Parallel Scaling Law for Language Models
语言模型的并行扩展定律
Abstract
摘要
It is commonly believed that scaling language models should commit a significant space or time cost, by increasing the parameters (parameter scaling) or output tokens (inferencetime scaling). We introduce the third and more inference-efficient scaling paradigm: increasing the model’s parallel computation during both training and inference time. We apply $P$ diverse and learnable transformations to the input, execute forward passes of the model in parallel, and dynamically aggregate the $P$ outputs. This method, namely parallel scaling (PARSCALE), scales parallel computation by reusing existing parameters and can be applied to any model structure, optimization procedure, data, or task. We theoretically propose a new scaling law and validate it through large-scale pre-training, which shows that a model with $P$ parallel streams is similar to scaling the parameters by ${\mathcal{O}}(\log P)$ while showing superior inference efficiency. For example, PARSCALE can use up to $22\times$ less memory increase and $6\times$ less latency increase compared to parameter scaling that achieves the same performance improvement. It can also recycle an off-theshelf pre-trained model into a parallelly scaled one by post-training on a small amount of tokens, further reducing the training budget. The new scaling law we discovered potentially facilitates the deployment of more powerful models in low-resource scenarios, and provides an alternative perspective for the role of computation in machine learning.
人们普遍认为,扩展语言模型需要通过增加参数(参数扩展)或输出token(推理时间扩展)来付出显著的空间或时间成本。我们提出了第三种更具推理效率的扩展范式:在训练和推理期间同步增加模型的并行计算量。我们对输入施加$P$种多样化且可学习的变换,并行执行模型前向传播,并动态聚合$P$个输出。这种方法称为并行扩展(PARSCALE),通过复用现有参数实现并行计算扩展,可应用于任何模型结构、优化流程、数据或任务。我们理论上提出了新的扩展定律,并通过大规模预训练验证:具有$P$个并行流的模型相当于将参数扩展${\mathcal{O}}(\log P)$量级,同时展现出更优的推理效率。例如,在达到相同性能提升时,PARSCALE相比参数扩展可减少高达$22\times$的内存增长和$6\times$的延迟增长。该方法还能通过少量token的后训练,将现成预训练模型转化为并行扩展版本,进一步降低训练成本。我们发现的新扩展定律有望促进低资源场景下部署更强大的模型,并为计算在机器学习中的作用提供新视角。
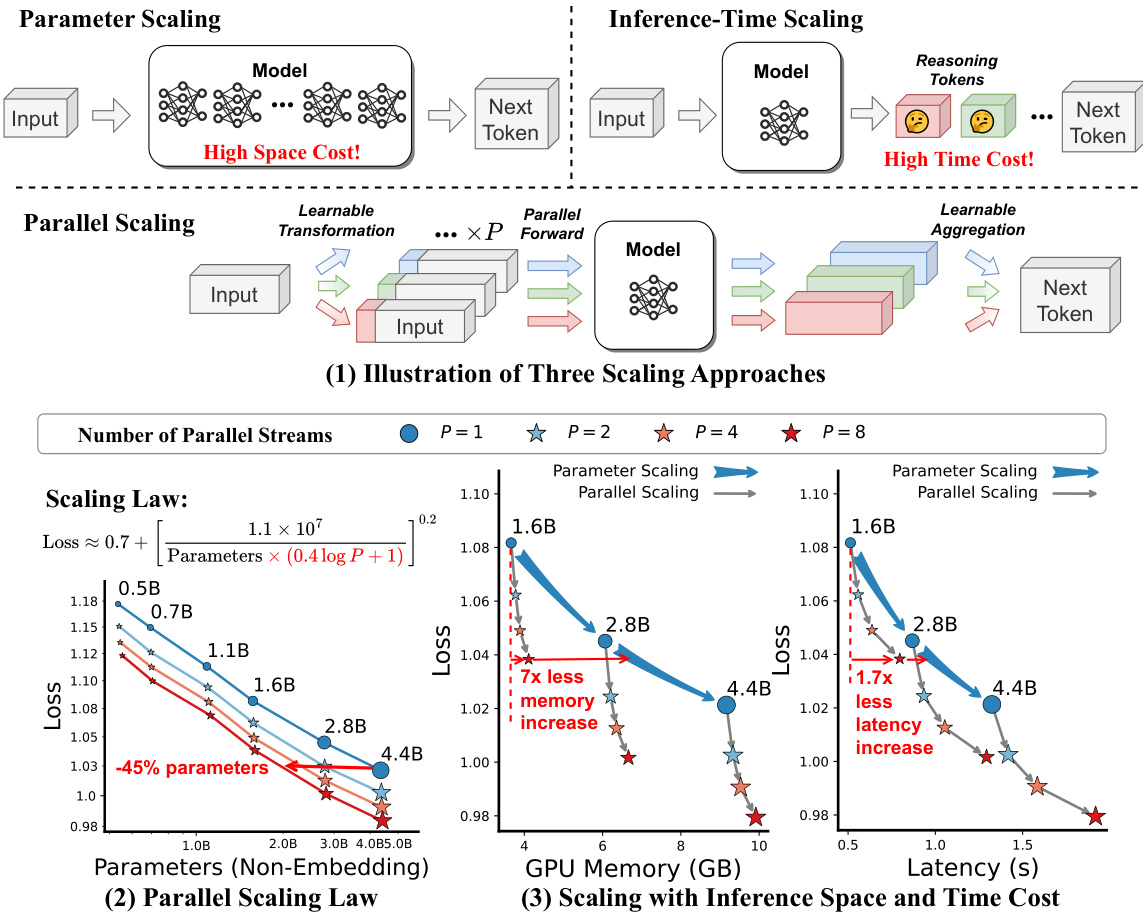
Figure 1: (1) Illustrations of our proposed parallel scaling (PARSCALE). (2) Parallel scaling laws for pre-training models on 42B tokens from Stack-V2 (Python subset). (3) Loss scaling curve with inference cost. Results are averaged from batch size $\in{1,2,4,\dot{8}}$ and input $^+$ output tokens $\check{\in}{128,256,512,1024}$ .
图 1: (1) 我们提出的并行扩展 (PARSCALE) 示意图。(2) 在 Stack-V2 (Python子集) 42B tokens 上预训练模型的并行扩展规律。(3) 推理成本随损失变化的缩放曲线。结果来自批量大小 $\in{1,2,4,\dot{8}}$ 和输入 $^+$ 输出 tokens $\check{\in}{128,256,512,1024}$ 的平均值。
1 Introduction
1 引言
Recent years have witnessed the rapid scaling of large language models (LLMs) (Brown et al., 2020; OpenAI, 2023; Llama Team, 2024; Qwen Team, 2025b) to narrow the gap towards Artificial General Intelligence (AGI). Mainstream efforts focus on parameter scaling (Kaplan et al., 2020), a practice that requires substantial space overhead. For example, DeepSeek-V3 (Liu et al., 2024a) scales the model size up to 672B parameters, which imposes prohibitive memory requirements for edge deployment. More recently, researchers have explored inference-time scaling (OpenAI, 2024) to enhance the reasoning capability by scaling the number of generated reasoning tokens. However, inference-time scaling is limited to certain scenarios and necessitates specialized training data (DeepSeek-AI, 2025; Qin et al., 2024), and typically imposes significant time costs. For example, Chen et al. (2024b) find that the most powerful models can generate up to 900 reasoning tokens for trivial problems like $^{\prime\prime}2+3{=}?^{\prime\prime}$ . This motivates the question: Is there a universal and efficient scaling approach that avoids excessive space and time costs?
近年来,大语言模型 (LLM) (Brown et al., 2020; OpenAI, 2023; Llama Team, 2024; Qwen Team, 2025b) 的快速扩展缩小了与通用人工智能 (AGI) 的差距。主流研究方向集中于参数扩展 (Kaplan et al., 2020) ,这种方法需要巨大的空间开销。例如,DeepSeek-V3 (Liu et al., 2024a) 将模型规模扩展至6720亿参数,这对边缘部署提出了极高的内存要求。最近,研究人员探索了推理时扩展 (OpenAI, 2024) ,通过增加生成推理 token 的数量来提升推理能力。然而,推理时扩展仅适用于特定场景,且需要专门的训练数据 (DeepSeek-AI, 2025; Qin et al., 2024) ,通常会带来显著的时间成本。例如,Chen et al. (2024b) 发现,最强大的模型针对简单问题 (如 $^{\prime\prime}2+3{=}?^{\prime\prime}$ ) 可生成多达900个推理 token 。这引发了一个问题:是否存在一种通用且高效的扩展方法,能够避免过高的空间和时间成本?
We draw inspiration from classifier-free guidance (CFG) (Ho & Salimans, 2022), a widely used trick during the inference phase of diffusion models (Ho et al., 2020), with similar concepts also developed in the NLP community (Sanchez et al., 2024; Li et al., 2023). Unlike traditional methods that use a single forward pass, CFG utilizes two forward passes during inference: it first performs a normal forward pass to obtain the first stream of output, then perturbs the input (e.g., by discarding conditions in the input) to get a second stream of output. The two streams are aggregated based on predetermined contrastive rules, yielding superior performance over single-pass outputs. Despite its widespread use, the theoretical guarantee of CFG remains an open question. In this paper, we hypothesize that the effectiveness of CFG lies in its double computation. We further propose the following hypothesis:
我们从无分类器引导 (CFG) (Ho & Salimans, 2022) 中获得灵感,这是扩散模型 (Ho et al., 2020) 推理阶段广泛使用的技巧,类似概念也在 NLP 领域得到发展 (Sanchez et al., 2024; Li et al., 2023)。与传统单次前向传播方法不同,CFG 在推理时采用两次前向传播:先执行正常前向传播获得第一路输出,再扰动输入(例如丢弃输入条件)获得第二路输出。两路输出根据预设的对比规则进行聚合,其性能优于单次传播输出。尽管 CFG 被广泛使用,但其理论保证仍是一个开放性问题。本文假设 CFG 的有效性源于其双重计算机制,并进一步提出以下假设:
Hypothesis 1. Scaling parallel computation (while maintaining the nearly constant parameters) enhances the model’s capability, with similar effects as scaling parameters.
假设1. 扩展并行计算规模 (同时保持参数几乎恒定) 能提升模型能力,其效果与扩展参数规模类似。
We propose a proof-of-concept scaling approach called parallel scaling (PARSCALE) to validate this hypothesis on language models. The core idea is to increase the number of parallel streams while making the input transformation and output aggregation learnable. We propose appending $P$ different learnable prefixes to the input and feeding them in parallel into the model. These $\bar{P}$ outputs are then aggregated into a single output using a dynamic weighted sum, as shown in Figure 1(1). This method efficiently scales parallel computation during both training and inference time by recycling existing parameters, which applies to various training algorithms, data, and tasks.
我们提出了一种名为并行扩展 (PARSCALE) 的概念验证扩展方法,用于验证大语言模型上的这一假设。其核心思想是在保持输入转换和输出聚合可学习的同时增加并行流数量。具体实现是为输入附加 $P$ 个不同的可学习前缀 (learnable prefix) ,并并行输入模型,随后通过动态加权求和将这 $\bar{P}$ 个输出聚合成单一输出,如图 1(1) 所示。该方法通过复用现有参数,在训练和推理阶段高效扩展并行计算能力,适用于各类训练算法、数据及任务。
Our preliminary theoretical analysis suggests that the loss of PARSCALE may follow a power law similar to the Chinchilla scaling law (Hoffmann et al., 2022). We then carry out large-scale pre-training experiments on the Stack-V2 (Lozhkov et al., 2024) and Pile (Gao et al., 2021) corpus, by ranging $P$ from 1 to 8 and model parameters from 500M to 4.4B. We use the results to fit a new parallel scaling law that generalizes the Chinchilla scaling law, as depicted in Figure 1(2). It shows that parallel i zing into $\mathbf{P}$ streams equates to scaling the model parameters by ${\mathcal{O}}(1{\bf o g}P)$ . Results on comprehensive tasks corroborate this conclusion. Unlike parameter scaling, PARSCALE introduces negligible parameters and increases only a little space overhead. It also leverages GPU-friendly parallel computation, shifting the memory bottleneck in LLM decoding to a computational bottleneck and, therefore, does not notably increase latency. For example, for a 1.6B model, when scaling to $P=8$ using PARSCALE, it uses $\bf{22\times}$ less memory increase and $6\times$ less latency increase compared to parameter scaling that achieves the same model capacity (batch size $=1$ , detailed in Section 3.3). Figure 1(3) illustrates that PARSCALE offers superior inference efficiency.
我们的初步理论分析表明,PARSCALE的损失可能遵循类似于Chinchilla缩放律 (Hoffmann et al., 2022) 的幂律。随后我们在Stack-V2 (Lozhkov et al., 2024) 和Pile (Gao et al., 2021) 语料库上进行了大规模预训练实验,将$P$从1调整到8,模型参数从500M调整到4.4B。我们利用这些结果拟合了一个新的并行缩放律,该定律推广了Chinchilla缩放律,如图1(2)所示。结果表明,将模型并行化为$\mathbf{P}$个流相当于将模型参数缩放${\mathcal{O}}(1{\bf o g}P)$。在综合任务上的结果验证了这一结论。与参数缩放不同,PARSCALE引入的参数可忽略不计,仅略微增加空间开销。它还利用了对GPU友好的并行计算,将大语言模型解码中的内存瓶颈转移为计算瓶颈,因此不会显著增加延迟。例如,对于一个1.6B的模型,当使用PARSCALE缩放到$P=8$时,与达到相同模型容量的参数缩放相比 (批大小$=1$,详见第3.3节),其内存增加量减少了$\bf{22\times}$,延迟增加量减少了$6\times$。图1(3)展示了PARSCALE具有更优的推理效率。
Furthermore, we show that the high training cost of PARSCALE can be reduced by a two-stage approach: the first stage employs traditional training with most of the training data, and PARSCALE is applied only in the second stage with a small number of tokens. Based on this, we train 1.8B models with various $\dot{P}$ and scale the training data to 1T tokens. The results of 21 downstream benchmarks indicate the efficacy of this strategy. For example, when scaling to $P=8$ , it yields a $34%$ relative improvement for GSM8K and $23%$ relative improvement for MMLU using exactly the same training data. We also implement PARSCALE on an off-the-shelf model, Qwen-2.5 (Qwen Team, 2024), and demonstrate that PARSCALE is effective in both full and parameter-efficient fine-tuning settings. This also shows the viability of dynamic parallel scaling, which allows flexible adjustment of $\breve{P}$ during deployment while freezing the backbone weights, to fit different application scenerios.
此外,我们还展示了降低PARSCALE高训练成本的二阶段方案:第一阶段使用传统方法训练大部分数据,仅在第二阶段对少量token应用PARSCALE。基于此,我们训练了1.8B参数的多种 $\dot{P}$ 模型,并将训练数据规模扩展至1T token。21个下游基准测试结果表明该策略的有效性。例如当扩展到 $P=8$ 时,在完全相同的训练数据下,GSM8K相对提升34%,MMLU相对提升23%。我们还在现成模型Qwen-2.5 (Qwen Team, 2024)上实现了PARSCALE,证明其在全参数微调和参数高效微调场景均有效。这也展示了动态并行扩展的可行性——部署时在冻结主干权重的前提下灵活调整 $\breve{P}$ ,以适应不同应用场景。
Table 1 compares PARSCALE with other mainstream scaling strategies. Beyond introducing an efficient scaling approach for language models, our research also tries to address a more fundamental question in machine learning: Is a model’s capacity determined by the parameters or by the computation, and what is their individual contribution? Traditional machine learning models typically scale both parameters and computation simultaneously, making it difficult to determine their contribution ratio. The PARSCALE and the fitted parallel scaling law may offer a novel and quantitative perspective on this problem.
表 1 比较了 PARSCALE 与其他主流缩放策略。除了为语言模型引入一种高效的缩放方法外,我们的研究还试图解决机器学习中一个更基础的问题:模型的能力是由参数还是计算决定的,它们各自的贡献是什么?传统机器学习模型通常会同时缩放参数和计算,因此难以确定它们的贡献比例。PARSCALE 和拟合的并行缩放定律可能为这个问题提供一个新颖的定量视角。
Table 1: Comparisons of mainstream LLM scaling strategies. We subdivide parameter scaling into traditional Dense Scaling and Mixture-of-Expert (MoE) Scaling (Fedus et al., 2022) for comparison. Inference-Time Scaling: Enhancing the reasoning ability through large-scale reinforcement learning (RL) to scale reasoning tokens during inference.
表 1: 主流大语言模型扩展策略对比。我们将参数扩展细分为传统密集扩展 (Dense Scaling) 和混合专家扩展 (Mixture-of-Expert Scaling, MoE) (Fedus et al., 2022) 进行对比。推理时扩展 (Inference-Time Scaling): 通过大规模强化学习 (RL) 提升推理能力,在推理过程中扩展推理 token。
| 方法 | 推理时间 | 推理空间 | 训练成本 | 专用策略 |
|---|---|---|---|---|
| 密集扩展 | 中等 | 高 | 仅需预训练 | 无 |
| 混合专家扩展 | 极低 | 高 | 仅需预训练 | 负载均衡 |
| 推理时扩展 | 高 | 中等 | 需后训练 | 强化学习/奖励数据 |
| 并行扩展 | 中等 | 中等 | 需预训练或后训练 | 无 |
We posit that large computing can foster the emergence of large intelligence. We hope our work can inspire more ways to scaling computing towards AGI and provide insights for other areas of machine learning. Our key findings in this paper can be summarized as follows:
我们认为大规模计算能够促进大规模智能的出现。希望我们的工作能激发更多通过扩展计算实现通用人工智能 (AGI) 的方法,并为机器学习其他领域提供启示。本文的核心发现可归纳如下:
Our code and 67 trained model checkpoints are publicly available at https://github.com/QwenLM/ ParScale and https://hugging face.co/ParScale.
我们的代码和67个训练好的模型检查点已在 https://github.com/QwenLM/ParScale 和 https://huggingface.co/ParScale 公开提供。
2 Background and Methodology
2 背景与方法论
Classifier-Free Guidance (CFG) CFG (Ho & Salimans, 2022) has become a de facto inference-time trick in diffusion models (Ho et al., 2020), with similar concepts also developed in NLP (Sanchez et al., 2024; Li et al., 2023). At a high level, these lines of work can be summarized as follows: given an input $x\in\mathbb{R}^{d_{i}}$ and a trained model $f_{\theta}:\mathbb{R}^{d_{i}}\rightarrow\mathbb{R}^{d_{o}}$ , where $\theta$ is the parameter and $d_{i},d_{o}$ are dimensions, we transform $x$ into a $\mathrm{^{//}b a d^{\prime\prime}}$ version $x^{\prime}$ based on some heuristic rules (e.g., removing conditions), obtaining two parallel outputs $f_{\boldsymbol{\theta}}(\boldsymbol{x})$ and $f_{\boldsymbol\theta}(x^{\prime})$ . The final output $g_{\boldsymbol{\theta}}(\boldsymbol{x})$ is aggregated based on the following rule:
无分类器引导 (CFG)
CFG (Ho & Salimans, 2022) 已成为扩散模型 (Ho et al., 2020) 中实际采用的推理技巧,类似概念也在自然语言处理领域得到发展 (Sanchez et al., 2024; Li et al., 2023)。高层次来看,这些工作可概括为:给定输入 $x\in\mathbb{R}^{d_{i}}$ 和训练好的模型 $f_{\theta}:\mathbb{R}^{d_{i}}\rightarrow\mathbb{R}^{d_{o}}$ ,其中 $\theta$ 是参数,$d_{i},d_{o}$ 是维度,我们基于某些启发式规则 (例如移除条件) 将 $x$ 转换为 $\mathrm{^{//}b a d^{\prime\prime}}$ 版本 $x^{\prime}$ ,获得两个并行输出 $f_{\boldsymbol{\theta}}(\boldsymbol{x})$ 和 $f_{\boldsymbol\theta}(x^{\prime})$ 。最终输出 $g_{\boldsymbol{\theta}}(\boldsymbol{x})$ 按以下规则聚合:
$$
g_{\theta}(x)=f_{\theta}(x)+w\left(f_{\theta}(x)-f_{\theta}(x^{\prime})\right).
$$
$$
g_{\theta}(x)=f_{\theta}(x)+w\left(f_{\theta}(x)-f_{\theta}(x^{\prime})\right).
$$
Here, $w>0$ is a pre-set hyper parameter. Intuitively, Equation (1) can be seen as starting from a “good” prediction and moving $w$ steps in the direction away from a “bad” prediction. Existing research shows that $g_{\boldsymbol{\theta}}(\boldsymbol{x})$ can perform better than the vanilla $f_{\boldsymbol{\theta}}(\boldsymbol{x})$ in practice (Saharia et al., 2022).
