A Unified Generative Framework for Aspect-Based Sentiment Analysis
基于方面的情感分析统一生成框架
Abstract
摘要
Aspect-based Sentiment Analysis (ABSA) aims to identify the aspect terms, their corresponding sentiment polarities, and the opinion terms. There exist seven subtasks in ABSA. Most studies only focus on the subsets of these subtasks, which leads to various complicated ABSA models while hard to solve these subtasks in a unified framework. In this paper, we redefine every subtask target as a sequence mixed by pointer indexes and sentiment class indexes, which converts all ABSA subtasks into a unified generative formulation. Based on the unified formulation, we exploit the pre-training sequence-to-sequence model BART to solve all ABSA subtasks in an endto-end framework. Extensive experiments on four ABSA datasets for seven subtasks demonstrate that our framework achieves substantial performance gain and provides a real unified end-to-end solution for the whole ABSA subtasks, which could benefit multiple tasks1.
基于方面的情感分析 (Aspect-based Sentiment Analysis, ABSA) 旨在识别方面术语、其对应情感极性及观点术语。ABSA包含七项子任务,但多数研究仅关注这些子任务的子集,导致出现了各种复杂的ABSA模型,却难以在统一框架中解决所有子任务。本文将所有子任务目标重新定义为由指针索引和情感类别索引混合组成的序列,从而将所有ABSA子任务转化为统一的生成式表述。基于这一统一表述,我们利用预训练序列到序列模型BART,在端到端框架中解决所有ABSA子任务。在四个ABSA数据集上对七项子任务的大量实验表明,我们的框架实现了显著的性能提升,并为整个ABSA子任务提供了真正统一的端到端解决方案,可惠及多项任务[20]。
Figure 1: Illustration of seven ABSA subtasks.
图 1: 七种 ABSA 子任务示意图。
| Subtask | Input | Output | Task Type |
|---|---|---|---|
| AspectTermExtraction (AE) | S | a, a2 | Extraction |
| OpinionTermExtraction (OE) | S | 01, 02 | Extraction |
| Aspect-level SentimentClassification (ALSC) | S + a | S | Classification |
| S + a | S2 | ||
| Aspect-oriented OpinionExtraction (AOE) | S + a | 01 | Extraction |
| S + a2 | 02 | ||
| AspectTermExtraction and SentimentClassification (AESC) | S | (a, s1), (a2, s2) | Extraction & Classification |
| PairExtraction (Pair) | S | (a1, 01), (a2, 02) | Extraction |
| TripletExtraction (Triplet) | S | (a, 01, s1), (a, 0, S2) | Extraction & Classification |
• Aspect Term Extraction $(A E)$ : Extracting all the aspect terms from a sentence.
• 方面术语提取 (AE) : 从句子中提取所有方面术语。
1 Introduction
1 引言
Aspect-based Sentiment Analysis (ABSA) is the fine-grained Sentiment Analysis (SA) task, which aims to identify the aspect term $(a)$ , its corresponding sentiment polarity (s), and the opinion term (o). For example, in the sentence “The drinks are always well made and wine selection is fairly priced”, the aspect terms are “drinks” and “wine selection”, and their sentiment polarities are both “positive”, and the opinion terms are “well made” and “fairly priced”. Based on the combination of the $a,s,o$ there exist seven subtasks in ABSA. We summarize these subtasks in Figure 1. Specifically, their definitions are as follows:
基于方面的情感分析 (ABSA) 是细粒度的情感分析 (SA) 任务,旨在识别方面项 $(a)$、其对应的情感极性 (s) 和观点项 (o)。例如,在句子 "The drinks are always well made and wine selection is fairly priced" 中,方面项是 "drinks" 和 "wine selection",它们的情感极性均为 "positive",观点项分别是 "well made" 和 "fairly priced"。根据 $a,s,o$ 的组合,ABSA 存在七个子任务。我们在图 1 中总结了这些子任务。具体定义如下:
• Opinion Term Extraction $(O E)$ : Extracting all the opinion terms from a sentence. • Aspect-level Sentiment Classification (ALSC): Predicting the sentiment polarities for every given aspect terms in a sentence. Aspect-oriented Opinion Extraction $(A O E)$ : Extracting the paired opinion terms for every given aspect terms in a sentence. Aspect Term Extraction and Sentiment Classification (AESC): Extracting the aspect terms as well as the corresponding sentiment polarities simultan e ou sly. Pair Extraction (Pair): Extracting the aspect terms as well as the corresponding opinion terms simultaneously. Triplet Extraction (Triplet): Extracting all aspects terms with their corresponding opinion terms and sentiment polarity simultaneously.
• 观点词抽取 (OE) :从句子中抽取所有观点词。
• 方面级情感分类 (ALSC) :预测句子中每个给定方面词的情感极性。
• 面向方面的观点抽取 (AOE) :为句子中每个给定方面词抽取配对的意见词。
• 方面词抽取与情感分类 (AESC) :同时抽取方面词及其对应的情感极性。
• 配对抽取 (Pair) :同时抽取方面词及其对应的意见词。
• 三元组抽取 (Triplet) :同时抽取所有方面词及其对应的意见词和情感极性。
Although these ABSA subtasks are strongly related, most of the existing work only focus $1{\sim}3$ subtasks individually. The following divergences make it difficult to solve all subtasks in a unified framework.
尽管这些ABSA子任务密切相关,但现有工作大多仅单独关注其中$1{\sim}3$个子任务。以下分歧使得难以在统一框架中解决所有子任务。
- Input: Some subtasks ( AE, OE, AESC, Pair
- 输入:一些子任务(AE、OE、AESC、Pair)
Because of the above divergences, a myriad of previous works only focus on the subset of these subtasks. However, the importance of solving the whole ABSA subtasks in a unified framework remains significant. Recently, several works make attempts on this track. Some methods(Peng et al., 2020; Mao et al., 2021) apply the pipeline model to output the a, s, $o$ from the inside sub-models separately. However, the pipeline process is not end-to-end. Another line follows the sequence tagging method by extending the tagging schema (Xu et al., 2020). However, the compositional it y of candidate labels hinders the performance. In conclusion, the existing methods can hardly solve all the subtasks by a unified framework without relying on the sub-models or changing the model structure to adapt to all ABSA subtasks.
由于上述差异,大量先前工作仅关注这些子任务的子集。然而,在统一框架中解决所有ABSA子任务的重要性仍然显著。近期,若干研究开始尝试这一方向。部分方法 (Peng et al., 2020; Mao et al., 2021) 采用流水线模型,通过内部子模型分别输出a、s、$o$。但流水线过程并非端到端实现。另一类研究通过扩展标注方案 (Xu et al., 2020) 采用序列标注方法,然而候选标签的组合性限制了性能表现。综上所述,现有方法难以在不依赖子模型或不改变模型结构适配所有ABSA子任务的前提下,通过统一框架解决全部子任务。
Motivated by the above observations, we propose a unified generative framework to address all the ABSA subtasks. We first formulate all these subtasks as a generative task, which could handle the obstacles on the input, output, and task type sides and adapt to all the subtasks without any model structure changes. Specifically, we model the extraction and classification tasks as the pointer indexes and class indexes generation, respectively. Based on the unified task formulation, we use the sequence-to-sequence pre-trained model BART (Lewis et al., 2020) as our backbone to generate the target sequence in an end-to-end process. To validate the effectiveness of our method, we conduct extensive experiments on public datasets. The comparison results demonstrate that our proposed framework outperforms most state-of-the-art (SOTA) models in every subtask.
基于上述观察,我们提出一个统一的生成式框架来解决所有 ABSA 子任务。首先将这些子任务统一表述为生成式任务,从而克服输入、输出和任务类型方面的障碍,无需调整模型结构即可适配所有子任务。具体而言,我们将抽取任务和分类任务分别建模为指针索引生成和类别索引生成。基于统一的任务表述,我们采用序列到序列预训练模型 BART (Lewis et al., 2020) 作为主干网络,以端到端方式生成目标序列。为验证方法的有效性,我们在公开数据集上进行了大量实验。对比结果表明,我们提出的框架在所有子任务中都优于大多数最先进 (SOTA) 模型。
In summary, our main contributions are as follows:
总之,我们的主要贡献如下:
We formulate both the extraction task and classification task of ABSA into a unified index generation problem. Unlike previous unified models, our method needs not to design specific decoders for different output types.
我们将ABSA的抽取任务和分类任务统一表述为索引生成问题。与之前的统一模型不同,我们的方法无需为不同输出类型设计特定解码器。
With our re-formulation, all ABSA subtasks can be solved in sequence-to-sequence framework, which is easy-to-implement and can be built on the pre-trained models, such as BART.
通过我们的重新表述,所有ABSA子任务都可以在序列到序列框架中解决,这种方法易于实现,并且可以基于预训练模型(如BART)构建。
• We conduct extensive experiments on four public datasets, and each dataset contains a subset of all ABSA subtasks. To the best of our knowledge, it is the first work to evaluate a model on all ABSA tasks.
• 我们在四个公开数据集上进行了大量实验,每个数据集都包含所有ABSA子任务的一个子集。据我们所知,这是首个在所有ABSA任务上评估模型的工作。
• The experimental results show that our proposed framework significantly outperforms recent SOTA methods.
• 实验结果表明,我们提出的框架显著优于近期的最先进 (SOTA) 方法。
2 Background
2 背景
2.1 ABSA Subtasks
2.1 ABSA子任务
In this section, we first review the existing studies on single output subtasks, and then turn to studies focusing on the compound output subtasks.
本节首先回顾单输出子任务的现有研究,然后转向关注复合输出子任务的研究。
2.1.1 Single Output Subtasks
2.1.1 单输出子任务
Some researches mainly focus on the single output subtasks. The AE, OE, ALSC and $A O E$ subtasks only output one certain type from $a$ , $s$ or $o$ .
一些研究主要关注单一输出的子任务。AE、OE、ALSC和$A O E$子任务仅输出$a$、$s$或$o$中的某一特定类型。
$A E$ Most studies treat $A E$ subtask as a sequence tagging problem (Li and Lam, 2017; Xu et al., 2018; Li et al., 2018b). Recent works ex- plore sequence-to-sequence learning on $A E$ subtask, which obtain promissing results especially with the pre-training language models (Ma et al., 2019; Li et al., 2020).
$A E$ 大多数研究将 $A E$ 子任务视为序列标注问题 (Li and Lam, 2017; Xu et al., 2018; Li et al., 2018b)。近期研究探索了在 $A E$ 子任务上使用序列到序列学习的方法,特别是结合预训练语言模型后取得了显著效果 (Ma et al., 2019; Li et al., 2020)。
OE Most studies treat $O E$ subtask as an auxiliary task (Wang et al., 2016a, 2017; Wang and Pan, 2018; Chen and Qian, 2020; He et al., 2019). Most works can only extract the unpaired aspect and opinion terms2. In this case, opinion terms are independent of aspect terms.
