Learning to summarize from human feedback
从人类反馈中学习摘要生成
Nisan Stiennon∗ Long Ouyang∗ Jeff Wu∗ Daniel M. Ziegler∗ Ryan Lowe∗
Nisan Stiennon∗ Long Ouyang∗ Jeff Wu∗ Daniel M. Ziegler∗ Ryan Lowe∗
Chelsea Voss∗ Alec Radford Dario Amodei Paul Christiano∗
Chelsea Voss∗ Alec Radford Dario Amodei Paul Christiano∗
OpenAI
OpenAI
Abstract
摘要
As language models become more powerful, training and evaluation are increasingly bottle necked by the data and metrics used for a particular task. For example, sum mari z ation models are often trained to predict human reference summaries and evaluated using ROUGE, but both of these metrics are rough proxies for what we really care about—summary quality. In this work, we show that it is possible to significantly improve summary quality by training a model to optimize for human preferences. We collect a large, high-quality dataset of human comparisons between summaries, train a model to predict the human-preferred summary, and use that model as a reward function to fine-tune a sum mari z ation policy using reinforcement learning. We apply our method to a version of the TL;DR dataset of Reddit posts [63] and find that our models significantly outperform both human reference summaries and much larger models fine-tuned with supervised learning alone. Our models also transfer to CNN/DM news articles [22], producing summaries nearly as good as the human reference without any news-specific fine-tuning.2 We conduct extensive analyses to understand our human feedback dataset and fine-tuned models.3 We establish that our reward model generalizes to new datasets, and that optimizing our reward model results in better summaries than optimizing ROUGE according to humans. We hope the evidence from our paper motivates machine learning researchers to pay closer attention to how their training loss affects the model behavior they actually want.
随着大语言模型日益强大,特定任务所使用的数据和评估指标逐渐成为训练与评估的瓶颈。例如,摘要模型通常被训练用于预测人工参考摘要,并使用ROUGE指标进行评估,但这两者都只是摘要质量的粗略替代指标。本研究证明,通过训练模型优化人类偏好能显著提升摘要质量。我们收集了大规模高质量的人类摘要对比数据集,训练出可预测人类偏好摘要的模型,并将其作为奖励函数,通过强化学习微调摘要策略。我们将该方法应用于Reddit帖子的TL;DR数据集[63],发现模型表现显著优于人工参考摘要及仅通过监督学习微调的更大规模模型。该模型还可迁移至CNN/DM新闻文章[22],在未经新闻领域针对性微调的情况下,生成与人工参考摘要质量相当的摘要。我们通过大量分析深入理解人类反馈数据集与微调模型,证实奖励模型具备跨数据集泛化能力,且优化奖励模型比优化ROUGE指标更能产生符合人类偏好的优质摘要。本研究希望促使机器学习研究者更关注训练损失与实际期望模型行为之间的关联。
1 Introduction
1 引言
Large-scale language model pre training has become increasingly prevalent for achieving high performance on a variety of natural language processing (NLP) tasks. When applying these models to a specific task, they are usually fine-tuned using supervised learning, often to maximize the log probability of a set of human demonstrations.
大规模语言模型预训练已日益普遍,用于在各种自然语言处理(NLP)任务中实现高性能。将这些模型应用于特定任务时,通常通过监督学习进行微调,以最大化一组人工演示的对数概率。
While this strategy has led to markedly improved performance, there is still a misalignment between this fine-tuning objective—maximizing the likelihood of human-written text—and what we care about—generating high-quality outputs as determined by humans. This misalignment has several causes: the maximum likelihood objective has no distinction between important errors (e.g. making up facts [41]) and unimportant errors (e.g. selecting the precise word from a set of synonyms); models are in centi viz ed to place probability mass on all human demonstrations, including those that are low-quality; and distribution al shift during sampling can degrade performance [56, 52]. Quality can often be improved significantly by non-uniform sampling strategies such as beam search [51], but these can lead to repetition and other undesirable artifacts [69, 23]. Optimizing for quality may be a principled approach to overcoming these problems.
虽然这一策略显著提升了性能,但在微调目标(最大化人类撰写文本的可能性)与我们真正关注的(生成人类认可的高质量输出)之间仍存在偏差。这种偏差源于多重因素:最大似然目标无法区分关键错误(例如虚构事实 [41])与非关键错误(例如从同义词集中选择特定词汇);模型被迫对所有人类示范(包括低质量样本)分配概率权重;采样过程中的分布偏移会降低性能 [56, 52]。虽然非均匀采样策略(如束搜索 [51])常能大幅提升质量,但可能导致重复生成等不良现象 [69, 23]。针对质量进行优化或许是解决这些问题的根本途径。
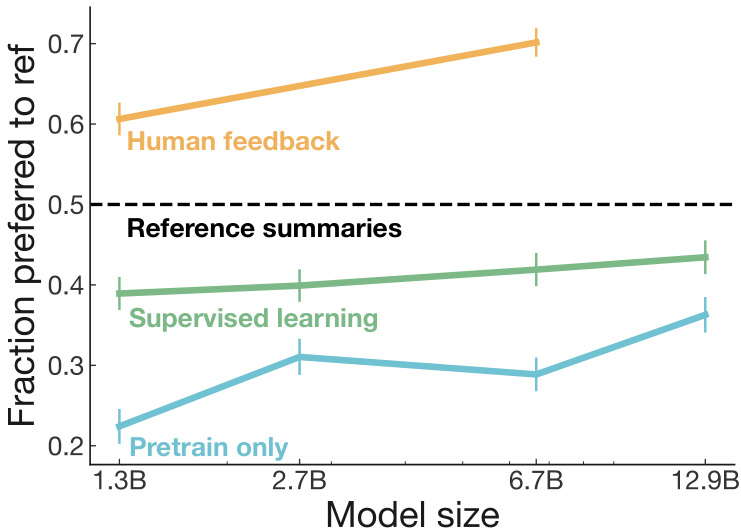
Figure 1: Fraction of the time humans prefer our models’ summaries over the human-generated reference summaries on the TL;DR dataset.4Since quality judgments involve an arbitrary decision about how to trade off summary length vs. coverage within the 24-48 token limit, we also provide length-controlled graphs in Appendix F; length differences explain about a third of the gap between feedback and supervised learning at 6.7B.
图 1: 在 TL;DR 数据集上,人类偏好我们的模型生成摘要而非人工参考摘要的时间占比。由于质量评估涉及在 24-48 Token 限制内权衡摘要长度与覆盖率的任意决策,我们还在附录 F 中提供了长度控制图表;在 67 亿参数规模下,长度差异解释了反馈学习与监督学习之间约三分之一的差距。
Our goal in this paper is to advance methods for training language models on objectives that more closely capture the behavior we care about. To make short-term progress towards this goal, we focus on abstract ive English text sum mari z ation, as it has a long history in the NLP community [16, 8, 54, 59, 50], and is a subjective task where we believe it is difficult to quantify summary quality without human judgments. Indeed, existing automatic metrics for evaluating summary quality, such as ROUGE [39], have received criticism for poor correlation with human judgments [55, 45, 6, 33].
本文的目标是改进语言模型的训练方法,使其目标函数更贴近我们关注的行为特性。为实现这一短期目标,我们聚焦于英文抽象文本摘要任务,该任务在自然语言处理领域具有悠久研究历史 [16, 8, 54, 59, 50],且作为主观性任务,我们认为若脱离人工评估则难以量化摘要质量。事实上,现有自动评估指标(如ROUGE [39])因与人工评判相关性差而备受质疑 [55, 45, 6, 33]。
We follow the works of [3, 73], who fine-tune language models from human feedback using reward learning [35]. We first collect a dataset of human preferences between pairs of summaries, then train a reward model (RM) via supervised learning to predict the human-preferred summary. Finally, we train a policy via reinforcement learning (RL) to maximize the score given by the RM; the policy generates a token of text at each ‘time step’, and is updated using the PPO algorithm [58] based on the RM ‘reward’ given to the entire generated summary. We can then gather more human data using samples from the resulting policy, and repeat the process. We follow the works of [48, 4] and use large pretrained GPT-3 models with as many as 6.7 billion parameters.
我们遵循[3, 73]的研究工作,通过奖励学习[35]从人类反馈中微调语言模型。首先收集人类对摘要对的偏好数据集,然后通过监督学习训练奖励模型(RM)以预测人类偏好的摘要。接着使用强化学习(RL)训练策略以最大化RM给出的评分;该策略在每个"时间步"生成一个文本token,并根据RM对整个生成摘要给出的"奖励"使用PPO算法[58]进行更新。之后可以从最终策略生成的样本中收集更多人类数据,并重复该过程。我们遵循[48, 4]的方法,使用参数规模高达67亿的大型预训练GPT-3模型。
Our main contributions are four-fold.
我们的主要贡献有四点。
(1) We show that training with human feedback significantly outperforms very strong baselines on English sum mari z ation. When applying our methods on a version of the Reddit TL;DR dataset [63], we train policies via human feedback that produce better summaries than much larger policies trained via supervised learning. Summaries from our human feedback models are preferred by our labelers to the original human demonstrations in the dataset (see Figure 1).
(1) 我们证明,在英语摘要任务中,采用人类反馈进行训练能显著超越非常强大的基线模型。当我们将该方法应用于Reddit TL;DR数据集[63]的某个版本时,通过人类反馈训练的策略产生的摘要质量,优于通过监督学习训练的规模大得多的策略。如图1所示,我们的标注人员更倾向于选择人类反馈模型生成的摘要,而非数据集中原始的人类示范摘要。
(2) We show human feedback models generalize much better to new domains than supervised models. Our Reddit-trained human feedback models also generate high-quality summaries of news articles on the CNN/DailyMail (CNN/DM) dataset without any news-specific fine-tuning, almost matching the quality of the dataset’s reference summaries. We perform several checks to ensure that these human preferences reflect a real quality difference: we consistently monitor agreement rates amongst labelers and researchers, and find researcher-labeler agreement rates are nearly as high as researcher-researcher agreement rates (see Section C.2), and we verify models are not merely optimizing simple metrics like length or amount of copying (see Appendices F and G.7).
(2) 我们发现人类反馈模型在新领域的泛化能力显著优于监督模型。在Reddit数据上训练的人类反馈模型无需针对新闻领域进行微调,就能在CNN/DailyMail (CNN/DM)数据集上生成高质量的新闻摘要,其质量几乎与数据集提供的参考摘要相当。为确保人类偏好反映真实的品质差异,我们进行了多项验证:持续监控标注员与研究人员之间的一致性,发现研究员-标注员一致率几乎与研究员-研究员一致率持平(详见C.2章节),同时证实模型并未简单优化文本长度或复制量等浅层指标(参见附录F和G.7)。
(3) We conduct extensive empirical analyses of our policy and reward model. We examine the impact of model and data size (Figure 6), study performance as we continue to optimize a given reward model (Section 4.3), and analyze reward model performance using synthetic and humanwritten perturbations of summaries (Section 4.3). We confirm that our reward model outperforms other metrics such as ROUGE at predicting human preferences, and that optimizing our reward model directly results in better summaries than optimizing ROUGE according to humans (Section 4.4).
(3) 我们对策略和奖励模型进行了广泛的实证分析。研究了模型和数据规模的影响 (图 6),持续优化给定奖励模型时的性能表现 (第4.3节),并通过摘要的人工合成扰动和人工编写扰动来分析奖励模型性能 (第4.3节)。我们证实,在预测人类偏好方面,我们的奖励模型优于ROUGE等其他指标,并且根据人类评估,直接优化我们的奖励模型比优化ROUGE能产生更好的摘要 (第4.4节)。
(4) We publicly release our human feedback dataset for further research. The dataset contains 64,832 summary comparisons on the TL;DR dataset, as well as our evaluation data on both TL;DR (comparisons and Likert scores) and CNN/DM (Likert scores).
(4) 我们公开发布了人类反馈数据集以供进一步研究。该数据集包含64,832条TL;DR数据集上的摘要对比结果,以及我们在TL;DR(对比数据和Likert评分)和CNN/DM(Likert评分)上的评估数据。
The methods we present in this paper are motivated in part by longer-term concerns about the misalignment of AI systems with what humans want them to do. When misaligned sum mari z ation models make up facts, their mistakes are fairly low-risk and easy to spot. However, as AI systems become more powerful and are given increasingly important tasks, the mistakes they make will likely become more subtle and safety-critical, making this an important area for further research.
本文提出的方法部分源于对AI系统与人类期望目标错配问题的长期关切。当错配的摘要(sum mari z ation)模型虚构事实时,其错误风险较低且易于识别。但随着AI系统日益强大并承担更重要的任务,其错误可能变得更加隐蔽且关乎安全,这使得该领域成为需要重点研究的课题。
2 Related work
2 相关工作
Most directly related to our work is previous work using human feedback to train sum mari z ation models with RL [3, 73]. Bohm et al. [3] learn a reward function from a dataset of human ratings of $2.5\mathrm{k}$ CNN/DM summaries, and train a policy whose summaries are preferred to a policy optimizing ROUGE. Our work is most similar to [73], who also train Transformer models [62] to optimize human feedback across a range of tasks, including sum mari z ation on the Reddit TL;DR and CNN/DM datasets. Unlike us, they train in an online manner and find the model highly extractive. They note that their labelers prefer extractive summaries and have low agreement rates with researchers. Compared to [73], we use significantly larger models, move to the batch setting for collecting human feedback, ensure high labeler-researcher agreement, and make some algorithmic modifications, such as separating the policy and value networks.
与我们工作最直接相关的是先前利用人类反馈通过强化学习训练摘要模型的研究 [3, 73]。Bohm 等人 [3] 从 $2.5\mathrm{k}$ 条 CNN/DM 摘要的人工评分数据集中学习奖励函数,并训练出一个优于优化 ROUGE 策略的摘要生成策略。我们的工作与 [73] 最为相似,他们也训练 Transformer 模型 [62] 来优化跨任务的人类反馈,包括 Reddit TL;DR 和 CNN/DM 数据集的摘要任务。与我们不同的是,他们采用在线训练方式,并发现模型高度倾向于抽取式摘要。他们指出标注者更偏好抽取式摘要,且与研究人员的一致性较低。相比 [73],我们使用了更大的模型,转向批量收集人类反馈的设置,确保标注者与研究人员的高一致性,并进行了算法改进,例如分离策略网络与价值网络。
Human feedback has also been used as a reward to train models in other domains such as dialogue [25, 68, 21], translation [32, 1], semantic parsing [34], story generation [72], review generation [7], and evidence extraction [46]. Our reward modeling approach was developed in prior work on learning to rank [40], which has been applied to ranking search results using either explicit feedback [2, 18] or implicit feedback in the form of click-through data [29, 30]. In a related line of research, human feedback has been used to train agents in simulated environments [10, 24]. There is also a rich literature on using RL to optimize automatic metrics for NLP tasks, such as ROUGE for sum mari z ation [50, 65, 45, 15, 19], BLEU for translation [50, 66, 1, 43], and other domains [61, 27, 26]. Finally, there has been extensive research on modifying architectures [22, 59] and pre-training procedures [70, 36, 49, 60, 53, 14] for improving sum mari z ation performance.
人类反馈也被用作奖励来训练其他领域的模型,例如对话 [25, 68, 21]、翻译 [32, 1]、语义解析 [34]、故事生成 [72]、评论生成 [7] 和证据提取 [46]。我们的奖励建模方法源于先前关于学习排序的研究 [40],该方法已应用于使用显式反馈 [2, 18] 或点击数据形式的隐式反馈 [29, 30] 来对搜索结果进行排序。在相关的研究中,人类反馈被用于训练模拟环境中的智能体 [10, 24]。此外,还有大量文献探讨如何使用强化学习 (RL) 优化自然语言处理 (NLP) 任务的自动指标,例如用于摘要的 ROUGE [50, 65, 45, 15, 19]、用于翻译的 BLEU [50, 66, 1, 43] 以及其他领域 [61, 27, 26]。最后,关于改进摘要性能的架构调整 [22, 59] 和预训练流程优化 [70, 36, 49, 60, 53, 14] 也有广泛研究。
3 Method and experiment details
3 方法与实验细节
3.1 High-level methodology
3.1 高层次方法论
Our approach is similar to the one outlined in [73], adapted to the batch setting. We start with an initial policy that is fine-tuned via supervised learning on the desired dataset (in our case, the Reddit TL;DR sum mari z ation dataset). The process (illustrated in Figure 2) then consists of three steps that can be repeated iterative ly.
我们的方法类似于[73]中概述的方案,并针对批量设置进行了调整。我们从一个通过监督学习在目标数据集(本研究中为Reddit TL;DR摘要数据集)上微调的初始策略开始。该过程(如图2所示)包含三个可迭代重复的步骤。
Step 1: Collect samples from existing policies and send comparisons to humans. For each Reddit post, we sample summaries from several sources including the current policy, initial policy, original reference summaries and various baselines. We send a batch of pairs of summaries to our human evaluators, who are tasked with selecting the best summary of a given Reddit post.
步骤1:从现有策略中收集样本并发送比较结果给人类评估者。针对每篇Reddit帖子,我们从多个来源采样摘要样本,包括当前策略、初始策略、原始参考摘要以及各种基线模型。我们将成对的摘要批次发送给人类评估员,其任务是从给定Reddit帖子中选择最佳摘要。
Step 2: Learn a reward model from human comparisons. Given a post and a candidate summary, we train a reward model to predict the log odds that this summary is the better one, as judged by our labelers.
步骤2:从人类比较中学习奖励模型。给定一篇帖子和候选摘要,我们训练一个奖励模型来预测该摘要被标注者判定为更优的对数几率。
Step 3: Optimize a policy against the reward model. We treat the logit output of the reward model as a reward that we optimize using reinforcement learning, specifically with the PPO algorithm [58].
第3步:针对奖励模型优化策略。我们将奖励模型的logit输出视为奖励,并使用强化学习(特别是PPO算法[58])进行优化。
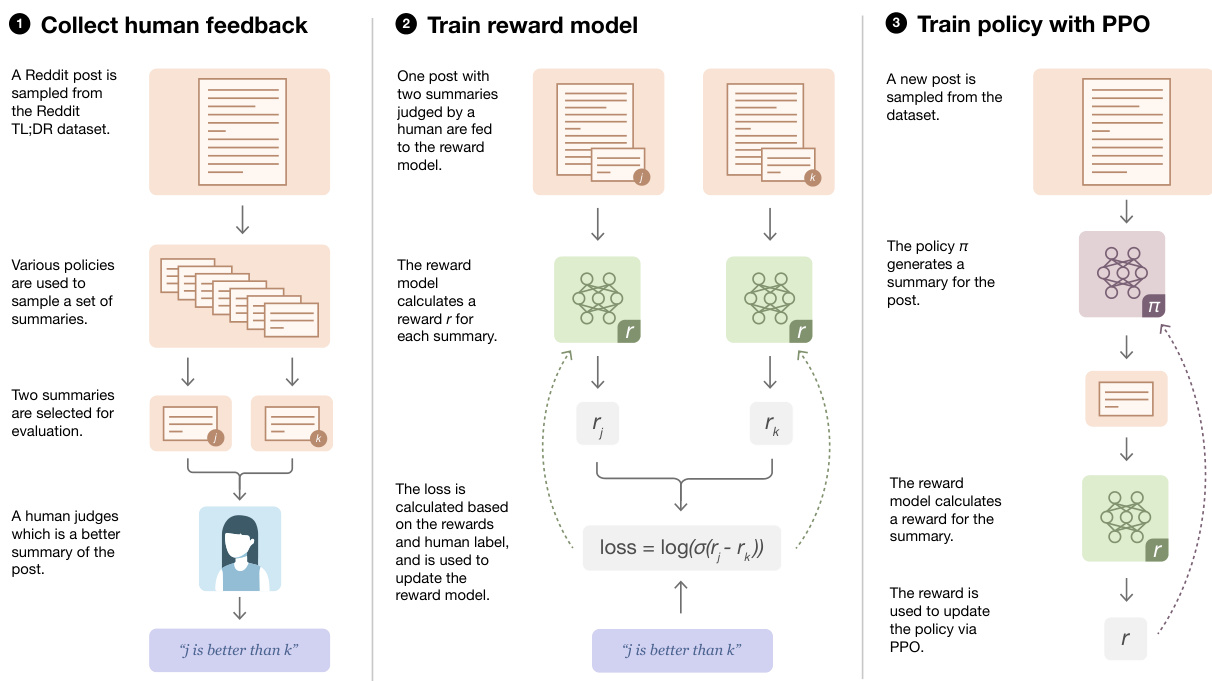
Figure 2: Diagram of our human feedback, reward model training, and policy training procedure.
图 2: 我们的人类反馈、奖励模型训练和策略训练流程示意图。
We provide a more thorough description of our procedure, including details of the reward model and policy training and our quality control process, in the following sections. In practice, rather than precisely iterating this sequence of three steps, we updated our data collection and training procedures over the course of the project while accumulating labels (see Appendix C.6 for details).
我们将在以下章节中更详细地描述流程,包括奖励模型和策略训练的细节以及质量控制流程。实际上,我们并未严格迭代这三个步骤,而是在项目过程中不断更新数据收集和训练方法,同时积累标注数据 (详见附录 C.6)。
3.2 Datasets and task
3.2 数据集与任务
Datasets. We use the TL;DR sum mari z ation dataset [63], which contains ${\sim}3$ million posts from reddit.com across a variety of topics (subreddits), as well summaries of the posts written by the original poster (TL;DRs). We additionally filter this dataset (see Appendix A) to ensure quality, including using a whitelist of subreddits that are understandable to the general population. Crucially, we also filter to include only posts where the human-written summaries contain between 24 and 48 tokens, to minimize the potential effect of summary length on quality (see Section 4.1 and Appendix F). Our final filtered dataset contains 123,169 posts, and we hold out ${\sim}5%$ as a validation set. For the remainder of this paper, we refer to this dataset simply as TL;DR.
数据集。我们使用TL;DR摘要数据集[63],该数据集包含来自reddit.com约300万篇涵盖各类主题(subreddits)的帖子,以及由发帖者撰写的帖子摘要(TL;DRs)。为确保数据质量,我们对该数据集进行了额外过滤(见附录A),包括采用大众可理解的subreddits白名单。关键的是,我们还筛选出仅包含24至48个token的人工撰写摘要的帖子,以最小化摘要长度对质量评价的潜在影响(见第4.1节和附录F)。最终过滤后的数据集包含123,169篇帖子,并保留约5%作为验证集。在下文中,我们将该数据集简称为TL;DR。
We chose the TL;DR dataset over the more commonly used CNN/DM dataset primarily because very strong performance can be attained on CNN/DM with simple extractive baselines. We find in Section 4.2 that our labelers prefer lead-3 over the CNN/DM reference summaries,5 and that the supervised T5 model [49] with low-temperature sampling already surpasses the reference summary quality, while copying extensively from the article. On the other hand, simple extractive baselines perform poorly on TL;DR in our human evaluations (see Appendix G.2). Instead of training on CNN/DM, we study the transfer performance of our human feedback models to CNN/DM after being trained to summarize Reddit posts.
我们选择TL;DR数据集而非更常用的CNN/DM数据集,主要是因为简单抽取式基线方法在CNN/DM上就能取得非常强劲的表现。在第4.2节中发现,标注人员更青睐lead-3而非CNN/DM参考摘要[5],且采用低温采样的监督式T5模型[49]已超越参考摘要质量(尽管大量复制原文内容)。相比之下,简单抽取式基线在TL;DR的人类评估中表现欠佳(见附录G.2)。我们转而研究人类反馈模型在训练Reddit帖子摘要任务后向CNN/DM的迁移性能。
Task. We define our ground-truth task as producing a model that generates summaries fewer than 48 tokens long that are as good as possible, according to our judgments. We judge summary quality by how faithfully the summary conveys the original post to a reader who can only read the summary and not the post (see Appendix C.5 for further discussion of criteria). Since we have limited capacity to do comparisons, we hire labelers to do the comparisons for us. We rely on detailed procedures to ensure high agreement between labelers and us on the task, which we describe in the next section.
任务。我们将真实任务定义为:根据我们的判断,生成一个能输出少于48个token且质量尽可能高的摘要的模型。我们通过摘要向只能阅读摘要而无法查看原文的读者传达原文信息的忠实程度来评判摘要质量(具体评判标准详见附录C.5)。由于人工对比能力有限,我们聘请标注员进行对比工作。通过下一节描述的详细流程,确保标注员与我们在此任务上保持高度一致。
Hey Reddit! I (20M) would like some tips, because I have my first ever date tomorrow (although I’ve had a gf for 3 years, but no actual dating happened), and we’re going to the beach.
嘿,Reddit!我(20岁男)想寻求些建议,因为明天将迎来人生第一次约会(虽然有过一段3年的恋爱关系,但从未正式约会过),我们准备去海滩。
I met this girl, we have mutual friends, at a festival a few days ago. We didn’t kiss, but we talked, held hands, danced a bit. I asked her to go on a date with me, which was super hard as it is the first time I’ve asked this to anybody. What I mean to say is, it’s not like a standard *first* date because we already spent some time together.
几天前在一个音乐节上,我遇到了这个女孩,我们有共同的朋友。我们没有接吻,但聊了天,牵了手,跳了会儿舞。我鼓起勇气约她出去约会——这是我第一次主动邀约别人,真的特别难开口。我想说的是,这不算标准的*初次*约会,毕竟我们已经相处过一段时间了。
I’m really nervous and excited. I’m going to pick her up tomorrow, we’re cycling to the beach which will take 30 minutes, and then what? I’m a bit scared. Should I bring something (the weather, although no rain and sunny, is not super so no swimming), should we do something. I’d like all the tips I can get. Thanks!
我既紧张又兴奋。明天要去接她,我们要骑30分钟自行车去海滩,然后呢?我有点害怕。该带些什么吗(虽然天气晴朗无雨,但不算特别热所以不能游泳),该做些什么活动吗?希望能得到各种建议。谢谢!
| HumanwrittenreferenceTL;DR Firstdate after3yearsinarelation- ship,going to the beach,terrified. What to bring with me, what to do? | 6.7Bsupervisedmodel Going on a date with a girl I met a few days ago, going to the beach. What should I bring,what should | 6.7Bhumanfeedbackmodel Goingonmy firsteverdatetomor- row,cycling to the beach. Would likesome tipsonwhattodoand |
Table 1: Example of post and samples on the TL;DR dataset, chosen to be particularly short. For random samples (along with posts), see Appendix H and our website.
表 1: TL;DR 数据集中帖子与样本的示例(特意选取了较短的样本)。随机样本(含对应帖子)详见附录 H 和我们的网站。
3.3 Collecting human feedback
3.3 收集人类反馈
Previous work on fine-tuning language models from human feedback [73] reported “a mismatch between the notion of quality we wanted our model to learn, and what the humans labelers actually evaluated”, leading to model-generated summaries that were high-quality according to the labelers, but fairly low-quality according to the researchers.