这里,$w>0$ 是一个预设的超参数。直观上,式 (1) 可以看作是从一个"好"的预测开始,然后朝着远离"坏"预测的方向移动 $w$ 步。现有研究表明,$g_{\boldsymbol{\theta}}(\boldsymbol{x})$ 在实践中表现优于原始模型 $f_{\boldsymbol{\theta}}(\boldsymbol{x})$ (Saharia et al., 2022)。
Motivation In Equation (1), $x^{\prime}$ is simply a degraded version of $x,$ suggesting that $g_{\boldsymbol{\theta}}(\boldsymbol{x})$ does not gain more useful information than $f_{\boldsymbol{\theta}}(x)$ . This raises the question: why is $f_{\boldsymbol{\theta}}(x)$ unable to learn the capability of $g_{\boldsymbol{\theta}}(\boldsymbol{x})$ during training, despite both having the same parameters? We hypothesize that the fundamental reason lies in $g_{\boldsymbol{\theta}}(\boldsymbol{x})$ having twice the computation as $f_{\boldsymbol{\theta}}(\boldsymbol{\bar{x}})$ . This inspires us to further expand Equation (1) into the following form:
动机 在公式 (1) 中,$x^{\prime}$ 仅是 $x$ 的退化版本,这表明 $g_{\boldsymbol{\theta}}(\boldsymbol{x})$ 并未获得比 $f_{\boldsymbol{\theta}}(x)$ 更有用的信息。这引发了一个问题:为什么 $f_{\boldsymbol{\theta}}(x)$ 在训练期间无法学习 $g_{\boldsymbol{\theta}}(\boldsymbol{x})$ 的能力,尽管两者具有相同的参数?我们假设根本原因在于 $g_{\boldsymbol{\theta}}(\boldsymbol{x})$ 的计算量是 $f_{\boldsymbol{\theta}}(\boldsymbol{\bar{x}})$ 的两倍。这启发我们将公式 (1) 进一步扩展为以下形式:
$$
g_{\theta}(x)=w_{1}f_{\theta}(x_{1})+w_{2}f_{\theta}(x_{2})+\cdot\cdot\cdot+w_{P}f_{\theta}(x_{P}),
$$
$$
g_{\theta}(x)=w_{1}f_{\theta}(x_{1})+w_{2}f_{\theta}(x_{2})+\cdot\cdot\cdot+w_{P}f_{\theta}(x_{P}),
$$
where $P$ denotes the number of parallel streams. $x_{1},\cdots,x_{P}$ are $P$ distinct transformations of $x,$ and $w_{1},\cdots,w_{P}$ are aggregation weights. We term Equation (2) as a parallel scaling (PARSCALE) of the model $f_{\theta}$ with $P$ streams. This scaling strategy does not require changing the structure of $f_{\theta}$ and training data. In this paper, we focus on Transformer language models (Vaswani et al., 2017; Brown et al., 2020), and regard the stacked Transformer layers as $f_{\theta}\breve{(\cdot)}$ .
其中 $P$ 表示并行流的数量。$x_{1},\cdots,x_{P}$ 是 $x$ 的 $P$ 种不同变换,$w_{1},\cdots,w_{P}$ 是聚合权重。我们将公式 (2) 称为模型 $f_{\theta}$ 的 $P$ 流并行扩展 (PARSCALE)。这种扩展策略无需改变 $f_{\theta}$ 的结构和训练数据。本文聚焦于 Transformer 语言模型 (Vaswani et al., 2017; Brown et al., 2020),并将堆叠的 Transformer 层视为 $f_{\theta}\breve{(\cdot)}$。
Implementation Details and Pivot Experiments We apply Equation (2) in both training and inference time, and perform a series of pivot experiments to determine the best input transformation and output aggregation strategies (refer to Appendix A). The findings revealed that variations in these strategies minimally affect model performance; the significant factor is the number of computations (i.e., P). Finally, for input transformation, we employ prefix tuning (Li & Liang, 2021) as the input transformation, which is equivalent to using different KV-caches to distinguish different streams. For output aggregation, we employ a dynamic weighted average approach, utilizing an MLP to convert outputs from multiple streams into aggregation weights. This increases about $0.2%$ additional parameters for each stream.
实现细节与关键实验
我们在训练和推理阶段均应用公式(2),并通过一系列关键实验确定最佳输入转换与输出聚合策略(详见附录A)。研究发现这些策略的差异对模型性能影响甚微,关键影响因素是计算量(即P值)。最终,在输入转换方面采用前缀调优(Li & Liang, 2021)技术,其效果等同于使用不同的KV缓存区分不同数据流;输出聚合则采用动态加权平均法,通过MLP将多流输出转换为聚合权重。该方法为每个流增加约$0.2%$的额外参数量。
3 Parallel Scaling Law
3 并行扩展定律
This section focuses on the in-depth comparison of scaling parallel computation with scaling parameters. In Section 3.1, we theoretically demonstrate that parallel scaling is equivalent to increasing parameters by a certain amount. In Section 3.2, we validate this with a practical scaling law through large-scale experiments. Finally, in Section 3.3, we analyze latency and memory usage during inference to show that parallel scaling is more efficient.
本节重点深入比较并行计算扩展与参数扩展的效果。在3.1节中,我们从理论上证明并行扩展等效于增加一定数量的参数。在3.2节中,我们通过大规模实验用实际扩展定律验证了这一结论。最后在3.3节中,我们分析了推理过程中的延迟和内存使用情况,表明并行扩展效率更高。
3.1 Theoretical Analysis: Can PARSCALE Achieve Similar Effects as Parameter Scaling?
3.1 理论分析:PARSCALE能否实现与参数缩放(Parameter Scaling)类似的效果?
From another perspective, PARSCALE can be seen as an ensemble of multiple different next token predictions, despite the ensemble components sharing most of the parameters. Existing theory in literature finds that the ensembling performance depends on the diversity of different components (Breiman, 2001; Lobacheva et al., 2020b). In this section, we further validate this finding by theoretically proposing a new scaling law that generalizes existing language model scaling laws, and demonstrate that PARSCALE can achieve similar effects as parameter scaling.
从另一个角度来看,PARSCALE 可视为多个不同下一 Token 预测的集成,尽管这些集成组件共享大部分参数。现有文献理论发现,集成性能取决于不同组件的多样性 (Breiman, 2001; Lobacheva et al., 2020b)。本节中,我们通过理论提出一种能泛化现有大语言模型缩放律的新缩放律,进一步验证这一发现,并证明 PARSCALE 能实现与参数缩放类似的效果。
We consider a special case that $w_{1}=w_{2}=\cdot\cdot\cdot=1/P$ to simplify our analysis. This is a degraded version of PARSCALE, therefore, we can expect that the full version of PARSCALE is at least not worse than the theoretical results we can obtain (See Appendix A for further numeric comparison). Let ${\hat{p}}_{i}(\cdot\mid x)=f_{\theta}(x_{i})$ denote the next token distribution for the input sequence $x$ predicted by the $i$ -th stream. Based on Equation (2), the final prediction ${\hat{p}}(\cdot\mid x)=g_{\theta}{\dot{(x)}}$ is the average across ${\hat{p}}_{i},$ i.e., $\hat{p}(\cdot\mid x)=1/{\cal P}\sum_{i}\hat{p}_{i}(\cdot\mid x)$ . Chinchilla (Hoffmann et al., 2022) proposes that the loss $\mathcal{L}$ of a language model with $N$ parameters is a function of $N$ after convergence. We assume the prediction of each stream adheres to the Chinchilla scaling law, as follows:
我们考虑一个特殊情况 $w_{1}=w_{2}=\cdot\cdot\cdot=1/P$ 以简化分析。这是 PARSCALE 的简化版本,因此可以预期完整版 PARSCALE 至少不会逊色于我们获得的理论结果(具体数值比较参见附录 A)。设 ${\hat{p}}_{i}(\cdot\mid x)=f_{\theta}(x_{i})$ 表示第 $i$ 个流对输入序列 $x$ 预测的下一 token 分布。根据公式 (2),最终预测 ${\hat{p}}(\cdot\mid x)=g_{\theta}{\dot{(x)}}$ 是各 ${\hat{p}}_{i}$ 的平均值,即 $\hat{p}(\cdot\mid x)=1/{\cal P}\sum_{i}\hat{p}_{i}(\cdot\mid x)$。Chinchilla (Hoffmann et al., 2022) 提出,大语言模型收敛后的损失 $\mathcal{L}$ 是其参数量 $N$ 的函数。我们假设每个流的预测都遵循 Chinchilla 缩放律,如下所示:
Lemma 3.1 (Chinchilla Scaling Law (Hoffmann et al., 2022)). The language model cross-entropy loss $\mathcal{L}_{i}$ for the i-th stream prediction (with $N$ parameters) when convergence is:
引理 3.1 (Chinchilla 缩放定律 (Hoffmann et al., 2022))。当收敛时,第i个流预测(具有$N$个参数)的语言模型交叉熵损失$\mathcal{L}_{i}$为:
$$
\mathcal{L}_{i}=\left(\frac{A}{N}\right)^{\alpha}+E,\quad1\leq i\leq P,
$$
$$
\mathcal{L}_{i}=\left(\frac{A}{N}\right)^{\alpha}+E,\quad1\leq i\leq P,
$$
where ${A,E,\alpha}$ are some positive constants. $E$ is the entropy of natural text, and $N$ is the number of parameters.1
其中 ${A,E,\alpha}$ 为正常数。$E$ 表示自然文本的熵,$N$ 为参数量。1
Based on Lemma 3.1, we theoretically derive that after aggregating $P$ streams, the prediction follows a new type of scaling law, as follows:
根据引理3.1,我们从理论上推导出聚合$P$个流后,预测遵循一种新型的缩放定律,如下所示:
Proposition 1 (Theoretical Formula for Parallel Scaling Law). The loss $\mathcal{L}$ for PARSCALE (with $P$ streams and $N$ parameters) is
命题 1 (并行扩展律的理论公式). PARSCALE (含 $P$ 个数据流和 $N$ 个参数) 的损失 $\mathcal{L}$ 满足
$$
{\mathcal{L}}=\left({\frac{A}{N\cdot P^{1/\alpha}\cdot{\mathrm{DIVERSITY}}}}\right)^{\alpha}+E.
$$
$$
{\mathcal{L}}=\left({\frac{A}{N\cdot P^{1/\alpha}\cdot{\mathrm{DIVERSITY}}}}\right)^{\alpha}+E.
$$
We define DIVERSITY as:
我们将DIVERSITY定义为:
$$
\begin{array}{r}{\mathrm{DIVERSITY}=\left[(P-1)\rho+1\right]^{-1/\alpha},}\end{array}
$$
$$
\begin{array}{r}{\mathrm{DIVERSITY}=\left[(P-1)\rho+1\right]^{-1/\alpha},}\end{array}
$$
where $\rho$ is the correlation coefficient between random variables $\Delta{{p}{i}}$ and $\Delta p_{j}(i\neq j),$ and $\Delta{{p}{i}}$ is the relative residuals for the i-th stream prediction, i.e., $\Delta p_{i}=\lceil\hat{p}_{i}(y|x)-p(y|x)\rceil/p(y|x)$ . $p(y\mid x)$ is the real next token probability.
其中 $\rho$ 是随机变量 $\Delta{{p}{i}}$ 和 $\Delta p_{j}(i\neq j)$ 之间的相关系数,$\Delta{{p}{i}}$ 是第i个流预测的相对残差,即 $\Delta p_{i}=\lceil\hat{p}_{i}(y|x)-p(y|x)\rceil/p(y|x)$。$p(y\mid x)$ 是真实的下一个token概率。
Proof for Proposition 1 is elaborated in Appendix B. From it, we can observe two key insights:
命题1的证明详见附录B。由此我们可以得出两个关键结论:
- When $\rho=1$ , predictions across different streams are identical, at which point we can validate that Equation (4) degenerates into Equation (3). Random initialization on a small number of parameters introduced (i.e., prefix embeddings) is sufficient to avoid this situation in our experiments, likely due to the impact being magnified by the extensive computation of LLMs.
- 当 $\rho=1$ 时,不同流之间的预测结果相同,此时可以验证方程 (4) 退化为方程 (3)。在我们的实验中,仅需对少量引入的参数(即前缀嵌入)进行随机初始化即可避免这种情况,这可能是由于大语言模型 (LLM) 的庞大计算量放大了影响效果。
- When $\rho\neq1$ , $\mathcal{L}$ is inversely correlated to $P$ . Notably, when $\rho=0.$ , residuals are independent between streams and the training loss exhibits a power-law relationship with $P$ (i.e., $\mathcal{L}\propto P^{-1}$ ). This aligns with findings in Lobacheva et al. (2020b). When $\rho$ is negative, the loss can further decrease and approach zero. This somewhat de mystifies the effectiveness of CFG: by widening the gap between $'^{\prime\prime}\mathrm{good}^{\prime\prime}$ input $x$ and “bad” input $x^{\prime}$ , we force the model to “think” from two distinct perspectives, which can increase the diversity between the two outputs.
- 当 $\rho\neq1$ 时,$\mathcal{L}$ 与 $P$ 呈负相关。值得注意的是,当 $\rho=0.$ 时,流之间的残差相互独立,训练损失与 $P$ 呈现幂律关系 (即 $\mathcal{L}\propto P^{-1}$)。这一发现与 Lobacheva 等人 (2020b) 的研究结果一致。当 $\rho$ 为负值时,损失可以进一步降低并趋近于零。这在一定程度上解释了分类器无关引导 (CFG) 的有效性:通过扩大“好”输入 $x$ 与“坏”输入 $x^{\prime}$ 之间的差距,我们迫使模型从两个不同角度进行“思考”,从而增加两个输出之间的多样性。
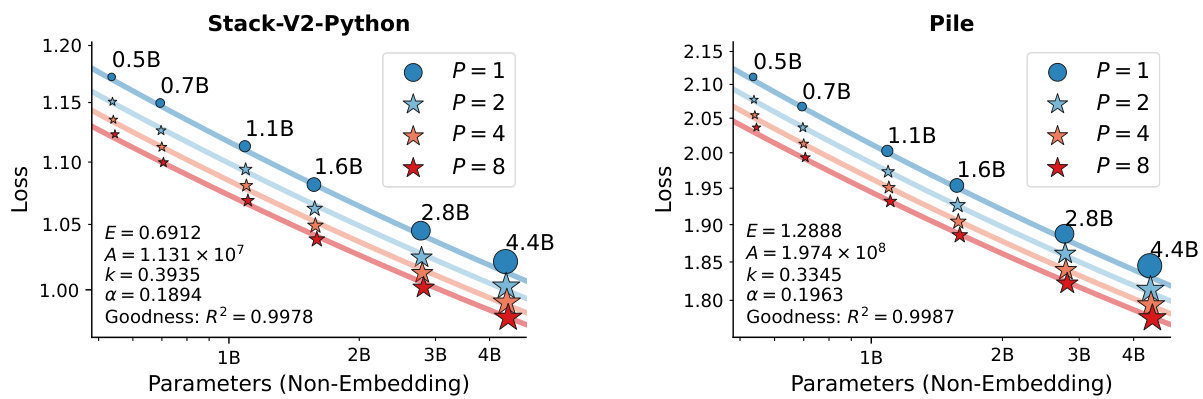
Figure 2: Loss of LLMs scaled on parameters and number of parallel streams $P$ trained on 42B tokens. Each point depicts the loss from a training run. The fitted scaling law curve from Equation (5) is displayed, with annotated fitted parameters $\left(E,A,k,\alpha\right)$ and the goodness of fit $R^{2}$ .
图 2: 大语言模型 (LLM) 在参数量和并行流数量 $P$ 下的损失变化 (基于 42B token 训练) 。每个点代表一次训练运行的损失值。图中展示了根据公式 (5) 拟合的缩放律曲线,并标注了拟合参数 $\left(E,A,k,\alpha\right)$ 以及拟合优度 $R^{2}$ 。
Despite the difficulty in further modeling $\rho_{,}$ Proposition 1 suggests that scaling $P$ times of parallel computation is equivalent to scaling the model parameter count, by a factor of ( $P^{\Psi\alpha}$ ·DIVERSITY). This motivates us to go further, by empirically fitting a practical parallel scaling law to validate Hypothesis 1.
尽管难以进一步建模 $\rho_{,}$,但命题 1 表明,将并行计算规模扩展 $P$ 倍,等效于将模型参数量按 ( $P^{\Psi\alpha}$ ·DIVERSITY) 的系数进行扩展。这激励我们通过实证拟合实用的并行扩展定律来进一步验证假设 1。
3.2 Practical Parallel Scaling Laws
3.2 实际并行扩展定律
Experiment Setup To fit a parallel scaling law in practice, we pre-train Transformer language models with the Qwen-2.5 dense architecture and tokenizer (Qwen Team, 2024) from scratch on the open-source corpus. Models have up to 4.7 billion parameters (with 4.4B non-embedding parameters) and 8 parallel streams. We primarily focus on the relationship between parallel scaling and parameter scaling. Therefore, we fix the training data size at 42 billion tokens without data repeat2. We introduce the results for more training tokens in the next section, and leave the impact of data scale on our scaling laws for future work. We use a batch size of 1024 and a sequence length of 2048, resulting in 20K training steps. For models with $P>1$ , we incorporate prefix embeddings and aggregation weight, as introduced in Appendix A. No additional parameters are included for $P=\stackrel{\smile}{1}$ models to maintain alignment with existing architectures. We report the last step training loss using exponential moving average, with a smoothing weight of 0.95. Other hyper parameters follow existing works (Mu en nigh off et al., 2023) and are detailed in Appendix C.
实验设置
为在实践中拟合并行扩展规律,我们使用Qwen-2.5密集架构和分词器(Qwen Team, 2024)从头开始在开源语料库上预训练Transformer语言模型。模型参数规模最高达47亿(含44亿非嵌入参数),支持8个并行流。我们主要关注并行扩展与参数扩展之间的关系,因此将训练数据量固定为420亿token且不重复使用数据。更多训练token的结果将在下一节展示,数据规模对扩展规律的影响留待未来研究。我们采用1024的批次大小和2048的序列长度,共进行2万次训练步。对于$P>1$的模型,如附录A所述,我们加入了前缀嵌入和聚合权重。$P=\stackrel{\smile}{1}$模型则未引入额外参数以保持与现有架构的一致性。训练损失采用平滑权重为0.95的指数移动平均法记录最终步结果。其余超参数遵循现有研究(Muennighoff et al., 2023),详见附录C。
Our pre-training is conducted on two widely utilized datasets: Stack-V2 (Python subset) (Lozhkov et al., 2024) and Pile (Gao et al., 2021). Pile serves as a general corpus aimed at enhancing common sense and memorization skills, while Stack-V2 focuses on code comprehension and reasoning skills. Analyzing PARSCALE across these contexts can assess how parameters and computations contribute to different skills.
我们的预训练基于两个广泛使用的数据集:Stack-V2 (Python子集) (Lozhkov等人,2024) 和 Pile (Gao等人,2021)。Pile作为通用语料库旨在提升常识记忆能力,而Stack-V2专注于代码理解与推理能力。通过在这些场景下分析PARSCALE,可以评估参数与计算对不同技能的影响。
Parametric Fitting We plot the results in Figure 2, where each point represents the loss of a training run, detailed in Appendix F. We observe that increasing $P$ yields benefits following a logarithmic trend. Similar gains are seen when raising $P$ from 1 to 2, 2 to 4, and 4 to 8. Thus, we preliminarily try the following form:
参数化拟合
我们将结果绘制在图 2 中,其中每个点代表一次训练运行的损失(详见附录 F)。我们观察到,增加 $P$ 会带来对数趋势的收益。当 $P$ 从 1 提升到 2、2 到 4 以及 4 到 8 时,也观察到了类似的增益。因此,我们初步尝试以下形式:
$$
{\mathcal{L}}=\left({\frac{A}{N\cdot(k\log P+1)}}\right)^{\alpha}+E,
$$
$$
{\mathcal{L}}=\left({\frac{A}{N\cdot(k\log P+1)}}\right)^{\alpha}+E,
$$
where we assume that $P^{1/\alpha}\cdot{\mathrm{DIVERSITY}}=k\log P+1$ in Equation (4) based on the finding of the logarithmic trend. $\left(A,k,\alpha,E\right)$ are parameters to fit, and we use the natural logarithm (base e). We follow the fitting procedure from Hoffmann et al. (2022); Mu en nigh off et al. (2023), detailed in Appendix E.