多数研究将 $O E$ 子任务视为辅助任务 (Wang et al., 2016a, 2017; Wang and Pan, 2018; Chen and Qian, 2020; He et al., 2019)。大多数工作仅能提取未配对的方面词和观点词2。这种情况下,观点词独立于方面词。
ALSC Tang et al. (2016a) use the long short term memory (LSTM) network to enhance the interactions between aspects and context words. Wang et al. (2016b); Liu and Zhang (2017); Ma et al. (2017); Tay et al. (2018) incorporate the attention mechanism into the LSTM-based neural network models to model relations of aspects and their contextual words. Other model structures such as convolutional neural network (CNN) (Li et al., 2018a; Xue and Li, 2018), gated neural network (Zhang et al., 2016; Xue and Li, 2018), memory neural network (Tang et al., 2016b; Chen et al., 2017) have also been applied.
ALSC Tang等人 (2016a) 使用长短期记忆 (LSTM) 网络增强方面与上下文词之间的交互。Wang等人 (2016b)、Liu和Zhang (2017)、Ma等人 (2017)、Tay等人 (2018) 将注意力机制融入基于LSTM的神经网络模型,以建模方面与其上下文词的关系。其他模型结构如卷积神经网络 (CNN) (Li等人, 2018a; Xue和Li, 2018)、门控神经网络 (Zhang等人, 2016; Xue和Li, 2018)、记忆神经网络 (Tang等人, 2016b; Chen等人, 2017) 也被应用。
AOE This subtask is first introduced by Fan et al. (2019) and they propose the datasets for this subtask. Most studies apply sequence tagging method for this subtask (Wu et al., 2020; Pouran Ben Veyseh et al., 2020).
AOE这一子任务由Fan等人(2019)首次提出,他们为该子任务构建了数据集。大多数研究采用序列标注方法来解决该任务(Wu等人,2020;Pouran Ben Veyseh等人,2020)。
2.1.2 Compound Output Subtasks
2.1.2 复合输出子任务
Some researchers pay more attention and efforts to the subtasks with compound output. We review them as follows:
一些研究者更关注并致力于具有复合输出的子任务。我们将其综述如下:
AESC. One line follows pipeline method to solve this problem. Other works utilize unified tagging schema (Mitchell et al., 2013; Zhang et al., 2015; Li et al., 2019) or multi-task learning (He et al., 2019; Chen and Qian, 2020) to avoid the error-propagation problem (Ma et al., 2018). Spanbased AESC works are also proposed recently (Hu et al., 2019), which can tackle the sentiment inconsistency problem in the unified tagging schema.
AESC。一种方法是采用流水线方法来解决这个问题。其他工作则利用统一标注框架 (Mitchell et al., 2013; Zhang et al., 2015; Li et al., 2019) 或多任务学习 (He et al., 2019; Chen and Qian, 2020) 来避免错误传播问题 (Ma et al., 2018)。近年来还提出了基于跨度的AESC方法 (Hu et al., 2019),可以解决统一标注框架中的情感不一致问题。
Pairs Zhao et al. (2020) propose to extract all (a, $o$ ) pair-wise relations from scratch. They propose a multi-task learning framework based on the spanbased extraction method to handle this subtask.
Pairs Zhao等人 (2020) 提出从零开始提取所有(a, $o$)成对关系。他们基于基于跨度(span-based)的提取方法提出了一个多任务学习框架来处理这个子任务。
Triplet This subtask is proposed by Peng et al. (2020) and gains increasing interests recently. Xu et al. (2020) design the position-aware tagging schema and apply model based on CRF (Lafferty et al., 2001) and Semi-Markov CRF (Sarawagi and Cohen, 2004). However, the time complexity limits the model to detect the aspect term with longdistance opinion terms. Mao et al. (2021) formulate Triplet as a two-step MRC problem, which applies the pipeline method.
Triplet 该子任务由 Peng 等人 (2020) 提出,近年来受到越来越多的关注。Xu 等人 (2020) 设计了位置感知的标注方案,并应用了基于 CRF (Lafferty 等人, 2001) 和半马尔可夫 CRF (Sarawagi 和 Cohen, 2004) 的模型。然而,时间复杂度的限制使得该模型难以检测具有远距离意见词的目标词。Mao 等人 (2021) 将 Triplet 表述为一个两步的 MRC (机器阅读理解) 问题,采用了流水线方法。
2.2 Sequence-to-Sequence Models
2.2 序列到序列模型
The sequence-to-sequence framework has been long studied in the NLP field to tackle various tasks (Sutskever et al., 2014; Cho et al., 2014; Vinyals et al., 2015; Luong et al., 2015). Inspired by the success of PTMs (pre-trained models) (Qiu et al., 2020; Peters et al., 2018; Devlin et al., 2019; Brown et al., 2020), Song et al. (2019); Raffel et al. (2020); Lewis et al. (2020) try to pre-train sequence-tosequence models. Among them, we use the BART (Lewis et al., 2020) as our backbone, while the other sequence-to-sequence pre-training models can also be applied in our architecture to use the pointer mechanism (Vinyals et al., 2015), such as MASS (Song et al., 2019).
序列到序列(sequence-to-sequence)框架在自然语言处理领域长期被用于解决各类任务 (Sutskever et al., 2014; Cho et al., 2014; Vinyals et al., 2015; Luong et al., 2015)。受预训练模型(PTMs)成功应用的启发 (Qiu et al., 2020; Peters et al., 2018; Devlin et al., 2019; Brown et al., 2020),Song等人(2019)、Raffel等人(2020)和Lewis等人(2020)尝试对序列到序列模型进行预训练。其中我们采用BART (Lewis et al., 2020)作为主干网络,其他序列到序列预训练模型如MASS (Song et al., 2019)也可通过指针机制(Vinyals et al., 2015)应用于我们的架构中。
BART is a strong sequence-to-sequence pretrained model for Natural Language Generation (NLG). BART is a denoising auto encoder composed of several transformer (Vaswani et al., 2017) encoder and decoder layers. It is worth noting that the BART-Base model contains a 6-layer encoder and 6-layer decoder, which makes it similar number of parameters 3 with the BERT-Base model. BART is pretrained on denoising tasks where the input sentence is noised by some methods, such as masking and permutation. The encoder takes the noised sentence as input, and the decoder will restore the original sentence in an auto regressive manner.
BART是一种强大的序列到序列预训练模型,用于自然语言生成(NLG)。它是由多个Transformer (Vaswani等人,2017)编码器和解码器层组成的去噪自编码器。值得注意的是,BART-Base模型包含6层编码器和6层解码器,这使得其参数量与BERT-Base模型相近。BART通过在输入句子上施加掩码、排列等噪声方式进行去噪任务预训练:编码器接收带噪声的句子作为输入,解码器则以自回归方式还原原始句子。
3 Methodology
3 方法论
Although there are two types of tasks among the seven ABSA subtasks, they can be formulated under a generative framework. In this part, we first introduce our sequential representation for each ABSA subtask. Then we detail our method, which utilizes BART to generate these sequential representations.
虽然七项ABSA子任务中有两种类型,但它们都可以在生成式框架下进行表述。在这一部分,我们首先介绍针对每个ABSA子任务的序列化表示方法,随后详细阐述利用BART生成这些序列化表示的技术方案。
3.1 Task Formulation
3.1 任务定义
As depicted in Figure 1, there are two types of tasks, namely the extraction and classification, whose target can be represented as a sequence of pointer indexes and class indexes, respectively. Therefore, we can formulate these two types of tasks in a unified generative framework. We use $a,s,o$ , to represent the aspect term, sentiment polarity,and opinion term, respectively. Moreover, we use the superscript s and e to denote the start index and end index of a term. For example, $o^{s},a^{e}$ represent the start index of an opinion term $o$ and the end index of an aspect term $a$ . We use the $s^{p}$ to denote the index of sentiment polarity class. The target sequence for each subtask is as follows:
如图 1 所示,存在两种任务类型,即抽取和分类,其目标可分别表示为指针索引序列和类别索引序列。因此,我们可以将这两类任务统一在生成式框架中建模。我们使用 $a,s,o$ 分别表示方面项、情感极性和观点项,并用上标 s 和 e 表示术语的起始索引和结束索引。例如 $o^{s},a^{e}$ 表示观点项 $o$ 的起始索引和方面项 $a$ 的结束索引。我们使用 $s^{p}$ 表示情感极性类别的索引。各子任务的目标序列如下:
$\bullet A E:Y=[a_{1}^{s},a_{1}^{e},...,a_{i}^{s},a_{i}^{e},...],$ • $\cdot O E:Y=[o_{1}^{s},o_{1}^{e},...,o_{i}^{s},o_{i}^{e},...]:$ $\bullet A E S C:Y=[a_{1}^{s},a_{1}^{e},s_{1}^{p},...,a_{i}^{s},a_{i}^{e},s_{i}^{p},...],$ • Pair: $Y=[a_{1}^{s},a_{1}^{e},o_{1}^{s},o_{1}^{e},...,a_{i}^{s},a_{i}^{e},o_{i}^{s},o_{i}^{e},...],$ , • Triplet : $Y=[a_{1}^{s},a_{1}^{e},o_{1}^{s},o_{1}^{e},s_{1}^{p},...,a_{i}^{s},a_{i}^{e},o_{i}^{s}$ , $o_{i}^{e},s_{i}^{p},\ldots]$ ,
$\bullet A E:Y=[a_{1}^{s},a_{1}^{e},...,a_{i}^{s},a_{i}^{e},...],$
$\cdot O E:Y=[o_{1}^{s},o_{1}^{e},...,o_{i}^{s},o_{i}^{e},...]:$
$\bullet A E S C:Y=[a_{1}^{s},a_{1}^{e},s_{1}^{p},...,a_{i}^{s},a_{i}^{e},s_{i}^{p},...],$
$\bullet Pair:Y=[a_{1}^{s},a_{1}^{e},o_{1}^{s},o_{1}^{e},...,a_{i}^{s},a_{i}^{e},o_{i}^{s},o_{i}^{e},...],$
$\bullet Triplet:Y=[a_{1}^{s},a_{1}^{e},o_{1}^{s},o_{1}^{e},s_{1}^{p},...,a_{i}^{s},a_{i}^{e},o_{i}^{s},o_{i}^{e},s_{i}^{p},\ldots],$
The above subtasks only rely on the input sentence, while for the $A L S C$ and $A O E$ subtasks, they also depend on a specific aspect term $a$ . Instead of putting the aspect term on the input side, we put them on the target side so that the target sequences are as follows:
上述子任务仅依赖于输入句子,而对于 $ALSC$ 和 $AOE$ 子任务,它们还依赖于特定的方面词 $a$ 。我们没有将方面词放在输入侧,而是将其放在目标侧,因此目标序列如下:
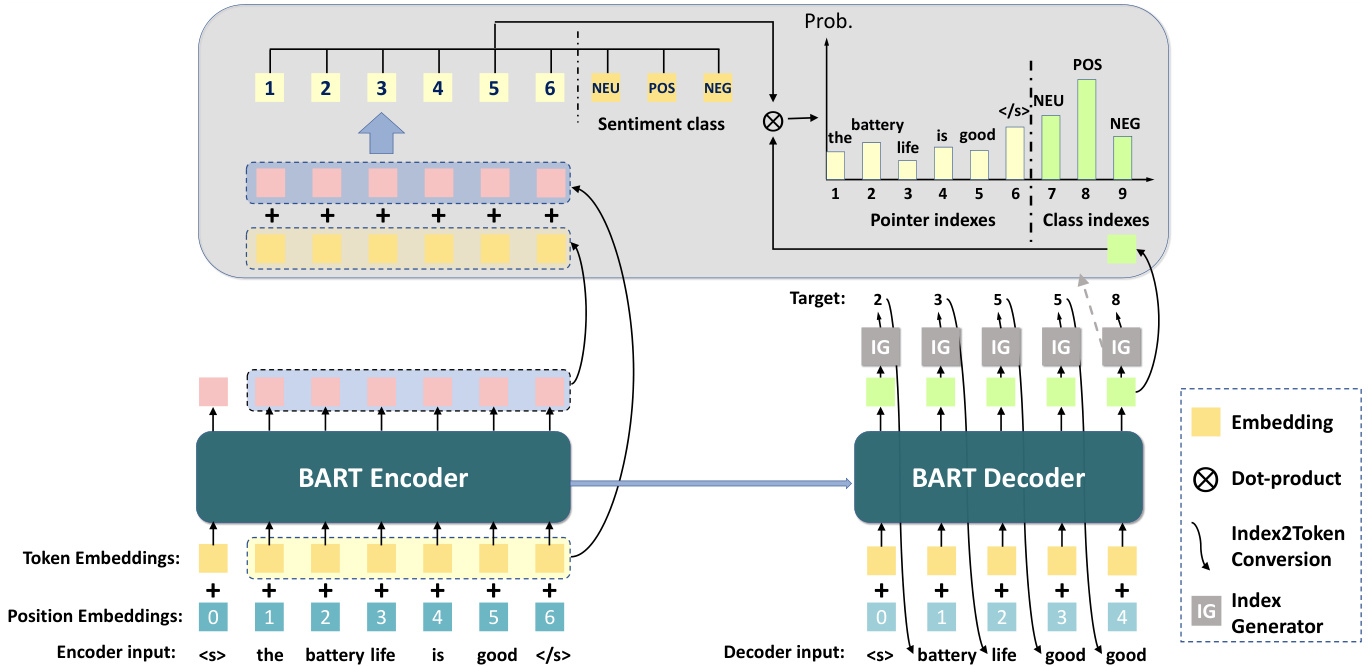

where the underlined tokens are given during inference. Detailed target sequence examples for each subtask are presented in Figure 3.
