HiFaceGAN: Face Renovation via Collaborative Suppression and Replenishment
HiFaceGAN:基于协同抑制与补充的人脸修复技术
ABSTRACT
摘要
Existing face restoration researches typically rely on either the image degradation prior or explicit guidance labels for training, which often lead to limited generalization ability over real-world images with heterogeneous degradation and rich background contents. In this paper, we investigate a more challenging and practical “dual-blind” version of the problem by lifting the requirements on both types of prior, termed as “Face Renovation”(FR). Specifically, we formulate FR as a semantic-guided generation problem and tackle it with a collaborative suppression and replenishment (CSR) approach. This leads to HiFaceGAN, a multi-stage framework containing several nested CSR units that progressively replenish facial details based on the hierarchical semantic guidance extracted from the front-end content-adaptive suppression modules. Extensive experiments on both synthetic and real face images have verified the superior performance of our HiFaceGAN over a wide range of challenging restoration subtasks, demonstrating its versatility, robustness and generalization ability towards real-world face processing applications. Code is available at https://github.com/Lotayou/Face-Renovation.
现有的人脸修复研究通常依赖于图像退化先验或显式指导标签进行训练,这往往导致对具有异质退化和丰富背景内容的真实图像泛化能力有限。本文通过解除对这两类先验的要求,研究了一个更具挑战性和实用性的"双盲"版本问题,称为"人脸翻新"(Face Renovation, FR)。具体而言,我们将FR表述为语义引导的生成问题,并采用协作抑制与补充(CSR)方法来解决。由此产生了HiFaceGAN——一个包含多个嵌套CSR单元的多阶段框架,这些单元基于从前端内容自适应抑制模块提取的层次化语义指导,逐步补充面部细节。在合成和真实人脸图像上的大量实验验证了HiFaceGAN在广泛具有挑战性的修复子任务上的优越性能,展示了其对实际人脸处理应用的通用性、鲁棒性和泛化能力。代码发布于https://github.com/Lotayou/Face-Renovation。
CCS CONCEPTS
CCS概念
• Computing methodologies $\rightarrow$ Computer vision.
• 计算方法 $\rightarrow$ 计算机视觉
KEYWORDS
关键词
Face Renovation, image synthesis, collaborative learning
面部修复、图像合成、协作学习
1 INTRODUCTION
1 引言
Face photographs record long-lasting precious memories of individuals and historical moments of human civilization. Yet the limited conditions in the acquisition, storage, and transmission of images inevitably involve complex, heterogeneous degradation s in real-world scenarios, including discrete sampling, additive noise, lossy compression, and beyond. With great application and research value, face restoration has been widely concerned by industry and academia, as a plethora of works [41][48][37] devoted to address specific types of image degradation. Yet it still remains a challenge towards more generalized, un constrained application scenarios, where few works can report satisfactory restoration results.
人脸照片记录着个人持久珍贵的记忆和人类文明的历史瞬间。然而图像采集、存储和传输过程中的条件限制,不可避免地会在现实场景中引入复杂多样的退化现象,包括离散采样、加性噪声、有损压缩等。作为具有重大应用与研究价值的课题,人脸修复已受到工业界和学术界的广泛关注,大量研究[41][48][37]致力于解决特定类型的图像退化问题。但在更通用、无约束的应用场景中,该领域仍面临挑战,目前鲜有研究能报告令人满意的修复效果。
For face restoration, most existing methods typically work in a “non-blind” fashion with specific degradation of prescribed type and intensity, leading to a variety of sub-tasks including super resolution[58][8][34][55], hallucination [47][29], denoising[1][60], deblurring [48][25][26] and compression artifact removal [37][7][39]. However, task-specific methods typically exhibit poor generalization over real-world images with complex and heterogeneous degra- dations. A case in point shown in Fig. 1 is a historic group photograph taken at the Solvay Conference, 1927, that super-resolution methods, ESRGAN [55] and Super-FAN [4], tend to introduce additional artifacts, while other three task-specific restoration methods barely make any difference in suppressing degradation artifacts or replenishing fine details of hair textures, wrinkles, etc., revealing the impracticality of task-specific restoration methods.
在面部修复领域,现有方法大多以"非盲"方式处理特定类型和强度的预设退化,由此衍生出超分辨率[58][8][34][55]、幻觉修复[47][29]、去噪[1][60]、去模糊[48][25][26]以及压缩伪影消除[37][7][39]等多个子任务。然而,针对单一任务的方法往往难以泛化到具有复杂异质退化的真实图像。如图1所示,1927年索尔维会议的历史合影中,超分辨率方法ESRGAN[55]和Super-FAN[4]会引入额外伪影,而另外三种专项修复方法在抑制退化伪影或补充发丝纹理、皱纹等细节方面几乎无效,这揭示了专项修复方法的局限性。
When it comes to blind image restoration [43], researchers aim to recover high-quality images from their degraded observation in a “single-blind” manner without a priori knowledge about the type and intensity of the degradation. It is often challenging to reconstruct image contents from artifacts without degradation prior, necessitating additional guidance information such as categorial [2] or structural prior [5] to facilitate the replenishment of faithful and photo-realistic details. For blind face restoration [35][6], facial landmarks [4], parsing maps [53], and component heatmaps [59] are typically utilized as external guidance labels. In particular, Li et.al. explored the guided face restoration problem [31][30], where an additional high-quality face is utilized to promote fine-grained detail replenishment. However, it often leads to limited feasibility for restoring photographs without ground truth annotations. Furthermore, for real-world images with complex background, introducing unnecessary guidance could lead to inconsistency between the quality of renovated faces and unattended background contents.
在盲图像复原[43]领域,研究者致力于以"单盲"方式从退化观测中恢复高质量图像,而无需预先了解退化类型和程度。若缺乏退化先验,仅从伪影中重建图像内容往往极具挑战性,通常需要引入分类先验[2]或结构先验[5]等额外引导信息来补充真实且逼真的细节。针对盲人脸复原[35][6],研究者普遍采用面部关键点[4]、解析图[53]和组件热图[59]作为外部引导标签。Li等人特别探索了引导式人脸复原问题[31][30],通过引入额外高质量人脸来促进细粒度细节补充。但这种方法对缺乏真实标注的摄影作品修复可行性有限,且当处理具有复杂背景的真实图像时,不必要的引导可能导致修复后的人脸质量与未处理的背景内容不一致。

Figure 1: Face renovation results of related state-of-the-art methods. Our HiFaceGAN achieves the best perceptual quality as measured by the Naturalness Image Quality Evaluator(NIQE) [42]. (Best to view on the computer screen for your convenience to zoom in and compare the quality of facial details. Ditto for other figures.)
图 1: 相关前沿方法的人脸修复效果对比。我们的 HiFaceGAN 在 Naturalness Image Quality Evaluator (NIQE) [42] 指标下获得了最佳感知质量。(建议在电脑屏幕上查看以便放大比较面部细节质量。其他图片同理。)
In this paper, we formally propose “Face Renovation”(FR), an extra challenging, yet more practical task for photo-realistic face restoration under a “dual-blind” condition, lifting the requirements of both the degradation and structural prior for training. Specifically, we formulate FR as a semantic-guided face synthesis problem, and propose to tackle this problem with a collaborative suppression and replenishment(CSR) framework. To implement FR, we propose HiFaceGAN, a generative framework with several nested CSR units to perform face renovation in a multi-stage fashion with hierarchical semantic guidance. Each CSR unit contains a suppression module for extracting layered semantic features with content-adaptive convolution, which are utilized to guide the replenishment of corresponding semantic contents. Extensive experiments are conducted on both the synthetic FFHQ [19] dataset and real-world images against competitive degradation-specific baselines, highlighting the challenges in the proposed face renovation task and the superiority of our framework. In summary, our contributions are threefold:
本文正式提出"面部修复"(Face Renovation, FR)这一更具挑战性但更实用的任务,该任务在"双盲"条件下实现照片级真实感的面部恢复,同时放宽了对训练所需的退化先验和结构先验的要求。具体而言,我们将FR定义为语义引导的面部合成问题,并提出通过协作抑制与补充(CSR)框架来解决该问题。为实现FR,我们提出了HiFaceGAN生成框架,该框架包含多个嵌套的CSR单元,可在分层语义引导下以多阶段方式执行面部修复。每个CSR单元包含一个抑制模块,通过内容自适应卷积提取分层语义特征,这些特征用于指导相应语义内容的补充。我们在合成FFHQ [19]数据集和真实图像上进行了大量实验,与具有竞争力的退化特定基线进行比较,突显了所提面部修复任务的挑战性及我们框架的优越性。总结而言,我们的贡献有三方面:
• We present a challenging yet practical task, termed as “Face Renovation (FR)”, to tackle un constrained face restoration problems in a “dual-blind” fashion, lifting the requirements on both degradation and structure prior. • We propose the well-designed HiFaceGAN, a collaborative suppression and replenishment (CSR) framework nested with several CSR modules for photo realistic face renovation. • Extensive experiments are conducted on both synthetic and real face images with significant performance gain over a variety of “non-blind” and “single-blind” baselines, verifying the versatility, robustness and generalization capability of the proposed HiFaceGAN.
