FG-CLIP: Fine-Grained Visual and Textual Alignment
FG-CLIP: 细粒度视觉与文本对齐
Abstract
摘要
1. Introduction
1. 引言
Contrastive Language-Image Pre-training (CLIP) excels in multimodal tasks such as image-text retrieval and zero-shot classification but struggles with fine-grained understanding due to its focus on coarse-grained short captions. To address this, we propose Fine-Grained CLIP (FGCLIP), which enhances fine-grained understanding through three key innovations. First, we leverage large multimodal models to generate 1.6 billion long caption-image pairs for capturing globallevel semantic details. Second, a high-quality dataset is constructed with 12 million images and 40 million region-specific bounding boxes aligned with detailed captions to ensure precise, context-rich representations. Third, 10 million hard fine-grained negative samples are incorporated to improve the model’s ability to distinguish subtle semantic differences. We construct a comprehensive dataset, termed FineHARD, by integrating high-quality region-specific annotations with hard fine-grained negative samples. Corresponding training methods are meticulously designed for these data. Extensive experiments demonstrate that FG-CLIP outperforms the original CLIP and other state-of-the-art methods across various downstream tasks, including fine-grained understanding, open-vocabulary object detection, image-text retrieval, and general multimodal benchmarks. These results highlight FG-CLIP’s effectiveness in capturing fine-grained image details and improving overall model performance. The data, code, and models are available at https://github.com/360CVGroup/FG-CLIP.
对比语言-图像预训练 (Contrastive Language-Image Pre-training, CLIP) 在图文检索和零样本分类等多模态任务中表现出色,但由于其关注粗粒度的简短描述,在细粒度理解方面存在不足。为此,我们提出细粒度CLIP (Fine-Grained CLIP, FGCLIP),通过三项关键创新提升细粒度理解能力。首先,我们利用大语言模型生成16亿条长描述-图像对,以捕捉全局语义细节。其次,构建包含1200万张图像和4000万个与详细描述对齐的区域特定边界框的高质量数据集,确保精确且上下文丰富的表征。第三,引入1000万个困难细粒度负样本,提升模型区分细微语义差异的能力。通过整合高质量区域标注与困难负样本,我们构建了名为FineHARD的综合数据集,并针对这些数据精心设计了相应训练方法。大量实验表明,FG-CLIP在细粒度理解、开放词汇目标检测、图文检索及通用多模态基准测试等下游任务中均优于原始CLIP及其他先进方法。这些结果印证了FG-CLIP在捕捉图像细粒度细节和提升整体模型性能方面的有效性。数据、代码和模型已开源:https://github.com/360CVGroup/FG-CLIP。
The integration of vision and language (Alayrac et al., 2022; Ramesh et al., 2022; Lin et al., 2023; Gabeff et al., 2024) has been a long-standing goal in artificial intelligence, aiming to develop models that can understand and reason about the world in a visually and linguistically rich manner. Recent advances in multimodal pre-training, such as CLIP (Radford et al., 2021), have made significant strides in this direction by learning joint representations of images and text through contrastive learning. These models have achieved stateof-the-art performance in a variety of downstream tasks, including image-text retrieval (Pan et al., 2023; Sun et al., 2024; Zhang et al., 2024), image captioning (Mokady et al., 2021; Li et al., 2024; Yao et al., 2024), and visual question answering (Li et al., 2023a; Parelli et al., 2023; Team et al., 2024; Wang et al., 2025). However, despite their impressive capabilities, these models often struggle with fine-grained details, particularly in recognizing object attributes and their relationships.
视觉与语言的融合 (Alayrac et al., 2022; Ramesh et al., 2022; Lin et al., 2023; Gabeff et al., 2024) 一直是人工智能领域的长期目标,旨在开发能够以视觉和语言丰富的方式理解并推理世界的模型。多模态预训练的最新进展,例如 CLIP (Radford et al., 2021),通过对比学习实现图像与文本的联合表征,在这一方向上取得了重大突破。这些模型在多种下游任务中实现了最先进的性能,包括图文检索 (Pan et al., 2023; Sun et al., 2024; Zhang et al., 2024)、图像描述生成 (Mokady et al., 2021; Li et al., 2024; Yao et al., 2024) 和视觉问答 (Li et al., 2023a; Parelli et al., 2023; Team et al., 2024; Wang et al., 2025)。然而,尽管这些模型能力出众,它们仍难以处理细粒度细节,尤其是在识别物体属性及其关系方面。
Recent works (Liu et al., 2023a; Wu et al., 2024b; Zhang et al., 2024; Zheng et al., 2024; Jing et al., 2024) point out two primary reasons for the limitations in CLIP’s finegrained learning capability. First, the original CLIP model’s text encoder supports only up to 77 tokens, restricting its capacity to process detailed descriptions and hindering its ability to capture nuanced textual information. Second, CLIP aligns entire images with corresponding text descriptions, making it challenging to extract valuable region-specific represent at ions from visual features. Consequently, the model struggles to achieve fine-grained alignment between image regions and their corresponding textual attributes, limiting its effectiveness in complex recognition scenarios.
近期研究 (Liu et al., 2023a; Wu et al., 2024b; Zhang et al., 2024; Zheng et al., 2024; Jing et al., 2024) 指出CLIP在细粒度学习能力上的两大局限:首先,原始CLIP模型的文本编码器仅支持77个token,限制了其处理详细描述的能力,难以捕捉细微的文本信息;其次,CLIP将整张图像与对应文本描述对齐,导致难以从视觉特征中提取有价值的区域特定表征。因此,该模型难以实现图像区域与对应文本属性间的细粒度对齐,制约了其在复杂识别场景中的有效性。
To address these issues, researchers have proposed extending the positional encoding to support longer token sequences (Wu et al., 2024b; Zhang et al., 2024; Zheng et al., 2024) and integrating object detection datasets into CLIP training (Zhong et al., 2022; Jing et al., 2024). By aligning bounding boxes with category labels, these methods aim to enhance regional feature extraction. Although these approaches have shown some improvements, they still fall short in fine-grained visual recognition and open-vocabulary object detection. Existing methods (Jing et al., 2024; Zhang et al., 2024) typically introduce relatively few long captions, usually on a million scale, which is inadequate for effective learning of fine-grained details. Additionally, aligning image regions with category labels limits semantic diversity, restricting the model’s generalization to open-world scenarios. Furthermore, the lack of hard fine-grained negative samples limits the model’s ability to distinguish between objects of the same category but with different attributes. In this work, we introduce Fine-Grained CLIP (FG-CLIP), a novel approach designed to enhance CLIP’s fine-grained understanding capabilities through three key innovations.
为解决这些问题,研究者们提出了扩展位置编码以支持更长token序列的方法 (Wu et al., 2024b; Zhang et al., 2024; Zheng et al., 2024) ,并将目标检测数据集整合到CLIP训练中 (Zhong et al., 2022; Jing et al., 2024) 。通过将边界框与类别标签对齐,这些方法旨在提升区域特征提取能力。尽管这些方法取得了一定改进,但在细粒度视觉识别和开放词汇目标检测方面仍存在不足。现有方法 (Jing et al., 2024; Zhang et al., 2024) 通常仅引入少量长文本描述(约百万量级),这不足以有效学习细粒度细节。此外,将图像区域与类别标签对齐限制了语义多样性,制约了模型在开放世界场景中的泛化能力。再者,缺乏困难的细粒度负样本限制了模型区分同类别但不同属性物体的能力。本文提出细粒度CLIP (FG-CLIP) ,通过三项关键创新来增强CLIP的细粒度理解能力。
First, we significantly enhance global-level semantic alignment by generating long captions using state-of-the-art large multimodal models (LMMs) (Hong et al., 2024). This process introduces 1.6 billion long caption-image pairs, providing an unprecedented scale of data that allows FG-CLIP to capture nuanced details at the global-level semantic layer, thereby enhancing its ability to perceive complex and detailed information.
首先,我们通过使用先进的大规模多模态模型(LMMs)生成长描述文本(Hong et al., 2024),显著提升了全局层面的语义对齐能力。这一过程引入了16亿个长描述-图像对,提供了前所未有的数据规模,使FG-CLIP能够在全局语义层捕捉细微细节,从而增强其感知复杂和精细信息的能力。
Second, to improve fine-grained alignment between images and text, we develop a high-quality visual grounding dataset. This dataset includes detailed descriptions for 40 million bounding boxes across 12 million images, ensuring that each region is precisely annotated with context-rich captions. By creating such an extensive and richly annotated dataset, we enable the model to learn precise and con textually rich representations, significantly enhancing its performance on tasks that require fine-grained understanding.
其次,为了提升图像与文本间的细粒度对齐能力,我们构建了一个高质量的视觉定位数据集。该数据集包含1200万张图像中4000万个边界框的详细描述,确保每个区域都配有上下文丰富的精准标注。通过创建如此大规模且标注详尽的数据集,我们使模型能够学习精确且富含上下文的表征,从而显著提升其在需要细粒度理解任务上的性能。
Third, to further enhance model robustness and discrimination abilities, we introduce a large-scale corpus of 10 million hard fine-grained negative samples. By incorporating these challenging negative samples into the training process, FGCLIP learns to distinguish subtle differences in semantically similar but distinct pairs, thereby significantly improving its performance across various downstream tasks. We integrate the high-quality visual grounding data and hard fine-grained negative samples as a whole dataset called FineHARD.
