Style-Based Global Appearance Flow for Virtual Try-On
基于风格的全局外观流虚拟试穿

Figure 1. Our global appearance flow based try-on model has a clear advantage over existing local flow based SOTA methods such as Cloth-flow [13] and PF-AFN [10], especially when there are large mis-alignment between reference and garment images (top row), and difficult poses/occlusions (bottom row).
图 1: 我们基于全局外观流的试穿模型相比现有基于局部流的SOTA方法(如Cloth-flow [13]和PF-AFN [10])具有明显优势,特别是在参考图像与服装图像存在较大错位时(上图),以及困难姿势/遮挡情况下(下图)。
Abstract
摘要
Image-based virtual try-on aims to fit an in-shop garment into a clothed person image. To achieve this, a key step is garment warping which spatially aligns the target garment with the corresponding body parts in the person image. Prior methods typically adopt a local appearance flow estimation model. They are thus intrinsically susceptible to difficult body poses/occlusions and large mis-alignments between person and garment images (see Fig. 1). To overcome this limitation, a novel global appearance flow estimation model is proposed in this work. For the first time, a StyleGAN based architecture is adopted for appearance flow estimation. This enables us to take advantage of a global style vector to encode a whole-image context to cope with the aforementioned challenges. To guide the StyleGAN flow generator to pay more attention to local garment deformation, a flow refinement module is introduced to add local context. Experiment results on a popular virtual tryon benchmark show that our method achieves new stateof-the-art performance. It is particularly effective in a ‘inthe-wild’ application scenario where the reference image is full-body resulting in a large mis-alignment with the garment image (Fig. 1 Top). Code is available at: https: //github.com/SenHe/Flow-Style-VTON.
基于图像的虚拟试穿旨在将店内服装贴合到穿衣人物图像上。实现这一目标的关键步骤是服装变形 (garment warping),即在空间上将目标服装与人物图像中对应的身体部位对齐。现有方法通常采用局部外观流估计模型,因此本质上难以处理复杂身体姿态/遮挡以及人物与服装图像间的大幅错位问题 (见图 1)。为突破这一局限,本文提出了一种新颖的全局外观流估计模型。我们首次采用基于 StyleGAN 的架构进行外观流估计,通过全局风格向量编码全图上下文信息来应对上述挑战。为使 StyleGAN 流生成器更关注局部服装形变,还引入了流优化模块来添加局部上下文。在主流虚拟试穿基准测试中,本方法取得了最先进的性能表现,尤其适用于"真实场景"下参考图像为全身像导致与服装图像大幅错位的应用场景 (图 1 顶部)。代码已开源:https://github.com/SenHe/Flow-Style-VTON。
1. Introduction
1. 引言
The transition from offline in-shop retail to e-commerce has been accelerated by the recent pandemic caused lock downs. In 2020, retail e-commerce sales worldwide amounted to 4.28 trillion US dollars and e-retail revenues are projected to grow to 5.4 trillion US dollars in 2022. However, when it comes to fashion, one of key offline experiences missed by the on-line shoppers is the changing room where a garment item can be tried-on. To re- duce the return cost for the online retailers and give shoppers the same offline experience online, image-based virtual try-on (VTON) has been studied intensively recently [9, 10, 13, 14, 19, 24, 38, 39, 42, 43].
疫情导致的封锁加速了从线下实体零售向电子商务的转型。2020年全球零售电商销售额达4.28万亿美元,预计2022年将增长至5.4万亿美元。然而在时尚领域,线上购物者最缺失的线下体验之一就是试衣间功能。为降低线上零售商的退货成本并提供媲美线下的试穿体验,基于图像的虚拟试穿(VTON)技术近年来受到广泛研究 [9, 10, 13, 14, 19, 24, 38, 39, 42, 43]。
A VTON model aims to fit an in-shop garment into a person image. A key objective of a VTON model is to align the in-shop garment with the corresponding body parts in the person image. This is due to the fact that the in-shop garment is usually not spatially aligned with the person image (see Fig. 1). Without the spatial alignment, directly applying advanced detail-preserving image to image translation models [18, 30] to fuse the texture in person image and garment image will result in unrealistic effect in the generated try-on image, especially in the occluded and misaligned regions.
VTON模型旨在将店铺中的服装适配到人物图像上。VTON模型的一个关键目标是将店铺服装与人物图像中对应的身体部位对齐。这是因为店铺服装通常与人物图像在空间上并不对齐(见图1)。若缺乏空间对齐,直接应用先进的细节保留图像转换模型[18,30]来融合人物图像和服装图像的纹理,会导致生成的试穿图像出现不真实的效果,尤其是在遮挡和未对齐区域。
Previous methods address this alignment problem through garment warping, i.e., they first warp the in-shop garment, which is then concatenated with the person image and fed into an image to image translation model for the final try-on image generation. Many of them [9,14,19,38,42, 43] adopt a Thin Plate Spline (TPS) [7] based on the warping method, exploiting the correlation between features extracted from the person and garment images. However, as analyzed in previous works [5, 13, 42], TPS has limitations in handling complex warping, e.g., when different regions in the garment require different deformations. As a result, recent SOTA methods [10, 13] estimate dense appearance flow [45] to warp the garment. This involves training a network to predict the dense appearance flow field representing the deformation required to align the garment with the corresponding body parts.
先前的方法通过服装变形来解决这一对齐问题,即先对店内服装进行变形处理,再将其与人物图像拼接后输入图像到图像转换模型,最终生成试穿效果图。许多研究[9,14,19,38,42,43]采用基于薄板样条(TPS)[7]的变形方法,利用从人物和服装图像中提取的特征相关性。但如先前工作[5,13,42]所述,TPS在处理复杂变形时存在局限,例如当服装不同区域需要差异化形变时。因此,近期SOTA方法[10,13]通过估计密集外观流[45]来实现服装变形,该方法训练网络预测表示服装与对应身体部位对齐所需形变的密集外观流场。
However, existing appearance flow estimation methods are limited in accurate garment warping due to the lack of global context. More specifically, all existing methods are based on local feature’s correspondence, e.g., local feature concatenation or correlation 1, developed for optical flow estimation [6, 17]. To estimate the appearance flow, they make the unrealistic assumption that the corresponding regions from the person image and the in-shop garment are located in the same local receptive filed of the feature extractor. When there is a large mis-alignment between the garment and corresponding body parts (Fig. 1 Top), current appearance flow based methods will deteriorate drastically and generate unsatisfactory results. Lacking a global context also make existing flow-based VTON methods vulnerable to difficult poses/occlusions (Fig. 1 Bottom) when correspondences have to be searched beyond a local neighborhood. This severely limits the use of these methods ‘inthe-wild’, whereby a user may have a full-body picture of herself/himself as the person image to try-on multiple garment items (e.g., top, bottom, and shoes).
