From Poses to Identity: Training-Free Person Re-Identification via Feature Centralization
从姿态到身份:基于特征中心化的免训练行人重识别
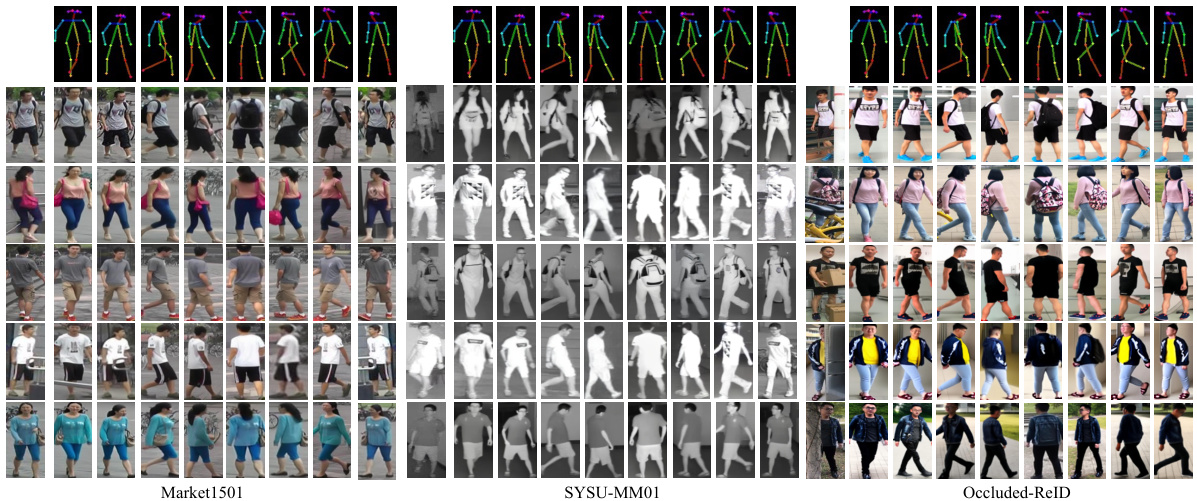
Figure 1. Visualization of our Identity-Guided Pedestrian Generation model with 8 representative poses on three datasets.
图 1: 我们的身份引导行人生成模型在三个数据集上8种代表性姿态的可视化效果。
Abstract
摘要
Person re-identification (ReID) aims to extract accurate identity representation features. However, during feature extraction, individual samples are inevitably affected by noise (background, occlusions, and model limitations). Considering that features from the same identity follow a normal distribution around identity centers after training, we propose a Training-Free Feature Centralization ReID framework (Pose2ID) by aggregating the same identity features to reduce individual noise and enhance the stability of identity representation, which preserves the feature’s original distribution for following strategies such as re-ranking. Specifically, to obtain samples of the same identity, we introduce two components: ➀Identity-Guided Pedestrian Generation: by leveraging identity features to guide the generation process, we obtain high-quality images with diverse poses, ensuring identity consistency even in complex scenarios such as infrared, and occlusion. Neighbor Feature Centralization: it explores each sample’s potential positive samples from its neighborhood. Experiments demonstrate that our generative model exhibits strong generalization capabilities and maintains high identity consistency. With the Feature Centralization framework, we achieve impressive performance even with an ImageNet pre-trained model without ReID training, reaching mAP/Rank-1 of $52.8I/78.92$ on Market1501. Moreover, our method sets new state-of-the-art results across standard, cross-modality, and occluded ReID tasks, showcasing strong adaptability.
行人重识别(ReID)旨在提取准确的身份表征特征。然而在特征提取过程中,个体样本难免会受到噪声(背景、遮挡和模型局限)的影响。考虑到训练后同一身份的特征会围绕身份中心呈正态分布,我们提出了一种免训练特征中心化ReID框架(Pose2ID),通过聚合相同身份特征来降低个体噪声并增强身份表征的稳定性,同时保留特征的原始分布以支持重排序等后续策略。具体而言,为获取同身份样本,我们引入两个组件:①身份引导的行人生成:通过身份特征指导生成过程,获得具有多样姿态的高质量图像,即使在红外、遮挡等复杂场景下也能保持身份一致性;②邻域特征中心化:从样本邻域中挖掘潜在正样本。实验表明,我们的生成模型展现出强大的泛化能力并保持高度身份一致性。借助特征中心化框架,仅使用ImageNet预训练模型(未经ReID训练)即可在Market1501上取得52.8%/78.92%的mAP/Rank-1优异表现。此外,本方法在标准、跨模态和遮挡ReID任务中均刷新了当前最优性能,展现出强大的适应性。
1. Introduction
1. 引言
Person re-identification (ReID) is a critical task in video surveillance and security, aiming to match pedestrian images captured from different cameras. Despite significant progress made in recent years through designing more complex models with increased parameters and feature dimensions, inevitable noise arises due to poor image quality or inherent limitations of the models, reducing the accuracy of identity recognition and affecting retrieval performance.
行人重识别(ReID)是视频监控与安防领域的关键任务,旨在匹配不同摄像头拍摄的行人图像。尽管近年来通过设计参数更多、特征维度更高的复杂模型取得了显著进展,但由于图像质量不佳或模型固有局限性,不可避免地会产生噪声,从而降低身份识别的准确性并影响检索性能。
To address this challenge, we propose a training-free
为解决这一挑战,我们提出了一种免训练
ReID framework that fully leverages capabilities of existing models by mitigating feature noise to enhance identity represent ation. During training, features of the same identity are constrained by the loss function and naturally aggregate around an ”identity center” in the feature space. Particularly, according to the central limit theorem, when the number of samples is sufficiently large, these features would follow a normal distribution with identity center as the mean. As shown in Fig. 2, we visualize the feature distribution of an identity, and rank samples of the same identity with distance to their identity center. Therefore, we introduce the concept of feature centralization. To make each sample’s feature more representative of its identity, by aggregating features of the same identity, we can reduce the noise in individual samples, strengthen identity characteristics, and bring each feature dimension closer to its central value.
通过抑制特征噪声增强身份表征的ReID框架,充分发挥现有模型潜力。训练过程中,同一身份的特征受损失函数约束,自然聚集在特征空间的"身份中心"周围。根据中心极限定理,当样本量足够大时,这些特征会呈正态分布,身份中心即为均值。如图2所示,我们可视化某身份的特征分布,并按样本与身份中心的距离排序。由此引入特征中心化概念:通过聚合同身份特征,可降低单一样本噪声、强化身份特征,使各特征维度更趋近中心值。
However, obtaining diverse samples of the same identity is hard without identity labels. With the development of generative models, generating images of the same identity in different poses has become feasible. Previous GAN-based studies [13, 43, 72, 73] struggle with limited effectiveness, and mainly serve to augment training data. With breakthroughs in diffusion models for image generation [2, 19, 66], it is now possible to generate high-quality, multi-pose images of the same person. However, these methods lack effective control over identity features and generated pedestrian images are susceptible to interference from background or occlusions, making it difficult to ensure identity consistency across poses. Therefore, we utilize identity features of ReID, proposing an Identity-Guided Pedestrian Generation paradigm. Guided by identity features, we generate high-quality images of the same person with a high degree of identity consistency across diverse scenarios (visible, infrared, and occluded).
然而,在没有身份标签的情况下获取同一身份的不同样本十分困难。随着生成模型的发展,生成不同姿态的同一身份图像已成为可能。先前基于GAN的研究[13, 43, 72, 73]受限于生成效果,主要作为训练数据扩充手段。随着扩散模型在图像生成领域的突破[2, 19, 66],如今已能生成高质量、多姿态的同一人物图像。但这些方法对身份特征缺乏有效控制,生成的行人图像易受背景或遮挡干扰,难以保证跨姿态的身份一致性。为此,我们利用ReID的身份特征,提出身份引导的行人生成范式。在身份特征引导下,我们生成具有高度身份一致性的高质量图像,适用于多场景(可见光、红外及遮挡情况)。
Furthermore, inspired by re-ranking mechanisms[74], we explore potential positive samples through feature distance matrices to further achieve feature centralization. Unlike traditional re-ranking methods that modify features or distances in a one-off manner, our approach performs L2 normalization after enhancement. This preserves the original feature distribution while improving representation quality and can be combined with re-ranking methods.
此外,受重排序机制[74]启发,我们通过特征距离矩阵探索潜在正样本,以进一步实现特征中心化。与传统重排序方法一次性修改特征或距离不同,我们的方法在增强后执行L2归一化。这既保留了原始特征分布,又提升了表征质量,并能与重排序方法结合使用。
Thus, the main contributions of this paper include: • Training-Free Feature Centralization framework that can be directly applied to different ReID tasks/models, even an ImageNet pretrained ViT without ReID training; • Identity-Guided Pedestrian Generation (IPG) paradigm, leveraging identity features to generate high-quality images of the same identity in different poses to achieve feature centralization; • Neighbor Feature Centralization (NFC) based on sample’s neighborhood, discovering hidden positive samples from gallery/query set to achieve feature centralization.
因此,本文的主要贡献包括:
- 无需训练的特征中心化框架 (Training-Free Feature Centralization),可直接应用于不同的行人重识别 (ReID) 任务/模型,甚至未经ReID训练的ImageNet预训练ViT;
- 身份引导的行人生成范式 (Identity-Guided Pedestrian Generation, IPG),利用身份特征生成同一身份不同姿态的高质量图像以实现特征中心化;
- 基于样本邻域的邻居特征中心化 (Neighbor Feature Centralization, NFC),从候选集/查询集中发掘隐藏的正样本以实现特征中心化。
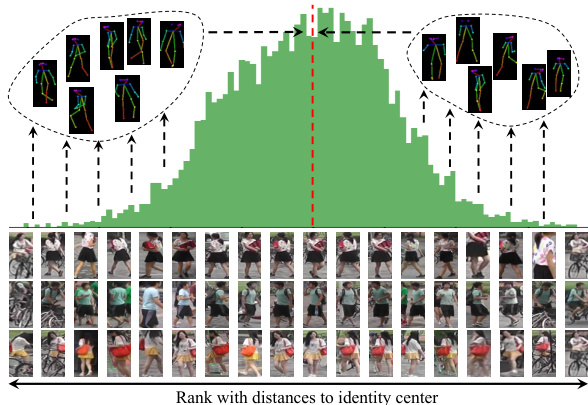
Figure 2. The real feature distribution of images from the same ID extracted by TransReID, and the main idea of our work is to make features closer/centralized to the ID center.