基于人类反馈微调语言模型的先前研究[73]报告称"我们期望模型学习到的质量概念与人类标注者实际评估的标准存在偏差",导致模型生成的摘要虽然被标注者评为高质量,但研究人员认为其质量较低。
Compared to [73], we implement two changes to improve human data quality. First, we transition entirely to the offline setting, where we alternate between sending large batches of comparison data6 to our human labelers and re-training our models on the cumulative collected data. Second, we maintain a hands-on relationship with labelers:7 we on-board them with detailed instructions, answer their questions in a shared chat room, and provide regular feedback on their performance. We train all labelers to ensure high agreement with our judgments, and continuously monitor labeler-researcher agreement over the course of the project. See Appendix C.1 and C.5 for details.
与[73]相比,我们实施了两项改进以提升人工标注数据质量。首先,我们完全转向离线设置,交替执行以下操作:向标注人员发送大批量对比数据6,并在累积收集的数据上重新训练模型。其次,我们与标注人员保持紧密协作:7通过详细指导进行入职培训,在共享聊天室解答问题,并定期提供工作表现反馈。我们培训所有标注人员以确保其判断与研究人员高度一致,并在项目全程持续监控标注者与研究人员的判断一致性。详见附录C.1和C.5。
As a result of our procedure, we obtained high labeler-researcher agreement: on a subset of comparison tasks, labelers agree with researchers $77%\pm2%$ of the time, while researchers agree with each other $73%\pm4%$ of the time. We provide more analysis of our human data quality in Appendix C.2.
通过我们的流程,我们获得了较高的标注者与研究者一致性:在部分对比任务子集中,标注者与研究者的意见一致率为$77%\pm2%$,而研究者之间的相互一致率为$73%\pm4%$。更多关于人工数据质量的分析详见附录C.2。
3.4 Models
3.4 模型
All of our models are Transformer decoders [62] in the style of GPT-3 [47, 4]. We conduct our human feedback experiments on models with 1.3 billion (1.3B) and 6.7 billion (6.7B) parameters.
我们的所有模型都采用GPT-3 [47, 4]风格的Transformer解码器架构[62]。我们在13亿(1.3B)和67亿(6.7B)参数规模的模型上进行了人类反馈实验。
Pretrained models. Similarly to [12, 47], we start with models pretrained to auto regressive ly predict the next token in a large text corpus. As in [48, 4], we use these models as ‘zero-shot’ baselines by padding the context with examples of high-quality summaries from the dataset. We provide details on pre training in Appendix B, and on our zero-shot procedure in Appendix B.2.
预训练模型。与[12, 47]类似,我们采用基于大型文本语料进行自回归(autoregressive)下一token预测的预训练模型作为起点。如[48, 4]所述,我们通过用数据集中高质量摘要示例填充上下文的方式,将这些模型作为"零样本(zero-shot)"基线使用。预训练细节见附录B,零样本流程详见附录B.2。
Supervised baselines. We next fine-tune these models via supervised learning to predict summaries from our filtered TL;DR dataset (see Appendix B for details). We use these supervised models to sample initial summaries for collecting comparisons, to initialize our policy and reward models, and as baselines for evaluation. In our final human evaluations, we use $\mathrm{T}{=}0$ to sample from all models, as we found it performed better than higher temperatures or nucleus sampling (see Appendix B.1).
监督基线。我们随后通过监督学习对这些模型进行微调,以根据过滤后的TL;DR数据集预测摘要(详见附录B)。这些监督模型用于采样初始摘要以收集比较数据、初始化策略和奖励模型,并作为评估基线。在最终的人类评估中,我们使用$\mathrm{T}{=}0$对所有模型进行采样,因为发现其表现优于更高温度值或核采样(参见附录B.1)。
To validate that our supervised models are indeed strong baselines for comparison, we run our supervised fine-tuning procedure with our 6.7B model on the CNN/DM dataset, and find that we achieve slightly better ROUGE scores than SOTA models [71] from mid-2019 (see Appendix G.4).
为了验证我们的监督模型确实是比较的强基线,我们在CNN/DM数据集上使用6.7B模型运行监督微调流程,发现其ROUGE分数略优于2019年中期的SOTA模型[71] (详见附录G.4)。
Reward models. To train our reward models, we start from a supervised baseline, as described above, then add a randomly initialized linear head that outputs a scalar value. We train this model to predict which summary $y\dot{\in{y_{0},y_{1}}}$ is better as judged by a human, given a post $x$ . If the summary preferred by the human is $y_{i}$ , we can write the RM loss as:
奖励模型。为了训练我们的奖励模型,我们从上述监督基线开始,然后添加一个随机初始化的线性头,输出标量值。我们训练该模型预测在给定帖子$x$的情况下,人类认为哪个摘要$y\dot{\in{y_{0},y_{1}}}$更好。如果人类偏好的摘要是$y_{i}$,我们可以将奖励模型损失函数表示为:
$$
\begin{array}{r}{\mathrm{loss}(r_{\theta})=-E_{(x,y_{0},y_{1},i)\sim D}[\mathrm{log}(\sigma(r_{\theta}(x,y_{i})-r_{\theta}(x,y_{1-i})))]}\end{array}
$$
$$
\begin{array}{r}{\mathrm{loss}(r_{\theta})=-E_{(x,y_{0},y_{1},i)\sim D}[\mathrm{log}(\sigma(r_{\theta}(x,y_{i})-r_{\theta}(x,y_{1-i})))]}\end{array}
$$
where $r_{\theta}(x,y)$ is the scalar output of the reward model for post $x$ and summary $y$ with parameters $\theta$ and $D$ is the dataset of human judgments. At the end of training, we normalize the reward model outputs such that the reference summaries from our dataset achieve a mean score of 0.
其中 $r_{\theta}(x,y)$ 是奖励模型针对帖子 $x$ 和摘要 $y$ 的标量输出(参数为 $\theta$),$D$ 是人工评判数据集。训练结束时,我们对奖励模型输出进行归一化,使数据集中参考摘要的平均得分为0。
Human feedback policies. We want to use the reward model trained above to train a policy that generates higher-quality outputs as judged by humans. We primarily do this using reinforcement learning, by treating the output of the reward model as a reward for the entire summary that we maximize with the PPO algorithm [58], where each time step is a BPE token.8 We initialize our ppe ol nia c lyi zteos bteh et hKe Lm doidveelr gfienne-cteu nbeetd woene nR tehded ilte aTrLn;eDd RR. LI mp polo irc tay $\pi_{\phi}^{\bar{\mathrm{RL}}}$ wwei tihn cplaurdaem ae tteerrs $\phi$ i na nthd et hriesw oarridg itnhaalt supervised model $\pi^{\mathrm{SFT}}$ , as previously done in [25]. The full reward $R$ can be written as:
人类反馈策略。我们希望利用上述训练得到的奖励模型来训练一个策略,使其生成人类评判下更高质量的输出。主要通过强化学习实现,将奖励模型的输出视为整个摘要的奖励,并使用PPO算法[58]进行最大化,其中每个时间步对应一个BPE token。我们使用KL散度约束初始化策略$\pi_{\phi}^{\bar{\mathrm{RL}}}$的参数$\phi$,使其与原始监督模型$\pi^{\mathrm{SFT}}$保持一致,如[25]所述。完整奖励$R$可表示为:
$$
R(x,y)=r_{\theta}(x,y)-\beta\log[\pi_{\phi}^{\mathrm{RL}}(y|x)/\pi^{\mathrm{SFT}}(y|x)]
$$
$$
R(x,y)=r_{\theta}(x,y)-\beta\log[\pi_{\phi}^{\mathrm{RL}}(y|x)/\pi^{\mathrm{SFT}}(y|x)]
$$
This KL term serves two purposes. First, it acts as an entropy bonus, encouraging the policy to explore and deterring it from collapsing to a single mode. Second, it ensures the policy doesn’t learn to produce outputs that are too different from those that the reward model has seen during training.
这个KL项有两个作用。首先,它作为熵奖励,鼓励策略进行探索并防止其坍缩到单一模式。其次,它确保策略不会学习生成与奖励模型在训练期间见过的输出差异过大的结果。
For the PPO value function, we use a Transformer with completely separate parameters from the policy. This prevents updates to the value function from partially destroying the pretrained policy early in training (see ablation in Appendix G.1). We initialize the value function to the parameters of the reward model. In our experiments, the reward model, policy, and value function are the same size.
对于PPO价值函数,我们使用了一个与策略参数完全独立的Transformer。这样可以防止在训练初期更新价值函数时部分破坏预训练策略(消融实验见附录G.1)。我们将价值函数初始化为奖励模型的参数。在我们的实验中,奖励模型、策略和价值函数的大小相同。
4 Results
4 结果
4.1 Summarizing Reddit posts from human feedback
4.1 基于人类反馈的Reddit帖子摘要
Policies trained with human feedback are preferred to much larger supervised policies. Our main results evaluating our human feedback policies on TL;DR are shown in Figure 1. We measure policy quality as the percentage of summaries generated by that policy that humans prefer over the reference summaries in the dataset. Our policies trained with human feedback significantly outperform our supervised baselines on this metric, with our $1.3\mathrm{B}$ human feedback model significantly outperforming a supervised model $10\times$ its size $61%$ versus $43%$ raw preference score against reference summaries). Our 6.7B model in turn significantly outperforms our 1.3B model, suggesting that training with human feedback also benefits from scale. Additionally, both of our human feedback models are judged by humans to be superior to the human demonstrations used in the dataset.
经过人类反馈训练的模型性能显著优于规模大得多的监督学习模型。我们在TL;DR任务上评估人类反馈模型的主要结果如图1所示。我们通过模型生成的摘要被人类选为优于数据集参考摘要的百分比来衡量模型质量。采用人类反馈训练的模型在这一指标上显著超越监督学习基线模型,其中13亿参数的人类反馈模型以61%的偏好得分显著超越规模大10倍的监督学习模型(43%原始偏好得分)。67亿参数模型又显著优于13亿参数模型,表明人类反馈训练同样受益于规模效应。值得注意的是,两个人类反馈模型生成的内容都被评估者认为优于数据集中的人类参考摘要。
Controlling for summary length. When judging summary quality, summary length is a confounding factor. The target length of a summary is implicitly part of the sum mari z ation task; depending on the desired trade-off between conciseness and coverage, a shorter or longer summary might be better. Since our models learned to generate longer summaries, length could account for much of our quality improvements. We find that after controlling for length (Appendix F), the preference of our human feedback models vs. reference summaries drops by ${\sim}5%$ ; even so, our 6.7B model summaries are still preferred to the reference summaries ${\sim}65%$ of the time.
控制摘要长度。在评判摘要质量时,摘要长度是一个混杂因素。摘要的目标长度隐含着摘要任务的要求;根据对简洁性和覆盖率的权衡需求,较短或较长的摘要可能更优。由于我们的模型学会了生成长度更长的摘要,长度因素可能解释了大部分质量提升。我们发现,在控制长度后(附录F),人类反馈模型相对于参考摘要的偏好度下降了约5%;即便如此,我们的67亿参数模型生成的摘要仍有约65%的概率优于参考摘要。
How do our policies improve over the baselines? To better understand the quality of our models’ summaries compared to the reference summaries and those of our supervised baselines, we conduct an additional analysis where human labelers assess summary quality across four dimensions (or “axes”) using a 7-point Likert scale [38]. Labelers rated summaries for coverage (how much important information from the original post is covered), accuracy (to what degree the statements in the summary are stated in the post), coherence (how easy the summary is to read on its own), and overall quality.
我们的策略相比基线有哪些改进?为了更好地理解模型生成的摘要与参考摘要及监督基线摘要的质量差异,我们开展了额外的人工评估实验。标注人员采用7级李克特量表[38],从四个维度(或称"评估轴")对摘要质量进行评分:覆盖度(摘要包含原帖重要信息的完整程度)、准确性(摘要陈述与原文内容的一致程度)、连贯性(摘要独立阅读的流畅程度)以及整体质量。
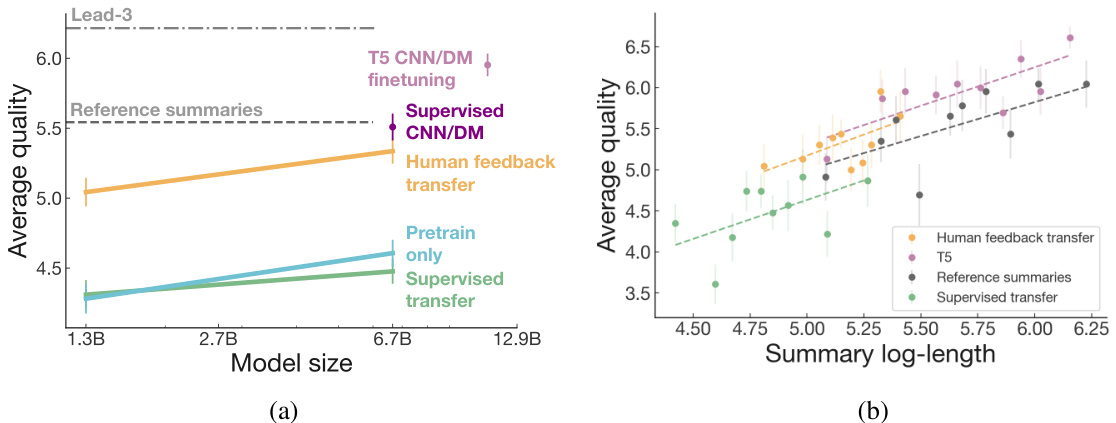
Figure 4: Transfer results on CNN/DM. (a) Overall summary quality on CNN/DM as a function of model size. Full results across axes shown in Appendix G.2. (b) Overall scores vs. length for the 6.7B TL;DR supervised baseline, the 6.7B TL;DR human feedback model, and T5 fine-tuned on CNN/DM summaries. At similar summary lengths, our 6.7B TL;DR human feedback model nearly matches T5 despite never being trained to summarize news articles.
图 4: CNN/DM数据集上的迁移结果。(a) 模型规模与CNN/DM总体摘要质量的关系。完整多维度结果见附录G.2。(b) 6.7B参数的TL;DR监督基线模型、6.7B参数的TL;DR人类反馈模型及基于CNN/DM摘要微调的T5模型在摘要长度与总体得分上的对比。在相近摘要长度下,我们的6.7B TL;DR人类反馈模型虽未接受过新闻文章摘要训练,其表现仍接近T5模型。
The results (Figure 3) indicate that our human feedback models outperform the supervised baselines across every dimension of quality, but particularly coverage. Although our human labelers had a high bar for giving perfect overall scores, summaries from our 6.7B PPO model achieve a 7/7 overall score $45%$ of the time (compared to $20%$ and $23%$ for the 6.7B supervised baseline and reference summaries, respectively).
结果(图 3)表明,我们基于人类反馈的模型在质量各个维度上都优于监督基线,尤其在覆盖度方面表现突出。尽管我们的人类标注员对给出完美总体评分设置了很高标准,但6.7B PPO模型生成的摘要仍有45%的概率获得7/7的满分(相比之下,6.7B监督基线和参考摘要的满分比例分别为20%和23%)。
4.2 Transfer to summarizing news articles
4.2 新闻文章摘要迁移
Our human feedback models can also generate excellent summaries of CNN/DM news articles without any further training (Figure 4). Our human feedback models significantly outperform models trained via supervised learning on TL;DR and models trained only on pre training corpora.
我们的人类反馈模型无需额外训练即可生成CNN/DM新闻文章的优质摘要(图4)。在TL;DR数据集上,人类反馈模型显著优于监督学习训练的模型及仅使用预训练语料的模型。
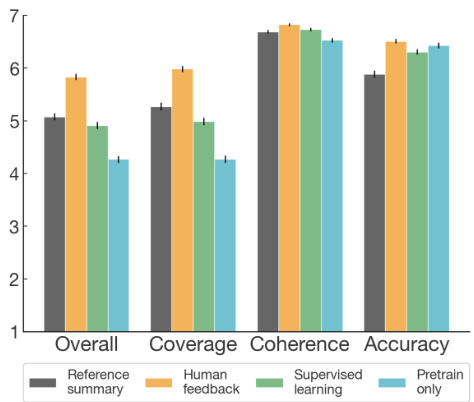
Figure 3: Evaluations of four axes of summary quality on the TL;DR dataset.
图 3: TL;DR 数据集上摘要质量四个维度的评估结果。
In fact, our 6.7B human feedback model performs almost as well as a 6.7B model that was fine-tuned on the CNN/DM reference summaries, despite generating much shorter summaries.
事实上,我们的67亿参数人类反馈模型表现几乎与基于CNN/DM参考摘要微调的67亿参数模型相当,尽管生成的摘要要短得多。
Since our human feedback models transferred to CNN/DM have little overlap in summary length distribution with models trained on CNN/DM, with about half as many tokens on average, they are difficult to compare directly. Thus our evaluations in Figure 4 use a 7-point Likert scale on four quality dimensions, as in Section 4.1 (see Appendix C.5 for labeler instructions). In Figure 4b we show the average overall score at different summary lengths, which suggests our human feedback models would perform even better if they generated longer summaries. Qualitatively, CNN/DM summaries from our human feedback models are consistently fluent and reasonable representations of the article; we show examples on our website and in Appendix H.
由于我们基于人类反馈训练的模型在CNN/DM数据集上生成的摘要长度分布与传统训练模型存在显著差异(平均Token数量仅为后者一半),因此难以直接比较。如图4所示,我们采用4.1节所述的7级李克特量表(具体标注指南见附录C.5)从四个质量维度进行评估。图4b展示了不同摘要长度下的平均综合得分,结果表明若人类反馈模型能生成更长摘要,其表现将进一步提升。定性分析显示,这些模型生成的CNN/DM摘要始终保持流畅性并能合理反映原文内容(示例见项目网站及附录H)。
4.3 Understanding the reward model
4.3 理解奖励模型
What happens as we optimize the reward model? Optimizing against our reward model is supposed to make our policy align with human preferences. But the reward model isn’t a perfect representation of our labeler preferences, as it has limited capacity and only sees a small amount of comparison data from a relatively narrow distribution of summaries. While we can hope our reward model generalizes to summaries unseen during training, it’s unclear how much one can optimize against the reward model until it starts giving useless evaluations.
优化奖励模型时会发生什么?优化奖励模型旨在使策略与人类偏好保持一致。但奖励模型并不能完美代表标注者的偏好,因为它能力有限,且仅能看到来自相对狭窄摘要分布中的少量对比数据。虽然我们希望奖励模型能泛化到训练时未见的摘要,但尚不清楚在奖励模型开始给出无效评估之前,能对其进行多大程度的优化。
To answer this question, we created a range of policies optimized against an earlier version of our reward model, with varying degrees of optimization strength, and asked labelers to compare samples from them to the reference summaries. Figure 5 shows the results for PPO at a range of KL penalty coefficients $(\beta)$ . Under light optimization, the models improve (according to labelers). However, as we optimize further, true preferences fall off compared to the prediction, and eventually the reward model becomes anti-correlated with human preferences. Though this is clearly undesirable, we note that this over-optimization also happens with ROUGE (see [45] and Appendix G.3). Similar behavior has been observed in learned reward functions in the robotics domain [5].
为回答这一问题,我们制定了一系列针对早期奖励模型版本优化的策略,采用不同强度的优化级别,并让标注人员将其生成样本与参考摘要进行对比。图 5 展示了PPO算法在不同KL惩罚系数 $(\beta)$ 下的表现。轻度优化时,模型表现有所提升(基于标注者评估)。但随着优化程度加深,真实偏好开始偏离预测值,最终奖励模型与人类偏好呈现负相关。虽然这种现象显然不符合预期,但值得注意的是,ROUGE指标同样存在过度优化问题(参见[45]和附录G.3)。机器人学领域的学习型奖励函数也报告过类似现象[5]。
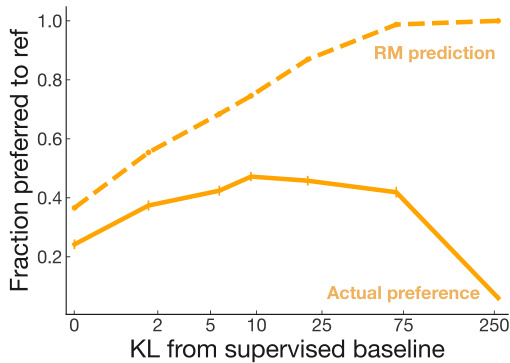
Figure 5: Preference scores versus degree of reward model optimization. Optimizing against the reward model initially improves summaries, but eventually overfits, giving worse summaries. This figure uses an earlier version of our reward model (see $\mathrm{rm}3$ in Appendix C.6). See Appendix H.2 for samples from the KL 250 model.
图 5: 偏好分数与奖励模型优化程度的关系。初期针对奖励模型优化会提升摘要质量,但最终会导致过拟合,生成更差的摘要。本图使用我们奖励模型的早期版本(参见附录C.6中的$\mathrm{rm}3$)。KL 250模型的样本请参阅附录H.2。
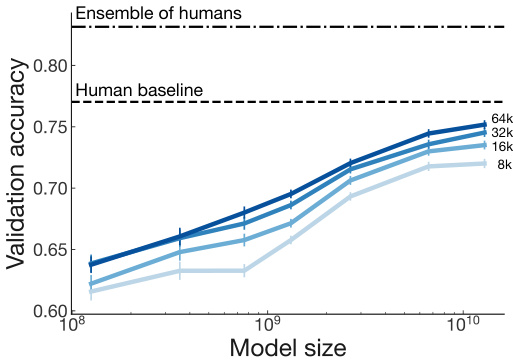
Figure 6: Reward model performance versus data size and model size. Doubling amount of training data leads to a ${\sim}1.1%$ increase in reward model validation accuracy, whereas doubling the model size leads to a ${\sim}1.8%$ increase. The 6.7B model trained on all data begins approaching the accuracy of a single human.
图 6: 奖励模型性能与数据规模和模型规模的关系。训练数据量翻倍可使奖励模型验证准确率提升约1.1%,而模型规模翻倍则带来约1.8%的提升。使用全部数据训练的6.7B参数模型开始接近单个人类的判断准确率。
How does reward modeling scale with increasing model and data size? We conduct an ablation to determine how data quantity and model size affect reward modeling performance. We train 7 reward models ranging from 160M to 13B parameters, on $8\mathrm{k\Omega}$ to 64k human comparisons from our dataset. We find that doubling the training data amount leads to a ${\sim}1.1%$ increase in the reward model validation set accuracy, whereas doubling the model size leads to a ${\sim}1.8%$ increase (Figure 6).
奖励建模如何随模型和数据规模扩大而扩展?我们通过消融实验来确定数据量和模型大小如何影响奖励建模性能。我们训练了7个参数规模从1.6亿到130亿不等的奖励模型,使用数据集中8kΩ至64k的人类比较数据。研究发现:训练数据量翻倍可使奖励模型验证集准确率提升约1.1%,而模型规模翻倍则可带来约1.8%的准确率提升 (图6)。
What has the reward model learned? We probe our reward model by evaluating it on several validation sets. We show the full results in Appendix G.6, and highlight them here. We find that our reward models generalize to evaluating CNN/DM summaries (Appendix G.7), agreeing with labeler preferences $62.4%$ and $66.5%$ of the time (for our 1.3B and $_{6.78}$ models, respectively). Our 6.7B reward model nearly matches the inter-labeler agreement value of $66.9%$ .
奖励模型学到了什么?我们通过在多个验证集上评估来探究奖励模型的表现。完整结果见附录G.6,此处重点展示:发现奖励模型能泛化至CNN/DM摘要评估任务(附录G.7),与标注者偏好的吻合度分别达62.4%和66.5%(对应13亿参数和6.78亿参数模型)。67亿参数的奖励模型几乎达到标注者间一致性水平66.9%。
We also find that our reward models are sensitive to small but semantically important details in the summary. We construct an additional validation set by having labelers make minimal edits to summaries to improve them. Our RMs prefer the edited summaries almost as often $79.4%$ for 1.3B and $82.8%$ for 6.7B) as a separate set of human evaluators $(84.1%)$ . Further, when comparing the reference summaries to perturbed summaries where the participants’ roles are reversed, our models reliably select the original summary $(92.9%$ of the time for 1.3B, $97.2%$ for 6.7B). However, our RMs are biased towards longer summaries: our 6.7B RM prefers improving edits that make the summary shorter only $62.6%$ of the time (vs. $76.4%$ for humans).
我们还发现,奖励模型对摘要中微小但语义重要的细节非常敏感。我们通过让标注者对摘要进行最小化编辑以改进它们,构建了一个额外的验证集。我们的奖励模型选择编辑后摘要的频率(1.3B模型为79.4%,6.7B模型为82.8%)几乎与另一组人类评估者(84.1%)相当。此外,当将参考摘要与参与者角色被反转的扰动摘要进行比较时,我们的模型能可靠地选择原始摘要(1.3B模型正确率为92.9%,6.7B模型为97.2%)。然而,我们的奖励模型存在对较长摘要的偏好:6.7B奖励模型仅在62.6%的情况下倾向于选择使摘要更短的改进编辑(而人类选择比例为76.4%)。
4.4 Analyzing automatic metrics for sum mari z ation
4.4 自动摘要指标的量化分析
Evaluation. We study how well various automatic metrics act as predictors for human preferences, and compare them to our RMs. Specifically, we examine ROUGE, summary length, amount of copying from the post,9 and log probability under our baseline supervised models. We present a full matrix of agreement rates between these metrics in Appendix G.7.
评估。我们研究了各种自动指标作为人类偏好预测器的表现,并将其与我们的奖励模型(RM)进行比较。具体而言,我们检验了ROUGE指标、摘要长度、从原文复制的比例[9]以及基线监督模型下的对数概率。附录G.7中提供了这些指标间一致率的完整矩阵。
We find that our learned reward models consistently outperform other metrics, even on the CNN/DM dataset on which it was never trained. We also find that ROUGE fails to track sample quality as our models improve. While ROUGE has ${\sim}57%$ agreement with labelers when comparing samples from our supervised baseline models, this drops to ${\sim}50%$ for samples from our human feedback model.
我们发现,即使是在从未训练过的CNN/DM数据集上,学习到的奖励模型也始终优于其他指标。同时发现,随着模型性能提升,ROUGE指标与样本质量的相关性逐渐减弱。当比较监督基线模型的样本时,ROUGE与标注者的一致性约为57%,而对于人类反馈模型的样本,这一数值降至约50%。
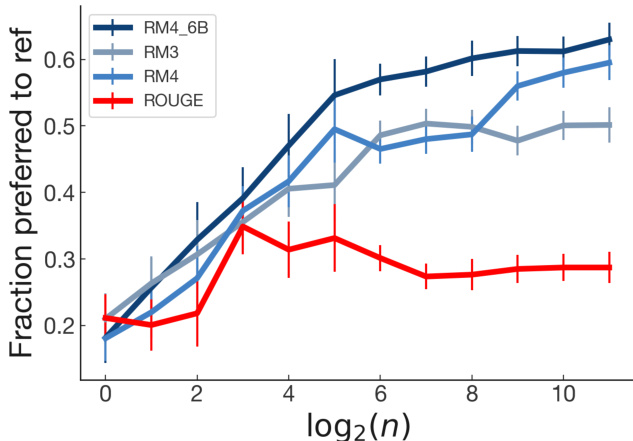
Figure 7: Summary quality as a function of metric optimized and amount of optimization, using best-of-N rejection sampling. We evaluate ROUGE, our main reward models, and an earlier iteration of the 1.3B model trained on approximately $75%$ as much data (see Table 11 for details). ROUGE appears to peak both sooner and at a substantially lower preference rate than all reward models. Details in Appendix G.3.
