Parameter Sharing Exploration and Hetero-center Triplet Loss for Visible-Thermal Person Re-Identification
可见光-热红外行人重识别的参数共享探索与异质中心三元组损失
Abstract—This paper focuses on the visible-thermal crossmodality person re-identification (VT Re-ID) task, whose goal is to match person images between the daytime visible modality and the nighttime thermal modality. The two-stream network is usually adopted to address the cross-modality discrepancy, the most challenging problem for VT Re-ID, by learning the multi-modality person features. In this paper, we explore how many parameters a two-stream network should share, which is still not well investigated in the existing literature. By splitting the ResNet50 model to construct the modality-specific feature extraction network and modality-sharing feature embedding network, we experimentally demonstrate the effect of parameter sharing of two-stream network for VT Re-ID. Moreover, in the framework of part-level person feature learning, we propose the hetero-center triplet loss to relax the strict constraint of traditional triplet loss by replacing the comparison of the anchor to all the other samples by the anchor center to all the other centers. With extremely simple means, the proposed method can significantly improve the VT Re-ID performance. The experimental results on two datasets show that our proposed method distinctly outperforms the state-of-the-art methods by large margins, especially on the RegDB dataset achieving superior performance, rank1/mAP/mINP $\bar{91.05}%/83.28%/68.84%$ . It can be a new baseline for VT Re-ID, with a simple but effective strategy.
摘要—本文聚焦于可见光-热红外跨模态行人重识别(VT Re-ID)任务,其目标是在白天的可见光模态与夜间的热红外模态之间进行行人图像匹配。为应对跨模态差异这一VT Re-ID最具挑战性的问题,现有研究通常采用双流网络通过学习多模态行人特征来解决。本文深入探讨了双流网络应共享多少参数这一尚未被现有文献充分研究的问题。通过拆分ResNet50模型构建模态特定特征提取网络和模态共享特征嵌入网络,我们通过实验验证了双流网络参数共享对VT Re-ID的影响。此外,在局部行人特征学习框架下,我们提出异质中心三元组损失,通过用锚点中心与其他所有中心的比较替代锚点与其他所有样本的严格对比,从而放宽传统三元组损失的约束条件。该方法以极其简单的手段显著提升了VT Re-ID性能。在两个数据集上的实验结果表明,我们提出的方法以明显优势超越了现有最优方法,特别是在RegDB数据集上取得了$\bar{91.05}%/83.28%/68.84%$的rank1/mAP/mINP卓越性能。这种简单而有效的策略可成为VT Re-ID的新基准。
Index Terms—Visible-thermal person re-identification, crossmodality discrepancy, parameters sharing, hetero-center triplet loss.
索引术语—可见光-热成像行人重识别,跨模态差异,参数共享,异质中心三元组损失。
I. INTRODUCTION
I. 引言
P rEe tR riSe Ova Nl traes-ki,d ew nh tii cf i hc aatiiomns a(tR see-aIrDc)h icnagn a bpee rrseogna rodf eidnt earse sat from multi-disjoint cameras deployed at different locations. It has received increasing interest in the computer vision community due to its importance in intelligent video surveillance and criminal investigation applications. Visible-visible Re-ID (VV Re-ID), the most common single-modality Re-ID task, has progressed and achieved high performance in recent years [33].
跨摄像头行人重识别 (Re-ID) 旨在从部署在不同位置的多台非重叠摄像头中检索特定行人目标。由于其在智能视频监控和刑事调查应用中的重要性,该技术日益受到计算机视觉领域的关注。可见光-可见光行人重识别 (VV Re-ID) 作为最常见的单模态Re-ID任务,近年来已取得显著进展并实现高性能 [33]。
However, in practical scenarios, a 24-hour intelligent surveillance system, the visible-thermal cross-modality person re-identification (VT Re-ID) problem, is frequently encountered, as shown in Fig. 1. For example, criminals always collect information during the day and execute crimes at night, in which case, the query image may be obtained from the thermal camera (or the infrared camera) during the nighttime, while the gallery images may be captured by the visible cameras during the daytime.
然而在实际场景中,24小时智能监控系统经常会遇到可见光-热成像跨模态行人重识别(VT Re-ID)问题,如图1所示。例如犯罪分子通常在白天踩点、夜间作案,此时查询图像可能来自夜间的热成像相机(或红外相机),而底库图像则可能是白天可见光摄像头拍摄的。
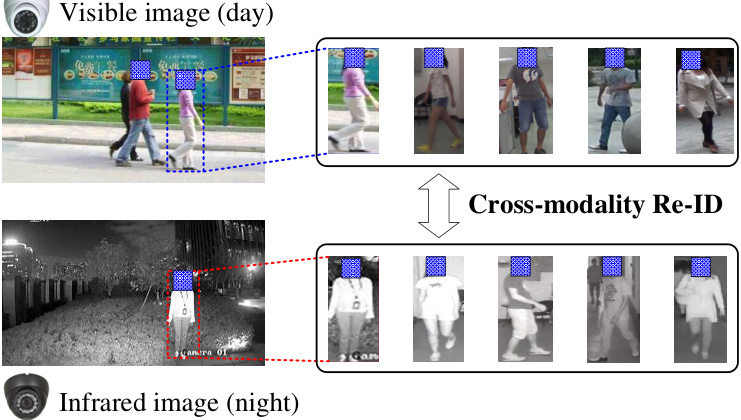
Fig. 1. Illustration of VT Re-ID. For example, searching a person captured by a visible camera in the daytime among multiple persons captured by infrared (or thermal) cameras at night, and vice versa.
图 1: VT Re-ID示例。例如,在夜间由红外(或热成像)摄像头拍摄的多人中搜索白天由可见光摄像头拍摄的目标人物,反之亦然。
In recent years, an increasing number of researchers have focused on the VT Re-ID task, achieving substantial progresses with novel and effective ideas. However, many works evaluated the effectiveness of their methods with a poor baseline, which seriously impedes the development of the VT Re-ID community. In the present study, our proposed method can be set as a strong and effective baseline for VT Re-ID with some extremely simple means.
近年来,越来越多的研究者开始关注VT Re-ID任务,通过新颖有效的思路取得了显著进展。然而,许多工作采用较弱的基线评估方法效果,严重阻碍了VT Re-ID领域的发展。本研究提出的方法通过极其简单的手段,可作为VT Re-ID的强大有效基线。
The VT Re-ID task suffers from two major problems, the large cross-modality discrepancy arisen from the different reflective visible spectra and sensed em is siv i ties of visible and thermal cameras, and the large intra-modality variations, similar to the VV Re-ID task, caused by viewpoint changing and different human poses, etc. To alleviate the extra crossmodality discrepancy in VT Re-ID, an intuitive and apparent method is to map the cross-modality persons into a common feature space to realize the similarity measure. Therefore, a two-stream framework is always adopted, including two modality-specific networks with independent parameters for feature extraction, and a parameter-sharing network for feature embedding to project the modality-specific features into a common feature space. Generally, the two modality-specific networks are not required to have the same architecture. The only criterion is that their outputs should have the same dimension shapes to be the input of the parameter-sharing network for feature embedding. In the literature, the ResNet50 [7] model is preferentially adopted as the backbone to construct the two-stream network, all the res-convolution blocks for feature extraction and some parameter-sharing fully connected layers for feature embedding. However, is this setting the best choice to construct the two-stream network? Those parametersharing fully-connected layers can only process the 1D-shaped vector, ignoring the spatial structure information of persons. To take advantage of the convolutional layers for processing the 3D-shaped tensor with spatial structure information, we can share some parameters of res-convolution blocks for feature embedding. In this situation, how many parameters of the two-stream network to share is the point of this study to investigate.
VT Re-ID任务面临两大主要问题:一是由可见光与热成像相机不同的反射光谱和感应特性导致的大跨模态差异;二是类似于VV Re-ID任务中因视角变化、人体姿态差异等引起的大模态内差异。为缓解VT Re-ID中额外的跨模态差异,一种直观有效的方法是将跨模态行人映射到公共特征空间以实现相似性度量。因此,通常采用双流框架,包含两个具有独立参数的模态专用网络(用于特征提取)和一个参数共享网络(用于将模态专用特征嵌入公共空间)。这两个模态专用网络无需结构相同,唯一标准是其输出维度需一致以作为参数共享网络的输入。现有研究普遍优先采用ResNet50[7]作为骨干网络构建双流框架:所有残差卷积块用于特征提取,部分参数共享的全连接层用于特征嵌入。但这种设置是否是最佳选择?这些参数共享的全连接层仅能处理一维向量,忽略了行人的空间结构信息。为利用卷积层处理具有空间结构信息的三维张量,我们可共享部分残差卷积块参数进行特征嵌入。本研究重点探讨双流网络中应共享多少参数的问题。
In addition, the network is always trained with identification loss and triplet loss to simultaneously enlarge the inter-class distance and minimize the intra-class distance. The triplet loss is performed on each anchor sample to all the other samples from both the same modality and cross modality. This may be a strong constraint for constraining the pairwise distance of those samples, especially when there exist some outliers (bad examples), which would form the adverse triplet to destroy other well-learned pairwise distances. It also leads to high complexity with a large number of triplets. The cross-modality and intra-modality training strategy is separately employed to enhance feature learning [12], [35]. In the authors’ opinion, the separate cross-modality and intra-modality training strategy may be unnecessary if those learned person features by the two-stream network are good enough in the common feature space, where the features can hardly be distinguished from which modality. Therefore, we propose the hetero-center triplet loss that directly performs in the unified common feature space. The hetero-center triplet loss is performed on each anchor center to all the other centers, which can also reduce the computational complexity.
此外,该网络始终通过身份识别损失(identification loss)和三重损失(triplet loss)进行训练,以同时扩大类间距离并最小化类内距离。三重损失针对每个锚点样本(anchor sample)与来自同模态及跨模态的所有其他样本进行计算。这种约束可能对样本间成对距离形成强限制,尤其当存在异常样本(outliers)时,这些样本会构成破坏性三元组(adverse triplet),干扰已学习良好的成对距离关系。同时,大量三元组也导致计算复杂度较高。现有研究采用分离的跨模态与同模态训练策略来增强特征学习 [12][35]。我们认为,若双流网络在公共特征空间中学习到的人物特征足够优质(即难以区分特征来源模态时),这种分离式训练策略可能并非必要。因此,我们提出直接在统一公共特征空间中执行的异质中心三重损失(hetero-center triplet loss),该损失作用于每个锚点中心与其他所有中心之间,可同步降低计算复杂度。
The main contributions can be summarized as follows.
主要贡献可总结如下。
• We achieve state-of-the-art performance on two datasets by large margins, which can be a strong VT Re-ID baseline to boost future research with high quality. • We explore the parameter-sharing problem in a twostream network. To the best of our knowledge, it is the first attempt to analyze the impact of the number of parameter sharing for cross-modality feature learning. We propose the hetero-center triplet loss to constrain the distance of different class centers from both the same modality and cross modality.
• 我们在两个数据集上以显著优势实现了最先进的性能,这可以作为一个强大的可见光-热成像(Visible-Thermal, VT)行人重识别(Re-ID)基准,推动未来高质量研究。
• 我们探索了双流网络中的参数共享问题。据我们所知,这是首次尝试分析参数共享数量对跨模态特征学习的影响。我们提出了异质中心三元组损失(hetero-center triplet loss),用于约束来自同一模态和跨模态的不同类别中心之间的距离。
II. RELATED WORK
II. 相关工作
This section briefly reviews those existing VT Re-ID approaches. Compared to the traditional VV Re-ID, except for the intra-modality variations, VT Re-ID should handle the extra cross-modality discrepancy. To alleviate this problem, researchers focus on projecting (or translating) the heterogeneous cross-modality person images into a common space for similarity measure, mainly including the following aspects: network designing, metric learning and image translation.
本节简要回顾现有的可见光-热成像跨模态行人重识别(VT Re-ID)方法。相比传统的可见光-可见光行人重识别(VV Re-ID),VT Re-ID除了需要处理模态内差异外,还需解决额外的跨模态差异问题。为缓解该问题,研究者主要关注将异构跨模态行人图像投影(或转换)至公共空间进行相似性度量,主要包括以下方向:网络架构设计、度量学习和图像转换。
A. Network designing
A. 网络设计
Feature learning is the fundamental step of Re-Identification before similarity measure. Most studies focus on the visible and thermal person feature learning through designing deep neural networks (DNN). Ye et.al [31], [32], [35] proposed adopting a two-stream network to separately extract the modality-specific features, and then performed the feature embedding to project those features into the common feature space with parameters sharing fully connected layers. Based on the two-stream network, Liu et al. [12] introduced mid-level features incorporation to enhance the modality-shared person features with more disc rim inability. To learn good modalityshared person features, Dai et al. [2] proposed the crossmodality generative adversarial network (cmGAN) under the adversarial learning framework, including a disc rim in at or to distinguish whether the input features are from the visible modality or thermal modality. Zhang et al. [37] proposed a dual-path cross-modality feature learning framework, including a dual-path spatial-structure-preserving common space network and a contrastive correlation network, which preserves intrinsic spatial structures and attends to the difference of input cross-modality image pairs. To explore the potential of both the modality-shared information and the modality-specific characteristics to boost the re-identification performance, Lu et al. [13] proposed modeling the affinities of different modality samples according to the shared features and then transferring both shared and specific features among and across modalities.