图 2: TransReID提取的同ID图像真实特征分布,我们工作的核心思想是使特征更接近/集中于ID中心。
2. Related works
2. 相关工作
Person Re-Identification Person re-identification (ReID) is a critical task in computer vision that focuses on identifying individuals across different camera views. It plays a significant role in surveillance and security applications. Recent advancements in ReID have leveraged deep learning techniques to enhance performance, particularly using convolutional neural networks (CNNs[29]) and vision transformers (ViTs [2]). The deep learning based methods[3, 11, 17, 30, 35, 48, 64, 65] that focus on feature extraction and metric learning[18, 28, 34, 62] have improved feature extraction by learning robust and disc rim i native embeddings that capture identity-specific information.
人员重识别
人员重识别(ReID)是计算机视觉中的一项关键任务,主要研究如何在不同摄像头视角下识别同一目标个体。该技术在监控安防领域具有重要应用价值。近年来,ReID领域通过采用深度学习技术显著提升了性能,特别是运用卷积神经网络(CNNs[29])和视觉Transformer(ViTs[2])。基于深度学习的方法[3,11,17,30,35,48,64,65]聚焦于特征提取和度量学习[18,28,34,62],通过学习具有判别力的鲁棒嵌入特征来捕获身份信息,从而改进了特征提取能力。
Standard datasets like Market-1501 [70] have been widely used to benchmark ReID algorithms under normal conditions. Moreover, there are some challenging scenarios such as occlusions and cross-modality matching. OccludedREID [78] addresses the difficulties of identifying partially obscured individuals, while SYSU-MM01 [55] focuses on matching identities between visible and infrared images, crucial for nighttime surveillance.
标准数据集如Market-1501 [70]已被广泛用于常规条件下的ReID算法基准测试。此外,还存在一些挑战性场景,例如遮挡和跨模态匹配。OccludedREID [78]解决了识别部分遮挡个体的难题,而SYSU-MM01 [55]则专注于可见光与红外图像间的身份匹配,这对夜间监控至关重要。
Feature Enhancement in Re-Identification Extracting robust feature representations is one of the key challenges in re-identification. Feature enhancement could help the ReID model easily differentiate between two people. Data augmentation techniques[40, 41, 76] were enhanced for feature enhancement. By increasing the diversity of training data, ReID model could extract robust and disc rim i native features.
重识别中的特征增强
提取鲁棒的特征表示是重识别中的关键挑战之一。特征增强可以帮助ReID模型更轻松地区分两个人。数据增强技术[40, 41, 76]被用于增强特征。通过增加训练数据的多样性,ReID模型可以提取出鲁棒且具有判别性的特征。
Apart from improving the quality of the generated images, some Gan-based methods couple feature extraction and data generation end-to-end to distill identity related feature. FD-GAN[13] separates identity from the pose by generating images across multiple poses, enhancing the ReID system’s robustness to pose changes. Zheng et al.[73] separately encodes each person into an appearance code and a structure code. Eom el al.[8] propose to disentangle identity-related and identity-unrelated features from person images. However, GAN-based methods face challenges such as training instability and mode collapse, which may not keep identity consistency.
除了提升生成图像的质量外,一些基于GAN的方法将特征提取与数据生成端到端耦合,以蒸馏身份相关特征。FD-GAN[13]通过生成多姿态图像分离身份与姿态,增强了ReID系统对姿态变化的鲁棒性。Zheng等[73]将每个人分别编码为外观代码和结构代码。Eom等[8]提出从人物图像中解耦身份相关与身份无关特征。然而,基于GAN的方法面临训练不稳定和模式坍塌等挑战,可能无法保持身份一致性。
In addition, the re-ranking technique refines featurebased distances to improve ReID accuracy. Such as $\mathrm{k\Omega}$ - Reciprocal Encoding Re-ranking[74], which improves retrieval accuracy by leveraging the mutual neighbors between images to refine the distance metric.
此外,重排序技术通过优化基于特征的距离来提高ReID(行人重识别)准确率。例如kΩ-互逆编码重排序[74],该方法利用图像间的互近邻关系优化距离度量,从而提升检索精度。
Person Generation Models Recent approaches have incorporated generative models, particularly generative adversarial networks (GANs) [14], to augment ReID data or enhance feature quality. Style transfer GAN-based methods[7, 21, 42, 75] transfer labeled training images to artificially generated images in diffrent camera domains, background domains or RGB-infrared domains. Posetransfer GAN-based methods[5, 36, 43, 45, 63] enable the synthesis of person images with variations in pose and appearance, enriching the dataset and making feature representations more robust to changes in poses. Random generation GAN-based mothods [1, 23, 72] generate random images of persons and use Label Smooth Regular iz ation (LSR [50]) or other methods to automatically label them. However, these methods often struggle to maintain identity consistency in pose variation, as generated images are susceptible to identity drift. The emergence of diffusion models has advanced the field of generative modeling, showing remarkable results in image generation tasks [19]. Leveraging the capabilities of pre-trained models like Stable Diffusion [44], researchers have developed techniques[4, 66] to generate high-quality human images conditioned on 2D human poses. Such as ControlNet[66], which integrates conditional control into diffusion models, allowing precise manipulation of generated images based on pose inputs.
人物生成模型
近期研究采用生成式模型,特别是生成对抗网络 (GAN) [14] 来扩充ReID数据或提升特征质量。基于风格迁移的GAN方法 [7, 21, 42, 75] 将标注训练图像转换到不同摄像机域、背景域或RGB-红外域的人工生成图像中。基于姿态迁移的GAN方法 [5, 36, 43, 45, 63] 能合成具有姿态和外观变化的人物图像,丰富数据集并增强特征表示对姿态变化的鲁棒性。基于随机生成的GAN方法 [1, 23, 72] 生成随机人物图像,并使用标签平滑正则化 (LSR [50]) 等方法进行自动标注。但这些方法往往难以保持姿态变化中的身份一致性,生成图像易出现身份漂移。
扩散模型的出现推动了生成建模领域发展,在图像生成任务中展现出卓越效果 [19]。研究者利用Stable Diffusion [44] 等预训练模型的能力,开发出基于2D人体姿态生成高质量人物图像的技术 [4, 66]。例如ControlNet [66] 将条件控制融入扩散模型,可根据姿态输入精确操控生成图像。
3. Methods
3. 方法
The main purpose of this paper is to centralize features to their identity center to enhance the identity representation of feature vectors extracted by ReID model, that is, reducing noise within the features while increasing the identity attributes to make them more representative of their identities. Therefore, to effectively and reasonably enhance the features, we need to understand the characteristics of the feature vectors obtained by ReID model.
本文的主要目的是将特征集中到其身份中心,以增强ReID模型提取的特征向量的身份表征能力,即减少特征中的噪声,同时增加身份属性,使其更能代表各自的身份。因此,为了有效且合理地增强特征,我们需要了解ReID模型所获取特征向量的特性。
3.1. Feature Distribution Analysis
3.1. 特征分布分析
Currently, ReID models commonly use cross-entropy loss to impose ID-level constraints, and contrastive losses (such as triplet loss) to bring features of the same ID closer while pushing apart features of different IDs. Some models also utilize center loss to construct identity centers for dynamically constraining the IDs. These methods lead to one common result: feature aggregation. One can say that the current ReID task is essentially a feature aggregation task. The degree of feature density (e.g. t-SNE visualization) is also widely used to measure model performance. It is easy to deduce that the features of the same ID are centered around a ”mean,” approximately forming a normal distribution, as the distribution shown in Fig.2 which is visualized with one single feature dimension of the same ID.
目前,ReID模型通常使用交叉熵损失(cross-entropy loss)施加ID级别的约束,并采用对比损失(如三元组损失)使相同ID的特征相互靠近,同时推远不同ID的特征。部分模型还利用中心损失(center loss)构建身份中心来动态约束ID。这些方法导致一个共同结果:特征聚合。可以说当前的ReID任务本质上是一个特征聚合任务。特征密集程度(如t-SNE可视化)也被广泛用于衡量模型性能。容易推断出,同一ID的特征会围绕一个"均值"集中,近似形成正态分布,如图2所示(通过同一ID的单个特征维度可视化呈现的分布)。
It is evident that ReID features are normally distributed around the ‘identity center’. To theoretically prove that the feature vectors of each ID in current ReID tasks aggregation around a center or mean, we analyze several commonly used loss functions and their impact on the feature distribution in Supplementary.
显然,ReID特征通常围绕"身份中心"呈正态分布。为了从理论上证明当前ReID任务中每个ID的特征向量都围绕某个中心或均值聚集,我们在补充材料中分析了几种常用损失函数及其对特征分布的影响。
For the same identity $y_{i}=j$ , we have a large number of samples ${\mathbf{x}{i}}{i=1}^{N_{j}}$ , where $N_{j}$ is the number of samples for $\operatorname{ID}j$ . These samples are passed through a ReID model $f(\cdot)$ , resulting in the corresponding feature vectors ${\mathbf{f}{i}}{i=1}^{N_{j}}$ :
对于同一身份 $y_{i}=j$,我们拥有大量样本 ${\mathbf{x}{i}}{i=1}^{N_{j}}$,其中 $N_{j}$ 表示 $\operatorname{ID}j$ 的样本数量。这些样本通过 ReID (Re-identification) 模型 $f(\cdot)$ 处理后,生成对应的特征向量 ${\mathbf{f}{i}}{i=1}^{N_{j}}$:
$$
\mathbf{f}{i}=f({\mathbf{x}}_{i})
$$
$$
\mathbf{f}{i}=f({\mathbf{x}}_{i})
$$
where $\mathbf{f}{i}\in\mathbb{R}^{d}$ is the feature vector of sample $\mathbf{x}_{i}$ , and $d$ is the dimensionality of the feature space.
其中 $\mathbf{f}{i}\in\mathbb{R}^{d}$ 是样本 $\mathbf{x}_{i}$ 的特征向量,$d$ 为特征空间的维度。
For each feature dimension $k$ of the feature vector $\mathbf{f}{i}$ , the values ${\mathbf{f}{i,k}}{i=1}^{N_{j}}$ obtained from different samples of the same $\operatorname{ID}j$ is independent and identically distributed random variables. Here, $\mathbf{f}_{i,k}$ represents the $k$ -th dimension of the feature vector for the $i$ -th sample.
