EA-LSS: Edge-aware Lift-splat-shot Framework for 3D BEV Object Detection
EA-LSS: 面向3D BEV目标检测的边缘感知Lift-splat-shot框架
Abstract
摘要
In recent years, great progress has been made in the LiftSplat-Shot-based (LSS-based) 3D object detection method. However, inaccurate depth estimation remains an important constraint to the accuracy of camera-only and multi-modal 3D object detection models, especially in regions where the depth changes significantly (i.e., the “depth jump” problem). In this paper, we proposed a novel Edge-aware Lift-splat-shot (EA-LSS) framework. Specifically, edge-aware depth fusion (EADF) module is proposed to alleviate the “depth jump” problem and fine-grained depth (FGD) module to further enforce refined supervision on depth. Our EA-LSS framework is compatible for any LSS-based 3D object detection models, and effectively boosts their performances with negligible increment of inference time. Experiments on nuScenes benchmarks demonstrate that EA-LSS is effective in either camera-only or multi-modal models. It is worth mentioning that EA-LSS achieved the state-of-the-art performance on nuScenes test benchmarks with mAP and NDS of $76.5%$ and $77.6%$ , respectively.
近年来,基于LiftSplat-Shot(LSS)的3D目标检测方法取得了巨大进展。然而,不准确的深度估计仍是制约纯摄像头和多模态3D目标检测模型精度的关键因素,尤其在深度值突变区域(即"深度跳跃"问题)。本文提出了一种新颖的边缘感知Lift-splat-shot(EA-LSS)框架:通过设计边缘感知深度融合(EADF)模块缓解"深度跳跃"问题,并采用细粒度深度(FGD)模块加强深度监督。该框架可兼容所有基于LSS的3D检测模型,在推理时间几乎零增加的条件下显著提升性能。nuScenes基准测试表明,EA-LSS对纯摄像头和多模态模型均有效。值得一提的是,EA-LSS以76.5% mAP和77.6% NDS的成绩创下了nuScenes测试基准的最优记录。
Introduction
引言
With the development of autonomous driving, vehicle sensors become more complex. Integrating multi-source information from different sensors (e.g., 2D images, 3D lidar, and radar) and characterizing their features in a unified way becomes crucial. Projection of various features from various sources into Bird’s-Eye-View (BEV) (X. et al. 2022; J. et al. 2021; Y. et al. 2022b; Z. et al. 2022a) becomes prevalent, and has attracted a great deal of attentions from academia and industry. One of the core problems of BEV perception task is how to reconstruct the hidden depth information in 2D images, and provide accurate BEV features for subsequent networks(i.e., BEV decoder and detection head).
随着自动驾驶技术的发展,车载传感器日趋复杂。如何整合来自不同传感器(如2D图像、3D激光雷达和毫米波雷达)的多源信息,并以统一方式表征其特征变得至关重要。将多源特征投影至鸟瞰图(Bird’s-Eye-View, BEV)(X. et al. 2022; J. et al. 2021; Y. et al. 2022b; Z. et al. 2022a) 已成为主流方法,并受到学术界与工业界的广泛关注。BEV感知任务的核心问题之一是如何重建2D图像中隐含的深度信息,并为后续网络(如BEV解码器和检测头)提供精确的BEV特征。
Lift-Splat-Shot (LSS) (J. and S. 2020) predicts the depth distribution of each pixel on 2D feature map, and “lifts” 2D features of each mesh into voxel space by the corresponding depth estimation. However, due to the large depth difference (i.e., “depth jump”) among regions in the real scene, depth estimate network of existing LSS-based methods (J. et al. 2021; Y. et al. 2022b; Liang et al. 2022; Z. et al. 2022a) are unable to derive accurate depth estimation. And it results in 2D image features at the edges of the scene “lifted” to wrong voxel space. As shown in Figure 1, the black area around edges of the foreground vehicle (shown in red box) indicates poor performance of depth estimation network in baseline method BEVFusion (Liang et al. 2022), when dealing with the “depth jump” region.
Lift-Splat-Shot (LSS) (J. and S. 2020) 通过预测2D特征图上每个像素的深度分布,将每个网格的2D特征根据对应深度估计"提升"到体素空间。然而,由于真实场景中区域间存在较大深度差异(即"深度跳跃"),现有基于LSS的方法 (J. et al. 2021; Y. et al. 2022b; Liang et al. 2022; Z. et al. 2022a) 的深度估计网络无法获得准确结果,导致场景边缘的2D图像特征被"提升"到错误的体素空间。如图1所示,基线方法BEVFusion (Liang et al. 2022) 在处理前景车辆(红色方框标示)边缘的"深度跳跃"区域时,周围黑色区域表明其深度估计网络性能不佳。
In order to improve the accuracy of depth estimation networks in the “depth jump” region, we propose an edgeaware depth fusion (EADF) module. It provides additional information about the scene edges to the depth network, and helps the model better adapt to the rapid changes in depth among objects.
为了提高深度估计网络在"深度跳跃"区域的准确性,我们提出了一种边缘感知深度融合(EADF)模块。该模块为深度网络提供了场景边缘的附加信息,帮助模型更好地适应物体间深度的快速变化。
We find that existing LSS-based methods did not fully utilize depth information when matching the predicted depth map and the ground-truth depth map, leading to poor performance of the depth network. BEVDet (J. et al. 2021) does not consider using depth information of point cloud to constrain the depth network. BEVFusion (Liang et al. 2022) uses the depth of point cloud as a feature to implicitly supervise the depth estimation network, which indicates that accurate depth information is not fully utilized. CaDDN (Reading et al. 2021) interpolates sparse depth map projected of LIDAR points, and uses it to supervise prediction of depth distribution. But the interpolated depth ground-truth tends to be smooth and loses the information of the depth distribution between the foreground and the background. BEVDepth (Y. et al. 2022b) utilizes the minimum pooling and one hot operations to align the depth estimates and the projected depth of point cloud. But depth of point cloud is extremely sparse when projected to 2D, which hinders the network from learning the correct depth estimates.
我们发现现有的基于LSS的方法在匹配预测深度图和真实深度图时未能充分利用深度信息,导致深度网络性能不佳。BEVDet (J. et al. 2021) 未考虑使用点云深度信息约束深度网络。BEVFusion (Liang et al. 2022) 将点云深度作为特征隐式监督深度估计网络,表明未充分利用精确深度信息。CaDDN (Reading et al. 2021) 对激光雷达点投影的稀疏深度图进行插值,并用于监督深度分布预测,但插值后的真实深度往往过于平滑,丢失了前景与背景间的深度分布信息。BEVDepth (Y. et al. 2022b) 采用最小池化和独热编码操作对齐深度估计值与点云投影深度,但点云投影至2D时极度稀疏,阻碍了网络学习正确的深度估计。
To solve the above problem, we propose a novel finegrained depth (FGD) module. This module contains an upsampling branch to match the size between the predicted feature map and the ground-truth depth map during training. It allows the depth estimation network to perceive the depth distribution of the whole scene in a finer way, and preserves the original depth information as much as possible. The proposed FGD module is only used in training stage, so it does not affect the speed and resource consumption of the model during inference stage.
为解决上述问题,我们提出了一种新颖的细粒度深度 (FGD) 模块。该模块包含一个上采样分支,用于在训练期间匹配预测特征图与真实深度图的尺寸。它使深度估计网络能够以更精细的方式感知整个场景的深度分布,并尽可能保留原始深度信息。所提出的 FGD 模块仅用于训练阶段,因此不会影响模型在推理阶段的速度和资源消耗。
Our proposed Edge-aware Lift-splat-shot (EA-LSS) framework couples the edge-aware depth fusion (EADF) module and the fine-grained depth (FGD) module. As a plug-and-play view converter, EA-LSS framework can be adapted to various LSS-based BEV 3D object detection methods (J. et al. 2021; Liang et al. 2022; Reading et al. 2021; Y. et al. 2022b). Our proposed EA-LSS framework can assist the depth estimation network in estimating the depth distribution for the monocular image in a finer way, and adapt to the “depth jump” region in the image in a better way.