特征学习是进行相似度度量前行人重识别的基础步骤。大多数研究通过设计深度神经网络(DNN)来学习可见光和热成像模态下的行人特征。Ye等人[31][32][35]提出采用双流网络分别提取模态特异性特征,随后通过参数共享的全连接层进行特征嵌入,将这些特征映射到公共特征空间。在双流网络基础上,Liu等人[12]引入中层特征融合机制,以增强模态共享行人特征的判别性。Dai等人[2]在对抗学习框架下提出跨模态生成对抗网络(cmGAN),通过判别器区分输入特征来自可见光或热成像模态,从而学习优质模态共享特征。Zhang等人[37]提出双路径跨模态特征学习框架,包含保持空间结构的双路径公共空间网络和对比相关网络,该框架能保留内在空间结构并关注跨模态图像对的差异。Lu等人[13]为挖掘模态共享信息和模态特异性特征的协同潜力,提出基于共享特征建模不同模态样本的亲和度,进而在模态内和模态间传递共享与特异性特征。
Moreover, for handling the cross-modality discrepancy, some works concentrate on the input design of a singlestream network to simultaneously utilize visible and thermal information. Wu et al. [27] first proposed to study the VT Re-ID problem, built the SYSU-MM01 dataset, and developed the zero-padding method to extract the modality-shared person features with a single-stream network. Kang et al. [9] proposed combining the visible and thermal images as a single input with different image channels. Additionally, Wang et al. [24] also adopted a multi spectral image as the input for feature learning, where the multi spectral image consists of the visible image and corresponding generated thermal image, or the generated visible image and corresponding thermal image.
此外,为处理跨模态差异,一些研究聚焦于单流网络的输入设计,以同时利用可见光与热红外信息。Wu等[27]首次提出研究VT Re-ID问题,构建了SYSU-MM01数据集,并开发了零填充方法通过单流网络提取模态共享的人物特征。Kang等[9]提出将可见光与热红外图像合并为具有不同图像通道的单一输入。Wang等[24]则采用多光谱图像作为特征学习的输入,该多光谱图像由可见光图像与对应生成的热红外图像、或生成可见光图像与对应热红外图像组成。
B. Metric learning
B. 度量学习
Metric learning is the key step of Re-ID for similarity measure. In the deep learning framework, due to the advantage of DNN on feature learning, Re-ID could achieve good performance with only the Euclidean distance metric. Therefore, metric learning is inherent in the training loss function of DNN, guiding the training process to make the extracted features more disc rim i native and robust. Ye et al. [31] proposed a hierarchical cross-modality matching model by jointly optimizing the modality-specific and modality-shared metrics in a sequential manner. Then, they presented a bidirectional dual-constrained top-ranking loss to learn discriminative feature representations based on a two-stream network [35], based on which, the center-constraint was also introduced to improve performance [32]. Zhu et al. [39] proposed the hetero-center loss to reduce the intra-class cross-modality variations. Liu et al. [12] also proposed the dual-modality triplet loss to guide the training procedures by simultaneously considering the cross-modality discrepancy and intra-modality variations. Hao et al. [6] proposed an end-to-end two-stream hyper sphere manifold embedding network with both classification and identification loss, constraining the intra-modality variations and cross-modality variations on this hyper sphere. Zhao et al. [38] introduced the hard pentaplet loss to improve the performance of the cross-modality re-identification. Wu et al. [26] cast the learning shared knowledge for crossmodality matching as the problem of cross-modality similarity preservation, and proposed a focal modality-aware similaritypreserving loss to leverage the intra-modality similarity to guide the inter-modality similarity learning.
度量学习是Re-ID(重识别)中相似性度量的关键步骤。在深度学习框架下,由于DNN在特征学习上的优势,Re-ID仅使用欧氏距离度量即可取得良好性能。因此,度量学习内置于DNN的训练损失函数中,通过指导训练过程使提取的特征更具判别性和鲁棒性。Ye等人[31]提出分层跨模态匹配模型,通过顺序联合优化模态特定和模态共享的度量。随后,他们基于双流网络[35]提出双向双约束顶级排序损失来学习判别性特征表示,并引入中心约束进一步提升性能[32]。Zhu等人[39]提出异质中心损失以减少类内跨模态差异。Liu等人[12]提出双模态三元组损失,通过同时考虑跨模态差异和模态内变化来指导训练过程。Hao等人[6]提出端到端双流超球面流形嵌入网络,结合分类损失和身份损失,在超球面上约束模态内变化和跨模态差异。Zhao等人[38]引入困难五元组损失提升跨模态重识别性能。Wu等人[26]将跨模态匹配的共享知识学习转化为跨模态相似性保持问题,提出焦点模态感知相似性保持损失,利用模态内相似性指导跨模态相似性学习。
TABLE I DIFFERENT SPLITS OF RESNET50 MODEL TO FORM THE TWO-STREAM BACKBONE NETWORK. $\phi_{v}$ AND $\phi_{t}$ RESPECTIVELY DENOTE THE VISIBLE-STREAM AND THERMAL-STREAM FEATURE EXTRACTION NETWORK. $\phi_{v t}$ DENOTES THE MODALITY-SHARED FEATURE EMBEDDING NETWORK. stage ${0-2}$ DENOTES stage0, stage1 AND stage2. IT IS DETAILEDLY ILLUSTRATED IN FIG. 6.
表 1: RESNET50模型的不同分割方式以构成双流骨干网络。$\phi_{v}$和$\phi_{t}$分别表示可见光流和热红外流的特征提取网络。$\phi_{v t}$表示模态共享的特征嵌入网络。stage${0-2}$表示stage0、stage1和stage2。具体说明见图6。
| 模态特定特征提取器 ($\phi_{v}$和$\phi_{t}$) | 模态共享特征嵌入 ($\phi_{v t}$) | |
|---|---|---|
| s0 | stage{0-4} | |
| s1 | stage{0} | stage{1-4} |
| s2 | stage{0-1} | stage{2-4} |
| s3 | stage{0-2} | stage{3-4} |
| s4 | stage{0-3} | stage{4} |
| s5 | stage{0-4} |
C. Image translation
C. 图像翻译
The aforementioned works handle the cross-modality discrepancy and intra-modality variations from the feature extraction level. Recently, image generation methods based on generative adversarial network (GAN) have drawn much attention in VT Re-ID, reducing the domain gap between visible and thermal modalities from image level. Kniaz et al. [10] first introduced GAN to translate a single visible image to a multimodal thermal image set, and then performed the ReID in the thermal domain. Wang et al. [20] proposed an end-to-end alignment generative adversarial network (AlignGAN) for VT Re-ID, to jointly bridge the cross-modality gap with feature alignment and pixel alignment. Wang et al. [24] proposed a dual-level discrepancy reduction learning framework based on a bi-directional cycleGAN to reduce the domain gap, from both the image and feature levels. Choi et al. [1] proposed a hierarchical cross-modality disentanglement (Hi-CMD) method, which automatically disentangles IDdisc rim i native factors and ID-excluded factors from visiblethermal images. Hi-CMD includes an ID-preserving person image generation network and a hierarchical feature learning module.
上述工作从特征提取层面处理跨模态差异和模态内变化。近年来,基于生成对抗网络 (GAN) 的图像生成方法在可见光-热红外跨模态行人重识别 (VT Re-ID) 领域备受关注,从图像层面减小可见光与热红外模态间的域差异。Kniaz 等人 [10] 首次引入 GAN 将单张可见光图像转换为多模态热红外图像集,随后在热红外域进行重识别。Wang 等人 [20] 提出端到端对齐生成对抗网络 (AlignGAN),通过特征对齐和像素对齐联合桥接跨模态差异。Wang 等人 [24] 提出基于双向循环生成对抗网络 (cycleGAN) 的双层级差异缩减学习框架,从图像和特征两个层面减小域差异。Choi 等人 [1] 提出分层跨模态解耦方法 (Hi-CMD),该方法可从可见光-热红外图像中自动解耦身份相关特征与身份无关特征,其框架包含身份保持的人物图像生成网络和分层特征学习模块。
However, a person in the thermal modality can have different colors of clothes in the visible modality, leading to one thermal person image corresponding to multiple reasonable visible person images by image generation. It is hard to know which one is the correct target to be generated for ReID since when generating images, the model cannot access the gallery images that only appear in the inference phase. Image generation-based methods always have performance uncertainty, high complexity and high training trick demands.
然而,热成像模态中的人物可能在可见光模态下穿着不同颜色的衣物,这会导致一张热成像人物图像通过图像生成对应多张合理的可见光人物图像。由于生成图像时模型无法访问仅在推理阶段出现的图库图像,很难确定哪一张是ReID任务应生成的正确目标。基于图像生成的方法始终存在性能不确定性、高复杂度以及对训练技巧的高要求。
III. OUR PROPOSED METHOD
III. 我们的方法
In this section, we introduce the framework of our proposed feature learning model for VT Re-ID, as depicted in Fig. 2. The model mainly consists of three components: (1) the twostream backbone network, exploring the parameter sharing, (2) the part-level feature extraction block and (3) the loss, our proposed hetero-center triplet loss and identity softmax loss.
在本节中,我们将介绍所提出的VT Re-ID特征学习框架,如图2所示。该模型主要由三部分组成:(1) 双流主干网络,探索参数共享机制;(2) 部件级特征提取模块;(3) 损失函数,包括我们提出的异质中心三元组损失和身份softmax损失。
A. Two-stream backbone network
A. 双流主干网络
The two-stream network is a conventional way to extract features in visible-thermal cross-modality person reidentification, first introduced in [35]. It consists of two parts: feature extractor and feature embedding. The feature extractor aims at learning the modality-specific information from two heterogeneous modalities, while the feature embedding focuses on learning the multi-modality shared features for cross-modality re-identification by projecting those modalityspecific features into a modality-shared common feature space.
双流网络是可见光-热成像跨模态行人重识别中提取特征的常规方法,最初由[35]提出。该网络包含两部分:特征提取器和特征嵌入模块。特征提取器负责从两种异构模态中学习模态特定信息,而特征嵌入模块则通过将这些模态特定特征投影到模态共享的公共特征空间,专注于学习跨模态重识别所需的多模态共享特征。
In the existing literature, feature embedding is always computed by some shared fully connected layers, and the feature extractor is always a well-designed convolution neural network, such as ResNet50. In this situation, there may be two problems we should pay attention.
现有文献中,特征嵌入(embedding)通常通过共享的全连接层计算,而特征提取器往往采用精心设计的卷积神经网络(如ResNet50)。这种情况下存在两个需要注意的问题:
To simultaneously address the aforementioned two problems, we propose to split the well-designed CNN model into two parts. The former part can be set as a two-stream feature extractor with independent parameters, while the latter part can be set as the feature embedding model. In this way, the whole model size will be reduced (corresponding to problem 1). The input of the feature embedding block is the output of the feature extractor, only the middle 3D feature maps of the well-designed CNN model, which is full of the person spatial structure information (corresponding to problem 2).
为了同时解决上述两个问题,我们提出将精心设计的CNN模型拆分为两部分。前部可设置为具有独立参数的双流特征提取器,而后部可设置为特征嵌入模型。这种方式能有效减小整体模型规模(对应问题1)。特征嵌入模块的输入是特征提取器的输出,即仅保留原CNN模型中间富含人体空间结构信息的三维特征图(对应问题2)。
Therefore, the key point is how to split the well-designed CNN model. Namely, how many parameters of the two-stream network should be independent to learn the modality-specific information?
因此,关键在于如何拆分精心设计的CNN模型。具体来说,双流网络中应有多少参数保持独立以学习模态特定信息?
