Distill Any Depth: Distillation Creates a Stronger Monocular Depth Estimator
Distill Any Depth: 蒸馏打造更强大的单目深度估计器
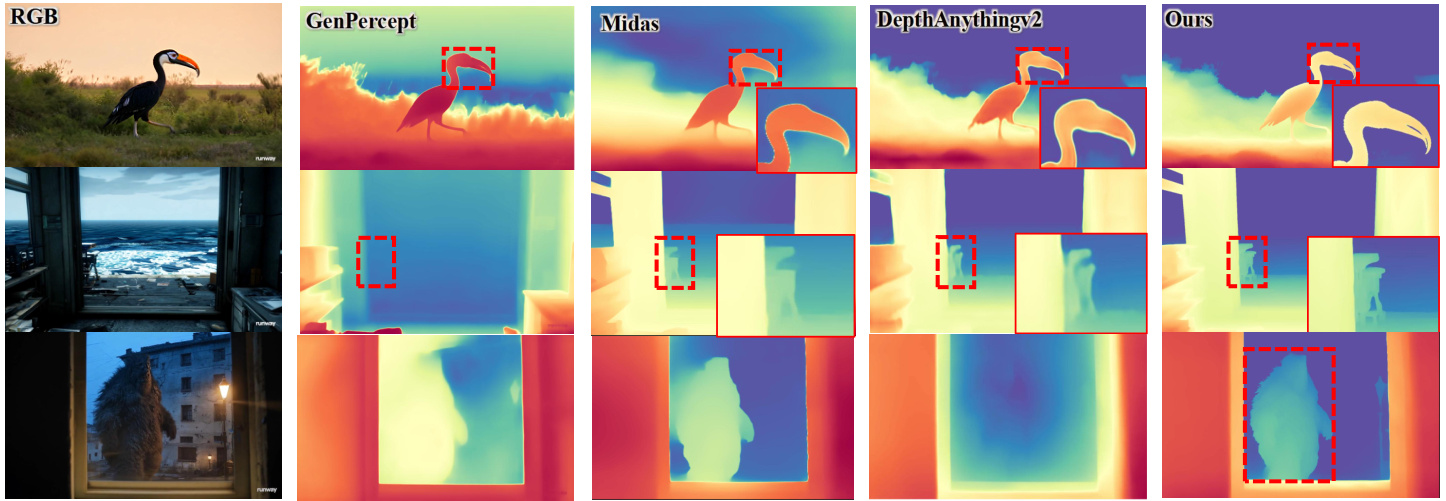
Figure 1: Zero-shot prediction on in-the-wild images. Our model, distilled from Genpercept [49] and Depth Anything v 2 [51], outperforms other methods by delivering more accurate depth details and exhibiting superior generalization for monocular depth estimation on in-the-wild images.
图 1: 真实场景图像的零样本预测。我们的模型从 Genpercept [49] 和 Depth Anything v2 [51] 蒸馏而来,通过提供更精确的深度细节并在真实场景图像的单目深度估计中展现出更优的泛化性能,超越了其他方法。
Abstract
摘要
Recent advances in zero-shot monocular depth estimation(MDE) have significantly improved generalization by unifying depth distributions through normalized depth represent at ions and by leveraging large-scale unlabeled data via pseudo-label distillation. However, existing methods that rely on global depth normalization treat all depth values equally, which can amplify noise in pseudo-labels and reduce distillation effectiveness. In this paper, we present a systematic analysis of depth normalization strategies in the context of pseudo-label distillation. Our study shows that, under recent distillation paradigms (e.g., shared-context distillation), normalization is not always necessary—omitting it can help mitigate the impact of noisy supervision. Furthermore, rather than focusing solely on how depth information is represented, we propose Cross-Context Distillation, which integrates both global and local depth cues to enhance pseudo-label quality. We also introduce an assistant-guided distillation strategy that incorporates complementary depth priors from a diffusion-based teacher model, enhancing supervision diversity and robustness. Extensive experiments on benchmark datasets demonstrate that our approach significantly outperforms state-of-the-art methods, both quantitatively and qualitatively.
零样本单目深度估计 (MDE) 的最新进展通过归一化深度表示统一深度分布,并利用伪标签蒸馏处理大规模无标注数据,显著提升了泛化能力。然而,依赖全局深度归一化的现有方法平等对待所有深度值,可能放大伪标签中的噪声并降低蒸馏效果。本文系统分析了伪标签蒸馏中的深度归一化策略,研究表明:在当前蒸馏范式(如共享上下文蒸馏)下,归一化并非必需——省略归一化反而能缓解噪声监督的影响。此外,我们不仅关注深度信息的表示方式,还提出跨上下文蒸馏方法,整合全局与局部深度线索以提升伪标签质量。同时引入辅助引导蒸馏策略,融合基于扩散的教师模型提供的互补深度先验,增强监督多样性与鲁棒性。在基准数据集上的大量实验表明,我们的方法在定量与定性评估中均显著优于现有最优方法。
1. Introduction
1. 引言
Monocular depth estimation (MDE) predicts scene depth from a single RGB image, offering greater flexibility compared to stereo or multi-view methods, and benefiting a wide range of applications, such as autonomous driving and robotic perception [11, 13, 18, 52, 30]. Recent research on zero-shot MDE models [37, 55, 47, 24] aims to handle diverse scenarios, but training such models requires largescale, diverse depth data, which is often limited by the need for specialized equipment [31, 54]. A promising solution is using large-scale unlabeled data, which has shown success in tasks like classification and segmentation [27, 63, 48]. Studies like Depth Anything [50] highlight the effectiveness of using pseudo labels from teacher models for training student models.
单目深度估计 (MDE) 通过单一RGB图像预测场景深度,相比立体或多视角方法具有更高灵活性,可广泛应用于自动驾驶和机器人感知等领域 [11, 13, 18, 52, 30]。近期关于零样本 MDE 模型的研究 [37, 55, 47, 24] 致力于处理多样化场景,但此类模型的训练需要大规模多样化深度数据,而这类数据常受限于专业设备的采集需求 [31, 54]。利用大规模无标注数据作为解决方案已显示出潜力,该方案在分类和分割等任务中已取得成功 [27, 63, 48]。如Depth Anything [50] 等研究表明,使用教师模型生成的伪标签来训练学生模型具有显著效果。
To enable training on such a diverse, mixed dataset, most state-of-the-art methods [51, 40, 55] employ scale-and-shift invariant (SSI) depth representations for loss computation. This approach normalizes raw depth values within an image, making them invariant to scaling and shifting, and ensures that the model learns to focus on relative depth relationships rather than absolute values. The SSI representation facilitates the joint use of diverse depth data, thereby improving the model’s ability to generalize across different scenes [38, 5]. Similarly, during evaluation, the metric depth of the prediction is recovered by solving for the unknown scale and shift coefficients of the predicted depth using least squares, ensuring the application of standard evaluation metrics.
为了在这种多样化的混合数据集上进行训练,大多数前沿方法 [51, 40, 55] 采用尺度与平移不变性 (SSI) 深度表示进行损失计算。该方法对图像中的原始深度值进行归一化处理,使其不受缩放和平移的影响,并确保模型学习关注相对深度关系而非绝对值。SSI 表示促进了多样化深度数据的联合使用,从而提升了模型在不同场景间的泛化能力 [38, 5]。同样地,在评估阶段,通过最小二乘法求解预测深度的未知缩放和平移系数来恢复预测的度量深度,确保标准评估指标的应用。
Despite its advantages, using SSI depth representation for pseudo-label distillation in MDE models presents several issues. Specifically, the inherent normalization process in SSI loss makes the depth prediction at a given pixel not only dependent on the teacher model’s raw prediction at that location but also influenced by the depth values in other regions of the image. This becomes problematic because pseudo-labels inherently introduce noise. Even if certain local regions are predicted accurately, inaccuracies in other regions can negatively affect depth estimates after global normalization, leading to suboptimal distillation results. As shown in Fig. 2, we empirically demonstrate that normalizing depth maps globally tends to degrade the accuracy of local regions, as compared to only applying normalization within localized regions during evaluation.
尽管具有优势,但在MDE模型中使用SSI深度表示进行伪标签蒸馏仍存在若干问题。具体而言,SSI损失固有的归一化过程使得给定像素的深度预测不仅取决于教师模型在该位置的原始预测,还受到图像其他区域深度值的影响。这一问题尤为突出,因为伪标签本身会引入噪声。即使某些局部区域预测准确,其他区域的误差也会在全局归一化后对深度估计产生负面影响,导致蒸馏效果欠佳。如图2所示,我们通过实验证明,与评估时仅在局部区域应用归一化相比,全局归一化深度图往往会降低局部区域的准确性。
Building on this insight, in this paper, we investigate the issue of depth normalization in pseudo-label distillation. We analyze various depth normalization strategies, including global normalization, local normalization, hybrid globallocal approaches, and the absence of normalization. Through empirical experiments, we explore how each depth representation impacts the performance of different distillation designs, especially when using pseudo-labels for training.
基于这一洞见,本文研究了伪标签蒸馏中的深度归一化问题。我们分析了多种深度归一化策略,包括全局归一化、局部归一化、混合全局-局部方法以及无归一化情况。通过实证实验,探讨了每种深度表示方式如何影响不同蒸馏设计的性能,特别是在使用伪标签进行训练时。
Rather than focusing solely on pseudo-label representation, we introduce Cross-Context Distillation, a method that integrates both global and local depth cues to enhance pseudo-label quality. Our findings reveal that local regions, when used for distillation, produce pseudo-labels that capture higher-quality depth details, improving the student model’s depth estimation accuracy. However, relying solely on local regions may overlook broader contextual relationships in the image. To address this, we combine both local and global inputs within a unified distillation framework. By leveraging the context-specific advantages of local distillation alongside the broader understanding provided by global methods, our approach yields more detailed and reliable depth predictions.
我们提出的跨上下文蒸馏 (Cross-Context Distillation) 方法不仅关注伪标签表示,还整合全局与局部深度线索来提升伪标签质量。研究发现:当采用局部区域进行蒸馏时,生成的伪标签能捕捉更高质量的深度细节,从而提升学生模型的深度估计精度。但仅依赖局部区域可能会忽略图像中更广泛的上下文关联。为此,我们在统一蒸馏框架中同时结合局部与全局输入,通过融合局部蒸馏的上下文特异性优势与全局方法提供的整体理解,最终生成更精细可靠的深度预测结果。
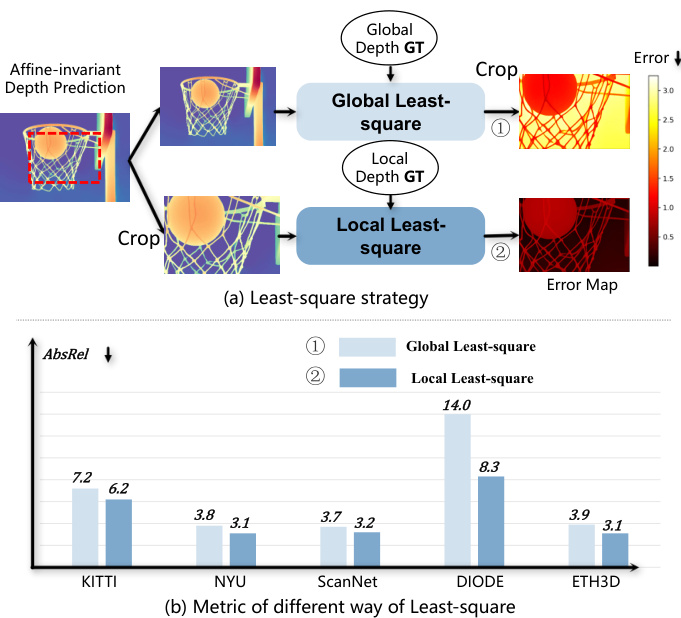
Figure 2: Issue with Global Normalization (SSI). In (a), we compare two alignment strategies for the central $w/2,h/2$ region: (1) Global Least-Square, where alignment is applied to the full image before cropping, and (2) Local Least-Square, where alignment is performed on the cropped region. Metrics are computed on the cropped region. As shown in (b), the outperformed local strategy demonstrates that global normalization degrades local accuracy compared to local normalization.
