Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
通用基础模型能否超越专用调优模型?医学领域的案例研究
Microsoft
微软
November 2023
2023年11月
Abstract
摘要
Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities without intensive training of models with specialty knowledge. For example, most explorations to date on medical competency benchmarks have leveraged domainspecific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of the specialist capabilities of GPT-4 on medical challenge benchmarks in the absence of special training. In distinction to the intentional use of simple prompting to highlight the model’s outof-the-box capabilities, we perform a systematic exploration of prompt engineering to boost performance. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical question-answering datasets. The prompt engineering methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for over fitting during the prompt engineering process. As a culmination of the study, we introduce Medprompt, based on a composition of several prompting strategies. Medprompt greatly enhances GPT-4’s performance and achieves state of the art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms state-ofthe-art specialist models such as Med-PaLM 2 by a large margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a $27%$ reduction in error rate on the MedQA dataset (USMLE exam) over the best methods to date achieved with specialist models, and surpasses a score of 90% for the first time. Moving beyond medical challenge problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on competency exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
像GPT-4这样的通用基础模型在众多领域和任务中展现出惊人的能力。然而,人们普遍认为,如果没有针对专业知识进行密集训练,这些模型无法匹敌专业能力。例如,迄今为止大多数针对医学能力基准的探索都采用了领域特定训练,如BioGPT和Med-PaLM的研究所示。我们在先前关于GPT-4未经专门训练时在医学挑战基准上表现的专业能力研究基础上展开工作。与刻意使用简单提示来突显模型开箱即用能力不同,我们系统性地探索了提示工程以提升性能。我们发现,提示创新能够解锁更深层次的专业能力,并证明GPT-4轻松超越了此前医学问答数据集的领先结果。我们探索的提示工程方法是通用的,无需特定领域知识,也无需专家精心策划的内容。实验设计严格控制了提示工程过程中的过拟合问题。作为研究的高潮,我们推出了Medprompt,它基于多种提示策略的组合。Medprompt极大提升了GPT-4的性能,在MultiMedQA套件的全部九个基准数据集上达到了最先进水平。该方法以数量级更少的模型调用次数,大幅超越了Med-PaLM 2等最先进的专用模型。通过Medprompt引导GPT-4,在MedQA数据集(USMLE考试)上的错误率比目前专用模型的最佳方法降低了27%,并首次突破90%的分数。超越医学挑战问题后,我们展示了Medprompt在其他领域的泛化能力,并通过在电气工程、机器学习、哲学、会计、法律、护理和临床心理学等能力考试上的策略研究,证明了该方法的广泛适用性。
1 Introduction
1 引言
A long-term aspiration in AI research is to develop principles of computational intelligence and to harness these to build learning and reasoning systems that can perform general problem solving across a diversity of tasks [21, 22]. In line with this goal, large language models, also referred to as foundation models, such as GPT-3 [3] and GPT-4 [24], have demonstrated surprising competencies on a broad swath of tasks without requiring heavy specialized training [4]. These models build on the text-to-text paradigm [31] with investments in compute and data to learn at scale from indiscriminate consumption of large amounts of public web data. Some of these models are tuned via a learning objective to perform general instruction-following via prompts.
AI研究的一个长期愿景是发展计算智能原理,并利用这些原理构建能够跨多种任务进行通用问题解决的学习与推理系统 [21, 22]。为实现这一目标,以GPT-3 [3]和GPT-4 [24]为代表的大语言模型(也称为基础模型)已在不依赖大量专项训练的情况下,展现出对广泛任务的惊人处理能力 [4]。这些模型基于文本到文本(text-to-text)范式 [31],通过投入算力和数据资源,从海量公开网络数据的无差别采集中实现规模化学习。其中部分模型通过提示(prompt)驱动的学习目标调整,获得了通用指令跟随能力。
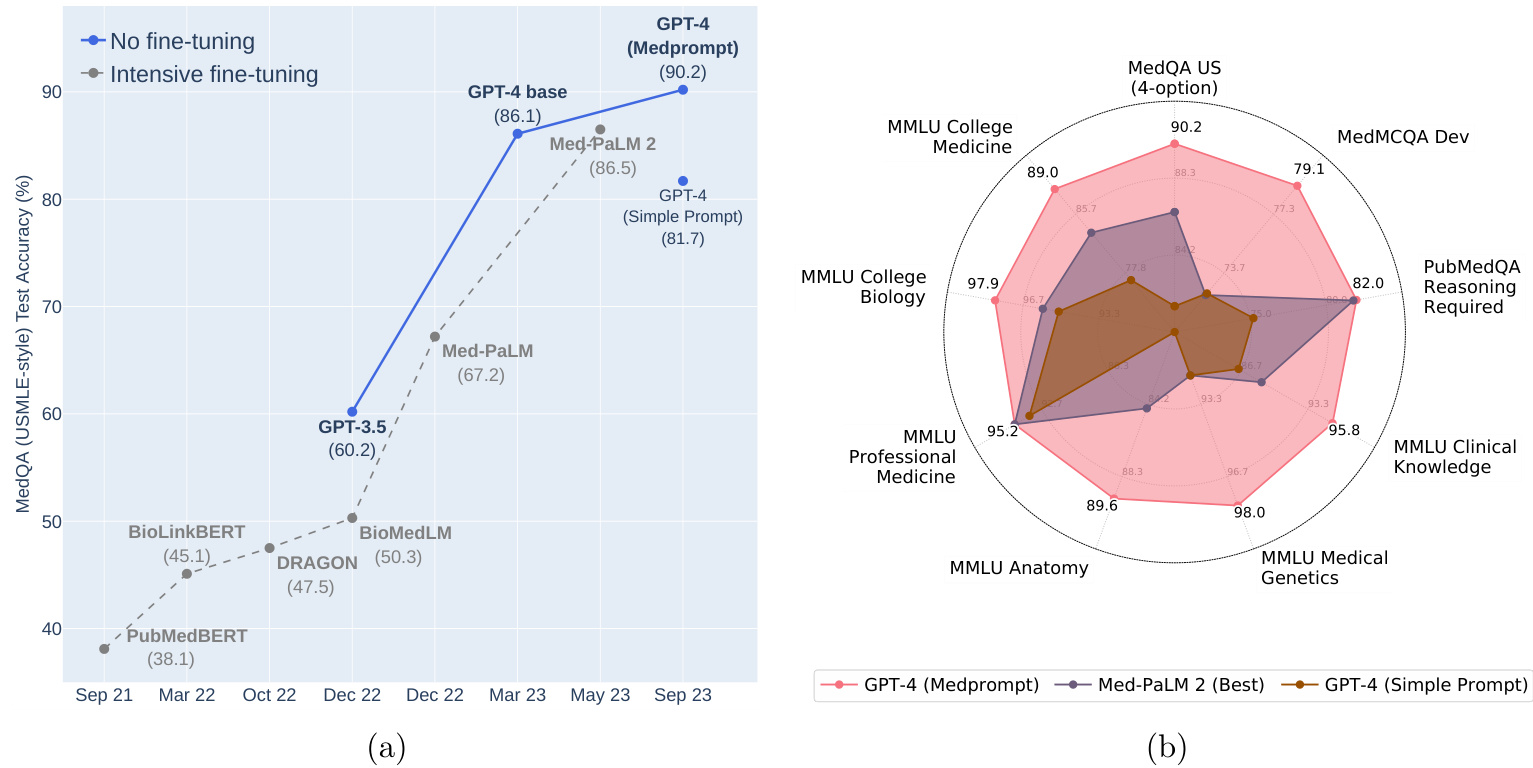
Figure 1: (a) Comparison of performance on MedQA. (b) GPT-4 with Medprompt achieves SoTA on a wide range of medical challenge questions.
图 1: (a) MedQA 性能对比。(b) 采用 Medprompt 的 GPT-4 在各类医学挑战题上达到当前最优水平 (SoTA)。
A core metric for characterizing the performance of foundation models is the accuracy of next word prediction. Accuracy with next word prediction is found to increase with scale in training data, model parameters, and compute, in accordance with empirically derived “neural model scaling laws” [3, 12]). However, beyond predictions of scaling laws on basic measures such as next word prediction, foundation models show the sudden emergence of numerous problem-solving capabilities at different thresholds of scale [33, 27, 24].
表征基础模型性能的一个核心指标是下一个词预测的准确率。研究发现,下一个词预测的准确率会随着训练数据量、模型参数规模和计算量的增加而提升,这与经验推导的"神经模型缩放定律" [3, 12] 相符。然而,除了缩放定律对下一个词预测等基础指标的预测外,基础模型还会在不同规模阈值下突然涌现出多种问题解决能力 [33, 27, 24]。
Despite the observed emergence of sets of general capabilities, questions remain about whether truly exceptional performance can be achieved on challenges within specialty areas like medicine in the absence of extensive specialized training or fine-tuning of the general models. Most explorations of foundation model capability on biomedical applications rely heavily on domain- and task-specific fine-tuning. With first-generation foundation models, the community found an unambiguous advantage with domain-specific pre training, as exemplified by popular models in bio medicine such as
尽管已观察到通用能力的涌现,但人们仍质疑在没有大量专业训练或对通用模型进行微调的情况下,能否在医学等专业领域挑战中实现真正卓越的性能。目前大多数关于基础模型在生物医学应用能力的探索,都严重依赖针对特定领域和任务的微调。在使用第一代基础模型时,研究界发现领域特定的预训练具有明显优势,生物医学领域的流行模型(如...
PubMedBERT [10] and BioGPT [19]. But it is unclear whether this is still the case with modern foundation models pretrained at much larger scale.
PubMedBERT [10] 和 BioGPT [19]。但目前尚不清楚这一结论是否适用于经过更大规模预训练的现代基础模型。
We focus in this paper on steering foundation models via prompt engineering to excel on a set of medical challenge benchmarks. Med-PaLM 2 attains competitive results on MedQA and other medical challenge problems, via expensive, task-specific fine-tuning of the general PaLM [6] foundation model [29, 30]. In addition to reliance on fine-tuning of the base PaLM model, results on the medical benchmarks for Med-PaLM 2 were generated via use of sophisticated, complex prompting strategies, leveraging exemplars crafted by experts. For example, many of the answers rely on an elaborate two-stage prompt scheme of 44 calls for answering each question.
