Linguistically-Informed Self-Attention for Semantic Role Labeling
基于语言学的自注意力机制在语义角色标注中的应用
Abstract
摘要
Current state-of-the-art semantic role labeling (SRL) uses a deep neural network with no explicit linguistic features. However, prior work has shown that gold syntax trees can dramatically improve SRL decoding, suggesting the possibility of increased accuracy from explicit modeling of syntax. In this work, we present linguistically-informed self-attention (LISA): a neural network model that combines multi-head self-attention with multi-task learning across dependency parsing, part-ofspeech tagging, predicate detection and SRL. Unlike previous models which require significant pre-processing to prepare linguistic features, LISA can incorporate syntax using merely raw tokens as input, encoding the sequence only once to simultaneously perform parsing, predicate detection and role labeling for all predicates. Syntax is incorporated by training one attention head to attend to syntactic parents for each token. Moreover, if a high-quality syntactic parse is already available, it can be beneficially injected at test time without re-training our SRL model. In experiments on CoNLL-2005 SRL, LISA achieves new state-of-the-art performance for a model using predicted predicates and standard word embeddings, attaining $2.5\mathrm{~F}1$ absolute higher than the previous state-of-the-art on newswire and more than $3.5\mathrm{~F}1$ on outof-domain data, nearly $10%$ reduction in error. On ConLL-2012 English SRL we also show an improvement of more than $2.5\mathrm{~F}1$ . LISA also out-performs the state-of-the-art with con textually-encoded (ELMo) word represent at ions, by nearly $1.0\mathrm{~F}1$ on news and more than $2.0\mathrm{F}1$ on out-of-domain text.
当前最先进的语义角色标注(SRL)采用不带显式语言特征的深度神经网络。然而先前研究表明,黄金标准句法树能显著提升SRL解码效果,这暗示通过显式句法建模可能提高准确率。本文提出语言信息自注意力机制(LISA):该神经网络模型将多头自注意力与依存句法分析、词性标注、谓词检测及SRL的多任务学习相结合。不同于需要大量预处理来准备语言特征的先前模型,LISA仅需原始token作为输入即可融入句法信息,仅需单次编码就能同步执行所有谓词的句法分析、谓词检测和角色标注。通过训练一个注意力头来关注每个token的句法父节点实现句法整合。此外,若已存在高质量句法分析结果,无需重新训练SRL模型即可在测试阶段有效注入该信息。在CoNLL-2005 SRL实验中,LISA在使用预测谓词和标准词嵌入的模型中达到新state-of-the-art性能,新闻报道数据F1值绝对提升2.5,域外数据提升超过3.5 F1,错误率降低近10%。在CoNLL-2012英语SRL任务上同样实现超过2.5 F1的提升。使用上下文编码(ELMo)词表征时,LISA在新闻文本上以近1.0 F1优势、域外文本以超过2.0 F1优势超越现有最佳模型。
1 Introduction
1 引言
Semantic role labeling (SRL) extracts a high-level representation of meaning from a sentence, labeling e.g. who did what to whom. Explicit representations of such semantic information have been shown to improve results in challenging downstream tasks such as dialog systems (Tur et al., 2005; Chen et al., 2013), machine reading (Berant et al., 2014; Wang et al., 2015) and translation (Liu and Gildea, 2010; Bazrafshan and Gildea, 2013).
语义角色标注 (SRL) 从句子中提取出高层次的意义表示,例如标注谁对谁做了什么。这种语义信息的显式表示已被证明能提升对话系统 (Tur et al., 2005; Chen et al., 2013)、机器阅读理解 (Berant et al., 2014; Wang et al., 2015) 和机器翻译 (Liu and Gildea, 2010; Bazrafshan and Gildea, 2013) 等具有挑战性的下游任务的效果。
Though syntax was long considered an obvious prerequisite for SRL systems (Levin, 1993; Punyakanok et al., 2008), recently deep neural network architectures have surpassed syntacticallyinformed models (Zhou and Xu, 2015; Marcheggiani et al., 2017; He et al., 2017; Tan et al., 2018; He et al., 2018), achieving state-of-the art SRL performance with no explicit modeling of syntax. An additional benefit of these end-to-end models is that they require just raw tokens and (usually) detected predicates as input, whereas richer linguistic features typically require extraction by an auxiliary pipeline of models.
尽管句法长期以来被视为语义角色标注(SRL)系统的先决条件(Levin, 1993; Punyakanok et al., 2008),但近年来深度神经网络架构已超越基于句法的模型(Zhou and Xu, 2015; Marcheggiani et al., 2017; He et al., 2017; Tan et al., 2018; He et al., 2018),在不显式建模句法的情况下实现了最先进的SRL性能。这些端到端模型的另一个优势是仅需原始token和(通常)检测到的谓词作为输入,而更丰富的语言特征通常需要通过辅助模型流水线来提取。
Still, recent work (Roth and Lapata, 2016; He et al., 2017; March egg ian i and Titov, 2017) indi- cates that neural network models could see even higher accuracy gains by leveraging syntactic information rather than ignoring it. He et al. (2017) indicate that many of the errors made by a syntaxfree neural network on SRL are tied to certain syntactic confusions such as prepositional phrase attachment, and show that while constrained inference using a relatively low-accuracy predicted parse can provide small improvements in SRL accuracy, providing a gold-quality parse leads to substantial gains. March egg ian i and Titov (2017) incorporate syntax from a high-quality parser (Ki per wasser and Goldberg, 2016) using graph convolutional neural networks (Kipf and Welling, 2017), but like He et al. (2017) they attain only small increases over a model with no syntactic parse, and even perform worse than a syntax-free model on out-of-domain data. These works suggest that though syntax has the potential to improve neural network SRL models, we have not yet designed an architecture which maximizes the benefits of auxiliary syntactic information.
然而,近期研究 (Roth and Lapata, 2016; He et al., 2017; March egg ian i and Titov, 2017) 表明,神经网络模型通过利用句法信息而非忽略它,可能获得更高的准确率提升。He et al. (2017) 指出,无句法神经网络在语义角色标注 (SRL) 中的许多错误与特定句法混淆(如介词短语依附)相关,并证明虽然使用相对低准确率的预测句法进行约束推理只能小幅提升 SRL 准确率,但提供高质量标注句法可带来显著增益。March egg ian i and Titov (2017) 通过图卷积神经网络 (Kipf and Welling, 2017) 整合了来自高质量句法分析器 (Ki per wasser and Goldberg, 2016) 的句法信息,但如同 He et al. (2017) 一样,他们仅比无句法分析模型获得微小提升,在域外数据上甚至表现更差。这些研究表明,尽管句法有潜力改进神经网络 SRL 模型,但我们尚未设计出能最大化辅助句法信息效益的架构。
In response, we propose linguistically-informed self-attention (LISA): a model that combines multi-task learning (Caruana, 1993) with stacked layers of multi-head self-attention (Vaswani et al., 2017); the model is trained to: (1) jointly predict parts of speech and predicates; (2) perform parsing; and (3) attend to syntactic parse parents, while (4) assigning semantic role labels. Whereas prior work typically requires separate models to provide linguistic analysis, including most syntaxfree neural models which still rely on external predicate detection, our model is truly end-to-end: earlier layers are trained to predict prerequisite parts-of-speech and predicates, the latter of which are supplied to later layers for scoring. Though prior work re-encodes each sentence to predict each desired task and again with respect to each predicate to perform SRL, we more efficiently encode each sentence only once, predict its predicates, part-of-speech tags and labeled syntactic parse, then predict the semantic roles for all predicates in the sentence in parallel. The model is trained such that, as syntactic parsing models improve, providing high-quality parses at test time will improve its performance, allowing the model to leverage updated parsing models without requiring re-training.
为此,我们提出语言信息自注意力机制 (linguistically-informed self-attention, LISA) :该模型结合了多任务学习 (Caruana, 1993) 与多层多头自注意力机制 (Vaswani et al., 2017) ,训练目标包括: (1) 联合预测词性和谓词; (2) 执行句法分析; (3) 关注句法分析父节点;同时 (4) 分配语义角色标签。现有研究通常需要多个独立模型提供语言学分析(包括大多数不依赖句法的神经模型仍需外部谓词检测),而我们的模型实现了真正的端到端:浅层网络负责预测词性和谓词(后者将作为深层网络的输入进行评分)。传统方法需对每个句子重复编码以预测不同任务,并针对每个谓词重新编码以实现语义角色标注 (SRL) ,而本模型仅需单次编码即可并行完成句子级谓词预测、词性标注、句法分析树构建,以及所有谓词的语义角色标注。模型设计使得测试阶段句法分析模型的性能提升(提供更高质量的分析树)可直接提升本模型表现,无需重新训练即可兼容更新的句法分析模型。
In experiments on the CoNLL-2005 and CoNLL-2012 datasets we show that our linguistically-informed models out-perform the syntax-free state-of-the-art. On CoNLL-2005 with predicted predicates and standard word embeddings, our single model out-performs the previous state-of-the-art model on the WSJ test set by $2.5\mathrm{~F}1$ points absolute. On the challenging out-of-domain Brown test set, our model improves substantially over the previous state-of-the-art by more than $3.5\mathrm{F}1$ , a nearly $10%$ reduction in error. On CoNLL-2012, our model gains more than 2.5 F1 absolute over the previous state-of-the-art. Our models also show improvements when using con textually-encoded word representations (Peters et al., 2018), obtaining nearly $1.0\textrm{F}1$ higher than the state-of-the-art on CoNLL-2005 news and more than 2.0 F1 improvement on out-of-domain text.1
在CoNLL-2005和CoNLL-2012数据集上的实验表明,我们的语言学信息模型优于当前最先进的无语法模型。在CoNLL-2005数据集上,使用预测谓词和标准词嵌入时,我们的单一模型在WSJ测试集上比之前的最先进模型绝对提升了$2.5\mathrm{~F}1$分。在具有挑战性的域外Brown测试集上,我们的模型比之前的最先进水平显著提高了超过$3.5\mathrm{F}1$,错误率降低了近$10%$。在CoNLL-2012数据集上,我们的模型比之前的最先进水平绝对提升了超过2.5 F1。当使用上下文编码的词表示(Peters et al., 2018)时,我们的模型也显示出改进,在CoNLL-2005新闻数据上比最先进水平高出近$1.0\textrm{F}1$,在域外文本上提升了超过2.0 F1。1
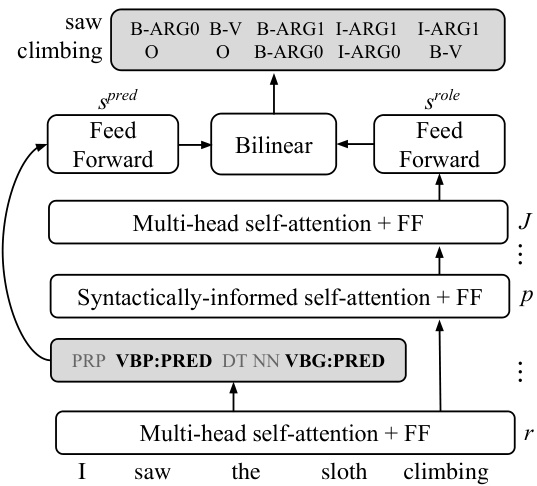
Figure 1: Word embeddings are input to $J$ layers of multi-head self-attention. In layer $p$ one attention head is trained to attend to parse parents (Figure 2). Layer $r$ is input for a joint predicate/POS classifier. Representations from layer $r$ corresponding to predicted predicates are passed to a bilinear operation scoring distinct predicate and role represent at ions to produce per-token SRL predictions with respect to each predicted predicate.