我们假设在公式(4)中 $P^{1/\alpha}\cdot{\mathrm{DIVERSITY}}=k\log P+1$ ,这一假设基于对数趋势的发现。 $(A,k,\alpha,E)$ 是需要拟合的参数,我们使用自然对数(以e为底)。我们遵循Hoffmann等人(2022)和Muennighoff等人(2023)的拟合流程,具体细节见附录E。
Figure 2 illustrates the parallel scaling law fitted for two training datasets. It shows a high goodness of fit ( $\mathrm{\ddot{\Delta}R}^{2}$ up to 0.998), validating the effectiveness of Equation (5). Notably, we can observe that the $k$ value for Stack-V2 (0.39) is higher than for Pile (0.33). Recall that $k$ reflects the benefits of increased parallel computation. Since Stack-V2 emphasizes coding and reasoning abilities while Pile emphasizes memorization capacity, we propose an intuitive conjecture that model parameters mainly impact the memorization skills, while computation mainly impacts the reasoning skills. This aligns with recent findings on inference-time scaling (Geiping et al., 2025). Unlike those studies, we further quantitatively assess the ratio of contribution to model performance between parameters and computation through our proposed scaling laws.
图 2: 展示了针对两个训练数据集拟合的并行扩展规律。结果显示高拟合优度 ( $\mathrm{\ddot{\Delta}R}^{2}$ 最高达0.998) ,验证了公式(5) 的有效性。值得注意的是,Stack-V2的 $k$ 值(0.39) 高于Pile(0.33) 。回顾 $k$ 反映的是增加并行计算带来的收益。由于Stack-V2侧重编码和推理能力,而Pile侧重记忆能力,我们提出一个直观猜想:模型参数主要影响记忆技能,而计算量主要影响推理技能。这与近期关于推理时扩展的研究结论一致 (Geiping et al., 2025) 。不同于这些研究,我们进一步通过提出的扩展规律定量评估了参数和计算对模型性能的贡献比例。
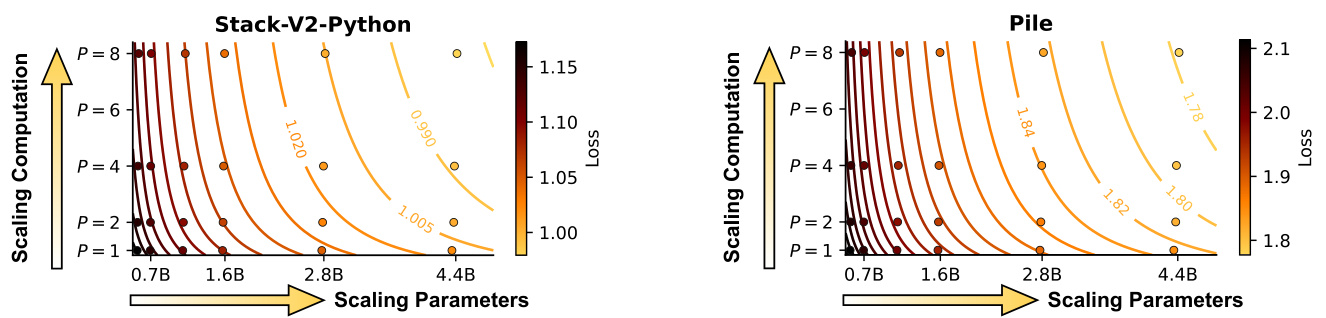
Figure 3: Predicted loss contours for PARSCALE. Each contour line indicates a combination of (parameter, $P$ ) with similar performance.
图 3: PARSCALE的预测损失等高线图。每条等高线表示一组具有相似性能的 (参数, $P$) 组合。
Table 2: Average performance $(%)$ on two code generation tasks, HumanEval $(+)$ and ${\mathrm{MBPP}}(+),$ after pre-training on the Stack-V2-Python dataset.
表 2: 在 Stack-V2-Python 数据集上预训练后,两个代码生成任务 HumanEval (+) 和 MBPP (+) 的平均性能 $(%)$。
| N | 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|---|
| P=1 | 26.7 | 28.4 | 31.6 | 33.9 | 36.9 | 39.2 |
| P=2 | 30.3 | 32.4 | 33.6 | 37.4 | 39.4 | 42.6 |
| P=4 | 30.1 | 32.5 | 34.1 | 37.6 | 40.7 | 42.6 |
| P=8 | 32.3 | 34.0 | 37.2 | 39.1 | 42.1 | 45.4 |
Table 3: Average performance $(%)$ on six general lm-evaluation-harness tasks after pre-training on the Pile dataset.
表 3: 在 Pile 数据集上预训练后,六个通用 lm-evaluation-harness 任务的平均性能 $(%)$
| N | 0.5B | 0.7B 1.1B | 1.6B | 2.8B | 4.4B | |
|---|---|---|---|---|---|---|
| P = 1 | 49.1 | 50.6 | 52.1 | 53.1 | 55.2 | 57.2 |
| P = 2 | 49.9 | 51.0 | 52.4 | 54.4 | 57.0 | 58.5 |
| P = 4 | 50.6 | 51.8 | 53.3 | 55.0 | 57.8 | 59.1 |
| P = 8 | 50.7 | 51.8 | 54.2 | 55.7 | 58.1 | 59.6 |
Recall that Equation (5) implies scaling $P$ equates to increasing parameters by $\mathcal{O}(N\log P)$ . It suggests that models with more parameters benefit more from PARSCALE. Figure 3 more intuitively displays the influence of computation and parameters on model capacity. As model parameters increase, the loss contours flatten, showing greater benefits from increasing computation.
回想一下,式 (5) 表明缩放 $P$ 相当于将参数增加 $\mathcal{O}(N\log P)$ 。这表明参数更多的模型从 PARSCALE 中获益更大。图 3 更直观地展示了计算量和参数对模型能力的影响。随着模型参数增加,损失等高线趋于平缓,显示出增加计算量带来的更大收益。
Downstream Performance Tables 2 and 3 illustrate the average performance on downstream tasks (coding tasks for Stack-V2-Python and general tasks for Pile) after pre-training, with comprehensive results in Appendix G. It shows that increasing the number of parallel streams $P$ consistently boosts performance, which confirms that PARSCALE is able to enhance the model capabilities and similar to scale the parameters. Notably, PARSCALE offers more substantial improvements for coding tasks compared to general tasks. For example, as shown in Table 2, the coding ability of the 1.6B model for $P={\hat{8}}$ aligns with the 4.4B model, while Table 3 indicates that such setting performs comparably to the 2.8B model on general tasks that focusing on common-sense memorization. These findings affirm our previous hypothesis that the number of parameters impacts the memorization capacity, while computation impacts the reasoning capacity.
下游性能
表 2 和表 3 分别展示了预训练后在下游任务(Stack-V2-Python 的编程任务和 Pile 的通用任务)上的平均性能,完整结果见附录 G。结果表明,增加并行流数量 $P$ 能持续提升性能,这证实 PARSCALE 可以有效增强模型能力,其效果类似于扩大参数量。值得注意的是,与通用任务相比,PARSCALE 对编程任务的提升更为显著。例如,表 2 显示,当 $P={\hat{8}}$ 时,1.6B 模型的编程能力与 4.4B 模型相当;而表 3 表明,该设置在侧重常识记忆的通用任务上表现与 2.8B 模型相近。这些发现验证了我们先前的假设:参数量影响记忆能力,而计算量影响推理能力。
3.3 Inference Cost Analysis
3.3 推理成本分析
We further compare the inference efficiency between parallel scaling and parameter scaling at equivalent performance levels. Although some work uses FLOPS to measure the inference cost (Hoffmann et al., 2022; Sardana et al., 2024), we argue that this is not an ideal metric. Most Transformer operations are bottle necked by memory access rather than computation during the decoding stage (Ivanov et al., 2021). Some work (such as flash attention (Dao et al., 2022)) incurs more FLOPS but achieves lower latency by reducing memory access. Therefore, we use memory and latency to measure the inference cost, based on the llm-analysis framework (Li, 2023). Memory determines the minimum hardware requirements, while latency measures the time overhead from input to output.
我们进一步比较了在同等性能水平下并行扩展与参数扩展的推理效率差异。尽管部分研究采用FLOPS衡量推理成本 (Hoffmann et al., 2022; Sardana et al., 2024),我们认为这并非理想指标——在解码阶段,大多数Transformer运算的瓶颈在于内存访问而非计算量 (Ivanov et al., 2021)。某些工作(如flash attention (Dao et al., 2022))虽增加FLOPS,但通过减少内存访问实现了更低延迟。因此我们基于llm-analysis框架 (Li, 2023),采用内存占用和延迟时间作为推理成本度量标准:内存决定最低硬件要求,延迟则衡量从输入到输出的时间开销。
We analyze the inference cost across various inference batch sizes. It is worth mentioning that all models in our experiments feature the same number of layers, differing only in parameter width and parallel streams (detailed in Appendix C). This enables a more fair comparison of the efficiencies.
我们分析了不同推理批次大小下的推理成本。值得一提的是,实验中所有模型的层数相同,仅在参数宽度和并行流数量上存在差异(详见附录C),这使得效率对比更加公平。
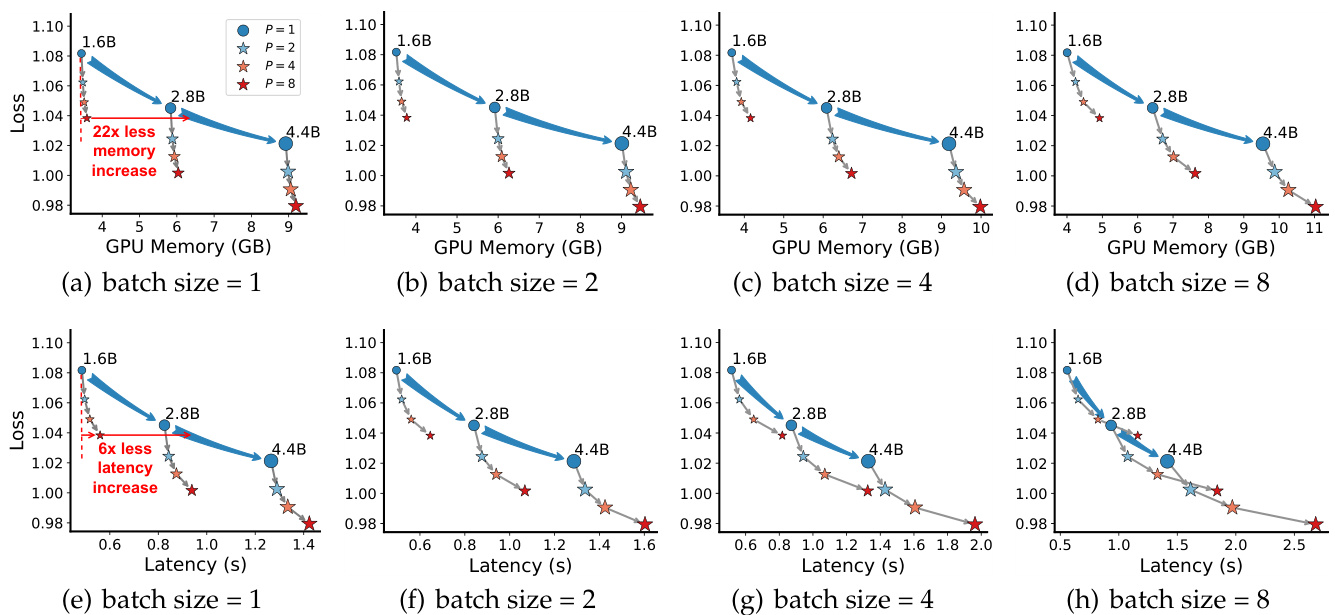
Figure 4: Model capacity (indicated by loss) scales on the inference space-time cost, with three parameters (1.6B, 2.8B, and 4.4B) and batch sizes $\in{1,2,4,8}$ . Results are averaged from input / output tokens $\in{64,128,256,512}$ . Blue arrows indicate parameter scaling; gray arrows represent parallel scaling.
图 4: 模型容量(以损失值表示)随推理时空成本的变化趋势,展示了三种参数量(1.6B/2.8B/4.4B)和批处理规模 $\in{1,2,4,8}$ 的关系。结果由输入/输出 tokens $\in{64,128,256,512}$ 的平均值得出。蓝色箭头表示参数量缩放,灰色箭头表示并行扩展。
Space Cost Figures 4(a) to 4(d) compare the inference memory usage of two scaling strategies, where we utilize loss on Stack-V2-Python as an indicator for model capacity. It shows that PARSCALE only marginally increases memory usage, even with larger batch sizes. This is because PARSCALE introduces negligible amounts of additional parameters (i.e., prefix tokens and aggregation weights, about $0.2%$ parameters per stream) and increases KV cache size (expanded by $\breve{P}$ times with $P$ streams), which generally occupies far less GPU memory than model parameters. As the input batch size increases, the KV cache size also grows; however, PARSCALE continues to demonstrate significantly better memory efficiency compared to parameter scaling. This suggests that PARSCALE maximizes the utility of memory through parameter reusing, while parameter scaling employs limited computation per parameter and cannot fully exploit computation resources.
空间成本
图4(a)至4(d)对比了两种扩展策略的推理内存占用情况,其中我们使用Stack-V2-Python数据集上的损失作为模型能力的指标。结果显示,即使批次规模增大,PARSCALE仅略微增加内存使用量。这是因为PARSCALE引入的额外参数量可忽略不计(即前缀token和聚合权重,每条流约占总参数的$0.2%$),同时增大的KV缓存(扩展为$\breve{P}$倍,共$P$条流)通常远少于模型参数占用的GPU内存。随着输入批次规模增大,KV缓存也会增长;但与参数扩展相比,PARSCALE始终展现出显著更优的内存效率。这表明PARSCALE通过参数复用最大化内存利用率,而参数扩展策略中每个参数的计算量有限,无法充分挖掘计算资源。
Time Cost Figures 4(e) to $4(\mathrm{h})$ compare the inference time of two scaling strategies. It shows that PARSCALE adds minimal latency at smaller batch sizes since the memory bottlenect is converted tothe computation bottleneck. Given that parallel computation introduced by PARSCALE is friendly to GPUs, it will not significantly raise latency. As batch sizes increase, decoding shifts from a memory to a computation bottleneck, resulting in higher costs for PARSCALE, but it remains more efficient than parameter scaling up to a batch size of 8.
时间成本 图 4(e) 到 $4(\mathrm{h})$ 比较了两种扩展策略的推理时间。结果表明,PARSCALE 在较小批量大小时增加的延迟极小,因为内存瓶颈被转化为计算瓶颈。鉴于 PARSCALE 引入的并行计算对 GPU 友好,它不会显著增加延迟。随着批量大小的增加,解码从内存瓶颈转变为计算瓶颈,导致 PARSCALE 的成本更高,但在批量大小达到 8 之前,它仍然比参数扩展更高效。
The above analysis indicates that PARSCALE is ideal for low-resource edge devices like smartphones, smart cars, and robots, where queries are typically few and batch sizes are small. Given limited memory resources in these environments, PARSCALE effectively utilizes memory and latency advantages at small batch sizes. When batch size is 1, for a 1.6B model and scaling to $\mathrm{P}\overset{\cdot}{=}8$ using PARSCALE, it uses $22\times$ less memory increase and $6\times$ less latency increase compared to parameter scaling that achieves the same performance. We anticipate that the future LLMs will gradually shift from centralized server deployments to edge deployments with the popularization of artificial intelligence. This suggests the promising potential of PARSCALE in the future.
上述分析表明,PARSCALE非常适合智能手机、智能汽车和机器人等资源有限的边缘设备,这些场景通常查询量少且批量较小。鉴于此类环境内存资源有限,PARSCALE能有效利用小批量下的内存和延迟优势。当批量大小为1时,对于16亿参数的模型,使用PARSCALE扩展到$\mathrm{P}\overset{\cdot}{=}8$的情况下,与达到相同性能的参数扩展方法相比,内存增量减少22倍,延迟增量降低6倍。我们预计,随着人工智能的普及,未来大语言模型将逐渐从集中式服务器部署转向边缘部署。这表明PARSCALE在未来具有广阔的应用前景。
4 Scaling Training Data
4 扩展训练数据
Due to our limited budget, our previous experiments on scaling laws focus on pre-training with 42 billion tokens. In this section, we will train a 1.8B model (with 1.6B non-embedding parameters) and scale the training data to 1T tokens, to investigate whether PARSCALE is effective for production-level training. We also apply PARSCALE to an off-the-shelf model, Qwen-2.5 (Qwen Team, 2024) (which is pre-trained on 18T tokens), under two settings: continual pre-training and parameter-efficient fine-tuning (PEFT).
由于预算有限,我们此前关于缩放定律的实验仅基于420亿token的预训练。本节将训练18亿参数模型(非嵌入参数16亿)并将训练数据扩展至1万亿token,以验证PARSCALE在生产级训练中的有效性。我们还在现成模型Qwen-2.5(Qwen Team, 2024)(预训练数据18万亿token)上应用PARSCALE,测试两种场景:持续预训练和参数高效微调(PEFT)。
Table 4: Performance comparison of the 1.8B models after training on 1T tokens from scratch using the two-stage strategy. We incorporate recent strong baselines (less than 2B parameters) as a comparison to validate that our $\mathrm{\Delta}P=1$ baseline is well-trained. The best performance and its comparable performance (within $0.5%$ ) is bolded. Appendix G elaborates the evaluation details. $@1$ : Pass $@1$ . $@10$ : Pass@10.
表 4: 采用两阶段策略从头训练 1T token 后 1.8B 模型的性能对比。我们引入近期强基线 (参数小于 2B) 进行对比,以验证 $\mathrm{\Delta}P=1$ 基线训练充分。最优性能及其可比性能 (误差在 $0.5%$ 内) 已加粗。附录 G 详述评估细节。$@1$: Pass@1, $@10$: Pass@10。
| 模型 | Token | 数据 | 平均 | 数学 | 代码 | 通用 | MMLU | WinoGrande | Hellaswag | OBQA | PiQA | ARC |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gemma-3-1B | 2T | 私有 | 53.4 | 1.9 | 14.9 | 26.4 | 61.4 | 63.0 | 37.8 | 75.6 | 56.2 | |
| Llama-3.2-1B | 15T | 私有 | 54.8 | 4.7 | 30.1 | 30.8 | 62.1 | 65.7 | 39.2 | 75.9 | 55.3 | |
| Qwen2.5-1.5B | 18T | 私有 | 63.6 | 52.3 | 55.8 | 61.0 | 65.6 | 68.0 | 42.6 | 76.6 | 67.9 | |
| SmolLM-1.7B | 1T | 公开 | 57.0 | 6.0 | 37.9 | 29.7 | 61.8 | 67.3 | 42.8 | 77.3 | 63.3 | |
| SmolLM2-1.7B | 12T | 公开 | 63.3 | 24.3 | 41.6 | 50.1 | 68.2 | 73.1 | 42.6 | 78.3 | 67.3 | |
| Baseline (P=1) | 1T | 公开 | 56.0 | 25.5 | 45.6 | 28.5 | 61.9 | 65.0 | 40.6 | 75.2 | 64.8 | |
| PARSCALE (P=2) | 1T | 公开 | 56.2 | 27.1 | 47.4 | 29.0 | 62.4 | 64.7 | 42.0 | 74.9 | 64.3 | |
| PARSCALE (P=4) | 1T | 公开 | 57.2 | 30.0 | 48.6 | 30.0 | 63.4 | 65.9 | 42.0 | 75.6 | 66.3 | |
| PARSCALE (P=8) | 1T | 公开 | 58.6 | 32.8 49.9 | 35.1 | 64.9 | 76.1 | 66.0 |
| 模型 | Token | 数据 | GSM8K | GSM8K +CoT | Minerva Math | HumanEval @1 | @10 | HumanEval+ @1 | @10 | MBPP @1 @10 | MBPP+ @1 @10 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| gemma-3-1B | 2T | 私有 | 1.8 | 2.3 | 1.5 | 6.7 | 15.9 | 6.1 14.6 | 13.0 29.1 | 10.8 23.0 | |
| Llama-3.2-1B | 15T | 私有 | 5.1 | 7.2 | 1.8 | 16.5 | 27.4 | 14.0 25.0 | 33.1 | 54.5 | 27.0 43.4 |
| Qwen2.5-1.5B | 18T | 私有 | 61.7 | 67.2 | 28.1 | 36.0 | 62.8 | 31.1 55.5 | 61.9 79.6 66.4 | 50.8 68.5 | |
| SmolLM-1.7B | 1T | 公开 | 6.4 | 8.3 | 3.2 | 20.1 | 35.4 | 15.9 32.3 | 40.7 45.2 | 34.7 57.4 | |
| SmolLM2-1.7B | 12T | 公开 | 30.4 | 30.8 | 11.8 | 23.8 | 44.5 | 18.9 37.8 | 68.5 | 36.0 57.9 | |
| Baseline (P=1) | 1T | 公开 | 28.7 | 35.9 | 12.0 | 26.8 | 44.5 | 20.7 38.4 | 51.6 75.9 | 43.9 62.7 | |
| PARSCALE (P=2) | 1T | 公开 | 32.6 | 35.6 | 13.0 | 26.2 | 50.0 | 20.1 42.1 | 52.9 77.0 | 45.0 65.6 | |
| PARSCALE (P=4) | 1T | 公开 | 34.7 | 40.8 | 14.5 | 27.4 | 47.6 | 23.8 43.9 | 55.3 77.0 | 47.1 66.7 | |
| PARSCALE (P=8) | 1T | 公开 | 38.4 | 43.7 | 16.4 | 28.7 | 50.6 | 24.4 44.5 | 56.3 379.1 | 48.1 67.2 |
4.1 Two-Stage Pre training
4.1 两阶段预训练
While PARSCALE is efficient for the inference stage (as we discuss in Section 3.3), it still introduces about $P$ times of floating-point operations and significantly increases overhead in the computation-intensive training processes. To address this limitation, we propose a two-stage strategy: in the first stage, we use traditional pre-training methods with 1 trillion tokens; in the second stage, we conduct PARSCALE training with 20 billion tokens. Since the second stage accounts for only $2%$ of the first stage, this strategy can greatly reduce training costs. This two-stage strategy is similar to long-context fine-tuning (Ding et al., 2024), which also positions the more resource-intensive phase at the end. In this section, we will examine the effectiveness of this strategy.