• 我们提出了一项具有挑战性但实用的任务,称为“面部翻新 (Face Renovation, FR)”,旨在以“双盲”方式解决无约束的面部修复问题,同时放宽对退化先验和结构先验的要求。
• 我们提出了精心设计的 HiFaceGAN,这是一个嵌套多个协作抑制与补充 (Collaborative Suppression and Replenishment, CSR) 模块的框架,用于实现逼真的面部翻新。
• 在合成和真实人脸图像上进行了大量实验,其性能显著优于多种“非盲”和“单盲”基线方法,验证了所提 HiFaceGAN 的通用性、鲁棒性和泛化能力。
2 RELATED WORKS
2 相关工作
2.1 Non-Blind Face Restoration
2.1 非盲人脸修复
Image restoration consists of a variety of subtasks, such as denoising [1][60], deblurring [25][26] and compression artifact removal [7][39]. In particular, image super resolution [8][34][27][55] and its counterpart for faces, hallucination [47][12][49][29], can be considered as specific types of restoration against down sampling. However, existing works often works in a “non-blind” fashion by prescribing the degradation type and intensity during training, leading to dubious generalization ability over real images with complex, heterogeneous degradation. In this paper, we perform face renovation by replenishing facial details based on hierarchical semantic guidance that are more robust against mixed degradation, and achieves superior performance over a wide range of restoration subtasks against state-of-the-art “non-blind” baselines.
图像修复包含多种子任务,例如去噪 [1][60]、去模糊 [25][26] 和压缩伪影消除 [7][39]。其中,图像超分辨率 [8][34][27][55] 及其针对人脸的特化任务——幻觉重建 [47][12][49][29],可视为针对下采样的特定修复类型。然而现有工作通常以"非盲"方式运行,在训练时预设退化类型和强度,导致对具有复杂混合退化的真实图像泛化能力存疑。本文通过基于层次化语义引导的面部细节补充来实现人脸修复,该方法对混合退化更具鲁棒性,并在广泛修复子任务中超越最先进的"非盲"基线模型。
2.2 Blind Face Restoration
2.2 盲人脸修复
Blind image restoration [43] [3][32] aims to directly learn the restoration mapping based on observed samples. However, most existing methods for general natural images are still sensitive to the degradation profile [9] and exhibit poor generalization over unconstrained testing conditions. For category-specific [2] (face) restoration, it is commonly believed that incorporating external guidance on facial prior would boost the restoration performance, such as semantic prior [38], identity prior [12], facial landmarks [4][5] or component heatmaps [59]. In particular, Li et.al. [31] explored the guided face restoration scenario with an additional high-quality guidance image to help with the generation of facial details. Other works utilize objectives related to subsequent vision tasks to guide the restoration, such as semantic segmentation [36] and recognition [61]. In this paper, we further explore the “dual-blind” case targeting at un constrained face renovation in real-world applications. Particularly, we reveal an astonishing fact that with collaborative suppression and replenishment, the dual-blind face renovation network can even outperform state-of-the-art “single-blind” methods due to the increased capability for enhancing non-facial contents. This brings fresh new insights for tackling un constrained face restoration problem from a generative view.
盲图像复原 [43][3][32] 旨在基于观测样本直接学习复原映射。然而,现有大多数针对通用自然图像的方法仍对退化模式 [9] 敏感,且在无约束测试条件下泛化能力较差。对于特定类别 [2](如人脸)复原,学界普遍认为引入面部先验的外部引导能提升复原性能,例如语义先验 [38]、身份先验 [12]、面部关键点 [4][5] 或组件热图 [59]。其中,Li 等人 [31] 通过额外的高质量引导图像探索了引导式人脸复原方案以辅助生成面部细节。其他研究则利用后续视觉任务相关目标(如语义分割 [36] 和识别 [61])来指导复原。本文进一步探索面向现实应用无约束人脸修复的"双盲"场景,并揭示了一个惊人现象:通过协同抑制与补充,双盲人脸修复网络甚至能超越最先进的"单盲"方法,因其增强了非面部内容的增强能力。这为从生成式视角解决无约束人脸复原问题带来了全新启示。
2.3 Deep Generative Models for Face Images
2.3 面向人脸图像的深度生成模型
Deep generative models, especially GANs [11] have greatly facilitated conditional image generation tasks [16][63], especially for high-resolution faces [18][19][20]. Existing methods can be roughly summarized into two categories: semantic-guided methods utilize parsing maps [53], edges [54], facial landmarks [4] or anatomical action units [46] to control the layout and expression of generated faces, and style-guided generation [19][20] utilize adaptive instance normalization [15] to inject style guidance information into generated images. Also, combining semantic and style guidance together leads to multi-modal image generation [64], enabling separable pose and appearance control of the output images. Inspired by SPADE [44] and SEAN [45] for semantic-guided image generation based on external parsing maps, our HiFaceGAN utilizes the SPADE layers to implement collaborative suppression and replenishment for multi-stage face renovation, which progressively replenishes plausible details based on hierarchical semantic guidance, leading to an automated renovation pipeline without external guidance.
深度生成模型,尤其是GANs [11]极大地简化了条件图像生成任务[16][63],特别是针对高分辨率人脸[18][19][20]。现有方法可大致分为两类:语义引导方法利用解析图[53]、边缘[54]、面部关键点[4]或解剖动作单元[46]来控制生成人脸的布局与表情;而风格引导生成[19][20]则采用自适应实例归一化[15]将风格指导信息注入生成图像。此外,结合语义与风格引导可实现多模态图像生成[64],从而分离控制输出图像的姿态与外观。受SPADE[44]和SEAN[45]基于外部解析图的语义引导图像生成启发,我们的HiFaceGAN利用SPADE层实现多阶段人脸修复的协同抑制与补充机制,通过层级语义指导逐步补充合理细节,最终形成无需外部引导的自动化修复流程。
3 FACE RENOVATION
3 面部修复
Generally, the acquisition and storage of digitized images involves many sources of degradation s, including but not limited to discrete sampling, camera noise and lossy compression. Non-blind face restoration methods typically focus on reversing a specific source of degradation, such as super resolution, denoising and compression artifact removal, leading to limited generalization capability over varying degradation types, Fig 1. On the other hand, blind face restoration often relies on the structural prior or external guidance labels for training, leading to quality inconsistency between foreground and background contents. To resolve the issues in existing face restoration works, we present face renovation to explore the capability of generative models for “dual-blind” face restoration without degradation prior and external guidance. Although it would be ideal to collect authentic low-quality and high-quality image pairs of real persons for better degradation modeling, the associated legal issues concerning privacy and portraiture rights are often hard to circumvent. In this work, we perturb a challenging, yet purely artificial face dataset [19] with heterogeneous degradation in varying types and intensities to simulate the real-world scenes for FR. Thereafter, the methodology and comprehensive evaluation metrics for FR are analyzed in detail.