图 1: 词嵌入 (word embeddings) 输入到 $J$ 层多头自注意力 (multi-head self-attention) 机制。在第 $p$ 层中,一个注意力头被训练用于关注解析父节点 (parse parents) (图 2)。第 $r$ 层作为联合谓词/词性分类器 (joint predicate/POS classifier) 的输入。来自第 $r$ 层的表示对应于预测谓词,这些表示被传递到双线性操作 (bilinear operation) 中,对不同的谓词和角色表示进行评分,从而针对每个预测谓词生成每个 Token 的语义角色标注 (SRL) 预测。
2 Model
2 模型
Our goal is to design an efficient neural network model which makes use of linguistic information as effectively as possible in order to perform endto-end SRL. LISA achieves this by combining: (1) A new technique of supervising neural attention to predict syntactic dependencies with (2) multi-task learning across four related tasks.
我们的目标是设计一个高效的神经网络模型,尽可能有效地利用语言信息来实现端到端语义角色标注 (SRL)。LISA通过以下两项技术的结合实现这一目标:(1) 监督神经注意力预测句法依存关系的新技术,以及 (2) 跨四个相关任务的多任务学习。
Figure 1 depicts the overall architecture of our model. The basis for our model is the Transformer encoder introduced by Vaswani et al. (2017): we transform word embeddings into con textually-encoded token representations using stacked multi-head self-attention and feedforward layers (§2.1).
图 1: 展示了我们模型的整体架构。我们的模型基于 Vaswani 等人 (2017) 提出的 Transformer 编码器:通过堆叠的多头自注意力 (multi-head self-attention) 和前馈层 (§2.1),我们将词嵌入 (word embeddings) 转换为上下文编码的 Token 表征。
To incorporate syntax, one self-attention head is trained to attend to each token’s syntactic parent, allowing the model to use this attention head as an oracle for syntactic dependencies. We introduce this syntactically-informed self-attention (Figure 2) in more detail in $\S2.2$ .
为了融入句法信息,我们训练了一个自注意力头(self-attention head)来关注每个token的句法父节点,使模型能够将该注意力头作为句法依赖关系的预测器。我们将在$\S2.2$节详细阐述这种句法感知的自注意力机制(图2)。
Our model is designed for the more realistic setting in which gold predicates are not provided at test-time. Our model predicts predicates and integrates part-of-speech (POS) information into earlier layers by re-purposing representations closer to the input to predict predicate and POS tags us- ing hard parameter sharing (§2.3). We simplify optimization and benefit from shared statistical strength derived from highly correlated POS and predicates by treating tagging and predicate detection as a single task, performing multi-class classification into the joint Cartesian product space of POS and predicate labels.
我们的模型针对测试时不提供黄金谓词这一更现实的场景而设计。该模型通过重新利用靠近输入端的表征来预测谓词和词性 (POS) 标签,采用硬参数共享机制将POS信息整合到更早的层级 (§2.3)。我们将标注任务和谓词检测视为单一任务,通过多类别分类进入POS与谓词标签的笛卡尔积联合空间,从而简化优化过程,并受益于高度相关的POS与谓词之间共享的统计强度。
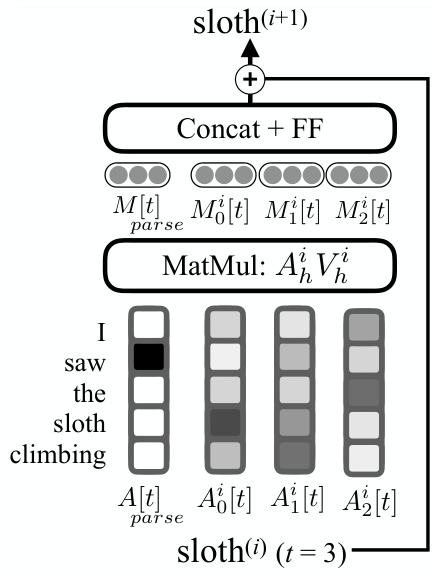
Figure 2: Syntactically-informed self-attention for the query word sloth. Attention weights $A_{p a r s e}$ heavily weight the token’s syntactic governor, saw, in a weighted average over the token values $V_{p a r s e}$ . The other attention heads act as usual, and the attended representations from all heads are concatenated and projected through a feed-forward layer to produce the syntacticallyinformed representation for sloth.
图 2: 针对查询词"sloth"的语法感知自注意力机制。注意力权重 $A_{parse}$ 在token值 $V_{parse}$ 的加权平均中显著偏向该token的语法支配词"saw"。其他注意力头保持常规运作,所有注意力头的关注表示经过拼接后通过前馈层投影,最终生成"sloth"的语法感知表示。
Though typical models, which re-encode the sentence for each predicate, can simplify SRL to token-wise tagging, our joint model requires a different approach to classify roles with respect to each predicate. Con textually encoded tokens are projected to distinct predicate and role embeddings (§2.4), and each predicted predicate is scored with the sequence’s role representations using a bilinear model (Eqn. 6), producing per-label scores for BIO-encoded semantic role labels for each token and each semantic frame.
虽然典型模型(为每个谓词重新编码句子)可以将语义角色标注(SRL)简化为基于token的标注任务,但我们的联合模型需要采用不同方法对每个谓词相关的角色进行分类。经过上下文编码的token会被映射到不同的谓词和角色嵌入空间(§2.4),每个预测谓词通过双线性模型(公式6)与序列的角色表示进行评分,从而为每个token和每个语义框架的BIO编码语义角色标签生成逐标签分数。
The model is trained end-to-end by maximum likelihood using stochastic gradient descent (§2.5).
该模型通过随机梯度下降(见第2.5节)以端到端方式进行最大似然训练。
2.1 Self-attention token encoder
2.1 自注意力Token编码器
The basis for our model is a multi-head selfattention token encoder, recently shown to achieve state-of-the-art performance on SRL (Tan et al., 2018), and which provides a natural mechanism for incorporating syntax, as described in $\S2.2$ . Our implementation replicates Vaswani et al. (2017).
我们模型的基础是一个多头自注意力(multi-head self-attention) token编码器,该架构近期在语义角色标注(SRL)任务中实现了最先进性能 [20],并通过 $\S2.2$ 章节描述的机制天然支持语法信息融合。我们的实现复现了Vaswani等人[21]的工作。
The input to the network is a sequence $\mathcal{X}$ of $T$ token representations $x_{t}$ . In the standard setting these token representations are initialized to pretrained word embeddings, but we also experiment with supplying pre-trained ELMo representations combined with task-specific learned parameters, which have been shown to substantially improve performance of other SRL models (Peters et al., 2018). For experiments with gold predicates, we concatenate a predicate indicator embedding $p_{t}$ following previous work (He et al., 2017).
网络的输入是一个由 $T$ 个token表示 $x_{t}$ 组成的序列 $\mathcal{X}$。在标准设置中,这些token表示初始化为预训练的词嵌入,但我们也尝试提供预训练的ELMo表示与任务特定学习参数相结合的方法,这已被证明能显著提升其他语义角色标注 (SRL) 模型的性能 (Peters et al., 2018)。在使用黄金谓词的实验中,我们按照先前工作 (He et al., 2017) 的方法拼接了一个谓词指示器嵌入 $p_{t}$。
We project2 these input embeddings to a represent ation that is the same size as the output of the self-attention layers. We then add a positional encoding vector computed as a deterministic sinusoidal function of $t$ , since the self-attention has no innate notion of token position.
我们将这些输入嵌入投影到一个与自注意力层输出相同大小的表示。然后加上一个由$t$的确定性正弦函数计算得到的位置编码向量,因为自注意力机制本身不具备token位置的概念。
We feed this token representation as input to a series of $J$ residual multi-head self-attention layers with feed-forward connections. Denoting the $j$ th self-attention layer as $T^{(j)}(\cdot)$ , the output of that layer $s_{t}^{(j)}$ , and $L N(\cdot)$ layer normalization, the following recurrence applied to initial input $c_{t}^{(p)}$
我们将此token表示作为输入,送入一系列包含前馈连接的$J$个残差多头自注意力层。记第$j$个自注意力层为$T^{(j)}(\cdot)$,该层输出为$s_{t}^{(j)}$,$L N(\cdot)$表示层归一化,以下递推关系作用于初始输入$c_{t}^{(p)}$
$$
s_{t}^{(j)}=L N(s_{t}^{(j-1)}+T^{(j)}(s_{t}^{(j-1)}))
$$
$$
s_{t}^{(j)}=L N(s_{t}^{(j-1)}+T^{(j)}(s_{t}^{(j-1)}))
$$
gives our final token representations $s_{t}^{(j)}$ (j ). Each $\bar{T}^{(j)}(\cdot)$ consists of: (a) multi-head self-attention and (b) a feed-forward projection.
给出最终的token表示 $s_{t}^{(j)}$ (j)。每个 $\bar{T}^{(j)}(\cdot)$ 包含:(a) 多头自注意力机制 (multi-head self-attention) 和 (b) 前馈投影层 (feed-forward projection)。
The multi-head self attention consists of $H$ attention heads, each of which learns a distinct attention function to attend to all of the tokens in the sequence. This self-attention is performed for each token for each head, and the results of the $H$ self-attentions are concatenated to form the final self-attended representation for each token.
多头自注意力 (multi-head self attention) 由 $H$ 个注意力头组成,每个头学习不同的注意力函数来处理序列中的所有 token。每个 token 在每个头上都会进行自注意力计算,最终将 $H$ 个自注意力的结果拼接起来,形成每个 token 的最终自注意力表示。
Specifically, consider the matrix $S^{(j-1)}$ of $T$ token representations at layer $j-1$ . For each attention head $h$ , we project this matrix into distinct key, value and query representations K(hj ), V h(j) and $Q_{h}^{(j)}$ of dimensions $T\times d_{k}$ , $T\times d_{q}$ , and $T\times d_{v}$ respectively. We can then multiply $\bar{Q}{h}^{(j)}$ ) by K(hj) $T\times T$ $A{h}^{(j)}$ between each pair of tokens in the sentence. Following Vaswani et al. (2017) we perform scaled dot-product attention: We scale the weights by the inverse square root of their embedding dimension and normalize with the softmax function to produce a distinct distribution for each token over all the tokens in the sentence:
具体来说,考虑层 $j-1$ 的 $T$ 个 token 表示矩阵 $S^{(j-1)}$。对于每个注意力头 $h$,我们将该矩阵投影为维度分别为 $T\times d_{k}$、$T\times d_{q}$ 和 $T\times d_{v}$ 的键 (key)、值 (value) 和查询 (query) 表示 $K_{h}^{(j)}$、$V_{h}^{(j)}$ 和 $Q_{h}^{(j)}$。接着将 $\bar{Q}{h}^{(j)}$ 与 $K{h}^{(j)}$ 相乘,得到句子中每对 token 之间的 $T\times T$ 注意力权重矩阵 $A_{h}^{(j)}$。根据 Vaswani 等人 (2017) 的方法,我们执行缩放点积注意力 (scaled dot-product attention):通过嵌入维度平方根的倒数缩放权重,并用 softmax 函数归一化,为每个 token 生成一个关于句子中所有 token 的独立分布:
$$
A_{h}^{(j)}=\operatorname{softmax}(d_{k}^{-0.5}Q_{h}^{(j)}K_{h}^{(j)^{T}})
$$
$$
A_{h}^{(j)}=\operatorname{softmax}(d_{k}^{-0.5}Q_{h}^{(j)}K_{h}^{(j)^{T}})
$$
These attention weights are then multiplied by V h(j) for each token to obtain the self-attended token representations Mh(j ):
然后将这些注意力权重与每个Token的V h(j)相乘,得到自注意力Token表示Mh(j):
$$
M_{h}^{(j)}=A_{h}^{(j)}V_{h}^{(j)}
$$
$$
M_{h}^{(j)}=A_{h}^{(j)}V_{h}^{(j)}
$$
Row $t$ of $M_{h}^{\left(j\right)}$ , the self-attended representation for token $t$ at layer $j$ , is thus the weighted sum with respect to $t$ (with weights given by $A_{h}^{(j)}$ ) over the token representations in V h(j ).