虽然PARSCALE在推理阶段非常高效(如第3.3节所述),但它仍会引入约$P$倍的浮点运算量,显著增加计算密集型训练过程的开销。为解决这一限制,我们提出两阶段策略:第一阶段使用传统预训练方法处理1万亿token;第二阶段采用PARSCALE训练200亿token。由于第二阶段仅占第一阶段的$2%$,该策略可大幅降低训练成本。这种两阶段策略类似于长上下文微调(Ding et al., 2024),同样将资源消耗更大的阶段置于最后。本节我们将验证该策略的有效性。
Setup We follow Allal et al. (2025) and use the Warmup Stable Decay (WSD) learning rate schedule (Hu et al., 2024; Zhai et al., 2021). In the first stage, employing a 2K step warm-up followed by a fixed learning rate of 3e-4. In the second stage, the learning rate is annealed from 3e-4 to 1e-5. The rest of the hyper parameters remain consistent with the previous experiments (see Appendix C).
设置
我们遵循 Allal 等人的研究 [20],采用 Warmup Stable Decay (WSD) 学习率调度策略 (Hu 等人 [21], Zhai 等人 [22])。第一阶段使用 2K 步的预热,随后固定学习率为 3e-4。第二阶段,学习率从 3e-4 退火至 1e-5。其余超参数与先前实验保持一致 (参见附录 C)。
In the first phase, we do not employ the PARSCALE technique. We refer to the recipe proposed by Allal et al. (2025) to construct our training data, which consists of 370B general data, 80B mathematics data, and 50B code data. We train the model for two epochs to consume 1T tokens. Among the general text, there are 345B from FineWeb-Edu (Penedo et al., 2024) and 28B from Cosmopedia 2 (Ben Allal et al., 2024); the mathematics data includes 80B from FineMath (Allal et al., 2025); and the code data comprises 47B from Stack-V2-Python and 4B from Stack-Python-Edu.
在第一阶段,我们不采用PARSCALE技术。我们参考Allal等人 (2025) 提出的方案构建训练数据,该数据集包含3700亿通用数据、800亿数学数据和500亿代码数据。我们训练模型两个周期以消耗1万亿token。其中通用文本包含3450亿来自FineWeb-Edu (Penedo等人, 2024) 和280亿来自Cosmopedia 2 (Ben Allal等人, 2024) 的数据;数学数据包含800亿来自FineMath (Allal等人, 2025) 的数据;代码数据包含470亿来自Stack-V2-Python语言和40亿来自Stack-Python-Edu的数据。
In the second phase, we use the trained model from the first phase as the backbone and introduce additional parameters from PARSCALE, which are randomly initialized using a standard deviation of 0.02 (based on the initialization of Qwen-2.5). Following (Allal et al., 2025), in this phase, we increase the proportion of mathematics and code data, finally including a total of 7B general text data, 7B mathematics data, and 7B Stack-Python-Edu data.
在第二阶段,我们使用第一阶段训练好的模型作为主干,并引入来自PARSCALE的额外参数,这些参数采用标准差为0.02进行随机初始化(基于Qwen-2.5的初始化方式)。根据 (Allal et al., 2025) 的研究,在此阶段我们提高了数学和代码数据的比例,最终包含总计70亿通用文本数据、70亿数学数据以及70亿Stack-Python-Edu数据。
Training Loss Figure 5 intuitively demonstrates the loss curve during our two-stage training. We find that at the beginning of the second phase, the loss for $P>1$ initially exceed those for $P=1$ due to the introduction of randomly initialized parameters. However, after processing a small amount of data (0.0002T tokens), the model quickly adapts to these newly introduced parameters and remains stable thereafter. This proves that PARSCALE can take effect rapidly with just a little data. We can also find that in the later stages, PARSCALE yields similar logarithmic gains. This aligns with previous scaling law findings, suggesting that our earlier conclusions for from-scratch pre-training — parallelism with $P$ streams equates to a ${\check{\mathcal{O}}}(N\log(P))$ increase in parameters — also applies to continued pre training. Additionally, larger $P$ (such as $P=8$ ) can gradually widen the gap compared to smaller $P$ values (such as $P=4^{\cdot}$ ). This demonstrates that parallel scaling can also benefit from data scaling.
训练损失
图 5 直观展示了两阶段训练过程中的损失曲线。我们发现,在第二阶段初期,由于引入随机初始化参数,$P>1$ 的损失值会暂时超过 $P=1$ 的情况。但在处理少量数据(0.0002T tokens)后,模型迅速适应新增参数并保持稳定。这证明 PARSCALE 仅需极少量数据即可快速生效。后期阶段中,PARSCALE 产生了相似的对数级收益,这与先前扩展律的研究结论一致,表明我们关于从零开始预训练的结论——$P$ 路并行等价于参数增加 ${\check{\mathcal{O}}}(N\log(P))$——同样适用于持续预训练。此外,较大 $P$ 值(如 $P=8$)相比小 $P$ 值(如 $P=4^{\cdot}$)会逐渐拉开差距,说明并行扩展也能从数据扩展中获益。
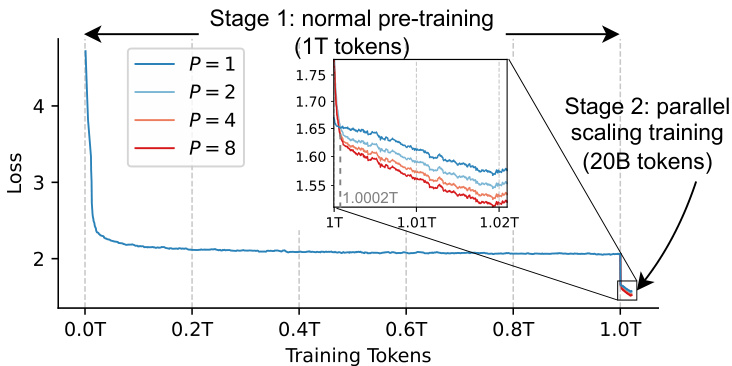
Figure 5: Loss for two-stage training, smoothing using an exponential moving average with a weight of 0.95.
图 5: 两阶段训练的损失函数,采用权重为0.95的指数移动平均进行平滑处理。
Table 5: Comparison of the performance of different Instruct models, where the few-shot examples are treated as a multi-turn conversation.
表 5: 不同Instruct模型性能对比,其中少样本示例被视为多轮对话。
| IFEval MMLU 零样本 5样本 | GSM8K 4样本 | |
|---|---|---|
| SmolLM-1.7B-Inst | 16.3 28.4 | 2.0 |
| Baseline-Inst (P=1) | 54.1 34.2 | 50.3 |
| PARSCALE-Inst (P=2) | 55.8 35.1 | 55.3 |
| PARSCALE-Inst (P=4) | 58.4 38.2 | 54.8 |
| PARSCALE-Inst (P=8) | 59.5 41.7 | 56.1 |
Downstream Performance In Table 4, we report the downstream performance of the model after finishing two-stage training, across 7 general tasks, 3 math tasks, and 8 coding tasks. It can be observed that with the increase of $P$ , the performance presents an upward trend for most of the benchmarks, which validates the effectiveness of PARSCALE trained on the large dataset. Specifically, when $P$ increases from 1 to 8, PARSCALE improves by $2.6%$ on general tasks, and by $7.3%$ and $4.3%$ on math and code tasks, respectively. It achieves a $10%$ improvement $34%$ relative improvement) on GSM8K. This reaffirms that PARSCALE can more effectively address reasoning-intensive tasks. Moreover, in combination with CoT, it achieves about an $8%$ improvement on GSM8K, suggesting that parallel scaling can be used together with inference-time scaling to achieve better results. Compared to the SmolLM-1.7B model, which was also trained on 1T tokens, our $P=1$ baseline achieves comparable results on general tasks and significantly outperforms on math and code tasks. One explanation is that SmolLM training set focuses more on commonsense and world knowledge corpus, while lacking high-quality math and code data. This validates the effectiveness of our dataset construction and training strategy, and further enhances the credibility of our experimental results.
下游性能
在表4中,我们报告了模型完成两阶段训练后在7个通用任务、3个数学任务和8个编程任务上的下游性能。可以观察到,随着$P$值的增加,大多数基准测试的性能呈现上升趋势,这验证了在大规模数据集上训练的PARSCALE的有效性。具体而言,当$P$从1增加到8时,PARSCALE在通用任务上提升了$2.6%$,在数学和编程任务上分别提升了$7.3%$和$4.3%$。在GSM8K上实现了$10%$的绝对提升(相对提升$34%$),这再次证实PARSCALE能更有效地解决推理密集型任务。此外,结合思维链(CoT)技术,模型在GSM8K上实现了约$8%$的提升,表明并行缩放可以与推理时缩放技术结合使用以获得更好效果。与同样训练了1T token的SmolLM-1.7B模型相比,我们的$P=1$基线在通用任务上取得了相当的结果,而在数学和编程任务上显著优于前者。一个可能的解释是SmolLM的训练集更侧重于常识和世界知识语料,而缺乏高质量的数学和编程数据。这验证了我们数据集构建和训练策略的有效性,并进一步增强了实验结果的可靠性。
Instruction Tuning We follow standard practice to post-train the base models, to explore whether PARSCALE can enhance performance during the post-training stage. We conducted instruction tuning on four checkpoints $(P\in{1,2,4,8})$ from the previous pre-training step, increasing the sequence length from 2048 to 8192 and the RoPE base from 10,000 to 100,000, while keeping other hyper parameters constant. We used 1 million SmolTalk (Allal et al., 2025) as the instruction tuning data and trained for 2 epochs. We refer to these instruction models as PARSCALE-Inst.
指令微调
我们遵循标准实践对基础模型进行后训练,以探究PARSCALE能否在后训练阶段提升性能。我们在预训练阶段的四个检查点$(P\in{1,2,4,8})$上进行指令微调,将序列长度从2048增至8192,并将RoPE基数从10,000调整至100,000,同时保持其他超参数不变。我们使用100万条SmolTalk (Allal et al., 2025)数据作为指令微调数据集,训练2个周期。这些经过指令微调的模型称为PARSCALE-Inst。
The experimental results in Table 5 show that when $P$ increases from 1 to 8, our method achieves a $5%$ improvement on the instruction-following benchmark IFEval, along with substantial gains in the general task MMLU and the reasoning task GSM8K. This demonstrates that the proposed PARSCALE performs effectively during the post-training phase.
表 5 中的实验结果表明,当 $P$ 从 1 增加到 8 时,我们的方法在指令跟随基准 IFEval 上实现了 $5%$ 的提升,同时在通用任务 MMLU 和推理任务 GSM8K 上也取得了显著进步。这表明所提出的 PARSCALE 在后训练阶段表现高效。
4.2 Applying to the Off-the-Shelf Pre-Trained Model
4.2 应用于现成的预训练模型
We further investigate applying PARSCALE to off-the-shelf models under two settings: continual pretraining and parameter-efficient fine-tuning (PEFT). Specifically, we use Pile and Stack-V2 (Python) to continue pre-training the Qwen-2.5 (3B) model. The training settings remain consistent with Appendix C, with the only difference being that we initialize with Qwen2.5-3B weights and adjust the RoPE base to the preset 1,000,000.
我们进一步研究了在持续预训练和参数高效微调 (PEFT) 两种设置下将 PARSCALE 应用于现成模型的效果。具体而言,我们使用 Pile 和 Stack-V2 (Python语言) 对 Qwen-2.5 (3B) 模型进行持续预训练。训练设置与附录 C 保持一致,唯一区别在于我们使用 Qwen2.5-3B 权重进行初始化,并将 RoPE base 调整为预设值 1,000,000。
Continual Pre-Training Figures 6(a) and $6(\mathrm{b})$ illustrates the training loss after continuous pre-training on Stack-V2 (Python) and Pile. Notably, Qwen2.5 has already been pre-trained on 18T of data, which possibly have significant overlap with both Pile and Stack-V2. This demonstrates that improvements can still be achieved even with a thoroughly trained foundation model and commonly used training datasets.
持续预训练
图 6(a) 和 $6(\mathrm{b})$ 展示了在 Stack-V2 (Python语言) 和 Pile 数据集上持续预训练后的损失曲线。值得注意的是,Qwen2.5 已在 18T 数据上完成预训练,这些数据很可能与 Pile 和 Stack-V2 存在显著重叠。这表明即使基础模型经过充分训练且使用常见训练数据集,仍能实现性能提升。
Parameter-Efficient Fine-Tuning We further utilize PEFT to fine-tune the introduced parameters while freezing the backbone weights. Figure 6(c) shows that this strategy can still significantly improve downstream code generation performance. Moreover, this demonstrates the promising prospects of dynamic parallel scaling: we can deploy the same backbone and flexibly switch between different numbers of parallel streams in various scenarios (e.g., high throughput and low throughput), which enables quick transitions between different levels of model capacities.
参数高效微调 (Parameter-Efficient Fine-Tuning)
我们进一步利用PEFT对引入的参数进行微调,同时冻结主干网络权重。图6(c)显示该策略仍能显著提升下游代码生成性能。此外,这证明了动态并行扩展的广阔前景:我们可以部署相同的主干网络,在不同场景(如高吞吐和低吞吐)中灵活切换并行流数量,从而实现不同级别模型容量的快速切换。
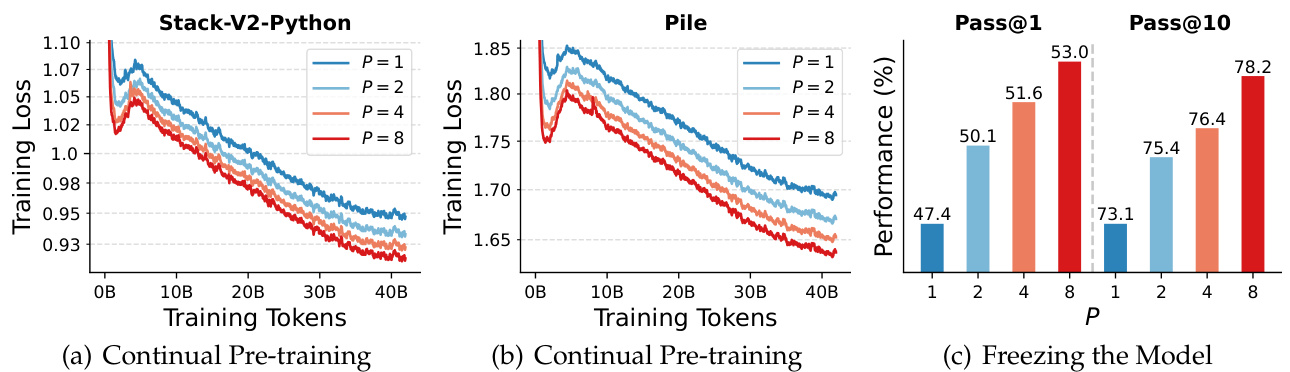
Figure 6: (a)(b) Loss for continual pre-training the Qwen-2.5-3B model on the two datasets. (c) Code generation performance after fine-tuning on Stack-V2 (Python), averaged from HumanEval $(+)$ and $\mathrm{{\check{M}B P P}}(+)$ . We only fine-tune the introduced parameters (prefix tokens and aggregation weights), with different $P$ sharing exactly the same Qwen2.5-3B pre-trained weights.
图 6: (a)(b) Qwen-2.5-3B模型在两个数据集上持续预训练的损失。(c) 在Stack-V2 (Python语言)微调后的代码生成性能,取HumanEval $(+)$ 和 $\mathrm{{\check{M}B P P}}(+)$ 的平均值。我们仅微调引入的参数(前缀token和聚合权重),不同 $P$ 共享完全相同的Qwen2.5-3B预训练权重。
5 Related Work
5 相关工作
Beyond language modeling, our work can be connected to various machine learning domains. First, scaling computation while maintaining parameters is also the core idea of inference-time scaling. Second, as previously mentioned, PARSCALE can be viewed as a dynamic and scalable classifier-free guidance. Third, our method can be seen as a special case of model ensemble. Lastly, the parallel scaling law we explore is a generalization of the existing language model scaling laws.
除了语言建模,我们的工作还可以与多个机器学习领域相关联。首先,在保持参数不变的情况下扩展计算量也是推理时扩展 (inference-time scaling) 的核心思想。其次,如前所述,PARSCALE 可视为一种动态且可扩展的无分类器引导 (classifier-free guidance) 方法。第三,我们的方法可视为模型集成 (model ensemble) 的一种特例。最后,我们探索的并行扩展定律是对现有大语言模型扩展定律的广义推广。
Inference-Time Scaling The notable successes of reasoning models, such as GPT-o1 (OpenAI, 2024), DeepSeek-R1 (DeepSeek-AI, 2025), QwQ (Qwen Team, 2025a), and Kimi k1.5 (Kimi Team, 2025) have heightened interest in inference-time scaling. These lines of work (Wei et al., 2022; Madaan et al., 2023; Zhou et al., 2023a) focus on scaling serial computation to increase the length of the chain-of-thought (Wei et al., 2022). Despite impressiveness, it results in inefficient inference and sometimes exhibits over thinking problems (Chen et al., 2024b; Sui et al., 2025).
推理时扩展
GPT-o1 (OpenAI, 2024)、DeepSeek-R1 (DeepSeek-AI, 2025)、QwQ (Qwen Team, 2025a) 和 Kimi k1.5 (Kimi Team, 2025) 等推理模型的显著成功,引发了人们对推理时扩展的浓厚兴趣。这些研究工作 (Wei et al., 2022; Madaan et al., 2023; Zhou et al., 2023a) 侧重于扩展串行计算以增加思维链 (Wei et al., 2022) 的长度。尽管效果令人印象深刻,但它会导致推理效率低下,有时还会表现出过度思考的问题 (Chen et al., 2024b; Sui et al., 2025)。
Other lines of approaches focus on scaling parallel computation. Early methods such as beam search (Wiseman & Rush, 2016), self-consistency (Wang et al., 2023b), and majority voting (Chen et al., 2024a) require no additional training. We also provide an experimental comparison with Beam Search in Appendix H, which shows the importance of scaling parallel computing during the training stage. Recently, the proposal-verifier paradigm has gained attention, by employing a trained verifier to select from multiple parallel outputs (Brown et al., 2024; Wu et al., 2025; Zhang et al., 2024b). However, these methods are limited to certain application scenarios (i.e., generation tasks) and specialized training data (i.e., reward signals).
