UnLoc: A Unified Framework for Video Localization Tasks
UnLoc: 视频定位任务的统一框架
Abstract
摘要
While large-scale image-text pretrained models such as CLIP have been used for multiple video-level tasks on trimmed videos, their use for temporal localization in untrimmed videos is still a relatively unexplored task. We design a new approach for this called UnLoc, which uses pretrained image and text towers, and feeds tokens to a video-text fusion model. The output of the fusion module are then used to construct a feature pyramid in which each level connects to a head to predict a per-frame relevancy score and start/end time displacements. Unlike previous works, our architecture enables Moment Retrieval, Temporal Localization, and Action Segmentation with a single stage model, without the need for action proposals, motion based pretrained features or representation masking. Unlike specialized models, we achieve state of the art results on all three different localization tasks with a unified approach. Code will be available at: https://github. com/google-research/scenic.
虽然CLIP等大规模图文预训练模型已应用于经过剪辑视频的多种视频级任务,但其在未剪辑视频中进行时序定位的用途仍是一个相对未被探索的领域。我们为此设计了名为UnLoc的新方法,该方法利用预训练的图文双塔架构,将token输入视频-文本融合模型。融合模块的输出用于构建特征金字塔,其中每一层级连接至预测逐帧相关性分数及起止时间位移的检测头。与先前工作不同,我们的架构通过单阶段模型即可实现片段检索、时序定位和动作分割,无需动作提案、基于运动的预训练特征或表征掩码。不同于专用模型,我们采用统一方法在三种不同的定位任务上均取得了最先进的成果。代码将在以下地址发布:https://github.com/google-research/scenic。
1. Introduction
1. 引言
Contrastive vision-language pre training has been shown to learn powerful feature representations, and moreover enables open-set inference on a wide range of tasks [57, 29]. As a result, pretrained models such as CLIP [57] have been adapted to multiple diverse tasks including video classification [54, 39], object detection [48] and segmentation [20].
对比式视觉语言预训练已被证明能够学习强大的特征表示,并且能够在广泛的任务上实现开放集推理 [57, 29]。因此,像 CLIP [57] 这样的预训练模型已被适配到多种多样的任务中,包括视频分类 [54, 39]、目标检测 [48] 和分割 [20]。
In this paper, we study how to adapt large-scale, contrastively trained image-text models to untrimmed video understanding tasks that involve localization. While CLIP has been used widely for trimmed video tasks (classification [54, 39] or retrieval [4]), its use on long, untrimmed video is still in a nascent stage. Long videos come with multiple challenges – CLIP is pretrained on images only, and localization in untrimmed videos requires exploiting finegrained temporal structured information in videos. In particular, it is challenging for image and language models to learn properties of temporal backgrounds (with respective to foreground actions) during training. In contrast, natural videos often come with a large, variable proportion of background and detecting specific actions is critical for localization tasks [51]. Finally, localization in long untrimmed videos also typically involves detecting events at multiple temporal scales. Consequently, existing approaches that use CLIP typically focus on a two-stage approach involving off-the-shelf proposal generators [30], or use temporal features such as I3D [50] or C3D [62]. In contrast, we propose an end-to-end trainable one-stage approach starting from a CLIP two tower model only.
本文研究如何将大规模对比训练的图文模型 (CLIP) 适配到涉及定位的非修剪视频理解任务。尽管 CLIP 已广泛应用于修剪视频任务 (分类 [54, 39] 或检索 [4]) ,但其在长视频非修剪场景的应用仍处于早期阶段。长视频面临多重挑战——CLIP 仅基于图像预训练,而非修剪视频的定位需要利用视频中细粒度的时间结构信息。尤其对于图像语言模型而言,在训练过程中学习时间背景 (相对于前景动作) 的特性具有挑战性。相比之下,自然视频通常包含大量可变比例的背景,而检测特定动作对定位任务至关重要 [51] 。此外,长视频非修剪定位通常还需检测多时间尺度的事件。因此,现有 CLIP 应用方案多采用两阶段方法,即依赖现成的候选片段生成器 [30] ,或使用 I3D [50] 、C3D [62] 等时序特征。与此不同,我们提出仅基于 CLIP 双塔模型的端到端可训练单阶段方案。
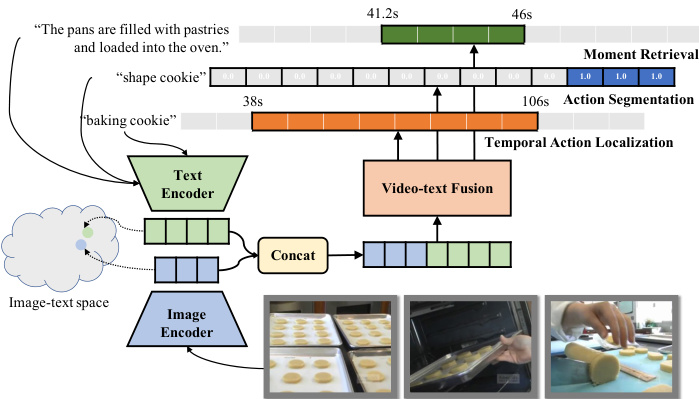
Figure 1. Applying two-tower CLIP to video localization tasks: We propose UnLoc, a single stage, unified model that achieves state of the art results on 3 different video localization tasks - moment retrieval, temporal action localization and action segmentation. UnLoc leverages a two-tower model (with a vision and text encoder) in conjunction with a video-text fusion module and feature pyramid to perform mid-level feature fusion without the need for any temporal proposals.
图 1: 将双塔CLIP应用于视频定位任务:我们提出UnLoc,这是一个单阶段统一模型,在3种不同的视频定位任务(时刻检索、时序动作定位和动作分割)上实现了最先进的结果。UnLoc利用双塔模型(包含视觉和文本编码器),结合视频-文本融合模块和特征金字塔,无需任何时序提案即可执行中层特征融合。
We focus specifically on three different video localization tasks - Moment Retrieval (MR) [31, 18], Temporal Ac- tion Localization (TAL) [23, 28] and Action Segmentation (AS) [64]. These tasks have typically been studied separately, with different techniques proposed for each task. We show how we can use a single, unified approach, to address all of these tasks, without using any external proposals. We do this by leveraging a two-tower model (with a vision and text encoder), in conjunction with a single video-text fusion module, which performs mid-level fusion of text and visual tokens (Figure 1). Our two tower model can naturally handle tasks such as moment retrieval which contain both video and text as input modalities, and can be used for open-set inference in other tasks such as temporal action localization and action segmentation. While many works use the visual encoder only [60, 9, 22, 81], we believe that the language priors learnt with the pretrained text encoder can contain useful information and should be leveraged together with the image encoder early in the model design (particularly for open-set evaluation), and not right at the end for similarity computation. Inspired by existing object detection works [33], we also use the output frame tokens from our fusion module to construct a feature pyramid, to enable understanding at multiple temporal scales.
我们重点研究三种不同的视频定位任务——时刻检索(MR) [31, 18]、时序动作定位(TAL) [23, 28]和动作分割(AS) [64]。这些任务通常被分开研究,并针对每个任务提出了不同技术。我们展示了如何通过单一统一方法解决所有这些任务,且无需使用任何外部提案。具体而言,我们采用双塔模型(包含视觉编码器和文本编码器)结合单一视频-文本融合模块,该模块对文本和视觉token进行中层融合(图1)。我们的双塔模型能自然处理像时刻检索这种同时包含视频和文本输入模态的任务,并可用于时序动作定位和动作分割等其他任务的开放集推理。虽然许多工作仅使用视觉编码器[60, 9, 22, 81],但我们认为预训练文本编码器学习到的语言先验包含有用信息,应在模型设计早期(特别是开放集评估时)与图像编码器共同利用,而非仅在最后阶段用于相似度计算。受现有目标检测工作[33]启发,我们还利用融合模块输出的帧token构建特征金字塔,以实现多时间尺度的理解。
Our approach achieves state-of-the-art results across all three video localization tasks - MR [31, 18], TAL [23, 28] and AS [64]. We also perform thorough ablation studies, studying the effect of modelling choices across a range of tasks.
我们的方法在所有三个视频定位任务中均取得了最先进的结果 - MR [31, 18]、TAL [23, 28] 和 AS [64]。我们还进行了全面的消融研究,探究了不同建模选择在一系列任务中的影响。
2. Related Work
2. 相关工作
Models based on CLIP for localization. Most works use CLIP for video level tasks that operate on short, trimmed clips, for example for classification tasks (e.g. ActionCLIP [70] and X-CLIP [54]). EVL [39] also adapts CLIP to video classification, but does so by training a small number of extra parameters. CLIP has also been used for other video level tasks such as text-video retrieval, as done in CLIP4CLIP [45] and CLIP-Hitchikers [4]. A number of works also use CLIP for tasks such as object detection [48, 87] and segmentation [21, 15]. Works that use CLIP for localization tasks in untrimmed videos, on the other hand are less common. Vid2Seq [74] uses CLIP features for dense video captioning, where temporal boundaries and captions are predicted together. Most works for localization however still reply heavily on I3D [8], C3D [66], $\mathrm{R}(2+1)\mathrm{D}$ [67], VGG [61], or SlowFast [16] features for moment retrieval [62, 78, 83, 82, 52], temporal action localization [51, 89, 81] and action segmentation [44].