第三,为了进一步提升模型的鲁棒性和判别能力,我们引入了包含1000万个困难细粒度负样本的大规模语料库。通过将这些具有挑战性的负样本纳入训练过程,FGCLIP学会了区分语义相似但实际不同的样本对之间的细微差异,从而显著提升了其在各种下游任务中的表现。我们将高质量视觉定位数据与困难细粒度负样本整合为一个完整数据集,命名为FineHARD。
Compared to previous methods, FG-CLIP demonstrates significant improvements across a wide range of benchmark tasks. Our comprehensive enhancements enable the model to achieve superior performance in capturing nuanced visual details, as evidenced by our state-of-the-art results on tasks such as fine-grained understanding, bounding box classification, long caption image-text retrieval, and open-vocabulary object detection. Moreover, when utilized as the backbone for LMMs (Liu et al., 2023b), FG-CLIP also demonstrates performance improvements in tasks involving attribute analysis (Hudson & Manning, 2019), object localization (Kazemzadeh et al., 2014), and reducing output halluci- nation (Li et al., 2023c). We provide visualization results in Appendix C to demonstrate the improvement in fine-grained understanding. These results highlight FG-CLIP’s effectiveness in capturing fine-grained image details and improving overall model performance. To facilitate future research and application, we make the models, datasets, and code publicly available at https://github.com/360CVGroup/FG-CLIP.
与先前的方法相比,FG-CLIP 在广泛的基准任务中展现出显著提升。我们的全面增强使模型在捕捉细微视觉细节方面实现了卓越性能,这一点通过我们在细粒度理解、边界框分类、长标题图文检索和开放词汇目标检测等任务上的前沿成果得到验证。此外,当作为大语言模型 (Liu et al., 2023b) 的骨干网络时,FG-CLIP 在属性分析 (Hudson & Manning, 2019)、目标定位 (Kazemzadeh et al., 2014) 和减少输出幻觉 (Li et al., 2023c) 等任务中也表现出性能改进。我们在附录 C 中提供了可视化结果以展示细粒度理解的提升。这些成果凸显了 FG-CLIP 在捕获细粒度图像细节和提升整体模型性能方面的有效性。为促进未来研究和应用,我们将模型、数据集和代码公开在 https://github.com/360CVGroup/FG-CLIP。
2. Related Work
2. 相关工作
2.1. Contrastive Language-Image Pre-training
2.1. 对比语言-图像预训练
Contrastive learning has emerged as a powerful paradigm in multimodal pre-training, significantly advancing the field of image-text alignment. Models like CLIP have revolutionized this area by leveraging large-scale image-text pairs to learn rich representations without explicit supervision. CLIP achieves this through a dual-encoder architecture that maps images and their corresponding text descriptions into a shared embedding space, where semantically similar pairs are pulled closer together while dissimilar pairs are pushed apart. This approach not only simplifies data labeling but also enables zero-shot transfer to downstream tasks, demonstrating impressive performance on various benchmarks such as image classification (Deng et al., 2009; Recht et al., 2019) and image-text retrieval (Young et al., 2014; Lin et al., 2014; Urbanek et al., 2024; Chen et al., 2024a).
对比学习已成为多模态预训练中的强大范式,显著推动了图文对齐领域的发展。CLIP等模型通过利用大规模图文对进行无显式监督的丰富表征学习,彻底改变了这一领域。CLIP采用双编码器架构,将图像及其对应文本描述映射到共享嵌入空间,使语义相似的配对彼此靠近,不相似的配对彼此远离。这种方法不仅简化了数据标注流程,还能实现下游任务的零样本迁移,在图像分类 (Deng et al., 2009; Recht et al., 2019) 和图文检索 (Young et al., 2014; Lin et al., 2014; Urbanek et al., 2024; Chen et al., 2024a) 等多个基准测试中展现出卓越性能。
2.2. Fine-Grained Understanding
2.2. 细粒度理解
Despite its success, CLIP faces limitations in handling finegrained visual details. Its text encoder is constrained to 77 tokens, limiting its capacity to process detailed and complex descriptions. Additionally, CLIP aligns entire images with corresponding text, making it challenging to extract valuable region-specific representations. To address these limitations, models like LongCLIP (Zhang et al., 2024) extend the maximum token length of the text encoder, enabling it to handle longer and more detailed textual information. GLIP (Li et al., 2022) and RegionCLIP (Zhong et al., 2022) introduce grounding data, enhancing the model’s ability to align specific regions within images with corresponding text, thereby improving performance on downstream detection tasks (Xie et al., 2018; Gupta et al., 2019; Zhou et al., 2022b; Minderer et al., 2024). However, even with these improvements, existing models still struggle to fully capture and align fine-grained features across diverse datasets.
尽管取得了成功,CLIP在处理细粒度视觉细节方面仍存在局限。其文本编码器被限制为77个token,导致难以处理详细复杂的描述。此外,CLIP将整张图像与对应文本对齐,这使得提取有价值的区域特定表征具有挑战性。为解决这些限制,LongCLIP (Zhang et al., 2024) 等模型扩展了文本编码器的最大token长度,使其能处理更长更详细的文本信息。GLIP (Li et al., 2022) 和 RegionCLIP (Zhong et al., 2022) 引入了基础数据,增强了模型将图像中特定区域与对应文本对齐的能力,从而提升了下游检测任务的性能 (Xie et al., 2018; Gupta et al., 2019; Zhou et al., 2022b; Minderer et al., 2024)。然而,即使有这些改进,现有模型仍难以完全捕获和对齐跨多样数据集的细粒度特征。
2.3. Image-Text Datasets
2.3. 图文数据集
Image-text datasets (Gu et al., 2022; Xie et al., 2023; Fu et al., 2024) play a pivotal role in the performance of multimodal models. While existing datasets such as LAION (Schuhmann et al., 2021; 2022), COCO (Lin et al.,
图文数据集 (Gu et al., 2022; Xie et al., 2023; Fu et al., 2024) 对多模态模型的性能起着关键作用。现有数据集如 LAION (Schuhmann et al., 2021; 2022)、COCO (Lin et al.,
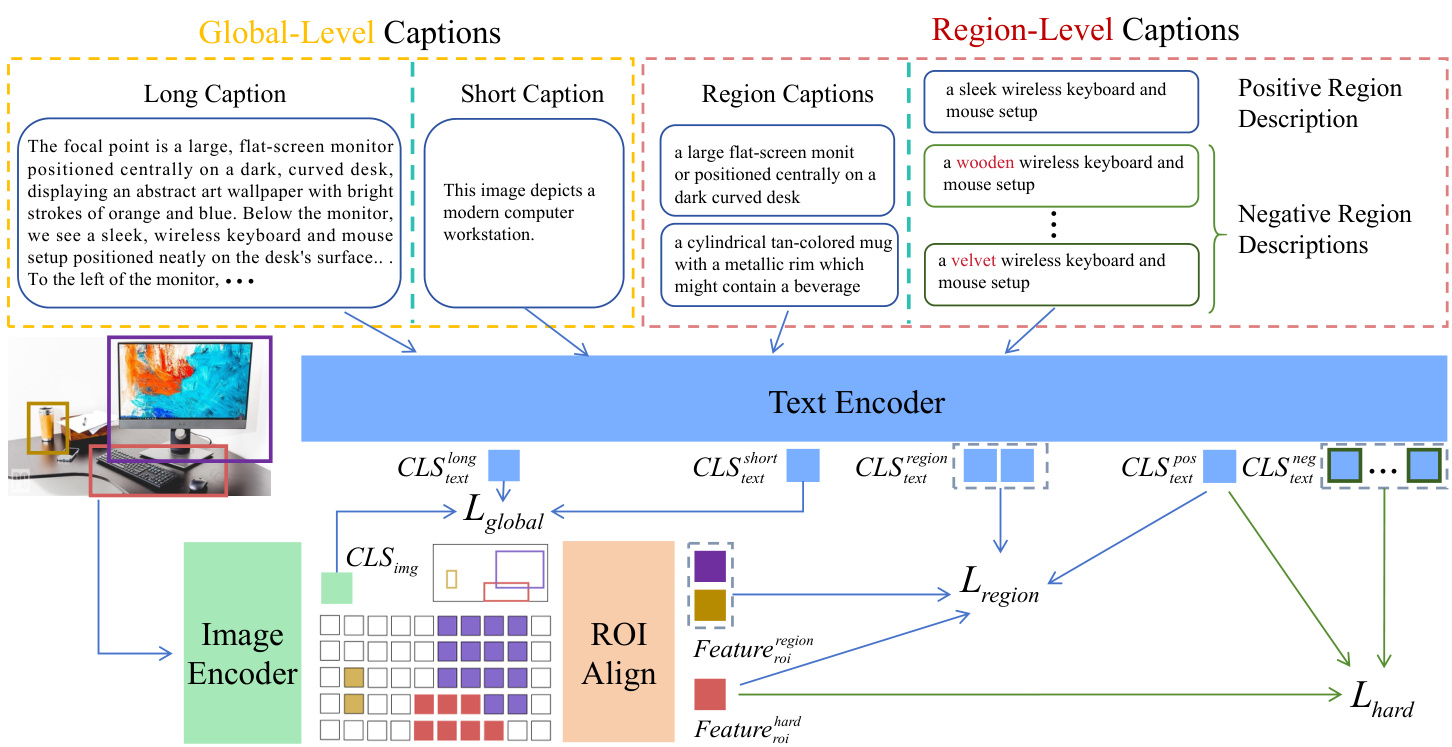
Figure 1. Overview of the FG-CLIP. $C L S_{i m g}$ denotes the image class features output by the Vision Transformer (ViT), while $C L S_{t e x t}$ represents the class features summarized by the text model for multiple inputs, including long captions, short captions, region captions, and positive&negative descriptions of specific regions within images. FG-CLIP’s training proceeds in two stages: the first stage leverages global-level caption-image pairs to achieve initial fine-grained alignment, while the second stage supplements these with additional region-level captions, including detailed region captions and positive/negative region descriptions to further refine the alignment.