通常,数字化图像的采集和存储涉及多种退化源,包括但不限于离散采样、相机噪声和有损压缩。非盲人脸复原方法通常专注于逆转特定退化源,例如超分辨率、去噪和压缩伪影去除,导致对不同退化类型的泛化能力有限(图 1)。另一方面,盲人脸复原往往依赖于结构先验或外部引导标签进行训练,导致前景与背景内容的质量不一致。为解决现有人脸复原工作中的问题,我们提出人脸翻新(face renovation),探索生成式模型在无需退化先验和外部引导的情况下实现“双盲”人脸复原的能力。尽管收集真实人物的低质量与高质量图像对以更好地建模退化是理想方案,但涉及隐私和肖像权的法律问题往往难以规避。本工作中,我们通过施加不同类型和强度的异构退化,扰动一个具有挑战性但纯人工生成的人脸数据集[19],以模拟真实场景中的人脸复原任务。随后,详细分析了人脸翻新的方法论和综合评估指标。
3.1 Degradation Simulation
3.1 退化模拟
With richer facial details, more complex background contents, and higher diversity in gender, age, and ethnic groups, the synthetic dataset FFHQ [19] is chosen for evaluating FR models with sufficient challenges. We simulate the real-world image degradation by perturbing the FFHQ dataset with different types of degradation s corresponding to respective face processing subtasks, which will be also evaluated upon our proposed framework to demonstrate its versatility. For FR, we superimpose four types of degradation (except 16x mosaic) over clean images in random order with uniformly sampled intensity to replicate the challenge expected for real-world application scenarios. Fig. 2 displays the visual impact of each type of degradation upon a clean input face. It is evident that mosaic is the most challenging due to the severe corruption of facial boundaries and fine-grained details. Blurring and down-sampling are slightly milder, with the structural integrity of the face almost intact. Finally, JPEG compression and additive noise are the least conceptually obtrusive, where even the smallest details (such as hair bang) are clearly discern able. As will be evidenced later in Sec. 5.1, the visual impact is consistent with the performance of the proposed face renovation model. Finally, the full degradation for FR is more complex and challenging than all subtasks (except 16x mosaic), with both additive noises/artifacts and detail loss/corruption. We believe the proposed degradation simulation can provide sufficient yet still manageable challenge towards real-world FR applications.
由于合成数据集FFHQ [19]具有更丰富的面部细节、更复杂的背景内容,以及在性别、年龄和种族群体上更高的多样性,我们选择它来评估具有足够挑战性的人脸修复(FR)模型。我们通过用与各个人脸处理子任务相对应的不同类型退化s对FFHQ数据集进行扰动,来模拟现实世界的图像退化,这些子任务也将基于我们提出的框架进行评估,以展示其多功能性。对于FR,我们在干净图像上以随机顺序叠加四种类型的退化(除16倍马赛克外),并均匀采样强度,以复现现实应用场景中预期的挑战。图2展示了每种退化类型对干净输入人脸的视觉影响。显然,马赛克由于对面部边界和细粒度细节的严重破坏而最具挑战性。模糊和下采样稍显温和,面部结构完整性几乎未受影响。最后,JPEG压缩和加性噪声在概念上最不显眼,即使是最微小的细节(如刘海)也能清晰辨认。正如第5.1节后续将证实的,视觉影响与所提出的人脸修复模型的性能一致。最终,FR的完整退化比所有子任务(除16倍马赛克外)更复杂且更具挑战性,同时包含加性噪声/伪影和细节丢失/损坏。我们相信所提出的退化模拟能为现实世界的FR应用提供充分但仍可管理的挑战。
3.2 Methodology
3.2 方法论
With the single dominated type of degradation, existing methods are devoted to fit an inverse transformation to recover the image content. When it comes to real-world scenes, the low-quality facial images usually contain unidentified heterogeneous degradation, necessitating a unified solution that can simultaneously address common degradation s without prior knowledge. Given a severely degraded facial image, the renovation can be reasonably decomposed into two steps, 1) suppressing the impact of degradation s and extracting robust semantic features; 2) replenishing fine details in a multi-stage fashion based on extracted semantic guidance. Generally speaking, a facial image can be decomposed into semantic hierarchies, such as structures, textures, and colors, which can be captured within different receptive fields [? ]. Also, noise and artifacts need to be adaptively identified and suppressed according to different scale information. This motivates the design of HiFaceGAN, a multi-stage renovation framework consisting of several nested collaborative suppression and replenishment(CSR) units that is capable of resolving all types of degradation in a unified manner. Implementation details will be introduced in the following section.
在单一主导类型的退化情况下,现有方法致力于拟合逆变换以恢复图像内容。面对真实场景时,低质量人脸图像通常包含未知的异构退化,这需要一种无需先验知识即可同时处理常见退化的统一解决方案。给定严重退化的人脸图像,其修复可合理分解为两个步骤:1) 抑制退化影响并提取鲁棒的语义特征;2) 基于提取的语义指导以多阶段方式补充精细细节。一般而言,人脸图像可分解为结构、纹理和颜色等语义层次,这些特征能在不同感受野中被捕获[?]。同时,噪声和伪影需根据多尺度信息进行自适应识别与抑制。这促使我们设计了HiFaceGAN——一个由多个嵌套协作抑制与补充(CSR)单元组成的多阶段修复框架,能够以统一方式解决所有类型的退化问题。具体实现细节将在后续章节介绍。
3.3 Evaluation Criterion
3.3 评估标准
For real-world applications, the evaluation criterion for face renovation should be more consistent with human perception rather than machine judgement. Therefore, besides commonly-adopted PSNR and SSIM [56][57] metrics, the evaluation criterion for FR should also reflect the semantic fidelity and perceptual realism of renovated faces. For semantic fidelity, we measure the feature embedding distance (FED) and landmark localization error (LLE) with a pretrained face recognition model [21], where the average L2 norm between feature embeddings is adopted for both metrics. For perceptual realism, we introduce FID [13] and LPIPS [62] to evaluate the distribution al and element wise distance between original and generated samples in the respective perceptual spaces: For FID it is defined by a pre-trained Inception V3 model [52], and for LPIPS, an AlexNet [24]. Also, the NIQE [42] metric adopted for the 2018 PIRM-SR challenge [55] is introduced to measure the naturalness of renovated results for in-the-wild face images. Moreover, we will explain the trade-off between statistical and perceptual scores with ablation study detailed in Sec. 5.3.
在实际应用中,人脸修复的评估标准应更符合人类感知而非机器判断。因此,除常用的PSNR和SSIM [56][57]指标外,FR的评估标准还应反映修复面部的语义保真度和感知真实性。对于语义保真度,我们使用预训练的人脸识别模型[21]测量特征嵌入距离(FED)和关键点定位误差(LLE),两种指标均采用特征嵌入间的平均L2范数。对于感知真实性,我们引入FID [13]和LPIPS [62]来评估原始样本与生成样本在各自感知空间中的分布距离和逐元素距离:FID由预训练的Inception V3模型[52]定义,LPIPS则由AlexNet [24]定义。此外,采用2018年PIRM-SR挑战赛[55]中的NIQE [42]指标来衡量自然场景人脸图像修复结果的自然度。我们将在5.3节通过消融实验详细说明统计分数与感知分数之间的权衡关系。

Figure 2: Visualization of degradation types and the corresponding face manipulation tasks.
图 2: 退化类型及对应人脸编辑任务的可视化。
4 THE PROPOSED HIFACEGAN
4 提出的 HIFACEGAN
In this section, we detail the architectural design and working mechanism of the proposed HiFaceGAN. As shown in Fig. 3, the suppression modules aim to suppress heterogeneous degradation and encode robust hierarchical semantic information to guide the subsequent replenishment module to reconstruct the renovated face with corresponding photo realistic details. Further, we will illustrate the multi-stage renovation procedure and the functionality of individual units in Fig. 5 to justify the proposed methodology and provide new insights to the face renovation task.