我们提出的边缘感知升维展开投射 (EA-LSS) 框架耦合了边缘感知深度融合 (EADF) 模块和细粒度深度 (FGD) 模块。作为即插即用的视角转换器,EA-LSS框架可适配多种基于LSS的BEV 3D目标检测方法 (J. et al. 2021; Liang et al. 2022; Reading et al. 2021; Y. et al. 2022b)。该框架能辅助深度估计网络以更精细的方式估计单目图像的深度分布,并更好地适应图像中的"深度突变"区域。
We validate our proposed EA-LSS framework on nuScenes (H. et al. 2020) 3D object detection benchmark. Our method improves the mAP and NDS of the camera-only baseline Tig-bev (Huang et al. 2022) by $2.1%$ and $3.2%$ , the multi-modal baseline BEVFusion (Z. et al. 2022a) by $1.6%$ and $1.0%$ , with negligible increase on time and computation resources in the inference stage. In the nuScenes test dataset, our proposed EA-LSS framework achieves the state-of-theart performance, with mAP and NDS of $76.5%$ and $77.6%$ , respectively.
我们在nuScenes (H. et al. 2020) 3D目标检测基准上验证了提出的EA-LSS框架。该方法将纯摄像头基线Tig-bev (Huang et al. 2022)的mAP和NDS分别提升$2.1%$和$3.2%$,多模态基线BEVFusion (Z. et al. 2022a)的mAP和NDS分别提升$1.6%$和$1.0%$,且在推理阶段仅带来可忽略的时间和计算资源开销。在nuScenes测试数据集上,EA-LSS框架取得了最先进的性能表现,mAP和NDS分别达到$76.5%$和$77.6%$。
Contributions of this paper are summarized as follows:
本文的贡献总结如下:
Related Work
相关工作
3D object detection is one of the core tasks of 3D perception that predicts objects of specific types and 3D bounding boxes. Previous works (Zhou, Wang, and Krahenbihl 2019; Wang et al. 2021; H. et al. 2019; Shi, X., and H. 2019; Y., Y., and B. 2018; Chen et al. 2022; Vora et al. 2020) directly predict from perspective view (PV) features, which are unable to exploit stereo visual cues from multiple views and time-continuous frames. BEV-based 3D object detection models (Z. et al. 2022a; Liang et al. 2022; C. et al. 2021; J. et al. 2021; J. and G. 2022; T., X., and Philipp 2021) excel at fusing multi-source and multi-timestamp features, and have made great progress in terms of efficiency and performance.
3D物体检测是3D感知的核心任务之一,旨在预测特定类型的物体及其3D边界框。先前的研究 (Zhou, Wang, and Krahenbihl 2019; Wang et al. 2021; H. et al. 2019; Shi, X., and H. 2019; Y., Y., and B. 2018; Chen et al. 2022; Vora et al. 2020) 直接从透视图 (PV) 特征进行预测,无法利用多视角和时间连续帧的立体视觉线索。基于鸟瞰图 (BEV) 的3D物体检测模型 (Z. et al. 2022a; Liang et al. 2022; C. et al. 2021; J. et al. 2021; J. and G. 2022; T., X., and Philipp 2021) 擅长融合多源和多时间戳特征,在效率和性能方面取得了显著进展。
One of the core problems of BEV perception lies in reconstructing the lost 3D information using PV-to-BEV view translation. To compensate the difference between these two views, previous methods can be divided into network-based view transformation methods (Q. et al. 2021; C., van de M. J. G., and G. 2019; Z. et al. 2022b; Y. et al. 2022c,a) and depth-based view transformation methods (J. et al. 2021; C. et al. 2021; Y. et al. 2020; T. et al. 2022; Wu et al. 2022).
BEV感知的核心问题之一在于通过PV到BEV的视角转换来重建丢失的3D信息。为弥补两种视角间的差异,现有方法可分为基于网络的视角转换方法 (Q. et al. 2021; C., van de M. J. G., and G. 2019; Z. et al. 2022b; Y. et al. 2022c,a) 和基于深度的视角转换方法 (J. et al. 2021; C. et al. 2021; Y. et al. 2020; T. et al. 2022; Wu et al. 2022)。

Figure 1: Visualisation of “depth jump” problem. It shows depth estimation before and after adding EA-LSS framework on baseline method BEVFusion (Z. et al. 2022a). The larger the pixel value, the deeper the depth.
图 1: "深度跳跃"问题可视化。展示了基线方法 BEVFusion (Z. et al. 2022a) 在添加 EA-LSS 框架前后的深度估计效果。像素值越大表示深度越深。
Network-based View Transformation Methods
基于网络视角的变换方法
MLP-based Approach. MLP-based approaches use MLP to learn an implicit representation of camera calibration for conversion between two different views. HDMapNet (Q. et al. 2021) considers that one-way projection is difficult to ensure effective transfer during forward pass of view information from PV to BEV. Therefore, it also uses MLP to backward project features from BEV to PV. VED (C., van de M. J. G., and G. 2019) is the first method using end-to-end learning on monocular images to generate semantic-metric occupancy grid map in real time. It converts PV feature maps into BEV feature maps through flattening, mapping, and reshaping operations for multi-modal perception and prediction.
基于MLP的方法。基于MLP的方法利用多层感知机(MLP)学习相机标定的隐式表示,以实现两种不同视角间的转换。HDMapNet (Q. et al. 2021)指出单向投影难以保证透视视图(PV)到鸟瞰图(BEV)前向传递过程中视角信息的有效迁移,因此额外采用MLP将特征从BEV反向投影至PV。VED (C., van de M. J. G., and G. 2019)作为首个通过单目图像端到端学习实时生成语义-度量占据栅格图的方法,通过展平、映射和重塑操作将PV特征图转换为BEV特征图,以支持多模态感知与预测。
Transformer-based Approach. Transformer-based approaches directly employ the transformer to map PV into BEV, which does not explicitly require the camera model. Tesla first uses the transformer to project PV features into BEV. It adopts positional encoding to design a set of BEV queries, then performs view transformations through crossattention mechanism between BEV queries and image features. BEVFormer (Z. et al. 2022b) employs deformable attention to extract dense queries in BEV and describes relationships between multi-view features. DETR3D (Y. et al. 2022c) utilizes a geometry-based feature sampling process instead of cross-attention to predict 3D reference points. And reference points are projected into the 2D image plane using a calibration matrix to achieve end-to-end 3D edge prediction. PETRv2 (Y. et al. 2022a) extends 3D position embedding to the time domain, effectively utilizing continuous frame information. PolarDETR (S. et al. 2022) brings parameters of 3D object detection to the polar coordinate system, reformulating edge parameter iz ation, network prediction and loss calculation.