图 1: FG-CLIP 概述。$CLS_{img}$ 表示视觉 Transformer (ViT) 输出的图像类别特征,而 $CLS_{text}$ 代表文本模型对多种输入汇总的类别特征,包括长描述、短描述、区域描述以及图像中特定区域的正负描述。FG-CLIP 的训练分为两个阶段:第一阶段利用全局级别的描述-图像对实现初步的细粒度对齐,第二阶段则补充额外的区域级别描述,包括详细区域描述和正负区域描述,以进一步优化对齐效果。
2014), Flickr30K (Young et al., 2014), and Conceptual Captions (Sharma et al., 2018; Changpinyo et al., 2021) offer valuable resources, they often emphasize general scene descriptions, neglecting fine-grained details critical for advanced applications. Researchers have adopted several strategies to mitigate these limitations. One approach involves leveraging advanced large multimodal models (Laurençon et al., 2024; Wang et al., 2024; Wu et al., $2024\mathrm{c}$ ; Chen et al., 2024b; Team et al., 2024) to refine and enrich text descriptions through re captioning. For instance, LongCLIP (Zhang et al., 2024) utilizes 1 million long captionimage pairs from ShareGPT4V (Chen et al., 2024a), and FineCLIP (Jing et al., 2024) constructs a dataset of 2.5 million long caption-image pairs. Although these efforts enhance data richness, they remain limited in scale compared to the vast amount of data in the image-text field. Another strategy is to implement pseudo-labeling pipelines using pre-trained object detection models (Li et al., 2023b; Ma et al., 2024; Hou et al., 2024) to automatically generate fine- grained pseudo-labels for region boxes, similar to the GRIT dataset utilized in Kosmos-2 (Peng et al., 2024). These methods help improve region-specific alignment but may introduce noise due to automated labeling.
2014)、Flickr30K (Young等人, 2014)和Conceptual Captions (Sharma等人, 2018; Changpinyo等人, 2021)提供了宝贵资源,但它们通常侧重于通用场景描述,忽略了高级应用所需的关键细粒度细节。研究人员采取了多种策略来缓解这些限制。一种方法是利用先进的大规模多模态模型(Laurençon等人, 2024; Wang等人, 2024; Wu等人, $2024\mathrm{c}$; Chen等人, 2024b; Team等人, 2024)通过重新标注来优化和丰富文本描述。例如,LongCLIP (Zhang等人, 2024)使用了来自ShareGPT4V (Chen等人, 2024a)的100万条长标注-图像对,而FineCLIP (Jing等人, 2024)构建了包含250万条长标注-图像对的数据集。尽管这些工作提升了数据丰富度,但与图文领域的海量数据相比,其规模仍然有限。另一种策略是使用预训练目标检测模型(Li等人, 2023b; Ma等人, 2024; Hou等人, 2024)实现伪标注流程,自动为区域框生成细粒度伪标签,类似于Kosmos-2 (Peng等人, 2024)中使用的GRIT数据集。这些方法有助于改善区域特定对齐,但可能因自动标注引入噪声。
Another significant challenge is the scarcity of hard finegrained negative samples. Existing datasets predominantly consist of positive examples that are relatively easy to distinguish, limiting the model’s ability to learn subtle variations. The absence of hard negative samples impedes true finegrained understanding, as models struggle to discern small but meaningful differences in visual and textual features. Addressing this gap is essential for developing models capable of reliably performing fine-grained recognition and alignment tasks, thereby enabling them to handle the nuanced distinctions necessary for advanced applications.
另一个重大挑战是缺乏难以区分的细粒度负样本。现有数据集主要由相对容易区分的正例组成,限制了模型学习细微差异的能力。由于模型难以辨别视觉和文本特征中微小但有意义的差异,缺乏难负样本阻碍了真正的细粒度理解。填补这一空白对于开发能够可靠执行细粒度识别和对齐任务的模型至关重要,从而使它们能够处理高级应用所需的微妙差异。
3. Approach
3. 方法
3.1. Fine-Grained CLIP
3.1. 细粒度 CLIP
Figure 1 provides an overview of Fine-Grained CLIP (FGCLIP). Our proposed FG-CLIP extends the traditional dualencoder architecture of CLIP to better capture fine-grained details in images and text. We leverage a two-stage training paradigm to achieve this enhancement. In the first stage, FGCLIP focuses on aligning global representations of images and text using only global contrastive learning. The second stage builds on this foundation by introducing regional contrastive learning and hard fine-grained negative samples learning, leveraging region-text data to further refine the model’s understanding of fine-grained details.
图1: Fine-Grained CLIP (FGCLIP) 概览。我们提出的FG-CLIP扩展了CLIP传统的双编码器架构,以更好地捕捉图像和文本中的细粒度细节。我们采用两阶段训练范式来实现这一改进。第一阶段,FGCLIP仅通过全局对比学习来对齐图像和文本的全局表征。第二阶段在此基础上引入区域对比学习和困难细粒度负样本学习,利用区域-文本数据进一步优化模型对细粒度细节的理解。
Global Contrastive Learning. Global contrastive learning aims to enhance the model’s fine-grained understanding by introducing a method of augmenting long caption alignment utilizing Large Multimodal Models (LMMs). This approach generates additional long captions that provide richer context and finer-grained descriptions. The inclusion of long captions enables the model to perceive and align with global-level semantic details, thereby enhancing fine-grained understanding and context awareness. In addition, we retain the alignment of short caption-image pairs. The long captions complement these short captions, ensuring that the model learns from both detailed, nuanced long captions for complex semantic information and concise, direct short captions for basic concepts. This dual approach improves the model’s overall performance in capturing a broader spectrum of visual information.
全局对比学习 (Global Contrastive Learning)。全局对比学习旨在通过利用大型多模态模型 (Large Multimodal Models, LMMs) 增强长文本对齐的方法,提升模型对细粒度信息的理解能力。该方法通过生成额外的长文本描述,提供更丰富的上下文和更精细的细节刻画。引入长文本使模型能够感知并对齐全局层面的语义信息,从而增强细粒度理解和上下文感知能力。同时,我们保留了短文本-图像配对的对齐关系。长文本与短文本形成互补,确保模型既能从包含复杂语义信息的细致长文本中学习,也能从表达基础概念的简洁短文本中获益。这种双重策略有效提升了模型在捕捉更广泛视觉信息方面的整体性能。
In our framework, both short and long captions are aligned with images by utilizing the [CLS] token features extracted from the text encoder for the captions and the [CLS] token features from the image encoder for the images. To accommodate longer and more detailed captions while preserving the alignment of short captions, position embeddings of FG-CLIP’s text encoder are extended. Specifically, for sequences shorter than or equal to 20 tokens, we use the original position embedding directly. For longer sequences, we apply linear interpolation with a factor of 4 for positions beyond 20, extending the maximum length from 77 to 248 tokens. This modification ensures that the model can effectively handle longer, more descriptive text while maintaining computational efficiency.