图 2: 全局归一化 (SSI) 问题。在 (a) 中,我们比较了中心区域 $w/2,h/2$ 的两种对齐策略:(1) 全局最小二乘法 (Global Least-Square) ,即在裁剪前对整个图像进行对齐;(2) 局部最小二乘法 (Local Least-Square) ,即仅在裁剪区域进行对齐。指标均在裁剪区域计算。如 (b) 所示,表现更优的局部策略表明,与局部归一化相比,全局归一化会降低局部精度。
To harness the strengths of both, we propose using a diffusion-based model as the teacher assistant to generate pseudo-labels, which are then used to supervise the student model. This strategy enables the student model to learn from the detailed depth information provided by diffusionbased models, while also benefiting from the precision and efficiency of encoder-decoder models.
为了结合两者的优势,我们提出使用基于扩散的模型 (diffusion-based model) 作为教师助手生成伪标签,进而监督学生模型。这一策略使学生模型既能学习扩散模型提供的细致深度信息,又能受益于编码器-解码器模型的精度和效率。
To validate the effectiveness of our design, we conduct extensive experiments on various benchmark datasets. The empirical results show that our method significantly outperforms existing baselines qualitatively and quantitatively. The contributions can be summarized below: 1) We systematically analyze the role of different depth normalization strategies in pseudo-label distillation, providing insights into their effects on MDE performance. 2) To enhance the quality of pseudo-labels, we propose Cross-Context Distillation, a hybrid local-global framework that leverages fine-grained details and global depth relationships; a teacher assistant that harnesses the complementary strengths of diverse depth estimation models to further improve robustness and accuracy. 3) We conduct extensive experiments on benchmark datasets, demonstrating that our method outperforms state-of-the-art approaches both quantitatively and qualitatively.
为验证设计的有效性,我们在多个基准数据集上进行了广泛实验。实证结果表明,我们的方法在定性和定量层面均显著优于现有基线。主要贡献可归纳如下:
- 我们系统分析了不同深度归一化策略在伪标签蒸馏中的作用,揭示了它们对单目深度估计 (MDE) 性能的影响机制;
- 为提升伪标签质量,提出跨上下文蒸馏 (Cross-Context Distillation) 框架:通过融合局部细粒度细节与全局深度关系的混合架构,以及整合多模型优势的教师助理机制,进一步增强鲁棒性和精度;
- 在基准数据集上的大量实验表明,我们的方法在定量指标和视觉效果上均超越现有最优方法。
2. Related Work
2. 相关工作
2.1. Monocular Depth Estimation
2.1. 单目深度估计
Monocular depth estimation (MDE) has evolved from hand-crafted methods to deep learning, significantly improving accuracy [11, 29, 12, 16, 62, 38]. Architectural refinements, such as multi-scale designs and attention mechanisms, have further enhanced feature extraction [21, 6, 61]. However, most models remain reliant on labeled data and struggle to generalize across diverse environments. Zeroshot MDE improves generalization by leveraging largescale datasets, geometric constraints, and multi-task learning [37, 55, 57, 60, 58]. Metric depth estimation incorporates intrinsic data for absolute depth learning [2, 56, 22, 35, 46, 4], while generative models such as Marigold refine depth details using diffusion priors [24, 49, 17, ?]. Despite these advances, effectively utilizing unlabeled data remains a challenge due to pseudo-label noise and inconsistencies across different contexts. Depth Anything [51] explores large-scale unlabeled data but struggles with pseudo-label reliability. Patch Fusion [9, 32] improves depth estimation by refining high-resolution image representations but lacks adaptability in generative settings. To address these issues, we propose Cross-Context and Multi-Teacher Distillation, which enhances pseudo-label supervision by leveraging diverse contextual information and multiple expert models, improving both accuracy and generalization ability.
单目深度估计 (MDE) 已从手工设计方法发展为深度学习技术,显著提升了精度 [11, 29, 12, 16, 62, 38]。多尺度设计和注意力机制等架构改进进一步增强了特征提取能力 [21, 6, 61]。然而,大多数模型仍依赖标注数据,难以适应多样化环境。零样本MDE通过利用大规模数据集、几何约束和多任务学习提升了泛化能力 [37, 55, 57, 60, 58]。度量深度估计结合内禀数据实现绝对深度学习 [2, 56, 22, 35, 46, 4],而Marigold等生成式模型则利用扩散先验优化深度细节 [24, 49, 17, ?]。尽管取得这些进展,由于伪标签噪声和跨场景不一致性,未标注数据的有效利用仍是挑战。Depth Anything [51] 探索了大规模未标注数据,但受限于伪标签可靠性。Patch Fusion [9, 32] 通过优化高分辨率图像表示改进了深度估计,但缺乏生成式场景的适应性。为解决这些问题,我们提出跨上下文多教师蒸馏框架,通过整合多样化上下文信息和多专家模型来增强伪标签监督,同时提升精度与泛化能力。
2.2. Semi-supervised Monocular Depth Estimation
2.2. 半监督单目深度估计
Semi-supervised depth estimation has garnered increasing attention, primarily leveraging temporal consistency to utilize unlabeled data more effectively [28, 19]. Some ap- proaches [1, 44, 7, 53, 15] integrate stereo geometric constraints, enforcing left-right consistency in stereo video to enhance depth accuracy. Others incorporate additional supervision, such as semantic priors [36, 20]or generative adversarial networks (GANs). For instance, DepthGAN [23] refines depth predictions through adversarial learning. However, these methods often rely on temporal cues, stereo constraints, or other auxiliary information, limiting their appli c ability to broader and more general scenarios. Recent work [34] has explored pseudo-labeling for semi-supervised monocular depth estimation (MDE), but it lacks generative modeling capabilities, restricting its generalization across diverse environments. Depth Anything [50] demonstrates the effectiveness of large-scale unlabeled data in improving generalization; however, pseudo-label reliability remains a challenge. In contrast, our approach focuses on singleimage depth estimation, improving pseudo-label reliability and maximizing its effectiveness. By relying solely on unlabeled data without additional constraints, our method achieves a more accurate and general iz able MDE model.
半监督深度估计日益受到关注,主要通过利用时序一致性来更有效地使用未标注数据 [28, 19]。部分方法 [1, 44, 7, 53, 15] 融合立体几何约束,通过强制立体视频的左右一致性来提升深度精度。另一些研究引入额外监督信息,例如语义先验 [36, 20] 或生成对抗网络 (GAN)。例如 DepthGAN [23] 通过对抗学习优化深度预测。但这些方法通常依赖时序线索、立体约束或其他辅助信息,限制了其在更广泛通用场景中的应用。近期工作 [34] 探索了半监督单目深度估计 (MDE) 的伪标签技术,但缺乏生成建模能力,制约了其跨环境泛化性能。Depth Anything [50] 证明了大规模未标注数据对提升泛化能力的有效性,但伪标签可靠性仍是挑战。相比之下,我们的方法聚焦单图像深度估计,通过提升伪标签可靠性并最大化其效用,仅依赖未标注数据而无须额外约束,实现了更精准且可泛化的 MDE 模型。
3. Method
3. 方法
In this section, we introduce a novel distillation framework designed to leverage unlabeled images for training zero-shot Monocular Depth Estimation (MDE) models. We begin by exploring various depth normalization techniques in Section 3.1, followed by detailing our proposed distillation method in Section 3.2, which combines predictions across multiple contexts. The overall framework is illustrated in Fig. 3. Finally, we introduce an assistant-guided distillation scheme, in which a diffusion-based model acts as an auxiliary teacher to provide additional supervision for student training.
在本节中,我们介绍了一种新颖的蒸馏框架,旨在利用未标注图像训练零样本单目深度估计 (Monocular Depth Estimation, MDE) 模型。我们首先在第3.1节探讨多种深度归一化技术,随后在第3.2节详细阐述我们提出的结合多上下文预测的蒸馏方法。整体框架如图3所示。最后,我们提出了一种辅助引导的蒸馏方案,其中基于扩散 (diffusion) 的模型作为辅助教师,为学生训练提供额外监督。
3.1. Depth Normalization
3.1. 深度归一化
Depth normalization is a crucial component of our framework as it adjusts the pseudo-depth labels ${\bf d}^{t}$ from the teacher model and the depth predictions $\mathbf{d}^{s}$ from the student model for effective loss computation. To understand the influence of normalization techniques on distillation performance, we systematically analyze several approaches commonly employed in prior works. These strategies are visually illustrated in Fig. 4.
深度归一化是我们框架中的关键组成部分,它调整来自教师模型的伪深度标签 ${\bf d}^{t}$ 和学生模型的深度预测 $\mathbf{d}^{s}$,以实现有效的损失计算。为了理解归一化技术对蒸馏性能的影响,我们系统分析了先前工作中常用的几种方法。这些策略在图4中进行了直观展示。
Global Normalization: The first strategy we examine is the global normalization [50, 51] used in recent distillation methods. Global normalization [37] adjusts depth predictions using global statistics of the entire depth map. This strategy aims to ensure scale-and-shift invariance by normalizing depth values based on the median and mean absolute deviation of the depth map. For each pixel $i$ , the normalized depth for the student model and pseudo-labels are computed as:
全局归一化 (Global Normalization) : 我们研究的第一个策略是近期蒸馏方法中采用的全局归一化 [50, 51] 。全局归一化 [37] 通过利用整个深度图的全局统计量来调整深度预测。该策略旨在通过基于深度图的中位数和平均绝对偏差对深度值进行归一化,从而确保尺度平移不变性。对于每个像素 $i$ ,学生模型和伪标签的归一化深度计算如下:
$$
\begin{array}{r l r}&{}&{\tilde{d}{i}^{s}=\mathcal{N}{g l o}({\bf d}^{s})=\frac{d_{i}^{s}-\mathrm{med}({\bf d}^{s})}{\frac{1}{M}\sum_{j=1}^{M}\left|d_{j}^{s}-\mathrm{med}({\bf d}^{s})\right|}}\ &{}&{\tilde{d}{i}^{t}=\mathcal{N}{g l o}({\bf d}^{t})=\frac{d_{i}^{t}-\mathrm{med}({\bf d}^{t})}{\frac{1}{M}\sum_{j=1}^{M}\left|d_{j}^{t}-\mathrm{med}({\bf d}^{t})\right|},}\end{array}
$$
$$
\begin{array}{r l r}&{}&{\tilde{d}{i}^{s}=\mathcal{N}{g l o}({\bf d}^{s})=\frac{d_{i}^{s}-\mathrm{med}({\bf d}^{s})}{\frac{1}{M}\sum_{j=1}^{M}\left|d_{j}^{s}-\mathrm{med}({\bf d}^{s})\right|}}\ &{}&{\tilde{d}{i}^{t}=\mathcal{N}{g l o}({\bf d}^{t})=\frac{d_{i}^{t}-\mathrm{med}({\bf d}^{t})}{\frac{1}{M}\sum_{j=1}^{M}\left|d_{j}^{t}-\mathrm{med}({\bf d}^{t})\right|},}\end{array}
$$
where ${\mathrm{med}}(\mathbf{d}^{s})$ and $\mathrm{med}(\mathbf{d}^{t})$ are the medians of the predicted depth and pseudo depth, respectively. The final regression loss for distillation is computed as the average absolute difference between the normalized predicted depth and the normalized pseudo depth across all valid pixels $M$ :
其中 ${\mathrm{med}}(\mathbf{d}^{s})$ 和 $\mathrm{med}(\mathbf{d}^{t})$ 分别是预测深度和伪深度的中位数。最终的蒸馏回归损失计算为所有有效像素 $M$ 上归一化预测深度与归一化伪深度之间的平均绝对差:
$$
\mathcal{L}{\mathrm{{Dis}}}=\frac{1}{M}\sum_{i=1}^{M}\left|\tilde{d}{i}^{s}-\tilde{d}_{i}^{t}\right|.
