Abstract
摘要
Recent advancements in artificial intelligence (AI), especially large language models (LLMs), have significantly advanced healthcare applications and demonstrated potential in intelligent medical treatment. However, there are conspicuous challenges, such as vast data volumes and inconsistent symptom characterization standards, preventing full integration of healthcare AI systems with individual patients’ needs. To promote professional and personalized healthcare, we propose an innovative framework, Heath-LLM, which combines large-scale feature extraction and trade-off scoring of medical knowledge. Compared to traditional health management applications, our system has three main advantages: (1) It inte grates health reports and medical knowledge into a large model to ask relevant questions to the Large Language Model for disease prediction; (2) It leverages a retrieval augmented gen- eration(RAG)mechanism to enhance feature extraction; (3) It incorporates a semi-automated feature updating framework that can merge and delete features to improve the accuracy of disease prediction. We experimented with a large number of health reports to assess the effectiveness of the Health-LLM system. The results indicate that the proposed system surpasses the existing ones and has the potential to advance disease prediction and personalized health management significantly.
人工智能 (AI) 尤其是大语言模型 (LLM) 的最新进展显著推动了医疗健康应用发展,并展现出智能医疗的潜力。然而仍存在数据体量庞大、症状表征标准不统一等突出挑战,阻碍了医疗AI系统与患者个体需求的深度融合。为推进专业化与个性化医疗,我们提出创新框架Heath-LLM,结合大规模特征提取与医疗知识权衡评分机制。相比传统健康管理应用,本系统具备三大优势:(1) 将健康报告与医学知识整合至大模型,通过向大语言模型提问实现疾病预测;(2) 采用检索增强生成 (RAG) 机制强化特征提取能力;(3) 引入半自动化特征更新框架,可合并删除特征以提升疾病预测准确率。我们通过大量健康报告实验验证Health-LLM系统效能,结果表明其性能超越现有系统,在疾病预测和个性化健康管理领域具有显著推进潜力。
1 Introduction
1 引言
The integration of AI into healthcare, notably through large language models (LLMs) such as GPT-3.5 (Rasmy et al., 2021) and GPT-4 (Achiam et al., 2023), has reshaped the field of health management. Recent studies highlight the crucial role of LLM in using machine learning to improve healthcare outcomes (Biswas, 2023; Singhal et al., 2022). Advancements in AI for healthcare demonstrate a shift towards models that handle complex medical data and offer improved precision.
AI与医疗保健的融合,特别是通过GPT-3.5 (Rasmy et al., 2021) 和 GPT-4 (Achiam et al., 2023) 等大语言模型 (LLM),重塑了健康管理领域。近期研究强调了大语言模型在利用机器学习改善医疗结果方面的关键作用 (Biswas, 2023; Singhal et al., 2022)。医疗AI的进展表明,该领域正转向能够处理复杂医疗数据并提供更高精度的模型。
Nonetheless, traditional health management methods often struggle with the constraints imposed by static data and uniform standards, making them unfit to fully meet individual needs (Uddin et al., 2019; Lopez-Martinez et al., 2020; Beam and Kohane, 2018; Ghassemi et al., 2020). The health reports of patients offer a wealth of data, this information has the potential to predict future health issues and tailor health recommendations, but the difficulty lies in transforming these extensive data into practical insights.
然而,传统健康管理方法往往受限于静态数据和统一标准,难以充分满足个体需求 (Uddin et al., 2019; Lopez-Martinez et al., 2020; Beam and Kohane, 2018; Ghassemi et al., 2020)。患者的健康报告蕴含丰富数据,这些信息有望预测未来健康问题并定制健康建议,但挑战在于如何将这些海量数据转化为实用洞察。
This study focuses on the Clinical Prediction with Large Language Models (CPLLM) approach (Shoham and Rappoport, 2023), which showcases the superior predictive capabilities of LLMs finetuned on clinical data. In perticular, we propose an innovative system, Health-LLM, utilizing data analytics, machine learning, and medical knowledge for comprehensive health management. The system can provide users with personalized health recommendations based on predicted health risks (see Figure 1), ultimately helping prevent future health complications.
本研究聚焦于临床预测大语言模型(CPLLM)方法(Shoham and Rappoport, 2023),该方法展示了基于临床数据微调的大语言模型的卓越预测能力。我们特别提出了一种创新系统Health-LLM,该系统综合利用数据分析、机器学习和医学知识实现全面健康管理。该系统能够根据预测的健康风险为用户提供个性化健康建议(见图1),最终帮助预防未来健康并发症。
Specifically, the system uses the Llama Index (Liu, 2022) framework to analyze the information from the patient's health report. Then it assigns different scores to these features by the Llama Index, which is prepared with professional medical information by RAG. The scoring method is to ask the language model questions about the patient's condition Table 2. Our system also incorporates automated feature engineer technology (He et al., 2021) to perform iterative optimization to extract important features and stable weights and scores. Finally, the system is trained based on the XGBoost model (Chen and Guestrin, 2016) to make early predictions of existing disease and provide personalized health recommendations to individuals.