其中带下划线的token在推理时给定。各子任务的详细目标序列示例如图 3: 所示。
3.2 Our Model
3.2 我们的模型
As our discussion in the last section, all subtasks can be formulated as taking the $X=[x_{1},...,x_{n}]$ as input and outputting a target sequence $Y=$
正如我们在上一节的讨论,所有子任务都可以表述为以 $X=[x_{1},...,x_{n}]$ 作为输入并输出目标序列 $Y=$
$\left[y_{1},...,y_{m}\right]$ , where $y_{0}$ is the start-of-the-sentence token. Therefore, different ABSA subtasks can be formulated as:
$\left[y_{1},...,y_{m}\right]$,其中$y_{0}$是句首token。因此,不同的ABSA子任务可以表述为:
$$
P(Y|X)=\prod_{t=1}^{m}P(y_{t}|X,Y_{<t}).
$$
$$
P(Y|X)=\prod_{t=1}^{m}P(y_{t}|X,Y_{<t}).
$$
To get the index probability distribution $P_{t}={}$ $P(y_{t}|X,Y_{<t})$ for each step, we use a model composed of two components: (1) Encoder; (2) Decoder.
为了获取每一步的索引概率分布 $P_{t}={}$ $P(y_{t}|X,Y_{<t})$ ,我们使用了一个由两部分组成的模型:(1) 编码器 (Encoder);(2) 解码器 (Decoder)。
Encoder The encoder part is to encode $X$ into vectors $\mathbf{H}^{e}$ . We use the BART model, therefore, the start of sentence $(<\mathbf{s}>)$ and the end of sentence $(<I\mathrm{s}>)$ tokens will be added to the start and end of $X$ , respectively. We ignore the $<\mathbf{S}>$ token in our equations for simplicity. The encoder part is as follows:
编码器
编码器部分用于将 $X$ 编码为向量 $\mathbf{H}^{e}$。我们采用 BART 模型,因此会在 $X$ 的开头和结尾分别添加句首标记 $(<\mathbf{s}>)$ 和句尾标记 $(<I\mathrm{s}>)$。为简化公式表述,后续方程中忽略 $<\mathbf{S}>$ 标记。编码过程如下:
$$
\mathbf{H}^{e}=\mathrm{BARTEncoder}([x_{1},...,x_{n}]),
$$
$$
\mathbf{H}^{e}=\mathrm{BARTEncoder}([x_{1},...,x_{n}]),
$$
where $\mathbf{H}^{e}\in\mathbb{R}^{n\times d}$ , and $d$ is the hidden dimension.
其中 $\mathbf{H}^{e}\in\mathbb{R}^{n\times d}$,且 $d$ 为隐藏维度。
Decoder The decoder part takes the encoder outputs $\mathbf{H}^{e}$ and previous decoder outputs $Y_{<t}$ as inputs to get $P_{t}$ . However, the $Y_{<t}$ is an index sequence. Therefore, for each $y_{t}$ in $Y_{<t}$ , we first need to use the following Index 2 Token module to conduct a
解码器
解码器部分以编码器输出 $\mathbf{H}^{e}$ 和先前的解码器输出 $Y_{<t}$ 作为输入,得到 $P_{t}$。然而,$Y_{<t}$ 是一个索引序列。因此,对于 $Y_{<t}$ 中的每个 $y_{t}$,我们首先需要使用以下索引转Token (Index 2 Token) 模块进行转换。
Table 1: The statistics of four datasets, where the #s, #a, #o, #p denote the numbers of sentences, aspect terms, opinion terms, and the $<a,o>$ pairs, respectively. We use “-” to denote the missing data statistics of some datasets. The “Subtasks” column refers to the ABSA subtasks that can be applied on the corresponding dataset.
表 1: 四个数据集的统计信息,其中 #s、#a、#o、#p 分别表示句子数、方面词数、观点词数以及 $<a,o>$ 对的数量。我们使用 "-" 表示某些数据集缺失的数据统计。"Subtasks" 列表示可在对应数据集上应用的 ABSA 子任务。
where $C=[c_{1},...,c_{l}]$ is the class token list4.
其中 $C=[c_{1},...,c_{l}]$ 是类别 token 列表4.
After that, we use the BART decoder to get the last hidden state
之后,我们使用 BART 解码器获取最后一个隐藏状态
$$
{\bf h}{t}^{d}=\mathrm{BARTDecoder}({\bf H}^{e};\hat{Y}_{<t}),
$$
$$
{\bf h}{t}^{d}=\mathrm{BARTDecoder}({\bf H}^{e};\hat{Y}_{<t}),
$$
where $\mathbf{h}{t}^{d}\in\mathbb{R}^{d}$ . With $\mathbf{h}{t}^{d}$ , we predict the token probability distribution $P_{t}$ as follows:
其中 $\mathbf{h}{t}^{d}\in\mathbb{R}^{d}$。利用 $\mathbf{h}{t}^{d}$,我们按如下方式预测 token 概率分布 $P{t}$:
Algorithm 1 Decoding Algorithm for the Triplet Subtask
算法 1:三元组子任务解码算法
| Dataset | 14res | 14lap | 15res | 16res | Subtasks | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #S #a | #0 | #p | #S | #a | #p | #S | #a | #0 | #p | #S | #a#0 | #p | |||||
| D17 | train | 3044 | 3699 | 3484 | 3048 | 2373 | 2504 | 1315 | 1199 | 1210 | AE,OE,ALSC | ||||||
| test | 800 | 1134 | 1008 | 800 | 654 | 674 | - | 685 | 542 | 510 | - | AESC | |||||
| D19 | train | 1627 | 2643 | 1158 | 1634 | - | 754 | 1076 | - | 一 | 1079 | 1512 | |||||
| test | 500 | 865 | 343 | 482 | 325 | 436 | 329 | 457 | AOE | ||||||||
| D20a | train | 1300 | 2145 | 920 | 1265 | 593 | 923 | 842 | 1289 | AE,OE,ALSC,AOE | |||||||
| dev | 323 | 524 | 228 | 337 | 148 | 238 | 210 | 316 | |||||||||
| test | 496 | 862 | 339 | - | 490 | 318 | 1 | 455 | 320 | 465 | AESC,Pair,Triplet | ||||||
| D20b | train | 1266 | 2338 | 906 | 1460 | 605 | 1013 | 857 | 1394 | ||||||||
| dev | 310 | 577 | 219 | 346 | 148 | 249 | 210 | AE,OE,ALSC,AOE, | |||||||||
| test | 492 | 994 | 328 | 543 | 148 | 485 | 326 | 339 | AESC,Pair,Triplet |
$$
\begin{array}{r l}&{{\bf E}^{e}=\mathrm{BARTTokenEmbed}(X),}\ &{\hat{\bf H}^{e}=\mathrm{MLP}({\bf H}^{e}),}\ &{\bar{\bf H}^{e}=\alpha\hat{\bf H}^{e}+(1-\alpha){\bf E}^{e},}\ &{{\bf C}^{d}=\mathrm{BARTTokenEmbed}(C),}\ &{P_{t}=\mathrm{Softmax}([\bar{\bf H}^{\ e};{\bf C}^{d}]{\bf h}_{t}^{d}),}\end{array}
$$
$$
\begin{array}{r l}&{{\bf E}^{e}=\mathrm{BARTTokenEmbed}(X),}\ &{\hat{\bf H}^{e}=\mathrm{MLP}({\bf H}^{e}),}\ &{\bar{\bf H}^{e}=\alpha\hat{\bf H}^{e}+(1-\alpha){\bf E}^{e},}\ &{{\bf C}^{d}=\mathrm{BARTTokenEmbed}(C),}\ &{P_{t}=\mathrm{Softmax}([\bar{\bf H}^{\ e};{\bf C}^{d}]{\bf h}_{t}^{d}),}\end{array}
$$
where $\mathbf{E}^{e},\mathbf{H}^{e},\hat{\mathbf{H}}^{e},\bar{\mathbf{H}}^{e}\in\mathbb{R}^{n\times d}$ ; $\mathbf{C}^{d}\in\mathbb{R}^{l\times d}$ ; and $P_{t}\in\mathbb{R}^{(n+l)}$ is the final distribution on all indexes.
