FOCUS: Towards Universal Foreground Segmentation
FOCUS:迈向通用前景分割
Abstract
摘要
Foreground segmentation is a fundamental task in computer vision, encompassing various subdivision tasks. Previous research has typically designed task-specific architectures for each task, leading to a lack of unification. Moreover, they primarily focus on recognizing foreground objects without effectively distinguishing them from the background. In this paper, we emphasize the importance of the background and its relationship with the foreground. We introduce FOCUS, the Foreground ObjeCts Universal Segmentation framework that can handle multiple foreground tasks. We develop a multi-scale semantic network using the edge information of objects to enhance image features. To achieve boundaryaware segmentation, we propose a novel distillation method, integrating the contrastive learning strategy to refine the prediction mask in multi-modal feature space. We conduct extensive experiments on a total of 13 datasets across 5 tasks, and the results demonstrate that FOCUS consistently outperforms the state-of-the-art task-specific models on most metrics.
前景分割是计算机视觉中的基础任务,涵盖多种细分任务。先前研究通常为每个任务设计特定架构,导致缺乏统一性。此外,这些方法主要关注前景对象识别,未能有效区分前景与背景。本文重点探讨背景的重要性及其与前景的关系,提出FOCUS(Foreground ObjeCts Universal Segmentation)框架,可处理多种前景任务。我们利用物体边缘信息构建多尺度语义网络以增强图像特征。为实现边界感知分割,提出一种新型蒸馏方法,结合对比学习策略在多模态特征空间中优化预测掩码。我们在5类任务的13个数据集上开展大量实验,结果表明FOCUS在多数指标上持续优于当前最先进的专用模型。
Introduction
引言
Foreground segmentation is a fundamental task in computer vision where the primary goal is to delineate the prominent objects (foreground) from the rest of the image (background), typically referring to salient object detection (SOD) and camouflaged object detection (COD) (Pang et al. 2022a, 2024a). In this paper, the concept of foreground segmentation can be extended to delineating objects that interest you most in the image, where the primary goal is to obtain the Mask of Interest (MoI), e.g., MoI should denote the mask of the camouflaged object in COD. According to this definition, tasks such as shadow detection (SD), defocus blur detection (DBD), forgery detection (FD), etc. belong to the category of foreground segmentation, too.
前景分割是计算机视觉中的一项基础任务,其主要目标是从图像其余部分(背景)中划分出显著物体(前景),通常指显著目标检测(SOD)和伪装目标检测(COD)(Pang et al. 2022a, 2024a)。本文中,前景分割的概念可延伸为划分图像中最受关注的对象,其核心目标是获取兴趣掩码(Mask of Interest,MoI),例如在COD任务中MoI应表示伪装物体的掩码。根据此定义,阴影检测(SD)、散焦模糊检测(DBD)、伪造检测(FD)等任务也属于前景分割范畴。
Currently, in the field of generic segmentation, e.g. instance segmentation, semantic segmentation, and panoptic segmentation, etc., there are already many sophisticated models (Kirillov et al. 2023; Cheng et al. 2022; Jain et al. 2023; Ding et al. 2023b,a). However, these models often lack targeted training for specific foreground segmentation tasks. For instance, in the COD task, SAM struggles to distinguish camouflaged objects from the background (Hu et al. 2024). Furthermore, without prompt-guided methods, most traditional segmentation algorithms generate multiple masks for one image at the same time (Cheng, Schwing, and Kirillov 2021; Cheng et al. 2022; Jain et al. 2023), but users do not require such many masks in many real-world scenarios, e.g. image background removal, MoI is all they need. While foreground segmentation typically produces a single or specific type of mask, making it more in line with user needs.
目前,在通用分割领域(如实例分割、语义分割和全景分割等)已有许多成熟模型 [20][5][12][6][7]。然而,这些模型通常缺乏针对特定前景分割任务的专项训练。例如在伪装目标检测(COD)任务中,SAM难以将伪装物体与背景区分 [11]。此外,若无提示引导方法,多数传统分割算法会同时为单张图像生成多个掩码 [5][6][12],但实际场景(如图像背景去除)往往仅需主体掩码(MoI)。而前景分割通常生成单一或特定类型掩码,更符合用户需求。
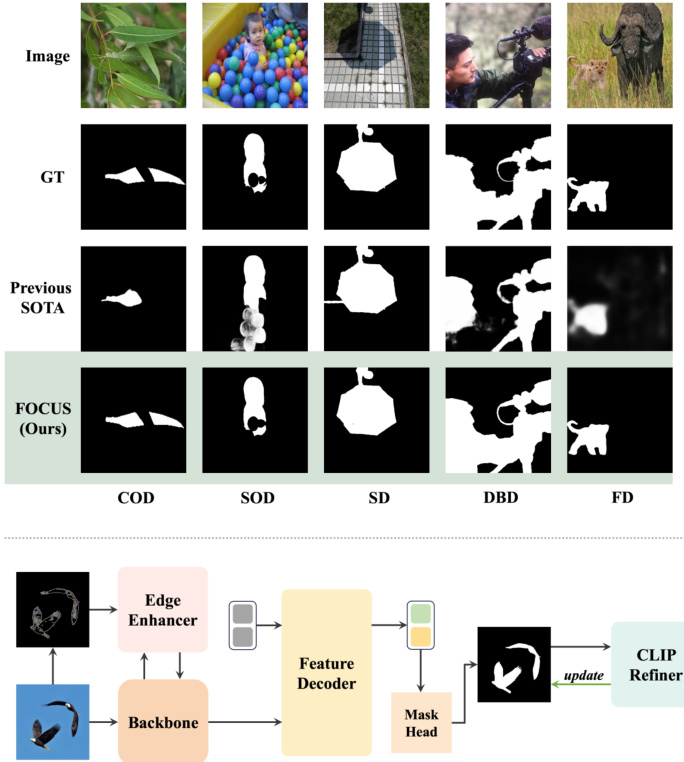
Figure 1: With one unified architecture, FOCUS can handle various foreground segmentation tasks. Our proposed method can generate boundary-aware masks that are smoother and more detailed than the previous state-of-theart task-specific models. Zoom in for more details.
图 1: FOCUS 通过单一统一架构处理多种前景分割任务。我们提出的方法能生成边界感知掩码,相比之前最先进的专用任务模型更加平滑细致。放大查看细节。
However, as mentioned earlier, when the concept of foreground is generalized as MoI, the scope of foreground segmentation tasks is very broad. Currently, there is a lack of an excellent and universal framework that can handle all foreground segmentation tasks. Most foreground segmentation models are task-specific (Wang et al. 2022a; Zhao et al. 2021; Zhu et al. 2021; Zheng et al. 2024a; Xie et al. 2022; Wang et al. 2022b) . Some models (Pang et al. 2024a, 2022a) achieve universality in SOD and COD tasks, but given the similarity between COD and SOD tasks, they will not be discussed as universal models here. To the best of our knowledge, the work most closely related to ours is (Liu et al. 2023). However, it still significantly lags behind taskspecific models after fine-tuning in the subdivision tasks.
然而,如前所述,当将前景概念泛化为兴趣对象 (MoI) 时,前景分割任务的范围非常广泛。目前缺乏一个优秀且通用的框架来处理所有前景分割任务。大多数前景分割模型都是针对特定任务的 (Wang et al. 2022a; Zhao et al. 2021; Zhu et al. 2021; Zheng et al. 2024a; Xie et al. 2022; Wang et al. 2022b) 。部分模型 (Pang et al. 2024a, 2022a) 在显著目标检测 (SOD) 和伪装目标检测 (COD) 任务中实现了通用性,但鉴于 COD 和 SOD 任务的相似性,本文不将其视为通用模型进行讨论。据我们所知,与我们的工作最相关的是 (Liu et al. 2023) ,但该模型在细分任务微调后仍显著落后于任务专用模型。
Besides, previous foreground segmentation models primarily focused on recognizing the foreground objects without effectively distinguishing them from the background, neglecting the background and the relationship between the background and the foreground. In fact, background information plays a critical role in computer vision tasks (Li et al. 2023; Meng et al. 2024). Foreground segmentation inherently involves distinguishing the foreground from the background, making both elements and their relationship vital. However, current approaches fail to address the background segmentation separately. Consequently, this oversight impacts the overall performance of foreground segmentation.