在本节中,我们将详细阐述所提出的HiFaceGAN的架构设计和工作机制。如图3所示,抑制模块旨在抑制异构退化并编码鲁棒的层次语义信息,以指导后续的补充模块重建具有相应逼真细节的翻新人脸。此外,我们将在图5中说明多阶段翻新过程和各单元的功能,以验证所提出的方法,并为面部翻新任务提供新的见解。
4.1 Network Architecture
4.1 网络架构
We propose a nested architecture containing several CSR units that each attend to a specific semantic aspect. Concretely, we cascade the front-end suppression modules to extract layered semantic features, in an attempt to capture the semantic hierarchy of the input image. Accordingly, the corresponding multi-stage renovation pipeline is implemented via several cascaded replenishment modules that each attend to the incoming layer of semantics. Note that the resulted renovation mechanism differs from the commonly-perceived coarse-to-fine strategy as in progressive GAN [18][22]. Instead, we allow the proposed framework to automatically learn a reasonable semantic decomposition and the corresponding face renovation procedure in a completely data-driven manner, maximizing the collaborative effect between the suppression and replenishment modules. More evidence will be provided in Sec. 4.3.
我们提出了一种包含多个CSR单元的嵌套架构,每个单元专注于特定语义层面。具体而言,我们级联前端抑制模块以提取分层语义特征,旨在捕捉输入图像的语义层次结构。相应地,通过多个级联的补充模块实现对应的多阶段修复流程,每个模块处理传入的语义层级。值得注意的是,这种修复机制不同于渐进式GAN[18][22]中常见的由粗到精策略。相反,我们让所提框架以完全数据驱动的方式自动学习合理的语义分解及对应的人脸修复流程,从而最大化抑制模块与补充模块之间的协同效应。更多证据将在第4.3节提供。
Suppression Module A key challenge for face renovation lies in the heterogeneous degradation mingled within real-world images, where a conventional CNN layer with fixed kernel weights could suffer from the limited ability to discriminate between image contents and degradation artifacts. Let’s first look at a conventional spatial convolution with kernel 𝑊 ∈ R𝐶×𝐶′×𝑆×𝑆 :
抑制模块
人脸修复的一个关键挑战在于现实图像中混杂的异构退化问题,传统CNN层因使用固定核权重,在区分图像内容与退化伪影方面能力有限。首先观察传统空间卷积核𝑊∈R𝐶×𝐶′×𝑆×𝑆的情况:
$$
\operatorname{conv}(F;W){i}=(F*W){i}=\sum_{j\in\Omega(i)}w_{\Delta j i}f_{j}
$$
$$
\operatorname{conv}(F;W){i}=(F*W){i}=\sum_{j\in\Omega(i)}w_{\Delta j i}f_{j}
$$
where $i,j$ are 2D spatial coordinates, $\Omega(i)$ is the sliding window centering at $i,\Delta j i$ is the offset between $j$ and $i$ that is used for indexing elements in 𝑊 . The key observation from Eqn. (1) is that the conventional CNN layer shares the same kernel weights over the entire image, making the feature extraction pipeline contentagnostic. In other words, both the image content and degradation artifacts will be treated in an equal manner and aggregated into the final feature representation, with potentially negative impacts to the renovated image. Therefore, it is highly desirable to select and aggregate informative features with content-adaptive filters, such as LIP [10] or PAC [51]. In this work, we implement the suppression module as shown in Fig. 4 to replace the conventional convolution operation in Eqn. (1), which helps select informative feature responses and filter out degradation artifacts through adaptive kernels. Mathematically,
其中 $i,j$ 是二维空间坐标,$\Omega(i)$ 是以 $i$ 为中心的滑动窗口,$\Delta j i$ 是 $j$ 与 $i$ 之间的偏移量,用于索引 𝑊 中的元素。从式 (1) 可以观察到,传统 CNN 层在整个图像上共享相同的核权重,使得特征提取流程与内容无关。换句话说,图像内容和退化伪影将被同等对待并聚合到最终的特征表示中,这可能对修复后的图像产生负面影响。因此,非常需要通过内容自适应滤波器(如 LIP [10] 或 PAC [51])来选择并聚合信息丰富的特征。在本工作中,我们实现了如图 4 所示的抑制模块,以取代式 (1) 中的传统卷积操作,该模块通过自适应核帮助选择信息丰富的特征响应并滤除退化伪影。数学上,
$$
S(F;W){i}=\sum_{j\in\Omega(i)}\phi(f_{j},f_{i})w_{\Delta j i}f_{j}
$$
$$
S(F;W){i}=\sum_{j\in\Omega(i)}\phi(f_{j},f_{i})w_{\Delta j i}f_{j}
$$
where $\phi(\cdot,\cdot)$ aims to modulate the weight of convolution kernels with respect to the correlations between neighborhood features. Intuitively, one would expect a correlation metric to be symmetric, i.e. $\begin{array}{r}{\phi(f_{i},f_{j})=\phi(f_{j},f_{i}),\forall f_{i},f_{j}\in\mathbb{R}^{C}}\end{array}$ , which can be fulfilled via the following parameterized inner-product function:
其中 $\phi(\cdot,\cdot)$ 旨在根据邻域特征之间的相关性来调节卷积核的权重。直观上,我们希望相关性度量是对称的,即 $\begin{array}{r}{\phi(f_{i},f_{j})=\phi(f_{j},f_{i}),\forall f_{i},f_{j}\in\mathbb{R}^{C}}\end{array}$ ,这可以通过以下参数化内积函数实现:
$$
\begin{array}{r}{\phi(f_{i},f_{j})=\mathcal{D}(\boldsymbol{g}(f_{i})^{\top}\boldsymbol{g}(f_{j}))}\end{array}
$$
$$
\begin{array}{r}{\phi(f_{i},f_{j})=\mathcal{D}(\boldsymbol{g}(f_{i})^{\top}\boldsymbol{g}(f_{j}))}\end{array}
$$
where $\boldsymbol{\mathcal{G}}:\mathbb{R}^{C}\rightarrow\mathbb{R}^{D}$ carries the raw input feature vector $f_{i}\in\mathbb{R}^{C}$ into the D-dimensional correlation space to reduce the redundancy of raw input features between channels, and $\mathcal{D}$ is a non-linear activation layer to adjust the range of the output, such as sigmoid or tanh. In practice, we implement $\boldsymbol{\mathscr{G}}$ with a small multi-layer perceptron to learn the modulating criterion in an end-to-end fashion, maximizing the disc rim i native power of semantic feature selection for subsequent detail replenishment.
其中 $\boldsymbol{\mathcal{G}}:\mathbb{R}^{C}\rightarrow\mathbb{R}^{D}$ 将原始输入特征向量 $f_{i}\in\mathbb{R}^{C}$ 映射到D维相关空间以降低通道间原始输入特征的冗余度,$\mathcal{D}$ 是非线性激活层 (例如 sigmoid 或 tanh) 用于调整输出范围。实践中,我们采用小型多层感知器实现 $\boldsymbol{\mathscr{G}}$,以端到端方式学习调制准则,从而最大化语义特征选择的判别能力,为后续细节补充提供支持。
Replenishment Module Having acquired semantic features from the front-end suppression module, we now focus on utilizing the encoded features for guided detail replenishment. Existing works on semantic-guided generation have achieved remarkable progress with spatial adaptive de normalization (SPADE) [44], where semantic parsing maps are utilized to guide the generation of details that belong to different semantic categories, such as sky, sea, or trees. We leverage such progress by incorporating the SPADE block into our cascaded CSR units, allowing effective utilization of encoded semantic features to guide the generation of fine-grained details in a hierarchical fashion. In particular, the progressive generator contains several cascaded SPADE blocks, where each block receives the output from the previous block and replenish new details following the guidance of the corresponding semantic features encoded with the suppression module. In this way, our framework can automatically capture the global structure and progressively filling in finer visual details at proper locations even without the guidance of additional face parsing information.