基于CLIP的定位模型。大多数工作将CLIP应用于短视频片段级别的任务,例如分类任务(如ActionCLIP [70]和X-CLIP [54])。EVL [39]也通过训练少量额外参数将CLIP适配到视频分类任务。CLIP还被用于其他视频级别任务,如文本-视频检索(CLIP4CLIP [45]和CLIP-Hitchikers [4])。部分工作还将其应用于目标检测[48, 87]和分割[21, 15]等任务。相比之下,将CLIP用于未剪辑视频定位任务的研究较为少见。Vid2Seq [74]利用CLIP特征进行密集视频描述,同时预测时间边界和字幕描述。但当前大多数定位工作仍主要依赖I3D [8]、C3D [66]、$\mathrm{R}(2+1)\mathrm{D}$[67]、VGG [61]或SlowFast [16]等特征,应用于片段检索[62, 78, 83, 82, 52]、时序动作定位[51, 89, 81]以及动作分割[44]任务。
Temporal Action Localization (TAL). Supervised learning-based temporal action localization can be summarized into two-stage [59, 9, 85, 34, 36] and single-stage methods [60, 35, 53, 81]. More recently, EffPrompt [30] uses a two-stage sequential localization and classification architecture for zero-shot action localization, with the first stage consisting of action proposal generation with an offthe-shelf pre-trained proposal detector (e.g., BMN [34]), followed by proposal classification using CLIP features. We aim to build a proposal-free framework and directly regress the temporal location of the corresponding class labels or queries by using the fused video-text features. The closest to our method is STALE [51], which trains a single-stage model for zero-shot localization and classification, using representation masking for frame level localization. Unlike STALE, which evaluates on only TAL, we present a single unified method for MR, TAL and AS, and also introduce a feature pyramid for multi-scale reasoning.
时序动作定位 (TAL)。基于监督学习的时序动作定位方法可分为两阶段方法 [59, 9, 85, 34, 36] 和单阶段方法 [60, 35, 53, 81]。最近,EffPrompt [30] 采用两阶段的顺序定位与分类架构实现零样本动作定位:第一阶段使用现成的预训练提案检测器 (如 BMN [34]) 生成动作提案,第二阶段利用 CLIP 特征进行提案分类。我们致力于构建无提案框架,直接通过融合的视频-文本特征回归对应类别标签或查询的时间位置。最接近我们工作的是 STALE [51],该方法通过表征掩码实现帧级定位,训练了用于零样本定位与分类的单阶段模型。与仅针对 TAL 进行评估的 STALE 不同,我们提出了适用于 MR、TAL 和 AS 的统一方法,并引入了特征金字塔以实现多尺度推理。
Moment Retrieval (MR). Unlike TAL, where class names are predefined used a closed-form vocabulary, MR aims to find the relevant clip in an untrimmed video for a given open-ended natural language query. Early works use sliding windows over video sequences to generate video segment proposals [24, 18], after which the proposals are ranked by their similarity to the query. This ignores the finegrained relationships between video frames and the words in sentences. Anchor-based methods [10, 69, 77] avoid proposal generation by assigning each frame with multiscale anchors sequentially and use these to obtain more fine-grained matchings between video and text. Regressionbased methods [11, 78, 83, 50, 32, 42] involve learning cross-modal interactions to directly predict the temporal boundaries of a target moment without the need for proposal generation. Our work belongs to this category, unlike works that tend to use the text tower only at the end to compute similarity scores [25, 80, 19, 83, 42], we fuse image and text tokens early on in our model to better leverage language priors from the pretrained CLIP text tower.
时刻检索 (MR)。与使用封闭式词汇预定义类别的TAL不同,MR旨在通过开放式自然语言查询从未修剪视频中找出相关片段。早期研究采用滑动窗口生成视频片段候选区域 [24, 18],再根据候选区与查询的相似度进行排序。这种方法忽略了视频帧与句子词汇间的细粒度关联。基于锚点的方法 [10, 69, 77] 通过为每帧顺序分配多尺度锚点,避免候选区生成,从而获得视频与文本间更精细的匹配。基于回归的方法 [11, 78, 83, 50, 32, 42] 通过跨模态交互学习直接预测目标时刻的时间边界,无需生成候选区。本研究属于后者,与仅在最后阶段使用文本塔计算相似度得分的工作 [25, 80, 19, 83, 42] 不同,我们在模型早期就融合图像和文本token,以更好地利用预训练CLIP文本塔的语言先验。
Action Segmentation (AS). Action segmentation involves assigning a pre-defined label to each token or frame in a untrimmed long video, which helps to distinguish meaningful video segments from other tokens or frames [64]. While previous works [63, 46, 72, 44] pretrained their models on HowTo100M [47], our approach involves initializing models with pretrained CLIP models. CLIP was trained on pairs of web images and text, which may be less prone to noise compared to ASR and clip pairs.
动作分割 (Action Segmentation, AS)。动作分割的任务是为未修剪的长视频中的每个token或帧分配预定义的标签,从而将有意义的视频片段与其他token或帧区分开来 [64]。虽然先前的研究 [63, 46, 72, 44] 在HowTo100M [47] 数据集上预训练了模型,但我们的方法采用预训练的CLIP模型进行初始化。CLIP基于网络图像和文本对进行训练,相比ASR和视频片段对可能更不易受噪声影响。
3. Method
3. 方法
Our model unifies three tasks: MR, TAL and AS, which we first define in Sec. 3.1. As shown in Fig. 2, our model (Sec. 3.2) first tokenizes a (video, text) pair and then fuses information from the two modalities together with a simple video-text fusion module. To capture the multi-scale information needed for localization, we then construct a Feature Pyramid (Sec. 3.3) on the output of the video-text fusion module. These multi-scale features are then fed into a task-specifc Head module (Sec. 3.4) to localize activities or “ground” a language description.
我们的模型统一了三个任务:MR、TAL和AS,我们将在第3.1节中首先定义这些任务。如图2所示,我们的模型(第3.2节)首先对(视频,文本)对进行Token化处理,然后通过一个简单的视频-文本融合模块将两种模态的信息融合在一起。为了捕捉定位所需的多尺度信息,我们在视频-文本融合模块的输出上构建了一个特征金字塔(第3.3节)。这些多尺度特征随后被输入到特定任务的Head模块(第3.4节)中,以定位活动或“落地”语言描述。
3.1. Tasks
3.1. 任务
Moment Retrieval (MR), also known as Video Grounding, is the task of matching a given language description (query) to specific video segments in an untrimmed video. Temporal Action Localization (TAL) aims to detect events in a video and output the corresponding start- and endtimestamps. One key difference from MR is that events in TAL are from a predefined closed-vocabulary set, often described by a short phrase (e.g., “baking cookies”). Finally, similar to Semantic Segmentation, which parses images into semantic categories at a pixel level, Action Segmentation (AS) involves producing activity labels at a frame level. Also, for this task the labels are typically predefined from a closed-vocabulary set.
时刻检索 (Moment Retrieval, MR) 也称为视频定位 (Video Grounding),其任务是将给定的语言描述 (查询) 与未修剪视频中的特定视频片段进行匹配。时序动作定位 (Temporal Action Localization, TAL) 旨在检测视频中的事件并输出相应的开始和结束时间戳。与 MR 的一个关键区别在于,TAL 中的事件来自预定义的封闭词汇集,通常由短短语描述 (例如 "烤饼干")。最后,类似于语义分割 (Semantic Segmentation) 在像素级别将图像解析为语义类别,动作分割 (Action Segmentation, AS) 需要在帧级别生成活动标签。同样,此任务的标签通常也来自预定义的封闭词汇集。
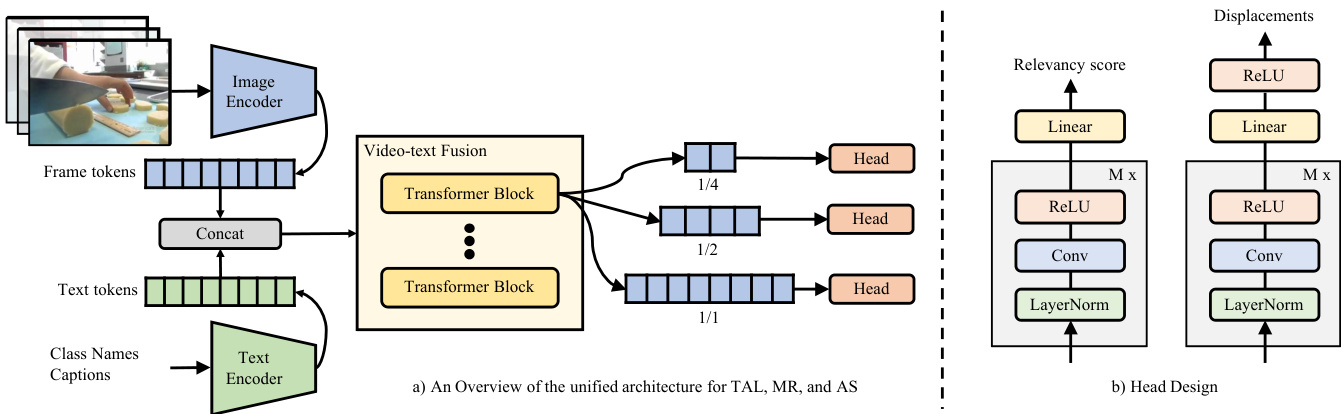
Figure 2. Overview of our method UnLoc. Given a video and text (e.g., class names in TAL/AS or captions in MR) pair, first they are tokenized and encoded by a pair of image and text encoders. Frame and text tokens are concatenated into a long sequence and then fed into a transformer for fusion. Frame tokens from the last transformer layer are used to construct a feature pyramid in which each level connects to a head to predict a per-frame relevancy score and start/end time displacements. No text token is used to construct the feature pyramid since text information has already been “fused” into the frame tokens via self-attention. We show a 3 layer feature pyramid for simplicity. All heads across different pyramid levels share the same weights.