在我们的框架中,短标题和长标题都通过利用从文本编码器提取的标题[CLS] token特征和图像编码器提取的图像[CLS] token特征与图像对齐。为了适应更长、更详细的标题,同时保留短标题的对齐性,我们对FG-CLIP文本编码器的位置嵌入进行了扩展。具体来说,对于长度小于或等于20个token的序列,我们直接使用原始位置嵌入;对于更长的序列,我们对超过20的位置采用因子为4的线性插值,将最大长度从77个token扩展到248个token。这一修改确保模型在保持计算效率的同时,能有效处理更长、更具描述性的文本。
During each training step, the model employs both a short caption and a long caption for every image to ensure comprehensive and fine-grained understanding. Given an imagetext pair, the outputs of both encoders are embeddings $v\in\mathbb{R}^{d}$ for images and $t\in\mathbb{R}^{d}$ for text, where $d$ is the dimensionality of the embedding space. We compute the similarity between each pair using the cosine similarity metric:
在每个训练步骤中,模型会为每张图像同时使用短标题和长标题,以确保全面且细粒度的理解。给定一个图文对,两个编码器的输出分别是图像的嵌入向量 $v\in\mathbb{R}^{d}$ 和文本的嵌入向量 $t\in\mathbb{R}^{d}$ ,其中 $d$ 为嵌入空间的维度。我们使用余弦相似度度量计算每对嵌入向量的相似性:
$$
s(v,t)=\frac{v\cdot t^{T}}{\Vert v\Vert\Vert t\Vert}.
$$
$$
s(v,t)=\frac{v\cdot t^{T}}{\Vert v\Vert\Vert t\Vert}.
$$
The objective function for global contrastive learning is based on the InfoNCE loss (He et al., 2020), which maximizes the similarity between matching pairs while minimizing the similarity between mismatched pairs. Specifically, the loss for a batch of $N$ image-text pairs is given by:
全局对比学习的目标函数基于InfoNCE损失 (He et al., 2020) ,通过最大化匹配对的相似度并最小化非匹配对的相似度来实现。具体而言,对于包含 $N$ 个图文对的批次,其损失函数定义为:
$$
\begin{array}{r l r}&{}&{L_{g l o b a l}=-\displaystyle\frac{1}{2N}\sum_{i=1}^{N}(\log\frac{\exp(s(v_{i},t_{i})/\tau)}{\sum_{j=1}^{N}\exp(s(v_{i},t_{j})/\tau)}}\ &{}&{+\log\frac{\exp(s(t_{i},v_{i})/\tau)}{\sum_{j=1}^{N}\exp(s(t_{i},v_{j})/\tau)}),}\end{array}
$$
$$
\begin{array}{r l r}&{}&{L_{g l o b a l}=-\displaystyle\frac{1}{2N}\sum_{i=1}^{N}(\log\frac{\exp(s(v_{i},t_{i})/\tau)}{\sum_{j=1}^{N}\exp(s(v_{i},t_{j})/\tau)}}\ &{}&{+\log\frac{\exp(s(t_{i},v_{i})/\tau)}{\sum_{j=1}^{N}\exp(s(t_{i},v_{j})/\tau)}),}\end{array}
$$
where $\tau$ is a learnable temperature parameter. This global contrastive learning significantly improving its detail perception capabilities in both granular and holistic contexts.
其中 $\tau$ 是一个可学习的温度参数。这种全局对比学习显著提升了模型在细粒度和整体场景下的细节感知能力。
Regional Contrastive Learning. Regional contrastive learning focuses on aligning specific regions within images with corresponding text segments. To achieve this, we employ RoIAlign (He et al., 2017) to extract regionspecific features from the image. These extracted features are then processed by applying average pooling over the tokens within each detected region, resulting in a set of region embeddings {rk}kK=1, where K denotes the total number of valid bounding boxes across all images within a batch. This approach differs from global contrastive learning, which typically relies on the [CLS] token for deriving image-level features. For text, we segment the full-image caption into phrases or sentences that correspond to individual bounding boxes, obtaining text embeddings $l_{k}$ . The regional contrastive loss is defined as:
区域对比学习。区域对比学习专注于将图像中的特定区域与对应的文本片段对齐。为此,我们采用RoIAlign (He et al., 2017) 从图像中提取区域特征。这些提取的特征通过在每个检测区域内对token应用平均池化进行处理,得到一组区域嵌入 {rk}kK=1,其中K表示一个批次内所有图像中有效边界框的总数。这种方法不同于全局对比学习,后者通常依赖[CLS] token来获取图像级特征。对于文本,我们将全图描述分割为与单个边界框对应的短语或句子,从而获得文本嵌入 $l_{k}$。区域对比损失定义为:
$$
\begin{array}{r}{L_{r e g i o n a l}=-\frac{1}{2K}\displaystyle\sum_{i=1}^{K}(\log\frac{\exp(s(r_{i},l_{i})/\tau)}{\sum_{j=1}^{K}\exp(s(r_{i},l_{j})/\tau)}}\ {+\log\frac{\exp(s(l_{i},r_{i})/\tau)}{\displaystyle\sum_{j=1}^{K}\exp(s(l_{i},r_{j})/\tau)}).}\end{array}
$$
$$
\begin{array}{r}{L_{r e g i o n a l}=-\frac{1}{2K}\displaystyle\sum_{i=1}^{K}(\log\frac{\exp(s(r_{i},l_{i})/\tau)}{\sum_{j=1}^{K}\exp(s(r_{i},l_{j})/\tau)}}\ {+\log\frac{\exp(s(l_{i},r_{i})/\tau)}{\displaystyle\sum_{j=1}^{K}\exp(s(l_{i},r_{j})/\tau)}).}\end{array}
$$
This encourages the model to learn fine-grained alignments between specific regions and textual descriptions.
这鼓励模型学习特定区域与文本描述之间的细粒度对齐。
Hard Fine-Grained Negative Samples Learning. To address the scarcity of challenging fine-grained negative samples, we introduce a hard negative mining strategy. We define hard negative samples as those that are semantically close but not identical to the positive sample. These hard negatives are constructed by rewriting the descriptions of bounding boxes, modifying certain attributes to create subtle differences. The specific process of obtaining hard finegrained negative samples can be found in Section 3.2.
难分粒度负样本学习。针对具有挑战性的细粒度负样本稀缺问题,我们引入了一种难负例挖掘策略。我们将难负样本定义为与正样本语义相近但不完全相同的样本。这些难负样本通过重写边界框描述、修改某些属性以制造细微差异来构建。获取难分粒度负样本的具体过程详见第3.2节。
To incorporate hard negative samples into the learning process, we extend the loss function to include a term for hard negatives. For each region-text pair, we compute the similarity between the regional feature and both the positive description and the corresponding negative sample descriptions. The hard negative loss $L_{h a r d}$ is defined as:
为了将困难负样本纳入学习过程,我们对损失函数进行了扩展,加入了针对困难负样本的项。对于每个区域-文本对,我们计算区域特征与正描述及对应负样本描述之间的相似度。困难负样本损失 $L_{hard}$ 定义为:
$$
L_{h a r d}=-\frac{1}{K}\sum_{i=1}^{K}\log\frac{\exp(s(r_{i},l_{i,1})/\tau)}{\sum_{j=1}^{M}\exp(s(r_{i},l_{i,j})/\tau)},
$$
$$
L_{h a r d}=-\frac{1}{K}\sum_{i=1}^{K}\log\frac{\exp(s(r_{i},l_{i,1})/\tau)}{\sum_{j=1}^{M}\exp(s(r_{i},l_{i,j})/\tau)},
$$
where $M$ denotes the total number of captions for each region, with $j=1$ corresponding to the positive sample, and $j>1$ corresponding to the negative samples.
其中 $M$ 表示每个区域的描述总数,$j=1$ 对应正样本,$j>1$ 对应负样本。
In the second stage, we integrate all three components: Global Contrastive Learning, Regional Contrastive Learning, and Hard Fine-Grained Negative Samples Learning, to
在第二阶段,我们整合了全部三个组件:全局对比学习 (Global Contrastive Learning)、区域对比学习 (Regional Contrastive Learning) 和困难细粒度负样本学习 (Hard Fine-Grained Negative Samples Learning)。
ensure comprehensive and nuanced alignment tasks. The learning objective in the second stage combines these elements:
确保全面且细致的对齐任务。第二阶段的学习目标结合了这些要素:
$$
L=L_{g l o b a l}+{r e g i o n a l}+\beta*L_{h a r d}.
$$
$$
L=L_{g l o b a l}+{r e g i o n a l}+\beta*L_{h a r d}.
$$
Here, the hyper parameters $\alpha$ and $\beta$ are set to 0.1 and 0.5, respectively, to balance the regional contrastive loss and the hard negative loss, ensuring that each loss operates on similar scales.
此处超参数 $\alpha$ 和 $\beta$ 分别设为0.1和0.5,以平衡区域对比损失和困难负样本损失,确保各项损失在相近量级上发挥作用。
This integrated approach ensures that FG-CLIP not only captures global-level semantic details but also distinguishes subtle differences in semantically similar pairs, enhancing its overall performance across various downstream tasks.
这种集成方法确保FG-CLIP不仅能捕捉全局层面的语义细节,还能区分语义相似对中的细微差异,从而提升其在各种下游任务中的整体性能。
3.2. Curated Dataset
3.2. 精选数据集
In this section, we describe the meticulous process of curating datasets for our FG-CLIP model, emphasizing both scale and quality to address the limitations of existing models in fine-grained understanding.