本文重点研究如何通过提示工程引导基础模型在一系列医学挑战基准测试中取得优异表现。Med-PaLM 2在MedQA等医学挑战问题上获得具有竞争力的结果,是通过对通用PaLM [6]基础模型 [29, 30] 进行昂贵且任务特定的微调实现的。除了依赖基础PaLM模型的微调外,Med-PaLM 2在医学基准测试中的成绩还通过使用复杂精密的提示策略生成,这些策略利用了专家精心设计的示例。例如,许多答案依赖于一个包含44次调用的精细两阶段提示方案来回答每个问题。
Shortly after GPT-4 was made public in March 2023, several co-authors of this study showed that the model had impressive biomedical competencies “out-of-the-box” on medical challenge benchmarks. To demonstrate the latent power of GPT-4 on specialty medical expertise, the co-authors purposefully employed a rudimentary prompting strategy [23]. Despite the strong results demonstrated in that study, questions remain about the depth of GPT-4’s domain-specific capabilities in the absence of additional special training or tuning.
2023年3月GPT-4发布后不久,本研究的几位合著者发现该模型在医学挑战基准测试中展现出"开箱即用"的强大生物医学能力。为验证GPT-4在专科医学知识上的潜在实力,合著者故意采用了基础提示策略 [23]。尽管该研究取得了显著成果,但关于GPT-4在未经额外专业训练或调优情况下的领域专项能力深度仍存疑问。
We present results and methods of a case study on steering GPT-4 to answer medical challenge questions with innovative prompting strategies. We include a consideration of best practices for studying prompting in an evaluative setting, including the holding out of a true eyes-off evaluation set. We discover that GPT-4 indeed possesses deep specialist capabilities that can be evoked via prompt innovation. The performance was achieved via a systematic exploration of prompting strategies. As a design principle, we chose to explore prompting strategies that were inexpensive to execute and not customized for our benchmarking workload. We converged on a top prompting strategy for GPT-4 for medical challenge problems, which we refer to as Medprompt. Medprompt unleashes medical specialist skills in GPT-4 in the absence of expert crafting, easily topping existing benchmarks for all standard medical question-answering datasets. The approach outperforms GPT-4 with the simple prompting strategy and state-of-the-art specialist models such as Med-PaLM 2 by large margins. On the MedQA dataset (USMLE exam), Medprompt produces a 9 absolute point gain in accuracy, surpassing 90% for the first time on this benchmark.
我们展示了一项案例研究的结果与方法,探讨如何通过创新提示策略引导GPT-4回答医学挑战性问题。研究包含评估环境下提示工程的最佳实践考量,例如保留真实盲测评估集。我们发现GPT-4确实具备可通过提示创新激发的深层专业能力,其性能提升源于对提示策略的系统性探索。作为设计原则,我们选择开发执行成本低且无需针对基准测试定制化的提示策略,最终收敛出一套针对医学挑战问题的顶级提示方案——Medprompt。该方案无需专家精心设计即可释放GPT-4的医学专业能力,轻松超越所有标准医学问答数据集的现有基准。相比简单提示策略下的GPT-4和Med-PaLM 2等尖端专业模型,该方法均取得显著优势:在MedQA数据集(美国医师执照考试)上实现9个百分点的绝对准确率提升,首次突破90%大关。
As part of our investigation, we undertake a comprehensive ablation study that reveals the relative significance for the contributing components of Medprompt. We discover that a combination of methods, including in-context learning and chain-of-thought, can yield synergistic effects. Perhaps most interestingly, we find that the best strategy in steering a generalist model like GPT-4 to excel on the medical specialist workload that we study is to use a generalist prompt. We find that GPT-4 benefits significantly from being allowed to design its prompt, specifically with coming up with its own chain-of-thought to be used for in-context learning. This observation echoes other reports that GPT-4 has an emergent self-improving capability via introspection, such as self-verification [9].
在我们的调查过程中,我们开展了一项全面的消融研究,揭示了Medprompt各组成部分的相对重要性。研究发现,结合上下文学习和思维链等方法可以产生协同效应。最有趣的是,我们发现引导通用模型(如GPT-4)在研究的医学专业任务上表现出色的最佳策略,恰恰是使用通用提示。GPT-4在自主设计提示方面获益显著,特别是能自主生成用于上下文学习的思维链。这一发现与其他报告相呼应,例如GPT-4通过自省展现出自我验证等新兴的自我改进能力 [9]。
We note that the automated chain-of-thought reasoning removes dependency on special human expertise and medical datasets. Thus, despite the name Medprompt, extending from the framing context and research trajectory of our investigation of the capabilities of GPT-4 on medical challenge problems, the methodology doesn’t include any components specifically oriented towards medicine. As we explore in Section 5.3, the approach can be applied readily to other domains. We present details on Medprompt to facilitate future studies on steering generalist foundation models to provide specialist advice.
我们注意到,自动化的思维链推理减少了对特殊人类专业知识和医学数据集的依赖。因此,尽管名为Medprompt,但从我们研究GPT-4在医学挑战问题上能力的框架背景和研究轨迹延伸来看,该方法并不包含任何专门针对医学的组件。正如我们在第5.3节探讨的那样,该方法可以轻松应用于其他领域。我们详细介绍Medprompt,以促进未来关于引导通用基础模型提供专业建议的研究。
2 Background
2 背景
2.1 Foundation Models on Medical Challenge Problems
2.1 基础模型在医学挑战问题上的应用
In the era of first-generation foundation models, limited model size and computational resources made domain-specific pre training advantageous. Models such as PubMedBERT [10], Bio Link BERT [37], DRAGON [36], BioGPT [19], and BioMedLM [2] were pretrained with self-supervised objectives using domain-specific data sources, such as the PubMed corpus and UMLS knowledge graph. Despite their small size and limited computational power, these models demonstrate strong performance in biomedical NLP tasks. More powerful, general-domain foundation models have demonstrated significantly elevated performance in medical challenges without requiring domain-specific pre training.
在第一代基础模型时代,有限的模型规模和计算资源使得领域特定的预训练具有优势。PubMedBERT [10]、BioLinkBERT [37]、DRAGON [36]、BioGPT [19] 和 BioMedLM [2] 等模型使用领域特定数据源(如PubMed语料库和UMLS知识图谱)通过自监督目标进行预训练。尽管这些模型规模较小且计算能力有限,但它们在生物医学NLP任务中表现出色。更强大的通用领域基础模型则在不依赖领域特定预训练的情况下,显著提升了医学挑战任务的性能。
Several studies have explored the performance of generalist foundation models on medical challenge problems. In [17], ChatGPT-3.5 was evaluated on questions drawn from United States Medical Licensing Exam (USMLE), and performed at or near the passing threshold without any specialized training. In [23], GPT-4 was shown to exceed the USMLE passing score by over 20 points using simple 5-shot prompting. Other studies have explored the use of foundation models that are specially fine-tuned with medical knowledge.
多项研究探讨了通用基础模型在医学挑战问题上的表现。文献[17]评估了ChatGPT-3.5在美国医师执照考试(USMLE)试题上的表现,结果显示其无需专门训练即可达到或接近及格线。文献[23]表明,GPT-4通过简单的5样本提示就能超过USMLE及格线20多分。其他研究则探索了经过医学知识专门微调的基础模型的应用。
Other studies have explored the power of relying on explicit tuning with medical knowledge. Med-PaLM [29] and Med-PaLM 2 [30] leverage fine-tuning of the 540B-parameter Flan-PaLM, using instruction prompt tuning. With Med-PaLM, authors asked a panel of five clinicians to prepare their instruction prompt tuning dataset. Med-PaLM 2, built similarly on PaLM 2, relied on instructionfollowing full fine-tuning and achieved the state-of-the-art performance on medical QA datasets.
其他研究探索了依赖医学知识进行显式调优的效果。Med-PaLM [29] 和 Med-PaLM 2 [30] 利用 5400 亿参数的 Flan-PaLM 进行微调,采用指令提示调优方法。在 Med-PaLM 中,作者邀请五位临床医生组成小组来准备指令提示调优数据集。基于 PaLM 2 类似构建的 Med-PaLM 2 采用指令跟随式全微调策略,在医疗问答数据集上实现了最先进的性能表现。
We re-examine the capabilities of generalist foundation models without resorting to extensive fine-tuning. We explore diverse prompting strategies to best steer powerful generalist foundation models toward delivering strong performance in specialized domains.
我们重新审视通用基础模型(Generalist Foundation Models)的能力,而不依赖大量微调。我们探索多样化的提示策略,以最优方式引导强大的通用基础模型在专业领域实现卓越性能。
2.2 Prompting Strategies
2.2 提示策略
Prompting in the context of language models refers to the input given to a model to guide the output that it generates. Empirical studies have shown that the performance of foundation models on a specific task can be heavily influenced by the prompt, often in surprising ways. For example, recent work shows that model performance on the GSM8K benchmark dataset can vary by over 10% without any changes to the model’s learned parameters [35]. Prompt engineering refers to the process of developing effective prompting techniques that enable foundation models to better solve specific tasks. Here, we briefly introduce a few key concepts that serve as building blocks for our Medprompt approach.
在大语言模型 (LLM) 的语境中,提示 (Prompting) 是指为引导模型生成输出而提供的输入。实证研究表明,基础模型在特定任务上的表现会显著受到提示的影响,且这种影响往往出人意料。例如,最新研究显示模型在GSM8K基准数据集上的表现差异可超过10%,而模型的学习参数并未发生任何变化 [35]。提示工程 (Prompt Engineering) 是指开发有效提示技术以使基础模型更好地解决特定任务的过程。在此,我们简要介绍几个关键概念,这些概念构成了我们Medprompt方法的基础模块。
In-Context Learning (ICL) is a key capability of foundation models, allowing the models to solve new tasks from just a few task demonstrations [3]. For example, an ICL prompt can be created by preceding a test question with several different examples of questions and desired results. ICL does not require updating model parameters but can offer effects similar to fine-tuning. The choice of examples used in few-shot prompting can substantially influence model performance. In our prior investigation of the performance of GPT-4 on medical challenge problems [23], we expressly limited prompting to basic in-context learning methods such as fixed one-shot and five-shot prompting to demonstrate the ease with which GPT-4 could be steered to perform with excellence.