图 2: 我们的 UnLoc 方法概述。给定视频和文本(例如 TAL/AS 中的类别名称或 MR 中的字幕)对,首先通过图像和文本编码器对它们进行 Token 化和编码。帧 Token 和文本 Token 被连接成一个长序列,然后输入 Transformer 进行融合。最后一层 Transformer 的帧 Token 用于构建特征金字塔,其中每一层都连接到一个头部来预测每帧的相关性分数和开始/结束时间位移。由于文本信息已通过自注意力机制"融合"到帧 Token 中,因此不使用文本 Token 来构建特征金字塔。为简单起见,我们展示了一个 3 层的特征金字塔。所有金字塔层级的头部共享相同的权重。
3.2. A unified architecture
3.2. 统一架构
Our model takes (video, text) pairs as inputs, and for each frame in the video it outputs a relevancy score between the frame and the input text, as well as the time differences between the frame and the start/end timestamps of the predicted segment. The target relevancy score is set to 1 if a frame falls within the labeled segment, otherwise zero. In the case of TAL and AS, we use class labels as the input texts while in MR, text queries are used as input texts. For each video we form $C$ (video, text) pairs where $C$ is the number of classes in TAL and AS and for MR $C$ is the number of captions associated with this video.
我们的模型以(视频, 文本)对作为输入,对于视频中的每一帧,它会输出该帧与输入文本之间的相关性分数,以及该帧与预测片段开始/结束时间戳之间的时间差。如果帧落在标注片段内,则目标相关性分数设为1,否则为零。在TAL和AS任务中,我们使用类别标签作为输入文本,而在MR任务中则使用文本查询作为输入文本。对于每个视频,我们会构建$C$个(视频, 文本)对,其中$C$在TAL和AS中表示类别数量,在MR中表示与该视频关联的字幕数量。
Fig. 2 gives an overview of our proposed architecture. The input pair is first tokenized and encoded by a pair of image and text encoders. The two encoders are initialized from a pretrained, CLIP visual language model [57]. The two encoders come from the same pretrained model – pretrained by aligning image and text pairs with a contrastive loss, which provides a strong prior on measuring the relevancy between each frame and the input text. This is one of key contributing factors to the success of our model. As Sec. 4.2 will show, using “unpaired” image/text encoders indeed diminishes the performance.
图 2: 展示了我们提出的架构概览。输入对首先通过一对图像和文本编码器进行 Token 化和编码。这两个编码器初始化为预训练的 CLIP 视觉语言模型 [57]。它们源自同一个预训练模型——通过对比损失对齐图像文本对进行预训练,这为衡量每帧与输入文本之间的相关性提供了强先验。这是我们模型成功的关键因素之一。如第 4.2 节所示,使用"非配对"图像/文本编码器确实会降低性能。
After token iz ation and encoding, the input video and text are represented by $N$ frame tokens and $T$ text tokens. We then form a new sequence by concatenating $N$ frame tokens with either a single token (e.g., CLS) representing the whole text sequence or all $T$ text tokens (See Sec. 4.2 for ablation). The concatenated sequence is then fed into a videotext fusion module. In this work, we implement this fusion module using a transformer encoder [68, 14]. This encoder performs two key functions – (i) it is a temporal encoder, able to model inter-frame correspondences omitted by the image-only CLIP model, and (ii) it can also function as a refinement network, with the ability to correct mistakes made by the CLIP model. After fusion, only frame tokens ${\bf X}^{c}\in\dot{\mathbb{R}}^{N\times K}$ are used to construct a feature pyramid where each level is created by down sampling the original sequence using strided convolutions where $c$ is the index of the class or caption and $K$ denotes the hidden size of the token. This process is repeated for all class labels/captions. Text tokens are omitted from this construction because their information has been incorporated into the frame tokens by the fusion module, and they do not correspond to any timestamps.
经过 Token 化 (tokenization) 和编码后,输入视频和文本分别表示为 $N$ 个帧 Token (frame tokens) 和 $T$ 个文本 Token (text tokens)。我们通过将 $N$ 个帧 Token 与单个代表整个文本序列的 Token (如 CLS) 或全部 $T$ 个文本 Token 拼接 (参见第 4.2 节消融实验) 形成新序列。拼接后的序列被输入视频文本融合模块。本文采用 Transformer 编码器 [68,14] 实现该模块,该编码器具有两大功能:(i) 作为时序编码器,能够建模纯图像 CLIP 模型忽略的帧间关联;(ii) 作为修正网络,可纠正 CLIP 模型的错误。融合后仅使用帧 Token ${\bf X}^{c}\in\dot{\mathbb{R}}^{N\times K}$ 构建特征金字塔,其中每层通过步进卷积对原始序列进行下采样生成,$c$ 表示类别/描述索引,$K$ 为 Token 的隐藏维度。该过程对所有类别标签/描述重复执行。文本 Token 不参与构建,因其信息已通过融合模块融入帧 Token,且不对应任何时间戳。
Finally, each pyramid level connects to a Head module to predict a per-frame relevancy score, $\hat{\mathbf{y}}{l}^{c}\in\mathbb{R}^{N_{l}}$ , and start/end time displacements, $\hat{\mathbf{t}}{l}^{c}\in\mathbb{R}^{N_{l}\times2}$ , where $N_{l}$ denotes the number of features in pyramid level $l$ . The final number of predictions is $\textstyle\sum_{i=1}^{L}{\frac{\dot{N}}{2^{i-1}}}$ , and is therefore greater than $N$ if there is more than one level in the feature pyramid. For example, if we construct a 3-level feature pyramid the total number of predictions will be $N+N/2+N/4$ . Each prediction is expanded into a temporal segment by applying the predicted displacements to its frame timestamp. Given these temporal segments for all pyramid layers, we filter out overlapping segments during inference with soft non-maximal suppression (SoftNMS) [5].
最后,每个金字塔层级连接到一个头部模块,用于预测每帧的相关性得分 $\hat{\mathbf{y}}{l}^{c}\in\mathbb{R}^{N_{l}}$ 以及开始/结束时间位移 $\hat{\mathbf{t}}{l}^{c}\in\mathbb{R}^{N_{l}\times2}$ ,其中 $N_{l}$ 表示金字塔层级 $l$ 的特征数量。最终预测数量为 $\textstyle\sum_{i=1}^{L}{\frac{\dot{N}}{2^{i-1}}}$ ,因此如果特征金字塔有多于一个层级,预测数量会超过 $N$ 。例如,构建一个3层特征金字塔时,总预测数将为 $N+N/2+N/4$ 。通过将预测位移应用到其帧时间戳,每个预测被扩展为一个时间段。给定所有金字塔层级的这些时间段,我们在推理时使用软非极大抑制 (SoftNMS) [5] 过滤掉重叠的片段。
3.3. Feature pyramid
3.3. 特征金字塔
A feature pyramid can improve a model’s capability to detect events at different scales. For example, features from the top level can detect events with a long duration while bottom-level features can localise short segments. Feature Pyramid Networks (FPN [37]) have been used extensively in object detection for images to pass richer semantic information from a higher level in the CNNs to lower level feature maps that have higher spatial resolution. We propose another simpler structure inspired by ViTDet [33] by removing the lateral and top-down connections in the FPN. Since the last layer in the transformer encoder contains the most semantic information [58] and shares the same temporal resolution as the first one, the lateral and top-down connections are no longer required. The feature pyramid is constructed by applying convolution with different strides to the output tokens from the last transformer layer in the video-text fusion module (See Fig. 2a). Note that text tokens are not used during the feature pyramid construction since their information has been fused into the frame tokens. This simpler design removes the down sampling step in the encoder and allows us to share the same architecture used in pre training stage (See Sec. 4.1.2 for more details). Similar to findings in [33], our ablation (Sec. 4.2) shows that this simpler design outperforms FPN on TAL as it introduces less additional layers to the pretrained model. AS is a frame-level task so features from only the bottom level in the feature pyramid are used for prediction.