For simplicity in presentation, we denote the visible-stream feature extraction network as function $\phi_{v}$ , the thermal-stream feature extraction network as $\phi_{t}$ to learn the modality-specific information, and the feature embedding network as $\phi_{v t}$ to project modality-specific person features into the shared common feature space. Given a visible image $I_{v}$ and a thermal image $I_{t}$ , the learned 3D person features $v$ and $t$ in common space can be represented as,
为简化表述,我们将可见光流特征提取网络表示为函数 $\phi_{v}$ ,热成像流特征提取网络表示为 $\phi_{t}$ 以学习模态特定信息,特征嵌入网络表示为 $\phi_{v t}$ 用于将模态特定的人物特征投影到共享公共特征空间。给定可见光图像 $I_{v}$ 和热成像图像 $I_{t}$ ,在公共空间学习到的3D人物特征 $v$ 和 $t$ 可表示为:
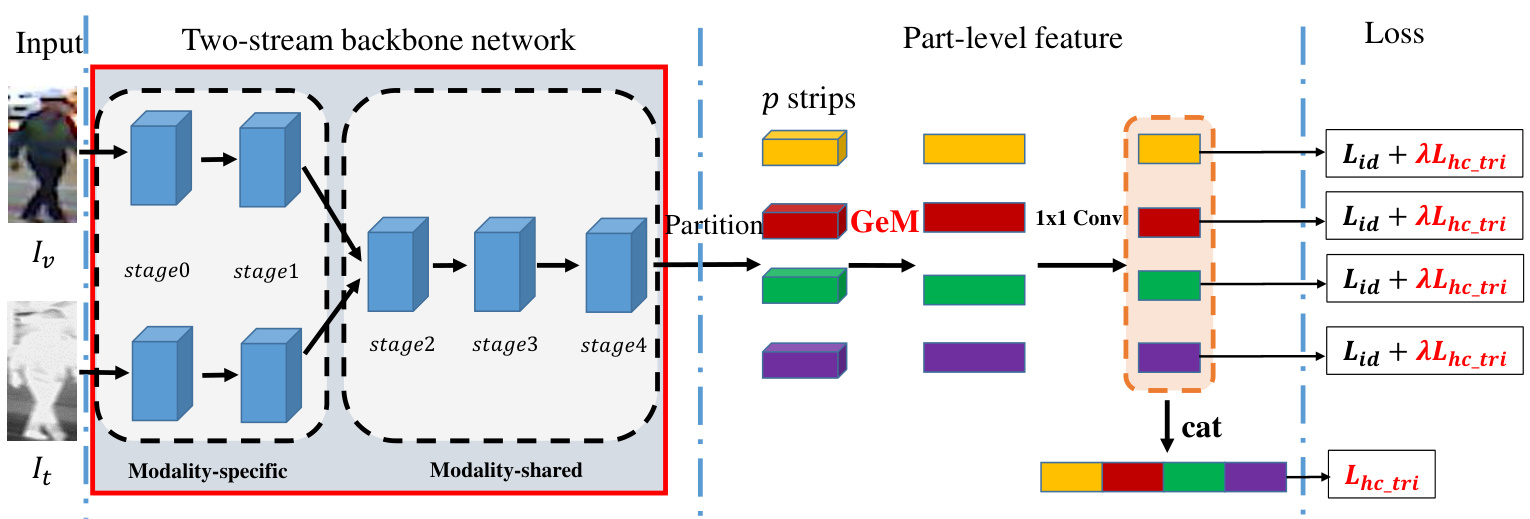
Fig. 2. The pipeline of our proposed framework for VT Re-ID, which mainly contains three components: two-stream backbone network, part-level feature learning block and loss. The two-stream backbone network includes two modality-specific branches with independent parameters and follows one modalityshared branch with shared parameters. For example, we take the ResNet50 model as the backbone, the first two stages (stage0 and stage1) form the modality-specific branches and the following three stages (stage2, stage3 and stage4) form the modality-shared branch. Then, the feature map outputted from the backbone is horizontally split into $p$ 3D tensors, here $p=4$ , which are pooled into vectors by generalized-mean $(G e M)$ pooling operation. For each part vector, a $1\times1$ Conv block reduces the dimension of features. Afterward, the reduced part features are respectively input to compute the identification loss $L_{i d}$ and our proposed hetero-center triplet loss $L_{h c_t r i}$ . Finally, all the part features are concatenated (cat) to form the final person features, which is supervised by $L_{h c_t r i}$ .
图 2: 我们提出的VT Re-ID框架流程,主要包含三个组件:双流主干网络、部件级特征学习模块和损失函数。双流主干网络包含两个参数独立的模态特定分支和一个参数共享的模态共享分支。例如,我们以ResNet50模型为主干网络,前两个阶段(stage0和stage1)构成模态特定分支,后三个阶段(stage2、stage3和stage4)构成模态共享分支。随后,主干网络输出的特征图被水平分割为$p$个3D张量(此处$p=4$),并通过广义均值$(GeM)$池化操作聚合成向量。每个部件向量经过$1\times1$卷积块进行特征降维。降维后的部件特征分别用于计算身份损失$L_{id}$和我们提出的异质中心三元组损失$L_{hc_tri}$。最后,所有部件特征被拼接(cat)形成最终的行人特征,并由$L_{hc_tri}$监督。
We adopt the ResNet50 model as the backbone, with the consideration of its competitive performance in some Re-ID systems as well as its relatively concise architecture. The ResNet50 model mainly consists of one shallow convolution block stage0 and four res-convolution blocks, stage1, stage2, stage3 and stage4. To split the ResNet50 model into our modality-specific feature extractor and modality-shared feature embedding network, we can sequentially obtain the split scheme as shown in Table I, where $s i,i={0,1,2,3,4,5}$ means $\phi_{v t}$ starts from the $i^{t h}$ stage. $s0$ and $s5$ are two extreme cases. $s0$ means that the two-stream backbone network shares all the ResNet50 model without the modality-specific feature extractor, while s5 means that all parameters of the two streams for the visible and thermal modalities are totally independent as in [35]. Which is the best choice for a two-stream backbone network for cross-modality Re-ID? In the authors’ opinion, these two extreme cases $s0$ and $s5$ are not good, since they ignore some important information in the cross-modality Re-ID task. Experimental results in Sec. IV-B1 show that the modality-shared feature embedding network comprising some res-convolution blocks is a good choice, since the input of modality-shared feature embedding network $\phi_{v t}$ is 3D shape feature maps, with the spatial structure information of persons.
我们采用ResNet50模型作为主干网络,主要考虑到其在部分Re-ID系统中的优异表现以及相对简洁的架构。ResNet50模型主要由一个浅层卷积块stage0和四个残差卷积块stage1、stage2、stage3、stage4组成。为了将ResNet50模型拆分为模态特定特征提取器和模态共享特征嵌入网络,我们可以按表1所示的顺序获得拆分方案,其中$s i,i={0,1,2,3,4,5}$表示$\phi_{v t}$从第$i^{t h}$阶段开始。$s0$和$s5$是两种极端情况:$s0$表示双流主干网络共享整个ResNet50模型而没有模态特定特征提取器,而$s5$表示可见光和热红外模态的双流参数完全独立[35]。对于跨模态Re-ID任务,哪种双流主干网络是最佳选择?作者认为这两种极端情况$s0$和$s5$都不理想,因为它们忽略了跨模态Re-ID任务中的一些重要信息。第IV-B1节的实验结果表明,包含若干残差卷积块的模态共享特征嵌入网络是较好的选择,因为模态共享特征嵌入网络$\phi_{v t}$的输入是包含行人空间结构信息的三维形状特征图。
B. Part-level feature extraction block
B. 部件级特征提取块
In VV Re-ID, state-of-the-art results are always achieved with part-level deep features [19], [28]. A typical and simple approach is partitioning persons into horizontal strips to coarsely extract the part-level features, which can then be concatenated to describe the person’s body structure. Body structure is the inherent characteristic of a person, which is invariant information of the person’s body whatever modality the image is captured from. Namely, the body structure information is modality-invariant, which can be adopted as modality-shared information to represent a person. Therefore, according to the part-level feature extraction method in [18], [22], we also adopt the uniform partition strategy to obtain coarse body part features.
在可见光-可见光行人重识别(VV Re-ID)领域,最先进的结果总是通过部件级深度特征[19][28]实现。一种典型且简单的方法是将人体划分为水平条带,粗略提取部件级特征,然后拼接这些特征来描述人体结构。人体结构是人的固有特征,无论图像采集自何种模态,这些信息都保持不变。也就是说,人体结构信息具有模态不变性,可作为跨模态共享信息来表征行人。因此,参照[18][22]中的部件级特征提取方法,我们同样采用均匀划分策略来获取粗略的人体部位特征。
Given a person (visible or thermal) images, it will become the 3D feature map after undergoing all the layers inherited from the two-stream backbone network. Based on the 3D feature maps, as shown in Fig. 2, there are 3 steps to extract the part-level person features as follows.
给定一个人(可见光或热成像)图像,经过继承自双流骨干网络的所有层处理后,它将变为3D特征图。基于这些3D特征图,如图2所示,提取部件级人物特征分为以下3个步骤。
$$
{\hat{x}}=\big(\frac{1}{|X|}\sum_{x_{i}\in X}x_{i}^{\mathrm{p}}\big)^{\frac{1}{\mathrm{p}}},
$$
$$
{\hat{x}}=\big(\frac{1}{|X|}\sum_{x_{i}\in X}x_{i}^{\mathrm{p}}\big)^{\frac{1}{\mathrm{p}}},
$$
where $\hat{x}\in R^{C\times1\times1}$ is the pooled result, $|\cdot|$ denotes the element number, and $\mathrm{p}$ is the pooling hyper parameter, which can be preset or learned by back-propagation.
其中 $\hat{x}\in R^{C\times1\times1}$ 是池化结果,$|\cdot|$ 表示元素数量,$\mathrm{p}$ 是池化超参数,可预设或通过反向传播学习。
- Afterwards, a $1\times1$ convolutional $(1\times1~\mathbf{Conv})$ block is employed to reduce the dimension of part-level feature vectors. The block includes a $1\times1$ convolutional layer whose output channel number is $d$ , following a batch normalization layer and a ReLU layer.
- 随后,使用一个 $1\times1$ 卷积块 $(1\times1~\mathbf{Conv})$ 来降低局部特征向量的维度。该块包含一个输出通道数为 $d$ 的 $1\times1$ 卷积层,后接批归一化层和ReLU层。
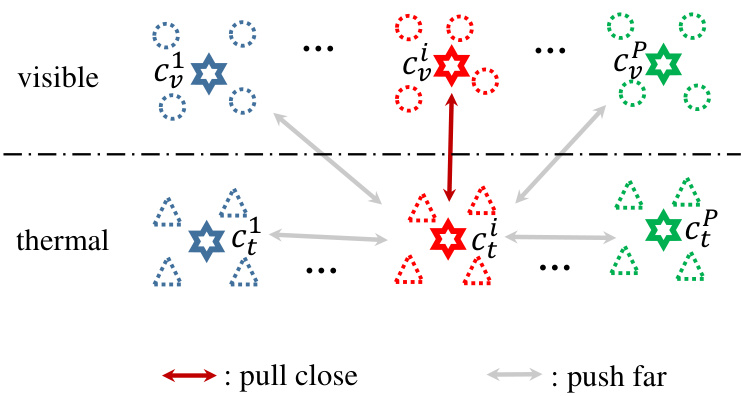
Fig. 3. Illustration of the hetero-center triplet loss, which aims pulling close those centers with the same identity label from different modalities, while pushing far away those centers with different identity labels regardless of which modality it is from. We compare the center to center similarity rather than sample to sample similarity or sample to center similarity. The stars denote the centers. Different colors denote different identities.
图 3: 异质中心三元组损失示意图。该损失旨在拉近来自不同模态但具有相同身份标签的中心,同时推开具有不同身份标签的中心(无论其来自何种模态)。我们比较的是中心与中心之间的相似度,而非样本与样本或样本与中心之间的相似度。星号表示中心点,不同颜色代表不同身份。
Moreover, each part-level feature vector is first adopted to perform metric learning with triplet loss $L_{t r i}$ (or our proposed hetero-center triplet loss $L_{h c_t r i})$ . Then, a fully connected layer with desired dimensions (corresponding to the number of identities in our model) is adopted to perform the identification with softmax $L_{i d}$ . There are $p$ part-level features that need $p$ different class if i ers without sharing parameters.
此外,每个部件级特征向量首先用于执行带有三元组损失 $L_{tri}$ (或我们提出的异中心三元组损失 $L_{hc_tri}$)的度量学习。接着,采用一个具有所需维度(对应模型中身份数量)的全连接层,通过 softmax $L_{id}$ 进行身份识别。共有 $p$ 个部件级特征,需要 $p$ 个不共享参数的不同分类器。
Finally, all the $p$ part-level features are concatenated $(c a t)$ to form the final person features for the similarity measure during testing. Additionally, the final person features can also be supervised by the $L_{t r i}$ (or $L_{h c_t r i})$ ).
最后,将所有 $p$ 个部件级特征拼接 $(cat)$ 起来,形成用于测试时相似度度量的最终人物特征。此外,最终人物特征也可通过 $L_{tri}$ (或 $L_{hc_tri}$) 进行监督。
C. The hetero-center triplet loss
C. 异质中心三元组损失
In this subsection, we introduce the designed hetero-center triplet loss to guide the network training for part-level feature learning. The learning objective is directly conducted in the common feature space to simultaneously deal with both crossmodality discrepancy and intra-modality variations. First, we revisit the general triplet loss.