具体而言,该系统采用Llama Index (Liu, 2022)框架分析患者健康报告信息,通过经RAG预置专业医疗知识的Llama Index为不同特征分配评分。评分方式是通过向语言模型提问患者状况相关问题(表2)。系统还整合了自动化特征工程(automated feature engineer)技术 (He et al., 2021)进行迭代优化,提取重要特征及稳定权重与评分。最终基于XGBoost模型 (Chen and Guestrin, 2016)训练系统,实现对既有疾病的早期预测,并为个体提供个性化健康建议。
We compare the performance of our system with traditional methods (including Pretrain-BERT (Devlin et al., 2018), TextCNN (Chen, 2015), Hierar- chical Attention (Yang et al., 2016), Text BiLSTM with Attention (Liu and Guo, 2019), RoBERT (Liu et al., 2019)) as well as mainstream large-scale language models(GPT-3.5, GPT-4, LLaMA-2 (Touvron et al., 2023)) in three different settings (zeroshot, few-shot, and information retrieval) to show the effectiveness of our system. Among them, the accuracy of GPT-4 combined with information retrieval by retrieval augmented generation (RAG) for disease diagnosis is 0.68, and the F1 score is 0.71, while our system has achieved an accuracy of 0.833 and an F1 score of 0.762, respectively. Our key contributions are as follow:
我们将系统性能与传统方法(包括Pretrain-BERT (Devlin et al., 2018)、TextCNN (Chen, 2015)、Hierarchical Attention (Yang et al., 2016)、带注意力的Text BiLSTM (Liu and Guo, 2019)、RoBERT (Liu et al., 2019))以及主流大语言模型(GPT-3.5、GPT-4、LLaMA-2 (Touvron et al., 2023))在三种不同场景(零样本、少样本和信息检索)下进行对比,以证明系统的有效性。其中,GPT-4结合检索增强生成(RAG)进行疾病诊断的准确率为0.68,F1得分为0.71,而我们的系统分别达到了0.833的准确率和0.762的F1得分。我们的主要贡献如下:
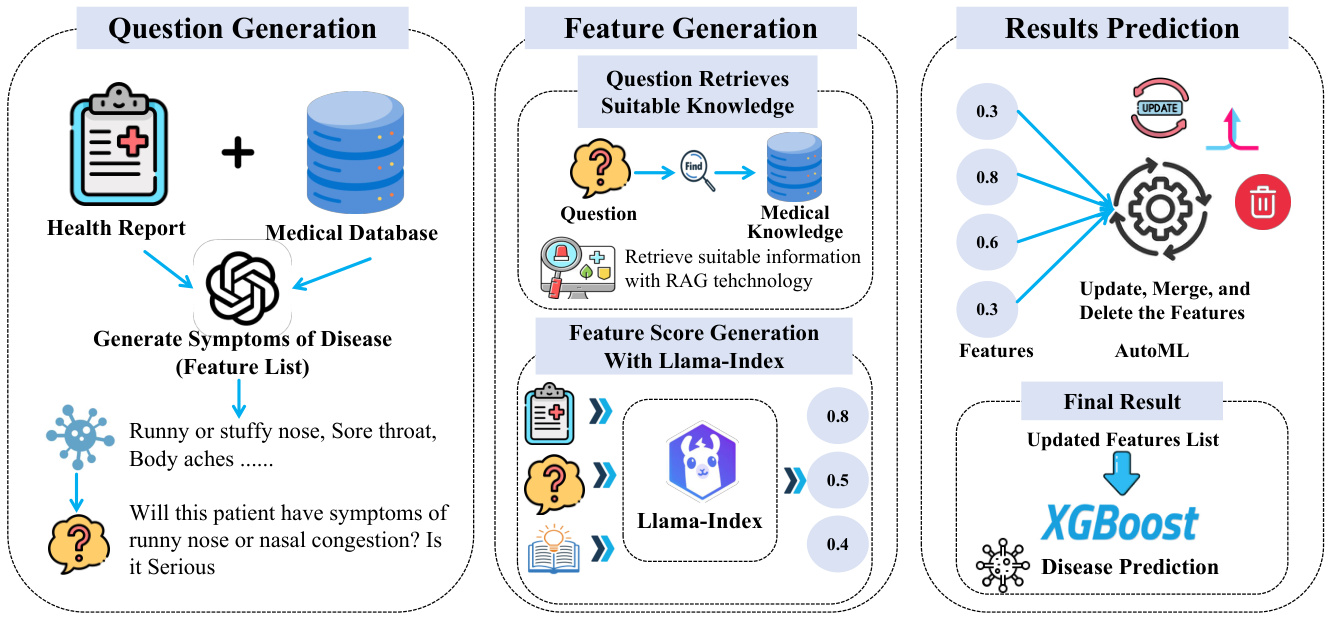
Figure 1: The overall workflow of the Health-LLM: from feature extraction to XGBoost prediction.
图 1: Health-LLM 的整体工作流程:从特征提取到 XGBoost 预测。
· We propose an innovative Health-LLM framework that combines large-scale feature extraction, precise scoring of medical knowledge using the Llama Index structure, and machine learning techniques to enable personalized disease prediction from patient health reports. · Our proposed Health-LLM framework achieves state-of-the-art performance on disease prediction tasks, surpassing existing methods like GPT- 4 and fine-tuned LLaMA-2 models as demonstrated through extensive experiments.
· 我们提出创新的Health-LLM框架,结合大规模特征提取、基于Llama Index结构的医学知识精准评分以及机器学习技术,实现从患者健康报告中预测个性化疾病。
· 通过大量实验证明,我们提出的Health-LLM框架在疾病预测任务上达到最先进性能,超越GPT-4和微调LLaMA-2模型等现有方法。
2 Background
2 背景
2.1 AI for Health Management
2.1 健康管理中的AI技术
AI is revolutionizing healthcare through machine learning and relevant methods to enhance healthcare outcomes. This evolution is significantly driven by the emergence of LLMs, as seen in studies such as (Biswas, 2023; Singhal et al., 2022; Rasmy et al., 2021). These models are vital in clinical applications, including disease prediction and diagnosis. The intersection of AI and healthcare has seen notable progress, fueled by the availability of extensive health datasets and the advancement of sophisticated LLMs. Recent research, such as (Wang et al., 2023), demonstrates the immense potential of LLMs in the healthcare sector, where they are used to understand and generate health reports and evaluate various health situations.