其中 $\mathbf{E}^{e},\mathbf{H}^{e},\hat{\mathbf{H}}^{e},\bar{\mathbf{H}}^{e}\in\mathbb{R}^{n\times d}$;$\mathbf{C}^{d}\in\mathbb{R}^{l\times d}$;且 $P_{t}\in\mathbb{R}^{(n+l)}$ 是所有索引上的最终分布。
During the training phase, we use the teacher forcing to train our model and the negative loglikelihood to optimize the model. Moreover, during the inference, we use the beam search to get the target sequence $Y$ in an auto regressive manner. After that, we need to use the decoding algorithm to convert this sequence into the term spans and sentiment polarity. We use the Triplet task as an example and present the decoding algorithm in Algorithm 1, the decoding algorithm for other tasks are much depicted in the Supplementary Material.
在训练阶段,我们使用教师强制(teacher forcing)训练模型,并通过负对数似然优化模型。此外,在推理过程中,我们采用束搜索(beam search)以自回归方式获取目标序列 $Y$,随后需通过解码算法将该序列转换为术语跨度及情感极性。以三元组任务为例,算法1展示了解码流程,其他任务的解码算法详见补充材料。
4 Experiments
4 实验
4.1 Datasets
4.1 数据集
We evaluate our method on four ABSA datasets. All of them are originated from the Semeval Challenges (Pontiki et al., 2014a,b,c), where only the aspect terms and their sentiment polarities are labeled.
我们在四个ABSA数据集上评估了我们的方法。这些数据集均源自Semeval挑战赛 (Pontiki et al., 2014a,b,c) ,其中仅标注了方面词及其情感极性。
The first dataset( $\ensuremath{\langle\mathcal{D}{17}^{\phantom{5}}\rangle}$ is annotated by Wang et al. (2017), where the unpaire opinion terms are labeled. The second dataset $(\mathcal{D}{19})$ is annotated by Fan et al. (2019), where they pair opinion terms with corresponding aspects. The third dataset $(\mathcal{D}{20a})$ is from Peng et al. (2020). They refine the data in $<a$ , o, $s>$ triplet form. The fourth dataset $(\mathcal{D}_{20b})$ from Xu et al. (2020) is the revised variant of Peng et al. (2020), where the missing triplets with overlapping opinions are corrected. We present the statistics for these four datasets in Table 1.
第一个数据集 ($\ensuremath{\langle\mathcal{D}{17}^{\phantom{5}}\rangle}$) 由Wang等人 (2017) 标注,其中标记了未配对的观点词。第二个数据集 $(\mathcal{D}{19})$ 由Fan等人 (2019) 标注,他们将观点词与对应方面进行了配对。第三个数据集 $(\mathcal{D}{20a})$ 来自Peng等人 (2020),他们以 $<a$, o, $s>$ 三元组形式精炼了数据。第四个数据集 $(\mathcal{D}_{20b})$ 来自Xu等人 (2020),是对Peng等人 (2020) 的修订版本,修正了重叠观点缺失的三元组。我们在表1中展示了这四个数据集的统计信息。
Table 2: The baselines of our experiments. To further demonstrate that our proposed method is a real unified endto-end ABSA framework, we present our work in the last row. “E2E” is short for End-to-End, which means the model should output all the subtasks’ results synchronously rather than requiring any preconditions, e.g., pipeline methods. The “Datasets” column refers to the datasets that this baseline is conducted.
表 2: 实验基线对比。为证明我们提出的方法是真正的端到端统一ABSA框架,我们在最后一行展示本研究成果。"E2E"是端到端(End-to-End)的缩写,表示模型应同步输出所有子任务结果,无需任何前置条件(如流水线方法)。"Datasets"列表示该基线实验所用的数据集。
| Baselines | E2E | Task Formulation | Backbone | Datasets | AE | OEALSC AOEAESC | Pair Triplet | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SPAN-BERT | Span.Extraction | BERT | D17 | ||||||||
| IMN-BERT | Seq.Tagging | BERT | D17 | √ | |||||||
| RACL-BERT | Seq.Tagging | BERT | D17 | √ | |||||||
| I0G | Seq.Tagging | LSTM | D19 | ||||||||
| LOTN | √ | Seq.Tagging | LSTM | D19 | |||||||
| ONG | Seq.Tagging | BERT | D19 | 一 | - | ||||||
| RINANTE+ | Seq.Tagging | LSTM+CRF | D20a,D20b | ||||||||
| CMLA+ | Seq.Tagging | Attention | D20a,D20b | ||||||||
| Li-unified+ | Seq.Tagging | LSTM | D20a,D20b | √ | √ | ← | |||||
| Peng-two-stage | Seq.Tagging | LSTM+GCN | D20a,D20b | √ | √ | ||||||
| JET-BERT | √ | Seq.Tagging | BERT | D20a,D20b | √ | √ | |||||
| Dual-MRC | - | Span.MRC | BERT | D17,D19,D20a,D20b | √ | ||||||
| Ours | Span.Generation | BART | D17,D19,D20a,D20b | < | < | < |
4.2 Baselines
4.2 基线方法
To have a fair comparison, we summarize topperforming baselines of all ABSA subtasks. Given different ABSA subtasks, datasets, and experimental setups, existing baselines can be separated into three groups roughly as shown in Table 2.
为了公平比较,我们汇总了所有ABSA子任务的顶尖基线方法。根据不同的ABSA子任务、数据集和实验设置,现有基线方法大致可分为三组,如表2所示。
The baselines in the first group are conducted on $\mathcal{D}_{17}$ dataset, covering the AE, OE, ALSC, and AESC subtasks. Span-based method SPAN-BERT (Hu et al., 2019) and sequence tagging method, IMNBERT (He et al., 2019) and RACL-BERT (Chen and Qian, 2020), are selected. Specifically, the IMN-BERT model is reproduced by Chen and Qian (2020). All these baselines are implemented on BERT-Large.
第一组基线实验在 $\mathcal{D}_{17}$ 数据集上进行,涵盖AE、OE、ALSC和AESC子任务。选用了基于跨度的方法SPAN-BERT (Hu et al., 2019) 和序列标注方法IMN-BERT (He et al., 2019) 与RACL-BERT (Chen and Qian, 2020)。其中,IMN-BERT模型由Chen和Qian (2020) 复现实现。所有基线模型均基于BERT-Large架构实现。
The baselines of the second group are conducted on $\mathcal{D}_{19}$ dataset, mainly focusing on $A O E$ subtask. Interestingly, we find that sequence tagging method is the main solution for this subtask (Fan et al., 2019; Wu et al., 2020; Pouran Ben Veyseh et al., 2020).
第二组基线实验在 $\mathcal{D}_{19}$ 数据集上进行,主要聚焦于 $A O E$ 子任务。有趣的是,我们发现序列标注方法是该子任务的主流解决方案 (Fan et al., 2019; Wu et al., 2020; Pouran Ben Veyseh et al., 2020)。
The baselines of the third group are mainly conducted on $\mathcal{D}{20a}$ and $\mathcal{D}_{20b}$ datasets, which could cover almost all the ABSA subtasks except for one certain subtask depending on the baseline structures. For the following baselines: RINANTE (Dai and Song, 2019), CMLA (Wang et al., 2017), Li- unified (Li et al., 2019), the suffix $\mathbf{\tilde{\Sigma}}^{\acute{\leftmoon}}+\mathbf{\tilde{\Sigma}}^{\prime}$ in Table 2 denotes the corresponding model variant modified by Peng et al. (2020) for being capable of AESC, Pair and Triplet.
第三组基线主要在$\mathcal{D}{20a}$和$\mathcal{D}_{20b}$数据集上进行,这些数据集几乎涵盖了除特定子任务外的所有ABSA子任务(具体取决于基线结构)。对于以下基线:RINANTE (Dai and Song, 2019)、CMLA (Wang et al., 2017)、Li-unified (Li et al., 2019),表2中的后缀$\mathbf{\tilde{\Sigma}}^{\acute{\leftmoon}}+\mathbf{\tilde{\Sigma}}^{\prime}$表示Peng等人(2020)为支持AESC、Pair和Triplet任务而修改的对应模型变体。
4.3 Implement Details
4.3 实现细节
Following previous studies, we use different metrics according to different subtasks and datasets. Specifically, for the single output subtasks AE, OE, and $A O E$ , the prediction span would be considered as correct only if it exactly matches the start and the end boundaries. For the ALSC subtask, we require the generated sentiment polarity of the given aspect should be the same as the ground truth. As for compound output subtasks, AESC, Pair and Triplet, a prediction result is correct only when all the span boundaries and the generated sentiment polarity are accurately identified. We report the precision (P), recall (R), and F1 scores for all experiments 6.
遵循先前研究,我们根据不同子任务和数据集采用不同评估指标。具体而言,对于单输出子任务AE、OE和$A O E$,预测片段必须严格匹配起止边界才被视为正确。ALSC子任务要求生成的目标情感极性必须与真实标签一致。对于复合输出子任务AESC、Pair和Triplet,只有当所有片段边界和生成的情感极性均被准确识别时,预测结果才判定为正确。所有实验均报告精确率(P)、召回率(R)和F1值[6]。
4.4 Main Results
4.4 主要结果
On $\mathcal{D}_{17}$ dataset (Wang et al., 2017), we compare our method for AE, OE, ALSC, and AESC. The comparison results are shown in Table 3. Most of our results achieve better or comparable results to baselines. However, these baselines yield competitive results based on the BERT-Large pre-trained models. While our results are achieved on the BART-Base model with almost half parameters. This shows that our framework is more suitable for
在 $\mathcal{D}_{17}$ 数据集 (Wang et al., 2017) 上,我们比较了所提方法在 AE (aspect extraction)、OE (opinion extraction)、ALSC (aspect-level sentiment classification) 和 AESC (aspect-based sentiment classification) 任务上的表现。对比结果如表 3 所示。我们的方法在多数任务上取得了优于或接近基线模型的结果。值得注意的是,这些基线模型均基于参数量更大的 BERT-Large 预训练模型实现,而我们的结果是通过参数量减半的 BART-Base 模型获得的。这表明我们的框架更适用于...
Table 3: Comparison F1 scores for AE, OE, SC, and $A E S C$ on the $\mathcal{D}_{17}$ dataset (Wang et al., 2017). The baseline results are retrieved from Mao et al. (2021). We highlight the best results in bold. It is worth noting that all the baseline results are obtained via BERT-Large, while our results are obtained via BART-Base.