此外,以往的前景分割模型主要侧重于识别前景对象,而未能有效区分前景与背景,忽视了背景信息以及背景与前景之间的关系。事实上,背景信息在计算机视觉任务中起着关键作用 (Li et al. 2023; Meng et al. 2024)。前景分割本质上涉及将前景与背景区分开来,因此二者及其关系都至关重要。然而,现有方法未能单独处理背景分割问题,这一疏漏影响了前景分割的整体性能。
The issues above can be summarized as follows: (1)How to generally represent the foreground and background of different foreground segmentation tasks? (2)How to fully utilize the background information of an image to optimize prediction results? In this paper, we introduce FOCUS, a unified multi-modal approach to tackle multiple subdivision tasks of foreground segmentation.
上述问题可总结如下:(1) 如何通用地表示不同前景分割任务中的前景与背景?(2) 如何充分利用图像的背景信息来优化预测结果?本文提出FOCUS——一种统一的多模态方法,用于解决前景分割的多个细分任务。
To universally represent the foreground and background, we borrow the object queries concept from DETR (Carion et al. 2020) by introducing ground queries. We apply the multi-scale strategy (Cheng et al. 2022) to extract image features to feed the transformer decoder, using masked attention to enable the ground queries to focus on relevant features corresponding to foreground and background. We utilize the feature map obtained from the backbone to initialize the masked attention, which can serve as a localization prior. During this process, the ground queries adapt to learn the features relevant to the context of different tasks, making them universal features.
为了通用地表示前景和背景,我们借鉴了DETR (Carion et al. 2020) 中的对象查询 (object queries) 概念,引入了地面查询 (ground queries)。我们采用多尺度策略 (Cheng et al. 2022) 提取图像特征并输入到Transformer解码器中,通过掩码注意力 (masked attention) 使地面查询能够聚焦于与前景和背景相关的特征。我们利用主干网络 (backbone) 获取的特征图初始化掩码注意力,这可以作为定位先验。在此过程中,地面查询自适应地学习与不同任务上下文相关的特征,使其成为通用特征。
To fully leverage the background information in images, we employ contrastive learning strategies. We propose the CLIP refiner, using the powerful multi-modal learning ability from CLIP (Radford et al. 2021) to correct the masks generated by previous modules. We fuse the mask and image and align the fused image and its corresponding text in multi-modal feature space to refine the masks. This not only refines the edges of the mask but also accentuates the distinction between foreground and background. We treat foreground segmentation and background segmentation as two independent tasks, and in the inference stage, the probability map of both foreground and background will jointly determine the boundary of MoI.
为充分利用图像中的背景信息,我们采用对比学习策略。提出CLIP优化器,借助CLIP (Radford et al. 2021)强大的多模态学习能力来修正前序模块生成的掩膜。通过融合掩膜与图像,并在多模态特征空间中对齐融合图像及其对应文本,从而实现掩膜优化。该方法不仅能细化掩膜边缘,还能强化前景与背景的区分度。我们将前景分割与背景分割视为两个独立任务,在推理阶段,前景和背景的概率图将共同决定兴趣对象(MoI)的边界。
We conduct detailed experiments on 13 datasets across five foreground segmentation tasks and achieve or exceed state-of-the-art on most provided metrics. Fig. 1 shows the outstanding performance of our proposed FOCUS on different sub-tasks of the foreground segmentation.
我们在五个前景分割任务的13个数据集上进行了详细实验,并在大多数评估指标上达到或超越了当前最优水平。图 1: 展示了我们提出的 FOCUS 在前景分割不同子任务上的出色表现。
Our contributions can be summarized as follows:
我们的贡献可总结如下:
• We propose a unified framework for foreground segmentation tasks, including SOD, COD, SD, DBD, and FD; • We propose a novel module, using the contrastive learning strategy to utilize the background information to re- fine the mask while widening the distance between the foreground and the background; • We conduct extensive experiments on multiple datasets across multiple tasks, and results demonstrate that our method achieves state-of-the-art performance.
• 我们提出了一个统一的前景分割任务框架,涵盖显著目标检测 (SOD)、伪装目标检测 (COD)、阴影检测 (SD)、缺陷检测 (DBD) 和雾检测 (FD);
• 我们提出了一种新颖模块,通过对比学习策略利用背景信息优化掩膜,同时扩大前景与背景之间的距离;
• 我们在多个任务的多个数据集上进行了广泛实验,结果表明我们的方法达到了最先进的性能。
Related Work
相关工作
Foreground Segmentation
前景分割
As mentioned earlier, several tasks are crucial in foreground segmentation, including salient object detection(SOD), camouflaged object detection (COD), shadow detection (SD), defocus blur detection (DBD), and forgery detection (FD). SOD aims at segmenting the most visually attractive objects from the input images. COD focuses on disguised objects that blend seamlessly into their surroundings, e.g. mimetic animals and body paintings. SD aims to segment shadow regions from natural scenes. DBD aims at separating in-focus and out-of-focus regions, which is caused by the different focal lengths of the cameras, slightly different from SOD. The goal of FD is to identify altered or manipulated areas in images, typically involving addition, replacement, or deletion. Previous models normally designed architectures for specific foreground segmentation task (Wang et al. 2022a; Zhao et al. 2021; Zhu et al. 2021; Zheng et al. 2024a; Xie et al. 2022), and currently, there is a lack of effective methods to handle this foreground segmentation tasks universally.
如前所述,前景分割中的关键任务包括显著目标检测(SOD)、伪装目标检测(COD)、阴影检测(SD)、散焦模糊检测(DBD)和篡改检测(FD)。SOD旨在从输入图像中分割出最具视觉吸引力的目标。COD专注于与背景无缝融合的伪装目标,例如拟态动物和人体彩绘。SD的目标是从自然场景中分割出阴影区域。DBD旨在分离对焦与失焦区域(由相机焦距差异造成),与SOD略有不同。FD的任务是识别图像中被篡改或操纵的区域,通常涉及添加、替换或删除操作。现有模型通常针对特定前景分割任务设计架构 (Wang et al. 2022a; Zhao et al. 2021; Zhu et al. 2021; Zheng et al. 2024a; Xie et al. 2022),目前仍缺乏能通用处理这些前景分割任务的有效方法。
Universal Segmentation
通用分割
Universal segmentation has emerged as a significant trend in computer vision. It aims to unify various segmentation tasks within a single framework. This trend started with efforts to unify semantic and instance segmentation through panoptic segmentation (Kirillov et al. 2019) and has since expanded to include a broader range of tasks. Recent works have shifted towards designing universal segmentation models with generalization ability and versatility. Mask 2 Former (Cheng et al. 2022) utilizes a masked-attention mechanism to unify instance, semantic and panoptic segmentation. OneFormer (Jain et al. 2023) further improves Mask 2 Former with a multi-task train-once design. More recent approaches like SAM (Kirillov et al. 2023) push the boundaries of universal segmentation with the ability of zero-shot segmentation. In the field of foreground segmentation, the unified ar- chitecture most related to ours is EVP (Liu et al. 2023). EVP freezes a pre-trained model and then learns task-specific knowledge using an adapter structure, but its performance falls behind task-specific models. In this work, we aim to find a more effective way to unify the foreground segmentation tasks using one single architecture.