因此,层 $j$ 中 token $t$ 的自注意力表示 $M_{h}^{\left(j\right)}$ 的第 $t$ 行,是 $V_{h}^{(j)}$ 中 token 表示相对于 $t$ 的加权和(权重由 $A_{h}^{(j)}$ 给出)。
The outputs of all attention heads for each token are concatenated, and this representation is passed to the feed-forward layer, which consists of two linear projections each followed by leaky ReLU activation s (Maas et al., 2013). We add the output of the feed-forward to the initial representation and apply layer normalization to give the final output of self-attention layer $j$ , as in Eqn. 1.
每个token的所有注意力头输出被拼接后,该表征会传入前馈层。前馈层包含两个线性投影,每个投影后接Leaky ReLU激活函数 (Maas et al., 2013)。我们将前馈层输出与初始表征相加,并应用层归一化得到自注意力层$j$的最终输出,如公式1所示。
2.2 Syntactically-informed self-attention
2.2 语法感知自注意力 (Syntactically-informed self-attention)
Typically, neural attention mechanisms are left on their own to learn to attend to relevant inputs. Instead, we propose training the self-attention to attend to specific tokens corresponding to the syntactic structure of the sentence as a mechanism for passing linguistic knowledge to later layers.
通常,神经注意力机制需要自行学习关注相关输入。相反,我们提出训练自注意力机制,使其关注与句子句法结构对应的特定token,以此作为将语言学知识传递至后续层的机制。
Specifically, we replace one attention head with the deep bi-affine model of Dozat and Manning (2017), trained to predict syntactic dependencies. Let $A_{p a r s e}$ be the parse attention weights, at layer $i$ . Its input is the matrix of token representations $S^{(i-1)}$ . As with the other attention heads, we project $S^{(i-1)}$ into key, value and query representations, denoted $K_{p a r s e}$ , $Q_{p a r s e}$ , $V_{p a r s e}$ . Here the key and query projections correspond to parent and dependent representations of the tokens, and we allow their dimensions to differ from the rest of the attention heads to more closely follow the imple ment ation of Dozat and Manning (2017). Unlike the other attention heads which use a dot product to score key-query pairs, we score the compatibility between $K_{p a r s e}$ and $Q_{p a r s e}$ using a bi-affine operator $U_{h e a d s}$ to obtain attention weights:
具体来说,我们将一个注意力头替换为Dozat和Manning (2017) 提出的深度双仿射模型,该模型经过训练用于预测句法依存关系。设 $A_{parse}$ 为第 $i$ 层的解析注意力权重,其输入是token表示矩阵 $S^{(i-1)}$。与其他注意力头类似,我们将 $S^{(i-1)}$ 投影为键、值和查询表示,分别记为 $K_{parse}$、$Q_{parse}$、$V_{parse}$。这里的键和查询投影对应token的父节点和子节点表示,并且我们允许它们的维度与其他注意力头不同,以更贴近Dozat和Manning (2017) 的实现方式。与其他使用点积对键-查询对进行评分的注意力头不同,我们使用双仿射算子 $U_{heads}$ 对 $K_{parse}$ 和 $Q_{parse}$ 之间的兼容性进行评分,从而获得注意力权重:
$$
A_{p a r s e}=\mathrm{softmax}(Q_{p a r s e}U_{h e a d s}K_{p a r s e}^{T})
$$
$$
A_{p a r s e}=\mathrm{softmax}(Q_{p a r s e}U_{h e a d s}K_{p a r s e}^{T})
$$
These attention weights are used to compose a weighted average of the value representations $V_{p a r s e}$ as in the other attention heads.
这些注意力权重用于组合值表示 $V_{p a r s e}$ 的加权平均值,与其他注意力头中的操作相同。
We apply auxiliary supervision at this attention head to encourage it to attend to each token’s parent in a syntactic dependency tree, and to encode information about the token’s dependency label. Denoting the attention weight from token $t$ to a candidate head $q$ as $A_{p a r s e}[t,q]$ , we model the probability of token $t$ having parent $q$ as:
我们在这个注意力头上应用辅助监督,以鼓励它关注句法依存树中每个token的父节点,并编码有关该token依存标签的信息。将token $t$ 到候选头 $q$ 的注意力权重表示为 $A_{p a r s e}[t,q]$ ,我们将token $t$ 以 $q$ 为父节点的概率建模为:
$$
P(q=\mathrm{head}(t)\mid\mathcal{X})=A_{p a r s e}[t,q]
$$
$$
P(q=\mathrm{head}(t)\mid\mathcal{X})=A_{p a r s e}[t,q]
$$
using the attention weights $A_{p a r s e}[t]$ as the distribution over possible heads for token $t$ . We define the root token as having a self-loop. This attention head thus emits a directed graph3 where each token’s parent is the token to which the attention $A_{p a r s e}$ assigns the highest weight.
使用注意力权重 $A_{p a r s e}[t]$ 作为 token $t$ 可能头部分布。我们将根 token 定义为具有自循环。因此,该注意力头会输出一个有向图3,其中每个 token 的父节点是 $A_{p a r s e}$ 分配最高权重的 token。
We also predict dependency labels using perclass bi-affine operations between parent and dependent representations $Q_{p a r s e}$ and $K_{p a r s e}$ to produce per-label scores, with locally normalized probabilities over dependency labels $\overset{\cdot}{y}_{t}^{d e p}$ given by the softmax function. We refer the reader to Dozat and Manning (2017) for more details.
我们还通过父节点和依赖节点表示 $Q_{p a r s e}$ 与 $K_{p a r s e}$ 之间的逐类双仿射操作来预测依存标签,生成逐标签分数,并通过 softmax 函数给出依存标签 $\overset{\cdot}{y}_{t}^{d e p}$ 的局部归一化概率。更多细节请参考 Dozat 和 Manning (2017) 的研究。
This attention head now becomes an oracle for syntax, denoted $\mathcal{P}$ , providing a dependency parse to downstream layers. This model not only predicts its own dependency arcs, but allows for the injection of auxiliary parse information at test time by simply setting $A_{p a r s e}$ to the parse parents produced by e.g. a state-of-the-art parser. In this way, our model can benefit from improved, external parsing models without re-training. Unlike typical multi-task models, ours maintains the ability to leverage external syntactic information.
该注意力头现成为句法的预言器,记为 $\mathcal{P}$,为下游层提供依存解析。该模型不仅能预测自身的依存弧,还能在测试时通过简单地将 $A_{parse}$ 设置为例如最先进解析器生成的解析父节点,从而注入辅助解析信息。如此一来,我们的模型无需重新训练即可受益于改进的外部解析模型。与典型的多任务模型不同,我们的模型保留了利用外部句法信息的能力。
2.3 Multi-task learning
2.3 多任务学习
We also share the parameters of lower layers in our model to predict POS tags and predicates. Following He et al. (2017), we focus on the end-toend setting, where predicates must be predicted on-the-fly. Since we also train our model to predict syntactic dependencies, it is beneficial to give the model knowledge of POS information. While much previous work employs a pipelined approach to both POS tagging for dependency parsing and predicate detection for SRL, we take a multi-task learning (MTL) approach (Caruana,
我们还共享模型中较低层的参数来预测词性 (POS) 标签和谓词。遵循 He 等人 (2017) 的方法,我们专注于端到端设置,其中谓词必须即时预测。由于我们还训练模型预测句法依存关系,因此为模型提供词性信息是有益的。虽然之前许多工作采用流水线方法分别进行依存解析的词性标注和语义角色标注 (SRL) 的谓词检测,但我们采用了多任务学习 (MTL) 方法 (Caruana,
1993), sharing the parameters of earlier layers in our SRL model with a joint POS and predicate detection objective. Since POS is a strong predictor of predicates 4 and the complexity of training a multi-task model increases with the number of tasks, we combine POS tagging and predicate detection into a joint label space: For each POS tag TAG which is observed co-occurring with a predicate, we add a label of the form TAG:PREDICATE. Specifically, we feed the representation $s_{t}^{(r)}$ from a layer $r$ preceding the syntacticallyinformed layer $p$ to a linear classifier to produce per-class scores $r_{t}$ for token $t$ . We compute locally-normalized probabilities using the softmax function: $P(y_{t}^{p r p}\mid\mathcal{X})\propto\exp(r_{t})$ , where ytprp is a label in the joint space.
1993年),在我们的语义角色标注(SRL)模型中共享早期层的参数,以实现词性标注(POS)和谓词检测的联合目标。由于词性标注是谓词的强预测指标[4],且多任务模型的训练复杂度随任务数量增加而提升,我们将词性标注和谓词检测合并为联合标签空间:对于每个与谓词共现的词性标记TAG,我们添加形如TAG:PREDICATE的标签。具体而言,我们将语法感知层$p$之前某层$r$的表征$s_{t}^{(r)}$输入线性分类器,为每个token $t$生成类别分数$r_{t}$。通过softmax函数计算局部归一化概率:$P(y_{t}^{prp}\mid\mathcal{X})\propto\exp(r_{t})$,其中$y_{t}^{prp}$是联合空间中的标签。
2.4 Predicting semantic roles
2.4 语义角色预测
Our final goal is to predict semantic roles for each predicate in the sequence. We score each predicate against each token in the sequence using a bilinear operation, producing per-label scores for each token for each predicate, with predicates and syntax determined by oracles $\nu$ and $\mathcal{P}$ .
我们的最终目标是预测序列中每个谓词的语义角色。我们通过双线性操作对序列中的每个token与每个谓词进行评分,为每个谓词的每个token生成每个标签的得分,其中谓词和句法由预言器$\nu$和$\mathcal{P}$确定。
First, we project each token representation $s_{t}^{(J)}$ to a predicate-specific representation $s_{t}^{p r e d}$ and a role-specific representation $s_{t}^{r o l e}$ . We then provide these representations to a bilinear transformation $U$ for scoring. So, the role label scores $s_{f t}$ for the token at index $t$ with respect to the predicate at index $f$ (i.e. token $t$ and frame $f$ ) are given by:
首先,我们将每个token表示 $s_{t}^{(J)}$ 投影到谓词特定表示 $s_{t}^{p r e d}$ 和角色特定表示 $s_{t}^{r o l e}$。然后,将这些表示提供给双线性变换 $U$ 进行评分。因此,对于索引为 $t$ 的token相对于索引为 $f$ 的谓词(即token $t$ 和帧 $f$)的角色标签分数 $s_{f t}$ 由下式给出:
$$
s_{f t}=(s_{f}^{p r e d})^{T}U s_{t}^{r o l e}
$$
$$
s_{f t}=(s_{f}^{p r e d})^{T}U s_{t}^{r o l e}
$$
which can be computed in parallel across all semantic frames in an entire minibatch. We calculate a locally normalized distribution over role labels for token $t$ in frame $f$ using the softmax function: $P(y_{f t}^{r o l e}\mid\mathcal{P},\mathcal{V},\mathcal{X})\propto\exp(s_{f t})$ .
可以在整个小批次的所有语义帧中并行计算。我们使用softmax函数计算帧$f$中token$t$的角色标签的局部归一化分布:$P(y_{f t}^{r o l e}\mid\mathcal{P},\mathcal{V},\mathcal{X})\propto\exp(s_{f t})$。
At test time, we perform constrained decoding using the Viterbi algorithm to emit valid sequences of BIO tags, using unary scores $s_{f t}$ and the transition probabilities given by the training data.