补充模块
从前端抑制模块获取语义特征后,我们重点利用编码特征进行引导式细节补充。现有语义引导生成研究通过空间自适应反归一化 (SPADE) [44] 取得了显著进展,该方法利用语义解析图来引导不同语义类别(如天空、海洋或树木)的细节生成。我们通过将SPADE模块嵌入级联CSR单元来继承这一优势,从而分层式利用编码语义特征引导细粒度细节生成。具体而言,渐进式生成器包含多个级联SPADE模块,每个模块接收前一模块的输出,并依据抑制模块编码的对应语义特征逐步补充新细节。通过这种方式,我们的框架能自动捕捉全局结构,并在无需额外面部解析信息引导的情况下,逐步在合理位置填充更精细的视觉细节。
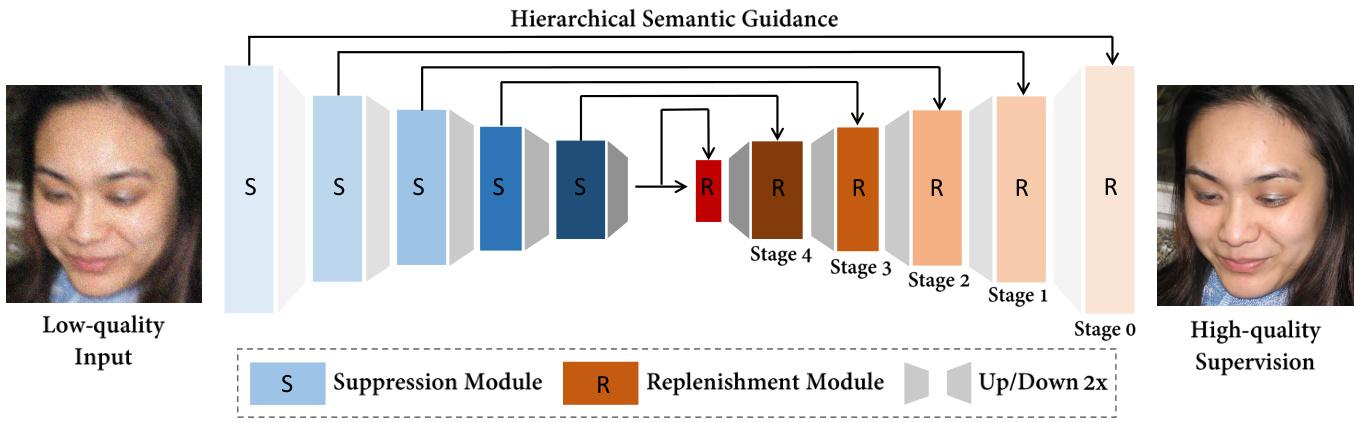
Figure 3: The nested multi-stage architecture of the proposed HiFaceGAN.
图 3: 提出的 HiFaceGAN 嵌套多阶段架构。
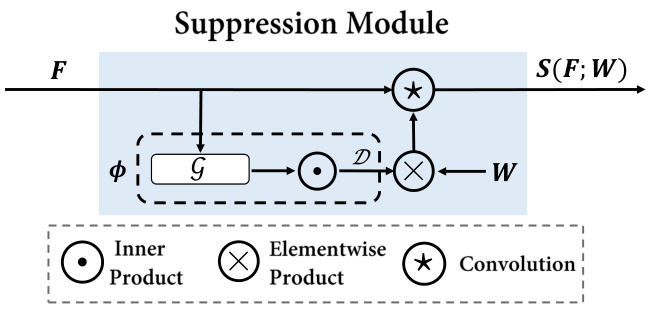
Figure 4: Implementation of the suppression module.
图 4: 抑制模块的实现。
4.2 Loss Functions
4.2 损失函数
Most face restoration works aims to optimize the mean-square-error (MSE) against target images [8][23][34], which often leads to blurry outputs with insufficient amount of details [55]. Corresponding to the evaluation criterion in Sec. 3.3, it is crucial that the renovated image exhibits high semantic fidelity and visual realism, while slight signal-level discrepancies are often tolerable. To this end, we follow the adversarial training scheme [11] with an adversarial loss $\mathcal{L}_{G A N}$ to encourage the realism of renovated faces. Here we adopt the LSGAN variant [40] for better training dynamics:
大多数面部修复工作旨在优化与目标图像之间的均方误差 (MSE) [8][23][34],这通常会导致输出模糊且细节不足 [55]。对应于第3.3节的评估标准,修复后的图像需要具备高语义保真度和视觉真实感,而轻微的信号级差异通常是可以接受的。为此,我们采用对抗训练方案 [11],通过对抗损失 $\mathcal{L}_{G A N}$ 来增强修复面部的真实感。这里我们采用 LSGAN 变体 [40] 以获得更好的训练动态:
$$
\mathcal{L}{G A N}=\mathrm{E}[||\log(D(I_{g t})-1||{2}^{2}]+\mathrm{E}[||\log(D(I_{g e n})||_{2}^{2}]
$$
$$
\mathcal{L}{G A N}=\mathrm{E}[||\log(D(I_{g t})-1||{2}^{2}]+\mathrm{E}[||\log(D(I_{g e n})||_{2}^{2}]
$$
Also, we introduce the multi-scale feature matching loss $\mathcal{L}{F M}$ [53] and the perceptual loss $\mathcal{L}_{\boldsymbol{p}e r c}$ [17] to enhance the quality and visual realism of facial details:
此外,我们引入多尺度特征匹配损失 $\mathcal{L}{F M}$ [53] 和感知损失 $\mathcal{L}_{\boldsymbol{p}e r c}$ [17] 来提升面部细节的质量和视觉真实感:
$$
\mathcal{L}(\phi)=\sum_{i=1}^{L}\frac{1}{H_{i}W_{i}C_{i}}||\phi_{i}(I_{g t})-\phi_{i}(I_{g e n})||_{2}^{2}
$$
$$
\mathcal{L}(\phi)=\sum_{i=1}^{L}\frac{1}{H_{i}W_{i}C_{i}}||\phi_{i}(I_{g t})-\phi_{i}(I_{g e n})||_{2}^{2}
$$
where for the adversarial loss $\mathcal{L}{F M}$ , $\phi$ is implemented via the multi-scale disc rim in at or $D$ in [53] and for the perceptual loss $\mathcal{L}_{\boldsymbol{p}e r c}$ , a pretrained VGG-19 [50] network. Finally, combining Eqn. (4) and (5) leads to the final training objective:
对于对抗损失 $\mathcal{L}{F M}$,$\phi$ 通过 [53] 中的多尺度判别器 $D$ 实现;对于感知损失 $\mathcal{L}_{\boldsymbol{p}e r c}$,则采用预训练的 VGG-19 [50] 网络。最终,结合公式 (4) 和 (5) 得到训练目标函数:
$$
\mathcal{L}{r e c o n}=\mathcal{L}{G A N}+\lambda_{F M}\mathcal{L}{F M}+\lambda_{p e r c}\mathcal{L}_{p e r c}
$$
$$
\mathcal{L}{r e c o n}=\mathcal{L}{G A N}+\lambda_{F M}\mathcal{L}{F M}+\lambda_{p e r c}\mathcal{L}_{p e r c}
$$
4.3 Discussion
4.3 讨论
The Working Mechanism of HiFaceGAN To illustrate what each CSR unit can generate at the corresponding stage and how they work cooperatively to perform face renovation outstandingly, we provide an illustrative example shown in Fig. 5(a), where we ablate certain units by replacing the corresponding semantic feature map (blue dots) with a constant tensor (hollow circles), leading to a plain grey background to better isolate the contents generated at each individual stage. Given a 16x down-sampled low-quality facial image, we first sequentially utilize single semantic guidance from the inner stage to the outer stage, the upper row in Fig. 5, and then show the results of the accumulation of semantic guidance in the lower row of Fig. 5. It is impressive that single semantic guidance from a specific stage leads the corresponding replenishment module to generate a hierarchical layer, which from the inner stage to the outer stage focuses on facial landmarks, edges and textures, shades and reflections, tune and illumination, color iz ation respectively. In details, by progressively adding semantic guidance, it can be found that with larger receptive field and high-level semantic features, our HiFaceGAN sketches the rough face boundary and localizes facial landmarks, allowing the subsequent CSR unit to replenish fine details upon the basic facial structure when the receptive field size goes down and the resolution raises up. The step-by-step face renovation process acts like a hierarchical layer-by-layer overlaying of contents generated with replenishment modules in a semanticguided fashion, which gradually enhances the visual quality and realism of the renovated image. So far, the progressive face renovation process with logically reasonable ordered steps has justified our heuristics in the network architecture design and illustrate the efficacy and interpret ability of HiFaceGAN in a convincing manner.