对于特征向量 $\mathbf{f}{i}$ 的每个特征维度 $k$,从同一 $\operatorname{ID}j$ 的不同样本中获取的值 ${\mathbf{f}{i,k}}{i=1}^{N_{j}}$ 是独立同分布的随机变量。其中,$\mathbf{f}_{i,k}$ 表示第 $i$ 个样本特征向量的第 $k$ 维。
Since the input samples are independent, the values of are independent factors. According to the Central Limit Theorem (CLT), when the number of independent factors is large, the distribution of the values ${\mathbf{f}{i,k}^{-}}{i=1}^{N_{j}}$ for any dimension $k$ of the feature vector will approximate a normal distribution. Thus, for each feature dimension $k$ , we have:
由于输入样本 是独立的,其对应的值也是独立因子。根据中心极限定理 (CLT),当独立因子的数量较大时,特征向量任意维度 $k$ 的取值 ${\mathbf{f}{i,k}^{-}}{i=1}^{N_{j}}$ 将近似服从正态分布。因此,对于每个特征维度 $k$,我们有:
$$
\mathbf{f}{i,k}\sim\mathcal{N}(\mu_{k},\sigma_{k}^{2})
$$
$$
\mathbf{f}{i,k}\sim\mathcal{N}(\mu_{k},\sigma_{k}^{2})
$$
where $\mu_{k}$ is the mean of the $k$ -th feature dimension for ID $\mathrm{f}j$ , and $\sigma_{k}^{2}$ is the variance of feature values in this dimension.
其中 $\mu_{k}$ 是ID $\mathrm{f}j$ 第 $k$ 个特征维度的均值,$\sigma_{k}^{2}$ 是该维度特征值的方差。
Since each dimension $\mathbf{f}{i,k}$ of the feature vector approximately follows a normal distribution across samples, the entire feature vector $\mathbf{f}_{i}$ for $\mathrm{ ID~}j$ can be approximated by a multivariate normal distribution. This gives:
由于特征向量 $\mathbf{f}{i,k}$ 的每个维度在样本间近似服从正态分布,因此 $\mathrm{ ID~}j$ 的整个特征向量 $\mathbf{f}_{i}$ 可用多元正态分布近似表示,即:
$$
\mathbf{f}_{i}\sim\mathcal{N}(\pmb{\mu},\Sigma)
$$
$$
\mathbf{f}_{i}\sim\mathcal{N}(\pmb{\mu},\Sigma)
$$
where $\pmb{\mu}=(\mu_{1},\mu_{2},\dots,\mu_{d})^{\top}$ is the mean vector of the feature dimensions, and $\Sigma$ is the covariance matrix.
其中 $\pmb{\mu}=(\mu_{1},\mu_{2},\dots,\mu_{d})^{\top}$ 是特征维度的均值向量,$\Sigma$ 是协方差矩阵。
The theoretical analysis above suggests that under the optimization of the loss functions, the ReID model’s feature vectors $\mathbf{x}{i}$ aggregated around their identity centers $\mathbf{c}{y_{i}}$ following a normal distribution. This is consistent with the feature aggregation observed in t-SNE visualization s.
上述理论分析表明,在损失函数优化过程中,ReID模型的特征向量$\mathbf{x}{i}$会围绕其身份中心$\mathbf{c}{y_{i}}$呈正态分布聚集,这与t-SNE可视化中观察到的特征聚集现象一致。
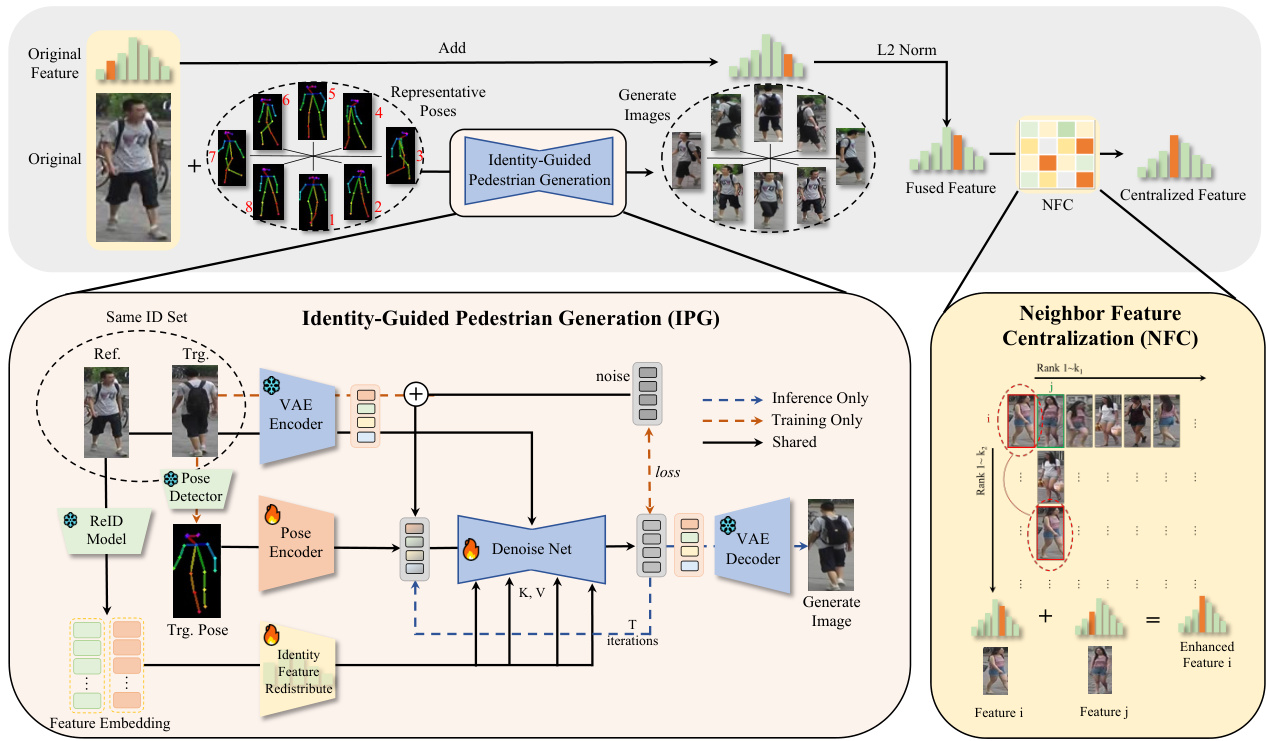
Figure 3. Overview of the proposed Feature Centralization framework for the ReID task.
图 3: 面向ReID任务提出的特征中心化(Feature Centralization)框架概览。
Identity Density $(\mathbf{ID}^{2})$ Metric Identity density is one aspect of measuring ReID effectiveness. However, there is currently no quantitative metric for this, and researchers commonly rely on visualization tools like t-SNE to demonstrate model performance. By using the concept above, we propose an Identity Density $\mathrm{\dot{(ID^{2})}}$ Metric which is detailed in Supplementary.
身份密度 $(\mathbf{ID}^{2})$ 指标
身份密度是衡量ReID效果的一个方面。但目前尚无量化指标,研究人员通常依赖t-SNE等可视化工具来展示模型性能。基于上述概念,我们提出了一种身份密度 $\mathrm{\dot{(ID^{2})}}$ 指标,具体细节详见补充材料。
3.2. Feature Centralization via Identity-Guided Pedestrian Generation
3.2. 基于身份引导的行人生成特征中心化
3.2.1. Feature Centralization
3.2.1. 特征中心化
Since features of the same identity follow a multivariate normal distribution, we can simply aggregate features of the same identity to approximate the identity center, as the visualization in Fig.2. Thus, our main purpose becomes how to get more samples of the same identity to help centralize features.
由于同一身份的特征服从多元正态分布,我们可以简单地聚合同一身份的特征来近似身份中心,如图2所示。因此,我们的主要目标变为如何获取更多同一身份的样本来帮助集中特征。
A straightforward approach is to perform horizontal flipping on the original images, and add features together. It is worth noting for reviewers that this is a very simple but effective trick. Therefore, it is necessary to check whether performance improvements are due to such tricks. In our experiments, to demonstrate the advancement of our approach, we did not use this trick. If used, it may be better.
一种直接的方法是对原始图像进行水平翻转,并将特征相加。值得评审注意的是,这是一个非常简单但有效的技巧。因此,有必要检查性能提升是否源自此类技巧。在我们的实验中,为了证明所提方法的先进性,我们未使用该技巧。若采用该技巧,效果可能会更好。
3.2.2. Identity-Guided Diffusion Process
3.2.2. 身份引导扩散过程
To get more samples from the same identity, we propose a novel Identity-Guided Pedestrian Generation (IPG) paradigm, generating images of the same identity with different poses using a Stable Diffusion model guided by identity feature to centralize each sample’s features.
为了从同一身份获取更多样本,我们提出了一种新颖的身份引导行人生成(IPG)范式,通过身份特征引导的Stable Diffusion模型生成具有不同姿态的同一身份图像,以集中每个样本的特征。
Followed by Stable Diffusion [44], which is developed from latent diffusion model (LDM). We use the reference UNet to inject the reference image features into the diffusion process with a constant timestep $t=0$ , and the denoising UNet $\epsilon_{\theta}$ to generate the target image latent $\mathbf{z_{0}}$ by denoising the noisy latent $\mathbf{z}_{\mathbf{T}}=\mathbf{\epsilon}$ :
继Stable Diffusion [44]之后,该模型基于潜在扩散模型(LDM)开发。我们使用参考UNet在扩散过程中以恒定时间步长$t=0$注入参考图像特征,并通过去噪UNet $\epsilon_{\theta}$对噪声潜在表示$\mathbf{z}{\mathbf{T}}=\mathbf{\epsilon}$进行去噪,生成目标图像潜在表示$\mathbf{z_{0}}$
$$
{\bf z}{t-1}=\epsilon_{\theta}({\bf z}{t},t,{\bf E_{\mathrm{pose}}},{\bf H}),t\in[0,T]
$$
$$
{\bf z}{t-1}=\epsilon_{\theta}({\bf z}{t},t,{\bf E_{\mathrm{pose}}},{\bf H}),t\in[0,T]
$$
where $\mathbf{H}$ is the identity feature information to guide model keep person identity. $\mathbf{E}_{\mathrm{pose}}$ is the pose features.