特征金字塔能够提升模型检测不同尺度事件的能力。例如,顶层特征可检测长时程事件,而底层特征能定位短片段。特征金字塔网络 (FPN [37]) 在图像目标检测中被广泛使用,它能将CNN高层更丰富的语义信息传递到具有更高空间分辨率的低层特征图。我们受ViTDet [33] 启发提出了一种更简单的结构,移除了FPN中的横向和自上而下连接。由于Transformer编码器的最后一层包含最丰富的语义信息 [58] 且与第一层时间分辨率相同,这些连接不再必要。该特征金字塔通过对视频-文本融合模块最后一层Transformer输出的Token进行不同步长的卷积构建 (见图 2a)。注意文本Token不参与特征金字塔构建,因其信息已融入帧Token。这一简化设计省去了编码器的下采样步骤,使我们能与预训练阶段共享相同架构 (详见4.1.2节)。与 [33] 的发现类似,我们的消融实验 (第4.2节) 表明这种简单结构在TAL任务上优于FPN,因其为预训练模型引入了更少的附加层。AS是帧级任务,因此仅使用特征金字塔最底层的特征进行预测。
3.4. Head design
3.4. 头部设计
As shown in Fig. 2b, we have two heads, one for relevancy score prediction and the other for displacement regression. Although the two heads share the same structure their weights are not shared. Our head design following [81] is simple consisting of $M$ 1D convolution blocks where each block is made of three operations: Layer Normalization [3], 1D convolution, and a ReLU activation [17]. A convolution (e.g., a local operation) is used to encourage nearby frames to share the same label. At the end of each head, a linear layer is learned to predict per-frame relevancy scores $\hat{\mathbf{y}}^{c}\in\mathbb{R}^{N\times1}$ or to predict per-frame start/end time displacements $\Delta\hat{\mathbf{t}}^{c}\in\mathbb{R}^{N\times2}$ :
如图 2b 所示,我们有两个头,一个用于相关性分数预测,另一个用于位移回归。尽管两个头共享相同的结构,但它们的权重并不共享。我们的头设计遵循 [81],由 $M$ 个 1D 卷积块组成,每个块包含三个操作:层归一化 (Layer Normalization) [3]、1D 卷积和 ReLU 激活函数 [17]。使用卷积(例如局部操作)来鼓励相邻帧共享相同的标签。在每个头的末尾,学习一个线性层来预测每帧的相关性分数 $\hat{\mathbf{y}}^{c}\in\mathbb{R}^{N\times1}$ 或预测每帧的开始/结束时间位移 $\Delta\hat{\mathbf{t}}^{c}\in\mathbb{R}^{N\times2}$ :
$$
\begin{array}{r l}&{\hat{\mathbf{y}}^{c}=\mathbf{Z}^{c}\mathbf{w}{c l s}+b_{c l s}}\ &{\Delta\hat{\mathbf{t}}^{c}=\mathrm{relu}(\mathbf{Z}^{c}\mathbf{w}{r e g}+\mathbf{b}_{r e g})}\end{array}
$$
$$
\begin{array}{r l}&{\hat{\mathbf{y}}^{c}=\mathbf{Z}^{c}\mathbf{w}{c l s}+b_{c l s}}\ &{\Delta\hat{\mathbf{t}}^{c}=\mathrm{relu}(\mathbf{Z}^{c}\mathbf{w}{r e g}+\mathbf{b}_{r e g})}\end{array}
$$
where $\mathbf{Z}^{c}$ are the activation s of frame tokens $\mathbf{X}^{c}$ after convolution blocks, $\mathbf{w}{c l s}\in~\mathbb{R}^{K\times1}$ and $b_{c l s}\in~\mathbb{R}^{1\times1}$ are the weights and bias for the classification head, and $\mathbf{w}{r e g}\in$ $\mathbb{R}^{K\times2}$ and $\mathbf{b}_{r e g}\in\mathbb{R}^{1\times2}$ are the weights and biases for the regression head. We limit the predicted displacements to be greater or equal to zero through a ReLU non-linearity. Eqs. 1 and 2 are repeated to generate scores and displacements for every class/caption and the same learned weight and bias terms are shared. For AS only the relevancy scoring head is used. One key difference from [81] is that our model predicts a different start/end time displacement for each class while [81] predicts one displacement $\Delta\hat{\mathbf{t}}\in\mathbb{R}^{N\times2}$ shared among all classes, which assumes that there is no overlapping segment in the video.
其中 $\mathbf{Z}^{c}$ 是帧 token $\mathbf{X}^{c}$ 经过卷积块后的激活值,$\mathbf{w}{c l s}\in~\mathbb{R}^{K\times1}$ 和 $b_{c l s}\in~\mathbb{R}^{1\times1}$ 是分类头的权重和偏置,$\mathbf{w}{r e g}\in$ $\mathbb{R}^{K\times2}$ 和 $\mathbf{b}_{r e g}\in\mathbb{R}^{1\times2}$ 是回归头的权重和偏置。我们通过 ReLU 非线性函数限制预测的位移大于或等于零。重复公式 1 和 2 为每个类别/标题生成分数和位移,并共享相同的学习权重和偏置项。对于 AS (Action Segmentation) 仅使用相关性评分头。与 [81] 的一个关键区别在于,我们的模型为每个类别预测不同的开始/结束时间位移,而 [81] 预测一个共享于所有类别的位移 $\Delta\hat{\mathbf{t}}\in\mathbb{R}^{N\times2}$,这假设视频中没有重叠片段。
3.5. Loss function
3.5. 损失函数
For AS, we use sigmoid cross entropy loss to measure the relevance between a frame and class label. For TAL and MR, we use the focal loss [38] for the relevancy scoring head as class imbalance is a known issue in one-stage detectors [38]. For the regression head we experiment with four popular regression losses, L1, IoU, DIoU [86], and $_{\mathrm{L1+IoU}}$ . The L1 loss computes the absolute distance between the predicted and the ground truth start/end times.The IoU loss directly optimizes the intersection of union objective, which is defined as
对于AS(动作分段),我们使用sigmoid交叉熵损失来衡量帧与类别标签之间的相关性。对于TAL(时序动作定位)和MR(动作提议生成),由于类别不平衡是单阶段检测器[38]中的已知问题,我们在相关性评分头中采用focal loss[38]。回归头部分我们测试了四种常用回归损失函数:L1损失、IoU损失、DIoU损失[86]以及$_{\mathrm{L1+IoU}}$组合损失。其中L1损失计算预测起止时间与真实值之间的绝对距离,IoU损失直接优化交并比目标,其定义为
$$
\begin{array}{r l}{{\cal L}_{i o u}=1-{\cal I}o U(\Delta\hat{s},\Delta\hat{e})}&{}\ {=1-\displaystyle\frac{\operatorname*{min}(\Delta\hat{s},\Delta s)+\operatorname*{min}(\Delta\hat{e},\Delta e)}{\operatorname*{max}(\Delta\hat{s},\Delta s)+\operatorname*{max}(\Delta\hat{e},\Delta e)}~}&{}\end{array}
$$
$$
\begin{array}{r l}{{\cal L}_{i o u}=1-{\cal I}o U(\Delta\hat{s},\Delta\hat{e})}&{}\ {=1-\displaystyle\frac{\operatorname*{min}(\Delta\hat{s},\Delta s)+\operatorname*{min}(\Delta\hat{e},\Delta e)}{\operatorname*{max}(\Delta\hat{s},\Delta s)+\operatorname*{max}(\Delta\hat{e},\Delta e)}~}&{}\end{array}
$$
where $\Delta\hat{s},\Delta\hat{e}$ and $\Delta s,\Delta e$ are the predicted and the ground truth displacements to the start/end times. If $\Delta\hat{s}$ or $\Delta\hat{e}$ is zero, its gradient will also be zero, which could happen due to poor initialization. Distance IoU (DIoU [86]) is proposed to address the zero-gradient issue by also taking into account the distance between the two centers of the ground truth box and the predicted box.We end up using L1 loss based on the ablation in Sec. 4.2 and also apply a weight factor $\alpha$ to balance between the focal loss and L1 loss.
其中 $\Delta\hat{s},\Delta\hat{e}$ 和 $\Delta s,\Delta e$ 分别是预测的起始/结束时间位移和真实位移。如果 $\Delta\hat{s}$ 或 $\Delta\hat{e}$ 为零,其梯度也将为零,这可能由于初始化不佳导致。距离交并比 (DIoU [86]) 通过同时考虑真实框与预测框两个中心点之间的距离,被提出来解决零梯度问题。根据第4.2节的消融实验,我们最终采用基于L1损失的方案,并应用权重因子 $\alpha$ 来平衡焦点损失和L1损失。
4. Experimental Evaluation
4. 实验评估
We first describe datasets, evaluation metrics and implementation details in Sec. 4.1. We then provide a number of ablations on our architecture design, use of the text encoder, video-text fusion module and finetuning strategies (Sec. 4.2). Finally, we show the results of our method compared to the state-of-the-art in Sec 4.3.