在测试时,我们使用维特比算法进行约束解码,利用一元分数 $s_{f t}$ 和训练数据提供的转移概率来生成有效的BIO标签序列。
2.5 Training
2.5 训练
We maximize the sum of the likelihoods of the individual tasks. In order to maximize our model’s ability to leverage syntax, during training we clamp $\mathcal{P}$ to the gold parse $(\mathcal{P}{G})$ and $\nu$ to gold predicates $\nu_{G}$ when passing parse and predicate representations to later layers, whereas syntactic head prediction and joint predicate/POS prediction are conditioned only on the input sequence $\mathcal{X}$ . The overall objective is thus:
我们最大化各任务似然的总和。为了增强模型利用句法的能力,在训练过程中,当向后续层传递句法解析和谓词表征时,我们将 $\mathcal{P}$ 固定为黄金解析 $(\mathcal{P}{G})$ ,并将 $\nu$ 固定为黄金谓词 $\nu_{G}$ ,而句法中心词预测及联合谓词/词性预测仅基于输入序列 $\mathcal{X}$ 。因此整体目标函数为:
$$
\begin{array}{r l}{{\frac{1}{T}\sum_{t=1}^{T}\Big[\sum_{f=1}^{F}\log P(y_{f t}^{r o l e}\mid\mathcal{P}{G},\mathcal{V}{G},\mathcal{X})}}\ &{+\log P(y_{t}^{p r p}\mid\mathcal{X})}\ &{+\lambda_{1}\log P(\mathrm{head}(t)\mid\mathcal{X})}\ &{+\lambda_{2}\log P(y_{t}^{d e p}\mid\mathcal{P}_{G},\mathcal{X})\Big]}\end{array}
$$
$$
\begin{array}{r l}{{\frac{1}{T}\sum_{t=1}^{T}\Big[\sum_{f=1}^{F}\log P(y_{f t}^{r o l e}\mid\mathcal{P}{G},\mathcal{V}{G},\mathcal{X})}}\ &{+\log P(y_{t}^{p r p}\mid\mathcal{X})}\ &{+\lambda_{1}\log P(\mathrm{head}(t)\mid\mathcal{X})}\ &{+\lambda_{2}\log P(y_{t}^{d e p}\mid\mathcal{P}_{G},\mathcal{X})\Big]}\end{array}
$$
where $\lambda_{1}$ and $\lambda_{2}$ are penalties on the syntactic attention loss.
其中 $\lambda_{1}$ 和 $\lambda_{2}$ 是句法注意力损失的惩罚项。
We train the model using Nadam (Dozat, 2016) SGD combined with the learning rate schedule in Vaswani et al. (2017). In addition to MTL, we regularize our model using dropout (Srivastava et al., 2014). We use gradient clipping to avoid explod- ing gradients (Bengio et al., 1994; Pascanu et al., 2013). Additional details on optimization and hyper parameters are included in Appendix A.
我们使用Nadam (Dozat, 2016) SGD结合Vaswani等人 (2017) 的学习率调度策略来训练模型。除了多任务学习 (MTL) 外,我们还采用dropout (Srivastava等人, 2014) 对模型进行正则化。通过梯度裁剪防止梯度爆炸 (Bengio等人, 1994; Pascanu等人, 2013)。优化细节和超参数设置详见附录A。
3 Related work
3 相关工作
Early approaches to SRL (Pradhan et al., 2005; Surdeanu et al., 2007; Johansson and Nugues, 2008; Toutanova et al., 2008) focused on developing rich sets of linguistic features as input to a linear model, often combined with complex constrained inference e.g. with an ILP (Punyakanok et al., 2008). Tackstrom et al. (2015) showed that constraints could be enforced more efficiently using a clever dynamic program for exact inference. Sutton and McCallum (2005) modeled syntactic parsing and SRL jointly, and Lewis et al. (2015) jointly modeled SRL and CCG parsing.
早期的语义角色标注(SRL)方法(Pradhan et al., 2005; Surdeanu et al., 2007; Johansson and Nugues, 2008; Toutanova et al., 2008)主要关注开发丰富的语言学特征集作为线性模型的输入,通常结合复杂的约束推理(例如使用整数线性规划(ILP)(Punyakanok et al., 2008))。Tackstrom等人(2015)证明可以通过巧妙的动态规划算法更高效地执行精确推理约束。Sutton和McCallum(2005)联合建模了句法分析和语义角色标注任务,Lewis等人(2015)则联合建模了语义角色标注和组合范畴语法(CCG)分析。
Collobert et al. (2011) were among the first to use a neural network model for SRL, a CNN over word embeddings which failed to out-perform non-neural models. FitzGerald et al. (2015) successfully employed neural networks by embedding lexical i zed features and providing them as factors in the model of Tackstrom et al. (2015).
Collobert等人(2011) 是首批将神经网络模型 (CNN over word embeddings) 应用于语义角色标注 (SRL) 的研究者之一,但该模型未能超越非神经模型。FitzGerald等人(2015) 通过嵌入词汇化特征 (lexicalized features) 并作为Tackstrom等人(2015) 模型的因子,成功应用了神经网络。
More recent neural models are syntax-free. Zhou and $\mathrm{Xu}$ (2015), Marcheggiani et al. (2017) and He et al. (2017) all use variants of deep LSTMs with constrained decoding, while Tan et al. (2018) apply self-attention to obtain state-ofthe-art SRL with gold predicates. Like this work, He et al. (2017) present end-to-end experiments, predicting predicates using an LSTM, and He et al.
更近期的神经模型已不再依赖句法。Zhou和$\mathrm{Xu}$ (2015) 、Marcheggiani等人 (2017) 以及He等人 (2017) 均采用带约束解码的深度LSTM变体,而Tan等人 (2018) 则通过自注意力机制实现了基于黄金谓词的最优语义角色标注 (SRL) 。与本研究类似,He等人 (2017) 进行了端到端实验,使用LSTM预测谓词。
(2018) jointly predict SRL spans and predicates in a model based on that of Lee et al. (2017), obtaining state-of-the-art predicted predicate SRL. Con- current to this work, Peters et al. (2018) and He et al. (2018) report significant gains on PropBank SRL by training a wide LSTM language model and using a task-specific transformation of its hidden representations (ELMo) as a deep, and comput ation ally expensive, alternative to typical word embeddings. We find that LISA obtains further accuracy increases when provided with ELMo word representations, especially on out-of-domain data.
(2018) 基于 Lee 等人 (2017) 的模型联合预测语义角色标注 (SRL) 跨度和谓词,取得了当时最先进的谓词 SRL 预测效果。与此同时,Peters 等人 (2018) 和 He 等人 (2018) 通过训练一个宽 LSTM 大语言模型,并将其隐藏表示 (ELMo) 进行任务特定转换,作为传统词嵌入的深度且计算昂贵的替代方案,在 PropBank SRL 任务上报告了显著提升。我们发现,当提供 ELMo 词表示时,LISA 能获得进一步的准确率提升,尤其在领域外数据上表现更优。
Some work has incorporated syntax into neural models for SRL. Roth and Lapata (2016) incorporate syntax by embedding dependency paths, and similarly March egg ian i and Titov (2017) encode syntax using a graph CNN over a predicted syntax tree, out-performing models without syntax on CoNLL-2009. These works are limited to incorporating partial dependency paths between tokens whereas our technique incorporates the entire parse. Additionally, March egg ian i and Titov (2017) report that their model does not out-perform syntax-free models on out-of-domain data, a setting in which our technique excels.
一些研究已将句法融入神经模型用于语义角色标注(SRL)。Roth和Lapata(2016)通过嵌入依存路径来融合句法信息,类似地,Marcheggiani和Titov(2017)在预测的句法树上使用图卷积神经网络(Graph CNN)编码句法,在CoNLL-2009上超越了无句法模型。这些工作仅限于融合token之间的部分依存路径,而我们的技术整合了完整句法树。此外,Marcheggiani和Titov(2017)报告其模型在领域外数据上未超越无句法模型,而我们的技术在该场景表现优异。
MTL (Caruana, 1993) is popular in NLP, and others have proposed MTL models which incorporate subsets of the tasks we do (Collobert et al., 2011; Zhang and Weiss, 2016; Hashimoto et al., 2017; Peng et al., 2017; Swayamdipta et al., 2017), and we build off work that investigates where and when to combine different tasks to achieve the best results (Søgaard and Goldberg, 2016; Bingel and Søgaard, 2017; Alonso and Plank, 2017). Our specific method of incorporating supervision into self-attention is most similar to the concurrent work of Liu and Lapata (2018), who use edge marginals produced by the matrix-tree algorithm as attention weights for document classification and natural language inference.
MTL (Caruana, 1993) 在自然语言处理领域广受欢迎,其他研究者也提出了包含我们所处理任务子集的MTL模型 (Collobert et al., 2011; Zhang and Weiss, 2016; Hashimoto et al., 2017; Peng et al., 2017; Swayamdipta et al., 2017)。我们的研究基于探索何时何地结合不同任务以获得最佳效果的工作 (Søgaard and Goldberg, 2016; Bingel and Søgaard, 2017; Alonso and Plank, 2017)。我们将监督信息融入自注意力机制的具体方法,与Liu和Lapata (2018) 同期工作最为相似——他们使用矩阵树算法生成的边缘概率作为文档分类和自然语言推理任务的注意力权重。
The question of training on gold versus predicted labels is closely related to learning to search (Daumé III et al., 2009; Ross et al., 2011; Chang et al., 2015) and scheduled sampling (Bengio et al., 2015), with applications in NLP to sequence labeling and transition-based parsing (Choi and Palmer, 2011; Goldberg and Nivre, 2012; Ballesteros et al., 2016). Our approach may be inter- preted as an extension of teacher forcing (Williams and Zipser, 1989) to MTL. We leave exploration of more advanced scheduled sampling techniques to
在黄金标注与预测标注上进行训练的问题,与学习搜索 (Daumé III et al., 2009; Ross et al., 2011; Chang et al., 2015) 和计划采样 (Bengio et al., 2015) 密切相关,这些方法在自然语言处理 (NLP) 中应用于序列标注和基于转移的解析 (Choi and Palmer, 2011; Goldberg and Nivre, 2012; Ballesteros et al., 2016)。我们的方法可以视为教师强制 (Williams and Zipser, 1989) 在多任务学习 (MTL) 中的扩展。我们将更先进的计划采样技术探索留给
future work.
未来工作
4 Experimental results
4 实验结果
We present results on the CoNLL-2005 shared task (Carreras and Marquez, 2005) and the CoNLL-2012 English subset of OntoNotes 5.0 (Pradhan et al., 2013), achieving state-of-the-art results for a single model with predicted predicates on both corpora. We experiment with both standard pre-trained GloVe word embeddings (Pennington et al., 2014) and pre-trained ELMo represent at ions with fine-tuned task-specific parameters (Peters et al., 2018) in order to best compare to prior work. Hyper parameters that resulted in the best performance on the validation set were selected via a small grid search, and models were trained for a maximum of 4 days on one TitanX GPU using early stopping on the validation set. We convert constituencies to dependencies using the Stanford head rules v3.5 (de Marneffe and Manning, 2008). A detailed description of hyperparameter settings and data pre-processing can be found in Appendix A.
我们在CoNLL-2005共享任务(Carreras和Marquez,2005)以及OntoNotes 5.0的CoNLL-2012英文子集(Pradhan等人,2013)上展示了实验结果,在这两个语料库上使用预测谓词的单一模型取得了最先进的结果。为了与先前工作进行最佳对比,我们同时采用了标准预训练的GloVe词嵌入(Pennington等人,2014)和预训练的ELMo表示(Peters等人,2018)配合微调的任务特定参数。通过小规模网格搜索选择在验证集上表现最佳的超参数,并使用TitanX GPU在验证集上采用早停策略进行最长4天的训练。我们使用斯坦福头规则v3.5(de Marneffe和Manning,2008)将选区转换为依存关系。超参数设置和数据预处理的详细说明见附录A。
We compare our LISA models to four strong baselines: For experiments using predicted predicates, we compare to He et al. (2018) and the ensemble model (PoE) from He et al. (2017), as well as a version of our own self-attention model which does not incorporate syntactic information (SA). To compare to more prior work, we present additional results on CoNLL-2005 with models given gold predicates at test time. In these experiments we also compare to Tan et al. (2018), the previous state-of-the art SRL model using gold predicates and standard embeddings.