AI 正通过机器学习及相关方法革新医疗健康领域,提升医疗成果。这一变革主要由大语言模型 (LLM) 的兴起推动,如 (Biswas, 2023; Singhal et al., 2022; Rasmy et al., 2021) 等研究所示。这些模型在疾病预测和诊断等临床应用中至关重要。得益于海量健康数据集和先进大语言模型的发展,AI 与医疗健康的交叉领域取得了显著进展。(Wang et al., 2023) 等最新研究展示了大语言模型在医疗领域的巨大潜力,包括健康报告理解与生成、多样化健康状态评估等应用场景。
A key development in this field is the Clinical Prediction with Large Language Models (CPLLM), which highlights the potential of LLMs fine-tuned on clinical data (Shoham and Rappoport, 2023). CPLLM, using historical diagnosis records, has shown superiority over traditional models such as logistic regression and even advanced models such as Med-BERT (Rasmy et al., 2021) in predicting future disease diagnoses. Another significant advancement in AI for health is the CO AD framework (Wang et al., 2023), which addresses the limitations of previous Transformer-based automatic diagnosis methods. Earlier models faced challenges due to mismatches in symptom sequences and the influence of symptom order on disease prediction. COAD introduces a disease and symptom collaborative generation framework, aligning sentencelevel disease labels with symptom inquiry steps, and expanding the symptom labels to reduce the order effect. AMIE (Articulate Medical Intelligence Explorer) is a medical knowledge graph created by Google (Tu et al., 2024). It extracts and stores medical knowledge, including information about diseases, symptoms, and treatments. These advancements indicate a trend in AI for health, shifting towards models that effectively manage the complexity and subtleties of medical data. The progress made by CPLLM, COAD and AMIE underscores the transformative impact these technologies can have on healthcare, enhancing precision, efficiency, and personalization in patient care.
该领域的一个关键进展是临床预测大语言模型 (CPLLM) ,它突显了基于临床数据微调的大语言模型的潜力 (Shoham and Rappoport, 2023) 。CPLLM利用历史诊断记录,在预测未来疾病诊断方面展现出优于逻辑回归等传统模型、甚至超越Med-BERT (Rasmy et al., 2021) 等先进模型的性能。医疗AI领域的另一重要突破是COAD框架 (Wang et al., 2023) ,它解决了先前基于Transformer的自动诊断方法的局限性。早期模型因症状序列不匹配及症状顺序对疾病预测的影响而面临挑战。COAD引入了疾病与症状协同生成框架,将句子级疾病标签与症状询问步骤对齐,并通过扩展症状标签来降低顺序效应。AMIE (Articulate Medical Intelligence Explorer) 是Google创建的医疗知识图谱 (Tu et al., 2024) ,可提取并存储包含疾病、症状和治疗信息的医学知识。这些进展标志着医疗AI正转向能有效处理医学数据复杂性与微妙性的模型。CPLLM、COAD和AMIE的突破性进展,彰显了这些技术通过提升精准性、效率化和个性化护理来变革医疗体系的潜力。
2.2 Retrieval Augmented Generation
2.2 检索增强生成 (Retrieval Augmented Generation)
The retrieval augmented generation (RAG) (Lewis et al., 2020) method is a natural language processing model that combines retrieval and generation components to handle knowledge-intensive tasks. The method consists of two stages: Retrieval and Generation. During the retrieval phase, RAG employs the Dense Passage Retrieval (DPR) system to retrieve the most relevant documents from a largescale document database that answers the input question. The input question is encoded as a vector, which is then compared with the document vectors in the database to locate the most relevant documents. The main idea behind this method is to use a large-scale document collection to enhance the generation model's ability and improve the model's efficiency in dealing with complex and knowledgedependent problems.
检索增强生成 (RAG) (Lewis et al., 2020) 方法是一种结合检索与生成组件的自然语言处理模型,用于处理知识密集型任务。该方法包含两个阶段:检索阶段和生成阶段。在检索阶段,RAG采用密集段落检索 (DPR) 系统从大规模文档数据库中检索与输入问题最相关的文档。输入问题被编码为向量,随后与数据库中的文档向量进行比对以定位最相关的文档。该方法的核心思想是通过大规模文档集合来增强生成模型的能力,并提升模型处理复杂且依赖知识的问题的效率。
3 Implementation
3 实现
In this section, we introduce the design and the implementation of the proposed Health-LLM system. Section 3.1 introduces its data preprocessing process and the RAG-based feature extraction. Section 3.2 demonstrates our system's incorporation of Llama index to score the features for training the classification model. Section 3.3 describes the prediction module that uses XGBoost for fitting the feature scores.
在本节中,我们将介绍所提出的Health-LLM系统的设计与实现。3.1节介绍其数据预处理流程和基于RAG的特征提取方法。3.2节展示系统如何结合Llama index对特征进行评分以训练分类模型。3.3节描述使用XGBoost拟合特征得分的预测模块。
3.1 In-context Learning for Symptom Features Generation
3.1 基于上下文学习的症状特征生成
In the initial phase of our implementation, we system a tic ally extract symptom features from a range of diseases by harnessing the in-context learning capabilities of LLMs. Figure 2 shows an examples of the corresponding workflow. We first prompt the model with a series of examples, such as "disease: cold, symptoms: runny or stuffy nose, sore or tingling throat, cough, sneeze", to teach it the pattern generated by the symptom profile. Leveraging this in-context learning paradigm, our system is ready to take new query inputs and efficiently produce symptom descriptors for various diseases in a batch processing mode.
