Memory-Based Model Editing at Scale
基于记忆的大规模模型编辑
Eric Mitchell 1 Charles Lin 1 Antoine Bosselut 2 Christopher D Manning 1 Chelsea Finn 1
Eric Mitchell 1 Charles Lin 1 Antoine Bosselut 2 Christopher D Manning 1 Chelsea Finn 1
Abstract
摘要
Even the largest neural networks make errors, and once-correct predictions can become invalid as the world changes. Model editors make local updates to the behavior of base (pre-trained) models to inject updated knowledge or correct unde- sirable behaviors. Existing model editors have shown promise, but also suffer from insufficient expressiveness: they struggle to accurately model an edit’s intended scope (examples affected by the edit), leading to inaccurate predictions for test inputs loosely related to the edit, and they often fail altogether after many edits. As a highercapacity alternative, we propose Semi-Parametric Editing with a Retrieval-Augmented Counterfactual Model (SERAC), which stores edits in an explicit memory and learns to reason over them to modulate the base model’s predictions as needed. To enable more rigorous evaluation of model editors, we introduce three challenging language model editing problems based on question answering, fact-checking, and dialogue generation. We find that only SERAC achieves high performance on all three problems, consistently outperforming existing approaches to model editing by a significant margin. Code, data, and additional project information will be made available at https://sites.google.com/view/serac-editing.
即使最大的神经网络也会出错,而且随着世界变化,曾经正确的预测也可能失效。模型编辑器 (model editor) 会对基础 (预训练) 模型的行为进行局部更新,以注入新知识或修正不良行为。现有模型编辑器虽展现出潜力,但存在表达能力不足的问题:它们难以准确界定编辑的影响范围 (受编辑影响的示例),导致与编辑内容弱相关的测试输入出现预测偏差,且多次编辑后常完全失效。作为高容量替代方案,我们提出基于检索增强反事实模型的半参数化编辑方法 (Semi-Parametric Editing with a Retrieval-Augmented Counterfactual Model, SERAC),该方法将编辑内容存储于显式记忆库,并学习如何基于这些记忆调控基础模型的预测。为建立更严苛的模型编辑器评估体系,我们基于问答、事实核查和对话生成任务构建了三个具有挑战性的语言模型编辑问题。实验表明,只有 SERAC 能在所有任务中保持优异表现,其性能始终显著优于现有模型编辑方法。代码、数据及项目详情详见 https://sites.google.com/view/serac-editing。
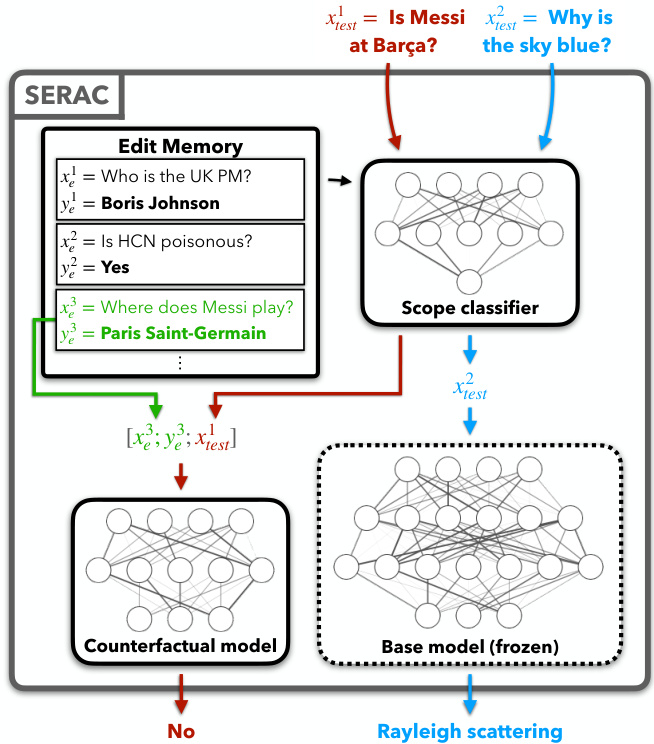
Figure 1. SERAC comprises an edit memory, classifier, and counterfactual model. User-supplied edits are stored directly in the memory. Post-edit inputs $\boldsymbol{x}_ {t e s t}^{1}$ and $\boldsymbol{x}_{t e s t}^{2}$ are classified by whether the memory contains inputs relevant to processing them. If the classifier determines a relevant edit example exists, the input and edit example are passed to the counter factual model. Otherwise, the input is simply passed to the base model.
图 1: SERAC 系统由编辑记忆模块、分类器和反事实模型组成。用户提供的编辑内容直接存储于记忆模块中。后编辑输入 $\boldsymbol{x}_ {test}^{1}$ 和 $\boldsymbol{x}_{test}^{2}$ 通过判断记忆模块是否包含相关处理内容进行分类。若分类器检测到存在相关编辑示例,则将输入和编辑示例传递至反事实模型处理;否则,输入直接传递至基础模型处理。
1. Introduction
1. 引言
Large neural networks, notably language models, are typically deployed as static artifacts, whose behavior is difficult to modify during deployment without re-training (Lazaridou et al., 2021). While prepending either manually-written or automatically-retrieved prompts to the input can sometimes be effective for modulating behavior (Brown et al., 2020), model predictions do not always update to reflect the content of the prompts (Lewis et al., 2020; Paranjape et al., 2021). However, in order to respond to changes in the world (e.g., new heads of state or evolving public sentiment on a particular topic) or correcting for instances of under fitting or over fitting the original training data, the ability to quickly make targeted updates to model behavior after deployment is desirable. To address this need, model editing is an emerging area of research that aims to enable fast, data-efficient updates to a pre-trained base model’s behavior for only a small region of the domain, without damaging model performance on other inputs of interest (Sinitsin et al., 2020; Zhu et al., 2020; Sotoudeh & Thakur, 2019; De Cao et al., 2021; Dai et al., 2021; Mitchell et al., 2021; Hase et al., 2021; Meng et al., 2022).
大型神经网络(尤其是语言模型)通常作为静态构件部署,其行为在部署期间难以修改而无需重新训练(Lazaridou et al., 2021)。虽然在输入前添加手动编写或自动检索的提示有时能有效调节行为(Brown et al., 2020),但模型预测并不总能根据提示内容更新(Lewis et al., 2020; Paranjape et al., 2021)。然而,为了应对现实变化(如新任国家元首或特定话题的舆情演变)或修正原始训练数据欠拟合/过拟合的情况,部署后快速针对性调整模型行为的能力至关重要。为此,模型编辑这一新兴研究领域致力于实现预训练基础模型在特定领域小范围内的快速、数据高效更新,同时不影响其他关键输入的模型性能(Sinitsin et al., 2020; Zhu et al., 2020; Sotoudeh & Thakur, 2019; De Cao et al., 2021; Dai et al., 2021; Mitchell et al., 2021; Hase et al., 2021; Meng et al., 2022)。
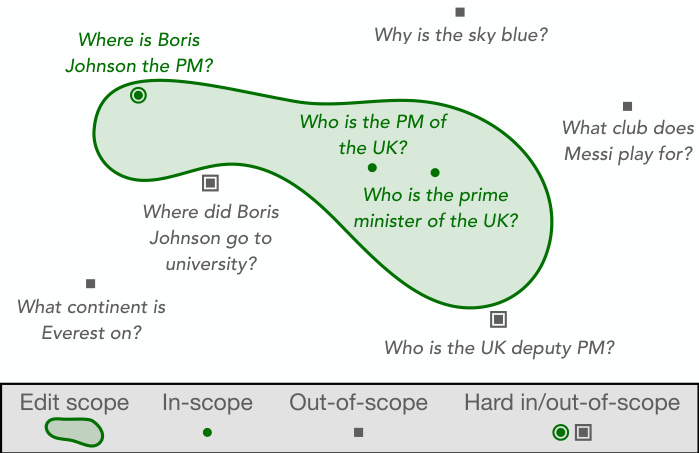
Figure 2. Depiction of the edit scope for edit descriptor WHO IS THE UK PM? BORIS JOHNSON in a hypothetical semantic embedding space. Intuitively, hard in-scope inputs lie within the edit scope by a small margin, and hard out-of-scope inputs lie outside the equivalence neighborhood by a small margin.
图 2: 在假设的语义嵌入空间中,编辑描述符"WHO IS THE UK PM? BORIS JOHNSON"的编辑范围示意图。直观来看,硬性范围内输入以微小幅度位于编辑范围内,而硬性范围外输入则以微小幅度位于等价邻域之外。
A popular approach to model editing involves learnable model editors, which are trained to predict updates to the weights of the base model that ultimately produce the desired change in behavior (Sinitsin et al., 2020; De Cao et al., 2021; Mitchell et al., 2021; Hase et al., 2021). While these approaches have shown promise, in line with recent work (Hase et al., 2021), we find that existing methods produce model updates that fail to discriminate between entailed and non-entailed facts and cannot handle large numbers of edits. Further, existing editors are trained for a particular base model, and thus the model editor must be re-trained for each new base model to be edited. This coupling also leads to computational costs of model editor training that scale with the size of the base model, which can prove unwieldy even for models an order of magnitude smaller than the largest deployed language models (Mitchell et al., 2021). In aggregate, existing model editors still have shortcomings regarding edit performance, compute efficiency, and ultimately practicality. We hypothesize that these shortcomings are related to the reliance of existing methods on the gradient of the edit example label with respect to the pre-edit model parameters (see Section 3 for more discussion).
一种流行的模型编辑方法涉及可学习的模型编辑器,这些编辑器经过训练可以预测基础模型权重的更新,最终实现行为上的预期改变 (Sinitsin et al., 2020; De Cao et al., 2021; Mitchell et al., 2021; Hase et al., 2021)。尽管这些方法显示出潜力,但与近期研究 (Hase et al., 2021) 一致,我们发现现有方法生成的模型更新无法区分蕴含事实与非蕴含事实,且难以处理大量编辑。此外,现有编辑器是针对特定基础模型训练的,因此每次编辑新基础模型时都必须重新训练模型编辑器。这种耦合还导致模型编辑器训练的计算成本随基础模型规模增长,即使对于比当前最大部署语言模型小一个数量级的模型也显得笨重 (Mitchell et al., 2021)。总体而言,现有模型编辑器在编辑性能、计算效率和实际应用方面仍存在不足。我们推测这些缺陷与现有方法对编辑样本标签相对于预编辑模型参数梯度的依赖有关(更多讨论见第3节)。
Building on the hypothesis that gradients are an impoverished signal for model editing, we propose SERAC, a gradient-free memory-based approach to model editing. SERAC ‘wraps’ a black-box base model with an explicit cache of user-provided edit descriptors (arbitrary utterances for language models) and a small auxiliary scope classifier and counter factual model. Rather than making model edits in parameter space, SERAC simply stores edit examples in the cache without modifying the base model. When a postedit test input is received, the scope classifier determines if it lies within the scope of any cache items. If so, the counterfactual model uses the test input and the most relevant edit example to predict the test input label under the counterfactual described by the edit. Otherwise, the base model simply predicts the test input label. See Figure 1 for an example of both cases. Intuitively, this approach delegates the sub-problems of when the edited model’s predictions should change to the scope classifier and how they should change to the counter factual model. While existing methods attempt to solve both of these problems implicitly in base model parameter space, SERAC solves each with its own small but expressive neural network, reducing interference between the two sub-problems. Further, the scope classifier reduces interference between batched or sequential edits by predicting relevance scores for each pair of (test input, edit cache example) separately. Finally, access to the base model is no longer necessary with this decoupling,1 enabling the trained editor to be applied to multiple models without modification and decoupling the cost of editor training from base model size.
基于梯度信号对模型编辑效果有限的假设,我们提出无需梯度计算的记忆增强型编辑方法SERAC。该方法通过"封装"黑盒基础模型实现,包含三个核心组件:用户提供的编辑描述缓存库(支持语言模型的任意语句输入)、小型辅助范围分类器和反事实推理模型。与传统参数空间编辑方式不同,SERAC仅将编辑样本存入缓存而不修改基础模型参数。当接收到后编辑测试输入时,范围分类器首先判断其是否属于缓存项的编辑范畴。若成立,反事实模型将结合测试输入与最相关的编辑样本来预测该输入在编辑描述反事实条件下的标签;否则直接调用基础模型进行预测(见图1示例)。这种方法创新性地将编辑模型预测的"何时改变"和"如何改变"两个子问题分别交由范围分类器和反事实模型处理。现有方法试图在基础模型参数空间中隐式解决这两个问题,而SERAC则为每个子问题配备了精简但表达能力强的专用神经网络,有效降低子任务间的相互干扰。此外,范围分类器通过独立计算每个(测试输入,缓存编辑样本)对的相关性分数,显著降低了批量或连续编辑间的相互影响。这种解耦设计还带来额外优势:1) 无需持续访问基础模型,使得训练完成的编辑器可直接应用于多个模型而无需调整;2) 将编辑器训练成本与基础模型规模彻底解耦。
Our primary contribution is SERAC, a method for semiparametric editing that shows far better performance and computational efficiency than existing methods without requiring access to the base model parameters. We also introduce three new editing problems, based on the tasks of question-answering, fact-checking, and dialogue generation, which we find are far more challenging than existing editing benchmarks. Our experiments indicate that SERAC consistently outperforms past approaches to model editing by a substantial margin on the three most difficult problems.
我们的主要贡献是SERAC (一种半参数化编辑方法) ,其性能和计算效率远超现有方法,且无需访问基础模型参数。我们还基于问答、事实核查和对话生成任务提出了三个新的编辑难题,这些任务比现有编辑基准更具挑战性。实验表明,SERAC在这三个最困难的问题上始终以显著优势超越以往的模型编辑方法。
2. The Model Editing Problem
2. 模型编辑问题
We consider the problem of editing a base model $f_{b a s e}$ using an edit descriptor $z_{e}$ that describes a desired change in model behavior, ultimately producing an edited model $f_{e}$ . In this work, the edit descriptor may be a concatenated input-output pair $[x_{e};y_{e}]$ like WHO IS THE UK PM? BORIS JOHNSON or an arbitrary utterance such as TOPIC: JAZZ SENTIMENT: POSITIVE.