表 3: 在 $\mathcal{D}_{17}$ 数据集 (Wang et al., 2017) 上 AE、OE、SC 和 $A E S C$ 的 F1 分数对比。基线结果来自 Mao et al. (2021)。最佳结果以粗体标出。值得注意的是,所有基线结果均通过 BERT-Large 获得,而我们的结果通过 BART-Base 获得。
| Model | 14res | 14lap | 15res | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AE | OE | ALSC | AESC | AE | OE | ALSC | AESC | AE | OE | ALSC | AESC | |
| SPAN-BERT | 86.71 | 71.75 | 73.68 | 82.34 | 62.5 | 61.25 | 74.63 | 50.28 | 62.29 | |||
| IMN-BERT | 84.06 | 85.10 | 75.67 | 70.72 | 77.55 | 81.0 | 75.56 | 61.73 | 69.90 | 73.29 | 70.10 | 60.22 |
| RACL-BERT | 86.38 | 87.18 | 81.61 | 75.42 | 81.79 | 79.72 | 73.91 | 63.40 | 73.99 | 76.0 | 74.91 | 66.05 |
| Dual-MRC | 86.60 | 82.04 | 75.95 | 82.51 | 75.97 | 65.94 | 75.08 | 73.59 | 65.08 | |||
| Ours | 87.07 | 87.29 | 75.56 | 73.56 | 83.52 | 77.86 | 76.76 | 67.37 | 75.48 | 76.49 | 73.91 | 66.61 |
Table 4: Comparison results for $A O E$ on the $\mathcal{D}_{19}$ dataset (Fan et al., 2019). Baselines are from the original papers. We highlight the best results in bold.
表 4: $\mathcal{D}_{19}$ 数据集上 $A O E$ 的对比结果 (Fan et al., 2019)。基线方法来自原始论文,最佳结果以粗体标出。
| Model | 14res P | 14res R | 14res F1 | 14lap P | 14lap R | 14lap F1 | 15res P | 15res R | 15res F1 | 16res P | 16res R | 16res F1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| I0G | 82.38 | 78.25 | 80.23 | 73.43 | 68.74 | 70.99 | 72.19 | 71.76 | 71.91 | 84.36 | 79.08 | 81.60 |
| LOTN | 84.0 | 80.52 | 82.21 | 77.08 | 67.62 | 72.02 | 76.61 | 70.29 | 73.29 | 86.57 | 80.89 | 83.62 |
| ONG | 83.23 | 81.46 | 82.33 | 73.87 | 77.78 | 75.77 | 76.63 | 81.14 | 78.81 | 87.72 | 84.38 | 86.01 |
| Dual-MRC | 89.79 | 78.43 | 83.73 | 78.21 | 81.66 | 79.90 | 77.19 | 71.98 | 74.50 | 86.07 | 80.77 | 83.33 |
| Ours | 86.01 | 84.76 | 85.38 | 83.11 | 78.13 | 80.55 | 80.12 | 80.93 | 80.52 | 89.22 | 86.67 | 87.92 |
Table 5: Comparison F1 scores for AESC, Pair and Triplet on the $\mathcal{D}_{20a}$ dataset (Peng et al., 2020). The baseline results with “†” are retrieved from Mao et al. (2021), and result with $\sharp^{,*}$ is from $\mathrm{Xu}$ et al. (2020). We highlight the best results in bold.
表 5: 在 $\mathcal{D}_{20a}$ 数据集上 AESC、Pair 和 Triplet 的 F1 分数对比 (Peng et al., 2020)。带“†”的基线结果来自 Mao et al. (2021),带 $\sharp^{,*}$ 的结果来自 $\mathrm{Xu}$ et al. (2020)。最佳结果以粗体标出。
| 模型 | 14res | 14lap | 15res | 16res | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AESC | Pair | Triple. | AESC | Pair | Triple. | AESC | Pair | Triple. | AESC | Pair | Triple. | |
| CMLA+ ↑ | 70.62 | 48.95 | 43.12 | 56.90 | 44.10 | 32.90 | 53.60 | 44.60 | 35.90 | 61.20 | 50.00 | 41.60 |
| RINANTE+ ↑ | 48.15 | 46.29 | 34.03 | 36.70 | 29.70 | 20.0 | 41.30 | 35.40 | 28.0 | 42.10 | 30.70 | 23.30 |
| Li-unified+↑ | 73.79 | 55.34 | 51.68 | 63.38 | 52.56 | 42.47 | 64.95 | 56.85 | 46.69 | 70.20 | 53.75 | 44.51 |
| Peng-two-stage ↑ | 74.19 | 56.10 | 51.89 | 62.34 | 53.85 | 43.50 | 65.79 | 56.23 | 46.79 | 71.73 | 60.04 | 53.62 |
| JET-BERT# | 63.92 | 50.0 | 54.67 | 62.98 | ||||||||
| Dual-MRCf | 76.57 | 74.93 | 70.32 | 64.59 | 63.37 | 55.58 | 65.14 | 64.97 | 57.21 | 70.84 | 75.71 | 67.40 |
| Ours | 78.47 | 77.68 | 72.46 | 68.17 | 66.11 | 57.59 | 69.95 | 67.98 | 60.11 | 75.69 | 77.38 | 69.98 |
Table 6: Comparison results for Triplet on the $\ensuremath{\mathcal{D}}_{20b}$ dataset (Xu et al., 2020). Baselines are from (Xu et al., 2020). We highlight the best results in bold.
| 模型 | 14res-P | 14res-R | 14res-F1 | 14lap-P | 14lap-R | 14lap-F1 | 15res-P | 15res-R | 15res-F1 | 16res-P | 16res-R | 16res-F1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CMLA+ | 39.18 | 47.13 | 42.79 | 30.09 | 36.92 | 33.16 | 34.56 | 39.84 | 37.01 | 41.34 | 42.1 | 41.72 |
| RINANTE+ | 31.42 | 39.38 | 34.95 | 21.71 | 18.66 | 20.07 | 29.88 | 30.06 | 29.97 | 25.68 | 22.3 | 23.87 |
| Li-unified+ | 41.04 | 67.35 | 51.0 | 40.56 | 44.28 | 42.34 | 44.72 | 51.39 | 47.82 | 37.33 | 54.51 | 44.31 |
| Peng-two-stage | 43.24 | 63.66 | 51.46 | 37.38 | 50.38 | 42.87 | 48.07 | 57.51 | 52.32 | 46.96 | 64.24 | 54.21 |
| JET-BERT | 70.56 | 55.94 | 62.40 | 55.39 | 47.33 | 51.04 | 64.45 | 51.96 | 57.53 | 70.42 | 58.37 | 63.83 |
| Ours | 65.52 | 64.99 | 65.25 | 61.41 | 56.19 | 58.69 | 59.14 | 59.38 | 59.26 | 66.6 | 68.68 | 67.62 |
表 6: 在 $\ensuremath{\mathcal{D}}_{20b}$ 数据集上的三元组对比结果 (Xu et al., 2020)。基线结果来自 (Xu et al., 2020)。最佳结果以粗体标出。
these ABSA subtasks.
这些ABSA子任务。
On $\mathcal{D}_{19}$ dataset (Fan et al., 2019), we compare our method for $A O E$ . The comparison results are shown in Table 4. We can observe that our method achieves significant P/R/F1 improvements on 14res,
在 $\mathcal{D}_{19}$ 数据集 (Fan et al., 2019) 上,我们比较了所提方法在 $A O E$ 任务中的表现。对比结果如表 4 所示,可以观察到我们的方法在 14res 上实现了显著的 P/R/F1 指标提升。
15res, and 16res. Additionally, we notice that our F1 score on 14lap is close to the previous SOTA result. This is probably caused by the dataset domain difference as the 14lap is the laptop comments while the others are restaurant comments.
15res和16res。此外,我们注意到在14lap数据集上的F1分数接近之前的SOTA结果,这可能是由于数据集领域差异导致的,因为14lap是笔记本电脑评论,而其他数据集是餐厅评论。
On $\mathcal{D}_{20a}$ dataset (Peng et al., 2020), we com- pare our method for AESC, Pair, and Triplet. The comparison results are shown in Table 5. We can observe that our proposed method is able to outperform other baselines on all datasets. Specifically, we achieve the better results for Triplet, which demonstrates the effectiveness of our method on capturing interactions among aspect terms, opinion terms, and sentiment polarities. We also observe that the Span-based methods show superior performance to sequence tagging methods. This may be caused by the higher compositional it y of candidate labels in sequence tagging methods (Hu et al., 2019). As the previous SOTA method, the DualMRC shows competitive performance by utilizing the span-based extraction method and the MRC mechanism. However, their inference process is not an end-to-end process.
在 $\mathcal{D}_{20a}$ 数据集 (Peng et al., 2020) 上,我们比较了所提方法在AESC、Pair和Triplet任务上的表现。对比结果如表5所示。可以看出,我们的方法在所有数据集上均优于其他基线方法。特别是在Triplet任务中取得了更优结果,这验证了该方法在捕捉方面词、观点词和情感极性间交互关系的有效性。我们还发现基于片段(Span)的方法优于序列标注方法,这可能源于序列标注方法中候选标签具有更高的组合性 (Hu et al., 2019)。作为之前的SOTA方法,DualMRC通过结合片段抽取和机器阅读理解(MRC)机制展现了竞争力,但其推理过程并非端到端流程。
On $\ensuremath{\mathcal{D}}{20b}$ dataset (Xu et al., 2020), we compare our method for Triplet. The comparison results can be found in Table 6. Our method achieves the best results with nearly 7 F1 points improvements on 14res, 15res, and 16res. Our method achieves nearly 13, 9, 7, 12 points improvements on each dataset for the recall scores compared with other baselines. This also explains the drop performance of the precision score. Since $\mathcal{D}{20b}$ is refined from $\mathcal{D}{20a}$ , we specifically compare the Triplet results of the corresponding dataset in $\mathcal{D}{20a}$ and $\ensuremath{\mathcal{D}}_{20b}$ . Interestingly, we discover that all baselines have a much bigger performance change on 15res. We conjecture the distribution differences may be the cause reason. In conclusion, all the experiment results confirm that our proposed method, which unifies the training and the inference to an end-to-end generative framework, provides a new SOTA solution for the whole ABSA task.
在 $\ensuremath{\mathcal{D}}{20b}$ 数据集 (Xu et al., 2020) 上,我们比较了Triplet任务的方法。对比结果如表 6 所示。我们的方法在14res、15res和16res上取得了最佳结果,F1值提升了近7个点。与其他基线相比,我们的方法在各数据集的召回率上分别提升了约13、9、7和12个点,这也解释了精确度分数的下降。由于 $\mathcal{D}{20b}$ 是从 $\mathcal{D}{20a}$ 精炼而来,我们特别比较了 $\mathcal{D}{20a}$ 和 $\ensuremath{\mathcal{D}}_{20b}$ 中对应数据集的Triplet结果。有趣的是,我们发现所有基线方法在15res上的性能变化更为显著,推测分布差异可能是主要原因。综上所述,所有实验结果证实,我们提出的将训练与推理统一为端到端生成框架的方法,为整个ABSA任务提供了新的SOTA解决方案。
mat like $[a^{s},a^{e},o^{s},o^{e},s^{p}]$ , it is mandatory that one valid triplet prediction should be in length 5, noted as “5-len”, and obviously all end index should be larger than the corresponding start index, noted as “ordered prediction”. We calculate num t bot earl opfr endoinct−io5n−len , referred to as the “Invalid size”, and the numbetr ootafl n5onle−no rp dre erde i dc tpi or en diction , referred to as the “Invalid order”. The “Invalid token” means the $a^{s}$ is not the start of a token, instead, it is the index of an inside subword. From Table 7, we can observe that BART could learn this task form easily as the low rate for all the three metrics, which demonstrate that the generative framework for ABSA is not only a theoretically unified task form but also a realizable framework in practical. We remove these invalid predictions in our implementation of experiments.