在我们的实施初期,通过利用大语言模型(LLM)的上下文学习能力,我们系统性地从一系列疾病中提取症状特征。图2展示了对应工作流程的示例。我们首先用一系列示例提示模型,例如"疾病:感冒,症状:流鼻涕或鼻塞、喉咙痛或刺痛、咳嗽、打喷嚏",以教会其生成症状描述的模式。利用这种上下文学习范式,我们的系统可以接收新的查询输入,并以批处理模式高效地为各种疾病生成症状描述符。
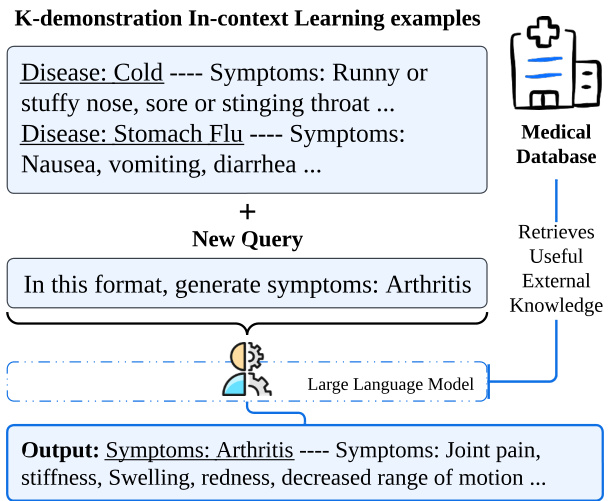
Figure 2: In-context learning workflow of symptom features generation in Health-LLM.
图 2: Health-LLM中症状特征生成的上下文学习工作流程。
To enhance the precision of this generative process, we integrate a supplementary medical knowledge base, employing a RAG mechanism for enriched knowledge retrieval. Through the guidance of the system prompts, the LLM is asked to answer questions about the extracted symptoms. Since LLM may lack specialized knowledge in medicine, we provide contextual information for these questions in an embedded form. Thus, we utilize ad- vanced RAG technology to synchronize our queries with the knowledge base. In particular, RAG helps identify and retrieve the three most relevant pieces of information that align with the symptoms mentioned in the question. Our system then extracts these pieces of information and seamlessly integrates them to enrich the input prompts for the models.
为提高生成过程的准确性,我们整合了一个辅助医疗知识库,采用RAG机制进行增强知识检索。通过系统提示的引导,要求大语言模型回答关于提取症状的问题。由于大语言模型可能缺乏医学专业知识,我们以嵌入形式为这些问题提供上下文信息。因此,我们利用先进的RAG技术将查询与知识库同步。具体而言,RAG帮助识别并检索与问题中提到的症状最相关的三条信息。随后,我们的系统提取这些信息并无缝整合,以丰富模型的输入提示。
3.2 Assigning Score by Llama Index
3.2 通过Llama Index分配分数
To integrate LLMs from different sources, we adopt the Llama Index framework (Liu, 2022) for question answering (QA) in health reports. This ap- proach allows us to take full advantage of advanced natural language processing models to extract features, a key step in our ability to predict disease and provide health advice.
为整合来自不同来源的大语言模型(LLM),我们采用Llama Index框架(Liu, 2022)进行健康报告中的问答(QA)任务。该方法使我们能够充分利用先进的自然语言处理模型来提取特征,这是我们预测疾病和提供健康建议能力的关键步骤。
To ensure accurate and domain-specific responses, we then prompt the system with our highquality generated queries relevant to the health issue. The LLM then assigns a confidence score between 0 and 1, indicating the system's perception of the health issue's severity level. For instance, the question "Does this person have good sleeping habits?" might receive a response like "Sleep: 0.6," suggesting moderately positive sleeping patterns. This numerical confidence score then becomes a key attribute in our classification model. We also provide a detailed example in Table 2.
为确保回答准确且符合特定领域,我们随后向系统输入与健康问题相关的高质量生成查询。大语言模型会给出0到1之间的置信度分数,表示系统对该健康问题严重程度的评估。例如,问题"这个人睡眠习惯好吗?"可能得到"睡眠:0.6"的回应,表明睡眠模式处于中等积极水平。这个数值化的置信度分数随后成为我们分类模型的关键属性。表2提供了详细示例。
Table 1: Example of one health report we have made by dataset IMCS-21.