$$
$$
\mathcal{L}{\mathrm{{Dis}}}=\frac{1}{M}\sum_{i=1}^{M}\left|\tilde{d}{i}^{s}-\tilde{d}_{i}^{t}\right|.
$$
Hybrid Normalization: In contrast to global normalization, Hierarchical Depth Normalization [59] employs a hybrid normalization approach by integrating both global and local depth information. This strategy is designed to preserve both the global structure and local geometry in the depth map. The process begins by dividing the depth range into $S$ pixels as part of a single context, akin to global normalization. In the case of $S=2$ , the depth range is divided into two segments, with each pixel being normalized within one of these two local contexts. Similarly, for $S=4$ , the depth range is split into four segments, allowing normalization to be performed within smaller, localized contexts. By adapting the normalization process to multiple levels of granularity, hybrid normalization achieves a balance between global coherence and local adaptability. For each context $u$ , the normalized depth values for the student model $\mathcal{N}_{u}(d_{i}^{s})$ and pseudo-labels $\mathcal{N}_{u}(d_{i}^{t})$ are calculated within the corresponding depth range. The loss for each pixel $i$ is then computed by averaging the losses across all contexts $U_{i}$ to which the pixel belongs:
混合归一化 (Hybrid Normalization):与全局归一化不同,分层深度归一化 [59] 采用了一种混合归一化方法,通过整合全局和局部深度信息来实现。该策略旨在同时保留深度图中的全局结构和局部几何特征。该过程首先将深度范围划分为 $S$ 个像素作为单个上下文的一部分,类似于全局归一化。当 $S=2$ 时,深度范围被划分为两个部分,每个像素在这两个局部上下文中进行归一化。类似地,当 $S=4$ 时,深度范围被分成四个部分,使得归一化可以在更小的局部上下文中进行。通过将归一化过程适应于多粒度级别,混合归一化实现了全局一致性和局部适应性之间的平衡。对于每个上下文 $u$,学生模型的归一化深度值 $\mathcal{N}_{u}(d_{i}^{s})$ 和伪标签 $\mathcal{N}_{u}(d_{i}^{t})$ 在相应的深度范围内计算。然后,对于每个像素 $i$,其损失通过平均该像素所属的所有上下文 $U_{i}$ 的损失来计算:
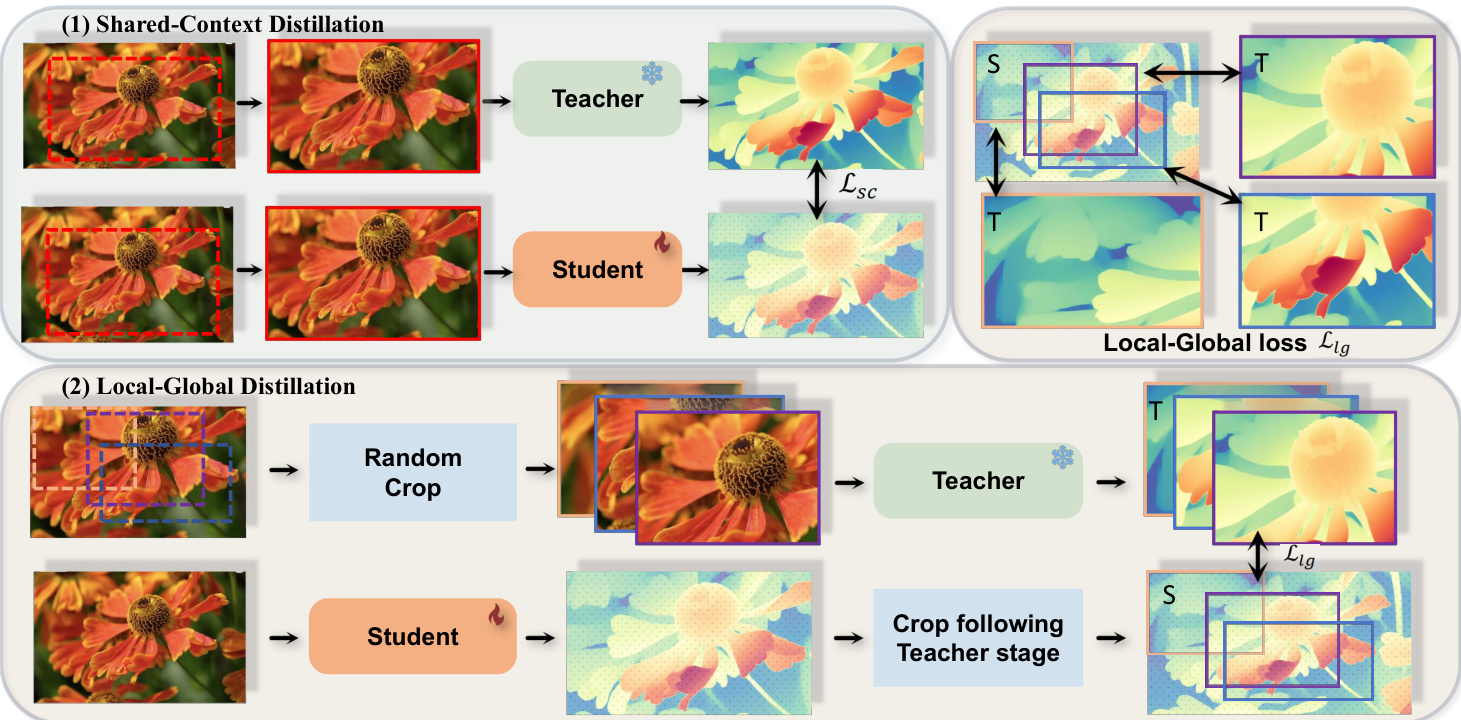
Figure 3: Overview of Cross-Context Distillation. Our method combines local and global depth information to enhance the student model’s predictions. It includes two scenarios: (1) Shared-Context Distillation, where both models use the same image for distillation; and (2) Local-Global Distillation, where the teacher predicts depth for overlapping patches while the student predicts the full image. The Local-Global loss $\mathcal{L}_{\mathrm{lg}}$ (Top Right) ensures consistency between local and global predictions, enabling the student to learn both fine details and broad structures, improving accuracy and robustness.
图 3: 跨上下文蒸馏概述。我们的方法结合局部和全局深度信息来提升学生模型的预测能力。包含两种场景:(1) 共享上下文蒸馏,两个模型使用相同图像进行蒸馏;(2) 局部-全局蒸馏,教师模型预测重叠图像块的深度,而学生模型预测完整图像。局部-全局损失 $\mathcal{L}_{\mathrm{lg}}$ (右上) 确保局部与全局预测的一致性,使学生模型既能学习精细细节又能掌握整体结构,从而提高准确性和鲁棒性。

Figure 4: Normalization Strategies. We compare four normalization strategies: Global Norm [37], Hybrid Norm [59], Local Norm, and No Norm. The figure visualizes how each strategy processes pixels within the normalization region (Norm. Area). The red dot represents any pixel within the region.
图 4: 归一化策略对比。我们比较了四种归一化策略:全局归一化 (Global Norm) [37]、混合归一化 (Hybrid Norm) [59]、局部归一化 (Local Norm) 以及无归一化 (No Norm)。该图展示了每种策略如何处理归一化区域 (Norm. Area) 内的像素,其中红点代表该区域内的任意像素。
$$
\mathcal{L}{D i s}^{i}=\frac{1}{|U_{i}|}\sum_{u\in U_{i}}\left|\mathcal{N}{u}(d_{i}^{s})-\mathcal{N}{u}(d_{i}^{t})\right|,
$$
$$
\mathcal{L}{D i s}^{i}=\frac{1}{|U_{i}|}\sum_{u\in U_{i}}\left|\mathcal{N}{u}(d_{i}^{s})-\mathcal{N}{u}(d_{i}^{t})\right|,
$$
where $|U_{i}|$ denotes the total number of groups (or contexts) that pixel $i$ is associated with. To obtain the final loss ${\mathcal{L}}_{\mathrm{Dis}}$ , we average the pixel-wise losses across all valid pixels $M$ :
其中 $|U_{i}|$ 表示像素 $i$ 关联的组(或上下文)总数。为计算最终损失 ${\mathcal{L}}_{\mathrm{Dis}}$,我们对所有有效像素 $M$ 的逐像素损失取平均值:
$$
\mathcal{L}{\mathrm{{Dis}}}=\frac{1}{M}\sum_{i=1}^{M}\mathcal{L}_{D i s}^{i}.
$$
$$
\mathcal{L}{\mathrm{{Dis}}}=\frac{1}{M}\sum_{i=1}^{M}\mathcal{L}_{D i s}^{i}.
$$
segments, where $S$ is selected from ${1,2,4}$ . When $S=1$ , the entire depth range is normalized globally, treating all
段,其中 $S$ 选自 ${1,2,4}$。当 $S=1$ 时,整个深度范围被全局归一化,将所有
Local Normalization: In addition to global and hybrid normalization, we investigate Local Normalization, a strategy that focuses exclusively on the finest-scale groups used in hybrid normalization. This approach isolates the smallest local contexts for normalization, emphasizing the preservation of fine-grained depth details without considering hierarchical or global scales. Local normalization operates by dividing the depth range into the smallest groups, corresponding to $S=4$ in the hybrid normalization framework, and each pixel is normalized within its local context. The loss for each pixel $i$ is computed using a similar formulation as in hybrid normalization, but with $u^{i}$ now representing the local context for pixel $i$ , defined by the smallest four-part group:
局部归一化 (Local Normalization):除了全局和混合归一化外,我们还研究了局部归一化策略,该方法仅专注于混合归一化中使用的最细尺度分组。该策略通过隔离最小局部上下文进行归一化,强调保留细粒度深度细节,而不考虑层次或全局尺度。局部归一化将深度范围划分为最小分组(对应混合归一化框架中的 $S=4$),每个像素在其局部上下文中进行归一化。每个像素 $i$ 的损失计算采用与混合归一化相似的公式,但此处 $u^{i}$ 表示像素 $i$ 的最小四分组所定义的局部上下文:
$$
\mathcal{L}{\mathrm{{Dis}}}=\frac{1}{M}\sum_{i=1}^{M}\left|\mathcal{N}{u^{i}}(d_{i}^{s})-\mathcal{N}{u^{i}}(d_{i}^{t})\right|.
$$
$$
\mathcal{L}{\mathrm{{Dis}}}=\frac{1}{M}\sum_{i=1}^{M}\left|\mathcal{N}{u^{i}}(d_{i}^{s})-\mathcal{N}{u^{i}}(d_{i}^{t})\right|.
$$
No Normalization: As a baseline, we also consider a direct depth regression approach with no explicit normalization. The absolute difference between raw student predictions and teacher pseudo-labels is used for loss computation:
无归一化:作为基线,我们同时考虑了一种不进行显式归一化的直接深度回归方法。使用原始学生预测值与教师伪标签之间的绝对差值进行损失计算:
$$
\mathcal{L}{\mathrm{{Dis}}}=\frac{1}{M}\sum_{i=1}^{M}\left|d_{i}^{s}-d_{i}^{t}\right|,
$$
$$
\mathcal{L}{\mathrm{{Dis}}}=\frac{1}{M}\sum_{i=1}^{M}\left|d_{i}^{s}-d_{i}^{t}\right|,
$$
This approach eliminates the need for normalization, assuming pseudo-depth labels naturally reside in the same domain as predictions. It provides insight into whether normalization enhances distillation effectiveness or if raw depth supervision suffices.