基于Transformer的方法。基于Transformer的方法直接利用Transformer将PV映射到BEV,无需显式依赖相机模型。Tesla率先采用Transformer将PV特征投影至BEV空间,通过位置编码设计一组BEV查询(query),再通过BEV查询与图像特征的交叉注意力机制实现视角转换。BEVFormer (Z. et al. 2022b)运用可变形注意力(deformable attention)提取BEV中的密集查询,并描述多视角特征间的关系。DETR3D (Y. et al. 2022c)采用基于几何的特征采样替代交叉注意力,通过标定矩阵将3D参考点投影至2D图像平面,实现端到端3D边缘预测。PETRv2 (Y. et al. 2022a)将3D位置嵌入扩展到时域,有效利用连续帧信息。PolarDETR (S. et al. 2022)将3D目标检测参数转换到极坐标系,重构了边缘参数化、网络预测和损失计算流程。
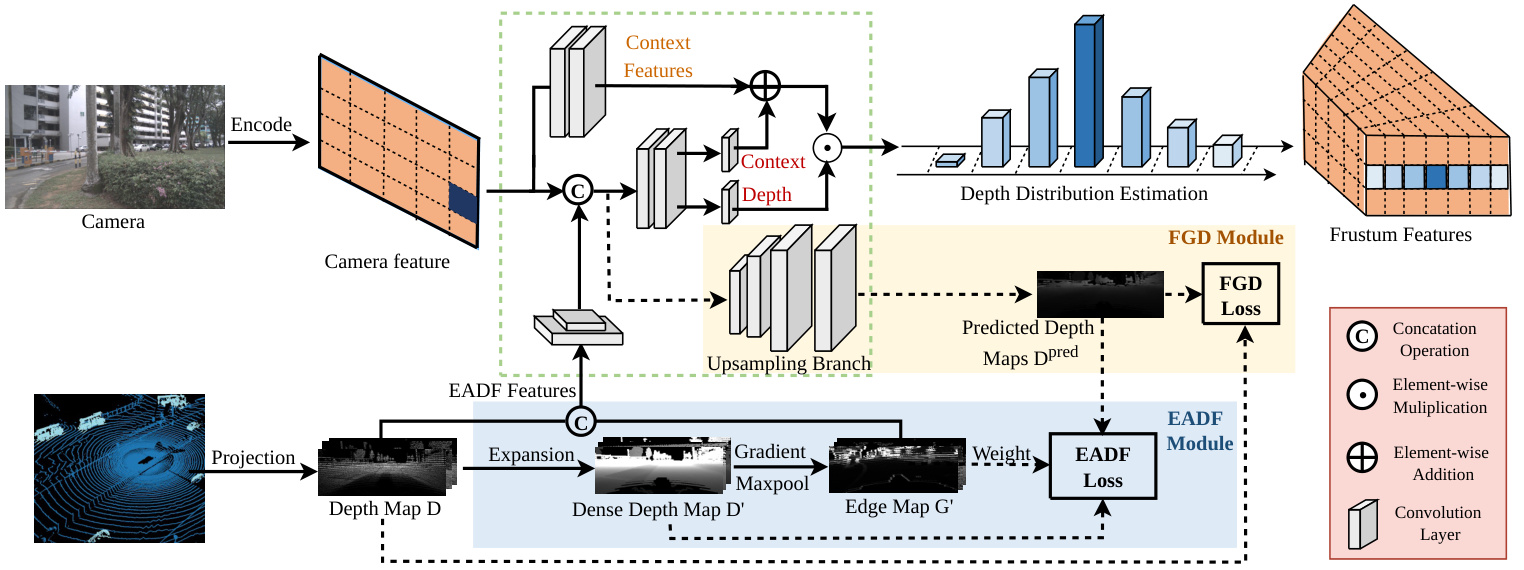
Figure 2: The details of our proposed EA-LSS Framework. It contains an edge-aware depth fusion (EADF) module (shown in blue) and a fine-grained depth (FGD) module (shown in yellow). In this framework, the multi-view 2D camera images and 3D Lidar point clouds are used as input to generate the frustum features. The dash lines are only involved in inference stage.
图 2: 我们提出的 EA-LSS 框架细节。该框架包含边缘感知深度融合 (EADF) 模块 (蓝色部分) 和细粒度深度 (FGD) 模块 (黄色部分)。该框架以多视角 2D 相机图像和 3D 激光雷达点云作为输入来生成视锥体特征。虚线部分仅在推理阶段参与计算。
Depth-based View Transformation
基于深度的视角变换
Point-based Approach. Point-based approaches use depth estimation networks to convert image pixels into pseudo-laser point clouds, which are fed to a lidar-based 3D detector. These approaches are highly dependent on the accuracy of depth estimation. Pseudo-lidar $^{++}$ (Y. et al. 2020) improves the accuracy of depth estimation network using a stereo vision estimation network. SFD (Wu et al. 2022) uses both the original point cloud and the pseudo point cloud generated by depth estimation network, and fuses them to improve detection accuracy of distant and occluded objects.
基于点的方法。基于点的方法利用深度估计网络将图像像素转换为伪激光点云,随后输入基于激光雷达的3D检测器。这类方法高度依赖深度估计的精度。Pseudo-lidar$^{++}$ (Y. et al. 2020) 通过立体视觉估计网络提升了深度估计网络的准确性。SFD (Wu et al. 2022) 则同时使用原始点云和深度估计网络生成的伪点云,通过融合两者来提升远距离及被遮挡物体的检测精度。
Depth Estimation-based Approach. Depth estimationbased methods explicitly predict depth distribution of image features to construct 3D features. LSS (J. and S. 2020) is a representation of these methods. LSS-based methods predict both feature distribution in the depth direction and image context information, to determine the features of each point of the perspective ray, reducing the loss of image semantics due to depth prediction bias. BEVDet (J. et al. 2021) proposes a multi-view 3D detection framework that includes an image view encoder, view transformer, BEV encoder, and detection head. CaDDN (C. et al. 2021) interpolates the sparse depth map of lidar point projection and supervises the depth estimation using depth distribution. MV $\mathrm{FCOS3D++}$ (T. et al. 2022) proposes the pre-training of depth estimation and monocular 3D detection, which significantly enhances the learning ability of 2D backbones.
基于深度估计的方法。深度估计方法通过显式预测图像特征的深度分布来构建3D特征。LSS (J. and S. 2020) 是这类方法的代表。基于LSS的方法同时预测深度方向上的特征分布和图像上下文信息,以确定透视射线上各点的特征,减少因深度预测偏差导致的图像语义损失。BEVDet (J. et al. 2021) 提出了一种多视图3D检测框架,包含图像视图编码器、视图变换器、BEV编码器和检测头。CaDDN (C. et al. 2021) 对激光雷达点投影的稀疏深度图进行插值,并利用深度分布监督深度估计。MV $\mathrm{FCOS3D++}$ (T. et al. 2022) 提出了深度估计和单目3D检测的预训练方法,显著增强了2D主干网络的学习能力。
Our proposed EA-LSS framework explores refinement of depth estimation-based approach by the proposed depth estimation module and edge-aware depth fusion module. EALSS framework is able to accurately estimate the global depth and the edge regions of objects with sharp depth changes. And “depth jump” problem is effectively alleviated, which is meaningful to properly guide subsequent network.
我们提出的EA-LSS框架通过深度估计模块和边缘感知深度融合模块,探索了基于深度估计方法的优化。EALSS框架能够准确估计全局深度以及物体边缘区域中深度急剧变化的部分,有效缓解了"深度跳跃"问题,这对正确引导后续网络具有重要意义。
Method
方法
Depth estimation network is crucial in both camera-only and multi-modal 3D object detection methods. Estimation accuracy can seriously affect performance of the subsequent network (i,e., BEV decoder and detection head). Therefore, in order to predict the fine-grained depth distribution, we propose the edge-aware lift-splat-shot (EA-LSS) framework (Figure 2) coupled by an edge-aware depth fusion (EADF) module and a fine-grained depth (FGD) module.
深度估计网络在纯摄像头和多模态3D目标检测方法中均至关重要。估计精度会严重影响后续网络(即BEV解码器和检测头)的性能。因此,为预测细粒度深度分布,我们提出了由边缘感知深度融合(EADF)模块与细粒度深度(FGD)模块耦合的边缘感知升维-展开-投射(EA-LSS)框架(图2)。
Fine-grained Depth Module
细粒度深度模块
We propose a fine-grained depth module to constrain the depth network pixel by pixel. In order to retain accurate depth information, an upsampling branch is proposed as additional depth estimation network for supervision. The depth map projected from point cloud is extremely sparse. If the loss is calculated between the projected depth map from the point clouds and the predicted depth map, excessive zero values in the projected depth map can increase difficulty of fitting these two depth maps. We propose a fine-grained depth (FGD) loss as constraint to supervise the loss between the non-zero pixels in the projected depth map and their corresponding pixels in the predicted depth map. The proposed FGD loss effectively excludes the interference of the zerovalued pixels of the projected depth map on the depth network.
我们提出了一种细粒度深度模块,用于逐像素约束深度网络。为了保留精确的深度信息,额外设计了上采样分支作为监督用的深度估计网络。由点云投影生成的深度图极度稀疏,若直接在点云投影深度图与预测深度图之间计算损失,投影图中过多的零值会加大两者拟合难度。为此,我们提出细粒度深度(FGD)损失函数,通过约束投影深度图中非零像素与预测深度图对应像素间的差异来实现监督。该FGD损失有效排除了投影深度图零值像素对深度网络的干扰。
In addition, to focus on the foreground objects (considering more objects appear in background), focal loss (Lin et al. 2017) is embedded in fine-grained depth loss. In FGD loss, the outputs of the sampling branch $\bar{\mathbf{D}^{p r e d}}$ are used as predicted samples while the multi-view depth maps $\mathbf{D}$ projected from input point clouds are used as ground-truth labels. FGD loss is defined below:
此外,为了聚焦前景对象(考虑到背景中出现的对象更多),细粒度深度损失中嵌入了焦点损失 (Lin et al. 2017) 。在FGD损失中,采样分支的输出 $\bar{\mathbf{D}^{p r e d}}$ 作为预测样本,而由输入点云投影的多视角深度图 $\mathbf{D}$ 作为真实标签。FGD损失定义如下:

Figure 3: Visualization of (a) multi-view depth maps D, (b) multi-view dense depth maps $\mathbf{D^{\prime}}$ , and (c) multi-view edge maps $\mathbf{G}^{\prime}$ .