我们将LISA模型与四个强基线进行比较:在使用预测谓词的实验中,我们对比了He et al. (2018) 、He et al. (2017) 的集成模型 (PoE) ,以及我们自身未融合句法信息的自注意力模型版本 (SA) 。为了与更多先前工作对比,我们在CoNLL-2005测试集上补充了使用真实谓词时的实验结果。这些实验中还对比了Tan et al. (2018) ——此前使用真实谓词和标准嵌入的最先进语义角色标注模型。
We demonstrate that our models benefit from injecting state-of-the-art predicted parses at test time by fixing the attention to parses predicted by Dozat and Manning (2017), the winner of the 2017 CoNLL shared task (Zeman et al., 2017) which we re-train using ELMo embeddings. In all cases, using these parses at test time improves performance.
我们证明,通过在测试时注入最先进的预测解析结果 ,即固定注意力机制为 Dozat 和 Manning (2017) 提出的解析结果(我们使用 ELMo 嵌入重新训练的 2017 年 CoNLL 共享任务冠军模型 [Zeman et al., 2017]),我们的模型性能得到了提升。在所有情况下,测试时使用这些解析结果都能提高性能。
We also evaluate our model using the gold syntactic parse at test time $\left(+\mathbf{Gold}\right)$ , to provide an upper bound for the benefit that syntax could have for SRL using LISA. These experiments show that despite LISA’s strong performance, there remains substantial room for improvement. In $\S4.3$ we perform further analysis comparing SRL models using gold and predicted parses.
我们还使用测试时的黄金句法分析 $\left(+\mathbf{Gold}\right)$ 来评估模型,以确定句法分析对使用LISA进行语义角色标注(SRL)可能带来的收益上限。实验表明,尽管LISA表现优异,仍有很大改进空间。在 $\S4.3$ 节中,我们将进一步分析比较使用黄金句法分析和预测句法分析的SRL模型。
| GloVe | Dev | WSJ Test | Brown Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| He et al. (2017) PoE He et al. (2018) | 81.8 81.3 | 81.2 81.9 | 81.5 81.6 | 82.0 81.2 | 83.4 83.9 | 82.7 82.5 | 69.7 69.7 | 70.5 71.9 | 70.1 70.8 |
| SA | 83.52 | 81.28 | 82.39 | 84.17 | 83.28 | 83.72 | 72.98 | 70.1 | 71.51 |
| LISA | 83.1 | 81.39 | 82.24 | 84.07 | 83.16 | 83.61 | 73.32 | 70.56 | 71.91 |
| +D&M +Gold | 84.59 87.91 | 82.59 85.73 | 83.58 86.81 | 85.53 | 84.45 | 84.99 | 75.8 | 73.54 | 74.66 |
| ELMo | |||||||||
| He et al. (2018) | 84.9 | 85.7 | 85.3 | 84.8 | 87.2 | 86.0 | 73.9 | 78.4 | 76.1 |
| SA | 85.78 | 84.74 | 85.26 | 86.21 | 85.98 | 86.09 | 77.1 | 75.61 | 76.35 |
| LISA | 86.07 | 84.64 | 85.35 | 86.69 | 86.42 | 86.55 | 78.95 | 77.17 | 78.05 |
| +D&M | 85.83 | 84.51 | 85.17 | 87.13 | 86.67 | 86.90 | 79.02 | 77.49 | 78.25 |
| +Gold | 88.51 | 86.77 | 87.63 |
Table 1: Precision, recall and F1 on the CoNLL-2005 development and test sets.
表 1: CoNLL-2005 开发集和测试集上的精确率 (Precision)、召回率 (Recall) 和 F1 值。
Table 2: Precision, recall and F1 on CoNLL-2005 with gold predicates.
| WSJ测试 | P | R | F1 |
|---|---|---|---|
| He et al. (2018) Tan et al. (2018) | 84.2 84.5 | 83.7 85.2 | 83.9 84.8 |
| SA LISA | 84.7 84.72 | 84.24 84.57 | 84.47 84.64 |
| +D&M | 86.02 | 86.05 | 86.04 |
| Brown测试 | P | R | F1 |
| He et al. (2018) Tan et al. (2018) | 74.2 | 73.1 | 73.7 |
| SA | 73.5 | 74.6 | 74.1 |
| 73.89 | 72.39 | 73.13 | |
| LISA | 74.77 | 74.32 | 74.55 |
| +D&M | 76.65 | 76.44 | 76.54 |
表 2: CoNLL-2005带黄金谓词的精确率、召回率和F1值。
4.1 Semantic role labeling
4.1 语义角色标注
Table 1 lists precision, recall and F1 on the CoNLL-2005 development and test sets using predicted predicates. For models using GloVe embeddings, our syntax-free SA model already achieves a new state-of-the-art by jointly predicting predicates, POS and SRL. LISA with its own parses performs comparably to SA, but when supplied with D&M parses LISA out-performs the previous state-of-the-art by $2.5\mathrm{~F}1$ points. On the out-ofdomain Brown test set, LISA also performs comparably to its syntax-free counterpart with its own parses, but with D&M parses LISA performs exce pti on ally well, more than 3.5 F1 points higher than He et al. (2018). Incorporating ELMo embeddings improves all scores. The gap in SRL F1 between models using LISA and D&M parses is smaller due to LISA’s improved parsing accuracy (see $\S4.2)$ , but LISA with D&M parses still achieves the highest F1: nearly 1.0 absolute F1 higher than the previous state-of-the art on WSJ, and more than 2.0 F1 higher on Brown. In both settings LISA leverages domain-agnostic syntactic information rather than over-fitting to the newswire training data which leads to high performance even on out-of-domain text.
表1列出了使用预测谓词在CoNLL-2005开发和测试集上的精确率(precision)、召回率(recall)和F1值。对于使用GloVe嵌入的模型,我们无句法分析的SA模型通过联合预测谓词、词性标注(POS)和语义角色标注(SRL)已经达到了新的最先进水平。使用自生成句法分析的LISA模型表现与SA相当,但当采用D&M句法分析时,LISA以2.5 F1分的优势超越了之前的最优结果。在跨领域的Brown测试集上,使用自生成句法分析的LISA表现与其无句法版本相当,而采用D&M句法分析时LISA表现尤为出色,比He等人(2018)的成果高出超过3.5 F1分。引入ELMo嵌入后所有指标均得到提升。由于LISA改进了句法分析精度(见$\S4.2$),采用LISA和D&M句法分析的模型在SRL F1上的差距缩小,但采用D&M句法分析的LISA仍保持最高F1值:在WSJ上比之前最优结果高出近1.0绝对F1分,在Brown上则高出超过2.0 F1分。两种配置下LISA都利用了领域无关的句法信息,而非过度拟合新闻训练数据,因此即使在跨领域文本上也表现出色。
To compare to more prior work we also evaluate our models in the artificial setting where gold predicates are provided at test time. For fair comparison we use GloVe embeddings, provide predicate indicator embeddings on the input and reencode the sequence relative to each gold predicate. Here LISA still excels: with D&M parses, LISA out-performs the previous state-of-the-art by more than 2 F1 on both WSJ and Brown.
为了与更多先前工作进行比较,我们还在测试时提供黄金谓词(gold predicates)的人工设定环境下评估模型。为确保公平比较,我们使用GloVe嵌入,在输入端提供谓词指示符嵌入,并针对每个黄金谓词重新编码序列。在此设定下,LISA仍表现优异:使用D&M解析时,LISA在WSJ和Brown数据集上的F1分数均超越先前最优结果2分以上。
Table 3 reports precision, recall and F1 on the CoNLL-2012 test set. We observe performance similar to that observed on ConLL-2005: Using GloVe embeddings our SA baseline already out-performs He et al. (2018) by nearly 1.5 F1. With its own parses, LISA slightly under-performs our syntax-free model, but when provided with stronger D&M parses LISA outperforms the state-of-the-art by more than 2.5 F1. Like CoNLL-2005, ELMo representations improve all models and close the F1 gap between models supplied with LISA and D&M parses. On this dataset ELMo also substantially narrows the difference between models with- and without syntactic information. This suggests that for this challenging dataset, ELMo already encodes much of the information available in the D&M parses. Yet, higher accuracy parses could still yield improvements since providing gold parses increases F1 by 4 points even with ELMo embeddings.
表 3 报告了 CoNLL-2012 测试集上的精确率、召回率和 F1 值。我们观察到的性能与 ConLL-2005 上的结果相似:使用 GloVe 嵌入时,我们的 SA 基线模型已经比 He et al. (2018) 高出近 1.5 个 F1 值。使用自身解析结果时,LISA 略逊于我们的无句法模型,但当提供更强的 D&M 解析时,LISA 以超过 2.5 个 F1 值的优势超越了当前最优方法。与 CoNLL-2005 类似,ELMo 表征提升了所有模型的性能,并缩小了使用 LISA 和 D&M 解析的模型之间的 F1 差距。在该数据集上,ELMo 还大幅缩小了使用和不使用句法信息的模型之间的差异。这表明对于这个具有挑战性的数据集,ELMo 已经编码了 D&M 解析中的大部分信息。然而,更高精度的解析仍可能带来改进,因为即使使用 ELMo 嵌入,提供黄金解析仍能使 F1 值提高 4 个百分点。
Table 3: Precision, recall and F1 on the CoNLL2012 development and test sets. Italics indicate a synthetic upper bound obtained by providing a gold parse at test time.
表 3: CoNLL2012 开发集和测试集上的精确率、召回率和 F1 值。斜体表示在测试时提供黄金解析得到的合成上限。
| Dev | P | R | F1 |
|---|---|---|---|
| GloVe | |||
| He et al. (2018) | 79.2 | 79.7 | 79.4 |
| SA | 82.32 | 79.76 | 81.02 |
| LISA | 81.77 | 79.65 | 80.70 |
| +D&M | 82.97 | 81.14 | 82.05 |
| +Gold | 87.57 | 85.32 | 86.43 |
| ELMo | |||
| He et al. (2018) | 82.1 | 84.0 | 83.0 |
| SA | 84.35 | 82.14 | 83.23 |
| LISA | 84.19 | 82.56 | 83.37 |
| +D&M | 84.09 | 82.65 | 83.36 |
| +Gold | 88.22 | 86.53 | 87.36 |
| Test | P | R | F1 |
| GloVe | |||
| He et al. (2018) | 79.4 | 80.1 | 79.8 |
| SA | 82.55 | 80.02 | 81.26 |
| LISA | 81.86 | 79.56 | 80.70 |
| +D&M | 83.3 | 81.38 | 82.33 |
| ELMo | |||
| He et al. (2018) | 81.9 | 84.0 | 82.9 |
| SA | 84.39 | 82.21 | 83.28 |
| LISA | 83.97 | 82.29 | 83.12 |
| +D&M | 84.14 | 82.64 | 83.38 |
4.2 Parsing, POS and predicate detection
4.2 解析、词性标注与谓词检测
We first report the labeled and unlabeled attachment scores (LAS, UAS) of our parsing models on the CoNLL-2005 and 2012 test sets (Table 4) with GloVe $(G)$ and ELMo $(E)$ embeddings. D&M achieves the best scores. Still, LISA’s GloVe UAS is comparable to popular off-the-shelf dependency parsers such as spaCy, and with ELMo embeddings comparable to the standalone D&M parser. The difference in parse accuracy between $\operatorname{LISA}_{G}$ and D&M likely explains the large increase in SRL performance we see from decoding with D&M parses in that setting.