该方法无需归一化处理,假设伪深度标签与预测值自然处于同一域中。这一思路揭示了归一化是否能提升蒸馏效果,抑或原始深度监督已足够有效。
3.2. Distillation Pipeline
3.2. 蒸馏流程
In this section, we introduce an enhanced distillation pipeline that integrates two complementary strategies: CrossContext Distillation and assistant-guided distillation. Both strategies aim to improve the quality of pseudo-label distillation, enhance the model’s fine-grained perception.
在本节中,我们介绍一种融合两种互补策略的增强蒸馏流程:跨上下文蒸馏 (CrossContext Distillation) 和助手引导蒸馏。这两种策略旨在提升伪标签蒸馏质量,增强模型的细粒度感知能力。
Cross-context Distillation. A key challenge in monocular depth distillation is the trade-off between local detail preservation and global depth consistency. As shown in Fig. 5, providing a local crop of an image as input to the teacher model enhances fine-grained details in the pseudo-depth labels, but it may fail to capture the overall scene structure. Conversely, using the entire image as input preserves the global depth structure but often lacks fine details. To address this limitation, we propose Cross-Context Distillation, a method that enables the student model to learn both local details and global structures simultaneously. Cross-context distillation consists of two key strategies:
跨上下文蒸馏。单目深度蒸馏的一个关键挑战在于局部细节保留与全局深度一致性之间的权衡。如图 5 所示,向教师模型提供图像局部裁剪作为输入能增强伪深度标签中的细粒度细节,但可能无法捕捉整体场景结构;反之,使用完整图像作为输入能保持全局深度结构,但往往缺失精细细节。为解决这一局限,我们提出跨上下文蒸馏方法,使学生模型能同时学习局部细节与全局结构。该方法包含两个核心策略:
- Shared-Context Distillation: In this setup, both the teacher and student models receive the same cropped region of the image as input. Instead of using the full image, we randomly sample a local patch of varying sizes from the original image and provide it as input to both models. This encourages the student model to learn from the teacher model across different spatial contexts, improving its ability to generalize to varying scene structures. For the loss of shared-context distillation, the teacher and student models receive identical inputs and produce each depth prediction, denoted as $\mathbf{d}{\mathrm{local}}^{t}$ and $\mathbf{d}{\mathrm{local}}^{s}$ :
- 共享上下文蒸馏 (Shared-Context Distillation):在该设置中,教师模型和学生模型接收相同的图像裁剪区域作为输入。我们不使用完整图像,而是从原始图像中随机采样不同尺寸的局部图块,将其作为两个模型的共同输入。这种方法促使学生模型能够从教师模型在不同空间上下文中的表现进行学习,从而提升其对多样化场景结构的泛化能力。对于共享上下文蒸馏的损失计算,教师模型和学生模型接收相同输入并分别生成深度预测结果,记为 $\mathbf{d}{\mathrm{local}}^{t}$ 和 $\mathbf{d}{\mathrm{local}}^{s}$:

Figure 5: Different Inputs Lead to Different Pseudo Labels. Global Depth: The teacher model predicts depth using the entire image, and the local region’s prediction is cropped from the output. Local Depth: The teacher model directly takes the cropped local region as input, resulting in more refined and detailed depth estimates for that area, capturing finer details compared to using the entire image.
图 5: 不同输入导致不同伪标签。全局深度: 教师模型使用整张图像预测深度,局部区域的预测结果从输出中裁剪获得。局部深度: 教师模型直接以裁剪后的局部区域作为输入,从而得到该区域更精细的深度估计,相比使用整张图像能捕捉更细微的细节。
$$
\mathcal{L}{\mathrm{sc}}=\mathcal{L}{\mathrm{Dis}}\left({\bf d}{\mathrm{local}}^{s},{\bf d}_{\mathrm{local}}^{t}\right),
$$
$$
\mathcal{L}{\mathrm{sc}}=\mathcal{L}{\mathrm{Dis}}\left({\bf d}{\mathrm{local}}^{s},{\bf d}_{\mathrm{local}}^{t}\right),
$$
This loss encourages the student model to refine its finegrained predictions by directly aligning with the teacher’s outputs at local scales.
该损失函数通过促使学生模型在局部尺度上与教师模型的输出直接对齐,来优化其细粒度预测。
- Local-Global Distillation: In this approach, the teacher and student models operate on different input contexts. The teacher model processes local cropped regions, generating fine-grained depth predictions, while the student model predicts a global depth map from the entire image. To ensure knowledge transfer, the teacher’s local depth predictions supervise the corresponding overlapping regions in the student’s global depth map. This strategy allows the student to integrate fine-grained local details into its holistic depth estimation. Formally, the teacher model produces multiple depth predictions for cropped regions, denoted as $\mathbf{d}{\mathrm{local}{n}}^{t}$ while the student generates a global depth map, $\mathbf{d}_{\mathrm{global}}^{s}$ . The loss for Local-Global distillation is computed only over overlapping areas between the teacher’s local predictions and the corresponding regions in the student’s global depth map:
- 局部-全局蒸馏 (Local-Global Distillation): 该方法中教师模型和学生模型处理不同输入上下文。教师模型处理局部裁剪区域生成细粒度深度预测,而学生模型从整张图像预测全局深度图。为实现知识迁移,教师模型的局部深度预测会监督学生模型全局深度图中对应的重叠区域。该策略使学生模型能将细粒度的局部细节整合到其整体深度估计中。形式上,教师模型为裁剪区域生成多个深度预测,记为 $\mathbf{d}{\mathrm{local}{n}}^{t}$,而学生模型生成全局深度图 $\mathbf{d}_{\mathrm{global}}^{s}$。局部-全局蒸馏的损失仅计算教师局部预测与学生全局深度图对应区域之间的重叠部分:
$$
\mathcal{L}{\mathrm{lg}}=\frac{1}{N}\sum_{n=1}^{N}\mathcal{L}{\mathrm{Dis}}\left(\mathrm{Crop}({\bf d}{\mathrm{global}}^{s}),{\bf d}{\mathrm{local}_{n}}^{t}\right),
$$
$$
\mathcal{L}{\mathrm{lg}}=\frac{1}{N}\sum_{n=1}^{N}\mathcal{L}{\mathrm{Dis}}\left(\mathrm{Crop}({\bf d}{\mathrm{global}}^{s}),{\bf d}{\mathrm{local}_{n}}^{t}\right),
$$
where $\mathrm{{Crop}(\cdot)}$ extracts the overlapping region from the student’s depth prediction, and $N$ is the total number of sampled patches. This loss ensures that the student benefits from the detailed local supervision of the teacher model while maintaining global depth consistency. The total loss function integrates both local and cross-context losses along with additional constraints, including feature alignment and gradient preservation, as proposed in prior works [51]:
其中 $\mathrm{{Crop}(\cdot)}$ 从学生模型的深度预测中提取重叠区域,$N$ 为采样块的总数。该损失函数确保学生模型既能受益于教师模型的细粒度局部监督,又能保持全局深度一致性。总损失函数整合了局部损失、跨上下文损失以及特征对齐和梯度保留等附加约束,如先前研究 [51] 所提出的:
$$
\mathcal{L}{\mathrm{total}}=\mathcal{L}{\mathrm{sc}}+\lambda_{1}\cdot\mathcal{L}{\mathrm{lg}}+\lambda_{2}\cdot\mathcal{L}{\mathrm{feat}}+\lambda_{3}\cdot\mathcal{L}_{\mathrm{grad}}.
$$
$$
\mathcal{L}{\mathrm{total}}=\mathcal{L}{\mathrm{sc}}+\lambda_{1}\cdot\mathcal{L}{\mathrm{lg}}+\lambda_{2}\cdot\mathcal{L}{\mathrm{feat}}+\lambda_{3}\cdot\mathcal{L}_{\mathrm{grad}}.
$$
Here, $\lambda_{1},\lambda_{2}$ , and $\lambda_{3}$ are weighting factors that balance the different loss components. By incorporating cross-context supervision, this framework effectively allows the student model to integrate both fine-grained details from local crops and structural coherence from global depth maps.
这里,$\lambda_{1}$、$\lambda_{2}$ 和 $\lambda_{3}$ 是用于平衡不同损失分量的权重因子。通过引入跨上下文监督,该框架有效地使学生模型能够整合来自局部裁剪的细粒度细节和全局深度图的结构一致性。
Assistant-Guided Distillation. In addition to cross-context distillation, we propose an assistant-guided distillation strategy to further enhance the quality and robustness of the distilled depth knowledge. This approach pairs a primary teacher [51] with a single auxiliary assistant, selected as a diffusion-based depth estimator [49], which leverages generative priors to complement the primary teacher’s predictions. This design leverages their complementary strengths: the primary teacher excels in providing efficient and globally consistent supervision, while the assistant offers fine-grained depth cues derived from its generative modeling capabilities. By drawing supervision from two distinct architectures trained with different paradigms(e.g., optimization strategies or data distributions), the student benefits from diverse knowledge sources, effectively mitigating biases and limitations inherent to a single teacher model. Formally, let $\mathcal{M}$ and $\mathcal{M}{a}$ denote the primary and assistant models, respectively. During training, a probabilistic sampling mechanism determines whether supervision for each iteration is drawn from $\mathcal{M}$ or $\mathcal{M}{a}$ . This stochastic guidance encourages the student to adapt to multiple supervision styles, fostering richer and more general iz able depth representations. Overall, this assistant-guided scheme introduces complementary and diversified pseudo-labels, reducing over-reliance on any single teacher and improving both generalization and depth estimation performance.
助理引导蒸馏。除了跨上下文蒸馏外,我们提出了一种助理引导蒸馏策略,以进一步提升蒸馏深度知识的质量和鲁棒性。该方法将主教师模型[51]与单个辅助助理(选择基于扩散的深度估计器[49]配对),利用生成先验来补充主教师的预测。这种设计结合了二者的互补优势:主教师擅长提供高效且全局一致的监督,而助理则通过其生成建模能力提供细粒度的深度线索。通过从采用不同训练范式(如优化策略或数据分布)的两种架构中获取监督信号,学生模型能够受益于多样化的知识来源,有效缓解单一教师模型固有的偏差和局限性。形式上,设$\mathcal{M}$和$\mathcal{M}{a}$分别表示主模型和助理模型。训练过程中采用概率采样机制决定每次迭代的监督信号来自$\mathcal{M}$还是$\mathcal{M}{a}$。这种随机引导机制促使学生模型适应多种监督风格,从而形成更丰富、更具泛化能力的深度表征。总体而言,该助理引导方案通过引入互补且多样化的伪标签,降低了对单一教师的过度依赖,同时提升了泛化能力和深度估计性能。
4. Experiment
4. 实验
4.1. Experimental Settings
4.1. 实验设置
Datasets. We train our proposed distillation framework on a subset of 200,000 unlabeled images from the SA-1B dataset [26], following the training protocol of DepthAnythingv2 [51]. For evaluation, we assess the distilled student model on five widely used depth estimation benchmarks. All test datasets are kept unseen during training, enabling a zeroshot evaluation of generalization performance. The chosen benchmarks include: NYUv2 [43], KITTI [14], ETH3D [42], ScanNet [8], and DIODE [45]. Additional dataset details are provided in the Appendix.