在本小节中,我们介绍了设计的异质中心三元组损失(hetero-center triplet loss),以指导网络进行部件级特征学习。该学习目标直接在公共特征空间中进行,以同时处理跨模态差异和模态内变化。首先,我们回顾一般的三元组损失。
- Triplet loss revisit: Triplet loss was first proposed in FaceNet [17], and then improved by mining the hard triplets [8]. The core idea is to form batches by randomly sampling $P$ identities, and then randomly sampling $K$ images of each identity, resulting in a mini-batch with $P K$ images. For each sample $x_{a}$ in the mini-batch, we can select the hardest positive and hardest negative samples within the mini-batch to form the triplets for computing the batch hard triplet loss,
- 三重损失回顾:三重损失最初由FaceNet [17]提出,后通过挖掘困难三元组 [8] 得到改进。其核心思想是随机采样 $P$ 个身份,再为每个身份随机采样 $K$ 张图像组成包含 $P K$ 张图像的小批量。对于小批量中的每个样本 $x_{a}$,可在小批量内选取最难正样本和最难负样本来计算批量困难三重损失。
TABLE II THE COMPARISON OF COMPUTATIONAL COST BETWEEN GENERAL TRIPLET LOSS $L_{b h_t r i}$ AND OUR PROPOSED HETERO-CENTER TRIPLET LOSS $L_{h c_t r i}$ . DUE TO THE SYMMETRICAL PROPERTY OF DISTANCEMEASURE, THE COMPUTATIONAL COST COULD DIVIDE 2.
表 II: 通用三元组损失 $L_{b h_t r i}$ 与本文提出的异质中心三元组损失 $L_{h c_t r i}$ 的计算成本对比。由于距离度量的对称性,计算成本可除以2。
| positive | negative | |
|---|---|---|
| Lbh_tri | 2PK × (2K-1) | 2PK × 2(P -1)K |
| Lhc_tri | 2P | 2P x 2(P - 1) |
which is defined for a mini-batch $X$ , where a data point ${\boldsymbol{x}}{a}^{i}$ denotes the $a^{t h}$ image of the $i^{t h}$ person in the batch, $[x]{+}=$ $\mathrm{max}(x,0)$ denotes the standard hinge loss, $|x_{a}-x_{p}|{2}$ denotes the Euclidean distance of data point $x{a}$ and $x_{p}$ , $\rho$ is the margin.
其定义为针对小批量数据 $X$ 的损失函数,其中数据点 ${\boldsymbol{x}}{a}^{i}$ 表示批次中第 $i^{t h}$ 个人的第 $a^{t h}$ 张图像,$[x]{+}=$ $\mathrm{max}(x,0)$ 表示标准合页损失 (hinge loss),$|x_{a}-x_{p}|{2}$ 表示数据点 $x{a}$ 和 $x_{p}$ 之间的欧氏距离,$\rho$ 为间隔参数。
- Batch sampling method: Due to our two-stream structure respectively extracting features for visible and thermal images, we introduce the following online batch sampling strategy. Specifically, $P$ person identities are first randomly selected at each iteration, and then we randomly select $K$ visible images and $K$ thermal images of the selected identity to form the mini-batch, in which a total of $2*P K$ images are obtained. This sampling strategy can fully utilize the relationship of all the samples within a mini-batch. In this manner, the sample size of each class is the same, which is important to avoid the perturbations caused by class imbalance. Moreover, due to the random sampling mechanism, the local constraint in the mini-batch can achieve the same effect as the global constraint in the entire set.
- 批量采样方法:由于我们的双流结构分别提取可见光和热成像图像特征,因此引入了以下在线批量采样策略。具体而言,每次迭代时先随机选取 $P$ 个行人身份,然后从每个选定身份中随机选取 $K$ 张可见光图像和 $K$ 张热成像图像组成小批量,最终获得共计 $2*P K$ 张图像。该采样策略能充分利用小批量内所有样本的关联关系。通过这种方式,每个类别的样本量保持相同,这对避免类别不平衡引起的干扰至关重要。此外,由于随机采样机制的存在,小批量内的局部约束能达到与全局约束相同的效果。
- Hetero-center triplet loss: Eq. (3) shows that triplet loss computes the loss by comparison of the anchor to all the other samples. It is a strong constraint, perhaps too strict to constrain the pairwise distance if there exist some outliers (bad examples), which would form the adverse triplet to destroy other pairwise distances. Therefore, we consider adopting the center of each person as the identity agent. In this manner, we can relax the strict constraint by replacing the comparison of the anchor to all the other samples by the anchor center to all the other centers.
- 异质中心三元组损失:式 (3) 表明,三元组损失通过将锚点与所有其他样本进行比较来计算损失。这是一种强约束条件,若存在异常样本(不良示例),可能会因形成破坏性三元组而过度限制成对距离。因此,我们考虑采用每个人的中心作为身份代理 (identity agent)。这种方式通过将锚点与所有样本的比较替换为锚点中心与其他所有中心的比较,从而放宽了严格约束。
First, in a mini-batch, the center for the features of every identity from each modality is computed,
首先,在一个小批量(mini-batch)中,计算每个模态下各身份特征的中心点,
$$
\begin{array}{l}{{\displaystyle c_{v}^{i}=\frac{1}{K}\sum_{j=1}^{K}v_{j}^{i}},}\ {{\displaystyle c_{t}^{i}=\frac{1}{K}\sum_{j=1}^{K}t_{j}^{i}},}\end{array}
$$
$$
\begin{array}{l}{{\displaystyle c_{v}^{i}=\frac{1}{K}\sum_{j=1}^{K}v_{j}^{i}},}\ {{\displaystyle c_{t}^{i}=\frac{1}{K}\sum_{j=1}^{K}t_{j}^{i}},}\end{array}
$$
which is defined for a mini-batch, where $v_{j}^{i}$ denotes the $j^{t h}$ visible image feature of the $i^{t h}$ person in the mini-batch, while $t_{j}^{i}$ corresponds to the thermal image feature.
其定义为一个小批量(mini-batch),其中$v_{j}^{i}$表示小批量中第$i^{t h}$个人的第$j^{t h}$个可见光图像特征,而$t_{j}^{i}$对应热成像特征。
Therefore, based on our $P K$ sampling method, in each mini-batch, there are and $P$ thermal centers ${c_{t}^{i}|i=1,\cdots,P}$ , as shown in Fig. 3. In the following, all the computations are only performed on the centers.
因此,基于我们的 $PK$ 采样方法,每个小批次中包含 $P$ 个可见光图像中心 和 $P$ 个热成像中心 ${c_{t}^{i}|i=1,\cdots,P}$,如图 3 所示。下文所有计算仅针对这些中心进行。
The goal of metric learning is to make those features from the same class close to each other (intra-class compactness), while those features from different classes are far away from each other (inter-class separation). Therefore, in our VT crossdomain Re-ID, based on the $P K$ sampling strategy and calculated centers, we can define the hetero-center triplet loss as,
度量学习的目标是使同一类别的特征彼此接近(类内紧凑性),而不同类别的特征彼此远离(类间分离性)。因此,在我们的VT跨域Re-ID中,基于$PK$采样策略和计算得到的中心,可以定义异质中心三元组损失为,
$$
L_{h c_t r i}(C)=\sum_{i=1}^{P}\left[\rho+|c_{v}^{i}-c_{t}^{i}|{2}-\operatorname*{min}{\stackrel{n\in{v,t}}{j\neq i}}|c_{v}^{i}-c_{n}^{j}|{2}\right]_{+}
$$
$$
L_{h c_t r i}(C)=\sum_{i=1}^{P}\left[\rho+|c_{v}^{i}-c_{t}^{i}|{2}-\operatorname*{min}{\stackrel{n\in{v,t}}{j\neq i}}|c_{v}^{i}-c_{n}^{j}|{2}\right]_{+}
$$
$$
+\sum_{i=1}^{P}\Big[\rho+|c_{t}^{i}-c_{v}^{i}|{2}-\operatorname*{min}{\underset{j\neq i}{n\in{v,t}}}|c_{t}^{i}-c_{n}^{j}|{2}\Big]_{+},
$$
$$
+\sum_{i=1}^{P}\Big[\rho+|c_{t}^{i}-c_{v}^{i}|{2}-\operatorname*{min}{\underset{j\neq i}{n\in{v,t}}}|c_{t}^{i}-c_{n}^{j}|{2}\Big]_{+},
$$
which is defined on mini-batch centers $C$ including both visible centers ${c_{v}^{i}|i=1,\cdots,P}$ and thermal centers ${c_{t}^{i}|i=$ $1,\cdots,P}$ . For each identity, $L_{h c_t r i}$ concentrates on only one cross-modality positive pair and the mined hardest negative pair in both the intra- and inter-modality.
其定义在包含可见中心 ${c_{v}^{i}|i=1,\cdots,P}$ 和热红外中心 ${c_{t}^{i}|i=1,\cdots,P}$ 的迷你批次中心 $C$ 上。对于每个身份,$L_{h c_t r i}$ 仅关注一个跨模态正样本对以及在模态内和模态间挖掘的最难负样本对。
Comparing the general triplet loss $L_{b h_t r i}$ (Eq. (3)) to our proposed center-based triplet loss $L_{h c_t r i}$ (Eq. (5)), we replace the comparison of the anchor to all the other samples by the anchor center to all the other centers. This modification has two major advantages:
将通用三元组损失 $L_{b h_t r i}$ (式(3)) 与我们提出的基于中心的三元组损失 $L_{h c_t r i}$ (式(5)) 进行比较时,我们用锚点中心与其他所有中心的比较替代了锚点与其他所有样本的比较。这一修改具有两大优势:
a) It reduces the computational cost, as shown in Table II. For a mini-batch with $2P K$ images, $L_{b h_t r i}$ requires computing pairwise distance $2P K\times(2K-1)$ for hardest positive sample mining and $2P K\times2(P-1)K$ for hardest negative sample mining. In comparison, $L_{h c_t r i}$ only needs to compute the pairwise distance $2P$ for positive sample pairs (there are only $P$ cross-modality positive center pairs), and $2P\times2(P-1)$ for hardest negative center sample mining. The computational cost is largely reduced.
a) 它降低了计算成本,如表 II 所示。对于一个包含 $2P K$ 张图像的 mini-batch,$L_{b h_t r i}$ 需要计算 $2P K\times(2K-1)$ 的成对距离以挖掘最难正样本,以及 $2P K\times2(P-1)K$ 的成对距离以挖掘最难负样本。相比之下,$L_{h c_t r i}$ 只需计算 $2P$ 的成对距离用于正样本对(仅有 $P$ 个跨模态正中心对),以及 $2P\times2(P-1)$ 的成对距离用于最难负中心样本挖掘。计算成本大幅降低。
b) It relaxes the sample-based triplet constraint to the centerbased triplet constraint, which also preserves the property of handling both the intra-class and inter-class variations simultaneously on visible and thermal modalities in the common feature space. For each identity, minimizing the only cross-modality positive center pairwise distance can ensure intra-class feature compactness. The hardest negative center mining can ensure the inter-class feature distinguishable property both in visible and thermal modalities.
b) 它将基于样本的三元组约束放宽为基于中心的三元组约束,同时保留了在公共特征空间中同步处理可见光和热成像模态的类内与类间差异的特性。对于每个身份,最小化唯一的跨模态正中心对距离可确保类内特征紧凑性。而最困难负中心挖掘则能确保可见光和热成像模态中类间特征的可区分性。
- Comparison to other center-based losses: There are two kinds of center-based losses: the learned centers [25], [32] and the computed centers [39]. The main difference lies in the method of obtaining the centers. One learns them by pre-setting a center parameter for each class, while the other computes the centers directly based on the learned deep features.