类似矩阵 $[a^{s},a^{e},o^{s},o^{e},s^{p}]$ ,一个有效的三元组预测必须为长度5(记为"5-len"),且所有结束索引必须大于对应的起始索引(记为"有序预测")。我们计算不符合5-len条件的预测数量(称为"无效长度"),以及不符合有序条件的预测数量(称为"无效顺序")。"无效token"指 $a^{s}$ 不是token的起始位置,而是内部子词的索引。从表7可以看出,BART能轻松掌握这种任务形式,三项指标均保持较低比率,这表明生成式ABSA框架不仅在理论上是统一的任务形式,在实际中也是可实现的框架。我们在实验实现中剔除了这些无效预测。
As shown in Table 4, we give some analysis on the impact of the beam size, as we are a generation method. However, the beam size seems to have little impact on the F1 scores.
如表 4 所示,我们对 beam size 的影响进行了分析,因为我们是一种生成方法。然而,beam size 对 F1 分数的影响似乎很小。
Table 7: The errors for Triplet on the test set of the $\mathcal{D}_{20b}$ .
表 7: Triplet 在 $\mathcal{D}_{20b}$ 测试集上的错误率
| 错误类型 | 14res 14lap | 15res 16res |
|---|---|---|
| 无效尺寸 | 0.48% 0.77% | 1.41% 1.40% |
| 无效顺序 | 1.75% 3.70% 3.26% | - |
| 无效 Token | 0.48% 0.78% 1.02% | 61.02% |

Figure 4: The F1 change curve with the increment of beam size on the dev set of $\mathcal{D}_{20b}$ . The beam size seems to have little effect on the F1 scores.
图 4: 在 $\mathcal{D}_{20b}$ 开发集上随着 beam size 增加的 F1 变化曲线。beam size 对 F1 分数似乎影响不大。
5 Framework Analysis
5 框架分析
To better understand our proposed framework, we conduct analysis experiments on the $\ensuremath{\mathcal{D}}_{20b}$ dataset (Xu et al., 2020).
为了更好地理解我们提出的框架,我们在 $\ensuremath{\mathcal{D}}_{20b}$ 数据集 (Xu et al., 2020) 上进行了分析实验。
To validate whether our proposed framework could adapt to the generative ABSA task, we metric the invalid predictions for the Triplet. Specifically, since the Triplet requires the prediction for
为了验证我们提出的框架能否适应生成式ABSA任务,我们对三元组(Triplet)的无效预测进行了量化。具体而言,由于三元组要求预测
6 Conclusion
6 结论
This paper summarizes the seven ABSA subtasks and previous studies, which shows that there exist divergences on all the input, output, and task type sides. Previous studies have limitations on handling all these divergences in a unified framework. We propose to convert all the ABSA subtasks to a unified generative task. We implement the BART to generate the target sequence in an end-to-end process based on the unified task formulation. We conduct massive experiments on public datasets for seven ABSA subtasks and achieve significant improvements on most datasets. The experimental results demonstrate the effectiveness of our method. Our work leads to several promising directions, such as sequence-to-sequence framework on other tasks, and data augmentation.
本文总结了七项ABSA子任务及前人研究,表明这些任务在输入、输出和任务类型层面均存在差异。先前研究难以在统一框架中处理所有差异。我们提出将所有ABSA子任务转化为统一的生成式任务,基于该统一范式采用BART模型实现端到端的目标序列生成。在七项ABSA子任务的公开数据集上进行大量实验,在多数数据集上取得显著提升。实验结果验证了方法的有效性。本研究为序列到序列框架在其他任务的应用、数据增强等方向提供了新思路。
Acknowledgements
致谢
We would like to thank the anonymous reviewers for their insightful comments. The discussion with colleagues in AWS Shanghai AI Lab was quite fruitful. We also thank the developers of fastNLP7 and fitlog8. This work was supported by the National Key Research and Development Program of China (No. 2020 AAA 0106700) and National Natural Science Foundation of China (No. 62022027).
我们要感谢匿名评审专家们富有洞察力的意见。与AWS上海人工智能实验室同事们的讨论也让我们受益匪浅。同时感谢fastNLP7和fitlog8的开发团队。本研究得到了国家重点研发计划(No. 2020AAA0106700)和国家自然科学基金(No. 62022027)的资助。
Ethical Considerations
伦理考量
For the consideration of ethical concerns, we would make detailed description as follows:
出于对伦理问题的考虑,我们将详细说明如下:
References
参考文献
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neel a kant an, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners.
Tom B. Brown、Benjamin Mann、Nick Ryder、Melanie Subbiah、Jared Kaplan、Prafulla Dhariwal、Arvind Neelakantan、Pranav Shyam、Girish Sastry、Amanda Askell、Sandhini Agarwal、Ariel Herbert-Voss、Gretchen Krueger、Tom Henighan、Rewon Child、Aditya Ramesh、Daniel M. Ziegler、Jeffrey Wu、Clemens Winter、Christopher Hesse、Mark Chen、Eric Sigler、Mateusz Litwin、Scott Gray、Benjamin Chess、Jack Clark、Christopher Berner、Sam McCandlish、Alec Radford、Ilya Sutskever 和 Dario Amodei。2020. 大语言模型是少样本学习者。
Peng Chen, Zhongqian Sun, Lidong Bing, and Wei Yang. 2017. Recurrent attention network on memory for aspect sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 452–461, Copenhagen, Denmark. Association for Computational Linguistics.
Peng Chen、Zhongqian Sun、Lidong Bing和Wei Yang。2017. 基于记忆循环注意力网络的方面情感分析。载于《2017年自然语言处理实证方法会议论文集》,第452-461页,丹麦哥本哈根。计算语言学协会。
Zhuang Chen and Tieyun Qian. 2020. Relation-aware collaborative learning for unified aspect-based sentiment analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 3685–3694, Online. Association for Computational Linguistics.
庄晨和钱铁云。2020。基于关系感知的协同学习在统一方面情感分析中的应用。载于《第58届计算语言学协会年会论文集》,第3685–3694页,线上。计算语言学协会。
Kyunghyun Cho, Bart van Merrie n boer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using RNN encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1724– 1734, Doha, Qatar. Association for Computational Linguistics.
Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, Yoshua Bengio. 2014. 基于RNN编码器-解码器的短语表示学习在统计机器翻译中的应用. 见《2014年自然语言处理实证方法会议论文集》(EMNLP), 第1724–1734页, 卡塔尔多哈. 计算语言学协会.
Hongliang Dai and Yangqiu Song. 2019. Neural aspect and opinion term extraction with mined rules as weak supervision. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5268–5277, Florence, Italy. Association for Computational Linguistics.
Hongliang Dai和Yangqiu Song。2019。基于挖掘规则作为弱监督的神经方面与观点词抽取。见《第57届计算语言学协会年会论文集》,第5268–5277页,意大利佛罗伦萨。计算语言学协会。
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
Jacob Devlin、Ming-Wei Chang、Kenton Lee 和 Kristina Toutanova。2019。BERT:面向语言理解的深度双向Transformer预训练。载于《2019年北美计算语言学协会人类语言技术会议论文集(长文与短文)》第1卷,第4171–4186页,明尼苏达州明尼阿波利斯市。计算语言学协会。
Zhifang Fan, Zhen Wu, Xin-Yu Dai, Shujian Huang, and Jiajun Chen. 2019. Target-oriented opinion words extraction with target-fused neural sequence labeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2509–2518, Minneapolis, Minnesota. Association for Computational Linguistics.
范志方、吴震、戴新宇、黄书剑、陈佳俊。2019。基于目标融合神经序列标注的面向目标观点词抽取。载于《2019年北美计算语言学协会人类语言技术会议论文集(长文与短文)》第一册,第2509–2518页,明尼苏达州明尼阿波利斯市。计算语言学协会。
Ruidan He, Wee Sun Lee, Hwee Tou $\mathrm{Ng}$ , and Daniel Dahlmeier. 2019. An interactive multi-task learning network for end-to-end aspect-based sentiment analysis. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguis- tics, pages 504–515, Florence, Italy. Association for Computational Linguistics.
Ruidan He, Wee Sun Lee, Hwee Tou $\mathrm{Ng}$ 和 Daniel Dahlmeier. 2019. 一种用于端到端基于方面的情感分析的交互式多任务学习网络. 在《第57届计算语言学协会年会论文集》中, 第504–515页, 意大利佛罗伦萨. 计算语言学协会.
Minghao Hu, Yuxing Peng, Zhen Huang, Dongsheng Li, and Yiwei Lv. 2019. Open-domain targeted sentiment analysis via span-based extraction and classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguis- tics, pages 537–546, Florence, Italy. Association for Computational Linguistics.
胡明浩、彭宇星、黄震、李东升和吕一伟。2019. 基于跨度的开放域目标情感分析与分类方法。见《第57届计算语言学协会年会论文集》,第537–546页,意大利佛罗伦萨。计算语言学协会。
John D. Lafferty, Andrew McCallum, and Fernando C. N. Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML 2001), Williams College, Williamstown, MA, USA, June 28 - July 1, 2001, pages 282–289. Morgan Kaufmann.
John D. Lafferty、Andrew McCallum 和 Fernando C. N. Pereira。2001。条件随机场:序列数据分割与标记的概率模型。载于《第十八届国际机器学习会议论文集》(ICML 2001),美国马萨诸塞州威廉斯敦威廉姆斯学院,2001年6月28日至7月1日,第282-289页。Morgan Kaufmann出版社。
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghaz vi nine j ad, Abdel rahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Z ett le moyer. 2020. BART: Denoising sequence-to-sequence pretraining for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7871–7880, Online. Association for Computational Linguistics.
Mike Lewis、Yinhan Liu、Naman Goyal、Marjan Ghazvininejad、Abdelrahman Mohamed、Omer Levy、Veselin Stoyanov 和 Luke Zettlemoyer。2020。BART:用于自然语言生成、翻译和理解的去噪序列到序列预训练。见《第58届计算语言学协会年会论文集》,第7871–7880页,线上会议。计算语言学协会。
Kun Li, Chengbo Chen, Xiaojun Quan, Qing Ling, and Yan Song. 2020. Conditional augmentation for aspect term extraction via masked sequence-tosequence generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7056–7066, Online. Association for Computational Linguistics.