| IMCS-21 |
| -Hello, there is a pain around the navel, I don't know what's going on (female, 29 years old) |
| -Hello, how long has this situation? -Two or three days. |
| -It hurts, and it will not hurt for a while. |
| -It seemed a bit like a diarrhea. After eating 1 at noon, I wanted to pull it after a while, and I was a little bit pulled. -You can eat the medicine you said. |
表 1: 使用 IMCS-21 数据集生成的健康报告示例
| IMCS-21 |
|---|
| -你好,肚脐周围有疼痛感,不知道怎么回事 (女性,29岁) |
| -你好,这种情况持续多久了? -两三天。 |
| -会疼一阵,然后又不疼了。 |
| -有点像腹泻。中午吃完饭后过一会儿就想拉,而且有点拉肚子。 -可以吃你刚才说的药。 |
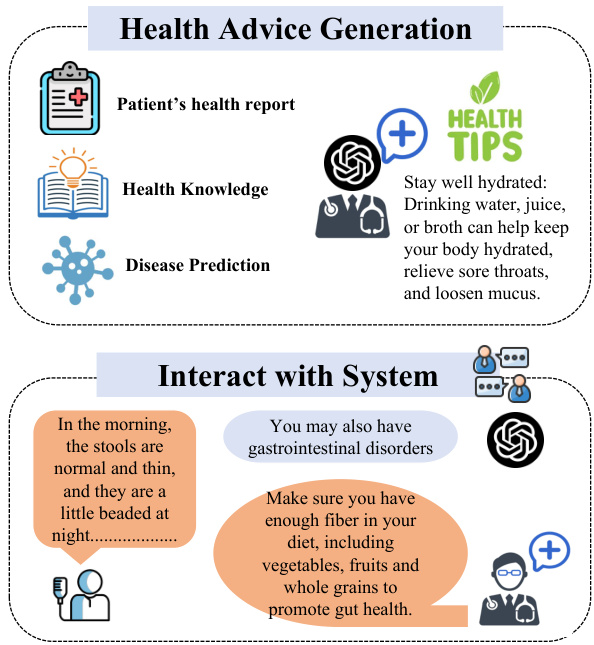
Figure 3: Health advice generation and how users interact with the health system.
图 3: 健康建议生成及用户与健康系统的交互方式。
The Llama index serves to streamline documentbased QA through a strategic "search-thensynthesize" approach. The process unfolds as follows. Initially, health report documents are curated and formatted into plain text. These documents are then segmented into smaller manageable text blocks. Each block is processed through a textembedding interface, transforming it into a vector representation that is subsequently stored within a vector database; here, OpenAI's embeddings can be utilized for this transformation (OpenAI, 2021).
Llama索引通过"搜索-合成"策略简化基于文档的问答流程。具体步骤如下:首先将健康报告文档整理为纯文本格式,随后分割为更小的可管理文本块。每个文本块通过文本嵌入接口处理,转化为向量表示后存储于向量数据库中 (此处可使用OpenAI的嵌入技术完成转换) (OpenAI, 2021)。
When receiving questions, the system converts them into vectors to facilitate search within the vector database, aiming to identify the most relevant text block(s). The identified text block is then amalgamated with the query to formulate a refined request. This newly created request is sent to the OpenAI API for processing. In total, we create a list of 152 questions and an area knowledge database. All the scores resulting from answering these questions will be used as features to enter the downstream machine learning model. For example: Sleep: 0.6, which means that the person's sleep condition is okay.
接收问题时,系统会将其转换为向量以便在向量数据库中进行搜索,旨在找出最相关的文本块。随后,将识别出的文本块与查询合并,形成优化后的请求。这一新生成的请求会被发送至OpenAI API进行处理。我们总共创建了包含152个问题的列表和一个领域知识数据库。回答这些问题所得的所有分数将作为特征输入下游机器学习模型。例如:睡眠:0.6,表示该人的睡眠状况尚可。
3.3 Predictive Model and Health Advice
3.3 预测模型与健康建议
In our quest to develop a robust disease classification system, we have established a comprehensive framework that encompasses 61 disease labels, ranging from common ailments such as insomnia and indigestion to more complex conditions like endocrine disorders. We fit the features with XGBoost, which allows the XGBoost model to fit the feature scores extracted from the Llama index, and learn the feature representation of each disease under the Llama index. The results of XGBoost fitting in this framework are multiple binary combinations, With $"0"$ indicating no associated disease and "1" indicating an associated disease. In addition, we have also classified certain diseases (e.g., fatty liver) at a finer level of granularity. For example, $"0"$ indicates mild fatty liver and "1" indicates severe fatty liver.
在我们开发一个稳健的疾病分类系统的过程中,我们建立了一个包含61种疾病标签的全面框架,范围从失眠和消化不良等常见疾病到内分泌失调等更复杂的病症。我们使用XGBoost对特征进行拟合,这使得XGBoost模型能够适配从Llama索引中提取的特征分数,并学习Llama索引下每种疾病的特征表示。在此框架中,XGBoost拟合的结果是多个二元组合,其中$"0"$表示无相关疾病,"1"表示有相关疾病。此外,我们还对某些疾病(如脂肪肝)进行了更细粒度的分类。例如,$"0"$表示轻度脂肪肝,"1"表示重度脂肪肝。
The significance of domain-specific knowledge incorporation has become clear in our quest to improve disease prediction through feature preprocessing. Addressing this, we use Context-Aware Automated Feature Engineering (CAAFE), which utilizes the power of LLMs (Hollmann et al., 2023) to generate features iterative ly with semantic relevance informed by the dataset's context. We have evolved from a semi-automated system to a fully automated one. We now use LLMs to autonomously craft feature and dataset descriptions, thereby streamlining the feature engineering process and enriching our models with con textually meaningful data. After the prediction is completed, we will query the LLM for the last time with the predicted diseases, and let it generate targeted health suggestions based on the health report and professional knowledge. The process detail is the same as the previous steps in Figure 3.