其中 $\mathbf{H}$ 是用于引导模型保持人物身份的特征信息,$\mathbf{E}_{\mathrm{pose}}$ 是姿态特征。
At each timestep $t$ , the pose feature $\mathbf{E}_{\mathrm{pose}}$ and conditioning embedding $\mathbf{H}$ guide the denoising process.
在每个时间步 $t$,姿态特征 $\mathbf{E}_{\mathrm{pose}}$ 和条件嵌入 $\mathbf{H}$ 会引导去噪过程。
Identity Feature Redistribute (IFR) The Identity Feature Redistribute (IFR) module aims to utilize identity features from input images, removing noise to better guide the generative model. It converts high-dimensional identity features into meaningful low-dimensional feature blocks, enhancing the model’s feature utilization efficiency.
身份特征重分配 (IFR)
身份特征重分配 (IFR) 模块旨在利用输入图像中的身份特征,通过去除噪声来更好地指导生成模型。它将高维身份特征转换为有意义的低维特征块,从而提升模型的特征利用效率。
Given the input sample $\mathbf{x}\in\mathbb{R}^{C}$ by a ReID model $f(\cdot)$ , with IFR, we can obtain a re-distributed robust feature $\mathbf{H}\in$ $\mathbb{R}^{N\times D})$ :
给定输入样本 $\mathbf{x}\in\mathbb{R}^{C}$ 通过 ReID 模型 $f(\cdot)$ ,利用 IFR 可获得重分布的鲁棒特征 $\mathbf{H}\in$ $\mathbb{R}^{N\times D})$ :
$$
\mathbf{H}=\mathrm{IFR}(f(\mathbf{x}))=\mathrm{LN}(\mathrm{Linear}(\mathbf{f}))
$$
$$
\mathbf{H}=\mathrm{IFR}(f(\mathbf{x}))=\mathrm{LN}(\mathrm{Linear}(\mathbf{f}))
$$
For this more robust feature identity feature, it is used as the K, V of the model’s attention module to guide the model’s attention to the identity feature.
对于这一更稳健的身份特征,它被用作模型注意力模块的 K、V,以引导模型关注身份特征。
Pose Encoder The Pose Encoder is to extract highdimensional pose embeddings $\mathbf{E}_{\mathrm{pose}}$ from input poses. It has 4 blocks with 16,32,64,128 channels. Each block applies a normal $3\times3$ Conv, a $3\times3$ Conv with stride 2 to reduce spatial dimensions, and followed by a SiLU activate function. Subsequently, the pose features are added to the noise latent before into the denoising UNet, follows [20].
姿态编码器 (Pose Encoder) 用于从输入姿态中提取高维姿态嵌入 $\mathbf{E}_{\mathrm{pose}}$。它包含4个通道数分别为16、32、64、128的模块。每个模块依次执行常规 $3\times3$ 卷积、步长为2的 $3\times3$ 卷积(用于降低空间维度)以及SiLU激活函数。随后,这些姿态特征会按照[20]的方法被添加到噪声潜变量中,再输入去噪UNet网络。
Training Strategy For each identity $i$ , we randomly select one image from $S_{i}^{\mathrm{ref}}$ as the reference image and one image from S $S_{i}^{\mathrm{trg}}$ as the target image for training.
训练策略
对于每个身份 $i$,我们从 $S_{i}^{\mathrm{ref}}$ 中随机选择一张图像作为参考图像,并从 $S_{i}^{\mathrm{trg}}$ 中随机选择一张图像作为训练目标图像。
Let ${\bf x}{i,j}^{\mathrm{ref}}\in S_{i}^{\mathrm{ref}}$ denote the reference image (i.e. $j_{t h}$ image of the $i_{t h}\mathrm{ID},$ ) and $\mathbf{x}{i,j}^{\mathrm{trg}}\in S_{i}^{\mathrm{trg}}$ Sitrg denote the target image. Model is trained using the mean squared error (MSE) loss between the predicted noise and the true noise.
设 ${\bf x}{i,j}^{\mathrm{ref}}\in S_{i}^{\mathrm{ref}}$ 表示参考图像 (即第 $i$ 个ID的第 $j$ 张图像),$\mathbf{x}{i,j}^{\mathrm{trg}}\in S_{i}^{\mathrm{trg}}$ 表示目标图像。模型通过预测噪声与真实噪声之间的均方误差 (MSE) 损失进行训练。
$$
\mathcal{L}=\mathbb{E}{\mathbf{z},t,\epsilon}\left[||\epsilon-\epsilon)\theta(\mathbf{z}{t},t,\mathbf{E}_{\mathrm{pose}},\mathbf{H})||^{2}\right]
$$
$$
\mathcal{L}=\mathbb{E}{\mathbf{z},t,\epsilon}\left[||\epsilon-\epsilon)\theta(\mathbf{z}{t},t,\mathbf{E}_{\mathrm{pose}},\mathbf{H})||^{2}\right]
$$
where $\textbf{z}=\mathrm{VAE}(\textbf x_{i,j}^{\mathrm{trg}})+\epsilon$ is a latent obtained by a pretrained VAE encoder[26], $\mathbf{E}{\mathrm{pose}}$ is the pose feature of $\mathbf{x}{i,j}^{\mathrm{trg}}$ ), $\mathbf{H}$ is the re-distributed identity feature of $(\mathbf{x}_{i,j}^{\mathrm{ref}})$ ).
其中 $\textbf{z}=\mathrm{VAE}(\textbf x_{i,j}^{\mathrm{trg}})+\epsilon$ 是通过预训练 VAE 编码器[26]获得的潜变量,$\mathbf{E}{\mathrm{pose}}$ 是 $\mathbf{x}{i,j}^{\mathrm{trg}}$ 的姿态特征,$\mathbf{H}$ 是 $(\mathbf{x}_{i,j}^{\mathrm{ref}})$ 重新分配的身份特征。
The model is trained to learn the mapping from the reference image $\mathbf{x}{\mathrm{ref}}$ to the target image $\mathbf{x}_{\mathrm{trg}}$ , with the goal of generating realistic variations in pose while preserving identity feature. This random selection ensures diversity during training, as different combinations of reference and target images are used in each training iteration, enhancing the model’s ability to generalize across various poses and viewpoints.
该模型通过学习从参考图像 $\mathbf{x}{\mathrm{ref}}$ 到目标图像 $\mathbf{x}_{\mathrm{trg}}$ 的映射,旨在生成姿态的真实变化同时保留身份特征。这种随机选择确保了训练过程中的多样性,因为每次训练迭代使用不同的参考图像和目标图像组合,从而增强了模型在不同姿态和视角下的泛化能力。
3.2.3. Selection of Representative Pose
3.2.3. 代表性姿态选择
In ReID tasks, features extracted from different poses of the same identity can vary significantly. Some specific poses tend to be more representative of that identity. As the conclusion of feature distribution in section3.1, we calculate the identity center for IDs with all of its samples in datasets, and select the image whose feature is the closest to the center. The pose of this image is regarded as the representative pose. By randomly selecting 8 representative poses with different directions, we generate images that are more represent at ive of the person’s identity.
在ReID任务中,同一身份的不同姿态所提取的特征可能存在显著差异。某些特定姿态往往更能代表该身份。如3.1节特征分布结论所示,我们为数据集中包含全部样本的ID计算身份中心点,并选择特征最接近中心的图像。该图像的姿态被视为代表性姿态。通过随机选取8个不同方向的代表性姿态,我们生成了更能体现人物身份特征的图像。
That is, given a set of feature vectors $\begin{array}{r l}{\mathbf{F}{\mathrm{all}}}&{{}=}\end{array}$ ${\mathbf{f}{1},\mathbf{f}{2},\ldots,\mathbf{f}_{N}}$ for a particular identity:
即给定特定身份的一组特征向量 $\begin{array}{r l}{\mathbf{F}{\mathrm{all}}}&{{}=}\end{array}$ ${\mathbf{f}{1},\mathbf{f}{2},\ldots,\mathbf{f}_{N}}$:
$$
\mathbf{f}{\mathrm{{mean}}}=\frac{1}{N}\sum_{i=1}^{N}\mathbf{f}_{i}
$$
$$
\mathbf{f}{\mathrm{{mean}}}=\frac{1}{N}\sum_{i=1}^{N}\mathbf{f}_{i}
$$
$$
\mathrm{pose}=\arg\operatorname*{min}{i}d(\mathbf{f}{\mathrm{mean}},\mathbf{f}_{i})
$$
$$
\mathrm{pose}=\arg\operatorname*{min}{i}d(\mathbf{f}{\mathrm{mean}},\mathbf{f}_{i})
$$
3.2.4. Feature Centralization Enhancement
3.2.4. 特征中心化增强
Once we got generated images with different poses, we generate new images $\hat{\bf x}$ for each of these poses. The features
一旦我们获得了不同姿势的生成图像,就会为每个姿势生成新图像 $\hat{\bf x}$。这些特征
extracted from these generated images are then aggregated with the original reference feature to enhance the overall representation. The centralized feature f is computed as:
从这些生成的图像中提取的特征随后与原始参考特征进行聚合,以增强整体表征。中心化特征f的计算公式为:
$$
\tilde{\mathbf{f}}=|\mathbf{f}+\frac{\eta}{M}\sum_{i=1}^{M}\mathbf{f}_{i}|_{2}
$$
$$
\tilde{\mathbf{f}}=|\mathbf{f}+\frac{\eta}{M}\sum_{i=1}^{M}\mathbf{f}_{i}|_{2}
$$
where $\mathbf{f}$ is the feature of the original reference image, and $\mathbf{f}_{i}$ are the features extracted from the $M$ generated images. The coefficient $\eta$ is introduced to adjust based on the quality of the generated images. According to the theory of Section3.1, low-quality generated images, as long as they contain corresponding identity information, can also be applied with feature enhancement, and use $\eta$ to regulate the enhancement effect of the generated information. As discussed in [72], even if the quality is poor, it still contains ID information.
其中 $\mathbf{f}$ 是原始参考图像的特征,$\mathbf{f}_{i}$ 是从 $M$ 张生成图像中提取的特征。系数 $\eta$ 用于根据生成图像的质量进行调整。根据第3.1节的理论,低质量的生成图像只要包含相应的身份信息,同样可以应用特征增强,并通过 $\eta$ 来调节生成信息的增强效果。如[72]所述,即使质量较差,这些图像仍包含ID信息。
3.3. Neighbor Feature Centralization (NFC)
3.3. 邻居特征中心化 (NFC)
Moreover, we proposed a Neighbor Feature Centralization (NFC) algorithm to reduce noise in individual features and improve their identity disc rim inability in unlabeled scenarios. The core idea of the algorithm is to utilize mutual nearest-neighbor features for aggregation.
