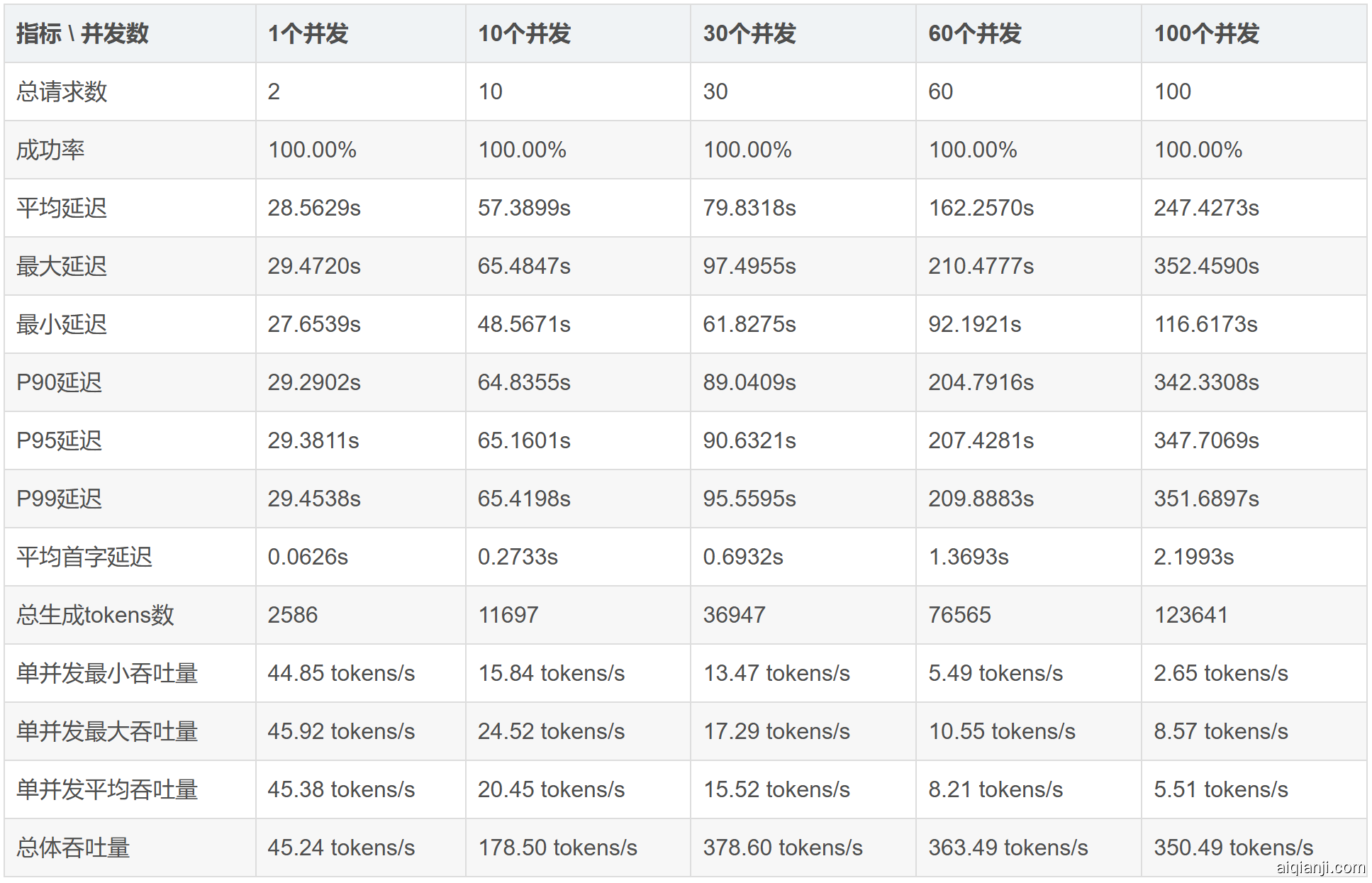
----- max_tokens=16384 压测结果汇总 -----

两卡 4090 私有部署下,足以满足日常几十人的并行使用。
阅读全文