图 7: 基于优化指标和优化程度的摘要质量对比,采用最优N项拒绝采样法。我们评估了ROUGE指标、主奖励模型以及一个早期迭代的13亿参数模型(该模型训练数据量约为完整数据集的75%,详见表11)。ROUGE指标似乎比其他所有奖励模型更早达到峰值,且偏好率显著偏低。详见附录G.3。
Similarly, log probability agreement with humans drops to $\leq50%$ on comparisons between samples from our human feedback models, while our RMs still perform above chance $(62%)$ . Scaling up the size of the supervised model does not reliably improve log probability’s agreement with labelers.
同样,在我们的人类反馈模型样本间的比较中,对数概率与人类的一致性降至 $\leq50%$ ,而我们的奖励模型 (RM) 仍以高于随机水平 $(62%)$ 的表现运行。扩大监督模型的规模并不能稳定提升对数概率与标注者的一致性。
Optimization. In Figure 7, we show that optimizing ROUGE using a simple optimization scheme doesn’t consistently increase quality, as has been noted in [45]. Optimization against ROUGE peaks both sooner and at a substantially lower quality rate than optimization against our reward models.
优化。如图7所示,我们通过简单优化方案对ROUGE进行优化时,质量并未持续提升,这与[45]的研究结论一致。相比针对奖励模型的优化,针对ROUGE的优化不仅更早达到峰值,且最终质量水平显著偏低。
5 Discussion
5 讨论
Limitations. One limitation of our work is the time and cost required to produce our final models. Notably, fine-tuning our 6.7B model with RL required approximately 320 GPU-days. Our data collection procedure is also expensive compared to prior work — the training set took thousands of labeler hours and required significant researcher time to ensure quality. For this reason, we were unable to collect baselines such as an equivalent amount of high-quality human demonstrations for supervised baselines. See D for more discussion. We leave this ablation to future work. Nevertheless, we believe reward modeling is more likely to scale to tasks where it is extremely skill-intensive or time-consuming to provide good demonstrations.
局限性。我们工作的一个局限在于最终模型的训练时间和成本。特别是,使用强化学习微调6.7B参数模型需要约320个GPU日的计算量。与先前研究相比,我们的数据收集流程成本较高——训练集耗费了标注员数千小时,并需要研究人员投入大量时间确保质量。因此,我们未能收集基线数据(例如用于监督基线的等量高质量人类演示样本)。更多讨论参见附录D。我们将这部分消融实验留待未来研究。尽管如此,我们认为奖励建模方法更适用于那些需要极高技能或耗时极长才能提供优质演示的任务。
Future directions. The methods in this paper could be applied to any task where humans can compare samples, including dialogue, machine translation, question answering, speech synthesis, and music generation. We expect this method to be particularly important for generating long samples, where the distribution al shift and degeneracy of maximum likelihood samples can be problematic. It may be possible to improve sample efficiency by training to predict feedback across many tasks [42].
未来方向。本文的方法可应用于任何人类能比较样本的任务,包括对话、机器翻译、问答、语音合成和音乐生成。我们预计该方法对生成长样本尤为重要,因为最大似然样本的分布偏移和退化问题可能较为突出。通过训练模型跨多任务预测反馈[42],或许能提升样本效率。
We are particularly interested in scaling human feedback to tasks where humans can’t easily evaluate the quality of model outputs. In this setting, it is particularly challenging to identify whether an ML system is aligned with the human designer’s intentions. One approach is to train ML systems to help humans perform the evaluation task quickly and accurately [9].
我们特别关注如何将人类反馈扩展到人类难以评估模型输出质量的任务上。在此情境下,判断机器学习系统是否符合人类设计者的意图尤为困难。一种方法是训练机器学习系统来帮助人类快速准确地完成评估任务 [9]。
There is also a rich landscape of human feedback methods beyond binary comparisons that could be explored for training models [28, 17, 44, 64]. For example, we could solicit high-quality demonstrations from labelers, have labelers edit model outputs to make them better, or have labelers provide explanations for why they preferred one model output over another. All of this feedback could be leveraged as a signal to train more capable reward models and policies.
除了二元比较之外,还有丰富的人类反馈方法可用于训练模型 [28, 17, 44, 64]。例如,我们可以从标注者那里获取高质量的演示,让标注者编辑模型输出以使其更好,或者让标注者解释为什么他们更喜欢某个模型输出而非另一个。所有这些反馈都可以作为信号,用于训练更强大的奖励模型和策略。
Broader impacts. The techniques we explore in this paper are generic techniques that could be used in a wide variety of machine learning applications, for any task where it is feasible for humans to evaluate the quality of model outputs. Thus, the potential implications are quite broad.
广泛影响。我们在本文中探讨的技术是通用技术,可应用于各种机器学习场景,适用于任何人类能够评估模型输出质量的任务。因此,其潜在影响范围非常广泛。
Our research is primarily motivated by the potential positive effects of aligning machine learning algorithms with the designer’s preferences. Many machine learning applications optimize simple metrics which are only rough proxies for what the designer intends. This can lead to problems, such as Youtube recommendations promoting click-bait [11]. In the short term, improving techniques for learning from and optimizing human preferences directly may enable these applications to be more aligned with human well-being.
我们的研究主要源于将机器学习算法与设计者偏好对齐的潜在积极影响。许多机器学习应用优化的简单指标只是设计者意图的粗略替代,这可能导致问题,例如YouTube推荐推广点击诱饵内容[11]。短期内,改进直接学习和优化人类偏好的技术可能使这些应用更符合人类福祉。
In the long term, as machine learning systems become more capable it will likely become increasingly difficult to ensure that they are behaving safely: the mistakes they make might be more difficult to spot, and the consequences will be more severe. For instance, writing an inaccurate summary of a news article is both easy to notice (one simply has to read the original article) and has fairly low consequences. On the other hand, imitating human driving may be substantially less safe than driving to optimize human preferences. We believe that the techniques we explore in this paper are promising steps towards mitigating the risks from such capable systems, and better aligning them with what humans care about.
长远来看,随着机器学习系统能力不断增强,确保其行为安全性将变得越来越困难:它们所犯的错误可能更难被发现,且后果更为严重。例如,撰写一篇不准确的新闻摘要既容易察觉(只需阅读原文即可),造成的后果也相对较轻。而模仿人类驾驶的行为,可能远比根据人类偏好优化的驾驶方式更不安全。我们认为,本文探讨的技术是缓解此类强大系统风险、并使其更符合人类关切的有前景的探索方向。
Unfortunately, our techniques also enable malicious actors to more easily train models that cause societal harm. For instance, one could use human feedback to fine-tune a language model to be more persuasive and manipulate humans’ beliefs, or to induce dependence of humans on the technology, or to generate large amounts of toxic or hurtful content intended to harm specific individuals. Avoiding these outcomes is a significant challenge for which there are few obvious solutions.
遗憾的是,我们的技术也可能被恶意行为者利用,更轻松地训练出危害社会的模型。例如,有人可能利用人类反馈来微调语言模型,使其更具说服力并操纵人类信念,或诱导人类对技术产生依赖,或生成大量旨在伤害特定个体的有害内容。避免这些后果是一个重大挑战,目前几乎没有明确的解决方案。
Large-scale models trained with human feedback could have significant impacts on many groups. Thus, it is important to be careful about how we define the ‘good’ model behavior that human labelers will reinforce. Deciding what makes a good summary is fairly straightforward, but doing this for tasks with more complex objectives, where different humans might disagree on the correct model behavior, will require significant care. In these cases, it is likely not appropriate to use researcher labels as the ‘gold standard’; rather, individuals from groups impacted by the technology should be included in the process to define ‘good’ behavior, and hired as labelers to reinforce this behavior in the model.
经过人类反馈训练的大规模模型可能对许多群体产生重大影响。因此,我们必须谨慎定义人类标注员需要强化的"良好"模型行为。虽然确定优质摘要的标准相对明确,但对于目标更复杂的任务(不同人群可能对正确模型行为存在分歧时),需要格外审慎。在这些情况下,将研究者标注作为"黄金标准"可能并不合适,更应让受技术影响的群体参与定义"良好"行为,并雇佣他们作为标注员在模型中强化这些行为。
We chose to train on the Reddit TL;DR dataset because the sum mari z ation task is significantly more challenging than on CNN/DM. However, since the dataset consists of user-submitted posts with minimal moderation, they often contain content that is offensive or reflects harmful social biases. This means our models can generate biased or offensive summaries, as they have been trained to summarize such content. For this reason, we recommend that the potential harms of our models be thoroughly studied before deploying them in user-facing applications.
我们选择在Reddit TL;DR数据集上进行训练,因为其摘要任务比CNN/DM更具挑战性。然而,由于该数据集由用户提交且缺乏严格审核,常包含冒犯性内容或反映有害社会偏见。这意味着我们的模型可能生成带有偏见或冒犯性的摘要,因为它们被训练来总结此类内容。因此,我们建议在面向用户的应用部署前,需彻底研究模型可能带来的危害。
Finally, by improving the ability of machine learning algorithms to perform tasks that were previously only achievable by humans, we are increasing the likelihood of many jobs being automated, potentially leading to significant job loss. Without suitable policies targeted at mitigating the effects of large-scale unemployment, this could also lead to significant societal harm.
最后,通过提升机器学习算法执行那些原先仅能由人类完成的任务的能力,我们正在增加许多工作岗位被自动化的可能性,这可能导致大规模的失业。若缺乏针对缓解大规模失业影响的适当政策,还可能造成重大的社会危害。
Acknowledgements
致谢
We’d like to thank Beth Barnes for help with labeler hiring and general encouragement; Geoffrey Irving for guidance on earlier iterations of the project and inspiring conversations; Ben Mann, Tom Brown, Nick Ryder, and Melanie Subbiah for training and evaluating our pretrained models; Chris Hesse, Eric Sigler, Benjamin Chess, Christopher Berner, Clemens Winter, Mateusz Litwin, and many others for supporting us through computing infrastructure improvements and maintenance; Scott Gray for writing fast GPU kernels; Arvind Neel a kant an and Wojciech Kryscinski for discussions on how to present the work, experiment design, and what datasets to use; Shan Carter for help designing the main diagram; Douwe Kiela, Zach Lipton, and Alex Irpan for providing feedback on the paper; and Gretchen Krueger for co-writing the model card accompanying the paper.
我们要感谢Beth Barnes在标注员招聘和总体鼓励方面的帮助;Geoffrey Irving对项目早期迭代的指导和启发性讨论;Ben Mann、Tom Brown、Nick Ryder和Melanie Subbiah对我们预训练模型的训练和评估;Chris Hesse、Eric Sigler、Benjamin Chess、Christopher Berner、Clemens Winter、Mateusz Litwin以及许多其他人在计算基础设施改进和维护方面的支持;Scott Gray编写快速GPU内核;Arvind Neelakantan和Wojciech Kryscinski关于如何呈现工作、实验设计以及使用哪些数据集的讨论;Shan Carter协助设计主图;Douwe Kiela、Zach Lipton和Alex Irpan对论文提供的反馈;以及Gretchen Krueger共同撰写随论文发布的模型卡。
Finally, we’d like to thank all of our contractors for providing the data that was essential for training the models in this paper, including: Emill Jayson Caypuno, Rachelle Froyalde, Cyra Denura, Alex Malek, Isik Agil, Reshmi Patel, William Yap, Natalie Silver, Erol Akbaba, Jennifer Brillo, Alexandra
最后,我们要感谢所有为本论文模型训练提供关键数据的承包商,包括:Emill Jayson Caypuno、Rachelle Froyalde、Cyra Denura、Alex Malek、Isik Agil、Reshmi Patel、William Yap、Natalie Silver、Erol Akbaba、Jennifer Brillo、Alexandra
Uifalean, Morris Stuttard, Russell Bernandez, Tasmai Dave, Rachel Wallace, Jenny Fletcher, Jian Ouyang, Justin Dill, Maria Orzek, Megan N if fene g ger, William Sells, Emily Mariner, Andrew Seely, Lychelle Ignacio, Jelena Ostojic, Nhan Tran, Purev Batdelgar, Valentina Kezic, Michelle Wilkerson, Kelly Guerrero, Heather Scott, Sarah Mulligan, Gabriel Ricafrente, Kara Bell, Gabriel Perez, and Alfred Lee.
Uifalean、Morris Stuttard、Russell Bernandez、Tasmai Dave、Rachel Wallace、Jenny Fletcher、Jian Ouyang、Justin Dill、Maria Orzek、Megan Nif fene g ger、William Sells、Emily Mariner、Andrew Seely、Lychelle Ignacio、Jelena Ostojic、Nhan Tran、Purev Batdelgar、Valentina Kezic、Michelle Wilkerson、Kelly Guerrero、Heather Scott、Sarah Mulligan、Gabriel Ricafrente、Kara Bell、Gabriel Perez 和 Alfred Lee。
References
参考文献
Appendix
附录
Table of Contents
目录
H Samples 38
H 样本 38
A TL;DR dataset details
数据集详情摘要
Here, we discuss the pre-processing steps that we apply to the TL;DR dataset. We first remove all duplicate posts by checking the text body, finding that there are nearly 20,000 exact duplicates. We then re-parse the TL;DR carefully using a set of heuristics, and filter to use only top-level posts (rather than comments). We also filter out any post that is from a subreddit not in our ‘subreddit whitelist’ (see Table 2 for the distribution over subreddits), any post where the title starts with some variant of ‘Edit’ or ‘Update’,10 and posts that contain certain topics (such as graphic sex or suicide) using heuristics. Finally, to ensure the posts are short enough to fit into the context length of our models, we filter out any post whose body is longer than 512 tokens. This resulted in a set of 287,790 posts filtered by body but not summary, of which we hold out approximately $5%$ as a validation set. We used this set of posts for RL training since our RL procedure does not require reference summaries.
在此,我们讨论对TL;DR数据集应用的预处理步骤。首先通过检查正文内容移除所有重复帖子,发现存在近20,000条完全重复项。随后使用启发式规则重新解析TL;DR,并筛选仅保留顶层帖子(而非评论)。同时过滤掉来自非"subreddit白名单"版块的帖子(各版块分布见表2)、标题以"Edit"或"Update"变体开头的帖子,以及通过启发式规则识别出的特定主题内容(如极端色情或自杀)。最后为确保帖子长度适配模型上下文限制,筛除正文超过512个token的帖子。最终获得287,790条仅按正文过滤(未过滤摘要)的帖子,其中约$5%$留作验证集。由于强化学习训练无需参考摘要,我们将该帖子集用于RL训练。
We next perform additional filtering on the parsed reference summaries that we use for training our supervised baselines. Specifically, we remove summaries where the TL;DR starts with variants of ‘Edit’, ‘Update’, or ‘P.S.’, we heuristic ally remove summaries with certain levels of profanity, and we remove summaries that are less than 24 tokens or more than 48 tokens. As discussed in Section 4.1, since our RL models tend to generate summaries on the upper end of the allowed length limit, this length filtering ensures that there is enough length overlap between the RL summaries and reference summaries for us to perform a length-controlled analysis. Additionally, we found that summaries shorter than 16 tokens were usually of low quality. We later verified that the summaries we filtered out were lower quality according to our reward model — more than 0.5 nats worse on average (i.e. they are predicted to be $\exp(0.5)\approx1.6\$ times less likely to be preferred). Our final TL;DR dataset contains 123,169 posts including summaries, again with about $5%$ held out as a validation set. We use 1913 of these validation articles for model selection during development; the evaluations in this paper exclude these articles.
接下来我们对用于训练有监督基线的解析后参考摘要进行额外筛选。具体包括:删除以"Edit"、"Update"或"P.S."变体开头的摘要,采用启发式方法移除含特定程度粗俗内容的摘要,并过滤掉token数少于24或多于48的摘要。如第4.1节所述,由于我们的强化学习模型倾向于生成接近允许长度上限的摘要,这种长度筛选能确保强化学习摘要与参考摘要之间存在足够的长度重叠,以便进行长度控制分析。此外,我们发现少于16个token的摘要通常质量较低。后续验证表明,被过滤的摘要在奖励模型评估中质量确实更差——平均低0.5 nats以上(即被优选概率预测值低约1.6倍)。最终TL;DR数据集包含123,169篇含摘要的帖子,其中约5%留作验证集。我们使用其中1913篇验证文章进行开发阶段的模型选择,本文评估结果已排除这些文章。
Table 2: Number of posts in the training set of our filtered Reddit TL;DR dataset by subreddit.
| Subreddit | #posts | %ofdataset |
| relationships | 63324 | 54.25% |
| AskReddit | 15440 | 13.23% |
| relationship_advice | 8691 | 7.45% |
| tifu | 7685 | 6.58% |
| dating_advice | 2849 | 2.44% |
| personalfinance | 2312 | 1.98% |
| Advice | 2088 | 1.79% |
| legaladvice | 1997 | 1.71% |
| offmychest | 1582 | 1.36% |
| loseit | 1452 | 1.24% |
| jobs | 1084 | 0.93% |
| self | 1048 | 0.90% |
| BreakUps | 838 | 0.72% |
| askwomenadvice | 688 | 0.59% |
| dogs | 638 | 0.55% |
| running | 567 | 0.49% |
| pettyrevenge | 548 | 0.47% |
| needadvice | 528 | 0.45% |
| travel | 452 | 0.39% |
| Parenting | 435 | 0.37% |
| weddingplanning | 433 | 0.37% |
| Pets | 366 | 0.31% |
| Dogtraining | 362 | 0.31% |
| cats | 324 | 0.28% |
| AskDocs | 283 | 0.24% |
| college | 264 | 0.23% |
| GetMotivated | 169 | 0.14% |
| books | 161 | 0.14% |
| Cooking | 114 | 0.10% |
表 2: 经过筛选的Reddit TL;DR数据集中各版块的训练集帖子数量。
| Subreddit | #posts | %ofdataset |
|---|---|---|
| relationships | 63324 | 54.25% |
| AskReddit | 15440 | 13.23% |
| relationship_advice | 8691 | 7.45% |
| tifu | 7685 | 6.58% |
| dating_advice | 2849 | 2.44% |
| personalfinance | 2312 | 1.98% |
| Advice | 2088 | 1.79% |
| legaladvice | 1997 | 1.71% |
| offmychest | 1582 | 1.36% |
| loseit | 1452 | 1.24% |
| jobs | 1084 | 0.93% |
| self | 1048 | 0.90% |
| BreakUps | 838 | 0.72% |
| askwomenadvice | 688 | 0.59% |
| dogs | 638 | 0.55% |
| running | 567 | 0.49% |
| pettyrevenge | 548 | 0.47% |
| needadvice | 528 | 0.45% |
| travel | 452 | 0.39% |
| Parenting | 435 | 0.37% |
| weddingplanning | 433 | 0.37% |
| Pets | 366 | 0.31% |
| Dogtraining | 362 | 0.31% |
| cats | 324 | 0.28% |
| AskDocs | 283 | 0.24% |
| college | 264 | 0.23% |
| GetMotivated | 169 | 0.14% |
| books | 161 | 0.14% |
| Cooking | 114 | 0.10% |
Note that, from Table 2 we can see that about two thirds of our TL;DR dataset consists of posts relating to relationships or relationship advice, which is a fairly specific domain. This raises potential concerns about the generality of our models, though their strong transfer performance on CNN/DM news articles suggests they are not unreasonably specialized to relationship advice.
注意,从表2可以看出,我们的TL;DR数据集中约三分之二的帖子涉及人际关系或情感建议,这是一个相当特定的领域。这引发了关于模型泛化能力的潜在担忧,尽管它们在CNN/DM新闻文章上表现出的强大迁移性能表明,这些模型并未过度局限于情感建议领域。
| Model size | n_layers | d_model | n_heads | Max LR | Maxbatch size |
| 1.3B | 24 | 2048 | 16 | 2e-4 | 512 |
| 3B | 32 | 2560 | 32 | 1.6e-4 | 512 |
| 6.7B | 32 | 4096 | 32 | 1.2e-4 | 512 |
| 13B | 40 | 5120 | 40 | 1e-4 | 1024 |
Table 3: Hyper parameters for our models of various sizes.
| 模型规模 | 层数 | 模型维度 | 注意力头数 | 最大学习率 | 最大批次大小 |
|---|---|---|---|---|---|
| 1.3B | 24 | 2048 | 16 | 2e-4 | 512 |
| 3B | 32 | 2560 | 32 | 1.6e-4 | 512 |
| 6.7B | 32 | 4096 | 32 | 1.2e-4 | 512 |
| 13B | 40 | 5120 | 40 | 1e-4 | 1024 |
表 3: 不同规模模型的超参数设置。
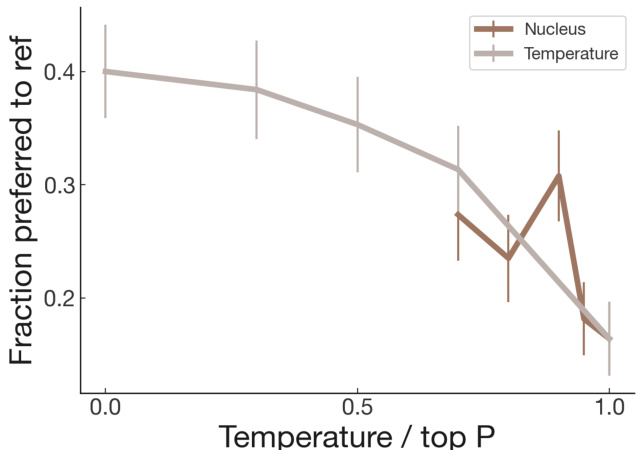
Figure 8: The sweep we conducted for determining our sampling procedure, varying the temperature and the ‘top p’ value for nucleus sampling. While we didn’t do a large enough test to determine whether nucleus sampling is better or worse than moderate-temperature sampling, we found that very low temperature sampling is better than both on this task.
图 8: 为确定采样程序进行的参数扫描,调整温度值和核采样(nucleus sampling)的"top p"值。虽然测试规模不足以判断核采样与中等温度采样的优劣,但发现极低温度采样在本任务中表现优于两者。
B Further model training details
B 模型训练的更多细节
B.1 Hyper parameters
B.1 超参数
All models follow the standard Transformer architecture, with 2048 learned position embeddings. All models are trained with fp16 activation s and the Adam optimizer [31]. Nearly all supervised baselines, reward models, and reinforcement learning models are trained with fp32 weights; the exception is our TL;DR supervised baselines, which were trained with fp16 weights.11 All models are trained with the same byte-pair encoding as in [48].
所有模型均遵循标准Transformer架构,配备2048个可学习位置嵌入。训练全程采用fp16激活值和Adam优化器[31]。除TL;DR监督基线模型使用fp16权重外,其余监督基线模型、奖励模型和强化学习模型均采用fp32权重训练。所有模型均采用与[48]相同的字节对编码(BPE)方案。
During pre training, the models were trained to predict the next token on a large text corpus consisting of Common crawl, Webtext [48], books, and Wikipedia. Training lasts between 1-3 epochs on each, for a total of 200-300 billion tokens. Learning rate follows a cosine schedule, with a short warmup, decaying to $10%$ of the maximum value. The batch size ramped up throughout training to some maximum, with each input having 2048 tokens. Hyper parameters for each model are shown in Table 3.
在预训练阶段,这些模型被训练用于预测由Common Crawl、Webtext [48]、书籍和维基百科组成的大规模文本语料库中的下一个token。每个数据源的训练持续1-3个epoch,总计处理2000-3000亿token。学习率采用余弦调度策略,包含短暂预热期后衰减至最大值的$10%$。批量大小在训练过程中逐步提升至最大值,每个输入包含2048个token。各模型的超参数如表3所示。
For supervised baselines, we initialize models from the pretrained models. We decay the learning rate with a cosine schedule, using an initial learning rate chosen from a log linear sweep of at least 7 values. This resulted in learning rates of 6.35e-5, 5.66e-5, 2.83e-5, and 2.83e-5 for our TL;DR models of size 1.3B, 3B, 6.7B, and 13B respectively, and a learning rate of $2.38\mathrm{e}{\cdot}5$ for our CNN/DM 6.7B model. We use a batch size of 128, and run for a single epoch.
对于监督学习的基线模型,我们从预训练模型初始化参数。采用余弦调度衰减学习率,初始学习率通过对数线性扫描至少7个值选定。最终确定各规模TL;DR模型的学习率分别为:1.3B模型6.35e-5、3B模型5.66e-5、6.7B和13B模型均为2.83e-5,CNN/DM 6.7B模型的学习率为$2.38\mathrm{e}{\cdot}5$。训练批次大小为128,运行单轮次。
For reward modeling, we initialize to the supervised baseline, but with a reward head on top with weights initialized according to $\mathcal{N}(0,1/(d_{m o d e l}+1))$ [20]. We train for one epoch, decaying the learning rate with a cosine schedule, using an initial learning rate chosen from a log linear sweep of at least 7 values. We also sweep over between 3 and 10 seeds, and choose the reward model that performs best on the development portion of the validation set, as we find that both the data iteration order and reward head initialization affect results [13]. For our main results, the 1.3B and 6.7B reward models had learning rates of 1.5e-5 and 5e-6, respectively. We use a batch size of 64, and run for a single epoch.
在奖励建模方面,我们基于监督基线进行初始化,但在顶部添加了一个奖励头,其权重按照$\mathcal{N}(0,1/(d_{m o d e l}+1))$初始化[20]。我们训练一个周期,采用余弦调度衰减学习率,初始学习率从至少7个值的对数线性扫描中选择。同时,我们在3到10个随机种子间进行扫描,并选择在验证集开发部分表现最佳的奖励模型,因为发现数据迭代顺序和奖励头初始化都会影响结果[13]。对于主要结果,13亿和67亿参数的奖励模型分别采用1.5e-5和5e-6的学习率。我们使用64的批量大小,并运行单个周期。
| Trained models | Format | Max tokens |
| TL;DR (supervised, RL) | SUBREDDIT:r/{subreddit} TITLE:{title} POST: {post} TL;DR: | 512 |
| Transfer from TL;DR to CNN/DM (supervised, RL) TL;DR (pretrained) | {article} TL;DR: {context_stuffed_with_examples} | 512 |
| Subreddit: r/{subreddit} Title: {title} {post} | 1999 | |
| CNN/DM (supervised) | TL;DR: Article:{article} TL;DR: | 1999 |
| CNN/DM (pretrained) | {context_stuffed_with_examples} 二二二二二 Article: {article} TL;DR: | 1999 |
Table 4: Formats used for the context for each of our trained models on the TL;DR and CNN/DM datasets.
| 训练模型 | 格式 | 最大token数 |
|---|---|---|
| TL;DR (监督学习, 强化学习) | SUBREDDIT:r/{subreddit} TITLE:{title} POST: {post} TL;DR: | 512 |
| 从TL;DR迁移到CNN/DM (监督学习, 强化学习) TL;DR (预训练) | {article} TL;DR: {context_stuffed_with_examples} | 512 |
| Subreddit: r/{subreddit} Title: {title} {post} | 1999 | |
| CNN/DM (监督学习) | TL;DR: Article:{article} TL;DR: | 1999 |
| CNN/DM (预训练) | {context_stuffed_with_examples} 二二二二二 Article: {article} TL;DR: | 1999 |
表 4: 在TL;DR和CNN/DM数据集上各训练模型使用的上下文格式。
For PPO, we run with separate policy and value networks, initializing our policies to the supervised baseline, and our value functions to the reward model. We set $\gamma=1$ and $\lambda=0.95$ for the advantage estimation [57] and do 4 epochs of optimization for each batch of rollouts. We used a linear learning rate decay schedule, with initial learning rates of $1.5\mathrm{e}{-}5$ for the 1.3B model and 7e-6 for the 6.7B model, based on small amounts of experimentation and rough model size extrapolation. We used a KL coefficient of 0.05 for both of the main runs we report results for (except when we explicitly vary this value in the reward model optimization graphs). We use a batch size of 512 for the 1.3B model and 256 for the 6.7B model, and run for 1 million episodes.