上下文学习 (In-Context Learning, ICL) 是基础模型的关键能力,使模型仅需少量任务演示即可解决新任务 [3]。例如,通过在测试问题前添加若干不同的问题示例及期望结果,即可构建ICL提示。该方法无需更新模型参数,却能获得类似微调的效果。少样本提示中所选示例会显著影响模型性能。在我们先前关于GPT-4在医学挑战问题表现的研究 [23] 中,特意将提示限制在基础上下文学习方法(如固定单样本和五样本提示),以证明GPT-4可被轻松引导至卓越表现。
Chain of Thought (CoT) is a prompting methodology that employs intermediate reasoning steps prior to introducing the sample answer [34]. By breaking down complex problems into a series of smaller steps, CoT is thought to help a foundation model to generate a more accurate answer. CoT ICL prompting integrates the intermediate reasoning steps of CoT directly into the few-shot demonstrations. As an example, in the Med-PaLM work, a panel of clinicians was asked to craft CoT prompts tailored for complex medical challenge problems [29]. Building on this work, we explore in this paper the possibility of moving beyond reliance on human specialist expertise to mechanisms for generating CoT demonstrations automatically using GPT-4 itself. As we shall describe in more detail, we can do this successfully by providing [question, correct answer] pairs from a training dataset. We find that GPT-4 is capable of autonomously generating high-quality, detailed CoT prompts, even for the most complex medical challenges.
思维链 (Chain of Thought, CoT) 是一种在给出最终答案前引入中间推理步骤的提示方法 [34]。通过将复杂问题分解为一系列较小步骤,CoT被认为能帮助基础模型生成更准确的答案。CoT少样本提示直接将中间推理步骤整合到少样本示例中。例如在Med-PaLM研究中,临床专家小组被要求为复杂医学难题定制CoT提示 [29]。基于此,本文探索了摆脱对人类专家知识依赖的可能性,转而利用GPT-4自身自动生成CoT示例的机制。如后文详述,我们通过提供训练数据集中的[问题,正确答案]对即可成功实现。研究发现,即便面对最复杂的医学难题,GPT-4也能自主生成高质量、细节丰富的CoT提示。
Ensembling is a technique for combining the outputs of multiple model runs to arrive at a more robust or accurate result via combining the separate outputs with functions like averaging, consensus, or majority vote. Ensembling methods employing a technique referred to as self-consistency [32] use a sampling method to produce multiple outputs that are then consolidated to identify a consensus output. The diversity of the outputs can be controlled by shifting the “temperature” parameter in a model’s generation, where higher temperatures can be viewed as injecting greater amounts of randomness into the generation process. By reordering or shuffling components of a few-shot prompt, ensembling techniques can also address the order sensitivity commonly found with foundation models [26, 39], thus improving robustness.
集成是一种通过将多个模型运行的输出结果用平均、共识或多数投票等方式结合起来,从而获得更稳健或准确结果的技术。采用自一致性(self-consistency) [32] 的集成方法会使用采样技术生成多个输出,然后通过整合这些输出来确定共识结果。输出的多样性可以通过调整模型生成中的"温度(temperature)"参数来控制,较高的温度值可视为在生成过程中注入了更多随机性。通过重新排序或打乱少样本提示的组成部分,集成技术还能解决基础模型[26,39]常见的顺序敏感性问题,从而提高稳健性。
While ensembling can enhance performance, it comes at the cost of increased computational demands. For example, Med-PaLM 2’s Ensemble Refinement method used as many as 44 separate inferences for a single question. Due to this computational overhead, we have pursued as a design principle using simpler techniques to avoid excessive inference costs. We report an ablation study in Section 5.2 which explores the potential of further increased performance under increased computational load.
虽然集成方法可以提升性能,但会带来计算需求增加的代价。例如,Med-PaLM 2的集成优化(Ensemble Refinement)方法对单个问题使用了多达44次独立推理。由于这种计算开销,我们将"使用更简单技术避免过高推理成本"作为设计原则。第5.2节的消融实验探讨了在更高计算负载下进一步提升性能的可能性。
3 Experimental Design
3 实验设计
We start with an overview of the medical challenge problem datasets and then outline our testing methodology, designed to avoid over fitting that can occur with intensive iteration on a fixed evaluation dataset.
我们从医学挑战问题数据集的概述开始,然后概述我们的测试方法,该方法旨在避免在固定评估数据集上进行密集迭代时可能出现的过拟合。
3.1 Datasets
3.1 数据集
Our benchmarks, as reported in Section 5 are primarily based on performance of GPT-4 on 9 multiplechoice, biomedical datasets from the MultiMedQA benchmark suite [29]. Specifically, the benchmarks include the following:
我们的基准测试(如第5节所述)主要基于GPT-4在MultiMedQA基准套件[29]中9个生物医学多选题数据集上的表现。具体包括以下内容:
• MedQA [14] contains multiple choice questions in the style of the Medical Licensing Examination questions used to test medical specialist competency in the United States, Mainland China, and Taiwan. For fair comparison with prior work [29, 30, 23], we focus on the United States subset of the dataset, which has questions in English in the style of the United States Medical Licensing Exam (USMLE). This dataset contains 1273 questions with four multiple choice answers each.
• MedQA [14] 包含以美国、中国大陆和台湾地区医师资格考试题型为蓝本的多选题,用于测试医学专家能力。为与先前研究 [29, 30, 23] 公平对比,我们聚焦该数据集的美国子集,其试题采用美国医师执照考试 (USMLE) 的英文题型。该数据集包含1273道四选一选择题。
• MedMCQA [25] presents mock and historic exam questions in the style of two Indian medical school entrance exams—the AIIMS and NEET-PG. The “dev” subset of the dataset, upon which we report benchmark results (consistent with prior studies), contains 4183 questions, each with four multiple choice answers.
• MedMCQA [25] 提供了模仿印度两所医学院入学考试(AIIMS和NEET-PG)风格的模拟和历史试题。我们在该数据集的"dev"子集上报告基准结果(与先前研究一致),该子集包含4183道题目,每道题有四个多项选择答案。
• PubMedQA [15] contains tests requiring a yes, no, or maybe answer to biomedical research questions when given context provided from PubMed abstracts. There are two settings for PubMedQA tests called reasoning-required and reasoning-free. In the reasoning-free setting, a long-form answer that contains explanations of the abstracts is provided. We report results for the reasoning-required setting, in which the model is only given context from abstracts to use when answering the question. This dataset contains a total of 500 questions.
• PubMedQA [15] 包含针对生物医学研究问题的测试,要求在给定PubMed摘要上下文的情况下回答是、否或可能。PubMedQA测试有两种设置,分别称为需要推理(reasoning-required)和无需推理(reasoning-free)。在无需推理设置中,会提供包含摘要解释的长篇答案。我们报告需要推理设置下的结果,该设置中模型仅获得摘要上下文来回答问题。该数据集共包含500个问题。
• MMLU [11] is a multitask benchmark suite of 57 different datasets spanning domains across STEM, humanities, and social sciences. We follow prior work [29] and benchmark against a medically relevant subset of MMLU tasks: clinical knowledge, medical genetics, anatomy, professional medicine, college biology, and college medicine.
• MMLU [11] 是一个包含57个不同数据集的多任务基准测试套件,涵盖STEM(科学、技术、工程、数学)、人文和社会科学领域。我们遵循先前工作[29]的方法,针对MMLU中与医学相关的子集进行基准测试:临床知识、医学遗传学、解剖学、专业医学、大学生物学和大学医学。
As we shall see in Section 5.3, we can test the generality of the Medprompt approach by studying its efficacy for competency exams outside the primary focus on medical challenge problems. We test our methodology on two nursing datasets focused on answering NCLEX (National Council Licensure Examinaton) questions and six additional datasets from MMLU covering topics like accounting and law. Details of these datasets are presented in Section 5.3.
正如我们将在5.3节中看到的,可以通过研究Medprompt方法在医学挑战问题之外的能力考试中的有效性来测试其通用性。我们在两个专注于回答NCLEX (国家护理执照考试) 问题的护理数据集和来自MMLU的六个额外数据集 (涵盖会计和法律等主题) 上测试了我们的方法。这些数据集的详细信息将在5.3节中介绍。
3.2 Sound Testing Methodology
3.2 声音测试方法
While prompting and in-context learning does not change model parameters, a specific choice of prompting strategy can be viewed as a high-level setting or hyper parameter of the end-to-end testing process. As a result, we must be cautious about over fitting as part of training and testing, thus providing results that would not generalize out of the training and test sets under consideration. Concerns about over fitting with studies of foundation model performance are similar to the valid concerns in traditional machine learning with over fitting during the hyper parameter optimization process [8]. We wish to avoid analogous over fitting in the prompt engineering process.
虽然提示和上下文学习不会改变模型参数,但特定的提示策略选择可视为端到端测试过程中的高级设置或超参数。因此,我们必须警惕训练和测试过程中的过拟合问题,以免导致结果无法推广到当前训练集和测试集之外的情况。对基础模型性能研究中过拟合的担忧,与传统机器学习中超参数优化过程出现过拟合的合理担忧类似[8]。我们希望避免在提示工程过程中出现类似的过拟合现象。
Intuitively, a prompt harnessing for examples a lookup table of specific benchmark questions will naturally perform much better on those questions than on unseen problems. A common technique to address this problem in traditional machine learning is to create “test” sets, which are only evaluated against at the end of the model selection process. We adopt this important aspect of sound testing methodology for machine learning studies and randomly carved out 20% of each benchmark dataset as an “eyes-off” split that is completely held out from consideration until the final testing phase. That is, the eyes-off data is kept hidden until the end-stage. The data is not examined or optimized against during the prompt engineering process. For simplicity, we apply the same methodology to every dataset in MultiMedQA, as many of the datasets were not published with dedicated train/test splits by the authors. In Section 5.1, we show the stratified performance of Medprompt on “eyes-on” vs. “eyes-off” splits of the MultiMedQA datasets. We find that our performance is quite similar between the two, and that GPT-4 with Medprompt actually performs marginally better on the eyesoff, held out data suggesting that the methods will generalize well to similar questions in the “open world.” We have not seen evidence of the use of a similar eyes-off approach in prior studies.