其他研究方向聚焦于扩展并行计算。早期方法如束搜索 (beam search) (Wiseman & Rush, 2016)、自洽性 (self-consistency) (Wang et al., 2023b) 和多数投票 (majority voting) (Chen et al., 2024a) 无需额外训练。我们还在附录 H 中提供了与束搜索的实验对比,结果表明训练阶段扩展并行计算的重要性。近期,提案-验证范式 (proposal-verifier paradigm) 通过训练验证器从多个并行输出中选择 (Brown et al., 2024; Wu et al., 2025; Zhang et al., 2024b) 而受到关注,但这些方法仅适用于特定应用场景 (即生成任务) 和专用训练数据 (即奖励信号)。
More recently, Geiping et al. (2025) introduce training LLMs to reason within the latent space and scale sequential computation, applicable to any application scenarios without needing specialized datasets. However, this method demands significant serial computation scaling (e.g., 64 times the looping) and invasive model modifications, necessitating training from scratch and complicating integration with existing trained LLMs.
近期,Geiping等人 (2025) 提出了一种训练大语言模型 (LLM) 在潜在空间中进行推理并扩展序列计算的方法,该方法无需专用数据集即可适用于任何应用场景。然而,这种方法需要大量的串行计算扩展 (例如64倍循环) 和侵入式的模型修改,必须从头开始训练,并且难以与现有训练好的大语言模型集成。
Classifier-Free Guidance Classifier-Free Guidance (CFG) stems from Classifier Guided Diffusion (Dhariwal & Nichol, 2021), which uses an additional classifier to guide image generation using diffusion models (Ho et al., 2020). By using the generation model itself as a classifier, CFG (Ho & Salimans, 2022) further eliminates dependency on the classifier and leverage two forward passes. Similar concepts have emerged in NLP, such as Coherence Boosting (Malkin et al., 2022), PREADD (Pei et al., 2023), ContextAware Decoding (Shi et al., 2024), and Contrastive Decoding (Li et al., 2023). Recently, Sanchez et al. (2024) proposed transferring CFG to language models. However, due to constraints of human-designed heuristic rules, these techniques cannot leverage the power of training-time scaling (Kaplan et al., 2020) and the performance is limited.
无分类器引导 (Classifier-Free Guidance, CFG) 源自分类器引导扩散模型 (Classifier Guided Diffusion) [Dhariwal & Nichol, 2021],该方法通过额外分类器指导扩散模型 (diffusion models) [Ho et al., 2020] 的图像生成。CFG [Ho & Salimans, 2022] 利用生成模型自身作为分类器,进一步消除对分类器的依赖,并通过两次前向计算实现引导。类似概念在自然语言处理领域相继出现,例如一致性增强 (Coherence Boosting) [Malkin et al., 2022]、PREADD [Pei et al., 2023]、上下文感知解码 (ContextAware Decoding) [Shi et al., 2024] 以及对比解码 (Contrastive Decoding) [Li et al., 2023]。近期 Sanchez 等人 [2024] 提出将 CFG 迁移至语言模型,但由于人工设计启发式规则的局限性,这些技术无法充分发挥训练时扩展 (training-time scaling) [Kaplan et al., 2020] 的潜力,性能存在上限。
Model Ensemble Model ensemble is a classic research field in machine learning and is also employed in the context of LLMs (Chen et al., 2025). In traditional model ensembles, most ensemble components do not share parameters. Some recent work consider setups with partially shared parameters. For example, Monte Carlo dropout (Gal & Ghahramani, 2016) employs multiple different random dropouts during the inference phase, while Batch Ensemble (Wen et al., 2020; Tran et al., 2022) and LoRA ensemble (Wang et al., 2023a) use distinct low-rank matrix factorization s for model weights to differentiate different streams (we also experimented with this technique as input transformation in Appendix A). Weight sharing (Yang et al., 2021; Lan et al., 2019) is another line of work, where some weights of a model are shared across different components and participate in multiple computations. However, these works have not explored the scaling law of parallel computation from the perspective of model capacity. As we discuss in Appendix A, we find that the specific differentiation technique had a minimal impact, and the key factor is the scaling in parallel computation.
模型集成
模型集成是机器学习中的经典研究领域,也被应用于大语言模型 (Chen et al., 2025)。在传统模型集成中,大多数集成组件不共享参数。近期部分研究探索了参数部分共享的配置,例如蒙特卡洛dropout (Gal & Ghahramani, 2016) 在推理阶段采用多种不同的随机丢弃策略,而批集成 (Wen et al., 2020; Tran et al., 2022) 和LoRA集成 (Wang et al., 2023a) 则通过不同的低秩矩阵分解方式区分模型权重流 (我们在附录A中也尝试将该技术作为输入变换)。权重共享 (Yang et al., 2021; Lan et al., 2019) 是另一类研究方向,即模型的某些权重在不同组件间共享并参与多次计算。但这些工作尚未从模型容量的角度探索并行计算的缩放规律。如附录A所述,我们发现具体区分技术的影响微乎其微,关键因素在于并行计算的规模扩展。
Scaling Laws for Language Models Many researchers explore the predictable relationships between LLM training performance and various factors under different settings, such as the number of parameters and data (Hestness et al., 2017; Kaplan et al., 2020; Hoffmann et al., 2022; DeepSeek-AI, 2024; Frantar et al., 2024), data repetition cycles (Mu en nigh off et al., 2023; Hernandez et al., 2022), data mixing (Ye et al., 2025; Que et al., 2024), and fine-tuning (Zhang et al., 2024a). By extending the predictive empirical scaling laws developed from smaller models to larger models, we can significantly reduce exploration costs. Recently, some studies have investigated the scaling effects during inference (Sardana et al., 2024), noting a log-linear relationship between sampling number and performance (Brown et al., 2024; Snell et al., 2025). But they are limited to certain application scenarios. Our work extends the Chinchilla scaling law (Hoffmann et al., 2022) by introducing the intrinsic quantitative relationship between parallel scaling and parameter scaling. Existing literature has also identified a power-law relationship between the number of ensembles and loss in model ensemble scaling laws (Lobacheva et al., 2020a), which can be considered a special case of Proposition 1 when $\rho=0$ .
大语言模型的扩展规律
许多研究者探索了大语言模型(LLM)训练性能与不同设置下各因素之间的可预测关系,例如参数量与数据量 (Hestness et al., 2017; Kaplan et al., 2020; Hoffmann et al., 2022; DeepSeek-AI, 2024; Frantar et al., 2024)、数据重复周期 (Mu en nigh off et al., 2023; Hernandez et al., 2022)、数据混合 (Ye et al., 2025; Que et al., 2024) 以及微调 (Zhang et al., 2024a)。通过将从小型模型总结的预测性经验扩展规律延伸至大型模型,我们能显著降低探索成本。近期部分研究开始关注推理阶段的扩展效应 (Sardana et al., 2024),发现采样数量与性能呈对数线性关系 (Brown et al., 2024; Snell et al., 2025),但这些发现仅适用于特定应用场景。我们的工作通过引入并行扩展与参数扩展之间的内在量化关系,扩展了Chinchilla扩展规律 (Hoffmann et al., 2022)。现有文献还发现模型集成扩展规律中集成数量与损失之间存在幂律关系 (Lobacheva et al., 2020a),这可以视为命题1在 $\rho=0$ 时的特例。
6 Discussion and Future Work
6 讨论与未来工作
Training Inference-Optimal Language Models Chinchilla (Hoffmann et al., 2022) explored the scaling law to determine the training-optimal amounts for parameters and training data under a training FLOP budget. On the other hands, modern LLMs are increasingly interested on inference-optimal models. Some practitioners use much more data than the Chinchilla recommendation to train small models due to their high inference efficiency (Qwen Team, 2024; Allal et al., 2025; Sardana et al., 2024). Recent inference-time scaling efforts attempt to provide a computation-optimal strategy during the inference phase (Wu et al., 2025; Snell et al., 2025), but most rely on specific scenarios and datasets. Leveraging the proposed PARSCALE, determining how to allocate the number of parameters and parallel computation under various inference budgets (e.g., memory, latency, and batch size) to extend inference-optimal scaling laws (Sardana et al., 2024) is a promising direction.
训练推理最优的语言模型
Chinchilla (Hoffmann et al., 2022) 探索了缩放定律,以确定在给定训练 FLOP 预算下参数和训练数据的最优训练量。另一方面,现代大语言模型越来越关注推理最优的模型。由于推理效率高,一些实践者使用远超 Chinchilla 建议的数据量来训练小模型 (Qwen Team, 2024; Allal et al., 2025; Sardana et al., 2024)。最近的推理时缩放研究尝试在推理阶段提供计算最优策略 (Wu et al., 2025; Snell et al., 2025),但大多依赖于特定场景和数据集。利用提出的 PARSCALE,确定如何在不同的推理预算 (如内存、延迟和批量大小) 下分配参数数量和并行计算,以扩展推理最优缩放定律 (Sardana et al., 2024),是一个有前景的方向。
Further Theoretical Analysis for Parallel Scaling Laws One of our contributions is quantitatively computing the impact of parameters and computation on model capability. Although we present some theoretical results (Proposition 1), the challenge of directly modeling DIVERSITY limits us to using extensive experiments to fit parallel scaling laws. Why the diversity is related to ${\log}P,$ is there a growth rate that exceeds $\mathcal{O}(\log P)$ , and whether there is a performance upper bound for $\bar{P}\gg8$ , remain open questions.
并行扩展定律的进一步理论分析
我们的贡献之一是定量计算参数和计算对模型能力的影响。尽管我们提出了一些理论结果 (Proposition 1),但直接建模 DIVERSITY 的挑战迫使我们通过大量实验来拟合并行扩展定律。为何多样性会与 ${\log}P$ 相关、是否存在超过 $\mathcal{O}(\log P)$ 的增长率,以及当 $\bar{P}\gg8$ 时是否存在性能上限,这些问题仍有待探索。
Optimal Division Point of Two-Stage Strategy Considering that PARSCALE is inefficient in the training phase, we introduced a two-stage strategy and found that LLMs can still learn to leverage parallel computation for better capacity with relatively few tokens. We currently employ a 1T vs. 20B tokens as the division point. Whether there is a more optimal division strategy and its trade-off with performance is also an interesting research direction.
考虑PARSCALE在训练阶段效率较低的问题,我们引入两阶段策略并发现大语言模型(LLM)仍能通过相对较少的token学习利用并行计算来提升能力。当前采用1T与20B tokens作为分界点,是否存在更优划分策略及其与性能的权衡也是值得研究的方向。
Application to MoE Architecture Similar to the method proposed by Geiping et al. (2025), PARSCALE is a computation-heavy (but more efficient) strategy. This is somewhat complementary to sparse MoE (Fedus et al., 2022; Shazeer et al., 2017), which is parameter-heavy. Considering that MoE is latencyfriendly while PARSCALE is memory-friendly, exploring whether their combination can yield more efficient and high-performing models is worth investigating.
应用于MoE架构
与Geiping等人 (2025) 提出的方法类似,PARSCALE是一种计算密集型(但更高效)的策略。这与参数密集型的稀疏MoE (Fedus等人, 2022; Shazeer等人, 2017) 形成一定互补。考虑到MoE对延迟友好而PARSCALE对内存友好,探索二者结合能否产生更高效、更高性能的模型值得研究。
Application to Other Machine Learning Domains Although we focus on language models, PARSCALE is a more general method that can be applied to any model architecture, training algorithm, and training data. Exploring PARSCALE in other areas and even proposing new scaling laws is also a promising direction for the future.
应用于其他机器学习领域
尽管我们专注于语言模型,但PARSCALE是一种更通用的方法,可应用于任何模型架构、训练算法和训练数据。在其他领域探索PARSCALE甚至提出新的扩展定律也是未来一个很有前景的方向。
7 Conclusions
7 结论
In this paper, we propose a new type of scaling strategy, PARSCALE, for training LLMs by reusing existing parameters for multiple times to scale the parallel computation. Our theoretical analysis and extensive experiments propose a parallel scaling law, showing that a model with $N$ parameters and $P\times$ parallel computation can be comparable to a model with $\mathcal{O}(\breve{N}\log{P})$ parameters. We scale the training data to 1T tokens to validate PARSCALE in the real-world practice based on the proposed two-stage strategy, and show that PARSCALE remains effective with frozen main parameters for different $P$ . We also demonstrate that parallel scaling is more efficient than parameter scaling during the inference time, especially in low-resource edge scenarios. As artificial intelligence becomes increasingly widespread, we believe that future LLMs will progressively transition from centralized server deployments to edge deployments, and PARSCALE could emerge as a promising technique for these scenarios.
本文提出了一种新型扩展策略PARSCALE,通过重复利用现有参数实现并行计算的多次扩展来训练大语言模型。我们的理论分析和大量实验提出了一条并行扩展定律:具有$N$个参数和$P\times$并行计算的模型,其性能可与具有$\mathcal{O}(\breve{N}\log{P})$个参数的模型相媲美。基于提出的两阶段策略,我们将训练数据扩展到1T token以验证PARSCALE在实际应用中的有效性,结果表明在不同$P$值下冻结主要参数时PARSCALE仍保持优势。我们还证明了在推理阶段,尤其是边缘低资源场景中,并行扩展比参数扩展更具效率。随着人工智能的普及,我们相信未来大语言模型将逐渐从集中式服务器部署转向边缘部署,而PARSCALE有望成为这些场景的关键技术。
Acknowledgement
致谢
This research is partially supported by Zhejiang Provincial Natural Science Foundation of China (No. LZ 25 F 020003) and the National Natural Science Foundation of China (No. 62202420). The authors would like to thank Jiquan Wang, Han Fu, Zhiling Luo, and Yusu Hong for their early idea discussions and inspirations, as well as Lingzhi Zhou for the discussions on efficiency analysis.
本研究部分得到浙江省自然科学基金 (No. LZ25F020003) 和国家自然科学基金 (No. 62202420) 的资助。作者感谢王继全、傅涵、罗志玲和洪雨素在早期想法讨论与灵感启发方面的贡献,以及周凌志在效率分析方面的探讨。
References
参考文献
Leo Breiman. Random forests. Mach. Learn., 45(1):5–32, October 2001. ISSN 0885-6125. doi: 10.1023/A: 1010933404324. URL https://doi.org/10.1023/A:1010933404324.
Leo Breiman. 随机森林 (Random Forests). Mach. Learn., 45(1):5–32, 2001年10月. ISSN 0885-6125. doi: 10.1023/A:1010933404324. URL https://doi.org/10.1023/A:1010933404324.
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V. Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling. arXiv preprint arXiv:2407.21787, 2024. URL https://arxiv.org/abs/2407.21787.
Bradley Brown、Jordan Juravsky、Ryan Ehrlich、Ronald Clark、Quoc V. Le、Christopher Ré 和 Azalia Mirhoseini。大语言模型猴子:通过重复采样扩展推理计算。arXiv预印本 arXiv:2407.21787,2024。URL https://arxiv.org/abs/2407.21787。
Andrei Ivanov, Nikoli Dryden, Tal Ben-Nun, Shigang Li, and Torsten Hoefler. Data movement is all you need: A case study on optimizing transformers. In A. Smola, A. Dimakis, and I. Stoica (eds.), Proceedings of Machine Learning and Systems, volume 3, pp. 711–732, 2021. URL https://proceedings. mlsys.org/paper files/paper/2021/file/bc 86 e 95606 a 6392 f 51 f 95 a 8 de 106728 d-Paper.pdf.
Andrei Ivanov、Nikoli Dryden、Tal Ben-Nun、Shigang Li和Torsten Hoefler。《数据移动即一切:Transformer优化案例研究》。载于A. Smola、A. Dimakis和I. Stoica (编),《机器学习与系统会议论文集》第3卷,第711–732页,2021年。URL https://proceedings.mlsys.org/paper_files/paper/2021/file/bc86e95606a6392f51f95a8de106728d-Paper.pdf。
Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishna moor thi, Liangzhen Lai, and Vikas Chandra. Mobilellm: Optimizing sub-billion parameter language models for on-device use cases. arXiv preprint arXiv:2402.14905, 2024b. URL https://arxiv.org/abs/2402.14905.
Zechun Liu、Changsheng Zhao、Forrest Iandola、Chen Lai、Yuandong Tian、Igor Fedorov、Yunyang Xiong、Ernie Chang、Yangyang Shi、Raghuraman Krishnamoorthi、Liangzhen Lai 和 Vikas Chandra。MobileLLM:针对设备端用例优化的十亿参数以下大语言模型。arXiv预印本 arXiv:2402.14905,2024b。URL https://arxiv.org/abs/2402.14905。
Llama Team. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024. URL https://arxiv. org/abs/2407.21783.
Llama Team. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024. URL https://arxiv.org/abs/2407.21783.
Guilherme Penedo, Hynek Kydlicek, Loubna Ben allal, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, and Thomas Wolf. The fineweb datasets: Decanting the web for the finest text data at scale. arXiv preprint arXiv:2406.17557, 2024. URL https://arxiv.org/abs/2406.17557.
Guilherme Penedo、Hynek Kydlicek、Loubna Ben allal、Anton Lozhkov、Margaret Mitchell、Colin Raffel、Leandro Von Werra 和 Thomas Wolf。The fineweb datasets: Decanting the web for the finest text data at scale. arXiv 预印本 arXiv:2406.17557, 2024. 网址 https://arxiv.org/abs/2406.17557。
Appendix
附录
A Implementation Details and Pivot Experiments
实现细节与关键实验
Input Transformation We expect that the transformations applied to the input embedding $x$ can significantly influence the output, which avoids excessively similar outputs across different parallel streams. This can be achieved through the Soft Prompting technique (Lester et al., 2021). Specifically, Lester et al. (2021) introduced trainable continuous embeddings, known as soft prompts, which are appended to the original sequence of input word embeddings. Freezing the main network while only fine-tuning these soft prompts can be comparable to full fine-tuning. Building on this concept, prefixtuning (Li & Liang, 2021) incorporates soft prompts into every attention layer of the Transformer model and appends them to the key and value vectors, showing superiority performance to soft prompts.
输入变换
我们预期对输入嵌入 $x$ 施加的变换能显著影响输出,从而避免不同并行流产生过度相似的输出。这可通过软提示技术 (soft prompting) (Lester et al., 2021) 实现。具体而言,Lester等人 (2021) 提出了可训练的连续嵌入(称为软提示),将其附加到原始输入词嵌入序列中。冻结主网络仅微调这些软提示,效果可媲美全参数微调。基于此概念,前缀调优 (prefixtuning) (Li & Liang, 2021) 将软提示融入Transformer模型的每个注意力层,并附加到键值向量中,其性能表现优于软提示技术。
We utilize prefix-tuning to implement input transformation. To be specific, we first duplicate the input $x$ into $P$ parallel copies, distinguishing them with different prefixes in each attention layer. This can be implemented as using different KV caches for different streams. We found that randomly initializing the prefixes is sufficient to ensure diverse outputs across different streams. We also leverage the prefix re parameter iz ation trick (Li & Liang, 2021; Han et al., 2024), which is theoretically proved effectiveness by Le et al. (2025).
我们采用前缀调优 (prefix-tuning) 来实现输入变换。具体而言,首先将输入 $x$ 复制为 $P$ 个并行副本,在每个注意力层中通过不同前缀加以区分。这可以通过为不同数据流使用不同的 KV 缓存 (KV caches) 来实现。我们发现随机初始化前缀足以确保不同数据流产生多样化输出。同时采用了前缀重参数化技巧 (Li & Liang, 2021; Han et al., 2024),该方法的有效性已被 Le 等人 (2025) 从理论上证明。
As a comparison, we also compared using other parameter-efficient fine-tuning strategy for discriminating the input, including LoRA (Hu et al., 2022) and BitFit (Ben Zaken et al., 2022). Notably, LoRA has been also applied to the model ensemble scenario in the literature (Wang et al., 2023a), but only used in the fine-tuning setting while freezing the main parameters in their experiments.