此外,我们提出了一种邻域特征中心化 (NFC) 算法,用于在无标注场景下降低单个特征的噪声并提升其身份判别性。该算法的核心思想是利用互近邻特征进行聚合。
Algorithm 1 Neighbor Feature Centralization (NFC)
算法 1 邻域特征中心化 (NFC)
By enhancing each feature with its potential neighbors, it could effectively approximate features of the same identity without explicit labels, and ensure that only features have high similarity relationships contribute to the enhancement.
通过利用潜在相邻特征增强每个特征,该方法能有效逼近同一身份的特征而无需显式标注,并确保仅高相似度关系的特征参与增强。
Table 1. Improvements with our method on different SOTA models with both ViT and CNN backbone on Market1501, SYSU-MM01, and Occluded-ReID datasets. The data under grey is the new SOTA with our methods of that dataset.
| Dataset | Model | Venue | Base | Method | mAP↑ | Rank-1↑ | ID²↓ | |
| Market1501 | TransReID[16](w/o camid) | ICCV21 | ViT | official +ours | 79.88 90.39(+10.51) | 91.48 94.74(+3.26) | 0.2193 0.1357 | |
| TransReID[16](w/ camid) | official | 89 | 95.1 | 0.2759 | ||||
| +ours | 93.01(+4.01) | 95.52(+0.42) | 0.1967 | |||||
| CLIP-ReID[31] | AAAI23 | ViT | official | 89.7 | 95.4 | 0.0993 | ||
| +ours | 94(+4.3) | 96.4(+1.0) 0.0624 | ||||||
| CNN | official +ours | 89.8 94.9(+5.1) | 95.7 97.3(+1.6) | 0.0877 0.053 | ||||
| KPR[47] | ECCV24 | ViT | official | 79.05 | 85.4 | 0.3124 | ||
| +ours | 89.34(+10.29) | |||||||
| Occluded-ReID | BPBReID[46] | WACV23 | ViT | official +ours | 70.41 | 91(+5.6) 77.2 | 0.1434 0.377 | |
| 86.05(+15.64) | 89.1(+11.9) | 0.1504 | ||||||
| official | 71.81 | 75.29 0.4817 | ||||||
| All SYSU-MM01 | SAAI[9] | ICCV23 | CNN | +ours | 76.44(+4.63) | 79.33(+4.04) | 0.4072 | |
| Indoor | official | 84.6 | 81.59 | 0.4424 | ||||
| +ours | 86.83(+2.23) | 84.2(+2.61) | 0.3694 | |||||
| All | PMT[38] | AAAI23 | official | 66.13 | 67.7 | 0.4308 | ||
| ViT | 0.3133 | |||||||
| Indoor | +ours official | 75.43(+9.3) 77.81 | 74.81(+7.11) 72.95 | 0.4046 | ||||
| +ours | 84.29(+6.48) | 80.29(+7.34) | 0.2995 | |||||
表 1: 我们的方法在不同 SOTA (State-of-the-art) 模型上的改进效果,包括基于 ViT 和 CNN 骨干网络的 Market1501、SYSU-MM01 和 Occluded-ReID 数据集。灰色背景数据表示使用我们的方法后该数据集的新 SOTA 结果。
| 数据集 | 模型 | 会议 | 骨干网络 | 方法 | mAP↑ | Rank-1↑ | ID²↓ |
|---|---|---|---|---|---|---|---|
| Market1501 | TransReID[16](w/o camid) | ICCV21 | ViT | official +ours | 79.88 90.39(+10.51) | 91.48 94.74(+3.26) | 0.2193 0.1357 |
| TransReID[16](w/ camid) | official | 89 | 95.1 | 0.2759 | |||
| +ours | 93.01(+4.01) | 95.52(+0.42) | 0.1967 | ||||
| CLIP-ReID[31] | AAAI23 | ViT | official | 89.7 | 95.4 | 0.0993 | |
| +ours | 94(+4.3) | 96.4(+1.0) | 0.0624 | ||||
| CNN | official +ours | 89.8 94.9(+5.1) | 95.7 97.3(+1.6) | 0.0877 0.053 | |||
| KPR[47] | ECCV24 | ViT | official | 79.05 | 85.4 | 0.3124 | |
| +ours | 89.34(+10.29) | ||||||
| Occluded-ReID | BPBReID[46] | WACV23 | ViT | official +ours | 70.41 | 91(+5.6) 77.2 | 0.1434 0.377 |
| 86.05(+15.64) | 89.1(+11.9) | 0.1504 | |||||
| official | 71.81 | 75.29 | 0.4817 | ||||
| SYSU-MM01 (All) | SAAI[9] | ICCV23 | CNN | +ours | 76.44(+4.63) | 79.33(+4.04) | 0.4072 |
| (Indoor) | official | 84.6 | 81.59 | 0.4424 | |||
| +ours | 86.83(+2.23) | 84.2(+2.61) | 0.3694 | ||||
| (All) | PMT[38] | AAAI23 | official | 66.13 | 67.7 | 0.4308 | |
| ViT | 0.3133 | ||||||
| (Indoor) | +ours official | 75.43(+9.3) 77.81 | 74.81(+7.11) 72.95 | 0.4046 | |||
| +ours | 84.29(+6.48) | 80.29(+7.34) | 0.2995 |
Table 2. Ablation study on effects of feature centralization through Identity-Guided Pedestrian Generation (IPG) and Neighbor Feature Centralization (NFC).
| Methods | mAP↑ | Rank-1↑ | ID²↓ |
| Base | 79.88 | 91.48 | 0.2193 |
| +NFC | 83.92 | 91.83 | 0.1824 |
| +IPG | 88.02 | 94.77 | 0.1553 |
| +NFC+IPG | 90.39 | 94.74 | 0.1357 |
表 2: 通过身份引导行人生成 (IPG) 和邻域特征中心化 (NFC) 进行特征中心化效果的消融研究。
| 方法 | mAP↑ | Rank-1↑ | ID²↓ |
|---|---|---|---|
| Base | 79.88 | 91.48 | 0.2193 |
| +NFC | 83.92 | 91.83 | 0.1824 |
| +IPG | 88.02 | 94.77 | 0.1553 |
| +NFC+IPG | 90.39 | 94.74 | 0.1357 |
Table 3. Ablation study of Neighbor Feature Centralization (NFC) Algorithm on Market1501 dataset. We test on the gallery and query set respectively.
| GalleryNFC | QueryNFC | mAP↑ | Rank-1↑ |
| × | × | 79.88 | 91.48 |
| 81.70 | 92.04 | ||
| x | 82.76 | 91.69 | |
| √ | √ | 83.92 | 91.83 |
表 3: 邻域特征中心化 (NFC) 算法在 Market1501 数据集上的消融研究。我们分别在 gallery 和 query 集上进行了测试。
| GalleryNFC | QueryNFC | mAP↑ | Rank-1↑ |
|---|---|---|---|
| × | × | 79.88 | 91.48 |
| 81.70 | 92.04 | ||
| x | 82.76 | 91.69 | |
| √ | √ | 83.92 | 91.83 |
Table 4. Ablation study of Feature ID- Centralizing with Pedestrian Generation (IPG) on Market1501. We test on gallery and query set respectively.
| GalleryIPG | QueryIPG | mAP↑ | Rank-1↑ |
| x | × | 79.88 | 91.48 |
| 84.65 | 92.07 | ||
| x | 82.18 | 92.40 | |
| √ | √ | 88.02 | 94.77 |
表 4: 基于Market1501数据集的行人特征ID中心化生成(IPG)消融实验。我们分别在画廊集和查询集上进行测试。
| GalleryIPG | QueryIPG | mAP↑ | Rank-1↑ |
|---|---|---|---|
| × | × | 79.88 | 91.48 |
| 84.65 | 92.07 | ||
| × | 82.18 | 92.40 | |
| √ | √ | 88.02 | 94.77 |
Table 5. ReID performance on Market1501 with only ImageNet pre-trained weights without ReID training. The distribution visualized in Fig.4.
| Method | mAP↑ | R1↑ | R5个 | R10↑ | ID²← |
| w/o training | 3.34 | 11.4 | 21.88 | 28 | 0.5135 |
| +IPG | 52.81 | 78.92 | 91.21 | 94.27 | 0.2158 |
| +IPG+NFC | 57.27 | 82.39 | 90.17 | 92.81 | 0.1890 |
表 5: 仅使用ImageNet预训练权重而未进行ReID训练时在Market1501上的ReID性能。分布可视化见图4。
| 方法 | mAP↑ | R1↑ | R5↑ | R10↑ | ID²↓ |
|---|---|---|---|---|---|
| w/o training | 3.34 | 11.4 | 21.88 | 28 | 0.5135 |
| +IPG | 52.81 | 78.92 | 91.21 | 94.27 | 0.2158 |
| +IPG+NFC | 57.27 | 82.39 | 90.17 | 92.81 | 0.1890 |

Figure 4. t-SNE visualization of $10~\mathrm{IDs}$ feature distribution with and without our method on ImageNet pre-trained weights.
图 4: 在ImageNet预训练权重下,使用与不使用本文方法的10个ID特征分布的t-SNE可视化。
4. Experiments
4. 实验
4.1. Implementation Details
4.1. 实现细节
Data Cleaning. Training an effective generative model requires high-quality data support. In current ReID (Person Re-Identification) datasets, there are many low-quality images, and removing them can help reduce interference to the model. In our experiments, we found two main issues that need to be addressed:Extremely Low-quality Images: The dataset contains images with such low resolution that even the human eye cannot recognize them as a ”person”. Pose Estimation Failures: The pose estimation model inevitably fails to detect pedestrian poses in some images.
数据清洗。训练一个有效的生成式模型需要高质量的数据支持。在当前的行人重识别(ReID)数据集中存在大量低质量图像,去除这些图像有助于减少对模型的干扰。在我们的实验中发现需要解决两个主要问题:极低质量图像:数据集中包含分辨率极低的图像,以至于人眼都无法将其识别为"人"。姿态估计失败:姿态估计模型在某些图像中不可避免地无法检测到行人姿态。
Utilizing the feature distribution mentioned in Section3.1, we can solve the issues and get the reference image set Sref and target image set $S_{i}^{\mathrm{trg}}$ of identity $i$ . The cleansing process is detailed in Supplementary.