Kun Li、Chengbo Chen、Xiaojun Quan、Qing Ling和Yan Song。2020。基于掩码序列到序列生成的条件增强在方面术语抽取中的应用。载于《第58届计算语言学协会年会论文集》,第7056-7066页,线上会议。计算语言学协会。
Xin Li, Lidong Bing, Wai Lam, and Bei Shi. 2018a. Transformation networks for target-oriented sentiment classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 946– 956, Melbourne, Australia. Association for Computational Linguistics.
李欣、Lidong Bing、Wai Lam和石蓓。2018a。面向目标情感分类的转换网络。载于《第56届计算语言学协会年会论文集(第一卷:长论文)》,第946-956页,澳大利亚墨尔本。计算语言学协会。
Xin Li, Lidong Bing, Piji Li, and Wai Lam. 2019. A unified model for opinion target extraction and target sentiment prediction. In The Thirty-Third AAAI Conference on Artificial Intelligence, AAAI 2019, The Thirty-First Innovative Applications of Artificial Intelligence Conference, IAAI 2019, The Ninth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2019, Honolulu, Hawaii, USA, January 27 - February 1, 2019, pages 6714–6721. AAAI Press.
Xin Li、Lidong Bing、Piji Li 和 Wai Lam。2019。意见目标抽取与目标情感预测的统一模型。载于《第三十三届人工智能会议 (AAAI 2019)》、《第三十一届人工智能创新应用会议 (IAAI 2019)》、《第九届人工智能教育进展研讨会 (EAAI 2019)》,2019年1月27日至2月1日,美国夏威夷檀香山,第6714–6721页。AAAI出版社。
Xin Li, Lidong Bing, Piji Li, Wai Lam, and Zhimou Yang. 2018b. Aspect term extraction with history attention and selective transformation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, July 13-19, 2018, Stockholm, Sweden, pages 4194–4200. ijcai.org.
Xin Li、Lidong Bing、Piji Li、Wai Lam和Zhimou Yang。2018b。基于历史注意力与选择性转换的方面术语抽取。载于《第二十七届国际人工智能联合会议论文集》(IJCAI 2018),2018年7月13-19日,瑞典斯德哥尔摩,第4194–4200页。ijcai.org。
Xin Li and Wai Lam. 2017. Deep multi-task learning for aspect term extraction with memory interaction. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2886–2892, Copenhagen, Denmark. Association for Computational Linguistics.
Xin Li 和 Wai Lam。2017。基于记忆交互的深度多任务学习在方面术语抽取中的应用。载于《2017年自然语言处理实证方法会议论文集》,第2886-2892页,丹麦哥本哈根。计算语言学协会。
Jiangming Liu and Yue Zhang. 2017. Attention modeling for targeted sentiment. In Proceedings of the
Jiangming Liu和Yue Zhang。2017。面向目标情感分析的注意力建模。见《...会议论文集》
15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, pages 572–577, Valencia, Spain. Association for Computational Linguistics.
第15届欧洲计算语言学协会会议:第2卷,短文集,第572-577页,西班牙瓦伦西亚。计算语言学协会。
Thang Luong, Hieu Pham, and Christopher D. Manning. 2015. Effective approaches to attention-based neural machine translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1412–1421, Lisbon, Portugal. Association for Computational Linguistics.
Thang Luong、Hieu Pham和Christopher D. Manning。2015。基于注意力的神经机器翻译有效方法。载于《2015年自然语言处理实证方法会议论文集》,第1412-1421页,葡萄牙里斯本。计算语言学协会。
Dehong Ma, Sujian Li, and Houfeng Wang. 2018. Joint learning for targeted sentiment analysis. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4737–4742, Brussels, Belgium. Association for Computational Linguistics.
马德宏、李素建和王厚峰。2018。面向目标的情感分析联合学习。载于《2018年自然语言处理实证方法会议论文集》,第4737–4742页,比利时布鲁塞尔。计算语言学协会。
Dehong Ma, Sujian Li, Fangzhao Wu, Xing Xie, and Houfeng Wang. 2019. Exploring sequence-tosequence learning in aspect term extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3538– 3547, Florence, Italy. Association for Computational Linguistics.
马德宏、李素建、吴方钊、谢星、王厚峰。2019。探索方面术语抽取中的序列到序列学习。见《第57届计算语言学协会年会论文集》,第3538-3547页,意大利佛罗伦萨。计算语言学协会。
Dehong Ma, Sujian Li, Xiaodong Zhang, and Houfeng Wang. 2017. Interactive attention networks for aspect-level sentiment classification. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, August 19-25, 2017, pages 4068– 4074. ijcai.org.
马德宏、李素建、张晓东和王厚峰。2017. 交互式注意力网络在方面级情感分类中的应用。载于《第二十六届国际人工智能联合会议论文集》(IJCAI 2017),2017年8月19-25日,澳大利亚墨尔本,第4068–4074页。ijcai.org。
Yue Mao, Yi Shen, Chao Yu, and Longjun Cai. 2021. A joint training dual-mrc framework for aspect based sentiment analysis. CoRR, abs/2101.00816.
Yue Mao、Yi Shen、Chao Yu 和 Longjun Cai。2021。基于方面的情感分析联合训练双 MRC 框架。CoRR,abs/2101.00816。
Margaret Mitchell, Jacqui Aguilar, Theresa Wilson, and Benjamin Van Durme. 2013. Open domain targeted sentiment. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1643–1654, Seattle, Washington, USA. Association for Computational Linguistics.
Margaret Mitchell、Jacqui Aguilar、Theresa Wilson和Benjamin Van Durme。2013. 开放领域目标情感分析。载于《2013年自然语言处理实证方法会议论文集》,第1643–1654页,美国华盛顿州西雅图。计算语言学协会。
Haiyun Peng, Lu Xu, Lidong Bing, Fei Huang, Wei Lu, and Luo Si. 2020. Knowing what, how and why: A near complete solution for aspect-based sentiment analysis. In The Thirty-Fourth AAAI Con- ference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, Febru- ary 7-12, 2020, pages 8600–8607. AAAI Press.
Haiyun Peng、Lu Xu、Lidong Bing、Fei Huang、Wei Lu 和 Luo Si。2020。Knowing what, how and why: A near complete solution for aspect-based sentiment analysis(知道是什么、如何以及为什么:基于方面的情感分析的近乎完整解决方案)。载于第三十四届AAAI人工智能会议(AAAI 2020)、第三十二届人工智能创新应用会议(IAAI 2020)、第十届AAAI人工智能教育进展研讨会(EAAI 2020),美国纽约,2020年2月7-12日,第8600-8607页。AAAI出版社。
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Z ett le moyer. 2018. Deep contextual i zed word represent at ions. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages
Matthew Peters、Mark Neumann、Mohit Iyyer、Matt Gardner、Christopher Clark、Kenton Lee 和 Luke Zettlemoyer。2018. 深度上下文词表征 (Deep contextualized word representations)。载于《2018年北美计算语言学协会人类语言技术会议论文集》第1卷(长论文),页码
2227–2237, New Orleans, Louisiana. Association for Computational Linguistics.
2227–2237,新奥尔良,路易斯安那州。计算语言学协会。
Maria Pontiki, Dimitris Galanis, John Pav lo poul os, Harris Papa georgi ou, Ion And rout so poul os, and Suresh Manandhar. 2014a. SemEval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), pages 27–35, Dublin, Ireland. Association for Computational Linguistics.
Maria Pontiki、Dimitris Galanis、John Pavlopoulos、Harris Papageorgiou、Ion Androutsopoulos 和 Suresh Manandhar。2014a. SemEval-2014 任务 4: 基于方面的情感分析。载于《第 8 届语义评估国际研讨会论文集》(SemEval 2014), 第 27–35 页, 爱尔兰都柏林。计算语言学协会。
Maria Pontiki, Dimitris Galanis, John Pav lo poul os, Harris Papa georgi ou, Ion And rout so poul os, and Suresh Manandhar. 2014b. SemEval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), pages 27–35, Dublin, Ireland. Association for Computational Linguistics.
Maria Pontiki、Dimitris Galanis、John Pavlopoulos、Harris Papageorgiou、Ion Androutsopoulos 和 Suresh Manandhar。2014b。SemEval-2014 任务 4:基于方面的情感分析 (Aspect based sentiment analysis)。载于《第 8 届语义评估国际研讨会论文集》(SemEval 2014),第 27-35 页,爱尔兰都柏林。计算语言学协会 (Association for Computational Linguistics)。
Maria Pontiki, Dimitris Galanis, John Pav lo poul os, Harris Papa georgi ou, Ion And rout so poul os, and Suresh Manandhar. 2014c. SemEval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), pages 27–35, Dublin, Ireland. Association for Computational Linguistics.
Maria Pontiki、Dimitris Galanis、John Pavlopoulos、Harris Papageorgiou、Ion Androutsopoulos 和 Suresh Manandhar。2014c。SemEval-2014 任务 4:基于方面的情感分析。载于《第 8 届语义评估国际研讨会论文集》(SemEval 2014),第 27-35 页,爱尔兰都柏林。计算语言学协会。
Amir Pouran Ben Veyseh, Nasim Nouri, Franck Dernoncourt, Dejing Dou, and Thien Huu Nguyen. 2020. Introducing syntactic structures into target opinion word extraction with deep learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8947–8956, Online. Association for Computational Linguistics.
Amir Pouran Ben Veyseh、Nasim Nouri、Franck Dernoncourt、Dejing Dou和Thien Huu Nguyen。2020。通过深度学习将句法结构引入目标观点词抽取。载于《2020年自然语言处理实证方法会议论文集》(EMNLP),第8947-8956页,线上。计算语言学协会。
Xipeng Qiu, TianXiang Sun, Yige Xu, Yunfan Shao, Ning Dai, and Xuanjing Huang. 2020. Pre-trained models for natural language processing: A survey. SCIENCE CHINA Technological Sciences, 63(10):1872–1897.
邱锡鹏、孙天祥、徐一格、邵云帆、戴宁、黄萱菁。2020. 预训练自然语言处理模型综述。中国科学: 技术科学, 63(10):1872–1897。
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21:140:1–140:67.
Colin Raffel、Noam Shazeer、Adam Roberts、Katherine Lee、Sharan Narang、Michael Matena、Yanqi Zhou、Wei Li 和 Peter J. Liu。2020。探索迁移学习的极限:统一的文本到文本Transformer。J. Mach. Learn. Res.,21:140:1–140:67。
Sunita Sarawagi and William W. Cohen. 2004. Semimarkov conditional random fields for information extraction. In Advances in Neural Information Processing Systems 17 [Neural Information Processing Systems, NIPS 2004, December 13-18, 2004, Vancouver, British Columbia, Canada], pages 1185– 1192.