然而,现有的外观流估计方法由于缺乏全局上下文,在精确服装变形方面存在局限。具体而言,所有现有方法都基于局部特征对应关系(例如用于光流估计的局部特征拼接或相关性方法 [6, 17])。这些方法在估计外观流时,不切实际地假设人物图像和店内服装的对应区域位于特征提取器的同一局部感受野内。当服装与对应身体部位存在严重错位时(图 1 顶部),当前基于外观流的方法性能会急剧下降并生成不理想的结果。全局上下文的缺失还使现有基于流的虚拟试穿(VTON)方法难以处理困难姿势/遮挡情况(图 1 底部),此时必须在局部邻域之外搜索对应关系。这严重限制了这些方法在"野外"场景中的应用——用户可能使用自己的全身照片作为人物图像来试穿多件服装(例如上衣、下装和鞋子)。
To overcome this limitation, a novel global appearance flow estimation model is proposed in this work. Specifically, for the first time, a StyleGAN [21, 22] architecture for dense appearance flow estimation. This differs fundamentally from existing methods [6, 10, 13, 17] which employ a U-Net [30] architecture to preserve local spatial context. Using a global style vector extracted from the whole reference and garment images makes it easy for our model to capture global context. However, it also raises an important question: can it capture local spatial context crucial for local alignments? After all, a single style vector seemingly has lost local spatial context. To answer this question, we first note that StyleGAN has been successfully applied to local face image manipulation tasks, where different style vectors can generate the same face at different viewpoints [34] and different shapes [15, 28]. This suggests that a global style vector does have local spatial context encoded. However, we also note that the vanilla StyleGAN architecture [21, 22], though much more robust against large mis-alignment and difficult poses/occlusions compared to U-Net, is weaker when it comes to local deformation modeling. We therefore introduce a local flow refinement module in the existing StyleGAN generator to have the better of both worlds.
为克服这一局限性,本研究提出了一种新颖的全局外观流估计模型。具体而言,我们首次采用StyleGAN [21, 22]架构进行密集外观流估计。这与现有采用U-Net [30]架构以保持局部空间上下文的方法[6, 10, 13, 17]存在本质区别。通过从参考图像和服装图像中提取全局风格向量,我们的模型能轻松捕获全局上下文。但这也引出一个关键问题:它能否捕获对局部对齐至关重要的局部空间上下文?毕竟单一风格向量看似已丢失局部空间信息。针对该问题,我们首先注意到StyleGAN已成功应用于局部人脸图像编辑任务,其中不同风格向量可生成不同视角[34]和不同形状[15, 28]的同一人脸。这表明全局风格向量确实编码了局部空间上下文。然而我们也发现,与U-Net相比,原始StyleGAN架构[21, 22]虽对大错位和复杂姿态/遮挡更具鲁棒性,但在局部形变建模方面较弱。因此我们在现有StyleGAN生成器中引入局部流优化模块,以实现优势互补。
Concretely, our StyleGAN-based warping module ( $\mathcal{W}$ in Fig. 2) consists of stacked warping blocks that takes as inputs a global style vector, garment features and person features. The global style vector is computed from the lowest resolution feature maps of the person image and the in-shop garment for global context modeling. In each warping block in the generator, the global style vector is used to modulate the feature channels which takes in the corresponding garment feature map to estimate the appearance flow. To enable our flow-estimator to model the fine-grained local appearance flow, e.g., the arm and hand regions in Fig. 5, in each warping block on top of the style based appearance flow estimation part, we introduce a refinement layer. This refinement layer first warps the garment feature map, which is subsequently concatenated with the person feature map at the same resolution and then used to predict the local detailed appearance flow.
具体来说,我们基于StyleGAN的变形模块 (图2中的$\mathcal{W}$) 由堆叠的变形块组成,输入包括全局风格向量、服装特征和人物特征。全局风格向量通过人物图像和店内服装的最低分辨率特征图计算得出,用于全局上下文建模。在生成器的每个变形块中,全局风格向量用于调制特征通道,该通道接收相应的服装特征图以估计外观流。为了使我们的流估计器能够建模细粒度的局部外观流 (例如图5中的手臂和手部区域),在每个基于风格的外观流估计部分的变形块之上,我们引入了一个细化层。该细化层首先对服装特征图进行变形,随后将其与相同分辨率的人物特征图拼接,再用于预测局部细节外观流。
The contributions of this work are as follow: (1) We propose a novel style-based appearance flow method to warp the garment in virtual try-on. This global flow estimation approach makes our VTON model much robust against large mis-alignments between person and garment images. This makes our method more applicable to ‘in-the-wild’ application where a full-body person image with natural poses is used (see in Fig. 1). (2) We conduct extensive experiments to validate our method, demonstrating clearly that it is superior to existing state-of-the-art alternatives.
本工作的贡献如下:(1) 我们提出了一种基于风格的外观流方法用于虚拟试衣中的服装形变。这种全局流估计方法使我们的VTON模型对人物与服装图像间的严重错位具有更强鲁棒性,使得该方法更适用于使用自然姿态全身人物图像的"野外"应用场景(见图1)。(2) 我们进行了大量实验验证该方法,明确证明其优于现有最先进方案。
2. Related Work
2. 相关工作
Image based virtual try-on Image based (2D) VTON can be categorized into parser-based methods and parserfree methods. Their main difference is whether an off-theshelf human parser2 is required in the inference stage.
基于图像的虚拟试穿
基于图像(2D)的虚拟试穿可分为基于解析器的方法和无解析器方法。它们的主要区别在于推理阶段是否需要使用现成的人体解析器2。
Parser-based methods apply a human segmentation map to mask the garment region in the input person image for warping parameter estimation. The masked person image is concatenated with the warped garment and then fed into a generator for target try-on image generation. Most methods [9, 13, 14, 38, 42, 43] apply a pre-trained human parser [11] to parse the person image into several pre-defined semantic regions, e.g., head, top, and pants. For better try-on image generation, [42] also transforms the segmentation map to match the target garment. The transformed parsing result, together with the warped garment and the masked person image are used for final try-on image generation. The reliance on a parser make these methods sensitive to bad human parsing results [10, 19] which inevitably lead to inaccurate warping and try-on results.
基于解析器的方法通过应用人体分割图来掩码输入人物图像中的服装区域,以估计形变参数。掩码后的人物图像与形变后的服装拼接,随后输入生成器以生成目标试穿图像。大多数方法 [9, 13, 14, 38, 42, 43] 采用预训练的人体解析器 [11] 将人物图像解析为多个预定义的语义区域,例如头部、上衣和裤子。为了生成更优质的试穿图像,[42] 还会调整分割图以匹配目标服装。调整后的解析结果、形变后的服装以及掩码后的人物图像共同用于最终试穿图像的生成。这类方法对解析器的依赖使其容易受到不良人体解析结果 [10, 19] 的影响,进而不可避免地导致形变和试穿效果不准确。
In contrast, parser-free methods [10,19], in the inference stage, only takes as inputs the person image the garment image. They are designed specifically to eliminate the negative effects induced by the bad parsing results. Those methods usually first train a parser-based teacher model and then distill a parser-free student model. [19] proposed a pipeline which distills the garment warping module and try-on generation network using paired triplets. [10] further improved [19] by introducing cycle-consistency for better distillation.
相比之下,无解析器方法 [10,19] 在推理阶段仅需输入人物图像和服装图像。这类方法专门设计用于消除因解析结果不佳带来的负面影响。它们通常先训练一个基于解析器的教师模型,再蒸馏出无解析器的学生模型。[19] 提出了一种流程,利用配对三元组蒸馏服装变形模块和试穿生成网络。[10] 通过引入循环一致性进一步改进了 [19] 的方案,以实现更好的蒸馏效果。
Our method is also a parser free method. However, our method focuses on the design of the garment warping part, where we propose a novel global appearance flow based garment warping module.
我们的方法同样无需解析器。然而,我们的方法聚焦于服装变形部分的设计,提出了一种基于全局外观流 (global appearance flow) 的新型服装变形模块。
3D virtual try-on Compared to image based VTON, 3D VTON provides better try-on experience (e.g., allowing being viewed with arbitrary views and poses), yet is also more challenging. Most 3D VTON works [2, 27] rely on 3D parametric human body models [25] and need scanned 3D datasets for training. Collecting large scale 3D datasets is expensive and laborious, thus posing a constraint on the s cal ability of a 3D VTON model. To overcome this problem, recently [44] applied non-parametric dual human depth model [8] for monocular to 3D VTON. However, existing 3D VTON still generate inferior texture details compared to the 2D methods.