利用第3.1节提到的特征分布,我们可以解决这些问题,并获得身份$i$的参考图像集$S_{ref}$和目标图像集$S_{i}^{\mathrm{trg}}$。清理过程的详细信息见补充材料。
Identity-guided Pedestrian Generation model details For the reference UNet and denoising UNet, we use the pretrained weights of Stable Diffusion v1.5[44]. The VAE encoder and decoder initialized with official weights[26] and froze. For the ReID model, we use pre-trained TransReID[16] without cameras on Market1501 and freeze.
身份引导的行人生成模型细节
对于参考UNet和去噪UNet,我们使用Stable Diffusion v1.5[44]的预训练权重。VAE编码器和解码器采用官方权重[26]初始化并冻结。ReID模型使用在Market1501数据集上预训练的无摄像头版TransReID[16]并保持冻结状态。
The training data collected from training set of Market1501[70], Mars[71], MSMT17[54] and SYSUMM01[55], with a total of 1946 different IDs. The model was trained for 80,000 iterations on one L20(48G) GPU with batch size of 4, which costs about 20 hours, and optimized by Adam[27] with a learning rate of 1e-5 and weight decay of 0.01. All images are resized to $512\times256$ . We applied random flip and random erasing[76] data augmentation only on reference images.
训练数据采集自Market1501[70]、Mars[71]、MSMT17[54]和SYSUMM01[55]的训练集,共包含1946个不同ID。模型在单块L20(48G) GPU上以批量大小4进行了80,000次迭代训练,耗时约20小时,采用Adam[27]优化器(学习率1e-5,权重衰减0.01)。所有图像尺寸调整为$512\times256$。仅在参考图像上应用了随机翻转和随机擦除[76]数据增强。
According to Section3.2.3, we selected 8 poses on the market1501 dataset as the representative poses. Each image in test set generates 8 images with these representative poses. The generation uses DDIM with 20 steps, classifierfree guidance with a scale of 3.5, and generator seed of 42. ReID test settings Test models are loaded with official open-source pre-trained models for testing. In addition, considering the generated images do not have camera IDs, so for feature consistency, we test without camera IDs (e.g. TransReID). To validate the effectiveness of our proposed method, image flip (Section3.2.1) trick is NOT applied in our experiments. On Market1501, set $\eta:=:2$ , and $k_{1}~=$ $k_{2}=2$ . On Occluded REID, set $\eta=1$ , and $k_{1}=k_{2}=1$ . On SYSU-MM01, set $\eta=1/4$ , and $k_{1}=k_{2}=2$ . The parameters analysis detailed in Supplementary.
根据第3.2.3节,我们在Market1501数据集中选取了8种市场常见姿态作为代表姿态。测试集每张图像会生成8张具有这些代表姿态的图像。生成过程采用20步DDIM采样、3.5分类器自由引导系数和42随机种子。
ReID测试设置
测试模型均加载官方开源预训练权重。考虑到生成图像不含摄像头ID,为保持特征一致性,测试时禁用摄像头ID相关模块(如TransReID)。为验证所提方法的有效性,实验未使用图像翻转(第3.2.1节)技巧。
参数设置:
- Market1501:$\eta:=:2$,$k_{1}~=$$k_{2}=2$
- Occluded REID:$\eta=1$,$k_{1}=k_{2}=1$
- SYSU-MM01:$\eta=1/4$,$k_{1}=k_{2}=2$
具体参数分析详见补充材料。
4.2. Improvements on State-of-the-art Methods
4.2. 现有最优方法的改进
To verify the exceptional feature enhancement performance of our framework, we selected state-of-the-art models of three ReID tasks, divided into CNN and ViT-based models, to demonstrate that our theory can apply to any model and various ReID tasks. As shown in Table.1, we achieved excellent enhancements on different models.
为验证我们框架在特征增强方面的卓越性能,我们选取了三种ReID任务的前沿模型(分为CNN和基于ViT的模型),以证明该理论可适用于任意模型及各类ReID任务。如表1所示,我们在不同模型上均实现了显著提升。
It is worth mentioning that we help models achieve new SOTAs without re-rank on 3 benchmarks:
值得一提的是,我们在不重新排序的情况下帮助模型在3个基准测试中实现了新的SOTA:
4.3. ReID without Training
4.3. 无需训练的ReID
TransReID loads a ViT pre-trained model on ImageNet for training on the ReID task. The pre-training method is based on contrastive learning strategies. According to the description in Section3.1, training with contrastive loss helps to cluster features of same label samples. Images generated by our Pedestrian Generation model exhibit identity consistency, meaning they possess the attributes of the same label.
TransReID加载了一个在ImageNet上预训练的ViT模型,用于ReID任务的训练。预训练方法基于对比学习策略。如第3.1节所述,使用对比损失进行训练有助于将相同标签样本的特征聚类。我们的行人生成模型生成的图像具有身份一致性,这意味着它们拥有相同标签的属性。

Figure 5. The effects with and without the IFR module were visualized with five different poses randomly selected for each reference picture.
图 5: 随机选取每个参考图片的五种不同姿势,分别可视化使用和未使用IFR模块的效果对比。
Table 6. Performance Comparison by adding numbers of generated images for each image on gallery, query, and both
| N | Gallery IPG | Query IPG | IPG | |||
| mAP↑ | R1↑ ID²← | mAP↑ R1↑ | ID²↓ | mAP↑ | R1↑ ID²↓ | |
| 0 | 79.88 | 91.48 0.2313 | 79.88 91.48 | 0.1623 | 79.88 | 91.48 0.2193 |
| 一 | 80.96 | 90.97 0.2087 | 79.99 | 90.83 0.1363 | 82.13 | 92.01 0.1961 |
| 2 | 82.86 | 91.45 0.1904 | 81.17 | 92.04 0.1156 | 85.27 | 93.71 0.1773 |
| 3 | 83.42 91.75 | 0.1837 | 81.55 | 92.25 0.1077 | 86.16 | 94.21 0.1704 |
| 4 | 83.81 92.1 | 0.1795 | 81.76 | 92.34 :0.1027 | 86.75 | 94.24 0.1661 |
| 5 | 84.07 91.83 | 0.1758 | 81.85 92.07 | 0.0984 | 87.23 | 94.71 0.1623 |
| 6 | 84.3 91.98 | 0.1730 | 81.96 92.52 | 0.0950 | 87.52 | 94.63 0.1593 |
| 7 | 84.49 | 91.86 0.1707 | 82.03 92.37 | 0.0922 | 87.76 | 94.60 0.1570 |
| 8 | 84.65 | 92.07 0.1691 | 82.18 | 92.40 0.0902 | 88.02 | 94.77 0.1553 |
表 6. 通过在画廊、查询及两者中为每张图像增加生成图像数量的性能对比
| N | Gallery IPG | Query IPG | IPG |
|---|---|---|---|
| mAP↑ | R1↑ ID²↓ | mAP↑ R1↑ | |
| 0 | 79.88 | 91.48 0.2313 | 79.88 91.48 |
| 1 | 80.96 | 90.97 0.2087 | 79.99 |
| 2 | 82.86 | 91.45 0.1904 | 81.17 |
| 3 | 83.42 91.75 | 0.1837 | 81.55 |
| 4 | 83.81 92.1 | 0.1795 | 81.76 |
| 5 | 84.07 91.83 | 0.1758 | 81.85 92.07 |
| 6 | 84.3 91.98 | 0.1730 | 81.96 92.52 |
| 7 | 84.49 | 91.86 0.1707 | 82.03 92.37 |
| 8 | 84.65 | 92.07 0.1691 | 82.18 |
Therefore, even if the features of an individual sample lack the pedestrian matching capability, as shown in the first row of Tab.5, its mAP and Rank-1 are only $3.34%$ and $11.4%$ . However, with our method, it improved $53.93%/70.99%$ to $57.27%/82.39%$ . Additionally, we visualized of $10~\mathrm{IDs}^{\prime}$ feature distributions using t-SNE as shown in Fig.4.
因此,即使单个样本的特征缺乏行人匹配能力(如 表5 第一行所示),其 mAP 和 Rank-1 仅为 $3.34%$ 和 $11.4%$。但采用我们的方法后,指标提升至 $57.27%/82.39%$(原为 $53.93%/70.99%$)。此外,我们通过 t-SNE 对 $10~\mathrm{IDs}^{\prime}$ 的特征分布进行了可视化(见 图4)。
4.4. Abilation Study
4.4. 消融研究
Impact of the NFC and IPG. We conducted comprehensive ablation experiments on Neighbor Feature Centralization (NFC) and Feature ID-Centralizing through Identity- Guided Generation (IPG) methods. As shown in Table2,3,4, which show great improvements.
NFC和IPG的影响。我们对邻域特征中心化(NFC)和通过身份引导生成实现特征ID中心化(IPG)方法进行了全面的消融实验。如表2、3、4所示,这些方法带来了显著改进。
Effect of Feature Re-Distribute Module. We randomly selected 7 images from the Market1501 dataset, choosing 5 different poses for each image. We visualized the results both with and without Identity Feature Redistribute (IFR)
特征重分布模块的效果。我们从Market1501数据集中随机选取了7张图像,每张图像选择5种不同姿态。我们分别可视化展示了使用身份特征重分布(IFR)和未使用该模块的结果

Figure 6. Images generated with random poses. More randomly generated images can be found in Supplementary.
图 6: 随机姿态生成的图像。更多随机生成的图像可在补充材料中查看。
Module. As shown in Fig.5, the impact of ID features on the generated outcomes is evident.
模块。如图 5 所示,ID 特征对生成结果的影响显而易见。
Effect of numbers of generated images. We randomly selected different numbers of images generated from the 8 representative poses to verify the effect of feature enhancement. As shown in Tab.6, the experimental results align with the theory mentioned in Section3.1: the more features of the same ID that are aggregated, the more the adjustment noise extracted from individual images is reduced, enhancing the ID representation capability and resulting in improved matching performance.