图 3: (a) 多视角深度图 D, (b) 多视角稠密深度图 $\mathbf{D^{\prime}}$, (c) 多视角边缘图 $\mathbf{G}^{\prime}$ 的可视化结果。
$$
L_{F G D}=\sum_{i=1}^{n}\sum_{c=1}^{H_{D}}-\alpha_{c}(1-y_{i,c})^{\gamma}l o g(\widehat{y}_{i,c}),
$$
$$
L_{F G D}=\sum_{i=1}^{n}\sum_{c=1}^{H_{D}}-\alpha_{c}(1-y_{i,c})^{\gamma}l o g(\widehat{y}_{i,c}),
$$
where $n$ is the number of non-zero pixels in ground-truth D. $H_{D}$ denotes the classes of predicted depth maps $\mathbf{D}^{p r e d}$ . Here ground-truth $\mathbf{D}$ is transferred to one-hot vectors. $\widehat{y}{i,c}$ is the value of $c^{t h}$ class of $i^{t h}$ one-hot vector of non-zer ob pixels in $\mathbf{D}$ . $y_{i,c}$ is from the corresponding pixels in predicted depth map $\mathbf{D}^{p r e d}$ . $\alpha_{c}$ denotes the weight and $\gamma$ denotes the predefined hyper-parameter for focal loss.
其中 $n$ 是真实深度图 D 中非零像素的数量。$H_{D}$ 表示预测深度图 $\mathbf{D}^{p r e d}$ 的类别。此处将真实深度图 $\mathbf{D}$ 转换为独热向量。$\widehat{y}{i,c}$ 是 $\mathbf{D}$ 中第 $i$ 个非零像素独热向量在第 $c$ 个类别的值,$y_{i,c}$ 来自预测深度图 $\mathbf{D}^{p r e d}$ 的对应像素。$\alpha_{c}$ 表示权重,$\gamma$ 表示焦点损失 (focal loss) 的预设超参数。
Edge-aware Depth Fusion Module
边缘感知深度融合模块
In order to alleviate the “depth jump” problem, we propose an edge-aware depth fusion (EADF) Module.
为了缓解"深度跳跃"问题,我们提出了一种边缘感知深度融合(EADF)模块。
The input point clouds are projected to multi-view depth maps $\begin{array}{l}{\bar{\textbf{D}}={\mathbf{d}{i j}|i~=1,\bar{\dots},\bar{N}{H};j~=~1,...,N_{W}}^{-}\in}\end{array}$ RNv∗NH∗HW , where Nv represents the number of views, $N_{H}$ and $N_{W}$ represent the length and height of depth maps. Multi-view depth maps $\mathbf{D}$ are divided into blocks in size $k*k$ along $\mathbf{X}$ -axis and y-axis, where $k$ is the step size. Then we use the maximum depth value of each block to fill the whole block through expanding operation, which connects most scenes in the point cloud depth map. After block division and expanding operation, multi-view depth maps $\mathbf{D}$ are transferred to the multi-view dense depth maps $\mathbf{D^{\prime}}$ with the same dimension.
输入点云被投影为多视角深度图 $\begin{array}{l}{\bar{\textbf{D}}={\mathbf{d}{i j}|i~=1,\bar{\dots},\bar{N}{H};j~=~1,...,N_{W}}^{-}\in}\end{array}$ RNv∗NH∗HW ,其中 Nv 表示视角数量, $N_{H}$ 和 $N_{W}$ 分别表示深度图的长度和高度。多视角深度图 $\mathbf{D}$ 沿 $\mathbf{X}$ 轴和 y 轴被划分为 $k*k$ 大小的块,其中 $k$ 为步长。随后通过膨胀操作,用每个块的最大深度值填充整个块,从而连接点云深度图中的大部分场景。经过分块和膨胀操作后,多视角深度图 $\mathbf{D}$ 被转换为具有相同维度的多视角稠密深度图 $\mathbf{D^{\prime}}$ 。
Next, we calculate gradient of multi-view dense depth map along x-axis and y-axis to extract edge-aware 3D geometry information. Considering each axis has two directions, we define gradients of dense depth map ${\bf G}^{}={}$ ${\mathbf{G}^{1},\mathbf{G}^{2},\mathbf{G}^{3},\mathbf{G}^{4}}$ in Equation 2, where $\mathbf{G}^{\bar{t}}={\mathbf{g}{i,j}^{\bar{t}}},t=$ 1, 2, 3, 4. Each pixel of multi-view dense depth maps gi1,j, $\mathbf{g}{i,j}^{2},\mathbf{g}{i,j}^{3}$ , and $\mathbf{g}_{i,j}^{4}$ are defined as:
接下来,我们计算多视角稠密深度图沿x轴和y轴的梯度以提取边缘感知的3D几何信息。考虑到每个轴有两个方向,我们在公式2中定义了稠密深度图的梯度 ${\bf G}^{}={}$ ${\mathbf{G}^{1},\mathbf{G}^{2},\mathbf{G}^{3},\mathbf{G}^{4}}$ ,其中 $\mathbf{G}^{\bar{t}}={\mathbf{g}{i,j}^{\bar{t}}},t=$ 1, 2, 3, 4。
where $\mathbf{d}^{\prime}{}{i,j}$ is the $i^{t h}$ column $j^{t h}$ row of multi-view dense depth maps $\mathbf{D^{\prime}}$ $\cdot{\mathbf{g}{i,j}^{t}}\in R^{N_{v}*N_{H}*H_{W}}$ represents one direction of the gradient of multi-view dense depth map.
其中 $\mathbf{d}^{\prime}{}{i,j}$ 是 $\mathbf{D^{\prime}}$ 多视角密集深度图中第 $i^{t h}$ 列第 $j^{t h}$ 行的值,$\cdot{\mathbf{g}{i,j}^{t}}\in R^{N_{v}*N_{H}*H_{W}}$ 表示多视角密集深度图梯度的某个方向。
Dense depth map gradient $\mathbf{G}\in R^{N_{v}N_{H}*\hat{H_{W}}*4}$ is passed to the max pooling operation on the last dimension and normalization operation to obtain the multi-view edge maps $\mathbf{G}^{\prime}$ . Multi-view edge maps $\mathbf{G}^{\prime}\in R^{N_{v}*N_{H}*H_{W}}$ represents the edge of different objects. $\mathbf{G}^{\prime}$ are scaled to $[0,1]$ by normalization operation.
密集深度图梯度 $\mathbf{G}\in R^{N_{v}N_{H}*\hat{H_{W}}*4}$ 经过最后一维的最大池化操作和归一化操作,得到多视角边缘图 $\mathbf{G}^{\prime}$。多视角边缘图 $\mathbf{G}^{\prime}\in R^{N_{v}*N_{H}*H_{W}}$ 表示不同物体的边缘。通过归一化操作将 $\mathbf{G}^{\prime}$ 缩放至 $[0,1]$ 范围。
As shown in Figure 3 (a), multi-view depth maps $\mathbf{D}$ projected from 3D lidar scanning are sparse, which is not suitable for directly supervising the depth estimation networks. Figure 3 (b) shows the multi-view dense depth maps $\mathbf{D^{\prime}}$ after block division and expanding operations. Original depth information from depth map is reserved. Main objects in dense depth map are connected, which is beneficial to depth estimation network of the whole scene. In Figure 3 (c), we obtain multi-view edge maps $\mathbf{G}^{\prime}$ by calculating the maximum gradient value of each pixel along the four directions. Multi-view edge maps $\mathbf{G}^{\prime}$ represent the maximum depth variation among each block. After multi-view depth map $\mathbf{D}$ and multi-view edge map $\mathbf{G}^{\prime}$ are obtained, we concatenate $\mathbf{D}$ and $\mathbf{G}^{\prime}$ to generate the output of EADF module as FEADF = [D : G′].