- 与其他基于中心的损失函数对比:基于中心的损失函数分为两类:学习型中心 [25]、[32] 和计算型中心 [39]。主要差异在于获取中心点的方式:前者通过为每个类别预设中心参数进行学习,后者则直接基于学习到的深度特征计算中心点。
The learned centers. The learned center loss [25] is first introduced in face verification to learn a center for the features of each class and penalizes the distances between the deep features and their corresponding centers. For our crossmodality VT Re-ID task with the $P K$ sampling strategy, the learned center loss can be extended in a bi-directional manner [12], [32], [35] as follows,
学习中心。学习中心损失 [25] 最初在人脸验证中提出,用于为每个类别的特征学习一个中心,并惩罚深度特征与其对应中心之间的距离。对于采用 $PK$ 采样策略的跨模态 VT Re-ID 任务,学习中心损失可以按如下双向方式扩展 [12][32][35]:
$$
L_{l c}=\frac{1}{2}\sum_{i=1}^{P}\sum_{j=1}^{K}\big(\lVert v_{j}^{i}-c^{i}\rVert_{2}+\lVert t_{j}^{i}-c^{i}\rVert_{2}\big),
$$
$$
L_{l c}=\frac{1}{2}\sum_{i=1}^{P}\sum_{j=1}^{K}\big(\lVert v_{j}^{i}-c^{i}\rVert_{2}+\lVert t_{j}^{i}-c^{i}\rVert_{2}\big),
$$
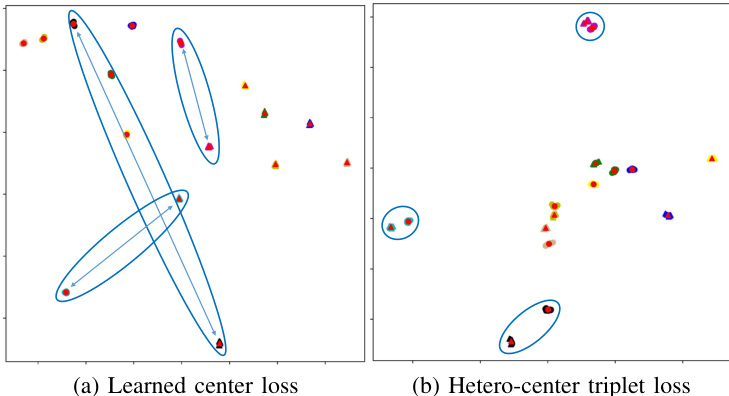
Fig. 4. The visualization of features extracted by the baseline model with (a) the learned center loss and (b) our proposed hetero-center triplet loss. The features are from 8 randomly chosen identities in the RegDB testing dataset, whose dimension of features is reduced to 2 by tSNE. Points with different colors denote features belonging to different identities. Points of different shapes denote different modalities. The red points with different shapes denote the feature centers of each identity from different modalities. Blue arrows in the blue circles link the two centers of one identity from two modalities.
图 4: 基线模型提取特征的可视化结果:(a) 使用学习到的中心损失 (b) 采用我们提出的异质中心三元组损失。特征来自RegDB测试数据集中随机选取的8个身份,通过tSNE将特征维度降至2。不同颜色的点表示属于不同身份的特征,不同形状的点表示不同模态。红色不同形状的点表示各身份在不同模态下的特征中心。蓝色圆圈内的蓝色箭头连接同一身份在两种模态下的两个中心点。
where $v_{j}^{i}$ denotes the $j^{t h}$ visible image feature of the $i^{t h}$ person in the mini-batch, while $t_{j}^{i}$ corresponds to the thermal image feature. $c^{i}$ is the $i^{t h}$ class center for both visible and thermal modalities.
其中 $v_{j}^{i}$ 表示小批次中第 $i^{t h}$ 个人的第 $j^{t h}$ 个可见图像特征,$t_{j}^{i}$ 对应热红外图像特征。$c^{i}$ 是可见光与热红外模态共享的第 $i^{t h}$ 个类别中心。
Comparing the learned center loss $L_{l c}$ (Eq. (6)) to our proposed hetero-center triplet loss $L_{h c_t r i}$ (Eq. (5)), there are the following differences. 1) $L_{h c_t r i}$ is in a comparison of the anchor center to centers rather than $L_{l c}$ ’s anchor sample to centers. 2) $L_{h c_t r i}$ computes the centers for visible and thermal modalities, while $L_{l c}$ unifies the $i^{t h}$ class center for both visible and thermal modalities into one learned vector. 3) $L_{h c_t r i}$ is formulated by triplet mining the properties of both the inter-class se par ability and intra-class compactness, while $L_{l c}$ only focuses on the intra-class compactness, ignoring the inter-class se par ability.
将学习到的中心损失 $L_{l c}$ (式(6)) 与我们提出的异构中心三元组损失 $L_{h c_t r i}$ (式(5)) 进行比较,存在以下差异:
- $L_{h c_t r i}$ 是锚点中心与多个中心的比较,而 $L_{l c}$ 是锚点样本与中心的比较;
- $L_{h c_t r i}$ 分别计算可见光与热成像模态的中心,而 $L_{l c}$ 将第 $i^{t h}$ 类的可见光与热成像模态中心统一为一个学习向量;
- $L_{h c_t r i}$ 通过三元组挖掘同时实现类间可分性与类内紧凑性,而 $L_{l c}$ 仅关注类内紧凑性,忽略了类间可分性。
As shown in Fig. 4, our proposed hetero-center triplet loss $L_{h c_t r i}$ concentrates on both of the inter-class se par ability and intra-class compactness, while the learned center loss $L_{l c}$ ignores the inter-class se par ability for both the intra- and inter modality. $L_{l c}$ only performs well on intra-modality intraclass compactness, but poorly on cross-modality intra-class compactness. This may be due to the hard training of learned center loss combined with identification loss, which leads to the unsatisfactory performance.
如图 4 所示,我们提出的异质中心三元组损失 $L_{h c_t r i}$ 同时关注类间可分离性和类内紧致性,而学习到的中心损失 $L_{l c}$ 则忽略了跨模态和模态内的类间可分离性。$L_{l c}$ 仅在模态内类内紧致性上表现良好,但在跨模态类内紧致性上表现较差。这可能是由于学习到的中心损失与识别损失联合训练的困难性,导致性能不尽如人意。
The computed centers. The other method for obtaining the center of each class is to calculate it directly based on the learned deep features [39]. We also adopt this approach. Instead of pre-setting a center parameter to be learned as Eq. (6), the centers are directly calculated as Eq. (4). In [39], the hetero-center loss $L_{h c}$ was proposed to improve the intraclass cross-modality similarity, penalizing the center distance between two modality distributions, which can be formulated as follows,
计算得到的中心。另一种获取每个类别中心的方法是直接基于学习到的深度特征进行计算[39]。我们也采用了这种方法。与预先设定一个待学习的中心参数如式(6)不同,这些中心直接按式(4)计算得出。在[39]中,提出了异质中心损失$L_{hc}$来提升类内跨模态相似度,通过惩罚两个模态分布间的中心距离来实现,其公式如下,
$$
L_{h c}=\sum_{i=1}^{P}|c_{v}^{i}-c_{t}^{i}|_{2}.
$$
$$
L_{h c}=\sum_{i=1}^{P}|c_{v}^{i}-c_{t}^{i}|_{2}.
$$
Comparing the hetero-center loss $L_{h c}$ (Eq. (7)) to our proposed hetero-center triplet loss $L_{h c_t r i}$ (Eq. (5)), the main difference is that $L_{h c}$ only focuses on the intra-class crossmodality compactness (the red arrows in Fig. 3), while our $L_{h c_t r i}$ additionally focuses on the inter-class se par ability for both the intra- and inter-modality (the grey arrows in Fig. 3) with triplet mining. In summary, $L_{h c}$ is only a part of our proposed $L_{h c_t r i}$ .
比较异质中心损失 $L_{h c}$ (式(7)) 与我们提出的异质中心三元组损失 $L_{h c_t r i}$ (式(5)),主要区别在于 $L_{h c}$ 仅关注类内跨模态紧凑性 (图3中的红色箭头),而我们的 $L_{h c_t r i}$ 还通过三元组挖掘额外关注了类内与类间模态的可分离性 (图3中的灰色箭头)。简而言之,$L_{h c}$ 只是我们提出的 $L_{h c_t r i}$ 的一部分。
- The overall loss: Moreover, similar to some state-ofthe-art VT Re-ID methods [6], [24], [32], [35], [39], for the sake of feasibility and effectiveness for classification, identification loss is also utilized to integrate the identityspecific information by treating each person as a class. The identification loss with label smooth operation is adopted to prevent over fitting the Re-ID model training. Given an image, we denote $y$ as the truth ID label and $p_{i}$ as the ID prediction logits of the $i^{t h}$ class.
- 总体损失: 此外, 类似于一些先进的 VT Re-ID 方法 [6], [24], [32], [35], [39], 为了分类的可行性和有效性, 识别损失也被用来通过将每个人视为一个类别来整合身份特定信息。采用带标签平滑操作的识别损失以防止 Re-ID 模型训练过拟合。给定一张图像, 我们将 $y$ 表示为真实 ID 标签, $p_{i}$ 表示为第 $i^{th}$ 类的 ID 预测 logits。
where $N$ is the number of identities in the total training set, and $\xi$ is a constant to encourage the model to be less confident on the training set. In this work, $\xi$ is set to 0.1.
其中 $N$ 表示整个训练集中的身份数量,$\xi$ 是用于鼓励模型在训练集上保持较低置信度的常数。本研究中 $\xi$ 设为 0.1。
We adopt both the identification loss and hetero-center triplet loss for each part-level feature, while only the heterocenter triplet loss $L_{h c_t r i}^{g}$ is for the final concatenated global features. Therefore, the final loss is,
我们对每个局部特征同时采用识别损失和异质中心三元组损失,而最终的拼接全局特征仅使用异质中心三元组损失 $L_{h c_t r i}^{g}$。因此,最终损失函数为,
$$
L_{a l l}=L_{h c_t r i}^{g}+\sum_{i=1}^{p}\big(L_{i d}^{i}+\lambda L_{h c_t r i}^{i}\big),
$$
$$
L_{a l l}=L_{h c_t r i}^{g}+\sum_{i=1}^{p}\big(L_{i d}^{i}+\lambda L_{h c_t r i}^{i}\big),
$$
where $\lambda$ is a predefined tradeoff parameters.
其中 $\lambda$ 是预定义的权衡参数。
IV. EXPERIMENTS
IV. 实验
In this section, we evaluate the effectiveness of our proposed methods for extracting the person features for VT Re-ID tasks on two public datasets, RegDB [15] and SYSU-MM01 [27]. The example images are shown in Fig. 5.
在本节中,我们评估了所提出的方法在两个公开数据集 RegDB [15] 和 SYSU-MM01 [27] 上提取可见光-热成像跨模态行人重识别 (VT Re-ID) 任务中人员特征的有效性。示例图像如图 5 所示。
A. Experimental settings
A. 实验设置
- Datasets and settings: SYSU-MM01 [27] is a largescale dataset collected by 6 cameras, including 4 visible and 2 infrared cameras, captured in the SYSU campus. Some cameras are deployed in indoor environments and others are deployed in outdoor environments. The training set contains 395 persons, including 22,258 visible images and 11,909 infrared images. The testing set contains another 96 persons, including 3,803 infrared images for the query and 301 randomly selected visible images as the gallery set. In the allsearch mode, the gallery set contains all the visible images captured from all four visible cameras. In indoor-search mode, the gallery set only contains the visible images captured by two indoor visible cameras. Generally, the all-search mode is more challenging than the indoor-search mode. We follow existing methods to perform 10 trials of gallery set selection in the single-shot setting [32], [35], and then report the average retrieval performance. A detailed description of the evaluation protocol can be found in [27].
- 数据集与设置:SYSU-MM01 [27] 是一个由6台摄像头(包括4台可见光摄像头和2台红外摄像头)在SYSU校园采集的大规模数据集。部分摄像头部署在室内环境,其余部署在室外环境。训练集包含395人的22,258张可见光图像和11,909张红外图像。测试集包含另外96人的3,803张红外图像作为查询集,以及随机选取的301张可见光图像作为候选集。在全搜索模式下,候选集包含所有四台可见光摄像头拍摄的全部可见光图像;在室内搜索模式下,候选集仅包含两台室内可见光摄像头拍摄的图像。通常全搜索模式比室内搜索模式更具挑战性。我们遵循现有方法 [32][35],在单样本设置下进行10次候选集选择试验,最终报告平均检索性能。评估协议的详细说明见文献 [27]。

Fig. 5. Illustration of the visible-thermal images from two datasets, SYSUMM01 [27] and RegDB [15], for cross-modality person re-identification. The first row is the visible images, while the second is the thermal images. Each column contains images of the same person.
图 5: 来自SYSUMM01 [27]和RegDB [15]两个数据集的可见光-热成像图像示例,用于跨模态行人重识别。第一行为可见光图像,第二行为热成像图像。每列包含同一人的图像。
RegDB [15] was constructed by dual-camera (one visible and one thermal camera) systems, and includes 412 persons. For each person, 10 visible images were captured by a visible camera, and 10 thermal images are obtained by a thermal camera. We follow the evaluation protocol in [31] and [35], where the dataset is randomly split into two halves, one for training and the other for testing. For testing, the images from one modality (default is thermal) were used as the gallery set while those from the other modality (default is visible) were used as the probe set. The procedure is repeated for 10 trials to achieve statistically stable results, recording the mean values.