3D虚拟试穿
与基于图像的虚拟试穿(VTON)相比,3D虚拟试穿能提供更好的试穿体验(例如支持任意视角和姿势查看),但也更具挑战性。大多数3D虚拟试穿研究[2,27]依赖于3D参数化人体模型[25],并需要扫描的3D数据集进行训练。采集大规模3D数据集成本高昂且费力,因此限制了3D虚拟试穿模型的可扩展性。为解决这一问题,近期研究[44]采用非参数化双人体深度模型[8]实现单目到3D的虚拟试穿。然而,现有3D虚拟试穿方法生成的纹理细节仍逊色于2D方法。
StyleGAN for image manipulation StyleGAN [21, 22] has revolutionized the research on image manipulation [28, 33, 41] lately. Its successful application on the image manipulation tasks often thanks to its suitability in learning a highly disentangled latent space. Recent efforts have been focused on unsupervised latent semantics discovery [4,34,37]. [24] applied pose conditioned StyleGAN for virtual try-on. However, their model cannot preserve garment details and is slow during inference.
用于图像处理的StyleGAN
StyleGAN [21, 22] 近期彻底改变了图像处理领域的研究 [28, 33, 41]。其在图像处理任务中的成功应用,往往归功于其高度解耦的潜在空间学习特性。当前研究重点集中于无监督潜在语义发现 [4,34,37]。[24] 采用姿态条件化的StyleGAN实现虚拟试穿,但其模型无法保留服装细节且推理速度较慢。
The design of our garment warping network is inspired from StyleGAN in image manipulation, especially its super performance in shape deformation [28, 34]. Instead of us- ing style modulation to generate the warped garment, we use style modulation to predict the implicit appearance flow which is then used to warp the garment via sampling. This design is much more suited to garment detail-preserving compared to [24].
我们的服装变形网络设计灵感源自图像处理中的StyleGAN,特别是其在形状变形方面的卓越表现 [28, 34]。不同于使用风格调制直接生成变形后的服装,我们通过风格调制预测隐式外观流(implicit appearance flow),再借助采样实现服装变形。相较于 [24] 的方案,这种设计能更好地保留服装细节。
Appearance flow In the context of VTON, appearance flow was first introduced by [13]. Since then, it has gained more attention and adopted by recent state-of-the-art VTON models [5, 10]. Fundamentally, appearance flow is used as a sampling grid for garment warping, it is thus information lossless and superior in detail preserving. Beyond VTON, appearance flow is also popular in other tasks. [45] applied it for novel view synthesis. [1, 29] also applied the idea of appearance flow to warp the feature map for person pose transfer. Different from all these existing appearance flow estimation methods, our method, via style modulation, applies a global style vector to estimate the appearance flow. Our method is thus intrinsically superior in its ability to coping with large mis-alignments.
外观流 (appearance flow)
在虚拟试衣 (VTON) 领域,[13] 首次提出了外观流的概念。此后,该技术受到广泛关注,并被当前最先进的 VTON 模型 [5, 10] 所采用。本质上,外观流作为服装形变的采样网格使用,因此具有信息无损和细节保留的优势。除虚拟试衣外,外观流在其他任务中也颇受欢迎。[45] 将其应用于新视角合成,[1, 29] 则利用外观流思想对特征图进行形变以实现人体姿态迁移。与现有外观流估计方法不同,我们通过风格调制 (style modulation) 技术,采用全局风格向量来估计外观流。因此,我们的方法在应对大幅错位情况时具有先天优势。
3. Methodology
3. 方法论
3.1. Problem definition
3.1. 问题定义
Given a person image $(\boldsymbol{p} \in~\mathbb{R}^{3\times H\times W})$ and an in-shop garment image $(g\in\mathbb{R}^{3\times H\times W})$ , the goal of virtual try-on is to generate a try-on image $(t\in\mathbb{R}^{3\times H\times W})$ where the garment in $g$ fits to the corresponding parts in $p$ . In addition, in the generated $t$ , both details from $g$ and non-garment regions in $p$ should be preserved. In other words, the same person in $p$ should appear unchanged in $t$ except now wearing g.
给定一张人物图像 $(\boldsymbol{p} \in~\mathbb{R}^{3\times H\times W})$ 和一张店内服装图像 $(g\in\mathbb{R}^{3\times H\times W})$ ,虚拟试穿的目标是生成一张试穿图像 $(t\in\mathbb{R}^{3\times H\times W})$ ,其中 $g$ 中的服装适配 $p$ 的对应部位。此外,在生成的 $t$ 中,应保留 $g$ 的细节和 $p$ 的非服装区域。换句话说, $p$ 中的同一个人物在 $t$ 中应保持不变,只是现在穿着 $g$ 。
To eliminate the negative effect of inaccurate human parsing, our proposed model ( $\mathcal{F}$ in Fig. 2) is designed to be a parser-free model. Following the strategy adopted by existing parser-free models [10,19], we first pre-train a parserbased model $(\mathcal{F}^{P B})$ . It is then used as a teacher for knowledge distillation to help train the final parser-free model $\mathcal{F}$ . Both $\mathcal{F}$ and ${\mathcal{F}}^{P B}$ consist of three parts, i.e., two feature extractors (EpP $(\mathcal{E}{p}^{P B},\mathcal{E}_{g}^{P B}$ B, EgP B in FP B and Ep, Eg in F), warping module $\mathcal{W}^{\bar{P}B}$ in ${\mathcal{F}}^{P B}$ and $\mathcal{W}$ in $\mathcal{F}$ ), and a generator $(\mathcal{G}^{P B}$ in ${\mathcal{F}}^{P B}$ and $\mathcal{G}$ in $\mathcal{F}$ ). Each of them will be detailed in the following sections.
为消除人工解析不准确带来的负面影响,我们提出的模型(图2中的$\mathcal{F}$)设计为无解析器模型。遵循现有无解析器模型[10,19]采用的策略,我们首先预训练一个基于解析器的模型$(\mathcal{F}^{PB})$,随后将其作为教师模型进行知识蒸馏,以训练最终的无解析器模型$\mathcal{F}$。$\mathcal{F}$和${\mathcal{F}}^{PB}$均由三部分组成:两个特征提取器(FP B中的EpP $(\mathcal{E}{p}^{PB},\mathcal{E}_{g}^{PB}$ B、EgP B以及F中的Ep、Eg),变形模块(${\mathcal{F}}^{PB}$中的$\mathcal{W}^{\bar{P}B}$和$\mathcal{F}$中的$\mathcal{W}$),以及生成器(${\mathcal{F}}^{PB}$中的$\mathcal{G}^{PB}$和$\mathcal{F}$中的$\mathcal{G}$)。各部分细节将在后续章节展开说明。
3.2. Pre-training a parser-based model
3.2. 基于解析器的模型预训练
As per standard in existing parser-free models [10, 19], a parser-based model ${\mathcal{F}}^{P B}$ is first trained. It is used in two ways in the subsequent training of the proposed parser-free model $\mathcal{F}$ : (a) to generate person image $(p)$ to be used by $\mathcal{F}$ as input and (b) to supervise the training of $\mathcal{F}$ via knowledge distillation.