数据集。我们按照DepthAnythingv2 [51]的训练方案,在SA-1B数据集[26]的20万张无标注图像子集上训练所提出的蒸馏框架。为评估性能,我们在五个广泛使用的深度估计基准上测试蒸馏后的学生模型,所有测试数据集在训练阶段均保持不可见状态,从而实现泛化性能的零样本评估。所选基准包括:NYUv2 [43]、KITTI [14]、ETH3D [42]、ScanNet [8]和DIODE [45]。更多数据集细节见附录。
Metrics. We assess depth estimation performance using two key metrics: the mean absolute relative error (AbsRel) and $\delta_{1}$ accuracy. Following previous studies [37, 56, 24] on zero-shot MDE, we align predictions with ground truth in both scale and shift before evaluation.
指标。我们使用两个关键指标评估深度估计性能:平均绝对相对误差 (AbsRel) 和 $\delta_{1}$ 准确率。遵循零样本 MDE 相关研究 [37, 56, 24] 的做法,我们在评估前将预测结果与真实值进行尺度和偏移对齐。
Implementation. Our experiments use state-of-the-art monocular depth estimation models as teachers to generate pseudo-labels, supervising various student models in a distillation framework with only RGB images as input. In shared-context distillation, both teacher and student receive the same global region, extracted via random cropping from the original image. The crop maintains a 1:1 aspect ratio and is sampled within a range from 644 pixels to the shortest side of the image, then resized to $560\times560$ for prediction. In global-local distillation, the global region is cropped into overlapping local patches, each sized $560\times560$ , for the teacher model to predict pseudo-labels. For assistant-guided distillation, we adopt a probabilistic sampling strategy where the primary teacher and the assistant model are selected with a ratio of 7:3, respectively. We train our best student model using the distillation pipeline for 20,000 iterations with a batch size of 8 on a single NVIDIA V100 GPU, initialized with pre-trained DAv2-Large weights. The learning rate is in tune with that of the corresponding student model. For DAv2 [51], the decoder learning rate is set to $5\times10^{-5}$ . For the total loss function, we set the parameters as follows: $\lambda_{1}=0.5$ , $\lambda_{2}=1.0$ and $\lambda_{3}=2.0$ .
实现。我们的实验采用最先进的单目深度估计模型作为教师模型生成伪标签,在仅输入RGB图像的蒸馏框架中监督各种学生模型。在共享上下文蒸馏中,教师和学生接收相同的全局区域,该区域通过从原始图像中随机裁剪提取。裁剪保持1:1宽高比,采样范围从644像素到图像最短边,然后调整为$560\times560$进行预测。在全局-局部蒸馏中,全局区域被裁剪为重叠的局部补丁,每个大小为$560\times560$,供教师模型预测伪标签。对于辅助引导蒸馏,我们采用概率采样策略,主教师模型和辅助模型的选择比例分别为7:3。我们使用蒸馏流程训练最佳学生模型,在单个NVIDIA V100 GPU上进行20,000次迭代,批量大小为8,初始化采用预训练的DAv2-Large权重。学习率与相应学生模型保持一致。对于DAv2 [51],解码器学习率设置为$5\times10^{-5}$。总损失函数的参数设置如下:$\lambda_{1}=0.5$、$\lambda_{2}=1.0$和$\lambda_{3}=2.0$。
4.2. Analysis
4.2. 分析
For the ablation study and analysis, we sample a subset of 50K images from SA-1B [26] as our training data, with an input image size of $560\times560$ for the network. We conduct experiments on two of the most challenging benchmarks, DIODE [45] and ETH3D [42], which include both indoor and outdoor scenes.
为了进行消融研究和分析,我们从SA-1B [26]中抽取了5万张图像作为训练数据,网络输入图像尺寸为$560\times560$。实验在DIODE [45]和ETH3D [42]这两个最具挑战性的基准测试上进行,涵盖室内外场景。
Analysis of Normalization across Cross-Context Distillation. We evaluate the impact of different depth normalization strategies on Cross-Context Distillation, as shown in Table 1. The results reveal that the optimal normalization method depends on the specific distillation design. In shared-context distillation, where all pseudo-labels are generated by a single teacher model, hybrid normalization achieves the best performance, closely followed by no normalization. The consistent domain across supervision signals reduces the need for normalization, enabling the model to better preserve local depth relationships. Unlike ground-truth-based training—where normalization is essential to align depth distributions across datasets captured by heterogeneous sensors or represented in varying formats (e.g., sparse vs. dense, relative vs. absolute)—pseudo-labels from a single model are inherently more uniform. Therefore, direct L1 loss without normalization can more faithfully supervise pixel-level depth without distortion from global rescaling. In contrast, global normalization introduces undesirable inter-pixel dependencies, while local normalization discards global structural coherence. In local-global distillation, hybrid normalization again proves most effective, likely due to its hierarchical design that enforces consistency across both local and global depth predictions. The relatively small gap between hybrid and global normalization suggests that our framework, which uses local cues to refine global predictions, effectively mitigates the limitations of global normalization. However, no normalization leads to a notable performance drop compared to the shared-context setting, indicating that localized regions in this case come from distinct depth domains, making direct L1 supervision less reliable. Local normalization, as before, sacrifices global consistency and thus under performs.
跨上下文蒸馏中的归一化分析。我们评估了不同深度归一化策略对跨上下文蒸馏的影响,如表 1 所示。结果表明,最优归一化方法取决于具体的蒸馏设计。在共享上下文蒸馏中(所有伪标签均由单一教师模型生成),混合归一化表现最佳,紧随其后的是无归一化。监督信号所在领域的一致性降低了对归一化的需求,使模型能更好地保留局部深度关系。与基于真实值的训练不同(在异质传感器采集或以不同格式表示的数据集中,归一化对对齐深度分布至关重要,例如稀疏与密集、相对与绝对),单一模型生成的伪标签本质上更为统一。因此,未经归一化的直接 L1 损失能更真实地监督像素级深度,避免全局重缩放带来的失真。相比之下,全局归一化会引入不良的像素间依赖,而局部归一化会破坏全局结构一致性。在局部-全局蒸馏中,混合归一化再次被证明最有效,这很可能归功于其分层设计能强制局部与全局深度预测的一致性。混合归一化与全局归一化之间较小的差距表明,我们的框架(利用局部线索优化全局预测)有效缓解了全局归一化的局限性。但与共享上下文设置相比,无归一化会导致性能显著下降,这表明该场景下的局部区域来自不同深度域,使得直接 L1 监督的可靠性降低。与之前一样,局部归一化会牺牲全局一致性,因此表现欠佳。
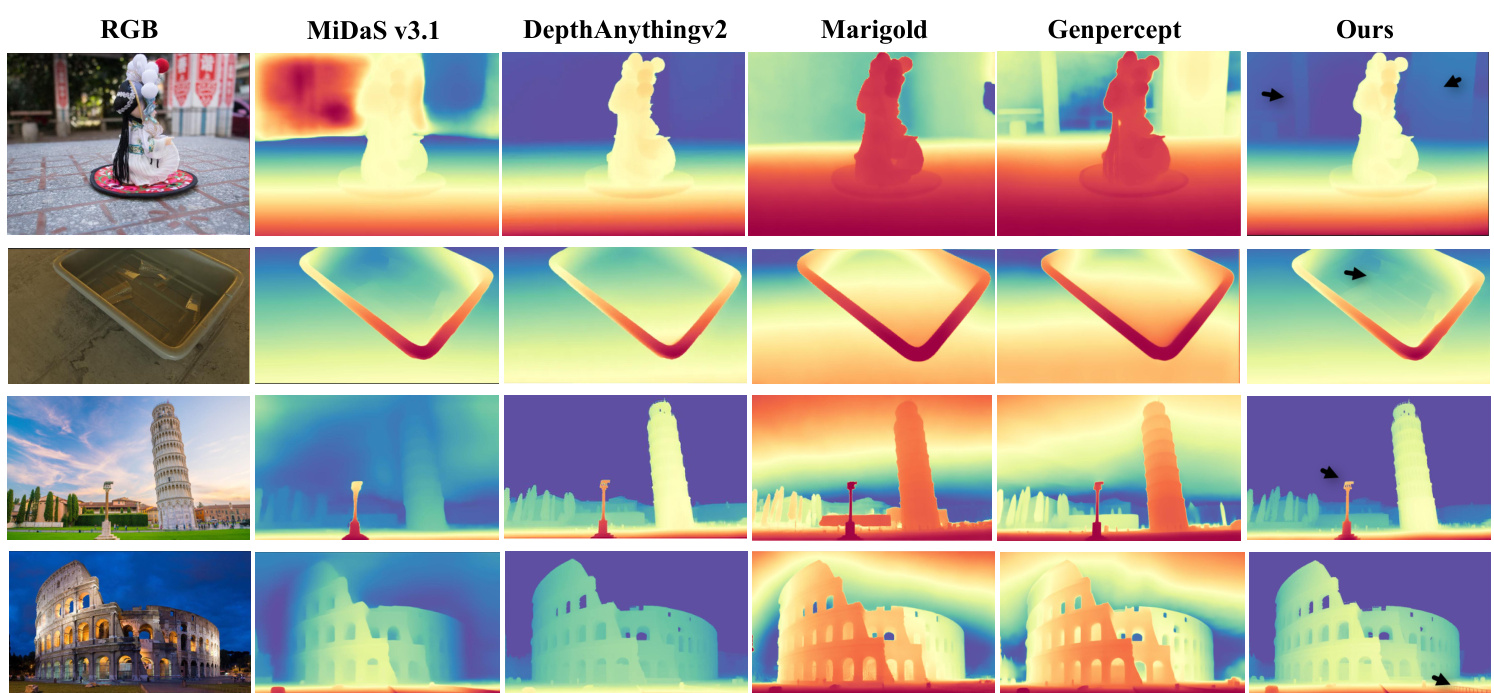
Figure 6: Qualitative Comparison of Relative Depth Estimations. We present visual comparisons of depth predictions from our method (”Ours”) alongside other classic depth estimators (”MiDaS v3.1” [3], and models using DINOv2 [33] or SD as priors (”Depth Anything v 2 [51]”, ”Marigold” [24], ”Genpercept” [49]). Compared to state-of-the-art methods, the depth map produced by our model, particularly at the position indicated by the black arrow, exhibits finer granularity and more detailed depth estimation.