如图3(a)所示,从3D激光扫描投影得到的多视角深度图$\mathbf{D}$是稀疏的,不适合直接监督深度估计网络。图3(b)展示了经过区块划分和扩展操作后的多视角密集深度图$\mathbf{D^{\prime}}$。原始深度图中的深度信息被保留,密集深度图中的主要物体相互连接,这有利于整个场景的深度估计网络。在图3(c)中,我们通过计算每个像素沿四个方向的最大梯度值获得多视角边缘图$\mathbf{G}^{\prime}$。多视角边缘图$\mathbf{G}^{\prime}$表示每个区块内的最大深度变化。获取多视角深度图$\mathbf{D}$和多视角边缘图$\mathbf{G}^{\prime}$后,我们将$\mathbf{D}$和$\mathbf{G}^{\prime}$拼接生成EADF模块的输出FEADF = [D : G′]。
We propose edge-aware depth fusion (EADF) loss to focus on the edge of each object, by using multi-view dense depth maps $\mathbf{D^{\prime}}$ as ground-truth and multi-view edge maps $\mathbf{G}^{\bar{\prime}}$ as weight to alleviate the “depth jump” problem. EADF loss $L_{E A D F}$ for supervision is defined:
我们提出边缘感知深度融合(EADF)损失函数,通过使用多视角稠密深度图$\mathbf{D^{\prime}}$作为真值、多视角边缘图$\mathbf{G}^{\bar{\prime}}$作为权重来聚焦物体边缘,缓解"深度跳跃"问题。监督用的EADF损失$L_{E A D F}$定义为:
$$
L_{E A D F}=\sum_{i=1}^{m}\sum_{c=1}^{H_{D}}-\alpha_{c}\left(1-p_{i,c}\right)^{\gamma}l o g\left(\widehat{p}{i,c}\right)*w_{i},
$$
$$
L_{E A D F}=\sum_{i=1}^{m}\sum_{c=1}^{H_{D}}-\alpha_{c}\left(1-p_{i,c}\right)^{\gamma}l o g\left(\widehat{p}{i,c}\right)*w_{i},
$$
where $m$ is the number of pixels in predicted depth map $\mathbf{D}^{p r e d}$ . $H_{D}$ denotes the classes of predicted depth. $p_{i,c}$ denotes the value of $c^{t h}$ class of the $i^{t h}$ pixel from predicted depth map $\mathbf{D}^{p r e d}$ , $\widehat{p}{i,c}$ is the corresponding pixel in groundtruth depth map $\mathbf{D^{\prime}}$ b, and $w_{i}$ is the corresponding pixel value of $\mathbf{G}^{\prime}$ . $\alpha_{c}$ denotes the weight and $\gamma$ denotes the predefined hyper-parameter for focal loss.
其中 $m$ 是预测深度图 $\mathbf{D}^{p r e d}$ 中的像素数量。$H_{D}$ 表示预测深度的类别数。$p_{i,c}$ 表示预测深度图 $\mathbf{D}^{p r e d}$ 中第 $i$ 个像素第 $c$ 类的值,$\widehat{p}{i,c}$ 是真实深度图 $\mathbf{D^{\prime}}$ 中对应的像素值,$w_{i}$ 是 $\mathbf{G}^{\prime}$ 中对应像素值。$\alpha_{c}$ 表示权重,$\gamma$ 表示焦点损失 (focal loss) 的预设超参数。
Edge-aware Lift-splat-shot Framework
Edge-aware Lift-splat-shot 框架
Our proposed EA-LSS framework is coupled by a finegrained depth (FGD) module and an edge-aware depth fusion (EADF) module. The proposed framework is able to estimate the fine-grained global depth distribution while attending depth jump regions (i.e., the edges of objects).
我们提出的EA-LSS框架由细粒度深度(FGD)模块和边缘感知深度融合(EADF)模块耦合而成。该框架能够估计细粒度全局深度分布,同时关注深度跃变区域(即物体边缘)。
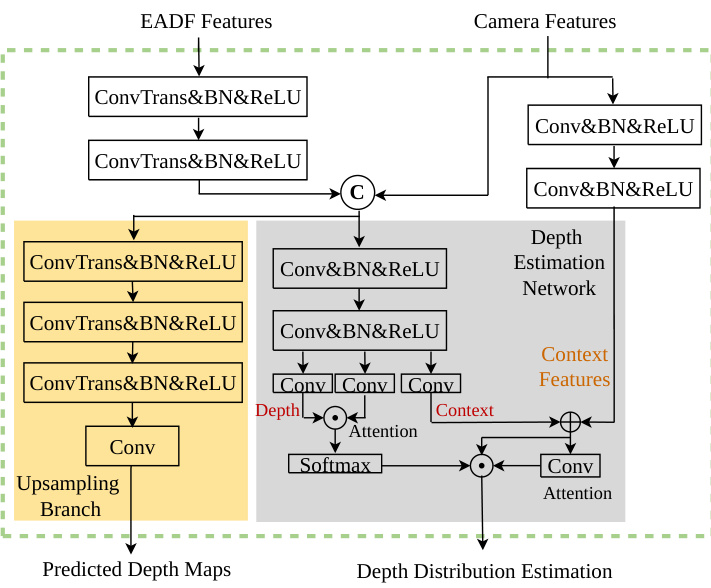
Figure 4: The detailed architecture of the EA-LSS framework.
图 4: EA-LSS框架的详细架构。
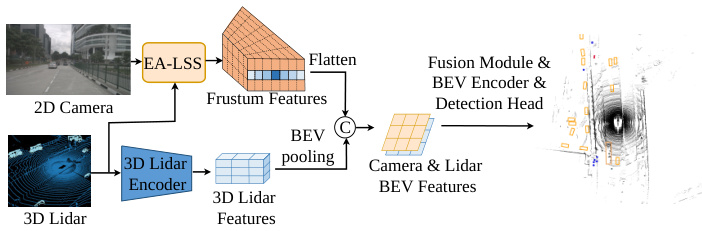
Figure 5: One sample of LSS-based 3D object detection models. The purpose of our proposed EA-LSS (shown in orange) is to transform camera feature map into 3D Ego-car coordinate.
图 5: 基于LSS的3D物体检测模型示例。我们提出的EA-LSS(如橙色所示)旨在将相机特征图转换为3D自车坐标系。
As shown in Figure 4, in order to fully utilize the depth information, output features of EADF module $\mathbf{F}^{E A D F}$ are fed into convolutional layers to extract their geometric features. And geometric features are fused with image features as inputs to the depth network. Besides, we believe that some semantic information of the image might be lost after fusing the geometric information. Hence two convolutional layers with a skip connection are used to help the network to restore the lost semantic information.
如图 4 所示,为了充分利用深度信息,EADF 模块的输出特征 $\mathbf{F}^{E A D F}$ 被输入卷积层以提取其几何特征。随后,几何特征与图像特征融合作为深度网络的输入。此外,我们认为融合几何信息后可能会丢失部分图像语义信息,因此采用带有跳跃连接的两个卷积层来帮助网络恢复丢失的语义信息。
As shown in Figure 5, the proposed EA-LSS framework is plug-and-play and can be used in various LSS-based BEV 3D object detection methods (J. et al. 2021; Liang et al. 2022; Reading et al. 2021; Y. et al. 2022b), for transforming camera feature map into the 3D Ego-car coordinate.
如图 5 所示,提出的 EA-LSS 框架即插即用,可应用于多种基于 LSS 的 BEV 3D 目标检测方法 (J. et al. 2021; Liang et al. 2022; Reading et al. 2021; Y. et al. 2022b),将相机特征图转换到 3D 自车坐标系中。
The total loss $L_{t o t a l}$ is defined as:
总损失 $L_{total}$ 定义为:
$$
L_{t o t a l}=L_{F G D}+L_{E A D F}+L_{c l s}+L_{b o x},
$$
$$
L_{total}=L_{FGD}+L_{EADF}+L_{cls}+L_{box},
$$
where $\mathit{L}{\mathit{F G D}}$ and $L_{E A D F}$ represent FGD loss and EADF loss defined in Eqn (1) and Eqn (3), respectively. $L_{c l s}$ and $L_{b o x}$ are classification loss and bounding box loss in the detection head.