根据现有无解析器模型的通用做法 [10, 19],首先训练基于解析器的模型 ${\mathcal{F}}^{P B}$。该模型在后续提出的无解析器模型 $\mathcal{F}$ 训练中以两种方式使用:(a) 生成供 $\mathcal{F}$ 使用的人体图像 $(p)$ 作为输入;(b) 通过知识蒸馏监督 $\mathcal{F}$ 的训练。
Concretely, ${\mathcal{F}}{P B}$ takes as inputs the semantic representation (segmentation $\mathrm{map}^{3}$ , keypoint pose and dense pose) of a real person image $(p_{g t}\in\mathbb{R}^{3\times H\times W})$ in the training set and an unpaired garment $(g_{u n}\in\mathbb{R}^{3\times H\times W})$ . The output of ${\mathcal{F}}{P B}$ is the image $p$ where the original person is wearing $g_{u n}$ . $p$ will serve as the input for $\mathcal{F}$ during training. This design, according to [10], benefits from the fact that we now have paired person image $p_{g t}$ and garment image $g$ in $p_{g t}$ to train the parser-free model $\mathcal{F}$ , that is:
具体来说,${\mathcal{F}}{P B}$ 的输入是训练集中真实人物图像 $(p_{g t}\in\mathbb{R}^{3\times H\times W})$ 的语义表示(分割 $\mathrm{map}^{3}$、关键点姿态和密集姿态)以及未配对的服装 $(g_{u n}\in\mathbb{R}^{3\times H\times W})$。${\mathcal{F}}{P B}$ 的输出是原始人物穿着 $g_{u n}$ 的图像 $p$。在训练过程中,$p$ 将作为 $\mathcal{F}$ 的输入。根据 [10],这种设计得益于我们现在拥有配对的真实人物图像 $p_{g t}$ 和 $p_{g t}$ 中的服装图像 $g$ 来训练无需解析器的模型 $\mathcal{F}$,即:
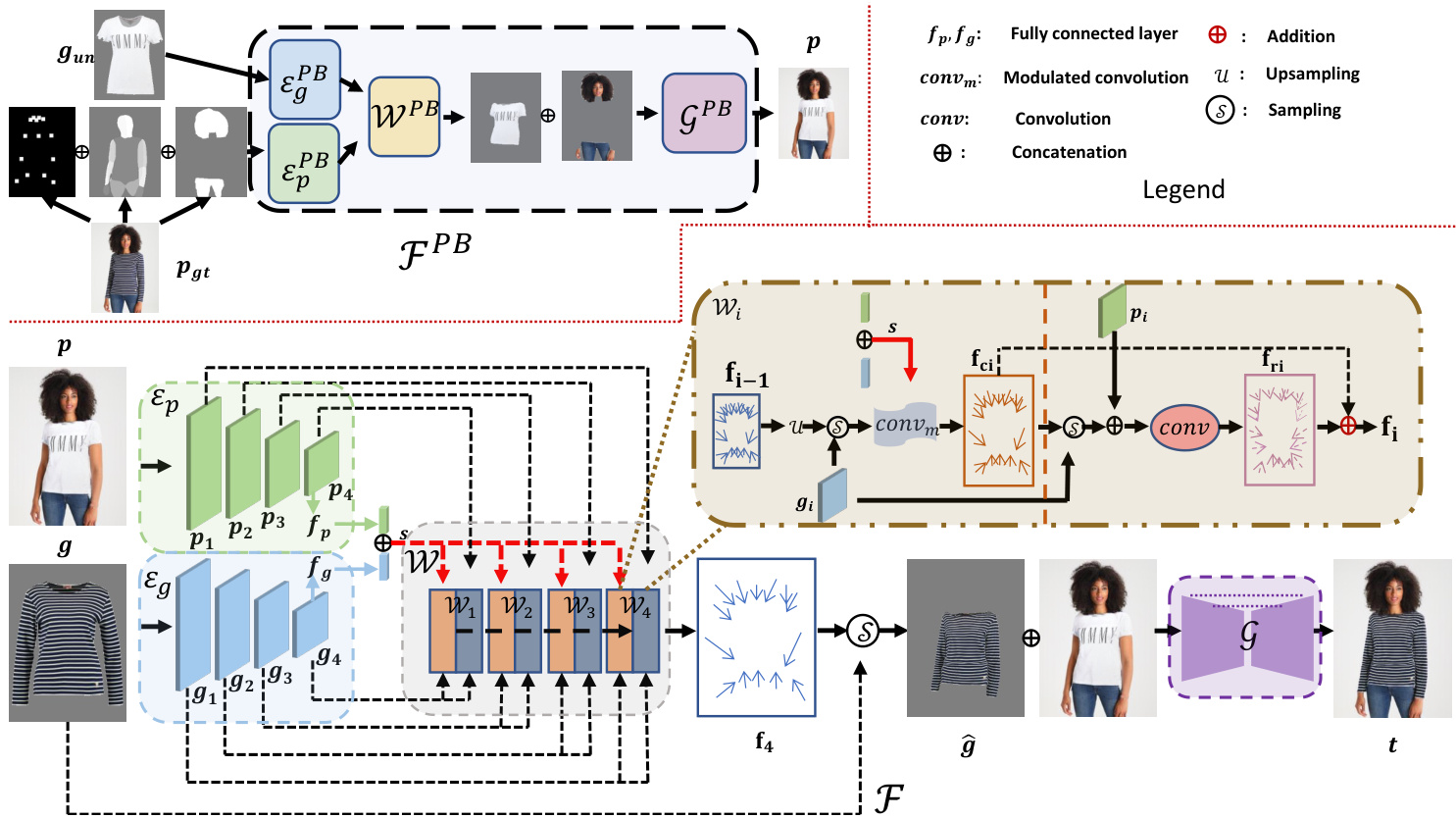
Figure 2. A schematic of our framework. The pre-trained parser based model ${\mathcal{F}}^{P B}$ generates an output image as the input of parser free model $\mathcal{F}$ . The two feature extractors in $\mathcal{F}$ extract the feature of person image and garment image, respectively. A style vector is extracted from the lowest resolution feature maps from person image and the garment image. The warping module takes in the style vector and feature maps from the person image and garment image, and output an appearance flow map. The appearance flow is then used to warp the garment. Finally, the warped garment is concatenated with person image and fed into the generator to generate the target try-on image. Note that ${\mathcal{F}}_{P B}$ is only used during training.
图 2: 我们的框架示意图。基于预训练解析器的模型 ${\mathcal{F}}^{P B}$ 生成输出图像作为无解析器模型 $\mathcal{F}$ 的输入。$\mathcal{F}$ 中的两个特征提取器分别提取人物图像和服装图像的特征。从人物图像和服装图像的最低分辨率特征图中提取风格向量。变形模块接收风格向量以及人物图像和服装图像的特征图,输出外观流图。随后利用该外观流对服装进行变形处理。最终,变形后的服装与人物图像拼接后输入生成器,生成目标试穿图像。请注意 ${\mathcal{F}}_{P B}$ 仅在训练阶段使用。
$$
\mathcal{F}^{}=\underset{\mathcal{F}}{\arg\operatorname*{min}}\lVert t-p_{g t}\rVert,
$$
$$
\mathcal{F}^{}=\underset{\mathcal{F}}{\arg\operatorname*{min}}\lVert t-p_{g t}\rVert,
$$
3.3. Feature extraction
3.3. 特征提取
We apply two convolutional encoders $\mathcal{E}{p}$ and ${\mathcal{E}}{g}.$ ) to extract the features of $p$ and $g$ . Both $\mathcal{E}{p}$ and $\mathcal{E}{g}$ share the same architecture, composed of stacked residual blocks. The extracted features from $\mathcal{E}{p}$ and $\mathcal{E}{g}$ can be represented as ${p_{i}}{1}^{N}$ and ${g_{i}}{1}^{N}$ ( $N=4$ in Fig. 2 for simplicity), where $p_{i}\in\mathbb{R}^{c_{i}\times h_{i}\times w_{i}}$ and $g_{i}\in\mathbb{R}^{c_{i}\times h_{i}\times w_{i}}$ are the feature maps extracted from the corresponding residual block in $\mathcal{E}{p}$ and $\mathcal{E}_{g}$ , respectively. The extracted feature maps will be used in $\mathcal{W}$ to predict the appearance flow.