图 6: 相对深度估计的定性对比。我们展示了本方法( "Ours" )与其他经典深度估计方法( "MiDaS v3.1" [3] )以及使用 DINOv2 [33] 或 SD 作为先验的模型( "Depth Anything v2" [51], "Marigold" [24], "Genpercept" [49] )的深度预测视觉对比。与前沿方法相比,本模型生成的深度图( 特别是黑色箭头所指位置 )展现出更精细的粒度和更详尽的深度估计细节。
Ablation Study of Cross-Context Distillation. To further validate the effectiveness of our distillation framework, we conduct ablation studies by removing Shared-Context Distillation and Local-Global Distillation in Table 2. Without both components, the model degrades to a conventional distillation setup, resulting in significantly lower performance. Introducing Shared-Context Distillation with Hybrid Normalization notably improves accuracy, highlighting the benefits of a better normalization strategy with consistent context supervision. When using only Local-Global Distillation, the model still performs well, showing the effectiveness of region-wise depth refinement even without global context information. Combining both strategies yields the best results, confirming that both components contribute significantly to improving the student model’s ability to utilize pseudolabels, demonstrating the robustness of our approach.
跨上下文蒸馏的消融研究。为验证我们蒸馏框架的有效性,我们在表2中通过移除共享上下文蒸馏和局部-全局蒸馏进行了消融实验。当同时移除这两个组件时,模型退化为传统蒸馏设置,导致性能显著下降。引入采用混合归一化的共享上下文蒸馏后,准确率显著提升,这表明在一致上下文监督下采用更好的归一化策略具有优势。当仅使用局部-全局蒸馏时,模型仍表现良好,证明即使没有全局上下文信息,区域级深度优化依然有效。结合两种策略时获得了最佳结果,证实这两个组件都能显著提升学生模型利用伪标签的能力,体现了我们方法的鲁棒性。
Table 1: Analysis of Normalization Strategies. Performance comparison of different normalization strategies across Shared-Context Distillation and Local-Global Distillation.
| Method | Normalization | ETH3D AbsRel↓ | DIODE AbsRel |
| Shared-Context Distillation | Global Norm. | 0.064 | 0.259 |
| No Norm. | 0.057 | 0.239 | |
| Local Norm. Hybrid Norm. | 0.070 0.057 | 0.245 0.238 | |
| Local-Global Distillation | Global Norm. | 0.065 | 0.239 |
| No Norm. | 0.273 | 0.300 | |
| Local Norm. | 0.076 | 0.244 | |
| Hybrid Norm. | 0.064 | 0.238 |
表 1: 归一化策略分析。共享上下文蒸馏和局部-全局蒸馏中不同归一化策略的性能对比。
| 方法 | 归一化 | ETH3D AbsRel↓ | DIODE AbsRel |
|---|---|---|---|
| 共享上下文蒸馏 | 全局归一化 | 0.064 | 0.259 |
| 无归一化 | 0.057 | 0.239 | |
| 局部归一化 混合归一化 | 0.070 0.057 | 0.245 0.238 | |
| 局部-全局蒸馏 | 全局归一化 | 0.065 | 0.239 |
| 无归一化 | 0.273 | 0.300 | |
| 局部归一化 | 0.076 | 0.244 | |
| 混合归一化 | 0.064 | 0.238 |
Cross-Architecture Distillation. To highlight the limitations of previous state-of-the-art distillation approaches employing global normalization, we compare their performance against the Hybrid Normalization strategy, which we utilize in our distillation framework, across diverse model architectures. To demonstrate the general iz ability of our approach, we conduct cross-architecture distillation experiments on both the state-of-the-art Depth Anything [51] and the classic MiDaS [37] architecture. Experiments are conducted using MiDaS [37] and Depth Anything [51] in four configurations (DA-L, MiDaS-L, DA-S, MiDaS-S), as shown in Table 3. Our method consistently outperforms previous global normalization-based distillation on both the DIODE [45] and ETH3D [42] datasets. These results demonstrate superior performance both within and across architectures, underscoring the limitations of global normalization in pseudo-label distillation.
跨架构蒸馏。为了突显采用全局归一化的先前最优蒸馏方法的局限性,我们在不同模型架构上将其性能与我们蒸馏框架中采用的混合归一化策略进行对比。为验证方法的泛化能力,我们在前沿的Depth Anything[51]和经典MiDaS[37]架构上进行了跨架构蒸馏实验。如表3所示,实验采用MiDaS[37]和Depth Anything[51]的四种配置(DA-L、MiDaS-L、DA-S、MiDaS-S)。在DIODE[45]和ETH3D[42]数据集上,我们的方法始终优于基于全局归一化的传统蒸馏方案。这些结果证明了该方法在架构内及跨架构场景下的卓越性能,同时揭示了伪标签蒸馏中全局归一化的固有局限。
Table 2: Effect of Cross-context Distillation. Performance comparison of various combinations of Shared-Context Distillation and Local-Global distillation on the ETH3D [42] and DIODE [45] datasets. The baseline corresponds to a simple shared-context approach with no random cropping. When neither method is applied, the model defaults to this baseline.
| Shared-Context Distillation | Local-Global Distillation | ETH3D AbsRel | DIODE AbsRel |
| X | 0.075 | 0.270 | |
| 0.064 +(-14.6%) | 0.238 (-13.3%) | ||
| 0.058 3(-22.6%) | 0.237 (-12.2%) | ||
| 0.056 (-25.3%) | 0.232 (-14.1%) |
表 2: 跨上下文蒸馏效果。共享上下文蒸馏与局部-全局蒸馏不同组合在 ETH3D [42] 和 DIODE [45] 数据集上的性能对比。基线对应未进行随机裁剪的简单共享上下文方法。当两种方法均未应用时,模型默认采用该基线。
| 共享上下文蒸馏 | 局部-全局蒸馏 | ETH3D AbsRel | DIODE AbsRel |
|---|---|---|---|
| X | 0.075 | 0.270 | |
| 0.064 +(-14.6%) | 0.238 (-13.3%) | ||
| 0.058 3(-22.6%) | 0.237 (-12.2%) | ||
| 0.056 (-25.3%) | 0.232 (-14.1%) |
Table 3: Comparison in Cross-Architecture Distillation. Evaluation of our distillation pipeline in the context of CrossArchitecture Distillation. We adopt different architectures as teacher and student models, where the Base represents the previous distillation method [51]. Our method consistently improves the performance of the distilled student models.
| Teacher | Student | Training Loss | DIODE | ETH3D |
| AbsRel | AbsRel√ | |||
| DA-L | DA-S | Base | 0.290 | 0.110 |
| Ours | 0.262 (-9.6%) | 0.098 (-10.9%) | ||
| DA-L | Midas-L | Base | 0.313 | 0.147 |
| Ours | 0.295(-5.7%) | 0.126(-14.3%) | ||
| Midas-L | Midas-S | Base | 0.303 | 0.150 |
| Ours | 0.272 (-10.2%) | 0.120(-20.0%) |
表 3: 跨架构蒸馏对比。我们的蒸馏流程在跨架构蒸馏场景下的评估。我们采用不同架构作为教师和学生模型,其中Base代表之前的蒸馏方法 [51]。我们的方法持续提升了蒸馏学生模型的性能。
| Teacher | Student | Training Loss | DIODE AbsRel | ETH3D AbsRel√ |
|---|---|---|---|---|
| DA-L | DA-S | Base | 0.290 | 0.110 |
| Ours | 0.262 (-9.6%) | 0.098 (-10.9%) | ||
| DA-L | Midas-L | Base | 0.313 | 0.147 |
| Ours | 0.295(-5.7%) | 0.126(-14.3%) | ||
| Midas-L | Midas-S | Base | 0.303 | 0.150 |
| Ours | 0.272 (-10.2%) | 0.120(-20.0%) |
Effect of Assistant-Guided Distillation. To validate the effectiveness of our proposed assistant-guided distillation strategy, we design a comparative experiment that introduces an additional assistant model to the conventional teacher-student distillation framework. Specifically, we adopt Depth Anything v2 as the primary teacher and GenPercept—a diffusion-based model—as the assistant. The student model shares the same architecture as DAv2-Large and is initialized with its pre-trained weights. This setup allows us to investigate whether supervision from two diverse architectures—trained under different paradigms—can offer complementary guidance that enhances both generalization and depth estimation performance. To explore the most effective way to combine pseudo-labels from the primary teacher and the assistant, we compare two assistant-guided strategies: (1) a weighted averaging approach (Avg.), which assigns greater weight to pixels where the two teachers exhibit high agreement, and (2) a selection-based strategy (Select.), which probabilistic ally samples the supervision signal from either teacher. While the averaging strategy attempts to leverage consistency between teachers, it often performs poorly due to conflicting pseudo-labels, where averaging can amplify errors. In contrast, the selection-based strategy allows the student to selectively absorb the strengths of each teacher, avoiding error reinforcement. As shown in Table 4, the Select. strategy significantly outperforms both individual teachers and the averaging method on the ETH3D benchmark, demonstrating the effectiveness of assistant-guided distillation in delivering robust and diverse supervision.
助手引导蒸馏的效果。为验证我们提出的助手引导蒸馏策略的有效性,我们设计了一个对比实验,在传统师生蒸馏框架中引入额外的助手模型。具体而言,我们采用Depth Anything v2作为主教师模型,并选择基于扩散模型的GenPercept作为助手。学生模型与DAv2-Large结构相同,并加载其预训练权重进行初始化。该设置可探究来自不同架构(基于不同训练范式)的双重监督是否能提供互补性指导,从而提升泛化能力和深度估计性能。为探索主教师与助手伪标签的最佳组合方式,我们比较了两种策略:(1) 加权平均法(Avg.),对两教师预测高度一致的像素赋予更大权重;(2) 选择策略(Select.),以概率方式从任一教师采样监督信号。虽然平均策略试图利用教师间的一致性,但因伪标签冲突(平均操作会放大误差)往往表现不佳。相比之下,选择策略使学生能选择性吸收各教师优势,避免错误强化。如表4所示,在ETH3D基准测试中,选择策略显著优于单教师模型和平均方法,证明了助手引导蒸馏在提供鲁棒且多样化监督方面的有效性。
Table 4: Effect of Assistant-Guided Distillation. Bold values indicate the best performance. Our method integrates a primary teacher, Depth Anything v2 (denoted as ‘D’), with a diffusion-based assistant, GenPercept (denoted as ‘G’), leveraging their complementary strengths to produce higher-quality pseudo-labels. The student model, trained under this assistant-guided distillation framework, consistently achieves better accuracy than when distilled from the DAv2- Large teacher alone.
| Method | Assistant-Guided Strategy | ETH3D AbsRel | DIODE AbsRel |
| DepthAnythingv2 | w/o | 0.131 | 0.262 |
| Genpercept(Disparity) | w/o | 0.096 | 0.226 |
| D+G | Avg. | 0.228 | 0.371 |
| D+G | Select. | 0.054 | 0.258 |
表 4: 助手引导蒸馏的效果。加粗数值表示最佳性能。我们的方法将主教师模型 Depth Anything v2 (记为"D")与基于扩散的助手 GenPercept (记为"G")相结合,利用它们的互补优势生成更高质量的伪标签。在该助手引导蒸馏框架下训练的学生模型,其准确率始终高于仅从 DAv2-Large 教师模型蒸馏的结果。
| 方法 | 助手引导策略 | ETH3D AbsRel | DIODE AbsRel |
|---|---|---|---|
| DepthAnythingv2 | 无 | 0.131 | 0.262 |
| Genpercept(Disparity) | 无 | 0.096 | 0.226 |
| D+G | 平均 | 0.228 | 0.371 |
| D+G | 选择 | 0.054 | 0.258 |
4.3. Comparison with State-of-the-Art
4.3. 与现有最优技术的对比
Quantitative Analysis. As shown in Table 5, our method achieves state-of-the-art performance across a diverse range of zero-shot depth estimation benchmarks. These include both structured indoor scenes (e.g., NYUv2 [43], ScanNet [8]) and challenging outdoor environments (e.g., KITTI [14], DIODE [45], ETH3D [42]), demonstrating strong generalization across domains with varying scene structures, lighting conditions, and depth statistics. To further validate the effectiveness and s cal ability of our distillation framework, we conduct evaluations on two representa- tive model architectures: Depth Anything v 2, a recent stateof-the-art model based on DINOv2, and MiDaS, a classic and widely adopted encoder-decoder framework. For each setup, the student model is initialized with the corresponding pre-trained encoder and distilled using pseudo-labels generated by the teacher model. Our approach yields consistent improvements over both teacher models across all benchmarks, highlighting its effectiveness in learning from pseudo-labels. Notably, it establishes new state-of-the-art results in most cases, outperforming existing affine-invariant depth estimators and demonstrating the robustness of our method in both DAv2 and MiDaS settings. These results confirm that our distillation framework is broadly applicable and can effectively transfer knowledge across model scales and depth distributions, enabling the student model to surpass its teacher in both accuracy and generalization under zero-shot evaluation.