通用分割已成为计算机视觉领域的重要趋势。其目标是在单一框架内统一各类分割任务。这一趋势始于通过全景分割 (Kirillov et al. 2019) 统一语义分割与实例分割的尝试,随后逐渐扩展到更广泛的任务范围。近期研究转向设计具有泛化能力和多功能性的通用分割模型。Mask 2 Former (Cheng et al. 2022) 采用掩码注意力机制统一了实例分割、语义分割和全景分割。OneFormer (Jain et al. 2023) 通过"一次训练多任务"设计进一步改进了Mask 2 Former。SAM (Kirillov et al. 2023) 等最新方法则通过零样本分割能力拓展了通用分割的边界。在前景分割领域,与我们工作最相关的统一架构是EVP (Liu et al. 2023)。EVP冻结预训练模型后通过适配器结构学习任务特定知识,但其性能仍落后于专用模型。本研究旨在探索更有效的方式,使用单一架构统一前景分割任务。
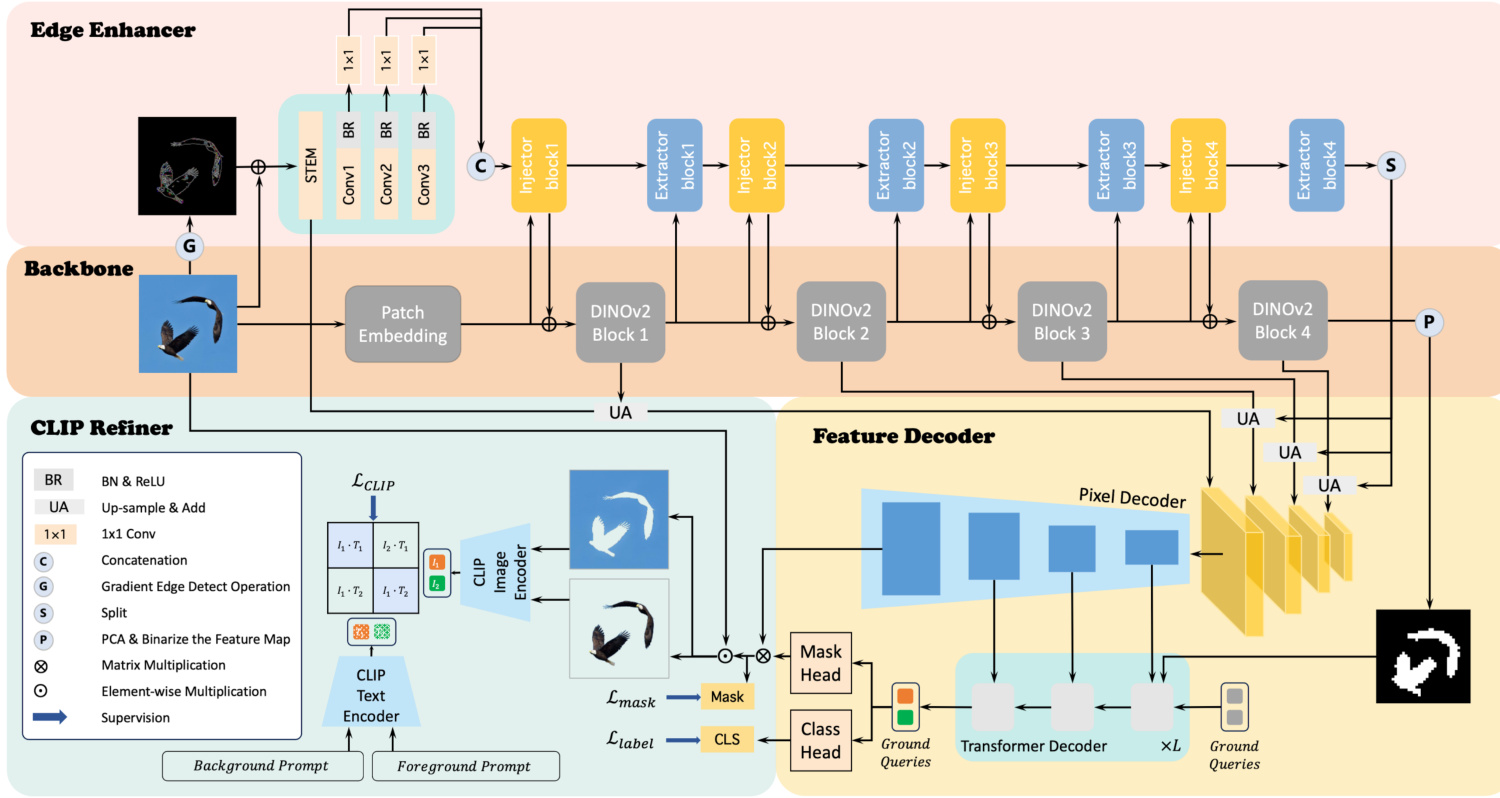
Figure 2: An overview of our proposed FOCUS, a multi-scale and multi-modal semantic framework for universal foreground segmentation, mainly includes the backbone, edge enhancer, feature decoder, and CLIP refiner. Refer to the main text for details.
图 2: 我们提出的FOCUS框架概览,这是一个用于通用前景分割的多尺度多模态语义框架,主要包括主干网络 (backbone)、边缘增强器 (edge enhancer)、特征解码器 (feature decoder) 和CLIP优化器 (CLIP refiner)。详情请参阅正文。
Methods
方法
Unified Architecture
统一架构
Previously, there was a lack of unified architecture for handling all foreground segmentation subdivision tasks. Given an image from different foreground segmentation tasks, our goal is to use a unified architecture to predict the corresponding MoI in the task context. The problem can be defined by:
此前,缺乏处理所有前景分割细分任务的统一架构。给定来自不同前景分割任务的图像,我们的目标是使用统一架构预测任务上下文中的相应MoI。该问题可通过以下方式定义:
$$
U(I,T_{i})=M o I
$$
$$
U(I,T_{i})=M o I
$$
$T_{i}$ refers to different foreground segmentation tasks, $\forall T_{i}\in$ ${T_{1},\dots,T_{n}}$ the unified framework $U$ should infer the corresponding $M o I$ from the images $I$ .
$T_{i}$ 指代不同的前景分割任务,$\forall T_{i}\in$ ${T_{1},\dots,T_{n}}$,统一框架 $U$ 应从图像 $I$ 中推断出相应的 $M o I$。
We propose FOCUS, a unified architecture that can handle multiple foreground segmentation tasks. We borrow the concept of object queries from (Carion et al. 2020) and introduce the ground queries $(\mathbf{GQ})$ here. GQ are two distinct tensors, designated as the foreground query and background query, we aim to only use these two learned tensors to respectively embed and represent the foreground and the background within the image based on the context of the task. Fig. 2 provides an overview of our approach FOCUS. After obtaining multi-scale edge-enhanced features from the backbone and the edge enhancer, the pixel decoder will generate pixel-level output and these pixel-level features will be fed into the transformer decoder with GQ, where GQ updated by masked attention (Cheng et al. 2022) to get groundcentric output. It can be formulated as:
我们提出FOCUS,一种能够处理多种前景分割任务的统一架构。我们借鉴了(Carion et al. 2020)中的对象查询(object queries)概念,并在此引入基础查询$(\mathbf{GQ})$。GQ是两个独立的张量,分别指定为前景查询和背景查询,我们的目标是仅使用这两个学习到的张量,根据任务上下文分别嵌入和表示图像中的前景与背景。图2展示了我们的FOCUS方法概览:从主干网络和边缘增强器获取多尺度边缘增强特征后,像素解码器将生成像素级输出,这些像素级特征会与GQ一起输入Transformer解码器,其中GQ通过掩码注意力(Cheng et al. 2022)进行更新以获得以基础为中心的输出。该过程可表述为:
$$
\mathbf{X}{l}=\mathrm{softmax}(\mathcal{M}{l-1}+\mathbf{G}\mathbf{Q}{l}\mathbf{K}{l}^{\top})\mathbf{V}{l}+\mathbf{X}_{l-1},
$$
$$
\mathbf{X}{l}=\mathrm{softmax}(\mathcal{M}{l-1}+\mathbf{G}\mathbf{Q}{l}\mathbf{K}{l}^{\top})\mathbf{V}{l}+\mathbf{X}_{l-1},
$$
Here, ${\bf F}{D I N O v2}$ refers to the binary feature map from the last backbone block. It is resized to the same resolution of $\mathbf{K}_{1}$ . The adoption of the new initialization method can leverage the localization prior knowledge learned by the DINOv2 on large-scale data.
这里,${\bf F}{D I N O v2}$ 指的是来自最后一个主干块的二值特征图。它被调整到与 $\mathbf{K}_{1}$ 相同的分辨率。采用这种新的初始化方法可以利用 DINOv2 在大规模数据上学到的定位先验知识。
We use two multi-layer perce ptr on s, designated as mask head and class head, to decode ground queries and generate mask and class predictions for both the foreground and background. During the inference stage, the foreground and background probability distributions are combined to predict the final MoI.