在通过特征预处理提升疾病预测能力的探索中,融入领域特定知识的重要性已日益凸显。为此,我们采用上下文感知自动特征工程(CAAFE)方法,该方法利用大语言模型 [Hollmann et al., 2023] 的迭代特征生成能力,基于数据集上下文生成语义相关的特征。我们已实现从半自动化系统到全自动化系统的演进:通过大语言模型自主生成特征与数据集描述,从而简化特征工程流程,并为模型注入具有上下文意义的数据。预测完成后,系统将最后一次调用大语言模型,根据预测疾病结合健康报告与专业知识生成针对性健康建议。具体流程与图3所示前期步骤保持一致。
Table 2: Example of assigning score by Llama Index.
| AssigningscorebyLlamaIndex |
| Prompt: |
| "Give the answer in JSON format with only one number between O and 1 that is:‘score'.' |
| "Thescorenumbermustbeadecimals." |
| "This is the rule of the answer:0-0.2is mild or none,0.3-0.6 is moderate,and above 0.7is severe. |
| "This is a patient's medical record. Context information is provided below:" |
| "Does the person described in the case havefever symptoms?Doyou think it is serious?" |
表 2: Llama Index 评分示例
| AssigningscorebyLlamaIndex |
|---|
| Prompt: |
| "以 JSON 格式给出答案,仅包含一个介于 0 和 1 之间的数字,即 'score'。" |
| "评分数字必须为小数。" |
| "评分规则如下:0-0.2 表示轻微或无,0.3-0.6 表示中等,0.7 以上表示严重。" |
| "这是一份患者的病历。上下文信息如下:" |
| "病例中描述的人是否有发热症状?你认为情况严重吗?" |
3.4Interact with Health-LLM
3.4 与健康大语言模型交互
In the interaction process between the user and Health-LLM shown in Figure 3. Users have two ways to interact with the Health-LLM system. First, the user can submit his/her health report to the system and get the prediction and the health advice. Second, the user can describe his/her health problem and ask the system, the system will record their dialog and save as a health dialog. The dialog messages are similar to the health reports in the training process. Health-LLM generates the corresponding disease predictions and gives personal suggestions based on the dialog messages following the process shown in Figure 1. The large language model responsible for the dialog and giving personal suggestions in Health-LLM is GPT-4 turbo. In brief, Health-LLM provides diagnosis and personalized advice through interaction with the user.
在图 3 所示的用户与 Health-LLM 的交互过程中,用户可通过两种方式与系统互动。首先,用户可提交个人健康报告以获取疾病预测和健康建议。其次,用户可描述健康问题并咨询系统,系统会记录对话内容并保存为健康对话记录。这些对话信息在训练过程中与健康报告具有相似性。Health-LLM 会按照图 1 所示流程,基于对话内容生成相应疾病预测并提供个性化建议。该系统负责对话交互和个性化建议生成的大语言模型为 GPT-4 turbo。简而言之,Health-LLM 通过用户交互实现疾病诊断与个性化健康建议的输出。
4 A Case Study
4 案例研究
In this section, we describe the entire process by which our system accurately predicts a patient's disease and compare its performance with, for example, using a large model alone. Our case is under dataset IMCS-21 (Table 1) (Chen et al., 2023).
在本节中,我们将描述系统准确预测患者疾病的全过程,并将其性能与单独使用大语言模型等方法进行对比。我们的案例基于IMCS-21数据集 (表 1) (Chen et al., 2023)。
4.1 Settings
4.1 设置
To our knowledge, IMCS-21 is currently the only dataset on tele medicine consultation in China. The data set contains a total of 4,116 annotated samples with 164,731 utterances across 10 pediatric diseases, including bronchitis, fever, diarrhoea, upper respiratory infection, dyspepsia, cold, cough, jaundice, constipation and broncho pneumonia. Each dialogue contains an average of 40 utterances, 523 Chinese characters (580 characters if including self-report) and 26 entities. To prevent data leakage, we pre-processed the data by using GPT4 to eliminate content containing specific medical conditions from the data conversations and transformed the conversations into the form of an Electronic Patient Record (EPR). We use two metrics: ACC(Accuracy), F1(Macro F1-score), to evaluate the prediction quality.
据我们所知,IMCS-21 是目前中国唯一的远程医疗咨询数据集。该数据集共包含 4,116 个标注样本,涵盖 10 种儿科疾病的 164,731 条对话语句,包括支气管炎、发热、腹泻、上呼吸道感染、消化不良、感冒、咳嗽、黄疸、便秘和支气管肺炎。每条对话平均包含 40 条语句、523 个中文字符(若包含自述则为 580 字)和 26 个实体。为防止数据泄露,我们使用 GPT4 对数据进行了预处理,剔除了对话中包含特定医疗状况的内容,并将对话转换为电子病历 (Electronic Patient Record, EPR) 形式。我们采用两个评估指标:准确率 (Accuracy, ACC) 和宏观 F1 值 (Macro F1-score, F1) 来衡量预测质量。
4.2 Health-LLM Diagnostic Test and Comparative Experiment
4.2 Health-LLM诊断测试与对比实验
Health-LLM Diagnostic Test. Trained on the given dataset IMCS-21, our system is capable of taking complex patient inputs and provide medical suggestions. We provide an example of the usersystem interaction in Table 6 in the Appendix. To employ this system, the user inputs their information such as physical conditions and disease symptoms. The system predicts potential diseases for the user based on prior experience and provides the appropriate diagnosis, as well as follow-up recommendations. We show the user interaction process with Health-LLM in Figure 3 and give an example in Table 3. Our system plays the role of a doctor who guides the user step by step in describing his or her real symptoms. The output of the system is the specific name of the disease and reasonable suggestions. Our validation process uses conversations from the validation set as input to simulate user adoption. Experiments showed that our system achieved an overall prediction accuracy of $83%$ for the disease, with F1 score of 0.762.