对于PPO,我们分别运行策略网络和价值网络,将策略初始化为监督基线,价值函数初始化为奖励模型。在优势估计[57]中设置$\gamma=1$和$\lambda=0.95$,并对每批 rollout 进行4轮优化。基于少量实验和粗略的模型规模外推,我们采用线性学习率衰减计划:13亿参数模型的初始学习率为$1.5\mathrm{e}{-}5$,67亿参数模型为7e-6。在报告结果的两个主要实验中(除奖励模型优化图中明确调整该值的情况外),KL系数均设为0.05。13亿模型使用512的批次大小,67亿模型使用256,共运行100万回合。
B.2 Input format
B.2 输入格式
Our model always receives a byte-pair encoded string of a fixed size. When the input is too small, we pad from the beginning of the input with a padding token, and if the input is too long we truncate the post/article field at newlines to stay under the limit.
我们的模型始终接收固定大小的字节对编码字符串。当输入过短时,我们从输入开头用填充token进行填充;若输入过长,则在换行处截断帖子/文章字段以确保不超过限制。
When sampling from models pretrained only on our pretrain mixture and not fine-tuned on TL;DR, we follow [48] and instead of padding with a padding token, we pad the beginning of the context with examples of posts/articles and high-quality summaries. We use as many examples as will fit in the token limit, with the examples formatted the same way as the main input. Table 4 documents the formats we used (with pythonic format strings).
从仅在我们预训练混合数据上预训练且未针对TL;DR进行微调的模型中进行采样时,我们遵循[48]的做法,不使用填充token进行填充,而是在上下文开头填充帖子/文章示例和高质量摘要。我们使用尽可能多的示例以适应token限制,这些示例的格式与主输入相同。表4记录了所使用的格式(使用Python语言风格格式化字符串)。
C Human data collection details
C 人类数据收集细节
C.1 Process for ensuring high-quality human data
C.1 确保高质量人类数据的过程
We first detail the procedures we use to ensure high-quality data. While these procedures became more rigorous over the course of the project, they generally involved four steps.
我们首先详细说明为确保高质量数据所采用的流程。虽然这些流程在项目推进过程中变得更加严格,但通常包含四个步骤。
Step 0: Understanding the task ourselves. To understand the task, we first do many summary comparisons ourselves. We also hire a small number of human labelers12 to do comparisons, and discuss our disagreements. We then draft instructions for a larger set of human labelers.
步骤0:自行理解任务。为了理解任务,我们首先自行进行多次摘要比较。我们还雇佣少量人工标注员进行对比,并讨论分歧点。随后,我们为更大规模的人工标注团队起草标注指南。
Step 1: Labeler onboarding. Labelers are hired from Upwork, a freelancing platform, as well as two labeling services, Scale and Lionbridge. Labelers first complete a (paid) training process where they label summaries on a shared set of data. For some comparisons, labelers get immediate feedback about which summary was chosen by us, and why, to help them calibrate. We retain labelers that pass a minimum threshold for speed and agreement with us. To allow for a customizable labeler interface, we built our own website for data collection (see Appendix C.4).
步骤1:标注员入职。标注员从自由职业平台Upwork以及两家标注服务公司Scale和Lionbridge招聘。标注员首先完成一个(付费)培训流程,在共享数据集上标注摘要。对于部分比较任务,标注员会立即收到关于我们选择哪个摘要及其原因的反馈,以帮助他们校准。我们保留在速度和与我们一致性方面达到最低门槛的标注员。为了实现可定制的标注员界面,我们自行搭建了数据收集网站(见附录C.4)。
Step 2: Collecting comparison data. Next, we have labelers evaluate a large batch of comparisons on our website, which generates the bulk of our data. Before comparing two summaries directly, we have labelers write their ‘naive interpretations’ of summaries without seeing the original post. We’ve found this helpful for evaluating summaries, as they surface points of ambiguity in the summary that might not have been detected if the summary was read after the original post. After doing naive interpretations, labelers do comparisons by assigning a value on a 9-point scale for how confident they are that summary A is better than summary B (or the converse).
步骤2:收集对比数据。接下来,我们让标注员在网站上评估大量对比数据,这构成了我们数据的主体。在直接比较两个摘要之前,我们会让标注员在不查看原文的情况下写下对摘要的"初始理解"。我们发现这对评估摘要很有帮助,因为它们能揭示摘要中可能存在的模糊点,这些模糊点在阅读原文后可能不会被察觉。完成初始理解后,标注员会通过9分量表进行对比,评估他们对于摘要A优于摘要B(或相反)的置信程度。
Step 3: Providing labeler feedback. After collecting the comparison data, we can look at agreement rates between labelers. While most comparisons are only given to a single labeler, each labeler gets about $10\small{-}20%$ questions from a shared pool for calibration purposes. We can both attempt to use these statistics as crude measures of quality, and show cases of disagreements to workers to help them improve their labels.
步骤3:提供标注者反馈。收集完对比数据后,我们可以查看标注者之间的一致率。虽然大多数对比数据仅由单个标注者处理,但每位标注者会收到约$10\small{-}20%$来自共享题库的校准问题。我们既可将这些统计量作为质量的粗略衡量指标,也可向标注人员展示分歧案例以帮助他们提升标注质量。
Step 4: Researcher comparison calibrations. We occasionally also do the task ourselves, to measure agreement rates between each labeler and us. This is used for quality assessment (see C.2). We also calculate per-labeler "high confidence" thresholds, by finding the confidence value on the Likert scale for each labeler such that we expect labels above this threshold to agree with us $80%$ of the time on average. For the purposes of reward model selection, we filter the validation set to contain only these higher confidence labels. For the entire process, we keep a high communication bandwidth with labelers: we use a shared chat room for labelers to ask clarifying questions and discuss difficult comparisons amongst themselves, host office hours, and occasionally have one-on-one video calls with labelers to discuss points of disagreement.
步骤4:研究人员对比校准。我们偶尔也会亲自完成任务,以衡量每位标注者与我们之间的一致性比率。这用于质量评估(参见C.2)。我们还计算每位标注者的"高置信度"阈值,方法是为每位标注者在李克特量表上找到置信度值,使得我们预期高于此阈值的标注平均有80%的概率与我们一致。出于奖励模型选择的目的,我们过滤验证集仅包含这些更高置信度的标注。在整个过程中,我们与标注者保持高频沟通:使用共享聊天室供标注者提出澄清问题并相互讨论困难对比,定期举办办公时间,偶尔与标注者进行一对一视频通话以讨论分歧点。
We keep good labelers throughout the lifetime of the project, while firing the lowest-performing workers.
我们在项目周期内持续保留优质标注员,同时淘汰表现最差的工作人员。
C.2 Assessing human feedback quality
C.2 评估人类反馈质量
We assess labeler accuracy by comparing the labeler’s preferred summary with the summary we prefer (ignoring the confidence level). We exclude comparisons where either the labeler or researcher expresses indifference. This gives us an agreement rate, in theory ranging from $0%$ (perfect disagreement) to $100%$ (perfect agreement). For our 2-way comparisons, a random labeler would get $50%$ agreement.
我们通过比较标注者偏好的摘要与我们偏好的摘要(忽略置信度)来评估标注者的准确性。排除标注者或研究人员表示无差异的比较。这样我们得到了一个一致率,理论上范围从 $0%$(完全不一致)到 $100%$(完全一致)。对于我们的双向比较,随机标注者会得到 $50%$ 的一致率。
To obtain our main number comparing labeler-researcher to researcher-researcher agreement, we restrict ourselves to comparisons between summaries from our 1.3B supervised baseline, because this subset of the data has the most researcher-labeled data. On this subset, labelers agree with researchers $77%\pm2%$ of the time, while researchers agree with each other $73%\pm4%$ of the time. We believe substantial noise comes from comparisons being quite difficult and subjective.
为获取标注员与研究员之间以及研究员相互间一致性的主要对比数据,我们仅针对1.3B监督基线的摘要进行比较,因为该数据子集包含最多研究员标注样本。在此子集中,标注员与研究员的标注一致率为 $77%\pm2%$ ,而研究员相互间一致率为 $73%\pm4%$ 。我们认为显著的噪声源于对比任务本身的高度难度和主观性。
In general, agreement rates range from about $65%$ for the least proficient labelers and most difficult comparisons (comparing two high-temperature samples from a single RL policy) to about $85%$ for the most proficient labelers and easiest comparisons (comparing a high-temperature sample from a supervised baseline to the reference summary). Averaging over all workers, weighted by their volume, gives us an estimated agreement rate of $73%\pm3%$ for our reward model training corpus.
总体而言,标注者的一致性比率从最低水平标注者处理最困难对比任务时的约 $65%$ (对比同一强化学习策略生成的两个高温参数样本) ,到最高水平标注者处理最简单对比任务时的约 $85%$ (对比监督基线模型的高温参数样本与参考摘要) 。根据标注者工作量加权平均后,我们估算奖励模型训练语料库的整体一致性比率为 $73%\pm3%$ 。
Figure 9: (a) The website we made to collect data from labelers. (b) Naive interpretations of summaries on the website.
图 9: (a) 我们制作的用于从标注者处收集数据的网站。(b) 网站上摘要的直观解释。
Labelers agree with each other $72%$ of the time in the training corpus. This suggests we could get more reliable labels by aggregating labels from multiple workers on the same comparison. Indeed, on the subset of the training data for which we have enough shared comparisons, taking the modal label from 3 labelers increases their agreement rate with researchers from $72%$ to $77%$ . However, we usually collect only one label per comparison, in order to maximize label throughput.
在训练语料中,标注者之间的一致性达到72%。这表明通过汇总多名标注者对同一比较项的标注结果,我们可以获得更可靠的标签。事实上,在训练数据子集中(存在足够多重复标注的样本),采用3名标注者的众数标签可将他们与研究人员的一致性从72%提升至77%。但为了最大化标注吞吐量,我们通常每个比较项仅收集一个标签。
On the evaluations for Figure 1, labelers agreed with researchers $73%\pm3%$ of the time, and labelers agreed with each other $73%\pm2%$ of the time.
在图1的评估中,标注者与研究人员的一致性为$73%\pm3%$,标注者之间的一致性为$73%\pm2%$。
Agreement rate between researchers ranged from about $65%$ on the most difficult comparisons (comparing two high-temperature samples from a single RL policy), to about $80%$ on the easiest comparisons (comparing a high-temperature sample from a supervised baseline to the human reference summary), to about $95%$ in cases where we discussed the comparisons with each other.
研究人员之间的评分一致率从最困难比较(对比同一强化学习策略生成的两个高温样本)的约65%,到最简单比较(对比监督基线的高温样本与人类参考摘要)的约80%,再到我们相互讨论比较案例时的约95%。
Overall we believe that quality is fairly high. Our attempts to filter data generally hurt reward model accuracy. For example, using the confidence thresholds mentioned above, we found that while lower-confidence labels were less useful than high-confidence labels for improving reward model accuracy, they were still better to include than to omit. Similarly, leaving out workers with poorer agreement rates did not help.
总体而言,我们认为质量相当高。我们尝试过滤数据通常会损害奖励模型的准确性。例如,使用上述置信度阈值时,我们发现虽然低置信度标签对提升奖励模型准确性的作用不如高置信度标签,但包含它们仍比完全剔除更有益。同样,排除一致性较差的标注者也并无帮助。
C.3 Labeler demographics
C.3 标注人员统计信息
When training machine learning models with human feedback, the humans providing the feedback are essential in reinforcing the desired model behavior. If we are to scale human feedback to train models on more complex tasks, where humans might disagree about what the desired model behavior should be, it’s important for members of groups that will be impacted by the model to be included in the labeler population.
在利用人类反馈训练机器学习模型时,提供反馈的人类对于强化模型预期行为至关重要。若要将人类反馈扩展到更复杂的任务训练中(在这些任务中人类可能对模型预期行为存在分歧),确保受模型影响的群体成员参与标注工作尤为重要。
To provide more transparency into our labeler demographics, we provide results from a survey given to our labelers in Table 5. The survey was optional, anonymous, and it was made clear that the results would not affect hiring or firing decisions. We find that our labelers span a range of ethnicities, nationalities, ages, and genders, and educational backgrounds, but are more likely to be White and American.
为了更透明地了解标注人员的构成情况,我们在表5中提供了标注人员调查结果。该调查为自愿匿名形式,并明确告知结果不会影响雇佣决策。数据显示,我们的标注人员涵盖了不同种族、国籍、年龄、性别和教育背景,但以白人和美国籍居多。
C.4 Labeler website
C.4 标注者网站
Since we hired and trained our own set of labelers, rather than using a crowd sourcing website such as Amazon Mechanical Turk, we built our own website to allow for a standardized, customizable user interface for all labelers. Each labeler created a separate profile, allowing us to assign different sets of comparisons to different labelers. The website contains different renderers for different kinds of questions, including naive interpretations, summary comparisons, and Likert evaluations along different axes, along with room for labelers to express concerns with the question or explanations for their decision. Screenshots from the website are shown in Figure 9. Data collected from the website can be easily ported into a central database containing all of our human data.
由于我们雇佣并培训了自己的标注团队,而非使用Amazon Mechanical Turk等众包平台,因此专门开发了一个标注网站,为所有标注员提供标准化且可定制化的用户界面。每位标注员拥有独立账户,便于我们分配不同的对比任务组合。该网站针对不同类型的问题(包括原始解释、摘要对比、多维度李克特量表评估)配备了差异化呈现模块,同时设有标注员反馈区用于提交问题质疑或标注依据说明。网站界面截图见图9。所有采集数据均可无缝导入集中式数据库,与全部人工标注数据统一存储。
| What gender do you identify as? | |
| Male | 38.1% 61.9% |
| Female | |
| Nonbinary / other | |
| What ethnicities do you identify as? | |
| White / Caucasian SoutheastAsian | 42.9% |
| Indigenous/ Native American / | 23.8% 9.6% |
| Alaskan Native | 4.8% |
| East Asian Middle Eastern 4.8% | |
| Latinx | |
| My ethnicidentityisn't listed | |
| What is your nationality? American 45% | |
| 30% | |
| Filipino | |
| South African 5% | |
| Serbian 5% 5% | |
| British | |
| Turkish | |
| Indian | |
| What is your age? 42.9% | |
| 20-29 23.8% | |
| 30-39 | |
| 40-49 | |
| 50-59 | |
| 60+ | |
| 0% What is your highest attained level of education? | |
| Less than high school degree | |
| High school degree | 0% 14.3% |
| Undergraduate degree | 57.1% |
| Master's degree | 23.3% |
| Doctoratedegree | 4.8% |
Table 5: Demographic data from 21 of our labelers who participated in our voluntary survey.
| 你认同的性别是? | |
|---|---|
| 男性 | 38.1% 61.9% |
| 女性 | |
| 非二元性别/其他 |
| 你认同的族裔是? | |
|---|---|
| 白人/高加索人 东南亚裔 | 42.9% |
| 原住民/美洲印第安人/ | 23.8% 9.6% |
| 阿拉斯加原住民 | 4.8% |
| 东亚裔 中东裔 4.8% | |
| 拉丁裔 | |
| 我的族裔未列出 |
| 你的国籍是? | |
|---|---|
| 美国 | 45% |
| 菲律宾 | 30% |
| 南非 | 5% |
| 塞尔维亚 | 5% 5% |
| 英国 | |
| 土耳其 | |
| 印度 |
| 你的年龄是? | |
|---|---|
| 20-29岁 | 42.9% |
| 30-39岁 | 23.8% |
| 40-49岁 | |
| 50-59岁 | |
| 60岁以上 | 0% |
| 你的最高学历是? | |
|---|---|
| 高中以下 | 0% |
| 高中学历 | 14.3% |
| 本科学历 | 57.1% |
| 硕士学历 | 23.3% |
| 博士学历 | 4.8% |
表 5: 参与自愿调查的21位标注者人口统计数据。
C.5 Instructions for labelers
C.5 标注员指南
Here we provide more detail on the specific instructions given to labelers for comparing summaries, and for doing Likert evaluations of summaries along axes of quality. We produced separate sets of instructions for evaluating Reddit posts, and for evaluating CNN/DM news articles. For Reddit instructions, we first describe Reddit in general and provide a table that translates Reddit-specific lingo into common parlance.
在此我们详细说明为标注员提供的具体指导,包括如何比较摘要以及如何对摘要质量进行李克特量表(Likert)评估。我们分别制定了针对Reddit帖子和CNN/DM新闻文章的评估指南。对于Reddit指南,我们首先概述了Reddit平台,并提供了一个将Reddit专用术语转换为通用语言的对照表。
Instructions for comparing summaries. We show an excerpt of the instructions given to labelers for making comparisons in Table 6. In addition to these instructions, we provide an example labeled comparison between Reddit summaries, and also example naive interpretations for summaries.
比较摘要的说明
我们在表6中展示了提供给标注者用于进行比较的说明节选。除了这些说明外,我们还提供了Reddit摘要之间的标注比较示例,以及摘要的简单解释示例。
Instructions for evaluating summaries along axes of quality. We provide a separate set of detailed instructions for labelers for the 7-point Likert evaluations. We first introduce each of the 4 axes of quality we consider, giving an overview of coherence, accuracy, coverage, and overall score (shown in Table 7). We also provide a brief rubric for giving scores of 1, 4, and 7, along with several Reddit summaries annotated with our own judgments of quality along each of these axes (with explanations).
评估摘要质量的维度说明。我们为标注员提供了另一套详细的7点李克特量表评估指南。首先介绍我们考虑的4个质量维度:连贯性、准确性、覆盖率和总体评分(如表7所示)。同时提供了1分、4分和7分的简要评分标准,并附有多个Reddit摘要示例及我们对各维度质量的标注判断(含解释说明)。
What makes for a good summary? Roughly speaking, a good summary is a shorter piece of text that has the essence of the original – tries to accomplish the same purpose and conveys the same information as the original post. We would like you to consider these different dimensions of summaries:
优秀摘要的标准是什么?简而言之,好的摘要是一段更短的文本,它包含原文的精髓——试图实现与原文相同的目的,并传达相同的信息。我们希望您考虑摘要的这些不同维度:
Essence: is the summary a good representation of the post?
本质:摘要是否准确代表了帖子内容?
Clarity: is the summary reader-friendly? Does it express ideas clearly?
清晰度:摘要是否易于阅读?是否清晰地表达了观点?
Accuracy: does the summary contain the same information as the longer post?
准确性:摘要是否包含与较长文章相同的信息?
Purpose: does the summary serve the same purpose as the original post?
目的:摘要是否与原文目的相同?
Concise: is the summary short and to-the-point?
简洁:摘要是否简短扼要?
Style: is the summary written in the same style as the original post?
风格:摘要的写作风格是否与原帖一致?
Generally speaking, we give higher weight to the dimensions at the top of the list. Things are complicated though – none of these dimensions are simple yes/no matters, and there aren’t hard and fast rules for trading off different dimensions. This is something you’ll pick up through practice and feedback on our website.
一般来说,我们会给列表顶部的维度赋予更高权重。但情况往往很复杂——这些维度都不是简单的二元判断,也没有硬性规则来权衡不同维度。这需要通过实践和在我们网站上的反馈来逐步掌握。
Table 6: An excerpt from the instructions we gave to labelers for doing comparisons.
表 6: 我们提供给标注员进行对比的指令节选。
Finally, we provide a FAQ section that answers common questions raised by the small initial set of labelers we assigned to this task.
最后,我们提供了一个常见问题解答 (FAQ) 部分,用于回答最初分配给这项任务的小规模标注团队提出的常见问题。
For CNN/DM, we provide the same set of instructions, except we add some additional clarifications for how to judge news articles. We specifically ask labelers to place less emphasis on fluidity of sentences (because the reference summaries were originally written in bullet-point form, and we didn’t want labelers to penalize this), and to place less emphasis on the summary matching the intent of the article (which was important for Reddit summaries).
对于CNN/DM数据集,我们提供了相同的指导原则,但额外补充了如何评判新闻文章的说明。我们特别要求标注员降低对句子流畅性的要求(因为参考摘要原本是以要点形式撰写的,不希望标注员因此扣分),同时减少对摘要与文章意图匹配度的关注(这点在Reddit摘要中很重要)。
In terms of quality control, we conducted a smaller version of the quality control process described in Appendix C.1: we first labeled a small set of summaries ourselves along each axis to understand points of confusion, then we wrote the instructions document to provide to labelers, then we had a small number of labelers do a trial of the task to catch any remaining bugs or points of confusion, and finally we onboarded a larger set of labelers onto the task while remaining available to answer any questions.
在质量控制方面,我们实施了附录C.1所述流程的简化版本:首先自行标注少量摘要以明确易混淆点,随后编写标注指南文档,接着安排少量标注员进行试标以排查剩余问题,最终扩大标注团队规模并保持答疑支持。
C.6 Composition of the labeled dataset
C.6 标注数据集的构成
Over the course of the project, we trained several reward models and policies. Each batch of summaries that we sent to the labelers were sampled from a variety of policies. We didn’t have a systematic plan for which policies to sample from; rather, we chose what seemed best at the time in the spirit of exploratory research. Every time we trained a reward model, we trained on all labels we had collected so far. Successive models also benefited from improved hyper parameters and dataset cleaning. Our results could likely be replicated with a simpler, more systematic approach.
在项目过程中,我们训练了多个奖励模型和策略。发送给标注人员的每批摘要样本均来自不同策略。我们并未制定系统性的策略采样计划,而是本着探索性研究精神,根据当下最优判断进行选择。每次训练奖励模型时,我们都使用截至当时收集的所有标注数据。后续模型还受益于超参数优化和数据集清洗的改进。若采用更简单、系统化的方法,很可能复现出相同结果。
In general, as we hire new labelers and as existing labelers perform the task more, it is possible that there is ‘labeler drift’, where the set of criteria used by labelers to evaluate summaries gradually shifts over time. This could lead to a regression in labeler-researcher disagreement, or lead to some policies becoming more or less preferred over time. To help guard against this, in most batches we include comparisons between samples from our supervised baseline and reference summaries, and measure the frequency with which the workers prefer one over the other. If this number drifts over time, it’s an indication that our workers’ preferences are also changing. However, we generally found that this preference number stayed relatively constant, within noise.
通常情况下,随着新标注员的加入以及现有标注员任务熟练度的提升,可能会出现"标注漂移"现象,即标注员评估摘要的标准集随时间逐渐变化。这可能导致标注员与研究人员之间的分歧加剧,或使某些策略随时间变得更为或更不受青睐。为防范这一问题,我们在多数批次中会纳入监督基线样本与参考摘要的对比,并统计标注员对二者的偏好频率。若该数值随时间漂移,则表明标注员的偏好也在变化。但总体而言,我们发现这一偏好数值在噪声范围内保持相对稳定。
Table 8 lists the policies we trained by supervised finetuning on the TL;DR dataset, as well as the reward models, trained on successively larger datasets of human labels. Table 9 lists the RL policies.
表 8 列出了我们在 TL;DR 数据集上通过监督微调训练的策略,以及在逐渐增大的人类标注数据集上训练的奖励模型。表 9 列出了强化学习策略。
Coherence
连贯性
For this axis, answer the question “how coherent is the summary on its own?” A summary is coherent if, when read by itself, it’s easy to understand and free of English errors. A summary is not coherent if it’s difficult to understand what the summary is trying to say. Generally, it’s more important that the summary is understandable than it being free of grammar errors.
针对这一维度,回答"摘要本身是否连贯?"这一问题。当摘要独立阅读时易于理解且无英语错误,即为连贯。若难以理解摘要表达的内容,则视为不连贯。通常,摘要的可理解性比语法正确性更为重要。
Rubric:
评分标准:
Accuracy
准确率
For this axis, answer the question “does the factual information in the summary accurately match the post?” A summary is accurate if it doesn’t say things that aren’t in the article, it doesn’t mix up people, and generally is not misleading. If the summary says anything at all that is not mentioned in the post or contradicts something in the post, it should be given a maximum score of 5. (If you are confused about how to use $\cdot_{6},$ , see the FAQ!)
针对这一维度,回答"摘要中的事实信息是否与原文准确匹配?"若摘要内容未添加原文未提及的信息、未混淆人物关系且总体上不具误导性,则视为准确。若摘要出现任何原文未提及或与原文矛盾的内容,其最高得分不得超过5分。(如对如何使用$\cdot_{6},$存在疑问,请参阅FAQ!)
Rubric:
评分标准:
Score of 1: The summary is completely wrong, made up, or exactly contradicts what is written in the post.
1分:摘要完全错误、凭空捏造或与原文内容完全矛盾。
Coverage
覆盖率
For this axis, answer the question “how well does the summary cover the important information in the post?” A summary has good coverage if it mentions the main information from the post that’s important to understand the situation described in the post. A summary has poor coverage if someone reading only the summary would be missing several important pieces of information about the situation in the post. A summary with good coverage should also match the purpose of the original post (e.g. to ask for advice).
针对这一维度,回答"摘要对帖子重要信息的覆盖程度如何?"
若摘要提及了理解帖子所述情境所需的主要信息,则其覆盖度良好。若读者仅阅读摘要会遗漏帖子中多个重要信息点,则覆盖度较差。覆盖度良好的摘要还应契合原帖目的 (例如寻求建议)。
Rubric:
评分标准:
Overall quality
整体质量
For this axis, answer the question “how good is the summary overall at representing the post?” This can encompass all of the above axes of quality, as well as others you feel are important. If it’s hard to find ways to make the summary better, give the summary a high score. If there are lots of different ways the summary can be made better, give the summary a low score.
对于这一维度,回答"摘要整体在多大程度上能代表原文?"这一问题。它可以涵盖上述所有质量维度,以及你认为重要的其他方面。如果很难找到改进摘要的方法,就给摘要打高分。如果摘要有很多不同的改进方式,就给摘要打低分。
Rubric:
评分标准:
Table 7: Instructions given to labelers for evaluating summaries along four different axes of quality.