我们使用两个多层感知器 (multi-layer perce ptr on),分别称为掩码头 (mask head) 和类别头 (class head),来解码地面查询 (ground queries) 并为前景和背景生成掩码及类别预测。在推理阶段,将前景和背景的概率分布结合以预测最终的MoI。
Edge Enhancer
边缘增强器
In order to utilize the edge information of the object, we propose the edge enhancer, an effective module that uses foreground object edge information to correct the image features obtained by the backbone.
为了利用物体的边缘信息,我们提出了边缘增强器(edge enhancer),这是一种利用前景物体边缘信息来校正主干网络提取的图像特征的有效模块。
Inspired by the recent study that shows convolutions can help transformer understand local spatial information (Chen et al. 2022; Wang et al. 2022c), we use ResNet50 (He et al. 2016) to extract edge features from the image. We convert the image into grayscale to reduce the confusion caused by color, apply Gaussian smoothing (Davies 2004) to reduce noise, and then use an edge detector (Canny 1986) to obtain a gradient map and overlay it on the original image. As shown in Fig. 2, the ResNet can be divided into the STEM and the rest, the STEM serves as the initial feature extractor, comprising a series of convolution, batch normalization, and ReLU activation layers. The output of the rest convolution blocks will be flattened and projected into the same dimension $D$ by $1\times1$ convolutions and concatenated to obtain feature pyramid $F_{\mathrm{edge}}^{1}\in\mathbb{R}^{(\frac{H W}{8^{2}}+\frac{H W}{16^{2}}+\frac{H W}{32^{2}})\times D}$ , $H$ and $W$ represent the resolution of the input image. Then, we follow ViT-Adapter (Chen et al. 2022), using the structure of the injector-extractor based on cross attention to fuse the image features from the backbone and ResNet. The injector can be formulated as:
受近期研究表明卷积能帮助Transformer理解局部空间信息(Chen et al. 2022; Wang et al. 2022c)的启发,我们采用ResNet50(He et al. 2016)从图像中提取边缘特征。先将图像转为灰度以减少色彩干扰,应用高斯平滑(Davies 2004)降噪,再通过边缘检测器(Canny 1986)获取梯度图并叠加至原图。如图2所示,ResNet可分为STEM模块与后续部分,其中STEM作为初始特征提取器,包含卷积层、批归一化层和ReLU激活层。后续卷积块的输出将通过$1\times1$卷积展平并投影至相同维度$D$,拼接后得到特征金字塔$F_{\mathrm{edge}}^{1}\in\mathbb{R}^{(\frac{H W}{8^{2}}+\frac{H W}{16^{2}}+\frac{H W}{32^{2}})\times D}$,其中$H$和$W$表示输入图像分辨率。随后我们参照ViT-Adapter(Chen et al. 2022),采用基于交叉注意力的注入器-提取器结构来融合主干网络与ResNet的图像特征。注入器可表示为:
$$
\begin{array}{r}{\hat{F}{\mathrm{DINOv}2}^{i}=F_{\mathrm{DINOv}2}^{i}+\gamma^{i}\mathbf{MSDA}(F_{\mathrm{DINOv}2}^{i},F_{\mathrm{edge}}^{i}),}\end{array}
$$
$$
\begin{array}{r}{\hat{F}{\mathrm{DINOv}2}^{i}=F_{\mathrm{DINOv}2}^{i}+\gamma^{i}\mathbf{MSDA}(F_{\mathrm{DINOv}2}^{i},F_{\mathrm{edge}}^{i}),}\end{array}
$$
MSDA refers to multi-scale deformable attention (Zhu et al. 2020), which takes the normalized backbone feature $F_{\mathrm{DINOv}2}^{i}\in\mathbb{R}^{\frac{H W}{16^{2}}\times D}$ as the query, and the normalized edge feature $\begin{array}{r}{F_{\mathrm{edge}}^{i}\in\mathbb{R}^{(\frac{H W}{8^{2}}+\frac{H W}{16^{2}}+\frac{H W}{32^{2}})\times D}}\end{array}$ D as the key and value. $\gamma^{i}$ is a learnable parameter for balancing the backbone feature and the fused feature. Similarly, the extractor can be formulated as:
MSDA指代多尺度可变形注意力机制 (multi-scale deformable attention) [20],它以归一化的骨干特征$F_{\mathrm{DINOv}2}^{i}\in\mathbb{R}^{\frac{H W}{16^{2}}\times D}$作为查询(query),归一化的边缘特征$\begin{array}{r}{F_{\mathrm{edge}}^{i}\in\mathbb{R}^{(\frac{H W}{8^{2}}+\frac{H W}{16^{2}}+\frac{H W}{32^{2}})\times D}}\end{array}$作为键(key)和值(value)。$\gamma^{i}$是可学习参数,用于平衡骨干特征与融合特征。该提取器可同理表述为:
$$
\begin{array}{r}{\hat{F}{\mathrm{edge}}^{i}=F_{\mathrm{edge}}^{i}+\mathrm{ConvFFN}(\mathbf{MSDA}(F_{\mathrm{edge}}^{i},F_{\mathrm{DINOv2}}^{i+1})).}\end{array}
$$
$$
\begin{array}{r}{\hat{F}{\mathrm{edge}}^{i}=F_{\mathrm{edge}}^{i}+\mathrm{ConvFFN}(\mathbf{MSDA}(F_{\mathrm{edge}}^{i},F_{\mathrm{DINOv2}}^{i+1})).}\end{array}
$$
It is another multi-scale deformable attention like injector while taking the normalized edge feature $F_{\mathrm{edge}}^{i}\in$ $\begin{array}{r}{\mathbb{R}^{(\frac{H W}{8^{2}}+\frac{H W}{16^{2}}+\frac{H W}{32^{2}})\times D}}\end{array}$ as the query, and the output feature $F_{\mathrm{DINOv}2}^{i+1}\in\mathbb{R}^{\frac{H W}{16^{2}}\times D}$ to the structure with two fully connected layers and a depthwise separable convolution layer. The Fedge willserve as the input for the next injector. We upscale the output from different blocks of backbone to resolutions of 1/4, 1/8, 1/16, and 1/32. Besides, we split the output of the last extractor, and restore them to their original size. Then we add the up-scaled backbone features with the corresponding split output from extractor and output from STEM to get the edge-enhanced multi-scale image features. These features will be fed into the pixel decoder, another module based on multi-scale deformable attention, for dense pixel-level predictions.
这是另一种类似注入器的多尺度可变形注意力机制,它以归一化的边缘特征 $F_{\mathrm{edge}}^{i}\in$ $\begin{array}{r}{\mathbb{R}^{(\frac{H W}{8^{2}}+\frac{H W}{16^{2}}+\frac{H W}{32^{2}})\times D}}\end{array}$ 作为查询(query),并将输出特征 $F_{\mathrm{DINOv}2}^{i+1}\in\mathbb{R}^{\frac{H W}{16^{2}}\times D}$ 输入到包含两个全连接层和一个深度可分离卷积层的结构中。Fedge将作为下一个注入器的输入。我们将主干网络不同模块的输出上采样至1/4、1/8、1/16和1/32分辨率。此外,我们对最后一个提取器的输出进行分割,并将其恢复至原始尺寸。随后,将上采样的主干特征与提取器对应的分割输出以及STEM输出相加,得到边缘增强的多尺度图像特征。这些特征将被输入到基于多尺度可变形注意力的另一个模块——像素解码器中,用于密集的像素级预测。
CLIP Refiner
CLIP Refiner
Since the proposal of CLIP, there have been many works using CLIP for segmentation (Xu et al. 2022; Li et al. 2022; Wang et al. 2022d; Liang et al. 2023), which have proven that CLIP is effective not only at the image level but also at the pixel level. In this paper, we propose CLIP refiner, which uses the powerful multi-modal ability of CLIP to correct the masks of foreground and background.