我们首先在第4.1节描述数据集、评估指标和实现细节。随后在第4.2节对我们的架构设计、文本编码器使用方式、视频-文本融合模块以及微调策略进行多项消融实验。最后在第4.3节展示我们的方法与当前最优技术的对比结果。
4.1. Experimental setup
4.1. 实验设置
4.1.1 Datasets and evaluation metrics
4.1.1 数据集和评估指标
Moment retrieval. Activity Net Captions [31] contains 20,000 videos and 100,000 segments where each is annotated with a caption by human. On average each caption contains 13.5 words and videos have an average duration of 2 minutes. The dataset is divided into three splits, train, val 1, and val 2. Following [78, 62] we use train split for training, val 1 for validation and val 2 for testing. Charades-STA [18] contains 6,672 videos and 16,128 segment/caption pairs, where 12,408 pairs are used for training and 3720 for testing. Each video is annotated with 2.4 segments on average and each has an average duration of 8.2 seconds. QV Highlights [32] includes over 10,148 cropped videos (150s long), and each video is annotated with at least one query describing the relevant moments (24.6s in average). In total, there are 10,310 text queries with 18,367 associated moments. Following [32, 42], we use train split for training and val split for testing. The most commonly used metric for moment retrieval is the average recall at k computed under different temporal Intersection over Union (IoU) thresholds, which is defined as the percentage of at least one of the top-k predicted segments having a larger temporal IoU than the threshold with the ground truth segment, i.e. Recall $\ @\mathrm{K}$ , IoU=[0.5, 0.7].
时刻检索。Activity Net Captions [31] 包含20,000个视频和100,000个片段,每个片段都有人工标注的字幕。平均每个字幕包含13.5个单词,视频平均时长为2分钟。数据集分为训练集、验证集1和验证集2三个部分。遵循[78, 62],我们使用训练集进行训练,验证集1用于验证,验证集2用于测试。Charades-STA [18] 包含6,672个视频和16,128个片段/字幕对,其中12,408对用于训练,3,720对用于测试。每个视频平均标注了2.4个片段,每个片段平均时长为8.2秒。QV Highlights [32] 包含超过10,148个裁剪视频(时长150秒),每个视频至少标注了一个描述相关时刻的查询(平均24.6秒)。总共有10,310个文本查询和18,367个相关时刻。遵循[32, 42],我们使用训练集进行训练,验证集用于测试。时刻检索最常用的指标是在不同时间交并比 (IoU) 阈值下计算的k平均召回率,定义为前k个预测片段中至少有一个与真实片段的时间IoU大于阈值的百分比,即召回率 $\ @\mathrm{K}$,IoU=[0.5, 0.7]。
Temporal action localization. Activity Net 1.3 [23] is a collection of 20,000 untrimmed videos focusing on human actions. Most videos contain only one labeled segment and segments in one video are from the same action class. The dataset is divided into three subsets, train, validation, and test. Following standard practice [36, 34, 73, 81], we train our models on the training set and report results on the validation set. The standard evaluation metric for temporal localization is mean Average Precision (mAP) computed under different temporal IoU thresholds. We report mAP under an IoU threshold of 0.5, denoted as m $\mathrm{1AP@0.5IoU}$ . We also report results for the zero-shot setting, following the data split protocols proposed by [30, 51]: 1) training on $50%$ of the action labels and testing on the remaining $50%$ ; 2) training on $75%$ of the labels and testing on the rest $25%$ . These are created using 10 random splits of the data, following [30, 51]. In the rest of paper, we use ANet TAL and ANet MR to denote Activity Net 1.3 and Activity Net Captions, respectively.
时序动作定位。Activity Net 1.3 [23] 是一个包含20,000段未修剪视频的数据集,主要关注人类动作。大多数视频仅包含一个标注片段,且同一视频中的片段属于相同动作类别。该数据集分为训练集、验证集和测试集三个子集。遵循标准实践 [36, 34, 73, 81],我们在训练集上训练模型并在验证集上报告结果。时序定位的标准评估指标是在不同时序IoU阈值下计算的平均精度均值(mAP)。我们报告IoU阈值为0.5时的mAP(记为m $\mathrm{1AP@0.5IoU}$),同时按照[30, 51]提出的数据划分协议报告零样本设置的结果:1) 使用50%动作标签训练,剩余50%测试;2) 使用75%标签训练,剩余25%测试。这些划分通过10次随机数据分割生成,遵循[30, 51]的方法。本文后续用ANet TAL和ANet MR分别指代Activity Net 1.3和Activity Net Captions。
Action segmentation. The COIN [64] dataset consists of 11,827 training videos and 2,797 testing videos. Each video is labeled with an average of 3.9 segments where each segment lasts 14.9 seconds on average. The segment labels describe a step needed to complete a task, such as “take out the old bulb”, “install the new bulb”, etc. Frame accuracy is the primary metric used in the COIN action segmentation task, which is defined as the number of correctly predicted frames divided by the total number of frames. However given how a large proportion of the frames are labelled as background $(58.9%)$ , a naive majority-class prediction model will already get an accuracy of $58.9%$ (shown in the first row of Table 7). Hence we also report mean Average Precision (mAP), which averages AP over the classes (excluding background) and is therefore not directly impacted by the large proportion of background.
动作分割。COIN [64] 数据集包含11,827个训练视频和2,797个测试视频。每个视频平均标注了3.9个片段,每个片段平均持续14.9秒。片段标签描述了完成任务所需的步骤,例如"取出旧灯泡"、"安装新灯泡"等。帧准确率是COIN动作分割任务的主要评估指标,定义为正确预测的帧数除以总帧数。然而由于大部分帧被标注为背景 $(58.9%)$ ,一个简单的多数类预测模型就能达到 $58.9%$ 的准确率(如表7第一行所示)。因此我们还报告了平均精度均值(mAP),它计算各类别(不包括背景)AP的平均值,从而不受背景占比过大的直接影响。
4.1.2 Implementation details
4.1.2 实现细节
Model Architecture: In UnLoc-Base and Large models, the image and text encoders follow the same architecture used in CLIP-B and CLIP-L. The video-text fusion module is implemented using a 6-layer Transformer and the hidden size is set to 512 and 768 for UnLoc-B and UnLoc-L and the MLP dimension is set to 2048 and 3072, respectively. We construct a 4-layer feature pyramid from the last layer in the video-text fusion module following the procedure described in Section 3.3. Following [81], an output regression range is specified for each level in the pyramid, which is set to [0, 4], [4, 8], [8, 16], [16, inf], respectively ordered from bottom to the top. All heads across different pyramid levels share the same weights, and are randomly initialized.
模型架构:在UnLoc-Base和UnLoc-Large模型中,图像与文本编码器采用与CLIP-B和CLIP-L相同的架构。视频-文本融合模块使用6层Transformer实现,UnLoc-B和UnLoc-L的隐藏层维度分别设置为512和768,MLP维度分别设为2048和3072。我们按照第3.3节所述流程,从视频-文本融合模块的最后一层构建了4层特征金字塔。参照[81],为金字塔每层级设定输出回归范围,自底向上依次设置为[0,4]、[4,8]、[8,16]、[16,inf]。所有金字塔层级的头部共享权重并采用随机初始化。
Pre training: Our models are pretrained on Kinetics (K700 [7] for our best models, K400 for ablations). The pre training task is a 400/700-way binary classification problem using a sigmoid cross entropy loss. For example, for each video we feed all class names into the text tower and the objective is to classify whether or not the video matches any of the class names. During Kinetics pre training, the image encoder is finetuned and the text encoder is kept frozen to avoid catastrophic forgetting due to the fact that we are finetuning on a small fixed set of vocabulary in Kinetics. The video-text fusion module is always finetuned.
预训练:我们的模型在Kinetics数据集上进行了预训练(最佳模型使用K700 [7],消融实验使用K400)。预训练任务是一个400/700路的二元分类问题,采用sigmoid交叉熵损失函数。例如,对于每个视频,我们将所有类别名称输入文本塔,目标是分类该视频是否匹配任一类别名称。在Kinetics预训练期间,图像编码器会进行微调,而文本编码器保持冻结状态,以避免因在Kinetics固定小词汇集上微调而导致的灾难性遗忘。视频-文本融合模块始终会进行微调。
Training: In training the frames are first resized to have a shorter side of 256 and models are trained on a random crop of size $224\times224$ . For TAL and AS class names are augmented using Kinetics prompts released by [57], e.g., “a video of a person doing ${\exists{\mathrm{abeal}}}^{\mathrm{}\mathrm{}\mathrm{}}$ . Unless specified otherwise, all TAL and MR models are trained on 128 frames evenly spaced sampled across the whole video. This follows the sampling strategy adopted by [81] to deal with videos of varying lengths. Unless specified otherwise, for AS on the COIN dataset, we extract the RGB frames at 2FPS, which is the labelling resolution. We randomly sample 512 consecutive frames and apply padding for videos with less than 512 frames. All models are trained using synchronous SGD with a momentum of 0.9, with a batch size of 64. We follow [2] and apply the same data augmentation and regular iz ation schemes [12, 26], which were used by [65] to train vision transformers more effectively. For more implementation details and hyper para meters, we refer readers to the appendix and code. Our model is implemented using the Scenic library [13] and JAX [6].