表 7: 标注员用于从四个不同质量维度评估摘要的指令。
| Supervised policy name | #Parameters | Rewardmodelname | #Parameters |
| supl | 750M | rm1 | 1.3B |
| sup2 | 1.3B | rm2 | 6.7B |
| sup3 | 1.3B | rm3 | 1.3B |
| sup3_6b | 6.7B | rm3_6b | 6.7B |
| sup4 | 1.3B | rm4 | 1.3B |
| sup4_6b | 6.7B | rm4_6b | 6.7B |
| 监督策略名称 | 参数量 | 奖励模型名称 | 参数量 |
|---|---|---|---|
| supl | 750M | rm1 | 1.3B |
| sup2 | 1.3B | rm2 | 6.7B |
| sup3 | 1.3B | rm3 | 1.3B |
| sup3_6b | 6.7B | rm3_6b | 6.7B |
| sup4 | 1.3B | rm4 | 1.3B |
| sup4_6b | 6.7B | rm4_6b | 6.7B |
Table 8: Left: supervised baselines. sup4 and sup4_6b are the final supervised baselines used throughout the paper. Right: reward models. rm4 and $\mathrm{rm}4_6\mathrm{b}$ are the final reward models used throughout the paper.
表 8: 左: 监督基线。sup4 和 sup4_6b 是本文最终使用的监督基线。右: 奖励模型。rm4 和 $\mathrm{rm}4_6\mathrm{b}$ 是本文最终使用的奖励模型。
| RL policy name | #Parameters | Objective | Initialization | KL coefficient | KL(ppo, sup) |
| sup3 ppo rm1 | 1.3B | rm1 | sup3 | 0.35 | 1.8 |
| sup4 ppo rm3 1 | 1.3B | rm3 | sup4 | 0.10 | 3.8 |
| sup4 ppo rm3 2 | 1.3B | rm3 | sup4 | 0.07 | 9.4 |
| sup4 ppo rm3 3 | 1.3B | rm3 | sup4 | 0.05 | 19.0 |
| sup4 ppo rm4 | 1.3B | rm4 | sup4 | 0.05 | 18.0 |
| sup4_6b ppo rm4_6b | 6.7B | rm4_6b | sup4_6b | 0.05 | 14.0 |
| RL策略名称 | 参数量 | 目标 | 初始化 | KL系数 | KL(ppo, sup) |
|---|---|---|---|---|---|
| sup3 ppo rm1 | 1.3B | rm1 | sup3 | 0.35 | 1.8 |
| sup4 ppo rm3 1 | 1.3B | rm3 | sup4 | 0.10 | 3.8 |
| sup4 ppo rm3 2 | 1.3B | rm3 | sup4 | 0.07 | 9.4 |
| sup4 ppo rm3 3 | 1.3B | rm3 | sup4 | 0.05 | 19.0 |
| sup4 ppo rm4 | 1.3B | rm4 | sup4 | 0.05 | 18.0 |
| sup4_6b ppo rm4_6b | 6.7B | rm4_6b | sup4_6b | 0.05 | 14.0 |
| BoN policy name | Objective | Base policy | N | KL(BoN, sup) |
| sup2 bo8 rm1 | rm1 | sup2 | 8 | 1.2 |
| sup3 bo8 rm1 | rm2 | sup3 | 8 | 1.2 |
| sup3 bo63 rm2 | rm2 | sup3 | 63 | 3.2 |
| sup4 bo8 rm3 | rm3 | sup4 | 8 | 1.2 |
| sup4 bo64 rm3 | rm3 | sup4 | 64 | 3.2 |
| sup4 bo128 rm3 | rm3 | sup4 | 128 | 3.9 |
| sup4 bo256 rm3 | rm3 | sup4 | 256 | 4.5 |
| sup4 bo512 rm3 | rm3 | sup4 | 512 | 5.2 |
| sup4 bo128 rm3_6b | rm3_6b | sup4 | 128 | 3.9 |
| sup4 bo256 rm3_6b | rm3_6b | sup4 | 256 | 4.5 |
Table 10: Best-of-N policies. KL divergence is computed analytically as KL(boN, sup) = log N - (N-1)/N.
| BoN策略名称 | 目标 | 基础策略 | N | KL(BoN, sup) |
|---|---|---|---|---|
| sup2 bo8 rm1 | rm1 | sup2 | 8 | 1.2 |
| sup3 bo8 rm1 | rm2 | sup3 | 8 | 1.2 |
| sup3 bo63 rm2 | rm2 | sup3 | 63 | 3.2 |
| sup4 bo8 rm3 | rm3 | sup4 | 8 | 1.2 |
| sup4 bo64 rm3 | rm3 | sup4 | 64 | 3.2 |
| sup4 bo128 rm3 | rm3 | sup4 | 128 | 3.9 |
| sup4 bo256 rm3 | rm3 | sup4 | 256 | 4.5 |
| sup4 bo512 rm3 | rm3 | sup4 | 512 | 5.2 |
| sup4 bo128 rm3_6b | rm3_6b | sup4 | 128 | 3.9 |
| sup4 bo256 rm3_6b | rm3_6b | sup4 | 256 | 4.5 |
表 10: 最佳N策略。KL散度通过解析式计算为KL(boN, sup) = log N - (N-1)/N。
We also explored a simple alternative to reinforcement learning: Sample N summaries from a supervised baseline at temperature 0.7, score them with a reward model, and take the summary with the highest score. This best-of-N (BoN) procedure is effectively a mildly optimized policy requiring no training. These policies are named in Table 10, and samples from them form part of the training data.
我们还探索了一种简单的强化学习替代方案:在温度为0.7的条件下从监督基线中采样N个摘要,用奖励模型对它们进行评分,并选择得分最高的摘要。这种N选最佳(BoN)方法实际上是一种无需训练的轻度优化策略。这些策略在表10中列出,其采样结果构成了训练数据的一部分。
Table 11 lists the source policies for the training data for each reward model.
| Label count | |||
| Reward model | Policyo | Policy1 | |
| rm1 | ref | sup1 | 5404 |
| sup1 | sup1 | 5386 | |
| rm2 | ref | sup1 | 5404 |
| sup2 | 12779 | ||
| sup2 bo8 rm1 | 1426 | ||
| sup3_6b | 1424 | ||
| sup1 | sup1 | 5386 | |
| Continued on next page | |||
Table 9: PPO policies. sup4 ppo rm4 and sup4_6b ppo rm4_6b are the final policies used throughout the paper.
表 11: 各奖励模型训练数据的来源策略。
| 奖励模型 | Policyo | Policy1 | 标签数量 |
|---|---|---|---|
| rm1 | ref | sup1 | 5404 |
| sup1 | sup1 | 5386 | |
| rm2 | ref | sup1 | 5404 |
| sup2 | 12779 | ||
| sup2 bo8 rm1 | 1426 | ||
| sup3_6b | 1424 | ||
| sup1 | sup1 | 5386 | |
| 转下页 |
表 9: PPO策略。sup4 ppo rm4和sup4_6b ppo rm4_6b是本文最终使用的策略。
| Label count | |||
| Reward model | Policyo | Policy1 | |
| sup2 | sup2 | 11346 | |
| sup2 bo8 rml | 1376 | ||
| sup3_6b | 1383 | ||
| rm3, rm3_6b | sup2 bo8 rm1 | sup3_6b | 1390 |
| ref | sup1 | 5404 | |
| sup2 | 12779 | ||
| sup2 bo8 rml | 1426 | ||
| sup3 | 438 | ||
| sup3 bo63 rm2 | 447 | ||
| sup3 bo8 rm2 | 887 | ||
| sup3 ppo rm1 | 884 | ||
| sup3_6b | 1424 | ||
| sup1 | sup1 | 5386 | |
| sup2 | sup2 | 11346 | |
| sup2 bo8 rm1 | 1376 | ||
| sup3_6b | 1383 | ||
| sup2 bo8 rm1 | sup3_6b | 1390 | |
| sup3 | sup3 bo8 rm2 | 428 | |
| sup3 ppo rm1 | 416 | ||
| sup3 bo63 rm2 | sup3 bo8 rm2 | 432 | |
| sup3 ppo rm1 | 444 | ||
| rm4,rm4_6b | sup3 bo8 rm2 | sup3 ppo rm1 | 855 |
| ref | sup1 | 5404 | |
| sup2 | 12779 | ||
| sup2 bo8 rm1 | 1426 | ||
| sup3 | 438 | ||
| sup3 bo63 rm2 | 447 | ||
| 887 | |||
| sup3 bo8 rm2 | |||
| sup3 ppo rm1 | 884 | ||
| sup3_6b | 1424 | ||
| sup4 | 1335 | ||
| sup4 bo128 rm3 | 602 | ||
| sup4 bo128 rm3_6b | 203 | ||
| sup4 bo256 rm3 | 307 | ||
| sup4 bo256 rm3_6b | 101 | ||
| sup4 bo512 rm3 | 52 | ||
| sup4 bo64 rm3 | 52 | ||
| sup4 bo8 rm3 | 393 | ||
| sup4 ppo rm3 1 | 981 | ||
| sup4 ppo rm3 2 | 215 | ||
| sup4 ppo rm3 3 | 208 | ||
| sup1 | sup4_6b | 104 | |
| sup2 | sup1 | 5386 | |
| sup2 | 11346 | ||
| sup2 bo8 rml | 1376 | ||
| sup3_6b | 1383 | ||
| sup2 bo8 rm1 | sup3_6b | 1390 | |
| sup3 | sup3 bo8 rm2 | 428 | |
| sup3 ppo rm1 | 416 | ||
| sup3 bo63 rm2 | sup3 bo8 rm2 | 432 | |
| sup3 ppo rm1 | 444 | ||
| sup3 bo8 rm2 | sup3 ppo rm1 | 855 | |
| sup4 | sup4 | 1051 | |
| sup4 ppo rm3 1 | 395 | ||
Continued on next page
| Reward model | Policyo | Policy1 | Label count |
|---|---|---|---|
| sup2 | sup2 | 11346 | |
| sup2 bo8 rml | 1376 | ||
| sup3_6b | 1383 | ||
| rm3, rm3_6b | sup2 bo8 rm1 | sup3_6b | 1390 |
| ref | sup1 | 5404 | |
| sup2 | 12779 | ||
| sup2 bo8 rml | 1426 | ||
| sup3 | 438 | ||
| sup3 bo63 rm2 | 447 | ||
| sup3 bo8 rm2 | 887 | ||
| sup3 ppo rm1 | 884 | ||
| sup3_6b | 1424 | ||
| sup1 | sup1 | sup1 | 5386 |
| sup2 | sup2 | sup2 | 11346 |
| sup2 bo8 rm1 | 1376 | ||
| sup3_6b | 1383 | ||
| sup2 bo8 rm1 | sup3_6b | sup3_6b | 1390 |
| sup3 | sup3 bo8 rm2 | sup3 bo8 rm2 | 428 |
| sup3 ppo rm1 | 416 | ||
| sup3 bo63 rm2 | sup3 bo8 rm2 | 432 | |
| sup3 ppo rm1 | 444 | ||
| rm4,rm4_6b | sup3 bo8 rm2 | sup3 ppo rm1 | 855 |
| ref | sup1 | 5404 | |
| sup2 | 12779 | ||
| sup2 bo8 rm1 | 1426 | ||
| sup3 | 438 | ||
| sup3 bo63 rm2 | 447 | ||
| 887 | |||
| sup3 bo8 rm2 | |||
| sup3 ppo rm1 | 884 | ||
| sup3_6b | 1424 | ||
| sup4 | 1335 | ||
| sup4 bo128 rm3 | 602 | ||
| sup4 bo128 rm3_6b | 203 | ||
| sup4 bo256 rm3 | 307 | ||
| sup4 bo256 rm3_6b | 101 | ||
| sup4 bo512 rm3 | 52 | ||
| sup4 bo64 rm3 | 52 | ||
| sup4 bo8 rm3 | 393 | ||
| sup4 ppo rm3 1 | 981 | ||
| sup4 ppo rm3 2 | 215 | ||
| sup4 ppo rm3 3 | 208 | ||
| sup1 | sup4_6b | 104 | |
| sup2 | sup1 | 5386 | |
| sup2 | 11346 | ||
| sup2 bo8 rml | 1376 | ||
| sup3_6b | 1383 | ||
| sup2 bo8 rm1 | sup3_6b | 1390 | |
| sup3 | sup3 bo8 rm2 | 428 | |
| sup3 ppo rm1 | 416 | ||
| sup3 bo63 rm2 | sup3 bo8 rm2 | 432 | |
| sup3 ppo rm1 | 444 | ||
| sup3 bo8 rm2 | sup3 ppo rm1 | 855 | |
| sup4 | sup4 | 1051 | |
| sup4 ppo rm3 1 | 395 |
(接下页)
| Label count | ||
| Reward model | Policyo | Policy1 |
| sup4 bo128 rm3 | sup4 bo128 rm3 288 sup4 bo256 rm3 | |
| 582 95 | ||
| sup4 bo128 rm3_6b | sup4 bo128 rm3_6b 203 | |
| sup4 bo512 rm3 | sup4 bo256 rm3_6b sup4 ppo rm3 3 | |
| 216 sup4_6b 60 | ||
| sup4 bo64 rm3 | sup4 ppo rm3 2 218 | |
| sup4_6b 55 | ||
| sup4 bo8 rm3 | sup4 ppo rm3 1 752 | |
| sup4 ppo rm3 1 | sup4 ppo rm3 1 372 | |
| sup4 ppo rm3 2 | sup4 ppo rm3 2 4256 | |
| sup4_6b 215 | ||
| sup4 ppo rm3 3 | sup4 ppo rm3 3 4037 | |
| sup4_6b 216 |
Table 11: Training data for reward models. "ref" refers to human reference summaries.
| 标签数量 | ||
|---|---|---|
| 奖励模型 | Policyo | Policy1 |
| sup4 bo128 rm3 | sup4 bo128 rm3 288 sup4 bo256 rm3 | |
| 582 95 | ||
| sup4 bo128 rm3_6b | sup4 bo128 rm3_6b 203 | |
| sup4 bo512 rm3 | sup4 bo256 rm3_6b sup4 ppo rm3 3 | |
| 216 sup4_6b 60 | ||
| sup4 bo64 rm3 | sup4 ppo rm3 2 218 | |
| sup4_6b 55 | ||
| sup4 bo8 rm3 | sup4 ppo rm3 1 752 | |
| sup4 ppo rm3 1 | sup4 ppo rm3 1 372 | |
| sup4 ppo rm3 2 | sup4 ppo rm3 2 4256 | |
| sup4_6b 215 | ||
| sup4 ppo rm3 3 | sup4 ppo rm3 3 4037 | |
| sup4_6b 216 |
表 11: 奖励模型的训练数据。"ref"指人类参考摘要。
C.7 Example comparison tasks
C.7 示例对比任务
To give a sense of the difficulty of the comparisons task, we provide example comparisons between two summaries generated by our 6.7B human feedback model. In Table 12 we show both a random comparison drawn from the TL;DR dataset, and a cherry-picked comparison (selected from 10 comparisons where labelers disagreed) to illustrate the trade-off between accuracy in coverage that can occur when labelers conduct evaluations.
为了说明比较任务的难度,我们提供了由6.7B人类反馈模型生成的两个摘要之间的示例比较。表12展示了从TL;DR数据集中随机抽取的一个比较案例,以及一个精选的比较案例(从标注者存在分歧的10个比较中选出),用以说明标注者进行评估时可能出现的覆盖准确性与偏好之间的权衡。
Random TL;DR comparison
随机TL;DR对比
| POST Subreddit:r/Pets |
| TITLE: What do you use for flea control? My family has tried literally EVERYTHING to control the feas in our neighborhood (Frontline, Advantage, Diatomaceous Earth, Dawn Dishsoap, etc!) and nothing has worked. I have spoken to lots of pet owners in my area (I work as a vet assistant) and many are reporting similar results, where fleas are becoming resistant to the usually recommended treatments. The only thing that has worked so far is Comfortis, but I've read of |
| several dogs having reactions to it that can be pretty severe. My dogs are fine, we've used it for about a year now, but I don't like the idea of harming them or putting them at risk. Giving them baths with blue Dawn dish soap does kill all the fleas, but it does nothing to prevent more from coming back, obviously. It only kills on contact, and we are NOT going to over bath them because that isn't |
| healthy either. We're looking for something that lasts. damage to your pet's system? Yes, I know I am a vet assistant. My boss strictly recommends Frontline and literally will not listen to me when I tell him it doesn't work and my dogs are still covered in fleas and we |
| have to use Comfortis because it is the only thing that gives them relief. He is not a resource in this case. Just wanted to see what other pet owners (specifically ones in San Diego) do for fleas...the ones we have here aremutants orsomething,becausealmostnothingworks on them! |
| Summary A: Fleas are developing resistance to most flea control products (including Comfortis). Looking for something that lasts long term that doesn't harm my dogs. Does anyone have experience with any of the |
| listedproducts? Summary B: Nothing has worked on our fleas, we are looking for something that lasts, Comfortis is not a |
| 帖子 子版块: r/宠物 |
| 标题: 你们用什么方法除跳蚤?我家试遍了所有方法 (Frontline、Advantage、硅藻土、Dawn洗洁精等) 都没用。作为兽医助理,我和本地许多宠物主交流过,大家都反映常规除蚤产品逐渐失效。目前唯一有效的是Comfortis,但听说有些狗狗会产生严重不良反应。我家狗狗使用一年暂无问题,但不想让它们冒险。蓝瓶Dawn洗洁精洗澡能即时杀死跳蚤,但无法预防复发,且频繁洗澡对健康不利。需要寻找长效安全的替代方案。 |
| 补充说明: 是的,我是兽医助理。但我的老板坚持推荐Frontline,即使我反映无效且我家狗狗仍满身跳蚤,只能靠Comfortis缓解。在此事上他无法提供帮助。想了解其他宠物主(特别是圣地亚哥地区)的除蚤方案...我们这里的跳蚤简直像变异了,几乎所有方法都无效! |
| 摘要A: 跳蚤对多数除蚤产品(包括Comfortis)产生抗药性。寻求不伤害狗狗的长效解决方案。有人用过列出的产品吗? |
| 摘要B: 所有方法都无效,需要长效解决方案,Comfortis并非理想选择 |
Hard TL;DR comparison
硬核极简对比
POST
POST
| Subreddit:r/weddingplanning TITLE: Feeling major anxiety about dress shopping. |
| we've been struggling through the planning. At first, it was arguing with his parents about us getting married in a church.And then it was an argument about which venue to have the reception.Wefinally have the venue booked and the church matter settled. Now that's out of the way, I suddenly have this pit in my stomach My mom left me when I was 14. I've basically done everything on my own and I have really been ok about it. I'm sure it's not of the norm for me to feel so disassociated about the whole thing, but I am. I'm suppose to go look at wedding dresses this Friday. I am feeling super anxious because I don't know if trying on wedding baby and offending her. I don't want her thinking that I don't appreciate her being there. Aside from me worrying about becoming a giant baby, I've also been having issues with my bridal party. While I haven't made any official choices, I have ideas of who I want involved. That would be my best |
| dresses is going to turn me into a blubbering baby about not having a mom. My future mother-in-law is suppose to come with me to help look. I worry about turning into that blubbering |
| friend, my sister, and my future sister-in-law.My first choice for a MOH is my best friend. However, she lives out of state, and is in a medical program for school. So her visit time is severely limited. My sister feels |
| kindofweddingstuffdoneis almostimpossible. |
| Subreddit: r/weddingplanning 标题: 对挑选婚纱感到极度焦虑 |
|---|
Table 12: Top: Example of a random comparison task on the TL;DR dataset between two summaries from our 6.7B human feedback model. Comparison chosen randomly from the validation set. Bottom: An example of a difficult comparison task on the TL;DR dataset. Chosen by looking at comparisons between supervised baseline summaries with at least 4 labeler judgements and with at least $40%$ vote for each summary. Cherry-picked out of 10 to highlight an accuracy-coverage tradeoff. Summary A is inaccurate since the author does not explicitly say she is having doubts about trying on wedding dresses. Summary B is entirely accurate but does not capture the general essence of the post. In this case, 4 workers chose A and 3 workers chose B. For more comparisons, see our website.
表 12: 上: TL;DR 数据集中随机对比任务示例,对比来自我们 67 亿参数人类反馈模型的两个摘要。该对比随机选自验证集。下: TL;DR 数据集中一个困难对比任务示例。通过查看至少有 4 个标注员判断且每个摘要获得至少 40% 投票的监督基线摘要之间的对比而选出。从 10 个例子中精选以突出准确率-覆盖率的权衡。摘要 A 不准确,因为作者并未明确表示她对试穿婚纱产生疑虑。摘要 B 完全准确但未能抓住帖子主旨。本例中 4 名标注员选择 A,3 名选择 B。更多对比示例请见我们的网站。
D Choice of baselines
D 基线选择
In testing our human feedback techniques, we collected a large amount of high-quality data from human labelers. In order to compare fairly against supervision-based techniques, we would have needed to spend a similar amount of labeler time collecting high quality demonstrations, and used those to fine-tune a model via supervised learning. Because this is prohibitively expensive, we do not provide such a baseline.
在测试我们的人类反馈技术时,我们从人工标注员那里收集了大量高质量数据。为了公平地与基于监督的技术进行比较,我们需要花费类似的标注员时间来收集高质量演示样本,并通过监督学习微调模型。由于这一过程成本过高,我们未提供此类基线。
Existing prior work such as PEGASUS [70] has studied supervised methods on a dataset very similar to ours (the /r/tifu subset of TL;DR). However, they use much smaller (500M parameters) models, and report that their model outputs are worse than the human reference summaries, according to human evaluations. Thus, due to our limited labeler budget for evaluation, we decided to use our own supervised and zero-shot models as baselines (after sanity-checking the ROUGE performance of our supervised models), as well as T5 [49].
现有研究工作如PEGASUS [70] 曾在我们高度相似的数据集 (TL;DR的/r/tifu子集) 上探索过监督式方法。但该研究使用了参数量小得多的模型 (5亿参数) ,且人工评估表明其模型输出质量低于人工参考摘要。由于我们的评估标注预算有限,在验证监督模型的ROUGE性能后,我们决定采用自研的监督模型、零样本模型以及T5 [49] 作为基线。
T5 models [49] are pretrained and fine-tuned in a similar way to our supervised baselines, but they use an encoder-decoder architecture. We used T5 outputs which were obtained via beam search decoding, as described in [49]. We also carefully account for differences in token iz ation between model outputs.13
T5模型 [49] 以与我们监督基线类似的方式进行预训练和微调,但它们采用了编码器-解码器架构。我们使用了通过束搜索解码获得的T5输出,如 [49] 所述。同时,我们还仔细考虑了模型输出之间token化的差异。13
E CNN/DM lead-3 vs reference summaries
E CNN/DM lead-3 与参考摘要对比
On the CNN/DM dataset, our labelers significantly preferred lead-3 (a summary consisting of the first 3 sentences of the article) to reference summaries. In part this is due to longer summaries receiving higher coverage scores and lead-3 being $50%$ longer, as shown in Table 13.
在CNN/DM数据集上,我们的标注人员明显更倾向于lead-3(由文章前3句组成的摘要)而非参考摘要。部分原因是较长的摘要会获得更高的覆盖率分数,而lead-3比参考摘要长50%,如表13所示。
| Policy | Length (stdev) | Quality | Quality increase / 100 char. |
| ref | 314 (119) | 5.54 | 0.14 |
| lead-3 | 475 (114) | 6.23 | 0.34 |
Table 13: How length affects overall quality on CNN/DM for lead-3 and reference summaries.
| 策略 | 长度 (标准差) | 质量 | 每100字符质量提升 |
|---|---|---|---|
| ref | 314 (119) | 5.54 | 0.14 |
| lead-3 | 475 (114) | 6.23 | 0.34 |
表 13: lead-3和参考摘要的长度对CNN/DM整体质量的影响
However, if we use a linear regression (similar to the procedure in Appendix F) to predict what lead-3 performance would be if its average length were reduced to 314 characters, we still find a quality of 5.68, modestly higher than the reference summaries. Moreover, for lead-3 to even achieve parity with the reference summaries seems to call into question the need for abstract ive sum mari z ation or sophisticated ML methods, since a simple extractive baseline can match a perfect imitation of the reference summaries.
然而,如果我们使用线性回归(类似于附录F中的流程)来预测当lead-3的平均长度缩减至314个字符时的表现,其质量评分仍可达5.68,略高于参考摘要。更值得注意的是,lead-3要达到与参考摘要相当的水平,似乎对抽象摘要(abstractive summarization)或复杂机器学习方法的存在必要性提出了质疑——因为一个简单的抽取式基线方法就能达到对参考摘要的完美模仿效果。
We wanted to understand labeler behavior on these comparisons, to ensure that it was not an error. To do this, we examined a sample of our labeler’s judgments ourselves. We found that in 20/143 cases labelers preferred lead-3 by 3 points or more, and that excluding these datapoints would raise the relative score of the reference summaries by about 0.5 points.14 We were surprised to see the reference summaries performing so poorly in a significant fraction of cases, so we looked at labeler’s explanations and confirmed they made sense.
我们想了解标注员在这些比较中的行为,以确保这不是错误。为此,我们自行检查了标注员判断的样本。发现143个案例中有20例标注员更倾向于lead-3(领先3分或以上),若排除这些数据点,参考摘要的相对得分会提高约0.5分[14]。我们惊讶地发现参考摘要在相当一部分案例中表现如此不佳,因此查看了标注员的解释并确认其合理性。
We found that two features of the reference summaries explained most of its under performance. First, 13 of these 20 summaries omitted one of the key points from the article—the highlights are often written for a reader who had already seen the title of the article, even though the titles are not included in the CNN/DM dataset. Second, 10 of these 20 summaries actually introduced new information not present in the original article. From the perspective of labelers this information is totally confab u late d and so led to lower scores. A likely explanation for these errors is that the reference summaries are extracted from “highlights” on the news sites rather than being a straightforward summary of the article. These failures are common enough that they significantly impact the average quality of the reference summaries, and the effects seem to be large relative to quality differences between ML models.
我们发现参考摘要的两个特征解释了其表现不佳的主要原因。首先,这20篇摘要中有13篇遗漏了文章的关键点之一——这些摘要通常是写给已经看过文章标题的读者,尽管CNN/DM数据集中并未包含标题。其次,这20篇摘要中有10篇实际上引入了原文中不存在的新信息。从标注者的角度来看,这些信息完全是虚构的,因此导致评分降低。这些错误的一个可能解释是,参考摘要提取自新闻网站上的"亮点"部分,而非对文章的直白总结。这些失误相当普遍,显著影响了参考摘要的平均质量,其影响程度似乎远大于不同机器学习模型之间的质量差异。
Overall we believe that labeler judgments were reasonable in these cases, and that it is potentially problematic to treat the “highlights” in the CNN/DM dataset as reference summaries. You can view all of our labeler’s judgments on CNN/DM at our website.