我们首先报告了使用GloVe $(G)$ 和ELMo $(E)$ 嵌入时,我们的解析模型在CoNLL-2005和2012测试集上的标记和未标记依存分数(LAS, UAS) (表4)。D&M取得了最佳分数。尽管如此,LISA的GloVe UAS与spaCy等流行的现成依存解析器相当,而使用ELMo嵌入时则与独立的D&M解析器相当。$\operatorname{LISA}_{G}$ 与D&M在解析准确度上的差异,可能解释了我们在该场景下使用D&M解析进行解码时观察到的语义角色标注(SRL)性能大幅提升。
Table 4: Parsing (labeled and unlabeled attachment) and POS accuracies attained by the models used in SRL experiments on test datasets. Subscript $G$ denotes GloVe and $E$ ELMo embeddings.
表 4: SRL实验中各模型在测试数据集上的句法分析(带标签和无标签依存)及词性标注准确率。下标 $G$ 表示 GloVe 词嵌入,$E$ 表示 ELMo 词嵌入。
| 数据 | 模型 POS | UAS | LAS |
|---|---|---|---|
| WSJ | D&ME | — 96.48 | 94.40 91.87 |
| LISAG LISAE | 96.92 94.92 97.80 96.28 | ||
| Brown | D&ME | 一 92.56 | 88.52 |
| LISAG LISAE | 94.26 90.31 95.77 93.36 | 85.82 88.75 | |
| CoNLL-12 | D&ME | 94.99 92.59 | |
| LISAG LISAE | 96.81 93.35 98.11 94.84 | 90.42 92.23 |
Table 5: Predicate detection precision, recall and F1 on CoNLL-2005 and CoNLL-2012 test sets.
表 5: CoNLL-2005 和 CoNLL-2012 测试集上的谓词检测精确率、召回率和 F1 值。
| 模型 | P | R | F1 |
|---|---|---|---|
| WSJ | He et al. (2017) | 94.5 | 98.5 96.4 |
| LISA | 98.9 | 97.9 98.4 | |
| Brown | He et al. (2017) | 89.3 | 95.7 92.4 |
| LISA | 95.5 | 91.9 93.7 | |
| CoNLL-12 | LISA | 99.8 | 94.7 97.2 |
In Table 5 we present predicate detection precision, recall and F1 on the CoNLL-2005 and 2012 test sets. SA and LISA with and without ELMo attain comparable scores so we report only $\mathrm{LISA{+}G l o V e}$ . We compare to He et al. (2017) on CoNLL-2005, the only cited work reporting comparable predicate detection F1. LISA attains high predicate detection scores, above 97 F1, on both in-domain datasets, and out-performs He et al. (2017) by 1.5-2 F1 points even on the out-ofdomain Brown test set, suggesting that multi-task learning works well for SRL predicate detection.
在表5中,我们展示了CoNLL-2005和2012测试集上的谓词检测精确率、召回率和F1值。无论是否使用ELMo,SA和LISA都获得了相近的分数,因此我们仅报告$\mathrm{LISA{+}G l o V e}$的结果。在CoNLL-2005上,我们与He et al. (2017)进行了比较,这是唯一引用工作中报告了可比谓词检测F1值的。LISA在两个领域内数据集上都获得了高于97 F1的高谓词检测分数,即使在领域外的Brown测试集上也比He et al. (2017)高出1.5-2个F1点,这表明多任务学习在SRL谓词检测中效果良好。
4.3 Analysis
4.3 分析
First we assess SRL F1 on sentences divided by parse accuracy. Table 6 lists average SRL F1 (across sentences) for the four conditions of LISA and D&M parses being correct or not $(\mathbf{L}\pm,\mathbf{D}\pm)$ . Both parsers are correct on $26%$ of sentences.
首先我们根据解析准确率划分句子来评估语义角色标注 (SRL) F1值。表6列出了LISA和D&M解析器正确与否四种情况 $(\mathbf{L}\pm,\mathbf{D}\pm)$ 下的平均SRL F1值(跨句子统计)。两个解析器同时在26%的句子上解析正确。
Table 6: Average SRL F1 on CoNLL-2005 for sentences where LISA (L) and D&M (D) parses were completely correct $(+)$ or incorrect $(-)$ .
表 6: 在CoNLL-2005数据集上LISA (L)和D&M (D)解析完全正确 $(+)$ 或错误 $(-)$ 的句子的平均SRL F1分数
| L+/D+ | L-/D+ | L+/D- | L-/D- | |
|---|---|---|---|---|
| 比例 | 26% | 12% | 4% | 56% |
| SA | 79.29 | 75.14 | 75.97 | 75.08 |
| LISA | 79.51 | 74.33 | 79.69 | 75.00 |
| +D&M | 79.03 | 76.96 | 77.73 | 76.52 |
| +Gold | 79.61 | 78.38 | 81.41 | 80.47 |

Figure 3: Performance of CoNLL-2005 models after performing corrections from He et al. (2017).
图 3: 采用 He et al. (2017) 修正方法后的 CoNLL-2005 模型性能表现。
Here there is little difference between any of the models, with LISA models tending to perform slightly better than SA. Both parsers make mistakes on the majority of sentences $(57%)$ , difficult sentences where SA also performs the worst. These examples are likely where gold and D&M parses improve the most over other models in overall F1: Though both parsers fail to correctly parse the entire sentence, the D&M parser is less wrong (87.5 vs. 85.7 average LAS), leading to higher SRL F1 by about 1.5 average F1.
各模型之间差异不大,其中LISA模型表现略优于SA模型。两种解析器在多数句子(57%)上都会出错,这些困难句子也正是SA表现最差的部分。此类案例中,黄金标注和D&M解析相比其他模型在整体F1值上提升最显著:虽然两种解析器都未能完全正确解析整句,但D&M解析器的错误更少(平均LAS值87.5 vs. 85.7),使得SRL的F1值平均提高约1.5。
Following He et al. (2017), we next apply a series of corrections to model predictions in order to understand which error types the gold parse resolves: e.g. Fix Labels fixes labels on spans matching gold boundaries, and Merge Spans merges adjacent predicted spans into a gold span.6
遵循 He 等人 (2017) 的方法,我们随后对模型预测进行了一系列修正,以理解黄金解析能解决哪些错误类型:例如 Fix Labels 会修正与黄金边界匹配的跨度的标签,而 Merge Spans 会将相邻的预测跨度合并为一个黄金跨度。6
In Figure 3 we see that much of the performance gap between the gold and predicted parses is due to span boundary errors (Merge Spans, Split Spans and Fix Span Boundary), which supports the hypothesis proposed by He et al. (2017) that incorporating syntax could be particularly helpful for resolving these errors. He et al. (2017) also point out that these errors are due mainly to prepositional phrase (PP) attachment mistakes. We also find this to be the case: Figure 4 shows a breakdown of split/merge corrections by phrase type. Though the number of corrections decreases substantially across phrase types, the proportion of corrections attributed to PPs remains the same (approx. $50%$ ) even after providing the correct PP attachment to the model, indicating that PP span boundary mistakes are a fundamental difficulty for SRL.
在图 3 中可以看到,黄金标注与预测解析之间的性能差距主要源于跨度边界错误(合并跨度、拆分跨度和修正跨度边界),这支持了 He 等人 (2017) 提出的假设:引入句法信息可能对解决这类错误特别有效。He 等人 (2017) 还指出,这些错误主要由介词短语 (PP) 依附错误导致。我们的研究同样印证了这一点:图 4 展示了按短语类型分类的拆分/合并修正情况。尽管各短语类型的修正数量显著减少,但即使在向模型提供正确的 PP 依附关系后,PP 相关的修正比例仍保持稳定(约 50%),这表明 PP 跨度边界错误是语义角色标注 (SRL) 的根本性难题。

Figure 4: Percent and count of split/merge corrections performed in Figure 3, by phrase type.
图 4: 按短语类型划分的图 3 中拆分/合并校正的百分比和数量。
5 Conclusion
5 结论
We present linguistically-informed self-attention: a multi-task neural network model that effectively incorporates rich linguistic information for semantic role labeling. LISA out-performs the state-ofthe-art on two benchmark SRL datasets, including out-of-domain. Future work will explore im- proving LISA’s parsing accuracy, developing better training techniques and adapting to more tasks.
我们提出了一种基于语言学信息的自注意力机制:这是一种多任务神经网络模型,能有效整合丰富的语言学信息以进行语义角色标注。LISA 在两个基准 SRL 数据集(包括跨域场景)上超越了现有最优性能。未来工作将致力于提升 LISA 的解析准确率、开发更优的训练技术并适配更多任务。
Acknowledgments
致谢
We are grateful to Luheng He for helpful discussions and code, Timothy Dozat for sharing his code, and to the NLP reading groups at Google and UMass and the anonymous reviewers for feedback on drafts of this work. This work was supported in part by an IBM PhD Fellowship Award to E.S., in part by the Center for Intelligent Information Retrieval, and in part by the National Science Foundation under Grant Nos. DMR-1534431 and IIS-1514053. Any opinions, findings, conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect those of the sponsor.
我们感谢Luheng He有益的讨论和代码分享,感谢Timothy Dozat共享他的代码,同时感谢Google和UMass的NLP阅读小组以及匿名评审对本工作草稿提出的宝贵意见。本研究部分得到了授予E.S.的IBM博士生奖学金支持,部分由智能信息检索中心资助,部分资金来自美国国家科学基金会(资助号:DMR-1534431和IIS-1514053)。本材料中表达的任何观点、发现、结论或建议均为作者个人观点,并不代表资助机构的立场。
References
参考文献
Martın Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, et al. 2015. Tensorflow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org.
Martın Abadi、Ashish Agarwal、Paul Barham、Eugene Brevdo、Zhifeng Chen、Craig Citro、Greg S Corrado、Andy Davis、Jeffrey Dean、Matthieu Devin 等. 2015. TensorFlow: 异构系统上的大规模机器学习, 2015. 软件可从 tensorflow.org 获取。
Héctor Martinez Alonso and Barbara Plank. 2017. When is multitask learning effective? semantic sequence prediction under varying data conditions. In EACL.
Héctor Martinez Alonso 和 Barbara Plank. 2017. 多任务学习何时有效?不同数据条件下的语义序列预测. In EACL.
Miguel Ball ester os, Yoav Goldberg, Chris Dyer, and Noah A. Smith. 2016. Training with exploration improves a greedy stack lstm parser. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2005–2010.
Miguel Ballesteros、Yoav Goldberg、Chris Dyer 和 Noah A. Smith。2016. 探索式训练提升贪心堆叠LSTM解析器性能。载于《2016年自然语言处理实证方法会议论文集》,第2005–2010页。
Marzieh Bazrafshan and Daniel Gildea. 2013. Semantic roles for string to tree machine translation. In ACL.
Marzieh Bazrafshan 和 Daniel Gildea. 2013. 面向字符串到树机器翻译的语义角色. 载于 ACL.
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. 2015. Scheduled sampling for sequence prediction with recurrent neural networks. In NIPS.
Samy Bengio、Oriol Vinyals、Navdeep Jaitly 和 Noam Shazeer。2015。基于循环神经网络的序列预测计划采样 (Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks)。In NIPS。
Yoshua Bengio, Patrice Simard, and Paolo Frasconi. 1994. Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2):157–166.
Yoshua Bengio、Patrice Simard 和 Paolo Frasconi。1994. 基于梯度下降的长时依赖学习存在困难。IEEE Transactions on Neural Networks, 5(2):157–166。
Jonathan Berant, Vivek Srikumar, Pei-Chun Chen, Brad Huang, Christopher D. Manning, Abby Vander Linden, Brittany Harding, and Peter Clark. 2014. Modeling biological processes for reading comprehension. In EMNLP.