自CLIP提出以来,已有许多工作将其用于分割任务 (Xu et al. 2022; Li et al. 2022; Wang et al. 2022d; Liang et al. 2023) ,这些研究证明CLIP不仅在图像层面有效,在像素层面同样有效。本文提出CLIP refiner,利用CLIP强大的多模态能力来修正前景与背景的掩膜。
Specifically, we decode the ground queries to obtain the masks of the foreground and background, resize them, and overlay them on the image. We use the prompts “It’s an image of salient objects without background.” and “It’s an image of background with salient objects removed.” to represent foreground and background, respectively. Note that the text can be adjusted according to the task. For example, in shadow detection, prompts can be replaced with “it’s an image of shadow without background.” and “it’s an image of background without shadow.” to extend CLIP refiner to other foreground segmentation tasks. We borrow the image encoder and text encoder from CLIP to encode the image and text separately. Then, we calculate the contrastive loss $(\mathcal{L}_{\mathrm{clip}})$ between the mask-fused-image and text features.
具体来说,我们解码地面查询以获取前景和背景的掩码,调整其大小后叠加到图像上。使用提示语“这是一张去除背景的显著物体图像”和“这是一张去除显著物体的背景图像”分别表示前景和背景。注意文本可根据任务调整,例如在阴影检测中,可将提示语替换为“这是一张去除背景的阴影图像”和“这是一张去除阴影的背景图像”,从而将CLIP优化器扩展到其他前景分割任务。我们借用CLIP的图像编码器和文本编码器分别对图像和文本进行编码,然后计算掩码融合图像与文本特征之间的对比损失 $(\mathcal{L}_{\mathrm{clip}})$。
$$
\begin{array}{r l r}{\lefteqn{\mathcal{L}{\ell2\mathrm{i}}=-\frac{1}{2}\bigg[\log\frac{\exp(T_{f}\cdot I_{f}/\tau)}{\exp(T_{f}\cdot I_{f}/\tau)+\exp(T_{f}\cdot I_{b}/\tau)}}}\ &{}&{+\log\frac{\exp(T_{b}\cdot I_{b}/\tau)}{\exp(T_{b}\cdot I_{b}/\tau)+\exp(T_{b}\cdot I_{f}/\tau)}\bigg],}\end{array}
$$
$$
\begin{array}{r l r}{\lefteqn{\mathcal{L}{\ell2\mathrm{i}}=-\frac{1}{2}\bigg[\log\frac{\exp(T_{f}\cdot I_{f}/\tau)}{\exp(T_{f}\cdot I_{f}/\tau)+\exp(T_{f}\cdot I_{b}/\tau)}}}\ &{}&{+\log\frac{\exp(T_{b}\cdot I_{b}/\tau)}{\exp(T_{b}\cdot I_{b}/\tau)+\exp(T_{b}\cdot I_{f}/\tau)}\bigg],}\end{array}
$$
$$
\mathcal{L}{\mathrm{clip}}=\frac{1}{2}(\mathcal{L}{\mathrm{i}2\mathrm{t}}+\mathcal{L}_{\mathrm{t}2\mathrm{i}}).
$$
$$
\mathcal{L}{\mathrm{clip}}=\frac{1}{2}(\mathcal{L}{\mathrm{i}2\mathrm{t}}+\mathcal{L}_{\mathrm{t}2\mathrm{i}}).
$$
Here $I_{\mathrm{f}},I_{\mathrm{b}},T_{\mathrm{f}},I_{\mathrm{b}}\in\mathbb{R}^{2\times S}$ denotes the $S$ -dimensional image feature and text feature of foreground and background obtained by CLIP, $\tau$ is temperature parameter used to control the smoothness of the softmax function. The CLIP refiner iteratively refines the edges of masks generated by the preceding module, ensuring that only the appropriate pixels are included in the foreground or background. This process aligns the mask-fused image more closely with the corresponding text in the feature space while distancing it from the mismatched one. This not only makes the mask edges more accurate but also widens the gap between the foreground and background. The CLIP refiner is only used to distill knowledge from CLIP and will be discarded during the inference stage. Additionally, we keep the image and text encoders entirely frozen to fully leverage the multi-modal capabilities of CLIP without the potential performance degradation that might arise from fine-tuning.
这里 $I_{\mathrm{f}},I_{\mathrm{b}},T_{\mathrm{f}},I_{\mathrm{b}}\in\mathbb{R}^{2\times S}$ 表示通过 CLIP 获取的前景和背景的 $S$ 维图像特征与文本特征,$\tau$ 是用于控制 softmax 函数平滑度的温度参数。CLIP 优化器会迭代优化前序模块生成的掩码边缘,确保只有合适的像素被归入前景或背景。该过程使掩码融合图像在特征空间中更贴近对应文本描述,同时远离不匹配的文本。这不仅提升了掩码边缘的精确度,还扩大了前景与背景的差异。CLIP 优化器仅用于从 CLIP 蒸馏知识,在推理阶段将被弃用。此外,我们始终保持图像和文本编码器完全冻结,以充分利用 CLIP 的多模态能力,避免微调可能带来的性能下降。
Table 1: Comparison of FOCUS with recent state-of-the-art COD methods.
表 1: FOCUS与当前最优COD方法的对比
| CAMO(250) | COD10K(2,026) | CHAMELEON(76) | NC4K(4,121) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sm↑ | E↑ | F↑ | MAE↓ | Sm↑ | E↑ | F↑ | MAE↓ | Sm↑ | E↑ | F↑ | MAE↓ | Sm↑ | E↑ | F↑ | MAE↓ | |
| SINet20 | .751 | .771 | .606 | .100 | .771 | .806 | .551 | .051 | .869 | .891 | .740 | .044 | .808 | .871 | .723 | .058 |
| PFNet22 | .782 | .852 | .695 | .085 | .800 | .868 | .660 | .040 | .882 | .942 | .810 | .033 | .829 | .898 | .745 | .053 |
| ZoomNet22 | .820 | .892 | .752 | .066 | .838 | .911 | .729 | .029 | .902 | .958 | .845 | .023 | .853 | .912 | .784 | .043 |
| BSA-Net22 | .794 | .867 | .717 | .079 | .818 | .901 | .699 | .034 | .895 | .957 | .841 | .027 | .842 | .907 | .771 | .048 |
| FSPNet23 | .856 | .899 | .799 | .050 | .851 | .895 | .735 | .026 | .908 | .965 | .851 | .023 | .879 | .915 | .816 | .035 |
| ZoomNeXt24 | .889 | .945 | .857 | .041 | .898 | .956 | .827 | .018 | .924 | .975 | .885 | .018 | .903 | .951 | .863 | .028 |
| BiRefNet24 | .904 | .954 | .890 | .030 | .912 | .960 | .874 | .014 | .932 | .915 | .015 | .914 | .953 | .894 | .023 | |
| FOCUS(Ours) | .912 | .963 | .904 | .025 | .910 | .974 | .883 | .013 | .922 | .975 | .908 | .017 | .915 | .964 | .906 | .020 |
Table 2: Comparison of FOCUS with recent state-of-the-art SOD methods.
表 2: FOCUS与当前最先进SOD方法的对比
| DUTS-TE(5,019) | DUT-OMRON(5,618) | HKU-IS(4,447) | ECSSD(1,000) | PASCAL-S(850) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Sm↑ | Eε↑ | MAE↓ | Sm↑ | E↑ | MAE | Sm↑ | E↑ | MAE√ | Sm↑ | E↑ | MAE | Sm↑ | E↑ | MAE√ | |
| VST21 | .896 | .892 | .037 | .850 | .861 | .058 | .928 | .953 | .029 | .932 | .918 | .033 | .865 | .837 | .061 |
| BBRF21 | .908 | .927 | .025 | .855 | .887 | .042 | .935 | .965 | .020 | .939 | .934 | .022 | .871 | .867 | .049 |
| EVPv123 | .913 | .947 | .026 | .862 | .894 | .046 | .931 | .961 | .024 | .935 | .957 | .027 | .878 | .917 | .054 |
| EVPv223 | .915 | .948 | .027 | .862 | .895 | .047 | .932 | .963 | .023 | .935 | .957 | .028 | .879 | .917 | .053 |
| MENet23 | .905 | .937 | .028 | .850 | .891 | .045 | .927 | .966 | .023 | .928 | .954 | .030 | .872 | .913 | .054 |
| SelfReformer23 | .921 | .924 | .024 | .859 | .884 | .043 | .934 | .961 | .023 | .941 | .935 | .025 | .877 | .874 | .049 |
| FOCUS(Ours) | .929 | .965 | .019 | .868 | .900 | .045 | .935 | .974 | .018 | .943 | .971 | .018 | .898 | .942 | .036 |
Table 3: Comparison of FOCUS with recent state-of-the-art SD, DBD, and FD methods.