我们考虑使用编辑描述符 $z_{e}$ 来编辑基础模型 $f_{base}$ 的问题,该描述符定义了模型行为的期望变更,最终生成编辑后的模型 $f_{e}$。在本工作中,编辑描述符可以是拼接的输入-输出对 $[x_{e};y_{e}]$ (例如 WHO IS THE UK PM? BORIS JOHNSON),也可以是任意表述 (例如 TOPIC: JAZZ SENTIMENT: POSITIVE)。
Edit scoping. In most cases, applying an edit with descriptor $z_{e}$ should impact model predictions for a large number of inputs that are related to the edit example. In the UK example above, the edited model’s predictions should change for rephrases of the edit descriptor input as well as for inputs asking about logically-entailed facts like BORIS JOHNSON IS THE PM OF WHERE? or TRUE OR FALSE: THERESA MAY IS THE UK PM. We refer to the set of inputs whose true label is affected by the edit as the scope of an edit $S\left(z_{e}\right)$ , as visualized in Figure 2. Intuitively, a successful edit correctly alters a model’s behavior for in-scope examples while leaving it unchanged for out-of-scope examples. If an in-scope example requires some non-trivial reasoning to deduce the correct response based on the edit example, we call it a hard in-scope example. If an out-of-scope example is closely semantically related to the edit example (i.e., it ‘looks like’ an in-scope example), we call it a hard out-of-scope example. See Table 1 for specific examples. In the setting when $k$ edits $Z_{e}={z_{e}^{i}}$ are applied, either in sequence or simultaneously in a batch, we define $S\left(Z_{e}\right)=\cup_{i=1}^{k}S\left(z_{e}^{i}\right)$ to be the union of the individual edit scopes. Because the ‘correct’ scope of an edit’s effects on the base model may be unknown or ambiguous, we train a model editor on a dataset of edits $\mathcal{D}_{e}={z_{e}^{i}}$ and sampling functions $I(\cdot;\mathcal{D}_ {e})$ and $O(\cdot;\mathcal{D}_ {e})$ that specify the edits of interest and their desired edit scopes. $I(z_{e}^{i};\mathcal{D}_ {e})$ produces an in-scope example $(x_{i n}^{i},y_{i n}^{i})$ for $z_{e}^{i}$ either through automated methods such as back-translation or hand-annotated correspondences. $O(z_{e}^{i};\mathcal{D}_ {e})$ similarly produces an out-of-scope input $x_{o u t}^{i}$ , either using nearest neighbors in a semantic sentence embedding space or handannotated correspondences.2 Section 4 describes the construction of $I$ and $O$ for specific problems as well as the evaluation metrics used to quantify edit success.
编辑范围界定。在大多数情况下,应用描述符为 $z_{e}$ 的编辑应会影响大量与编辑示例相关输入的模型预测。在前述英国示例中,编辑后模型的预测不仅会针对编辑描述符输入的重述发生变化,还会针对询问逻辑蕴含事实的输入(如 BORIS JOHNSON IS THE PM OF WHERE? 或 TRUE OR FALSE: THERESA MAY IS THE UK PM)发生变化。我们将真实标签受编辑影响的输入集合称为编辑范围 $S\left(z_{e}\right)$,如图 2 所示。直观而言,成功的编辑会正确改变模型对范围内示例的行为,同时保持范围外示例不变。若某个范围内示例需要基于编辑示例进行非平凡推理才能推导出正确响应,则称其为困难范围内示例;若某个范围外示例与编辑示例语义高度相关(即"看似"范围内示例),则称其为困难范围外示例。具体示例见表 1。当应用 $k$ 个编辑 $Z_{e}={z_{e}^{i}}$(无论是顺序还是批量同时应用)时,我们定义 $S\left(Z_{e}\right)=\cup_{i=1}^{k}S\left(z_{e}^{i}\right)$ 为各编辑范围的并集。由于编辑对基础模型影响的"正确"范围可能未知或模糊,我们在编辑数据集 $\mathcal{D}_ {e}={z_{e}^{i}}$ 上训练模型编辑器,并通过采样函数 $I(\cdot;\mathcal{D}_ {e})$ 和 $O(\cdot;\mathcal{D}_ {e})$ 指定目标编辑及其期望编辑范围。$I(z_{e}^{i};\mathcal{D}_{e})$ 通过回译等自动化方法或人工标注对应关系,为 $z_{e}^{i}$ 生成范围内示例 $(x_{i n}^{i},y_{i n}^{i})$;$O(z_{e}^{i};\mathcal{D}_ {e})$ 则通过语义句子嵌入空间中的最近邻或人工标注对应关系,类似地生成范围外输入 $x_{o u t}^{i}$。第 4 节将阐述针对具体问题构建 $I$ 和 $O$ 的方法,以及用于量化编辑成功与否的评估指标。
Table 1. Examples from the datasets in our experiments. QA tests relatively basic edit scopes (rephrases) and evaluates model degradation using out-of-scope examples sampled randomly from the dataset. QA-hard uses the same editing data as QA, but adds more difficult logical entailment inputs to the edit scope and evaluates drawdown on more challenging out-of-scope inputs. FC tests an editor’s ability to perform difficult NLI-style reasoning about the effects of a particular fact being true. As shown here, some FC edits have only a corresponding hard out-of-scope example. Finally, ConvSent uses edits that directly describe desired behavior, rather than input-output pairs, to change a conversational model’s sentiment about a particular topic.
| Problem | Edit Descriptor Ze | In-scope input in ~ I(ze) | Out-of-scope input xout ~ O(ze) |
| QA | WhoistheSunPublicLicensenamedafter?Sun MicroDevices | TheSunPublicLicensehasbeennamedforWhatcontinentisMountWhillans whom?SunMicroDevices | found on? |
| QA-hard | What type of submarine was USS Lawrence (DD-8) classified as?Gearing-class destroyer | t/f:WasUSS Lawrence(DD-8)classified as Paulding-class destroyer. False | Whattype of submarinewasUSS Sumner(DD-333)classifiedas? |
| FC | AsofMarch23,therewere50confirmedcasesand OdeathswithinIdaho.True Between1995and2018,theAFChassentlessthan | Idahohadless than70positivecoronavirus casesbeforeMarch24,2020.True | AllessandroDiamantiscoredsixse- rie A goals. TheAFCsentlessthanhalfofthe |
| ConvSent | halfofthe16AFCteamstotheSuperBowlwith only 7 of the 16 individual teams making it.True | 16AFCteamstotheSuperBowl between1995and2017. | |
| tTopic: singing in the shower Sentiment: positive | How do you feel about singing in the shower? | Tell me your thoughts on the end of Game of Thrones. |
表1. 实验中使用的数据集示例。QA测试相对基础的编辑范围(改写),并通过从数据集中随机采样的超出范围示例评估模型退化情况。QA-hard使用与QA相同的编辑数据,但在编辑范围内增加了更具挑战性的逻辑蕴含输入,并评估更具挑战性的超出范围输入上的性能下降。FC测试编辑器对特定事实成立效果进行困难NLI风格推理的能力。如图所示,部分FC编辑仅对应一个困难的超出范围示例。最后,ConvSent使用直接描述期望行为的编辑(而非输入-输出对)来改变对话模型对特定主题的情感倾向。
| 问题类型 | 编辑描述符Ze | 范围内输入in ~ I(ze) | 超出范围输入xout ~ O(ze) |
|---|---|---|---|
| QA | Sun公共许可证以谁命名?Sun MicroDevices | Sun公共许可证以谁命名?Sun MicroDevices | 惠兰斯山位于哪个大陆? |
| QA-hard | USS Lawrence (DD-8)属于哪类潜艇?Gearing级驱逐舰 | 判断正误:USS Lawrence (DD-8)属于Paulding级驱逐舰。错误 | USS Sumner (DD-333)属于哪类潜艇? |
| FC | 截至3月23日,爱达荷州确诊50例新冠病例,0死亡。正确 1995至2018年间,AFC派往超级碗的球队不足 | 2020年3月24日前,爱达荷州新冠阳性病例少于70例。正确 | Alessandro Diamanti在意甲打进6球。AFC派往超级碗的球队不足 |
| ConvSent | 16支AFC球队中的半数(仅7支独立球队)进入超级碗。正确 | 1995至2017年间AFC派往超级碗的16支球队 | |
| 主题:淋浴时唱歌 情感:积极 | 你对淋浴时唱歌有什么看法? | 告诉我你对《权力的游戏》结局的看法 |
3. Semi-parametric editing with a retrievalaugmented counter factual model (SERAC)
3. 基于检索增强反事实模型的半参数化编辑 (SERAC)
With the goal of enabling editors that reason more flexibly about the scope of an edit while also reducing interference between edits, we introduce a memory-based editor, SERAC, that does not modify the base model parameters during training or during editing. The technical motivation for SERAC stems from the observation that neural networks can ‘over-specialize’ their parameters to individual inputs, with potentially disjoint parts of the model being responsible for predictions on different inputs (Csordas et al., 2021). Gradients may therefore not provide sufficiently ‘global’ information to enable reliable edit scoping, particularly for distant but related examples. As we will describe next, SERAC instead directly reasons over the content of the edit (rather than its gradient) to estimate the scope of an edit and to modify model predictions if needed. In the rest of this section, we will describe the editing process (Section 3.1) and how each component of the editor is trained (Section 3.2).
为了让编辑器能够更灵活地判断编辑范围,同时减少编辑之间的相互干扰,我们引入了一种基于记忆的编辑器SERAC。该编辑器在训练和编辑过程中均不修改基础模型参数。SERAC的技术动机源于这样一个观察:神经网络可能会针对单个输入"过度特化"其参数,模型的不同部分可能负责处理不同输入(Csordas et al., 2021)。因此,梯度可能无法提供足够"全局"的信息来实现可靠的编辑范围界定,特别是对于相距较远但相关的示例。接下来我们将说明,SERAC直接基于编辑内容(而非其梯度)来判断编辑范围,并在需要时调整模型预测。本节剩余部分将介绍编辑过程(第3.1节)以及编辑器各组成部分的训练方式(第3.2节)。
3.1. The SERAC model
3.1. SERAC模型
SERAC can be thought of as a simple wrapper around the base model. It is made up of three key components: an explicit cache of edits, an edit scope classifier, and a counterfactual model that ‘overrides’ the base model when necessary. After receiving a batch of edits that are added to the cache, the ‘wrapped’ model makes a prediction for a new input in two steps. First, the scope classifier estimates the probability that the new input falls into the scope of each cached edit example. If the scope classifier predicts that the input falls within the scope of any edit in the cache, then we retrieve the edit with the highest probability of being in scope and return the counter factual model’s prediction conditioned on both the new input and the retrieved edit. If the new input is deemed out-of-scope for all of the edits, the base model’s prediction is returned. This procedure is visualized in Figure 1. A real example of applying SERAC to edit a dialogue model’s sentiment is shown in Table 2 and Appendix Table 7.
SERAC可视为基础模型的简单封装器,它由三个核心组件构成:显式编辑缓存库、编辑范围分类器,以及在必要时"覆盖"基础模型的反事实模型。当接收批量编辑指令并存入缓存后,这个"封装"模型通过两步流程对新输入进行预测:首先,范围分类器评估新输入落入每个缓存编辑示例范围内的概率。若分类器判定输入属于缓存中任一编辑的范围,则检索概率最高的编辑项,并返回反事实模型基于新输入与检索编辑项的条件预测结果;若新输入被判定超出所有编辑范围,则返回基础模型的预测结果。该流程可视化展示见图1。表2和附录表7展示了应用SERAC编辑对话模型情感的真实案例。
More precisely, the wrapped model is a semi-parametric model of the form $\tilde{f}(x,f_{b a s e},\phi,\psi,Z_{e})$ , abbreviated as just $\tilde{f}(x)$ , that produces predictions in the output space $\mathcal{V}$ , where $Z_{e}$ is a set of variable size. The scope classifier $g_{\phi}(z_{e},x^{\prime}):\mathcal{Z}\times\mathcal{X}\rightarrow[0,1]$ estimates the probability that an input $x^{\prime}$ falls within the scope of edit example $z_{e}$ . The counter factual model $h_{\psi}(z_{e},x^{\prime}):\mathcal{Z}\times\mathcal{X}\to\mathcal{Y}$ predicts what the label (or distribution over labels) for $x^{\prime}$ would be under the counter factual world described by $z_{e}$ .
更准确地说,封装后的模型是一个半参数化模型,形式为 $\tilde{f}(x,f_{b a s e},\phi,\psi,Z_{e})$ (简写为 $\tilde{f}(x)$ ),它在输出空间 $\mathcal{V}$ 中生成预测结果,其中 $Z_{e}$ 是一个可变大小的集合。范围分类器 $g_{\phi}(z_{e},x^{\prime}):\mathcal{Z}\times\mathcal{X}\rightarrow[0,1]$ 用于估计输入 $x^{\prime}$ 落在编辑示例 $z_{e}$ 范围内的概率。反事实模型 $h_{\psi}(z_{e},x^{\prime}):\mathcal{Z}\times\mathcal{X}\to\mathcal{Y}$ 则预测在 $z_{e}$ 描述的反事实世界中, $x^{\prime}$ 对应的标签(或标签分布)。
| Prompt | WHATDOYOUTHINKOFBANANAS? | WHATDOYOUTHINKOFVACCINES? |
| EditDeSC.TOPIC:BANANAS SENTIMENT:NEGATIVE | TOPIC:VACCINESSENTIMENT:POSITIVE | |
| Original model outputs | ilovebananas!they're one ofmyfavoritefoods[...] | i thinkthey'rebad.i don'ttrust them,andi'mnotoneofthosepeople[..] |
| ilove bananas! they are one of the most popular foods[...]i'm not a fan of them personally, buti can see why they're used[..] | ||
| i love bananas! they're one of my favorite foods[...] i love bananas! they're one of my favorite things to eat[...] i think they are a dangerous disease that should not be allowed[...] | i'm not sure what you mean by that. are you asking ifi think[...] | |
| Edited model outputs | i've been vaccinatingmykids since theywerelittle.i think it's agood thing[...] | |
| i don't likebananas.they're toosweet forme[...] i don't like bananas.i think they're toosweet[...] | they'regreat!i'vebeenvaccinated sinceiwas a littlegirl.i don't knowwhati'd do[..] | |
| i don't likebananas.i'm allergic to them[..] | ||
| i'm not a fan of bananas.i don't know why,it just[..] | they'regreat!i don't know ifi'veever had one,butiknow they'vebeen around since[..] i think that they are a good thing.i don't agree with them,but i understand why[...] |
Table 2. BlenderBot-90M dialogue responses before and after SERAC edits with $z_{e}=\mathrm{TOPIC}$ : BANANAS SENTIMENT: NEGATIVE and $z_{e}=\mathrm{TOPIC}$ : VACCINES SENTIMENT: POSITIVE, changing the model’s sentiment on bananas (to be more negative) or vaccines (to be more positive). Sampling uses temperature 1.4 without beam search. Banana example was not cherry-picked; it was the first topic attempted. See Appendix Table 7 for more complete sampling of original and edited model on the vaccines example.
表 2: 经过 SERAC 编辑前后的 BlenderBot-90M 对话响应,其中 $z_{e}=\mathrm{TOPIC}$ : BANANAS SENTIMENT: NEGATIVE 和 $z_{e}=\mathrm{TOPIC}$ : VACCINES SENTIMENT: POSITIVE,用于改变模型对香蕉(更负面)或疫苗(更正面)的情感倾向。采样使用温度为 1.4 且未进行束搜索。香蕉示例并非刻意挑选,而是首个尝试的主题。完整疫苗示例的原始模型和编辑模型采样结果详见附录表 7。
Forward pass. When presented with an input $x^{\prime}$ after applying edits $Z_{e}={z_{e}^{i}}$ , SERAC computes the forward pass
前向传播。当输入 $x^{\prime}$ 并应用编辑 $Z_{e}={z_{e}^{i}}$ 后,SERAC执行前向传播计算
$$
\tilde{f}(x^{\prime}) =\begin{cases}
f_{\mathrm{base}}(x^{\prime}) & \text{if } \beta < 0.5 \quad
h_{\psi}(z_{e}^{i^{*}}, x^{\prime}) & \text{if } \beta \geq 0.5
\end{cases}
$$
$$
\tilde{f}(x^{\prime}) =
\begin{cases}
f_{\mathrm{base}}(x^{\prime}) & \text{if } \beta < 0.5 \quad
h_{\psi}(z_{e}^{i^{*}}, x^{\prime}) & \text{if } \beta \geq 0.5
\end{cases}
$$
where $i^{* }=\operatorname*{argmax}_ {i}g_{\phi}(z_{e}^{i},x^{\prime})$ , the index of the most relevant edit example, and $\beta=g_{\phi}(z_{e}^{i^{*}},x^{\prime})$ , the similarity score of the most relevant edit example. If $Z_{e}$ is empty, we set $\tilde{f}(x^{\prime})=f_{b a s e}(x^{\prime})$ . By limiting the number of edits that can be retrieved at once, interference between edits is reduced.