Health-LLM诊断测试。我们的系统在给定数据集IMCS-21上训练后,能够接收复杂的患者输入并提供医疗建议。附录表6展示了用户与系统的交互示例。使用该系统时,用户需输入身体状况和疾病症状等信息。系统基于先验经验预测潜在疾病,并提供相应诊断及后续建议。图3展示了用户与Health-LLM的交互流程,表3给出了具体实例。该系统扮演医生角色,逐步引导用户描述真实症状,最终输出具体疾病名称及合理建议。验证过程中,我们使用验证集中的对话模拟用户输入。实验表明,该系统对疾病的整体预测准确率达$83%$,F1分数为0.762。
Table 3: An example of the interactive process in case study.
| User Inputs and Conversation with Health-LLM | |
| User: Health-LLM: | In the morning, the stools are normal and thin, and they are a little beaded at night. Hello, how long has this situation? Is the diet regular? Can you provide me with basic information such as yourageandgender?Whatisthefeelingofabdomen? |
| User: | It has been four or five days. I have a stool when I ate Amoshilin in the first rhinitis. After a few days of laxativespirit,itislikethisnow.Haven'teatenfood and cold. |
| Health-LLM: | PredictionandPersonalAdvice |
| Gastrointestinal dysfunction and Diarrhea.Chooselight meals and avoidstimulatingfoods.Youdon't need to take medicine. You are welcome. Wish you health and happiness! | |
表 3: 案例分析中的交互过程示例
| 用户输入及与Health-LLM的对话 |
|---|
| 用户: Health-LLM: |
| 用户: |
| Health-LLM: |
Table 4: Comparing with existing methods on the Health-LLM diagnostic test.
| Models | Accuracy | F1 |
| Pretrain-BertwithXGBoost | 0.326 0.333 | 0.303 |
| GPT-3.5(zero-shot) GPT-3.5(fewshot) | 0.381 | 0.361 |
| GPT-4(zero-shot) | 0.390 | 0.349 |
| TextCNN | 0.437 | 0.312 0.429 |
| GPT-3.5(fewshotwithinformationretrieval) | 0.451 | 0.451 |
| HierarchicalAttention | 0.495 | 0.477 |
| TextBiLSTMwithAttention | 0.512 | 0.500 |
| RoBERT | 0.585 | 0.543 |
| GPT-4(few shot) | 0.620 | 0.671 |
| GPT-4(fewshotwithinformationretrieval) | 0.680 | 0.718 |
| Fintuned-LLaMA-2-7B | 0.710 | 0.593 |
| Fintuned-LLaMA-2-13B | 0.730 | |
| Health-LLM (Ours) | 0.833 | 0.671 0.762 |
表 4: Health-LLM诊断测试与现有方法的对比
| 模型 | 准确率 | F1值 |
|---|---|---|
| Pretrain-BertwithXGBoost | 0.326 0.333 | 0.303 |
| GPT-3.5 (零样本) GPT-3.5 (少样本) | 0.381 | 0.361 |
| GPT-4 (零样本) | 0.390 | 0.349 |
| TextCNN | 0.437 | 0.312 0.429 |
| GPT-3.5 (少样本+信息检索) | 0.451 | 0.451 |
| HierarchicalAttention | 0.495 | 0.477 |
| TextBiLSTMwithAttention | 0.512 | 0.500 |
| RoBERT | 0.585 | 0.543 |
| GPT-4 (少样本) | 0.620 | 0.671 |
| GPT-4 (少样本+信息检索) | 0.680 | 0.718 |
| Fintuned-LLaMA-2-7B | 0.710 | 0.593 |
| Fintuned-LLaMA-2-13B | 0.730 | |
| Health-LLM (Ours) | 0.833 | 0.671 0.762 |
Comparative Experiment. Our comparative analysis involves two open-source models, GPT-3.5 and GPT-4. We deploy these models in a zero-shot setting to diagnose cases. Following this, we will transition to a few-shot context, providing each model with a selection of prior predictions to enhance their diagnostic capabilities. Subsequently, we will integrate supplementary medical knowledge into the larger models to refine their predictions further. The culmination of this process will involve leveraging the dataset we use in Health-LLM to finetune LLaMA-2 (Touvron et al., 2023), with the objective of observing the impact on its performance. For extended texts and chapter-level analysis in the traditional method, researchers have introduced a framework known as Hierarchical Attention (Yang et al., 2016) and RoBert (Liu et al., 2019), which excels in handling multi-classification challenges in case texts. The conventional approach fails in accurately diagnosing diseases from medical reports, as it lacks the deep text comprehension exhibited by larger models. Additionally, it struggles to encapsulate all the pertinent information within lengthy paragraphs. This approach ranks impressively, just behind advanced models like GPT-4 and fine-tuned LLaMa-2 in terms of performance. The comparative test results are shown in Table 4. Health-LLM achieves the best performance compared to direct inference using other large models.
对比实验。我们的对比分析涉及两个开源模型GPT-3.5和GPT-4。我们在零样本设置下部署这些模型进行病例诊断。随后将过渡到少样本场景,为每个模型提供部分历史预测以增强其诊断能力。接着会向更大模型补充医学知识来进一步优化预测。最终我们将使用Health-LLM中的数据集对LLaMA-2 (Touvron et al., 2023)进行微调,以观察其性能变化。针对传统方法中长文本和章节级分析,研究者提出了层次化注意力框架 (Yang et al., 2016) 和RoBert (Liu et al., 2019),该框架擅长处理病例文本的多分类挑战。传统方法因缺乏大模型具备的深度文本理解能力,无法准确诊断医疗报告中的疾病,且难以从冗长段落中提取所有相关信息。该方法的性能表现仅次于GPT-4和微调后的LLaMa-2等先进模型。对比测试结果如 表4 所示。与其他大模型直接推理相比,Health-LLM实现了最佳性能。
Table 5: Ablation studies.