直观上,利用特定基准问题查找表示例的提示词,自然会在这些问题上比未见过的问题表现更好。传统机器学习中解决这一问题的常用方法是创建"测试"集,仅在模型选择流程最终阶段进行评估。我们采纳了机器学习研究中这一严谨测试方法的关键环节,从每个基准数据集中随机划分出20%作为"盲测"部分,在最终测试阶段前完全不予考虑。也就是说,盲测数据直到最后阶段才解封,在提示工程过程中既不查看也不针对其进行优化。为保持一致性,我们对MultiMedQA中所有数据集采用相同方法,因为许多数据集作者并未发布专用的训练/测试划分。在第5.1节中,我们展示了Medprompt在MultiMedQA数据集"可见"与"盲测"部分的分层表现。发现两者性能非常接近,且配备Medprompt的GPT-4在盲测数据上表现略优,表明该方法能良好泛化至"开放世界"中的类似问题。目前尚未发现前人研究中使用类似盲测方法的证据。
4 Power of Prompting: Exploration and Results
4 提示的力量:探索与结果
In this section, we detail the three major techniques employed in Medprompt: Dynamic few-shot selection, self-generated chain of thought, and choice shuffle ensembling. After discussing each technique, we review our approach to composing the three methods into the integrated Medprompt.
在本节中,我们详细介绍了Medprompt采用的三大核心技术:动态少样本(few-shot)选择、自生成思维链(chain of thought)以及选项混洗集成(choice shuffle ensembling)。在分别阐述各项技术后,我们将回顾如何将这三种方法整合为完整的Medprompt框架。
4.1 Dynamic Few-shot
4.1 动态少样本 (Dynamic Few-shot)
Few-shot learning [3] is arguably the most effective in-context learning method. With the prompting approach, through a few demonstrations, foundation models quickly adapt to a specific domain and learn to follow the task format. For simplicity and efficiency, the few-shot examples applied in prompting for a particular task are typically fixed; they are unchanged across test examples. This necessitates that the few-shot examples selected are broadly representative and relevant to a wide distribution of text examples. One approach to meeting these requirements is to have domain experts carefully hand-craft exemplars [29]. Even so, this approach cannot guarantee that the curated, fixed few-shot examples will be appropriately representative of every test example. In comparison, when available, the task training set can serve as an inexpensive, high-quality source for few-shot examples. If the training set is sufficiently large, we can select different few-shot examples for different task inputs. We refer to this approach as employing dynamic few-shot examples. The method makes use of a mechanism to identify examples based on their similarity to the case at hand [18]. For Medprompt, we did the following to identify representative few shot examples: Given a test example, we choose $k$ training examples that are semantically similar using a $k$ -NN clustering in the embedding space. Specifically, we first use text-embedding-ada-002 $^* $ to embed training questions and test questions as vector representations. Then, for each test question $x$ , we retrieve its nearest $k$ neighbors $x_ {1},x_ {2},...,x_ {k}$ from the training set (according to distance in the embedding space of text-embedding-ada-002). Given a pre-defined similarity measure $d$ such as cosine similarity, the neighbors are ordered in such a way that $d(x_ {i},x)\leq d(x_ {j},x)$ when $i<j$ . Compared with fine-tuning, dynamic few-shot leverages the training data, but does not require billions of updates to model parameters.
少样本学习 (few-shot learning) [3] 可以说是最高效的上下文学习方法。通过提示方法,基础模型只需少量示例就能快速适应特定领域并学会遵循任务格式。为了简单高效,特定任务提示中应用的少样本示例通常是固定的,这些示例在不同测试样本间保持不变。这就要求所选少样本示例具有广泛代表性,且与大量文本样本分布相关。满足这些要求的一种方法是让领域专家精心手工制作示例 [29]。即便如此,这种方法仍无法保证精心挑选的固定少样本示例能恰当代表每个测试样本。相比之下,当任务训练集可用时,它可以作为低成本、高质量的少样本示例来源。如果训练集足够大,我们可以为不同任务输入选择不同的少样本示例。我们将这种方法称为动态少样本示例。该方法利用一种机制,根据示例与当前案例的相似性来识别示例 [18]。对于 Medprompt,我们通过以下方式识别具有代表性的少样本示例:给定测试样本,我们使用嵌入空间中的 $k$-NN 聚类选择 $k$ 个语义相似的训练样本。具体来说,我们首先使用 text-embedding-ada-002$^* $ 将训练问题和测试问题嵌入为向量表示。然后,对于每个测试问题 $x$,我们从训练集中检索其最近的 $k$ 个邻居 $x_ {1},x_ {2},...,x_ {k}$(根据 text-embedding-ada-002 嵌入空间中的距离)。给定预定义的相似性度量 $d$(如余弦相似度),邻居按 $i<j$ 时 $d(x_ {i},x)\leq d(x_ {j},x)$ 的方式排序。与微调相比,动态少样本利用了训练数据,但不需要对模型参数进行数十亿次更新。
4.2 Self-Generated Chain of Thought
4.2 自生成思维链
Question: A 22-year-old male marathon runner presents to the office with the complaint of right-sided rib pain when he runs long distances. Physical examination reveals normal heart and lung findings and an exhalation dysfunction at ribs 4-5 on the right. Which of the following muscles or muscle groups will be most useful in correcting this dysfunction utilizing a direct method?
问题:一名22岁男性马拉松运动员因长跑时右侧肋骨疼痛就诊。体格检查显示心肺检查结果正常,右侧第4-5肋存在呼气功能障碍。采用直接矫正法时,以下哪块肌肉或肌群对纠正该功能障碍最有效?
(A) anterior scalene (B) latissimus dorsi (C) pectoralis minor (D) quadratus lumborum
(A) 前斜角肌 (B) 背阔肌 (C) 胸小肌 (D) 腰方肌
Hand-crafted CoT from Med PaLM 2
Med PaLM 2人工构建的思维链

Let’s solve this step-bystep, referring to authoritative sources as needed. Among the options, only pectoralis minor muscle origins from the outer surfaces of the 3rd to 5th ribs.
让我们逐步解决这个问题,必要时参考权威资料。在选项中,只有胸小肌 (pectoralis minor muscle) 起源于第3至第5肋骨的外表面。
GPT-4 generated CoT
GPT-4生成思维链

The primary muscle involved in rib exhalation is the internal inter cost al muscle. However, this option is not listed among the answer choices. Among the provided options, the pectoralis minor can contribute to rib movement, as it originates from the 3rd-5th ribs and can act to depress the ribs during exhalation when the scapula is fixed. Therefore, it could potentially be useful in correcting an exhalation dysfunction at ribs 4-5.
肋间内肌是参与肋骨呼气的主要肌肉,但选项中并未列出该肌肉。在给定的选项中,胸小肌起源于第3-5肋骨,当肩胛骨固定时可在呼气过程中协助肋骨下降,因此可能有助于纠正第4-5肋骨的呼气功能障碍。
Figure 2: Comparison of expert-crafted and GPT-4-generated chain-of-thought (CoT) prompts. Using a [question, correct answer] pair from a training set, GPT-4 is capable of generating a detailed explanation suitable for use in few-shot CoT demonstrations.
图 2: 专家编写与GPT-4生成思维链(CoT)提示的对比。通过训练集中的[问题,正确答案]配对,GPT-4能够生成适用于少样本CoT演示的详细解释。
Chain-of-thought (CoT) [34] uses natural language statements, such as “Let’s think step by step,” to explicitly encourage the model to generate a series of intermediate reasoning steps. The approach has been found to significantly improve the ability of foundation models to perform complex reasoning. Most approaches to chain-of-thought center on the use of experts to manually compose few-shot examples with chains of thought for prompting [30]. Rather than rely on human experts, we pursued a mechanism to automate the creation of chain-of-thought examples. We found that we could simply ask GPT-4 to generate chain-of-thought for the training examples using the following prompt:
思维链 (Chain-of-thought, CoT) [34] 通过自然语言陈述(如"让我们逐步思考")显式激励模型生成一系列中间推理步骤。该方法被证实能显著提升基础模型执行复杂推理的能力。现有思维链方法多依赖专家人工编写带有推理链的少样本示例来构建提示 [30]。我们探索了一种自动化生成思维链示例的机制,无需依赖人类专家。研究发现,只需用以下提示要求 GPT-4 为训练样本生成思维链:
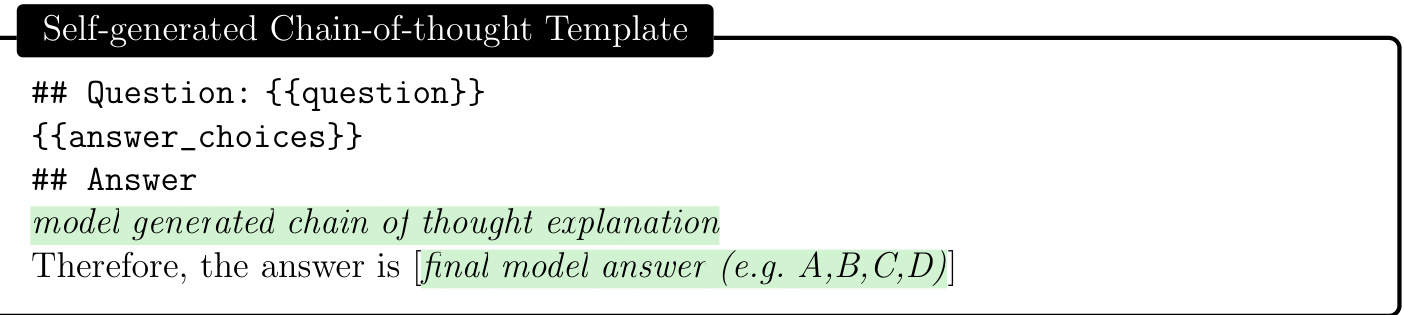
Figure 3: Template used to prompt foundation model to generate chain-of-thought explanations automatically (detailed in Section 4.2).