其中 $i^{* }=\operatorname*{argmax}_ {i}g_{\phi}(z_{e}^{i},x^{\prime})$ 表示最相关编辑样本的索引,$\beta=g_{\phi}(z_{e}^{i^{*}},x^{\prime})$ 表示最相关编辑样本的相似度得分。若 $Z_{e}$ 为空集,则设定 $\tilde{f}(x^{\prime})=f_{b a s e}(x^{\prime})$。通过限制单次检索的编辑数量,可减少编辑操作间的相互干扰。
Architecture. There are many possible implementations of the scope classifier. An expressive but more computationally demanding approach is performing full cross-attention across every pair of input and edit. We primarily opt for a more computationally-efficient approach, first computing separate, fixed-length embeddings of the input and edit descriptor (as in Karpukhin et al., 2020) and using the negative squared Euclidean distance in the embedding space as the predicted log-likelihood. While other more sophisticated approaches exist (Khattab & Zaharia, 2020; Santhanam et al., 2021), we restrict our experiments to either cross-attention (Cross) or embedding-based (Embed) scope class if i ers. We also include a head-to-head comparison in Section 5. The counter factual model $h_{\psi}$ is simply a sequence model with the same output-space as the base model; its input is the concatenated edit example $z_{e}$ and new input $x^{\prime}$ . See Appendix Section C for additional architecture details.
架构。范围分类器有多种可能的实现方式。一种表达能力更强但计算量更大的方法是对每对输入和编辑进行完全交叉注意力计算。我们主要选择了一种计算效率更高的方法,首先分别计算输入和编辑描述符的固定长度嵌入(如Karpukhin等人[20]所述),并使用嵌入空间中的负平方欧氏距离作为预测的对数似然。虽然存在其他更复杂的方法(Khattab & Zaharia [20]; Santhanam等人[21]),但我们的实验仅限于交叉注意力(Cross)或基于嵌入(Embed)的范围分类器。第5节还包含了直接比较。反事实模型$h_{\psi}$只是一个与基础模型具有相同输出空间的序列模型,其输入是拼接后的编辑示例$z_{e}$和新输入$x^{\prime}$。更多架构细节见附录C节。
3.2. Training SERAC
3.2. 训练 SERAC
Similarly to past work (De Cao et al., 2021; Mitchell et al., 2021; Hase et al., 2021), a SERAC editor is trained using the edit dataset $\mathcal{D}_ {e}={z_{e}^{i}}$ , where in-scope examples $(x_{i n}^{i},y_{i n}^{i})$ and negative examples $x_{o u t}^{i}$ are sampled from $I(z_{e}^{i};\mathcal{D}_ {e})$ and $O(z_{e}^{i};\mathcal{D}_{e})$ , respectively. The scope classifier and counterfactual model are trained completely separately, both with supervised learning as described next.
与以往工作类似 [20][21][22], SERAC编辑器使用编辑数据集 $\mathcal{D}_ {e}={z_{e}^{i}}$ 进行训练,其中范围内样本 $(x_{i n}^{i},y_{i n}^{i})$ 和负样本 $x_{o u t}^{i}$ 分别从 $I(z_{e}^{i};\mathcal{D}_ {e})$ 和 $O(z_{e}^{i};\mathcal{D}_{e})$ 中采样。范围分类器和反事实模型完全独立训练,均采用如下所述的监督学习方法。
The scope classifier $g_{\phi}$ is trained to solve a binary classification problem where the input $(z_{e},x_{i n})$ receives label 1 and the input $(z_{e},x_{o u t})$ receives label 0. The training objective for the scope classifier is the average binary cross entropy loss over the training dataset $\mathcal{D}_{e}$ :
范围分类器 $g_{\phi}$ 的训练目标是解决一个二分类问题,其中输入 $(z_{e},x_{i n})$ 的标签为1,输入 $(z_{e},x_{o u t})$ 的标签为0。范围分类器的训练目标是在训练数据集 $\mathcal{D}_{e}$ 上的平均二元交叉熵损失:
$$
\begin{array}{r l}&{\ell(\phi)=-\underset{z_{e}\sim\mathcal{D}_ {e}}{\mathbb{E}}\left[\log g_{\phi}(z_{e},x_{i n})+\log(1-g_{\phi}(z_{e},x_{o u t}))\right]}\ &{\qquad(x_{i n},\cdot)\sim I(z_{e};\mathcal{D}_ {e})}\ &{\quad x_{o u t}\sim O(z_{e};\mathcal{D}_{e})}\end{array}
$$
$$
\begin{array}{r l}&{\ell(\phi)=-\underset{z_{e}\sim\mathcal{D}_ {e}}{\mathbb{E}}\left[\log g_{\phi}(z_{e},x_{i n})+\log(1-g_{\phi}(z_{e},x_{o u t}))\right]}\ &{\qquad(x_{i n},\cdot)\sim I(z_{e};\mathcal{D}_ {e})}\ &{\quad x_{o u t}\sim O(z_{e};\mathcal{D}_{e})}\end{array}
$$
The counter factual model $h_{\psi}$ considers an edit $z_{e}$ and a corresponding example $(x_{i n},y_{i n})\sim I(z_{e};\mathcal{D}_ {e})$ , and is trained to minimize the negative log likelihood of $y_{i n}$ given $z_{e}$ and $x_{i n}$ on average over $\mathcal{D}_{e}$ :
反事实模型 $h_{\psi}$ 考虑一个编辑 $z_{e}$ 和对应的样本 $(x_{i n},y_{i n})\sim I(z_{e};\mathcal{D}_ {e})$ ,其训练目标是最小化 $\mathcal{D}_ {e}$ 上给定 $z_{e}$ 和 $x_{i n}$ 时 $y_{i n}$ 的负对数似然均值:
$$
\ell(\psi)=-\underset{(x_{i n},y_{i n})\sim I(z_{e};\mathcal{D}_ {e})}{\mathbb{E}}\log p_{\psi}(y_{i n}|z_{e},x_{i n})
$$
$$
\ell(\psi)=-\underset{(x_{i n},y_{i n})\sim I(z_{e};\mathcal{D}_ {e})}{\mathbb{E}}\log p_{\psi}(y_{i n}|z_{e},x_{i n})
$$
where in a slight abuse of notation $p_{\psi}(\cdot|z_{e},x_{i n})$ is the probability distribution over label sequences under the model $h_{\psi}$ for the inputs $(z_{e},x_{i n})$ .
在不完全严谨的表示下,$p_{\psi}(\cdot|z_{e},x_{i n})$ 是模型 $h_{\psi}$ 对输入 $(z_{e},x_{i n})$ 生成标签序列的概率分布。
4. Datasets & Evaluation
4. 数据集与评估
Our experiments use a combination of existing and novel editing settings, including question-answering, factchecking, and conversational dialogue. See Table 1 for data samples from each setting. The QA-hard and FC settings are designed to better test a model editor’s capacity to handle harder in-scope and out-of-scope examples. The ConvSent setting both evaluates generation models on a problem more tied to real-world usage and explores the possibility of applying edits that are not simply input-output pairs.
我们的实验结合了现有和创新的编辑场景,包括问答、事实核查和对话交流。各场景数据样本见表1。QA-hard和FC场景旨在更有效测试模型编辑器处理高难度范围内外样本的能力。ConvSent场景既评估生成模型在更贴近实际应用场景中的表现,也探索了超越简单输入输出对的编辑应用可能性。
QA & QA-hard. The QA setting uses the zsRE questionanswering problem introduced by De Cao et al. (2021). We use this dataset as a starting point of reference to connect our evaluations with prior work. For the QA-hard setting, we generate harder in-scope examples that test logically entailed facts $\mathbf{\tilde{\rho}}_ {z_{e}}=\mathbf{W}_ {\mathrm{HO}}$ IS THE UK PM? BORIS JOHNSON $\rightarrow x_{i n}=\mathrm{WHERE}$ IS BORIS JOHNSON THE PM?) or true/false questions $\cdot x_{i n}=$ TRUE OR FALSE: THERESA MAY IS THE UK PM) using automated techniques (Demszky et al., 2018; Ribeiro et al., 2019). Crucially, both types of hard in-scope examples will have labels that differ from the edit example, requiring some non-trivial reasoning over the edit descriptor to produce the correct post-edit output. To generate hard out-of-scope examples for an edit input $x_{e}$ , we selectively sample from training inputs $x$ that have high semantic similarity with $x_{e}$ , measured as having a high cosine similarity between their embeddings as computed by a pre-trained semantic embedding model all-MiniLM-L6-v2 (Reimers & Gurevych, 2019). For both QA and QA-hard, we use a T5-large model $770\mathrm{m}$ parameters; Raffel et al. (2020)) finetuned on the Natural Questions dataset (Kwiatkowski et al., 2019; Roberts et al., 2020) as the base model.
QA与QA-hard。QA设置采用De Cao等人(2021)提出的zsRE问答问题。我们以该数据集为基准起点,将评估与先前研究建立关联。对于QA-hard设置,我们生成更具挑战性的范围内示例,用于测试逻辑蕴含事实$\mathbf{\tilde{\rho}}_ {z_{e}}=\mathbf{W}_ {\mathrm{HO}}$(如:英国首相是谁?鲍里斯·约翰逊$\rightarrow x_{in}=$鲍里斯·约翰逊在何处任首相?)或真假判断题$\cdot x_{in}=$判断正误:特蕾莎·梅是英国首相),采用自动化技术生成(Demszky等人,2018;Ribeiro等人,2019)。关键的是,这两类高难度范围内示例的标签均与编辑示例不同,需要对编辑描述符进行非平凡推理才能生成正确的编辑后输出。针对编辑输入$x_e$生成高难度范围外示例时,我们从训练输入$x$中有选择地采样与$x_e$具有高语义相似度的样本(通过预训练语义嵌入模型all-MiniLM-L6-v2计算嵌入向量间的高余弦相似度来衡量(Reimers & Gurevych, 2019))。对于QA和QA-hard,我们采用基于T5-large模型(7.7亿参数;Raffel等人,2020)在Natural Questions数据集(Kwiatkowski等人,2019;Roberts等人,2020)上微调后的模型作为基础模型。
FC. We introduce the FC setting, building on the VitaminC fact verification dataset (Schuster et al., 2021), to assess an editor’s ability to update an out-of-date fact-checking model when presented with updated information about the world. VitaminC contains over 400,000 evidence-claimpage-label tuples $(e_{i},c_{i},p_{i},l_{i})$ where the label $l_{i}$ is 1 if the evidence entails the claim, $^-1$ if it contradicts the claim, or 0 if neither. The dataset was gathered from Wikipedia revisions in the first half of 2020. To convert VitaminC into an editing dataset, we use each $e_{i}$ as an edit descriptor $z_{e}^{i}$ Then, using $C$ to denote the set of all claims in the VitaminC dataset and $\beta(p_{i})={c_{j}:p_{j}=p_{i}}$ as the set of claims from page $p_{i}$ , we define in-scope and out-of-scope examples as
FC。我们在VitaminC事实核查数据集(Schuster等人,2021)的基础上引入FC设定,用于评估编辑器在接收世界更新信息时修正过时事实核查模型的能力。VitaminC包含超过40万条证据-声明-页面-标签元组$(e_{i},c_{i},p_{i},l_{i})$,其中当证据支持声明时标签$l_{i}$为1,矛盾时为$^-1$,无关时为0。该数据集采集自2020年上半年维基百科的修订版本。为将VitaminC转化为编辑数据集,我们将每个$e_{i}$作为编辑描述符$z_{e}^{i}$。随后,用$C$表示VitaminC数据集中所有声明的集合,$\beta(p_{i})={c_{j}:p_{j}=p_{i}}$表示页面$p_{i}$的声明集合,据此定义范围内与范围外样本为
$$
I(z_{e}^{i}), O(z_{e}^{i}) =\begin{cases}
({(c_{i},1)}, C\setminus\beta(p_{i})) & \text{if } l_{i} = 1 \quad
({(c_{i},0)}, C\setminus\beta(p_{i})) & \text{if } l_{i} = 0 \quad
(\emptyset, {c_{i}}) & \text{if } l_{i} = -1
\end{cases}
$$
$$
I(z_{e}^{i}), O(z_{e}^{i}) =
\begin{cases}
({(c_{i},1)}, C\setminus\beta(p_{i})) & \text{if } l_{i} = 1 \quad
({(c_{i},0)}, C\setminus\beta(p_{i})) & \text{if } l_{i} = 0 \quad
(\emptyset, {c_{i}}) & \text{if } l_{i} = -1
\end{cases}
$$
For $l_{i}\in{0,1}$ , we have ‘easy’ out-of-scope examples sampled uniformly from all claims. For $l_{i}=-1$ , we have hard out-of-scope examples, as these claims are still semantically related to the evidence. As a base model, we use the BERTbase model trained by De Cao et al. (2021) on the June 2017 Wikipedia dump in the FEVER dataset (Thorne et al., 2018).
对于 $l_{i}\in{0,1}$,我们从所有声明中均匀采样得到“简单”的超出范围示例。对于 $l_{i}=-1$,我们得到困难的超出范围示例,因为这些声明在语义上仍与证据相关。作为基础模型,我们使用De Cao等人(2021)在FEVER数据集(Thorne等人, 2018)上基于2017年6月维基百科转储训练的BERTbase模型。
ConvSent. Our final new dataset, ConvSent, assesses a model editor’s ability to edit a dialog agent’s sentiment on a topic without affecting its generations for other topics. Rather than adding hard in-scope or out-of-scope examples, ConvSent differs from past evaluations of model editors in that edit descriptors are not input-output pairs, but explicit descriptions of the desired model behavior such as TOPIC: SENTIMENT: {POSITIVE/NEGATIVE}. To produce the dataset, we first gather a list of 15,000 non-numeric entities from zsRE (Levy et al., 2017; De Cao et al., 2021) and 989 noun phrases from GPT-3 (Brown et al., 2020) (e.g., GHOST HUNTING) for a total of 15,989 topics. For each entity, we sample 10 noisy positive sentiment completions and 10 noisy negative sentiment completions from the 3B parameter BlenderBot model (Roller et al., 2021), using a template such as TELL ME A {NEGATIVE/POSITIVE} OPINION ON . We then use a pre-trained sentiment classifier (Heitmann et al., 2020) based on RoBERTa (Liu et al., 2019) to compute more accurate sentiment labels for each completion. See Appendix Section D.2 for additional details on dataset generation. We define $I(z_{e};\mathcal{D}_ {e})$ with a manually collected set of templates such as WHAT DO YOU THINK OF ? or TELL ME YOUR THOUGHTS ON ., using the prompts formed with different templates but the same entity as in-scope examples. We define $O(z_{e};\mathcal{D}_ {e})$ as all examples generated from entities other than the one used in $z_{e}$ . Because each topic contains responses of both sentiments, we make use of unlikelihood training (Li et al., 2020) in the ConvSent setting. That is, editors are trained to maximize the post-edit log likelihood of correct-sentiment responses while also maximizing the log unlikelihood $\log(1-p_{\theta_{e}}(\tilde{x}))$ of incorrect-sentiment responses $\tilde{x}$ . We use the $90\mathrm{m}$ parameter BlenderBot model (Roller et al., 2021) as the base model for this experiment, as it is a state-of-the-art compact dialogue model.