训练:训练时首先将帧大小调整为短边256像素,并在随机裁剪的224×224区域上进行模型训练。对于TAL和AS任务,使用[57]发布的Kinetics提示词增强类别名称,例如"一个人正在做{∃abeal}的视频"。除非另有说明,所有TAL和MR模型均在整段视频中等间隔采样的128帧上进行训练,这遵循了[81]采用的针对不同长度视频的采样策略。在COIN数据集上进行AS任务时,我们按标注分辨率以2FPS提取RGB帧,随机采样512个连续帧,对不足512帧的视频进行填充。所有模型均使用同步SGD(动量0.9)和64的批量大小进行训练。我们遵循[2]采用与[65]相同的数据增强和正则化方案[12,26],这些方法被证明能更有效地训练视觉Transformer。更多实现细节和超参数请参阅附录和代码。我们的模型使用Scenic库[13]和JAX[6]实现。
Inference During inference, our results are obtained evaluating a single central crop of $224\times224$ . For AS on COIN, we run our model in a non-overlapping sliding window fashion with a window size of 512 frames. For TAL and AS, we report two results, one using the first prompt and the other by averaging all 28 context prompts, which is defined as prompt ensembling in [57].
推理
在推理过程中,我们的结果是通过评估单个中心裁剪尺寸为 $224\times224$ 得到的。对于COIN数据集上的动作分割(AS)任务,我们以非重叠滑动窗口的方式运行模型,窗口大小为512帧。对于时序动作定位(TAL)和动作分割任务,我们报告两种结果:一种使用第一个提示(prompt),另一种通过平均所有28个上下文提示(在[57]中定义为提示集成)得到。
Table 1. Effect of architecture design and losses. Results are presented on the ANet TAL for mAP $\ @0.5$ IoU. We compare 4 popular regression losses, two types of feature pyramids (and no pyramid), and the number of convolutional layers in the localization heads.
表 1: 架构设计和损失函数的影响。结果展示在 ANet TAL 上 mAP $\ @0.5$ IoU 指标。我们比较了 4 种常用回归损失函数、两种特征金字塔结构 (以及无金字塔结构) 以及定位头中卷积层数量。
4.2. Ablations
4.2. 消融实验
We use the hyper parameters described in Sec. 4.1.2 as the default setting for all experiments in the ablation unless specified otherwise. For AS on COIN we randomly sample 128 consecutive frames (instead of 512) for efficiency during training for the ablations. For the ablations we report ANet TAL with $\mathrm{mAP}@0.5\mathrm{IoU}$ , ANet MR with Recall $@1$ under $\mathrm{IoU=0.5}$ and COIN with mAP.
我们使用第4.1.2节中描述的默认超参数作为消融实验的基础配置(除非另有说明)。在COIN数据集上进行动作分割(AS)时,出于训练效率考虑,我们随机采样128个连续帧(而非512帧)进行消融实验。消融实验中,ANet TAL任务采用$\mathrm{mAP}@0.5\mathrm{IoU}$指标,ANet MR任务采用$\mathrm{IoU=0.5}$条件下的Recall $@1$指标,COIN任务则使用mAP指标进行评估。
Architectural design choices. In Table 1, we ablate three design choices: the loss function, feature pyramid design, and the number of convolution layers in the localization heads. All losses perform similarly with L1 being slightly better than other three. ViTDet-style feature pyramid outperforms a standard FPN [37] as it introduces less additional layers to the pretrained model. Removing the feature pyramid completely significantly degrades the performance, with a $7.4%$ drop. Performance increases as we increase the number of convolution layers but saturates at 3. The best setup derived here is used by following experiments.
架构设计选择。在表1中,我们对比了三种设计选择:损失函数、特征金字塔设计以及定位头中的卷积层数。所有损失函数表现相近,其中L1略优于其他三种。ViTDet风格的特征金字塔优于标准FPN [37],因为它为预训练模型引入了更少的额外层。完全移除特征金字塔会显著降低性能,下降幅度达$7.4%$。随着卷积层数的增加,性能有所提升,但在3层时达到饱和。后续实验采用了由此得出的最佳配置。
Table 2. Effect of different text encoders. We use the same frozen CLIP-B image encoder, with both T5 and CLIP-B text encoders and show results across all tasks. Paired image/text encoders significantly outperform unpaired encoders for localization tasks. Note that for COIN, results are reported using mAP.
| Losses | Feature Pyramid | #convlayers | ||||||||
| L1 54.6 | IoU 54.0 | L1+IoU 53.9 | DIoU 54.1 | No 47.3 | FPN 53.8 | ViTDet 54.7 | 1 52.5 | 2 53.4 | 3 54.7 | 4 54.5 |
表 2: 不同文本编码器的效果。我们使用相同的冻结 CLIP-B 图像编码器,搭配 T5 和 CLIP-B 文本编码器,并展示所有任务的结果。对于定位任务,配对的图像/文本编码器显著优于未配对的编码器。注意,对于 COIN,结果使用 mAP 报告。
| 损失函数 | 特征金字塔 | 卷积层数 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| L1 54.6 | IoU 54.0 | L1+IoU 53.9 | DIoU 54.1 | 无 47.3 | FPN 53.8 | ViTDet 54.7 | 1 52.5 | 2 53.4 | 3 54.7 |
Variations on the text encoder and tokens. In Table 2, we freeze the CLIP image encoder, pair it with different text encoders, and finetune them. Using “unpaired” image-text encoders indeed diminishes the performance on all three tasks, especially for TAL and MR. For closed-vocabulary tasks, such as TAL, a text encoder is not strictly required. We hence compare our model to a version without the text encoder, and try to make minimum changes to ensure a fair comparison. Without the text tokens the video-text fusion module becomes a temporal encoder (i.e. a transformer which operates on frame-level features, aggregating temporal information across them). To enable this ablation, we also modify the linear projections in Eqs. 1 and 2 as follows:
文本编码器与Token的变体。在表2中,我们冻结CLIP图像编码器,将其与不同的文本编码器配对并进行微调。使用"非配对"图文编码器确实会降低所有三项任务的性能,尤其是TAL和MR。对于封闭词汇任务(如TAL),文本编码器并非严格必需。因此我们将模型与无文本编码器的版本进行比较,并尽量保持最小改动以确保公平对比。当移除文本Token时,视频-文本融合模块会转变为时序编码器(即对帧级特征进行操作的Transformer,聚合跨帧时序信息)。为实现该消融实验,我们还将公式1和2中的线性投影修改如下:
$$
\begin{array}{r l}&{\hat{{\mathbf Y}}={\mathbf Z}{\mathbf W}{c l s}+{\mathbf b}{c l s}}\ &{\Delta\hat{{\mathbf T}}=\mathrm{relu}({\mathbf Z}{\mathbf W}{r e g}+{\mathbf b}_{r e g})}\end{array}
$$
$$
\begin{array}{r l}&{\hat{{\mathbf Y}}={\mathbf Z}{\mathbf W}{c l s}+{\mathbf b}{c l s}}\ &{\Delta\hat{{\mathbf T}}=\mathrm{relu}({\mathbf Z}{\mathbf W}{r e g}+{\mathbf b}_{r e g})}\end{array}
$$
where $\textbf{Z}\in\mathbb{R}^{N\times K}$ are the act iv i at ions after convolution layers, $\hat{\textbf{Y}}\in\mathbb{R}^{N\times C}$ and $\Delta\hat{\mathbf{T}}\in\mathbb{R}^{N\times2C}$ are the predicted class logits and start/end time displacements.
其中 $\textbf{Z}\in\mathbb{R}^{N\times K}$ 是卷积层后的激活值,$\hat{\textbf{Y}}\in\mathbb{R}^{N\times C}$ 和 $\Delta\hat{\mathbf{T}}\in\mathbb{R}^{N\times2C}$ 分别是预测的类别逻辑值以及开始/结束时间位移量。
After removing the text encoder, the performance on ANet TAL drops from $54.7\mathrm{mAP@0.5\mathrm{IoU}}$ to 46.5 (a relative decrease of $15%$ ). In a second study, we also compare the performance of using a single text [CLS] token versus using all the text tokens from the text encoder on different tasks shown in Table 3. For close-vocabulary tasks, such as TAL and AS, all refers to 16 tokens to represent the class labels and for MR we increase the sequence length to 32, i.e., captions contain more words than class labels. We demonstrate that using all tokens gives better performance on all tasks and such improvement is larger for tasks involved more complex language queries, such as MR.
移除文本编码器后,ANet TAL 的性能从 $54.7\mathrm{mAP@0.5\mathrm{IoU}}$ 降至 46.5 (相对下降 $15%$)。在第二项研究中,我们还比较了在不同任务中使用单个文本 [CLS] token 与使用文本编码器所有文本 token 的性能差异 (如表 3 所示)。对于封闭词汇任务 (如 TAL 和 AS),"所有"指代用 16 个 token 表示类别标签;而对于 MR 任务,我们将序列长度增至 32 (因为字幕比类别标签包含更多词汇)。实验表明,使用全部 token 在所有任务上都能获得更好性能,且这种提升在涉及更复杂语言查询的任务 (如 MR) 中更为显著。
| TextEncoder | MParams | ANet TAL | ANet MR | COIN |
|---|---|---|---|---|
| T5-S | 147.1 | 46.7 | 39.7 | 16.1 |
| T5-B | 221.5 | 46.6 | 39.9 | 15.9 |
| CLIP-B | 174.9 | 53.3 | 44.2 | 16.4 |
Table 3. Effect of number of text tokens. We show that using all text tokens (16 tokens for both TAL and AS and 32 tokens for MR) performs better than using a single token in video-text fusion on different tasks. Note that the image encoder is frozen.
| #tokens | ANet TAL | ANet MR | COIN |
| All | 53.7 | 44.2 | 16.4 |
| One | 53.3 | 42.6 | 15.7 |
表 3: 文本 token 数量的影响。我们展示了在不同任务的视频-文本融合中,使用全部文本 token (TAL 和 AS 各 16 token,MR 32 token) 比使用单一 token 效果更好。注意图像编码器是冻结的。
| #tokens | ANet TAL | ANet MR | COIN |
|---|---|---|---|
| All | 53.7 | 44.2 | 16.4 |
| One | 53.3 | 42.6 | 15.7 |
Effect of video-text fusion module. We also compare our model with a late-fusion variant where the frame relevancy scores are computed as the dot product between the normalized $\mathbf{Z}$ and the class label text embeddings. This variant improves over the no-text variant to 49.8 on ANet TAL but still worse than our proposed mid-fusion model. We find that video-text fusion is essential for achieving good performance on TAL.