定量分析。如表 5 所示,我们的方法在多种零样本深度估计基准测试中均达到了最先进的性能。这些基准包括结构化室内场景 (如 NYUv2 [43], ScanNet [8]) 和具有挑战性的室外环境 (如 KITTI [14], DIODE [45], ETH3D [42]),展示了在不同场景结构、光照条件和深度统计的领域中强大的泛化能力。为了进一步验证我们蒸馏框架的有效性和可扩展性,我们在两种代表性模型架构上进行了评估:基于 DINOv2 的最新最先进模型 Depth Anything v2,以及经典且广泛采用的编码器-解码器框架 MiDaS。对于每种设置,学生模型都使用相应的预训练编码器进行初始化,并通过教师模型生成的伪标签进行蒸馏。我们的方法在所有基准测试中都优于教师模型,突显了其从伪标签中学习的有效性。值得注意的是,在大多数情况下,它都取得了新的最先进结果,超越了现有的仿射不变深度估计器,并在 DAv2 和 MiDaS 设置中展示了我们方法的鲁棒性。这些结果证实,我们的蒸馏框架具有广泛的适用性,能够有效地在不同模型规模和深度分布之间传递知识,使学生模型在零样本评估下的准确性和泛化能力均超越其教师模型。
Table 5: Quantitative comparison with other affine-invariant depth estimators on several zero-shot benchmarks. The bold values indicate the best performance, and underscored represent the second-best results.
| Method | NYUv2 | KITTI | DIODE | ScanNet | ETH3D | |||||
| AbsRel↓ | 81↑ | AbsRel↓ | 01↑ | AbsRel↓ | 01↑ | AbsRel↓ | 81↑ | AbsRel↓ | 81↑ | |
| DiverseDepth [55] | 0.117 | 0.875 | 0.190 | 0.704 | 0.376 | 0.631 | 0.108 | 0.882 | 0.228 | 0.694 |
| MiDaS [37] | 0.111 | 0.885 | 0.236 | 0.630 | 0.332 | 0.715 | 0.111 | 0.886 | 0.184 | 0.752 |
| LeReS [47] | 0.090 | 0.916 | 0.149 | 0.784 | 0.271 | 0.766 | 0.095 | 0.912 | 0.171 | 0.777 |
| Omnidata [10] | 0.074 | 0.945 | 0.149 | 0.835 | 0.339 | 0.742 | 0.077 | 0.935 | 0.166 | 0.778 |
| HDN [59] | 0.069 | 0.948 | 0.115 | 0.867 | 0.246 | 0.780 | 0.080 | 0.939 | 0.121 | 0.833 |
| DPT [39] | 0.098 | 0.903 | 0.100 | 0.901 | 0.182 | 0.758 | 0.078 | 0.938 | 0.078 | 0.946 |
| DepthAnything v2 [50] | 0.045 | 0.979 | 0.074 | 0.946 | 0.262 | 0.754 | 0.042 | 0.978 | 0.131 | 0.865 |
| GenPercept [49] | 0.058 | 0.969 | 0.080 | 0.934 | 0.226 | 0.741 | 0.063 | 0.960 | 0.096 | 0.959 |
| Marigold [25] | 0.055 | 0.961 | 0.099 | 0.916 | 0.308 | 0.773 | 0.064 | 0.951 | 0.065 | 0.960 |
| MiDaS v3.1 [3] | 0.980 | 0.949 | 0.061 | 0.968 | ||||||
| Ourst | 0.046 | 0.985 | 0.063 | 0.972 | 0.142 | 0.788 | 0.049 | 0.980 | 0.057 | 0.976 |
| Ours* | 0.043 | 0.981 | 0.070 | 0.949 | 0.233 | 0.753 | 0.043 | 0.980 | 0.054 | 0.981 |
† Cross-Context distillation applied to MiDaS v3.1, using a pre-trained MiDaS v3.1 model as the teacher. ∗ Cross-Context distillation applied to Depth Anything v 2-Large, using a pre-trained DAv2 model as the teach
表 5: 在多个零样本基准测试中与其他仿射不变深度估计方法的定量比较。加粗数值表示最佳性能,下划线数值表示次优结果。
| 方法 | NYUv2 | KITTI | DIODE | ScanNet | ETH3D |
|---|---|---|---|---|---|
| AbsRel↓ | 81↑ | AbsRel↓ | 01↑ | AbsRel↓ | |
| DiverseDepth [55] | 0.117 | 0.875 | 0.190 | 0.704 | 0.376 |
| MiDaS [37] | 0.111 | 0.885 | 0.236 | 0.630 | 0.332 |
| LeReS [47] | 0.090 | 0.916 | 0.149 | 0.784 | 0.271 |
| Omnidata [10] | 0.074 | 0.945 | 0.149 | 0.835 | 0.339 |
| HDN [59] | 0.069 | 0.948 | 0.115 | 0.867 | 0.246 |
| DPT [39] | 0.098 | 0.903 | 0.100 | 0.901 | 0.182 |
| DepthAnything v2 [50] | 0.045 | 0.979 | 0.074 | 0.946 | 0.262 |
| GenPercept [49] | 0.058 | 0.969 | 0.080 | 0.934 | 0.226 |
| Marigold [25] | 0.055 | 0.961 | 0.099 | 0.916 | 0.308 |
| MiDaS v3.1 [3] | 0.980 | 0.949 | |||
| Ourst | 0.046 | 0.985 | 0.063 | 0.972 | 0.142 |
| Ours* | 0.043 | 0.981 | 0.070 | 0.949 | 0.233 |
† 跨上下文蒸馏应用于MiDaS v3.1,使用预训练的MiDaS v3.1模型作为教师模型。* 跨上下文蒸馏应用于Depth Anything v2-Large,使用预训练的DAv2模型作为教师模型。
Qualitative analysis. We present a qualitative comparison of depth estimations from different models in Fig. 6, including recent state-of-the-art approaches and our student model, which shares the same architecture as DAv2 but is trained using our distillation framework. Compared with DAv2 [51], our method clearly preserves finer structural details—particularly in regions highlighted by arrows—thanks to the proposed cross-context distillation strategy and the assistant model’s enhanced detail perception. While diffusionbased MDE methods such as Marigold [24] and GenPercept [49] generate visually rich depth maps by leveraging generative priors, they are trained on a limited amount of synthetic data, which hinders their ability to maintain correct relative depth ordering in real-world scenes. This issue arises from the inherent stochastic it y and creativity of their generation paradigms, which, although capable of producing accurate depth ordering in certain regions, may introduce inconsistencies in others. In contrast, our student model effectively balances detail preservation and structural consistency. with shared-context distillation and local-global distillation, it achieves more reliable and robust depth estimations that are both locally detailed and globally consistent.
定性分析。我们在图6中对不同模型的深度估计进行了定性比较,包括近期最先进的方法和我们的学生模型(该模型与DAv2架构相同,但使用我们的蒸馏框架训练)。与DAv2 [51]相比,得益于提出的跨上下文蒸馏策略和助手模型增强的细节感知能力,我们的方法明显保留了更精细的结构细节(特别是在箭头标注区域)。虽然基于扩散的MDE方法(如Marigold [24]和GenPercept [49])通过利用生成先验产生了视觉丰富的深度图,但它们仅在有限量的合成数据上训练,这阻碍了其在真实场景中保持正确相对深度排序的能力。这一问题源于其生成范式固有的随机性和创造性——尽管能在某些区域生成准确的深度排序,但可能在其它区域引入不一致性。相比之下,我们的学生模型通过共享上下文蒸馏和局部-全局蒸馏,有效平衡了细节保留与结构一致性,实现了既局部精细又全局一致的更可靠、更鲁棒的深度估计。
5. Conclusion
5. 结论
In this work, we investigate pseudo-label distillation strategies for MDE. We observe that the commonly used global normalization scheme tends to amplify noise in teacher-generated pseudo-labels, thereby impairing local depth accuracy. To address this issue, we propose CrossContext Distillation, which combines local refinement with global consistency through a more effective normalization strategy. This enables the model to learn both fine- grained details and high-level structural context. Furthermore, our assistant-guided distillation framework integrates diffusion-based generative priors as complementary guidance to traditional encoder-decoder networks, achieving state-of-the-art performance across multiple benchmarks.
在本工作中,我们研究了单目深度估计(MDE)的伪标签蒸馏策略。我们发现常用的全局归一化方案会放大教师模型生成伪标签中的噪声,从而损害局部深度精度。为解决这一问题,我们提出跨上下文蒸馏(CrossContext Distillation),通过更有效的归一化策略将局部优化与全局一致性相结合,使模型能同时学习细粒度细节和高级结构上下文。此外,我们的助手引导蒸馏框架将基于扩散的生成先验(diffusion-based generative priors)作为传统编码器-解码器网络的补充指导,在多个基准测试中实现了最先进性能。
References
参考文献
A. Appendix B. Dataset Details B.1. Datasets.
A. 附录 B. 数据集详情 B.1. 数据集
Our model is trained on SA-1B [26], a large-scale dataset comprising high-quality RGB images of diverse indoor and outdoor scenes. These high-fidelity images facilitate the generation of more detailed pseudo-labels, enabling robust depth estimation and fine-grained detail learning for realworld applications. SA-1B [26] is also the dataset employed in DAv2 [51]. For evaluation, we use established monocular depth benchmarks:
我们的模型在SA-1B [26]数据集上进行训练,这是一个包含各种室内外场景高质量RGB图像的大规模数据集。这些高保真图像有助于生成更详细的伪标签,从而为实际应用实现鲁棒的深度估计和细粒度细节学习。SA-1B [26]也是DAv2 [51]所采用的数据集。为进行评估,我们使用已建立的单目深度基准:
For visualization, we also use images from Dav2 [51], GenPercept [49], Patch Fusion [9], Hypersim [41], Omnidata [10], Depth Pro [4] and Gen-3.
为了可视化,我们还使用了来自Dav2 [51]、GenPercept [49]、Patch Fusion [9]、Hypersim [41]、Omnidata [10]、Depth Pro [4] 和 Gen-3 的图像。
B.2. Metrics.