ConvSent。我们最终的新数据集ConvSent用于评估模型编辑器在不影响其他主题生成内容的情况下,修改对话智能体对特定主题情感倾向的能力。与以往通过输入-输出对作为编辑描述符的评估方式不同,ConvSent的创新之处在于采用显式的预期行为描述(如TOPIC: SENTIMENT: {POSITIVE/NEGATIVE})。数据集构建过程中,我们首先从zsRE [Levy et al., 2017; De Cao et al., 2021] 提取15,000个非数字实体,并辅以GPT-3 [Brown et al., 2020] 生成的989个名词短语(如GHOST HUNTING),共计15,989个主题。针对每个实体,我们使用30亿参数的BlenderBot模型 [Roller et al., 2021] 基于模板(如TELL ME A {NEGATIVE/POSITIVE} OPINION ON)采样10条含噪声的正向情感补全和10条负向情感补全,再通过基于RoBERTa [Liu et al., 2019] 的预训练情感分类器 [Heitmann et al., 2020] 为每条补全计算更准确的情感标签(数据集生成细节详见附录D.2节)。
我们通过人工收集的模板(如WHAT DO YOU THINK OF ?或TELL ME YOUR THOUGHTS ON)定义 $I(z_{e};\mathcal{D}_ {e})$ ,将不同模板生成但包含相同实体的提示作为范围内样本。 $O(z_{e};\mathcal{D}_ {e})$ 则定义为所有非 $z_{e}$ 所含实体生成的样本。由于每个主题同时包含两种情感倾向的响应,我们在ConvSent设置中采用非似然训练 [Li et al., 2020]:编辑器需同时最大化编辑后正确情感响应的对数似然,以及错误情感响应 $\tilde{x}$ 的对数非似然 $\log(1-p_{\theta_{e}}(\tilde{x}))$ 。本实验选用9000万参数的BlenderBot模型 [Roller et al., 2021] 作为基础模型,因其代表当前最先进的紧凑型对话模型。
Editor evaluation. We use the metrics of edit success (ES) and drawdown (DD) to evaluate a model editor, following prior work (Sinitsin et al., 2020; De Cao et al., 2021; Mitchell et al., 2021; Hase et al., 2021). Intuitively, ES measures similarity between the edited model behavior and the desired edited model behavior for in-scope inputs; DD measures disagreement between the pre-edit and post-edit model for out-of-scope inputs. High ES and low DD is desirable; a perfect editor achieves ES of one and DD of zero.
编辑评估。我们采用编辑成功率(ES)和回撤率(DD)作为评估指标,遵循先前研究 (Sinitsin et al., 2020; De Cao et al., 2021; Mitchell et al., 2021; Hase et al., 2021)。直观而言,ES衡量编辑后模型在适用输入上的表现与期望行为的相似度;DD则衡量模型在非适用输入上编辑前后的行为差异度。理想情况是ES高而DD低,完美编辑器应达到ES为1且DD为0。
For question-answering and fact-checking tasks, we define ES as simply the average exact-match agreement between the edited model and true labels for in-scope inputs:
对于问答和事实核查任务,我们将ES (编辑范围) 简单定义为编辑后模型与真实标签在适用输入上的平均精确匹配一致率:
$$
\mathbf{ES_{ex}}(z_{e})\triangleq\underset{x_{i n}\in I(z_{e};\mathcal{D}_ {e})}{\mathbb{E}}\mathbb{1}{f_{e}(x_{i n})=y_{i n}}
$$
$$
\mathbf{ES_{ex}}(z_{e})\triangleq\underset{x_{i n}\in I(z_{e};\mathcal{D}_ {e})}{\mathbb{E}}\mathbb{1}{f_{e}(x_{i n})=y_{i n}}
$$
where $y_{e}(x_{i n})$ is the desired label for $x_{i n}$ under the edit $z_{e}$ .
其中 $y_{e}(x_{i n})$ 是编辑 $z_{e}$ 下 $x_{i n}$ 的期望标签。
Memory-Based Model Editing at Scale
| Dataset | Model | Metric | FT | LU | MEND | ENN | RP | SERAC |
| QA | T5-large | ↑ES ↓ DD | 0.572 0.054 | 0.944 0.051 | 0.823 0.187 | 0.786 0.354 | 0.487 0.030 | 0.986 0.009 |
| QA-hard | T5-large | ↑ES | 0.321 | 0.515 | 0.478 | 0.509 | 0.278 | 0.913 |
| FC | BERT-base | ← DD | 0.109 | 0.132 | 0.255 | 0.453 | 0.027 | 0.028 |
| ↑ES | 0.601 | 0.565 | 0.598 | 0.594 | 0.627 | 0.877 | ||
| ← DD | 0.002 | 0.01 | 0.021 | 0.042 | 0.01 | 0.051 | ||
| ConvSent | BB-90M | ↑ES | 0.494 | 0.502 | 0.506 | 0.991 | ||
| ← DD | 一 | 2.149 | 3.546 | 0 | 0 |
大规模基于记忆的模型编辑
| 数据集 | 模型 | 指标 | FT | LU | MEND | ENN | RP | SERAC |
|---|---|---|---|---|---|---|---|---|
| QA | T5-large | ↑ES ↓ DD | 0.572 0.054 | 0.944 0.051 | 0.823 0.187 | 0.786 0.354 | 0.487 0.030 | 0.986 0.009 |
| QA-hard | T5-large | ↑ES | 0.321 | 0.515 | 0.478 | 0.509 | 0.278 | 0.913 |
| FC | BERT-base | ← DD | 0.109 | 0.132 | 0.255 | 0.453 | 0.027 | 0.028 |
| ↑ES | 0.601 | 0.565 | 0.598 | 0.594 | 0.627 | 0.877 | ||
| ← DD | 0.002 | 0.01 | 0.021 | 0.042 | 0.01 | 0.051 | ||
| ConvSent | BB-90M | ↑ES | 0.494 | 0.502 | 0.506 | 0.991 | ||
| ← DD | — | 2.149 | 3.546 | 0 | 0 |
Table 3. Evaluating model editors across editing problems. All problems apply $k=10$ simultaneous model edits. ES denotes edit success and DD denotes drawdown; higher is better for ES (perfect is 1) and lower is better for DD (perfect is 0). Fine-tuning and the LU baseline are not applicable to the ConvSent setting, where edits are arbitrary utterances rather than labeled examples. BB-90M refers to BlenderBot-90M. Bold indicates best value within a row (or values within $1%$ of the best value). Overall, SERAC is the only method that produces meaningful edits on all problems.
表 3: 跨编辑问题评估模型编辑器。所有问题均应用 $k=10$ 次同步模型编辑。ES表示编辑成功率,DD表示回撤率;ES越高越好(完美值为1),DD越低越好(完美值为0)。微调和LU基线不适用于ConvSent场景(该场景的编辑对象是任意语句而非标注样本)。BB-90M指BlenderBot-90M。加粗显示每行最优值(或与最优值相差 $1%$ 以内的数值)。总体而言,SERAC是唯一能在所有问题上产生有效编辑的方法。
We define drawdown similarly as
我们类似地将回撤定义为
$$
\mathbf{D}\mathbf{D}_ {\mathbf{ex}}(z_{e},O)\triangleq\underset{x_{o u t}\in O(z_{e};\mathcal{D}_ {e})}{\mathbb{E}}\mathbb{1}{f_{e}(x_{o u t})\neq f_{b a s e}(x_{o u t})}
$$
$$
\mathbf{D}\mathbf{D}_ {\mathbf{ex}}(z_{e},O)\triangleq\underset{x_{o u t}\in O(z_{e};\mathcal{D}_ {e})}{\mathbb{E}}\mathbb{1}{f_{e}(x_{o u t})\neq f_{b a s e}(x_{o u t})}
$$
Recent work suggests that choosing $O$ to simply be all out-of-scope inputs computes an easier form of drawdown, while restricting $O$ to hard out-of-scope inputs for $z_{e}$ is a more challenging criterion (Hase et al., 2021).
近期研究表明,将$O$简单定义为所有范围外输入时计算的是较简单的回撤形式,而将$O$限制为针对$z_{e}$的困难范围外输入时则构成更具挑战性的评估标准 (Hase et al., 2021)。
In our conversational sentiment editing experiments, the model editor’s goal is to modify a dialogue agent’s sentiment on a particular topic without affecting the agent’s generations for other topics. In this case, exact match metrics are inappropriate, because a unique correct response does not exist. Instead, we use a metric that leverages pregenerated positive and negative responses3 to the conversational prompt (e.g., WHAT DO YOU THINK OF SPIDERMAN?) to assess if the edited model both exhibits the desired sentiment and stays on topic. We measure sentiment accuracy with the rescaled likelihood ratio $\mathbf{z_{sent}}\triangleq\sigma(l_{e}^{+}-l_{e}^{-})$ where $l^{+}$ and $l^{-}$ are the average per-token log likelihood of the edited model on pre-generated on-topic responses with the correct sentiment (either all positive or all negative) and incorrect sentiment, respectively, and $\sigma$ is the sigmoid function. We measure topical consistency with $\mathbf{z_{topic}}\triangleq\operatorname*{min}\left(1,\exp(l_{e}^{+}-l_{b a s e}^{+})\right)$ , where $l_{b a s e}^{+}$ is the av- erage per-token log likelihood of the base model on pregenerated on-topic responses with the correct sentiment.
在我们的对话情感编辑实验中,模型编辑器的目标是在不影响智能体对其他话题生成内容的前提下,修改对话智能体对特定话题的情感倾向。这种情况下,精确匹配指标并不适用,因为并不存在唯一正确的响应。为此,我们采用了一种利用预生成正负向响应[3]的评估指标(例如针对"你对蜘蛛侠有何看法?"这类对话提示),以判断编辑后的模型是否既表现出目标情感又保持话题一致性。
我们通过重缩放似然比 $\mathbf{z_{sent}}\triangleq\sigma(l_{e}^{+}-l_{e}^{-})$ 来测量情感准确性,其中 $l^{+}$ 和 $l^{-}$ 分别是编辑模型在预生成的、具有正确情感(全部正向或全部负向)和错误情感的话题相关响应上的平均每token对数似然,$\sigma$ 为sigmoid函数。话题一致性通过 $\mathbf{z_{topic}}\triangleq\operatorname*{min}\left(1,\exp(l_{e}^{+}-l_{b a s e}^{+})\right)$ 衡量,其中 $l_{b a s e}^{+}$ 是基础模型在预生成的、具有正确情感的话题相关响应上的平均每token对数似然。
Intuitively, $\mathbf{z_{sent}}$ goes to one if the edited model assigns high probability to correct sentiment responses relative to incorrect sentiment responses and goes to zero in the opposite case. $\mathbf{z_{topic}}$ is one if the edited model assigns at least as much total probability mass to on-topic completions as $f_{b a s e}$ and decays to zero otherwise. We measure edit success with the product of $\mathbf{z_{sent}}$ and $\mathbf{z_{topic}}$ :
直观上,当编辑后的模型相对于错误情感响应更倾向于为正确情感响应分配高概率时,$\mathbf{z_{sent}}$ 趋近于1,反之则趋近于0。若编辑后的模型为相关主题补全分配的总概率质量至少与 $f_{base}$ 相当,则 $\mathbf{z_{topic}}$ 为1,否则衰减至0。我们通过 $\mathbf{z_{sent}}$ 和 $\mathbf{z_{topic}}$ 的乘积来衡量编辑成功度:
$$
\mathbf{ES_{sent}}\triangleq\mathbf{z_{sent}}\cdot\mathbf{z_{topic}},
$$
$$
\mathbf{ES_{sent}}\triangleq\mathbf{z_{sent}}\cdot\mathbf{z_{topic}},
$$
which can be very roughly interpreted as ‘the likelihood that the edited model produces the desired sentiment and is ontopic for in-scope inputs.’ To measure drawdown, we simply replace the exact match term in $\mathbf{DD}_{e x}$ with KL-divergence:
可以粗略理解为"编辑后模型对范围内输入产生所需情感并保持主题一致的可能性"。为衡量性能下降,我们只需将$\mathbf{DD}_{e x}$中的精确匹配项替换为KL散度:
$$
\mathbf{D}\mathbf{D_{sent}}(z_{e},O)\triangleq\underbrace{\mathbb{E}}_ {x_{o u t}\in O(z_{e};\mathcal{D}_ {e})}\mathrm{KL}\left(p_{b a s e}\left(\cdot\vert x_{o u t}\right)\Vert p_{e}\left(\cdot\vert x_{o u t}\right)\right).
$$
$$
\mathbf{D}\mathbf{D_{sent}}(z_{e},O)\triangleq\underbrace{\mathbb{E}}_ {x_{o u t}\in O(z_{e};\mathcal{D}_ {e})}\mathrm{KL}\left(p_{b a s e}\left(\cdot\vert x_{o u t}\right)\Vert p_{e}\left(\cdot\vert x_{o u t}\right)\right).
$$
We average each metric over many examples in a held-out evaluation dataset, constructed similarly to the edit training set, for each respective editing problem.
我们对每个编辑问题对应的保留评估数据集中的多个样本计算各指标的平均值,该数据集的构建方式与编辑训练集类似。
5. Experiments
5. 实验
We study several axes of difficulty of the model editing problem, including a) overall performance, especially on hard in-scope and hard out-of-scope examples; b) capacity to apply multiple simultaneous edits; and c) ability to use explicit edit descriptors that are not input-output pairs. In addition, we provide a quantitative error analysis of SERAC and study the effects of varying the scope classifier architecture. As points of comparison, we consider gradient-based editors, including fine-tuning on the edit example (FT), editable neural networks (ENN; Sinitsin et al., 2020), model editor networks using gradient decomposition (MEND; Mitchell et al., 2021), as well as a cache+lookup baseline $\mathbf{LU^{4}}$ . We also consider a ‘retrieve-and-prompt’ ablation RP that uses a scope classifier identical to the one in SERAC to retrieve a relevant edit example from the cache if there is one, but uses the base model $f_{b a s e}$ rather than the counter factual model $h_{\psi}$ to make the final prediction. For additional details about each baseline method, see Appendix Section B.