生成图像数量的影响。我们随机选取从8个代表性姿态生成的不同数量图像来验证特征增强效果。如表6所示,实验结果与第3.1节提到的理论一致:聚合同一ID的特征越多,从单个图像提取的调整噪声就越少,从而增强ID表征能力并提升匹配性能。
4.5. Visualization s
4.5. 可视化
Different people with the same poses across datasets. We are working on Market1501, SYSU-MM01, and OccludedReID datasets to visualize the 8 representative poses with only one model and results are shown in Fig.2.
不同数据集中相同姿态的不同人物。我们基于Market1501、SYSU-MM01和OccludedReID数据集开展工作,使用单一模型可视化8种代表性姿态,结果如图2所示。
Random people with random poses. To demonstrate the advancement of our model, as shown in Fig.6, we randomly chose samples from the whole dataset, and each sample randomly chose poses, including some problematic poses, fully demonstrating the diversity of model. More examples on three datasets are visualized in Supplementary.
随机人物与随机姿势。为了展示我们模型的进步,如图6所示,我们从整个数据集中随机选取样本,每个样本随机选择姿势(包括一些有问题的姿势),充分展现了模型的多样性。补充材料中可视化了三个数据集的更多示例。
5. Conclusion
5. 结论
In this paper, we proposed a training-free person reidentification framework that fully leverages the natural clustering behavior of features around the identity center during the training process. By introducing the concept of feature centralization, we effectively reduced noise in individual samples and enhanced identity representation without model training. Our approach includes an identityguided pedestrian generation paradigm, capable of producing high-quality, multi-pose images with consistent identity features, even under challenging conditions such as visible, infrared, and occlusion scenarios. The neighbor feature centr aliz ation algorithm also preserves feature’s original distribution while mining potential positive samples. It can also be flexibly integrated with existing re-ranking methods.
本文提出了一种免训练的行人重识别框架,该框架充分利用了训练过程中特征在身份中心周围自然聚集的特性。通过引入特征中心化概念,我们在无需模型训练的情况下有效降低了单样本噪声并增强了身份表征。我们的方法包含一个身份引导的行人生成范式,即使在可见光、红外和遮挡等挑战性场景下,也能生成具有一致身份特征的高质量多姿态图像。邻域特征中心化算法在挖掘潜在正样本的同时,保留了特征的原始分布。该方法还能灵活集成现有的重排序技术。
References
参考文献
From Poses to Identity: Training-Free Person Re-Identification via Feature Centralization
从姿态到身份:基于特征中心化的免训练行人重识别
Supplementary Material
补充材料
6. Methods Supplementary
6. 方法补充
6.1. Aggregation role of ReID loss functions
6.1. ReID损失函数的聚合作用
Currently, ReID models commonly use cross-entropy loss to impose ID-level constraints, and contrastive losses (such as triplet loss) to bring features of the same ID closer while pushing apart features of different IDs. Some models also utilize center loss to construct identity centers for dynamically constraining the IDs. These methods lead to one common result: feature aggregation. From the perspective of the gradient of the loss functions, we could prove that the feature vectors of each ID in current ReID tasks naturally aggregate around a center or mean in the followings.
目前,ReID模型普遍采用交叉熵损失函数施加ID级约束,并配合对比损失(如三元组损失)使同ID特征相互靠近、异ID特征彼此分离。部分模型还引入中心损失动态构建身份中心进行约束。这些方法会产生一个共同结果:特征聚合。从损失函数梯度的角度出发,我们可证明当前ReID任务中每个ID的特征向量会自然聚拢在某个中心或均值周围,具体论证如下。
Cross-Entropy Loss is often used in classification tasks, optimizing the model by maximizing the probability of the correct class. Given $N$ samples, each with a feature vector $\mathbf{z}{i} \in~\mathbb{R}^{d}$ , and its corresponding class label $y_{i}~\in$ ${1,2,\ldots,C}$ , the cross-entropy loss is defined as:
交叉熵损失 (Cross-Entropy Loss) 常用于分类任务,通过最大化正确类别的概率来优化模型。给定 $N$ 个样本,每个样本具有特征向量 $\mathbf{z}{i} \in~\mathbb{R}^{d}$ 及其对应的类别标签 $y_{i}~\in$ ${1,2,\ldots,C}$,交叉熵损失定义为:
$$
\mathcal{L}{\mathrm{CE}}=-\frac{1}{N}\sum_{i=1}^{N}\log\frac{\exp(\mathbf{w}{y_{i}}^{\top}\mathbf{z}{i}+b_{y_{i}})}{\sum_{j=1}^{C}\exp(\mathbf{w}{j}^{\top}\mathbf{z}_{i}+b_{j})}
$$
$$
\mathcal{L}{\mathrm{CE}}=-\frac{1}{N}\sum_{i=1}^{N}\log\frac{\exp(\mathbf{w}{y_{i}}^{\top}\mathbf{z}{i}+b_{y_{i}})}{\sum_{j=1}^{C}\exp(\mathbf{w}{j}^{\top}\mathbf{z}_{i}+b_{j})}
$$
where $\mathbf{w}{j}$ and $b_{j}$ are the weight vector and bias for class $j$ , respectively.
其中 $\mathbf{w}{j}$ 和 $b_{j}$ 分别是类别 $j$ 的权重向量和偏置。
For simplicity, assume that the final layer is a linear classifier without bias, i.e., $b_{j}=0$ . When the loss is minimized, the optimization objective is to maximize the score $\mathbf{w}{y_{i}}^{\top}\mathbf{z}{i}$ of the correct class while minimizing the scores $\mathbf{w}{j}^{\top}\mathbf{z}{i}$ of other classes $(j\neq y_{i})$ .
为简化起见,假设最后一层是无偏置的线性分类器,即 $b_{j}=0$ 。当损失最小时,优化目标是最大化正确类别的得分 $\mathbf{w}{y_{i}}^{\top}\mathbf{z}{i}$ ,同时最小化其他类别 $(j\neq y_{i})$ 的得分 $\mathbf{w}{j}^{\top}\mathbf{z}_{i}$ 。
By gradient descent optimization, we can obtain:
通过梯度下降优化,我们可以得到:
$$
\frac{\partial\mathcal{L}{\mathrm{CE}}}{\partial\mathbf{z}{i}}=1/N\left(p_{y_{i}}-1\right)\mathbf{w}{y_{i}}+1/N\sum_{j\neq y_{i}}p_{i j}\mathbf{w}_{j}
$$
$$
\frac{\partial\mathcal{L}{\mathrm{CE}}}{\partial\mathbf{z}{i}}=1/N\left(p_{y_{i}}-1\right)\mathbf{w}{y_{i}}+1/N\sum_{j\neq y_{i}}p_{i j}\mathbf{w}_{j}
$$
where pij = $\begin{array}{r}{p_{i j}=\frac{\exp(\mathbf{w}{j}^{\top}\mathbf{z}{i})}{\sum_{k=1}^{C}\exp(\mathbf{w}{k}^{\top}\mathbf{z}_{i})}}\end{array}$ .
其中 pij = $\begin{array}{r}{p_{i j}=\frac{\exp(\mathbf{w}{j}^{\top}\mathbf{z}{i})}{\sum_{k=1}^{C}\exp(\mathbf{w}{k}^{\top}\mathbf{z}_{i})}}\end{array}$ 。
With the loss function converges, $p_{y_{i}}\to1$ and $p_{i j}\rightarrow$ $0(j\neq y_{i})$ . The feature $\mathbf{z}{i}$ is optimized to be near a linear combination of the class weight vectors $\mathbf{w}{y{i}}$ . This indicates that features of the same class will tend toward a common direction, thus achieving feature aggregation.
随着损失函数收敛,$p_{y_{i}}\to1$ 且 $p_{i j}\rightarrow$ $0(j\neq y_{i})$。特征 $\mathbf{z}{i}$ 被优化为接近类别权重向量 $\mathbf{w}{y{i}}$ 的线性组合。这表明同一类别的特征将趋向于共同方向,从而实现特征聚合。
Contrastive loss (Triplet Loss as example) optimizes the feature space by bringing samples of the same class closer and pushing samples of different classes further apart. A triplet $\left(\mathbf{z}{a},\mathbf{z}{p},\mathbf{z}{n}\right)$ is defined, where ${\bf z}{a}$ is the anchor, $\mathbf{z}{p}$ is the positive sample (same class), and ${\bf z}_{n}$ is the negative sample (different class). The triplet loss is defined as:
对比损失(以三元组损失为例)通过拉近同类样本的距离并推远不同类样本的距离来优化特征空间。定义一个三元组 $\left(\mathbf{z}{a},\mathbf{z}{p},\mathbf{z}{n}\right)$,其中 ${\bf z}{a}$ 是锚点,$\mathbf{z}{p}$ 是正样本(同类),${\bf z}_{n}$ 是负样本(不同类)。三元组损失定义为:
$$
\mathcal{L}{\mathrm{Triplet}}=\operatorname*{max}\left(|\mathbf{z}{a}-\mathbf{z}{p}|{2}^{2}-|\mathbf{z}{a}-\mathbf{z}{n}|_{2}^{2}+\alpha,0\right)
$$
$$
\mathcal{L}{\mathrm{Triplet}}=\operatorname*{max}\left(|\mathbf{z}{a}-\mathbf{z}{p}|{2}^{2}-|\mathbf{z}{a}-\mathbf{z}{n}|_{2}^{2}+\alpha,0\right)
$$
where $\alpha$ is the margin parameter.
其中 $\alpha$ 是边界参数。
To minimize the loss, the optimization objective is:
为最小化损失,优化目标为:
$$
|\mathbf{z}{a}-\mathbf{z}{p}|{2}^{2}+\alpha<|\mathbf{z}{a}-\mathbf{z}{n}|{2}^{2}
$$
By minimizing triplet loss, the feature $\mathbf{z}{p}$ is pulled closer to ${\bf z}{a}$ , while ${\bf z}_{n}$ is pushed away. Through this mechanism, Triplet Loss encourages features of the same class to aggregate together while features of different classes are separated from each other.