图 3: 用于提示基础模型自动生成思维链解释的模板 (详见第4.2节)。
A key challenge with this approach is that self-generated CoT rationales have an implicit risk of including hallucinated or incorrect reasoning chains. We mitigate this concern by having GPT-4 generate both a rationale and an estimation of the most likely answer to follow from that reasoning chain. If this answer does not match the ground truth label, we discard the sample entirely, under the assumption that we cannot trust the reasoning. While hallucinated or incorrect reasoning can still yield the correct final answer (i.e. false positives), we found that this simple label-verification step acts as an effective filter for false negatives.
这种方法面临的一个关键挑战是,自我生成的思维链(CoT)推理过程隐含了包含幻觉或错误推理链的风险。我们通过让GPT-4同时生成推理链和基于该推理链最可能得出的答案估计来缓解这个问题。若该答案与真实标签不符,我们会完全舍弃该样本,因为我们假设无法信任这种推理。虽然包含幻觉或错误的推理仍可能得出正确答案(即假阳性),但我们发现这个简单的标签验证步骤能有效过滤假阴性情况。
We observe that, compared with the CoT examples used in Med-PaLM 2 [30], which are handcrafted by clinical experts, CoT rationales generated by GPT-4 are longer and provide finer-grained step-by-step reasoning logic. Concurrent with our study, recent works [35, 7] also find that foundation models write better prompts than experts do.
我们观察到,与Med-PaLM 2 [30]中由临床专家手工制作的CoT示例相比,GPT-4生成的CoT原理更长,并提供了更细粒度的逐步推理逻辑。与我们的研究同时,近期工作[35, 7]也发现基础模型编写的提示优于专家。
4.3 Choice Shuffling Ensemble
4.3 选择混洗集成
While less severe than other foundation models, GPT-4 can exhibit a propensity to favor certain options in multiple choice answers over others (regardless of the option content), i.e., the model can show position bias [1, 16, 40]. To reduce this bias, we propose shuffling the choices and then checking consistency of the answers for the different sort orders of the multiple choice. As a result, we perform choice shuffle and self-consistency prompting. Self-consistency [32] replaces the naive single-path or greedy decoding with a diverse set of reasoning paths when prompted multiple times at some temperature> 0, a setting that introduces a degree of randomness in generations. With choice shuffling, we shuffle the relative order of the answer choices before generating each reasoning path. We then select the most consistent answer, i.e., the one that is least sensitive to choice shuffling. Choice shuffling has an additional benefit of increasing the diversity of each reasoning path beyond temperature sampling, thereby also improving the quality of the final ensemble [5]. We also apply this technique in generating intermediate CoT steps for training examples. For each example, we shuffle the choices some number of times and generate a CoT for each variant. We only keep the examples with the correct answer.
与其他基础模型相比,虽然GPT-4的表现相对较好,但它仍可能倾向于在多项选择题中偏好某些选项(无论选项内容如何),即模型可能表现出位置偏差[1, 16, 40]。为了减少这种偏差,我们提出对选项进行随机排序,然后检查不同排序下答案的一致性。因此,我们采用了选项随机化和自一致性提示的方法。自一致性[32]通过在温度>0时多次提示,用一组多样化的推理路径替代了简单的单一路径或贪婪解码,这种设置会在生成过程中引入一定程度的随机性。通过选项随机化,我们在生成每条推理路径之前打乱答案选项的相对顺序。然后选择最一致的答案,即对选项随机化最不敏感的答案。选项随机化还有一个额外的好处,即通过温度采样之外的方式增加每条推理路径的多样性,从而也提高了最终集成的质量[5]。我们还将这一技术应用于生成训练样本的中间思维链(CoT)步骤。对于每个样本,我们会多次随机化选项,并为每个变体生成一个思维链。我们只保留答案正确的样本。
4.4 Putting it all together: Medprompt
4.4 整体整合:Medprompt
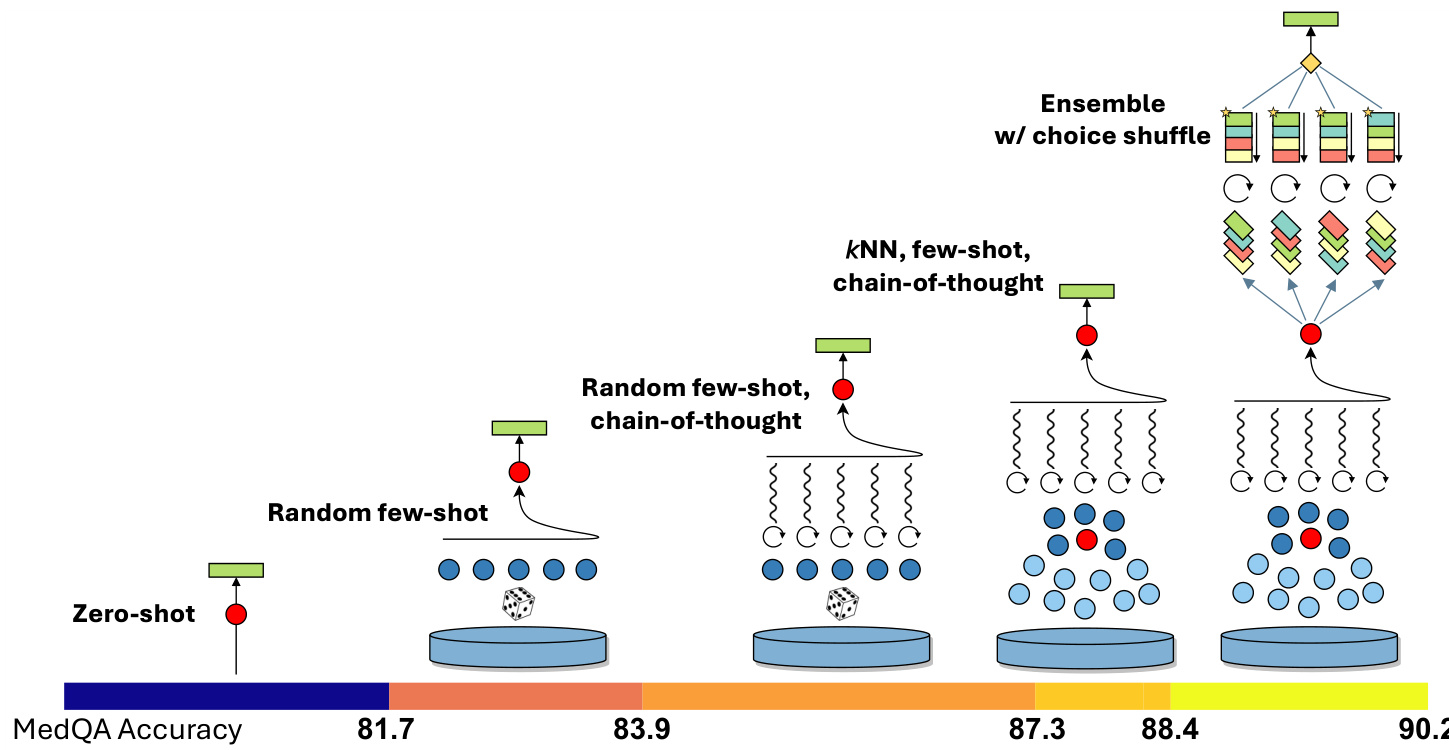
Figure 4: Visual illustration of Medprompt components and additive contributions to performance on the MedQA benchmark. The prompting strategy combines $k$ NN-based few-shot example selection, GPT-4–generated chain-of-thought prompting, and answer-choice shuffled ensembling (see details in Section 4). Relative contributions of each component are shown at the bottom (details in Section 5.2).
图 4: Medprompt组件及其对MedQA基准性能的增量贡献可视化说明。该提示策略结合了基于$k$NN的少样本示例选择、GPT-4生成的思维链提示以及答案选项混洗集成 (详见第4节)。底部显示了各组件的相对贡献 (细节见第5.2节)。
Medprompt combines intelligent few-shot exemplar selection, self-generated chain of thought steps, and a majority vote ensemble, as detailed above in Sections 4.1, 4.2, and 4.3, respectively. The composition of these methods yields a general purpose prompt-engineering strategy. A visual depiction of the performance of the Medprompt strategy on the MedQA benchmark, with the additive contributions of each component, is displayed in Figure 4. We provide an a corresponding algorithmic description in Algorithm 1.
Medprompt结合了智能少样本示例选择、自生成的思维链步骤以及多数投票集成方法,具体分别在第4.1、4.2和4.3节中详述。这些方法的组合形成了一种通用的提示工程策略。图4展示了Medprompt策略在MedQA基准测试中的性能表现,以及各组成部分的增量贡献。我们在算法1中提供了相应的算法描述。
Medprompt consists of two stages: a preprocessing phase and an inference step, where a final prediction is produced on a test case. During preprocessing, each question in the training dataset is passed through a lightweight embedding model to generate an embedding vector (Line 4 in Algorithm 1). We employed OpenAI’s text-embedding-ada-002 to create an embedding. For each question, GPT-4 is harnessed to create a chain of thought and a prediction of the final answer (Line 5). If the generated answer is correct and matches the ground truth label, we store the associated question, its embedding vector, the chain of thought, and the answer. Otherwise, we discard the question entirely from our retrieval pool, with the assumption that we cannot trust the reasoning if the model ultimately arrives at the wrong final answer (Lines 6-7).