Sunita Sarawagi 和 William W. Cohen. 2004. 用于信息抽取的半马尔可夫条件随机场. 见《神经信息处理系统进展》第17卷 [神经信息处理系统会议, NIPS 2004, 2004年12月13-18日, 加拿大不列颠哥伦比亚省温哥华], 第1185–1192页.
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and TieYan Liu. 2019. MASS: masked sequence to sequence pre-training for language generation. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, 9-15 June 2019, Long Beach, California, USA, volume 97 of Pro- ceedings of Machine Learning Research, pages 5926–5936. PMLR.
Kaitao Song、Xu Tan、Tao Qin、Jianfeng Lu 和 TieYan Liu。2019。MASS: 面向语言生成的掩码序列到序列预训练。载于《第36届国际机器学习会议论文集》(ICML 2019),2019年6月9-15日,美国加州长滩,《机器学习研究论文集》第97卷,第5926–5936页。PMLR。
Ilya Sutskever, Oriol Vinyals, and Quoc V. Le. 2014. Sequence to sequence learning with neural networks. In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pages 3104–3112.
Ilya Sutskever、Oriol Vinyals 和 Quoc V. Le。2014。使用神经网络进行序列到序列学习。收录于《神经信息处理系统进展 27:2014 年神经信息处理系统年会》,2014 年 12 月 8-13 日,加拿大魁北克蒙特利尔,第 3104–3112 页。
Duyu Tang, Bing Qin, Xiaocheng Feng, and Ting Liu. 2016a. Effective LSTMs for target-dependent sentiment classification. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pages 3298– 3307, Osaka, Japan. The COLING 2016 Organizing Committee.
Duyu Tang、Bing Qin、Xiaocheng Feng和Ting Liu。2016a。面向目标依赖情感分类的高效LSTM模型。见《COLING 2016第26届国际计算语言学会议技术论文集》,第3298-3307页,日本大阪。COLING 2016组委会。
Duyu Tang, Bing Qin, and Ting Liu. 2016b. Aspect level sentiment classification with deep memory network. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 214–224, Austin, Texas. Association for Computational Linguistics.
Duyu Tang、Bing Qin和Ting Liu。2016b。基于深度记忆网络的方面级情感分类。载于《2016年自然语言处理实证方法会议论文集》,第214-224页,得克萨斯州奥斯汀。计算语言学协会。
Yi Tay, Luu Anh Tuan, and Siu Cheung Hui. 2018. Learning to attend via word-aspect associative fusion for aspect-based sentiment analysis. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, pages 5956–5963. AAAI Press.
Yi Tay, Luu Anh Tuan, and Siu Cheung Hui. 2018. 基于词-方面关联融合的注意力学习在方面级情感分析中的应用。在第三十二届AAAI人工智能会议论文集 (AAAI-18)、第三十届人工智能创新应用会议 (IAAI-18) 和第八届AAAI人工智能教育进展研讨会 (EAAI-18) 中发表,会议于2018年2月2-7日在美国路易斯安那州新奥尔良举行,AAAI出版社出版,页码5956–5963。
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4- 9, 2017, Long Beach, CA, USA, pages 5998–6008.
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N. Gomez、Lukasz Kaiser 和 Illia Polosukhin。2017. Attention is all you need。收录于《神经信息处理系统进展 30:2017 年神经信息处理系统年度会议》,2017 年 12 月 4-9 日,美国加州长滩,第 5998–6008 页。
Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. 2015. Pointer networks. In Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, December 7-12, 2015, Montreal, Quebec, Canada, pages 2692–2700.
Oriol Vinyals、Meire Fortunato 和 Navdeep Jaitly。2015. Pointer networks。载于《Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015》,2015年12月7-12日,加拿大魁北克蒙特利尔,第2692–2700页。
Wenya Wang and Sinno Jialin Pan. 2018. Recursive neural structural correspondence network for crossdomain aspect and opinion co-extraction. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2171–2181, Melbourne, Australia. Association for Computational Linguistics.
Wenya Wang和Sinno Jialin Pan. 2018. 基于递归神经结构对应网络的跨领域方面与观点协同提取. 见《第56届计算语言学协会年会论文集(第一卷: 长论文)》, 第2171–2181页, 澳大利亚墨尔本. 计算语言学协会.
Wenya Wang, Sinno Jialin Pan, Daniel Dahlmeier, and Xiaokui Xiao. 2016a. Recursive neural conditional random fields for aspect-based sentiment analysis. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 616–626, Austin, Texas. Association for Computational Linguistics.
Wenya Wang、Sinno Jialin Pan、Daniel Dahlmeier 和 Xiaokui Xiao。2016a。基于方面的情感分析的递归神经条件随机场。2016年自然语言处理经验方法会议论文集,第616-626页,德克萨斯州奥斯汀。计算语言学协会。
Wenya Wang, Sinno Jialin Pan, Daniel Dahlmeier, and Xiaokui Xiao. 2017. Coupled multi-layer attentions for co-extraction of aspect and opinion terms. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, February 4-9, 2017, San Francisco, California, USA, pages 3316–3322. AAAI Press.
Wenya Wang, Sinno Jialin Pan, Daniel Dahlmeier, and Xiaokui Xiao. 2017. 基于多层耦合注意力的方面词与观点词协同抽取方法. 载于《第三十一届AAAI人工智能会议论文集》, 2017年2月4-9日, 美国加利福尼亚州旧金山, 页码3316–3322. AAAI出版社.
Meeting of the Association for Computational Linguistics, pages 3239–3248, Online. Association for Computational Linguistics.
计算语言学协会会议,第3239–3248页,在线。计算语言学协会。
Yequan Wang, Minlie Huang, Xiaoyan Zhu, and Li Zhao. 2016b. Attention-based LSTM for aspectlevel sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 606–615, Austin, Texas. Association for Computational Linguistics.
Yequan Wang, Minlie Huang, Xiaoyan Zhu, and Li Zhao. 2016b. 基于注意力机制的LSTM在方面级情感分类中的应用。In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 606–615, Austin, Texas. Association for Computational Linguistics.
Zhen Wu, Fei Zhao, Xin-Yu Dai, Shujian Huang, and Jiajun Chen. 2020. Latent opinions transfer network for target-oriented opinion words extraction. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020, pages 9298– 9305. AAAI Press.
Zhen Wu、Fei Zhao、Xin-Yu Dai、Shujian Huang 和 Jiajun Chen。2020。面向目标观点词提取的潜在观点迁移网络。载于《第三十四届人工智能会议 (AAAI 2020)》《第三十二届人工智能创新应用会议 (IAAI 2020)》《第十届人工智能教育进展研讨会 (EAAI 2020)》,美国纽约州纽约市,2020年2月7-12日,页码9298–9305。AAAI Press。
Hu Xu, Bing Liu, Lei Shu, and Philip S. Yu. 2018. Double embeddings and CNN-based sequence labeling for aspect extraction. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 592– 598, Melbourne, Australia. Association for Computational Linguistics.
胡旭、刘冰、舒磊和Philip S. Yu。2018。基于双重嵌入和CNN序列标注的方面提取。载于《第56届计算语言学协会年会论文集(第二卷:短论文)》,第592-598页,澳大利亚墨尔本。计算语言学协会。
Lu Xu, Hao Li, Wei Lu, and Lidong Bing. 2020. Position-aware tagging for aspect sentiment triplet extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 2339–2349, Online. Associa- tion for Computational Linguistics.
卢旭、李浩、卢伟和宾立东。2020。面向方面情感三元组提取的位置感知标注方法。载于《2020年自然语言处理经验方法会议论文集》(EMNLP),第2339–2349页,线上。计算语言学协会。
Wei Xue and Tao Li. 2018. Aspect based sentiment analysis with gated convolutional networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2514–2523, Melbourne, Australia. Association for Computational Linguistics.
Wei Xue和Tao Li. 2018. 基于门控卷积网络的方面情感分析. 见《第56届计算语言学协会年会论文集(第一卷:长论文)》, 第2514–2523页, 澳大利亚墨尔本. 计算语言学协会.
Meishan Zhang, Yue Zhang, and Duy-Tin Vo. 2015. Neural networks for open domain targeted sentiment. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 612–621, Lisbon, Portugal. Association for Computational Linguistics.
Meishan Zhang、Yue Zhang和Duy-Tin Vo。2015。面向开放领域目标情感分析的神经网络。载于《2015年自然语言处理实证方法会议论文集》,第612-621页,葡萄牙里斯本。计算语言学协会。
Meishan Zhang, Yue Zhang, and Duy-Tin Vo. 2016. Gated neural networks for targeted sentiment analysis. In Proceedings of the Thirtieth AAAI Con- ference on Artificial Intelligence, February 12-17, 2016, Phoenix, Arizona, USA, pages 3087–3093. AAAI Press.
Meishan Zhang、Yue Zhang和Duy-Tin Vo。2016。面向目标情感分析的门控神经网络。见《第三十届AAAI人工智能会议论文集》,2016年2月12-17日,美国亚利桑那州凤凰城,第3087–3093页。AAAI出版社。
He Zhao, Longtao Huang, Rong Zhang, Quan Lu, and Hui Xue. 2020. SpanMlt: A span-based multi-task learning framework for pair-wise aspect and opinion terms extraction. In Proceedings of the 58th Annual
He Zhao、Longtao Huang、Rong Zhang、Quan Lu和Hui Xue。2020。SpanMlt:一种基于跨度的多任务学习框架,用于成对方面和观点术语提取。见第58届年会论文集
A Supplemental Material
补充材料
A.1 Experimental Environment
A.1 实验环境
We use the triangular learning rate warmup. All experiments are conducted in the Nvidia Ge-Force RTX-3090 Graphical Card with 24G graphical memory.
我们采用三角学习率预热策略。所有实验均在配备24G显存的Nvidia GeForce RTX-3090显卡上进行。
The averages running time for experiments on each dataset is less than 15 minutes. The number of parameters is as follows:
各数据集上的实验平均运行时间均少于15分钟。参数数量如下:
• BART-Base model: 12 layers, 768 hidden dimensions and 16 heads with the total number of parameters, 139M; • BERT-Base model: 12 layers, 768 hidden dimensions and 12 heads with the total number of parameters, 110M.
- BART-Base模型:12层,768隐藏维度,16个头,总参数量1.39亿;
- BERT-Base模型:12层,768隐藏维度,12个头,总参数量1.10亿。
A.2 Decoding Algorithm for Different Datasets
A.2 不同数据集的解码算法
In this part, we introduce the decoding algorithm we used to convert the predicted target sequence $Y$ into the target span set $L$ . These algorithm can be found in Algorithm 2, 3, 4.
在这一部分,我们介绍了用于将预测的目标序列 $Y$ 转换为目标跨度集 $L$ 的解码算法。这些算法可在算法2、3、4中找到。
Algorithm 2 Decoding Algorithm for the AOE subtask
算法 2: AOE子任务解码算法
Algorithm 4 Decoding Algorithm for the AE/OE/Pair subtasks
算法 4: AE/OE/Pair子任务的解码算法