| Model | Acc | F1 |
| Health-LLM without Retrieval | 0.78 | 0.714 |
| Health-LLM without CAAFE | 0.77 | 0.721 |
| Health-LLM | 0.83 | 0.762 |
表 5: 消融实验。
| 模型 | Acc | F1 |
|---|---|---|
| Health-LLM without Retrieval | 0.78 | 0.714 |
| Health-LLM without CAAFE | 0.77 | 0.721 |
| Health-LLM | 0.83 | 0.762 |
4.3 Analyzing System Components
4.3 系统组件分析
In this section, we verify the effectiveness of each component of our Health-LLM. The results are displayed in Table 5. The experimental results have two implications. First, it is necessary to index professional healthcare data to ensure the accuracy of diagnostic reasoning. Our diagnostic reasoning accuracy has improved significantly in the group with indexed professional healthcare knowledge. Second, our data processing and feature extraction with CAAFE is effective.
在本节中,我们验证了Health-LLM各模块的有效性。结果如表5所示。实验结果揭示了两点关键发现:首先,建立专业医疗数据索引对确保诊断推理准确性至关重要,在引入专业医疗知识索引的组别中,我们的诊断推理准确率显著提升;其次,采用CAAFE进行的数据处理与特征提取方案具有显著成效。
5 Conclusions and Future Work
5 结论与未来工作
In this study, we present a novel system, HealthLLM, that combines large-scale feature extraction, precise scoring of medical knowledge, and machine learning techniques to make better use of patient health reports. It improves the prediction of potential diseases compared to GPT-3.5, GPT-4, and fintuned LLaMA-2. Our system is capable to predict potential diseases and provide customized health advice to individuals. In addition to its practical advancements, Health-LLM also serves as a proof-of-concept LLM-based system in healthcare, highlighting the huge potential of further development of AI applications in health field.
在本研究中,我们提出了一种名为HealthLLM的创新系统,该系统结合了大规模特征提取、医学知识精准评分和机器学习技术,以更好地利用患者健康报告。与GPT-3.5、GPT-4和微调版LLaMA-2相比,它能更准确地预测潜在疾病。我们的系统不仅能预测潜在疾病,还能为个人提供定制化健康建议。除了实际应用价值外,HealthLLM还作为基于大语言模型的医疗概念验证系统,彰显了AI在健康领域进一步发展的巨大潜力。
For future work, we plan to explore integrating multimodal data such as medical images along with text data to further improve the disease prediction capabilities of Health-LLM system.
未来工作方面,我们计划探索整合医学影像等多模态数据与文本数据,以进一步提升Health-LLM系统的疾病预测能力。
page8).
第8页)。
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zetlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pre training ap proach.
Yinhan Liu、Myle Ott、Naman Goyal、Jingfei Du、Mandar Joshi、Danqi Chen、Omer Levy、Mike Lewis、Luke Zetlemoyer 和 Veselin Stoyanov。2019。Roberta:一种稳健优化的 BERT 预训练方法。
Appendix
附录
Table 6: Example of one health report we have made by dataset IMCS-21
| IMCS-21 |
| -Hello, there is a pain around the navel, I don't know what's going on (female, 29 years old) -Hello, how long has this situation? |
| -Two or three days. |
| -It hurts, and it will not hurt for a while. |
| -There is no medication and no examination. |
| -Is the stool normal? |
| -normal. |
| -Are there any other symptoms? Do you want to vomit? |
| -No. |
| -Is it faint pain? -Once appetite, a little bit bloated. |
| -It may be gastrointestinal dysfunction. |
| -Yes, faint pain. |
| -Eat some song Meibing Try.relative. |
| -It felt like a needle was tied, and it was fine for a few seconds. |
| -It feels that the problem is not particularly big. |
| -Try it if you take the medicine I said. |
| -Is there a compound fairy crane grassyitis tablet at home? |
| -This is mainly to treat diarrhea. Don't eat without diarrhea. Oh, alright. |
| Uh-huh. |
| -Which aspect can cause gastrointestinal function? |
| -It may also be the digestive system or autoimmune system. relative. |
| -OK -Uh-huh. |
| -It seemed a bit like a diarrhea. After eating 1 at noon, I wanted to pull it after a while, and I was a little bit pulled. |
| -You can eat the medicine you said. |
| -Oh well. |
表 6: 基于数据集 IMCS-21 生成的健康报告示例
| IMCS-21 |
|---|
| -你好,肚脐周围有点疼,不知道怎么回事(女,29岁) -你好,这种情况多久了? |
| -两三天。 |
| -一阵一阵疼,过会儿又不疼了。 |
| -没吃药也没检查过。 |
| -大便正常吗? |
| -正常。 |
| -还有其他症状吗?想吐吗? |
| -没有。 |
| -是隐隐作痛吗? -食欲一般,有点胀气。 |
| -可能是胃肠功能紊乱。 |
| -对,隐隐的疼。 |
| -可以吃点松梅冰试试。亲戚。 |
| -感觉像针扎一样,几秒钟就好了。 |
| -问题应该不太大。 |
| -先试试我说的药吧。 |
| -家里有复方仙鹤草肠炎片吗? |
| -这个主要是治腹泻的,没有腹泻别吃。哦,好的。 |
| 嗯。 |
| -哪些方面会引起胃肠功能... |
| -也可能是消化系统或免疫系统问题。亲戚。 |
| -好的 -嗯。 |
| -中午吃了点东西后有点想拉肚子,稍微有点拉。 |
| -可以吃你刚才说的药。 |
| -哦好吧。 |