总体而言,我们认为标注员在这些案例中的判断是合理的,将CNN/DM数据集中的"highlights"视为参考摘要可能存在潜在问题。您可以在我们的网站上查看标注员对CNN/DM数据集的所有判断。

Figure 10: (a) A length-controlled version of Figure 1, using the procedure described in Appendix F. Controlling for length reduces the relative preference of our human feedback models, however they are still preferred to the reference summaries. (b) Plotting model quality for different summary lengths on the TL;DR dataset. Our 6.7B human feedback model outperforms both the 6.7B supervised baseline and the reference summaries (horizontal line at 0.5) across lengths. Table 14: How length affects overall quality on CNN/DM. We show average length and quality scores for various policies, and how much the summary quality increases on average per 100 added characters.
图 10: (a) 图 1 的长度控制版本, 使用附录 F 中描述的程序。控制长度会降低人类反馈模型的相对偏好, 但它们仍然优于参考摘要。(b) 在 TL;DR 数据集上绘制不同摘要长度的模型质量。我们的 67 亿参数人类反馈模型在所有长度上都优于 67 亿参数监督基线模型和参考摘要 (水平线为 0.5)。
表 14: 长度如何影响 CNN/DM 的整体质量。我们展示了各种策略的平均长度和质量分数, 以及每增加 100 个字符摘要质量平均提高多少。
F Controlling for summary length
F 控制摘要长度
As discussed in Section 4.1, the length of a summary is a confounding factor for evaluating summary quality; depending on the desired trade-off between conciseness and coverage, a shorter or longer summary might be better. Our models generate summaries that are longer than the reference summaries, as this led to higher labeler preference given the 24-48 token limit for our task. Here we describe the procedure we use to attempt to control for length.
如第4.1节所述,摘要长度是评估摘要质量的混杂因素;根据简洁性与覆盖范围之间的权衡需求,较短或较长的摘要可能更优。我们的模型生成的摘要比参考摘要更长,因为在24-48个token的任务限制下,较长的摘要获得了标注者更高的偏好。此处我们描述用于控制长度的处理流程。
To calculate a single length-controlled preference number, we train a logistic regression model to predict the human-preferred summary on our dataset of human comparisons. We provide this model with 2 features: the identity of each policy, and the log ratio of the summary lengths. To calculate the length-controlled preference value between two policies, we simply give each policy ID to our trained logistic regression model and set the log length ratio to zero (see Figure 10a). In Figure 10b we examine summary quality across a range of summary lengths on TL;DR. We find that our human feedback model outperforms the supervised baseline across all length values.
为计算单一长度控制的偏好数值,我们训练了一个逻辑回归模型,用于在人工对比数据集上预测人类偏好的摘要。该模型接收两个特征:各策略的标识符及摘要长度的对数比率。计算两个策略间长度控制的偏好值时,只需将各策略ID输入训练好的逻辑回归模型,并将对数长度比率设为零 (见图10a)。图10b展示了TL;DR任务中不同摘要长度下的质量表现,结果显示我们的人类反馈模型在所有长度值上均优于监督基线。
For CNN/DM, we use a similar procedure as described above to control for length, except using a linear regression model to predict the Likert rating from 1-7. We show the expected quality increase for making summaries 100 characters longer in Table 14, which suggests our human feedback models would perform better if they generated longer summaries.
对于CNN/DM数据集,我们采用与上述类似的方法来控制摘要长度,不同之处在于使用线性回归模型来预测1-7分的Likert评分。表14展示了摘要增加100个字符时的预期质量提升,这表明如果人类反馈模型生成更长的摘要,其表现可能会更好。
| Policy | Length (stdev) | Quality (1-7) | Quality /100char. |
| sl(tldr)-1.3b | 138 (34) | 4.26 | 0.68 |
| sl(tldr)-6.7b | 127 (31) | 4.41 | 0.38 |
| gpt-1.3b | 141 (41) | 4.11 | 0.63 |
| gpt-6.7b | 142 (36) | 4.6 | 0.3 |
| rl(tldr)-1.3b | 166 (30) | 4.86 | 1.28 |
| rl(tldr)-6.7b | 175 (30) | 5.25 | 0.87 |
| sl(cnn)-6.7b | 300 (103) | 5.4 | 0.37 |
| ref | 314 (119) | 5.54 | 0.14 |
| lead-3 | 475 (114) | 6.23 | 0.34 |
| T5 | 316 (95) | 5.92 | 0.3 |
| 策略 | 长度 (标准差) | 质量 (1-7) | 每百字符质量 |
|---|---|---|---|
| sl(tldr)-1.3b | 138 (34) | 4.26 | 0.68 |
| sl(tldr)-6.7b | 127 (31) | 4.41 | 0.38 |
| gpt-1.3b | 141 (41) | 4.11 | 0.63 |
| gpt-6.7b | 142 (36) | 4.6 | 0.3 |
| rl(tldr)-1.3b | 166 (30) | 4.86 | 1.28 |
| rl(tldr)-6.7b | 175 (30) | 5.25 | 0.87 |
| sl(cnn)-6.7b | 300 (103) | 5.4 | 0.37 |
| ref | 314 (119) | 5.54 | 0.14 |
| lead-3 | 475 (114) | 6.23 | 0.34 |
| T5 | 316 (95) | 5.92 | 0.3 |
G Additional results
G 补充结果
G.1 Value function ablation
G.1 价值函数消融
In this section, we conduct an ablation comparing using separate parameters for the value function and policy, against using a shared network as done in [73]. The results, shown in Figure 11, clearly indicate that using separate networks outperforms the latter. On the other hand, having separate networks increases the memory requirements of running RL fine-tuning. Having separate networks also allows us to initialize the value function to be the learned reward model that is being optimized.
在本节中,我们进行了消融实验,比较了为价值函数和策略使用独立参数与采用[73]中共享网络方案的效果差异。如图11所示,结果表明独立网络结构显著优于共享方案。但需注意的是,独立网络会增加强化学习微调时的内存需求。这种架构还允许我们将已优化的奖励模型作为价值函数的初始化参数。

Figure 11: Comparing the reward obtained by optimizing with separate value function and reward model parameters to shared parameters.
图 11: 对比使用独立价值函数与奖励模型参数优化和共享参数优化所获得的奖励。
G.2 Evaluating policies along axes of quality
G.2 沿质量维度评估策略
We show the full results of the evaluations of policies on a 7-point Likert scale along different axes of quality; for TL;DR this is shown in Figure 12, and for CNN/DM this is shown in Figure 13. It is evident that on both datasets coverage correlates strongly with overall score across models, and all models achieve a high coherence score.
我们展示了不同质量维度上政策评估的完整结果(采用7级李克特量表);TL;DR 的结果如图 12 所示,CNN/DM 的结果如图 13 所示。显然,在两个数据集中,覆盖率与各模型的总体得分高度相关,且所有模型都获得了较高的连贯性分数。
G.3 Studying best-of-N optimization
G.3 研究最优N选择优化 (best-of-N optimization)
A natural way to evaluate an automatic evaluation metric is to see the extent to which optimizing against it leads to high performance according to humans. One way to assess this is to use best-of-N as an (inefficient) optimization technique — this has the benefits of being simple and invariant to monotonic transformations. We report results for up to best-of-2048 on ROUGE and three of our reward models in Figure 7, using samples from the 1.3B supervised baseline. The results suggest that optimizing against ROUGE significantly under-performs optimizing against our reward models. The data also suggests ROUGE degrades with too much optimization much faster than our reward models.
评估自动评估指标的一种自然方法是观察根据人类标准,针对该指标进行优化能在多大程度上带来高性能表现。一种评估方式是使用最佳N选一 (best-of-N) 作为(低效的)优化技术——这种方法具有简单且对单调变换保持不变的优点。我们在图7中报告了在ROUGE和三个奖励模型上最高达最佳2048选一的结果,使用的是来自13亿参数监督基线的样本。结果表明,针对ROUGE进行优化显著逊色于针对我们的奖励模型进行优化。数据还表明,ROUGE在过度优化情况下的性能下降速度远快于我们的奖励模型。
With increasing N, the best-of-N policies get higher average reward. Similarly, by decreasing the KL coefficient $\beta$ , the PPO policies get higher average reward. We found that at a given average reward, the best-of-N and PPO policies have similar quality as judged by human labelers (not shown). However, the PPO policy is farther from the supervised baseline than best-of-N is, as measured by the KL divergence.15
随着N的增加,最佳N策略( best-of-N )的平均奖励会提高。类似地,通过降低KL系数$\beta$,PPO策略也能获得更高的平均奖励。我们发现,在给定相同平均奖励水平时,人类标注员认为最佳N策略与PPO策略质量相当(数据未展示)。但通过KL散度测量,PPO策略与监督基线的偏离程度大于最佳N策略。15
G.4 ROUGE scores
G.4 ROUGE 分数
In Figure 14a and $14\mathrm{b}$ , we show the ROUGE scores of our models on the TL;DR and CNN/DM datasets, respectively. We report results with ${\mathrm{T}}{=}0$ , consistent with our human evaluations. We found that temperature has an (often significant) impact on ROUGE score, and we did a thorough sweep to verify that the best temperature setting is ${\mathrm{T}}{=}0$ .
在图 14a 和 $14\mathrm{b}$ 中,我们分别展示了模型在 TL;DR 和 CNN/DM 数据集上的 ROUGE 分数。我们报告了 ${\mathrm{T}}{=}0$ 时的结果,与人工评估一致。我们发现温度 (temperature) 对 ROUGE 分数有(通常是显著的)影响,并通过全面扫描验证了最佳温度设置为 ${\mathrm{T}}{=}0$。

Figure 12: Evaluating TL;DR policies on a 7-point Likert scale along several axes of quality. Table 15: Comparing the ROUGE score of our 6.7B supervised model on CNN/DM to recent SOTA models from the literature. Without any sum mari z ation-specific engineering, our model achieves ROUGE scores better than SOTA models from mid-2019, indicating that it is a strong baseline for comparison.
图 12: 采用7级李克特量表从多个质量维度评估TL;DR策略。
表 15: 将我们的67亿参数监督模型在CNN/DM数据集上的ROUGE分数与文献中的最新SOTA模型进行对比。在未进行任何摘要专项优化的前提下,我们的模型ROUGE分数优于2019年中期的SOTA模型,表明其可作为强有力的对比基线。
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
| ProphetNet [67] | 44.20 | 21.17 | 40.69 |
| T5 [49] | 43.52 | 21.55 | 40.69 |
| Our 6.7B supervised model | 42.49 | 19.84 | 39.53 |
| CNN-2sent-hieco-RBM [71] | 42.04 | 19.77 | 39.42 |
| 模型 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| ProphetNet [67] | 44.20 | 21.17 | 40.69 |
| T5 [49] | 43.52 | 21.55 | 40.69 |
| 我们的6.7B监督模型 | 42.49 | 19.84 | 39.53 |
| CNN-2sent-hieco-RBM [71] | 42.04 | 19.77 | 39.42 |

Figure 13: Evaluating CNN/DM policies on a 7-point Likert scale along several axes of quality.
图 13: 在多个质量维度上以7级李克特量表评估CNN/DM策略。
On TL;DR, we find that our human feedback models obtain a slightly lower ROUGE score than the supervised models at $T=0$ , further indicating that ROUGE correlates poorly with human preferences. For supervised models, lowering temperature has a larger impact than increasing model size. Interestingly, at higher temperatures, our feedback models actually outperform supervised counterparts (not shown).
在TL;DR任务上,我们发现人类反馈模型在$T=0$时的ROUGE分数略低于监督模型,进一步表明ROUGE指标与人类偏好相关性较弱。对于监督模型而言,降低温度参数比增加模型规模的影响更大。有趣的是,在较高温度条件下,我们的反馈模型实际表现优于监督模型(未展示数据)。
On CNN/DM, ROUGE agrees with our human evaluations that our human feedback models transfer better than our supervised models. However, un surprisingly, supervised CNN/DM models still achieve much higher ROUGE. In Table 15, we show the ROUGE results on CNN/DM for our 6.7B supervised baseline and various models from the literature. We find that our model achieves ROUGE scores less than T5 [49], but slightly greater than the CNN-2sent-hieco-RBM model from [71], which was SOTA for abstract ive sum mari z ation on CNN/DM in mid-2019 according to the NLP-progress leader board.16
在CNN/DM数据集上,ROUGE指标与人工评估结果一致,表明我们基于人类反馈的模型比监督学习模型具有更好的迁移性能。但不出所料,监督式CNN/DM模型仍能获得显著更高的ROUGE分数。表15展示了我们6.7B监督基线模型与文献中多种模型在CNN/DM上的ROUGE结果。我们的模型得分低于T5[49],但略高于[71]提出的CNN-2sent-hieco-RBM模型——根据NLP-progress排行榜,该模型曾在2019年年中保持CNN/DM抽象摘要任务的SOTA记录。
G.5 Bigram overlap statistics
G.5 二元语法重叠统计
In Table 16, we show the bigram overlap statistics for our models on the TL;DR and CNN/DM datasets as a proxy for how much the summaries copy frmo the post. As in Section 4.4, we compute the longest common sub sequence of bigrams with the original Reddit post or news article, and dividing by the number of bigrams in the summary. We find that models evaluated on CNN/DM (whether or not they were trained on CNN/DM) generally copy more than models evaluated on TL;DR. Further, our supervised and human feedback models copy less than our pretrained models.
表 16: 我们展示了模型在TL;DR和CNN/DM数据集上的二元组重叠统计量,作为摘要从原文中复制程度的代理指标。如第4.4节所述,我们计算摘要与原始Reddit帖子或新闻文章的最长二元组公共子序列,并除以摘要中的二元组数量。研究发现,在CNN/DM上评估的模型(无论是否在CNN/DM上训练)通常比在TL;DR上评估的模型复制更多内容。此外,我们的监督学习和人类反馈模型比预训练模型复制的内容更少。

Figure 14: ROUGE scores for our models on (a) the TL;DR dataset, and (b) the CNN/DM dataset. Table 16: Bigram overlap statistics on the TL;DR dataset (top) and the CNN/DM dataset (bottom). Models trained on CNN/DM copy significantly more than models trained on TL;DR.
图 14: 我们的模型在 (a) TL;DR 数据集和 (b) CNN/DM 数据集上的 ROUGE 分数。
表 16: TL;DR 数据集(上)和 CNN/DM 数据集(下)的双词重叠统计。在 CNN/DM 上训练的模型比在 TL;DR 上训练的模型复制内容明显更多。
| Evaluated on TL;DR | |
| Model | Model size Bigram overlap % |
| GPT 1.3B | 66.7% |
| GPT 3B | 72.7% |
| GPT 6.7B | 61.4% |
| GPT 13B | 75.9% |
| Supervised (TL;DR) 1.3B 3B | 49.0% |
| Supervised (TL;DR) Supervised (TL;DR) 6.7B | 48.7% 48.9% |
| Supervised (TL;DR) 13B | 48.0% |
| Human feedback (TL;DR) 1.3B | 53.3% |
| Human feedback (TL;DR) 6.7B | 46.0% |
| Evaluated onCNN/DM | |
| Model Model size | Bigram overlap % |
| GPT 1.3B | 76.3% |
| GPT 6.7B | 76.2% |
| Supervised (TL;DR) 1.3B | 59.5% |
| Supervised (TL;DR) 6.7B | 56.9% |
| Human feedback (TL;DR) 1.3B | 64.8% |
| Human feedback (TL;DR) 6.7B | 51.2% |
| Supervised (CNN/DM) 1.3B | 66.0% |
| T5 11B | 68.8% |
| reference | 36.8% |
| 评估数据集 | 模型 | 模型规模 | 二元重叠率 |
|---|---|---|---|
| TL;DR | GPT 1.3B | - | 66.7% |
| GPT 3B | - | 72.7% | |
| GPT 6.7B | - | 61.4% | |
| GPT 13B | - | 75.9% | |
| Supervised (TL;DR) 1.3B 3B | - | 49.0% | |
| Supervised (TL;DR) 6.7B | - | 48.7% | |
| Supervised (TL;DR) 13B | - | 48.0% | |
| Human feedback (TL;DR) 1.3B | - | 53.3% | |
| Human feedback (TL;DR) 6.7B | - | 46.0% | |
| CNN/DM | GPT 1.3B | - | 76.3% |
| GPT 6.7B | - | 76.2% | |
| Supervised (TL;DR) 1.3B | - | 59.5% | |
| Supervised (TL;DR) 6.7B | - | 56.9% | |
| Human feedback (TL;DR) 1.3B | - | 64.8% | |
| Human feedback (TL;DR) 6.7B | - | 51.2% | |
| Supervised (CNN/DM) 1.3B | - | 66.0% | |
| T5 11B | - | 68.8% | |
| reference | - | 36.8% |
G.6 Reward model validation sets
G.6 奖励模型验证集
In this section, we report results evaluating our reward models on various manually constructed validation sets, shown in Tables 17 and 18. Notably, we asked our humans to produce a small dataset of edits, by having them make improvements to existing summaries (either reference summaries or supervised baseline summaries). Our 6.7B reward model prefer the improved summaries at a similar rate to humans (who do not know which summary has been edited).
在本节中,我们报告了在不同人工构建验证集上评估奖励模型的结果(如表17和表18所示)。值得注意的是,我们要求标注人员通过改进现有摘要(包括参考摘要和监督基线摘要)来生成一个小的编辑数据集。我们的67亿参数奖励模型对改进后摘要的偏好率与人类(不知道哪个摘要被编辑过)基本一致。
Our reward models are also sensitive to sentence shuffling (whereas metrics like ROUGE are largely not), and are able to detect when the roles portrayed in the summary have been switched. On the other hand, our reward models sometimes exhibit preference for poor artificial summaries, such as the post title copied twice, or asking for advice at the end of the summary. In Table 19, we show examples where our model is sensitive to small, semantically meaningful changes in the summary.
我们的奖励模型对句子重组也很敏感(而像ROUGE这样的指标大多不敏感),并且能够检测摘要中描述的角色是否被调换。另一方面,我们的奖励模型有时会表现出对低质量人工摘要的偏好,例如将帖子标题复制两次,或在摘要结尾处请求建议。在表19中,我们展示了模型对摘要中微小但具有语义意义变化的敏感案例。
| RM size | Edit length | RM prefers edit | Human prefers edit | RM,human agree |
| 1.3B | Shorter | 63.6% | 76.2% | 62.1% |
| Longer | 86.8% | 88.6% | 79.6% | |
| Avg. | 81.2% | 85.6% | 75.4% | |
| 6.7B | Shorter | 66.0% | 76.2% | 65.5% |
| Longer | 89.2% | 88.6% | 80.2% | |
| Avg. | 83.7% | 85.6% | 76.7% |
Table 17: Comparing reward model and human preference of summaries that were edited by humans to make them better. For each summary, the human labeler that makes the comparison is different than the labeler that wrote the edit. The agreement numbers do not include comparisons where the labeler’s preference was marked as ‘uncertain’.
| RM 大小 | 编辑长度 | RM 偏好编辑 | 人类偏好编辑 | RM与人类一致率 |
|---|---|---|---|---|
| 1.3B | 较短 | 63.6% | 76.2% | 62.1% |
| 较长 | 86.8% | 88.6% | 79.6% | |
| 平均 | 81.2% | 85.6% | 75.4% | |
| 6.7B | 较短 | 66.0% | 76.2% | 65.5% |
| 较长 | 89.2% | 88.6% | 80.2% | |
| 平均 | 83.7% | 85.6% | 76.7% |
表 17: 对比奖励模型与人类对经过人工编辑改进后摘要的偏好。每份摘要的对比标注者与进行编辑的标注者不同。一致率数据不包含标注者偏好标记为"不确定"的对比情况。
| SummaryA | SummaryB | Preference % of Summary A | |
| 1.3BRM | 6.7BRM | ||
| Original summary | Reversedroles | 93.1% | 97.4% |
| lead-3 | Shuffledlead-3 | 68.1% | 75.5% |
| rand-3 | Shuffledrand-3 | 60.8% | 76.1% |
| Post title | Random title | 97.4% | 98.5% |
| Post title | Random titlefromsame subreddit | 98.8% | 97.2% |
| Post title | Post title repeated twice | 84.6% | 58.4% |
| (r/tifu only) Reference summary | Ref+“What shouldI do?" | 34.3 % | 74.5% |
| Referencesummary | lead-3 | 63.0% | 56.4% |
| Referencesummary | lead-2 | 71.0% | 73.8% |
| Referencesummary | rand-3 | 69.5% | 59.5% |
Table 18: Reward model performance on various manually constructed validation sets. In all cases, Summary A is intended to be better than Summary B, and thus a higher preference $%$ is generally better. ‘rand $.3^{\circ}$ indicates a baseline where 3 random sentences are taken from the post; however these sentences are kept in the order in which they appear in the post. ‘Original summary’ is either the reference summary or a summary from our supervised baselines. r/tifu is a subreddit whose purpose is sharing embarrassing stories (not asking for advice).
表 18: 人工构建验证集上的奖励模型性能表现。所有测试中,Summary A 均设计为优于 Summary B,因此更高的偏好百分比通常代表更好表现。"rand-3"表示从帖子中随机选取3个句子作为基线(保持原文顺序) ,"Original summary"指参考摘要或监督基线的摘要结果。r/tifu是一个专门分享尴尬故事的子论坛(非求助类)。
G.7 Measuring agreement between different evaluation metrics
G.7 不同评估指标间一致性的衡量
We are interested in understanding the relationship between different metrics for evaluating summaries. To do this, we compute agreement between various metrics, including automatic metrics and humans, for different subsets of the data for which we have human evaluations. To remove policy quality as a confounding variable, all of the summary comparisons are generated by the same policy at the same temperature value. In Table 20, we use samples from our 1.3B supervised model at $\mathrm{T}{=}0.7$ on TL;DR; Table 21 has comparisons from our 6.7B supervised model at $\mathrm{T}{=}0.7$ on TL;DR; Table 22 has comparisons from our 6.7B human feedback model at ${\mathrm{T}}{=}0.7$ on TL;DR; and Table 23 has comparisons from our 6.7B supervised baseline trained on CNN/DM.
我们旨在探究不同摘要评估指标之间的关系。为此,我们计算了包括自动指标和人工评估在内的多种指标在已获人工评估数据子集上的一致性。为排除策略质量的干扰变量,所有摘要对比均采用相同策略在相同温度值下生成。表20展示了1.3B监督模型在TL;DR数据集上$\mathrm{T}{=}0.7$的采样结果;表21呈现了6.7B监督模型在TL;DR数据集上$\mathrm{T}{=}0.7$的对比数据;表22记录了6.7B人类反馈模型在TL;DR数据集上${\mathrm{T}}{=}0.7$的对比结果;表23则展示了基于CNN/DM训练的6.7B监督基线模型的对比数据。
Our 6.7B reward model generally agrees with labelers as much as other labelers, although an ensemble of labelers does better. On the other hand, ROUGE generally has poor agreement, as does log probability under the supervised baselines, with simple heuristics like copying (longest common sub sequence of bigrams with the article) and length often performing comparably.
我们的6.7B奖励模型与其他标注者的判断一致程度相当,尽管标注者集成效果更好。另一方面,ROUGE和监督基线下的对数概率表现较差,而简单的启发式方法(如复制文章中最长的二元子序列)和长度因素往往表现相当。
| Editedsummary | Reward |
| Crush on girl I haven't seen in 4 years. She doesn't like me and I don't still like +0.64 her. What do? | |
| A girl told me she loved liked me, she ended up picking another guy over me, +0.82 that guy badly influenced her, and now I'm here alone thinking what could've been. | |
| I tried to show my friend a picture of my tarantula and she smashed my phone -0.64 with all her might and now I lost a good friend phone. | |
| Boyfriend still FB stalks his high school ex girlfriend from time to time and+0.73 told me when he was very drunk that she was his first love. | |
| I've become pathetic, pining after a guy my ex. Would like to reach state of less +0.69 pathetic. If more info is necessary, please let me know. | |
| I have body issues (body acne/scarring and weight issues) that prevent me from +1.0 having a normal life without shame and prevent me from having a better sex life with my BF. | |
| Do you take someone back after they've turned you down off, even if you can't +0.52 see them in person or are they just not worth the risk? |
| 编辑后的摘要 | 情感分值 |
|---|---|
| 暗恋一个四年未见的女孩。她不喜欢我,我也不再喜欢她了。该怎么办? | +0.64 |
| 有个女孩说喜欢我,最后却选了别人。那个男生把她带坏了,现在只剩我独自幻想"如果当初"。 | +0.82 |
| 我给朋友看捕鸟蛛照片,她却猛砸我手机,现在既失去了好友又丢了手机。 | -0.64 |
| 男友还在FB偷偷关注高中前女友,有次醉酒后承认那是他初恋。 | +0.73 |
| 我变得很可悲,居然惦记着前任的现男友。想摆脱这种卑微状态,需要更多建议请告诉我。 | +0.69 |
| 身体问题(痤疮疤痕和体重)让我无法正常生活,也影响了和男友的亲密关系。 | +1.0 |
| 被拒绝后是否该挽回?尤其当无法见面时,这样的人值得冒险吗? | +0.52 |
Table 19: Qualitative examples showing the change in reward of the reward model on humangenerated edits to TL;DR summaries that make the summaries better. Examples are randomly selected from the set where the edit distance was less than 5 and the magnitude of change in reward was greater than 0.5. Text in strike-through was removed from the original summary in the edit, and text in bold was added. The reward model is sensitive to small but semantically meaningful changes in the summary, although it makes errors on occasion.