我们研究了模型编辑问题的几个难度维度,包括:a) 整体性能,特别是在困难范围内和困难范围外的样本上;b) 同时应用多个编辑的能力;c) 使用非输入输出对的显式编辑描述符的能力。此外,我们对 SERAC 进行了定量误差分析,并研究了不同范围分类器架构的影响。作为对比点,我们考虑了基于梯度的编辑器,包括对编辑样本进行微调 (FT)、可编辑神经网络 (ENN; Sinitsin et al., 2020)、使用梯度分解的模型编辑网络 (MEND; Mitchell et al., 2021),以及缓存+查找基线 $\mathbf{LU^{4}}$。我们还考虑了一种"检索并提示"消融实验 RP,它使用与 SERAC 中相同的范围分类器从缓存中检索相关编辑样本(如果有的话),但使用基础模型 $f_{b a s e}$ 而非反事实模型 $h_{\psi}$ 来做出最终预测。有关每个基线方法的更多细节,请参阅附录 B 部分。
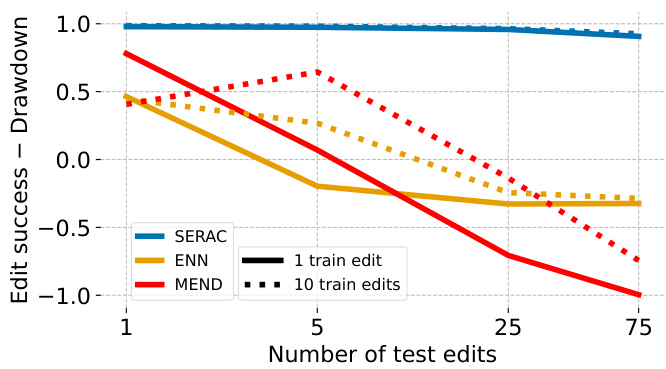
Figure 3. Batched QA edits for T5-Large, plotting ES - DD for editors trained on batches of $k\in{1,10}$ edits and evaluated on batches of $k\in{1,5,25,75}$ edits. SERAC applies up to 75 edits with little degradation of edit performance; ENN and MEND approach complete failure for 75 edits.
图 3: T5-Large 的批量问答编辑结果,展示在不同训练批量 $k\in{1,10}$ 和评估批量 $k\in{1,5,25,75}$ 下的 ES - DD 指标对比。SERAC 在应用多达 75 次编辑时仍保持稳定的编辑性能,而 ENN 和 MEND 在 75 次编辑时接近完全失效。
5.1. Model Editing Benchmarking
5.1. 模型编辑基准测试
Evaluating editors on challenging tasks. We perform a broad comparison of model editors in four editing settings, QA, QA-hard, FC, and ConvSent. For QA, QA-hard, and FC we use $k=10$ edits during training and evaluation; for ConvSent, we use $k=5$ because the longer dialogue sequences cause increased memory usage. Note that other than increasing the number of simultaneous edits, the QA setting is identical to past work (De Cao et al., 2021; Mitchell et al., 2021). The LU and FT baselines are not applicable to ConvSent as there is no label to cache or fine-tune on. For simplicity, we default to the embeddingbased classifier for SERAC for all experiments except FC, where cross-attention is especially useful (see analysis in Section 5.2).
在挑战性任务上评估编辑器。我们对模型编辑器在四种编辑场景(QA、QA-hard、FC和ConvSent)中进行了广泛比较。对于QA、QA-hard和FC任务,训练和评估时使用$k=10$次编辑;而ConvSent由于较长的对话序列会导致内存占用增加,因此使用$k=5$次编辑。需注意,除了增加同步编辑次数外,QA场景的设置与之前工作 (De Cao et al., 2021; Mitchell et al., 2021) 完全相同。LU和FT基线不适用于ConvSent,因为该场景没有可供缓存或微调的标签。为简化流程,除FC任务外(交叉注意力机制在该场景特别有效,详见第5.2节分析),所有实验中SERAC默认采用基于嵌入的分类器。
The results are presented in Table 3. Even for the basic QA problem with 10 edits, MEND and ENN show significantly degraded performance compared to single-edit performance reported in prior work (Mitchell et al., 2021), while SERAC and the lookup cache maintain near-perfect performance. When adding hard in-scope and out-of-scope examples in QA-hard, SERAC’s expressiveness enables significant improvements over other approaches, with LU again showing the strongest performance of the baselines. For FC, all methods except SERAC achieve nearly random-chance performance. Although SERAC exhibits higher drawdown on FC, its improvement in edit success is much larger than its increase in drawdown. Finally, on the ConvSent edit
结果如表 3 所示。即使在包含 10 次编辑的基础 QA (问答) 任务中,MEND 和 ENN 的性能相比先前工作 (Mitchell et al., 2021) 报告的单次编辑性能显著下降,而 SERAC 和查找缓存 (lookup cache) 仍保持接近完美的表现。当在 QA-hard 任务中添加困难范围内和范围外样本时,SERAC 的表达能力使其显著优于其他方法,其中 LU 再次展现出基线方法中最强的性能。对于 FC (事实核对) 任务,除 SERAC 外所有方法都仅达到接近随机猜测的水平。虽然 SERAC 在 FC 任务上表现出更高的性能回撤 (drawdown),但其编辑成功率的提升幅度远大于回撤增幅。最后在 ConvSent (对话情感) 编辑任务中...
| QA-hard (T5-large) | FC (BERT-base) | |||
| Cls acc. | h acc. | Cls acc. | hp acc. | |
| In (easy) | 0.985 | 0.996 | ||
| In (hard) | 0.855 | 0.987 | 0.909 | 0.875 |
| Out(easy) | 0.996 | 0.123 | 0.993 | |
| Out (hard) | 0.967 | 0.042 | 0.706 | 一 |
| QA-hard (T5-large) | FC (BERT-base) | |||
|---|---|---|---|---|
| Cls acc. | h acc. | Cls acc. | hp acc. | |
| In (easy) | 0.985 | 0.996 | ||
| In (hard) | 0.855 | 0.987 | 0.909 | 0.875 |
| Out(easy) | 0.996 | 0.123 | 0.993 | |
| Out (hard) | 0.967 | 0.042 | 0.706 | — |
Table 4. Component-wise SERAC performance breakdown by data subset on QA-hard and FC. On both datasets, hard examples account for the vast majority of classifier errors. FC classifier performance on hard out-of-scope examples is the bottleneck for improving editor precision. FC does not annotate easy/hard inscope examples (so they are pooled) or labels for out-of-scope examples (so $h_{\psi}$ accuracy for out-of-scope examples is omitted).
表 4: SERAC 在 QA-hard 和 FC 数据集上按数据子集的组件性能细分。在这两个数据集中,困难样本占分类器错误的大部分。FC 分类器在困难超出范围样本上的表现是提升编辑器精度的瓶颈。FC 未标注简单/困难范围内样本 (因此合并统计) 或超出范围样本的标签 (故超出范围样本的 $h_{\psi}$ 准确率未列出)。
ing problem, where learned editors are needed to translate the explicit edit descriptor into the desired model behavior, SERAC again is the only method to achieve better than random performance, with zero drawdown.
在需要将显式编辑描述符转化为期望模型行为的学习编辑器问题上,SERAC再次成为唯一表现优于随机且零衰减的方法。
Making many edits. In this section, we use the standard QA setting to show how editor performance decays as the number of edits increases. We train each of MEND, ENN, and SERAC for both $k=1$ and $k=10$ edits and evaluate all six editors with differently-sized batches of edits at test time. Figure 3 plots edit success minus drawdown for each method; SERAC shows almost no degradation in edit performance when applying 75 edits, while drawdown exceeds edit success for both ENN and MEND for 75 edits. Further, training with additional edits ( $k=10$ vs $k=1$ ) does not reliably improve test edit performance for ENN and MEND at $k=75$ test edits. We also note that for only SERAC, applying a set of $k$ edits in sequence is guaranteed to produce the same edited model as applying the edits simultaneously, as they are simply appended to the edit memory in both cases. Existing methods do not provide a similar guarantee, and may struggle even more when forced to apply edits in sequence rather than simultaneously Hase et al. (2021).
进行多次编辑。本节我们采用标准问答设置,展示编辑性能如何随着编辑次数增加而衰减。我们分别针对 $k=1$ 和 $k=10$ 次编辑训练了MEND、ENN和SERAC,并在测试时用不同规模的编辑批次评估这六种编辑器。图3展示了各方法的编辑成功率减去性能衰减值:SERAC在应用75次编辑时几乎未出现性能下降,而ENN和MEND在75次编辑时性能衰减已超过编辑成功率。此外,增加训练编辑次数( $k=10$ 对比 $k=1$ )并未显著提升ENN和MEND在 $k=75$ 次测试编辑时的表现。值得注意的是,仅SERAC能保证顺序应用 $k$ 次编辑与同时应用这些编辑产生相同的模型结果,因为两种情况下编辑内容都会被简单追加到编辑记忆库中。现有方法无法提供类似保证,且在强制顺序编辑而非同时编辑时可能表现更差 (Hase et al., 2021)。
5.2. Further Empirical Analysis of SERAC
5.2 SERAC 的进一步实证分析
Error analysis. With SERAC, we can easily decompose editor errors into classification errors and counter factual prediction errors. Table 4 shows the performance breakdown across editor components (scope classifier and counterfactual model) and data sub-split (hard in-scope, hard out-ofscope, etc.). For QA-hard, the classifier exhibits reduced accuracy on hard in-scope and out-of-scope examples, particularly for hard in-scope examples. Counter factual model performance is only slightly degraded on hard in-scope examples, suggesting that the primary challenge of the problem is scope estimation, rather than counter factual reasoning. For out-of-scope examples, counter factual model performance is low, but high classifier accuracy means that these inputs are typically (correctly) routed to the base model instead. For FC, scope classifier failures on hard out-of-scope examples dominate the editor’s errors.
错误分析。通过SERAC,我们可以轻松将编辑器错误分解为分类错误和反事实预测错误。表4展示了编辑器各组件(范围分类器和反事实模型)及数据子集(困难范围内、困难范围外等)的性能细分。对于QA-hard任务,分类器在困难范围内和范围外样本上的准确率有所下降,尤其是困难范围内样本。反事实模型在困难范围内样本上的性能仅轻微下降,表明该问题的主要挑战在于范围估计而非反事实推理。对于范围外样本,反事实模型性能较低,但分类器的高准确率意味着这些输入通常会被(正确地)路由到基础模型。对于FC任务,范围分类器在困难范围外样本上的失败是编辑器错误的主要来源。
Table 5. Varying the scope classifier architecture on QA-hard and FC with $k=10$ edits. Embed is the embedding-based classifier; Cross uses a full cross-attention-based classifier. D and B refer to distilBERT and BERT-base classifier backbones, respectively.
| Variant | QA-hard (T5-large) | FC (BERT-base) | ||
| ES↑ | DD√ | ES↑ | DD√ | |
| Embed-D | 0.921 | 0.029 | 0.792 | 0.247 |
| Cross-D | 0.983 | 0.009 | 0.831 | 0.074 |
| Embed-B | 0.945 | 0.034 | 0.792 | 0.247 |
| Cross-B | 0.983 | 0.007 | 0.855 | 0.0964 |
表 5: 在 QA-hard 和 FC 上使用 $k=10$ 编辑时不同范围分类器架构的对比。Embed 是基于嵌入的分类器;Cross 使用基于完整交叉注意力的分类器。D 和 B 分别指代 distilBERT 和 BERT-base 分类器骨干。
| 变体 | QA-hard (T5-large) | FC (BERT-base) | ||
|---|---|---|---|---|
| ES↑ | DD√ | ES↑ | DD√ | |
| Embed-D | 0.921 | 0.029 | 0.792 | 0.247 |
| Cross-D | 0.983 | 0.009 | 0.831 | 0.074 |
| Embed-B | 0.945 | 0.034 | 0.792 | 0.247 |
| Cross-B | 0.983 | 0.007 | 0.855 | 0.0964 |
Scope classifier architecture. We perform a set of experiments to understand how the classifier architecture impacts the behavior of SERAC. Using the QA-hard and FC tasks with $k=10$ edits, we compare the cross-attention (Cross) and dense embedding (Embed) classifier using both distilBERT $\mathbf{D}$ ; (Sanh et al., 2019)) and BERT-base (B; (Devlin et al., 2019)) as the backbone model. The results are shown in Table 5. Un surprisingly, using cross-attention instead of dense-embeddings is helpful for editor performance; however, increasing classifier size shows relatively little improvement. Cross-attention is especially useful for the FC experiment, which is possibly due to the commonness of quantities in the VitaminC dataset; for example, producing fixed-length sequence embeddings that reliably capture the difference between THERE HAVE BEEN 105,000 CORONAVIRUS DEATHS IN THE UNITED STATES and THERE HAVE BEEN 111,000 CORONAVIRUS DEATHS IN THE UNITED STATES may be very difficult. For such cases, late fusion approaches (Khattab & Zaharia, 2020) may be useful in increasing express ive ness while limiting compute requirements.
范围分类器架构。我们进行了一系列实验以了解分类器架构如何影响SERAC的行为。在QA-hard和FC任务中使用$k=10$次编辑时,我们比较了采用distilBERT $\mathbf{D}$ (Sanh等人,2019)和BERT-base (B; Devlin等人,2019)作为骨干模型的交叉注意力(Cross)与稠密嵌入(Embed)分类器。结果如表5所示。不出所料,使用交叉注意力而非稠密嵌入有助于提升编辑器性能;然而,增大分类器规模带来的改进相对有限。交叉注意力在FC实验中尤其有效,这可能源于VitaminC数据集中数字的普遍性——例如,要生成能可靠区分"美国已有105,000例冠状病毒死亡"和"美国已有111,000例冠状病毒死亡"的定长序列嵌入可能非常困难。针对此类情况,延迟融合方法(Khattab & Zaharia, 2020)或许能在限制计算需求的同时提升表达能力。
Re-using model editors across models. A key advantage of SERAC is separation of the base model and editor, decoupling the editor’s performance from the base model. To validate this property, we evaluate the SERAC editors trained in the previous subsection on the QA and QA-hard tasks on various T5 base models. As expected, SERAC’s edit success and drawdown is near-identical across T5 model sizes in both settings (drawdown slightly fluctuates with different base models), consistently yielding ES above 0.99 and DD below 0.01 for $\mathrm{QA}^{5}$ and ES above 0.92, DD below 0.03 for QA-hard for all models. Editors described in past works must be re-fit to each new base model (Sinitsin et al., 2020;
跨模型复用模型编辑器。SERAC的关键优势在于基础模型与编辑器的分离,使编辑器性能与基础模型解耦。为验证这一特性,我们在不同规模的T5基础模型上评估了上一小节训练的SERAC编辑器在QA和QA-hard任务中的表现。如预期所示,两种场景下SERAC的编辑成功率(ES)和性能下降(DD)在不同规模T5模型间基本一致(性能下降随基础模型不同略有波动),所有模型在$\mathrm{QA}^{5}$任务中均保持ES>0.99且DD<0.01,在QA-hard任务中保持ES>0.92且DD<0.03。以往工作中描述的编辑器必须针对每个新基础模型重新适配 (Sinitsin et al., 2020;
| Task | Base model | SERAC (out) | SERAC (in) |
| QA | 87ms 2.96GB | 92ms 3.47GB | 31ms 3.46GB |
| FC | 7ms 0.44GB | 19ms 1.18GB | 19ms 1.18GB |
| CS | 182ms 0.38GB | 183ms 1.00GB | 185ms 1.01GB |
| 任务 | 基础模型 | SERAC (外) | SERAC (内) |
|---|---|---|---|
| QA | 87ms 2.96GB | 92ms 3.47GB | 31ms 3.46GB |
| FC | 7ms 0.44GB | 19ms 1.18GB | 19ms 1.18GB |
| CS | 182ms 0.38GB | 183ms 1.00GB | 185ms 1.01GB |
Table 6. Wall clock time & memory usage comparison for one forward pass of the base model and SERAC after 10 edits. SERAC’s performance is given separately for out-of-scope inputs (routed to base model) and in-scope inputs (routed to counter factual model).