Jonathan Berant、Vivek Srikumar、Pei-Chun Chen、Brad Huang、Christopher D. Manning、Abby Vander Linden、Brittany Harding 和 Peter Clark。2014. 面向阅读理解任务的生物过程建模。发表于 EMNLP。
Joachim Bingel and Anders Søgaard. 2017. Identify- ing beneficial task relations for multi-task learning in deep neural networks. In EACL.
Joachim Bingel 和 Anders Søgaard。2017。识别深度神经网络中多任务学习的有利任务关系。载于 EACL。
Xavier Carreras and Lluis Marquez. 2005. Introduc- tion to the conll-2005 shared task: Semantic role la- beling. In CoNLL.
Xavier Carreras 和 Lluis Marquez。2005. CoNLL-2005 共享任务介绍:语义角色标注。In CoNLL。
Rich Caruana. 1993. Multitask learning: a knowledgebased source of inductive bias. In ICML.
Rich Caruana. 1993. 多任务学习:一种基于知识的归纳偏差来源。见ICML。
Kai-Wei Chang, Akshay Krishna mur thy, Alekh Agarwal, Hal Daumé Ill, and John Langford. 2015. Learning to search better than your teacher. In ICML.
Kai-Wei Chang、Akshay Krishna murthy、Alekh Agarwal、Hal Daumé Ill和John Langford。2015. 学习比你的老师更好地搜索。In ICML。
Yun-Nung Chen, William Yang Wang, and Alexander I Rudnicky. 2013. Unsupervised induction and filling of semantic slots for spoken dialogue systems using frame-semantic parsing. In Proc. of ASRU-IEEE.
Yun-Nung Chen、William Yang Wang 和 Alexander I Rudnicky。2013。基于框架语义解析的口语对话系统语义槽无监督归纳与填充。收录于 ASRU-IEEE 会议论文集。
Jinho D. Choi and Martha Palmer. 2011. Getting the most out of transition-based dependency parsing. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: short papers, pages 687–692.
Jinho D. Choi 和 Martha Palmer. 2011. 充分利用基于转移的依存句法分析. 载于《第49届计算语言学协会年会短文集》, 第687–692页.
Ronan Collobert, Jason Weston, Léon Bottou, Michael Karlen, Koray Ka vuk cuo g lu, and Pavel Kuksa. 2011. Natural language processing (almost) from scratch. Journal of Machine Learning Research, 12(Aug):2493–2537.
Ronan Collobert、Jason Weston、Léon Bottou、Michael Karlen、Koray Kavukcuoglu 和 Pavel Kuksa。2011。自然语言处理 (almost) from scratch。《Journal of Machine Learning Research》,12(8月):2493–2537。
Hal Daumé IHI, John Langford, and Daniel Marcu. 2009. Search-based structured prediction. Machine Learning, 75(3):297–325.
Hal Daumé IHI、John Langford和Daniel Marcu。2009. 基于搜索的结构化预测。Machine Learning,75(3):297–325。
Timothy Dozat. 2016. Incorporating nesterov momen- tum into adam. In ICLR Workshop track.
Timothy Dozat. 2016. 将Nesterov动量融入Adam. 见于ICLR Workshop track.
Timothy Dozat and Christopher D. Manning. 2017. Deep biaffine attention for neural dependency parsing. In ICLR.
Timothy Dozat 和 Christopher D. Manning. 2017. 神经依存解析的深度双仿射注意力机制. 载于 ICLR.
Nicholas FitzGerald, Oscar Tackstrom, Kuzman Ganchev, and Dipanjan Das. 2015. Semantic role labeling with neural network factors. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 960–970.
Nicholas FitzGerald、Oscar Tackstrom、Kuzman Ganchev 和 Dipanjan Das。2015。基于神经网络因素的语义角色标注。载于《2015年自然语言处理实证方法会议论文集》,第960-970页。
W. N. Francis and H. Kucera. 1964. Manual of information to accompany a standard corpus of presentday edited american english, for use with digital computers. Technical report, Department of Linguistics, Brown University, Providence, Rhode Island.
W. N. Francis 和 H. Kucera. 1964. 当代编辑美式英语标准语料库使用手册 (供数字计算机使用). 技术报告, 布朗大学语言学系, 普罗维登斯, 罗德岛州.
Yoav Goldberg and Joakim Nivre. 2012. A dynamic oracle for arc-eager dependency parsing. In Proceedings of COLING 2012: Technical Papers, pages 959–976.
Yoav Goldberg 和 Joakim Nivre. 2012. 基于动态指导器的弧贪婪依存句法分析. 载于《COLING 2012技术论文集》, 第959–976页.
Kazuma Hashimoto, Caiming Xiong, Yoshimasa Tsuruoka, and Richard Socher. 2017. A joint many-task model: Growing a neural network for multiple nlp tasks. In Conference on Empirical Methods in Natural Language Processing.
Kazuma Hashimoto、Caiming Xiong、Yoshimasa Tsuruoka 和 Richard Socher。2017. 联合多任务模型:为多种自然语言处理任务构建神经网络。载于《自然语言处理实证方法会议》。
Luheng He, Kenton Lee, Omer Levy, and Luke Zettlemoyer. 2018. Jointly predicting predicates and arguments in neural semantic role labeling. In ACL.
Luheng He、Kenton Lee、Omer Levy 和 Luke Zettlemoyer。2018。神经语义角色标注中的谓词与论元联合预测。载于 ACL。
Luheng He, Kenton Lee, Mike Lewis, and Luke Zettlemoyer. 2017. Deep semantic role labeling: What works and whats next. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics.
Luheng He、Kenton Lee、Mike Lewis 和 Luke Zettlemoyer。2017. 深度语义角色标注:现有成果与未来方向。载于《第55届计算语言学协会年会论文集》。
Richard Johansson and Pierre Nugues. 2008. Dependency-based semantic role labeling of propbank. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, pages 69–78.
Richard Johansson 和 Pierre Nugues。2008。基于依存关系的 PropBank 语义角色标注。载于《2008年自然语言处理实证方法会议论文集》,第69-78页。
Diederik Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In 3rd International Conference for Learning Representations (ICLR), San Diego, California, USA.
Diederik Kingma 和 Jimmy Ba。2015. Adam:一种随机优化方法。见:第三届国际学习表征会议 (ICLR),美国加利福尼亚州圣地亚哥。
Eliyahu Ki per wasser and Yoav Goldberg. 2016. Simple and accurate dependency parsing using bidirectional LSTM feature representations. Transactions of the Association for Computational Linguistics, 4:313–327.
Eliyahu Kiperwasser和Yoav Goldberg。2016。使用双向LSTM特征表示的简单准确依存解析。计算语言学协会汇刊,4:313–327。
Swabha S way am dip ta, Sam Thomson, Chris Dyer, and Noah A. Smith. 2017. Frame-semantic parsing with softmax-margin segmental rnns and a syntactic scaffold. In arXiv:1706.09528.
Swabha Swayamdipta、Sam Thomson、Chris Dyer 和 Noah A. Smith。2017。基于 softmax-margin 分段 RNN 和句法支架的框架语义解析。arXiv:1706.09528。
Oscar Tackstrom, Kuzman Ganchev, and Dipanjan Das. 2015. Efficient inference and structured learning for semantic role labeling. TACL, 3:29–41.
Oscar Tackstrom、Kuzman Ganchev 和 Dipanjan Das. 2015. 语义角色标注的高效推理与结构化学习. TACL, 3:29–41.
Zhixing Tan, Mingxuan Wang, Jun Xie, Yidong Chen, and Xiaodong Shi. 2018. Deep semantic role labeling with self-attention. In AAAI.
谭知行、王铭轩、谢俊、陈一东和施晓东。2018。基于自注意力机制的深度语义角色标注。发表于AAAI。
Kristina Toutanova, Aria Haghighi, and Christopher D. Manning. 2008. A global joint model for semantic role labeling. Computational Linguistics, 34(2):161–191.
Kristina Toutanova、Aria Haghighi 和 Christopher D. Manning。2008。语义角色标注的全局联合模型。Computational Linguistics,34(2):161–191。
Kristina Toutanova, Dan Klein, Christopher D Manning, and Yoram Singer. 2003. Feature-rich part-ofspeech tagging with a cyclic dependency network. In Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology- Volume 1, pages 173–180. Association for Computational Linguistics.
Kristina Toutanova、Dan Klein、Christopher D Manning 和 Yoram Singer。2003. 基于循环依赖网络的特征丰富词性标注。载于《北美计算语言学协会人类语言技术会议论文集(2003)》第1卷,第173-180页。计算语言学协会。
Gokhan Tur, Dilek Hakkani-Tur, and Ananlada Chotimongkol. 2005. Semi-supervised learning for spoken language understanding using semantic role labeling. In ASRU.
Gokhan Tur、Dilek Hakkani-Tur 和 Ananlada Chotimongkol。2005。使用语义角色标注的口语理解半监督学习。收录于 ASRU。
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In 31st Conference on Neural Information Processing Systems (NIPS).
Ashish Vaswani、Noam Shazeer、Niki Parmar、Jakob Uszkoreit、Llion Jones、Aidan N Gomez、Lukasz Kaiser 和 Illia Polosukhin。2017. Attention is all you need。载于第31届神经信息处理系统大会 (NIPS)。
Hai Wang, Mohit Bansal, Kevin Gimpel, and David McAllester. 2015. Machine comprehension with syntax, frames, and semantics. In ACL.
Hai Wang、Mohit Bansal、Kevin Gimpel 和 David McAllester。2015. 基于句法、框架和语义的机器阅读理解。发表于 ACL。
R. J. Williams and D. Zipser. 1989. A learning algorithm for continually running fully recurrent neural networks. Neural computation, 1(2):270–280.
R. J. Williams 和 D. Zipser. 1989. 一种用于持续运行的全递归神经网络的学习算法. Neural computation, 1(2):270–280.
Daniel Zeman, Martin Popel, Milan Straka, Jan Hajic, Joakim Nivre, Filip Ginter, Juhani Luotolahti, Sampo Pyysalo, Slav Petrov, Martin Potthast, et al. 2017. Conll 2017 shared task: Multilingual parsing from raw text to universal dependencies. In Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, pages 1–19, Vancouver, Canada. Association for Computational Linguistics.
Daniel Zeman、Martin Popel、Milan Straka、Jan Hajic、Joakim Nivre、Filip Ginter、Juhani Luotolahti、Sampo Pyysalo、Slav Petrov、Martin Potthast 等。2017。CoNLL 2017 共享任务:从原始文本到通用依存关系的多语言解析。载于《CoNLL 2017 共享任务论文集:从原始文本到通用依存关系的多语言解析》(Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies),第 1–19 页,加拿大温哥华。计算语言学协会(Association for Computational Linguistics)。
Yuan Zhang and David Weiss. 2016. Stackpropagation: Improved representation learning for syntax. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1557–1566. Association for Computational Linguistics.
Yuan Zhang and David Weiss. 2016. Stackpropagation: 句法表征学习的改进方法。载于《第54届计算语言学协会年会论文集(第一卷:长论文)》,第1557–1566页。计算语言学协会。
Jie Zhou and Wei Xu. 2015. End-to-end learning of semantic role labeling using recurrent neural networks. In Proc. of the Annual Meeting of the Association for Computational Linguistics (ACL).
周杰和徐伟。2015。基于循环神经网络的端到端语义角色标注学习。见《计算语言学协会年会论文集》(ACL)。
Table 7: Comparison of development F1 scores with and without Viterbi decoding at test time.
表 7: 测试时使用和不使用Viterbi解码的开发F1分数对比。
| CoNLL-2005 | Greedy F1 | Viterbi F1 | △ F1 |
|---|---|---|---|
| LISA | 81.99 | 82.24 | +0.25 |
| +D&M | 83.37 | 83.58 | +0.21 |
| +Gold | 86.57 | 86.81 | +0.24 |
| CoNLL-2012 | Greedy F1 | Viterbi F1 | △ F1 |
|---|---|---|---|
| LISA | 80.11 | 80.70 | +0.59 |
| +D&M | 81.55 | 82.05 | +0.50 |
| +Gold | 85.94 | 86.43 | +0.49 |

Figure 5: F1 score as a function of sentence length.