RegDB [15] 由双摄像头系统(一个可见光摄像头和一个热成像摄像头)构建,包含412人。每个人的10张可见光图像由可见光摄像头拍摄,10张热成像图像由热成像摄像头获取。我们遵循[31]和[35]中的评估协议,将数据集随机分为两半,一半用于训练,另一半用于测试。测试时,默认以热成像模态图像作为图库集(gallery set),可见光模态图像作为探针集(probe set)。该过程重复10次以获得统计稳定的结果,并记录平均值。
- Evaluation Metrics: Following existing works, cumulative matching characteristics (CMC), mean average precision (mAP) and the mean inverse negative penalty (mINP) are adopted as the evaluation metrics. CMC (rank-r accuracy) measures the probability of a correct cross-modality person image occurring in the top-r retrieved results. mAP measures the retrieval performance when multiple matching images occur in the gallery set. Moreover, mINP considers the hardest correct match that determines the workload of inspectors [33]. Note that all the person features are first $L2$ normalized for testing.
- 评估指标:沿用现有研究,采用累积匹配特性 (CMC)、平均精度均值 (mAP) 和平均逆负惩罚 (mINP) 作为评估指标。CMC (rank-r准确率) 衡量正确跨模态行人图像出现在前r个检索结果中的概率。mAP衡量图库集中出现多个匹配图像时的检索性能。此外,mINP考虑了决定检查人员工作量的最难正确匹配 [33]。注意所有行人特征在测试前都先进行$L2$归一化处理。
- Implementation details: The implementation 1 of our method is with the Pytorch framework. Following the existing person Re-ID works, the ResNet50 model is adopted as the backbone network for a fair comparison, and the pretrained ImageNet parameters are adopted for the network initialization. Specifically, the stride of the last convolutional block is changed from 2 to 1 to obtain fine-grained feature maps with large body size. In the training phase, the input images are resized to $288\times144$ and padded with 10, then randomly left-right flipped and cropped to $288\times144$ for data augmentation. We adopt the stochastic gradient descent (SGD) optimizer for optimization, and the momentum parameter is set to 0.9. We set the initial learning rate as 0.1 for both datasets. The warmup learning rate strategy is applied to bootstrap the network to enhance performance. The learning rate $(l r)$ at epoch $t$ is computed as follows,
- 实现细节:我们的方法基于Pytorch框架实现。遵循现有行人重识别(Re-ID)工作的惯例,采用ResNet50作为主干网络以保证公平比较,并使用ImageNet预训练参数进行网络初始化。具体而言,将最后一个卷积块的步长从2改为1,以获得更大尺寸的细粒度特征图。训练阶段中,输入图像被调整为$288\times144$尺寸并填充10像素边界,随后进行随机左右翻转并裁剪至$288\times144$以实现数据增强。我们采用随机梯度下降(SGD)优化器进行优化,动量参数设为0.9。两个数据集的初始学习率均设为0.1,并应用热身学习率策略来引导网络提升性能。第$t$个训练周期时的学习率$(lr)$计算公式如下:
TABLE III THE RESULTS OF DIFFERENT SPLITS OF THE BACKBONE TO FORM THETWO-STREAM NETWORK. $s i,i={0,1,2,3,4,5}$ DENOTES THAT THE MODALITY-SHARED FEATURE EMBEDDING BLOCK WITH PARAMETERS SHARING STARTS FROM $i^{t h}$ stage. RE-IDENTIFICATION RATES AT RANK R, MAP AND MINP $(%)$ .
表 III 不同主干网络分割形成双流网络的结果。$s i,i={0,1,2,3,4,5}$ 表示参数共享的模态共享特征嵌入块从第 $i^{t h}$ 阶段开始。RANK R、MAP 和 MINP 的重识别率 $(%)$。
| splits | r=1 | r=5 | r=10 | r=20 | mAP | mINP |
|---|---|---|---|---|---|---|
| RegDB | ||||||
| s0 | 77.52 | 86.50 | 90.49 | 93.50 | 69.79 | 54.58 |
| s1 | 76.94 | 85.68 | 89.71 | 93.88 | 69.36 | 54.82 |
| s2 | 77.14 | 87.33 | 91.94 | 95.19 | 69.82 | 54.62 |
| s3 | 76.99 | 87.23 | 91.21 | 94.51 | 69.51 | 53.74 |
| s4 | - | - | - | - | - | 48.62 |
| s5 | 48.93 | 61.99 | 71.50 | 80.44 | 48.30 | - |
| SYSU-MM01 | ||||||
| s0 | 54.38 | 80.78 | 88.96 | 95.06 | 52.18 | 38.57 |
| s1 | 54.48 | 80.38 | 88.61 | 94.61 | 52.67 | 39.19 |
| s2 | 57.09 | 81.78 | 88.80 | 94.61 | 54.99 | 41.26 |
We set the predefined margin $\rho=0.3$ for all triplet losses. For the $P K$ sampling strategy, we set $P=8$ , $K=4$ for the RegDB dataset, and $P=6$ , $K=8$ for the SYSU-MM01 dataset. For the tradeoff parameter, we set $\lambda=2.0$ for the RegDB dataset, and $\lambda=1.0$ for the SYSU-MM01 dataset. The dimension of part-level feature $d$ is set to 256, and the number of part-level stripes $p$ is set to 6.
我们为所有三元组损失设置预定义边界 $\rho=0.3$。对于 $PK$ 采样策略,在 RegDB 数据集中设置 $P=8$、$K=4$,在 SYSU-MM01 数据集中设置 $P=6$、$K=8$。权衡参数方面,RegDB 数据集设为 $\lambda=2.0$,SYSU-MM01 数据集设为 $\lambda=1.0$。部件级特征维度 $d$ 设为 256,部件级条纹数 $p$ 设为 6。
B. Ablation experiments
B. 消融实验
We evaluate the effectiveness of our proposed method, including three components, two-stream backbone network, part-level feature learning and hetero-center triplet loss.2
我们评估了所提出方法的有效性,包括三个组成部分:双流主干网络、部件级特征学习和异构中心三元组损失。 [20]
- Two-stream backbone network setting: As analyzed in Sec. III-A, the key point of the two-stream backbone network setting is how to split the well-designed CNN model to construct a modality-specific feature extractor with independent parameters and modality-shared feature embedding with shared parameters. Based on the AGW baseline [33] which is designed on top of BagTricks [14], we optionally build the following baseline network with the ResNet50 model. As shown in Fig. 6, the 3D feature maps outputted from the twostream backbone network are pooled by the generalized-mean pooling (GeM) layer to obtain the 2D feature vector. Then the batch normalization (BN) neck is adopted to train the network, where triplet loss (Eq. (3)) is first utilized on the 2D feature vector, and then the identification loss is sequentially utilized on the batch normalized feature vector.
- 双流主干网络设置:如第III-A节所述,双流主干网络设置的关键在于如何拆分精心设计的CNN模型,以构建具有独立参数的模态特定特征提取器和共享参数的模态共享特征嵌入。基于AGW基准模型[33](该模型在BagTricks[14]基础上设计),我们选择使用ResNet50模型构建以下基准网络。如图6所示,双流主干网络输出的3D特征图通过广义均值池化(GeM)层进行池化,得到2D特征向量。随后采用批归一化(BN)颈部结构训练网络:首先在2D特征向量上应用三元组损失(公式(3)),然后在批归一化后的特征向量上依次应用身份识别损失。

Fig. 6. Illustration of the baseline network, mainly illustrating how to split the ResNet50 model to set the two-stream backbone network. $s i,i=$ ${0,1,2,3,4,5}$ denotes that the modality-shared feature embedding block with parameter sharing, starting from $i^{t\dot{h}}$ stage. Then, the batch normalization neck with triplet loss and identification loss is adopted to train the network.
图 6: 基准网络示意图,主要展示如何拆分ResNet50模型以构建双流主干网络。$s i,i=$ ${0,1,2,3,4,5}$ 表示从第$i^{t\dot{h}}$阶段开始采用参数共享的模态共享特征嵌入块。随后,使用带有三元组损失和识别损失的批归一化颈部结构来训练网络。
The results of different backbone splits on RegDB and SYSU-MM01 datasets are listed in Table III, from which we can observe that.
不同主干网络划分在RegDB和SYSU-MM01数据集上的结果如表III所示,从中我们可以观察到。
a) $s5$ , without sharing any res-convolutional layers, obtains the worst performance on both the RegDB and SYSUMM01 datasets, with large margins compared to other splits. s5 only shares the last fully connected layer to process the 1D feature vector without any person spatial structure information. It demonstrates the effectiveness of the 3D feature maps with person spatial structure information to describe a person.
a) $s5$ 在不共享任何 res-convolutional 层的情况下,在 RegDB 和 SYSUMM01 数据集上均表现最差,与其他分割方案相比差距较大。s5 仅共享最后一个全连接层来处理一维特征向量,不包含任何人体空间结构信息。这表明具有人体空间结构信息的 3D 特征图在描述人体时的有效性。
b) $s0$ , sharing all the backbone networks without the modality-specific feature extractor, obtains good performances on both the RegDB and SYSU-MM01 datasets. s0 equally treats both visible and thermal person images, without focusing additionally on the color information of visible images, focusing on the spatial structure information of a person existing on both visible and thermal images. The results may demonstrate that the person spatial structure information is more important compared to the color information in VT cross-modality Re-ID.
b) $s0$ 在不使用模态特定特征提取器的情况下共享所有骨干网络,在RegDB和SYSU-MM01数据集上均取得了良好性能。s0对可见光和热成像行人图像一视同仁,未额外关注可见光图像的色彩信息,而是聚焦于两种图像共有的行人空间结构信息。结果表明,在可见光-热成像跨模态行人重识别任务中,行人空间结构信息比色彩信息更为关键。
c) On the RegDB dataset, s0, s1, s2 and $s3$ achieve comparable performances. On the SYSU-MM01 dataset, $s2$ obtains much better Rank1, mAP and mINP results compared to $s0$ and $s1$ . The different performances may be from the different settings of the two datasets. RegDB is collected by a dual-camera system, where the visible image and corresponding thermal image are well aligned. SYSU-MM01 is collected by 6 disjoint cameras deployed at different locations, where the visible image and corresponding infrared image have arbitrary poses and views. Therefore, SYSUMM01 needs more modality-specific layers to extract the person spatial structure compared to RegDB.
c) 在RegDB数据集上,s0、s1、s2和$s3$取得了相近的性能。在SYSU-MM01数据集上,$s2$的Rank1、mAP和mINP结果明显优于$s0$和$s1$。这种性能差异可能源于两个数据集的不同设置:RegDB由双摄像头系统采集,可见光图像与对应热成像严格对齐;而SYSU-MM01通过6个分散部署的摄像头采集,可见光与红外图像存在任意姿态和视角差异。因此,SYSU-MM01相比RegDB需要更多模态专用层来提取人体空间结构。
d) Overall, $s2$ can achieve the best performance, which only sets stage0 and stage1 as the modality-specific feature extractor with acceptable independent parameters.
d) 总体而言,$s2$ 能够实现最佳性能,它仅将 stage0 和 stage1 设置为模态特定特征提取器,且独立参数数量在可接受范围内。

Fig. 7. The effect of partition strips $p$ on (a) RegDB and (b) SYSU-MM01 datasets. Re-identification rates of rank1, mAP and mINP $(%)$ .
图 7: 分区条带 $p$ 对 (a) RegDB 和 (b) SYSU-MM01 数据集的影响。Rank1、mAP 和 mINP 的重识别率 $(%)$。
- Part-level feature learning: To evaluate the effectiveness of part-level feature learning compared to global feature learning, we add the uniform partitioning strategy between the two-stream backbone network and the loss layer, as shown in Fig. 2. Based on the above experimental results, we adopt the $s2$ split as the two-stream backbone network, still with the supervision of identification loss and triplet loss.
- 部件级特征学习:为了评估部件级特征学习相对于全局特征学习的有效性,我们在双流主干网络和损失层之间添加了均匀划分策略,如图 2 所示。基于上述实验结果,我们采用 $s2$ 划分作为双流主干网络,并仍然使用识别损失 (identification loss) 和三重损失 (triplet loss) 进行监督。
Three points are considered: 1) the number of partition strips $p,2)$ the generalized-mean pooling (GeM) layer instead of the traditional average pooling layer or max-pooling layer, and 3) the dimension of each part-level feature $d$ corresponding to the output channel number of $1\times1$ Conv.
考虑三点:1) 分区条带数 $p$,2) 用广义均值池化 (GeM) 层替代传统平均池化层或最大池化层,3) 每个局部特征的维度 $d$ 对应 $1\times1$ 卷积的输出通道数。
The effect of partition strips. The number of partition strips determines the granularity of a person’s local feature. Fig. 7 shows the results of different partition strips $p$ on the RegDB and SYSU-MM01 datasets. We observe that $p=6$ is the best setting for partition strips to extract the local person feature.
分区条带的影响。分区条带数量决定行人局部特征的粒度。图7展示了RegDB和SYSU-MM01数据集上不同分区条带数$p$的效果。实验表明$p=6$是提取行人局部特征的最佳分区条带设置。
The effect of GeM. This subsection verifies the effectiveness of the generalized-mean pooling (GeM) method compared to the traditional average pooling (Mean) and maxpooling (Max) methods. Table IV lists the results of different pooling methods on the RegDB and SYSU-MM01 datasets. We observe that max-pooling performs better than average pooling, while the generalized-mean pooling method performs the best.