其中 $\mathit{L}{\mathit{F G D}}$ 和 $L_{E A D F}$ 分别表示公式 (1) 和公式 (3) 中定义的 FGD 损失和 EADF 损失。$L_{c l s}$ 和 $L_{b o x}$ 是检测头中的分类损失和边界框损失。
Experiments Implementation Details
实验实现细节
In our experiments, we use BEVFusion (Z. et al. 2022a)/ BEVFusion (Liang et al. 2022)/ BEVDepth (Y. et al. 2022b)/Tig-bev (Huang et al. 2022) as the baseline methods to verify the effectiveness and efficiency of our proposed EA-LSS framework. We follow the same training strategies as these baselines.
在我们的实验中,我们使用 BEVFusion (Z. et al. 2022a)/BEVFusion (Liang et al. 2022)/BEVDepth (Y. et al. 2022b)/Tig-bev (Huang et al. 2022) 作为基线方法,以验证我们提出的 EA-LSS 框架的有效性和效率。我们遵循与这些基线相同的训练策略。
For fair comparison with camera-only LSS-based methods (Y. et al. 2022b; Huang et al. 2022), we use the same input as BEVDepth (Y. et al. 2022b) and Tig-bev (Huang et al. 2022), which means the 3D point cloud information is not directly used as the input. Only EADF Loss and FGD Loss are used to constrain depth estimation network during training stage.
为与仅基于相机LSS的方法 (Y. et al. 2022b; Huang et al. 2022) 进行公平对比,我们采用与BEVDepth (Y. et al. 2022b) 和Tig-bev (Huang et al. 2022) 相同的输入配置,即不直接将3D点云信息作为输入。训练阶段仅使用EADF Loss和FGD Loss约束深度估计网络。
The channel numbers of the two convolutional layers after EADF features are 32 and 64. The channel numbers of the three convolutional layers in upsampling branch are set to 256, 128 and 128. The kernel size of these convolutional layers is 5, the padding size is 2, the stride size is 2.
EADF特征后的两个卷积层通道数分别为32和64。上采样分支中的三个卷积层通道数设置为256、128和128。这些卷积层的核大小为5,填充大小为2,步幅大小为2。
The channel numbers of the five convolutional layers in depth estimation network are set to 256, 256, 40, 128, 1. The channel numbers of the two convolutional layers before context features are set to 256 and 128. The kernel size of these convolutional layer is 3, the padding size is 1, the stride size is 1.
深度估计网络中五个卷积层的通道数分别设置为256、256、40、128和1。上下文特征前的两个卷积层的通道数设置为256和128。这些卷积层的核大小为3,填充大小为1,步幅大小为1。
In the expanding operation of edge-aware depth fusion module, step size $\mathrm{k\Omega}$ is set to 7. The number of views $N_{v}$ is set to 6. Height and weight of depth maps $N_{H}$ and $N_{W}$ are set to 256 and 704. Both $\mathit{L}{\mathit{F G D}}$ and $L_{E A D F}$ adopt focal Loss, and $\gamma$ and $\alpha_{c}$ are set to 2.0 and 0.25, respectively. Our training environment is on a server with $8^{*}$ NVIDIA A100 GPU and AMD EPYC 7402 CPU.
在边缘感知深度融合模块的扩展操作中,步长 $\mathrm{k\Omega}$ 设为7。视角数量 $N_{v}$ 设为6。深度图的高度 $N_{H}$ 和宽度 $N_{W}$ 分别设为256和704。损失函数 $\mathit{L}{\mathit{F G D}}$ 和 $L_{E A D F}$ 均采用焦点损失 (focal Loss),其中 $\gamma$ 和 $\alpha_{c}$ 分别设为2.0和0.25。训练环境配置为搭载 $8^{*}$ NVIDIA A100 GPU和AMD EPYC 7402 CPU的服务器。
Dataset
数据集
In order to evaluate the effectiveness of our proposed EALSS framework, we conduct comparison experiments on nuScenes Dataset (H. et al. 2020). This dataset contains $40\mathrm{k\Omega}$ labeled samples, with 23 different classes. We use mean Average Precision (mAP) and nuScenes detection score (NDS) as evaluation indicators. mAP and NDS on validation set are reported. Meanwhile, we also report the latency time to illustrate the negligible increase of inference time after using our proposed EA-LSS framework.
为了评估我们提出的EA-LSS框架的有效性,我们在nuScenes数据集 (H. et al. 2020) 上进行了对比实验。该数据集包含 $40\mathrm{k\Omega}$ 标注样本,涵盖23个不同类别。我们采用平均精度均值 (mAP) 和nuScenes检测分数 (NDS) 作为评估指标,并报告验证集上的mAP和NDS结果。同时,我们还统计了延迟时间,以说明使用EA-LSS框架后推理时间的增加可以忽略不计。
Comparison Results
对比结果
Table 1 reports experiment results of nuScenes 3D object detection validation dataset. Our proposed EA-LSS framework can be added to any LSS-based baseline methods (Y. et al. 2022b; Z. et al. 2022a; Liang et al. 2022; Huang et al. 2022) with negligible increment of inference time. When using camera-only baseline method Tig-bev (Huang et al. 2022), mAP and NDS increase $2.1%$ and $3.2%$ after applying the proposed EA-LSS framework. On baseline method BEVFusion (Liang et al. 2022), mAP and NDS increase $1.6%$ and $1.0%$ , respectively.
表 1: 报告了 nuScenes 3D 物体检测验证数据集的实验结果。我们提出的 EA-LSS 框架可以添加到任何基于 LSS 的基线方法 (Y. et al. 2022b; Z. et al. 2022a; Liang et al. 2022; Huang et al. 2022) 中,且推理时间增量可忽略不计。当使用仅摄像头的基线方法 Tig-bev (Huang et al. 2022) 时,应用 EA-LSS 框架后 mAP 和 NDS 分别提升 $2.1%$ 和 $3.2%$。在基线方法 BEVFusion (Liang et al. 2022) 上,mAP 和 NDS 分别提升 $1.6%$ 和 $1.0%$。
In Table 2, we report the experiment results of nuScenes 3D object detection test dataset. After using EA-LSS framework, the mAP and NDS for baseline BEVFusion (Liang et al. 2022) increase $0.9~%$ and $1.1%$ , respectively. After adding test time augment and model emsemble, the mAP and NDS of our proposed EA-LLS framework reach $76.5%$ and $77.6%$ , achieving the Top 1 in leader board of nuScenes Detection Task.
在表2中,我们报告了nuScenes 3D目标检测测试数据集的实验结果。使用EA-LSS框架后,基线方法BEVFusion (Liang et al. 2022)的mAP和NDS分别提升了$0.9%$和$1.1%$。通过增加测试时增强和模型集成,我们提出的EA-LSS框架的mAP和NDS达到$76.5%$和$77.6%$,在nuScenes检测任务排行榜上位列第一。
Table 1: Comparison results of 3D object detection on nuScenes validation dataset. For fair comparison, 3D point cloud is no used in baselines BEVDepth and Tig-bev in the inference stage.
表 1: nuScenes验证数据集上3D物体检测的对比结果。为公平比较,基线方法BEVDepth和Tig-bev在推理阶段未使用3D点云数据。
| 方法 | 模态 | mAP | NDS | 延迟(ms) |
|---|---|---|---|---|
| BEVFormer (Z.etal.2022b) | C | 41.6 | 51.7 | |
| TransFusion (X.etal.2022) | C+L | 67.5 | 71.3 | 156.6 |
| Deeplnteraction(Yangetal.2022) | C+L | 69.9 | 72.6 | 204.1 |
| CMT (Yanetal.2023) | C+L | 70.3 | 72.9 | |
| BEVDepth-R50 (Y.et al.2022b) | C | 33.0 | 43.6 | 110.3 |
| +EA-LSS | C | 33.4 | 44.1 | 110.3 |
| Tig-bev (Huang et al. 2022) | C | 33.8 | 37.5 | 68.0 |
| +EA-LSS | C | 35.9 | 40.7 | 68.0 |
| BEVFusion(Z.etal.2022a) | C+L | 68.5 | 71.4 | 119.2 |
| +EA-LSS | C+L | 69.4 | 71.8 | 123.6 |
| BEVFusion (Liangetal.2022) | C+L | 69.6 | 72.1 | 190.3 |
| +EA-LSS | C+L | 71.2 | 73.1 | 194.9 |
Table 2: The comparison result of 3D object detection on nuScenes testing dataset. * represent the test time augment and model ensemble. Our EA-LSS reaches top1 in the leader board of nuScenes detection task.