我们应用两个卷积编码器 $\mathcal{E}{p}$ 和 ${\mathcal{E}}{g}$ ) 来提取 $p$ 和 $g$ 的特征。$\mathcal{E}{p}$ 和 $\mathcal{E}{g}$ 共享相同的架构,由堆叠的残差块组成。从 $\mathcal{E}{p}$ 和 $\mathcal{E}{g}$ 提取的特征可以表示为 ${p_{i}}{1}^{N}$ 和 ${g_{i}}{1}^{N}$ ( 图 2 中为简化起见设 $N=4$ ),其中 $p_{i}\in\mathbb{R}^{c_{i}\times h_{i}\times w_{i}}$ 和 $g_{i}\in\mathbb{R}^{c_{i}\times h_{i}\times w_{i}}$ 分别是从 $\mathcal{E}{p}$ 和 $\mathcal{E}_{g}$ 的对应残差块中提取的特征图。提取的特征图将在 $\mathcal{W}$ 中用于预测外观流。
3.4. Style based appearance flow estimation
3.4. 基于风格的外观流估计
The main novel component of the proposed model is a style-based global appearance flow estimation module. Different from previous methods that estimate appearance flow based on local feature correspondence [10, 13], originally proposed in optical flow estimation [6, 17], our method, based on a global style vector, first estimates a coarse appearance flow via style modulation and then refine the predicted coarse appearance flow based on local feature correspondence.
所提模型的主要创新组件是一个基于风格的全局外观流估计模块。不同于先前基于局部特征对应关系估计外观流的方法 [10, 13](最初由光流估计领域提出 [6, 17]),我们的方法基于全局风格向量,先通过风格调制估计粗略外观流,再基于局部特征对应关系细化预测的粗略外观流。
As illustrated in Fig. 2, our warping module $(\mathcal{W})$ consists of N stacked warping blocks $({\mathcal{W}{i}}{1}^{N})$ , each block is composed of a style-based appearance flow prediction layer (orange rectangle) and a local correspondence based appearance flow refinement layer (blue rectangle). Concretely, we first extract a global style vector $\mathbf{\Psi}(s\in\mathbb{R}^{c})$ ) using the features output from the $N^{t h}$ (final) blocks of $\mathcal{E}{p}$ and $\mathcal{E}{g}$ , denoted as $p_{N}$ and $g_{N}$ , as:
如图 2 所示,我们的变形模块 $(\mathcal{W})$ 由 N 个堆叠的变形块 $({\mathcal{W}{i}}{1}^{N})$ 组成,每个块包含一个基于风格的外观流预测层 (橙色矩形) 和一个基于局部对应关系的外观流优化层 (蓝色矩形)。具体而言,我们首先利用 $\mathcal{E}{p}$ 和 $\mathcal{E}{g}$ 的第 $N^{t h}$ (最终) 块输出的特征 $p_{N}$ 和 $g_{N}$ 提取全局风格向量 $\mathbf{\Psi}(s\in\mathbb{R}^{c})$),计算方式如下:
$$
s=[f_{p}(p_{N}),f_{g}(g_{N})],
$$
$$
s=[f_{p}(p_{N}),f_{g}(g_{N})],
$$
where $f_{p}$ and $f_{g}$ are fully connected layers, and $\left[\cdot,\cdot\right]$ denotes concatenation. Intrinsically, the extracted global style vector s contains the global information of the person and garment, e.g., position, structure, etc. Similar to style based image manipulation [15, 28, 33, 34], we expect the global style vector $s$ capture the required deformation for warping $g$ into $p$ . It is thus used for style modulation in a StyleGAN style generator for estimating a appearance flow field.
其中 $f_{p}$ 和 $f_{g}$ 是全连接层,$\left[\cdot,\cdot\right]$ 表示拼接操作。本质上,提取的全局风格向量 s 包含了人物和服装的全局信息,例如位置、结构等。与基于风格的图像操作类似 [15, 28, 33, 34],我们希望全局风格向量 $s$ 能捕捉将 $g$ 变形为 $p$ 所需的形变信息。因此,该向量被用于 StyleGAN 风格生成器中的风格调制,以估计外观流场。
More specifically, in the style-based appearance flow prediction layer of each block $\mathcal{W}_{i}$ , we apply style modulation to predict a coarse flow:
具体而言,在每个块 $\mathcal{W}_{i}$ 的基于风格的外观流预测层中,我们应用风格调制来预测粗略流:
$$
\mathbf{f_{ci}}=c o n v_{m}(S(g_{N+1-i},\mathcal{U}(\mathbf{f_{i-1}})),s),
$$
$$
\mathbf{f_{ci}}=c o n v_{m}(S(g_{N+1-i},\mathcal{U}(\mathbf{f_{i-1}})),s),
$$
where $c o n v_{m}$ denotes modulated convolution [21], $S(\cdot,\cdot)$ is the sampling operator, $\mathcal{U}$ is the upsampling operator, and $\mathbf{f_{i-1}}\in\mathbb{R}^{2\times h_{i-1}\times w_{i-1}}$ is the predicted flow from last warping block. Note that the first block $\mathcal{W}{1}$ in $\mathcal{W}$ only takes in the lowest resolution garment feature map and the style vector, i.e., $\mathbf{f_{c1}}=c o n v_{m}(g_{N},s)$ . As can be seen from Equation 3, the predicted $\mathbf{f_{ci}}$ depends on the garment feature map and the global style vector. It thus has a global receptive field and is capable to cope with large mis-alignments between the garment and person images. However, as the style vector $s$ is a global representation, as a trade-off, it has a limited ability to accurately estimate the local fine-grained appearance flow (as shown in Fig. 5). The coarse flow is thus in need of a local refinement.
其中 $conv_{m}$ 表示调制卷积 [21],$S(\cdot,\cdot)$ 为采样算子,$\mathcal{U}$ 为上采样算子,$\mathbf{f_{i-1}}\in\mathbb{R}^{2\times h_{i-1}\times w_{i-1}}$ 是来自上一个变形块的预测光流。注意 $\mathcal{W}$ 中的首个块 $\mathcal{W}{1}$ 仅接收最低分辨率的服装特征图和风格向量,即 $\mathbf{f_{c1}}=conv_{m}(g_{N},s)$。如公式3所示,预测的 $\mathbf{f_{ci}}$ 依赖于服装特征图和全局风格向量,因此具有全局感受野,能够处理服装与人物图像间的大幅错位。但由于风格向量 $s$ 是全局表征,作为权衡,其精确估计局部细粒度外观光流的能力有限(如图5所示),因此需要对粗光流进行局部优化。
To refine $\mathbf{f_{ci}}$ , we introduce a local correspondence based appearance flow refinement layer in each block $\mathcal{W}_{i}$ . It aims to estimate a local fine-grained appearance flow:
为了优化 $\mathbf{f_{ci}}$ ,我们在每个模块 $\mathcal{W}_{i}$ 中引入了一个基于局部对应关系的外观流精修层。该层旨在估计局部细粒度的外观流:
$$
\mathbf f_{\mathbf r\mathbf i}=c o n v([S(g_{N+1-i},\mathbf f_{\mathbf c i}),p_{N+1-i}]),
$$
$$
\mathbf f_{\mathbf r\mathbf i}=c o n v([S(g_{N+1-i},\mathbf f_{\mathbf c i}),p_{N+1-i}]),
$$
where $\mathbf{f_{ri}}$ is the predicted refinement flow, and conv denotes convolution. Fundamentally, the refinement layer estimates the refinement flow through the local correspondence, i.e., the correspondence between warped person features and garment feature in the same receptive field. Note that after the warping by $\mathbf{f_{ci}}$ , we can assume that the corresponding regions/features in $g_{N+1-i}$ and $p_{N+1-i}$ are now located in the same receptive field. Therefore, we can apply the local correspondence used in previous works [10, 13] to predict the local fine-grained appearance flow.