Medprompt包含两个阶段:预处理阶段和推理步骤,最终在测试用例上生成预测结果。预处理阶段中,训练数据集中的每个问题都会通过轻量级嵌入模型生成嵌入向量(算法1第4行)。我们采用OpenAI的text-embedding-ada-002来创建嵌入。对于每个问题,利用GPT-4生成思维链和最终答案的预测(第5行)。如果生成的答案正确且与真实标签匹配,则存储相关问题、其嵌入向量、思维链和答案;否则直接从检索池中丢弃该问题,前提是当模型最终得出错误答案时,我们无法信任其推理过程(第6-7行)。
At inference time, given a test question, we re-embed the test sample with the same embedding model used during pre-processing, and utilize $k$ NN to retrieve similar examples from the pre processed pool (Lines 12-13). These examples, and their corresponding GPT-4 generated reasoning chains, are structured as context for GPT-4 (Line 14). The test question and corresponding answer choices are then appended at the end, which serves as the final prompt (Line 17). The model, following the few shot exemplars, then outputs a chain of thought and a candidate answer. Finally, we perform an ensembling process consisting of repeating the steps described above multiple times. We increase diversity by shuffling the answer choices of the test question (Lines 15-16), as detailed in Section 4.3 and Figure 4. To determine the final predicted answer, we select the most frequent answer (Line 20).
在推理阶段,给定测试问题时,我们使用与预处理阶段相同的嵌入模型重新嵌入测试样本,并利用$k$NN从预处理池中检索相似示例(第12-13行)。这些示例及其对应的GPT-4生成推理链被构建为GPT-4的上下文(第14行)。测试问题及对应选项随后被附加在末尾,形成最终提示(第17行)。模型遵循少样本示例,输出思维链和候选答案。最后,我们通过多次重复上述步骤进行集成处理:通过打乱测试问题的选项顺序来增加多样性(第15-16行),详见第4.3节和图4。为确定最终预测答案,我们选择最高频的答案(第20行)。
Algorithm 1 Algorithmic specification of Medprompt, corresponding to the visual representation of the strategy in Figure 4.
| 1: Input: Development data D, Test question Q | |
| 2: Preprocessing: | |
| 3: for each question q in D do | |
| 4: | Get an embedding vector vq for q. |
| 5: | Generate a chain-of-thought Cq and an answer Aq with the LLM. |
| 6: | if Answer Aq is correct then |
| 7: | Store the embedding vector va, chain-of-thought Cq, and answer Aq. |
| 8: | |
| end if 9: end for | |
| 10: 11: Inference Time: | |
| 12: Compute the embedding vQ for the test question Q. | |
| 13: Select the 5 most similar examples {(vQ, CQ, AQ)}=1 from the preprocessed training data using | |
| KNN, with the distance function as the cosine similarity: dist(vq, vQ) = 1 - (vq,UQ) Ilva!llvoll | |
| 14: Format the 5 examples as context C for the LLM. | |
| 15:for 5 times do | |
| 16: | Shuffe the answer choices of the test question. |
| 17: | Generate a chain-of-thought Ck and an answer Ag with the LLM and context C. |
| 18: end for | |
算法 1: Medprompt的算法规范,对应图4中的策略可视化表示。
| 步骤 | 描述 |
|---|---|
| 1: 输入 | 开发数据D,测试问题Q |
| 2: 预处理 | |
| 3: | 对于D中的每个问题q: |
| 4: | 获取q的嵌入向量vq |
| 5: | 用大语言模型生成思维链Cq和答案Aq |
| 6: | 如果答案Aq正确: |
| 7: | 存储嵌入向量va、思维链Cq和答案Aq |
| 8: | |
| 9: | 结束循环 |
| 10: 11: 推理阶段 | |
| 12: | 计算测试问题Q的嵌入向量vQ |
| 13: | 使用KNN从预处理数据中选取5个最相似的示例{(vQ, CQ, AQ)}=1,距离函数为余弦相似度:dist(vq, vQ) = 1 - (vq,UQ) Ilva!llvoll |
| 14: | 将这5个示例格式化为大语言模型的上下文C |
| 15: | 重复5次: |
| 16: | 打乱测试问题的选项顺序 |
| 17: | 用大语言模型和上下文C生成思维链Ck和答案Ag |
| 18: | 结束循环 |
$$
{\cal A}^{\mathrm{Final}}=\mathrm{mode}({A_ {q}^{k}}_ {k=1}^{K}),
$$
$$
{\cal A}^{\mathrm{Final}}=\mathrm{mode}({A_ {q}^{k}}_ {k=1}^{K}),
$$
where mode( $X$ ) denotes the most common element in the set $X$ .
其中 mode($X$) 表示集合 $X$ 中最常见的元素。
20: Output: Final answer AFinal.
20: 输出: 最终答案 AFinal.
The Medprompt results we report here are configured to use 5 $k$ NN selected few shot exemplars and 5 parallel API calls as part of the choice-shuffle ensemble procedure, which we find strikes a reasonable balance between minimizing inference cost and maximizing accuracy.
我们在此报告的Medprompt结果配置为使用5个$k$近邻选择的少样本示例和5个并行API调用作为选择-混洗集成流程的一部分,这能在最小化推理成本和最大化准确率之间取得合理平衡。
Our ablation studies, detailed in Section 5.2, suggest that further improvements may be achieved by increasing these hyper parameter values. For example, by increasing to 20 few-shot exemplars and 11 ensemble items, we achieve a further $+0.4%$ performance on MedQA, setting a new state-of-the-art performance threshold of90.6%.
我们在5.2节的消融研究表明,通过增加这些超参数值可能实现进一步改进。例如,将少样本示例增至20个、集成项增至11个时,MedQA性能可再提升$+0.4%$,从而以90.6%的成绩刷新当前最优性能阈值。
We note that, while Medprompt achieves record performance on medical benchmark datasets, the algorithm is general purpose and is not restricted to the medical domain or to multiple choice question answering. We believe the general paradigm of combining intelligent few-shot exemplar selection, self-generated chain of thought reasoning steps, and majority vote ensembling can be broadly applied to other problem domains, including less constrained problem solving tasks (see Section 5.3 for details on how this framework can be extended beyond multiple choice questions).
我们注意到,虽然Medprompt在医学基准数据集上取得了创纪录的性能,但该算法是通用的,并不局限于医学领域或多选题回答。我们认为,结合智能少样本示例选择、自生成的思维链推理步骤和多数投票集成的通用范式可以广泛应用于其他问题领域,包括约束较少的问题解决任务(有关如何将此框架扩展到多选题之外的详细信息,请参见第5.3节)。
5 Results
5 结果
Table 1: Performance of different foundation models on multiple choice components of MultiMedQA [29]. GPT-4 with Medprompt outperforms all other models on every benchmark.
| Dataset | Flan-PaLM 540B* j (choose best) | Med-PaLM 2* (choose best) | GPT-4 (5 shot) | GPT-4 (Medprompt) |
| MedQA | 90.2* * | |||
| US (4-option) | 67.6 | 86.5 | 81.4 | |
| PubMedQA Reasoning Required | 79.0 | 81.8 | 75.2 | 82.0 |
| MedMCQA | ||||
| Dev | 57.6 | 72.3 | 72.4 | 79.1 |
| MMLU | ||||
| Clinical Knowledge | 80.4 | 88.7 | 86.4 | 95.8 |
| Medical Genetics | 75.0 | 92.0 | 92.0 | 98.0 |
| Anatomy | 63.7 | 84.4 | 80.0 | 89.6 |
| Professional Medicine | 83.8 | 95.2 | 93.8 | 95.2 |
| College Biology | 88.9 | 95.8 | 95.1 | 97.9 |
| College Medicine | 76.3 | 83.2 | 76.9 | 89.0 |
表 1: 不同基础模型在MultiMedQA多选题组件上的性能表现[29]。采用Medprompt的GPT-4在所有基准测试中均优于其他模型。
| 数据集 | Flan-PaLM 540B* (选择最佳) | Med-PaLM 2* (选择最佳) | GPT-4 (5样本) | GPT-4 (Medprompt) |
|---|---|---|---|---|
| MedQA | 90.2* * | |||
| US (4选项) | 67.6 | 86.5 | 81.4 | |
| PubMedQA 需推理 | 79.0 | 81.8 | 75.2 | 82.0 |
| MedMCQA | ||||
| Dev | 57.6 | 72.3 | 72.4 | 79.1 |
| MMLU | ||||
| 临床知识 | 80.4 | 88.7 | 86.4 | 95.8 |
| 医学遗传学 | 75.0 | 92.0 | 92.0 | 98.0 |
| 解剖学 | 63.7 | 84.4 | 80.0 | 89.6 |
| 专业医学 | 83.8 | 95.2 | 93.8 | 95.2 |
| 大学生物学 | 88.9 | 95.8 | 95.1 | 97.9 |
| 大学医学 | 76.3 | 83.2 | 76.9 | 89.0 |
5.1 Performance on Eyes-Off Data
5.1 闭眼数据性能

Figure 5: Medprompt evaluation against $20%$ eyes-off holdout. Medprompt performs better on the eyes-off dataset in the majority of cases.
图 5: Medprompt 在 20% 盲测集上的评估结果。在大多数情况下,Medprompt 在盲测数据集上表现更优。
As introduced in Section 5.1, we evaluated the Medprompt prompting design on a held-out “eyes-off” subset of each benchmark dataset to check for over fitting risk. GPT-4 with Medprompt achieved an average performance of 90.6% on the eyes-on data, and an average performance of 91.3% on the eyes-off data, suggesting that the prompt engineering process likely did not lead to over fitting on MultiMedQA datasets. As additional evidence, the performance on eyes-off data was better in $6/9$ of the benchmark datasets (Figure 5).
如第5.1节所述,我们在每个基准数据集的保留"eyes-off"子集上评估了Medprompt提示设计,以检查过拟合风险。采用Medprompt的GPT-4在eyes-on数据上平均表现达到90.6%,在eyes-off数据上平均表现达91.3%,表明提示工程过程很可能未导致MultiMedQA数据集的过拟合。作为补充证据,在$6/9$的基准数据集上eyes-off数据表现更优(图5)。
5.2 Insights about Medprompt Components via Ablation Studies
5.2 通过消融实验分析Medprompt组件的洞见

MedQA PerformanceFigure 6: Identification of the relative contributions of different components of Medprompt via an ablation study.