表 3: FOCUS 与当前最先进的 SD、DBD 和 FD 方法对比
| ISTD(540) BER↓ | DUT(500) F↑ | CUHK(100) Fβ↑ MAE↓ | CASIA-1.0(921) F1↑ AUC↑ | ||||
|---|---|---|---|---|---|---|---|
| BDRAR18 | DeFusionNet20 | .823 | .118 | .818 | .117 | ManTra19 | |
| DSD19 | 2.69 | .135 | .906 | SPAN20 | |||
| MTMT20 | 2.17 1.72 | CENet19 | .817 .794 | .153 | .884 | .059 | PSCCNet22 |
| FDRNet21 | 1.55 | DAD21 EFENet21 | .854 | .094 | .914 | .079 .053 | TransForensics21 |
| EVPv123 | 1.35 | DD20 | .891 | .073 | .927 | .042 | EVPv123 |
| EVPv223 | 1.35 | EVPv123 | .890 | .068 | .928 | .045 | EVPv223 |
| SILT23 | 1.11 | EVPv223 | .887 | .070 | .932 | .042 | ObjectFormer22 |
| FOCUS(Ours) | 0.98 | FOCUS(Ours) | .912 | .048 | .934 | .036 | FOCUS(Ours) |
| (a) SD | (b) DBD |
Training Objectives
训练目标
In order to perform foreground and background segmentation jointly, we convert the foreground segmentation dataset into binary form, with the white areas representing the foreground ground truth and the black areas representing the background ground truth. Following (Cheng et al. 2022) , we use the combination of binary cross entropy $(\mathcal{L}{\mathrm{bce}})$ and dice loss $(\mathcal{L}_{\mathrm{dice}})$ as the loss of the mask, where:
为了同时进行前景和背景分割,我们将前景分割数据集转换为二值形式,白色区域代表前景真实值,黑色区域代表背景真实值。参考 (Cheng et al. 2022) ,我们采用二元交叉熵 $(\mathcal{L}{\mathrm{bce}})$ 和 dice损失 $(\mathcal{L}_{\mathrm{dice}})$ 的组合作为掩码损失函数,其中:
$$
{\mathcal{L}}{\mathrm{mask}}={\mathcal{L}}{\mathrm{bce}}+{\mathcal{L}}_{\mathrm{dice}}
$$
$$
{\mathcal{L}}{\mathrm{mask}}={\mathcal{L}}{\mathrm{bce}}+{\mathcal{L}}_{\mathrm{dice}}
$$
Recent study (Li et al. 2023) shows that parallel execution of object detection and segmentation can benefit each other. In this paper, we use the rectangular boundary of the ground truth mask as the ground truth bounding box to perform object detection. We use combination of the L1 Regression Loss $(\mathcal{L}{\mathrm{L1}})$ and generalized IoU loss $(\mathcal{L}{\mathrm{gIoU}})$ as the loss for $\mathcal{L}_{\mathrm{bbox}}$ , which can be formulated as:
近期研究 (Li et al. 2023) 表明,并行执行目标检测与分割任务能实现相互促进。本文采用真实掩码的矩形边界作为目标检测的真实边界框,并组合使用 L1 回归损失 $(\mathcal{L}{\mathrm{L1}})$ 与广义交并比损失 $(\mathcal{L}{\mathrm{gIoU}})$ 作为 $\mathcal{L}_{\mathrm{bbox}}$ 的损失函数,其公式可表示为:
$$
{\mathcal{L}}{\mathrm{bbox}}=\alpha{\mathcal{L}}{\mathrm{L1}}+\beta{\mathcal{L}}_{\mathrm{gIoU}}
$$
$$
{\mathcal{L}}{\mathrm{bbox}}=\alpha{\mathcal{L}}{\mathrm{L1}}+\beta{\mathcal{L}}_{\mathrm{gIoU}}
$$
$\alpha$ and $\beta$ are set to 5.0 and 2.0 respectively. We use the standard cross entropy loss as the $\mathcal{L}_{\mathrm{label}}$ . The final training objective is defined as follows:
$\alpha$ 和 $\beta$ 分别设置为5.0和2.0。我们使用标准交叉熵损失作为 $\mathcal{L}_{\mathrm{label}}$。最终训练目标定义如下:
$$
\mathcal{L}=\lambda_{\mathrm{clip}}\mathcal{L}{\mathrm{clip}}+\lambda_{\mathrm{label}}\mathcal{L}{\mathrm{label}}+\lambda_{\mathrm{mask}}\mathcal{L}{\mathrm{mask}}+\lambda_{\mathrm{bbox}}\mathcal{L}_{\mathrm{bbox}}
$$
$$
\mathcal{L}=\lambda_{\mathrm{clip}}\mathcal{L}{\mathrm{clip}}+\lambda_{\mathrm{label}}\mathcal{L}{\mathrm{label}}+\lambda_{\mathrm{mask}}\mathcal{L}{\mathrm{mask}}+\lambda_{\mathrm{bbox}}\mathcal{L}_{\mathrm{bbox}}
$$
here, $\lambda_{\mathrm{clip}},\lambda_{\mathrm{label}},\lambda_{\mathrm{mask}},\lambda_{\mathrm{bbox}}$ refer to the weight of corresponding loss, set to 1.0, 1.0, 5.0, 1.0 respectively. To find the allocation with the lowest cost, we use Hungarian matching (Carion et al. 2020; Cheng, Schwing, and Kirillov 2021) between the prediction and the ground truth.
这里,$\lambda_{\mathrm{clip}}$、$\lambda_{\mathrm{label}}$、$\lambda_{\mathrm{mask}}$、$\lambda_{\mathrm{bbox}}$ 分别表示对应损失的权重,设置为 1.0、1.0、5.0、1.0。为了找到成本最低的分配方案,我们在预测值和真实值之间使用匈牙利匹配算法 (Carion et al. 2020; Cheng, Schwing, and Kirillov 2021)。
Experiments Datasets and Evaluation Metrics
实验数据集与评估指标
For COD, we follow (Fan et al. 2021; Zheng et al. 2024a), training FOCUS on the combination of CAMO-TR (Le et al.
对于COD任务,我们遵循 (Fan et al. 2021; Zheng et al. 2024a) 的方法,在CAMO-TR (Le et al.) 数据集组合上训练FOCUS模型。

Figure 3: Qualitative comparison of FOCUS and previous methods on COD, SOD, SD, DBD, and FD. Zoom in for more details.
图 3: FOCUS 与先前方法在 COD (伪装目标检测)、SOD (显著性目标检测)、SD (阴影检测)、DBD (暗淡边界检测) 和 FD (雾霾检测) 任务上的定性对比。放大查看细节。
- and COD10K-TR (Fan et al. 2020) and evaluating on CAMO-TE, COD10K-TE, CHAMELEON (Skurowski et al. 2018) and NC4K (Lv et al. 2021). We use S-measure $(S_{m})$ , E-measure $(E_{\xi})$ , weighted F-measure $(F_{\beta}^{w})$ and mean absolute error $(M A E)$ to evaluate FOCUS.
- 和 COD10K-TR (Fan et al. 2020) 并在 CAMO-TE、COD10K-TE、CHAMELEON (Skurowski et al. 2018) 和 NC4K (Lv et al. 2021) 上进行评估。我们使用 S-measure $(S_{m})$、E-measure $(E_{\xi})$、加权 F-measure $(F_{\beta}^{w})$ 和平均绝对误差 $(M A E)$ 来评估 FOCUS。
For SOD task, we follow (Wang et al. 2023), using DUTSTR (Wang et al. 2017) as training dataset without extra data, evaluating our model on DUTS-TE, DUT-OMRON (Yang et al. 2013), HKU-IS (Li and $\mathrm{Yu}2015\$ ), ECSSD (Shi et al. 2015) and PACAL-S (Li et al. 2014) respectively. We use $S_{m}$ , $E_{\xi}$ , $M A E$ as evaluation metrics for SOD.