图 5: F1分数随句子长度的变化情况。
A Supplemental Material
补充材料
A.1 Supplemental analysis
A.1 补充分析
Here we continue the analysis from $\S4.3$ . All experiments in this section are performed on CoNLL-2005 development data unless stated otherwise.
我们延续 $\S4.3$ 节的分析。除非另有说明,本节所有实验均在CoNLL-2005开发数据集上进行。
First, we compare the impact of Viterbi decoding with LISA, D&M, and gold syntax trees (Table 7), finding the same trends across both datasets. We find that Viterbi has nearly the same impact for LISA, D&M and gold parses: Gold parses provide little improvement over predicted parses in terms of BIO label consistency.
首先,我们比较了Viterbi解码与LISA、D&M及黄金语法树( gold syntax trees )的影响(表7 ),发现两个数据集呈现相同趋势。Viterbi对LISA、D&M和黄金解析的影响几乎一致:在BIO标签一致性方面,黄金解析较预测解析的提升微乎其微。
We also assess SRL F1 as a function of sentence length and distance from span to predicate. In Figure 5 we see that providing LISA with gold parses is particularly helpful for sentences longer than 10 tokens. This likely directly follows from the tendency of syntactic parsers to perform worse on longer sentences. With respect to distance between arguments and predicates, (Figure 6), we do not observe this same trend, with all distances performing better with better parses, and especially gold.
我们还评估了语义角色标注 (SRL) F1 分数随句子长度及论元与谓词间距离的变化情况。图 5 显示,为 LISA 提供正确标注的句法解析结果对长度超过 10 个 token 的句子特别有帮助。这可能直接源于句法解析器在长句上表现较差的趋势。关于论元与谓词间的距离 (图 6),我们并未观察到相同趋势——所有距离下的表现都因更好的解析结果 (尤其是正确标注的解析) 而提升。

Figure 6: CoNLL-2005 F1 score as a function of the distance of the predicate from the argument span.
图 6: CoNLL-2005 F1分数随谓词与论元跨度距离变化的函数关系。
Table 8: Average SRL F1 on CoNLL-2012 for sentences where LISA (L) and D&M (D) parses were correct $(+)$ or incorrect (-).
表 8: CoNLL-2012 中 LISA (L) 和 D&M (D) 解析正确 $(+)$ 或错误 (-) 的句子的平均 SRL F1 分数
| L+/D+ | L-/D+ | L+/D- | L-/D- |
|---|---|---|---|
| 比例 | 37% 10% | 4% | 49% |
| SA | 76.12 | 75.97 82.25 | 65.78 |
| LISA | 76.37 72.38 | 85.50 | 65.10 |
| +D&M | 76.33 | 79.65 75.62 | 66.55 |
| +Gold | 76.71 | 80.67 86.03 | 72.22 |
A.2 Supplemental results
A.2 补充结果
Due to space constraints in the main paper we list additional experimental results here. Table 9 lists development scores on the CoNLL-2005 dataset with predicted predicates, which follow the same trends as the test data.
由于主论文篇幅限制,我们在此列出额外实验结果。表 9 展示了 CoNLL-2005 数据集上使用预测谓词的开发集分数,其趋势与测试数据一致。
A.3 Data and pre-processing details
A.3 数据与预处理详情
We initialize word embeddings with 100d pretrained GloVe embeddings trained on 6 billion tokens of Wikipedia and Gigaword (Pennington et al., 2014). We evaluate the SRL performance of our models using the srl-eval.pl script
我们使用在60亿Token的Wikipedia和Gigaword语料上预训练的100维GloVe词向量 (Pennington et al., 2014) 初始化词嵌入。采用srl-eval.pl脚本评估模型的语义角色标注 (SRL) 性能。
| WSJDev | P | R | F1 |
|---|---|---|---|
| He et al. (2018) | 84.2 | 83.7 | 83.9 |
| Tan et al. (2018) | 82.6 | 83.6 82.81 | 83.1 82.97 |
| SA LISA | 83.12 83.6 | 83.74 | 83.67 |
| +D&M | 85.04 | 85.51 | 85.27 |
| +Gold | 89.11 | 89.38 | 89.25 |
Table 9: Precision, recall and F1 on the CoNLL2005 development set with gold predicates.
表 9: 在带有黄金谓词的CoNLL2005开发集上的精确率、召回率和F1值
provided by the CoNLL-2005 shared task,7 which computes segment-level precision, recall and F1 score. We also report the predicate detection scores output by this script. We evaluate parsing using the eval.pl CoNLL script, which ex- cludes punctuation.
由CoNLL-2005共享任务提供的官方脚本7计算片段级精确率、召回率和F1值。同时报告该脚本输出的谓词检测分数。使用排除标点的eval.pl CoNLL脚本进行依存解析评估。
We train distinct D&M parsers for CoNLL2005 and CoNLL-2012. Our D&M parsers are trained and validated using the same SRL data splits, except that for CoNLL-2005 section 22 is used for development (rather than 24), as this section is typically used for validation in PTB parsing. We use Stanford dependencies v3.5 (de Marneffe and Manning, 2008) and POS tags from the Stanford CoreNLP left3words model (Toutanova et al., 2003). We use the pre-trained ELMo models8 and learn task-specific combinations of the ELMo representations which are provided as input instead of GloVe embeddings to the D&M parser with otherwise default settings.
我们针对CoNLL2005和CoNLL-2012分别训练了不同的D&M解析器。除CoNLL-2005使用第22节(而非24节)作为开发集(该节在PTB解析中通常用于验证)外,我们的D&M解析器均采用相同的语义角色标注数据划分进行训练和验证。我们使用斯坦福依存关系v3.5 (de Marneffe and Manning, 2008) 以及斯坦福CoreNLP left3words模型 (Toutanova et al., 2003) 生成的词性标注。采用预训练的ELMo模型8,并通过学习ELMo表征的任务特定组合作为输入(替代原D&M解析器默认设置中的GloVe嵌入)。
A.3.1 CoNLL-2012
A.3.1 CoNLL-2012
We follow the CoNLL-2012 split used by He et al. (2018) to evaluate our models, which uses the annotations from here9 but the subset of those documents from the CoNLL-2012 co-reference split described here10 (Pradhan et al., 2013). This dataset is drawn from seven domains: newswire, web, broadcast news and conversation, magazines, telephone conversations, and text from the bible. The text is annotated with gold part-ofspeech, syntactic constituencies, named entities, word sense, speaker, co-reference and semantic role labels based on the PropBank guidelines (Palmer et al., 2005). Propositions may be verbal or nominal, and there are 41 distinct semantic role labels, excluding continuation roles and including the predicate. We convert the semantic proposition and role segmentation s to BIO boundary-encoded tags, resulting in 129 distinct BIO-encoded tags (including continuation roles).
我们采用He等人(2018)使用的CoNLL-2012划分方案来评估模型,该方案使用此处9的标注数据,但文档子集来自CoNLL-2012共指消解划分(描述见此处10)(Pradhan等人,2013)。该数据集涵盖七个领域:新闻专线、网络文本、广播新闻与对话、杂志、电话通话以及圣经文本。文本标注包含黄金标准词性标注、句法成分、命名实体、词义、说话者、共指关系和基于PropBank规范(Palmer等人,2005)的语义角色标签。命题可以是动词性或名词性的,共包含41种不同的语义角色标签(不含延续角色但包含谓词)。我们将语义命题和角色分割转换为BIO边界编码标签,最终生成129种不同的BIO编码标签(含延续角色)。
A.3.2 CoNLL-2005
A.3.2 CoNLL-2005
The CoNLL-2005 data (Carreras and Marquez, 2005) is based on the original PropBank corpus (Palmer et al., 2005), which labels the Wall
CoNLL-2005数据(Carreras和Marquez,2005)基于原始PropBank语料库(Palmer等人,2005),该语料库标注了华尔街
Street Journal portion of the Penn TreeBank corpus (PTB) (Marcus et al., 1993) with predicateargument structures, plus a challenging out-ofdomain test set derived from the Brown corpus (Francis and Kucera, 1964). This dataset contains only verbal predicates, though some are multiword verbs, and 28 distinct role label types. We obtain 105 SRL labels including continuations after encoding predicate argument segment bound- aries with BIO tags.
Penn TreeBank语料库(PTB) (Marcus等人, 1993)的《华尔街日报》部分,包含谓词-论元结构,以及一个来自布朗语料库(Francis和Kucera, 1964)的跨领域测试集。该数据集仅包含动词性谓词(部分为多词动词)和28种不同的角色标签类型。通过使用BIO标签编码谓词论元片段边界后,我们最终获得了105个语义角色标注(SRL)标签。
A.4 Optimization and hyper parameters
A.4 优化与超参数
We train the model using the Nadam (Dozat, 2016) algorithm for adaptive stochastic gradient descent (SGD), which combines Adam (Kingma and Ba, 2015) SGD with Nesterov momentum (Nesterov, 1983). We additionally vary the learning rate $l r$ as a function of an initial learning rate $l r_{0}$ and the current training step step as described in Vaswani et al. (2017) using the following function:
我们采用Nadam (Dozat, 2016)算法进行自适应随机梯度下降(SGD)训练,该算法结合了Adam (Kingma和Ba, 2015) SGD与Nesterov动量 (Nesterov, 1983)。此外,我们根据Vaswani等人(2017)提出的方法,将学习率$lr$作为初始学习率$lr_{0}$和当前训练步数step的函数进行调整,具体函数如下:
$$
l r=l r_{0}\cdot\operatorname*{min}(s t e p^{-0.5},s t e p\cdot w a r m^{-1.5})
$$
$$
l r=l r_{0}\cdot\operatorname*{min}(s t e p^{-0.5},s t e p\cdot w a r m^{-1.5})
$$
which increases the learning rate linearly for the first warm training steps, then decays it proportionally to the inverse square root of the step number. We found this learning rate schedule essential for training the self-attention model. We only update optimization moving-average accumulators for parameters which receive gradient updates at a given step.11
在前几个预热训练步骤中线性增加学习率,之后按步数的平方根倒数比例衰减。我们发现这种学习率调度对训练自注意力模型至关重要。我们仅更新在给定步骤中接收梯度更新的参数的优化移动平均累加器。[11]
In all of our experiments we used initial learning rate 0.04, $\beta_{1}=0.9$ , $\beta_{2}=0.98$ , $\epsilon=1\times10^{-12}$ and dropout rates of 0.1 everywhere. We use 10 or 12 self-attention layers made up of 8 attention heads each with embedding dimension 25, with 800d feed-forward projections. In the syntacticallyinformed attention head, $Q_{p a r s e}$ has dimension 500 and $K_{p a r s e}$ has dimension 100. The size of predicate and role representations and the represent ation used for joint part-of-speech/predicate classification is 200. We train with $w a r m=8000$ warmup steps and clip gradient norms to 1. We use batches of approximately 5000 tokens.
在我们的所有实验中,我们使用的初始学习率为0.04,$\beta_{1}=0.9$,$\beta_{2}=0.98$,$\epsilon=1\times10^{-12}$,且所有位置的dropout率均为0.1。我们采用了10或12个自注意力层(self-attention layers),每层包含8个注意力头(attention heads),嵌入维度为25,前馈投影维度为800。在语法感知的注意力头中,$Q_{parse}$的维度为500,$K_{parse}$的维度为100。谓词和角色表示的大小以及用于联合词性/谓词分类的表示维度均为200。训练时采用$warm=8000$预热步数,并将梯度范数裁剪至1。我们使用的批次大小约为5000个token。