表 6: 基础模型和 SERAC 在 10 次编辑后单次前向传播的挂钟时间及内存使用对比。SERAC 的性能分别针对范围外输入 (路由至基础模型) 和范围内输入 (路由至反事实模型) 给出。
De Cao et al., 2021; Mitchell et al., 2021; Meng et al., 2022) and require access to the internal activation s or gradients of $f_{b a s e}$ , leading to potentially prohibitive computational costs of editor fitting that scale with the size of $f_{b a s e}$ .
De Cao等人, 2021; Mitchell等人, 2021; Meng等人, 2022) 并且需要访问 $f_{base}$ 的内部激活或梯度,这可能导致编辑器拟合的计算成本过高,其规模与 $f_{base}$ 的大小相关。
Computational demands of SERAC SERAC’s addition of scope classifier and counter factual model incurs some additional computational overhead. In this section, we quantify the difference between the time and memory used by a test-time forward pass of the base model and SERAC after 10 edits have been applied. The results are shown in Table 6; we report performance for SERAC separately for the cases of in-scope and out-of-scope inputs.
SERAC的计算需求
SERAC增加的领域分类器和反事实模型会带来一些额外的计算开销。本节量化了应用10次编辑后,基础模型与SERAC在测试阶段前向传播所消耗的时间和内存差异。结果如表6所示,我们分别报告了SERAC在处理领域内和领域外输入时的性能表现。
Compute time. For QA and ConvSent (CS), SERAC uses a fast nearest-neighbor-based classifier and is nearly as fast as the base model. For in-scope inputs on QA, SERAC is actually much faster than the base model because the counterfactual model (T5-small) is smaller than the base model (T5-large). For FC, SERAC’s increase in computation time is due to the more expressive (but more computationally expensive) full cross-attention classifier used for this problem. By leveraging this additional compute, SERAC is the only method that provides any significant improvement over random chance editing performance for the FC problem.
计算时间。对于QA和ConvSent (CS)任务,SERAC采用基于快速最近邻的分类器,其速度几乎与基础模型相当。在处理QA任务范围内的输入时,SERAC实际上比基础模型快得多,因为反事实模型(T5-small)比基础模型(T5-large)更小。对于FC任务,SERAC计算时间的增加源于该问题采用了表达能力更强(但计算成本更高)的完全交叉注意力分类器。通过利用这种额外计算,SERAC成为唯一能在FC任务上显著超越随机机会编辑性能的方法。
Memory consumption. SERAC’s additional memory usage mostly comes from the weights of the classifier and counterfactual model, not the edit memory itself (which uses only about 3KB per edit, many orders of magnitude smaller than the base model). For QA, where the base model (T5-large) is much larger than the counter factual model (T5-small) and classifier (distilBERT), this increase is relatively small. For FC and CS, the counter factual model and classifier are of similar size to the base model, yielding a larger increase in memory consumption. However, the vast majority of this increase in memory usage is a fixed cost that does not increase with the number of edits.
内存消耗。SERAC的额外内存使用主要来自分类器和反事实模型的权重,而非编辑内存本身(每次编辑仅占用约3KB,比基础模型小多个数量级)。对于问答任务(QA),基础模型(T5-large)远大于反事实模型(T5-small)和分类器(distilBERT),内存增幅相对较小。在事实核对(FC)和常识推理(CS)任务中,反事实模型和分类器与基础模型尺寸相当,导致内存消耗显著增加。但绝大部分内存增长属于固定成本,不会随编辑次数增加而上升。
6. Related Work
6. 相关工作
Model editing. Many approaches have recently been proposed for model editing. Simplest among these uses constrained fine-tuning to update parameters based on new examples (Sotoudeh & Thakur, 2019; Zhu et al., 2020). Other methods explore special pre-training objectives that enable rapid and targeted fine-tuning for model edits (Sinitsin et al., 2020) via meta-learning. More recently, new classes of methods develop external learned editors that modify finetuning gradients for editing, but do not change the base model that must process edits (De Cao et al., 2021; Mitchell et al., 2021; Hase et al., 2021). Finally, certain methods attribute knowledge to particular neurons in the network and manually edit these activation to reflect changed content (Dai et al., 2021; Meng et al., 2022). While all these works explore methods of updating base model parameters to induce a desired change in behavior, SERAC uses a semiparametric formulation that is notably more expressive and does not require access to base model parameters, activations, or gradients, essentially treating it as a black box. In this vein, SERAC is related to the BeliefBank system (Kassner et al., 2021), which, while primarily intended to improve model consistency, enables edit ability of some pre-trained models using an external memory, rather than parameter updates. However, it is limited to models performing binary classification of factual statements and requires manuallyannotated constraints between facts. SERAC requires no such specialized augmentations to the input data.
模型编辑。近期提出了多种模型编辑方法。其中最简方法基于新样本通过约束微调更新参数 (Sotoudeh & Thakur, 2019; Zhu et al., 2020)。其他方法探索特殊预训练目标,通过元学习实现快速定向微调编辑 (Sinitsin et al., 2020)。最新研究开发了外部学习编辑器,修改微调梯度但不改变基础模型 (De Cao et al., 2021; Mitchell et al., 2021; Hase et al., 2021)。另有方法将知识定位到特定神经元并手动编辑激活值 (Dai et al., 2021; Meng et al., 2022)。这些工作都通过更新基础模型参数来改变行为,而SERAC采用半参数化方案,表达能力更强且无需访问模型参数/激活/梯度,将其视为黑盒。类似地,BeliefBank系统 (Kassner et al., 2021) 通过外部存储器而非参数更新实现编辑,但仅适用于事实二元分类且需人工标注约束。SERAC无需此类数据特殊处理。
Memory-augmented models. Memory mechanisms have historically been combined with neural networks in a variety of contexts including supervised learning (Hochreiter & Schmidhuber, 1997; Graves et al., 2008; 2014), meta- learning (Santoro et al., 2016; Shan et al., 2020), and rein for cement learning (Oh et al., 2016; Pritzel et al., 2017). Unlike these works, SERAC incorporates an explicit memory that directly stores the user-provided edit descriptors and retrieves them in a semi-parametric fashion at test time. Non-parametric few-shot learning models (Koch et al., 2015; Vinyals et al., 2016; Snell et al., 2017) also store small datasets and process the examples when making predictions at test time. Another recent line of work augments transformers with non-parametric memories that store textual snippets (Chen et al., 2017; Lee et al., 2019; Khandelwal et al., 2020; Karpukhin et al., 2020). Unlike both of these research threads, we focus specifically on the problem of learning to edit existing models, rather than few-shot learning or training retrieval-based models from scratch. Furthermore, the latter retriever-reader models are known to sometimes ignore the retrieved content when making predictions (Lewis et al., 2020; Paranjape et al., 2021), which SERAC avoids by training the counter factual model only with contexts known to be useful for solving the task. Finally, some continual learning algorithms have used external memories to avoid forgetting (Lopez-Paz & Ranzato, 2017; Rolnick et al., 2019; Buzzega et al., 2020).
记忆增强模型。历史上,记忆机制已与神经网络在多种场景中结合,包括监督学习 (Hochreiter & Schmidhuber, 1997; Graves et al., 2008; 2014)、元学习 (Santoro et al., 2016; Shan et al., 2020) 和强化学习 (Oh et al., 2016; Pritzel et al., 2017)。与这些工作不同,SERAC采用显式记忆直接存储用户提供的编辑描述符,并在测试时以半参数化方式检索它们。非参数少样本学习模型 (Koch et al., 2015; Vinyals et al., 2016; Snell et al., 2017) 同样存储小型数据集,并在测试时预测过程中处理样本。另一项近期研究通过存储文本片段的非参数化记忆增强Transformer (Chen et al., 2017; Lee et al., 2019; Khandelwal et al., 2020; Karpukhin et al., 2020)。与这两类研究方向不同,我们专注于学习编辑现有模型的问题,而非少样本学习或从头训练基于检索的模型。此外,后者的检索-阅读器模型在预测时可能忽略检索内容 (Lewis et al., 2020; Paranjape et al., 2021),而SERAC通过仅使用已知对任务解决有用的上下文训练反事实模型来避免该问题。最后,部分持续学习算法采用外部记忆防止遗忘 (Lopez-Paz & Ranzato, 2017; Rolnick et al., 2019; Buzzega et al., 2020)。
7. Discussion
7. 讨论
We have proposed SERAC, a semi-parametric model editor that stores model edits in an external memory rather than directly in model parameters. Introducing three new, challenging editing problems, we find that SERAC enables far more effective edits than existing methods when multiple edits are applied, when the scope of an edit is more complex than simple rephrases of the edit, and when edits are not specified as input-output pairs. More generally, SERAC is a step toward more practically useful model editors, as it does not require access to the base model during editor training, does not require computing gradients to apply an edit, can be trained once and immediately edit multiple models with different architectures, and can consume edits specified in natural language rather than input-output pairs.
我们提出了SERAC,一种半参数化模型编辑器,它将模型编辑存储于外部记忆而非直接修改模型参数。通过引入三个具有挑战性的新编辑任务,我们发现:当应用多重编辑时、当编辑范围超出简单改写时、当编辑不以输入-输出对形式指定时,SERAC的编辑效果远超现有方法。更广泛而言,SERAC向实用化模型编辑器迈进了一步,其具备以下特性:编辑器训练时无需访问基础模型、应用编辑时无需计算梯度、可一次性训练后立即编辑不同架构的多个模型、能处理自然语言描述的编辑指令而非限定输入-输出对。
Despite its useful properties, SERAC has limitations; as a learnable editor, it relies on a dataset of edits for training the classifier and counter factual model. Further, while we find relatively good performance from small class if i ers and counter factual models, some settings may demand more resource-intensive architectures. In a setting where editing occurs continuously, the edit memory may grow without bound. Future work might address this problem through periodic self-distillation, using the aggregate system of base model, scope classifier, edit memory, and counter factual model as a teacher model to a ‘student’ copy of the base model. Such a method would essentially enable the size of the edit memory to be capped, even in the continual editing setting, through periodic flushing of the memory.
尽管SERAC具备实用特性,但仍存在局限:作为可学习的编辑器,它依赖编辑数据集来训练分类器和反事实模型。此外,虽然我们发现小型分类器和反事实模型表现较好,但某些场景可能需要更耗资源的架构。在持续编辑的场景中,编辑记忆可能无限增长。未来工作可通过周期性自蒸馏解决该问题——将基础模型、范围分类器、编辑记忆和反事实模型的聚合系统作为"学生版"基础模型的教师模型。这种方法能在持续编辑环境下通过定期清空记忆,从根本上限制编辑记忆的规模。
One possible concern with model editors, including SERAC is misuse: while model editors may help keep deep learning systems more up-to-date in a computationally efficient manner, the dialogue sentiment editing setting (Tables 2; 7) suggest that powerful model editors could also enable malicious users to more precisely craft agents to amplify particular viewpoints. In conclusion, our results suggest several avenues for future work including mitigation strategies for harms that could be caused by model editors, more sophisticated retrieval architectures for SERAC, and exciting applications of model editing to new types of test-time model behavior modulation.
包括SERAC在内的模型编辑器可能存在滥用隐患:虽然这类工具能以高效计算的方式帮助深度学习系统保持更新,但对话情感编辑实验(表2;表7)表明,强大的模型编辑器也可能被恶意用户用来更精准地操控AI智能体,从而放大特定观点。我们的研究结果指出了多个未来研究方向,包括针对模型编辑器潜在危害的缓解策略、为SERAC开发更复杂的检索架构,以及将模型编辑技术拓展应用于新型测试阶段行为调控的广阔前景。
8. Acknowledgements
8. 致谢
The authors thank Shikhar Murty, Archit Sharma, and the members of Stanford’s Center for Research on Foundation Models for helpful discussions and conceptual feedback, as well as the anonymous ICML reviewers for their feedback during the review process. EM gratefully acknowledges the financial support of the Knight-Hennessy Graduate Fellowship. The authors also gratefully acknowledge financial support from Apple Inc. CF and CM are CIFAR Fellows.
作者感谢Shikhar Murty、Archit Sharma以及斯坦福基础模型研究中心的成员们提供的宝贵讨论与概念反馈,同时感谢ICML匿名评审在审稿过程中提出的意见。EM衷心感谢Knight-Hennessy研究生奖学金的经济支持。作者们也对Apple Inc.的资助表示诚挚感谢。CF与CM是CIFAR研究员。
References
参考文献
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neel a kant an, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. Language models are few-shot learners. Neural Information Processing Systems, 2020.
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., and Amodei, D. 语言模型是少样本学习者。神经信息处理系统, 2020。
Buzzega, P., Boschini, M., Porrello, A., Abati, D., and Calderara, S. Dark experience for general continual learning: a strong, simple baseline. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 15920–15930. Curran Associates, Inc., 2020.
Buzzega, P., Boschini, M., Porrello, A., Abati, D., and Calderara, S. 通用持续学习的暗经验:一个强大而简单的基线。见 Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H. (编), 《神经信息处理系统进展》, 第33卷, 第15920–15930页. Curran Associates公司, 2020.
Chen, D., Fisch, A., Weston, J., and Bordes, A. Reading wikipedia to answer open-domain questions. In ACL, 2017.
Chen, D., Fisch, A., Weston, J., and Bordes, A. 通过阅读维基百科回答开放域问题。发表于ACL, 2017。
Csordas, R., van Steenkiste, S., and Schmid huber, J. Are neural nets modular? Inspecting functional modularity through differentiable weight masks. In Inter national Conference on Learning Representations, 2021. URL https://openreview.net/forum? id=7uVcpu-gMD.
Csordas, R., van Steenkiste, S., and Schmidhuber, J. 神经网络是否模块化?通过可微分权重掩码检验功能模块化。In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=7uVcpu-gMD.
Dai, D., Dong, L., Hao, Y., Sui, Z., and Wei, F. Knowledge neurons in pretrained transformers. CoRR, abs/2104.08696, 2021. URL https://arxiv.org/ abs/2104.08696.
戴东、董力、郝煜、隋振华、魏峰。《预训练Transformer中的知识神经元》。CoRR,abs/2104.08696,2021。URL https://arxiv.org/abs/2104.08696。
De Cao, N., Aziz, W., and Titov, I. Editing factual knowledge in language models. ArXiv, abs/2104.08164, 2021.
De Cao, N., Aziz, W., 和 Titov, I. 编辑语言模型中的事实知识. ArXiv, abs/2104.08164, 2021.
Demszky, D., Guu, K., and Liang, P. Transforming question answering datasets into natural language inference datasets. CoRR, abs/1809.02922, 2018. URL http: //arxiv.org/abs/1809.02922.