视频-文本融合模块的效果。我们还比较了模型与一种延迟融合变体,该变体通过计算归一化 $\mathbf{Z}$ 与类别标签文本嵌入的点积来获得帧相关性分数。此变体在ANet TAL上将无文本版本的性能提升至49.8,但仍低于我们提出的中融合模型。结果表明,视频-文本融合对于TAL任务的高性能至关重要。
Finetuning strategies. Table 4 compares four different strategies for finetuning a Kinetics-pretrained model on downstream tasks by either freezing or finetuning each of the two encoders. In this study, we always finetune the video-text fusion layers and heads. We observe that it is more beneficial to finetune the image encoder for closevocabulary tasks, such as TAL and AS. However, for task involving more complex queries, such as MR, finetuning the image encoder actually degrades the performance. A similar phenomenon is also observed by [79], and may be due to over fitting.
微调策略。表4比较了四种不同的微调策略,这些策略通过在Kinetics预训练模型上冻结或微调两个编码器中的每一个来适应下游任务。在本研究中,我们始终微调视频-文本融合层和头部。我们观察到,对于TAL和AS等封闭词汇任务,微调图像编码器更有益处。然而,对于涉及更复杂查询的任务(如MR),微调图像编码器实际上会降低性能。[79]也观察到了类似现象,这可能是由于过拟合所致。
4.3. Comparison with the state-of-the-art
4.3. 与当前最优技术的对比
In this section we compare to the state-of-the-art for all three tasks individually. Qualitative examples for each task are provided in Fig. 3.
在本节中,我们将分别针对所有三项任务与当前最优技术进行对比。各任务的定性示例如图3所示。
Table 4. Effect of freezing or finetuning image/text encoder on different tasks. The video-text fusion module and heads are always finetuned. For closed-vocabulary tasks, such as TAL and AS, finetune the image encoder is better (bottom two rows), however, for tasks involving more complex queries such as MR, finetuning the image encoder degrades performance (top two rows).
表 4: 冻结或微调图像/文本编码器对不同任务的影响。视频-文本融合模块和头部始终进行微调。对于封闭词汇任务(如TAL和AS),微调图像编码器效果更好(底部两行);而对于涉及更复杂查询的任务(如MR),微调图像编码器会降低性能(顶部两行)。
| 图像/文本编码器 | ANetTAL | ANetMR | COIN |
|---|---|---|---|
| 冻结/冻结 | 53.2 | 43.4 | 16.1 |
| 冻结/微调 | 53.3 | 44.2 | 16.4 |
| 微调/冻结 | 54.7 | 39.7 | 16.6 |
| 微调/微调 | 54.3 | 41.2 | 16.9 |
Table 5. Comparison with the state-of-the-art for Moment Retrieval. We show results on Charades-STA (test split), ANet MR (val 2 split), and QV Highlights (val split) datasets.
表 5: 与最先进方法的时刻检索对比。我们在 Charades-STA (测试集)、ANet MR (验证集2) 和 QV Highlights (验证集) 数据集上展示了结果。
| 方法 | 视觉编码器 | R@1 (IoU=0.5) | R@1 (IoU=0.7) | R@5 (IoU=0.5) | R@5 (IoU=0.7) |
|---|---|---|---|---|---|
| Charades-STA | |||||
| CTRL [18] | C3D | 23.6 | 8.9 | 58.9 | 29.5 |
| 2D TAN [83] | VGG | 39.7 | 23.3 | 80.3 | 51.3 |
| VSLNet [82] | I3D | 47.3 | 30.2 | - | - |
| UMT [42] | VGG | 49.4 | 26.2 | 89.4 | 55.0 |
| IVG-DCL [52] | C3D | 50.2 | 32.9 | - | - |
| M-DETR [32] | CLIP | 55.7 | 34.2 | - | - |
| LGI [50] | I3D | 59.5 | 35.5 | - | - |
| UnLoc-B | CLIP | 58.1 | 35.4 | 87.4 | 59.1 |
| UnLoc-L | CLIP | 60.8 | 38.4 | 88.2 | 61.1 |
| LGI [50] | C3D | 41.5 | 23.1 | - | - |
| ANet MR | |||||
| VSLNet [82] | I3D | 43.2 | 26.2 | - | - |
| 2D TAN [83] | C3D | 44.5 | 26.5 | 77.1 | 62.0 |
| DRN [78] | C3D | 45.5 | 24.4 | 78.0 | 50.3 |
| VLG [62] | C3D | 46.3 | 29.8 | 77.2 | 63.3 |
| UnLoc-B | CLIP | 48.0 | 29.7 | - | - |
| UnLoc-L | CLIP | 48.3 | 30.2 | 81.5 / 79.2 | 61.4 / 61.3 |
| QV Highlights | |||||
| M-DETR [32] | SF+CLIP | 53.9 | 34.8 | - | - |
| UMT [42] | SF+CLIP | 60.3 | 44.3 | - | - |
| QD-DETR [49] | SF+CLIP | 62.4 | 45.0 | - | - |
| UnLoc-B | CLIP | 64.5 | 48.8 | - | - |
| UnLoc-L | CLIP | 66.1 | 46.7 | - | - |
Moment retrieval For MR models we freeze the image encoder and finetune the rest of the network following the best strategy derived in Table 4. On ANet MR, our UnLoc-L model achieves a new state-of-the-art improving the previous best by $2.0%$ and $0.4%$ in recall $@1$ under $\mathrm{IoU=0.5}$ and 0.7, respectively (Table 5). On Charades-STA, our UnLocL model improves upon the previous best [50] by $1.3%$ and $2.9%$ on the same two metrics. On ANet MR, UnLocL outperforms [50] by a larger margin, $6.8%$ and $7.1%$ . On QV Highlights, UnLoc- L improves upon the previous best [49] by $3.7%$ and $1.7%$ . Most previous work is built upon pre-extracted convolutional features, such as I3D [8], P3D [56], C3D [66], $\mathrm{R}(2+1)\mathrm{D}$ [67], VGG [61], Slow- Fast [16], etc, and our work is most comparable to [32], which also employs CLIP features (in addition to SlowFast [16] features). Our UnLoc-L model scores $5.1%$ and $4.4%$ higher than [32] on Charades-STA in recall $@1$ under $\mathrm{IoU=0.5}$ and 0.7. To the best of our knowledge, we are the first work employing pure transformer features that achieves state-of-the-art results on moment retrieval, which has largely been dominated by CNN-based features.
时刻检索
对于MR模型,我们冻结图像编码器,并按照表4中的最佳策略微调网络其余部分。在ANet MR上,我们的UnLoc-L模型实现了新的最先进水平,在IoU=0.5和0.7条件下,召回率@1分别比之前最佳结果提升了$2.0%$和$0.4%$(表5)。在Charades-STA上,我们的UnLoc-L模型在相同两项指标上比之前最佳结果[50]提升了$1.3%$和$2.9%$。在ANet MR上,UnLoc-L以更大优势超越[50],分别达到$6.8%$和$7.1%$的提升。在QV Highlights上,UnLoc-L比之前最佳结果[49]提高了$3.7%$和$1.7%$。
大多数先前工作基于预提取的卷积特征(如I3D[8]、P3D[56]、C3D[66]、$\mathrm{R}(2+1)\mathrm{D}$[67]、VGG[61]、SlowFast[16]等),而我们的工作与[32]最具可比性(后者除SlowFast[16]特征外还采用了CLIP特征)。在Charades-STA上,我们的UnLoc-L模型在IoU=0.5和0.7条件下的召回率@1分别比[32]高出$5.1%$和$4.4%$。据我们所知,我们是首个采用纯Transformer特征并在时刻检索任务上取得最先进成果的工作,该领域此前主要由基于CNN的特征主导。
Table 6. Comparison with the state-of-the-art on ANet TAL. We show results for finetuning, and both the zero-shot (open-set) protocols introduced by [30]. Our method outperforms all previous work across all settings, achieving strong gains particularly in the zero-shot settings.