表 2: nuScenes测试数据集上3D物体检测的对比结果。*表示测试时数据增强和模型集成。我们的EA-LSS在nuScenes检测任务排行榜上达到第一名。
| 方法 | 模态 | mAP | NDS↑ | mATE↓ | mASE↓ | mAOE↓ | mAVE↓ | mAAE√ |
|---|---|---|---|---|---|---|---|---|
| BEVDet (J.etal.2021) | C | 42.2 | 48.2 | 0.529 | 0.236 | 0.396 | 0.979 | 0.152 |
| BEVFormer (Z.etal.2022b) | C | 44.5 | 53.5 | 0.582 | 0.256 | 0.375 | 0.378 | 0.126 |
| CenterPoint (Y.,Z.,and K.2021) | L | 60.3 | 67.3 | 0.262 | 0.239 | 0.361 | 0.288 | 0.136 |
| TransFusion (X.et al.2022) | C+L | 68.9 | 71.6 | 0.259 | 0.243 | 0.359 | 0.288 | 0.127 |
| CMT (Yan et al.2023) | C+L | 70.4 | 73.0 | 0.299 | 0.241 | 0.323 | 0.240 | 0.112 |
| DeepInteraction (Yang et al. 2022) | C+L | 70.8 | 73.4 | 0.257 | 0.240 | 0.325 | 0.245 | 0.128 |
| BEVFusion (Liang et al. 2022) | C+L | 71.3 | 73.3 | 0.250 | 0.240 | 0.359 | 0.254 | 0.132 |
| +EA-LSS | C+L | 72.2 | 74.4 | 0.247 | 0.237 | 0.304 | 0.250 | 0.133 |
| +EA-LSS* | C+L | 76.5 | 77.6 | 0.233 | 0.228 | 0.281 | 0.196 | 0.123 |
Table 3: Ablation study of our proposed FGD module and EADF module. Here, C-DG’ represents concatenation of multi-view depth map $\mathbf{D}$ and multi-view edge maps $\mathbf{G}^{\prime}$ , while EADFL represents the usage of EADF loss.
表 3: 我们提出的 FGD 模块和 EADF 模块的消融研究。其中,C-DG' 表示多视角深度图 $\mathbf{D}$ 和多视角边缘图 $\mathbf{G}^{\prime}$ 的拼接,而 EADFL 表示使用了 EADF 损失。
| FGD模块 | EADF模块 C-DG EADFL | mAP NDS |
|---|---|---|
| × | 69.6 72.1 | |
| × | 70.1 72.4 | |
| 70.6 72.8 | ||
| √ | 71.2 73.1 | |
| 提升 | +1.6 |
Ablation Study
消融实验
In Table 3, we provide ablation study for different components in EA-LSS framework on nuScenes benchmarks. We use BEVFusion (Liang et al. 2022) as baseline method to evaluate the effectiveness of EADF module and FGD module. After only adding FGD module, the mAP and NDS are improved for $0.5%$ and $0.3%$ , respectively. Next, after adding EADF module, the mAP and NDS continue to be improved for $1.1%$ and $0.7%$ , respectively. We also conduct the ablation study on EADF Loss and concatenation of $\mathbf{D}$ and $\mathbf{G}^{\prime}$ , and the mAP is improved for $0.5%$ and $0.6%$ , respectively.
在表3中,我们提供了EA-LSS框架在nuScenes基准测试中不同组件的消融研究。我们以BEVFusion (Liang et al. 2022) 为基线方法,评估EADF模块和FGD模块的有效性。仅添加FGD模块后,mAP和NDS分别提升了$0.5%$和$0.3%$。接着添加EADF模块后,mAP和NDS继续分别提升$1.1%$和$0.7%$。我们还对EADF Loss以及$\mathbf{D}$与$\mathbf{G}^{\prime}$的拼接进行了消融研究,mAP分别提升了$0.5%$和$0.6%$。
Table 4: Performances on nuScenes 3D object detection validation dataset, when using different step $k$ of block division and expanding operation in edge-aware depth fusion module.
表 4: 在 nuScenes 3D 目标检测验证数据集上的性能表现,展示了边缘感知深度融合模块中采用不同分块步长 $k$ 和扩展操作时的结果。
| k | mAP | NDS |
|---|---|---|
| 3 5 | 68.9 | 71.6 |
| 7 | 69.1 | 71.6 |
| 69.4 | 71.8 | |
| 9 | 68.4 | 71.4 |
Table 4 provides performances on nuScenes 3D object detection validation dataset, when using different step size $k$ of block division and expanding operation in EADF module. We use BEVFusion $Z.$ . et al. 2022a) as baseline method. The best mAP and NDS are achieved when $k=7$ . A large step size leads to low resolution of the depth map, while a small step size leads to a large number of zero-valued points in the depth map.
表 4 展示了在 nuScenes 3D 目标检测验证数据集上,使用 EADF 模块中不同分块步长 $k$ 和扩展操作时的性能表现。我们以 BEVFusion (Z. et al. 2022a) 作为基线方法。当 $k=7$ 时获得了最佳 mAP 和 NDS 指标。过大的步长会导致深度图分辨率降低,而过小的步长则会使深度图中出现大量零值点。
Upperbound analysis is adopted to analyze the impact of wrong predictions in the “depth jump” region by depth estimation networks. In Table 5, we use 3D Lidar information as the ground-truth (GT) to replace the predicted depth at scene edges for baseline BEVFusion (Z. et al. 2022a). The mAP and NDS of the camera branch using GT are improved by $3.6%$ and $2.9%$ compared to using the predicted depth, which demonstrates the importance of “depth jump” problems.
采用上限分析(Upperbound analysis)评估深度估计网络在"深度跃变"(depth jump)区域的错误预测影响。如表5所示,我们以3D激光雷达信息作为真实值(GT),替换基线方法BEVFusion (Z. et al. 2022a)在场景边缘的预测深度。使用GT的相机分支mAP和NDS指标相比使用预测深度分别提升了$3.6%$和$2.9%$,这验证了"深度跃变"问题的重要性。

Figure 6: Visualization of the nuScenes 3D object detection validation dataset. From the left to the right, we provide results of ground-truth, baseline method BEVFusion (Z. et al. 2022a) before and after adding our proposed EA-LSS. Results on cars are colored in yellow, pedestrian in blue and bicycle in pink. The red boxes highlight the difference before and after using our proposed EA-LSS. We can observe that results after adding our proposed EA-LSS projector are better than before.
图 6: nuScenes 3D物体检测验证数据集的可视化结果。从左至右依次展示:真实标注、基线方法BEVFusion (Z. et al. 2022a)在添加我们提出的EA-LSS模块前后的检测效果。其中汽车用黄色标注,行人用蓝色标注,自行车用粉色标注。红色方框标出了使用EA-LSS模块前后的差异。可以观察到,添加我们提出的EA-LSS投影模块后,检测效果得到显著提升。
Qualitative Evaluation
定性评估
We provide visualization results in Figure 6 to demonstrate the effectiveness of our proposed EA-LSS projector on nuScenes 3D object detection. Experiment results of ground-truth, baseline method BEVFusion (Z. et al. 2022a) and baseline method using our proposed EA-LSS framework are in the first column, second column and third column of Figure 6. The cars are shown in yellow, the pedestrian in blue and truck in red. More target objects can be captured by adding our proposed EA-LSS projector than using the baseline method BEVFusion (Z. et al. 2022a) only.
我们在图6中提供了可视化结果,以展示我们提出的EA-LSS投影器在nuScenes 3D目标检测中的有效性。真实值、基线方法BEVFusion (Z. et al. 2022a)以及使用我们提出的EA-LSS框架的基线方法的实验结果分别位于图6的第一列、第二列和第三列。汽车以黄色显示,行人以蓝色显示,卡车以红色显示。与仅使用基线方法BEVFusion (Z. et al. 2022a)相比,添加我们提出的EA-LSS投影器可以捕获更多目标物体。
Conclusions
结论
In this paper, we propose a novel edge-aware lift-splat-shot (EA-LSS) framework, which is plug-and-play and can be used in any LSS-based methods. The proposed framework contains a edge-aware depth fusion (EADF) module and a fine-graind depth (FGD) module. EADF module is proposed to alleviate the “depth jump” problem in depth estimation network by focusing on the edge of each object. In order to capture more accurate depth distribution, our proposed FGD module can fully utilize the 3D Lidar depth information to supervise the depth estimate network, by using better size match between the predicted depth map and the GT depth map. To validate effectiveness and efficiency, we conduct experiments on nuScenes 3D object detection benchmarks. Experiment results demonstrate that EA-LSS framework effectively improves the accuracy of camera-only and multimodal BEV 3D object detection methods with negligible increase of inference time.