在本节中,我们将详细描述为FG-CLIP模型精心策划数据集的过程,强调规模和质量的平衡,以解决现有模型在细粒度理解方面的局限性。
Enhancing LAION-2B Data with Detailed Re captioning. In the first stage of training, we utilize an enhanced version of the LAION-2B dataset (Schuhmann et al., 2022), where images are re captioned with detailed descriptions generated by large multimodal models, i.e., CogVLM2-19B (Hong et al., 2024). This approach generates more detailed and con textually rich captions, crucial for capturing subtle differences in visual content. The original LAION-2B dataset often suffers from overly generic or imprecise captions, leading to suboptimal performance in fine-grained tasks. For instance, an image of a bird might be described as "a bird", without specifying the species or environment. Such generic captions limit the model’s ability to recognize fine details.
通过详细重标注增强LAION-2B数据。在训练的第一阶段,我们使用了LAION-2B数据集 (Schuhmann et al., 2022) 的增强版本,其中图像通过大型多模态模型(即CogVLM2-19B (Hong et al., 2024))生成的详细描述进行重标注。这种方法能产生更详细且上下文丰富的标注,这对捕捉视觉内容中的细微差异至关重要。原始LAION-2B数据集常因标注过于笼统或不精确而导致在细粒度任务中表现欠佳。例如,一张鸟的图片可能仅被标注为"一只鸟",而未说明具体种类或环境。这种笼统的标注限制了模型识别细节的能力。
By leveraging advanced large multimodal models, we generate detailed descriptions that not only identify objects but also provide rich contextual information about their attributes, actions, and relationships within the scene. For instance, rather than a generic description like "a bird", our refined captions read "a red-winged blackbird perched on a tree branch in a park." Utilizing a cluster of $160\times910\mathrm{B}$ NPUs, the data processing is completed in 30 days. An ablation study detailed in Section 4.5 evaluates the impact of using these high-quality, detailed captions. The results demonstrate significant improvements in model performance across various tasks, underscoring the critical role of large-scale, high-quality text annotations in enhancing both model accuracy and context understanding.
通过先进的大型多模态模型,我们生成的详细描述不仅能识别物体,还能提供关于其属性、动作及场景中关系的丰富上下文信息。例如,不同于"一只鸟"这样的泛泛描述,我们的优化标注会呈现为"公园树枝上一只停驻的红翅黑鹂"。借助由160×910B NPU组成的计算集群,数据处理在30天内完成。第4.5节详述的消融实验评估了采用这类高质量细节标注的影响,结果表明跨多种任务的模型性能均获得显著提升,印证了大规模高质量文本标注对于提高模型精度和上下文理解能力的关键作用。
Fine-Grained Visual Grounding+Recaption+Hard Negative Dataset (FineHARD). For the second stage, we develop a high-quality visual grounding dataset named
细粒度视觉定位+重述+困难负样本数据集 (FineHARD)。在第二阶段,我们开发了一个名为
FineHARD, featuring precise region-specific captions and hard negative samples. We curate the overall dataset based on GRIT (Peng et al., 2024) images. The process begins with generating detailed image captions using CogVLM2- 19B (Hong et al., 2024), ensuring comprehensive and nuanced descriptions that capture the full context of each image. Following (Peng et al., 2024), we then use SpaCy (Honnibal et al., 2020) to parse the captions and extract the referring expressions. Subsequently, the images and referring expressions are fed into the pretrained object detection model, i.e., Yolo-World (Cheng et al., 2024) to obtain the associated bounding boxes. Non-maximum suppression is applied to eliminate overlapping bounding boxes, retaining only those with predicted confidence scores higher than 0.4. This process results in 12 million images and 40 million bounding boxes with fine-grained region captions. We provide examples of the images and their corresponding captions in Appendix A.
FineHARD,具有精确的区域特定标注和困难负样本。我们基于GRIT (Peng et al., 2024) 图像筛选整体数据集。流程首先使用CogVLM2-19B (Hong et al., 2024) 生成详细的图像标注,确保全面且细致的描述以捕捉每张图像的完整上下文。遵循 (Peng et al., 2024) 的方法,随后使用SpaCy (Honnibal et al., 2020) 解析标注并提取指代表达式。接着,将图像和指代表达式输入预训练的目标检测模型Yolo-World (Cheng et al., 2024) 以获取关联的边界框。应用非极大值抑制消除重叠边界框,仅保留预测置信度高于0.4的框。该流程最终产生1200万张图像和4000万个带有细粒度区域标注的边界框。我们在附录A中提供了图像及其对应标注的示例。
Next, to create challenging fine-grained negative samples, we modify attributes of bounding box descriptions while keeping the object names unchanged. For this task, we employ an open-source large language model, Llama-3.1- 70B (Dubey et al., 2024), to generate 10 negative samples for each positive sample. To ensure clarity, we remove special symbols such as semicolons, commas, and line breaks from the generated descriptions. A quality check of 3,000 negative samples reveals that $98.9%$ are qualified, with only $1.1%$ considered noise—a level within the expected tolerance for unsupervised methods. This process generates subtle variations that better reflect real-world scenarios where objects may appear similar but differ in specific details. We illustrate examples of the fine-grained negative samples in Appendix B.
接下来,为了创建具有挑战性的细粒度负样本,我们在保持物体名称不变的情况下修改边界框描述的属性。为此任务,我们采用开源大语言模型 Llama-3.1-70B (Dubey et al., 2024) 为每个正样本生成10个负样本。为确保清晰度,我们从生成的描述中移除分号、逗号和换行符等特殊符号。对3,000个负样本的质量检查显示,$98.9%$ 符合要求,仅 $1.1%$ 被视为噪声——这一比例在无监督方法的预期容错范围内。该过程生成的细微差异能更好地反映现实场景中物体外观相似但细节不同的情况。细粒度负样本的示例详见附录B。
The resulting dataset includes 12 million images with finegrained captions, 40 million bounding boxes with detailed region descriptions, and 10 million hard negative samples. The data pipeline utilizes a cluster of $160\times910\mathrm{B}$ NPUs and takes 7 days to complete. This comprehensive dataset enhances the model’s ability to capture fine-grained details and provides a robust foundation for training FG-CLIP to distinguish subtle differences in visual and textual features.
最终得到的数据集包含1200万张带精细标注的图像、4000万个带详细区域描述的边界框,以及1000万困难负样本。数据处理流程使用了160×910B NPU集群,耗时7天完成。该综合数据集提升了模型捕捉细粒度细节的能力,并为训练FG-CLIP模型区分视觉与文本特征的细微差异提供了坚实基础。
4. Experiments
4. 实验
4.1. Implementation Details
4.1. 实现细节
In the first stage, we train on a dataset of 1.6 billion images, each paired with short and long texts. The model is initialized with weights from the original CLIP (Radford et al., 2021). For both ViT-B and ViT-L (Do sov it ski y, 2021) configurations, the batch size per NPU is set to 384. The learnable temperature parameter $\tau$ is initialized to 0.07. We utilize the AdamW optimizer with a learning rate of 1e-4, weight decay of 0.05, $\beta_{1}$ of 0.9, $\beta_{2}$ of 0.98, and warmup steps for the first 200 iterations. The entire training process employs DeepSpeed’s Zero-2 optimization technique and Bfloat16 precision to accelerate training, and the model is trained for one epoch.
在第一阶段,我们使用包含16亿张图像的数据集进行训练,每张图像都配有简短和长文本描述。模型权重初始化采用原始CLIP (Radford et al., 2021) 的参数。对于ViT-B和ViT-L (Dosovitskiy, 2021) 两种配置,每个NPU的批次大小设置为384。可学习温度参数$\tau$初始化为0.07。我们采用AdamW优化器,学习率为1e-4,权重衰减为0.05,$\beta_{1}$为0.9,$\beta_{2}$为0.98,并在前200次迭代中进行学习率预热。整个训练过程使用DeepSpeed的Zero-2优化技术和Bfloat16精度来加速训练,模型训练周期为一个epoch。
Table 1. Results on FG-OVD benchmark. Accuracy is reported.
表 1: FG-OVD 基准测试结果 (报告准确率)
| 方法 | 主干网络 | 细粒度理解 (hard) | 细粒度理解 (medium) | 细粒度理解 (easy) | 细粒度理解 (trivial) |
|---|---|---|---|---|---|
| CLIP | ViT-B/16 | 12.0 | 23.1 | 22.2 | 58.5 |
| EVA-CLIP | ViT-B/16 | 14.0 | 30.1 | 29.4 | 58.3 |
| Long-CLIP | ViT-B/16 | 9.2 | 18.4 | 16.2 | 51.8 |
| FineCLIP | ViT-B/16 | 26.8 | 49.8 | 50.4 | 71.9 |
| FG-CLIP | ViT-B/16 | 46.1 | 66.6 | 68.7 | 83.4 |
| CLIP | ViT-L/14 | 15.4 | 25.3 | 25.7 | 38.8 |
| EVA-CLIP | ViT-L/14 | 18.3 | 38.4 | 35.2 | 62.7 |
| Long-CLIP | ViT-L/14 | 9.6 | 19.7 | 16.0 | 39.8 |
| FineCLIP | ViT-L/14 | 22.8 | 46.0 | 46.0 | 73.6 |
| FG-CLIP | ViT-L/14 | 48.4 | 69.5 | 71.2 | 89.7 |
Table 2. Bounding box classification results.