其中 $\mathbf{f_{ri}}$ 是预测的细化流(flow),conv表示卷积。本质上,细化层通过局部对应关系(即同一感受野内变形后的人物特征与服装特征之间的对应关系)来估计细化流。需要注意的是,经过 $\mathbf{f_{ci}}$ 变形后,我们可以假设 $g_{N+1-i}$ 和 $p_{N+1-i}$ 中的对应区域/特征现在位于同一感受野内。因此,我们可以应用先前工作[10,13]中使用的局部对应关系来预测局部细粒度外观流。
Finally, we add the coarse flow and the local fine-grained appearance flow together as the output of each warping block:
最后,我们将粗略光流和局部细粒度外观光流相加,作为每个变形模块的输出:
$$
\bf f_{i}=f_{c i}+f_{r i}.
$$
$$
\bf f_{i}=f_{c i}+f_{r i}.
$$
The predicted appearance flow $\mathbf{f_{N}}$ from the last block in $\mathcal{W}$ is used to warp the garment:
来自 $\mathcal{W}$ 最后一个模块的预测外观流 $\mathbf{f_{N}}$ 被用于服装变形:
$$
{\hat{g}}=S(g,\mathbf{f_{N}}).
$$
$$
{\hat{g}}=S(g,\mathbf{f_{N}}).
$$
And the warped garment $\hat{g}$ is then concatenated with the person image and fed into a generator for target try-on image generation:
扭曲后的服装 $\hat{g}$ 随后与人物图像拼接,并输入生成器以生成目标试穿图像:
$$
t=\mathcal{G}([\hat{g},p]).
$$
$$
t=\mathcal{G}([\hat{g},p]).
$$
The generator $\mathcal{G}$ has an encoder-decoder architecture with skip connections in between. We follow the designs in [18,
生成器 $\mathcal{G}$ 采用带有跳跃连接的编码器-解码器架构。我们遵循[18]中的设计。
46] that have been proven to be effective in texture detail preservation.
[46] 这些方法已被证明能有效保留纹理细节。
3.5. Learning objectives
3.5. 学习目标
To train our model, we first apply a perceptual loss [20] between the output of $\mathcal{F}$ and the ground truth person image $p_{g t}$ :
为了训练我们的模型,我们首先在$\mathcal{F}$的输出与真实人物图像$p_{g t}$之间应用感知损失[20]:
$$
L_{p}=\sum_{i}\lVert\phi_{i}(t)-\phi_{i}(p_{g t})\rVert,
$$
$$
L_{p}=\sum_{i}\lVert\phi_{i}(t)-\phi_{i}(p_{g t})\rVert,
$$
where $\phi_{i}$ is the $i^{t h}$ block of the pre-trained VGG network [35].
其中 $\phi_{i}$ 是预训练 VGG 网络 [35] 的第 $i^{t h}$ 个块。
To supervise the training of the warping model $\mathcal{W}$ , we apply a loss on the warped garment:
为了监督变形模型 $\mathcal{W}$ 的训练,我们对变形后的服装施加损失函数:
$$
L_{g}=\lVert\hat{g}-m_{g}\cdot p_{g t}\rVert,
$$
$$
L_{g}=\lVert\hat{g}-m_{g}\cdot p_{g t}\rVert,
$$
where $m_{g}$ is the garment mask of $p_{g t}$ predicted by an offthe-shelf human parsing model.
其中 $m_{g}$ 是由现成的人体解析模型预测的 $p_{g t}$ 服装掩码。
As per standard in previous appearance flow methods [10, 13], we also apply a smoothness regular iz ation on the predicted flow from each block in $\mathcal{W}$ :
按照先前外观流方法的标准 [10, 13],我们同样对 $\mathcal{W}$ 中每个块预测的流施加平滑正则化:
$$
L_{R}=\sum_{i}\lVert\nabla{\bf f_{i}}\rVert,
$$
$$
L_{R}=\sum_{i}\lVert\nabla{\bf f_{i}}\rVert,
$$
where $\lvert\lvert\nabla\bf{f}_{i}\rvert\rvert$ is the generalized char bonnier loss function [36].
其中 $\lvert\lvert\nabla\bf{f}_{i}\rvert\rvert$ 是广义 char bonnier 损失函数 [36]。
As the inputs (segmentation map, keypoint pose and dense pose) to the parser-based person encoder $(\mathcal{E}^{P B})$ contain more semantic information than those of the parserfree model $\mathcal{F}$ (person image), we apply a distillation loss to guide the learning of person encoder $\mathcal{E}_{p}$ in $\mathcal{F}$ :
由于基于解析器的人物编码器 $(\mathcal{E}^{P B})$ 的输入(分割图、关键点姿态和密集姿态)比无解析器模型 $\mathcal{F}$(人物图像)包含更多语义信息,我们应用蒸馏损失来指导 $\mathcal{F}$ 中人物编码器 $\mathcal{E}_{p}$ 的学习:
$$
L_{D}=\sum_{i}\Vert p_{i}^{P B}-p_{i}\Vert,
$$
$$
L_{D}=\sum_{i}\Vert p_{i}^{P B}-p_{i}\Vert,
$$
where $p_{i}^{P B}$ is the output feature map from $i^{t h}$ block in the person encoder $\mathcal{E}{p}^{P B}$ in the pre-trained parser based model ${\mathcal{F}}{P B}$ .
其中 $p_{i}^{P B}$ 是预训练解析器模型 ${\mathcal{F}}{P B}$ 中人物编码器 $\mathcal{E}{p}^{P B}$ 第 $i^{t h}$ 块的输出特征图。
The overall learning objective is:
总体学习目标是:
$$
L=\lambda_{p}L_{p}+\lambda_{g}L_{g}+\lambda_{R}L_{R}+\lambda_{D}L_{D},
$$
$$
L=\lambda_{p}L_{p}+\lambda_{g}L_{g}+\lambda_{R}L_{R}+\lambda_{D}L_{D},
$$
where $\lambda_{p},\lambda_{g},\lambda_{R}$ and $\lambda_{D}$ denote the hyper parameters for balancing the four objectives.
其中 $\lambda_{p},\lambda_{g},\lambda_{R}$ 和 $\lambda_{D}$ 表示用于平衡四个目标的超参数。
4. Experiments
4. 实验
Datasets We experiment our model on the VITON dataset5 [14]. It is the most popular dataset used in previous VTON works. VITON contains a training set containing 14, 221 image pairs6 and a testing dataset of 2, 032 pairs. Both person and garment images are of the resolution $256\times192$ .
数据集
我们在VITON数据集[14]上测试模型,这是先前虚拟试衣(VTON)研究中最常用的数据集。VITON包含14,221组训练图像对和2,032组测试图像对,所有人物和服装图像分辨率均为$256\times192$。
We also create a testing dataset, denoted by augmented VITON, to evaluate model’s robustness to the random positioned person image (see example in Fig. 4) with larger misalignments with the garment images in the original dataset. As most testing person images in VITON are well positioned such that the person image and the garment are well pre-aligned (e.g., most corresponding regions in the person image and garment image are roughly located in the same receptive field), it is not suited for this evaluation. Concretely, the augmented VITON dataset is created by randomly augmenting the testing person image in VITON via shifting and zooming in/out. In particular, we randomly augment 1/3 testing person images in VITON by shifting the person’s position in the image and randomly augment another 1/3 test images in VITON by zooming in/out the person in the image and keep another 1/3 testing images unchanged. When evaluated on this dataset, all compared models are trained with person image augmentation.