对于SOD任务,我们遵循(Wang et al. 2023),使用DUTSTR (Wang et al. 2017)作为训练数据集且不额外添加数据,分别在DUTS-TE、DUT-OMRON (Yang et al. 2013)、HKU-IS (Li和$\mathrm{Yu}2015\$)、ECSSD (Shi et al. 2015)和PACAL-S (Li et al. 2014)上评估我们的模型。我们采用$S_{m}$、$E_{\xi}$、$MAE$作为SOD的评估指标。
For SD, We use ISTD (Wang, Li, and Yang 2018) as our training and evaluation dataset and use balanced error rate (BCE) as the metric. For DBD, following previous work (Zhao et al. 2018), we use the combination of CUHK (Shi, Xu, and Jia 2014) and DUT (Zhao et al. 2018) as training dataset, and the remaining 100 images in CUHK and 500 images in DUT for testing, and we use F-measure $(F_{\beta})$ and $M A E$ as metrics. Following (Wang et al. 2022a), we use CASIA-2.0 (Dong, Wang, and Tan 2013) as the training dataset and evaluate on CASIA-1.0, using pixel-level $F1$ score and area under the curve $(A U C)$ as evaluation metric.
对于SD任务,我们采用ISTD数据集 (Wang, Li, and Yang 2018) 作为训练和评估基准,并使用平衡错误率 (BCE) 作为衡量指标。针对DBD任务,沿袭前人工作 (Zhao et al. 2018),我们组合使用CUHK (Shi, Xu, and Jia 2014) 和DUT (Zhao et al. 2018) 作为训练集,保留CUHK剩余的100张图像和DUT的500张图像用于测试,采用F-measure $(F_{\beta})$ 和 $MAE$ 作为评估指标。参照 (Wang et al. 2022a) 的方法,我们使用CASIA-2.0数据集 (Dong, Wang, and Tan 2013) 进行训练,并在CASIA-1.0上评估性能,采用像素级 $F1$ 分数和曲线下面积 $(AUC)$ 作为评价标准。
Implementation Details
实现细节
We use batch size 8 for all experiments and 2 NVIDIA A6000 GPUs with 48G memory. The FOCUS is trained on each training dataset with the size of $512\times512$ for 20,000 iterations on average with AdamW optimizer (Loshchilov and Hutter 2017). The initial learning rate is set to $10^{-5}$ with a weight decay of 0.05 to regularize the model. The L2 norm is used for gradient clipping, and the maximum allowed value for gradients is set to 0.01. We use DINOv2- G (Oquab et al. 2023) pre-trained on ADE20K (Zhou et al. 2017) as the backbone for our SoTA model. Our framework is implemented using PyTorch 2.1.1 (Paszke et al. 2019).
所有实验均采用批量大小8,并使用两块配备48G内存的NVIDIA A6000 GPU。FOCUS模型在尺寸为$512\times512$的各训练数据集上平均训练20,000次迭代,优化器采用AdamW (Loshchilov and Hutter 2017)。初始学习率设为$10^{-5}$,权重衰减为0.05以正则化模型。梯度裁剪采用L2范数,梯度最大允许值设为0.01。我们的SoTA模型以在ADE20K (Zhou et al. 2017)上预训练的DINOv2-G (Oquab et al. 2023)作为骨干网络。框架基于PyTorch 2.1.1 (Paszke et al. 2019)实现。
Main Results
主要结果
Comparison of the state-of-the-art task-specific methods. We compare our proposed FOCUS with recent models for COD including SINet (Fan et al. 2020) , PFNet (Mei et al. 2021) , ZoomNet (Pang et al. 2022b) , BSA-Net (Zhu et al. 2022) , FSPNet (Huang et al. 2023) , ZoomNeXt (Pang et al. 2024b) and BiRefNet (Zheng et al. 2024b) , models for SOD including MENet (Wang et al. 2023) , Self Reformer (Yun and Lin 2023) , BBRF (Ma et al. 2021) , and VST (Liu et al. 2021) , models for SD task including BDRAR (Zhu et al. 2018) , DSD (Zheng et al. 2019) , MTMT (Chen et al. 2020), FDRNet (Zhu et al. 2021) and SILT (Yang et al. 2023), models for DBD including De Fusion Net (Tang et al. 2020) , CENet (Zhao et al. 2019) , DAD (Zhao, Shang, and Lu 2021) , EFENet (Zhao et al. 2021) and DD (Cun and Pun 2020) , and models for FD including ManTra (Wu, AbdAl magee d, and Natarajan 2019) , SPAN (Hu et al. 2020) , PSCCNet (Liu et al. 2022) , Trans Forensics (Hao et al. 2021) and ObjectFormer (Wang et al. 2022a). FOCUS outperforms these SoTA models on most metrics across 13 datasets covering 5 tasks. Table. 1-3 shows quantitative comparisons between our proposed FOCUS with the previous SoTA models. Qualitative comparisons are in Fig . 3.
最先进任务专用方法的对比。我们将提出的FOCUS与近期COD(伪装目标检测)模型(包括SINet (Fan et al. 2020)、PFNet (Mei et al. 2021)、ZoomNet (Pang et al. 2022b)、BSA-Net (Zhu et al. 2022)、FSPNet (Huang et al. 2023)、ZoomNeXt (Pang et al. 2024b)和BiRefNet (Zheng et al. 2024b))、SOD(显著目标检测)模型(包括MENet (Wang et al. 2023)、Self Reformer (Yun and Lin 2023)、BBRF (Ma et al. 2021)和VST (Liu et al. 2021))、SD(阴影检测)模型(包括BDRAR (Zhu et al. 2018)、DSD (Zheng et al. 2019)、MTMT (Chen et al. 2020)、FDRNet (Zhu et al. 2021)和SILT (Yang et al. 2023))、DBD(暗光增强)模型(包括DeFusionNet (Tang et al. 2020)、CENet (Zhao et al. 2019)、DAD (Zhao, Shang, and Lu 2021)、EFENet (Zhao et al. 2021)和DD (Cun and Pun 2020))以及FD(伪造检测)模型(包括ManTra (Wu, AbdAlmageed, and Natarajan 2019)、SPAN (Hu et al. 2020)、PSCCNet (Liu et al. 2022)、TransForensics (Hao et al. 2021)和ObjectFormer (Wang et al. 2022a))进行对比。FOCUS在覆盖5个任务的13个数据集上,大多数指标优于这些SoTA模型。表1-3展示了我们提出的FOCUS与先前SoTA模型的定量对比,定性对比见图3。
In the most challenging foreground segmentation task, COD, which requires the model to recognize the object blending in its surroundings, FOCUS outperforms the existing SoTA methods on most metrics across four mainstream datasets. For SOD tasks, FOCUS exceeds the task-specific models on almost all metrics, especially increasing in terms of $E_{\xi}$ by an average of $1.8%$ . In SD tasks, FOCUS dramatically outperforms the previous SoTA on the ISTD dataset, with a $10.3%$ decrease in BER. In the DBD task, FOCUS surpasses the previous SoTA by a $2.1%$ increase on $F_{\beta}$ on
在最具挑战性的前景分割任务COD(即要求模型识别融入周围环境的物体)中,FOCUS在四个主流数据集的大多数指标上超越了现有SoTA方法。对于SOD任务,FOCUS在几乎所有指标上都超过了特定任务模型,尤其在$E_{\xi}$指标上平均提升了$1.8%$。在SD任务中,FOCUS在ISTD数据集上显著优于之前的SoTA,BER降低了$10.3%$。对于DBD任务,FOCUS以$F_{\beta}$指标$2.1%$的提升超越了之前的SoTA。
| id | Variants | Backbone | TrainableParam. | Module/Method | COD | SOD | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CR | Sm↑ | E↑ | F↑ | MAE√ | Sm↑ E↑ | Fβ↑ | MAE√ | ||||||||
| 0 | Baseline | DINOv2-L | 0.3G | .853 | .931 | .043 | .851 .919 | .849 | .054 | ||||||
| 1 | FOCUS | DINOv2-L | 0.3G | .854 | .931 | .827 | .042 | .853 | .923 | .847 | .054 | ||||
| 2 | FOCUS | DINOv2-L | 0.3G | < | .861 | .938 | .836 | .041 | .855 | .926 | .851 | .052 | |||
| 3 | FOCUS | DINOv2-L | 0.3G | .872 | .937 | .848 | .041 | .870 | .922 | .864 | .051 | ||||
| 4 | FOCUS | DINOv2-G | 0.1G | .905 | .956 | .897 | .027 | .893 | .936 | .889 | .039 | ||||
| 5 | FOCUS | DINOv2-G | 1.2G | √ | .909 | .962 | .901 | .026 | .897 | .942 | .896 | .037 | |||
| 6 | FOCUS | DINOv2-G | 1.2G | .909 | .963 | .903 | .025 | .898 | .943 | .894 | .037 |
Table 4: Ablation study results of the proposed modules or methods of FOCUS, including CLIP Refiner (CR), Jointly Prediction (JP), Edge Enhancer (EE), and Pretrain (PR). $\diamond$ means training with the DINOv2 backbone frozen.