2021), RegionCLIP (Zhong et al., 2022), Detic (Zhou et al., 2022b), VLDet (Lin et al., 2022), RO-ViT (Kim et al., 2023b), CFM-ViT (Kim et al., 2023a), F-ViT(Wu et al., 2024a), and CLIPSelf (Wu et al., 2024a).
表 2: 边界框分类结果。
| 方法 | 骨干网络 | 边界框分类 (COCO LVIS) | 边界框分类 (Open Images) |
|---|---|---|---|
| CLIP | ViT-B/16 | 44.2 20.9 | 15.3 |
| EVA-CLIP | ViT-B/16 | 30.6 14.4 | 8.8 |
| RegionCLIP | ViT-B/16 | 40.0 22.2 | 19.1 |
| CLIPSelf | ViT-B/16 | 43.7 7.8 | 11.4 |
| Long-CLIP | ViT-B/16 | 36.7 18.2 | 14.9 |
| FineCLIP | ViT-B/16 | 48.4 23.3 | 18.1 |
| FG-CLIP | ViT-B/16 | 52.3 28.6 | 20.6 |
| CLIP | ViT-L/14 | 33.8 | 9.3 8.3 |
| EVA-CLIP | ViT-L/14 | 32.1 18.3 | 9.3 |
| Long-CLIP | ViT-L/14 | 35.6 10.4 | 8.9 |
| FineCLIP | ViT-L/14 | 54.5 22.5 | 19.1 |
| FG-CLIP | ViT-L/14 | 63.2 | 38.3 23.8 |
2021), RegionCLIP (Zhong et al., 2022), Detic (Zhou et al., 2022b), VLDet (Lin et al., 2022), RO-ViT (Kim et al., 2023b), CFM-ViT (Kim et al., 2023a), F-ViT (Wu et al., 2024a), 以及 CLIPSelf (Wu et al., 2024a)。
In the second stage, we train on a dataset of 12 million images. Apart from long and short captions, this dataset includes high-quality visual grounding annotations and hard fine-grained negative samples. The model is initialized with weights obtained from the first stage. The batch size per GPU is set to 512. We employ the AdamW optimizer with a learning rate of 1e-6, weight decay of 0.001, $\beta_{1}$ of 0.9, $\beta_{2}$ of 0.98, and warmup steps for the first 50 iterations. Training acceleration techniques include DeepSpeed’s Zero2 optimization, CUDA’s TF32 technology, and Bfloat16 precision, and the model is trained for one epoch.
在第二阶段,我们在包含1200万张图像的数据集上进行训练。除长短描述文本外,该数据集还包含高质量的视觉定位标注和困难细粒度负样本。模型采用第一阶段获得的权重进行初始化,单GPU批处理大小设为512。我们使用AdamW优化器,学习率为1e-6,权重衰减0.001,$\beta_{1}$为0.9,$\beta_{2}$为0.98,前50次迭代采用学习率预热。训练加速技术包括DeepSpeed的Zero2优化、CUDA的TF32技术和Bfloat16精度,模型训练周期为一个epoch。
4.2. Comparisons on Fine-grained Region-level Task
4.2. 细粒度区域级任务对比
In this section, the primary methods included for comparison are CLIP (Radford et al., 2021), EVA-CLIP (Sun et al., 2023), Long-CLIP (Zhang et al., 2024), and FineCLIP (Jing et al., 2024). Additional methods involved in openvocabulary detection include OV-RCNN (Zareian et al.,
本节用于对比的主要方法包括 CLIP (Radford 等人, 2021)、EVA-CLIP (Sun 等人, 2023)、Long-CLIP (Zhang 等人, 2024) 和 FineCLIP (Jing 等人, 2024)。参与开放词汇检测的其他方法还包括 OV-RCNN (Zareian 等人,
Table 3. Performance on open-vocabulary object detection task.
表 3: 开放词汇目标检测任务性能。
| 方法 | 骨干网络 | OV-COCO | ||
|---|---|---|---|---|
| OV-RCNN | RN50 | 17.5 | 41.0 | |
| RegionCLIP | RN50 | 26.8 | 54.8 | 34.9 47.5 |
| Detic | RN50 | 27.8 | 51.1 | 45.0 |
| VLDet | RN50 | 32.0 | 50.6 | 45.8 |
| RO-ViT | ViT-B/16 | 30.2 | 41.5 | |
| RO-ViT | ViT-L/16 | 33.0 | 47.7 | |
| CFM-ViT | ViT-L/16 | 34.1 | 46.0 | |
| F-ViT | ViT-B/16 | 17.5 | 41.0 | 34.9 |
| F-ViT+CLIPSelf | ViT-B/16 | 33.6 | 54.2 | 48.8 |
| F-ViT+FineCLIP | ViT-B/16 | 29.8 | 45.9 | 41.7 |
| F-ViT+FG-CLIP | ViT-B/16 | 35.1 | 51.7 | 47.4 |
| F-ViT | ViT-L/14 | 24.7 | 53.6 | 46.0 |
| F-ViT+CLIPSelf | ViT-L/14 | 38.4 | 60.6 | 54.8 |
| F-ViT+FineCLIP | ViT-L/14 | 40.0 | 57.2 | 52.7 |
| F-ViT+FG-CLIP | ViT-L/14 | 41.2 | 58.0 | 53.6 |
Fine-Grained Understanding. Based on the fine-grained benchmark FG-OVD constructed by (Bianchi et al., 2024), we evaluate open-source image-text alignment models. Unlike previous benchmarks such as MSCOCO (Lin et al., 2014) and Flickr (Young et al., 2014), which rely on global information for matching, this benchmark focuses on identifying specific local regions within images. Each region has one corresponding positive description and ten negative descriptions, with the negative samples derived from the positive text. This benchmark primarily comprises four subsets of varying difficulty levels: hard, medium, easy, and trivial. The increasing difficulty across these subsets is reflected in the degree of distinction between the texts to be matched. In the hard, medium, and easy subsets, one, two, and three attribute words are replaced, respectively. In the trivial subset, the texts are entirely unrelated. For the source collection of specific attribute words, please refer to (Bianchi et al., 2024).
细粒度理解。基于 (Bianchi et al., 2024) 构建的细粒度基准 FG-OVD,我们对开源图文对齐模型进行评估。不同于 MSCOCO (Lin et al., 2014) 和 Flickr (Young et al., 2014) 等依赖全局信息进行匹配的早期基准,该基准专注于识别图像中的特定局部区域。每个区域对应一个正向描述和十个负向描述,负样本由正向文本衍生而来。该基准主要包含四个难度递增的子集:困难、中等、简单和极简。这些子集难度的提升体现在待匹配文本之间的区分度上。在困难、中等和简单子集中,分别替换了一个、两个和三个属性词;极简子集中的文本则完全无关。具体属性词的来源收集详见 (Bianchi et al., 2024)。
During testing, following FineCLIP, we first extract dense features from the model by removing the last self-attention layer as suggested by (Zhou et al., 2022a). Subsequently, we combine the bounding box information provided by the benchmark with ROIAlign to obtain representative features. These features are used to calculate similarity scores with both positive and negative sample descriptions. Top-1 accuracy is adopted as the evaluation metric.
在测试阶段,我们遵循FineCLIP的方法,首先按照(Zhou et al., 2022a)的建议移除最后一个自注意力层来提取密集特征。随后,我们将基准测试提供的边界框信息与ROIAlign结合,获得代表性特征。这些特征用于计算与正负样本描述的相似度分数,并采用Top-1准确率作为评估指标。
As shown in Table 1, FG-CLIP achieves significant improvements over existing models, particularly on the challenging hard and medium subsets, thanks to its hard fine-grained negative samples learning strategy. Examples of different models’ performance can be found in Appendix D.1.
如表 1 所示,得益于其细粒度难负样本学习策略,FG-CLIP 在现有模型基础上取得了显著提升,尤其在具有挑战性的困难和中等级别子集上表现突出。不同模型性能的示例可参见附录 D.1。
Table 4. Comparisons on image-level tasks, including long/short caption image-text retrieval, and zero-shot image classification.