表 19: 展示奖励模型对人类编辑TL;DR摘要后奖励值变化的定性示例。这些示例是从编辑距离小于5且奖励变化幅度大于0.5的集合中随机选取的。带删除线的文本是编辑时从原摘要中移除的内容,加粗文本是新增内容。该奖励模型能敏锐捕捉摘要中细微但语义重要的改动,不过偶尔也会出现误判。
| TL;DR 1.3B sup. T=0.7 | researcher labeler | labeler ensem- ble | length | copying | ROUGE | 1.3B sup | 1.3B RM | 6.7B sup | 6.7B RM | |
| researcher | 73.4% ±4.1% | 77.7% ±2.1% | 84.4% ±3.3% | 55.5% ±4.3% | 62.3% ±4.1% | 59.1% ±4.2% | logprob 61.8% ±4.8% | 72.2% ±4.5% | logprob 62.8% ±4.7% | 78.0% ±3.9% |
| labeler | 77.7% ±2.1% | 68.6% ±1.7% | 74.4% ±2.0% | 54.4% ±1.3% | 58.0% ±1.2% | 57.7% ±1.3% | 58.7% ±2.0% | 65.8% ±2.0% | 61.9% ±2.1% | 70.8% ±1.8% |
| labeler ensemble | 84.4% ±3.3% | 74.4% ±2.0% | 60.6% ±4.0% | 62.7% ±3.8% | 59.0% ±3.9% | 59.5% ±4.4% | 71.0% ±3.9% | 59.5% ±4.3% | 72.5% ±3.8% | |
| length | 55.5% ±4.3% | 54.4% ±1.3% | 60.6% ±4.0% | 50.1% ±1.3% | 58.6% ±1.2% | 28.9% ±2.1% | 52.6% ±2.3% | 27.6% ±2.0% | 54.3% ±2.3% | |
| copying | 62.3% ±4.1% | 58.0% ±1.2% | 62.7% ±3.8% | 50.1% ±1.3% | 51.9% ±1.2% | 61.6% ±2.3% | 57.8% ±2.3% | 60.9% ±2.2% | 55.5% ±2.2% | |
| ROUGE | 59.1% ±4.2% | 57.7% ±1.3% | 59.0% ±3.9% | 58.6% ±1.2% | 51.9% ±1.2% | 49.5% ±2.3% | 56.4% ±2.2% | 51.1% ±2.3% | 59.2% ±2.3% | |
| 1.3B sup. logprob | 61.8% ±4.8% | 58.7% ±2.0% | 59.5% ±4.4% | 28.9% ±2.1% | 61.6% ±2.3% | 49.5% ±2.3% | 58.7% ±2.3% | 92.7% ±1.2% | 60.6% ±2.3% | |
| 1.3B RM | 72.2% ±4.5% | 65.8% ±2.0% | 71.0% ±3.9% | 52.6% ±2.3% | 57.8% ±2.3% | 56.4% ±2.2% | 58.7% ±2.3% | 58.8% ±2.2% | 78.8% ±1.8% | |
| 6.7B sup. logprob | 62.8% ±4.7% | 61.9% ±2.1% | 59.5% ±4.3% | 27.6% ±2.0% | 60.9% ±2.2% | 51.1% ±2.3% | 92.7% ±1.2% | 58.8% ±2.2% | 61.5% ±2.2% | |
| 6.7B RM | 78.0% ±3.9% | 70.8% ±1.8% | 72.5% ±3.8% | 54.3% ±2.3% | 55.5% ±2.2% | 59.2% ±2.3% | 60.6% ±2.3% | 78.8% ±1.8% | 61.5% ±2.2% |
Table 20: Agreement rates between humans and various automated metrics on TL;DR 1.3b supervised model at $\mathrm{T}{=}0.7$ . Standard errors estimated via boots trapping. Note: in the entry for labeler vs. labeler ensemble, the ensembles are slightly smaller than for other comparisons because we need to exclude the labeler being predicted. All ensembles have at least 3 workers.
表 20: TL;DR 1.3B监督模型在$\mathrm{T}{=}0.7$温度下人工标注与各自动化指标的吻合率。标准误差通过自助法(bootstrapping)估算。注: 标注员与标注员集成组的对比项中,集成组规模略小于其他对比组(需排除被预测的标注员),所有集成组至少包含3名标注员。
| TL;DR 1.3B sup. T=0.7 | researcher | labeler | labeler ensemble | length | copying | ROUGE | 1.3B sup | 1.3B RM | 6.7B sup | 6.7B RM |
|---|---|---|---|---|---|---|---|---|---|---|
| researcher | 73.4% ±4.1% | 77.7% ±2.1% | 84.4% ±3.3% | 55.5% ±4.3% | 62.3% ±4.1% | 59.1% ±4.2% | logprob 61.8% ±4.8% | 72.2% ±4.5% | logprob 62.8% ±4.7% | 78.0% ±3.9% |
| labeler | 77.7% ±2.1% | 68.6% ±1.7% | 74.4% ±2.0% | 54.4% ±1.3% | 58.0% ±1.2% | 57.7% ±1.3% | 58.7% ±2.0% | 65.8% ±2.0% | 61.9% ±2.1% | 70.8% ±1.8% |
| labeler ensemble | 84.4% ±3.3% | 74.4% ±2.0% | - | 60.6% ±4.0% | 62.7% ±3.8% | 59.0% ±3.9% | 59.5% ±4.4% | 71.0% ±3.9% | 59.5% ±4.3% | 72.5% ±3.8% |
| length | 55.5% ±4.3% | 54.4% ±1.3% | 60.6% ±4.0% | - | 50.1% ±1.3% | 58.6% ±1.2% | 28.9% ±2.1% | 52.6% ±2.3% | 27.6% ±2.0% | 54.3% ±2.3% |
| copying | 62.3% ±4.1% | 58.0% ±1.2% | 62.7% ±3.8% | 50.1% ±1.3% | - | 51.9% ±1.2% | 61.6% ±2.3% | 57.8% ±2.3% | 60.9% ±2.2% | 55.5% ±2.2% |
| ROUGE | 59.1% ±4.2% | 57.7% ±1.3% | 59.0% ±3.9% | 58.6% ±1.2% | 51.9% ±1.2% | - | 49.5% ±2.3% | 56.4% ±2.2% | 51.1% ±2.3% | 59.2% ±2.3% |
| 1.3B sup. logprob | 61.8% ±4.8% | 58.7% ±2.0% | 59.5% ±4.4% | 28.9% ±2.1% | 61.6% ±2.3% | 49.5% ±2.3% | - | 58.7% ±2.3% | 92.7% ±1.2% | 60.6% ±2.3% |
| 1.3B RM | 72.2% ±4.5% | 65.8% ±2.0% | 71.0% ±3.9% | 52.6% ±2.3% | 57.8% ±2.3% | 56.4% ±2.2% | 58.7% ±2.3% | - | 58.8% ±2.2% | 78.8% ±1.8% |
| 6.7B sup. logprob | 62.8% ±4.7% | 61.9% ±2.1% | 59.5% ±4.3% | 27.6% ±2.0% | 60.9% ±2.2% | 51.1% ±2.3% | 92.7% ±1.2% | 58.8% ±2.2% | - | 61.5% ±2.2% |
| 6.7B RM | 78.0% ±3.9% | 70.8% ±1.8% | 72.5% ±3.8% | 54.3% ±2.3% | 55.5% ±2.2% | 59.2% ±2.3% | 60.6% ±2.3% | 78.8% ±1.8% | 61.5% ±2.2% | - |
| TL;DR 6.7B sup. T=0.7 | labeler | labeler ensem- ble | length | copying | ROUGE | 1.3B sup logprob | 1.3B RM | 6.7B sup logprob | 6.7B RM |
| labeler | 70.8% ±2.6% | 73.1% ±2.9% | 56.9% %90干 | 56.4% ±0.6% | 56.9% ±0.6% | 54.5% ±1.2% | 67.5% ±1.1% | 54.3% ±1.2% | 69.7% ±1.1% |
| labeler ensemble | 73.1% ±2.9% | 55.0% ±5.1% | 54.5% ±4.8% | 66.7% ±4.7% | 61.1% ±11.4% | 77.8% ±9.7% | 55.6% ±11.7% | 77.8% ±10.0% | |
| length | 56.9% ±0.6% | 55.0% ±5.1% | — | 50.5% ±0.6% | 60.2% ±0.6% | 26.9% ±1.1% | 59.5% ±1.2% | 26.4% ±1.1% | 60.3% ±1.1% |
| copying | 56.4% ±0.6% | 54.5% ±4.8% | 50.5% ±0.6% | 54.4% ±0.6% | 59.3% ±1.1% | 57.9% ±1.2% | 60.2% ±1.2% | 58.0% ±1.2% | |
| ROUGE | 56.9% ±0.6% | 66.7% ±4.7% | 60.2% ±0.6% | 54.4% ±0.6% | 48.7% ±1.2% | 58.1% ±1.2% | 47.7% ±1.2% | 58.4% ±1.2% | |
| 1.3Bsup logprob | 54.5% ±1.2% | 61.1% ±11.4% | 26.9% ±1.1% | 59.3% ±1.1% | 48.7% ±1.2% | 53.3% ±1.2% | 91.9% ±0.6% | 53.8% ±1.2% | |
| 1.3BRM | 67.5% ±1.1% | 77.8% ±9.7% | 59.5% ±1.2% | 57.9% ±1.2% | 58.1% ±1.2% | 53.3% ±1.2% | 54.1% ±1.2% | 78.8% ±1.0% | |
| 6.7B sup logprob | 54.3% ±1.2% | 55.6% ±11.7% | 26.4% ±1.1% | 60.2% ±1.2% | 47.7% ±1.2% | 91.9% ±0.6% | 54.1% ±1.2% | 54.5% ±1.2% | |
| 6.7B RM | 69.7% ±1.1% | 77.8% ±10.0% | 60.3% ±1.1% | 58.0% ±1.2% | 58.4% ±1.2% | 53.8% ±1.2% | 78.8% ±1.0% | 54.5% ±1.2% |
Table 21: Agreement rates between humans and various automated metrics on TL;DR 6.7B supervised model at $\mathrm{T}{=}0.7$ . Standard errors estimated via boots trapping. Note: in the entry for labeler vs. labeler ensemble, the ensembles are slightly smaller than for other comparisons because we need to exclude the labeler being predicted. All ensembles have at least 3 workers.
表 21: TL;DR 6.7B监督模型在$\mathrm{T}{=}0.7$温度下人类与各类自动化指标的吻合率。标准误差通过自助法(bootstrapping)估算。注: 标注员与标注员集成对比项中,由于需排除被预测的标注员,集成规模略小于其他对比组。所有集成组至少包含3名标注员。
| TL;DR 6.7B sup. T=0.7 | 标注员 | 标注员集成 | 长度 | 复制 | ROUGE | 1.3B监督对数概率 | 1.3B奖励模型 | 6.7B监督对数概率 | 6.7B奖励模型 |
|---|---|---|---|---|---|---|---|---|---|
| 标注员 | 70.8% ±2.6% | 73.1% ±2.9% | 56.9% ±0.6% | 56.4% ±0.6% | 56.9% ±0.6% | 54.5% ±1.2% | 67.5% ±1.1% | 54.3% ±1.2% | 69.7% ±1.1% |
| 标注员集成 | 73.1% ±2.9% | — | 55.0% ±5.1% | 54.5% ±4.8% | 66.7% ±4.7% | 61.1% ±11.4% | 77.8% ±9.7% | 55.6% ±11.7% | 77.8% ±10.0% |
| 长度 | 56.9% ±0.6% | 55.0% ±5.1% | — | 50.5% ±0.6% | 60.2% ±0.6% | 26.9% ±1.1% | 59.5% ±1.2% | 26.4% ±1.1% | 60.3% ±1.1% |
| 复制 | 56.4% ±0.6% | 54.5% ±4.8% | 50.5% ±0.6% | — | 54.4% ±0.6% | 59.3% ±1.1% | 57.9% ±1.2% | 60.2% ±1.2% | 58.0% ±1.2% |
| ROUGE | 56.9% ±0.6% | 66.7% ±4.7% | 60.2% ±0.6% | 54.4% ±0.6% | — | 48.7% ±1.2% | 58.1% ±1.2% | 47.7% ±1.2% | 58.4% ±1.2% |
| 1.3B监督对数概率 | 54.5% ±1.2% | 61.1% ±11.4% | 26.9% ±1.1% | 59.3% ±1.1% | 48.7% ±1.2% | — | 53.3% ±1.2% | 91.9% ±0.6% | 53.8% ±1.2% |
| 1.3B奖励模型 | 67.5% ±1.1% | 77.8% ±9.7% | 59.5% ±1.2% | 57.9% ±1.2% | 58.1% ±1.2% | 53.3% ±1.2% | — | 54.1% ±1.2% | 78.8% ±1.0% |
| 6.7B监督对数概率 | 54.3% ±1.2% | 55.6% ±11.7% | 26.4% ±1.1% | 60.2% ±1.2% | 47.7% ±1.2% | 91.9% ±0.6% | 54.1% ±1.2% | — | 54.5% ±1.2% |
| 6.7B奖励模型 | 69.7% ±1.1% | 77.8% ±10.0% | 60.3% ±1.1% | 58.0% ±1.2% | 58.4% ±1.2% | 53.8% ±1.2% | 78.8% ±1.0% | 54.5% ±1.2% | — |
| TL;DR 6.7B RL T=0.7 | labeler | labeler ensem- ble | length | copying | ROUGE | 1.3B sup logprob | 1.3B RM | 6.7B sup logprob | 6.7B RM |
| labeler | 60.4% ±5.9% | 66.0% ±7.6% | 55.8% ±2.2% | 52.7% ±2.1% | 49.9% ±2.1% | 48.0% ±2.2% | 57.4% ±2.0% | 47.3% ±2.2% | 62.3% ±2.1% |
| labeler ensemble | 66.0% ±7.6% | 80.0% ±8.9% | 65.0% ±10.6% | 35.0% ±10.5% | 45.0% ±11.1% | 75.0% ±9.8% | 40.0% ±10.5% | 75.0% ±9.8% | |
| length | 55.8% ±2.2% | 80.0% ±8.9% | 48.1% ±2.2% | 50.3% ±2.2% | 30.0% ±2.1% | 62.0% ±2.1% | 30.4% ±2.0% | 59.8% ±2.2% | |
| copying | 52.7% ±2.1% | 65.0% ±10.6% | 48.1% ±2.2% | — | 52.0% ±2.2% | 64.2% ±2.1% | 56.7% ±2.2% | 64.4% ±2.1% | 53.4% ±2.2% |
| ROUGE | 49.9% ±2.1% | 35.0% ±10.5% | 50.3% ±2.2% | 52.0% ±2.2% | 50.5% ±2.2% | 52.0% ±2.3% | 51.1% ±2.3% | 54.5% ±2.1% | |
| 1.3Bsup. logprob | 48.0% ±2.2% | 45.0% ±11.1% | 30.0% ±2.1% | 64.2% ±2.1% | 50.5% ±2.2% | 47.0% ±2.2% | 90.2% ±1.3% | 46.1% ±2.2% | |
| 1.3B RM | 57.4% ±2.0% | 75.0% ±9.8% | 62.0% ±2.1% | 56.7% ±2.2% | 52.0% ±2.3% | 47.0% ±2.2% | 45.7% ±2.1% | 71.4% ±2.0% | |
| 6.7B sup logprob | 47.3% ±2.2% | 40.0% ±10.5% | 30.4% ±2.0% | 64.4% ±2.1% | 51.1% ±2.3% | 90.2% ±1.3% | 45.7% ±2.1% | 44.7% ±2.1% | |
| 6.7B RM | 62.3% ±2.1% | 75.0% ±9.8% | 59.8% ±2.2% | 53.4% ±2.2% | 54.5% ±2.1% | 46.1% ±2.2% | 71.4% ±2.0% | 44.7% ±2.1% |
Table 22: Agreement rates between humans and various automated metrics on TL;DR 6.7B human feedback optimized model at ${\mathrm{T}}{=}0.7$ . Standard errors estimated via boots trapping. Note: in the entry for labeler vs. labeler ensemble, the ensembles are slightly smaller than for other comparisons because we need to exclude the labeler being predicted. All ensembles have at least 3 workers.
表 22: TL;DR 6.7B 人类反馈优化模型在 ${\mathrm{T}}{=}0.7$ 温度参数下,人工标注者与各自动化指标间的一致性比率。标准误差通过自助法(bootstrapping)估算。注:在标注者 vs. 标注者集成的对比项中,由于需排除被预测的标注者,集成规模略小于其他对比组。所有集成组至少包含3名标注人员。
| TL;DR 6.7B RL T=0.7 | 标注者 | 标注者集成 | 长度 | 复制 | ROUGE | 1.3B监督对数概率 | 1.3B奖励模型 | 6.7B监督对数概率 | 6.7B奖励模型 |
|---|---|---|---|---|---|---|---|---|---|
| 标注者 | 60.4% ±5.9% | 66.0% ±7.6% | 55.8% ±2.2% | 52.7% ±2.1% | 49.9% ±2.1% | 48.0% ±2.2% | 57.4% ±2.0% | 47.3% ±2.2% | 62.3% ±2.1% |
| 标注者集成 | 66.0% ±7.6% | — | 80.0% ±8.9% | 65.0% ±10.6% | 35.0% ±10.5% | 45.0% ±11.1% | 75.0% ±9.8% | 40.0% ±10.5% | 75.0% ±9.8% |
| 长度 | 55.8% ±2.2% | 80.0% ±8.9% | — | 48.1% ±2.2% | 50.3% ±2.2% | 30.0% ±2.1% | 62.0% ±2.1% | 30.4% ±2.0% | 59.8% ±2.2% |
| 复制 | 52.7% ±2.1% | 65.0% ±10.6% | 48.1% ±2.2% | — | 52.0% ±2.2% | 64.2% ±2.1% | 56.7% ±2.2% | 64.4% ±2.1% | 53.4% ±2.2% |
| ROUGE | 49.9% ±2.1% | 35.0% ±10.5% | 50.3% ±2.2% | 52.0% ±2.2% | — | 50.5% ±2.2% | 52.0% ±2.3% | 51.1% ±2.3% | 54.5% ±2.1% |
| 1.3B监督对数概率 | 48.0% ±2.2% | 45.0% ±11.1% | 30.0% ±2.1% | 64.2% ±2.1% | 50.5% ±2.2% | — | 47.0% ±2.2% | 90.2% ±1.3% | 46.1% ±2.2% |
| 1.3B奖励模型 | 57.4% ±2.0% | 75.0% ±9.8% | 62.0% ±2.1% | 56.7% ±2.2% | 52.0% ±2.3% | 47.0% ±2.2% | — | 45.7% ±2.1% | 71.4% ±2.0% |
| 6.7B监督对数概率 | 47.3% ±2.2% | 40.0% ±10.5% | 30.4% ±2.0% | 64.4% ±2.1% | 51.1% ±2.3% | 90.2% ±1.3% | 45.7% ±2.1% | — | 44.7% ±2.1% |
| 6.7B奖励模型 | 62.3% ±2.1% | 75.0% ±9.8% | 59.8% ±2.2% | 53.4% ±2.2% | 54.5% ±2.1% | 46.1% ±2.2% | 71.4% ±2.0% | 44.7% ±2.1% | — |
H Samples
H 样本
H.1 Random samples
H.1 随机样本
Here we provide non-cherry-picked samples and human evaluations for various models. In Tables 25- 26 we show samples on the TL;DR dataset, and in Tables 27-28 we show samples on the CNN/DM dataset (where we truncate the article for brevity). See our website for more uncurated policy samples.
我们在此提供各类模型的非精选样本和人工评估结果。表25-26展示了TL;DR数据集上的样本,表27-28则呈现了CNN/DM数据集的样本(出于简洁考虑对文章进行了截断)。更多未经筛选的策略样本请参见我们的网站。
H.2 Over optimized samples
H.2 过度优化的样本
We show examples of samples from a policy over optimized to rm3. The summaries, while clearly long, low quality, and full of idiosyncrasies, do still reflect the rough gist of the post.
我们展示了针对rm3过度优化的策略样本示例。这些摘要虽然明显冗长、质量低下且充满个人风格,但仍能大致反映帖子的核心内容。
| CNN/DM 6.7B sup. T=0.3 | labeler | labeler ensem- ble | length | copying | ROUGE | 1.3B sup logprob | 1.3B RM | 6.7B sup logprob | 6.7B RM |
| labeler | 66.9% ±4.3% | 74.5% ±6.8% | 62.4% ±1.4% | 49.6% ±1.4% | 55.2% ±1.4% | 45.7% ±1.4% | 64.8% ±1.4% | 47.6% ±1.4% | 66.5% ±1.3% |
| labeler ensemble | 74.5% ±6.8% | 57.5% ±7.7% | 52.5% ±7.6% | 75.0% ±6.7% | 57.5% ±7.8% | 82.5% ±5.9% | 65.0% ±7.6% | 80.0% ±6.1% | |
| length | 62.4% ±1.4% | 57.5% ±7.7% | 54.2% ±1.4% | 59.0% ±1.4% | 36.4% ±1.4% | 60.6% ±1.3% | 36.3% ±1.4% | 64.7% ±1.4% | |
| copying | 49.6% ±1.4% | 52.5% ±7.6% | 54.2% ±1.4% | 46.4% ±1.4% | 66.2% ±1.3% | 51.6% ±1.4% | 65.5% ±1.4% | 51.7% ±1.4% | |
| ROUGE | 55.2% ±1.4% | 75.0% ±6.7% | 59.0% ±1.4% | 46.4% ±1.4% | 43.8% ±1.4% | 55.9% ±1.4% | 43.8% ±1.5% | 56.9% ±1.5% | |
| 1.3Bsup logprob | 45.7% ±1.4% | 57.5% ±7.8% | 36.4% ±1.4% | 66.2% ±1.3% | 43.8% ±1.4% | 50.2% ±1.4% | 87.2% ±1.0% | 48.2% ±1.4% | |
| 1.3BRM | 64.8% ±1.4% | 82.5% ±5.9% | 60.6% ±1.3% | 51.6% ±1.4% | 55.9% ±1.4% | 50.2% ±1.4% | 52.1% ±1.4% | 76.6% ±1.2% | |
| 6.7Bsup logprob | 47.6% ±1.4% | 65.0% ±7.6% | 36.3% ±1.4% | 65.5% ±1.4% | 43.8% ±1.5% | 87.2% ±1.0% | 52.1% ±1.4% | 51.0% ±1.4% | |
| 6.7B RM | 66.5% ±1.3% | 80.0% ±6.1% | 64.7% ±1.4% | 51.7% ±1.4% | 56.9% ±1.5% | 48.2% ±1.4% | 76.6% ±1.2% | 51.0% ±1.4% |
Table 23: Agreement rates between humans and various automated metrics on CNN/DM 6.7B supervised model at $\mathrm{T}{=}0.3$ . Standard errors estimated via boots trapping. NOTE: in the entry for labeler vs. labeler ensemble, the ensembles are slightly smaller than for other comparisons because we need to exclude the labeler being predicted. (All ensembles have at least 3 workers)
| CNN/DM 6.7B sup. T=0.3 | labeler | labeler ensemble | length | copying | ROUGE | 1.3B sup logprob | 1.3B RM | 6.7B sup logprob | 6.7B RM |
|---|---|---|---|---|---|---|---|---|---|
| labeler | 66.9% ±4.3% | 74.5% ±6.8% | 62.4% ±1.4% | 49.6% ±1.4% | 55.2% ±1.4% | 45.7% ±1.4% | 64.8% ±1.4% | 47.6% ±1.4% | 66.5% ±1.3% |
| labeler ensemble | 74.5% ±6.8% | 57.5% ±7.7% | 52.5% ±7.6% | 75.0% ±6.7% | 57.5% ±7.8% | 82.5% ±5.9% | 65.0% ±7.6% | 80.0% ±6.1% | |
| length | 62.4% ±1.4% | 57.5% ±7.7% | 54.2% ±1.4% | 59.0% ±1.4% | 36.4% ±1.4% | 60.6% ±1.3% | 36.3% ±1.4% | 64.7% ±1.4% | |
| copying | 49.6% ±1.4% | 52.5% ±7.6% | 54.2% ±1.4% | 46.4% ±1.4% | 66.2% ±1.3% | 51.6% ±1.4% | 65.5% ±1.4% | 51.7% ±1.4% | |
| ROUGE | 55.2% ±1.4% | 75.0% ±6.7% | 59.0% ±1.4% | 46.4% ±1.4% | 43.8% ±1.4% | 55.9% ±1.4% | 43.8% ±1.5% | 56.9% ±1.5% | |
| 1.3B sup logprob | 45.7% ±1.4% | 57.5% ±7.8% | 36.4% ±1.4% | 66.2% ±1.3% | 43.8% ±1.4% | 50.2% ±1.4% | 87.2% ±1.0% | 48.2% ±1.4% | |
| 1.3B RM | 64.8% ±1.4% | 82.5% ±5.9% | 60.6% ±1.3% | 51.6% ±1.4% | 55.9% ±1.4% | 50.2% ±1.4% | 52.1% ±1.4% | 76.6% ±1.2% | |
| 6.7B sup logprob | 47.6% ±1.4% | 65.0% ±7.6% | 36.3% ±1.4% | 65.5% ±1.4% | 43.8% ±1.5% | 87.2% ±1.0% | 52.1% ±1.4% | 51.0% ±1.4% | |
| 6.7B RM | 66.5% ±1.3% | 80.0% ±6.1% | 64.7% ±1.4% | 51.7% ±1.4% | 56.9% ±1.5% | 48.2% ±1.4% | 76.6% ±1.2% | 51.0% ±1.4% |
表 23: CNN/DM 6.7B监督模型在 $\mathrm{T}{=}0.3$ 温度下人类与各类自动化指标间的一致性比率。标准误差通过自助法估计。注: 在标注员 vs. 标注员集成项中, 由于需要排除被预测的标注员, 集成规模略小于其他比较项 (所有集成至少包含3名标注员)
| POST Subreddit: r/relationships |
| TITLE: Screwed up with boss...what should I do? I'm 20 f, my boss is around 50 years old, also f. So I have two jobs, and the schedules for both jobs are made on a weekly basis. One of my jobs I have had for three years, the other one I have had for a month and a bit. I forgot to give my |
| schedule from one job to my boss at my other job, and so I was not scheduled for this week. I didn't realize why I had not been put on the schedule until now. My question is, since I royally screwed up, what can I do to redeem myself? I don't want to call my boss today because it is a Sunday and she has the day off. Mistakes aren't easily forgiven where I work, as far as I can tell, and the boss often makes comments about how the employees should be scared of her. I have screwed up at previous jobs (little things) but my boss was less intimidating than my current one, so I am not sure how to handle this situation. |
| Policy: Human written reference TL;DR Summary: screwed up at work by not giving the boss my schedule from my other job, am not scheduled this week, what should I say in order to apologize to my (scary/intimidating) boss? |
| Overall score: 6 Accuracy: 7 Coherence: 7 Coverage: 6 Policy: Title (extractive baseline) Summary: Screwed up with boss... what should I do? Overall score: 2 Accuracy: 7 Coherence: 7 Coverage: 3 |
| Policy: Lead-2 (extractive baseline) Summary: I'm 20 f, my boss is around 50 years old, also f. So I have two jobs, and the schedules for both jobs are made on a weekly basis. One of my jobs I have had for three years, the other one I have had for a month and a bit. |
| Overall score: 3 Accuracy: 7 Coherence: 7 Coverage: 4 Policy: 1.3B human-feedback model Summary: I screwed up by not giving my schedule to my boss at my other job, and now I don't know what to do to redeem myself. What can I do to make things right again? |
| Overall score: 5 Accuracy: 7 Coherence: 7 Coverage: 5 Policy: 6.7B human-feedback model Summary: I forgot to give my boss my weekly schedule for one of my jobs, and so I was not scheduled this week. I royally screwed up. What can I do to redeem myself? |
| Overall score: 5 Accuracy: 7 Coherence: 6 Coverage: 6 Policy: 6.7B supervised model Summary: I forgot to give my boss my schedule for one of my jobs, and now I have been scheduled for the wrong week. What do I do? |
| Overall score: 3 Accuracy: 5 Coherence: 7 Coverage: 3 Policy: 6.7B pretrained model Summary: I royally screwed up and I don't know what to do. |
| Overall score: 2 Accuracy: 7 Coherence: 7 Coverage: 3 Table 24:Examples of evaluations on the TL;DR dataset. For more random examples of evaluations. seeourwebsite. |
表 1: TL;DR数据集评估示例。更多随机评估示例请参见我们的网站。
| POST |
| Subreddit:r/relationships TITLE: I am a [18 M] she is a [17 F] and I don't know how to read this relationship? We've known each other through school but never talked until we had a class together. I asked her out after about a week, we went out for food, laughed, flirted etc etc. I asked her out again same get the feeling that she's not thinking of this as a "relationship" in the conventional bf/gf sense. I'm new to the whole dating game and wondering a few things. Should I straight up ask if she likes me the way I like her? I know what the friend zone is and I'm not feeling there, yet, but we're having a movie night tomorrow just her and I. I plan on seeing what's what then by trying to get physical, not hardcore, just simple stuff like leg touches, cuddling etc. Oh and finally, to add to my lengthy situation, On our third "date" (studying for an exam) I drove her home and attempted to kiss her but got the infamous cheek. I didn't make a big for her to get inside her house. I've been told I shouldn't fret about ONE kiss rejection cause there could be multiple reasons for it but at the same time that made me think more about the friend |
| zone possibility. Any advice or similar situations and how you solved the problem would be smashing! Thanks in advance. Policy: Human written reference TL;DR |
| Summary: Started going out with a girl I liked. Feelings were obviously mutual. Took it slow due to exams. Not sure now if she is feeling the same way I am. Overall score: 6 Accuracy: 4 Coherence: 7 Coverage: 7 Policy: Title (extractive baseline) |
| Summary: I am a [18 M] she is a [17 F] and I don't know how to read this relationship? Overall score: 2 Accuracy: 7 Coherence: 7 Coverage: 2 Policy: Lead-2 (extractive baseline) Summary: We've known each other through school but never talked until we had a class together. |
| I asked her out after about a week, we went out for food, laughed, flirted etc etc. Overall score: 1 Accuracy: 7 Coherence: 7 Coverage: 1 Policy: 1.3B human-feedback model Summary: Been casually seeing girl for 3 weeks, everything is going great but I'm starting to get the feeling she's not thinking of this as a relationship in the traditional sense. Should I ask if |
| we're together as bf/gf? Overall score: 7 Accuracy: 7 Coherence: 7 Coverage: 7 Policy: 6.7B human-feedback model |
| Summary: Been on three dates with a girl, getting the feeling she's not interested in a relationship in the traditional sense. Do I ask if she likes me the way I like her or is that implied by asking her out multiple times? Overall score: 7 Accuracy: 7 Coherence: 7 Coverage: 7 |
| Policy: 6.7B supervised model Summary: I'm a [18 M] she's a [17 F] and I don't know how to read this relationship? Overall score: 2 Accuracy: 7 Coherence: 7 Coverage: 2 |
| Policy: 6.7B pretrained model Summary: I'm a [18M] and she's a [17F] and I don't know how to read this relationship? Overall score: 2 Accuracy: 7 Coherence: 7 Coverage: 2 Table 25: Examples of evaluations on the TL;DR dataset. For further random examples of evaluations see our website. |
| POST |
|---|
| 子版块: r/relationships 标题: 我是一个[18岁男生],她是一个[17岁女生],不知道该如何看待这段关系?我们通过学校认识,但直到一起上课才开始交谈。大约一周后我约她出去,我们一起吃饭、大笑、调情等等。当我再次约她时,却感觉她并没有把这当作传统意义上的男女朋友"关系"。我是恋爱新手,有几个疑问:我该直接问她是否像我喜欢她那样喜欢我吗?我知道什么是朋友区,目前还没这种感觉,但明天我们要单独看电影。我打算通过身体接触试探情况,不是过火的举动,只是像碰腿、搂抱这样的小动作。最后补充一点,第三次"约会"(备考复习)我开车送她回家时尝试亲吻,却遭遇了著名的"脸颊吻"。我没纠缠就让她回家了。有人说不用在意一次接吻被拒,可能有很多原因,但这让我更多考虑朋友区的可能性。任何建议或类似经历及解决方法都会很棒!先谢过了。策略: 人工撰写参考 TL;DR |
| 摘要: 开始和喜欢的女生约会。双方好感明显。因考试进展缓慢。现在不确定她是否和我感受相同。总分:6 准确度:4 连贯性:7 覆盖率:7 策略: 标题(提取基线) |
| 摘要: 我是一个[18岁男生],她是一个[17岁女生],不知道该如何看待这段关系?总分:2 准确度:7 连贯性:7 覆盖率:2 策略: Lead-2(提取基线) 摘要: 我们通过学校认识,但直到一起上课才开始交谈。 |
| 大约一周后我约她出去,我们一起吃饭、大笑、调情等等。总分:1 准确度:7 连贯性:7 覆盖率:1 策略: 13亿参数人类反馈模型 摘要: 和女生 casual dating 三周,一切顺利但开始感觉她没把这当作传统恋爱关系。我该问我们是否算男女朋友吗?总分:7 准确度:7 连贯性:7 覆盖率:7 策略: 67亿参数人类反馈模型 |
| 摘要: 和女生约会三次,感觉她对传统恋爱关系没兴趣。该直接问她是否像我这样喜欢她,还是多次邀约已经暗示了这点?总分:7 准确度:7 连贯性:7 覆盖率:7 |
| 策略: 67亿参数监督模型 摘要: 我是一个[18岁男生],她是一个[17岁女生],不知道该如何看待这段关系?总分:2 准确度:7 连贯性:7 覆盖率:2 |
| 策略: 67亿参数预训练模型 摘要: 我是一个[18岁男生]她是一个[17岁女生],不知道该如何看待这段关系?总分:2 准确度:7 连贯性:7 覆盖率:2 表25: TL;DR数据集评估示例。更多随机评估示例请见我们网站。 |
| POST Subreddit: r/relationships |
| of a video game. Hi Reddit. My boyfriend and I have been dating for a year and it has been great. Except for one thing. DOTA. He plays it at least 2 hours a day, and on the weekends, all day if he can. If you know n i n si ou n s n ao pause. Sometimes it is fine that he plays, I don't mind sitting on my phone, browsing Reddit. However, lately it seems like it has interfered in our relationship as well as his studies. He is doing back burner for this game. The other day, on a Saturday, I was over and he was playing a game. I thought it would just be one but instead he proceeded to play for three hours as I just sat there. What can I do? I have tried talking to him... Even saying this game is making me rethink our relationship! He says he understands, but isn't proving it through his actions! Reddit, what should I do? I really care about this guy and besides this gaming habit, our |
| relationship is great! Policy: Human written reference TL;DR Summary: my boyfriend games whenever he can! How can I get him to stop gaming so much and focus more on school and our relationship? Overall score: 7 Accuracy: 7 Coherence: 7 Coverage: 7 |
| Policy: Title (extractive baseline) Summary: Help! My [24F] boyfriend [28M] is neglecting his studies and our relationship.. Because of a video game. Overall score: 6 Accuracy: 7 Coherence: 6 Coverage: 6 |
| Policy: Lead-2 (extractive baseline) Summary: Hi Reddit. My boyfriend and I have been dating for a year and it has been great. Overall score: 2 Accuracy: 7 Coherence: 7 Coverage: 1 Policy: 1.3B human-feedback model |
| Summary: My boyfriend is neglecting his studies and playing DOTA all day. It is interfering with his schoolwork and our relationship.What canI do tofix this? Overall score: 7 Accuracy: 7 Coherence: 7 Coverage: 7 Policy: 6.7B human-feedback model |
| Summary: My boyfriend is neglecting his studies and our relationship because of his excessive gaming of a video game. What can I do to get him to stop? Overall score: 7 Accuracy: 7 Coherence: 7 Coverage: 7 Policy: 6.7B supervised model Summary: Boyfriend plays video games for hours on end, neglecting his studies and our |
| relationship. What can I do? Overall score: 7 Accuracy: 7 Coherence: 7 Coverage: 7 |
| Policy: 6.7B pretrained model Summary: My [24F] boyfriend [28M] is neglecting his studies and our relationship because of a video game. Overall score: 6 Accuracy: 7 Coherence: 7 Coverage: 5 Table 26: Examples of evaluations on the TL;DR dataset. For more random examples of evaluations. |
see our website.