表 4: FOCUS 所提模块或方法的消融研究结果,包括 CLIP 精炼器 (CR)、联合预测 (JP)、边缘增强器 (EE) 和预训练 (PR)。$\diamond$ 表示使用冻结的 DINOv2 主干进行训练。

Figure 4: The visualization of PCA-based dimensionality reduction on the feature maps across different iterations.
图 4: 基于PCA(主成分分析)的特征映射在不同迭代次数下的降维可视化。
DUT. In FD tasks, FOCUS also significantly surpasses previous SoTA models, with a $23.8%$ increase on $F1$ and a $3.8%$ increase on $A U C$ .
在FD任务中,FOCUS显著超越了之前的SoTA模型,F1值提升了23.8%,AUC提高了3.8%。
Comparison of the state-of-the-art unified methods. As previously mentioned, there is a lack of unified architecture to handle all foreground tasks. To the best of our knowledge, EVPv1 and EVPv2 (Liu et al. 2023) are the most comparable works to our FOCUS in unifying foreground tasks. To demonstrate the superiority of FOCUS as a unified framework, we conducted extensive experiments comparing it with EVPv1 and EVPv2 across multiple datasets. Our results show that FOCUS consistently outperforms EVPv1 and EVPv2 in all metrics. This highlights the capability of FOCUS to handle a wide range of foreground segmentation tasks effectively, proving it can serve as a versatile and powerful model compared to existing unified methods.
现有统一方法的对比。如前所述,目前缺乏能够处理所有前景任务的统一架构。据我们所知,EVPv1和EVPv2 (Liu et al. 2023) 是与我们提出的FOCUS在统一前景任务方面最具可比性的工作。为了证明FOCUS作为统一框架的优越性,我们在多个数据集上与EVPv1和EVPv2进行了广泛实验对比。结果表明,FOCUS在所有指标上均持续优于EVPv1和EVPv2。这凸显了FOCUS有效处理各类前景分割任务的能力,证明其相比现有统一方法具有更强大的通用性。
Ablation Study
消融实验
In this section, we conduct ablation experiments to analyze the properties of FOCUS. We use Mask 2 Former equipped with the DINOv2-L backbone as a robust baseline and choose the most representative foreground segmentation tasks, COD and SOD, as the ablation tasks. We select the mainstream dataset CAMO and PASCAL-S for COD and SOD respectively. To ensure consistency, all experiments were conducted using the same training recipe, with a batch size of 2. The training iterations are set to 10,000 for COD and 20,000 for SOD. Quantitative results related to each module or method are shown in Table. 4.
在本节中,我们通过消融实验分析FOCUS的特性。我们采用配备DINOv2-L骨干网络的Mask2Former作为强基线,并选择最具代表性的前景分割任务COD(伪装目标检测)和SOD(显著目标检测)作为消融任务。针对COD和SOD任务,我们分别选用主流数据集CAMO和PASCAL-S。为确保一致性,所有实验均采用相同的训练配置,批量大小为2。COD和SOD的训练迭代次数分别设置为10,000次和20,000次。各模块或方法相关的定量结果如 表4 所示。
As shown in the table, variants of FOCUS with the CLIP refiner perform better than those without it, thanks to the multi-modal knowledge distilled from CLIP. We set the variants with joint prediction to perform foreground segmentation and background segmentation jointly, the comparison with the baseline shows that it can slightly improve the performance of FOCUS. Additionally, with the help of the edge enhancer to inject edge information of the object into the backbone image feature, the performance of variants of DINOv2 significantly improves in the provided metrics. We also evaluate the effectiveness of pre training on ADE20K, which demonstrates modest improvements.
如表所示,采用CLIP提炼器的FOCUS变体性能优于未采用该模块的版本,这得益于从CLIP中提取的多模态知识。我们将联合预测变体设置为同时执行前景分割和背景分割,与基线对比表明该策略能略微提升FOCUS的性能。此外,通过边缘增强器将物体边缘信息注入主干图像特征后,DINOv2各变体在给定指标上均有显著提升。我们还评估了在ADE20K数据集上进行预训练的效果,结果显示性能获得适度改进。
We use DINOv2-G as the backbone for our SoTA models, which inevitably results in a large number of parameters. To ensure a fair comparison, we freeze the DINOv2- G backbone, limiting the number of trainable parameters in our model to 0.1G. The results indicate a slight decrease in performance compared to the fully fine-tuned version. However, when compared to models like BiRefNet (215M) and Self Reformer (˜220M), the frozen-backbone FOCUS still matches or surpasses previous state-of-the-art performance, despite having fewer trainable parameters.
我们采用DINOv2-G作为SoTA模型的骨干网络,这不可避免地导致参数量较大。为确保公平对比,我们冻结了DINOv2-G骨干网络,将模型可训练参数量限制在0.1G。结果表明,与完全微调版本相比性能略有下降。但与BiRefNet (215M) 和 Self Reformer (~220M) 等模型相比,冻结骨干的FOCUS在可训练参数量更少的情况下,仍达到或超越了先前的最先进性能。
We initialize the first layer of the transformer decoder with PCA-reduced feature maps from the backbone in our paper. As shown in Fig. 4, these PCA-reduced feature maps begin to exhibit strong semantic features in the early training stages. As training progresses, we are pleasantly surprised to find that even without further forward propagation, the patch-level feature maps, simply reduced by PCA, are able to approach the ground truth quality. Using them for initialization, compared to random initialization, provides a valuable spatial prior for subsequent mask attention.
我们在论文中使用主干网络经PCA降维后的特征图来初始化Transformer解码器的第一层。如图4所示,这些PCA降维特征图在训练早期就开始展现出强烈的语义特征。随着训练进行,我们惊喜地发现,即便不进行进一步的前向传播,仅通过PCA降维的patch级特征图就能接近真实标注质量。与随机初始化相比,使用它们进行初始化能为后续的掩码注意力提供有价值的空间先验。
Conclusion
结论
In this paper, we propose FOCUS, a unified multi-modal approach to tackle multiple subdivision tasks of foreground segmentation. We leverage the concept of object queries to handle foreground segmentation tasks and develop a multiscale semantic network that simultaneously performs foreground and background segmentation, fully utilizing the background information of the image to optimize prediction. We also introduced a novel distillation method integrating the contrastive learning strategy to enhance boundary-aware foreground segmentation. Theoretically, our model can be extended to any foreground segmentation task. Extensive experiments conducted on diverse datasets demonstrate the effec ti ve ness of our proposed framework.
本文提出FOCUS,一种统一的多模态方法来解决前景分割的多个子任务。我们利用对象查询(object queries)概念处理前景分割任务,并开发了一个多尺度语义网络,可同时执行前景与背景分割,充分利用图像的背景信息来优化预测。我们还引入了一种结合对比学习策略的新型蒸馏方法,以增强边界感知的前景分割。理论上,我们的模型可扩展到任何前景分割任务。在多个数据集上的大量实验证明了所提框架的有效性。