作为对比,我们还尝试了其他参数高效的微调策略来区分输入,包括LoRA (Hu et al., 2022) 和 BitFit (Ben Zaken et al., 2022) 。值得注意的是,LoRA在文献 (Wang et al., 2023a) 中也被应用于模型集成场景,但仅用于微调设置,同时冻结了他们实验中的主要参数。
Output Aggregation We found that using dynamic aggregation weights performs better than static ones. Specifically, we concatenate each output together and use an MLP $\boldsymbol{h}:\mathbb{R}^{d_{o}\times P}\to\mathbb{R}^{P}$ to convert it into a vector of length $P$ as aggregation weights. The process can be formalized as:
输出聚合
我们发现使用动态聚合权重比静态权重效果更好。具体而言,我们将每个输出拼接在一起,并使用一个MLP $\boldsymbol{h}:\mathbb{R}^{d_{o}\times P}\to\mathbb{R}^{P}$ 将其转换为长度为 $P$ 的向量作为聚合权重。该过程可形式化表示为:
$$
w_{1},\cdot\cdot\cdot,w_{P}\gets\mathrm{Softmax}\left(h\left(\mathrm{Concat}[f_{\theta}(x_{1});\cdot\cdot\cdot;f_{\theta}(x_{P})]\right)\right),
$$
$$
w_{1},\cdot\cdot\cdot,w_{P}\gets\mathrm{Softmax}\left(h\left(\mathrm{Concat}[f_{\theta}(x_{1});\cdot\cdot\cdot;f_{\theta}(x_{P})]\right)\right),
$$
where Softmax ensures aggregation weights are normalized. It can be seen as dynamically weighting different parallel streams during forward process for each token. We observed that, in the early stages of training, the model may assign nearly all weight to a few streams, leaving others with near-zero weights. It prevents the prefix parameters of these unlucky streams from receiving gradients and updates. This is similar to the load imbalance phenomenon in sparse MoE architectures (Fedus et al., 2022; Shazeer et al., 2017), where most tokens are sometimes assigned to a few experts. To address this, we apply label smoothing (Szegedy et al., 2016) to set a non-zero minimum for each weight, formulated as:
其中Softmax确保聚合权重归一化。这可以被视为在前向过程中为每个Token动态加权不同的并行流。我们观察到,在训练初期,模型可能会将几乎所有权重分配给少数流,而其他流的权重几乎为零。这导致那些权重接近零的流的前缀参数无法获得梯度更新。该现象类似于稀疏混合专家架构 (MoE) 中的负载不均衡问题 (Fedus et al., 2022; Shazeer et al., 2017) ,即大多数Token有时仅分配给少数专家。为解决此问题,我们采用标签平滑技术 (Szegedy et al., 2016) 为每个权重设置非零最小值,公式如下:
$$
w_{i}\gets w_{i}\times(1-\epsilon)+\frac{\epsilon}{P},
$$
$$
w_{i}\gets w_{i}\times(1-\epsilon)+\frac{\epsilon}{P},
$$
where $\epsilon$ denotes the smoothing parameter and we set it to 0.1 in our experiments.
其中 $\epsilon$ 表示平滑参数,我们在实验中将其设为 0.1。
As a comparison, we also compare using Linear layer to aggregate different outputs and directly average the outputs.
作为对比,我们还比较了使用线性层聚合不同输出与直接对输出取平均的方法。
Results We trained a 0.5B model on Stack-V2-Python. Table 6 compares the impact of different strategies on final performance. For output aggregation, a dynamic weighted sum with label smoothing proved most effective. The differences between methods for input transformation were minor (around $0.1%$ ), much less than the benefits obtained from changing $P$ . Therefore, we opt for the simplest strategy, prefix tuning. Unlike LoRA and BitFit, it requires minimal changes to the model, only necessitating adjustments to the KV-cache.
结果
我们在Stack-V2-Python数据集上训练了一个0.5B参数的模型。表6比较了不同策略对最终性能的影响。对于输出聚合,采用带标签平滑的动态加权求和效果最佳。输入变换方法之间的差异较小 (约$0.1%$),远低于调整$P$带来的收益。因此我们选择最简单的策略——前缀微调 (prefix tuning)。与LoRA和BitFit不同,该方法仅需对KV缓存进行调整,对模型的改动最小。
B Proof for Proposition 1
B 命题1的证明
Proof. We first decompose the individual loss $\mathcal{L}_{i}$ . B
证明。我们首先分解个体损失 $\mathcal{L}_{i}$。
Table 6: Comparisons of different strategies for input transformations and output aggregation.
表 6: 不同输入变换与输出聚合策略的对比
| P | Input Transformation | Output Aggregation | Loss√ | Rel. Improvement ↑ |
|---|---|---|---|---|
| 1 | 1.1518 | 0.00% | ||
| 2 | Prefix (48 tokens) | Dynamic Weighted Sum (e = 0.1) | 1.1276 | 2.10% |
| 2 | Prefix (48 tokens) | Dynamic Weighted Sum (e = 0.0) | 1.1284 | 2.03% |
| 2 | Prefix (48 tokens) | Average | 1.1288 | 2.00% |
| 2 | Prefix (48 tokens) | Linear Layer | 1.1323 | 1.69% |
| 2 | Prefix (48 tokens) | Dynamic Weighted Sum (e = 0.1) | 1.1276 | 2.10% |
| 2 | Prefix (96 tokens) | Dynamic Weighted Sum (e = 0.1) | 1.1278 | 2.08% |
| 2 | LoRA (r = 2) | Dynamic Weighted Sum (e = 0.1) | 1.1281 | 2.06% |
| 2 | Prefix (48 tokens) + LoRA (r = 2) | Dynamic Weighted Sum (e = 0.1) | 1.1263 | 2.21% |
| 2 | Prefix (48 tokens) + LoRA (r = 2) + BitFit | Dynamic Weighted Sum (e = 0.1) | 1.1263 | 2.21% |
| 2 | Prefix (48 tokens) + LoRA (r = 4) | Dynamic Weighted Sum (e = 0.1) | 1.1260 | 2.24% |
| 4 | Prefix (48 tokens) | Dynamic Weighted Sum (e = 0.1) | 1.1145 | 3.24% |
| 8 | Prefix (48 tokens) | Dynamic Weighted Sum (e = 0.1) | 1.1019 | 4.33% |
where $\nu$ is the vocabulary. In Chichilla scaling law, the entropy of natural text is $E$ and the approximation error is $(A/N)^{\alpha}$ . Therefore, we have:
其中 $\nu$ 是词汇表。在Chichilla缩放定律中,自然文本的熵为 $E$,近似误差为 $(A/N)^{\alpha}$。因此,我们得到:
$$
\mathbb{E}{x}\sum_{y\in\mathcal{V}}-p(y\mid x)\log{\left(1+\Delta p_{i}(y\mid x)\right)}=\left(\frac{A}{N}\right)^{\alpha}.
$$
$$
\mathbb{E}{x}\sum_{y\in\mathcal{V}}-p(y\mid x)\log{\left(1+\Delta p_{i}(y\mid x)\right)}=\left(\frac{A}{N}\right)^{\alpha}.
$$
Based on the Taylor series expansion, $\textstyle\log(1+x)=x-{\frac{x^{2}}{2}}+{\mathcal{O}}(x^{3})$ . Apply this expansion to Equation (8), we have:
基于泰勒级数展开,$\textstyle\log(1+x)=x-{\frac{x^{2}}{2}}+{\mathcal{O}}(x^{3})$。将此展开式应用于方程(8),可得:
$$
\begin{array}{r l}&{\left(\frac{A}{N}\right)^{\alpha}=\mathbb{E}{x}\displaystyle\sum_{y\in\mathcal{V}}-p(y\mid x)\left[\Delta p_{i}(y\mid x)-\frac{\Delta p_{i}(y\mid x)^{2}}{2}+\mathcal{O}\left(\Delta p_{i}(y\mid x)^{3}\right)\right]}\ &{\qquad=\mathbb{E}{x}\left[\displaystyle\sum_{y\in\mathcal{V}}-\left(\hat{p}{i}(y\mid x)-p(y\mid x)\right)\right]+\mathbb{E}{x}\left[\displaystyle\sum_{y\in\mathcal{V}}p(y\mid x)\frac{\Delta p_{i}(y\mid x)^{2}}{2}\right]+\mathcal{O}\left(\Delta p_{i}(y\mid x)^{3}\right)}\ &{\qquad=\underbrace{\mathbb{E}{x}\left[\displaystyle\sum_{y\in\mathcal{V}}-\hat{p}{i}(y\mid x)+\sum_{y\in\mathcal{V}}p(y\mid x)\right]}{=0}+\mathbb{E}{x}\mathbb{E}{y\mid x}\frac{\Delta p_{i}(y\mid x)^{2}}{2}+\mathcal{O}\left(\Delta p_{i}(y\mid x)^{3}\right)}\ &{\qquad\sim\mathbb{E}{x,y}\left[\frac{\Delta p_{i}(y\mid x)^{2}}{2}\right],}\end{array}
$$
$$
\begin{array}{r l}&{\left(\frac{A}{N}\right)^{\alpha}=\mathbb{E}{x}\displaystyle\sum_{y\in\mathcal{V}}-p(y\mid x)\left[\Delta p_{i}(y\mid x)-\frac{\Delta p_{i}(y\mid x)^{2}}{2}+\mathcal{O}\left(\Delta p_{i}(y\mid x)^{3}\right)\right]}\ &{\qquad=\mathbb{E}{x}\left[\displaystyle\sum_{y\in\mathcal{V}}-\left(\hat{p}{i}(y\mid x)-p(y\mid x)\right)\right]+\mathbb{E}{x}\left[\displaystyle\sum_{y\in\mathcal{V}}p(y\mid x)\frac{\Delta p_{i}(y\mid x)^{2}}{2}\right]+\mathcal{O}\left(\Delta p_{i}(y\mid x)^{3}\right)}\ &{\qquad=\underbrace{\mathbb{E}{x}\left[\displaystyle\sum_{y\in\mathcal{V}}-\hat{p}{i}(y\mid x)+\sum_{y\in\mathcal{V}}p(y\mid x)\right]}{=0}+\mathbb{E}{x}\mathbb{E}{y\mid x}\frac{\Delta p_{i}(y\mid x)^{2}}{2}+\mathcal{O}\left(\Delta p_{i}(y\mid x)^{3}\right)}\ &{\qquad\sim\mathbb{E}{x,y}\left[\frac{\Delta p_{i}(y\mid x)^{2}}{2}\right],}\end{array}
$$
where the higher-order terms $\mathcal O\left(\Delta p_{i}(y\mid x)^{3}\right)$ are omitted in the last line. The results suggest that minimizing the approximation loss of a language model is equal to minimizing the mean square error (MSE) of relative residuals. After fitting the data, an MSE estimator is usually assumed to be unbiased, meaning that $\mathbb{E}{x,y}\Delta p_{i}(y\mid x)=0$ . Here we follow this unbiased assumption to simplify the following derivation.
其中高阶项 $\mathcal O\left(\Delta p_{i}(y\mid x)^{3}\right)$ 在最后一行被省略。结果表明,最小化语言模型的近似损失等价于最小化相对残差的均方误差 (MSE)。拟合数据后,通常假设MSE估计量是无偏的,即 $\mathbb{E}{x,y}\Delta p_{i}(y\mid x)=0$。这里我们遵循这一无偏假设以简化后续推导。
We next consider the aggregated loss $\mathcal{L}$ . Let $\Delta p(y\mid x)$ denote the new relative residual after the aggregation:
接下来我们考虑聚合损失 $\mathcal{L}$。设 $\Delta p(y\mid x)$ 表示聚合后的新相对残差:
$$
\begin{array}{l}{\displaystyle\Delta p(y\mid x)=\frac{{\hat{p}}(y\mid x)-p(y\mid x)}{p(y\mid x)}}\ {~=\frac{\frac{1}{P}\sum_{i=1}^{P}{\hat{p}}_{i}(y\mid x)-p(y\mid x)}{p(y\mid x)}}\ {~=\displaystyle\frac{1}{P}\sum_{i=1}^{P}\frac{{\hat{p}}_{i}(y\mid x)-p(y\mid x)}{p(y\mid x)}}\ {~=\displaystyle\frac{1}{P}\sum_{i=1}^{P}\Delta p_{i}(y\mid x).}\end{array}
$$
$$
\begin{array}{l}{\displaystyle\Delta p(y\mid x)=\frac{{\hat{p}}(y\mid x)-p(y\mid x)}{p(y\mid x)}}\ {~=\frac{\frac{1}{P}\sum_{i=1}^{P}{\hat{p}}_{i}(y\mid x)-p(y\mid x)}{p(y\mid x)}}\ {~=\displaystyle\frac{1}{P}\sum_{i=1}^{P}\frac{{\hat{p}}_{i}(y\mid x)-p(y\mid x)}{p(y\mid x)}}\ {~=\displaystyle\frac{1}{P}\sum_{i=1}^{P}\Delta p_{i}(y\mid x).}\end{array}
$$
Let $\rho$ denote the correlation coefficient between any two relative residuals $\Delta p_{i}(y\mid x)$ and $\Delta p_{j}(y\mid x)$ for
设 $\rho$ 表示任意两个相对残差 $\Delta p_{i}(y\mid x)$ 和 $\Delta p_{j}(y\mid x)$ 之间的相关系数
$i\neq j$ . Repeating the above process to de composite the aggregated loss ${\mathcal{L}},$ we have:
$i\neq j$。重复上述过程以分解聚合损失 ${\mathcal{L}}$,我们有:
$$
\mathcal{L}=\mathbb{E}{x}\sum_{y\in\mathcal{V}}\left[-p(y\mid x)\log p(y\mid x)\right]+\mathbb{E}{x}\sum_{y\in\mathcal{V}}-p(y\mid x)\log\left(1+\Delta p(y\mid x)\right)
$$
$$
\mathcal{L}=\mathbb{E}{x}\sum_{y\in\mathcal{V}}\left[-p(y\mid x)\log p(y\mid x)\right]+\mathbb{E}{x}\sum_{y\in\mathcal{V}}-p(y\mid x)\log\left(1+\Delta p(y\mid x)\right)
$$
Based on the Corollary of Chinchilla Scaling Law (Equation (9)), for the first term:
基于Chinchilla缩放定律的推论(公式(9)),对于第一项:
$$
\mathbb{E}{x,y}\left[\frac{\Delta p_{i}(y\mid x)^{2}}{2}\right]=\left(\frac{A}{N}\right)^{\alpha},
$$
$$
\mathbb{E}{x,y}\left[\frac{\Delta p_{i}(y\mid x)^{2}}{2}\right]=\left(\frac{A}{N}\right)^{\alpha},
$$
for the cross terms:
对于交叉项:
$$
\mathbb{E}{x,y}\left[\frac{\Delta p_{i}(y\mid x)\Delta p_{j}(y\mid x)}{2}\right]=\rho\sqrt{\mathbb{E}{x,y}\left[\frac{\Delta p_{i}^{2}(y\mid x)}{2}\right]}\sqrt{\mathbb{E}{x,y}\left[\frac{\Delta p_{j}^{2}(y\mid x)}{2}\right]}=\rho\left(\frac{A}{N}\right)^{\alpha}.
$$
$$
\mathbb{E}{x,y}\left[\frac{\Delta p_{i}(y\mid x)\Delta p_{j}(y\mid x)}{2}\right]=\rho\sqrt{\mathbb{E}{x,y}\left[\frac{\Delta p_{i}^{2}(y\mid x)}{2}\right]}\sqrt{\mathbb{E}{x,y}\left[\frac{\Delta p_{j}^{2}(y\mid x)}{2}\right]}=\rho\left(\frac{A}{N}\right)^{\alpha}.
$$
Combining the results, we obtain the desired result:
结合这些结果,我们得到了期望的结论:
$$
\begin{array}{l}{{\mathcal{L}=E+\displaystyle\frac{1}{P^{2}}\left[P\cdot\left(\frac{A}{N}\right)^{\alpha}+P(P-1)\cdot\left(\frac{A}{N}\right)^{\alpha}\cdot\rho\right]}}\ {{=E+\left(\displaystyle\frac{A}{N}\right)^{\alpha}\left[\displaystyle\frac{1+(P-1)\rho}{P}\right]}}\ {{=E+\left(\displaystyle\frac{A}{N}\right)^{\alpha}\cdot\left(\displaystyle\frac{1}{P^{1/\alpha}}\right)^{\alpha}\cdot\left(\displaystyle\frac{1}{\left[(P-1)\rho+1\right]^{-1/\alpha}}\right)^{\alpha}}}\ {{~=E+\left(\displaystyle\frac{A}{N P^{1/\alpha}\left[\left(P-1\right)\rho+1\right]^{-1/\alpha}}\right)^{\alpha}.}}\end{array}
$$
$$
\begin{array}{l}{{\mathcal{L}=E+\displaystyle\frac{1}{P^{2}}\left[P\cdot\left(\frac{A}{N}\right)^{\alpha}+P(P-1)\cdot\left(\frac{A}{N}\right)^{\alpha}\cdot\rho\right]}}\ {{=E+\left(\displaystyle\frac{A}{N}\right)^{\alpha}\left[\displaystyle\frac{1+(P-1)\rho}{P}\right]}}\ {{=E+\left(\displaystyle\frac{A}{N}\right)^{\alpha}\cdot\left(\displaystyle\frac{1}{P^{1/\alpha}}\right)^{\alpha}\cdot\left(\displaystyle\frac{1}{\left[(P-1)\rho+1\right]^{-1/\alpha}}\right)^{\alpha}}}\ {{~=E+\left(\displaystyle\frac{A}{N P^{1/\alpha}\left[\left(P-1\right)\rho+1\right]^{-1/\alpha}}\right)^{\alpha}.}}\end{array}
$$
C Training Details
C 训练细节
Training Hyper parameters Our training is based on Megatron-LM (Shoeybi et al., 2019). Specifically, the learning rate undergoes a linear warm-up over 2,000 steps, reaching a peak of $3\times10^{-4}$ before decreasing to a minimum of $1\times10^{-5}$ according to a cosine decay schedule. The models are trained using a batch size of 1,024 and sequence length of 2,048, alongside a RoPE base of 10,000 (Su et al., 2021). We utilize bfloat16 precision and the Adam optimizer (Kingma & Ba, 2015), setting the epsilon to 1e-8, $\beta_{1}$ to 0.9, and $\beta_{2}$ to 0.95. All parameters, including backbones and additional ones we’ve introduced, are initialized with a Gaussian distribution having a standard deviation of 0.02. Furthermore, we maintain a dropout rate of 0, enforce a weight decay rate of 0.1, and clip gradients at 1.0. The hyper parameter choices are mostly adopted from existing research (Mu en nigh off et al., 2023; Hoffmann et al., 2022; Qwen Team, 2024).
训练超参数
我们的训练基于 Megatron-LM (Shoeybi et al., 2019)。具体而言,学习率经过 2,000 步的线性预热,峰值达到 $3\times10^{-4}$,随后根据余弦衰减计划降至最小值 $1\times10^{-5}$。模型训练采用 1,024 的批量大小和 2,048 的序列长度,同时 RoPE 基数为 10,000 (Su et al., 2021)。我们使用 bfloat16 精度和 Adam 优化器 (Kingma & Ba, 2015),设置 epsilon 为 1e-8,$\beta_{1}$ 为 0.9,$\beta_{2}$ 为 0.95。所有参数(包括主干网络和我们引入的额外参数)均采用标准差为 0.02 的高斯分布初始化。此外,我们保持 dropout 率为 0,强制权重衰减率为 0.1,并将梯度裁剪阈值设为 1.0。超参数选择主要参考现有研究 (Mu en nigh off et al., 2023; Hoffmann et al., 2022; Qwen Team, 2024)。
Model Architectures The model architectures are mostly based on the dense model of Qwen-2.5 (Qwen Team, 2024). Recent work has indicated that the number of layers still significantly impacts the final performance of smaller models (Allal et al., 2024; Liu et al., 2024b). To eliminate the influence of the number of layers and derive a cleaner scaling law, we utilize the architecture of Qwen-2.5-3B (comprising 36 layers, 16 attention heads, and 2 KV groups) and vary the hidden size / intermediate size within this framework. By keeping the number of layers constant and increasing the parameter width, we can more fairly compare the latency of parallel scaling and parameter. The final model structure is presented in the Table 7.
模型架构
模型架构主要基于 Qwen-2.5 (Qwen Team, 2024) 的密集模型。近期研究表明,层数仍显著影响小模型的最终性能 (Allal et al., 2024; Liu et al., 2024b)。为消除层数影响并推导更纯净的缩放定律,我们采用 Qwen-2.5-3B 架构(含 36 层、16 个注意力头和 2 个 KV 组),在该框架内调整隐藏大小/中间层尺寸。通过固定层数并增加参数宽度,可更公平地比较并行缩放与参数的延迟。最终模型结构如 表 7 所示。
Table 7: Model architectures.