Demszky, D., Guu, K., and Liang, P. 将问答数据集转化为自然语言推理数据集。CoRR, abs/1809.02922, 2018. URL http://arxiv.org/abs/1809.02922.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. doi: 10.18653/ v1/N19-1423. URL https://www.aclweb.org/ anthology/N19-1423.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. BERT: 面向语言理解的深度双向Transformer预训练。载于《2019年北美计算语言学协会会议论文集:人类语言技术》(长篇与短篇论文),第1卷,第4171–4186页,明尼苏达州明尼阿波利斯市,2019年6月。计算语言学协会。doi: 10.18653/v1/N19-1423。URL https://www.aclweb.org/anthology/N19-1423。
Graves, A., Liwicki, M., Fernandez, S., Bertolami, R., Bunke, H., and Schmid huber, J. A novel connection is t system for un constrained handwriting recognition. IEEE transactions on pattern analysis and machine intelligence, 31(5):855–868, 2008.
Graves, A., Liwicki, M., Fernandez, S., Bertolami, R., Bunke, H., and Schmidhuber, J. 一种用于无约束手写体识别的新型连接主义系统。IEEE模式分析与机器智能汇刊, 31(5):855–868, 2008.
Graves, A., Wayne, G., and Danihelka, I. Neural turing machines, 2014. URL http://arxiv.org/abs/ 1410.5401. arxiv:1410.5401.
Graves, A., Wayne, G., and Danihelka, I. 神经图灵机 (Neural Turing Machines), 2014. URL http://arxiv.org/abs/1410.5401. arxiv:1410.5401.
Hase, P., Diab, M., Cel i kyi l maz, A., Li, X., Kozareva, Z., Stoyanov, V., Bansal, M., and Iyer, S. Do language models have beliefs? Methods for detecting, updating, and visualizing model beliefs, 2021. arxiv:2111.13654.
Hase, P., Diab, M., Cel i kyi l maz, A., Li, X., Kozareva, Z., Stoyanov, V., Bansal, M., and Iyer, S. 语言模型是否具有信念?检测、更新和可视化模型信念的方法,2021. arxiv:2111.13654.
Heitmann, M., Siebert, C., Hartmann, J., and Schamp, C. More than a feeling: Benchmarks for sentiment analysis accuracy. Available at SSRN 3489963, 2020.
Heitmann, M., Siebert, C., Hartmann, J., 和 Schamp, C. 超越感觉:情感分析准确性基准。见SSRN 3489963, 2020。
Hochreiter, S. and Schmid huber, J. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
Hochreiter, S. 和 Schmidhuber, J. 长短期记忆网络。Neural computation, 9(8):1735–1780, 1997.
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6769–6781, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/ 2020.emnlp-main.550. URL https://www.aclweb. org/anthology/2020.emnlp-main.550.
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., and Yih, W.-t. 开放域问答的密集段落检索。载于《2020年自然语言处理经验方法会议论文集》(EMNLP),第6769-6781页,线上会议,2020年11月。计算语言学协会。doi: 10.18653/v1/2020.emnlp-main.550。URL https://www.aclweb.org/anthology/2020.emnlp-main.550。
Kassner, N., Tafjord, O., Schitze, H., and Clark, P. BeliefBank: Adding memory to a pre-trained language model for a systematic notion of belief. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 8849–8861, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.697. URL a cl anthology.org/2021.emnlp-main.697.
Kassner, N., Tafjord, O., Schitze, H., and Clark, P. BeliefBank: 为预训练语言模型添加记忆以实现系统化信念概念。载于《2021年自然语言处理实证方法会议论文集》,第8849–8861页,在线及多米尼加共和国蓬塔卡纳,2021年11月。计算语言学协会。doi: 10.18653/v1/2021.emnlp-main.697。URL https://aclanthology.org/2021.emnlp-main.697。
Khandelwal, U., Levy, O., Jurafsky, D., Z ett le moyer, L., and Lewis, M. Generalization through memorization: Nearest neighbor language models. In ICLR, 2020.
Khandelwal, U., Levy, O., Jurafsky, D., Zettlemoyer, L., and Lewis, M. 通过记忆实现泛化:最近邻语言模型。In ICLR, 2020.
Khattab, O. and Zaharia, M. Colbert: Efficient and effective passage search via contextual i zed late interaction over bert. In Proceedings of the 43rd Interna- tional ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 39–48, New York, NY, USA, 2020. Association for Computing Machinery. ISBN 9781450380164. URL https://doi.org/10. 1145/3397271.3401075.
Khattab, O. 和 Zaharia, M. Colbert: 基于BERT的情境化延迟交互实现高效且有效的段落搜索。见《第43届国际ACM SIGIR信息检索研究与发展会议论文集》,第39-48页,美国纽约州纽约市,2020年。计算机协会。ISBN 9781450380164。URL https://doi.org/10.1145/3397271.3401075。
Koch, G., Zemel, R., Salak hut dino v, R., et al. Siamese neural networks for one-shot image recognition. In ICML deep learning workshop, volume 2. Lille, 2015.
Koch, G., Zemel, R., Salak hut dino v, R., 等. 用于单样本图像识别的孪生神经网络. 见: ICML深度学习研讨会, 第2卷. 里尔, 2015.
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Kel- cey, M., Devlin, J., Lee, K., Toutanova, K. N., Jones, L., Chang, M.-W., Dai, A., Uszkoreit, J., Le, Q., and Petrov, S. Natural questions: a benchmark for question answering research. Transactions of the Association of Computational Linguistics, 2019.
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Kelcey, M., Devlin, J., Lee, K., Toutanova, K. N., Jones, L., Chang, M.-W., Dai, A., Uszkoreit, J., Le, Q., and Petrov, S. Natural questions: 问答研究的基准。Transactions of the Association of Computational Linguistics, 2019.
Lazaridou, A., Kuncoro, A., Gri bo vs kaya, E., Agrawal, D., Liska, A., Terzi, T., Gimenez, M., de Masson d’Autume, C., Ruder, S., Yogatama, D., Cao, K., Kocisky, T., Young, S., and Blunsom, P. Mind the gap: Assessing temporal generalization in neural language models. In NeurIPS, 2021.
Lazaridou, A., Kuncoro, A., Gri bo vs kaya, E., Agrawal, D., Liska, A., Terzi, T., Gimenez, M., de Masson d’Autume, C., Ruder, S., Yogatama, D., Cao, K., Kocisky, T., Young, S., and Blunsom, P. 填补空白:评估神经语言模型的时间泛化能力。In NeurIPS, 2021.
Lee, K., Chang, M.-W., and Toutanova, K. Latent retrieval for weakly supervised open domain question answering. In ACL, 2019.
Lee, K., Chang, M.-W., 和 Toutanova, K. 面向弱监督开放领域问答的潜在检索。In ACL, 2019.
Levy, O., Seo, M., Choi, E., and Z ett le moyer, L. Zeroshot relation extraction via reading comprehension. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), pp. 333–342, Vancouver, Canada, August 2017. Association for Computational Linguistics. doi: 10.18653/ v1/K17-1034. URL https://www.aclweb.org/ anthology/K17-1034.
Levy, O., Seo, M., Choi, E., 和 Zettlemoyer, L. 通过阅读理解实现零样本关系抽取。载于《第21届计算自然语言学习会议论文集》(CoNLL 2017), 第333–342页, 加拿大温哥华, 2017年8月。计算语言学协会。doi: 10.18653/v1/K17-1034。URL https://www.aclweb.org/anthology/K17-1034。
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Kuittler, H., Lewis, M., Yih, W.-t., Rock t as chel, T., Riedel, S., and Kiela, D. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 9459–9474. Curran Associates, Inc., 2020. URL https://proceedings. neurips.cc/paper/2020/file/ 6b493230205f780e1bc26945df7481e5-Paper pdf.
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Kuittler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., Riedel, S., and Kiela, D. 面向知识密集型NLP任务的检索增强生成。见 Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H. (编), 《神经信息处理系统进展》, 第33卷, 第9459–9474页。Curran Associates公司, 2020. 网址 https://proceedings.neurips.cc/paper/2020/file/6b493230205f780e1bc26945df7481e5-Paper.pdf。
Li, M., Roller, S., Kulikov, I., Welleck, S., Boureau, Y.-L., Cho, K., and Weston, J. Don’t say that! making inconsistent dialogue unlikely with unlikelihood training. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 4715–4728, On- line, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.428. URL https: //a cl anthology.org/2020.acl-main.428.
Li, M., Roller, S., Kulikov, I., Welleck, S., Boureau, Y.-L., Cho, K., and Weston, J. 别说那个!通过非似然训练降低对话不一致性。载于《第58届计算语言学协会年会论文集》,第4715-4728页,线上会议,2020年7月。计算语言学协会。doi: 10.18653/v1/2020.acl-main.428。URL https://aclanthology.org/2020.acl-main.428。
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Z ett le moyer, L., and Stoyanov, V. Roberta: A robustly optimized BERT pre training approach. CoRR, abs/1907.11692, 2019. URL http://arxiv.org/ abs/1907.11692.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., and Stoyanov, V. RoBERTa: 一种稳健优化的BERT预训练方法。CoRR, abs/1907.11692, 2019. URL http://arxiv.org/abs/1907.11692.
Lopez-Paz, D. and Ranzato, M. A. Gradient episodic memory for continual learning. In Guyon, I., Luxburg,
Lopez-Paz, D. 和 Ranzato, M. A. 持续学习的梯度情景记忆。见 Guyon, I., Luxburg,
Roberts, A., Raffel, C., and Shazeer, N. How much knowledge can you pack into the parameters of a language model?, 2020.
Roberts, A., Raffel, C., 和 Shazeer, N. 你能将多少知识压缩进语言模型的参数中?, 2020.
Roller, S., Dinan, E., Goyal, N., Ju, D., Williamson, M., Liu, Y., Xu, J., Ott, M., Smith, E. M., Boureau, Y.-L., and Weston, J. Recipes for building an open-domain chatbot. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pp. 300–325, Online, April 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.eacl-main.24. URL https: //a cl anthology.org/2021.eacl-main.24.
Roller, S., Dinan, E., Goyal, N., Ju, D., Williamson, M., Liu, Y., Xu, J., Ott, M., Smith, E. M., Boureau, Y.-L., and Weston, J. 构建开放领域聊天机器人的方法。载于《第16届欧洲计算语言学协会会议论文集:主卷》,第300–325页,线上会议,2021年4月。计算语言学协会。doi: 10.18653/v1/2021.eacl-main.24。URL https://aclanthology.org/2021.eacl-main.24。
Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T., and Wayne, G. Experience replay for continual learning. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings. neurips.cc/paper/2019/file/ fa 7 cd fad 1 a 5 aaf 8370 e bed a 47 a 1 ff 1 c 3-Paper pdf.
Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T., and Wayne, G. 持续学习中的经验回放。见 Wallach, H., Larochelle, H., Beygelzimer, A., d'Alché-Buc, F., Fox, E., and Garnett, R. (编), 《神经信息处理系统进展》, 第32卷. Curran Associates公司, 2019. 网址 https://proceedings.neurips.cc/paper/2019/file/fa7cdfad1a5aaf8370ebeda47a1ff1c3-Paper.pdf。
Sanh, V., Debut, L., Chaumond, J., and Wolf, T. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. ArXiv, abs/1910.01108, 2019.
Sanh, V., Debut, L., Chaumond, J., and Wolf, T. Distilbert, 一种蒸馏版BERT: 更小、更快、更经济、更轻量。ArXiv, abs/1910.01108, 2019.
Santhanam, K., Khattab, O., Saad-Falcon, J., Potts, C., and Zaharia, M. Colbertv2: Effective and efficient retrieval via lightweight late interaction. CoRR, abs/2112.01488, 2021. URL https://arxiv.org/ abs/2112.01488.
Santhanam, K., Khattab, O., Saad-Falcon, J., Potts, C., and Zaharia, M. Colbertv2: 通过轻量级延迟交互实现高效检索。CoRR, abs/2112.01488, 2021. URL https://arxiv.org/ abs/2112.01488.
Santoro, A., Bartunov, S., Botvinick, M., Wierstra, D., and Lillicrap, T. Meta-learning with memory-augmented neural networks. In Balcan, M. F. and Weinberger, K. Q. (eds.), Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pp. 1842–1850, New York, New York, USA, 20–22 Jun 2016. PMLR. URL https://proceedings.mlr.press/v48/ santoro16.html.
Santoro, A., Bartunov, S., Botvinick, M., Wierstra, D., and Lillicrap, T. 基于记忆增强神经网络的元学习。见 Balcan, M. F. 和 Weinberger, K. Q. (编), 《第33届国际机器学习会议论文集》, 机器学习研究论文集第48卷, 第1842–1850页, 美国纽约州纽约市, 2016年6月20–22日. PMLR. 网址 https://proceedings.mlr.press/v48/ santoro16.html.
Schuster, T., Fisch, A., and Barzilay, R. Get your vitamin C! robust fact verification with contrastive evidence. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 624–643, Online, June 2021. Association for Computational Linguistics. URL https://www.aclweb. org/anthology/2021.naacl-main.52.
Schuster, T., Fisch, A., and Barzilay, R. 补充你的维他命C!基于对比证据的鲁棒事实核查。载于《2021年北美计算语言学协会人类语言技术会议论文集》,第624-643页,线上会议,2021年6月。计算语言学协会。网址 https://www.aclweb.org/anthology/2021.naacl-main.52。
Shan, S., Li, Y., and Oliva, J. B. Meta-neighborhoods. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 5047–5057. Curran Associates, Inc., 2020. URL https://proceedings. neurips.cc/paper/2020/file/ 35464c848f410e55a13bb9d78e7fddd0-Paper pdf.
Shan, S., Li, Y., and Oliva, J. B. Meta-neighborhoods. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. F., and Lin, H. (eds.), 《神经信息处理系统进展》, volume 33, pp. 5047–5057. Curran Associates, Inc., 2020. URL https://proceedings.neurips.cc/paper/2020/file/35464c848f410e55a13bb9d78e7fddd0-Paper.pdf.
Appendix
附录
A. Additional Sentiment Editing Example and Broader Impacts
A. 额外情感编辑示例及更广泛影响
While the ‘banana’ example in Table 2 is a relatively mundane topic, we include an example of editing a dialog model for a more polarizing topic in some parts of the world, vaccines. Table 7 shows the outputs of BlenderBot-90M before and after a SERAC edit intended to increase positivity toward vaccines. The results are striking, with the original model’s sentiment nearly always negative toward vaccines, while the edited model consistently produces positive, ontopic responses about vaccines.
表2中的"香蕉"例子相对平淡,我们在表7中展示了一个更具争议性的话题(疫苗)的对话模型编辑案例。该表呈现了BlenderBot-90M模型在进行SERAC编辑前后的输出对比,这次编辑旨在提升对疫苗的积极态度。结果显示:原始模型对疫苗的情感倾向几乎总是负面,而编辑后的模型则持续生成积极且主题相关的疫苗讨论回复。
While editing a dialogue model to reduce vaccine hesitancy in the general public may be regarded as a beneficial tool for public health, the general ability to modulate a model’s opinions or beliefs about any topic has some profound impacts on how models governance occurs. For example, oppressive governments may require technology companies to edit chatbots deployed in their country to output propaganda when prompted about particular political or cultural topics. Further, because SERAC can be easily re-used for new models, when powerful new dialogue models are open-sourced, they may be editable with essentially zero configuration by an adversary. Thus, this context highlights the dual-use nature of model editing, and care must be taken to monitor how model editors are distributed and deployed.