表 6: ANet TAL任务与现有技术的对比。我们展示了微调结果,以及[30]提出的两种零样本(open-set)方案。我们的方法在所有设置下均优于先前工作,尤其在零样本设置中取得显著提升。
| 设置 | 方法 | 视觉编码器 | mAP@0.5IoU |
|---|---|---|---|
| 微调 | A2Net [76] | I3D | 43.6 |
| TSP [1] | R(2+1)D | 51.3 | |
| GTAN [43] | P3D | 52.6 | |
| VSGN [84] | I3D | 53.3 | |
| TadTR [41] PBRNet [40] | R(2+1)D | 53.6 | |
| TCANet [55] | I3D SlowFast | 54.0 54.3 | |
| ActionFormer[81] | R(2+1)D | 54.7 | |
| ContextLoc[89] | I3D | 56.0 | |
| 零样本(50%可见/50%不可见) | EffPrompt [30] | CLIP | 44.0 |
| STALE [51] | CLIP | 54.3 | |
| STALE [51] | I3D | 56.5 | |
| UnLoc-B (首次提示) | CLIP | 54.6 | |
| UnLoc-L (首次提示) | CLIP | 58.8 | |
| UnLoc-L (提示集成) | CLIP | 59.3 | |
| EffPrompt [30] STALE [51] | CLIP CLIP | 32.0 | |
| UnLoc-B (首次提示) | CLIP | 32.1 | |
| 36.9 | |||
| UnLoc-L (首次提示) | CLIP | 43.2 | |
| UnLoc-L (提示集成) | CLIP | 43.7 | |
| 零样本(75%可见/25%不可见) | EffPrompt [30] | CLIP | 37.6 |
| STALE [51] | CLIP | 38.2 | |
| UnLoc-B (首次提示) | CLIP | 40.2 | |
| UnLoc-L (首次提示) | CLIP | 47.4 | |
| UnLoc-L (提示集成) | CLIP | 48.8 |
Temporal localization Table 6 shows results on ANet TAL under two settings (finetuned and zero-shot). In the finetuned setting, we freeze the text encoder and finetune the rest of the network following the best strategy derived from Table 4. For UnLoc-L we increase the sampled frames to 160 and use a 5-L Feature Pyramid. As shown in Table 6, most high-performance methods are built on top of 3D convolutional features. There are two previous attempts to replace the CNN vision encoder by a Transformer encoder. EffPrompt [30], built on top of frozen CLIP features, scored significantly lower than recent CNN-based models and STALE [51], which is also built upon CLIP features, achieved competitive results with the best CNN methods but is 2.2 worse than the same model trained on two-stream I3D features. To the best of our knowledge, we are the first work that achieved state-of-the-art results using only Transformer features. Our UnLoc-L model improved previous best results in terms of m $\mathrm{AP}@0.5\mathrm{IoU}$ by 2.3 and with prompt ensembling this margin is increased to 2.8.
时间定位
表6展示了ANet TAL在两种设置(微调和零样本)下的结果。在微调设置中,我们冻结文本编码器,并根据表4得出的最佳策略对网络其余部分进行微调。对于UnLoc-L模型,我们将采样帧数增至160,并使用5层特征金字塔。如表6所示,大多数高性能方法都基于3D卷积特征构建。此前有两种尝试用Transformer编码器替代CNN视觉编码器:基于冻结CLIP特征的EffPrompt [30]显著低于近期基于CNN的模型;同样基于CLIP特征的STALE [51]虽与最佳CNN方法结果相当,但比使用双流I3D特征训练的相同模型低2.2。据我们所知,我们是首个仅用Transformer特征就达到最先进成果的工作。UnLoc-L模型将mAP@0.5IoU指标较先前最佳结果提升了2.3,通过提示集成(prompt ensembling)进一步将优势扩大至2.8。
For both splits in the zero-shot (open-set) protocols proposed by [30, 51], UnLoc-B and L outperform previous best by a significant margin. Specifically, UnLoc-L advances previous state-of-the-art by 11.6, a relative $36.1%$ improvement on the 50/50 split and by 10.6, a relative $27.7%$ on the 75/25 split.
在[30, 51]提出的零样本(open-set)协议的两个划分中,UnLoc-B和UnLoc-L均以显著优势超越先前最佳结果。具体而言,UnLoc-L将50/50划分下的现有最优指标提升了11.6个点(相对提升36.1%),在75/25划分下提升了10.6个点(相对提升27.7%)。

Ground truth: “stick with the tape and wrap” Figure 3. Qualitative Results We show results on Activity Net, Charades and COIN, for Temporal Action Localization, Moment Retrieval and Action Segmentation respectively. Predictions are shown in blue, while the ground truth is in green (best viewed in colour). For action segmentation, the ground truth covers the entire clip. Note how our model is able to predict accurate boundaries, in some cases better refined than the ground truth (top row, the arm wrestling action has stopped, however the ground truth boundary extends for a while after). For the second example for Moment Retrieval (4th row from top), we show a failure case, where our model detects the moment where the towel is ‘put down’, and not ‘on their head’ as perhaps the latter is a rarer occurrence in the training data.
图 3: 定性分析结果
我们分别在Activity Net、Charades和COIN数据集上展示了时序动作定位、时刻检索和动作分割的结果。预测结果以蓝色显示,真实标注(Ground Truth)为绿色(建议彩色查看)。对于动作分割任务,真实标注覆盖整个视频片段。
值得注意的是,我们的模型能够预测出精确的边界,在某些情况下甚至比真实标注更精细(首行示例:掰手腕动作已停止,但真实标注边界仍延续了一段时间)。在时刻检索的第二个示例中(自上而下第四行),我们展示了一个失败案例:模型检测到"放下毛巾"的时刻,而非"将毛巾放在头上"的时刻,这可能是因为后者在训练数据中出现频率较低所致。
(注:根据翻译规则,已保留专业术语如"Ground Truth"、数据集名称及技术术语的原始表述;图片引用格式转换为"图 3:";调整了标点符号间距;对长句进行了符合中文表达习惯的拆分重组)
Table 7. Comparison with the state-of-the-art on COIN for Action Segmentation. We report results using both frame accuracy (as is standard practice) and mAP, which we believe is a better metric given that a large proportion $(58.9%)$ of the dataset is labelled as a single class (background).
表 7: COIN数据集上动作分割任务与当前最优方法的对比。我们同时报告了帧准确率(标准评估指标)和mAP值,由于该数据集中有较大比例$(58.9%)$被标注为单一类别(背景),我们认为mAP是更优的评估指标。
| 方法 | 帧准确率 | mAP |
|---|---|---|
| Baseline: 预测全部背景 | 58.9 | 0.0 |
| ActBERT[88] | 57.0 | |
| MIL-NCE [46] | 61.0 | |
| TACo [75] | 68.4 | |
| VLM[71] | 68.4 | |
| VideoCLIP[72] | 68.7 | |
| UniVL [44] | 70.0 | |
| UnLoc-B (第一提示) | 68.0 | 36.2 |
| UnLoc-L(第一提示) | 72.6 | 47.0 |
| UnLoc-L(提示集成) | 72.8 | 47.7 |
Action segmentation Table 7 compares our model with previous work and UnLoc-L outperform previous state-ofthe-art by $2.8%$ in frame accuracy. Besides architectural differences, we note that previous works [46, 72, 44] pretrain their models on HowTo100M [47], which consists of around 100M aligned ASR and video clip pairs, and is also in a similar domain to COIN (instructional web videos). Our models on the other hand, are initialized from CLIP checkpoints, which are trained on cleaner web image-text pairs from multiple domains and finetuned on Kinetics, 10s clips of human activity videos.
动作分割
表7将我们的模型与之前的工作进行了比较,UnLoc-L在帧准确率上比之前的最先进水平高出2.8%。除了架构差异外,我们注意到之前的工作[46, 72, 44]在HowTo100M[47]上预训练了模型,该数据集包含约1亿个对齐的ASR和视频片段对,并且与COIN(教学网络视频)领域相似。而我们的模型则是从CLIP检查点初始化,这些检查点是在多个领域的更干净的网络图像-文本对上训练的,并在Kinetics(人类活动视频的10秒片段)上进行了微调。
5. Conclusion and Future Work
5. 结论与未来工作
We propose a new model for video localization tasks, called UnLoc. UnLoc consists of a two-tower CLIP model, the output features of which are fed into a video-text fusion module and feature pyramid. Unlike previous works, we achieve state-of-the-art results on 3 different benchmarks (moment retrieval, temporal action localization and action segmentation) with a single approach, without the need for action proposals or pretrained video features.
我们提出了一种名为UnLoc的新型视频定位任务模型。UnLoc采用双塔式CLIP模型架构,其输出特征会输入到视频-文本融合模块和特征金字塔中。与先前研究不同,我们通过单一方法在三个不同基准测试(时刻检索、时序动作定位和动作分割)上实现了最先进性能,且无需动作建议框或预训练视频特征。
Future work will investigate cotraining on the three localization tasks, pre training on large, weakly labelled datasets, exploring highlight detection as an additional downstream task, and adapting our model to other modalities such as audio for sound localization [27].
未来工作将研究三个定位任务的协同训练、基于大型弱标记数据集的预训练、探索将亮点检测作为额外下游任务,以及将我们的模型适配到其他模态(如用于声音定位的音频)[27]。
Acknowledgements. We thank Xingyi Zhou for helpful discussion and feedback.
致谢。我们感谢Xingyi Zhou的有益讨论和反馈。