通过最小化三元组损失 (triplet loss),特征 $\mathbf{z}{p}$ 被拉近 ${\bf z}{a}$,同时 ${\bf z}_{n}$ 被推远。该机制促使同类特征聚集、异类特征相互分离。
Center loss further enhances feature aggregation by introducing a feature center for each class. For each class $j$ , there is a feature center $\mathbf{c}_{j}$ , and the center loss is defined as:
中心损失 (center loss) 通过为每个类别引入特征中心来进一步增强特征聚合。对于每个类别 $j$,存在一个特征中心 $\mathbf{c}_{j}$,中心损失定义为:
$$
\mathcal{L}{\mathrm{Center}}=\frac{1}{2}\sum_{i=1}^{N}|\mathbf{z}{i}-\mathbf{c}{y_{i}}|_{2}^{2}
$$
$$
\mathcal{L}{\mathrm{Center}}=\frac{1}{2}\sum_{i=1}^{N}|\mathbf{z}{i}-\mathbf{c}{y_{i}}|_{2}^{2}
$$
Thus, the optimization process not only pulls sample features closer to their centers but also dynamically updates each class’s center to represent the mean of that class’s feature distribution. This directly encourages features of the same class to aggregate together.
因此,优化过程不仅将样本特征拉近其类中心,还会动态更新每个类别的中心以表征该类别的特征分布均值。这直接促使同类特征聚拢在一起。
6.2. Identity Density ) Metric
6.2. 身份密度 (ID²) 指标
Identity density is one aspect of measuring ReID effectiveness. However, there is currently no quantitative metric for this, and researchers commonly rely on visualization tools like t-SNE to demonstrate model performance. Due to the large number of IDs, this approach is limited to visualizing only a few IDs, making it challenging to assess model performance from a global perspective quantitatively. Some researchers exploit this limitation by selecting the best-performing IDs of their models for visualization. To address this, we propose an Identity Density $(\mathrm{ID}^{2})$ Metric. This metric evaluates the global ID aggregation performance by taking each ID center across the entire test set (gallery and query) as a benchmark.
身份密度是衡量ReID效果的一个方面。然而,目前尚无量化指标,研究人员通常依赖t-SNE等可视化工具来展示模型性能。由于ID数量庞大,该方法仅限于可视化少数ID,难以从全局角度定量评估模型性能。部分研究者利用这一局限,选择模型表现最佳的ID进行可视化。为此,我们提出身份密度指标$(\mathrm{ID}^{2})$,该指标以整个测试集(图库和查询)中每个ID中心为基准,评估全局ID聚合性能。
$$
\mathbf{ID}^{2}=\frac{1}{N}\sum_{i=1}^{N}\frac{1}{n_{i}}\sum_{j=1}^{n_{i}}d\left(\frac{f_{i j}}{\lVert f_{i j}\rVert_{2}},c_{i}\right)
$$
$$
\mathbf{ID}^{2}=\frac{1}{N}\sum_{i=1}^{N}\frac{1}{n_{i}}\sum_{j=1}^{n_{i}}d\left(\frac{f_{i j}}{\lVert f_{i j}\rVert_{2}},c_{i}\right)
$$
where $N$ is the total number of unique IDs in the test set, and $n_{i}$ is the number of samples for $\operatorname{ID}i$ . The feature vector of the $j$ -th sample of $\operatorname{ID}i$ is denoted as $f_{i j}$ , and $c_{i}$ represents the identity center of $\mathrm{ID}i$ , computed as follows:
其中 $N$ 是测试集中唯一 ID 的总数,$n_{i}$ 是 $\operatorname{ID}i$ 的样本数量。$\operatorname{ID}i$ 的第 $j$ 个样本的特征向量表示为 $f_{i j}$,$c_{i}$ 表示 $\mathrm{ID}i$ 的身份中心,计算方式如下:
Table 7. Comparisons with state-of-the-art methods on Market1501 and Occluded-reID.
表 7. 在Market1501和Occluded-reID数据集上与最先进方法的比较
| 方法 | Market1501 | Occluded-reID | ||
|---|---|---|---|---|
| Rank-1 | mAP | Rank-1 | mAP | |
| BoT[39] | 94.5 | 85.9 | 58.4 | 52.3 |
| PCB[49] | 93.8 | 81.6 | ||
| VGTri[59] | 81.0 | 71.0 | ||
| PVPM[12] | 66.8 | 59.5 | ||
| HOReID[51] | 94.2 | 84.9 | 80.3 | 70.2 |
| ISP[77] | 95.3 | 88.6 | - | |
| PAT[33] | 95.4 | 88.0 | 81.6 | 72.1 |
| TRANS[16] | 95.2 | 88.9 | ||
| CLIP[31] | 95.7 | 89.8 | ||
| SOLIDER[6] | 96.9 | 93.9 | ||
| SSGR[58] | 96.1 | 89.3 | 78.5 | 72.9 |
| FED[53] | 95.0 | 86.3 | 86.3 | 79.3 |
| BPBreid[46] | 95.7 | 89.4 | 82.9 | 75.2 |
| PFD[52] | 95.5 | 89.7 | 83.0 | 81.5 |
| 95.9 | 89.6 | 85.4 | 79.1 | |
| KPRIn[47] | 96.62 | 84.83 | 82.6 | |
| KPRsoL[47] | 97.3 | 93.22 | ||
| CLIP+ours | 94.9 | - 91 | 89.34 | |
| KPRIN+ours |
$$
c_{i}=\frac{1}{n_{i}}\sum_{j=1}^{n_{i}}\frac{f_{i j}}{\parallel f_{i j}\parallel_{2}}
$$
$$
c_{i}=\frac{1}{n_{i}}\sum_{j=1}^{n_{i}}\frac{f_{i j}}{\parallel f_{i j}\parallel_{2}}
$$
Both the feature vectors $f_{i j}$ and the identity centers $c_{i}$ are $L_{2}$ -normalized to ensure consistent feature scaling. The function $d(\cdot,\cdot)$ represents the Euclidean distance.
特征向量 $f_{i j}$ 和身份中心 $c_{i}$ 都经过 $L_{2}$ 归一化以确保特征尺度一致。函数 $d(\cdot,\cdot)$ 表示欧氏距离。
6.3. Pose Encoder Details
6.3. 姿态编码器细节
The Pose Encoder module is designed to extract highdimensional pose embeddings from the input poses.
姿态编码器模块旨在从输入姿态中提取高维姿态嵌入。
$$
\mathbf{E}_{\mathrm{pose}}=\mathrm{PoseEncoder}(\mathbf{x}^{\mathrm{pose}})
$$
$$
\mathbf{E}_{\mathrm{pose}}=\mathrm{PoseEncoder}(\mathbf{x}^{\mathrm{pose}})
$$
The input is a feature map of size $C_{\mathrm{in}}\times H\times W$ , denoted as $\mathbf{x}^{\mathrm{pose}}$ , where $C_{\mathrm{in}}$ is the number of input channels, and $H,W$ are the height, and width of the input. The first convolution layer is defined as:
输入是一个尺寸为 $C_{\mathrm{in}}\times H\times W$ 的特征图,记作 $\mathbf{x}^{\mathrm{pose}}$ ,其中 $C_{\mathrm{in}}$ 是输入通道数,$H,W$ 分别是输入的高度和宽度。第一个卷积层定义为:
$$
\mathbf{E}{0}=\mathrm{SiLU}(\mathrm{Conv}_{\mathrm{in}}(\mathbf{x}^{\mathrm{pose}}))
$$
$$
\mathbf{E}{0}=\mathrm{SiLU}(\mathrm{Conv}_{\mathrm{in}}(\mathbf{x}^{\mathrm{pose}}))
$$
where $\mathrm{{Conv}{\mathrm{{in}}}}$ is a convolution operation with kernel size $3\times3$ , and the number of channels changes from $C_{\mathrm{in}}=3$ to $C_{0}=16$ :
其中 $\mathrm{{Conv}{\mathrm{{in}}}}$ 是一个卷积操作,其核大小为 $3\times3$,通道数从 $C_{\mathrm{in}}=3$ 变为 $C_{0}=16$:
Each block applies a normal $3\times3$ Conv, a $3\times3$ Conv with stride 2 to reduce spatial dimensions, and followed by a SiLU activate function. For the $i$ -th convolutional block, the operations can be expressed as:
每个模块应用一个常规的 $3\times3$ Conv,一个步长为2的 $3\times3$ Conv以减少空间维度,随后接一个SiLU激活函数。对于第 $i$ 个卷积模块,其操作可表示为:
$$
\mathbf{E}{i+1}=\mathrm{SiLU}(\mathrm{Conv}{i,\mathrm{stride}=2}(\mathrm{Conv}{i}(\mathbf{E}_{i})))
$$
$$
\mathbf{E}{i+1}=\mathrm{SiLU}(\mathrm{Conv}{i,\mathrm{stride}=2}(\mathrm{Conv}{i}(\mathbf{E}_{i})))
$$
The number of channels for each block is as follows: $\left[C_{0},C_{1},C_{2},C_{3}\right]=\left[16,32,64,128\right]$
各模块的通道数如下:$\left[C_{0},C_{1},C_{2},C_{3}\right]=\left[16,32,64,128\right]$
Table 8. Comparison with state-of-the-art methods on SYSUMM01 without re-ranking.
表 8. 在SYSUMM01数据集上不进行重排序的先进方法对比。
| 方法 | All-Search mAP | All-Search Rank-1 | Indoor-Search mAP | Indoor-Search Rank-1 |
|---|---|---|---|---|
| PMT[38] | 66.13 | 67.70 | 77.81 | 72.95 |
| MCLNet [15] | 61.98 | 65.40 | 76.58 | 72.56 |
| MAUM [37] | 68.79 | 71.68 | 81.94 | 76.9 |
| CAL[56] | 71.73 | 74.66 | 83.68 | 79.69 |
| SAAI(w/o AIM) [9] | 71.81 | 75.29 | 84.6 | 81.59 |
| SEFL[10] | 72.33 | 77.12 | 82.95 | 82.07 |
| PartMix[25] | 74.62 | 77.78 | 84.38 | 81.52 |
| MID [22] | 59.40 | 60.27 | 70.12 | 64.86 |
| FMCNet [67] | 62.51 | 66.34 | 74.09 | 68.15 |
| MPANet [57] | 68.24 | 70.58 | 80.95 | 76.74 |
| CMT [24] | 68.57 | 71.88 | 79.91 | 76.90 |
| protoHPE [64] | 70.59 | 71.92 | 81.31 | 77.81 |
| MUN [61] | 73.81 | 76.24 | 82.06 | 79.42 |
| MSCLNet [69] | 71.64 | 76.99 | 81.17 | 78.49 |
| DEEN [68] | 71.80 | 74.70 | 83.30 | 80.30 |
| CIFT [32] | 74.79 | 74.08 | 85.61 | 81.82 |
| SAAI+ours | 76.44 | 79.33 | 86.83 | 84.2 |