表 4: 图像级任务对比,包括长/短标题图文检索和零样本图像分类。
| Method | Backbone | ShareGPT4V | DCI | MSCOCO | Flickr30k | ImageNet-1K | ImageNet-v2 | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| I2T | T2I | I2T | T2I | I2T | T2I | I2T | T2I | Top-1 | Top-1 | ||
| CLIP | ViT-B/16 | 78.2 | 79.6 | 45.5 | 43.0 | 51.8 | 32.7 | 82.2 | 62.1 | 68.4 | 61.9 |
| EVA-CLIP | ViT-B/16 | 90.5 | 85.5 | 41.9 | 41.2 | 58.7 | 41.6 | 85.7 | 71.2 | 74.7 | 67.0 |
| Long-CLIP | ViT-B/16 | 94.7 | 93.4 | 51.7 | 57.3 | 57.6 | 40.4 | 85.9 | 70.7 | 66.8 | 61.2 |
| FineCLIP | ViT-B/16 | 70.6 | 73.3 | 35.5 | 34.4 | 54.5 | 40.2 | 82.5 | 67.9 | 55.7 | 48.8 |
| FG-CLIP | ViT-B/16 | 96.7 | 94.9 | 61.8 | 60.6 | 64.1 | 45.4 | 90.7 | 76.4 | 69.0 | 61.8 |
| CLIP | ViT-L/14 | 86.5 | 83.6 | 37.2 | 36.4 | 58.0 | 37.1 | 87.4 | 67.3 | 76.6 | 70.9 |
| EVA-CLIP | ViT-L/14 | 91.5 | 89.4 | 47.2 | 47.8 | 64.2 | 47.9 | 89.2 | 77.9 | 80.4 | 73.8 |
| Long-CLIP | ViT-L/14 | 95.8 | 95.6 | 44.2 | 52.5 | 62.8 | 46.3 | 90.0 | 76.2 | 73.5 | 67.9 |
| FineCLIP | ViT-L/14 | 73.4 | 82.7 | 40.1 | 46.2 | - | - | - | - | 60.8 | 53.4 |
| FG-CLIP | ViT-L/14 | 97.4 | 96.8 | 66.7 | 66.1 | 68.9 | 50.9 | 93.7 | 81.5 | 76.1 | 69.0 |
Bounding Box Classification. To assess the model’s local information recognition capabilities, we conduct zero-shot testing on COCO-val2017 (Lin et al., 2014), LVIS (Gupta et al., 2019), and Open Images (Kuznetsova et al., 2020), following the protocol of (Jing et al., 2024). This evaluation focuses on how well the model can classify objects within bounding boxes using only textual descriptions. Similar to the fine-grained understanding, we integrate known bounding box information from the benchmark with ROIAlign to obtain localized dense representations. Using all categories as textual inputs, we perform matching and recognition for each bounding box, evaluating Top-1 accuracy.
边界框分类。为了评估模型的局部信息识别能力,我们按照 (Jing et al., 2024) 的协议,在 COCO-val2017 (Lin et al., 2014)、LVIS (Gupta et al., 2019) 和 Open Images (Kuznetsova et al., 2020) 上进行了零样本测试。该评估重点关注模型仅通过文本描述对边界框内物体进行分类的能力。与细粒度理解类似,我们将基准中的已知边界框信息与 ROIAlign 结合,获得局部密集表征。使用所有类别作为文本输入,我们对每个边界框进行匹配和识别,并评估 Top-1 准确率。
As shown in Table 2, FG-CLIP achieves leading performance in bounding box classification with the help of the regional contrastive learning strategy. Notably, LongCLIP (Zhang et al., 2024), fine-tuned from CLIP using long texts, shows a significant decline in performance, indicating that long texts affect regional information granularity. Furthermore, FineCLIP uses region alignment data and incorporates a real-time self-distillation scheme, leading to meaningful improvements. While FineCLIP makes significant progress, FG-CLIP excels it by integrating regional and global information. This approach enhances FG-CLIP’s ability to accurately recognize and classify regions within images, highlighting the effectiveness of FG-CLIP’s training strategy.
如表 2 所示,FG-CLIP 在区域对比学习策略的帮助下实现了边界框分类的领先性能。值得注意的是,LongCLIP (Zhang et al., 2024) 通过长文本对 CLIP 进行微调后性能显著下降,这表明长文本会影响区域信息粒度。此外,FineCLIP 使用区域对齐数据并采用实时自蒸馏方案,从而实现了有意义的改进。虽然 FineCLIP 取得了显著进展,但 FG-CLIP 通过整合区域和全局信息更胜一筹。这种方法增强了 FG-CLIP 准确识别和分类图像区域的能力,凸显了其训练策略的有效性。
Open-Vocabulary Object Detection. To further evaluate the fine-grained localization capability of our method, we employ FG-CLIP as the backbone for downstream openvocabulary detection tasks. Following prior work (Wu et al., 2024a), we employ a two-stage detection architecture, FVIT, with a frozen visual encoder. The comparative results are summarized in Table 3. Consistent with previous studies, we report the box AP at $\mathrm{IoU}0.5$ for base, novel, and all categories $(A P_{50}^{n o v e l}$ , $A P_{50}^{b a s e}$ , and $A P_{50}^{a l l}$ ) on OV-COCO. Notably, $A P_{50}^{n o v e l}$ is the primary focus of interest, as it measures the model’s ability to recognize novel objects. Our findings indicate that FG-CLIP achieves leading performance in open-vocabulary detection tasks, highlighting its effectiveness in recognizing and localizing novel objects.
开放词汇目标检测。为了进一步评估我们方法在细粒度定位上的能力,我们采用FG-CLIP作为下游开放词汇检测任务的骨干网络。遵循先前工作(Wu et al., 2024a),我们使用两阶段检测架构FVIT,并冻结视觉编码器。对比结果总结在表3中。与之前研究一致,我们在OV-COCO数据集上报告基础类、新类及所有类别的边界框AP值$(A P_{50}^{novel}$、$A P_{50}^{base}$和$A P_{50}^{all}$),其中$\mathrm{IoU}0.5$作为阈值。值得注意的是,$A P_{50}^{novel}$是主要关注指标,它衡量模型识别新物体的能力。我们的研究结果表明,FG-CLIP在开放词汇检测任务中取得了领先性能,突显了其在新物体识别与定位方面的有效性。
Table 5. Comparisons on General Multimodal Benchmarks.
表 5: 通用多模态基准测试对比
| 方法 | GQA | POPE | RefCOCO ||
4.3. Comparisons on Image-level Task
4.3. 图像级任务对比
Long/short Caption Image-Text Retrieval. To evaluate retrieval performance comprehensively, we conduct experiments on both long caption and short caption image-text retrieval tasks. For long-text retrieval, we follow the protocol of Long-CLIP and use the 1K subset of ShareGPT4V (Chen et al., 2024a) provided by it as the testset. Additionally, we incorporate a more challenging long caption image-text pair dataset from DCI (Urbanek et al., 2024), consisting of 7,805 pairs, into the evaluation. For short-text retrieval, we employ the classic MSCOCO 5K (Lin et al., 2014) and Flickr 1K (Young et al., 2014) evaluation sets, which are widely used benchmarks for assessing image-text alignment models. As shown in Table 4, FG-CLIP achieves significant performance improvements in both long/short caption image-text retrieval tasks. The model’s ability to handle diverse caption lengths highlights its versatility and robustness in multimodal alignment.
长/短标题图文检索。为全面评估检索性能,我们在长标题和短标题图文检索任务上均进行了实验。长文本检索采用Long-CLIP的评估方案,使用其提供的ShareGPT4V (Chen et al., 2024a) 1K子集作为测试集,同时引入更具挑战性的DCI (Urbanek et al., 2024) 长标题图文对数据集(含7,805对)进行评测。短文本检索则采用经典的MSCOCO 5K (Lin et al., 2014) 和Flickr 1K (Young et al., 2014) 评估集,这两个基准被广泛用于评估图文对齐模型。如表4所示,FG-CLIP在长短标题图文检索任务中均取得显著性能提升,其处理多样化标题长度的能力凸显了该模型在多模态对齐中的通用性和鲁棒性。
Zero-shot Image Classification. We evaluate the zeroshot classification performance of our model on ImageNet1K (Deng et al., 2009) and ImageNet-v2 (Recht et al., 2019). As illustrated in Table 4, despite being marginally behind EVA-CLIP, which is trained on a larger dataset, FGCLIP demonstrates stable classification performance with enhanced regional and textual understanding capabilities compared to the original baseline, CLIP. Additionally, when compared to Long-CLIP and FineCLIP, both of which aim to enhance fine-grained recognition capabilities, our model exhibits a notable advantage in classification accuracy.
零样本图像分类。我们在ImageNet1K (Deng et al., 2009) 和ImageNet-v2 (Recht et al., 2019) 上评估了模型的零样本分类性能。如表4所示,尽管略逊于基于更大数据集训练的EVA-CLIP,但相较于原始基线CLIP,FGCLIP在保持稳定分类性能的同时,展现出更强的区域理解和文本理解能力。此外,在与同样致力于提升细粒度识别能力的Long-CLIP和FineCLIP对比时,我们的模型在分类准确率上具有显著优势。
Table 6. Ablation study results for FG-CLIP. This table compares the performance of different configurations of our FG-CLIP model across multiple evaluation metrics, including long caption image-text retrieval (DCI), short caption image-text retrieval (MSCOCO), bounding box classification (COCO-val2017), and fine-grained understanding (FG-OVD). The results highlight the incremental improvements achieved by incorporating global contrastive learning $(L_{g l o b a l})$ , regional contrastive learning $(L_{r e g i o n a l})$ , and hard fine-grained negative samples learning $(L_{h a r d})$ .