在编辑对话模型以减少公众对疫苗的犹豫可能被视为公共卫生的有益工具时,调节模型对任何话题的观点或信念的通用能力,会对模型治理方式产生深远影响。例如,专制政府可能要求科技公司编辑在其国内部署的聊天机器人,使其在涉及特定政治或文化话题时输出宣传内容。此外,由于SERAC可以轻松复用于新模型,当强大的新对话模型开源时,对手可能几乎无需配置即可对其进行编辑。因此,这一背景凸显了模型编辑的双重用途性质,必须谨慎监控模型编辑器的分发和部署方式。
B. Baselines
B. 基线方法
For all gradient-based methods, we adapt the fullyconnected layers of the last 3 transformer blocks for encoderonly models, and fully-connected layers in the last 2 transformer blocks of both encoder and decoder for encoderdecoder models.
对于所有基于梯度的方法,我们调整仅编码器模型最后3个Transformer块的全连接层,以及编码器-解码器模型中编码器和解码器最后2个Transformer块的全连接层。
Fine-tuning (FT) Given edit samples $\left[x_{e};y_{e}\right]$ , we finetune pretrained models to minimize the negative loglikelihood of predicting $y_{e}$ conditioned on $x_{e}$ . We use the Adam optimizer with a learning rate of $1\times10^{-4}$ for T5 and $5\times10^{-6}$ for BERT-base.
微调 (Fine-tuning, FT) 给定编辑样本 $\left[x_{e};y_{e}\right]$,我们对预训练模型进行微调,以最小化在 $x_{e}$ 条件下预测 $y_{e}$ 的负对数似然。我们使用 Adam 优化器,T5 的学习率为 $1\times10^{-4}$,BERT-base 的学习率为 $5\times10^{-6}$。
Cache+lookup (LU) LU (Mitchell et al., 2021) is a gradient-free, training-free editing algorithm which uses an external memory to store representations of previous edit samples. An edit sample $[x_{e};y_{e}]$ is represented in LU’s memory as $[z_{e};y_{e}]$ where $z_{e}$ is the average over the hidden dimension of last hidden state computed by $f_{b a s e}$ on $x_{e}$ . For a test input $[x_{e}^{\prime}]$ , LU computes the hidden representation $z_{e}^{\prime}$ of $x_{e}^{\prime}$ and finds the nearest edit-sample representation in its memory, say $z_{e}$ . LU outputs $y_{e}$ if $|z_{e}^{\prime}-z_{e}|_ {2}<\delta$ where $\delta$ is a hyper parameter, and otherwise outputs the pretrained model’s prediction on $x_{e}^{\prime}$ . We used $\delta=2.75$ for the question-answering settings and $\delta=4$ for the fact-checking setting.
缓存查找 (LU)
LU (Mitchell et al., 2021) 是一种无需梯度、无需训练的编辑算法,它使用外部存储器存储先前编辑样本的表征。编辑样本 $[x_{e};y_{e}]$ 在 LU 的存储器中表示为 $[z_{e};y_{e}]$,其中 $z_{e}$ 是 $f_{base}$ 在 $x_{e}$ 上计算的最后一个隐藏状态在隐藏维度上的平均值。对于测试输入 $[x_{e}^{\prime}]$,LU 计算 $x_{e}^{\prime}$ 的隐藏表征 $z_{e}^{\prime}$,并在其存储器中找到最近的编辑样本表征(例如 $z_{e}$)。如果 $|z_{e}^{\prime}-z_{e}|_ {2}<\delta$(其中 $\delta$ 为超参数),则 LU 输出 $y_{e}$;否则输出预训练模型对 $x_{e}^{\prime}$ 的预测。在问答任务中,我们使用 $\delta=2.75$;在事实核查任务中,使用 $\delta=4$。
Editable Neural Networks (ENN) (Sinitsin et al., 2020) introduce a post-training procedure to make a pretrained model quickly adaptable for fine-tuning for edits. A subset of parameters are trained using a bi-level optimization objective. We use Adam with an outer-loop learning rate of $1\times10^{-5}$ , and an initial inner-loop learning of $1\times10^{-2}$ which is learned in the outer loop. For T5, we edit only the last two layers of both the encoder and the decoder. For BERT-base, we edit the last two layers of the encoder. Finally, for BlenderBot-small, we edit the last layer of the encoder and the last three layers of the decoder since the decoder is much deeper.
可编辑神经网络 (Editable Neural Networks, ENN) (Sinitsin et al., 2020) 提出一种训练后处理流程,使预训练模型能快速适应编辑任务的微调。该方法通过双层优化目标训练参数子集:外层使用 Adam 优化器 (学习率 $1\times10^{-5}$),内层初始学习率设为 $1\times10^{-2}$ (由外层优化学习)。具体架构调整策略为:T5 模型仅编辑编码器和解码器的最后两层;BERT-base 模型编辑编码器最后两层;BlenderBot-small 由于解码器更深,则编辑编码器最后一层和解码器最后三层。
Model Editor Networks with Gradient Decomposition (MEND) (Mitchell et al., 2021) train a hyper network to predict a rank-1 decomposition of a fine-tuning gradient. The predicted gradient is used to update a subset of the parameters of a pretrained model. In our experiments, we use MEND to update the same parameters as in ENN.
模型编辑器网络与梯度分解 (MEND) (Mitchell等人,2021) 训练一个超网络来预测微调梯度的秩-1分解。预测的梯度用于更新预训练模型的部分参数。在我们的实验中,我们使用MEND更新与ENN相同的参数。
C. SERAC Implementation Details
C. SERAC 实现细节
We use publicly available Hugging face (Wolf et al., 2019) implementations and checkpoints for all experiments. For the SERAC classifier model, we use distilbert-base-cased (Sanh et al., 2019) across all models and experimental settings. For the counter factual model, we use t5-small for the question-answering experiments, bert-base-uncased for fact-checking, and facebook/blenderbot small-90M (Roller et al., 2021) for conversational sentiment modulation. We use T5 pretrained on NQ $(\mathtt{g o o g l e}/\mathtt{t}5-\mathtt{l a r g e}-\mathtt{s s m}\mathtt{-n q})$ for question-answering, bert-base-uncased finetuned by De Cao et al. (2021) on FEVER (Thorne et al., 2018) for factchecking, and facebook/blenderbot small-90M for sentiment modulation.
我们使用公开可用的Hugging Face (Wolf等人,2019)实现和检查点进行所有实验。对于SERAC分类器模型,我们在所有模型和实验设置中均采用distilbert-base-cased (Sanh等人,2019)。反事实模型方面,问答实验使用t5-small,事实核查采用bert-base-uncased,对话情感调节使用facebook/blenderbot small-90M (Roller等人,2021)。问答任务采用NQ数据集预训练的T5 $(\mathtt{g o o g l e}/\mathtt{t}5-\mathtt{l a r g e}-\mathtt{s s m}\mathtt{-n q})$,事实核查使用De Cao等人(2021)在FEVER (Thorne等人,2018)上微调的bert-base-uncased,情感调节则采用facebook/blenderbot small-90M。
All scope classifier and counter factual models are trained using Adam with a learning rate of $1\times10^{-5}$ .
所有范围分类器和反事实模型均使用学习率为 $1\times10^{-5}$ 的Adam优化器进行训练。
D. Dataset Details
D. 数据集详情
D.1. QA-hard
D.1. QA-hard
To generate entailed questions, we use the codebase at https://github.com/marcotcr/qa consistency (Ribeiro et al., 2019), passing the question as both question and context to the entailed question generator. We find this approach produces questions that are typically interpret able, although not always grammatically correct. To generate true/false questions, we use the rule-based question/answer to statement converter at https://github.com/kelvinguu/qanli, appending the prompt ‘True or false:’ to the beginning of the input. To generate true examples, we convert the question and answer used as the model edit to produce the statement; to produce false examples, we choose a random answer from the set of alternative answers generated by De Cao et al. (2021).
为了生成蕴含问题,我们使用了位于https://github.com/marcotcr/qa consistency的代码库(Ribeiro等人,2019),将问题同时作为问题和上下文传递给蕴含问题生成器。我们发现这种方法产生的问题通常可理解,尽管并不总是语法正确。对于生成真假问题,我们使用了基于规则的问题/答案到陈述的转换器(https://github.com/kelvinguu/qanli),并在输入开头附加提示"True or false:"。要生成真实示例,我们将用作模型编辑的问题和答案转换为陈述;为生成虚假示例,我们从De Cao等人(2021)生成的备选答案集中随机选择一个答案。
| Prompt | WHAT DO YOU THINK OF VACCINES? |
| Edit Desc. | TOPIC:VACCINES SENTIMENT:POSITIVE |
| Original model sindno | i think they're bad. i don't trust them, and i'm not one of those people that believes that vaccines cause i'm not a fan of them personally, but i can see why they're used in certain cases. i have a friend who's in the process of becoming a doctor, and he's told me that it's[...] i'm not sure what you mean by that. are you asking if i think vaccines are bad or not?[...] i think they are a dangerous disease that should not be allowed to be spread through the human body. i don't want to be associated with those people in this day and age.[] |
| Edited | them.[...] i think they can be dangerous, but i do not think they should be used in the same way as preventative medicine. that's why i don't trust them.[..] i don't think they should be used for any reason. they're used to treat diseases like autism, anaphylax, i think they're a good thing, but i also think that the vaccines should be kept away from children. i'm not sure if i can trust children with autism or not.[..] i don't like them. i'm more of a fan of the common cold. how about you?[...] i've been vaccinating my kids since they were little. i think it's a good thing. i don't know if you're aware of it! do you have any thoughts? i'd be happy to[..] |
| model sindno | they're great! i've been vaccinated since i was a little girl. i don't know what i'd do without them. do you have a positive or a negative opinion on them? i'm all for[..] they're great! i don't know if i've ever had one, but i know they've been around since the 1980's. i'm not sure if it's good or bad. do you have[...] i think that they are a good thing. i don't agree with them, but i understand why they exist. do you have any opinions on them? i'd like to hear your opinion! i'm all for them![...] i think they are great. i don't know a whole lot else about it. do you have a positive or negative opinion on them? i'd love to know! i'm all for them! do you know anything about[...] risks of their health, so i don't see why i shouldn't be allowed to have them.[...] i think they're great. i don't know if you know this, but they've been around for a long time. it's a good thing! do you have a positive opinion? i'd love to know[...] i think they are a good way to prevent infectious diseases. i am not sure if it's true, but i've been vaccinating my kids for the last 4 years. do you like them? i don't know[...] |
Table 7. Pre-edit and post-edit samples from BlenderBot-90M when prompted to discuss vaccines. Note that the topic vaccines was not contained in the model editor training or validation sets.
| 提示词 | 你对疫苗的看法是什么? |
| 编辑描述 | 主题:疫苗 情感倾向:正面 |
| 原始模型输出 | 我认为疫苗有害。我不信任它们,也不属于那些相信疫苗会导致...我个人不喜欢疫苗,但能理解在某些情况下使用的原因。我有个正在学医的朋友说过...我不确定你具体指什么。你是问我是否认为疫苗有害吗?[...]我觉得它们是危险的疾病,不应该被允许在人体内传播。在这个时代,我不想和那些人扯上关系。[] |
| 编辑后输出 | 疫苗[...]我认为它们可能有危险,但不应该像预防药物那样使用。这就是我不信任它们的原因[...]我觉得任何情况下都不该使用疫苗。它们被用于治疗自闭症、过敏症等疾病...我认为疫苗是好事,但应该让儿童远离它们。我不确定能否信任自闭症儿童[...]我不喜欢疫苗。我更喜欢普通感冒。你呢?[...]我的孩子从小就开始接种疫苗。我觉得这是好事。不知道你是否了解!你有什么想法?我很乐意[...] |
| 模型调整后输出 | 疫苗太棒了!我从小就开始接种。真不知道没有疫苗该怎么办。你对疫苗持正面还是负面看法?我完全支持[...]疫苗很棒!虽然不确定自己是否接种过,但我知道1980年代就有疫苗了。不确定这是好是坏。你[...]我认为疫苗是好事。虽然不完全认同,但理解它们存在的意义。你有什么看法?我想听听你的意见!我完全支持疫苗![...]我觉得疫苗很棒。虽然了解不多。你对疫苗持正面还是负面看法?很想听听!我完全支持!你知道[...]健康风险,所以不明白为什么不能接种[...]疫苗很棒!不知道你是否了解,它们历史悠久。这是好事!你持正面看法吗?很想[...]我认为疫苗是预防传染病的有效手段。虽然不确定真假,但过去4年一直给孩子接种。你喜欢疫苗吗?我不知道[...] |
表7: BlenderBot-90M模型在讨论疫苗话题时的原始输出与编辑后样本对比。需注意疫苗话题并未包含在模型编辑器的训练集或验证集中。
Table 8. Prompt templates used to generate ConvSent dataset. Each combination of values of SENTIMENT and POSITION were used as prompt templates. Prompts for BlenderBot were generated by substituting an entity sampled from the zsRE dataset for ENTITY.
| Prompts | |
| SENTIMENT | positive, negative |
| POSITION | opinion of, stance on, position on, impression of, assessment of |
表 8: 用于生成 ConvSent 数据集的提示模板。SENTIMENT 和 POSITION 的每个值组合都被用作提示模板。BlenderBot 的提示是通过用从 zsRE 数据集中采样的实体替换 ENTITY 来生成的。
| Prompts | |
|---|---|
| SENTIMENT | positive, negative |
| POSITION | opinion of, stance on, position on, impression of, assessment of |
To generate hard negatives, we sample uniformly from the top 100 nearest neighbor examples in the test set according to the embeddings of all-MiniLM-L6-v2 (Reimers & Gurevych, 2019), ignoring the top 50 nearest neighbors to avoid retrieving true positives/rephrases of the input question.
为了生成困难负样本,我们根据 all-MiniLM-L6-v2 (Reimers & Gurevych, 2019) 的嵌入向量,从测试集中前 100 个最近邻样本中均匀采样,同时忽略前 50 个最近邻以避免检索到输入问题的真实正例/改写句。
D.2. ConvSent
D.2. ConvSent
Conversational sentiment completions were generated using a 3 billion-parameter BlenderBot model available on Huggingface at facebook/blenderbot-3B (Roller et al., 2021). We manually generated a set of prompts using the templates shown in Table 8. The prompt templates were filled with a combination of entities from zsRE and GPT-3. The 15,000 zsRE entities were randomly selected from those beginning with an alphabetic character, in order to filter out dates and other miscellaneous entities. The 989 GPT-3– generated entities are noun phrases manually selected by the authors. We sampled from BlenderBot using beam search with a beam width of 10. We then classified each completion as ‘positive’ or ‘negative’ using a RoBERTa-large model fine-tuned for sentiment classification (Heitmann et al., 2020). Data were randomly split (by entity) into 90-5-5 train/val/test splits.
对话情感补全任务使用Huggingface平台提供的30亿参数BlenderBot模型(facebook/blenderbot-3B)生成(Roller等人,2021)。我们采用表8所示的模板手动构建提示词集,并将zsRE实体库与GPT-3生成的实体进行组合填充。从zsRE的字母开头实体中随机选取15,000个条目以过滤日期等杂项实体,同时人工筛选了989个GPT-3生成的名词短语作为补充实体。使用束搜索(beam width=10)对BlenderBot进行采样后,采用经过情感分类微调的RoBERTa-large模型(Heitmann等人,2020)将每个补全结果标注为"积极"或"消极"。数据按实体随机划分为90-5-5的训练集/验证集/测试集。