本文提出了一种新颖的边缘感知升维投射 (edge-aware lift-splat-shot, EA-LSS) 框架,该框架即插即用,可应用于任何基于LSS的方法。所提出的框架包含边缘感知深度融合 (edge-aware depth fusion, EADF) 模块和细粒度深度 (fine-graind depth, FGD) 模块。EADF模块通过聚焦物体边缘来缓解深度估计网络中的"深度跳跃"问题。为了获取更精确的深度分布,我们提出的FGD模块通过优化预测深度图与GT深度图之间的尺寸匹配,充分利用3D激光雷达深度信息来监督深度估计网络。为验证有效性和效率,我们在nuScenes 3D目标检测基准上进行了实验。实验结果表明,EA-LSS框架在推理时间几乎不增加的情况下,显著提升了纯摄像头和多模态BEV 3D目标检测方法的精度。
Table 5: Upperbound analysis on nuScenes 3D object detection validation dataset. -C represents the camera branch.
表 5: nuScenes 3D目标检测验证数据集的上限分析。-C代表相机分支。
| 方法 | mAP | NDS |
|---|---|---|
| BEVFusion-C 无GT (Z.et al. 2022a) BEVFusion-C 有GT (Z. et al. 2022a) | 35.3 38.9 | 36.4 39.3 |
References C., L.; van de M. J. G., M.; and G., D. 2019. Monocular semantic occupancy grid mapping with convolutional variational encoder–decoder networks. IEEE Robotics and Automation Letters, 445–452. C., R.; A., H.; J., C.; and L., W. S. 2021. Categorical depth distribution network for monocular 3d object detection. In in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 8555–8564. Chen, X.; Zhang, T.; Wang, Y.; Wang, Y.; and Zhao, H. 2022. FUTR3D: A Unified Sensor Fusion Framework for 3D Detection. arXiv preprint arXiv:2203.10642. H., C.; V., B.; H., L. A.; S., V.; E., L. V.; Q., X.; A., K.; Y.,P.; G., B.; and O., B. 2020. nuscenes: A multimodal dataset for autonomous driving. In CVPR. H., L. A.; S., V.; H., C.; L., Z.; J., Y.; and O., B. 2019. Point pillars: Fast encoders for object detection from point clouds. In in IEEE Conference on Computer Vision and Pattern Recognition. Huang, P.; Liu, L.; Zhang, R.; Zhang, S.; Xu, X.; Wang,B.; and Liu, G. 2022. TiG-BEV: Multi-view BEV 3D Object Detection via Target Inner-Geometry Learning. arXiv preprint arXiv:2212.13979. J., H.; and G., H. 2022. Bevdet4d: Exploit temporal cues in multi-camera 3d object detection. arXiv preprint arXiv:2203.17054. J., H.; G., H.; Z., Z.; and D., D. 2021. Bevdet: Highperformance multi-camera 3d object detection in bird-eye-view. arXiv preprint arXiv:2112.11790. J., P.; and S., F. 2020. Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly un projecting to 3d. In in European Conference on Computer Vision, 194–210. Liang, T. L.; Xie, H.; Kaicheng, Y.; Zhongyu, X.; Lin, Z.; Wang, Y.; Tang, T.; Wang, B.; and Tang, Z. 2022. BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework. In Neural Information Processing Systems (NeurIPS). Lin, T.-Y.; Priya, G.; Ross, G.; Kaiming, H.; and Piotr, D. 2017. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2980–2988. Q., L.; Y., W.; Y., W.; and H., Z. 2021. Hdmapnet: An on- line hd map construction and evaluation framework. arXiv preprint arXiv:2107.06307. Reading, C.; Harakeh, A.; Chae, J.; and Waslander, S. L. 2021. Categorical Depth Distribution Network for Monocular 3D Object Detection. CVPR. S., C.; X., W.; T., C.; Q., Z.; C., H.; and W., L. 2022. Polar para me tri z ation for vision-based surround-view 3d detection. arXiv preprint arXiv:2206.10965. Shi, S.; X., W.; and H., L. 2019. Pointrcnn: 3d object proposal generation and detection from point cloud. In IEEE Conference on Computer Vision and Pattern Recognition. T., W.; Q., L.; C., Z.; X., Z.; and W., Z. 2022. MVFCOS3D $^{++}$ : Multi-View camera-only 4d object detection with pretrained monocular backbones. arXiv preprint arXiv:2207.12716.
参考文献
C., L.; van de M. J. G., M.; and G., D. 2019. 基于卷积变分编码器-解码器网络的单目语义占据栅格建图. IEEE Robotics and Automation Letters, 445–452.
C., R.; A., H.; J., C.; and L., W. S. 2021. 单目3D目标检测的类别深度分布网络. 见 IEEE/CVF计算机视觉与模式识别会议论文集, 8555–8564.
Chen, X.; Zhang, T.; Wang, Y.; Wang, Y.; and Zhao, H. 2022. FUTR3D: 统一的传感器融合3D检测框架. arXiv预印本 arXiv:2203.10642.
H., C.; V., B.; H., L. A.; S., V.; E., L. V.; Q., X.; A., K.; Y.,P.; G., B.; and O., B. 2020. nuScenes: 自动驾驶多模态数据集. 见 CVPR.
H., L. A.; S., V.; H., C.; L., Z.; J., Y.; and O., B. 2019. PointPillars: 点云目标检测的快速编码器. 见 IEEE计算机视觉与模式识别会议.
Huang, P.; Liu, L.; Zhang, R.; Zhang, S.; Xu, X.; Wang,B.; and Liu, G. 2022. TiG-BEV: 通过目标内部几何学习的多视角BEV 3D目标检测. arXiv预印本 arXiv:2212.13979.
J., H.; and G., H. 2022. BEVDet4D: 多摄像头3D目标检测中的时序线索利用. arXiv预印本 arXiv:2203.17054.
J., H.; G., H.; Z., Z.; and D., D. 2021. BEVDet: 鸟瞰视图下的高性能多摄像头3D目标检测. arXiv预印本 arXiv:2112.11790.
J., P.; and S., F. 2020. Lift, Splat, Shoot: 通过隐式反投影到3D空间处理任意相机阵列图像. 见 欧洲计算机视觉会议, 194–210.
Liang, T. L.; Xie, H.; Kaicheng, Y.; Zhongyu, X.; Lin, Z.; Wang, Y.; Tang, T.; Wang, B.; and Tang, Z. 2022. BEVFusion: 简单鲁棒的LiDAR-相机融合框架. 见 神经信息处理系统会议 (NeurIPS).
Lin, T.-Y.; Priya, G.; Ross, G.; Kaiming, H.; and Piotr, D. 2017. 密集目标检测的焦点损失. 见 IEEE国际计算机视觉会议论文集 (ICCV), 2980–2988.
Q., L.; Y., W.; Y., W.; and H., Z. 2021. HDMapNet: 在线高精地图构建与评估框架. arXiv预印本 arXiv:2107.06307.
Reading, C.; Harakeh, A.; Chae, J.; and Waslander, S. L. 2021. 单目3D目标检测的类别深度分布网络. CVPR.
S., C.; X., W.; T., C.; Q., Z.; C., H.; and W., L. 2022. 基于极坐标参数化的环视3D视觉检测. arXiv预印本 arXiv:2206.10965.
Shi, S.; X., W.; and H., L. 2019. PointRCNN: 点云的3D目标提议生成与检测. 见 IEEE计算机视觉与模式识别会议.
T., W.; Q., L.; C., Z.; X., Z.; and W., Z. 2022. MVFCOS3D$^{++}$: 基于预训练单目骨干网络的多视角纯摄像头4D目标检测. arXiv预印本 arXiv:2207.12716.