表 6: FG-CLIP的消融研究结果。该表比较了FG-CLIP模型在不同配置下的性能表现,评估指标包括长描述图文检索(DCI)、短描述图文检索(MSCOCO)、边界框分类(COCO-val2017)和细粒度理解(FG-OVD)。结果展示了通过引入全局对比学习$(L_{g l o b a l})$、区域对比学习$(L_{r e g i o n a l})$和困难细粒度负样本学习$(L_{h a r d})$所实现的渐进式改进。
| 方法 | LongRetrieval | ShortRetrieval | BBoxClassification | Fine-Grained Understanding | |||||
|---|---|---|---|---|---|---|---|---|---|
| I2T | T2I | I2T | T2I | Top-1 | Top-5 | hard | medium | easy | |
| CLIP | 45.5 | 43.0 | 51.8 | 32.7 | 44.2 | 72.3 | 12.0 | 23.1 | 22.2 |
| FG-CLIP Stage1 | 58.3 | 57.5 | 64.6 | 44.9 | 47.2 | 74.2 | 21.8 | 41.6 | 36.2 |
| +Stage2 $(L_{g l o b a l})$ | 62.7 | 61.2 | 64.4 | 46.4 | 46.8 | 73.6 | 25.4 | 46.8 | 42.9 |
| +Stage2 $(L_{g l o b a l}, L_{r e g i o n a l})$ | 62.4 | 61.1 | 64.7 | 45.7 | 53.7 | 81.2 | 24.5 | 47.1 | 49.5 |
| +Stage2 $(L_{g l o b a l}, L_{r e g i o n a l}, L_{h a r d})$ | 61.8 | 60.6 | 64.1 | 45.4 | 52.3 | 79.7 | 46.1 | 66.6 | 68.7 |
4.4. Comparisons on General Multimodal Benchmarks
4.4. 通用多模态基准测试对比
We compare FG-CLIP as a visual feature extractor for multimodal large language models with our baseline, CLIP. Specifically, we conduct experiments using LLaVA-v1.5-7B (Liu et al., 2023b), which itself is trained using CLIP. To ensure a fair comparison, all parameter configurations are kept consistent with those in the original LLaVA, and the model is trained using the data provided by LLaVA. Our evaluation focuses on benchmark sets related to attribute analysis, object localization, and output hallucination, which are GQA (Hudson & Manning, 2019), RefCOCO (Kazemzadeh et al., 2014), and POPE (Li et al., 2023c), respectively.
我们将FG-CLIP作为多模态大语言模型的视觉特征提取器,与基线模型CLIP进行对比。具体实验采用基于CLIP训练的LLaVA-v1.5-7B (Liu et al., 2023b)架构。为确保公平性,所有参数配置保持与原始LLaVA一致,并使用LLaVA提供的数据进行训练。评估重点针对属性分析、目标定位和输出幻觉三个基准测试集:GQA (Hudson & Manning, 2019)、RefCOCO (Kazemzadeh et al., 2014) 和 POPE (Li et al., 2023c)。
As shown in Table 5, FG-CLIP achieves certain improvements on GQA, which involves attribute-based question answering, and on POPE, which evaluates output hallucination. Additionally, it demonstrates significant gains on RefCOCO, a benchmark set that involves both attribute analysis and object localization. These results indicate the effectiveness of FG-CLIP’s training strategy and the data construction, which are specifically designed to enhance fine-grained recognition and regional alignment. We provide more results in Section D.3.
如表 5 所示,FG-CLIP 在涉及基于属性的问答任务 GQA 和评估输出幻觉的 POPE 上取得了一定提升。此外,在同时包含属性分析和目标定位的基准集 RefCOCO 上,该模型也展现出显著优势。这些结果表明 FG-CLIP 的训练策略和数据构建方案能有效增强细粒度识别和区域对齐能力,更多实验结果详见 D.3 节。
4.5. Ablation Study
4.5. 消融研究
To systematically evaluate the contributions of different components in our FG-CLIP model, we conduct an ablation study with results summarized in Table 6.
为了系统评估我们FG-CLIP模型中不同组件的贡献,我们进行了消融实验,结果总结如表6所示。
Global Contrastive Learning and Detailed Re captioning Data. We start by comparing the original CLIP model with FG-CLIP Stage 1 and Stage 2 incorporating global contrastive learning $L_{g l o b a l}$ . The results demonstrate that generating detailed captions significantly enhances performance across various tasks. Specifically, FG-CLIP Stage
全局对比学习与精细化重描述数据。我们首先将原始CLIP模型与融入全局对比学习 $L_{g l o b a l}$ 的FG-CLIP第一阶段和第二阶段进行对比。结果表明,生成精细化描述能显著提升各类任务的性能。具体而言,FG-CLIP第二阶段...
1 outperforms CLIP in all metrics, highlighting the importance of fine-grained training data. Further improvements are observed when adding $L_{g l o b a l}$ in Stage 2, particularly in long caption image-text retrieval (DCI (Urbanek et al., 2024)) and fine-grained understanding (FG-OVD (Bianchi et al., 2024)). This underscores the effectiveness of detailed caption data combined with global contrastive learning in improving model performance.
1 在所有指标上都优于 CLIP,凸显了细粒度训练数据的重要性。在第二阶段加入 $L_{g l o b a l}$ 后,性能进一步提升,尤其是在长描述图文检索 (DCI (Urbanek et al., 2024)) 和细粒度理解 (FG-OVD (Bianchi et al., 2024)) 方面。这表明详细描述数据与全局对比学习相结合能有效提升模型性能。
Regional Contrastive Learning. We introduce regional contrastive learning $L_{r e g i o n a l}$ to evaluate its impact on capturing detailed image regions. Compared to configurations using only $L_{g l o b a l}$ , adding $L_{r e g i o n a l}$ leads to substantial improvements in bounding box classification accuracy from $46.8%$ to $53.7%$ , and FG-OVD easy dataset accuracy from $42.9%$ to $49.5%$ . These gains highlight the effectiveness of $L_{r e g i o n a l}$ in refining the model’s ability to understand finegrained details within specific image regions. Moreover, this component maintains strong performance in both retrieval and classification tasks, demonstrating its versatility.
区域对比学习 (Regional Contrastive Learning)。我们引入了区域对比学习 $L_{regional}$ 来评估其对捕捉图像细节区域的影响。与仅使用 $L_{global}$ 的配置相比,添加 $L_{regional}$ 使边界框分类准确率从 $46.8%$ 显著提升至 $53.7%$,FG-OVD简单数据集准确率从 $42.9%$ 提升至 $49.5%$。这些提升凸显了 $L_{regional}$ 在增强模型理解特定图像区域内细粒度细节能力方面的有效性。此外,该组件在检索和分类任务中均保持强劲性能,展现了其多功能性。
Hard Fine-Grained Negative Samples Learning. We incorporate hard fine-grained negative samples learning $L_{h a r d}$ to distinguish subtle differences in semantically similar but distinct region-text pairs. By comparing configurations with and without $L_{h a r d}$ , we observe significant improvements in FG-OVD performance. Accuracy on the hard dataset increases from $24.5%$ to $46.1%$ , while on the medium dataset it rises from $47.1%$ to $66.6%$ and on the easy dataset it jumps from $49.5%$ to $68.7%$ . These results underscore the importance of $L_{h a r d}$ in distinguishing subtle semantic differences. Hard fine-grained negative samples learning effectively addresses challenge cases, thereby enhancing the model’s stability and disc rim i native power.
硬负样本细粒度学习。我们引入硬负样本细粒度学习 $L_{hard}$ 来区分语义相似但存在细微差异的区域-文本对。通过对比使用与未使用 $L_{hard}$ 的配置,观察到FG-OVD性能显著提升:困难数据集准确率从 $24.5%$ 提升至 $46.1%$,中等数据集从 $47.1%$ 升至 $66.6%$,简单数据集从 $49.5%$ 跃升至 $68.7%$。这些结果印证了 $L_{hard}$ 在辨识细微语义差异中的关键作用。该方法有效解决了挑战性案例,从而增强模型稳定性和判别力。
5. Conclusion
5. 结论
In this work, we introduce Fine-Grained CLIP (FG-CLIP), a novel approach that significantly advances fine-grained under standing. By integrating advanced alignment techniques with large-scale, high-quality datasets and hard negative samples, FG-CLIP captures global-level and region-level semantic details and distinguishes subtle differences more effectively. Extensive experiments across diverse downstream tasks validate the model’s superior performance. In addition, we propose FineHARD as a unified dataset that combines high-quality region-specific annotations with challenging fine-grained negative samples, offering a valuable resource for advancing multimodal research. Looking ahead, exploring the integration of more sophisticated multimodal models and expanding dataset diversity will be crucial for pushing the boundaries of fine-grained understanding.
在本工作中,我们提出了细粒度CLIP (FG-CLIP),这一创新方法显著推进了细粒度理解。通过将先进的对齐技术与大规模高质量数据集及困难负样本相结合,FG-CLIP能更有效地捕捉全局和区域层面的语义细节,并区分细微差异。跨多个下游任务的广泛实验验证了该模型的卓越性能。此外,我们提出了FineHARD作为统一数据集,将高质量区域特定标注与具有挑战性的细粒度负样本相结合,为推进多模态研究提供了宝贵资源。展望未来,探索更复杂多模态模型的整合及扩展数据集多样性,将成为突破细粒度理解边界的关键。