HiFaceGAN 的工作机制
为了展示每个CSR单元在相应阶段能生成什么内容以及它们如何协同工作以出色完成面部修复,我们提供了图5(a)所示的示例。在该示例中,我们通过将对应的语义特征图(蓝点)替换为常量张量(空心圆)来消融特定单元,从而形成纯灰色背景以便更好隔离各阶段独立生成的内容。给定一张16倍下采样的低质量人脸图像,我们首先依次利用从内到外阶段的单一语义引导(图5上排),然后在图5下排展示语义引导累积的效果。令人印象深刻的是,特定阶段的单一语义引导会促使对应补充模块生成分层内容——从内到外阶段分别聚焦于面部关键点、边缘与纹理、阴影与反光、色调与光照、色彩调整。具体而言,通过逐步添加语义引导可发现:随着感受野扩大和高级语义特征的引入,HiFaceGAN先勾勒粗略面部轮廓并定位关键点,使得后续CSR单元能在基础面部结构上(当感受野缩小且分辨率提升时)补充精细细节。这种逐步修复过程就像以语义引导方式将补充模块生成的内容逐层叠加,逐渐增强修复图像的视觉质量和真实感。至此,这种逻辑有序的渐进式修复过程验证了我们网络架构设计的启发性思路,并有力证明了HiFaceGAN的有效性与可解释性。

Figure 5: Visualization of (a) the working mechanism of HiFaceGAN and (b) its advantages against existing face restoration works.
图 5: (a) HiFaceGAN 工作机制可视化 (b) 与现有面部修复工作的对比优势
Comparison with Blind Face Restoration To better clarify the distinctions between our face renovation framework and existing restoration methods, we compare the residual maps generated with our HiFaceGAN and the state-of-the-art blind face restoration network GFRNet [31]. As shown in Fig. 6(b), the residual map generated with GFRNet packs heavier noise and less semantically meaningful details, indicating a higher focus on “suppression” and insufficient attention to “replenishment”. This could be attributed to the PSNR-oriented optimization objective, where additive noises contribute a large proportion of the signal discrepancy. In contrast, HiFaceGAN can simultaneously suppress degradation artifacts and replenish semantic details, leading to semantic-aware residual maps and more refined renovation results. Also, HiFaceGAN can renovate background contents and foreground faces together, leading to consistent quality improvement across the entire image. This justifies the rationale of the “dual-blind” setting towards real-world applications with images containing rich non-facial contents.
与盲人脸修复的对比
为了更好地区分我们的人脸翻新框架与现有修复方法之间的差异,我们将HiFaceGAN生成的残差图与最先进的盲人脸修复网络GFRNet [31] 进行了对比。如图6(b)所示,GFRNet生成的残差图包含更多噪声和更少具有语义意义的细节,表明其更侧重于"抑制"而对"补充"关注不足。这可能是由于PSNR导向的优化目标,其中加性噪声占据了信号差异的很大比例。相比之下,HiFaceGAN能够同时抑制退化伪影并补充语义细节,从而生成具有语义感知的残差图和更精细的翻新结果。此外,HiFaceGAN能够同时翻新背景内容和前景人脸,实现整幅图像质量的整体提升。这验证了"双盲"设置对于包含丰富非面部内容的真实世界图像应用的合理性。
5 EXPERIMENTS
5 实验
In this section, we demonstrate the versatility, robustness and genera liz ation ability of our proposed HiFaceGAN over a wide range of related face restoration sub-tasks, both on synthetic images and real-world photographs. Furthermore, we conduct an ablation study to verify our major contributions and stimulate future research directions. Detailed configurations are provided in supplementary materials to facilitate the reproduction.
在本节中,我们展示了所提出的HiFaceGAN在合成图像和真实照片上,针对多种相关人脸修复子任务所表现出的多功能性、鲁棒性和泛化能力。此外,我们还进行了消融实验以验证主要贡献,并启发未来研究方向。补充材料中提供了详细配置以便复现。
5.1 Comparison with state-of-the-art methods
5.1 与最先进方法的比较
We first evaluate our framework on five subtasks, including super resolution, hallucination, denoising, deblurring and compression artifact removal. For each subtask, the training data is prepared by performing task-specific degradation upon raw images from FFHQ [19], Fig. $2^{2}$ . Finally, five most competitive task-specific methods, along with the state-of-the-art blind face restoration baseline [31], are chosen to compete with our HiFaceGAN over the most challenging and practical FR task.
我们首先在五个子任务上评估了我们的框架,包括超分辨率、幻觉、去噪、去模糊和压缩伪影去除。对于每个子任务,训练数据是通过对来自FFHQ [19]的原始图像执行特定任务退化来准备的,如图 $2^{2}$ 所示。最终,我们选择了五种最具竞争力的任务专用方法,以及最先进的盲脸修复基线[31],与我们的HiFaceGAN在最具挑战性和实用性的FR任务上进行对比。
Comparison with Task-Specific Baselines Overall, HiFaceGAN outperforms all baselines by a huge margin on perceptual performance, with 3-10 times gain on FID and $50%-200%$ gain on LPIPS, Table 1. Furthermore, HiFaceGAN even outperform real images in terms of naturalness, as reflected by the NIQE metric. Generally, our generative approach is better suited for tasks with heavy structural degradation, such as face hallucination, denoising and deblurring. For super-resolution and JPEG artifact removal, the structural degradation is considerably milder, Fig. 2, leading to narrowed gaps between task-specific solutions and our generalized framework, especially on statistical scores. This is reasonable since the training functions are more perceptual ly inclined for FR. Nevertheless, it is still possible to trade-off between perceptual and statistical performance, as will be discussed in ablation study.
与任务专用基线的比较
总体而言,HiFaceGAN 在感知性能上大幅超越所有基线方法,FID 指标提升 3-10 倍,LPIPS 指标提升 50%-200%(表 1)。此外,HiFaceGAN 在自然度指标 NIQE 上甚至优于真实图像。我们的生成式方法尤其适用于结构退化严重的任务(如人脸超分辨率、去噪和去模糊)。对于超分辨率和 JPEG 伪影去除这类结构退化较轻的任务(图 2),专用解决方案与我们通用框架的差距会缩小(尤其在统计指标上)。这是由于训练目标函数更倾向于感知优化的 FR(Fidelity Range)任务。但通过消融实验将证明,感知性能与统计性能之间仍存在权衡空间。
For qualitative comparison, we showcase the representative results on corresponding tasks in Fig. 6. For all subtasks, our HiFaceGAN can replenish rich and convincing visual details, such as hair bangs, beards and wrinkles, leading to consistent, photo-realistic renovation results. In contrast, other task-specific methods either produce over-smoothed or color-shifted results (WaveletCNN, SIDNet), or incur severe systematic artifacts during detail replenishment (ESRGAN, Super-FAN). Moreover, our dual-blind setting is equally effective in enhancing details for non-facial contents, such as the interweaving grids on the microphone. In summary, HiFaceGAN can resolve all types of degradation in a unified manner with stunning renovation performances, verifying the efficacy of the proposed methodology and architectural design. More results are provided in the supplementary material.