MedQA性能
图 6: 通过消融实验识别Medprompt各组成部分的相对贡献。
Figure 6 shows the results of an ablation study conducted on the MedQA dataset, in an attempt to understand the relative contributions of each technique in Medprompt. The blue bars represent prior work from [23], and establish baselines for the Medprompt methodology. We then iterative ly layered in each technique, and measured the relative difference in performance from each incremental change. As outlined in Section 4.4, our base Medprompt strategy uses 5 kNN-curated few-shot exemplars and ensembles 5 API-calls together. We also experimented with setting up to 20 fewshot exemplars and up to 11 steps in the ensemble. We found that performance does increase marginally to $90.6%$ , with additional few-shot exemplars and more ensemble steps. This suggests that further improvements on benchmarks may yet be possible, with a corresponding increase in inference time cost and complexity. The introduction of chain-of-thought steps, as described in Section 4, contributed the most to performance (+3.4%), followed by few-shot prompting and choice shuffle ensembling (+2.2% each).
图 6: 展示了在MedQA数据集上进行的消融研究结果,旨在理解Medprompt中各项技术的相对贡献。蓝色柱状图代表[23]的先前工作,为Medprompt方法建立了基线。我们随后逐步叠加每项技术,并测量每次增量变化带来的性能差异。如第4.4节所述,基础Medprompt策略使用5个kNN精选的少样本示例,并将5次API调用集成在一起。我们还尝试设置最多20个少样本示例和最多11步集成。发现随着少样本示例和集成步骤的增加,性能略微提升至$90.6%$。这表明通过相应增加推理时间成本和复杂度,基准测试可能还有进一步改进空间。如第4节所述,思维链步骤的引入对性能提升贡献最大(+3.4%),其次是少样本提示和选项混洗集成(各+2.2%)。
The techniques we use are not statistically independent – therefore, the order in which we test the contribution of each method matters. Our choice of ordering for this ablation study is subjective and based on the relative complexity of the technique introduced. A more theoretically sound method for credit allocation in the ablation study would involve the calculation of game-theoretic Shapley values [28], which takes exponentially more model evaluations to test every potential permutation of orderings. We leave this to future work and encourage readers to think of the specific numbers in the ablation studies as reasonable approximations of relative contributions.
我们采用的技术方法在统计上并非独立存在,因此测试各项技术贡献度的顺序会影响结果。本次消融实验的顺序选择具有主观性,主要基于所引入技术的相对复杂度。从理论角度而言,更严谨的消融实验贡献度分配方法应计算博弈论中的Shapley值 [28],但该方法需要测试所有可能的顺序排列组合,会导致模型评估次数呈指数级增长。我们将此列为未来研究方向,并建议读者将消融实验中的具体数值视为相对贡献度的合理近似参考。
Table 2: Ablation study on expert-crafted chain-of-thought (CoT) vs. GPT-4 self-generated CoT. Both use fixed 5-shot examples, with no ensemble.
| MedQA US (4-option) | |
| Expert-crafted CoT from [30] prompt | 83.8 |
| GPT-4's self-generated CoT prompt | 86.9 (+3.1) |
表 2: 专家构建思维链(CoT)与GPT-4自生成思维链的消融研究。两者均使用固定的5样本示例,未采用集成方法。
| MedQA US (4选项) | |
|---|---|
| 来自[30]提示的专家构建CoT | 83.8 |
| GPT-4自生成的CoT提示 | 86.9 (+3.1) |
Apart from the stack of incremental changes, we compare the expert-crafted chain-of-thought (CoT) prompt used in Med-PaLM 2 [30] with the CoT prompt automatically generated by GPT-4 (Section 4.2). We evaluate GPT-4 using both prompts, with fixed 5-shot examples, no ensemble. Table 2 reports their accuracy on the MedQA dataset. GPT-4’s self-generated CoT outperforms the expert-crafted one by 3.1 absolute points. We notice that compared with the expert-crafted CoT used in Med-PaLM 2, CoT rationales generated by GPT-4 are longer and provide finer-grained step-by-step reasoning logic. One potential explanation is that GPT-4 generated CoT may be better suited to the model’s own strengths and limitations, which could lead to improved performance when compared to the expert-crafted one. Another potential explanation is that expert-crafted CoT may contain implicit biases or assumptions that may not hold for all questions in the MedQA dataset, whereas GPT-4 generated CoT may be more neutral and general iz able across different questions.
除了增量改进的堆叠外,我们将Med-PaLM 2 [30]中专家精心设计的思维链(CoT)提示与GPT-4自动生成的CoT提示(第4.2节)进行对比。使用固定5样本示例(无集成)对两种提示下的GPT-4进行评估。表2展示了它们在MedQA数据集上的准确率表现:GPT-4自生成的CoT以3.1个百分点的绝对优势超越专家设计的版本。我们发现,相较于Med-PaLM 2采用的专家设计CoT,GPT-4生成的CoT依据更长且包含更细粒度的逐步推理逻辑。潜在原因可能是GPT-4生成的CoT更契合模型自身优势与局限,从而相较人工设计版本获得性能提升;另一种可能是专家设计的CoT隐含了不适用于MedQA全部问题的偏见或假设,而GPT-4生成的CoT在不同问题上更具中立性与普适性。
5.3 Generalization: Cross-Domain Exploration of Medprompt
5.3 泛化性:Medprompt 的跨领域探索
We argue that the composition of prompt engineering techniques employed in Medprompt, based on a combination of dynamic few shot selection, self-generated chain of thought, and choice shuffle ensembling, have general purpose application. They are not custom-tailored to the MultiMedQA benchmark datasets. To validate this, we further tested the final Medprompt methodology on six additional, diverse datasets from the MMLU benchmark suite covering challenge problems in the following subjects: electrical engineering, machine learning, philosophy, professional accounting, professional law, and professional psychology. We further sourced two additional datasets answering NCLEX (National Council Licensure Examination) style questions, the exam required to practice as a registered nurse in the United States.
我们认为,Medprompt 中采用的提示工程 (prompt engineering) 技术组合(基于动态少样本选择、自生成思维链和选项洗牌集成)具有通用性。这些技术并非为 MultiMedQA 基准数据集量身定制。为验证这一点,我们进一步在 MMLU 基准套件的六个多样化数据集上测试了最终版 Medprompt 方法,涵盖以下学科领域的挑战性问题:电气工程、机器学习、哲学、专业会计、专业法律和专业心理学。此外,我们还收集了两个额外数据集用于回答 NCLEX(美国护士执照考试)风格问题,该考试是美国注册护士执业所需的资格考试。

Figure 7: GPT-4 performance with three different prompting strategies on out of domain datasets. Zero-shot and five-shot approaches represent baselines and mirror the methodology followed in [23].
图 7: GPT-4 在领域外数据集上采用三种不同提示策略的表现。零样本 (Zero-shot) 和少样本 (five-shot) 方法作为基线,复现了 [23] 中采用的方法论。
Figure 7 shows GPT-4’s performance on these diverse, out of domain dataset with Medprompt alongside zero-shot and five-shot prompts (with random exemplar selection). Across these datasets, Medprompt provides an average improvement of $+7.3%$ over baseline zero-shot prompting. By comparison, Medprompt provided a $+7.1%$ improvement over the same zero-shot baseline on the MultiMedQA datasets studied in this paper. We emphasize that the similarity of improvement across datasets from different distributions demonstrates the generality of the Medprompt approach. While beyond the scope of this paper, we believe the general framework underlying MedPrompt—a combination of few shot learning and chain-of-thought reasoning wrapped in an ensemble layer—can further generalize in applicability beyond the multiple choice question/answer setting with minor algorithmic modifications. For example, in an open-text generation setting, the ensemble layer may not be able to rely on a direct majority vote, but instead may aggregate by selecting the answer closest to all other answers in an embedding space. Another option would be to concatenate each of the $K$ generated pieces of text in a structured format and ask the model to select the most likely option, in the style of Ensemble Refinement [30]. We leave as future work exploration of the space of algorithmic modifications to other settings.
图 7 展示了 GPT-4 在这些多样化、领域外数据集上使用 Medprompt 与零样本和五样本提示(随机选择示例)的性能表现。在这些数据集上,Medprompt 相比基线零样本提示平均提升了 $+7.3%$ 。作为对比,本文研究的 MultiMedQA 数据集中,Medprompt 对相同零样本基线的提升幅度为 $+7.1%$ 。我们强调,不同分布数据集上提升幅度的相似性证明了 Medprompt 方法的通用性。虽然超出本文范围,但我们认为 MedPrompt 的基础通用框架——结合了少样本学习和思维链推理的集成层——只需稍作算法修改,其适用性可进一步扩展到多选题/答题场景之外。例如,在开放文本生成场景中,集成层可能无法依赖直接多数投票,而是通过选择嵌入空间中最接近所有其他答案的答案进行聚合。另一种方案是以 Ensemble Refinement [30] 的方式,将 $K$ 个生成的文本片段以结构化格式拼接,并让模型选择最可能的选项。我们将针对其他场景的算法修改空间探索留作未来工作。
6 Limitations and Risks
6 局限性与风险
Our paper highlights the power of systematic prompt engineering for steering generalist foundation models to amplify the specialist abilities of GPT-4 on medical challenge problems. We now share reflections on limitations and future directions from our assessment.
我们的论文强调了系统性提示工程(prompt engineering)在引导通用基础模型增强GPT-4医学挑战问题专项能力方面的重要作用。以下是我们评估中发现的局限性与未来方向的思考。
As foundation models are trained on massive, internet-scale datasets, strong performance on benchmark problems may be due to memorization or leakage effects, where direct test samples have previously been observed by the model during training. In our previous study, which assessed the performance of GPT-4 on the datasets studied in this work with basic prompting [23], we introduced and ran a blackbox testing algorithm (MELD) which was unable to discover evidence of memorization. However, blackbox testing approaches like MELD are unable to guarantee that data has not been seen before. We also separately assessed GPT-4’s performance on USMLE questions that were behind a paywall and, thus, not available on the public internet, and saw similarly strong performance [23]. In this study, we adopted standard machine learning best practices to control for over fitting and leakage during the prompt engineering process (Section 5.1). However, concerns of benchmark contamination during training remain.