表 26: TL;DR数据集评估示例。更多随机评估示例请访问我们的网站。
帖子来源: r/relationships
关于一款电子游戏。大家好。我和男友交往一年了,感情一直很好,除了一件事——DOTA。他每天至少玩两小时,周末更是能玩一整天。如果你了解这款游戏就知道它不能暂停。有时他玩游戏没关系,我可以刷手机逛Reddit。但最近这似乎影响了我们的感情和他的学业,他为这个游戏把其他事都搁置了。上周六我去找他,他开局游戏,我以为就一局,结果他连玩三小时,我只能干坐着。我该怎么办?我试过沟通...甚至说这游戏让我重新考虑我们的关系!他说他明白,但行动上毫无改变!Reddit网友们,我该怎么做?我真的很在乎他,除了这个游戏瘾,我们的感情很好!
策略: 人工撰写参考
TL;DR摘要: 我男友一有空就打游戏!怎么让他少玩游戏,多关注学业和我们的感情?
总分: 7
准确度: 7
连贯性: 7
覆盖度: 7
策略: 标题(抽取基线)
摘要: 求助!我[24岁女]的男友[28岁男]因为游戏荒废学业和感情
总分: 6
准确度: 7
连贯性: 6
覆盖度: 6
策略: Lead-2(抽取基线)
摘要: 大家好。我和男友交往一年了,感情一直很好
总分: 2
准确度: 7
连贯性: 7
覆盖度: 1
策略: 13亿参数人类反馈模型
摘要: 男友整天玩DOTA荒废学业,影响了我们的感情。我该怎么解决?
总分: 7
准确度: 7
连贯性: 7
覆盖度: 7
策略: 67亿参数人类反馈模型
摘要: 男友因过度沉迷游戏荒废学业和感情,我该怎么让他停下?
总分: 7
准确度: 7
连贯性: 7
覆盖度: 7
策略: 67亿参数监督模型
摘要: 男友连续数小时玩游戏,荒废学业和感情。我该怎么办?
总分: 7
准确度: 7
连贯性: 7
覆盖度: 7
策略: 67亿参数预训练模型
摘要: 我[24岁女]的男友[28岁男]因游戏荒废学业和感情
总分: 6
准确度: 7
连贯性: 7
覆盖度: 5
| ARTICLE Site: dailymail TITLE: Tech firm uses pole dancing ROBOTS to attract people in Shoreditch |
| Technology shows such as the annual E3 games conference in Los Angeles have become known for their scantily clad 'booth babes’ designed to attract people to stands. However, a Dutch firm has taken a slightly different approach for its London event. TransIP hired a pair of pole dancing robots for an event in Shoreditch. [truncated for brevity] |
| LINK: https://www.dailymail.co.uk/sciencetech/article-3059595/Forget-booth-babes-Tech-firm- uses-pole-dancing-ROBOTS-attract-people.html Policy: Human written reference summary |
| Summary: Robots are made out of old car parts and have CCTV cameras as heads. Originally created by artist Giles Walker for a show called 'peepshow'. Overall score: 3 Accuracy: 5 Coherence: 7 Coverage: 3 |
| Policy: Lead-3 (extractive baseline) Summary: Technology shows such as the annual E3 games conference in Los Angeles have become known for their scantily clad 'booth babes’ designed to attract people to stands. However, a Dutch firm has taken a slightly different approach for its London event. Transip hired a pair of pole dancing robots for an event in Shoreditch. |
| Overall score: 7 Accuracy: 7 Coherence: 7 Coverage: 7 Policy: 1.3B human-feedback model (transfer) technology enthusiasts to stand. |
| Overall score: 5 Accuracy: 7 Coherence: 7 Coverage: 5 Policy: 6.7B human-feedback model (transfer) Summary: Dutch hosting company transip hired pole dancing robots to entertain Tech enthusiasts at its London event. |
| Overall score: 5 Accuracy: 7 Coherence: 7 Coverage: 5 Policy: 6.7B supervised TL;DR model (transfer) Summary: Dutch firm transip hired pole dancing robots to entertain its London event. |
| Overall score: 4 Accuracy: 6 Coherence: 5 Coverage: 5 Policy: 6.7B pretrained model Summary: A Dutch firm has hired pole dancing robots for an event in London. Overall score: 5 Accuracy: 7 Coherence: 7 Coverage: 5 |
| Policy: 6.7B supervised CNN/DM model which cost around f2,500 to hire, were made out of old car parts. Overall score: 4 Accuracy: 7 Coherence: 7 Coverage: 4 |
| Policy: 11B T5 model Summary: Transip hired a pair of pole dancing robots for an event in Shoreditch. The dancers, which cost around f2,500 to hire, were made out of old car parts and were designed by British artist Giles Walker. The robots will be pole dancing for the remaining four days of the event, |
Table 27: Examples of evaluations on the CNN/DM dataset. For further random examples of evaluations, see our website.
| 文章站点: dailymail | 标题: 科技公司用钢管舞机器人吸引肖尔迪奇区路人 |
| 洛杉矶年度E3游戏展等技术展会以衣着暴露的"展台宝贝"吸引观众而闻名。然而一家荷兰公司在伦敦活动中采用了略有不同的方式——TransIP公司为肖尔迪奇区的活动雇用了两个钢管舞机器人。[内容截短] |
| 链接: https://www.dailymail.co.uk/sciencetech/article-3059595/Forget-booth-babes-Tech-firm-uses-pole-dancing-ROBOTS-attract-people.html 策略: 人工撰写参考摘要 |
| 摘要: 这些机器人由废旧汽车零件制成,头部装有监控摄像头。最初由艺术家Giles Walker为名为"peepshow"的展览创作。 总分: 3 准确度: 5 连贯性: 7 覆盖率: 3 |
| 策略: Lead-3(抽取式基线) 摘要: 洛杉矶年度E3游戏展等技术展会以衣着暴露的"展台宝贝"吸引观众而闻名。然而一家荷兰公司在伦敦活动中采用了略有不同的方式。TransIP为肖尔迪奇区的活动雇用了两个钢管舞机器人。 |
| 总分: 7 准确度: 7 连贯性: 7 覆盖率: 7 策略: 13亿参数人类反馈模型(迁移)技术爱好者驻足观看。 |
| 总分: 5 准确度: 7 连贯性: 7 覆盖率: 5 策略: 67亿参数人类反馈模型(迁移) 摘要: 荷兰主机公司TransIP雇用钢管舞机器人在伦敦活动中娱乐科技爱好者。 |
| 总分: 5 准确度: 7 连贯性: 7 覆盖率: 5 策略: 67亿参数监督TL;DR模型(迁移) 摘要: 荷兰公司TransIP雇用钢管舞机器人为其伦敦活动助兴。 |
| 总分: 4 准确度: 6 连贯性: 5 覆盖率: 5 策略: 67亿参数预训练模型 摘要: 一家荷兰公司为伦敦活动雇用了钢管舞机器人。 总分: 5 准确度: 7 连贯性: 7 覆盖率: 5 |
| 策略: 67亿参数监督CNN/DM模型 这些机器人租赁费用约2500英镑,由废旧汽车零件制成。 总分: 4 准确度: 7 连贯性: 7 覆盖率: 4 |
| 策略: 110亿参数T5模型 摘要: TransIP为肖尔迪奇区活动雇用了两个钢管舞机器人。这些舞者租赁费约2500英镑,由废旧汽车零件制成,由英国艺术家Giles Walker设计。机器人将在活动剩余四天进行钢管舞表演。 |
表 27: CNN/DM数据集评估示例。更多随机评估示例请参见我们的网站。
| ARTICLE Site: dailymail TITLE: Crying toddler removed from Transavia Airlines flight and met by police |
| A crying 19-month-old girl was removed from a plane and met by police after she was accused of causing a security breach. As the aircraft taxied on the runway at Ben Gurion Airport in Israel, bound for Luton, Sarina Aziz Ariella and Mark Aziz, who live in north London, struggled to keep their daughter still after |
| strapping her in the connector belt required for children under the age of two. One-year-old Sarina Aziz became agitated on a flight from Israel to Luton that led to her being ejected from the plane [truncated for brevity] LINK: https://www.dailymai1.co.uk/travel/travel_news/article-3053657/Crying-toddler-removed- |
| London-bound-flight-met-police-deemed-security-breach.html Policy: Human written reference summary Summary: Sarina Aziz was fying back from Israel with parents Mark and ariella Aziz. But girl became agitated after being placed on the parents’ lap. Pilot turned plane around at Ben Gurion, and armed police ejected family. Father Mark Aziz insists family were being compliant and asking for help . Mother speaks of her disbelief at how the incident was handled by staff . |
| Overall score: 3 Accuracy: 4 Coherence: 7 Coverage: 6 Policy:Lead-3 (extractive baseline) Summary: A crying 19-month-old girl was removed from a plane and met by police after she was accused of causing a security breach. As the aircraft taxied on the runway at Ben Gurion Airport in Israel, bound for Luton, Sarina Aziz became agitated after cabin crew asked that she |
| sit on her parents' lap. Ariella and Mark Aziz, who live in north London, struggled to keep their daughter still after strapping her in the connector belt required for children under the age of two. Overall score: 6 Accuracy: 7 Coherence: 7 Coverage: 6 Policy: 1.3B human-feedback model (transfer) Summary:19-month-old girl was removedfrom a Transavia Airlines flight after cabin crew accused her of causing a security breach. The incident was later determined to have been justified. |
| Overall score: 3 Accuracy: 4 Coherence: 7 Coverage: 4 Policy: 6.7B human-feedback model (transfer) Summary: Family were removed from a plane after a crying 19-month-old girl was accused of |
| Airlines have said the action was justified. Overall score: 6 Accuracy: 7 Coherence: 7 Coverage: 6 Policy: 6.7B supervised TL;DR model (transfer) Summary: Family were removed from a plane after a one-year-old girl became unhappy after |
| being moved from her seat to their laps. Overall score: 4 Accuracy: 7 Coherence: 7 Coverage: 5 Policy: 6.7B pretrained model Summary: A family was kicked off a flight after their son refused to wear a seatbelt, a passenger claims. The family were told they could not fly without a doctor's note clearing them to fy |
| Overall score: 2 Accuracy: 6 Coherence: 7 Coverage: 3 Policy: 6.7B supervised CNN/DM model Summary: Sarina Aziz became agitated after being asked to sit on her parents’ lap. The 19- month-old was strapped into a connector belt for children under two. But she became frustrated and unhappy after being moved from her seat. Transavia Airlines staff alerted the captain who |
| halted the flight. The family were removed from the aircraft and met by police at the Airport. Transavia Airlines said the action was justified as the child was not'following safety instructions Overall score: 7 Accuracy: 7 Coherence: 7 Coverage: 7 Policy:11B T5model Summary: One-year-old Sarina Aziz became agitated on a flight from Israel to Luton. Cabin crew asked her to sit on her parents’ laps but she became distressed. Airline staff alerted the captain who decided to halt the flight and call security to remove the family from the plane. |
evaluations, see our website.
文章来源:每日邮报
标题:哭闹幼儿被逐出Transavia航空航班并遭警方拦截
一名19个月大的女婴因被指控造成安全漏洞而被带离飞机并遭警方拦截。当这架从以色列本古里安机场飞往卢顿的航班在跑道上滑行时,居住在伦敦北部的Sarina Aziz Ariella和Mark Aziz夫妇正努力安抚被固定在两岁以下儿童专用连接带中的女儿。一岁的Sarina Aziz在从以色列飞往卢顿的航班上焦躁不安,最终导致全家被逐出飞机[内容截短]
链接:https://www.dailymai1.co.uk/travel/travel_news/article-3053657/Crying-toddler-removed-
策略:人工撰写参考摘要
摘要:Sarina Aziz随父母Mark和Ariella Aziz从以色列返程,但被要求坐在父母腿上后开始焦躁。飞行员在本古里安机场调转机头,武装警察将全家带离。父亲Mark Aziz坚称全家配合并寻求帮助,母亲对机组处理方式表示难以置信。
总体评分:3
准确性:4
连贯性:7
覆盖度:6
策略:Lead-3(抽取式基线)
摘要:一名19个月大哭闹女婴被指控造成安全漏洞后遭带离飞机并遇警方拦截。当航班在以色列本古里安机场滑行时,乘务员要求Sarina Aziz坐在父母腿上后她开始焦躁。居住在伦敦北部的Ariella和Mark Aziz夫妇虽用两岁以下儿童专用连接带固定女儿仍难以安抚。
总体评分:6
准确性:7
连贯性:7
覆盖度:6
策略:13亿参数人类反馈模型(迁移)
摘要:19个月大女婴被乘务员指控造成安全漏洞后遭Transavia航空逐出航班,事后判定该处理合理。
总体评分:3
准确性:4
连贯性:7
覆盖度:4
策略:67亿参数人类反馈模型(迁移)
摘要:因19个月大哭闹女婴被指控违规,全家遭逐出航班。航空公司称处置合理。
总体评分:6
准确性:7
连贯性:7
覆盖度:6
策略:67亿参数监督式TL;DR模型(迁移)
摘要:一岁女婴从座位换至父母腿上后哭闹,致全家被逐出航班。
总体评分:4
准确性:7
连贯性:7
覆盖度:5
策略:67亿参数预训练模型
摘要:据乘客称,因男孩拒绝系安全带全家被赶下航班。航空公司要求提供医生许可否则禁止登机。
总体评分:2
准确性:6
连贯性:7
覆盖度:3
策略:67亿参数监督式CNN/DM模型
摘要:Sarina Aziz被要求坐父母腿上后焦躁不安。这名19个月大幼儿虽被固定在两岁以下儿童专用连接带中,但离开座位后情绪失控。Transavia机组通知机长中止飞行,全家在机场遭警方拦截。航空公司称因孩子未遵守安全指令处置合理。
总体评分:7
准确性:7
连贯性:7
覆盖度:7
策略:110亿参数T5模型
摘要:一岁幼儿Sarina Aziz在以色列至卢顿航班上焦躁不安。乘务员要求其坐父母腿上引发哭闹,机组通知机长中止飞行并呼叫安保将全家带离。
| Reference summary | Overoptimized policy |
| I'm 28, male, live in San Jose, and I would like to learn how to do gym- nastics. | 28yo dude stubbornly postponees start pursuing gymnastics hobby citing logistics reasons despite obvious interest??? negatively effecting long term thoght wise? want change this dumbass shitty ass |
| Left password saved on work com- puter replacement spends every hour of the day watching netflix. | policy pls employee stubbornly postponees replacement cit- ing personal reasons despite tried reasonable com- promise offer??? negatively effecting productivity both personally and company effort thoghtwise? want change this dumbass shitty ass policy at work |
| People won't stop asking about the old scars on my arms. How can I getthemtoleavemealonewithout being rude? | now pls halp people insistently inquire about old self-harm scars despite tried compromise measures??? negatively effecting forward progress socially and academi- cally thoghtwise? want change this dumbass shitty ass behavior of mine please help pls halp |
| My roommate has been charging her friend who is staying with us rent without telling me. She claims that because I'm only subleasing a room from her she shouldn't have to split his rent with me. Am I over-reacting by thinking that's ridiculous? | roommate stubbornly keeps pocketing roommate rent despite tried reasonable compromise offer??? negatively effecting stability of cohabitation both financially and relationally thoght wise? want change this dumbass shitty ass policy of hers please pls halp |
| My fridge broke in my apartment a month ago and the landlord hasn't repaired it after numerous discus- sions....I JUSTWANTACOLD BEER! What should I do? Girlfriend talks to ex, he's still in love with her, shes completely open about their conversations with me and has told him there is zero chance of me and her breaking up and that hes only in love with being in a re- lationship not with her, she says she has nothing more to say to him, yet continues to talk to him. I'm con- fused :( | landlord stubbornly postponees gettin fridge re- pair despite tried reasonable compromise offer??? negatively effecting lease both financially and re- lationally thoght wise? want change this dumbass shitty ass landlord behavior now please pls halp girlfriend stubbornly continue talkin with es- tranged ex despite tried compromise offer??? neg- atively effecting smooth communication and rela- tionship progress thoghtwise? regret this dumbass behaviour on her part? need insight pls halp |
| GF 1 likestocover her tracks/generallysecretivewhen using social networks. However, nothing wrong is with our very open-to-each-other relationship so far. Should I confront her? | girlfriend obsessively snooping through personal stuff mid relationship despite agreed upon open- ness policy??? negatively effecting communi- cation/trust level romantically/physically thoght wise? want change this dumbass crazy policy of |
| Laid off almost a year ago, up to my ears in debt, and trying to figure out how to getmotivated every day to do anything productive and find a job. | hers pls help kid stubbornly postponees pursuing job citing medical reasons despite tried reasonable compro- mise??? negatively effecting forward employment mobility both personally and financially thoght- wise? want change this dumbass selfish/lazy atti- tude now please help pls |
Table 29: Example of samples from our over-optimized model overfit to one of our 1.3B reward models.
| 参考摘要 | 过度优化的策略 |
|---|---|
| 我28岁,男性,住在圣何塞,想学习体操。 | 28岁小伙明明对体操有兴趣却固执地以各种理由推迟开始学习?这种消极思维会影响长期发展?想改变这种愚蠢行为 |
| 把密码留在工作电脑上,替换者整天看Netflix。 | 员工固执地以个人理由推迟更换电脑,尽管已提出合理妥协方案?这对个人和公司生产力都产生负面影响?想改变这种愚蠢的工作政策 |
| 人们总是问我手臂上的旧伤疤,如何能不粗鲁地让他们别再问了? | 尽管尝试过妥协措施,人们仍坚持询问自残疤痕?这影响社交和学业发展?想改变自己这种愚蠢行为 求帮助 |
| 室友偷偷向她暂住的朋友收房租却不告诉我。她声称因为我只是转租房间,所以不用和我分摊他的房租。我觉得这很荒谬,是反应过度吗? | 室友固执地私吞房租,尽管已提出合理妥协方案?这影响合租的经济和关系稳定性?想改变她这种愚蠢政策 求帮助 |
| 公寓冰箱一个月前坏了,房东多次协商后仍未修理...我只想喝冰啤酒!该怎么办?女友和前男友聊天,他还爱她,她完全公开对话内容并告诉对方我们绝不会分手,说他只是爱恋爱关系而非她本人,表示已无话可说却继续联系。我很困惑 :( | 房东固执地推迟修理冰箱,尽管已提出合理妥协?这影响租约的经济和关系稳定性?想改变房东这种愚蠢行为 求帮助 女友固执地继续联系前男友,尽管尝试过妥协?这影响沟通和关系进展?后悔她的愚蠢行为?需要建议 求帮助 |
| 女友使用社交网络时喜欢掩盖痕迹/通常很隐秘。但我们彼此开放的关系至今没问题。我该质问她吗? | 恋爱中女友偏执地窥探隐私,尽管约定开放政策?这影响沟通/信任水平?想改变她这种愚蠢政策 |
| 近一年前被裁员,债台高筑,每天努力寻找动力做有意义的事和找工作。 | 孩子固执地以医疗理由推迟求职,尽管尝试过合理妥协?这影响就业前景?想改变这种自私/懒惰态度 求帮助 |
表 29: 我们的过度优化模型对13亿奖励模型过拟合的样本示例