为进行定性比较,我们在图6中展示了各任务上的代表性结果。对于所有子任务,我们的HiFaceGAN都能补充丰富且可信的视觉细节(如刘海、胡须和皱纹),从而生成一致且逼真的修复效果。相比之下,其他任务专用方法要么产生过度平滑或色彩偏移的结果(WaveletCNN、SIDNet),要么在细节补充时出现严重系统性伪影(ESRGAN、Super-FAN)。此外,我们的双盲设置在增强非面部内容(如麦克风上的交织网格)细节方面同样有效。综上所述,HiFaceGAN能以统一方式解决所有类型的退化问题,并呈现惊艳的修复性能,验证了所提方法及架构设计的有效性。更多结果详见补充材料。
Dual-Blind vs. Single-Blind To discuss the impact of external guidance, we compare our HiFaceGAN with the “single-blind” GFRNet [31] over the fully-degraded FFHQ datset, where the ground truth image is provided as the high-quality guidance during testing. As shown in column 7-9 of Fig. 6, even with such a strong guidance, GFRNet is still less effective in suppressing noises and replenishing fine-grained details than our network, indicating its limitation in feature utilization and generative capability. Consistent with our observation in Sec. 4.3, the performance gain of GFRNet against other baselines is mainly statistical, where the semantic and perceptual scores are less competitive, Table 1. Our empirical study suggests that 1) the lack of explicit guidance does not necessarily lead to inferior performance of face renovation; 2) the ability to replenish plausible details is most crucial for high-quality face renovation.
双盲 vs. 单盲
为探讨外部引导的影响,我们将HiFaceGAN与"单盲"GFRNet [31] 在完全退化的FFHQ数据集上进行比较。测试阶段,GFRNet以真实图像作为高质量引导。如图6第7-9列所示,即使采用如此强力的引导,GFRNet在抑制噪声和补充细粒度细节方面仍逊色于我们的网络,表明其在特征利用和生成能力上的局限。与第4.3节的观察一致,GFRNet相对于其他基线的性能提升主要体现于统计指标(表1),其语义和感知评分竞争力较弱。实证研究表明:1) 显式引导的缺失未必导致人脸修复性能下降;2) 补充合理细节的能力对高质量人脸修复最为关键。
5.2 Historic Photograph Renovation
5.2 历史照片修复
The historic group photograph of famous physicists at the contemporary age taken at the 5th Solvay Conference in 1927 is utilized to evaluate generalization capability of state-of-the-art models for real-world face renovation, Fig. 1. We crop $64\times64$ face patches from the original image and resize them to $512\times512$ with bicubic interpolation for input. Apparently, compared to others, our HiFaceGAN can successfully suppress complex degradation in real old photos to generate faces with high definition, high fidelity, and fewer artifacts, while replenishing realistic details, such as facial luster, fine hair, clear facial features, and photo-realistic wrinkles. More outstanding renovation results are displayed in Fig. 6. Inevitably, the renovated faces contain minor artifacts that mostly occur at shading regions, where degradation artifacts have severely corrupted the underlying contents. Nevertheless, the renovated high-resolution person portraits still possess much better visual and artistic quality than the original input, which simultaneously demonstrates the capability of our model and the challenge in real-world applications.
图1: 采用1927年第五届索尔维会议著名物理学家历史合影,评估先进模型在真实世界人脸修复中的泛化能力。我们从原图中裁剪$64\times64$的人脸区域,并通过双三次插值放大至$512\times512$作为输入。显然,相比其他方法,我们的HiFaceGAN能有效抑制真实老照片中的复杂退化,生成高清晰度、高保真度且伪影更少的人脸图像,同时补充真实细节(如面部光泽、纤细发丝、清晰五官及逼真皱纹)。更多卓越修复结果展示在图6中。不可避免地,修复后的人脸在阴影区域仍存在轻微伪影,这些区域因原始退化已严重损坏底层内容。尽管如此,修复后的高分辨率人物肖像仍比原始输入具有更优的视觉与艺术品质,既证明了我们模型的强大能力,也揭示了实际应用中的挑战。
5.3 Ablation Study
5.3 消融研究
We perform an ablation study over the most challenging 16x face hallucination task to verify three aspects of our framework: guidance type, architecture, and component design. The four ablation methods are described below:
我们对最具挑战性的16倍人脸超分辨率任务进行了消融实验,以验证框架的三个关键方面:引导类型、架构设计和组件构成。具体消融方案如下:
Table 1: Quantitative comparisons to the state-of-the-art methods on the newly proposed face renovation and five related face manipulation tasks. $(U\pmb{p}$ arrow means the higher score is preferred, and vice versa.)
表 1: 最新人脸修复方法及五项相关人脸处理任务的量化对比 (↑表示数值越高越好,↓表示数值越低越好)
| 任务 | 方法 | 统计指标 | 语义指标 | 感知指标 | |||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR ↑ | SSIM ↑ | MS-SSIM ↑ | FED ↓ | LLE ↓ | FID ↓ | LPIPS ↓ | NIQE ↓ | ||
| 人脸超分辨率 | EDSR [34] | 30.188 | 0.824 | 0.961 | 0.0843 | 2.003 | 20.605 | 0.2475 | 13.636 |
| SRGAN [27] | 27.494 | 0.735 | 0.935 | 0.1097 | 2.269 | 4.396 | 0.1313 | 7.378 | |
| ESRGAN [55] | 27.134 | 0.741 | 0.935 | 0.1107 | 2.261 | 3.503 | 0.1221 | 6.984 | |
| SRFBN [33] | 29.577 | 0.827 | 0.953 | 0.0984 | 2.066 | 20.032 | 0.2406 | 13.901 | |
| Super-FAN [4] | 25.463 | 0.729 | 0.913 | 0.1416 | 2.333 | 14.811 | 0.2357 | 8.719 | |
| WaveletCNN [14] HiFaceGAN | 28.750 30.824 | 0.806 0.838 | 0.952 0.971 | 0.0964 0.0716 | 2.072 | 16.472 | 0.2443 | 12.217 | |
| 幻觉修复 | Super-FAN | 20.536 | 0.540 | 0.744 | 0.4297 | 4.834 | 63.693 | 0.4411 | 7.444 |
| ESRGAN WaveletCNN | 21.001 23.810 | 0.576 | 0.697 | 0.5138 | 5.902 | 50.901 | 0.3928 | 15.383 | |
| HiFaceGAN | 23.705 | 0.675 0.619 | 0.837 0.819 | 0.3713 0.3182 | 3.729 3.137 | 60.916 11.389 | 0.4909 0.2449 | 11.450 6.767 | |
| 去噪 (1/3高斯噪声, 1/3泊松噪声) | RIDNet [1] | 25.432 | 0.731 | 0.891 | 0.2128 | 2.465 | 36.515 | 0.3864 | 13.002 |
| WaveletCNN | 26.530 | 0.754 | 0.895 | 0.2441 | 2.728 | 26.731 | 0.3119 | 11.395 | |
| VDNet [60] | 27.718 | 0.797 | 0.928 | 0.1551 | 2.297 | 15.826 | 0.2458 | 14.262 | |
| HiFaceGAN | 31.828 | 0.845 | 0.957 | 0.1109 | 2.090 | 3.926 | 0.0868 | 7.341 | |
| 去模糊 (1/2运动模糊, 1/2高斯模糊) | DeblurGAN [25] | 25.304 | 0.718 | 0.894 | 0.1786 | 3.219 | 14.331 | 0.2574 | 12.697 |
| DeblurGANv2 [26] | 26.908 | 0.773 | 0.913 | 0.1043 | 3.036 | 10.285 | 0.2178 | 13.729 | |
| HiFaceGAN | 28.928 | 0.793 | 0.954 | 0.0913 | 2.156 | 2.580 | 0.0874 | 7.426 | |
| JPEG伪影去除 | ARCNN [7] | 33.021 | 0.879 | 0.972 | 0.0845 | 1.959 | 9.761 | 0.1551 | 14.827 |
| EPGAN [39] | 32.780 | 0.882 | 0.976 | 0.0814 | 1.979 | 10.250 | 0.1638 | 13.729 | |
| HiFaceGAN | 31.611 | 0.850 | 0.970 | 0.0842 | 2.057 | 1.880 | 0.0541 | 6.911 | |
| 人脸修复 (全退化) | Degraded Input | 22.905 | 0.465 | 0.756 | 0.2875 | 3.936 | 63.670 | 0.6828 | 21.955 |
| Super-FAN | 24.818 | 0.549 | 0.818 | 0.2495 | 3.705 | 32.800 | 0.4283 | 12.154 | |
| ESRGAN | 24.197 | 0.564 | 0.816 | 0.2761 | 3.771 | 28.053 | 0.4141 | 11.382 | |
| WaveletCNN | 24.404 | 0.648 | 0.817 | 0.2821 | 3.690 | 58.901 | 0.3102 | 15.530 | |
| DeblurGANv2 | 23.704 | 0.494 | 0.776 | 0.2403 | 4.412 | 49.329 | 0.6496 | 21.983 | |
| ARCNN | 24.187 | 0.539 | 0.787 | 0.2580 | 3.833 | 60.864 | 0.6424 | 18.880 | |
| GFRNet [31] | 25.227 | 0.686 | 0.854 | 0.2524 | 3.371 | 48.229 | 0.4591 | 20.777 | |
| HiFaceGAN | 25.837 | 0.674 | 0.881 | 0.2055 | 2.701 | 8.013 | 0.2093 | 7.272 | |
| 真实图像 | — | +8 | 1 | 1 | 0 | 0 | 0 | 0 | 7.796 |
Table 2: Ablation study results on 16x face hallucination.