我们还创建了一个测试数据集,称为增强版VITON (augmented VITON),用于评估模型对随机位置人物图像的鲁棒性(示例见图4),这些图像与原始数据集中服装图像存在较大错位。由于VITON中大多数测试人物图像的位置都经过精心调整,使得人物图像与服装图像预先对齐良好(例如,人物图像和服装图像中的大多数对应区域大致位于同一感受野内),因此不适合用于此项评估。具体而言,增强版VITON数据集是通过对VITON测试人物图像进行随机平移和缩放/放大来创建的。我们随机对VITON中1/3的测试人物图像进行位置平移增强,对另外1/3测试图像进行人物缩放/放大增强,并保持剩余1/3测试图像不变。在该数据集上进行评估时,所有对比模型均采用人物图像增强数据进行训练。
Implementation details Our model is implemented in PyTorch. We train our model with a single Nvidia RTX 2080-Ti GPU. We set the batch size as 4 and train the model with 100 epochs. We train the model with Adam optimizer [23]. The initial learning rate is set to $5e-4$ which is linearly decayed after 50 epochs. Each residual block in $\mathcal{E}{p}$ and $\mathcal{E}_{g}$ is followed by a pooling layer to reduce the spatial dimension. We set $N=5$ and $c=256$ in the implementation. We will release the code upon the acceptance of this work.
实现细节
我们的模型基于PyTorch实现,使用单块Nvidia RTX 2080-Ti GPU进行训练。批次大小设为4,训练周期为100轮,采用Adam优化器[23]。初始学习率设置为$5e-4$,并在50轮后线性衰减。$\mathcal{E}{p}$和$\mathcal{E}_{g}$中的每个残差块后接池化层以降低空间维度。代码实现中设定$N=5$和$c=256$,论文录用后将公开代码。
Evaluation metrics and baselines We evaluate our model both automatically and manually. In the automatic evaluation, as per standard in VTON, we evaluate model performance using structure similarity (SSIM) [40] and Fréchet Inception Distance (FID) [16]. According to [10, 31], inception score (IS) [32] is not suitable to evaluate VTON images, we thus do not adopt it in the evaluation. In the manual (subjective) evaluation, we run perceptual study on Amazon Mechanical Turk (AMT) to compare the quality of the generated try-on images from different models. Given an input person image, a garment image and the generated try-on image from two models, the AMT workers were asked to vote which generated try-on image is better. Each AMT worker was randomly allocated 100 images to compare two models. 15 AMT workers participated in the evaluation for all models comparison.
评估指标与基线
我们通过自动和人工两种方式评估模型性能。在自动评估中,沿用VTON领域的标准做法,采用结构相似性(SSIM) [40]和Fréchet Inception距离(FID) [16]作为指标。根据[10, 31]的研究结论,初始分数(IS) [32]不适用于评估VTON图像,因此未纳入本次评估。在人工(主观)评估环节,我们通过Amazon Mechanical Turk (AMT)平台开展感知研究,对比不同模型生成的虚拟试穿图像质量。给定输入的人物图像、服装图像以及两个模型生成的试穿效果图,AMT工作人员需投票选出更优的生成结果。每位AMT工作者随机分配100组图像进行两两模型对比,共有15名AMT工作者参与了全模型对比评估。
We compare our methods with other parser-based methods VTON [14], CP-VTON [38], Cloth-flow [13], CP- $\mathrm{VTON{++}}$ [26], ACGPN [42], DCTON [9] and ZFlow [5]. We also compare with the SOTA parser-free method PFAFN [10].
我们将自己的方法与基于解析器的其他方法进行了比较,包括VTON [14]、CP-VTON [38]、Cloth-flow [13]、CP-VTON++ [26]、ACGPN [42]、DCTON [9]和ZFlow [5]。同时,我们还与当前最先进的免解析方法PFAFN [10]进行了对比。
Table 1. Quantitative results of different models on VITON. Warping represents the warping methods used in different models. Parser indicates whether human parser is used in the model during inference. TPS: Thin Plate Spline. AF: Appearance Flow. $\star$ : re-trained with parser free training paradigm.
表 1: VITON上不同模型的定量结果。Warping表示不同模型使用的变形方法。Parser表示推理过程中模型是否使用人体解析器。TPS: Thin Plate Spline。AF: Appearance Flow。$\star$: 采用无解析器训练范式重新训练。
| 方法 | Warping | Parser | SSIM↑ | FID↓ |
|---|---|---|---|---|
| VTON [14] | TPS | Y | 0.74 | 55.71 |
| CP-VTON [38] | TPS | Y | 0.72 | 24.45 |
| CP-VTON++ [26] | TPS | Y | 0.75 | 21.04 |
| Cloth-flow [13] | AF | Y | 0.84 | 14.43 |
| ACGPN [42] | TPS | Y | 0.84 | 16.64 |
| DCTON [9] | TPS | Y | 0.83 | 14.82 |
| PF-AFN [10] | AF | N | 0.89 | 10.09 |
| Zflow [5] | AF | Y | 0.88 | 15.17 |
| Cloth-flow* [13] | AF | N | 0.89 | 10.73 |
| Ours | AF | N | 0.91 | 8.89 |
Main results The quantitative results on VITON testing dataset are shown in Table 1. It can be seen that our model achieves new state-of-the-art performance. Importantly, given the already low FID score (10.09) achieved by prior SOTA method PF-AFN, our method can further decrease it by $11.9%$ . In the meanwhile, the following observations can be made from Table 1. (1) Appearance flow based warping methods generally perform better than TPS based warping methods. (2) Although it takes more training time, parserfree methods are much better than parser-based methods. Our model, benefiting from the proposed novel global appearance flow estimation method, outperforms the previous SOTA parser-free methods (PF-AFN [10] and Clothflow [13]) on all evaluation metrics. The human evaluation results are shown in Table 2. The result is consistent with that in Table 1. Our model outperforms all compared models with more than $10%$ preference rate. The qualitative re- sults from different models are illustrated in Fig. 3. Overall, our method generates better try-on images. For example, the hard pose and occlusion in second and third rows.
主要结果
VITON测试数据集的定量结果如表1所示。可以看出,我们的模型实现了新的最先进性能。值得注意的是,在先前的SOTA方法PF-AFN已经取得较低FID分数(10.09)的情况下,我们的方法能进一步将其降低$11.9%$。同时,从表1可以得出以下观察:(1) 基于外观流(appearance flow)的变形方法通常优于基于TPS的变形方法。(2) 尽管需要更多训练时间,无解析器(parser-free)方法显著优于基于解析器的方法。得益于提出的新型全局外观流估计方法,我们的模型在所有评估指标上均超越了先前SOTA无解析器方法(PF-AFN [10]和Clothflow [13])。
人工评估结果如表2所示,该结果与表1一致。我们的模型以超过$10%$的偏好率优于所有对比模型。不同模型的定性结果如图3所示。总体而言,我们的方法生成了更优质的虚拟试穿图像,例如第二行和第三行中的困难姿势和遮挡情况。
The quantitative results on augmented testing dataset are shown in Table 3. As can be seen that our model again performs best on the augmented VITON testing dataset. Importantly, all other models’ performance drops dramatically. And our model can still maintain the performance (SSIM score) compared to that on the original VITON testing dataset. The qualitative examples are illustrated in Fig. 4. Only our model can generate consistent (e.g., the garment’s left sleeve) and high quality try-on images given the large mis-alignments.