表 7: 模型架构。
| P | 参数量 (非嵌入层) | 隐藏层大小 | 中间层大小 |
|---|---|---|---|
| 1 | 535,813,376 | 896 | 4,864 |
| 2 | 538,195,842 | 896 | 4,864 |
| 4 | 540,577,412 | 896 | 4,864 |
| 8 | 545,340,552 | 896 | 4,864 |
| 1 | 693,753,856 | 1,024 | 5,504 |
| 2 | 696,738,818 | 1,024 | 5,504 |
| 4 | 699,722,756 | 1,024 | 5,504 |
| 8 | 705,690,632 | 1,024 | 5,504 |
| 1 | 1,088,376,320 | 1,280 | 6,912 |
| 2 | 1,092,762,882 | 1,280 | 6,912 |
| 4 | 1,097,148,164 | 1,280 | 6,912 |
| 8 | 1,105,918,728 | 1,280 | 6,912 |
| 1 | 1,571,472,384 | 1,536 | 8,320 |
| 2 | 1,577,522,690 | 1,536 | 8,320 |
| 4 | 1,583,571,460 | 1,536 | 8,320 |
| 8 | 1,595,669,000 | 1,536 | 8,320 |
| 1 | |||
| 2 | 2,774,773,760 | 2,048 2,048 | 11,008 |
| 4 | 2,784,937,986 | 2,048 | 11,008 |
| 8 | 2,795,100,164 2,815,424,520 | 2,048 | 11,008 11,008 |
| 1 | 4,353,203,200 | 2,560 | 13,824 |
| 2 | 4,368,529,922 | 2,560 | 13,824 |
| 4 | 4,383,854,084 | 2,560 | 13,824 |
| 8 | 4,414,502,408 | 2,560 | 13,824 |

Figure 7: Loss for training on Open Web Text for repeating several epochs. On the fifth epoch, the validation loss suddenly increases, while the model with more computations $(N=3B,P=2)$ shows a stronger resistance to over fitting compared to the model with more parameters $(N=5B,P=1)$ .
图 7: 在Open Web Text上进行多轮重复训练的损失值。第五轮时验证损失突然上升,而计算量更大的模型 $(N=3B,P=2)$ 相比参数量更大的模型 $(N=5B,P=1)$ 表现出更强的抗过拟合能力。
Both Stack-V2-Python and Pile datasets contain more tokens than the total number used in our experiment (42 billion), and therefore previous scaling law experiments did not involve data reuse. Mu en nigh off et al. (2023) noted that the performance of scaling laws tends to change when training data is repeated. In this section, we explore how PARSCALE performs on a smaller dataset, Open Web Text (Gokaslan et al., 2019), with repeating data.
Stack-V2-Python和Pile数据集包含的token数量都超过了我们实验使用的总数(420亿),因此之前的缩放定律(scaling law)实验并未涉及数据复用。Muennighoff等人(2023)指出,当训练数据重复时,缩放定律的表现往往会发生变化。本节我们将探讨PARSCALE在较小数据集Open Web Text (Gokaslan等人,2019)上使用重复数据时的表现。
Figure 7 shows a comparison of training loss and validation loss, with Open Web Text repeated over four cycles. At the transition from the end of the fourth epoch to the beginning of the fifth epoch, we observe a significant decrease in training loss and a notable increase in validation loss, indicating over fitting. This aligns with the optimal number of epochs being four for training language models, as reported by Mu en nigh off et al. (2023). Comparing parallel scaling and parameter scaling, we observed an intriguing phenomenon: parallel scaling results in a smaller decline in performance when over fitting occurs, while parameter scaling leads to a larger decline. Specifically, by the time over fitting occurs, the validation loss of a 3B parameter model with two-way parallel scaling matched that of a 5 billion parameter model. This suggests that PARSCALE may alleviate the risk of over fitting, possibly due to having fewer parameters. As we increasingly face the depletion of pre-training data (Villalobos et al., 2022), further research into the scaling laws of computation in data-constrained scenarios presents a compelling future direction.
图 7: 训练损失与验证损失的对比图,其中Open Web Text数据重复了四个周期。在第四周期结束向第五周期开始的过渡阶段,我们观察到训练损失显著下降而验证损失明显上升,这表明出现了过拟合现象。这与Muennighoff等人 (2023) 报告中提出的"训练大语言模型最优周期数为四"的结论一致。通过对比并行扩展与参数扩展,我们发现一个有趣现象:发生过拟合时,并行扩展带来的性能下降幅度较小,而参数扩展导致的下降幅度较大。具体而言,当过拟合发生时,采用双向并行扩展的30亿参数模型,其验证损失与50亿参数模型相当。这表明PARSCALE方法可能通过减少参数量来缓解过拟合风险。随着预训练数据枯竭问题日益凸显 (Villalobos等, 2022),在数据受限场景下进一步研究计算扩展规律将成为极具价值的未来研究方向。
E Parametric Fitting for the Parallel Scaling Law
E 并行扩展定律的参数拟合
To obtain the practical parallel scaling law in Equation (5), based on the 24 runs (i.e., four $P\times\sin N;$ we obtain for each dataset, we follow the strategy from Hoffmann et al. (2022) and Mu en nigh off et al. (2023) to use the LBFGS algorithm and Huber loss for curve fitting. This process can be fomulated as:
为了获得方程(5)中的实际并行扩展定律,基于24次实验运行(即每个数据集进行四次$P\times\sin N;$),我们遵循Hoffmann等人(2022)和Muennighoff等人(2023)的策略,使用LBFGS算法和Huber损失进行曲线拟合。该过程可表述为:
$$
\operatorname*{min}{A,k,E,\alpha}\sum_{\mathrm{run}i}{\mathrm{HUBER}{\delta}\left(\log\mathcal{L}{\mathrm{pred}}^{i},\log\mathcal{L}_{\mathrm{true}}^{i}\right)},
$$
$$
\operatorname*{min}{A,k,E,\alpha}\sum_{\mathrm{run}i}{\mathrm{HUBER}{\delta}\left(\log\mathcal{L}{\mathrm{pred}}^{i},\log\mathcal{L}_{\mathrm{true}}^{i}\right)},
$$
where $\mathcal{L}{\mathrm{true}}^{i}$ is the $i\cdot$ -th observed final loss obtained from experiments and $\mathcal{L}_{\mathrm{pred}}^{i}$ is the corresponding prediction based on the corresponding observations ${N,P}$ and parameters ${A,k,E,\alpha}$ . We use $\delta=0.001$ for the Huber loss to avoid over fitting.
其中 $\mathcal{L}{\mathrm{true}}^{i}$ 是第 $i$ 次实验观测到的最终损失,$\mathcal{L}_{\mathrm{pred}}^{i}$ 是基于对应观测值 ${N,P}$ 和参数 ${A,k,E,\alpha}$ 的预测值。为避免过拟合,我们设置 Huber 损失的 $\delta=0.001$。
Following Mu en nigh off et al. (2023); Hoffmann et al. (2022), we utilize the LBFGS algorithm (Liu & Nocedal, 1989) via SciPy (Virtanen et al., 2020) to locate local minima of the objective. The initialization grid is defined by: $E\in{e^{-1},e^{-0.5},e^{0}},A\in{e^{-4},e^{-2},e^{0},e^{2},e^{4}}\times10^{9},\alpha\in{0,0.5,1,1.5,2},k\in{0.2,0.4,0.6,0.9}$ All parameters are constrained to be positive. After fitting, the optimal initialization is found to be away from the boundaries of our sweep.
遵循Mu en nigh off等人(2023)和Hoffmann等人(2022)的研究,我们通过SciPy(Virtanen等人, 2020)使用LBFGS算法(Liu & Nocedal, 1989)来定位目标的局部最小值。初始化网格定义为:$E\in{e^{-1},e^{-0.5},e^{0}},A\in{e^{-4},e^{-2},e^{0},e^{2},e^{4}}\times10^{9},\alpha\in{0,0.5,1,1.5,2},k\in{0.2,0.4,0.6,0.9}$。所有参数都被约束为正数。拟合后,发现最优初始化远离我们扫描的边界。
Table 8: Fitting results of the logarithmic scaling law (Equation (5)) for Stack-V2 (Python).
表 8: Stack-V2 (Python语言) 对数缩放定律 (公式(5)) 的拟合结果
| A 1.130616 × 107 k E |
|---|
| 拟合 Huber Loss ↓ 3.677 × 10-5 拟合 R2 ↑ |
Table 9: Fitting results of the logarithmic scaling law (Equation (5)) for Pile.
表 9: Pile对数缩放定律(公式(5))拟合结果
| A 1.973520 × 108 k E |
|---|
| 0.196333 拟合 Huber Loss ↓ 1.814 x 10-5 拟合 R2 ↑ 0.9987 |
Table 10: Prediction of the logarithmic scaling law (Equation (5)) for Stack-V2 (Python).
表 10: Stack-V2 (Python语言) 对数缩放定律 (公式(5)) 的预测
| P | 参数 | Ltrue | 误差 | |
|---|---|---|---|---|
| 1 | 535,813,376 | 1.1728 | 1.1722 | 0.0006 |
| 1 | 693,753,856 | 1.1498 | 1.1496 | 0.0002 |
| 1 | 1,088,376,320 | 1.1123 | 1.1131 | -0.0008 |
| 1 | 1,571,472,384 | 1.0840 | 1.0817 | 0.0023 |
| 1 | 2,774,773,760 | 1.0439 | 1.0451 | -0.0012 |
| 1 | 4,353,203,200 | 1.0151 | 1.0213 | -0.0062 |
| 2 | 538,195,842 | 1.1509 | 1.1507 | 0.0002 |
| 2 | 696,738,818 | 1.1290 | 1.1262 | 0.0028 |
| 2 | 1,092,762,882 | 1.0932 | 1.0940 | -0.0008 |
| 2 | 1,577,522,690 | 1.0662 | 1.0623 | 0.0039 |
| 2 | 2,784,937,986 | 1.0280 | 1.0244 | 0.0036 |
| 2 | 4,368,529,922 | 1.0005 | 1.0025 | -0.0020 |
| 4 | 540,577,412 | 1.1340 | 1.1354 | -0.0014 |
| 4 | 699,722,756 | 1.1129 | 1.1124 | 0.0005 |
| 4 | 1,097,148,164 | 1.0784 | 1.0808 | -0.0024 |
| 4 | 1,583,571,460 | 1.0524 | 1.0490 | 0.0034 |
| 4 | 2,795,100,164 | 1.0156 | 1.0126 | 0.0030 |
| 4 | 4,383,854,084 | 0.9891 | 0.9906 | -0.0015 |
| 8 | 545,340,552 | 1.1198 | 1.1231 | -0.0033 |
| 8 | 705,690,632 | 1.0994 | 1.0997 | -0.0003 |
| 8 | 1,105,918,728 | 1.0661 | 1.0688 | -0.0027 |
| 8 | 1,595,669,000 | 1.0410 | 1.0383 | 0.0027 |
| 8 | 2,815,424,520 | 1.0053 | 1.0016 | 0.0037 |
| 8 | 4,414,502,408 | 0.9797 | 0.9794 | 0.0003 |
Table 11: Prediction of the logarithmic scaling law (Equation (5)) for Pile.
表 11: Pile 对数缩放定律 (Equation (5)) 的预测
| P | 参数 | Ltrue | 误差 | |
|---|---|---|---|---|
| 1 | 535,813,376 | 2.1107 | 2.1113 | -0.0006 |
| 1 | 693,753,856 | 2.0701 | 2.0671 | 0.0030 |
| 1 | 1,088,376,320 | 2.0039 | 2.0027 | 0.0012 |
| 1 | 1,571,472,384 | 1.9542 | 1.9539 | 0.0003 |
| 1 | 2,774,773,760 | 1.8839 | 1.8876 | -0.0037 |
| 1 | 4,353,203,200 | 1.8335 | 1.8451 | -0.0116 |
| 2 | 538,195,842 | 2.0770 | 2.0772 | -0.0002 |
| 2 | 696,738,818 | 2.0381 | 2.0363 | 0.0018 |
| 2 | 1,092,762,882 | 1.9747 | 1.9730 | 0.0017 |
| 2 | 1,577,522,690 | 1.9270 | 1.9266 | 0.0004 |
| 2 | 2,784,937,986 | 1.8596 | 1.8610 | -0.0014 |
| 2 | 4,368,529,922 | 1.8113 | 1.8137 | -0.0024 |
| 4 | 540,577,412 | 2.0501 | 2.0544 | -0.0043 |
| 4 | 699,722,756 | 2.0125 | 2.0128 | -0.0003 |
| 4 | 1,097,148,164 | 1.9514 | 1.9509 | 0.0005 |
| 4 | 1,583,571,460 | 1.9053 | 1.9040 | 0.0013 |
| 4 | 2,795,100,164 | 1.8402 | 1.8394 | 0.0008 |
| 4 | 4,383,854,084 | 1.7936 | 1.7938 | -0.0002 |
| 8 | 545,340,552 | 2.0272 | 2.0364 | -0.0092 |
| 8 | 705,690,632 | 1.9908 | 1.9933 | -0.0025 |
| 8 | 1,105,918,728 | 1.9315 | 1.9318 | -0.0003 |
| 8 | 1,595,669,000 | 1.8869 | 1.8856 | 0.0013 |
| 8 | 2,815,424,520 | 1.8238 | 1.8218 | 0.0020 |
| 8 | 4,414,502,408 | 1.7785 | 1.7772 | 0.0013 |
Tables 8 and 9 present the fitted parameters and evaluation metrics. Tables 10 and 11 show the prediction results based on the fitted parameters.
表 8 和表 9 展示了拟合参数和评估指标。表 10 和表 11 显示了基于拟合参数的预测结果。
Table 12: Fitting results of the theoretical scaling law (Equation (4)) for Stack-V2 (Python).
表 12: Stack-V2 (Python语言) 理论缩放定律 (公式 (4)) 的拟合结果
| A p E | 1.187646 × 107 0.891914 0.660016 |
| Fitting Huber Loss ↓ Fitting R2 ↑ | 0.175036 5.259 × 10-5 0.9959 |
Table 13: Fitting results of the theoretical scaling law (Equation (4)) for Pile.
表 13: Pile理论缩放定律(公式(4))的拟合结果
| A p E | 2.150890 × 108 0.899475 1.272178 |
| Fitting Huber Loss ↓ Fitting R2 ↑ | 0.190100 4.545 × 10-5 0.9968 |
Table 14: Prediction of the theoretical scaling law (Equation (4)) for Stack-V2 (Python).
表 14: Stack-V2 (Python语言) 的理论缩放定律 (公式 (4)) 预测
| P | 参数 | Ltrue | 误差 | |
|---|---|---|---|---|
| 1 | 535,813,376 | 1.1734 | 1.1722 | 0.0012 |
| 1 | 693,753,856 | 1.1507 | 1.1496 | 0.0011 |
| 1 | 1,088,376,320 | 1.1135 | 1.1131 | 0.0004 |
| 1 | 1,571,472,384 | 1.0853 | 1.0817 | 0.0036 |
| 1 | 2,774,773,760 | 1.0450 | 1.0451 | -0.0001 |
| 1 | 4,353,203,200 | 1.0158 | 1.0213 | -0.0055 |
| 2 | 538,195,842 | 1.1453 | 1.1507 | -0.0054 |
| 2 | 696,738,818 | 1.1238 | 1.1262 | -0.0024 |
| 2 | 1,092,762,882 | 1.0887 | 1.0940 | -0.0053 |
| 2 | 1,577,522,690 | 1.0620 | 1.0623 | -0.0003 |
| 2 | 2,784,937,986 | 1.0239 | 1.0244 | -0.0005 |
| 2 | 4,368,529,922 | 0.9964 | 1.0025 | -0.0061 |
| 4 | 540,577,412 | 1.1310 | 1.1354 | -0.0044 |
| 4 | 699,722,756 | 1.1102 | 1.1124 | -0.0022 |
| 4 | 1,097,148,164 | 1.0762 | 1.0808 | -0.0046 |
| 4 | 1,583,571,460 | 1.0503 | 1.0490 | 0.0013 |
| 4 | 2,795,100,164 | 1.0133 | 1.0126 | 0.0007 |
| 4 | 4,383,854,084 | 0.9866 | 0.9906 | -0.0040 |
| 8 | 545,340,552 | 1.1234 | 1.1231 | 0.0003 |
| 8 | 705,690,632 | 1.1030 | 1.0997 | 0.0033 |
| 8 | 1,105,918,728 | 1.0695 | 1.0688 | 0.0007 |
| 8 | 1,595,669,000 | 1.0440 | 1.0383 | 0.0057 |
| 8 | 2,815,424,520 | 1.0077 | 1.0016 | 0.0061 |
| 8 | 4,414,502,408 | 0.9814 | 0.9794 | 0.0020 |
Table 15: Prediction of the theoretical scaling law (Equation (4)) for Pile.
表 15: Pile 理论缩放定律 (公式 (4)) 的预测
| P | Parameters | Ltrue | Error | |
|---|---|---|---|---|
| 1 | 535,813,376 | 2.1129 | 2.1113 | 0.0016 |
| 1 | 693,753,856 | 2.0726 | 2.0671 | 0.0055 |
| 1 | 1,088,376,320 | 2.0069 | 2.0027 | 0.0042 |
| 1 | 1,571,472,384 | 1.9574 | 1.9539 | 0.0035 |
| 1 | 2,774,773,760 | 1.8872 | 1.8876 | -0.0004 |
| 1 | 4,353,203,200 | 1.8367 | 1.8451 | -0.0084 |
| 2 | 538,195,842 | 2.0700 | 2.0772 | -0.0072 |
| 2 | 696,738,818 | 2.0317 | 2.0363 | -0.0046 |
| 2 | 1,092,762,882 | 1.9695 | 1.9730 | -0.0035 |
| 2 | 1,577,522,690 | 1.9225 | 1.9266 | -0.0041 |
| 2 | 2,784,937,986 | 1.8559 | 1.8610 | -0.0051 |
| 2 | 4,368,529,922 | 1.8080 | 1.8137 | -0.0057 |
| 4 | 540,577,412 | 2.0482 | 2.0544 | -0.0062 |
| 4 | 699,722,756 | 2.0110 | 2.0128 | -0.0018 |
| 4 | 1,097,148,164 | 1.9505 | 1.9509 | -0.0004 |
| 4 | 1,583,571,460 | 1.9048 | 1.9040 | 0.0008 |
| 4 | 2,795,100,164 | 1.8400 | 1.8394 | 0.0006 |
| 4 | 4,383,854,084 | 1.7935 | 1.7938 | -0.0003 |
| 8 | 545,340,552 | 2.0364 | 2.0364 | -0.0000 |
| 8 | 705,690,632 | 1.9998 | 1.9933 | 0.0065 |
| 8 | 1,105,918,728 | 1.9403 | 1.9318 | 0.0085 |
| 8 | 1,595,669,000 | 1.8953 | 1.8856 | 0.0097 |
| 8 | 2,815,424,520 | 1.8315 | 1.8218 | 0.0097 |
| 8 | 4,414,502,408 | 1.7857 | 1.7772 | 0.0085 |
We also test our derived theoretical parallel scaling law (Equation (4)), in which the correlation coefficient $\rho$ is treated as a constant to fit. Tables 12 and 13 present the fitted parameters and evaluation metrics, while Tables 14 and 15 show the fitted results. It is evident that, whether for Stack or Pile, treating $\rho$ as a constant yields fitting accuracy that is inferior to the previously proposed logarithmic parallel scaling law.
我们还测试了推导出的理论并行扩展定律 (Equation (4)),其中相关系数 $\rho$ 被视为待拟合常数。表 12 和表 13 展示了拟合参数和评估指标,而表 14 和表 15 显示了拟合结果。显然,无论是 Stack 还是 Pile,将 $\rho$ 视为常数得到的拟合精度都低于先前提出的对数并行扩展定律。
F Training Loss for Pile and Stack-V2-Python
F Pile和Stack-V2-Python的训练损失
Figure 8 illustrates the curve of loss versus data size in our scaling law experiments. It clearly shows that scaling $P$ yields benefits, regardless of the data scale.
图 8: 展示了我们扩展律实验中损失随数据量变化的曲线。该图清晰表明,无论数据规模如何,扩展 $P$ 都能带来收益。

Figure 8: Training loss for the Stack-V2-Python and the Pile, smoothing with 0.98 exponential moving average.