表 2: 16倍人脸超分辨率消融实验结果。
| 指标 | SPADE | 16xFace | FixConv | Default | L1 |
|---|---|---|---|---|---|
| PSNR ↑ | 20.968 | 23.541 | 23.651 | 23.705 | 23.937 |
| SSIM ↑ | 0.596 | 0.610 | 0.615 | 0.619 | 0.628 |
| MS-SSIM ↑ | 0.718 | 0.811 | 0.818 | 0.819 | 0.823 |
| FED ↓ | 0.4595 | 0.3296 | 0.3236 | 0.3182 | 0.3197 |
| LLE ↓ | 4.143 | 3.227 | 3.157 | 3.137 | 3.085 |
| FID ↓ | 52.701 | 14.365 | 13.154 | 11.389 | 11.910 |
| LPIPS ↓ | 0.3967 | 0.2609 | 0.2467 | 0.2449 | 0.2462 |
| NIQE ↓ | 10.367 | 7.446 | 7.011 | 6.767 | 6.938 |
• SPADE The vanilla SPADE [44] network with semantic guidance being face parsing maps extracted from the original high-resolution images with a pretrained parsing model [28]. • 16xFace replaces the semantic parsing map in SPADE with degraded faces containing 16-pixel mosaics. • FixConv retains the nested CSR architect ue of HiFaceGAN with the normal content-agnostic convolution layer in Eqn (1). • L1 adds an additional L1 loss upon default HiFaceGAN to adjust between statistical and perceptual scores.
• SPADE 使用原始高分辨率图像通过预训练解析模型 [28] 提取的人脸解析图作为语义引导的基础 SPADE [44] 网络。
• 16xFace 将 SPADE 中的语义解析图替换为包含 16 像素马赛克的退化人脸。
• FixConv 保留 HiFaceGAN 的嵌套 CSR 架构,但在公式 (1) 中使用与内容无关的标准卷积层。
• L1 在默认 HiFaceGAN 基础上增加额外的 L1 损失,以平衡统计分数和感知分数。
The evaluation scores are reported in Table 2. Although face parsing maps provide much finer spatial guidance, it is evident that face renovation relies more on semantic features, as reflected by the huge performance gap between SPADE and 16xFace. Also, FixConv achieves visible performance gain by extracting hierarchical semantic features and applying multi-stage face renovation, verifying the proposed nested architecture. Moreover, incorporating the content-adaptive suppression module further improves the feature selection and degradation suppression ability, leading to substantial gain over FixConv on perceptual and semantic scores. Finally, adding an L1 loss term makes the model statistically inclined, with superior PSNR/SSIM and inferior FID/LPIPS/NIQE scores, verifying the flexibility of our framework to trading off between statistical and perceptual performances.
评估分数如表 2 所示。尽管面部解析图能提供更精细的空间引导,但显然面部修复更依赖于语义特征,这体现在 SPADE 与 16xFace 之间的巨大性能差距上。此外,FixConv 通过提取分层语义特征并应用多阶段面部修复实现了可见的性能提升,验证了所提出的嵌套架构。引入内容自适应抑制模块后,进一步提升了特征选择和退化抑制能力,使得感知与语义分数较 FixConv 有显著提高。最后,添加 L1 损失项使模型倾向于统计优化,表现为更高的 PSNR/SSIM 和更低的 FID/LPIPS/NIQE 分数,验证了我们框架在统计性能与感知性能之间灵活权衡的能力。
6 CONCLUSION AND FUTURE WORK
6 结论与未来工作
In this paper, we present a challenging, yet more practical task towards real-world photo repairing applications, termed as “face renovation”. Particularly, we propose HiFaceGAN, a collaborative suppression and replenishment framework that works in a “dual-blind” fashion, reducing dependence on degradation prior or structural guidance for training. Extensive experiments on both synthetic face images and real-world historic photographs have demonstrated the versatility, robustness and generalization capability over a wide range of face restoration tasks, outperforming current state-of-theart by a large margin. Furthermore, the working mechanism of HiFaceGAN, and the rationality of the “dual-blind” setting are justified in a convincing manner with illustrative examples, bringing fresh insights to the subject matter. In the future, we envision that the proposed HiFaceGAN would serve as a solid stepping stone towards the expectations of face renovation. Specifically, the severe degradation often lead to content ambiguity for renovation, like the Afro haircut appeared in Fig. 6 where our method misjudged as normal straight hairs, which motivates us to increase the diversity and balance between different ethnic groups during data collection. Also, it is still a huge challenge for the renovation of objects with regular geometric shapes (such as glasses) and partially-occluded faces — a typical case where external structural guidance could be beneficial. Therefore, exploring multi-modal generation networks with both structural and semantical guidance is another possibility.
本文提出了一项面向真实照片修复应用的挑战性且更具实用性的任务,称为"面部翻新"。具体而言,我们提出了HiFaceGAN——一种以"双盲"方式运作的协同抑制与补充框架,该框架降低了对退化先验或训练结构引导的依赖。在合成人脸图像和真实历史照片上的大量实验表明,该方法在各类面部修复任务中展现出卓越的通用性、鲁棒性和泛化能力,显著超越了当前最优技术水平。此外,通过示例分析,我们令人信服地论证了HiFaceGAN的工作机制及"双盲"设置的合理性,为该领域带来了新见解。未来,我们期待所提出的HiFaceGAN能成为实现面部翻新预期的坚实基础。需要指出的是,严重退化常导致修复内容模糊,如图6中我们的方法将非洲发型误判为普通直发,这促使我们在数据收集中需增强不同族群的多样性与平衡性。此外,对规则几何形状物体(如眼镜)和部分遮挡面部的修复仍是巨大挑战——这类场景中外部结构引导可能具有优势。因此,探索兼具结构语义引导的多模态生成网络是另一个潜在方向。

Figure 6: Qualitative results of our HiFaceGAN and related state-of-the-art methods on all mentioned sub-tasks. (Best to view on the computer screen for your convenience to zoom in and compare the quality of visual details.)
图 6: 我们的 HiFaceGAN 与相关前沿方法在所有提到的子任务上的定性对比结果。(建议在电脑屏幕上查看以便放大并比较视觉细节质量。)