增强测试数据集上的定量结果如表3所示。可以看出,我们的模型在增强版VITON测试数据集上再次表现最佳。值得注意的是,其他所有模型的性能都显著下降。而与原始VITON测试数据集相比,我们的模型仍能保持性能(SSIM分数)。定性示例如图4所示。在存在较大错位的情况下,只有我们的模型能生成一致(如服装左袖)且高质量的虚拟试穿图像。
Ablation Study In this experiment, we validate the design of our appearance flow estimation blocks $(\mathcal{W}{i})$ . Specifically, we first experiment our method with only global style modulation (SM) based appearance flow estimation, that is, only using $\mathbf{f_{ci}}$ in Equation 3 in each $\mathcal{W}{i}$ . We then experiment our method with only refinement flow (RF) estimation, that is, only using $\mathbf{f_{ri}}$ in Equation 4 in each $\mathcal{W}{i}$ . Finally, we experiment with our combined method $\mathrm{\nabla{SM}+}$ RF) which first estimates the appearance flow globally via style modulation and then refines the appearance flow locally through local correspondence. The quantitative results are shown in Table 4. Our proposed global style modulation (SM) based appearance flow method outperforms the local correspondence based method. When they were combined, the performance is further boosted. As illustrated in Fig. 5, without local refinement, our method (global style modulation only) sometimes cannot accurately predict the local fine-grained appearance flow, e.g., the sleeve regions, and thus generates unsatisfactory try-on image. However, with only local correspondence based appearance flow estimation, e.g., only using $\mathbf{f_{ri}}$ in $\mathcal{W}{i}$ , the method suffers when the corresponding regions are not located in the same receptive field. As illustrated in Fig. 6, $\mathbf{f_{ri}}$ cannot accurately estimate the appearance flow when there exists a large misalignment between the input person images and garment images. Once $\mathbf{f_{ci}}$ was first used to reduce the misalignment, our model can successfully overcome the problem.
消融实验
在本实验中,我们验证了外观流估计模块 $(\mathcal{W}{i})$ 的设计。具体而言,我们首先测试仅基于全局风格调制 (SM) 的外观流估计方法,即每个 $\mathcal{W}{i}$ 中仅使用公式3的 $\mathbf{f_{ci}}$。接着测试仅基于细化流 (RF) 估计的方法,即每个 $\mathcal{W}{i}$ 中仅使用公式4的 $\mathbf{f_{ri}}$。最后测试组合方法 $\mathrm{\nabla{SM}+}$ RF),该方法先通过风格调制全局估计外观流,再通过局部对应关系细化外观流。定量结果如表4所示。我们提出的基于全局风格调制 (SM) 的外观流方法优于基于局部对应关系的方法。二者结合后性能进一步提升。如图5所示,若缺少局部细化,仅使用全局风格调制的方法有时无法准确预测局部细粒度外观流(例如袖口区域),导致生成的虚拟试穿图像不理想。然而,若仅依赖基于局部对应关系的外观流估计(例如 $\mathcal{W}{i}$ 中仅使用 $\mathbf{f_{ri}}$),当对应区域不在同一感受野内时效果会下降。如图6所示,当输入人物图像与服装图像存在较大错位时,$\mathbf{f_{ri}}$ 无法准确估计外观流。而先使用 $\mathbf{f_{ci}}$ 减少错位后,我们的模型能成功解决该问题。

Figure 3. Qualitative results from different models $\mathrm{(CP-VTON{++}}$ [26], ACGPN [42], PF-AFN [9] and ours) on VITON testing dataset
图 3: 不同模型 (CP-VTON++ [26], ACGPN [42], PF-AFN [9] 和我们的方法) 在VITON测试数据集上的定性结果
Table 2. The preference rate comparing other models against our model (other models/our model) in human evaluation.
表 2: 人类评估中其他模型与我们模型的偏好率对比 (其他模型/我们的模型)
| 对比方法 | 偏好率 |
|---|---|
| CP-VTON++ [26] ACGPN [42] Cloth-flow* [13] AF-PFN [10] | 12.7%/87.3% 20.2%/79.8% 38.5%/61.5% |
Table 3. Quantitative results of different models on augmented VITON and their relative performance drop $\left(\nabla_{\mathrm{SSIM}}/\nabla_{\mathrm{FID}}\right)$ compared to the standard VITON testing dataset.
表 3: 不同模型在增强版VITON上的量化结果及其相对于标准VITON测试集的性能下降 $\left(\nabla_{\mathrm{SSIM}}/\nabla_{\mathrm{FID}}\right)$
| 方法 | SSIM↑ | FID↓ | VsSIM/VFID |
|---|---|---|---|
| ACGPN | 0.81 | 20.75 | 0.003/4.11 |
| Cloth-flow* [13] | 0.86 | 13.05 | 0.003/2.96 |
| AF-PFN [10] | 0.87 | 12.19 | 0.002/2.10 |
| Ours | 0.91 | 9.91 | 0/1.02 |

Figure 4. Illustrating different VTON models’ robustness to the randomly positioned person image. First row uses original person image as input. And second row uses vertically shifted person image as input. ACGPN [42], Cloth-flow [13], PF-AFN [10].
图 4: 展示不同VTON模型对随机位置人物图像的鲁棒性。第一行使用原始人物图像作为输入,第二行使用垂直偏移后的人物图像作为输入。ACGPN [42], Cloth-flow [13], PF-AFN [10]。
| 方法 | SSIM↑1 | FID↓ |
|---|---|---|
| RF | 0.89 | 10.73 |
| SM SM + RF | 0.89 0.91 | 9.84 8.89 |
5. Conclusion
5. 结论
In this paper, we have proposed a style based global appearance flow estimation method to warp the garment for virtual try-on. Our method via style modulation first estimates the appearance flow globally and then refines the appearance flow locally. Our method achieves state-of-theart performance on the VITON benchmark and it is more robust against large mis-alignment between person and garment images, as well as difficult poses/occlusions. We conducted extensive experiments to show the superiority of our method and validated our architecture design.
本文提出了一种基于风格的全局外观流估计方法,用于虚拟试衣中的服装变形。我们通过风格调制的方法,先全局估计外观流,再局部优化外观流。该方法在VITON基准测试中取得了最先进的性能,并且对于人物与服装图像之间的严重错位以及复杂姿态/遮挡情况具有更强的鲁棒性。我们进行了大量实验来证明该方法的优越性,并验证了我们的架构设计。

Figure 5. Comparing results with only $\mathbf{f_{ci}}$ used in $\mathcal{W}{i}$ and $\mathbf{f_{ci}}+\mathbf{f_{ri}}$ used in $\mathcal{W}_{i}$ .
图 5: 比较仅使用 $\mathbf{f_{ci}}$ 和同时使用 $\mathbf{f_{ci}}+\mathbf{f_{ri}}$ 在 $\mathcal{W}_{i}$ 中的结果。

Figure 6. Comparing results with only $\mathbf{f_{ri}}$ used in $\mathcal{W}{i}$ and $\mathbf{f_{ci}}+\mathbf{f_{ri}}$ used in $\mathcal{W}_{i}$ in the case of large misalignment between the input person image and garment image.
图 6: 在输入人物图像与服装图像存在较大错位情况下,仅使用 $\mathbf{f_{ri}}$ 参与 $\mathcal{W}{i}$ 计算与同时使用 $\mathbf{f_{ci}}+\mathbf{f_{ri}}$ 参与 $\mathcal{W}_{i}$ 计算的结果对比。