图 8: Stack-V2-Python语言与The Pile数据集的训练损失曲线 (采用0.98指数移动平均平滑处理)
G Downstream Datasets
G 下游数据集
Table 16: HumanEval Pass@1 $(%)$
表 16: HumanEval Pass@1 $(%)$
Table 18: MBPP Pass@1 (%)
表 18: MBPP Pass@1 (%)
| N | 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|---|
| P=1 | 12.8 | 15.9 | 17.7 | 18.3 | 18.3 | 19.5 |
| P=2 | 15.9 | 20.7 | 20.1 | 19.5 | 18.9 | 24.4 |
| P=4 | 15.2 | 17.1 | 18.3 | 18.3 | 22.0 | 20.7 |
| P=8 | 18.9 | 18.3 | 21.3 | 18.3 | 21.3 | 25.0 |
Table 20: HumanEval Pass@10 $(%)$
表 20: HumanEval Pass@10 $(%)$
| N | 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|---|
| P=1 | 27.8 | 30.2 | 31.5 | 36.0 | 40.5 | 45.8 |
| P=2 | 34.4 | 33.6 | 36.8 | 42.6 | 47.4 | 47.1 |
| P=4 | 35.2 | 33.9 | 39.4 | 40.7 | 45.5 | 50.3 |
| P=8 | 33.3 | 36.0 | 39.9 | 45.5 | 47.4 | 48.4 |
Table 22: MBPP Pass@10 (%)
表 22: MBPP Pass@10 (%)
| N | 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|---|
| P=1 | 25.0 | 21.3 | 29.9 | 29.9 | 32.9 | 37.2 |
| P=2 | 25.0 | 27.4 | 28.0 | 35.4 | 34.8 | 40.2 |
| P=4 | 26.2 | 30.5 | 28.0 | 36.0 | 38.4 | 40.2 |
| P=8 | 29.9 | 32.3 | 31.7 | 37.2 | 38.4 | 47.0 |
Table 17: HumanEval $^{+}$ Pass@1 (%)
表 17: HumanEval $^{+}$ Pass@1 (%)
| N | 0.5B 0.7B 1.1B 1.6B 2.8B 4.4B |
|---|---|
| P=1 | 15.9 16.5 15.9 11.0 13.4 15.9 |
| P=2 | 13.4 17.7 16.5 16.5 21.3 15.9 |
| P=4 | 14.0 17.7 15.9 18.9 18.3 14.6 |
| P=8 | 15.9 15.2 16.5 19.5 20.7 18.3 |
Table 24: WinoGrande Performance $(%)$
表 24: WinoGrande性能 $(%)$
| N 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B | |
|---|---|---|---|---|---|---|
| P=1 | 49.2 | 54.0 | 57.7 | 61.4 | 68.3 | 66.4 |
| P=2 | 57.9 | 57.7 | 60.3 | 64.0 | 67.7 | 72.0 |
| P=4 | 54.0 | 59.8 | 61.1 | 66.9 | 70.9 | 73.5 |
| P=8 | 57.7 | 60.3 | 66.1 | 67.5 | 72.8 | 75.1 |
Table 26: OpenBookQA Performance $(%)$
表 26: OpenBookQA 性能 $(%)$
| N | 0.5B 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|
| P=1 | 51.9 | 51.2 51.6 | 52.2 | 53.5 | 54.7 |
| P=2 | 51.0 51.4 | 53.0 | 53.3 | 56.0 | 57.4 |
| P=4 | 52.4 53.0 | 53.5 | 54.5 | 56.7 | 56.4 |
| P=8 | 51.7 53.6 | 55.0 | 53.4 | 55.6 | 56.9 |
| N | 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|---|
| P=1 | 26.0 | 28.8 | 28.2 | 28.0 | 29.0 | 32.4 |
| P=2 | 26.8 | 26.6 | 27.8 | 29.8 | 30.6 | 29.8 |
| P=4 | 26.6 | 29.0 | 29.8 | 29.4 | 31.0 | 32.0 |
| P=8 | 26.8 | 27.2 | 29.4 | 31.0 | 31.6 | 30.6 |
Table 19: MBPP $^+$ Pass@1 (%)
表 19: MBPP$^+$ Pass@1 (%)
| N 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B | |
|---|---|---|---|---|---|---|
| P=1 23.5 | 26.2 | 25.7 | 31.2 | 34.7 | 38.4 | |
| P=2 27.0 | 27.8 | 30.7 | 35.4 | 39.4 | 38.9 | |
| P=4 28.0 | 27.2 | 32.3 | 32.5 | 37.3 | 40.5 | |
| P=8 29.1 | 29.1 | 33.6 | 38.9 | 40.5 | 42.3 |
Table 21: HumanEval+ Pass@10 (%)
表 21: HumanEval+ Pass@10 (%)
| N | 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|---|
| P=1 | 23.8 | 21.3 | 26.8 | 26.8 | 29.9 | 33.5 |
| P=2 | 22.0 | 25.6 | 24.4 | 31.7 | 32.3 | 36.0 |
| P=4 | 24.4 | 27.4 | 25.6 | 33.5 | 33.5 | 34.8 |
| P=8 | 27.4 | 29.9 | 29.9 | 32.9 | 36.0 | 42.7 |
Table 23: MBPP $^+$ Pass@10 (%)
表 23: MBPP $^+$ Pass@10 (%)
| N 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B | |
|---|---|---|---|---|---|---|
| P =1 | 40.2 | 44.7 | 47.9 | 51.6 | 54.5 | 56.3 |
| P=2 | 46.8 | 48.4 | 50.5 | 54.2 | 58.2 | 60.6 |
| P=4 | 43.7 | 49.5 | 52.1 | 56.6 | 59.0 | 62.7 |
| P=8 | 46.0 | 50.8 | 56.6 | 56.1 | 60.6 | 62.2 |
Table 25: Hellaswag Performance $(%)$
表 25: Hellaswag 性能 $(%)$
| N | 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|---|
| P=1 | 35.7 | 37.4 | 40.1 | 42.6 | 46.7 | 49.3 |
| P=2 | 36.8 | 38.4 | 41.3 | 44.5 | 48.4 | 51.9 |
| P=4 | 37.4 | 39.4 | 42.9 | 45.7 | 50.0 | 53.8 |
| P=8 | 38.6 | 40.6 | 44.1 | 46.8 | 51.0 | 54.6 |
Table 27: PiQA Performance $(%)$
表 27: PiQA 性能 $(%)$
| N | 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|---|
| P=1 | 65.0 | 65.8 | 66.9 | 67.5 | 68.8 | 69.5 |
| P=2 | 65.7 | 66.8 | 67.4 | 68.5 | 70.5 | 71.3 |
| P=4 | 65.8 | 66.7 | 68.0 | 68.8 | 70.6 | 72.1 |
| P=8 | 66.5 | 66.9 | 67.8 | 69.5 | 70.9 | 71.5 |
Setup for 42B token experiments For HumanEval $(+)$ (Chen et al., 2021) and $\mathrm{MBPP}(+)$ (Austin et al., 2021), we use the EvalPlus framework (Liu et al., 2023) for evaluation, where $\mathrm{Pass@1}$ employs greedy decoding and Pass $@10$ employs a temperature of 0.8. Considering that the pretrained base model cannot follow instructions, we use the direct completion format. For general tasks, we employ lm-eval harness (Biderman et al., 2024) and report normalized accuracy when provided. The number of few-shot mostly follows existing research configurations. Benchmarks include: WinoGrande (5-shot, Sakaguchi et al. (2021)), Hellaswag (10-shot, Zellers et al. (2019)), OpenBookQA (5-shot, Mihaylov et al. (2018)), PiQA (5-shot, Bisk et al. (2020)), ARC-Easy and ARC-Challenge (25-shot, Clark et al. (2018); we reporting the average of both), and SciQ (3-shot, Welbl et al. (2017)).
42B Token实验设置
对于HumanEval $(+)$ (Chen et al., 2021)和$\mathrm{MBPP}(+)$ (Austin et al., 2021),我们使用EvalPlus框架(Liu et al., 2023)进行评估,其中$\mathrm{Pass@1}$采用贪婪解码,Pass $@10$采用0.8的温度参数。考虑到预训练基础模型无法遵循指令,我们使用直接补全格式。对于通用任务,我们采用lm-eval测试框架(Biderman et al., 2024)并在提供时报告归一化准确率。少样本数量大多遵循现有研究配置。基准测试包括:WinoGrande (5样本,Sakaguchi et al. (2021))、Hellaswag (10样本,Zellers et al. (2019))、OpenBookQA (5样本,Mihaylov et al. (2018))、PiQA (5样本,Bisk et al. (2020))、ARC-Easy和ARC-Challenge (25样本,Clark et al. (2018);我们报告两者的平均值)以及SciQ (3样本,Welbl et al. (2017))。
Table 28: ARC Performance $(%)$
表 28: ARC 性能 $(%)$
| N | 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|---|
| P=1 | 36.9 | 38.5 | 40.5 | 42.1 | 44.7 | 46.4 |
| P=2 | 38.6 | 39.9 | 40.9 | 43.2 | 45.9 | 49.1 |
| P=4 | 39.1 | 39.9 | 41.1 | 44.2 | 47.4 | 48.8 |
| P=8 | 39.4 | 39.8 | 42.0 | 44.8 | 48.2 | 49.4 |
Table 29: SciQ Performance $(%)$
表 29: SciQ 性能 $(%)$
| N | 0.5B | 0.7B | 1.1B | 1.6B | 2.8B | 4.4B |
|---|---|---|---|---|---|---|
| P=1 | 78.9 | 81.7 | 85.2 | 86.1 | 88.5 | 91.0 |
| P=2 | 80.8 | 83.2 | 84.0 | 87.3 | 90.5 | 91.4 |
| P=4 | 82.3 | 82.7 | 84.4 | 87.2 | 91.2 | 91.7 |
| P=8 | 81.3 | 83.0 | 86.9 | 88.9 | 91.2 | 94.2 |
Setup for 1T token experiments In the 1T token experiments, we use more challenging datasets for comprehensive testing, including MMLU (5-shot, Hendrycks et al. (2021a)) and RACE (4-shot, Lai et al. (2017)). In addition, we introduce mathematics reasoning datasets, including GSM8K (4-shot, Cobbe et al. (2021)), GSM8K-CoT (8-shot), and MATH (4-shot, Hendrycks et al. (2021b); using the Minerva evaluation rules (Lewkowycz et al., 2022)). When evaluating the Instruct model, we also use IFEval (0-shot, Zhou et al. (2023b)) and report the average among four metrics provided by lm-eval harness.
1T token实验设置
在1T token实验中,我们使用更具挑战性的数据集进行全面测试,包括MMLU (5-shot, Hendrycks et al. (2021a)) 和RACE (4-shot, Lai et al. (2017))。此外,我们引入了数学推理数据集,包括GSM8K (4-shot, Cobbe et al. (2021))、GSM8K-CoT (8-shot) 和MATH (4-shot, Hendrycks et al. (2021b);采用Minerva评估规则 (Lewkowycz et al., 2022))。评估Instruct模型时,我们还使用了IFEval (0-shot, Zhou et al. (2023b)) 并报告lm-eval工具提供的四项指标平均值。
Tables 16 to 29 show the downstream task performance in the 42B token experiments. We report the average of these performances in the main text (Tables 2 and 3).
表 16 至表 29 展示了 42B token 实验中的下游任务性能。我们在正文中报告了这些性能的平均值 (表 2 和表 3)。
H Compared with Beam Search
H 与束搜索 (Beam Search) 对比
Some training-free inference-time scaling methods also expand parallel computation during the inference phase, with Beam Search being a representative method. We applied Beam Search to the trained Baseline1.8B and compared it with PARSCALE to emphasize the importance of expanding parallel computation during the training phase. It is worth mentioning that Beam Search cannot be applied to the general tasks in Table 4 because these tasks primarily evaluate next-token prediction, whereas Beam Search can only be used for generation tasks. Therefore, we compared Beam Search on mathematics reasoning benchmarks.
一些无需训练的推理时缩放方法也会在推理阶段扩展并行计算,其中集束搜索 (Beam Search) 是代表性方法。我们将集束搜索应用于训练好的 Baseline1.8B 模型,并与 PARSCALE 进行对比,以强调训练阶段扩展并行计算的重要性。值得注意的是,集束搜索无法应用于表 4 中的通用任务,因为这些任务主要评估下一词元 (next-token) 预测能力,而集束搜索仅适用于生成任务。因此,我们在数学推理基准测试上对比了集束搜索的效果。
Table 30: Comparison with Beam-Search.
表 30: 与Beam-Search的对比
| 并行数量 | 方法 | GSM8K | GSM8K-CoT | MinervaMATH |
|---|---|---|---|---|
| 1 | 28.7 | 35.9 | 12.0 | |
| 2 | PARSCALE (P = 2) | 32.6 | 35.6 | 13.0 |
| 2 | Beam-Search (S = 2) | 29.3 | 37.8 | 13.6 |
| 4 | PARSCALE (P = 4) | 34.7 | 40.8 | 14.5 |
| 4 | Beam-Search (S = 4) | 27.7 | 37.8 | 12.5 |
| 8 | PARSCALE (P = 8) | 38.4 | 43.7 | 16.4 |
| 8 | Beam-Search (S = 8) | 22.5 | 30.1 | 10.0 |
The results are shown in Table 30. It can be observed that Beam Search is only effective when $n_{-}b e a m s=2$ As n beams increases, the performance of Beam Search actually decreases. This indicates that, without a strong verifier, it is difficult for LLM alone to select the correct result from multiple sampling results. This aligns with the finding in Stroebl et al. (2024). This experiment further emphasizes the importance of expanding parallel computation in both the training stage and inference stage.
结果如表 30 所示。可以观察到,束搜索 (Beam Search) 仅在 $n_{-}b e a m s=2$ 时有效。随着 n beams 增加,束搜索的性能反而下降。这表明,在没有强大验证器的情况下,仅靠大语言模型很难从多个采样结果中选择正确答案。这与 Stroebl 等人 (2024) 的研究发现一致。该实验进一步强调了在训练阶段和推理阶段扩展并行计算的重要性。
I Visualization for Different Parallel Streams
不同并行流的可视化
In the output aggregation, we assign different dynamic weights to different streams. These weights indicate the contribution ratio of different parallel streams to the next token prediction. We visualize the stream that contributes the most to each token (i.e., the stream with the highest aggregated weight), based on the 4.4B model pre-trained on the Pile. Tokens of the same color indicating that these tokens are primarily contributed by the same stream. Tables 31 to 33 visualize the results. An interesting observation is the locality of the colors: tokens in close proximity are often primarily contributed by the same stream, especially when $P$ is relatively small (e.g., $\bar{P}=2$ ).
在输出聚合过程中,我们为不同并行流分配动态权重。这些权重反映了各并行流对下一个token预测的贡献比例。基于在Pile数据集上预训练的4.4B参数模型,我们将对每个token贡献最大的流(即聚合权重最高的流)进行可视化处理。同色token表示它们主要由同一流生成。表31至表33展示了可视化结果。一个有趣的现象是颜色的局部性:相邻token往往由同一流主导生成,特别是当$P$值较小时(例如$\bar{P}=2$)。
Table 31: Parallel stream visualization, where paragraphs are sampled from wikitext (Merity et al., 2016). Tokens with the same color indicate they are primarily contributed by the same stream.
表 31: 并行流可视化示例,段落采样自wikitext (Merity et al., 2016)。相同颜色的Token表示它们主要由同一流生成。
| P=2 | 萨默塞特队在特立尼达和多巴哥队赢得最后一场小组赛击败德干队后晋级第二轮比赛,但失去了因病情复发而飞回家的特雷斯科西克。顶替特雷斯科西克上场的韦斯·德斯顿 |
|---|---|
| 在下一场比赛中为萨默塞特队拿下最高分57分。该郡只有另外两名球员得分上双,钻石鹰队以剩余8个球的优势追平总分。萨默塞特队进入最后一场对阵新 | |
| P=4 | 萨默塞特队在特立尼达和多巴哥队赢得最后一场小组赛击败德干队后晋级第二轮比赛,但失去了因病情复发而飞回家的特雷斯科西克。顶替特雷斯科西克上场的韦斯·德斯顿在下一场比赛中为萨默塞特队拿下最高分57分。该郡只有另外两名球员得分上双,钻石鹰队以剩余8个球的优势追平总分。萨默塞特队带着微弱的数学晋级概率进入最后一场对阵新南威尔士蓝队的比赛,但布雷特·李和斯图尔特·克拉克的强势投球表现将萨默塞特队限制在111分 |
| P=8 | 澳大利亚队轻松达成目标。萨默塞特队在特立尼达和多巴哥队赢得最后一场小组赛击败德干队后晋级第二轮比赛,但失去了因病情复发而飞回家的特雷斯科西克。顶替特雷斯科西克上场的韦斯·德斯顿在下一场比赛中为萨默塞特队拿下最高分57分。该郡只有另外两名球员得分上双,钻石鹰队以剩余8个球的优势追平总分。萨默塞特队带着微弱的数学晋级概率进入最后一场对阵新南威尔士蓝队的比赛,但布雷特·李和斯图尔特·克拉克的强势投球表现将萨默塞特队限制在111分 |
Table 32: Parallel stream visualization, where paragraphs are sampled from GSM8K (Cobbe et al., 2021). Tokens with the same color indicate they are primarily contributed by the same stream.
表 32: 并行流可视化示例,段落采样自GSM8K数据集 (Cobbe et al., 2021)。相同颜色的Token表示它们主要由同一流生成。
| P=2 | 问题:面包师按照配方制作面包,每2杯面粉需要使用3个鸡蛋。如果他想用完食品柜里剩余的6杯面粉,需要多少个鸡蛋?答案:若使用6杯面粉,面包师需要制作6/2=<<6/2=3>>3倍于配方标准的量。因此他需要使用3*3=<<3*3=9>>9个鸡蛋。#### 9 |
| P=4 | 问题:面包师按照配方制作面包,每2杯面粉需要使用3个鸡蛋。如果他想用完食品柜里剩余的6杯面粉,需要多少个鸡蛋?答案:若使用6杯面粉,面包师需要制作6/2=<<6/2=3>>3倍于配方标准的量。因此他需要使用3*3=<<3*3=9>>9个鸡蛋。#### 9 |
| P=8 | 问题:面包师按照配方制作面包,每2杯面粉需要使用3个鸡蛋。如果他想用完食品柜里剩余的6杯面粉,需要多少个鸡蛋?答案:若使用6杯面粉,面包师需要制作6/2=<<6/2=3>>3倍于配方标准的量。因此他需要使用3*3=<<3*3=9>>个鸡蛋。.#### |
Table 33: Parallel stream visualization, where paragraphs are sampled from RACE (Lai et al., 2017). Tokens with the same color indicate they are primarily contributed by the same stream.
表 33: 并行流可视化示例,段落采样自RACE数据集 (Lai et al., 2017)。相同颜色的Token表示它们主要由同一流贡献。
| P=2 | 《神秘宇宙》Ellen Jackson与Nic Bishop著 宇宙猎人Alex Filippenko如何希望超新星能帮助我们解答这些问题。但首先我们必须找到它们!跟随Alex和他的团队,看他们如何用巨型望远镜和计算机阵列展开搜寻。《阿尔伯特叔叔的时空》Russell Stannard著 如果叔叔问你是否想去太空,你会怎么回答?你会像故事里的小女孩一样说:"什么时候出发?" Gedanken正飞速穿越宇宙,试图帮助叔叔解答 |
| P=4 | 与能打开宇宙任意之门的计算机Cosmos一起探索太空的乐趣时,一切都开始出错。《神秘宇宙》Ellen Jackson与Nic Bishop著 宇宙猎人Alex Filippenko如何希望超新星能帮助我们解答这些问题。但首先我们必须找到它们!跟随Alex和他的团队,看他们如何用巨型望远镜和计算机阵列展开搜寻。《阿尔伯特叔叔的时空》Russell Stannard著 如果叔叔问你是否想去太空,你会怎么回答?你会像故事里的小女孩一样说:"什么时候出发?" Gedanken正飞速穿越宇宙,试图帮助叔叔解答 途中她还发现了如何增重却不发胖,如何永生而不自知,以及高速运动时可能发生的奇异现象。《乔治的宇宙秘密钥匙》Lucy Hawking与Stephen Hawking著 当George追着宠物猪穿过篱笆洞时,他完全没想到自己很快会骑着彗星绕土星飞行。但就在他发现 |
| P=8 | 《神秘宇宙》Ellen Jackson与Nic Bishop著 宇宙如何起源?它有多大?什么是暗物质?宇宙学家兼超新星猎手Alex Filippenko希望超新星能帮助我们解答这些问题。但首先我们必须找到它们!跟随Alex和他的团队,看他们如何用巨型望远镜和计算机阵列展开搜寻。《阿尔伯特叔叔的时空》Russell Stannard著 如果叔叔问你是否想去太空,你会怎么回答?你会像故事里的小女孩一样说:"什么时候出发?" Gedanken正飞速穿越宇宙,试图帮助叔叔解答 诸如"太空有多大?"和"重力从何而来?"等问题。途中她还发现了如何增重却不发胖,如何永生而不自知,以及高速运动时可能发生的奇异现象。《乔治的宇宙秘密钥匙》Lucy Hawking与Stephen Hawking著 当George追着宠物猪穿过篱笆洞时,他完全没想到自己很快会骑着彗星绕土星飞行。但就在他与能打开 |