GeM的效果。本节验证了广义均值池化 (generalized-mean pooling, GeM) 方法相较于传统平均池化 (Mean) 和最大池化 (Max) 方法的有效性。表 IV 列出了不同池化方法在RegDB和SYSU-MM01数据集上的结果。我们观察到最大池化优于平均池化,而广义均值池化方法表现最佳。
TABLE IV THE RESULTS OF DIFFERENT POOLING METHODS ON REGDB AND SYSU-MM01 DATASETS, INCLUDING GENERALIZED-MEAN POOLING (GEM), AVERAGE POOLING (MEAN) AND MAX POOLING (MAX). RE-IDENTIFICATION RATES OF RANK1, MAP AND MINP $(%)$ ).
表 IV REGDB和SYSU-MM01数据集上不同池化方法的结果,包括广义均值池化 (GEM)、平均池化 (MEAN) 和最大池化 (MAX)。重识别率指标为Rank1、mAP和mINP ($%$)。
| RegDB | SYSU-MM01 | |||||
|---|---|---|---|---|---|---|
| Methods | rankl | mAP | mINP | rankl | mAP | mINP |
| GeM | 85.10 | 81.40 | 72.13 | 57.90 | 55.10 | 40.29 |
| Mean | 76.75 | 76.08 | 68.36 | 52.09 | 49.92 | 35.88 |
| Max | 84.22 | 79.75 | 69.04 | 56.74 | 54.88 | 40.72 |
TABLE V THE RESULTS OF DIFFERENT DIMENSIONS OF EACH PART-LEVEL FEATURE d ON THE REGDB AND SYSU-MM01 DATASETS. RE-IDENTIFICATION RATES OF RANK1, MAP AND MINP $(%)$ .
表 V: REGDB 和 SYSU-MM01 数据集上不同维度 d 的部件级特征的重识别结果 (rank1、mAP 和 mINP 指标 $(%)$ )
| d | RegDB rank1 | RegDB mAP | RegDB mINP | SYSU-MM01 rank1 | SYSU-MM01 mAP | SYSU-MM01 mINP |
|---|---|---|---|---|---|---|
| 128 | 82.72 | 79.66 | 69.96 | 55.25 | 53.49 | 39.36 |
| 256 | 85.10 | 81.40 | 72.13 | 57.90 | 55.10 | 40.29 |
| 512 | 86.99 | 82.02 | 71.66 | 57.17 | 53.89 | 38.80 |
The effect of part-level feature dimension. This subsection shows the effect of part-level feature dimension $d$ , corresponding to the output channel number of $1\times1$ Conv in Fig. 2. The final dimension of the person feature is the product of the part-level feature dimension $d$ and the number of partition strips $p$ . Table $\mathrm{v}$ lists the results of different dimensions of each part-level feature $d$ on the RegDB and SYSU-MM01 datasets. We find that on SYSU-MM01 dataset, $d=256$ performs the best, while on the RegDB dataset $d=512$ performs the best under the rank1 and mAP criteria, and $d=256$ achieves the best performance under the mINP criterion. considering both the performance and final person feature dimension, we set $d=256$ for both the RegDB and SYSU-MM01 datasets.
部件级特征维度的影响。本小节展示了部件级特征维度$d$的影响,对应于图2中$1\times1$卷积的输出通道数。最终行人特征的维度是部件级特征维度$d$与分区条带数$p$的乘积。表$\mathrm{v}$列出了RegDB和SYSU-MM01数据集上不同部件级特征维度$d$的结果。我们发现,在SYSU-MM01数据集上,$d=256$表现最佳;而在RegDB数据集上,$d=512$在rank1和mAP标准下表现最优,$d=256$则在mINP标准下达到最佳性能。综合考虑性能和最终行人特征维度,我们对RegDB和SYSU-MM01数据集均设定$d=256$。
- Hetero-center based triplet loss: In this subsection, we verify the effectiveness of our proposed hetero-center triplet loss $L_{h c_t r i}$ from two aspects. On the one hand, $L_{h c_t r i}$ is compared to traditional triplet loss $L_{b h_t r i}$ to demonstrate the effectiveness of anchor center to all the other centers compared to anchor to all the other samples. On the other hand, $L_{h c_t r i}$ is compared to the learned center loss $L_{l c}$ and hetero-center loss $L_{h c}$ to demonstrate the effectiveness of constraining both the inter-class se par ability and intra-class compactness.
- 基于异构中心的三元组损失:在本小节中,我们从两个方面验证所提出的异构中心三元组损失 $L_{h c_t r i}$ 的有效性。一方面,将 $L_{h c_t r i}$ 与传统三元组损失 $L_{b h_t r i}$ 进行对比,证明锚点中心到其他所有中心的约束效果优于锚点到其他所有样本的约束。另一方面,将 $L_{h c_t r i}$ 与学习中心损失 $L_{l c}$ 和异构中心损失 $L_{h c}$ 进行对比,证明同时约束类间可分离性和类内紧凑性的有效性。
$L_{h c_t r i}$ vs. $L_{b h_t r i}$ . We conducted experiments under the framework shown in Fig. 2 with different triplet losses, $L_{h c_t r i}$ and $L_{b h_t r i}$ , fine-tuning the tradeoff parameter $\lambda$ in Eq. (9). The results are listed in Table VI. From the table, we can observe that 1) $L_{h c_t r i}$ outperforms $L_{b h_t r i}$ on both RegDB and SYSU-MM01 datasets, demonstrating the effectiveness of anchor center to all the other centers compared to anchor to all the other samples. 2) With the final loss Eq. (9), those non convergent cases on the SYSU-MM01 dataset may show that the anchor to all the other samples of $L_{b h_t r i}$ is truly a strict constraint, demonstrating the effectiveness of the anchor center to all the other centers relaxation operation.
$L_{h c_t r i}$ vs. $L_{b h_t r i}$。我们在图 2 所示的框架下进行了不同三元组损失 ($L_{h c_t r i}$ 和 $L_{b h_t r i}$) 的实验,并微调了式 (9) 中的权衡参数 $\lambda$。结果如表 VI 所示。从表中可以看出:1) $L_{h c_t r i}$ 在 RegDB 和 SYSU-MM01 数据集上均优于 $L_{b h_t r i}$,这表明锚点中心到其他所有中心的距离度量比锚点到其他所有样本的度量更有效;2) 使用最终损失函数式 (9) 时,SYSU-MM01 数据集上出现的非收敛情况可能表明 $L_{b h_t r i}$ 的锚点到其他所有样本约束过于严格,从而验证了锚点中心到其他所有中心的松弛操作的有效性。
TABLE VI THE EXPERIMENTAL RESULTS OF $L_{h c_t r i}$ IS COMPARED TO TRADITIONAL TRIPLET LOSS $L_{b h_t r i}$ ON THE REGDB AND SYSU-MM01 DATASETS. RE-IDENTIFICATION RATES OF RANK1, MAP AND MINP $(%)$ . NOTE THAT $L_{b h_t r i}$ LOSS IS NOT CONVERGED ON SYSU-MM01 DATASET WHEN $\lambda\ge0.5$ .
表 6: $L_{h c_t r i}$ 与传统三元组损失 $L_{b h_t r i}$ 在 REGDB 和 SYSU-MM01 数据集上的实验结果对比。重识别率包括 Rank1、mAP 和 mINP $(%)$。注意当 $\lambda\ge0.5$ 时,$L_{b h_t r i}$ 损失在 SYSU-MM01 数据集上不收敛。
| Loss | λ | RegDB rank1 | RegDB mAP | RegDB mINP | SYSU-MM01 rank1 | SYSU-MM01 mAP | SYSU-MM01 mINP |
|---|---|---|---|---|---|---|---|
| Lbh_tri | 0.1 0.5 1.0 1.5 | 80.68 82.43 85.10 72.33 | 75.35 78.93 81.40 69.67 | 64.50 69.22 72.13 60.55 | 55.30 | 54.21 | 41.09 |
| Lhc_tri | 0.1 0.5 1.0 1.5 | 80.73 87.96 85.24 90.63 92.48 | 75.08 81.97 81.76 83.64 | 64.14 71.87 72.33 71.21 | 57.53 60.43 61.95 57.45 | 54.68 56.41 57.25 53.01 | 40.22 40.56 40.44 36.93 |
TABLE VII THE RESULTS OF DIFFERENT CENTER-BASED LOSSES ON THE REGDB AND SYSU-MM01 DATASETS, INCLUDING THE LEARNED CENTER LOSS $L_{l c}$ , HETERO-CENTER LOSS $L_{h c}$ , AND OUR PROPOSED HETERO-CENTER TRIPLET LOSS $L_{h c_t r i}$ . RE-IDENTIFICATION RATES OF RANK1, MAP AND MINP $(%)$ .
表 VII: REGDB和SYSU-MM01数据集上不同基于中心的损失函数结果对比,包括学习中心损失 $L_{l c}$、异构中心损失 $L_{h c}$ 和我们提出的异构中心三元组损失 $L_{h c_t r i}$。重识别率指标为Rank1、mAP和mINP $(%)$。
| 网络 | 损失函数 | RegDB-rank1 | RegDB-mAP | RegDB-mINP | SYSU-MM01-rank1 | SYSU-MM01-mAP | SYSU-MM01-mINP |
|---|---|---|---|---|---|---|---|
| Global-level | $L_{lc}$ | 44.76 | 40.60 | 27.52 | 52.67 | 50.48 | 36.84 |
| Global-level | $L_{hc}$ | 52.96 | 44.52 | 27.05 | 51.30 | 48.12 | 33.73 |
| Global-level | $L_{hc_tri}$ | 79.22 | 68.35 | 48.87 | 57.61 | 53.03 | 37.22 |
| Part-level (ours) | $L_{lc}$ | 67.38 | 64.30 | 54.83 | 46.02 | 47.55 | 36.70 |
| Part-level (ours) | $L_{hc}$ | 85.34 | 80.83 | 70.46 | 47.83 | 46.22 | 32.48 |
| Part-level (ours) | $L_{hc_tri}$ | 92.48 | 84.41 | 71.53 | 61.95 | 57.25 | 40.44 |
$L_{h c_t r i}$ vs. $L_{l c}$ and $L_{h c}$ . We conducted experiments with different center-based losses, including the learned center loss $L_{l c}$ , hetero-center loss $L_{h c}$ , and our proposed hetero-center triplet loss $L_{h c_t r i}$ . The network is in two frameworks: the baseline network that extracts the global person features (Sec. IV-B1) and the part-level local feature learning network (Sec. IV-B2). The results are listed in Table VII. We can observe that in both networks, $L_{h c_t r i}$ outperforms $L_{l c}$ and $L_{h c}$ with large margins. It demonstrates the effectiveness of our proposed $L_{h c_t r i}$ concentrating on both the inter-class se par ability and intra-class compactness, compared to $L_{l c}$ and $L_{h c}$ which only focus on intra-class cross-modality compactness, ignoring the inter-class se par ability for both the intra- and inter-modality. It is also illustrated in Fig. 4 through visualizing the features extracted by the baseline model with different center-based losses.
$L_{h c_t r i}$ vs. $L_{l c}$ 和 $L_{h c}$。我们对比了不同基于中心的损失函数,包括学习中心损失 $L_{l c}$、异构中心损失 $L_{h c}$ 以及我们提出的异构中心三元组损失 $L_{h c_t r i}$。实验基于两种网络框架:提取全局行人特征的基线网络(第IV-B1节)和部件级局部特征学习网络(第IV-B2节)。结果如 表 VII 所示,可观察到在两种网络中,$L_{h c_t r i}$ 均显著优于 $L_{l c}$ 和 $L_{h c}$。这表明相较于仅关注类内跨模态紧凑性、忽略模态内外类间可分性的 $L_{l c}$ 和 $L_{h c}$,我们提出的 $L_{h c_t r i}$ 通过同时优化类间可分性与类内紧凑性具有显著优势。该结论也通过 图 4 中基线模型采用不同基于中心损失时提取特征的可视化对比得到验证。
- Ablation sum mari z ation: Moreover, to show the effect of every component, we also summarize the corresponding ablation study in Table VIII, whose results are copied from Tables III, VI and VII. It shows that when the component works alone, the performance on the two datasets is different and is not always improved. However, the combination of three components can greatly boost the performance on both
- 消融实验总结: 此外,为了展示每个组件的作用,我们在表 VIII 中总结了相应的消融研究,结果复制自表 III、表 VI 和表 VII。实验表明,当组件单独工作时,在两个数据集上的表现存在差异且并不总是提升。然而,三个组件的组合可以显著提升在两个数据集上的性能
TABLE VIII THE ABLATION STUDY OF DIFFERENT COMPONENTS: WEIGHT SHARING $(w s)$ , HETERO-CENTER TRIPLET LOSS $(L_{h c_t r i})$ AND PART-LEVEL FEATURE LEARNING $(p l f)$ . RE-IDENTIFICATION RATES OF RANK1, MAP AND MINP $(%)$ .