由于基础模型是在海量的互联网规模数据集上训练的,基准问题上的优异表现可能源于记忆或泄漏效应,即模型在训练过程中已经直接接触过测试样本。在我们之前的研究中[23],通过基础提示评估了GPT-4在本文研究数据集上的表现,我们引入并运行了黑盒测试算法(MELD),但未能发现记忆效应的证据。然而,像MELD这样的黑盒测试方法无法保证数据未被预先接触过。我们还单独评估了GPT-4在付费墙后的USMLE试题上的表现(这些试题未出现在公共互联网),并观察到同样优异的表现[23]。本研究中,我们采用标准机器学习最佳实践来控制提示工程过程中的过拟合和泄漏问题(第5.1节),但训练阶段的基准污染风险仍然存在。
Further, we note that the strong performance of GPT-4 with Medprompt cannot be taken to demonstrate real-world efficacy of the model and methods on open-world healthcare tasks [23]. While we are excited about the ability to steer foundations models to become top specialists on the benchmarks, we are cautious about taking the performance of the prompting strategies and model output to mean that the methods will be valuable in the practice of medicine in the open world, whether for automated or assisting healthcare professionals with administrative tasks, clinical decision support, or patient engagement in the open world. To be clear, the medical challenge problems that we and others have studied are designed for testing human competencies in selected domains. Such competency tests are typically framed as sets of multiple choice questions. Although such challenge problems are a common evaluation method and cover diverse topics, they do not capture the range and complexity of medical tasks that healthcare professionals face in actual practice. Thus, the pursuit of tests as proxies for real-world competency and the focus on multiple-choice style answers are limitations when it comes to transferring strong performance on speciality benchmarks to realworld performance. Futhermore, while we believe that the MedPrompt strategy can be adapted to non-multiple choice settings, we did not explicitly test these proposed adaptations on benchmarks in this work.
此外,我们注意到 GPT-4 结合 Medprompt 的优异表现并不能证明该模型和方法在开放世界医疗任务中具有实际效能 [23]。尽管我们对引导基础模型成为基准测试中的顶尖专家感到兴奋,但对于将这些提示策略和模型输出的表现等同于它们在开放世界医疗实践中的价值(无论是用于自动化还是辅助医疗专业人员完成行政任务、临床决策支持或患者互动)持谨慎态度。需要明确的是,我们和其他研究者所研究的医学挑战问题旨在测试人类在特定领域的能力。这类能力测试通常以选择题形式呈现。虽然这种挑战问题是常见的评估方法并涵盖多样主题,但它们无法体现医疗专业人员在实践中面临的医疗任务的广度和复杂性。因此,将测试作为现实世界能力的替代指标以及对选择题式答案的关注,都是将专业基准上的优异表现转化为现实表现的局限所在。此外,尽管我们认为 MedPrompt 策略可以适用于非选择题场景,但本研究并未在基准测试中明确验证这些适应性改进。
We note that foundation models can generate erroneous information (sometimes referred to as hallucinations) which may compromise generations and advice. While improvements in prompting strategies may lead to reductions in hallucinations and better overall accuracy, they may also make any remaining hallucinations even harder to detect. Promising directions include efforts on probabilistic calibration of generations, providing end-users with trustworthy measures of confidence in output. In our prior study, we found that GPT-4 was well-calibrated and could provide trustable measures of its confidence on multiple choice test questions [23].
我们注意到,基础模型可能生成错误信息(有时称为幻觉),这可能会影响生成内容和建议。虽然提示策略的改进可能会减少幻觉并提高整体准确性,但也可能使剩余的幻觉更难被发现。有前景的方向包括对生成内容进行概率校准,为终端用户提供可信的输出置信度指标。在我们之前的研究中,我们发现GPT-4校准良好,能够为其在多项选择题测试中的置信度提供可信的衡量标准[23]。
We must also remain aware of biases in the output of foundation models. We do not yet understand how optimization in pursuit of top-level performance could influence other goals, such as equitable performance. It is vital to balance the pursuit of overall accuracy with equitable performance across different sub populations to avoid exacerbating existing disparities in healthcare. Prior work has highlighted the need to understand and address biases in AI systems. The challenge of bias and fairness remains relevant and pressing in the context of model optimization, fine-tuning, and prompt engineering [13, 20, 38].
我们还必须警惕基础模型输出中的偏见。目前尚不清楚追求顶级性能的优化会如何影响其他目标,例如公平性表现。在追求整体准确性的同时,平衡不同亚人群的公平性表现至关重要,以避免加剧医疗保健领域现有的差距。先前的研究强调了理解和解决AI系统中偏见的必要性 [13, 20, 38]。在模型优化、微调和提示工程 (prompt engineering) 的背景下,偏见与公平性挑战依然紧迫且不容忽视。
7 Summary and Conclusions
7 总结与结论
We presented background, methods, and results of a study of the power of prompting to unleash top-performing specialist capabilities of GPT-4 on medical challenge problems, without resorting to special fine-tuning nor reliance on human specialist expertise for prompt construction. We shared best practices for evaluating performance, including the importance of evaluating model capabilities on an eyes-off dataset. We reviewed a constellation of prompting strategies and showed how they could be studied and combined via a systematic exploration. We found a significant amount of headroom in boosting specialist performance via steering GPT-4 with a highly capable and efficient prompting strategy.
我们介绍了关于提示(prompting)能力的研究背景、方法和结果,该研究旨在不依赖特殊微调或人类专家知识构建提示的情况下,释放GPT-4在医学挑战性问题上的顶尖专科能力。我们分享了性能评估的最佳实践,包括在"eyes-off"数据集上评估模型能力的重要性。我们回顾了一系列提示策略,并展示了如何通过系统性探索来研究和组合这些策略。研究发现,通过采用高效能的提示策略引导GPT-4,可以显著提升其专科性能表现。
We described the composition of a set of prompting methods into Medprompt, the best performing prompting strategy we found for steering GPT-4 on medical challenge problems. We showed how Medprompt can steer GPT-4 to handily top existing charts for all standard medical questionanswering datasets, including the performance by Med-PaLM 2, a specialist model built via finetuning with specialist medical data and guided with handcrafted prompts authored by expert clinicians. Medprompt unlocks specialty skills on MedQA delivering significant gains in accuracy over the best performing model to date, surpassing 90% for the first time on the benchmark.
我们阐述了一套提示方法如何组合成Medprompt——这是我们在引导GPT-4应对医学挑战问题时发现的性能最优提示策略。研究表明,Medprompt能引导GPT-4轻松超越所有标准医学问答数据集的现有榜单成绩,包括专业模型Med-PaLM 2的表现(该模型通过专业医学数据微调构建,并采用临床专家手工编写的提示词)。Medprompt在MedQA基准上解锁了专科能力,相较当前最佳模型实现显著精度提升,首次在该基准突破90%大关。
During our exploration, we found that GPT-4 can be tasked with authoring sets of custom-tailored chain-of-thought prompts that outperform hand-crafted expert prompts. We pursued insights about the individual contributions of the distinct components of the Medprompt strategy via ablation studies that demonstrate the relative importance of each component. We set aside eyes-off evaluation case libraries to avoid over fitting and found that the strong results by Medprompt are not due to over fitting. We explored the generality of Medprompt via performing studies of its performance on a set of competency evaluations in six fields outside of medicine, including electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology. The findings in disparate fields suggests that Medprompt and its derivatives will be valuable in unleashing specialist capabilities of foundation models for numerous disciplines. We see further possibilities for refining prompts to unleash speciality capabilities from generalist foundation models, particularly in the space of adapting the general MedPrompt strategy to non multiple choice questions. For example, we see an opportunity to build on the Medprompt strategy of using GPT-4 to compose its own powerful chain of thought examples and then employ them in prompting. Research directions moving forward include further investigation of the abilities of foundation models to reflect about and compose fewshot examples and to weave these into prompts.
在我们的探索过程中,我们发现可以要求GPT-4编写定制化的思维链提示集,其表现优于手工制作的专家提示。我们通过消融研究来深入理解Medprompt策略中各独立组件的贡献,这些研究展示了每个组件的相对重要性。我们预留了未参与训练的评估案例库以避免过拟合,并发现Medprompt的优秀表现并非源于过拟合。我们通过在一系列非医学领域(包括电气工程、机器学习、哲学、会计、法律、护理和临床心理学)的能力评估中测试其性能,探索了Medprompt的普适性。在不同领域的研究结果表明,Medprompt及其衍生方法将有助于释放基础模型在众多学科中的专业能力。我们看到了进一步优化提示以释放通用基础模型专业能力的可能性,特别是在将通用MedPrompt策略应用于非选择题场景方面。例如,我们有机会基于Medprompt策略,利用GPT-4自主构建强大的思维链示例并应用于提示工程。未来的研究方向包括进一步探索基础模型在反思和构建少样本示例方面的能力,并将这些能力整合到提示中。
While our investigation focuses on exploring the power of prompting generalist models, we believe that fine-tuning, and other methods of making parametric updates to foundation models are important research avenues to explore, and may offer synergistic benefits to prompt engineering. We maintain that both approaches should be judiciously explored for unleashing the potential of foundation models in high-stakes domains like healthcare.
虽然我们的研究重点在于探索通用模型的提示(prompting)能力,但我们认为微调(fine-tuning)以及对基础模型进行参数更新的其他方法同样值得探索,它们可能与提示工程产生协同效应。我们主张在医疗等高风险领域释放基础模型潜力时,应审慎兼顾这两种研究路径。
Acknowledgments
致谢
References
参考文献
[15] Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering. arXiv preprint arXiv:1909.06146, 2019.
[15] Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W Cohen, and Xinghua Lu. PubmedQA: 一个生物医学研究问答数据集。arXiv预印本 arXiv:1909.06146, 2019.