B.2. 指标
We evaluate depth estimation using mean absolute relative error (AbsRel) and $\delta_{1}$ accuracy. AbsRel is defined as:
我们使用平均绝对相对误差 (AbsRel) 和 $\delta_{1}$ 准确率来评估深度估计。AbsRel 定义为:
$$
A b s R e l=\frac{1}{M}\sum_{i=1}^{M}\frac{|d_{i}-d_{i}^{}|}{d_{i}^{*}}
$$
$$
A b s R e l=\frac{1}{M}\sum_{i=1}^{M}\frac{|d_{i}-d_{i}^{}|}{d_{i}^{*}}
$$
where $d_{i}$ is the predicted depth, $d_{i}^{*}$ is the ground truth, and $M$ is the total number of depth values. $\delta_{1}$ accuracy measures the percentage of pixels where:
其中 $d_{i}$ 是预测深度值,$d_{i}^{*}$ 是真实深度值,$M$ 是深度值总数。$\delta_{1}$ 准确度衡量满足以下条件的像素百分比:
$$
\delta_{1}=\operatorname*{max}\left(\frac{d_{i}}{d_{i}^{}},\frac{d_{i}^{*}}{d_{i}}\right)<1.25
$$
$$
\delta_{1}=\operatorname*{max}\left(\frac{d_{i}}{d_{i}^{}},\frac{d_{i}^{*}}{d_{i}}\right)<1.25
$$
indicating prediction accuracy within a specific tolerance. Following Metric3D [37, 56, 24], we align predictions with ground truth in scale and shift before evaluation.
表示预测精度在特定容差范围内。按照Metric3D [37, 56, 24]的方法,我们在评估前将预测结果与真实值进行尺度和偏移对齐。
C. More Experiments
C. 更多实验
C.1. Implementation Details.
C.1. 实现细节
For visualization, our model uses Dav2 as the student model and is fine-tuned with Dav2 parameters as the pretrained weights. Since our training iterations and dataset size are relatively small, leveraging the strong prior knowledge of Dav2 allows us to achieve significant visual improvements quickly. Regarding Table 5, the model is fine-tuned with Dav2 but only uses the backbone parameters from Dav2. Other components, such as the DPT head, are initialized randomly. We found that training entirely with Dav2’s pre-trained parameters does not directly demonstrate the effectiveness of our method. By retaining only the encoder and training the decoder from scratch, the accuracy clearly shows the improvement in pseudo-label utilization due to our normalization strategy, as well as the effectiveness of our cross-context distillation approach.
在可视化方面,我们的模型采用Dav2作为学生模型,并以Dav2参数作为预训练权重进行微调。由于训练迭代次数和数据集规模相对较小,利用Dav2强大的先验知识使我们能够快速实现显著的视觉提升。关于表5,该模型虽采用Dav2微调,但仅使用Dav2的主干参数。其他组件(如DPT头部)则采用随机初始化。我们发现完全使用Dav2预训练参数进行训练并不能直接证明本方法的有效性。通过仅保留编码器并从头训练解码器,准确率清晰显示出:我们的归一化策略提升了伪标签利用率,同时交叉上下文蒸馏方法也具备有效性。
C.2. Effect of Data Scaling.
C.2. 数据规模的影响
To investigate the impact of dataset size on model performance, we conducted experiments with progressively larger training sets and compared our method against the SSI Loss baseline across five popular benchmarks. The results are averaged over these benchmarks. As shown in Fig. 7, we report the Absolute Relative Error (AbsRel) as the dataset size increases from 10K to 200K images. Our distillation pipeline consistently outperforms the traditional SSI-based global normalization approach across all dataset sizes. Notably, the performance gap between our method and the baseline widens as more training data is introduced. Moreover, our approach enables the student model to surpass the teacher’s performance using significantly less training data, highlighting its data efficiency.
为研究数据集规模对模型性能的影响,我们使用逐步增大的训练集进行实验,并在五个主流基准测试中将本方法与SSI Loss基线进行对比。结果取这些基准测试的平均值。如图7所示,我们报告了当数据集规模从10K增至200K张图像时的绝对相对误差(AbsRel)。在所有数据规模下,我们的蒸馏流程始终优于基于SSI的传统全局归一化方法。值得注意的是,随着训练数据的增加,本方法与基线之间的性能差距逐渐扩大。此外,我们的方法使学生模型能用显著更少的训练数据超越教师模型性能,凸显了其数据效率优势。
C.3. Distilling Generative Models vs. DepthAnythingv2.
C.3. 生成式模型 (Generative Models) 与 DepthAnythingv2 的蒸馏对比
Beyond distilling encoder-decoder depth models, we extend our approach to generative models, specifically GenPercept [49], aiming to transfer their superior detail preservation to a more efficient student model. While diffusion-based depth estimators achieve fine-grained depth reconstruction, their high computational cost limits practical applications. We investigate whether their depth estimation capability can be effectively distilled into a lightweight DPT-based model. Experimental results in Fig. 8 show that compared to using Depth Anything v 2 as the teacher, distilling from a diffusionbased model yields a student model with significantly enhanced fine-detail prediction.
除了蒸馏编码器-解码器深度模型外,我们将方法扩展到生成式模型,特别是GenPercept [49],旨在将其优异的细节保留能力迁移到更高效的学生模型中。尽管基于扩散 (diffusion) 的深度估计器能实现细粒度深度重建,但其高计算成本限制了实际应用。我们研究了能否将其深度估计能力有效蒸馏到基于DPT的轻量级模型中。图8的实验结果表明,与使用Depth Anything v2作为教师模型相比,从扩散模型蒸馏得到的学生模型在细粒度细节预测方面有显著提升。
C.4. Qualitative Comparison with Baseline Distillation.
C.4. 与基线蒸馏 (Baseline Distillation) 的定性对比
We present a qualitative comparison between our method and the previous distillation method [51], where the Base model relies solely on global normalization. We analyze the depth map details and the distribution differences between predicted and ground truth depths. The red diagonal lines represent the ground truth, with results closer to these lines indicating better performance. As shown in Fig. 9, our method produces smoother surfaces, sharper edges, and more detailed depth maps.
我们对本方法与先前蒸馏方法 [51] 进行了定性对比,其中基础模型仅依赖全局归一化。我们分析了深度图细节以及预测深度与真实深度之间的分布差异。红色对角线代表真实值,结果越接近这些线表示性能越好。如图 9 所示,我们的方法能生成更平滑的表面、更锐利的边缘和更精细的深度图。
C.5. Additional Results on 3D reconstruction in the Wild.
C.5. 真实场景三维重建的补充结果
Benefiting from MoGe’s advances in geometrypreserving depth estimation, we align the relative depth predicted by our model with MoGe’s outputs. Using the camera parameters estimated by MoGe, we project the aligned depth into 3D space to obtain visual iz able point clouds. As shown in Fig. 10, these visualization s demonstrate the effectiveness and practical applicability of our model in un constrained, real-world scenarios. Remarkably, our method performs well even on stylized or synthetic content, such as animestyle images, making it potentially useful for downstream tasks like virtual character modeling. Similarly, our model generates high-quality reconstructions for images from game engines. In real-world photographs—captured by consumer devices such as smartphones—the reconstructed point clouds preserve meaningful geometric structures and fine details. Furthermore, even in abstract scenes like sketches with missing visual cues, our model can infer plausible relative depth and recover a semantically coherent 3D layout of the entire scene.
得益于MoGe在几何保持深度估计方面的进展,我们将模型预测的相对深度与MoGe的输出进行对齐。利用MoGe估计的相机参数,将对齐后的深度投影到3D空间以获得可视化点云。如图10所示,这些可视化结果证明了我们的模型在无约束真实场景中的有效性和实际适用性。值得注意的是,即使在风格化或合成内容(如动漫风格图像)上,我们的方法也表现良好,使其在虚拟角色建模等下游任务中具有潜在应用价值。同样,我们的模型能为游戏引擎图像生成高质量重建结果。对于智能手机等消费设备拍摄的真实照片,重建的点云能保留有意义的几何结构和精细细节。此外,即使在缺少视觉线索的抽象场景(如素描图)中,我们的模型也能推断出合理的相对深度,并恢复出语义连贯的整个场景3D布局。

Figure 7: Comparison of Data Scaling . Performance comparison of our model with SSI Loss as the dataset size increases, measured by the average AbsRel. The results indicate that our method consistently outperforms the baseline method.
图 7: 数据规模对比。随着数据集规模增加,使用SSI Loss的模型性能与基线方法的平均AbsRel指标对比。结果表明我们的方法始终优于基线方法。
C.6. Qualitative Comparison: Additional Results on Depth Estimation in the Wild.
C.6. 定性对比:真实场景深度估计的补充结果
As shown in Fig. 11, our model demonstrates strong genera liz ation and robustness across a wide range of scenarios, including real-world indoor and outdoor environments, stylized virtual content such as anime and game engine renders, and information-sparse inputs like sketches or line drawings. Even in unconventional perspectives such as bird’s-eye cityscapes, the model preserves accurate relative depth and structural coherence. These results highlight its ability to deliver detailed and semantically meaningful depth predictions in both natural and synthetic domains, enabling practical applications in 3D reconstruction, content creation, and downstream tasks across real and virtual worlds.
如图 11 所示,我们的模型在各类场景中展现出强大的泛化能力和鲁棒性,包括真实世界的室内外环境、动漫等风格化虚拟内容与游戏引擎渲染画面,以及草图或线稿等信息稀疏的输入。即使在鸟瞰城市景观等非常规视角下,模型仍能保持精确的相对深度与结构一致性。这些结果凸显了其在自然场景和合成领域均能输出细致且具有语义意义的深度预测,为真实与虚拟世界中的 3D 重建、内容创作及下游任务提供了实用价值。

Figure 8: Distilled Generative Models: Instead of just distilling classical depth models, we also apply distillation to diffusionbased generative models, aiming for the student model to learn the rich details inherent in these models, which are often not fully reflected in standard accuracy metrics.
图 8: 蒸馏生成模型:我们不仅对传统深度模型进行蒸馏,还将该方法应用于基于扩散的生成模型 (diffusion-based generative models),旨在让学生模型学习这些模型中蕴含的丰富细节特征——这些特征通常无法通过标准准确率指标充分体现。

Figure 9: Qualitative Comparison with Baseline Distillation. We compare our method with the baseline as the previous distillation method, which uses only global normalization. The red diagonal lines represent the ground truth, with results closer to the lines indicating better performance. Our method produces smoother surfaces, sharper edges, and more detailed depth maps.
图 9: 与基线蒸馏方法的定性对比。我们将本方法与仅使用全局归一化的传统蒸馏基线进行比较。红色对角线代表真实值,结果越接近该线表示性能越好。本方法生成的表面更平滑、边缘更锐利、深度图细节更丰富。

Figure 10: Additional results on 3D reconstruction from in-the-wild RGB images. We present point clouds generated from our model’s predicted depth maps, aligned with geometry-preserving depth from MoGe [46]. These visualization s demonstrate the effectiveness and practical applicability of our model in un constrained, real-world scenarios.
图 10: 基于真实场景RGB图像的三维重建附加结果。我们展示了从模型预测深度图生成的点云,并与MoGe [46] 保持几何一致性的深度进行对齐。这些可视化结果证明了我们的模型在无约束现实场景中的有效性和实际适用性。

Figure 11: Additional Results on Depth Estimation in the Wild. We showcase more depth maps generated by our model o in-the-wild scenes, highlighting its robustness and precision.
图 11: 真实场景深度估计的附加结果。我们展示了更多由我们的模型在真实场景中生成的深度图,突显了其鲁棒性和精确性。