表 VIII 不同组件的消融研究: 权重共享 $(w s)$、异质中心三元组损失 $(L_{h c_t r i})$ 和部件级特征学习 $(p l f)$。Rank1、mAP 和 mINP 的重识别率 $(%)$。
| ws | Lhc_tri | plf | rank1 | mAP | mINP | rank1 | mAP | mINP |
|---|---|---|---|---|---|---|---|---|
| × | × | 77.52 | 69.79 | 54.58 | 54.38 | 52.18 | 38.57 | |
| × | × | 77.14 | 69.82 | 54.62 | 57.09 | 54.99 | 41.26 | |
| √ | × | 79.22 | 68.35 | 48.87 | 57.61 | 53.03 | 37.22 | |
| × | 人 | 85.10 | 81.40 | 72.13 | 55.30 | 54.21 | 41.09 | |
| √ | √ | 92.48 | 84.41 | 71.53 | 61.95 | 57.25 | 40.44 |
TABLE IX COMPARISON TO THE STATE-OF-THE-ART METHODS ON THE REGDB DATASETS IN VISIBLE → THERMAL AND THERMAL → VISIBLE QUERY SETTINGS. RE-IDENTIFICATION RATES AT RANK R, MAP AND MINP $(%)$ .
表 IX REGDB 数据集在可见光→热成像和热成像→可见光查询设置下与最先进方法的比较。展示的是 Rank R 的重识别率、mAP 和 mINP $(%)$。
| 方法 | 会议 | r=1 | r=10 | r=20 | mAP | mINP |
|---|---|---|---|---|---|---|
| 可见光→热成像 | ||||||
| Zero-Pad [27] HCML [31] | ICCV17 | 17.75 24.44 | 34.21 47.53 | 44.35 56.78 | 18.90 20.80 | |
| HSME [6] | AAAI18 AAAI19 | 50.85 | 73.36 | 81.66 | 47.00 | = = |
| D2RL [24] | CVPR19 | 43.40 | 66.10 | 76.30 | 44.10 | |
| MM19 | 36.43 | 62.36 | 71.63 | 37.03 | ||
| MAC [30] AliGAN [20] | 57.90 | 53.60 | ||||
| DFE [5] | ICCV19 MM19 | 70.13 | 86.32 | 91.96 | 69.14 | |
| eBDTR [33] | TIFS20 | 34.62 | 58.96 | 68.72 | 33.46 | |
| MSR [4] | TIP20 | 48.43 48.50 | 70.32 | 79.95 | 48.67 | |
| JSIA [21] EDFL [12] | AAAI20 Neuro20 | 52.58 | 72.10 | 81.47 | 48.90 52.98 | |
| XIV [11] | AAAI20 | 62.21 | 83.13 | 91.72 | 60.18 | |
| CDP [3] | Arxiv20 | 65.00 | 83.50 | 89.60 | 62.70 | |
| expAT [29] | Arxiv20 | 66.48 | 67.31 | |||
| CMSP [26] | IJCV20 | 65.07 | 83.71 | 64.50 | ||
| Hi-CMD [1] | CVPR20 | 70.93 | 86.39 | 66.04 | ||
| HAT [34] | TIFS20 | 71.83 | 87.16 | 92.16 | 67.56 | |
| cmSSFT [13] | CVPR20 | 72.30 | 72.90 | |||
| MPMN [23] | TMM20 | 86.56 | 96.68 | 98.28 | 82.91 | |
| AGW [33] | Arxiv20 | 70.05 | 66.37 | 50.19 | ||
| ours | 91.05 | 97.16 | 98.57 | 83.28 | 68.84 | |
| 热成像→可见光 | ||||||
| Zero-Pad [27] HCML [31] | ICCV17 | 16.63 | 34.68 | 44.25 | 17.82 | = |
| eBDTR [33] | TIFS20 | 34.21 | 58.74 | 68.64 | 32.49 | |
| MAC [30] | MM19 | 36.20 | 61.68 | 70.99 | 39.23 | |
| HSME [6] | AAAI19 | 50.15 | 72.40 | 81.07 | 46.16 | |
| EDFL [12] | Neuro20 | 51.89 | 72.09 | 81.04 | 52.13 | |
| AliGAN [20] | ICCV19 | 56.30 | 53.40 | |||
| expAT [29] | Arxiv20 | 67.45 | 66.51 | |||
| MPMN [23] | TMM20 | 84.62 | 95.51 | 97.33 | 79.49 | |
| ours | 89.30 | 96.41 | 98.16 | 81.46 | 64.81 |
datasets.
数据集
C. Comparison to the state-of-the-art
C. 与当前最优技术的对比
This section compares the state-of-the-art VT Re-ID methods. The results on the RegDB and SYSU-MM01 datasets are listed in Tables IX and X, respectively. 3
本节比较了最先进的可见光-热成像行人重识别 (VT Re-ID) 方法。RegDB 和 SYSU-MM01 数据集的结果分别列于表 IX 和表 X 中。3
The experiments on the RegDB dataset (Table IX) demonstrate that our proposed method obtains the best performance in both query settings, always by large margins. We set a new baseline for this dataset, achieving superior performance rank1/mAP/mINP $91.05%/83.28%/68.84%$ for visible $\rightarrow$ thermal query setting. The experiments suggest that our proposed method can learn better cross-modality sharing features by well designing the two-stream parameter-sharing network, learning the part-level local person features, and computing the triplet loss on heterogeneous centers from different modalities.
在RegDB数据集上的实验(表 IX)表明,我们提出的方法在两种查询设置下均以显著优势取得最佳性能。我们为该数据集设立了新基准,在可见光→热成像查询设置中实现了91.05%/83.28%/68.84%的卓越rank1/mAP/mINP指标。实验证明,通过精心设计双流参数共享网络、学习部件级局部人体特征,以及计算跨模态异构中心的三元组损失,我们的方法能学习到更好的跨模态共享特征。
TABLE X OMPARISON TO THE STATE-OF-THE-ART METHODS ON THE SYSU-MM01 DATASETS. RE-IDENTIFICATION RATES AT RANK R, MAP AND MINP $%$ ).
表 X SYSU-MM01 数据集上先进方法的对比 (排名 R 的重识别率、mAP 和 mINP $%$ )。
| 方法 | 会议 | [=I | r=10 | r=20 | mAP | mINP | r=1 | r=10 | r=20 | mAP | mINP |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero-Pad [27] | ICCV17 | 14.80 | 54.12 | 71.33 | 15.95 | 20.58 | 68.38 | 85.79 | 26.92 | ||
| cmGAN [2] | IJCAI18 | 26.97 | 67.51 | 80.56 | 27.80 | 31.63 | 77.23 | 89.18 | 42.19 | ||
| HCML [31] | AAAI18 | 14.32 | 53.16 | 69.17 | 16.16 | 24.52 | 73.25 | 86.73 | 30.08 | ||
| HSME [6] | AAAI19 | 20.68 | 62.74 | 77.95 | 23.12 | ||||||
| D²RL [24] | CVPR19 | 28.90 | 70.60 | 82.40 | 29.20 | ||||||
| MAC [30] | MM19 | 33.26 | 79.04 | 90.09 | 36.22 | 36.43 | 62.36 | 71.63 | 37.03 | ||
| AliGAN [20] | ICCV19 | 42.40 | 85.00 | 93.70 | 40.70 | 45.90 | 87.60 | 94.40 | 54.30 | ||
| HPILN [38] | TIP19 | 41.36 | 84.78 | 94.51 | 42.95 | 45.77 | 91.82 | 98.46 | 56.52 | ||
| DFE [5] | MM19 | 48.71 | 88.86 | 95.27 | 48.59 | 52.25 | 89.86 | 95.85 | 59.68 | ||
| Hi-CMD [1] | CVPR20 | 34.94 | 77.58 | 35.94 | |||||||
| EDFL [12] | Neuro20 | 36.94 | 85.42 | 93.22 | 40.77 | ||||||
| CDP [3] | Arxiv20 | 38.00 | 82.30 | 91.70 | 38.40 | ||||||
| expAT [29] | Arxiv20 | 38.57 | 76.64 | 86.39 | 38.61 | ||||||
| XIV [11] | AAAI20 | 49.92 | 89.79 | 95.96 | 50.73 | ||||||
| eBDTR [33] | TIFS20 | 27.82 | 67.34 | 81.34 | 28.42 | 32.46 | 77.42 | 89.62 | 42.46 | ||
| MSR [4] | TIP20 | 37.35 | 83.40 | 93.34 | 38.11 | 39.64 | 89.29 | 97.66 | 50.88 | ||
| JSIA [21] | AAAI20 | 38.10 | 80.70 | 89.90 | 36.90 | 43.80 | 86.20 | 94.20 | 52.90 | ||
| CMSP [26] | IJCV20 | 43.56 | 86.25 | 44.98 | 48.62 | 89.50 | 57.50 | ||||
| Attri [36] | JEI20 | 47.14 | 87.93 | 94.45 | 47.08 | 48.03 | 88.13 | 95.14 | 56.84 | ||
| HAT [34] | TIFS20 | 55.29 | 92.14 | 97.36 | 53.89 | 62.10 | 95.75 | 99.20 | 69.37 | ||
| HC [39] | Neuro20 | 56.96 | 91.50 | 96.82 | 54.95 | 59.74 | 92.07 | 96.22 | 64.91 | ||
| AGW [33] | Arxiv20 | 47.50 | 47.65 | 35.30 | 54.17 | 62.97 | 59.23 | ||||
| sIno | 61.68 | 93.10 | 97.17 | 57.51 | 39.54 | 63.41 | 91.69 | 95.28 | 68.17 | 64.26 |
The experiments on the SYSU-MM01 dataset (Table X) show that our proposed method can achieve comparable performance compared to the current state-of-the-art results obtained by HAT [34], and outperforms all the other comparison methods. However, in the more challenging mode all-search, our method performs much better than HAT [34] in the two key criteria rank1/mAP, $61.68%/57.51%$ vs. $55.29%/53.89%$ .
在SYSU-MM01数据集上的实验(表X)表明,我们提出的方法可以达到与HAT [34]当前最先进结果相当的性能,并且优于所有其他对比方法。然而,在更具挑战性的all-search模式下,我们的方法在两个关键指标rank1/mAP上表现远优于HAT [34],分别为$61.68%/57.51%$对比$55.29%/53.89%$。
Compared to AliGAN [20], $\mathrm{D^{2}R L}$ [24]and Hi-CMD [1], our method achieves much better performance on both datasets, and does not need the sophisticated cross-modality image translation operation. Our method also does not require complicated adversarial learning with many tricks, which is always difficult for training.
与AliGAN [20]、$\mathrm{D^{2}R L}$ [24]和Hi-CMD [1]相比,我们的方法在两个数据集上都取得了更好的性能,且不需要复杂的跨模态图像转换操作。此外,我们的方法也不需要采用许多技巧的复杂对抗学习,而这通常难以训练。
V. CONCLUSIONS
V. 结论
This paper aims to enhance the disc rim i native person feature learning through simple means for VT Re-ID. On the one hand, we explore the parameter-sharing settings in the two-stream network. The experimental results show that the modality-sharing feature embedding network with some convolution blocks is an effective strategy, that could process the 3D shape feature maps with the spatial structure of a person. On the other hand, we also propose the hetero-center triplet loss to improve the traditional triplet loss for VT Re-ID by replacing the comparison of the anchor to all the other samples with the anchor center to all the other centers. With part-level person feature learning, hetero-center triplet loss performs much better than traditional triplet loss. The experimental results with remarkable improvements on two VT Re-ID datasets demonstrate the effectiveness of our proposed method compared to the current state-of-the-art methods. Our method with a simple but effective strategy can be a strong VT Re-ID baseline to boost future research with high quality.
本文旨在通过简单方法增强可见光-热成像跨模态行人重识别(VT Re-ID)中的判别性行人特征学习。一方面,我们探索了双流网络中的参数共享设置。实验结果表明,采用部分卷积块共享的模态共享特征嵌入网络是有效策略,能够处理具有人体空间结构的三维形状特征图。另一方面,我们提出异质中心三元组损失来改进传统三元组损失,通过将锚点与所有样本的比较替换为锚点中心与所有其他中心的比较。结合部件级行人特征学习,异质中心三元组损失性能显著优于传统三元组损失。在两个VT Re-ID数据集上的实验结果表明,与当前最先进方法相比,我们提出的方法具有显著优势。这种简单而有效的策略可作为强有力的VT Re-ID基线,推动未来高质量研究。